Dall’Analisi Psicoacustica al
formato MP3
Con l’arrivo dei primi Compact Disc (CD), agli inizi degli anni ottanta, cominciava la diffusione dell’audio digitale; di lì a poco l’alta fedeltà e la robu-stezza che garantiva ne hanno decretato il successo assieme al completo supera-mento della precedente tecnologia analogica. Nonostante i molti vantaggi offerti, tuttavia, l’audio digitale provoca seri problemi di memorizzazione e trasmissione vista la grossa quantità di dati che coinvolge. Per rendere l’idea basti pensare che il sistema di rappresentazione PCM (Pulse Code Modulation) prevede per i CD-Audio un campionamento con frequenza pari a 44,1kHz ed una codifica di ciascun campione su 16 bit, pertanto la trasmissione del segnale prodotto ha bisogno di una banda di 705,6kbps per canale: circa 1,4Mbps complessivi (considerando tra-smissioni stereo su due canali). Per lo standard DAT (Digital Audio Tape; 48kHz, 16 bit per campione) si arriva a 768kbps per canale ed 1,536Mbps complessivi. Per memorizzare un minuto di sonoro c’è bisogno di 10,6MB nel primo caso e di 11,5MB nel secondo. Da questi numeri risulta evidente l’importanza della
Le tecniche di compressione classiche ricercano ed eliminano le
ridon-danze statistiche presenti nei file cui sono applicate. Sui file dati sono ottenuti
buoni risultati mentre sui file audio dette tecniche realizzano fattori di compres-sione decisamente modesti. Ultimamente sono state spese molte risorse nella ri-cerca di algoritmi di compressione percettiva ideati appositamente per audio di-gitale di alta fedeltà. Le codifiche di tipo percettivo comprimono il segnale elimi-nando quelle parti che il nostro apparato uditivo non percepirebbe comunque. Si tratta di codifiche di tipo lossy (con perdite) che producono dei bit-rate molto bas-si (bas-si può arrivare a rappresentare un campione con poco più di due bit). Dopo l’eliminazione delle parti irrilevanti del segnale, dette tecniche eseguono una rie-laborazione del risultato onde evidenziare delle ridondanze statistiche ed ottenere alfine una compressione più spinta dall’applicazione di tecniche di compressione classiche lossless.
Naturalmente esiste un dibattito sulla qualità resa dalle compressioni di ti-po lossy ed invero è aperta una discussione anche sulla stessa qualità CD-Audio. Alcuni esperti ritengono che essa sia intrinsecamente inferiore a quella del segnale analogico di partenza e sostengono la necessità di campionare a frequenze supe-riori a 55kHz e di quantizzare con oltre 20 bit per ottenere una codifica trasparente in assenza di compressione. I nuovi formati Super Audio CD e DVD Audio ri-spondono a queste esigenze prevedendo frequenze di campionamento di 96kHz e quantizzazioni su 24 bit.
3.1 Elementi di psicoacustica
Compito della psicoacustica [17] è studiare il modo in cui il segnale emes-so da una emes-sorgente emes-sonora viene percepito dall’orecchio umano. La comprensione dei suoni da parte dell’uomo prevede tre livelli graduali: acustico, percettivo e co-gnitivo. A livello acustico si parla di segnale: rappresenta il prodotto dell’emissione di una sorgente; esso viene tradotto in sensazione a livello
percet-tivo da una parte dell’orecchio (orecchio interno) ed in musica o parole a livello cognitivo dalla corteccia uditiva (lobo temporale del cervello). A livello acustico il segnale viene descritto da ampiezza (intensità), frequenza, spettro o forma d’onda (a seconda che ci riferiamo al dominio delle frequenze o del tempo rispet-tivamente), di caratteristiche di propagazione in un mezzo. A livello percettivo la
sensazione uditiva viene descritta da un volume (loudness), una altezza (pitch), un
timbro, una direzionalità. A livello cognitivo, infine, il suono (musica/parole) ha una dinamica, una classe di toni, viene riconosciuto proveniente da una certa sor-gente sonora, permette la costruzione di una mappa spaziale dell’ambiente circo-stante con la disposizione delle varie sorgenti. Ovviamente esiste una corrispon-denza fra le grandezze acustiche, quelle percettive e quelle cognitive. Così il vo-lume dipende direttamente dall’intensità del segnale, ma pure dalla sua frequenza fondamentale e dallo spettro tutto; l’altezza segue direttamente dalla frequenza fondamentale del segnale acustico, il timbro dallo spettro e così via. Queste corri-spondenze non sono completamente nette poiché esistono delle relazioni com-plesse che coinvolgono più di una grandezza acustica nella determinazione di una grandezza percettiva. La psicoacustica approfondisce queste corrispondenze e stu-dia in particolare come i segnali emessi da una qualche sorgente dell’ambiente e-sterno vengano trasformati nella sensazione che avvertiamo a livello percettivo.
I moderni compressori di segnali audio prevedono una fase di analisi del segnale con l’applicazione di modelli psicoacustici per la determinazione delle in-formazioni irrilevanti. I principi psicoacustici che vengono sfruttati nell’ambito della compressione percettiva sono:
i. soglia assoluta di udibilità (Threshold in quiet), ii. bande critiche,
iii. mascheramento simultaneo, iv. mascheramento temporale.
Prima di descrivere questi principi è necessario definire l’unità di misura dell’intensità dello stimolo acustico. Il suono come noto è una vibrazione che si trasmette attraverso un mezzo. Il suono percepito dall’orecchio umano si trasmette
attraverso l’aria. L’intensità sonora è una misura dell’energia trasportata dalla vi-brazione e precisamente l’energia che attraversa una unità di superficie in una uni-tà di tempo; si misura in Watt/m2.
L’intensità sonora rapportata ad una intensità di riferimento ed espressa sulla scala dei deciBel prende il nome di Livello di Intensità Sonora (Sound Intensity Level –
SIL) ed è data dalla relazione
SIL = 10 log (I/I0) dB
dove I è l’intensità del suono, I0 = 10-12 Watt/m2 è l’intensità di riferimento: quella
del suono più debole (le misure sono eseguite per un suono sinusoidale puro ad 1kHz) che una persona media riesce ad ascoltare.
L’intensità del suono è tuttavia strettamente legata alla pressione che la vibrazione sonora esercita sul timpano. Si definisce dunque una ulteriore unità di misura sempre sulla scala dei deciBel che prende il nome di Livello di Pressione Sonora (Sound Pressure Level - SPL) ed è data dalla relazione
SPL = 20 log (P/P0) dB
dove P è la pressione e P0 = 20×10-6Paè la pressione di riferimento e caratterizza
la soglia minima di udibilità per un suono sinusoidale puro ad 1kHz. Poiché Pµ vale la seguente relazione: I2
20 log (P/P0) = 10 log (I/I0).
Nel seguito le misure di intensità vengono riportate in termini di SPL.
3.1.1 Soglia assoluta di udibilità
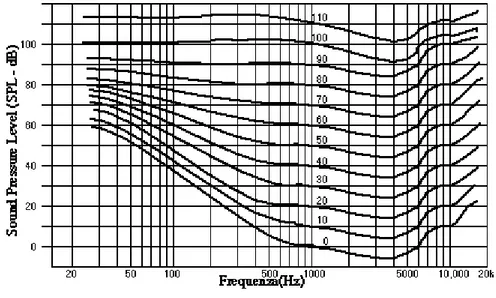
La soglia assoluta di udibilità [17, 20] indica la quantità minima di energia necessaria ad un suono affinché sia percepibile ad un ascoltatore in un ambiente privo di rumori. La soglia è una delle curve del diagramma di Fletcher-Munson (fig. 3.1) costruito nel 1940 con i risultati di uno studio condotto su di un vasto campione di ascoltatori americani. I punti del diagramma sono toni ossia suoni si-nusoidali puri. Un tono è caratterizzato da una frequenza, sulle ascisse, e da una
intensità, misurata in dB - SPL sulle ordinate. Le frequenze prese in considera-zione coprono tutto lo spettro dell’udibile che va da 20Hz a 20kHz all’incirca per un individuo di giovane età. Le curve del diagramma di Fletcher-Munson sono
i-sofoniche: mettono insieme tutti i toni che l’orecchio percepisce dello stesso
vo-lume. Il volume viene misurato in foni: un tono misura x foni di volume se viene percepito con il medesimo volume di un tono di frequenza 1kHz che misura x dB
– SPL in intensità.
Dal diagramma di Fletcher-Munson si legge ad esempio che un tono di 70dB a 70Hz, uno di 50dB a 600Hz ed uno di 60dB a 10kHz appartengono alla stessa curva isofonica di 50 foni e pertanto vengono percepiti con lo stesso volume.
fig. 3.1: Diagramma di Fletcher-Munson.
La curva a 0 foni è la soglia assoluta di udibilità (Threshold in quiet). Il diagramma prevede curve fino a 130 foni: limite ultimo alla sensibilità dell’orecchio umano ed oltre cui si sfocia nella sensazione di dolore (nella fig. 3.1 le ultime curve non sono visibili). La curva a 0 foni si mostra irregolare con delle incurvature accentuate alle estremità, ha il punto di minimo assoluto a 3,4kHz cir-ca; la curva a 130 foni è invece piuttosto regolare. Lo spazio compreso fra le due curve rappresenta la dinamica dell’orecchio umano e varia da frequenza a fre-quenza. Le dinamiche maggiori sono comprese fra i 2kHz ed i 4kHz, più limitate quelle agli estremi dello spettro dell’udibile dove l’orecchio percepisce i toni a
partire da livelli energetici più alti e per un numero inferiore di variazioni di vo-lume.
Per avere una rappresentazione digitale del suono è necessario codificare tutta la dinamica dell’orecchio: per le basse frequenze il numero di livelli di quantizza-zione necessario a coprire tutta la dinamica è inferiore a quello necessario in corri-spondenza di 3,4kHz dove la dinamica è massima. Questo si traduce nel ricorso ad una quantizzazione non uniforme sullo spettro.
La soglia assoluta di udibilità viene approssimata dalla funzione (si veda
[20]): 4 3 3 3 . 3 10 6 . 0 8 . 0 3 6.5 10 10 10 64 . 3 ) ( 2 3 ÷ ø ö ç è æ + -÷ ø ö ç è æ = ÷ø -ö ç è æ -f e f f T f q [dB SPL].
E’ possibile eliminare da un segnale le componenti frequenziali che hanno una energia inferiore alla soglia minima indicata dal valore corrispondente in Tq(f):
es-se sono percettivamente irrilevanti. Quello che invece sta al di sopra della
thre-shold in quiet deve essere preservato. Dall’analisi della threthre-shold in quiet risulta
in definitiva la quantità di energia che si può concedere alla codifica delle distor-sioni introdotte. Tipicamente si assegna 1 bit alla codifica del livello di energia minimo della soglia assoluta di udibilità (corrispondente a 3,4kHz) e si suddivide il resto della dinamica in un numero opportuno di livelli di quantizzazione asse-gnando all’interno di ciascuno di essi 1 bit ogni 6dB.
3.1.2 Bande critiche
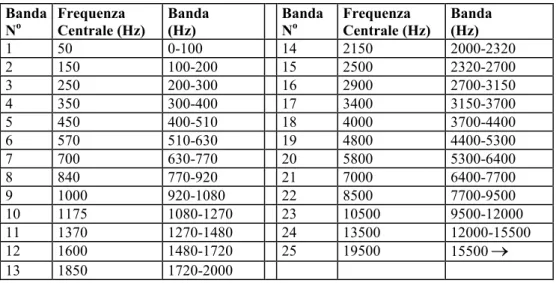
L’orecchio esegue una elaborazione del suono che è una vera e propria a-nalisi spettrale e la precisione con cui viene operata questa aa-nalisi è dettata dalla struttura delle bande critiche. L’analisi avviene ad opera della Membrana Basilare che si trova in una parte dell’orecchio chiamata orecchio interno. Essa è la desti-nataria ultima delle vibrazioni che, raccolte dal timpano, si propagano lungo le strutture auricolari e vengono parzialmente affinate allo scopo di migliorarne la
percezione [20, 27]. Quando la membrana viene sollecitata da una vibrazione, di-venta sede di un’onda viaggiante che si propaga come in una corda tesa, dalla base (dove giunge lo stimolo), fino all’apice. La membrana basilare ha una struttura di-somogenea lungo tutta la sua lunghezza (35mm appena): stretta e sottile in pros-simità della base, spessa e larga all’apice, è caratterizzata da una rigidità differente da punto a punto; questo fa si che durante la sua propagazione l’onda viaggiante abbia una ampiezza che dapprima aumenta, raggiunge un massimo e poi decresce fino ad estinguersi completamente.
Banda
No Frequenza Centrale (Hz) Banda (Hz) Banda No Frequenza Centrale (Hz) Banda (Hz)
1 50 0-100 14 2150 2000-2320 2 150 100-200 15 2500 2320-2700 3 250 200-300 16 2900 2700-3150 4 350 300-400 17 3400 3150-3700 5 450 400-510 18 4000 3700-4400 6 570 510-630 19 4800 4400-5300 7 700 630-770 20 5800 5300-6400 8 840 770-920 21 7000 6400-7700 9 1000 920-1080 22 8500 7700-9500 10 1175 1080-1270 23 10500 9500-12000 11 1370 1270-1480 24 13500 12000-15500 12 1600 1480-1720 25 19500 15500® 13 1850 1720-2000
Tabella 3.1: Bande critiche della Membrana Basilare.
Il punto della membrana basilare in cui l’onda raggiunge l’ampiezza mas-sima dipende dalla frequenza della sollecitazione: dalla base all’apice si hanno ri-sposte massime in corrispondenza di sollecitazioni a frequenze via via decrescenti. Ciascun punto della membrana risponde con ampiezza massima solo ad una ben precisa frequenza nota come frequenza caratteristica per quel punto; i punti dell’intorno che rispondono alla medesima frequenza, seppure con intensità infe-riore, appartengono alla banda critica di quella frequenza. Una banda critica si comporta dunque come un filtro passa–banda che ha come frequenza centrale la frequenza caratteristica, come banda l’ampiezza stessa della banda critica e che seleziona del suono in ingresso le componenti spettrali nell’intorno della fre-quenza caratteristica reiettando tutte le altre. Sono state individuate sulla mem-brana basilare 25 bande critiche (tabella 3.1), le loro ampiezze non sono costanti
ma aumentano con la frequenza caratteristica; resta tuttavia costante con buona approssimazione il fattore di qualità (Q = frequenza centrale / ampiezza di banda). La distanza fra bande critiche viene espressa in bark: uno, due, tre bark riferiscono la prima, seconda, terza
banda critica. Per capire come lavorano le bande critiche è utile descri-vere qualcuno degli e-sperimenti che hanno portato a definirne le ampiezze [20]. In una
prima esperienza si prevede l’utilizzo di una sorgente di rumore a banda stretta che emetta sempre alla medesima intensità (livello SPL), e che possa allargare la banda del rumore
pro-dotto fino a coprire la banda critica (fig. 3.2). Il volume che viene percepito dall’orecchio resta costante per tutto il tempo che lo spettro del rumore rimane
all’interno della banda critica, indipendentemente dalla sua larghezza; quando la banda del rumore supera i limiti della banda critica e vengono sollecitate bande adiacenti, il volume percepito aumenta.
Dunque in un pattern di stimolazione non conta il numero di frequenze stimolate all’interno della stessa banda critica (a parità di intensità):la risposta si mantiene immutata fino a quando non viene sollecitata un’altra banda critica la cui risposta si somma alla prima.
In una seconda esperienza si prevede ancora l’utilizzo di un generatore di rumore a banda stretta che possa stavolta emettere con livelli di intensità via via
Intensità
Rumore
Banda Larga
Freq. fig. 3.2: Misurazione bande critiche – prima esperienza.
Sound Pressure Level (dB) Soglia di udibilità
,f
Freq. fcb ,f fig. 3.3: Misurazione bande critiche – seconda esperienza.
Sound Pressure Level (dB) Soglia di udibilità ,f
Freq. fcb
,
f fig. 3.4: Misurazione bande critiche – seconda esperienza con tonie rumore invertiti.
crescenti, ed in aggiunta le sorgenti per due toni puri con frequenze poste ai due lati della banda del rumore. La percezione del rumore è “disturbata” dalla presen-za dei due toni, per poterlo avvertire è necessario aumentarne l’intensità fino al raggiungimento di una certa soglia di percezione. Spostando i due toni in modo che si allontanino dalla
banda del rumore, la soglia di percezione della sorgente di rumore a banda stretta resta costante per tutto il tempo che le
frequenze di separazione fra i toni restano all’interno della stessa banda critica. Oltre la banda critica, la soglia di percezione decresce rapidamente (fig. 3.3). Una esperienza analoga può essere ripetuta invertendo i ruoli di toni e rumore (fig. 3.4).
In conclusione, il comportamento della membrana basilare è in tutto assi-milabile ad uno scompositore di spettro e si parla a tal proposito di comporta-mento tonotopico. Ciascuna banda critica stimola un suo sottoinsieme di recettori neurali. Quando la membrana basilare è sollecitata da un suono complesso com-posto da più componenti frequenziali, vengono stimolate diverse bande critiche determinando un pattern di attivazione delle fibre nervose afferenti dal quale il si-stema nervoso riesce a dedurre sia l’altezza sia l’intensità del suono stimolatore.
3.1.3 Mascheramento Simultaneo
L’apparato uditivo umano riesce a discriminare perfettamente i toni che eccitano la membrana basilare in corrispondenza di bande critiche differenti, ana-logamente, nel caso di suoni complessi, esso riesce a distinguere nitidamente le singole componenti spettrali se localizzate in bande critiche diverse mentre delle parziali che ricadono in una stessa banda critica, qualcuna può mascherare le al-tre. Il mascheramento simultaneo [17, 20] si riferisce a quel fenomeno per il quale un forte rumore oppure un forte tono all’interno di una stessa banda critica ha la capacità di inibire la percezione di suoni più deboli. E’ oltremodo possibile de-scrivere la banda critica come quell’insieme di frequenze all’interno del quale si verificano i fenomeni di mascheramento.
Vengono distinte tre forme di mascheramento simultaneo: è possibile ave-re del rumoave-re che maschera un tono (Noise–Masking-Tone), un tono che maschera del rumore (Tone–Masking-Noise), del rumore che maschera dell’altro rumore (Noise–Masking-Noise).
Le esperienze condotte sul primo tipo di mascheramento (Noise-Masking-Tone) noto anche come mascheramento non tonale, hanno concluso che quando all’interno di una banda critica, per tutta la sua estensione, c’è del rumore di inten-sità costante su tutta la banda, i toni che, all’interno della stessa banda critica, hanno intensità inferiore ad una certa soglia, vengono completamente mascherati. L’altezza della soglia di mascheramento dei toni è predicibile e dipende dall’intensità del rumore stesso, ed, in minore misura, dalla sua frequenza cen-trale. Il mascheramento maggiore si ha in corrispondenza della frequenza centrale della banda del rumore (coincidente, per ipotesi, con la banda critica), alle fre-quenze via via distanti l’altezza della soglia si abbassa seguendo una “legge di dif-fusione”. Un tono alla frequenza centrale della banda di rumore deve avere per-tanto una ampiezza maggiore di quella che occorrerebbe in qualunque altro punto della banda critica per essere avvertito. L’indice SMR (Signal to Mask Ratio) mi-sura il rapporto fra l’ampiezza del segnale mascherante (Signal è il rumore in
que-sto caso) e quella della soglia di mascheramento (Mask); il suo valore in corri-spondenza della frequenza centrale della banda critica è minimo, compreso tra –5 e +5 dB.
Nel secondo tipo di mascheramento, noto come mascheramento tonale (Tone– Masking-Noise) si osserva come un tono all’interno di una banda critica riesca a mascherare la presenza di rumore a banda stretta diffuso su tutta la banda critica purché di intensità costantemente inferiore ad una certa soglia determinabile in funzione dell’ampiezza del tono mascherante e, seppure in minor misura, della sua frequenza.
Il minimo rapporto SMR (laddove cioè il tono maschera meglio il rumore) si ha quando la frequenza del tono mascherante è prossima alla frequenza centrale della banda del rumore mascherato; il suo valore compreso fra 21 e 28 dB.
E’ evidente come il mascheramento operato dal rumore sia più efficace di quello operato da un singolo tono: affinché un tono si avverta in presenza di rumore ma-scherante deve avere un livello di intensità molto elevato, più di quanto, nella stessa banda, servirebbe al rumore per essere avvertito in presenza di un tono ma-scherante (ovviamente a parità di intensità dei segnali mascheranti).
L’ultimo tipo di mascheramento, infine, è quello in cui si ha del rumore a banda stretta che maschera dell’altro rumore a banda stretta all’interno della banda cri-tica (Noise–Masking-Noise). E’ il tipo di mascheramento meno conosciuto per via delle complesse relazioni di fase fra i rumori.
I modelli matematici che descrivono le soglie di mascheramento sfruttano di solito le seguenti formule [20]:
THN = ET – 14.5 – B in esperimenti di TMN; THT = EN – K in esperimenti di NMT;
dove THN e THT sono rispettivamente le soglie di mascheramento del rumore e
del tono, ET ed EN sono i livelli energetici del tono mascherante e del rumore
ma-scherante rispettivamente, K è una costante che può essere scelta fra 3 e 5 dB, B è il numero della banda critica. Le formule descrivono il contributo individuale alle soglie dovuto ai singoli mascheranti di tipo tono o rumore.
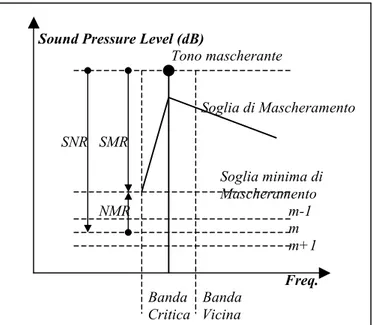
Sound Pressure Level (dB) Tono mascherante Soglia di Mascheramento SNR SMR Soglia minima di Mascheramento NMR m-1 m m+1 Freq. Banda Banda Critica Vicina
fig. 3.5: Rappresentazione schematica del mascheramento simultaneo.
Oltre al mascheramento intra-banda descritto fin qui, è stato osservato pure un mascheramento inter-bande. Un segnale mascherante, tono o rumore, all’interno di una banda critica, ha la capacità di influenzare le soglie di masche-ramento all’interno di altre bande critiche. Questa influenza viene spesso model-lata attraverso una funzione di diffusione (spreading function) dalla forma trian-golare:
SFdB(x) = 15.81 + 7.5(x + 0.474) – 17.5( 1 + (x + 0.474)2 )1/2 dB
Nell’ambito di uno schema di compressione di tipo percettivo è necessario individuare banda per banda le entità mascheranti distinguendole in toni (masche-ramento tonale) o rumore (masche(masche-ramento non tonale), costruire le rispettive so-glie di mascheramento e finalmente riunirle in un’unica soglia di mascheramento globale.
La soglia di maschera-mento globale realizza una stima del livello in cui il rumore di quantizzazione introdotto con la codifica diventa appena percepibile, viene infatti definita come
Just Noticeable Distorsion (JND); è necessario infine
tener conto della soglia as-soluta di udibilità, pertanto la soglia di distorsione
con-sentita viene ottenuta come Max(JND, Tq).
La fig. 3.5 offre una rappresentazione schematica del mascheramento si-multaneo. Si osserva una banda critica all’interno della quale è presente un tono mascherante che impone una soglia di mascheramento all’interno ed all’esterno della banda critica stessa (mascheramento intra- ed inter-banda). A seconda del numero di bit riservati alla codifica dell’intensità del tono (m, m+1, m-1), viene
ricoperta una dinamica più o meno ampia ed introdotta conseguentemente una di-storsione variabile: all’aumentare del numero di bit la dinamica coperta cresce mentre la distorsione introdotta diminuisce. Vengono indicati dei rapporti signifi-cativi:
· SNR (Signal to Noise Ratio) che misura in dB il rapporto fra l’ampiezza del tono mascherante e quella del rumore di quantizzazione introdotto; · SMR (Signal to Mask Ratio) che è il rapporto fra l’ampiezza del tono
mascherante e l’ampiezza minima della soglia di mascheramento all’interno della banda critica: maggiore questo rapporto, minore il potere mascherante del tono;
· NMR (Noise to Mask Ratio), infine, misura il rapporto fra la soglia del rumore di quantizzazione introdotto e la soglia minima di maschera-mento, coincide con il rapporto dei due indici di cui sopra.
Poiché la soglia minima di mascheramento corrisponde al livello di maschera-mento garantito su tutta la banda, essa misura pure la quantità di distorsione sop-portabile dalla banda tutta, pertanto l’allocazione di bit all’interno della banda può essere fatta sulla base di questa soglia, coprendo la dinamica descritta dal rapporto SMR.
3.1.4 Mascheramento temporale
Le capacità di mascheramento fin qui esaminate mostrano i loro effetti nell’arco temporale di durata del suono mascherante stesso: si è parlato infatti di mascheramento simultaneo. Il mascheramento simultaneo si manifesta temporal-mente dall’attacco del suono mascherante, fino all’istante in cui la sorgente ne termina l’emissione. E’ stato tuttavia osservato come taluni segnali riescano a produrre effetti di mascheramento che vanno al di là della loro durata temporale, elevando la soglia di udibilità sia prima dell’attacco (pre-mascheramento) sia do-po l’interruzione dell’emissione (do-post-mascheramento). Si parla di
Incremento Soglia di udibilità Segnale Mascherato (dB) 60
40 Pre- Simultaneo Post-Mascheramento 20
Tempo (ms) -50 0 50 100 150 0 50 100 150 200
fig. 3.6: Mascheramento temporale Mascherante
mento temporale [17, 20] poiché il fenomeno è legato unicamente alle caratteristi-che temporali del segnale mascaratteristi-cherante e non alla sua composizione spettrale come avviene nel mascheramento simultaneo. Nelle caratteristiche temporali sono com-prese la durata del segnale (dall’attacco all’interruzione di emissione) e la velocità dell’attacco: un segnale provoca mascheramento temporale se è improvviso e re-pentino (si pensi ai piatti di una batteria).
Il mascheramento temporale mostra caratteristiche di asimmetria: ma-scheramento e post-mama-scheramento hanno infatti durate differenti (fig. 3.6). Il pre-mascheramento può estendersi per al più 2ms secondo alcuni, 5ms secondo altri. L’incertezza sulla sua
durata massima è do-vuta al fatto che come fenomeno è poco cono-sciuto (meno del post-mascheramento). Dagli studi risulta che gli ef-fetti del
pre-maschera-mento decadono più velocemente di quanto non accada nel post-mascherapre-maschera-mento, infatti è stato osservato come 2ms prima dell’attacco del segnale mascherante la soglia di mascheramento scenda già di 25dB rispetto alla soglia di mascheramento simultaneo imposta dal segnale stesso. Tuttavia è stato pure osservato come la du-rata massima del pre-mascheramento sia fortemente dipendente dalla sensibilità e dall’allenamento uditivi dei soggetti impiegati nelle esperienze.
Il post-mascheramento può essere “osservato” in una esperienza in cui due suoni siano sovrapposti inizialmente ed uno cessi all’improvviso. L’orecchio riesce a percepire lo stop del primo segnale e ad avvertire nitidamente il secondo con un ritardo che va dai 50 ai 300ms. Altre esperienze hanno dimostrato come la durata del post-mascheramento imposto da un segnale mascherante su di un segnale campione dipenda in modo predicibile dalle intensità, durata e frequenza del tono mascherante, dal ritardo di attacco del tono campione dopo l’interruzione del
scherante e dalle frequenze mutue di tono mascherante e tono campione (il ma-scheramento è più efficace quando i due toni hanno la medesima frequenza).
Gli effetti del mascheramento temporale sono stati presi in considerazione in molti algoritmi di compressione audio; una particolare attenzione è stata pre-stata al pre-mascheramento ed alla sua capacità di coprire un artificio introdotto dalla compressione stessa ed avvertibile come un rumore che si diffonde prima dell’attacco del segnale stesso: prende il nome di pre-eco [25]. A volte il pre-ma-scheramento riesce a coprire la pre-eco, altre invece, la pre-eco ha una estensione che va oltre i limiti del pre-mascheramento.
3.1.5 Entropia percettiva
L’entropia percettiva è una misura dell’informazione percettivamente rile-vante in un segnale audio [17, 20]. Viene espressa in bit per campione e rappre-senta il limite teorico alla comprimibilità di un segnale audio: un compressore che si limiti a codificare solo l’entropia percettiva del segnale in ingresso ottiene co-munque un risultato percettivamente equivalente al suono originario prodotto alla sorgente. Da una ampia serie di misure di entropia percettiva risulta che gran parte del materiale audio di qualità CD-Audio può essere rappresentato, in trasparenza, con appena 2,1 bit per campione.
Per calcolare l’entropia percettiva di un segnale è necessario: i. suddividere il segnale in frammenti (nel dominio del tempo);
ii. fare una analisi frequenziale di ciascun frammento e separare le varie com-ponenti dello spettro nelle bande critiche di appartenenza;
iii. eseguire una analisi delle bande critiche (per frammento) discriminando, per ciascuna di esse, i casi di mascheramento da tono e quelli di mascheramento da rumore, definendo le soglie di mascheramento (tenendo oltremodo conto della soglia assoluta di udibilità) e calcolando il rapporto SMR;
iv. assegnare un certo numero di bit a ciascuna banda di ciascun frammento in base al rapporto SMR.
3.2 Schema generale di compressione percettiva
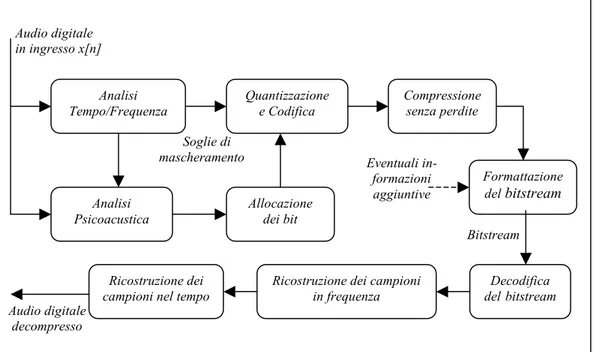
La compressione percettiva opera seguendo lo schema generale [17] mo-strato in fig. 3.7.
In ingresso c’è una sequenza di campioni temporali che rispetta uno standard CD-Audio o DAT o altro e che costituisce un segnale tempo discreto a valori binari:
siano x
[ ]
n la sequenza e T il suo periodo di campionamento.Il blocco di Analisi Tempo/Frequenza suddivide la sequenza
tempo-ralex
[ ]
n in frammenti (frame) ciascuno dei quali copre dai 2 ai 50ms di riprodu-zione. Un frammento è una sequenza aperiodica di N campioni e viene trattatoin-dipendentemente dagli altri come segnale a sé stante. All’interno del blocco viene eseguita l’analisi spettrale che produce per ciascun frammento temporale del se-gnale originario un corrispondente frammento nel dominio delle frequenze. Le modalità con cui viene eseguita l’analisi possono essere diverse: si parla di tran-sform coding quando viene eseguita un’unica operazione di tratran-sformazione; di
Audio digitale in ingresso x[n] Soglie di mascheramento Bitstream Audio digitale decompresso
fig. 3.7: Schema generale di compressione di tipo percettivo.
Compressione senza perdite Analisi Tempo/Frequenza Quantizzazione e Codifica Analisi Psicoacustica Allocazione dei bit Formattazione del bitstream Ricostruzione dei campioni nel tempo
Ricostruzione dei campioni in frequenza Decodifica delbitstream Eventuali in-formazioni aggiuntive
subband coding quando viene usato un banco di filtri passa-banda e ciascuno di
essi esegue la sua trasformazione.
Il frammento nel dominio delle frequenze è composto da N campioni (lo stesso
numero di campioni del frammento temporale) e descrive, con una certa appros-simazione, il frammento temporale di partenza. L’approssimazione dipende dal fatto che mentre l’esatto equivalente del frammento temporale in ingresso è un se-gnale continuo nel dominio delle frequenze, l’Analisi Tempo/Frequenza si limita a
ricavare una semplice sequenza spettrale (campionamento in frequenza). Lo spet-tro così viene idealmente suddiviso in sottobande: ogni campione della sequenza “rappresenta” una sottobanda, e la continuità dello spettro è ricostruita con un’operazione di mantenimento di ciascun campione nella sua sottobanda (sample & hold). Una singola sottobanda, ha un unico valore di ampiezza per tutte le sue frequenze. L’Analisi Tempo/Frequenza non è, per quanto detto, una operazione
reversibile.
In parallelo all’Analisi Tempo/Frequenza viene operata l’Analisi Psicoa-custica. Viene compiuta una analisi spettrale per frammento in ingresso molto
ac-curata, infatti dagli N (tipicamente N = 32) campioni del frammento temporale
vengono ricavati 1024 o 2048 campioni in frequenza tramite una trasformazione
Fast Fourier Transform (FFT). I campioni ottenuti vengono quindi raggruppati in
sottobande coincidenti con quelle usate nell’Analisi Tempo/Frequenza, e per
cia-scuna di esse viene determinata la soglia di mascheramento. Il calcolo delle soglie di mascheramento è tanto più accurato ed efficace dal punto di vista della com-pressione finale quanto meglio le sottobande individuate approssimano le bande critiche della Membrana Basilare. Le soglie di mascheramento servono a definire l’ammontare massimo di distorsione introducibile nella sottobanda in fase di quantizzazione. L’Analisi Psicoacustica termina con il calcolo del rapporto SMR
e dell’entropia percettiva di ciascuna sottobanda.
Il blocco di Allocazione dei bit definisce il numero di bit da assegnare alla
codifica di ciascuna sottobanda: esso deve essere sufficiente a coprire la dinamica descritta dal rapporto SMR per quella sottobanda e deve essere tale che la somma
dei bit assegnati alle varie sottobande non ecceda il limite massimo definito per il bit-stream.
Il blocco di Quantizzazione e Codifica riceve in ingresso i risultati prodotti
dai blocchi di Analisi Psicoacustica e di Allocazione dei bit, e prepara il “campo”
alla compressione vera e propria raggruppando per ciascuna sottobanda le infor-mazioni relative a frammenti temporali successivi. Ogni frammento temporale è costituito, si ricorda, da N campioni temporali e vi corrispondono N campioni
fre-quenziali: uno per ogni sottobanda. Siano l i frammenti temporali consecutivi
rac-colti: per ciascuna sottobanda si collezionano dunque l campioni frequenziali in
uscita che descrivono l’evoluzione temporale per quella sottobanda. Per ognuna di queste sequenze viene predisposta un’operazione di quantizzazione definendo i parametri opportuni oltre ad un “fattore di scala” che va a dividere tutte le am-piezze dei campioni della sottobanda (in fase di decodifica il fattore di scala va a moltiplicare i campioni); codificare infatti il fattore di scala e gli scostamenti dal medesimo piuttosto che i singoli campioni per intero, risulta più vantaggioso ai fini della compressione.
Le sequenze (contenenti ciascuna l campioni) di tutte le sottobande vengono fatte
confluire finalmente in un unico blocco, frame, in uscita: ad ogni frame vengono
assegnati i bit della codifica finale.
Il blocco Compressione senza perdite prevede l’applicazione di tecniche di
compressione lossless classiche, che sfruttino le ridondanze statistiche, al flusso in ingresso.
Il blocco Formattazione del bitstream formatta ulteriormente la sequenza
di codici prodotta dalla Compressione al passo precedente: altera l’ordine delle
in-formazioni per limitare gli errori di trasmissione e la loro propagazione ed ag-giunge eventuali informazioni ausiliarie. Definisce il bit-stream finale.
In fase di decodifica il processo fin qui descritto viene ripercorso al contrario, sal-vo che per la parte di Analisi Psicoacustica che costituisce la differenza
Nei blocchi di Decodifica del bitstream, Ricostruzione dei campioni in fre-quenza e Ricostruzione dei campioni nel tempo è prevista l’individuazione
all’interno del bit-stream, delle informazioni audio e di quelle accessorie, la de-compressione, l’applicazione dei fattori di scala, la ricostruzione corretta delle se-quenze dei campioni in frequenza prima, nel tempo poi.
3.3 Lo standard MPEG ed il formato MP3
MPEG (Moving Pictures Expert Group) è un gruppo di lavoro delle orga-nizzazioni internazionali ISO/IEC nato nel 1988 per sviluppare gli standard di co-difica per immagini in movimento, audio e loro combinazione. Successivamente MPEG ha intrapreso anche la standardizzazione delle tecniche di compressione video ed audio. La prima fase di lavoro del gruppo è stata denominata MPEG-1 ed è terminata nel 1992 con la produzione dello standard IS 11172. La sezione dello standard dedicata alla codifica audio (IS 11172-3) [21] descrive tre modalità di compressione chiamate livelli (layer-1, layer-2, layer-3). Ciascun livello è un per-fezionamento di quello precedente ed il livello 3 (MPEG-1 layer-3) è quello di complessità maggiore, ideato per provvedere la migliore qualità audio al minor bit-rate possibile (in genere 128kbps per un tipico segnale stereo): è meglio cono-sciuto come MP3, ed è diventato lo standard de facto per la trasmissione di audio
3.3.1 Algoritmo di compressione
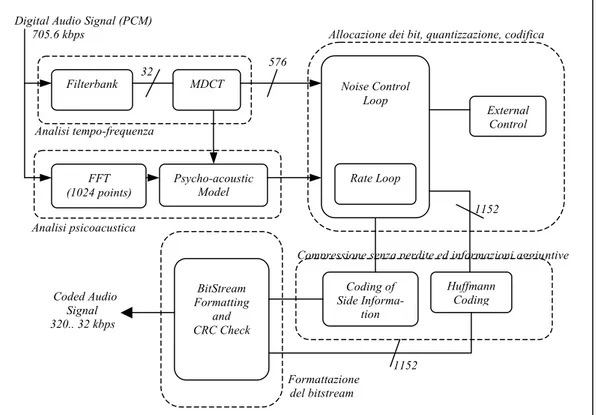
La compressione descritta nello standard MPEG-1 layer-3 [17, 18, 19, 25] rispetta nella struttura generale il modello visto per la compressione percettiva, i dettagli dei singoli moduli sono in parte visibili nella fig. 3.8.
Il segnale in ingresso (PCM a 16 bit) viene suddiviso in frammenti conte-nenti, ciascuno, 32 campioni audio temporali.
Il blocco Analisi Tempo/Frequenza (ricostruito dal tratteggio) esegue una codifica ibrida. Essa prevede un banco di filtri (Filterbank) in ingresso che fa
l’analisi spettrale di ciascun frammento: lo spettro è suddiviso in 32 sottobande di uguale ampiezza e vengono restituiti perciò 32 campioni in frequenza per ogni frammento temporale. In seguito viene applicata la trasformata MDCT (Modified Discrete Cosine Transform): dal susseguirsi di più frammenti temporali in
Digital Audio Signal (PCM)
705.6 kbps Allocazione dei bit, quantizzazione, codifica
576 32 Analisi tempo-frequenza 11521115151 Analisi psicoacustica
Compressione senza perdite ed informazioni aggiuntive Coded Audio Signal 320.. 32 kbps 1152 Formattazione del bitstream
fig. 3.8: Schema di compressione MPEG1-layer3 (MP3). BitStream Formatting and CRC Check Huffmann Coding Coding of Side Informa-tion 1152 External Control Noise Control Loop Rate Loop FFT (1024 points) Psycho-acoustic Model 32 MDCT Filterbank
gresso si ottiene che ciascuna delle 32 sottobande individuate dal filterbank venga suddivisa a sua volta in 18 parti (MDCT a 18 punti) e vengano restituiti così 18 campioni per ciascuna sottobanda. Il blocco di trasformazione MDCT fa corri-spondere uno spettro di 576 (18´32) campioni in uscita, ad una finestra tempo-rale in ingresso (al filterbank) di 36 frammenti ed un totale di 1152 campioni au-dio (36 frammenti ´ 32 campioni ciascuno). Le finestre temporali in ingresso si sovrappongono le une con le altre per metà, ed accade così che si abbia un’uscita di 576 campioni in frequenza ogni 18 frammenti temporali in ingresso corrispon-denti a 576 (18´32) campioni temporali: esiste, si può concludere, una corrispon-denza 1 ad 1 fra il numero di campioni temporali in ingresso ed il numero di cam-pioni frequenziali in uscita dal blocco Analisi Tempo/Frequenza. Su alcuni
fram-menti, soprattutto quelli soggetti a pre-eco, viene applicata la MDCT a 6 punti: per ciascuna sottobanda vengono prodotti 6 piuttosto che 18 campioni (in ingresso una finestra temporale di 12 frammenti che si riduce a 6, di fatto, per effetto della sovrapposizione) e vengono messe insieme 3 uscite consecutive (3 immagini con-secutive dello spettro) a creare nuovamente un blocco di 576 campioni in fre-quenza in uscita (32´6´3).
Terminata la codifica ibrida, il blocco Analisi Tempo/Frequenza ridefinisce le
sot-tobande in funzione di certe quantità denominate fattori di scala. Ciascuno dei
576 campioni in frequenza ottenuti, viene associato ad un fattore di scala per il quale viene diviso: da questo momento il campione è sostituito dalla coppia < fat-tore di scala, rapporto>. I fattori di scala vengono scelti in maniera tale che più campioni possano condividerne uno stesso: l’insieme dei campioni (fra i 576 pos-sibili) che condivide lo stesso fattore di scala costituisce una nuova sottobanda. Si
parla nello specifico di bande dei fattori di scala: esse approssimano bene le
ban-de critiche ban-della Membrana Basilare.
Il blocco di Analisi Psicoacustica (ricostruito dal tratteggio) applica una
trasformazione FFT a 1024 punti ottenendo una definizione assai accurata dello spettro di ciascun frammento in ingresso e definisce le soglie di mascheramento del rumore per ciascuna banda critica nello spettro e calcola i rapporti SMR che
serviranno nella fase di allocazione dei bit (è prima necessaria una procedura di allineamento con lo spettro calcolato dal blocco di Analisi Tempo/Frequenza). Lo
standard definisce due modelli psicoacustici di diversa complessità da poter se-guire in questa fase.
Il blocco di Quantizzazione e Codifica (Noise Control Loop + Rate Loop)
opera una quantizzazione non uniforme (companding) all’interno di ciascuna ban-da dei fattori di scala ed assegna ad ognuna di esse un certo numero di bit. L’assegnamento dei bit avviene in seguito a ripetute prove iterative organizzate in
due cicli annidati:
· il ciclo interno (rate loop) verifica che la dimensione in bit del frame in “costruzione” non ecceda il limite massimo fissato dal bit-stream (si veda sotto lunghezza nominale del frame): tiene conto del meccanismo del bit-reservoir (si veda sotto) e del fatto che i campioni verranno
successiva-mente compressi con l’algoritmo di Huffmann. Se il numero di bit che ri-sulta dalla codifica di una sottobanda è in esubero rispetto al numero di bit a disposizione, occorre applicare un compading più efficace allargando i passi di quantizzazione ed aumentando di conseguenza l’errore.
· il ciclo esterno (noise control loop) controlla che il rumore si mantenga sotto la soglia di mascheramento della sottobanda (che corrisponde all’incirca ad una banda critica). Ogni volta che il rumore di quantizza-zione di una sottobanda oltrepassa la soglia di mascheramento si corregge il fattore di scala aumentando così il numero di bit da assegnare alla sotto-banda e si ripete il ciclo interno per verificare la correttezza dell’intervento.
Al termine, i campioni quantizzati vengono ordinati per frequenze crescenti all’interno di ciascuna banda critica.
Il blocco di Codifica senza perdite (Huffmann Coding) comprime con
l’algoritmo di Huffmann i campioni quantizzati ed ordinati all’interno di ciascuna banda critica, assieme al fattore di scala ed alle informazioni sulla allocazione dei bit. L’algoritmo di Huffmann lavora su coppie di valori e, nel caso di ampiezze
piccole da codificare, su quadruple. Utilizza inoltre tabelle di codici differenti per diverse parti dello spettro che sono caratterizzate da statistiche differenti.
Il blocco di Formattazione del Bitstream (Bitstream Formatting and CRC Check) costruisce i frame (fig. 3.9) del bit-stream finale; ciascuno comprende
l’informazione audio vera e propria (Main Data) di 1152 (576´2) campioni in frequenza, un’intestazione (Header), una parola di controllo CRC opportunamente
calcolata, delle informazioni collaterali (Side Information). Le informazioni
col-laterali contengono, tra l’altro, i fattori di scala ed il numero di bit allocati a cia-scuna banda; in questa fase si tiene conto di:
· variabilità del bit-rate (VBR): ciascun frame può essere codificato con un bit-rate (realizzato in fase di compressione dai cicli annidati Noise Control Loop e Rate Loop) diverso ed avere pertanto una lunghezza differente
da-gli altri; il bit-rate della codifica è riportato nell’intestazione (Header) del
frame;
· Bit Reservoir: ogni volta che la compressione di 1152 campioni produce un risultato inferiore alla lunghezza nominale (si veda sotto) di un frame, i
bit inutilizzati vengono accantonati in un serbatoio da cui vengono
ripe-scati in seguito da frame che invece hanno dimensioni eccedenti la ca-pienza nominale. I frame più grossi dunque possono cominciare in
anti-cipo impegnando zone dello stream riservate a frame precedenti ma non sfruttate, avranno pertanto dei puntatori all’indietro (solo) che segnalano il
loro inizio effettivo. I puntatori sono riportati nelle informazioni collaterali (Side Information).
Costruiti i frame, la loro sequenza viene composta nel bit-stream finale secondo il formato standardizzato (si veda sotto Formato di un file MP3).
fig. 3.9: Formato di un frame in un file MP3.
Infine, il Decoder analizza un frame alla volta: estrae il campo Main Data,
decomprime secondo Huffmann, ricostruisce, tenendo conto delle indicazioni
sull’allocazione dei bit e sui fattori di scala, le bande dei fattori di scala con i ri-spettivi campioni in frequenza (se una sottobanda non ha bit allocati i campioni sono a 0), applica ai 1152 campioni in frequenza estratti il banco di filtri (filter-bank) in modalità di sintesi e ricava i 1152 campioni audio temporali.
3.3.2 Formato di un file MP3
Il file MP3 [23] è una sequenza che appare come di seguito: [TAGv2] frame1 frame2 frame3… [TAGv1]
manca un’intestazione globale ed i campi TAG sono opzionali: possono essere as-senti entrambi, preas-senti entrambi, oppure può essercene uno solo.
Il TAGv1 si trova alla fine del file, è lungo 128 byte e contiene informa-zioni sui nomi delle canzoni, gli artisti, l’album, l’anno di pubblicazione, il genere musicale ed alcuni commenti. Il TAGv2, più recente del TAGv1, consente di memorizzare una quantità di informazioni maggiore ma è anche più complicato. Prevede uno header, che comprende tra l’altro la lunghezza completa del TAG, e più frame ciascuno dei quali ha a sua volta una intestazione ed un corpo. Viene usato un frame per ciascun tipo di informazione, ad esempio artista o album; al-cuni tipi di frame sono predefiniti ma è possibile definirne di nuovi per scopi non previsti.
I frame MP3 che seguono l’eventuale TAGv2 contengono ciascuno (fig. 3.9) un’intestazione (header), un campo per il controllo di errori (Cyclic Redun-dancy Check), un campo per le informazioni collaterali (Side Information), le
in-formazioni audio vere e proprie (Main Data).
L’intestazione (Header) di un frame [21, 23, 24, 26] è lunga 4 byte (32bit) ed appare così:
AAAAAAAA AAABBCCD EEEEFFGH IIJJKLMM
ciascuna lettera corrisponde ad un bit; i bit contrassegnati dalla stessa lettera ap-partengono allo stesso campo. Nel seguito i dettagli di ciascun campo.
A. Bit di Sincronizzazione: un totale di 11 bit tutti settati ad 1 che occupano le
posizioni più significative dell’intestazione (31-21). Servono per indivi-duare l’inizio di un frame, tuttavia, all’interno di un file binario è possibile trovare sequenze contigue di 1 che non siano quelle di sincronizzazione e pertanto, l’individuazione dell’inizio di un frame deve prevedere qualche accorgimento in più rispetto alla semplice ricerca della prima sequenza di 11 bit ad 1 consecutivi.
B. ID della Versione MPEG: codificato su due bit (20, 19) come segue
00 MPEG Versione 2.5 01 Riservato
10 MPEG Versione 2 (ISO/IEC 13818-3) 11 MPEG Versione 1 (ISO/IEC 11172-3) Nei file MP3 è indicato l’ID 11.
C. Layer: su due bit (18, 17) codificato come segue
00 Riservato 01 Layer III 10 Layer II 11 Layer I
Nei file MP3 è specificato l’identificativo 01. D. Bit di Protezione: un bit (16) che può valere
0 Controllo CRC presente 1 Controllo CRC non presente
Nei casi in cui la protezione è prevista, l’intestazione è immediatamente seguita da una parola di 16 bit contenente il controllo CRC. Quasi mai nei file MP3 è presente il controllo CRC.
E. Identificativo del bit-rate: codifica su quattro bit (15-12) il bit-rate totale
indipendentemente dalla modalità stereo, joint-stereo, dual-channel, single-channel. Seguono le corrispondenze:
0000 libero 0001 32 0010 40 0011 48 0100 56 0101 64 0110 80 0111 96 1000 112 1001 128 1010 160 1011 192 1100 224 1101 256 1110 320 1111 Illegale
I valori indicati sono espressi in kbps. “libero” indica che il bit-rate cor-retto non è fra quelli della tabella e che deve essere calcolato dall’applicazione; esso però deve essere fisso per tutta la durata del brano (CBR). “illegale” segnala che il codice corrispondente non può essere usa-to per indicare un bit-rate.
F. Frequenza di campionamento: è espressa su due bit (11, 10) secondo il
se-guente schema 00 44100Hz 01 48000Hz 10 32000Hz 11 riservato
G. Bit di Padding: un singolo bit (9) che serve ad indicare se il frame
com-prende o meno uno slot di padding in fondo.
0 nessun padding nel frame
1 presente slot di padding nel frame
L’operazione di padding serve a completare il frame per raggiungere la capienza esatta calcolata in funzione del bit-rate. Uno slot di padding è formato da 8 bit. Il padding è necessario solo con la frequenza di campio-namento 44,1kHz.
H. Bit privato: un singolo bit (8) che può essere usato liberamente per i
fabbi-sogni specifici di un’applicazione, ad esempio, per sollevare degli eventi. Non verrà usato in futuro dallo standard ISO.
I. Modalità di Canale: su due bit (7, 6)
00 Stereo
01 Joint Stereo (Intensity e/o MS-Stereo) 10 Dual Channel
11 Single Channel
La modalità maggiormente presente nei file MP3 è 01.
J. Estensioni della modalità di canale (solo per Joint Stereo): su due bit (5,
4), specifica il tipo di codifica riservato nel frame ai due canali destro e si-nistro della modalità Joint Stereo. Risultati psicoacustici dimostrano come al di sopra di una certa soglia di frequenza (intorno ai 2kHz) il sistema uditivo umano basi la percezione dell’immagine stereo di un segnale sull’inviluppo temporale dello stesso piuttosto che sulla sua struttura fine. Le modalità Intensity Stereo e Middle/Side Stereo sfruttano questa caratte-ristica per ottenere una compressione più spinta del segnale audio. Nella modalità Intensity Stereo per frequenze inferiori alla soglia stimata i
se-gnali dei due canali vengono codificati indipendentemente, per frequenze superiori vengono sommati prima della codifica.
Nella modalità MS Stereo invece, in alcuni intervalli frequenziali i canali destro e sinistro vengono sommati (Middle) ed in altri sottratti (Side) pri-ma della codifica.
Gli intervalli frequenziali in cui sono applicate le modalità Intensity-Stereo ed MS-Stereo sono implicite nell’algoritmo.
Vengono rispettate le seguenti corrispondenze: Intensity Stereo MS Stereo
00 off off
01 on off
10 off on
11 on on
K. Copyright: su di un bit soltanto (3) specifica
0 Audio non protetto da copyright 1 Audio protetto da copyright
L. Originale: un bit (2) per specificare
0 Copia 1 Originale
M. Enfasi: due bit (1, 0) per indicare il tipo di de-enfasi che viene usato.
00 Nessuna enfasi 01 50/15ms di enfasi 10 Riservato 11 CCIT J.17
Dalle informazioni contenute nello header di un frame (bit-rate, frequenza di campionamento dell’audio originale, bit di padding) è possibile ricavare la lun-ghezza del frame stesso tramite la seguente formula [21]:
[
] [
]
[
/]
8 ; / / 1152 int ] / [ ÷÷ø ö ççè æ × + ú û ú ê ë ê × = Padding s sample SR s bit BR frame sample frame bit FLdove FL (Frame Length) è la lunghezza del frame in bit, BR il Bit-Rate, SR
(Sam-pling Rate) la frequenza di campionamento, Padding una variabile booleana che
vale 0 se nel frame non è presente lo slot di padding, 1 se è presente; il risultato comprende pure la dimensione dell’intestazione del frame. Nel seguito la lun-ghezza così calcolata (FL) viene chiamata lunlun-ghezza nominale del frame.
La maggior parte dei file MP3 è ottenuta da un campionamento del segnale CD-Audio a 44,1kHz (SR) e da una compressione a 128kbps (BR): la lunghezza
nomi-nale dei frame è pertanto di 417 byte senza padding e 418 con padding.
La lunghezza dei frame è costante nei file CBR (Constant Bit-Rate) e va-riabile nei file VBR (Variable Bit-Rate) grazie al cosiddetto bit-rate switching. Si tratta di un meccanismo introdotto dallo standard MP3 allo scopo di ottenere una compressione ancora più spinta: le parti del segnale audio che contengono alte frequenze richiedono infatti maggiore spazio nella codifica rispetto alle parti che contengono basse frequenze; viene perciò applicato un bit-rate maggiore per codi-ficare le prime, inferiore per le ultime. Ovviamente questo comporta uno sforzo maggiore in fase di compressione ma anche di gestione del file finale, nel quale per saltare da un frame ad un altro è necessario calcolare tutte le lunghezze dei frame intermedi.
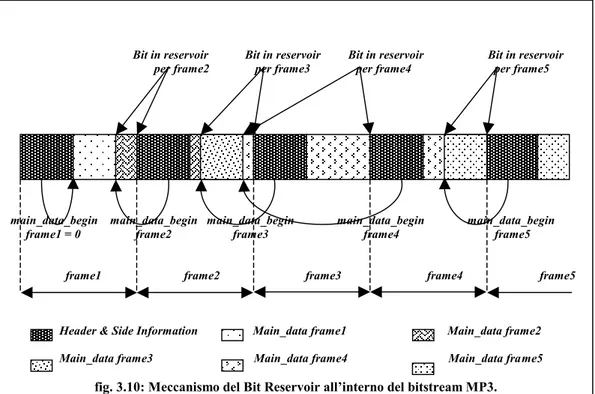
Nonostante le intestazioni separate i frame non sono completamente indi-pendenti gli uni dagli altri, ed anzi è presente una certa correlazione fra gli stessi dovuta al meccanismo di bit reservoir, introdotto come ulteriore novità dallo stan-dard MP3 (l’indipendenza consentirebbe alla riproduzione di partire da un qua-lunque punto del file oppure permetterebbe di riprodurre separatamente parti di-stinte del file). Come introdotto in precedenza, ogni volta che un blocco di 1152 campioni compressi non riempie tutta la capacità nominale di un frame, i bit inu-tilizzati vengono messi a disposizione dei frame successivi che possono aver bi-sogno di un numero maggiore di bit nella codifica. Nella zona riservata alle Side
punta-tore main_data_begin che punta al primo byte del contenuto audio di quel frame.
main_data_begin è un puntatore all’indietro e può indicare un salto di 512byte
(2 ) al massimo dal cui computo sono escluse le intestazioni dei frame. Il salto 9
maggiore all’indietro si ha quando i frame saltati hanno lunghezza minima (BR = 32kbps, SR = 48kHz) pari a 768 bit, intestazione (Header, CRC, Side Informa-tion) di ampiezza massima (32+16+256) pari a 304 bit e dimensione del campo Main Data (768-304) pari di conseguenza a 464 bit (58byte): il salto del
main_data_begin è dunque di úú ù êê é 58 512 = 9 frame.
La correlazione di un frame del bit-stream con gli altri si estende per quan-to osservaquan-to su di una finestra che comprende i 9 frame precedenti ed i 9 suc-cessivi. Nella fig. 3.10 viene mostrato il meccanismo del bit reservoir in un tratto del bit-stream.
L’intestazione del frame MP3 è seguita immediatamente dal campo CRC-check, nel caso in cui il bit di protezione dell’intestazione sia zero, e dalle Side In-formation che contengono il valore main_data_begin ed ancora, tra l’altro, i
Bit in reservoir Bit in reservoir Bit in reservoir Bit in reservoir per frame2 per frame3 per frame4 per frame5
main_data_begin main_data_begin main_data_begin main_data_begin main_data_begin frame1 = 0 frame2 frame3 frame4 frame5
frame1 frame2 frame3 frame4 frame5
Header & Side Information Main_data frame1 Main_data frame2 Main_data frame3 Main_data frame4 Main_data frame5
tori di scala ed il numero di bit allocati a ciascuna banda. Seguono in ultimo le in-formazioni audio vere e proprie (Main Data). Per maggiori dettagli sul contenuto dei campi si rimanda alle specifiche ISO [21].
Nel caso in cui il file MP3 sia di tipo VBR il primo frame della sequenza non ha contenuto audio, riporta bensì informazioni di controllo che servono a ge-stire la variabilità del bit-rate. Segue il formato [23] del primo frame:
i. Frame Header: dal byte 0 al byte 3, nella maggior parte dei casi vi si legge
il contenuto FF FB 30 4C che stabilisce tra l’altro che la lunghezza del frame è di 156 byte, sufficienti a raccogliere le informazioni sul file VBR.
ii. Sequenza non significativa: dal byte 4 fino alla stringa “Xing” (58 69 6E
67). La posizione a partire dalla quale si incontra questa stringa dipende dalla versione MPEG e dal tipo di canale.
iii. Stringa “Xing”: dal byte 36 al byte 39, nei file che esibiscono MPEG1 e
Canale ¹ Mono (più usato).
iv. Stringa “Xing”: dal byte 21 al byte 24, per i file che esibiscono MPEG1 e
Canale Mono.
Per i file MPEG1 con Canale ¹ Mono (i campi hanno importanza decrescente) si hanno poi:
v. Flags: dal byte 40 al byte 43. Sono previsti:
Valore Nome Descrizione
00 00 00 01 Frame flag 1 se presente il numero di frame del file 00 00 00 02 Byte flag 1 se presente la dimensione in byte del
file
00 00 00 04 TOC flag 1 se presente la tabella TOC 00 00 00 08 VBR Scale flag 1 se presente il VBR Scale
Tutti i valori possono essere presenti contemporaneamente.
vi. Frame: dal byte 44 al byte 47, specifica il numero di frame nel file.
viii. TOC (Type Of Content): dal byte 51 la byte 151, contiene una tabella di
100 indici (un byte ciascuno) per l’accesso diretto al file. Un byte può es-sere rintracciato all’interno del file con la seguente formula:
( TOC[i]/256 ) ´ FileLenInByte;
dove i è la posizione all’interno del file in termini percentuali. Se una can-zone dura ad esempio 240sec, e si vuole saltare al 60-esimo secondo di ri-produzione, si calcola dapprima i:
i = (60/240) ´ 100 = 25;
sia poi la dimensione complessiva del file pari a 5000000 byte: il byte cui saltare è approssimativamente (TOC[25]/256) ´ 5000000.
3.4 Protocolli per la trasmissione di un file Mp3 in
Internet
3.4.1 Real Time Protocol
La trasmissione di informazioni audio-video attraverso Internet è regolata da un protocollo che prende il nome di Real Time Protocol (RTP). L’applicazione che voglia spedire in rete delle informazioni audio-video le organizza in piccoli blocchi (chunk), assegna a ciascuno di essi una intestazione e li passa poi al li-vello di trasporto sottostante che ne gestisce la trasmissione. Tipicamente il lili-vello di trasporto è costituito da UDP ed offre all’applicazione un’interfaccia socket at-traverso la quale avviene la spedizione del pacchetto. Il protocollo RTP definisce un formato standard per le informazioni che l’applicazione deve aggiungere ai dati veri e propri in qualità di intestazione: il pacchetto così creato è il pacchetto RTP. Esso esibisce un’intestazione fissa che contiene informazioni generali, utili a qua-lunque applicazione che tratti dati audio-video ed una eventuale estensione inte-grativa dell’intestazione stessa. Le estensioni hanno lo scopo di specializzare il protocollo RTP in funzione della particolare classe di applicazioni che lo utilizza raccogliendo informazioni adeguate alle esigenze della stessa.
Le informazioni presenti nella parte fissa dell’intestazione del pacchetto RTP sono [11] (fig. 3.11):
· Versione (2 bit): specifica la versione del protocollo RTP; attualmente è in vigore la numero 2.
· Padding (1bit): settato quando in fondo al pacchetto ci sono dei byte ag-giuntivi di padding; l’ultimo byte del pacchetto ne specifica il numero. · Extension (1bit): settato quando è presente appena dopo la parte fissa
dell’intestazione, un extension header.
· CSRC count (4bit): specifica il numero di identificatori CSRC che seguono il formato fisso dell’intestazione.
· Marker (1 bit): una marca il cui significato cambia a seconda del Profilo RTP utilizzato. Il Profilo RTP è quella parte delle specifiche RTP dedicata ad una particolare classe di applicazioni e che oltre a definire il formato dell’ extension header ridefinisce alcuni campi dell’intestazione fissa.
0 2 3 4 8 9 16 31 V=2 P X CC M PT Sequence Number Timestamp SSRC CSRC …
fig. 3.11: Formato dello header RTP
· Payload Type (7 bit): identifica il formato audio/video trasportato nel pa-yload del pacchetto RTP. Tipicamente le tabelle di corrispondenza tipo-formato sono contenute nei Profili RTP.
· Sequence Number (16 bit): incrementato di una unità per ogni nuovo pac-chetto RTP trasmesso, serve a ripristinare lato ricevitore la sequenza di trasmissione dei pacchetti ed a scoprire eventuali perdite.
· Timestamp (32 bit): riflette l’istante di campionamento del primo byte con-tenuto nel pacchetto RTP; il timestamp è aumentato di una unità ad ogni istante di campionamento, pertanto due pacchetti RTP emessi conse-cutivamente esibiscono due timestamp che differiscono esattamente del numero di campioni memorizzati nel primo pacchetto.
· SSRC (Synchronization SouRCe identifier – 32 bit): identifica la sorgente che ha emesso i dati contenuti nel payload; non è un indirizzo IP bensì un numero random scelto dalla sorgente all’atto dell’emissione.
· CSRC (Contributing SouRCe identifers – da 0 a 15 valori, 32 bit
cia-scuno): identifica l’insieme delle sorgenti che hanno contribuito al payload
del pacchetto. Il numero di identificatori è dato dal precedente CSRC
en-tità chiamate Mixer dopo aver raccolto e rielaborato il contenuto di diversi stream, provenienti da diverse sorgenti, allo scopo di crearne uno solo, a-deguato alle esigenze specifiche di uno o più client destinatari: scopo degli identificatori CSRC è quello di documentare la provenienza originaria del-lo stream. Questi campi non sono sempre presenti e vengono usati soprat-tutto in scenari multicast.
L’incapsulamento RTP viene riconosciuto unicamente presso gli end-system di un contesto Internet
men-tre nessun router distingue datagram IP che trasportano pacchetti RTP da datagram IP che non li trasportano. Le informazioni dell’intestazione RTP vengono usate per ricostruire la sequenza temporale di invio dei pac-chetti, per riconoscere eventuali
per-dite, per identificare il formato audio/video dei dati presenti nel pacchetto, per controllare la sincronizzazione di differenti stream nella ricostruzione di un unico contenuto multimediale, per
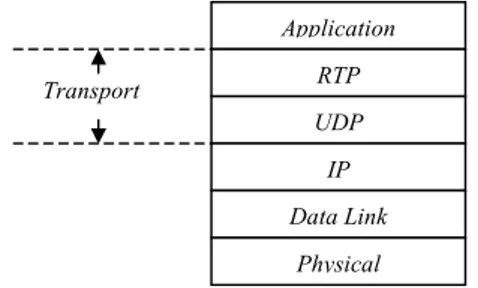
consen-tire corrette decodifica e riprodu-zione delle informazioni trasmesse. In qualità di protocollo che offre dei servizi al livello applicativo RTP può essere considerato un sottolivello del livello trasporto (fig. 3.12), tuttavia, a differenza di altri protocolli di
tra-sporto, non prevede nessun tipo di controllo di flusso né di congestione, non offre nessuna garanzia di affidabilità né di rispetto dei vincoli Real-Time di trasmissio-ne né di un qualche livello di qualità del servizio (QoS) trasmissio-nel trasferimento.
Application
fig. 3.13: RTP come parte del livello applicativo Application RTP Socket UDP IP Data Link Physical Transport
fig. 3.12: RTP come parte del livello trasporto Application RTP UDP IP Data Link Physical
E’ pur vero che RTP prevede la possibilità di aggiungere delle estensioni al for-mato standard del pacchetto, che potrebbero essere utilizzate per l’implementazione di funzionalità aggiuntive laddove necessario, e quindi anche affidabilità, controllo di flusso e controllo di congestione. Questo compito però è lasciato all’applicazione che gira sopra RTP e per la quale il protocollo RTP non è affatto trasparente.
Finora, RTP è stato implementato soprattutto nell’ambito applicativo e, sotto questa ottica, è possibile considerarlo parte integrante del livello applicativo stes-so (fig. 3.13). L’applicazione che voglia gestire la trasmissione e/o la ricezione di informazioni audio-video, deve infatti prevedere una parte di codice aggiuntiva al suo interno che realizzi le funzionalità RTP: che, in fase di trasmissione, incapsuli i blocchi di dati audio-video da trasferire nei pacchetti RTP e li spedisca at-traverso l’interfaccia offerta dal livello di trasporto e che, in fase di ricezione, prelevi i pacchetti che arrivano presso l’interfaccia del livello trasporto, ne estrag-ga il contenuto informativo ed utilizzi le informazioni delle intestazioni per con-trollare la decodifica dei dati e la loro riproduzione.
Il protocollo RTP è stato concepito attorno all’idea di Application Level
Framing (ALF) [14], in base alla quale la gestione delle perdite dei pacchetti,
co-me pure dell’arrivo dei pacchetti in ordine diverso da quello di spedizione deve essere delegata completamente all’applicazione. Essa soltanto, infatti, può deci-dere di ignorare le perdite oppure di ritrasmettere i dati mancanti prelevandoli da un buffer o rigenerandoli ex-novo o ancora, trasmettendo dei dati diversi da quelli perduti che li sostituiscano rendendoli obsoleti. Di fatto solo l’applicazione può scegliere la condotta migliore per gestire i suoi dati, scelte differenti saranno fatte da applicazioni differenti per via della loro diversa natura e dei loro diversi obiet-tivi.
Una gestione simile è possibile solo quando il livello di trasporto tratti i dati in u-nità cui sia riconosciuta integrità logica dall’applicazione stessa: si parla di
Ap-plication Data Unit (ADU). Una unità ADU è un insieme autonomo di dati che
dall’ordine di arrivo o dal fatto che le unità precedenti siano pervenute o meno. Una unità ADU contiene informazioni sufficienti a consentire la decompressione dei dati che contiene e la loro sistemazione ordinata all’interno della sequenza completa di informazioni in arrivo all’unità di ricezione. Per molte applicazioni un pacchetto RTP contiene naturalmente una unità ADU.
Un problema insidioso che può manifestarsi durante un trasferimento di dati è quello della frammentazione di livello IP imposta ai pacchetti che abbiano una lunghezza superiore alla Maximum Trasmission Unit (MTU) della rete sotto-stante. Questa pratica è responsabile in molti casi del fenomeno della
moltiplica-zione delle perdite. Se il contenuto di un pacchetto RTP viene frammentato in più
pacchetti IP, è possibile che il mancato arrivo di uno dei frammenti causi l’impossibilità di utilizzare anche le parti pervenute: è buona norma evitare di fare affidamento sulla frammentazione fatta a livello IP perché non rispetta l’unità lo-gica dei dati.
Le applicazioni che praticano un Application Level Framing concepiscono da sé le unità di trasferimento (framing) dei dati in base a criteri di indipendenza logica degli stessi e riescono a garantire quindi una certa tolleranza alle perdite e la pos-sibilità di decodificare ed utilizzare il contenuto di ciascun pacchetto indipenden-temente dagli altri.
Affinché un pacchetto RTP sia autonomo dagli altri è necessario:
i. costruire il payload del pacchetto secondo la concezione Application Level Framing,
ii. adattare lo RTP-header affinché contenga tutte le informazioni necessarie
alla decodifica del payload,
iii. aggiungere un po’ d’intelligenza presso gli end-point che devono cono-scere le caratteristiche della rete sottostante (part. MTU) ed effettuare un appropriato framing separando logicamente i dati prima della loro trasmis-sione.
Per realizzare quanto su esposto è necessario costruire i pacchetti RTP rispettando le seguenti indicazioni:
· I limiti di un pacchetto RTP dovrebbero coincidere con i limiti dei frame concepiti dal sistema di codifica/decodifica (codec) dei dati: un pacchetto RTP dovrebbe dunque comprendere uno o più codec frame completi. · Un codec frame non dovrebbe mai essere incapsulato in maniera tale da
trovarsi a cavallo fra due pacchetti RTP, a meno che la sua dimensione non ecceda la MTU (diminuita ovviamente delle lunghezze degli header IP, trasporto, RTP) della rete sottostante: in questo caso dovrà necessaria-mente attraversare la frontiera di un singolo pacchetto.
· Se la dimensione di un codec frame è maggiore della MTU (si veda so-pra), il formato del payload RTP non deve affidarsi alla frammentazione del livello IP ma definire il suo proprio meccanismo di frammentazione basato sulla conoscenza specifica del codec al fine di consentire la decodi-fica indipendente dei frame.
· I pacchetti RTP sono sottoposti alla compressione dello header; l’algoritmo di compressione funziona meglio quando il timestamp RTP cresce di un valore costante fra pacchetti consecutivi ossia quando i pac-chetti vengono trasmessi in ordine cronologico (trasmissioni out-of-order sono concepite per lo più come tecnica di FEC –si veda dopo
Interlea-ving-), e ciascuno di essi contiene un numero costante di codec frame.
3.4.2 RTP e formato MP3
Per il trasferimento di un file MP3 attraverso Internet è previsto l’utilizzo del protocollo RTP, tuttavia, il fatto che il sistema di compressione MP3 generi un
bit-stream piuttosto che una sequenza di frame indipendenti causa qualche
com-plicazione. In un file MP3 i singoli frame individuabili che cominciano con 11 bit di sincronizzazione e che hanno lunghezza nominale ricavabile indirettamente dal-le informazioni contenute nello header sono fra di loro fortemente dipendenti a causa del meccanismo di bit-reservoir. Un frame MP3, in breve, non è un’unità