3. MATERIALI E METODI
La tesi si è articolata in diverse fasi: • l’analisi dei dati epidemiologici;
• la raccolta e l’archiviazione degli articoli; • l’analisi quantitativa degli articoli;
• l’analisi qualitativa di alcuni articoli; • la costruzione del questionario;
• la somministrazione del questionario ad un campione di popolazione; • l’elaborazione dei dati raccolti;
• la valutazione della percezione del rischio alimentare.
Fig.3A: Diagramma di flusso sulle fasi principali della tesi
ANALISI QUANTITATIVA DEGLI ARTICOLI ANALISI QUALITATIVA DEGLI ARTICOLI ANALISI DATI EPIDEMIOLOGICI
COSTRUZIONE E SOMMINISTRAZIONE DEL QUESTIONARIO
VALUTAZIONE DELLA PERCEZIONE DEL
RISCHIO ALIMENTARE
ELABORAZIONE DEI DATI DEL QUESTIONARIO
RACCOLTA E ARCHIVIAZIONE DEGLI ARTICOLI
3.1 RACCOLTA ED ANALISI DEI DATI EPIDEMIOLOGICI
L’analisi dei dati epidemiologici esistenti sulle malattie trasmesse con gli alimenti e sulle allerte alimentari è stata condotta effettuando una ricerca sul materiale messo a disposizione dai principali organi e dalle più importanti istituzioni regionali e nazionali in ambito alimentare.
I dati epidemiologici sulle malattie trasmesse con gli alimenti sono stati estrapolati dai rapporti del CeRRTA (Centro di Riferimento Regionale per le Tossinfezioni Alimentari) e del Ministero della Salute, mentre quelle sulle allerte dai rapporti del RASFF (Rapid Alert SysTem for food and feed).
3.2 RACCOLTA DEGLI ARTICOLI
L’analisi degli articoli pubblicati dai tre quotidiani nazionali principali è stata effettuata utilizzando l’archivio dell’Osservatorio della Comunicazione Sanitaria.
L’Osservatorio della Comunicazione Sanitaria, rileva quotidianamente tutti gli articoli riguardanti temi legati alla salute pubblicati su tre quotidiani nazionali: La Stampa, La Repubblica ed il Corriere della Sera.
Questo lavoro di raccolta, iniziato nel 1998 su archivi cartacei e limitato al tema Aids, si è esteso a tutti gli argomenti sanitari a partire dal 1999 e dal 2002 utilizza la versione “on-line” dei quotidiani in questione (www.corriere.it / www.repubblica.it / www.banchedati.ilsole24ore.com ). La raccolta quotidiana degli articoli avviene attraverso una selezione manuale che prevede la scelta degli articoli fra tutti quelli pubblicati ogni giorno, considerando tutte le tematiche che hanno a che fare con la salute o il sistema sanitario.
La continuità di questo lavoro quotidiano ha subito negli anni alcune interruzioni che hanno causato lacune per colmare le quali sono stati utilizzati
gli archivi storici informatici dei tre quotidiani. In questo caso la ricerca poteva essere eseguita solo tramite l’impiego di parole chiave: tuttavia, la molteplicità e l’imprevedibilità dei temi da cercare rendevano molto difficile, se non impossibile, una raccolta completa. Per evitare la perdita di articoli, sono state quindi utilizzate parole chiave sicuramente presenti in tutti i testi: i tre articoli “il”, “lo” e “la”, inseriti nella modalità OR (“il” OR “lo” OR “la”). In tal modo sono stati scaricati tutti gli articoli giorno per giorno e quelli su temi sanitari sono stati selezionati con la stessa metodologia della raccolta giornaliera.
L’archivio si presenta oggi pressoché completo dal marzo 1999 al 30 giugno 2008 per quanto riguarda La Repubblica e Il Corriere della Sera, e fino al 30 giugno 2007 per quanto riguarda la Stampa.
La Fig. 3.2.A rappresenta lo schema dei periodi finora coperti dalla raccolta per i tre quotidiani.
Attualmente la raccolta degli articoli continua quotidianamente per il Corriere della Sera e La Repubblica, sull’archivio storico per La Stampa. Questa differenza è dovuta alla diversa organizzazione dell’accesso on line ai tre quotidiani.
Gli articoli raccolti, vengono archiviati quotidianamente come files “txt” e periodicamente (di solito ogni sei mesi) inseriti in una Banca Dati Testuale.
3.3 DATA BASE TESTUALE (DBT)
Il DBT (Data Base Testuale), creato e sviluppato presso l’Istituto di Linguistica Computazionale del Consiglio Nazionale delle Ricerche di Pisa (E. Picchi, 2000), consente di creare, gestire e interrogare banche dati testuali. Il concetto guida sotteso alla logica di sviluppo del motore di base è quello di consentire la ricerca di una parola in un testo, in modo da ricavarne la frequenza ed individuarne i contesti. Le funzioni del DBT sono molteplici dato che è possibile effettuare ricerche per lemmi potenziali e per sinonimi, per condivisione di una stringa, analisi sulla punteggiatura, restrizioni delle ricerca in base alla frequenza di una data forma etc.
Oltre alla ricerca diretta di informazioni tramite l’interfaccia di consultazione dei testi, il sistema DBT consente la creazione di vari tipi di indici salvati in files di output riutilizzabili con un qualunque programma di videoscrittura: - il calcolo delle frequenze assolute in ordine alfabetico o decrescente - gli index locorum, arricchiti da riferimenti puntuali
- la lista di forme co- occorrenti con i relativi valori di mutual information. - il calcolo dell’ indice di leggibilità, basato sulle formule statistiche più accreditate.
L’Indice di leggibilità è una funzione automatica, disponibile in DBT, che applica la formula GULPEASE ad un archivio testuale; tale formula è basata sulla correlazione fra il numero dei caratteri, delle parole e delle frasi individuate nel testo indicato e in ogni sua unità logica, attraverso costanti numeriche individuate sperimentalmente:
Indice di leggibilità GULPEASE = 89 – LP / 10 + FR × 3 dove LP = totale lettere × 100 / totale parole;
La valutazione del testo viene espressa in una scala di valori compresa tra 1 e 100, dalla maggiore alla minore difficoltà:
da 1 a 35: testo quasi incomprensibile da 36 a 49: testo molto difficile
da 50 a 59: testo difficile da 60 a 79: testo facile
da 80 a 100: testo facilissimo. (Cinini-Sassi, 2007).
3.4 INSERIMENTO DEGLI ARTICOLI NEL DBT
Affinché il data base consenta di effettuare le ricerche in base agli argomenti trattati nei singoli articoli, scaricandone il testo integrale per le analisi non informatizzate, è stato necessario inserire il materiale raccolto previa un’idonea “indicizzazione”, effettuata secondo il seguente schema:
%<T>(<S>)<A>-<M>-<G>.<L> Dove:
- %: codice che indica l’inizio di ogni testo inserito.
- T: lettera indicante la Testata (C per “Il Corriere della Sera”, S per “La Stampa”, R per “La Repubblica”)
- S: lettera indicante la sezione del giornale (Cr: Cronaca, In: Interni, Es: Esteri, Pp: Prima pagina, Ppi: Primo piano, Pol: Politica, Ec: Economia, Sal: Salute, Sc: Scienze, Tts: Tuttoscienze, supplemento scientifico con periodicità settimanale del quotidiano La Stampa, Sp: Sport, Va: Varie.)
- A: anno. - G : giorno. - M: mese.
- L: lettera progressiva (a, b, c, ecc.) per distinguere articoli pubblicati dalla stessa testata nella stessa data.
Quindi, ad esempio, un articolo pubblicato in prima pagina da La Repubblica del 20 agosto del 2000, risulta contrassegnato: %R(Pp)2000-08-20.a, mentre un articolo pubblicato dal Corriere della Sera il 30 giugno del 2008 nella sezione Cronaca e selezionato come secondo articolo di quel giorno, è contrassegnato dalla stringa: %C(Cr)2008-06-30.b.
Poiché negli anni precedenti al 2006 tale indicizzazione non era stata effettuata, negli anni 2006-2007-2008, si è provveduto all’inserimento della stringa identificativa per tutti gli articoli dell’archivio.
Il corpus degli articoli dell’Osservatorio di Comunicazione Sanitaria è stato suddiviso in sottogruppi costituiti ciascuno da 3 anni per ogni testata in quanto l’intero gruppo risultava troppo grande per essere archiviato come un tutt’uno.
3.5 ANALISI QUANTITATIVA DEGLI ARTICOLI
L’analisi quantitativa è utile in particolare per conoscere la frequenza complessiva con la quale si affronta un certo argomento e la sua evoluzione nel tempo oltre che per confrontare argomenti diversi. Essa consente di individuare i picchi di informazione e le tempeste comunicative.
Una tempesta comunicativa è l’espansione improvvisa e rapida di una notizia che attecchisce nell’immaginario collettivo generando nella popolazione stati d’ansia e modificazioni nel comportamento. Gli effetti di tale evento mediatico sono simili a quelli prodotti da una strategia pubblicitaria e possono essere più o meno a lungo termine a seconda della sua durata.
Gli articoli contenuti nel DBT possono essere contati in base a diverse variabili, quali la testata, il periodo di tempo (mese, anno), la sezione, una
tematica o più tematiche associate. Le variabili infatti possono essere considerate singole o in combinazione. La procedura per ottenere statistiche di questo tipo varia a seconda che si voglia lavorare sulle “occorrenze” e sui “contesti”, contando la semplice presenza di una o più parole, oppure che si ricerchi il numero degli articoli corrispondenti alle varie tipologie di ricerca. Nel primo caso si creano “Famiglie” di parole chiave o gruppi di parole, aggiungendo parametri stabiliti dall’utente. Nel secondo caso il numero totale degli articoli viene calcolato attraverso l’utilizzo di un semplice programma (Trovarif) implementato a questo scopo dal CNR.
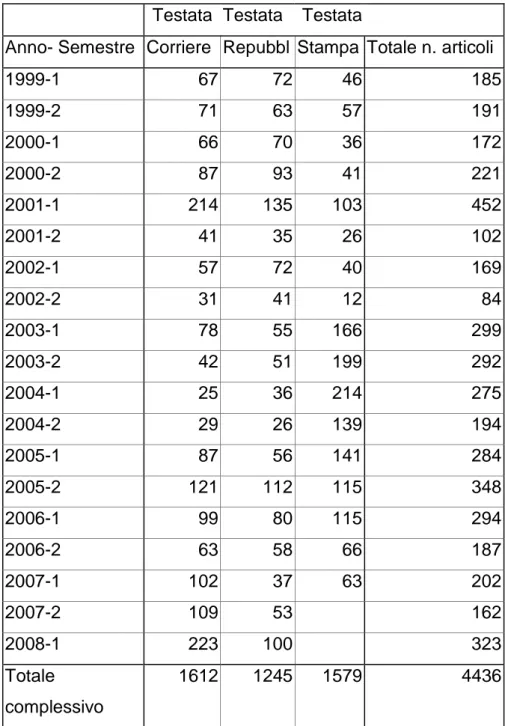
Al 30 giugno 2008 l’archivio risulta essere costituito da 24434 articoli per un totale di 10.932.344 occorrenze (parole), comprendenti 164.249 forme diverse.
Testata Testata Testata
Anno-Semestre Corriere Repubbl Stampa
Totale n. articoli 1999-1 290 268 192 750 1999-2 550 378 344 1272 2000-1 600 513 251 1364 2000-2 524 472 230 1226 2001-1 704 546 286 1536 2001-2 536 445 295 1276 2002-1 287 508 160 955 2002-2 159 406 34 599 2003-1 791 448 895 2134 2003-2 419 331 724 1474 2004-1 186 248 1086 1520 2004-2 256 211 655 1122 2005-1 586 272 555 1413 2005-2 472 307 343 1122 2006-1 259 225 362 846 2006-2 487 307 311 1105 2007-1 762 403 778 1943 2007-2 720 321 1041 2008-1 1191 545 1736 Totale complessivo 9779 7154 7501 24434
TAB 3.5.A Numero articoli di salute nei tre quotidiani
Dall’intero corpus di articoli sulla Comunicazione Sanitaria (CS), è stato estrapolato un sottoinsieme di articoli riguardanti la tematica dell’alimentazione, su cui fare le successive analisi, denominato appunto “alimentazione”.
Questo sottogruppo è stato generato dal DBT andando a cercare una lista di parole chiave, comprendenti il nome dei cibi più frequenti negli articoli e stringhe che permettessero di recuperare il maggior numero di parole collegate (sostantivi, verbi, aggettivi). La lista delle parole utilizzata è mostrata in tab. 3.2.
Tab. 3.5.B: lista di parole utilizzate per individuare il sottocorpus “alimentazione”.
alimentare cibano dietologia obesi
alimentari cibare dietologica obesità
alimentarista cibarie dietologico obeso
alimentaristi cibarsi dietologo orzo
alimentarsi cibasse EFSA pane
alimentazione cibata formaggi pasta
alimenti cibate formaggini patata
alimento cibati formaggino patate
anoressia cibato formaggio patatine
anoressica cibava frutta pollame
anoressiche cibavano latti pollami
anoressici cibi legumi polli
anoressico cibo mais pollo
anoressie diet mascarpone pomodori
barrette dieta mozzarella pomodoro
bulimia diete mozzarelle riso
bulimica dietetic nutrizionale snack
bulimiche dietetica nutrizionalmente soia
bulimici dietetiche nutrizione soja
bulimico dietetici nutrizionismo uova
caffé dietetico nutrizionista verdura
carne dietista nutrizioniste verdure
carni dietiste nutrizionisti yogurt
cereali dietisti nutrizionistica yoghurt
cibando dietologa obesa yogourt
cibandosi dietologi obese yogurth
Alcune famiglie di parole sono state generate introducendo nel DBT solo una radice con accanto l’asterisco; ad esempio: aliment*. In questo modo è stato possibile recuperare tutte le parole collegate a questa stringa.
Dopo aver esaminato un campione di contesti, è stato deciso di togliere alcune forme delle parole generate.
Ad esempio la stringa frutt* dava origine a frutta/frutto/frutti. Con l’analisi degli articoli è stato concluso che l’unica forma riconducibile alla tematica dell’alimentazione era “frutta”, mentre sia “frutto” che “frutti”, erano sempre utilizzati in senso figurato (frutto della disattenzione, frutto della ricerca, proficui frutti, ecc.).
Da una statistica sulla frequenza delle parole scelte all’interno degli articoli, è stato evidenziato che in alcuni casi la presenza di un termine era dovuto solo ad accenni sporadici e marginali della tematica, all’interno di articoli trattanti tutt’altro argomento. E’ stato adottato quindi il metodo di scartare tutti gli articoli con una frequenza pari a 1 (cioè quegli articoli in cui compariva una sola tra tutte le parole cercate ed una sola volta). In questo modo è stato possibile eliminare 2310 articoli che erano stati presi con la lista delle parole, ma che in realtà non trattavano di alimentazione.
Il corpus “alimentazione” è stato poi suddiviso in 3 sotto-corpora, uno per ogni testata, per rendere possibili le successive ricerche.
Il numero totale degli articoli che formano il corpus “alimentazione” è di 4436 articoli, costituiti da 2.341.513 occorrenze (parole), formati da 133.068 forme diverse.
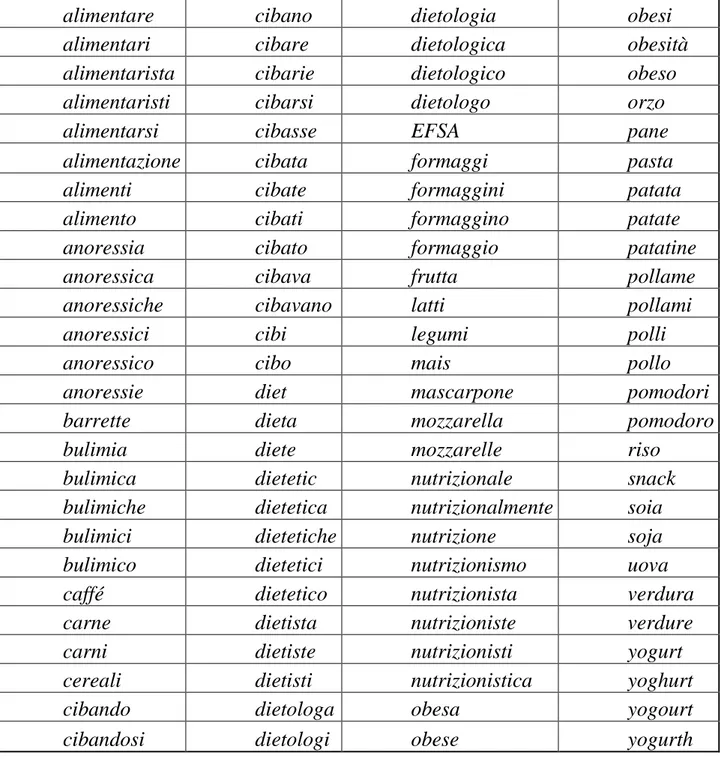
La tab. 3.5.3 mostra la suddivisione degli articoli secondo la testata e l’anno, suddiviso in semestri:
Tab. 3.5.C: Tabella riassuntiva del numero di articoli di alimentazione suddivisi per anno e per testata.
Testata Testata Testata
Anno- Semestre Corriere Repubbl Stampa Totale n. articoli
1999-1 67 72 46 185 1999-2 71 63 57 191 2000-1 66 70 36 172 2000-2 87 93 41 221 2001-1 214 135 103 452 2001-2 41 35 26 102 2002-1 57 72 40 169 2002-2 31 41 12 84 2003-1 78 55 166 299 2003-2 42 51 199 292 2004-1 25 36 214 275 2004-2 29 26 139 194 2005-1 87 56 141 284 2005-2 121 112 115 348 2006-1 99 80 115 294 2006-2 63 58 66 187 2007-1 102 37 63 202 2007-2 109 53 162 2008-1 223 100 323 Totale complessivo 1612 1245 1579 4436
Da questa, sono state generati grafici che permettono di visualizzare immediatamente la distribuzione degli articoli nel tempo.
3.6 ANALISI QUALITATIVA DEGLI ARTICOLI
La qualità degli articoli raccolti è stata valutata sulla base dei criteri formulati dal gruppo di lavoro multidisciplinare “Leggere Ascoltare la Salute” (Carducci A., et al., 2003): correttezza-completezza, affidabilità, comprensibilità, utilità, equilibrio, indipendenza.
La correttezza-completezza riguarda sia l’assenza di errori di concetto o di terminologia usata che l’esaustività delle informazioni fornite. La completezza delle informazioni diffuse è essenziale: notizie incomplete o presentate secondo punti di vista unidirezionali possono indurre opinioni distorte ed atteggiamenti negativi. In particolare risultano importanti informazioni esaurienti su sondaggi, studi statistici, sperimentazioni di laboratorio o cliniche: il metodo di campionamento, l’ampiezza del campione, la data della rilevazione, i criteri di verifica e controllo, i limiti di applicazione alla pratica, i tempi necessari per l’uso routinario di nuove tecniche diagnostiche e terapeutiche, dati relativi alla legislazione ed altre normative in materia come il codice deontologico del medico e del giornalista. Inoltre è essenziale l’impegno a dare uguale risalto a rettifiche su informazioni mediche, sanitarie o scientifiche risultate errate o incomplete, precisando i motivi dell’errore e dell’incompletezza.
Riguardo a questo criterio, la valutazione può essere effettuata soltanto da persone con competenze tecniche e documentazione specifica, vista la complessità di alcuni degli argomenti trattati. Un giudizio qualitativo (corretto o non corretto) viene espresso leggendo l’articolo e rilevando gli eventuali errori di concetto o di terminologia e le informazioni mancanti.
Per gli articoli non corretti vengono riportati gli errori, al fine di poter condurre ulteriori analisi e proporre eventuali correzioni di informazione.
L’affidabilità si basa sulla citazione della fonte di provenienza delle informazioni riportate, e sul tipo di fonte. La difficoltà di valutare la correttezza può essere in parte superata considerando l’affidabilità della fonte: una fonte scientifica accreditata e istituzionale con competenze scientifiche ed indicazioni bibliografiche precise possono essere una garanzia in questo senso.
Nel caso in cui non venga citata con precisione alcuna fonte l’articolo è considerato non affidabile. Se la fonte è indicata questa viene classificata in quattro categorie principali: riviste scientifiche, istituzioni competenti, esperti senza precisa veste istituzionale, associazioni, altro (aziende, periodici, quotidiani, ecc.).
La comprensibilità nasce in primo luogo dall’uso di un linguaggio semplice sulla base di reali criteri divulgativi che garantiscano una comunicazione chiara e univoca. I mass media usano abitualmente un linguaggio comprensibile anche a soggetti di basso livello culturale, ma su argomenti di salute la leggibilità e la chiarezza dei testi diminuiscono.
La comprensibilità di un articolo si compone di due aspetti: la leggibilità, intesa come il grado di difficoltà nella lettura, rapportabile al grado di alfabetizzazione dei possibili lettori, e la chiarezza dei concetti espressi, correlata invece alla non contraddittorietà degli stessi.
La valutazione del primo aspetto viene effettuata con procedura informatizzata dal DBT attraverso l’Indice di Leggibilità GULPEASE, che può essere associato ai gradi di istruzione:
Da 1 a 35: testo quasi incomprensibile, poco leggibile anche da laureati Da 36 a 49: testo molto difficile, leggibile da laureati.
Da 50 a 59: testo difficile, leggibile da diplomati.
Da 60 a 79: testo facile, leggibile da persone con licenza media inferiore. Da 80 a 100: testo facilissimo, leggibile da persone con licenza elementare.
La valutazione della chiarezza dei concetti è più complessa, dato che dovrebbe essere tarata sul grado di alfabetizzazione sanitaria: poiché attualmente non esistono strumenti adeguati a tale scopo, questo aspetto non viene valutato. Tuttavia una mancanza di completezza deve essere considerata anche mancanza di chiarezza.
L’utilità degli articoli è considerata in relazione a quello che può servire al cittadino per aumentare le sue conoscenze e per effettuare scelte consapevoli e positive per la salute. La valutazione di questo parametro implica necessariamente la lettura dell’articolo ed è di tipo qualitativo: presenza o assenza di informazioni utili.
L’equilibrio prende in considerazione il tono emotivo del messaggio diffuso e l’uso di parole enfatiche con valenza positiva o negativa. La valutazione viene fatta combinando la lettura dell’articolo con la ricerca automatica di parole allarmistiche, scelte in una lista derivante da quelle più frequentemente usate nel linguaggio giornalistico sulla salute. Nel caso di questioni controverse la valutazione dell’equilibrio conta il numero di affermazioni a favore o contro una determinata posizione.
L’indipendenza rappresenta l’assenza di pubblicità occulta o comunque di interessi nascosti: la difficoltà di valutare questo parametro in modo oggettivo ne limita l’applicazione ai casi in cui siano riconoscibili evidenti interessi commerciali.
Le informazioni ottenute attraverso la valutazione dei singoli articoli sono state codificate e schedate, al fine di poterne trarre statistiche descrittive, secondo la tabella 3.4 sotto riportata e i dati raccolti sono stati inseriti in tabelle Excel.
Tab. 3.6: tabella excel per l’inserimento dei dati raccolti. L e tt u ra a rt ic o lo N O S ì V ID E N T E IP E N D E N Z A In a u to m a ti c o N U M E R O P A R O L E N E G A T IV E Q U IL IB R IO N O S ì O M P R E N S IB IL IT A ’ L e tt u ra a rt ic o lo N O S ì O N T R A D D IT T O R IE T A ’ In a u to m a ti c o IN D IC E G U L P E A S E E G G IB IL IT A ’ L e tt u ra a rt ic o lo N O S ì T IL IT A ’ L e tt u ra a rt ic o lo A s s o c ia z io n i P e rs o n e Is ti tu z io n i R iv is te S c ie n tI fi c h e N O S ì F F ID A B IL IT A ’ N O S ì O R R E T T E Z Z A L e tt u ra a rt ic o lo In f. m a n c a n ti d i d a ti In f. m a n c a n ti d i c o n c e tt o In f. m a n c a n ti d i te rm in o lo g ia N O S ì O M P L E T E Z Z A L e tt u ra a rt ic o lo E R R O R E : E rr o ri d i te rm in o lo g ia E rr o ri d i c o n c e tt o N O S ì R E S E N Z A D I E R R O R I D IC E A R T IC O L O L e tt u ra a rt ic o lo N O S ì V ID E N T E IP E N D E N Z A In a u to m a ti c o N U M E R O P A R O L E N E G A T IV E Q U IL IB R IO N O S ì O M P R E N S IB IL IT A ’ L e tt u ra a rt ic o lo N O S ì O N T R A D D IT T O R IE T A ’ In a u to m a ti c o IN D IC E G U L P E A S E E G G IB IL IT A ’ L e tt u ra a rt ic o lo N O S ì T IL IT A ’ L e tt u ra a rt ic o lo A s s o c ia z io n i P e rs o n e Is ti tu z io n i R iv is te S c ie n tI fi c h e N O S ì F F ID A B IL IT A ’ N O S ì O R R E T T E Z Z A L e tt u ra a rt ic o lo In f. m a n c a n ti d i d a ti In f. m a n c a n ti d i c o n c e tt o In f. m a n c a n ti d i te rm in o lo g ia N O S ì O M P L E T E Z Z A L e tt u ra a rt ic o lo E R R O R E : E rr o ri d i te rm in o lo g ia E rr o ri d i c o n c e tt o N O S ì R E S E N Z A D I E R R O R I D IC E A R T IC O L O
3.7 INDAGINE SULLA POPOLAZIONE
Per soddisfare gli obiettivi di una ricerca è necessario mettere a punto un valido strumento di rilievo dei dati. Gli aspetti generali che devono essere tenuti in grande considerazione nella preparazione di un questionario sono gli obiettivi dell’indagine, le modalità di somministrazione e il tipo di elaborazione che si intende effettuare. (Signorelli, 1998).
Nella fase preliminare di studio della ricerca è stato deciso quali informazioni fosse necessario conoscere dagli intervistati ed è stata stabilita l’autosomministrazione del questionario ad un campione di cittadini di Pisa, Bari, Lucca e Montecatini.
Nello specifico il questionario è stato somministrato ad un campione di 323 utenti dell’Ufficio SUP (Sportello Unico di Prevenzione) della ASL 5 di Pisa e della ASL 2 di Lucca e di 200 cittadini di Bari per verificare la presenza o l’assenza di differenze sostanziali nelle risposte delle popolazioni di due regioni profondamente diverse dal punto di vista alimentare, come la Toscana e la Puglia.
Al fine di una verifica della rispondenza nelle risposte tra utenti ASL e cittadini non interagenti con il Sistema Sanitario al momento della somministrazione del questionario, l’indagine è stata svolta anche su un campione di 170 clienti dell’Ipercoop di Montecatini (Pistoia).
Fig. 3.7.A: Postazione di distribuzione del questionario nell’Ipercoop di Montecatini (PT).
L’indagine si è svolta nel periodo 26 maggio- 26 giugno 2008.
Il questionario è stato compilato autonomamente dai cittadini e inserito in un’urna chiusa per garantirne l’anonimato. Ai rispondenti è stata poi consegnata la scheda con le risposte alle domande dell’ultimo modulo.
3.7.1 FORMULAZIONE DEL QUESTIONARIO
Dopo un’attenta revisione bibliografica degli studi esistenti, e in relazione ai dati epidemiologici estrapolati dal CeRRTA (Centro di Riferimento Regionale per le Tossinfezioni Alimentari) e dal Ministeo della Salute, è stata effettuata una cernita delle potenziali domande da porre agli intervistati. Poiché l’obiettivo della ricerca era quello di valutare la percezione del rischio alimentare nei cittadini in relazione ai dati epidemiologici e agli allarmi mediatici degli ultimi anni, la scelta delle domande da somministrare è stata fatta in questa direzione.
L’auspicata semplicità e brevità di ogni questionario, al fine di ridurre i tempi di compilazione e facilitare l’elaborazione dei dati, si scontra spesso con
l’esigenza di analizzare a fondo il problema in studio e di considerare parallelamente anche problemi secondari, ma correlati a quello principale. Le domande di un questionario devono essere rivolte in modo chiaro, sintetico e non ambiguo e raggruppate per argomento in moduli o blocchi. (Signorelli, 1998)
Il questionario è stato perciò diviso in quattro moduli: A) percezione del rischio alimentare
B) allarmi alimentari
C) rapporto con le Istituzioni D) conoscenze dei cittadini
Nella prima sezione si è voluto indagare:
- il grado di preoccupazione dei cittadini rispetto a vari pericoli; si è fatta perciò una scelta in base ai maggiori rischi e agli argomenti più frequentemente apparsi negli articoli dei quotidiani: pesticidi, virus dell’aviaria, ormoni o antibiotici, batteri, mercurio, diossina, BSE, sostanze cancerogene, allergeni, OGM;
- il comportamento dei cittadini a seguito degli allarmi mediatici, individuati con l’analisi quantitativa degli articoli;
- il grado di preoccupazione nel mangiare o bere alcuni alimenti (carni rosse, pollame, latte e formaggi, uova, pesce e prodotti della pesca, succhi di frutta, acqua del rubinetto, acqua minerale).
- cosa sia decisivo nella scelta dei prodotti alimentari.
Per valutare l’impatto degli allarmi mediatici sì è valutato di chiedere:
- quando è stata l’ultima volta che si è sentito parlare di argomenti legati all’alimentazione, quali salmonellosi, febbre tifoide, epatite A, BSE, diossina negli alimenti, listeriosi, brucellosi, botulismo e OGM.
- quale fosse la principale fonte di informazione.
Per il rapporto con le Istituzioni abbiamo ritenuto importante chiedere: - a quale Istituzione si desse più fiducia
- se l’informazione sulla sicurezza alimentare fosse sufficiente - da quale fonte si vorrebbero più informazioni
- su che cosa si vorrebbero più informazioni
Nella sezione dedicata alla valutazione dell’alfabetizzazione sanitaria dei cittadini è stata inserita una serie di domande che valutassero le conoscenze di base sui rischi alimentari.
Nell’elaborazione delle domande del questionario è stata posta particolare attenzione a non colpire la suscettibilità dei rispondenti, con domande troppo difficili o invasive.
E’ stato inoltre adottato un linguaggio chiaro e semplice per tutti. Si è quindi proceduto a spiegare tutti quei termini che potessero risultare incomprensibili ad una parte degli intervistati. Tutte le sigle sono state esplicitate. All’acronimo OGM, ad esempio, è stata affiancata la spiegazione della sigla (Organismi geneticamente modificati), così come a BSE è stata affiancata la dizione comune “mucca pazza”.
Sempre nel rispetto della chiarezza e della semplicità, non sono stati utilizzati né termini tecnico- scientifici, né inglesismi.
La leggibilità del questionario è stata quindi valutata attraverso l’Indice di Gulpease; il valore calcolato di 80, ovvero “testo facilissimo”, leggibile anche da persone con licenza elementare.
Al questionario vero e proprio è stata fatta precedere una brevissima presentazione della ricerca: anche in questo caso la maggiore difficoltà è stata quella di essere concisi, ma chiari, senza creare ansie per la compilazione. Infatti una corretta ed elegante presentazione contribuisce ad aumentare la percentuale di rispondenti e l’attendibilità delle risposte fornite. Assieme alle finalità della ricerca, sono stati indicate anche le Istituzioni e gli Enti che hanno collaborato alla ricerca.
Le notizie anagrafiche necessarie per le successive elaborazioni statistiche sono state richieste nella garanzia dell’anonimato. Tutte le indagini epidemiologiche devono infatti rispettare le leggi vigenti sulla Privacy, ovvero nel nostro caso, la 196/03 sulla tutela dei dati personali.
Per facilitare la compilazione e l’elaborazione dei questionari, la maggior parte delle domande è stata formulata come “domande chiuse” (ovvero con una serie predefinita di risposte), ma alcune domande sono state inserite nella modalità “semiaperte” (ovvero con una serie di risposte predefinite ed un’ultima voce in cui l’intervistato può indicarne altre che non erano previste).
E’ stata altresì prevista la possibilità di più risposte ad una stessa domanda, ma al fine di un’elaborazione non troppo complessa, si è deciso di limitare le opzioni a due risposte al massimo (indicandolo chiaramente nella domanda). L’ordine delle domande è stato deciso in base all’importanza delle informazioni da ricevere (tenendo conto che nelle ultime domande l’attenzione può diminuire) e in base alla loro facilità ( in quanto partendo con domande troppo difficili si può correre il rischio di un abbandono della compilazione).
Anche la veste grafica assume una notevole importanza quando, come in questo caso, il questionario è autosomministrato. Si è perciò deciso di adottare un formato “leggero”, come quello della brochure pieghevole. Sono state inoltre inserite foto di alimenti e colori per rendere più gradevole la visione. Per facilitare la lettura, è stata scelta la maggior dimensione consentita del carattere, cercando di creare spazi e “arieggiature” tra le domande.
A questo punto è stata predisposta una bozza del questionario da validare. La bozza è stata fatta compilare ad un campione di convenienza di 15 cittadini di varie età, sesso e grado d’ istruzione, chiedendo loro di indicare varie difficoltà di linguaggio o concetto e ambiguità delle domande. A tale
campione è stato cronometrato il tempo di compilazione, in modo da essere sicuri che il questionario non fosse eccessivamente lungo.
A seguito delle indicazioni riportate e dei vari suggerimenti, sono state effettuate numerose modifiche e correzioni. La bozza a questo punto è stata sottoposta all’approvazione dell’Ufficio Privacy delle ASL di Pisa e Lucca.
Quindi si è proceduto alla stampa del definitivo questionario da somministrare (vedi All.3.1).
E’ stata inoltre predisposta una scheda con le risposte corrette dell’ultimo modulo del questionario da consegnare ai rispondenti dopo la compilazione (vedi All.3.2).
3.7.2 ARCHIVIAZIONE DEI DATI
I dati dei questionari raccolti sono stati codificati in una legenda (All.3.3) ed inseriti su fogli Microsoft Excel per le successive analisi statistiche (vedi appendice).