Capitolo 1 Introduzione
1
Capitolo 1
Introduzione
Lo scopo di questa tesi è di sviluppare una tecnica per la classificazione automatica di bersagli radar. Infatti le prestazioni e l’affidabilità dei sistemi radar risultano troppo spesso dipendenti dall’attenzione e dall’esperienza degli operatori; per ovviare a questi inconvenienti risulta di interesse lo sviluppo di tecniche di rivelazione e classificazione automatiche. In particolare il tema dell’Automatic Target Recognition risulta attualmente uno degli aspetti più innovativi nel campo del Radar Signal Processing; per approfondire questa tematica e applicarla in campo radar, utilizzeremo alcuni strumenti matematici di una disciplina più generale chiamata Pattern Recognition.
Il Pattern recognition è la disciplina scientifica che ha come obiettivo la classificazione di oggetti in un determinato numero di categorie o classi. A seconda delle applicazioni questi oggetti possono essere immagini o forme d’onda o qualsiasi tipo di dato; noi ci interesseremo della classificazione di bersagli radar.
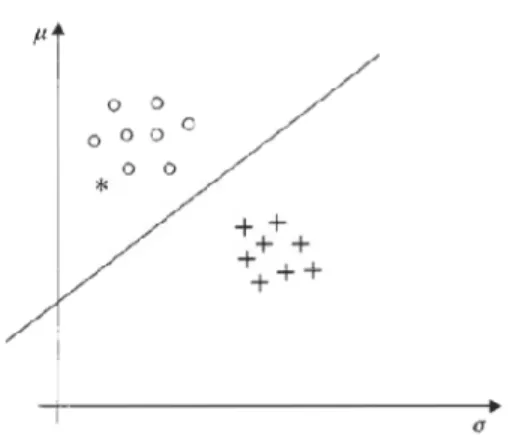
Un esempio di decisione binaria può essere il riconoscimento tra due generiche classi di bersagli (classe A e classe B), rappresentate ad esempio dalle loro statistiche, il valor medio e la deviazione standard.
Figura 1.1: Valor medio versus deviazione standard per un numero di differenti targets per la classe A(o) e la classe B(+)
Capitolo 1 Introduzione
2 Una regola di decisione opportuna può essere ad esempio trovare una retta che separi le due classi.
In pratica andiamo a misurare il valor medio e la deviazione standard nella regione di interesse e tracciamo il corrispondente punto indicato con * in figura 1.1. Naturalmente è più probabile che il pattern sconosciuto appartenga alla classe A che alla classe B.
Le misure utilizzate per la classificazione, il valor medio e la deviazione standard in questo caso, sono note con il nome di features.
Nel caso più generale vengono utilizzate l features che formano il feature vector :
1 2
[ ,x x ,..., ]xl =
x (0.1)
Ogni singolo feature vector identifica unicamente un singolo pattern (oggetto).
La linea retta in Fig.1 è nota coma decision line e costituisce il classificatore il cui ruolo è quello di dividere lo spazio delle features in due regioni che corrispondono alle due diverse classi.
Se il vettore delle features cade nella prima regione viene classificato come classe A, altrimenti come classe B. Questo non significa necessariamente che la decisione presa è corretta.
Per tracciare la linea retta in figura 1, si è sfruttata la conoscenza delle etichette (classe A o B) per ogni punto in figura. I vettori di features dei quali conosciamo la vera classe di appartenenza sono noti con il nome di training set, e sono utilizzati per addestrare il classificatore. Alla fine di questa fase (di training) è necessaria una seconda (di testing) in cui utilizzando un secondo set di vettori (test set) viene misurata l'accuratezza del classificatore. A partire dalla teoria della decisione statistica di Bayes (basata sul calcolo delle densità di probabilità delle classi (funzioni di verosimiglianza), diverse tecniche di classificazione sono state sviluppate fino ad oggi [2]-[3].
Noi ci interesseremo delle cosiddette neaural networks , così chiamate perchè ispirate alla struttura del sistema nervoso umano [2]. Si tratta di classificatori che non considerano le distribuzioni dei dati di training, e che dunque hanno un costo computazionale ridotto. In particolare rivolgeremo l'attenzione ad un tipo di rete neurale, la cosiddetta SVM (Support Vector Machine) [1].
L’obiettivo che ci poniamo è quello di utilizzare l’SVM per la classificazione di bersagli radar (identificare un bersaglio dal suo eco radar) confrontandone le prestazioni con quelle di altri
Capitolo 1 Introduzione
3 classificatori, e cercando di capire in quali situazioni questa tecnica offre dei vantaggi consistenti rispetto alle altre [5]-[7].
Le performance dei tradizionali metodi di classificazione sono teoricamente garantite solo quando si ha a disposizione un numero di dati di training molto elevato. Nelle situazioni reali invece, spesso il training set è limitato. L’introduzione e lo sviluppo della Support Vector Machine offre la possibilità di classificare i bersagli radar in spazi di features ad alta dimensione, utilizzando un training set ridotto. L’SVM è una nuova tecnica di classificazione recentemente sviluppata da Vapnik in “The nature of Learning Theory”, che confrontata con le tradizionali reti neurali, ha una struttura più semplice e performance in generali migliori [1].
L’idea principale che ha portato allo sviluppo dell’SVM è separare i diversi bersagli con una superficie che massimizza il margine tra le classi. Nel caso dell’Automatic Radar Target Recognition, è difficile avere un set di campioni elevato, ed in pratica i sistemi hanno solo un training data molto limitato.
Perciò, è un obiettivo interessante allenare un classificatore con training set ridotto, cercando di ottenere comunque buone prestazioni.
Nel capitolo 2 illustreremo brevemente alcune delle principali tecniche di classificazione con e senza supervisione.
Nel capitolo 3 concentreremo invece l’attenzione sulla classificazione SVM, descrivendone il funzionamento da un punto di vista teorico, prima nel caso binario, poi in quello multiclasse. Nel capitolo 4 si descrivono i 3 algoritmi di estrazione delle features utilizzati negli esperimenti di classificazione.
Nel capitolo 5 si presentano i risultati degli esperimenti di classificazione SVM binaria. Nel capitolo 6 si presentano i risultati degli esperimenti di classificazione SVM muliclasse. Nel capitolo 7 si analizzano le prestazioni e la robustezza del classificatore.