Peer-to-peer Networking
In recent years a great attention has been devoted to the so-called peer-to-peer (P2P ) networking paradigm, in opposition to the traditional client/server paradigm.
In the client/server architecture there is usually a host (server) that is providing some kind of services to some other hosts (clients). The number of clients can be very high, so the server needs to be a high performance computer with a broad bandwidth connection. Moreover, being it a single point of failure, the server is often actually a cluster of machines, in order to provide fault tolerance, with the additional benefit of a performance increase thanks to load balancing. Anyway, this architecture needs maintenance, which can reach high costs.
The first widespread application of the peer-to-peer paradigm was for file-sharing. Many Internet users wanted to exchange multimedia contents with other users for free, but this was severely limited in the client/server architecture, mainly for two reasons. The first one was that storage of mul-timedia contents requires high availability of mass memory and bandwidth, providing which is difficult for an organization offering a free service. The second reason was that the content the users wanted to share (typically music and movies) were often covered by copyright and not legally redistributable, so a company could not afford the risk of storing them.
which implemented a peer-to-peer architecture allowing a direct transfer of files between users, without passing through a server. This was the beginning of the popularity of P2P.
Since then, the complexity and efficiency of P2P algorithms has grown, and are also used to reduce bandwidth load on server and increase scalability in distribution of contents. For example, BitTorrent[7] is a highly exploited way of distribution of free software.
The key feature of the peer-to-peer architecture is that the resources of the network are shared between users and not bound to some central servers. Each node can act both as a client and as a server. The more peers connect to the network, the more is the request but also the availability of resources. Duty of the P2P algorithm is to ensure fair distribution of them.
3.1
VoIP and P2P
The same considerations can be applied to VoIP. Traditional SIP networks are based on a centralized infrastructure, that requires proper configuration and maintenance. This approach is suitable for an entity which wants to provide a telephony service and have complete control over users and calls; an example is a provider that offers interconnection with the PSTN, conference rooms, automatic answering service, etc.
On the other side, there are some situations in which we cannot rely on such a centralized structure or the connection to the Internet is limited. Nevertheless, the ability to establish a SIP session even in those cases is desirable. Examples are ad-hoc networks like in emergency cases or meetings, or LAN where a server can not be installed or we do not have the privileges to access the already present SIP infrastructure.
Integrating SIP with a peer-to-peer approach can improve connectivity in those particular environments, and also improve scalability.
3.1.1
Skype
Skype is a well-known example of a very successful fusion between a VoIP application and peer-to-peer technology. The key feature that made Skype gain such a great success is the ability to work well in many networking environments, including NATted and firewalled LANs, without requiring any configuration from the user. Moreover, thanks to scalability of the peer-to-peer approach, it could build an 8 million user VoIP network.
Nevertheless, Skype[4] is proprietary and closed solution. Other than lacking the interoperability with other VoIP solutions, it poses some security concerns. First of all Skype is gathering some information from the host PC and LAN (needed, for example, to decide if a peer has enough CPU power and bandwidth to act as a relay for other peers); it is unknown what kind of information it is actually sending to the Internet and if it including some kind of backdoor to give external access to the computer. Secondly, due to its peer-to-peer nature, Skype is opening many connection at the same time, in some cases overloading network devices; unfortunately Skype behavior can not be configured or controlled by network administrators, so it is sometimes considered hostile to the network stability.
3.2
Centralized peer-to-peer networks
Centralized peer-to-peer networks are the first type being developed. Despite offering a distributed service, some tasks are still performed in a centralized fashion.
For example (see figure 3.1), in Napster [51] network, peers connect to some centralized server and send their list of shared files. Those servers are used to index the available files and perform searches upon peer requests, while the actual file transfer is done end-to-end between two peers (think links in the figure).
server peer peer peer peer peer peer peer peer resource index
Figure 3.1: Centralized peer-to-peer network
3.3
Decentralized peer-to-peer networks
Though centralized P2P networks allow efficient searches, there is still a single point that is responsible for the functionality of the network. If the central server fails, gets overloaded or is administratively shut down (like in Napster case), the whole network gets stopped.
For this reason peer-to-peer overlays evolved towards a decentralized struc-ture, where there are no dedicated servers and the network topology is self-organizing. For this reason, they are also called pure peer-to-peer networks.
3.3.1
Unstructured peer-to-peer networks
The first type of decentralized peer-to-peer overlays, were unstructured ones. In these P2P networks, overlay links are established arbitrarily. Such net-works can be easily constructed as a new peer that wants to join the network can copy existing links of another node and then form its own links over time. In an unstructured P2P network, if a peer wants to find a desired piece of data in the network, the query is sent through the network using controlled
flooding or random-walks with increasing TTL1. The main disadvantage with
such networks is that the queries may not always be resolved. Popular content is likely to be available at several peers, but if a peer is looking for rare data shared by only a few other peers, then it is highly unlikely that search will be successful.
Flooding also causes a high amount of signaling traffic in the network and hence such networks typically have very poor search efficiency.
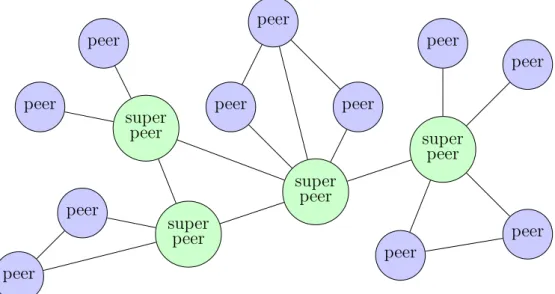
First unstructured networks had a flat topology, but had severe perfor-mance issues. Like Gnutella[35], they evolved into a hierarchical structure (figure 3.2), in order to improve the routing performance of the network. This separation into two classes of nodes derives from the consideration that not every peer has the same amount of free resources. Super-peers, therefore, are the nodes with more availability of bandwidth, memory and computational power. Super-peers are also used by FastTrack[33]/KaZaA[75] to index files shared by common peers and perform searches on their behalf.
peer peer peer peer super peer super peer peer peer super peer peer peer peer super peer peer peer
Figure 3.2: Unstructured decentralized peer-to-peer network
Gossip-based networks
A class of unstructured P2P overlays that has not received much attention in literature is gossip-based networks. The common property of these pro-tocols is that, periodically, every node of the distributed system exchanges information with some of its peers, including addresses of other peers.
Every node has a list of other peers, which is provided by an underlying service that in [41] the authors identify as Peer Sampling Service.
The continuous gossiping of information enables the building of unstruc-tured overlay, which is simple in term of maintenance and robust in case of peer failures.
Traditionally, this service is assumed to be implemented in such a way that any given node can exchange information with peers that are selected following a uniform random sample of all nodes in the system. However this article shows that this assumption is wrong, and in no case the gossip-based construction of overlays resemble traditional random graphs. Instead, they belong to the family of small world graphs[88], with large clustering and unbalanced degree distribution2.
Therefore, careful evaluation of the gossip protocol should be made, in order to verify that the created unstructured network satisfy the desired features.
3.3.2
Structured peer-to-peer networks and Distributed
Hash Tables (DHTs)
Structured peer-to-peer networks were born as an evolution inside the decen-tralized peer-to-peer overlays.
Structured P2P networks employ a globally consistent protocol to ensure that any node can efficiently route a search to some peer that has the desired file, even if the file is extremely rare. To achieve this aim, peers in this P2P network organize themselves building a precise topology and implement a Distributed Hast Table (DHT ) algorithm.
2Clustering and degree distribution of unstructured overlay will be examined in detail
Resources are then registered in the DHT, like in a common hash table, as pairs (key, value). Such pairs can be search and retrieved using the key.
A DHT is an algorithm to store the content of an hash table in a dis-tributed fashion: all participating nodes are responsible for holding and an-swering queries for a range of keys. DHT algorithms usually offer search complexity of O(log N ), where N is the number of nodes in the DHT.
Consistent Hashing
DHT also implement the consistent hashing scheme. This means that node identifiers and resource keys are hashed in the same hash space (e.g. for example, both hash values will be a 160-bit number).
Then, the node responsible for a particular key (also said to be its root node) is the node with ID closest to the hash value of the that key.
In this way, on addition or removal of nodes, the mapping of keys to nodes does not change significantly. For example, in most DHT, the insertion of the k-th node requires the remapping of only about 1/k of the stored keys.
Drawbacks
Structured peer-to-peer networks allow reliable and efficient searches for re-sources, reducing the network overhead for queries. However, they introduce a significant maintenance overhead; in fact, the functionality and efficiency of the DHT is guaranteed only if the links between peers, which build the defined topology, remain intact. This is not true is a common peer-to-peer network, where nodes enter and leave the overlay at a high rate (called churn rate). A complication derives also from the fact that peers may not announce that they are disconnecting (not performing graceful shutdown); for this rea-son there must be a protocol for quickly detecting failing peers and repairing the broken DHT structure.
The need for maintenance is the weakest side of DHTs. From this point of view structured overlays are less robust that unstructured one. Designers of DHT algorithms have been struggling to keep them working under high churn without increasing maintenance messages too much.
APIs
DHT algorithms offer at least the same three basic functions: • PUT(key, value): stores value under key;
• GET(key) → value: get the value associated to key;
• LOOKUP(key) → address: get the address of the node that is respon-sible for storing key (also called the root node of that key).
The distinctive characteristics of the different DHT algorithms are the overlay topology, the metric of the distance between nodes and the routing strategy of messages between peers. Major topologies and algorithms are described in section 3.4.
DHT lookup
Key lookups in a DHT can be divided into recursive and iterative. In a recursive query, the node initiating the query sends a message to the node it knows that is nearest to the target. If that contacted node does not have the resource, it will forward the query to the nearest node to the target it knows, and the process repeats until the target is reached. After sending the request forward, recursive algorithms can route the response in two ways. In the first, the response is symmetrically routed back through the overlay following the same path; this mechanism has been called Recursive Overlay Response Routing (RORR) in [16] (see figure 3.3a).
A B C query query reply reply a) RORR A B C query query reply b) RDRR A B C query redirect query reply c) iterative routing Figure 3.3: DHT lookups
Alternatively, once the destination is reached, the response can be sent directly back to the originating node (Recursive Direct Response Routing or RDRR, figure 3.3b).
In contrast, an iterative query (see figure 3.3c) has the initiating node sending the query to an intermediary node. Rather than forwarding the message along, the intermediary instead replies directly to the initiator node with a nearer location. The initiator then sends a new request to the nearer node recommended. The process continues until the target node is reached. RDRR is clearly the most efficient, because it involves a lower number of messages, thus decreasing the latency and the occupied bandwidth. However this query does not work when the querying node in not reachable by all the peers, for example if it is behind NAT or firewall.
RORR involves the same message number as iterative lookup, however it requires to open less connections between nodes. On their side, however, iterative query have the possibility of being parallelized and the fact that they reduce the burden on the other DHT nodes. Moreover DHT overlays based on recursive queries are more subject to DoS attacks, as they would forward the attacker’s queries.
3.4
DHT algorithms
3.4.1
Chord: ring topology
Chord is a simple and efficient DHT algorithm; its correctness has also been proved [82]. For these reasons it is the most used and analyzed DHT algo-rithm in academic peer-to-peer research.
Topology
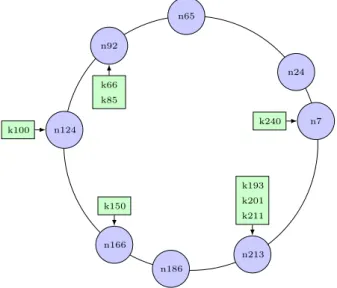
Nodes are organized in a ring topology (figure 3.4). Nodes have a unique ID derived form their IP address. The IP address is hashes into an m-bit identi-fier, which must be large enough to avoid collisions between node identifiers (ranging from 0 to 2m− 1). SHA-1 is usually choses as hashing algorithm, so
m is equal to 160. Each node knows its successor and predecessor, which are the nodes with the nearest IDs (before and after the ID the current node).
n7 n24 n65 n92 n124 n166 n186 n213 k66 k85 k100 k150 k193 k201 k211 k240
Figure 3.4: Chord ring topology
Resource keys are hashed with the same algorithm and placed in the same hash space as node IDs. A node with ID n is responsible for storing the values of all the keys which have a hash smaller or equal than its ID n and grater than the ID of its predecessor.
Routing and lookups
Chord nodes also maintain additional routing informations which allow loga-rithmic-complexity lookup of keys. Each node with ID n has a routing table (called finger table) of size m (the suggested size is the number of bits of the hashing function). Let successor(k) be the node with the smallest ID greater than k, the i-th entry of the finger table of node n contains the address of node successor(n + 2i−1). In this way, a node has a knowledge of the other nodes that is more detailed around its ID, and less precise for far nodes (figure 3.5).
When a node n wants to lookup a key with hash k two situations can happen:
n7 n29 n65 n92 n124 n166 n186 n213 135 71 39 23 15 11
Entry Target Node
1 8 n29 2 9 n29 3 11 n29 4 15 n29 5 23 n29 6 39 n65 7 71 n92 8 135 n166
Figure 3.5: Chord finger table of node n7
1. n ≤ k < successor(n): node n is the root node for that key, so it stores the value associated to that key and the search terminates;
2. otherwise it contacts the node n1in its finger table that has the smallest
ID greater or equal than k. n1 will be closer to k, so it will have better
knowledge of the nodes around it.
In the overlay is stable, this iterative algorithm is proved to find the resource in O(log N ) steps, where N is the number of nodes in the ring. In case routing tables are not correct, the performance degrades. The worst case is when finger tables are completely corrupted and only the link to the successor can be used to route the request.
Stabilization
Chord maintains updated each successor pointer using a stabilization proto-col in order to ensure correct lookups. This protoproto-col is executed periodically by each node in the background with the purpose of keeping updated the finger table and the successor pointers. At every stabilization cycle, a lookup for each ID in the finger table is performed.
In order to avoid incorrect lookups due to multiple-node failure, each Chord node keeps a successor list of size r, containing its first r successors. In this way if the immediate successors of the node does not respond, it can contact the next successor of the list. Increasing r makes the Chord system more robust.
Besides, each node notifies the its successors of its existence, giving the successor the chance to change its predecessor to the notifying node, in case of failure of intermediate nodes.
Since Chord is node-fault tolerant, it is possible to treat node departures as node failures. Anyway Chord performances can be improved during node departures using two enhancement:
1. a node may transfer its key to its successor before leaving the system; 2. a node n may notify its successor s to its predecessor p and p to s. In turn, node p will remove n from its successor list, and add the last node in successor list of n to its own list. Similarly, node s will replace its predecessor with predecessor of node n.
The weak point of Chord is the stabilization. To keep the overlay struc-ture consistent, the stabilization procedure must be executed frequently un-der high churn, generating high bandwidth usage.
3.4.2
Pastry: tree and ring topology
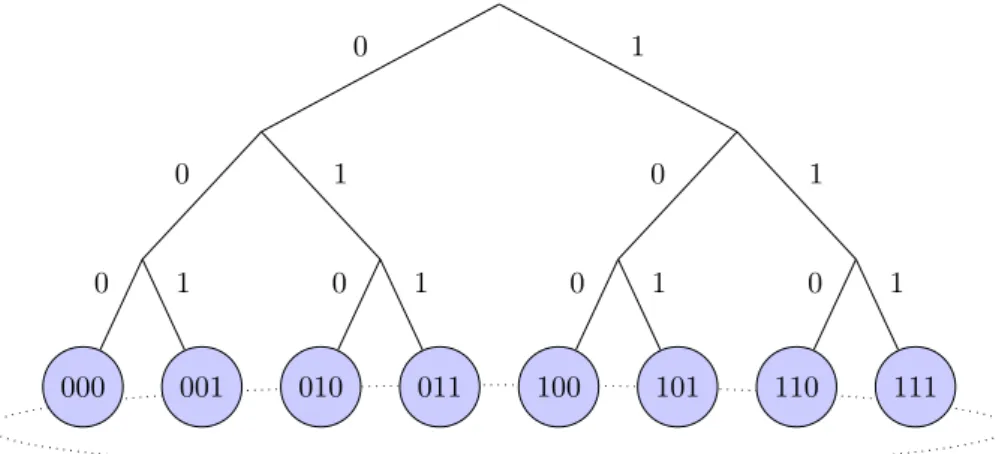
Pastry [74] makes use of Plaxton-like [56] prefix routing (tree topology). Each node in Pastry has a 128-bit identifier and these IDs and keys are thought of as a sequence of digits with base 2b (b is usually 4).
In a network with N nodes, Pastry can route to the numerically closest node to a given key in less than blog2bN c.
Pastry routes messages to the node whose ID is numerically closest to the given key. In each routing step, a node normally forwards the message to a node whose ID shares with the key a prefix that is at least one digit (b bits) longer than the prefix that the key shares with the present node’s id. If no such node is known, the message is forwarded to a node whose ID shares a
000 0 001 1 0 010 0 011 1 1 0 100 0 101 1 0 110 0 111 1 1 1
Figure 3.6: Tree + ring topology, with 3-bit keys and b = 1
prefix with the key as long as the current node, but is numerically closer to the key than the present node’s id.
Each Pastry node maintains a routing table, a neighborhood set and a leaf set. The routing table has dlog2bN e rows; each node in the ith row shares
the first i digits with the current node. Such row also holds 2b − 1 entires,
referring to nodes which have the ith digit assuming one of the 2b− 1 possible
values different from the one of the current node.
The leaf set contains the nodes that have the nearest node IDs to the current peer. Such leaf pointers build an additional ring topology.
The neighborhood set contains a group nodes which are closest in network proximity to the local peer. It is not used in routing messages, but plays an important role in detecting failing node and exchanging information about nearby peers.
Bamboo3 is a re-engineering of Pastry protocol, in order to better
with-stand large membership changes in the DHT as well as continuous churn in membership, especially in bandwidth-limited environments. Bamboo is em-ployed in OpenDHT [62], a publicly accessible distributed hash table (DHT) service.
3
3.4.3
Tapestry: tree topology
Tapestry [90] algorithm is similar to Pastry, except in the handling of network locality and data object replication. Also Tapestry employs a Plaxton-based prefix routing (so organizing nodes in a tree topology), but assigns multiple roots to an object, so as to increase scalability and availability in case of node failures of attacks.
Tapestry makes use of the so called surrogate routing to select root peers incrementally during publishing process to insert location information into Tapestry.
Moreover, for every pointer in the routing tables, multiple links to nodes with the same prefix are kept for recovery on node failure. The primary one is selected using proximity metrics.
Tapestry implementation is no longer developed. However Chimera4 is a
light-weight C implementation of a DHT based on Tapestry and Pastry.
3.4.4
Kademlia: XOR metric
Kademlia [48] employs a novel XOR metric to compute the distance between nodes. More precisely, being a and b the 160-bit IDs of two nodes, the distance between them is defined as d(a, b) = d(b, a) = a ⊕ b. XOR operator is symmetric and unidirectional, making sure that all lookups for the same key converge along the same path.
A Kademlia node stores a list of nodes for each distance interval [2i, 2i+1]. These list are called k-buckets and kept sorted by last time seen. k-buckets can grow up to k elements, where k is a system parameter.
The XOR metric is a different way to build a tree topology based on common prefix length between nodes. However the XOR metric adds the possibility to get closer to the desired node by fixing the bits not necessarily from the most to less significant.
To find a key, a Kademlia node send parallel queries to the n nodes in the closest non empty k-buckets. If may nodes are available from the same k-bucket, Kademlia chooses those with the lowest RTT.
0xx 1xx 11x 10x 100 101 d = 1 2 ≤ d < 4 4 ≤ d < 8
Figure 3.7: XOR metric derived tree for ID 101
Kademlia have no univocally defined association between a key and its responsible node ID, a peer which is performing a key lookup must contact all the k-closest nodes before considering the search failed.
Kademlia is currently widely employed as an indexing algorithm for eMule file-sharing content, and give proof of its scalability and robustness.
3.4.5
CAN: hypercube topology
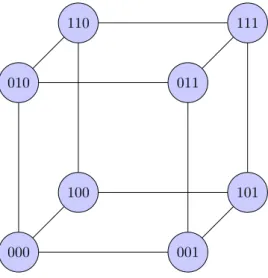
Content Addressable Network (CAN, [58]) employs a routing that resembles an hypercube geometry. CAN addresses nodes uses d-dimensional Cartesian coordinates on a d-torus, that is partitioned amongst nodes. A node ID is binary string, where each bit represents a coordinate. If there are n nodes in the overlay, each node has on average log2n neighbors, whose ID differs from just one bit.
The distance between two nodes is defined in the number of different bits in the IDs. The lookup algorithm is a simple greedy forwarding towards closer nodes. Due to the fact that at every step just one bit is fixed, there are many routes a search can follow; on the other side, the lookup complexity is not logarithmic but O(n1/d).
000 001 011 010 110 100 101 111
Figure 3.8: 3-torus topology
3.4.6
Kelips
Kelips implements a DHT by employing an hybrid structured and unstruc-tured approach. The identifier space is divided into g ≈√n affinity groups. Each node’s routing table contains an entry for each node in its group, and m “contact” nodes from each of the foreign groups.
Kelips does not define an explicit mapping of a give key to its responsible node, but replicates key/value pairs among all the nodes within a key’s group. For this reason, similarly to Kademlia, lookup for non-existent keys are not very efficient because all the nodes of the group must be contacted.
The main advantage of Kelips is that, in a static network, it allows lookup queries with a constant complexity of O(n). On the other side, the cost of this efficiency in searches is paid is the size of the routing table, that is √
n + m · (√n − 1) and thus scale only as O(√n) with the number of nodes in the overlay.
3.4.7
Comparison of DHT algorithms
The routing geometry deeply affects the efficiency of a DHT algorithm but it is hard to understand how a chosen geometry can influence its effectiveness. Gummadi et al. [37] focused on the routing level of most common DHT
algorithm. In particular the examined how the geometry influences the per-formance in in static resilience and proximity routing.
The static resilience is the ability of the algorithm to operate in an ex-tremely transient environment, where a significant fraction of nodes can be down at any one time.
The proximity routing is the characteristics of DHT paths to converge, in some degree, at the underlying Internet structure, in order to guarantee not too bigger latency times.
Flexibility
They observed that the most important feature for guaranteeing a good per-formance of the DHT algorithm is flexibility, which is the algorithmic freedom left by a specific routing geometry. It can be exercised at two levels:
• neighbor selection: how much freedom can be used to select the node to put in an entry in the routing tables, other than basing on its ID; the algorithm can have the freedom to choose among more nodes (and, for example, to select that with the smallest latency), or that node may be forced by the routing geometry;
• route selection: among how many next-hop nodes the routing algorithm can choose when it has to deliver a message; this kind of flexibility is important for robustness in case of next-hop node failure.
The tree, ring and XOR topologies have a flexibility in neighbor selection of O(nlog n/2), while only the hypercube have no such flexibility.
On the other side, only the ring and the hypercube topologies offer flex-ibility in route selection (O(log n)) while preserving the optimality of the route.
In addition, the ring topology offers the capability to get closer to the des-tination node though sequential neighbors links, which is particularly useful for recovery in case most routing links are broken.
For these reasons, in [37] the authors support the ring topology above the others, and propose a modification to Chord in order to be able to exploit the flexibility of the ring topology.
However, it must be observed that both Tapestry (tree topology) and Kademlia (XOR topology) store multiple nodes per entry in the routing table, thus gaining the otherwise missing flexibility in route selection.
Performance vs. cost
Another parameter for comparing DHT algorithm is the bandwidth require-ment. A very interesting work has been done in [44], where the authors presented a performance versus cost (PVC ) framework for evaluating the relationship between lookup latency and bandwidth requirements of DHT protocols.
Popular protocols have been evaluated under churn, devoting particular attention to the efficiency with which protocols use additional network re-sources to improve latency. Interesting general conclusions have been drawn: • DHTs that distinguish between state used for the correctness of lookups and state used for lookup performance can more efficiently achieve low lookup failure rates under churn; in fact, Chord has the lowest failure rate for very low bandwidth usage, because its correctness depends only to the pointer to the successor, which is easy to keep updated, more than an entire routing table.
• The strictness of a DHT protocol routing distance metric, while use-ful for ensuring progress during lookups, limits the number of possible paths, causing poor performance under pathological network condi-tions such as non-transitive connectivity; for example, in case of a non-transitive network5 the flexibility in route selection of Tapestry
guarantees a lower lookup failure rate than Chord, whose routing is strictly defined.
• Increasing routing table size to reduce the number of expected lookup hops is a more cost-efficient way to cope with churn-related timeouts than stabilizing more often.
5A network is non-transitive if it is possible to find three nodes such as A can
• Issuing copies of a lookup along many paths in parallel is more effective at reducing lookup latency due to timeouts than faster stabilization under a churn intensive workload; this technique is used by Kademlia, in particular.
• Learning about new nodes during the lookup process can essentially eliminate the need for stabilization in some workloads.
• Increasing the rate of lookups in the workload, relative to the rate of churn, favors all design choices that reduce the overall lookup traffic. For example, one should use extra state to reduce lookup hops (and hence forwarded lookup traffic). Less lookup parallelism is also pre-ferred as it generates less redundant lookup traffic.
Therefore, the importance of flexibility in route selection is again under-lined. Moreover, the plots of [44] show how the Kademlia is much more expensive in terms of bandwidth than other DHT protocols, in particular under intensive churn and lookup workloads.
On the other hand, thanks to its surrogate routing, Tapestry performed quite good on average.
3.5
Hybrid approach: BitTorrent
The first BitTorrent version [8] is a centralized P2P system that uses a central location to manage users’ downloads. A resource (file) is published in a .torrent file, which contains the resource file description and the address of a tracker. The tracker is a server that keeps track of all the peers which have such file (both partially and completely). Peers that want do download a file, connect to the tracker for that file and receive a random list of other peers downloading it. Then peers connect to each other and exchange chunks of that file.
Its evolution is called Trackerless BitTorrent [9]. In this version there is no longer a central tracker, but each peer acts also as tracker. All trackers are registered in a Kademlia DHT. This approach is a hybrid: it has some
concepts of a centralized systems, where there is a node that tracks which peers share a specific resource, but this tracker node is distributed across many peers in a decentralized fashion.
3.6
Bootstrap
A common issue that all kinds of peer-to-peer networks share, is how a node that wants to enter the overlay can join it. Such process is called the bootstrap process.
In order to enter the overlay, a node (called the joining peer ) needs to know the IP address of at least one other peer (called the admitting peer ). The joining peer ca acquire such address in five alternative ways:
1. multicast/broadcast : the joining peer can send through the network a message advertising its presence and polling for the presence of other peers; obviously this techniques works only if the other peers are in the same broadcast domain or can be reached by the multicast packet; nevertheless this method is suitable for ad-hoc and emergency networks; 2. cache: the joining peer can try to contact some peers at the IP addresses it knows from a previous executions and it stored in a persistent way for this purpose;
3. web site: the joining peer can download a list of long lived peers from a well-known web page; this is the mostly employed method for peer-to-peer file sharing applications;
4. static configuration: the joining peer can be statically configured with a bootstrap server, that is guaranteed by someone to be always on-line; 5. user provided : the IP address of the admitting peer is directly provided
by the user.
It is clear that a P2P client which wants to be easy to bootstrap and user-friendly, should implement all the above described techniques. They have been listed in the order a client is supposed to try: starting from the most
distributed methods and leaving centralized techniques and user intervention as last-resort.
3.7
P2P issues
The peer-to-peer paradigm owes its scalability to the ability to open many connections with arbitrary nodes on the network, which are offering their resources to provide a distributed service.
If the underlying network blocks part of these connection, the functional-ity of the overlay cannot be guaranteed. The typical critical configuration is a NAT or firewall which is blocking incoming connections towards the peer it is protecting. In the simplest case, such peer cannot receive the file it is looking for. More badly, if such peer is part of DHT, another peer which is performing a search cannot contact it, thus mining the effectiveness of the overlay.
Therefore, techniques must be studied in order to circumvent this prob-lem, and be addressable and able to accept incoming packets even behind a NAT device. These techniques are called NAT traversal practices, and will be examined in detail in chapter 4.2.
Another issue that affects peer-to-peer networking, is the amount of back-ground traffic and different connections that are flooding the network. This traffic is often the cause of network link saturation, network delay increase, and network device state tables overflow. Thus, peer-to-peer applications are often seen by network administrator as an enemy and source of network problems.