Resource Allocation
Un problema di particolare interesse nelle Reti di Telecomunicazioni è quello di condividere in modo equo ed efficiente, le risorse disponibili tra gli utenti della rete. Tali risorse includono la capacità dei links e lo spazio dei buffers nei routers o negli switches dove i pacchetti vengono accodati in attesa di essere trasmessi. In questo capitolo verrà data una panoramica generale al problema di resource allocation, quindi verranno discussi i diversi meccanismi e le tecniche più utilizzate, con particolare riguardo alla Qualità del Servizio ed alla necessità delle applicazioni di ricevere differenti quantità di risorse dalla rete.
1.1
Problematiche della Resource Allocation
L’allocazione delle risorse è un problema molto complesso e di importanza fondamentale nella progettazione e nella gestione delle reti di telecomunicazioni. La resource allocation è parzialmente implementata nei routers o negli switches all’interno della rete e parzialmente negli end-hosts attraverso il protocollo di trasporto. Gli hosts comunicano, attraverso opportuni protocolli di segnalazione, le risorse di cui hanno bisogno ai nodi della rete i quali rispondono con informazioni riguardanti le disponibilità attuali.
Con il termine resource allocation si intende pertanto, il processo mediante il quale gli elementi della rete cercano di mettere a disposizione delle applicazioni che ne fanno richiesta, le risorse necessarie. E’ ovvio che non sempre è possibile soddisfare tutte le richieste e quindi alcuni utenti potrebbero ricevere minori risorse di quelle richieste oppure non riceverne affatto. E’ compito della resource allocation decidere quando dire no e a chi.
1.2 Meccanismi di Resource Allocation
Nonostante i meccanismi di resource allocation differiscano tra loro sotto numerosi aspetti, andiamo a descrivere in questa sezione tre dimensioni mediante le quali è possibile caratterizzare tali meccanismi [9].
1.2.1 Router Centric vs. Host Centric
I meccanismi di resource allocation possono essere suddivisi in due grandi gruppi: quelli che affrontano il problema dall’interno della rete, cioè nei routers, e quelli che lo affrontano dalla periferia della rete, cioè negli hosts, tipicamente tramite il protocollo di trasporto. Dal momento che in realtà sia i routers sia gli hosts partecipano attivamente alla resource allocation, la distinzione viene fatta in base a chi vi partecipa maggiormente.
In un approccio router-centric ogni router ha il compito di decidere quando inoltrare i pacchetti, quali pacchetti scartare e di informare gli hosts, che stanno generando il traffico nella rete, su quanti pacchetti sono abilitati a spedire.
In un approccio host-centric, invece, sono gli end systems che, osservando la rete, regolano il loro comportamento sulla base di alcuni parametri come ad esempio la perdita di dati ed il ritardo sperimentato dai pacchetti.
E’ da notare che i due approcci non sono mutuamente esclusivi. Infatti, anche nell’approccio host-centric, i routers hanno ancora un ruolo ben preciso in quanto il loro comportamento influenza le condizioni della rete sulle quali gli hosts basano le loro decisioni.
1.2.2 Reservation Based vs. Feedback Based
Un altro modo in cui i meccanismi di allocazione delle risorse possono essere classificati è basato sull’utilizzo di reservations o feedback.
In un sistema reservation-based gli hosts chiedono alla rete una certa capacità nel momento in cui si apprestano ad inviare
il loro flusso di dati. Ogni router quindi alloca sufficienti risorse, in termini di spazio nel buffer e/o di percentuale della capacità del link, per soddisfare le richieste ricevute. Se le richieste non possono essere soddisfatte, perché le risorse non sono disponibili, il router rifiuterà la richiesta.
In un approccio feedback-based, gli hosts iniziano a spedire dati senza che sia stata riservata alcuna risorsa, e regolano il loro rate di trasmissione in accordo ai feedback (risposte) che ricevono dalla rete. I feedback possono essere espliciti, in cui cioè i router mandano opportuni messaggi di tipo “please go down” agli host; oppure impliciti, in cui cioè gli hosts regolano il loro rate trasmissivo sulla base del comportamento esterno della rete, come ad esempio la quantità di pacchetti scartati.
E’ da notare che un sistema reservation-based implica sempre un meccanismo di tipo router-centric. Questo perché ogni router ha il compito di tenere traccia di quanta della sua capacità totale è riservata ad un determinato flusso di dati. Dall’altro lato, un sistema feedback-based può implicare sia un meccanismo router-centric sia un meccanismo host-centric. Tipicamente, se il feedback è esplicito, il router è fortemente coinvolto nello schema di allocazione. Se il feedback è implicito l’allocazione delle risorse è gestita quasi totalmente dagli hosts, mentre i router devono solamente scartare i pacchetti in caso di congestione.
1.2.3 Window Based vs. Rate Based
Il mecanismo di resource allocation deve, in qualche modo, far sapere al trasmettitore quanti dati è abilitato a trasmettere.
Ci sono in generale due modi per farlo: tramite la comunicazione di una window o tramite l’assegnazione di un rate. Nel meccanismo window-based il ricevitore comunica la dimensione della window al trasmettitore. Questa finestra corrisponde alla quantità di spazio nel buffer del ricevitore e limita la quantità di dati che il trasmettitore può spedire. Il protocollo di trasporto TCP ne è un tipico esempio.
E’ anche possibile controllare il comportamento del trasmettitore mediante l’assegnazione di un rate, cioè quanti dati al secondo la rete o il ricevitore sono in grado di assorbire. Il trasmettitore deve quindi attenersi a questa specifica, non superando mai il valore del rate che gli è stato assegnato. Meccanismi di questo tipo prendono il nome di rate-based.
1.2.4 Applicazione dei meccanismi
Tramite la combinazione dei meccanismi appena discussi, si possono generare diverse strategie di allocazione. In pratica però sono due i tipi di architetture che prevalgono su tutte. Da un lato abbiamo il modello di servizio best-effort. Tale servizio non offre nessuna garanzia né di tipo quantitativo né di tipo qualitativo, il suo unico scopo è essenzialmente quello di far arrivare i pacchetti a destinazione. Il servizio best-effort, utilizzato ad esempio da molti protocolli connection-less come IP, implica un meccanismo feedback-based, dal momento che tale tipologia di servizio non permette agli utenti di riservare risorse. Inoltre, in questo modello, la maggior parte del lavoro è affidata agli hosts. Ciò implica che reti di questo tipo usino strategie window-based. Questa è la strategia più comunemente utilizzata in Internet.
Dall’altro lato si trova il modello di servizio QoS (Quality of Service), complementare al best-effort, che cerca di fornire prestazioni garantite sia dal punto di vista qualitativo che quantitativo, e per il quale è richiesta una qualche forma di reservation. Il supporto per questi tipi di reservation implica un forte coinvolgimento dei router, ad esempio tramite l’accodamento dei pacchetti a seconda del livello di servizio da essi richiesto. La forma più naturale di esprimere tali reservation è in termini di rate.
Best Effort: Host-Centric, Feedback-Based, Window-Based QoS: Router-Centric, Reservation-Based, Rate-Based
1.3 Resource Allocation e Admission Control
Le problematiche della resource allocation sono strettamente legate a quelle della admission control. Nelle reti a commutazione di pacchetto diverse connessioni (o flussi) a bit-rate variabile, possono condividere un link con una capacità minore della somma dei loro bit-rate massimi. Tipici esempi di tali flussi sono le trasmissioni video, nelle quali il rate istantaneo dipende dal tipo di scena trasmessa, ed il traffico di interconnessione tra LAN, caratterizzato da una notevole presenza di burst, cioè intervali di tempo in cui il traffico risulta essere molto elevato (traffico bursty). Dal momento che le risorse della rete sono finite e condivise tra le varie connessioni, uno dei ruoli di un algoritmo di admission control è decidere, a fronte di una richiesta di servizio, di ammettere o meno un nuovo flusso nel sistema. Altro compito è la determinazione di opportune resource
allocation, in modo che il nuovo flusso se ammesso, veda soddisfatte le proprie richieste senza che le prestazioni ricevute dai flussi già presenti siano degradate. Le richieste di Qualità del Servizio possono essere di tipo quantitativo, come ad esempio un rate di trasmissione garantito o un ritardo limitato, oppure di tipo qualitativo, come ad esempio “un basso ritardo medio”.
A questo scopo vengono brevemente introdotti nelle sezioni 1.3.2, 1.3.3 due tipi di approcci fondamentali agli algoritmi di admission control: parameter-based e measurement-based [8, 10].
1.3.1 Banda Equivalente
Con statistical multiplexing si intende il processo di aggregazione di pacchetti provenienti da sorgenti diverse. Il grado di multiplexing statistico è determinato dalle statistiche di ogni singola sorgente, in contrasto ad esempio con il grado di multiplexing di una semplice TDM, che è determinato dal numero di sorgenti che possono essere inserite in un unico intervallo temporale. L’importanza del multiplexing statistico deriva dal fatto che la funzione densità di probabilità di sorgenti indipendenti multiplate statisticamente è la convoluzione delle singole densità, e la probabilità che il traffico aggregato raggiunga un valore pari alla somma dei valori massimi che le sorgenti possono generare è infinitesima. Per questo motivo in reti in cui si verificano le condizioni di multiplexing statistico, si possono raggiungere elevati gradi di utilizzazione delle risorse ed elevate prestazioni in termini di qualità del servizio. Si possono cioè
fornire garanzie di tipo quantitativo mediante parametri statistici.
Un concetto sul quale si basano molti algoritmi di ammissione è quello di banda equivalente (equivalent bandwidth, effective bandwidth o equivalent capacity). Consideriamo la seguente probabilità:
(
)
{
}
P rate traffico aggegato banda disponibile− τ >buffer ≤ε in cui τ è un intervallo temporale, buffer indica la dimensione del buffer del nodo di rete ed ε prende il nome di loss rate. Il rate del traffico aggregato delle sorgenti multiplate statisticamente è chiamata appunto banda equivalente. In questo caso ε prende il nome di loss rate anche se in sistemi in cui una grande porzione di banda è occupata da traffico best-effort, il traffico con qualità del servizio che eccede la banda equivalente non è perso ma viene semplicemente trattato come best-effort.
1.3.2 Tecniche Parameter-Based
I metodi di tipo parameter-based, calcolano l’ammontare di risorse richieste per supportare un insieme di flussi mediante una caratterizzazione a priori del traffico. Questi metodi sono indicati per modelli di servizio che offrono un ritardo limitato nell’inoltro dei pacchetti, ad esempio per il supporto di applicazioni real-time. Quando un flusso richiede un servizio di questo tipo deve caratterizzare il suo traffico, in modo che la rete possa prendere la decisione di ammissione ed eventualmente allocare le risorse necessarie.
1.3.2.1 Regolatore Leaky Bucket
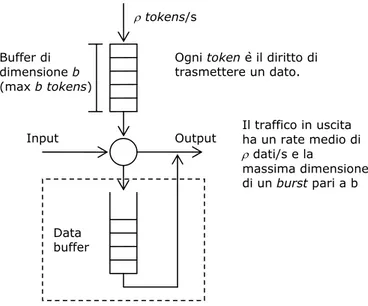
Tipicamente le sorgenti sono descritte tramite il loro rate medio e la massima dimensione del burst (ρ, b), mediante un opportuna tecnica chiamata token bucket. Concettualmente il token bucket è un processo che accumula tokens in un buffer di dimensione b (token depth) alla velocità di ρ tokens/secondo (token rate). Una unità di traffico in arrivo (tipicamente 1 Byte) deve spendere un token per poter essere trasmessa. Se non ci sono tokens nel buffer, la trasmissione si ferma fino ad un nuovo accumulo. In questo modo il traffico in arrivo subisce una limitazione di tipo lineare (LBAP, Linear-Bounded Arrival Process). La tecnica token bucket consente quindi una completa caratterizzazione ‘worst-case’ di una sorgente tramite l’uso dei due soli parametri b e ρ. Una sorgente di traffico LBAP limita il volume di traffico prodotto in un intervallo temporale τ mediante una relazione lineare. Indicato con A( )τ il traffico trasmesso dalla sorgente nell’intervallo τ, tale traffico è detto LBAP se esiste una coppia di parametri (b, ρ) che verifichi la seguente relazione:
( )Aτ ≤ +b ρτ, ∀ > (1.1) τ 0
in cui ρ è il rate medio del traffico trasmesso e b è il massimo valore del burst che la sorgente può generare in ogni intervallo di durata τ e rappresenta la massima deviazione che la sorgente può effettuare rispetto al suo rate medio. La rappresentazione grafica della limitazione LBAP è riportata in figura 1.1, in cui la linea retta con pendenza pari a ρ rappresenta il limite al traffico prodotto. In pratica una simile caratterizzazione può essere ottenuta usando un regolatore Leaky-Buket mostrato in figura 1.2. Se all’arrivo di un pacchetto costituito da un certo numero di unità di traffico,
non è presente un numero sufficiente di tokens, il traffico in eccesso viene scartato o memorizzato nel data buffer finché nel bucket non sono nuovamente presenti sufficienti tokens per poterlo trasmettere. In quest’ultimo caso il regolatore ha la funzione di shaper mentre nel caso in cui i pacchetti vengano scartati prende il nome di policer. Infine, se il valore del peak-rate p di una sorgente è conosciuto, può essere fatta una caratterizzazione più precisa ed il traffico da essa generato può essere limitato dalla relazione:
{
}
( ) min ,
Aτ ≤ b+ρτ τp (1.2)
Una sorgente che soddisfi tale relazione si dice regolata da un dual leaky-bucket con parametri (ρ, b, p).
La scelta dei parametri del regolatore dipende fortemente dalla tipologia del traffico prodotto dalla sorgente [19].
Figura 1.1 – Limitazione del traffico LBAP
b
τ A(τ)
Figura 1.2 – Schema di principio del regolatore Leaky Bucket
I flussi di traffico possono essere caratterizzati anche da altri parametri caratteristici come ad esempio il parametro di Hurst H per il traffico di tipo self similar (Cap. 2). Gli algoritmi di tipo parameter-based differiscono quindi tra di loro per il modo in cui viene caratterizzato il traffico e per i parametri che vengono scelti come valori caratteristici.
1.3.2.2 Simple Sum
Se il traffico è caratterizzato tramite il valore del suo rate trasmissivo medio può essere usato un algoritmo di ammissione chiamato simple sum [8, 10]. Indicata con υ la somma dei rate riservati ai flussi presenti nel sistema e con c la banda disponibile del link di uscita, l’algoritmo accetterà nel servizio un nuovo flusso i se:
Input
ρ tokens/s
Buffer di dimensione b (max b tokens)
Ogni token è il diritto di trasmettere un dato. Il traffico in uscita ha un rate medio di ρ dati/s e la massima dimensione di un burst pari a b Output Data buffer
i
r c
ν + <
in cui ri è il rate richiesto dal flusso i. Questo algoritmo di
admission control, nonostante la sua semplicità, è largamente implementato nei dispositivi di rete come router e switch. Per il raggiungimento di prestazioni garantite si fa spesso riferimento al worst case scenario, cioè la situazione in cui ogni flusso chiede la maggiore quantità di risorse alla rete. In questo caso la banda che viene riservata ad ogni sorgente è pari al valore del suo rate massimo. Questo caso è ottimo dal punto di vista della qualità del servizio offerta, ma porta ad avere un grado di utilizzazione delle risorse molto basso. 1.3.2.3 Fluid-Flow Approximation
Questo algoritmo calcola la banda equivalente di ogni singolo flusso, caratterizzato da rate medio r, massima dimensione del burst b e rate di picco p, considerando il traffico come un flusso continuo di bit modulato da un processo di Markov . La banda equivalente risulta:
2 (1 ) [ (1 ) ] 4 (1 ) ( ) 2 (1 ) F b p B b p B bB p C b α ρ α ρ α ρ ρ ε α ρ − − + − − + − = −
in cui α =ln(1/ )ε , /ρ=r p e B è la dimensione del buffer. La banda equivalente dell’aggregato di flussi viene calcolata come la somma delle bande equivalenti relative alla singola sorgente. Analogamente al caso simple sum (1.3.2.1), un nuovo flusso viene ammesso solamente se la somma delle bande equivalenti non eccede la banda disponibile. Questo schema di calcolo risulta efficiente per sorgenti non molto bursty, altrimenti il calcolo della banda equivalente risulta
sovrastimato a causa del non verificarsi del multiplexing statistico (1.3.1).
1.3.2.4 Gaussian Distribution
Il traffico aggregato è approssimato come un processo gaussiano. La sua banda equivalente, calcolata nel caso buffer-less è: ' ( ) G C ε = +m α σ in cui α' = −2ln( ) ln 2ε − π , i m=
∑
ρ , 2 i σ =∑
σ . Dove iρ è il rate medio del generico flusso i e 2
i
σ è la sua varianza. Questa approssimazione riflette le reali necessità di banda quando l’aggregato è costituito da molte sorgenti (>10) con lunghi periodi di burst. Altrimenti la banda è sovrastimata. Un algoritmo che utilizzi i vantaggi dell’approssimazione fluid flow e della distribuzione gaussiana è quello che calcola la banda equivalente come la banda minima tra quelle dei due modelli:
{
}
( ) min F( ), G( )
C ε = C ε C ε
in questo modo quando le sorgenti hanno brevi periodi di burst, prevale il modello fluid flow, altrimenti quello gaussiano.
1.3.3 Tecniche Measurement-Based
Questi metodi si servono delle misurazioni delle attuali condizioni di traffico per effettuare le decisioni di ammissione, e la relativa allocazione delle risorse. Data la dipendenza di questi algoritmi dal comportamento della sorgente, che non è statico e sconosciuto in generale, le richieste di servizio non possono essere assolute. Gli approcci measurement-based possono essere utilizzati solamente in quei contesti di servizio, in cui non vi è richiesta di prestazioni garantite. In questo modo a spese di deboli garanzie, possono essere raggiunte elevate utilizzazioni delle risorse di rete.
1.3.3.1 Measured Sum
Un semplice algoritmo measurement-based, analogo al simple sum della sezione precedente e chiamato measured sum [8, 10] si avvale delle misurazioni effettuate per stimare la quantità di traffico presente nel sistema. Questo algoritmo ammette un nuovo flusso i se è verificata la seguente condizione:
ˆ ri c
ν + <η
dove η è l’utilization target definito dall’utente, ˆν è la misura del rate del traffico esistente e ri è il rate richiesto dal nuovo
flusso. Una volta che un nuovo flusso è stato ammesso la stima viene incrementata del valore ri. E’ da notare che, in
quasi tutti i sistemi a coda la lunghezza del buffer e l’entità dei ritardi divergono man mano che l’utilizzazione del sistema si avvicina al 100% [11]. Si rende quindi necessario identificare un opportuno utilization target e far sì che
l’algoritmo di admission control mantenga l’utilizzazione del sistema strettamente al di sotto di tale valore.
1.3.3.2 Acceptance Region
Questo algoritmo è basato sul calcolo di una “regione di ammissione” che massimizzi l’utilizzazione del sistema e allo stesso tempo minimizzi la perdita di pacchetti. Una volta calcolata la regione di ammissione, l’algoritmo controlla che la somma della misura istantanea del rate del traffico e del valore del peak rate del nuovo flusso sia all’interno di tale regione. Se il peak-rate del nuovo flusso è sconosciuto viene derivato dai parametri del filtro token buket come:
ˆ /
p r b U= + (1.3)
dove ˆp è il peak-rate e U è un intervallo di tempo medio definito dall’utente. Se viene rifiutata l’ammissione di un flusso non saranno ammessi altri flussi fino a che almeno uno di quelli esistenti non cesserà il proprio servizio.
1.3.3.3 Hoeffding Bounds
Questo algoritmo si basa sul calcolo della banda equivalente di un insieme di flussi usando i limiti di Hoeffding. La banda equivalente basata sui limiti di Hoeffding è:
2
ˆ ( ) ˆ 0.5 ln(1/ )
H i
C ε = +ν ⋅ ε ⋅
∑
pin cui pi sono i peak rate dei flussi e ˆν è il rate medio
misurato dei flussi. L’algoritmo verifica che, alla richiesta di un nuovo flusso i sia:
ˆ
H i
Una volta che un nuovo flusso viene ammesso, la stima del rate misurato viene incrementata di pi. Se non si conosce il
peak-rate del nuovo flusso viene derivato dai parametri del filtro token buket come nella (1.3).
1.3.4 Tecniche di Misura
In questo paragrafo vengono illustrate alcune semplici tecniche per la misura delle grandezze da stimare negli algoritmi della sezione 1.3.3.
1.3.4.1 Time-Window
Per la misura del parametro ˆν nell’algoritmo measured sum descritto in 1.3.2.2 viene usata una tecnica a “finestra temporale”. Ad ogni periodo di campionamento τs viene
calcolato il rate medio. Quindi per ogni finestra temporale T = k τs viene scelta come stima ˆν il massimo valore calcolato.
Per ottenere stime non troppo conservative conviene scegliere 10
k ≥ .
1.3.4.2 Point Samples
Questo meccanismo usato ad esempio per acceptance region in 1.3.2.3 assume come stima del traffico presente nel sistema la media del rate valutata ogni τs.
1.3.4.3 Exponential Averaging
Nell’algoritmo Hoeffding Bounds può essere usata la seguente tecnica di misura. Il rate medio di arrivo totale ˆνs viene misurato ogni periodo di campionamento τs. Quindi il rate
medio viene calcolato con un filtro IIR di peso w (0.002) ricorsivamente:
'
ˆ (1 w) ˆ w ˆs
ν = − ⋅ + ⋅ ν ν
Aumentando w si ottiene una maggiore rapidità di risposta. Per il calcolo del peak-rate come nella (1.3) è consigliabile porre U=τs per una migliore corrispondenza con il peak-rate
rilevato dal meccanismo di misura.
In alcuni algoritmi al posto delle stima delle condizioni di traffico attuali, vengono usate predizioni dei valori che tale traffico assumerà in determinati istanti futuri (prediction-based). Metodi di questo tipo possono apportare notevoli miglioramenti nell’efficienza degli algoritmi di admission Control e di resource allocation, in quanto il traffico Internet è largamente provato essere di tipo LRD (Long Range Dependence). Questo significa che dall’osservazione del suo andamento negli istanti passati, si possano trarre molte informazioni che aiutino ad ottenere predizioni accurate dei valori assunti negli istanti futuri. L’argomento della predizione e del suo uso in algoritmi di resource allocation è oggetto dei capitoli seguenti. L’approfondimento del concetto di LRD e le sue implicazioni sulla predizione sono discussi nel capitolo 2.
1.4 Criteri di valutazione
Un problema comune a tutti i meccanismi di resource allocation è legato alla decisione riguardante la validità di un determinato algoritmo. Come già detto, un buon algoritmo di
resource allocation deve ripartire le risorse della rete in modo equo ed efficiente. Questo suggerisce almeno due metriche, mostrate nelle sezioni 1.4.1 e 1.4.2, con le quali valutare la bontà degli algoritmi [9].
1.4.1 Efficienza della Resource Allocation
Un buon punto di partenza nel valutare l’efficienza di uno schema di resource allocation, è considerare i due parametri principali in ambito di networking: il throughput ed il ritardo (delay). Chiaramente quello che si vuole è il maggior throughput possibile a fronte del minimo ritardo. A prima vista si potrebbe pensare che incrementando il throughput, automaticamente il ritardo diminuisca. In realtà questo non accade. Un modo sicuro per incrementare il throughput è quello di inoltrare nella rete il maggior numero possibile di pacchetti, in modo da far arrivare l’utilizzazione dei links vicina al 100%. Il problema di questa strategia è che incrementando il numero dei pacchetti all’interno della rete, si incrementa anche la lunghezza delle code all’interno dei singoli routers. Maggiore è la lunghezza delle code, maggiore è il ritardo che i pacchetti sperimenteranno.
Per descrivere la relazione tra i due parametri è stata proposta una metrica utile per la valutazione dell’efficienza di un meccanismo di resource allocation chiamata power, definita come:
Throughput Power
Delay =
E’ da notare che non è ovvio che la power sia la giusta metrica per la valutazione dell’efficienza. Innanzitutto la teoria da cui proviene tale metrica è basata sulla coda M/M/1 che assume la lunghezza della coda infinita. Inoltre la power è relativa ad un singolo flusso e non è del tutto chiaro come possa estendersi al caso di connessioni multiple. Questa metrica è comunque la più utilizzata per la misurazione dell’efficienza degli algoritmi
1.4.2 Equità della Resource Allocation
Uno schema di resource allocation, come già accennato, non deve essere valutato soltanto tramite la sua efficienza. Deve essere considerato anche il problema della sua equità (fairness). Purtroppo non è facile descrivere le caratteristiche che deve avere un meccanismo per essere equo (fair). Ad esempio, mediante uno schema reservation-based si realizza una seppur controllata iniquità in quanto, sullo stesso link, potremmo avere un flusso video abilitato a ricevere 1Mbps ed il trasferimento di un file che riceve solo 10Kbps.
Come prima istanza, si potrebbe pensare che quando diversi flussi condividono uno stesso link, essi debbano ricevere la stessa porzione di banda. Da ciò scaturisce che una divisione equa implichi una divisione uguale delle risorse tra i vari flussi. Questo non è vero in generale, soprattutto per il fatto che i vari flussi sono instradati lungo percorsi di lunghezza diversa. Comunque assumendo che equità implichi uguaglianza, e che tutti i percorsi siano della stessa lunghezza, Raj Jain ha proposto una metrica che può essere usata per quantificare l’equità di un algoritmo. L’indice di Jain è definito come segue. Dato l’insieme dei throughput di n
flussi
(
x x1, ,2 …,xn)
la seguente funzione assegna un indice di equità:(
)
2 1 1 2 2 1 , , , n i i n n i i x f x x x n x = = =∑
∑
…L’indice di Jain, chiamato fairness index, restituisce sempre un numero compreso tra 0 e 1 in cui 1 corrisponde alla massima equità.
1.5 Qualità del Servizio
Per molto tempo, il principale ostacolo al supporto di applicazioni multimediali in reti a commutazione di pacchetto è stata la necessità di disporre di link a banda sufficientemente larga. Negli ultimi anni nuovi algoritmi di codifica e compressione hanno ridotto drasticamente la quantità di risorse richiesta dalle applicazioni audio e video, inoltre i progressi tecnologici hanno messo a disposizione mezzi trasmissivi ad alta capacità. Tutto questo non è però sufficiente a far sì che le applicazioni multimediali possano essere supportate senza alcun problema. Ad esempio, durante una sessione telefonica è necessario che il ritardo end-to-end sia sufficientemente basso da non creare interferenza con la normale conversazione. Applicazioni sensibili ai ritardi prendono il nome di applicazioni real-time, di cui audio e video sono un tipico esempio. Altre distinzioni tra le diverse
requisiti di cui esse hanno bisogno. Nella sezione 1.5.1 viene data una panoramica delle varie tipologie di applicazioni.
1.5.1 Requisiti delle applicazioni
Le applicazioni possono essere suddivise in due tipologie principali: real-time e non-real-time. Quest’ultime sono le cosiddette “applicazioni tradizionali”, in quanto ne fanno parte la maggior parte delle applicazioni come Telnet, FTP, Email e WWW e possono lavorare senza la garanzia di un ritardo end-to-end particolarmente basso. Per questo motivo vengono anche definite elastic, stando a significare che il loro funzionamento non risente particolarmente di ritardi relativamente elevati. E’ da notare che queste applicazioni possono beneficiare di bassi ritardi, ma rimangono comunque utilizzabili anche se il ritardo cresce.
In figura 1.2 è mostrato uno schema che riassume le varie caratteristiche delle diverse applicazioni.
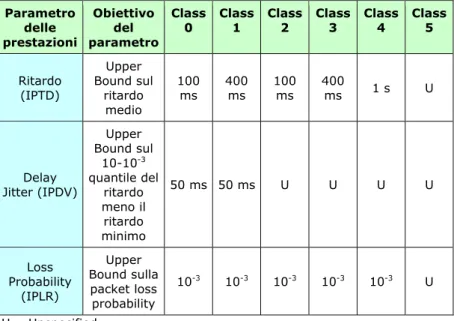
I parametri sui cui si basa la qualità del servizio sono sostanzialmente tre: average delay, delay jitter e loss rate. In genere le applicazioni multimediali, grazie alla capacità di interpolazione delle applicazioni stesse ed a quella dell’utilizzatore finale, sono abbastanza tolleranti rispetto alle perdite (loss rate) mentre richiedono vincoli stringenti riguardo al ritardo (delay) ed alle sue variazioni (delay jitter). Nella tabella 1.1 è mostrata la raccomandazione ITU-T Y.1541 in cui le applicazioni sono suddivise in classi a seconda dei requisiti di cui necessitano.
Figura 1.2 – Classificazione delle Applicazioni
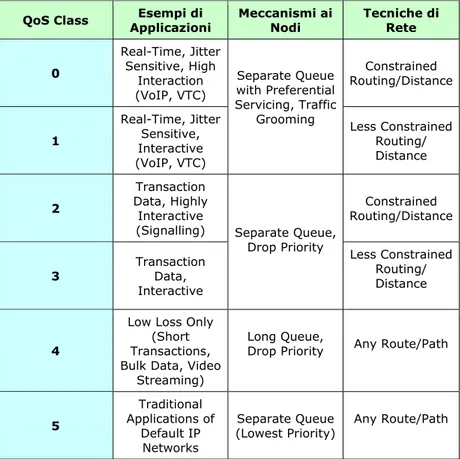
Nella tabella 1.2 si può vedere invece, sempre secondo la raccomandazione Y.1541, la classificazione delle applicazioni ed i meccanismi consigliati per ottenere le prestazioni desiderate.
In generale, per la realizzazione della qualità del servizio, sono necessarie opportune tecniche che prevedano adeguati meccanismi di resource allocation e di admission control. Le soluzioni più comuni si basano essenzialmente su due architetture: Integrated Services (IntServ) e Differentiated Services (DiffServ) i cui caratteri fondamentali vengono discussi nelle sezioni 1.5.2 e .15.3 seguenti.
Applications Real-Time
sensibili ai ritardi dati tradizionali Elastic
Non-Tolerant (musica hi-fi, controllo robot) Non-Adaptive Rate-Adaptive Non-Adaptive (controllo robot) Rate-Adaptive Bulk Transfer bassa sensibilità ai ritardi (FTP) Interactive media sensibilità ai ritardi (Telnet) Asynchronous ritardi ininfluenti (Email) Tolerant rispetto alla perdita dati o ai ritardi (voce) Adaptive Delay-Adaptive
1.5.2 Integrated Services (RSVP)
L’idea che sta alla base dell’architettura IntServ è quella di garantire Qualità del Servizio ad ogni singolo flusso (QoS fine grained). L’architettura IntServ è stata sviluppata negli anni 1995-1997 da un gruppo di lavoro della IETF, il quale definì le specifiche per una serie di classi di servizio ed associò l’intera architettura ad uno specifico protocollo: RSVP (Resource Reservation Protocol) usato per effettuare le dovute reservation per ogni singola classe.
Parametro delle prestazioni Obiettivo del parametro Class
0 Class 1 Class 2 Class 3 Class 4 Class 5
Ritardo (IPTD) Upper Bound sul ritardo medio 100 ms 400 ms 100 ms 400 ms 1 s U Delay Jitter (IPDV) Upper Bound sul 10-10-3 quantile del ritardo meno il ritardo minimo 50 ms 50 ms U U U U Loss Probability (IPLR) Upper Bound sulla packet loss probability 10-3 10-3 10-3 10-3 10-3 U U = Unspecified
Tabella 1.1 – Raccomandazione ITU-T Y.1541 per QoS su reti IP
La prima classe di servizio chiamata guaranteed service, è riservata alle applicazioni di tipo non-tolerant le quali necessitano di un ritardo limitato nella trasmissione dei dati.
La rete deve pertanto garantire un limite superiore al ritardo di ogni pacchetto.
QoS Class Applicazioni Esempi di Meccanismi ai Nodi Tecniche di Rete
0 Real-Time, Jitter Sensitive, High Interaction (VoIP, VTC) Constrained Routing/Distance 1 Real-Time, Jitter Sensitive, Interactive (VoIP, VTC) Separate Queue with Preferential Servicing, Traffic
Grooming Less Constrained Routing/ Distance 2 Transaction Data, Highly Interactive (Signalling) Constrained Routing/Distance 3 Transaction Data, Interactive Separate Queue,
Drop Priority Less Constrained Routing/ Distance
4
Low Loss Only (Short Transactions, Bulk Data, Video
Streaming)
Long Queue,
Drop Priority Any Route/Path
5 Traditional Applications of Default IP Networks Separate Queue
(Lowest Priority) Any Route/Path
Tabella 2.1 – ITU-T Rec. Y.1541: classificazione delle applicazioni
Un’altra classe di servizio, sviluppata principalmente per applicazioni tolerant e adaptive, prende il nome di controlled load. Lo sviluppo di questa classe è motivato dal fatto che applicazioni di tipo tolerant hanno buone prestazioni quando
controlled load è quindi emulare, per le applicazioni che richiedono il servizio, una rete in tali condizioni. Il metodo per fare questo è usare un meccanismo di scheduling, per isolare il traffico di tipo controlled load dal resto del traffico, assieme a qualche meccanismo di Admission Control che limiti tale traffico in modo che il carico sul link sia mantenuto su valori ragionevolmente bassi.
E’ chiaro che mentre nel caso di servizio best-effort l’unica informazione da specificare è l’indirizzo di destinazione dei pacchetti, per la richiesta di servizi real-time è necessario specificare un maggior numero di parametri, di tipo qualitativo o quantitativo, che descrivano le caratteristiche della sorgente e il tipo di risorse di cui essa ha bisogno. L’insieme di informazioni che una sorgente deve comunicare alla rete prende il nome di flowspec. Alla dichiarazione dei flowspec segue la fase di admission control, in cui la rete decide o meno se ammettere il flusso dati al servizio richiesto. Se il flusso è ammesso in rete si passa alla fase di resource allocation, in cui i componenti dell’architettura assegnano alla sorgente le risorse necessarie affinché le garanzie richieste vengano rispettate. Infine se le precedenti operazioni sono andate a buon fine, i pacchetti vengono processati dagli scheduler ed inoltrati a destinazione.
Lo scambio di informazioni tra rete ed utenti appena descritto avviene mediante il protocollo di segnalazione RSVP. Questo protocollo basa il suo funzionamento sul concetto di soft state all’interno dei routers, mediante il quale vengono memorizzate le informazioni relative ai flussi ed alle loro richieste. Il soft state, in contrasto con l’hard state delle reti connection-oriented in cui le informazioni vengono memorizzate all’atto della connessione, è temporaneo ed ha bisogno di continui messaggi di refresh per restare attivo. In questo modo i soft state possono adattarsi facilmente ai
cambiamenti che possono avvenire nei percorsi di routing o nelle specifiche dei flussi.
Purtroppo, proprio a causa del fatto che RSVP memorizza un insieme di informazioni in ogni router della rete per ogni singolo flusso, l’architettura IntServ va incontro a seri problemi di scalabilità. Per capire l’importanza di questo problema si pensi che un link di capacità 2.5 Gbps può supportare fino a 39000 flussi audio a 64Kbps. Per ognuno di questi flussi una certa quantità di informazioni deve essere memorizzata nei routers, in aggiunta alle varie operazioni di admission control, resource allocation, classificazione e scheduling che devono essere compiute anch’esse per ogni flusso. Per queste ragioni l’architettura IntServ tende ad essere accantonata come ogni altra architettura che richieda un elaborazione di tipo “per-flow”. Attualmente le ricerche sono focalizzate verso un altro modello di architettura, discusso nella prossima sezione 1.5.3, in cui la fornitura dei servizi non viene realizzata su ogni singolo flusso ma sul loro aggregato.
1.5.3 Differentiated Services
Mentre IntServ alloca le risorse ad ogni singolo flusso, l’idea alla base dell’architettura DiffServ, nata nella seconda metà degli anni ’90, è quella di allocare le risorse ad un piccolo numero di classi di traffico. Il primo vantaggio che DiffServ mostra nei confronti di IntServ è la scalabilità. La gestione dell’architettura si sposta infatti da tutti i router della rete ai soli router di periferia. La prima operazione richiesta a tali router è la classificazione dei pacchetti in arrivo, nelle varie classi di servizio. Questo può essere fatto facilmente mediante
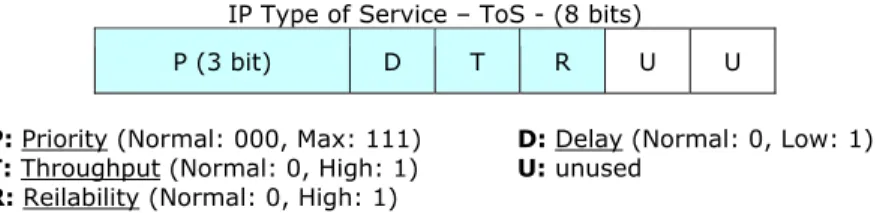
i primi 6 bit del campo Type of Service (Tos) del pacchetto IP. Il valore del campo identifica la classe di servizio che il pacchetto vuole ottenere. In questo modo le classi possono essere definite non solo in modo quantitativo ma anche qualitativo, intendendo che una generica classe “B” debba essere migliore di “C” e peggiore di “A”. In figura 1.2 è mostrata la corrente mappatura del campo ToS nel corrispondente DSCP (Differentiated Service Code Point) dell’architettura DiffServ.
IP Type of Service – ToS - (8 bits)
P (3 bit) D T R U U
P: Priority (Normal: 000, Max: 111) D: Delay (Normal: 0, Low: 1)
T: Throughput (Normal: 0, High: 1) U: unused
R: Reilability (Normal: 0, High: 1)
Figura 1.2 – Corrispondenza tra ToS e DSCP
Una volta che i bit del ToS sono stati opportunamente settati, il compito dei router è quello di trattare i pacchetti in accordo al valore del loro DSCP. La IETF ha standardizzato un insieme di trattamenti che i router devono applicare ai pacchetti, classificati dai router di periferia. Questi trattamenti sono chiamati per-hop behaviors (PHBs), intendendo che ciò che viene definito è il comportamento individuale dei router piuttosto che il servizio end-to-end. Il primo PHB è conosciuto come Expedited Forwarding (EF). I pacchetti marcati con questo tipo di PHB devono essere inoltrati dai router con il minimo ritardo e la minima probabilità di perdita. Questa classe di servizio può essere implementata limitando il traffico di tipo EF in arrivo. Un primo approccio molto conservativo potrebbe essere quello di assicurare che la somma dei rate di traffico EF sia minore della minima
capacità trasmissiva disponibile. Anche altre strategie sono possibili per la realizzazione del EF. Ad esempio si potrebbe assegnare un’alta priorità ai pacchetti EF, oppure usare un algoritmo di scheduling di tipo WFQ con il peso del traffico EF sufficientemente elevato.
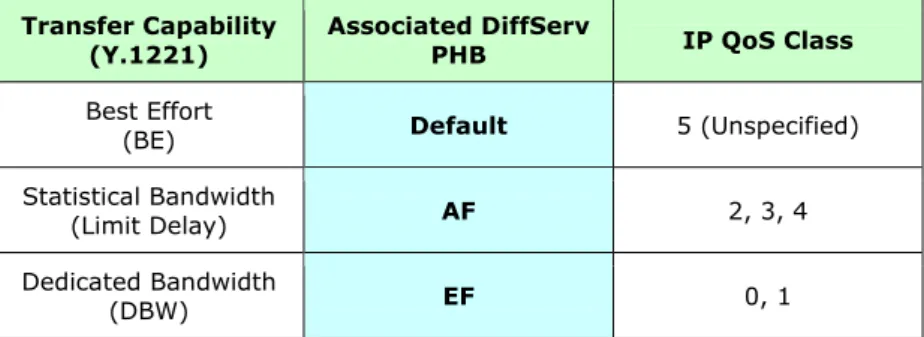
Un altro PHB standardizzato dalla IETF è chiamato Assured Forwarding (AF). Questa classe di servizio pone le sue basi nel meccanismo di “RED with IN and OUT” (RIO) o Weighted RED [9]. In questo meccanismo vengono definite due tipologie di pacchetti: il tipo “in” ed il tipo “out”. I pacchetti di tipo “in” sono sottoposti ad una certa probabilità di scarto, inferiore a quella a cui sono sottoposti quelli di tipo “out”. La classificazione tra in e out può avvenire nei router di periferia sulla base di un profilo concordato tra due entità. Un utente potrebbe per esempio, aver stipulato un accordo con il gestore della rete DiffServ per la fornitura di un certo servizio di Assured Forwarding. Il profilo potrebbe essere specificato in termini di bit rate massimo a cui l’utente può spedire i dati. I pacchetti il cui rate è inferiore a quello massimo concordato saranno marcati di tipo “in” altrimenti saranno di tipo “out”. Combinando tra loro RIO con tre diverse probabilità di scarto dei pacchetti, e uno scheduling di tipo WFQ con quattro diversi pesi da assegnare ad altrettanti flussi di traffico, sono state standardizzate 12 classi di servizio di tipo AF. Oltre a queste classi di servizio, l’architettura DiffServ ne prevede una di Default, di cui fanno parte i pacchetti non appartenenti ad alcuna classe di servizio tra quelle elencate, che corrisponde al normale Best Effort. Nella tabella 3.1 è mostrata una possibile corrispondenza tra le Transfer Capability (caratteristiche del traffico) della raccomandazione ITU-T Y.1221, i PHBs dell’architettura DiffServ e le classi di QoS della raccomandazione Y.1451.
Transfer Capability
(Y.1221) Associated DiffServ PHB IP QoS Class
Best Effort
(BE) Default 5 (Unspecified)
Statistical Bandwidth
(Limit Delay) AF 2, 3, 4
Dedicated Bandwidth
(DBW) EF 0, 1