Capitolo 3 - Metodologia RNA
3.1 Il codice RNALa modellazione Reactor Network Analysis (RNA) è uno strumento computazionale per l’analisi dei sistemi di combustione su scala industriale che consente di valutare le emissioni dei principali micro–inquinanti (NOx,SOx,CO,etc..) servendosi di un’analisi cinetica complessa del processo.
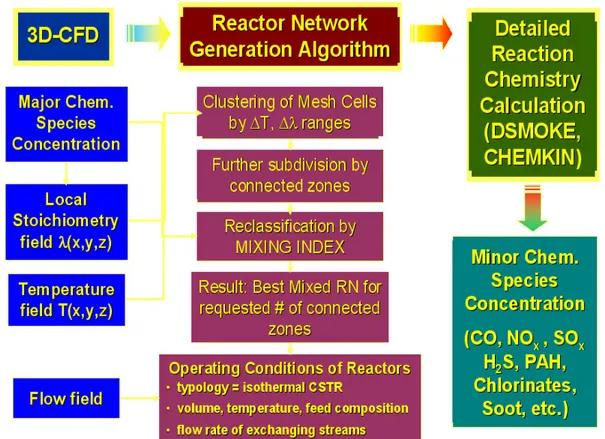
La tecnica RNA utilizza i campi prodotti da una precedente simulazione CFD per definire delle macro-regioni omogenee, caratterizzate dai rispettivi valori medi di temperatura, densità e composizione chimica. Queste unità 3D vengono quindi rappresentate come reattori chimici ideali (con perfetto mescolamento o con flusso a pistone), sui quali vengono definiti i flussi di materia di scambio realizzando un modello a rete di reattori relativamente semplice (fino ad alcune centinaia di reattori). A questo punto, è possibile applicare cinetiche chimiche dettagliate di combustione che descrivono la formazione/distruzione di inquinanti con un grado di dettaglio (nell’ordine dei 300 composti chimici e 3000 reazioni), tale da non consentire il loro utilizzo direttamente sui reticoli delle simulazioni CFD (numero di celle dell’ordine di 105).
Le simulazioni CFD-3D utilizzate per l’analisi RNA sono state prodotte facendo uso del codice KIEN per la simulazione di un combustore turbogas.
3.1.1 La Simulazione CFD 3D
La metodologia utilizzata per l’analisi dei processi e dei sistemi di combustione su scala industriale prende inizio da una simulazione 3D, eseguita con codici CFD. Tale simulazione si basa sulla suddivisione del volume della camera di combustione in un reticolo composto da celle esaedriche su cui viene eseguito un calcolo tridimensionale che definisce la fluidodinamica, la generazione termica e lo scambio di calore del processo. I risultati del calcolo CFD consentono la definizione di tre grandezze fisiche su tutto il volume:
campo di flusso: è un campo vettoriale che associa ad ogni faccia della cella il vettore velocità (ortogonale alla faccia) del flusso massivo transitante.
campo di temperatura: è un campo scalare che associa ad ogni cella il valore locale di temperatura.
campo di concentrazione: è un campo scalare che associa ad ogni cella il valore di concentrazione delle principali specie chimiche interessate nella combustione.
Una volta eseguita la simulazione CFD, viene utilizzato un programma di post-processamento che definisce, per ogni cella del reticolo, un campo scalare del valore di stechiometria tramite l’elaborazione del campo 3D delle concentrazioni.
L’algoritmo consiste nel calcolo delle moli totali di elementi riducenti presenti (C e H) in tutte le specie, espresse come “REQ_C” e “REQ_H”, da cui successivamente si ricavano le corrispondenti moli di O2 necessarie a completare l’ossidazione rispettivamente a CO2 ed a H2O (“O2_REQ_C” e “O2_REQ_H”).
3.1.2 Generazione della rete di reattori
Il programma CONNEX, scritto in FORTRAN90, rappresenta la codifica di un algoritmo completo che partendo dai campi CFD di portata massiva, temperatura e frazione di massa delle specie chimiche esegue un raggruppamento di celle al fine di ottenere un desiderato numero di zone, ciascuna geometricamente connessa e omogenea rispetto alle proprietà chimico-fisiche.
Tale modulo consente di generare in maniera automatica il modello a rete di reattori chimici sulla base di alcuni parametri da specificare in
input.
I criteri di classificazione applicati in CONNEX sono stati convalidati per fiamme turbolente e non premiscelate.
3.1.2.1 Classificazione delle celle e algoritmo di CONNEX
I dati di partenza utilizzati da CONNEX consistono nei campi CFD di: Temperatura
Densità
Frazione di massa del combustibile 4 CH Frazione di massa di 2 , , 2 , 2 , 2 , 2 N CO H O CO H O
Utilizzando i campi di frazione di massa delle specie chimiche, è possibile calcolare il campo di stechiometria locale [20] λ(x,y,z) come:
dove
av
O è la massa totale di Ossigeno disponibile, sommato su tutte le specie in cui tale elemento è presente e
req
O è la massa totale di Ossigeno richiesta per la completa ossidazione a
2
CO e H O
2 di tutto il carbonio e l’idrogeno presente nelle specie chimiche.
Una prima classificazione sommaria delle celle del reticolo viene realizzata considerando soltanto i valori di temperatura e stechiometria associati a ciascuna cella, senza considerare le proprietà geometriche. In questa fase le celle sono raggruppate in classi definite da intervalli di temperatura T∆ e stechiometria ∆ . Mentre per la temperatura viene λ adottata una spaziatura uniforme, dove il T∆ assegnato costituisce un dato di input al programma, per la stechiometria, dato un ∆ in λ ingresso, gli estremi di ogni intervallo ( n
n λ
λ ,
1
+ ) sono calcolati secondo la seguente relazione:
[
]
[
]
⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ≥ = ∆ − = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ≤ − − = ∆ + = feeds n n per n feeds n feeds n n per n feeds n λ λ λ λ λ λ λ λ λ λ ,... 2 , 1 , 0 1 1 ,... 2 , 1 , 0 con feeds λ calcolata come: (kg/s) totale le combustibi il per rica stechiomet Aria (Kg/s) one alimentazi di totale Aria = feeds λIn pratica suddividiamo il dominio della stechiometria in due zone, separate dal valore di stechiometria dell’alimentazione (
feeds
λ ) del caso studiato, che corrispondono circa alla zona sottostechiometrica e
a quella sovrastechiometrica: per stechiometrie inferiori a
feeds
λ si
impiega una suddivisione degli intervalli uniforme, mentre, per valori superiori, si applica una scansione proporzionale al reciproco di
λ
∆ con lo scopo di ottenere lo stesso grado di dettaglio su tutto il dominio (si ricerca una quantità di celle per classe simile alla zona sottostechiometrica).
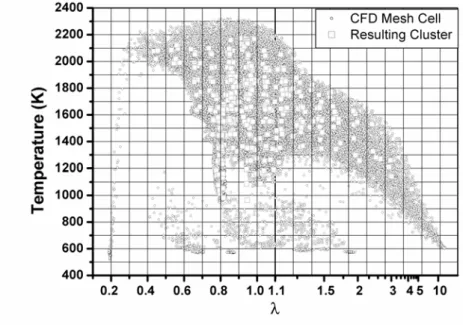
La Fig. 3. 1 mostra quanto detto per un caso in cui =1.1
feeds
λ : a
sinistra della stechiometria di alimentazione la scala è lineare, a destra è reciproca.
Fig. 3. 1 - Classificazione delle celle secondo i ∆T e ∆λ
Poiché la stechiometria di alimentazione delimita le due zone, la scelta del ∆λ dovrebbe essere tale da far coincidere il valore del
feeds
questo necessaria la definizione di un nuovo λ∗feeds che divida in due
parti il dominio e risulti il più vicino possibile al
feeds λ noto: ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ≥ ∆ ⎟⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎝ ⎛ + ∆ − + = ∗ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ≤ = ∗ 1 5 . 0 1 int 1 1 1 feeds feeds feeds feeds feeds λ λ λ λ λ λ λ
Abbiamo così ottenuto una suddivisione di poche centinaia di classi dove tuttavia sono raggruppate celle che fisicamente non si trovano vicine. Il passo successivo prevede quindi una suddivisione dei cluster ottenuti in raggruppamenti di celle adiacenti, che corrispondono quindi a un volume connesso caratterizzato da valori di stechiometria e temperatura appartenenti a un certo intervallo.
Il numero di zone ottenute nella fase precedente (alcune migliaia) può risultare ancora elevato per il calcolo cinetico, ovviamente, ciò dipende anche dai T∆ e ∆ scelti. λ
Per ovviare a tale situazione, si applica un criterio di riclassificazione che prende in considerazione le proprietà di miscelamento delle zone individuate.
Sia definito un indice di non-miscelamento
TOT Z : ∑ = = N i i Z N TOT Z 1 1
N è il numero di specie presenti nella zona considerata e i
Z è l’indice
di non-miscelamento binario della specie i-esima, definito come:
) 1 ( 2 2 i Y i Y i Y i Y i Z − − = con: ∑ ∑ = j j V j j i j Y j V j i Y ρ ρ , ∑ ∑ = j j V j j j i Y j V j i Y ρ ρ 2, 2 dove j ρ , j
V e Yi,j sono rispettivamente la densità, il volume e la frazione di massa dell’i-esima specie, relativa alla cella j-esima; la somma sull’indice j include tutte le celle che appartengono alla zona considerata.
L’indice di non-miscelamento così definito esprime lo stato di miscelamento di una miscela binaria: nei due casi limite vale 0 se i composti sono perfettamente miscelati e 1 se sono completamente segregati, indipendentemente dal titolo della miscela.
Lo stato di miscelamento di una zona espresso da
TOT
Z è la media aritmetica degli indici di non-miscelamento calcolati per ogni specie.
Il significato dell’indice può essere meglio evidenziato scrivendolo nella forma: ) 1 ( 2 i Y i Y i Y i Y i Z − − =
Per un reattore totalmente miscelato , in ogni cella Yi,j≡ costante
quindi: ij Y j V j j V j ij Y i Y ≡ ∑ ⋅ ∑ ⋅ ⋅ = ρ ρ . ≡ costante 2 2 i Y i Y = ⇒ 0 ) 1 ( 0 ≡ − = i Y i Z
al contrario se qualche specie nel reattore è completamente segregata in alcune celle j che supponiamo vadano da 1 a n , avrò che per queste
j i
Y, ≡1 mentre per le altre Yi,j≡0 quindi:
∑ ⋅ ∑ ⋅ = ∑ ∑ = n j Vj n j Vj jYi j jVj jYi j jVj i Y i Y , 1 , 1 , 2 , 2 ρ ρ ρ ρ =1 ⇒ 1 ) 1 ( ) 1 ( ≡ − − = i Y i Y i Z
Se il numero di volumi connessi, ottenuto come illustrato in precedenza, è maggiore del numero di reattori specificato in input, viene effettuata una riclassificazione, basata sull’indice di miscelamento
TOT
Z , secondo la seguente procedura:
1. le zone costituite da volumi connessi vengono ordinate in senso decrescente in base al numero di celle contenute, quindi, dato in input il massimo numero di reattori richiesto
MAX
N , la
classificazione delle celle che appartengono alle prime
MAX
N zone
è mantenuta, mentre per le rimanenti celle si applica una riassegnazione.
2. alle prime
MAX
N zone, vengono associate una ad una le celle da riclassificare, secondo il criterio del miglior miscelamento, fino ad includere tutto il volume da modellare.
Cominciando da una qualsiasi cella, vengono cercate tutte le zone ad essa contigue già classificate; in seguito viene calcolato l’incremento dell’indice di non-miscelamento, per ogni caso in cui la cella venga assegnata a ciascuna delle classi confinanti, utilizzando la formula:
(
n+1)
Z∗TOT −nZTOTdove, per una zona considerata, n è il numero di celle,
TOT
Z e
TOT
Z ∗ sono rispettivamente l’indice di non-miscelamento, prima e dopo l’assegnamento ipotizzato. Tra tutti gli assegnamenti considerati viene realizzato quello che corrisponde al minimo incremento
Tali operazioni vengono iterate finché tutte le celle da riclassificare non sono state assegnate ad una classe.
Una volta che tutto il dominio è classificato in zone connesse e omogenee ciascuna di esse può essere rappresentata come un reattore completamente miscelato isotermo (CSTR). Il grado di omogeneità può essere verificato tramite i valori dell’indice di non-miscelamento e dello scarto quadratico medio della temperatura.
Il volume globale di un reattore è dato dall’apporto di quello delle singole celle costituenti e la temperatura media operativa T è definita tramite l’espressione di conservazione dell’entalpia:
( )
=0 ∑ ∫ i T i T dT T p c i mdove m e i T sono la massa e la temperatura dell’i-esima cella e la i
3.1.3 Fase preliminare del calcolo cinetico
Il modulo SCAMAS esegue infine altre due operazioni prima dell’avvio del calcolo cinetico:
vengono calcolati tramite il campo CFD di portata massiva, gli scambi di materia tra tutti i reattori e le correnti di alimentazione, sommando i contributi di tutte le celle di confine tra le zone. In questo modo sono considerati tutti gli scambi di massa tra reattori, inclusi i ricicli.
vengono scritti i file di input per il programma DESIBCO che esegue il calcolo cinetico sui singoli reattori.
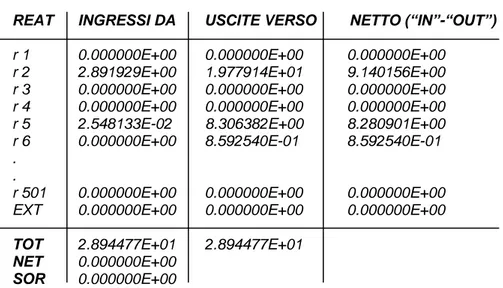
Questo codice in pratica fornisce, per ogni reattore, una matrice di tre colonne e tante righe quanti sono i reattori della rete più uno. La prima colonna (Fig. 3. 2) contiene le portate in ingresso, la seconda quelle in uscita e la terza il valore netto di portata (“IN” – “OUT”).
Ne deriva, quindi, che il generico elemento 1
j
a della matrice, contiene la portata in ingresso al reattore cui la matrice si riferisce, proveniente dal reattore j-esimo, il generico elemento
2
j
a , contiene la portata in uscita dal reattore cui la matrice si riferisce, verso il reattore j-esimo ed infine l’elemento
3
j
a contiene la portata netta scambiata che può essere positiva se è entrante o negativa se è uscente e diretta verso il reattore j-esimo.
L’ultima riga, infine, riporta le portate scambiate dal reattore considerato con l’esterno.
Riporto di seguito, come esempio, una matrice generata da SCAMAS.
SCAMBI DI MASSA REATTORE R 1
REAT INGRESSI DA USCITE VERSO NETTO (“IN”-“OUT”)
r 1 0.000000E+00 0.000000E+00 0.000000E+00 r 2 2.891929E+00 1.977914E+01 9.140156E+00 r 3 0.000000E+00 0.000000E+00 0.000000E+00 r 4 0.000000E+00 0.000000E+00 0.000000E+00 r 5 2.548133E-02 8.306382E+00 8.280901E+00 r 6 0.000000E+00 8.592540E-01 8.592540E-01 .
.
r 501 0.000000E+00 0.000000E+00 0.000000E+00 EXT 0.000000E+00 0.000000E+00 0.000000E+00
TOT 2.894477E+01 2.894477E+01
NET 0.000000E+00
SOR 0.000000E+00
Fig. 3. 2 - Esempio di matrice prodotta dal codice di calcolo SCAMAS
Compilata la matrice degli scambi il programma identifica, tramite il file dello standard input, i reattori sorgente, quelli cioè in cui viene alimentata l’aria ed il combustibile o, più in generale, quelli in cui viene immesso un flusso dall’esterno quantificandone le relative portate.
3.1.4 Calcolo del meccanismo cinetico dettagliato “DESIBCO”
I parametri operativi dei reattori, la dinamica degli scambi di massa e la composizione chimica delle alimentazioni vengono trascritti nel file di
input del programma che effettua il calcolo cinetico (DESIBCO). Come
risultato del calcolo cinetico si ottengono, reattore per reattore, i valori delle velocità di formazione/distruzione e delle concentrazioni delle specie chimiche del meccanismo. La versione aggiornata di DESIBCO, di cui si dispone, consente l'esecuzione del calcolo cinetico in tempi
relativamente brevi anche con un numero elevato di reattori (sono state effettuate simulazioni anche con 1000 reattori). Ogni classificazione del volume della caldaia in zone omogenee corrisponde automaticamente ad un'unica dinamica dei flussi tra i reattori.
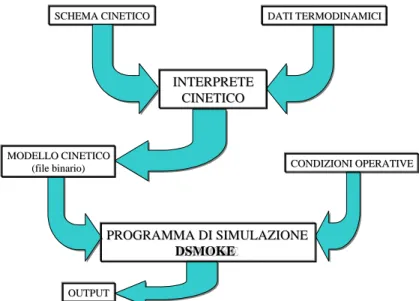
In Fig. 3. 3 vengono riportati i due stadi caratteristici di una simulazione cinetica, rappresentati da una prima fase di compilazione di un file binario a partire dai file contenenti i meccanismi cinetici e le proprietà termodinamiche delle varie specie coinvolte e da una seconda che, a partire dal file binario e dalle condizioni operative fissate attraverso la compilazione del file di input, realizza il calcolo cinetico vero e proprio, risolvendo, per ogni reattore, sistemi di equazioni non lineari, costituite dai bilanci materiali.
Bilancio materiale per un CSTR:
∑ = × × − = − n j ij rj PMi i i IN 1ν τ ω ω i
ω rappresenta la concentrazione della specie i-esima [fraz. massa], τ il tempo di contatto [s⋅m3/kg], νij il coefficiente stechiometrico della specie i-esima nella reazione j-esima negativo se la specie “i” è un reagente, positivo se è un prodotto,
j
r la velocità di reazione j-esima
[mol/l⋅s],
i
SCHEMA CINETICO
SCHEMA CINETICO DATI TERMODINAMICIDATI TERMODINAMICI
INTERPRETE INTERPRETE CINETICO CINETICO MODELLO CINETICO MODELLO CINETICO (file binario) (file binario) PROGRAMMA DI SIMULAZIONE PROGRAMMA DI SIMULAZIONE DSMOKE DSMOKE CONDIZIONI OPERATIVE CONDIZIONI OPERATIVE OUTPUT OUTPUT
Fig. 3. 3 - Rappresentazione a blocchi degli stadi della simulazione cinetica
Il file termodinamico in input all’interprete cinetico contiene le proprietà termodinamiche (calore specifico, entalpia standard, entropia standard) delle specie di interesse, sotto forma di due gruppi di sette coefficienti polinomiali, relativi rispettivamente alle temperature inferiori e superiori ai 1000K.
Le proprietà termodinamiche vengono calcolate secondo quanto segue: 4 5 3 4 2 3 2 1 a T a T a T a T a R p c + + + + = T a T a T a T a T a a RT H 4 6 5 5 3 4 4 2 3 3 2 2 1+ + + + + = o 6 4 4 5 3 3 4 2 2 3 2 ln 1 T a a T a T a T a T a R So = + + + + +
Il file cinetico contiene i parametri (fattore pre-esponenziale A, esponente della temperatura n , energia di attivazione E ) relativi alle reazione coinvolte nei meccanismi, sulla base dei quali la costante cinetica della reazione diretta i-esima viene calcolata per mezzo della relazione seguente: ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = RT i E i n T i A d i k exp
La costante della reazione inversa viene poi relazionata a quella della reazione diretta per mezzo della costante di equilibrio termodinamico:
i K d i k r i k = dove: ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ ∆ − ∆ = RT H R S i K exp o o
A conclusione riportiamo una schematizzazione complessiva delle fasi della procedura descritta in questo capitolo.
3.2 Interfacciamento KIEN-RNA
Tra le varie ipotesi prese in esame per l'interconnessione KIEN-RNA si è ritenuto che la più opportuna fosse quella di generare, a partire dalla base dati KIEN, degli appositi file contenenti i dati CFD necessari alla procedura RNA, in maniera analoga a quanto viene fatto con IPSE. Tuttavia, data la differenza tra la struttura di griglia dei due codici CFD, non è possibile generare dei file identici.
Allo scopo di standardizzare la costruzione e la gestione dei file di interfaccia, risulta preferibile generare un unico file strutturato nel modo seguente:
Intestazione:
nome del caso simulato
dimensioni originali del dominio CFD
elenco delle grandezze TFD contenute nel file Note integrative:
specie chimiche considerate
sezioni di interfaccia con l’esterno del settore estratto
descrizione dei flussi di interfaccia con l’esterno del settore estratto Corpo del file:
dimensioni del blocco estratto
successione dei campi dei valori delle grandezze CFD: • F - tipo cella : 0.0 = esclusa, altrimenti è attiva.
(anche se di volume nullo per quanto riguarda le celle virtuali) • Vol - volume delle celle (in 3
•
k
FM - flusso massico attraverso le facce k (in Kg /s) • TEMP- temperatura (in K)
• DEN −x con x=1,n_specie - densità delle specie coinvolte (in
3
/ m
kg )
Gli estremi del settore 3D estratto dal blocco CFD originario vengono selezionati definendo i piani dei nodi estremi nelle 3 direzioni logiche:
i
I , If , Ji, Jf , Ki, Kf .
Gli strati di celle del sottoblocco risultano quindi pari a : NI = If −Ii,
NJ = Jf −Ji,
NK =Kf −Ki ;
con numero totale di unità dato da NC = NI⋅NJ ⋅NK . Per quanto riguarda i piani di nodi :
NIp = NI +1, NJp = NJ +1, NKp = NK +1
e numero totale di vertici NV = NIp⋅NJp⋅NKp.
Per comodità, per tutte le grandezze vengono forniti NV dati, da cui, occorre scartare quelli relativi agli strati estremi; per le variabili definite sulle celle occorre eliminare i valori corrispondenti ai piani di nodi
p p
p NJ NK
NI , , , mentre, per le grandezze riferite alle facce si escludono i dati relativi alle superfici estreme dei vertici nelle 2 direzioni perpendicolari a quella della faccia.
Per la generazione dei file da fornire in input a Connex si ricorre ad un modulo separato, scritto in Fortran 90, che legge i campi di grandezze TFD suddetti e quindi produce in output i files necessari, in formato standard grafico.
Dato che il file di interfaccia riporta le densità delle n _specie è necessario generare il campo delle frazioni in massa delle specie chimiche: cell vol i mass i den _ =
(
)
∑ = = ∑ = ⋅ = n specie i massi specie ni deni vol cell cell mass _ 1 _ 1 _ _
(
)
cell mass cell vol i den i fraction mass _ _ _ = ⋅Nota la composizione, in ogni cella del settore estratto, si ricostruisce il campo di stechiometria locale λ(x,y,z):
(
)
(
x y z)
req O z y x av O z y x , , , , ) , , ( = λdove, come detto nel par. 3.1.2.1,
av
O è la massa totale di Ossigeno disponibile e
req
3.2.1 Modulo Connex
3.2.1.1 File di input
I file di input utilizzati dal programma sono i seguenti:
I campi di temperatura [K] ,di densità,di stechiometria e di frazione di massa delle specie chimiche riferiti ai centri delle celle, in formato Standard Grafico.
Il file delle celle escluse, in formato Standard Grafico.
3.2.1.2 File di output
I files prodotti in output sono:
I file della riclassificazione, nella rete di reattori, delle celle del dominio di calcolo. La nomenclatura dei files è del tipo r#.dat, dove # indica il numero di reattore.
Il file sintesi.dat che contiene l’elenco delle proprietà operative dei singoli reattori (volume, temperatura e deviazione standard della temperatura) ed il file #classe che specifica per ogni cella il reattore di appartenenza.
I files dei parametri caratteristici dei reattori: stechiometria, volume, temperatura, deviazione standard della temperatura e indice di miscelamento.
3.2.1.3 Standard Input
Lo standard input dell’eseguibile è un file ASCII che contiene nel seguente ordine:
etichetta dell’unità del disco fisso
nome caso (nome dei file di input dei campi CFD);
1 oppure 2 per indicare rispettivamente l’uso di un reticolo cartesiano o cilindrico ortogonale;
1 per indicare il formato dei file di dati CFD Standard Grafico; il numero di celle lungo X, lungo Y e lungo Z;
il numero di reattori risultanti nel caso di una eventuale classificazione originaria manuale ( = al numero di files “r#_old.dat” presenti nella directory);
il numero di reattori connessi che saranno prodotti dal programma; la spaziatura di stechiometria per la classificazione originaria; portata di aria di alimentazione totale al sistema (t/h);
portata di aria stechiometrica (t/h);
la spaziatura di temperatura per la classificazione originaria; numero delle specie combustibili;
Per ogni fuel:
o frazione in massa di idrogeno (H) nella specie combustibile
o frazione in massa di carbonio (C) nella specie combustibile o frazione in massa di ossigeno (O) nella specie
combustibile
3.2.1.4 Algoritmo del modulo Connex
A. Legge lo standard input.
B. Classificazione originaria.
B.1. Legge lo standard input.
B.2. Calcola la stechiometria di alimentazione. B.3. Alloca il pointer Dominio.
B.4. Carica Dominio con i campi di temperatura, delle celle escluse e di stechiometria.
B.5. Calcola la temperatura minima e massima. B.6. Calcola la stechiometria minima e massima.
B.7. Modifica per avere il taglio a SR = 1.
B.8. Aggiornamento della stechiometria di alimentazione. B.9. Calcolo Nx che è il numero di classi presenti in ogni riga del dominio.
B.10. Classifica le celle considerando le due zone, una a sinistra e una a destra della stechiometria di alimentazione.
B.11. Carico il numero delle classi delle celle in Dominio.
C. Individua le zone connesse all'interno dei reattori.
C.1. Alloca due stack.
C.2. Carica Stack_1 con le etichette delle celle appartenenti alle classi secondo il clustering originario.
C.3. Trasferisce il top di Stack_1 nel bottom di Stack_2. C.4. Inizio ciclo finché non finiscono le celle di Stack_1.
C.4.1. Inizio ciclo: scorre su tutte le celle di Stack_1 partendo da n_max.
C.4.2. controlla la contiguità di una cella di Stack_1 con le celle di Stack_2.
C.4.3.1. incrementa il contatore del top di Stack_2. C.4.3.2. trasferisce la cella di Stack_1 in Stack_2.
C.4.3.3. aggiorna il volume totale delle celle di Stack_2.
C.4.3.4. compatta Stack_1, spostando in basso di una posizione le celle superiori.
C.4.3.5. decrementa il contatore del top di Stack_1. C.4.3.6. esce dal ciclo e ricomincia il controllo dal top di Stack_1.
C.4.4. Fine ciclo.
C.4.5. Stack_2 è stato caricato con una nuova zona connessa, si aggiornano i puntatori.
C.5. Fine ciclo.
C.6. Stack_1 è vuoto, Stack_2 contiene le celle riclassificate in zone connesse.
C.7. Scrive sullo standard output la tabellina con il # di zone connesse per ogni reattore originario.
C.8. Carica in Stack_3 gli indici delle celle da riclassificare provenienti dalla classificazione originaria.
C.9. Carico l’array Clas_Con con i dati delle zone connesse per poter effettuare il sorting.
C.10. Esegue il sorting discendente di Clas_Con rispetto al numero di celle delle classi connesse contenute in Celle_Con. C.11. Carico Stack_1 secondo il nuovo ordinamento e modifico il bot e il top di Clas-Con.
C.12. Carico in stack_1 le celle da riclassificare provenienti dalla classificazione originaria.
E. Se il numero di zone connesse è maggiore del numero.
massimo di reattori desiderato, riclassifica le celle dei reattori che contengono meno celle.
E.3. Riclassificazione (Tipo Reclas glob).
E.3.1. Carica le etichette delle celle classificate. E.3.2. Carica le etichette delle celle non classificate.
E.3.3. Carica il pointer RC_Sort con le celle da classificare in modo casuale.
E.3.4. Se non sono associati delta_glob_cel e delta_mix_cel, li alloca.
E.3.5. Inizio ciclo finché esistono celle da riclassificare. E.3.5.1. Carica le etichette delle celle da classificare con quelle delle celle confinanti classificate.
E.3.5.2. Calcola il numero di classi contenenti la cella da riclassificare.
E.3.5.3. Calcola l’indice di miscelamento per le classi confinanti con la cella in esame.
E.3.5.4. Calcola delta_glob per ogni combinazione cella-classe confinante.
E.3.5.5. Calcola il minimo incremento dell’indice di miscelamento globale per l’intorno di una cella.
E.3.5.6. Aggiorna delta_glob_cel.
E.3.5.7. Cerca il minimo incremento dell’indice di miscelamento globale per tutte le celle tra low-bound e upper-bound.
E.3.5.8. Etichetta la cella secondo la situazione di miglior miscelamento.
E.3.5.9. Aggiorna Stack_1 e Clas_Con. E.3.5.10. Aggiorna il volume.
E.3.5.11. Aggiorna le altre voci di Clas_Con. E.3.5.12. Aggiorna l’indice di miscelamento. E.3.6. Fine ciclo.
E.3.7. Aggiorna la frazione volumetrica.
F. Calcola l’indice di miscelamento delle singole specie chimiche nella classe dopo la riclassificazione.
G. Calcola l’indice di miscelamento globale. H. Aggiornamento dei file di output.
H.1. Calcola la stechiometria dei reattori. H.2. Calcola la temperatura dei reattori.
H.3. Scrive i file r#.dat.
H.4. Scrive i file sintesi.dat con i parametri operativi dei reattori.
I. Scrive i file di output in formato Standard Grafico : temp_new, sr_new, sd_new, #classe_new, indmix_new, volume_new.
3.2.1.5 Modifiche al codice
Facendo riferimento all’algoritmo originale di Connex, riportato di sopra, illustro le modifiche effettuate sul codice per adeguarlo alle nuove caratteristiche dell’input di KIEN.
Nel file dello standard input (A.) è stata inserita una sezione dove si specifica il numero delle specie combustibili coinvolte e la loro composizione chimica (H,C,O) utilizzata per la valutazione della stechiometria nelle classi e nei reattori classificati.
La lettura, dal file delle celle escluse (.ESC), della geometria del sistema è eliminata considerando che il file di interfaccia KIEN-RNA non fornisce le coordinate fisiche dei nodi del dominio.
I valori di temperatura e stechiometria, massima e minima, vengono valutati escludendo dalla ricerca i dati corrispondenti alle celle attive virtuali (B.5. – B.6.).
Per quanto riguarda il pointer Dominio%n_classe le etichette delle celle hanno i seguenti valori (B.11.):
le celle virtuali attive sono settate a 2− (codice identificativo utilizzato per la classificazione di tali celle);
le celle escluse a 0 ;
le celle attive non virtuali sono identificate dal # della classe di appartenenza;
le celle scartate dal dominio di calcolo sono fissate a 1− .
La funzione che valuta il volume delle celle può essere eliminata in quanto il campo è fornito direttamente sul file di interfaccia (C.4.3.3.). Nella sezione del codice, dove si valuta l’indice di miscelamento dei reattori, si annulla la lettura da file delle frazioni di massa delle specie radicaliche, in quanto KIEN non ne prevede la presenza; le
concentrazioni di tali specie vengono settate ad un valore di soglia ≅ 0 per simularne una presenza pressoché nulla (D.).
L’algoritmo di classificazione considera le sole celle attive, escludendo da queste quelle virtuali che vengono annesse ai reattori della rete solo dopo la valutazione della tipologia e dei parametri caratteristici di ciascun reattore (I.).
Immediatamente prima della scrittura dei file r#.dat, che specificano quali sono le celle inserite in ciascuna classe, si procede alla classificazione secondo il criterio della connessione; per ogni cella si ricerca la congiunzione con uno dei reattori catalogati procedendo fino alla completa assegnazione delle unità virtuali (H.3.).
3.2.2 Procedura di correzione delle portate
Come detto nel par. 2.1, KIEN risolve le equazioni di Navier-Stokes in formulazione transitoria; questo causa fluttuazioni dell’andamento temporale delle portate che si traducono sulla rete di reattori, in sbilanci di materia sulle singole unità e sul sistema globale.
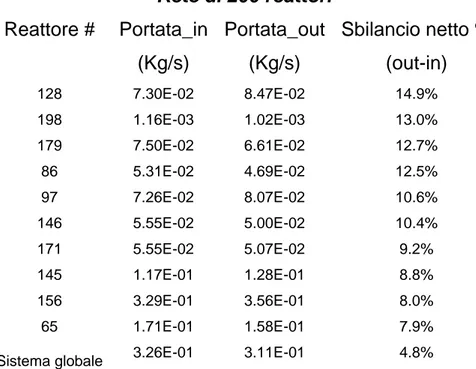
A titolo esplicativo riporto la seguente tabella:
Rete di 200 reattori Reattore # Portata_in (Kg/s) Portata_out (Kg/s) Sbilancio netto % (out-in) 128 7.30E-02 8.47E-02 14.9% 198 1.16E-03 1.02E-03 13.0% 179 7.50E-02 6.61E-02 12.7% 86 5.31E-02 4.69E-02 12.5% 97 7.26E-02 8.07E-02 10.6% 146 5.55E-02 5.00E-02 10.4% 171 5.55E-02 5.07E-02 9.2% 145 1.17E-01 1.28E-01 8.8% 156 3.29E-01 3.56E-01 8.0% 65 1.71E-01 1.58E-01 7.9%
Sistema globale 3.26E-01 3.11E-01 4.8%
Tab. 3. 1– Esempi di sbilancio di materia sui reattori della rete
La presenza di turbolenze nelle sezioni di ingresso ed uscita dal sistema creano dei flussi di ricircolazione; si vengono ad avere, per tale motivo, correnti con verso contrario a quella della portata principale. Nelle sezioni di alimentazione esistono correnti che fuoriescono ed allo stesso modo nella sezione di uscita fumi si hanno flussi in ingresso.
Ad esempio nel caso in esame, la corrente entrante al sistema, che dovrebbe coincidere con il valore dell’alimentazione nominale ( 3.2673E-01 Kg/s
4+ aria=
CH ), risulta di 3.259569E-01 kg/s, mentre
quella di uscita assume un valore di 3.107684E-01 kg/s.
Nella procedura di chiusura dei bilanci implementata, i flussi di ricircolazioni con l’esterno vengono annullati, inoltre, si impone che la corrente in ingresso al sistema coincida con la portata di alimentazione nominale.
Il modulo DESIBCO, del codice RNA, segue un algoritmo che richiede la chiusura perfetta dei bilanci di materia sulle singole unità della rete di reattori; questa necessità ha imposto la predisposizione di una procedura di correzione delle correnti.
La questione si traduce nella risoluzione di un problema dei minimi quadrati vincolato; la funzione obiettivo è rappresentata dalla somma dei quadrati degli scostamenti dalle portate medie dei reattori, i vincoli imposti sono i bilanci di materia su ciascun reattore e sul sistema globale, le variabili sono i coefficienti correttivi delle singole correnti di scambio.
Legenda:
≡
i
PM portata media non corretta del reattore i−esimo.
≡ *
i
PM portata media corretta del reattore i−esimo.
≡
ij
a flusso massivo dal reattore i verso j.
≡
ij
ε coefficiente correttivo della portata massiva dal reattore i verso j
≡
Definite, rispettivamente, le portate medie iniziali e corrette degli nrea reattori:
(
)
nrea i exti a iext a nrea i j j aij aji i PM 1, 2 1 = + + ∑ ≠ = + = ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛(
)
nrea i exti a exti iext a iext nrea i j j ijaij jiaji i PM 1, 2 1 * = + + ∑ ≠ = + = ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ε ε ε εil problema si imposta nel modo seguente:
min 2 1 * = ∑ = − =nrea⎜⎝⎛ ⎟⎠⎞ i PMi PMi F
(
)
0 1,nrea 1 = ∀ = ∑ ≠ = ⎜⎝⎛ − ⎟⎠⎞+ − =nrea i i jj ijaij jiaji iextaiext extiaexti i g ε ε ε ε
(
)
0 bilancioglobale 1 1= ∑= − = + nreai iextaiext extiaexti nrea
Il numero massimo di termini correttivi εij risulta:
(
nrea+1) (
2− nrea+1)
=nrea2+nreaIpotizzando una rete di 500 reattori, il numero massimo di variabili εij è 250500. Bisogna comunque considerare che il numero massimo di variabili si raggiunge soltanto nel caso limite in cui ciascun reattore scambia massa con tutti gli altri: in pratica molti termini
a
ij sono nulliper cui le variabili si riducono drasticamente.
La minimizzazione di
F
è stata effettuata ricorrendo ad una funzione predefinita del pacchetto IMSL Fortran 90 [18]: LCONG/DLCONG (Single/Double precision)
La subroutine è espressamente implementata per la minimizzazione, di funzioni generali, soggette a vincoli lineari di uguaglianza o diseguaglianza.
L’applicazione richiede la valutazione delle derivate parziali, rispetto ai termini correttivi εij, sia della funzione
F
che dei vincolii g e 1 + nrea g :
Derivate parziali della funzione
nrea j i, =1, ⎤ ⎡⎛ − ⎞+⎛ − ⎞ − = ∂F * *
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − − = ∂ ∂ * i PM i PM iext a iext F ε ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − − = ∂ ∂ * i PM i PM exti a exti F ε
Derivate parziali del vincolo i g :
considerato il reattore i−esimo:
xy a xy i g i y se xy a xy i g i x se xy i g i y x se nrea y x − = ∂ ∂ ⇒ = = ∂ ∂ ⇒ = = ∂ ∂ ⇒ ≠ = ε ε ε 0 , , 1 , ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ = ∂ ∂ − = ∂ ∂ ⇒ = = ∂ ∂ = ∂ ∂ ⇒ ≠ = xext a xext i g extx a extx i g i x se extx i g xext i g i x se nrea x ε ε ε ε 0 , 1
Derivate parziali del vincolo
1 + nrea g : 0 1 = ∂ + ∂ ij nrea g ε iext a iext nrea g = ∂ + ∂ ε 1 exti a exti nrea g − = ∂ + ∂ ε 1
3.2.3 Modulo Scamas
3.2.3.1 File di input
I file di input utilizzati dal programma sono i seguenti:
I file r#.dat della riclassificazione, prodotti dal modulo Connex.
I campi delle portate massive nelle tre direzioni i ,, j k, riferiti alle facce delle celle, in formato Standard Grafico.
Il file delle celle escluse, in formato Standard Grafico. Il file sintesi.dat prodotto in output da Connex.
3.2.3.2 File di output
I files prodotti in output sono:
DS#.dat che riporta, per un dato reattore, le eventuali correnti di alimentazione e la sequenza di apparecchiature che ne simulano le caratteristiche termofluidodinamiche.
DS#.RIC identifica, per un dato reattore della rete, le correnti di riciclo precisandone temperatura e portata.
Ricic4.inp utilizzato nel modulo DESIBCO del calcolo cinetico;
DSV64.RIC che specifica la provenienza delle correnti di riciclo ad ogni reattore.
Sorgenti.dat che identifica i reattori sorgente riportandone le correnti di alimentazione di aria e combustibile.
Scamas.res che contiene le portate di scambio, per ciascun reattore con i restanti della rete.
3.2.3.3 Standard Input
Lo S.I. dell’eseguibile è un file ASCII che contiene nel seguente ordine: nomi dei file in SG delle portate massive per 3 direzioni logiche; numero dei reattori della riclassificazione;
1 oppure 2 per indicare rispettivamente l’uso di un reticolo cartesiano o cilindrico ortogonale;
parametro moltiplicativo SD della deviazione standard della temperatura dei reattori: TEMP
( )
i +SD⋅DT( )
i ; nome del caso simulato;
nome della specie combustibile chiave; numero delle specie combustibili
ARIA comburente:
o Etichetta identificativa;
o numero delle sezioni di alimentazione: • indici f I i I , , f J i J , , f K i K , di definizione della sezione e portata in ingresso in kg / ; s
Per ogni specie combustibile:
o Etichetta identificativa del fuel
o numero delle sezioni di alimentazione: • indici f I i I , , f J i J , , f K i K , di definizione della sezione e portata in ingresso in kg / ; s
Fumi di uscita:
o Etichetta identificativa;
o numero delle sezioni di uscita fumi: • indici f I i I , , f J i J , , f K i K , di definizione della sezione e portata in kg / ; s
3.2.3.4 Algoritmo del modulo Scamas
A. Legge lo standard input
B. Chiama la subroutine PORTATE
B.1. Alloca il pointer POR. B.2. Per ogni direzione logica:
B.2.1. Apre il file V64.FM_*
B.2.2. Carica in POR le portate massive.
C. Chiama la subroutine LEGGE
C.1. Alloca il pointer NRCTRS. C.2. Apre il file delle celle escluse.
C.3. Legge ed scrive in NRCTRS le celle attive del reticolo: setta la locazione corrispondente a 0 se la cella è attiva, -1 altrimenti. C.4. Inizio ciclo: per ogni reattore della rete.
C.4.1. Apre il file r#.dat.
C.4.2. Inizio ciclo: per ogni cella classificata. C.4.2.1. Legge l’etichetta identificativa.
C.4.2.2. Calcola gli indici logici e carica in NRCTRS il numero del reattore di appartenenza.
C.4.2.3. Fine ciclo. C.5. Fine ciclo.
C.6. Si impone che siano rispettate le condizioni cicliche per il reticolo cilindrico.
C.7. Legge dallo standard input il blocco di descrizione delle sezioni di alimentazione caricando la classe SOR().
D. Chiama la subroutine MAT_SCAMBI.
D.2.2. Si carica M con il numero del reattore di tutte le celle contigue.
D.2.3. Inizio ciclo: per ogni cella contigua
D.2.3.1. Se l’ etichetta di reattore è diversa e le celle non sono escluse:
D.2.3.1.1. Si considera la portata del flusso in uscita.
D.2.3.1.2. Si valuta il segno della corrente suddetta.
D.2.3.1.3. Se il segno è positivo:
D.2.3.1.3.1. Si aggiorna SCAMBI incrementando la portata uscente dal primo reattore verso il secondo.
D.2.4. Fine ciclo. D.3. Fine ciclo.
D.4. Si ripete il ciclo in D.2 considerando le celle ai bordi del dominio per ricostruire gli scambi con l’esterno del sistema.
E. Chiama la subroutine SORGENTI.
E.1. Alloca i pointer VOL_CELL e FR.
E.2. Alloca SOR()%POR che contiene le portate di aria e combustibili per i reattori di alimentazione.
E.3. Legge il file del volume delle celle E.4. Carica VOL_CELL
E.5. Inizio ciclo: per l’ aria comburente e le specie combustibili E.5.1 Inizio ciclo: per tutte le sezioni di alimentazione
E.5.1.1. Calcola il volume complessivo delle celle che appartengono alla sezione.
E.5.1.2. Calcola la frazione di volume delle celle della sezione, rispetto al volume totale, caricando il pointer FR.
E.5.1.3. Valuta la porzione della corrente di alimentazione per ogni cella tramite la frazione volumetrica calcolata.
E.5.2. Fine ciclo. E.6. Fine ciclo.
E.7. Scrive il file Sorgenti.dat per la descrizione delle portate dei reattori di alimentazione.
F. Chiama la subroutine CHIUDI_BILANCIO.
F.1. Alloca il pointer P_SOR.
F.2. Carica P_SOR con le portate di alimentazione dei reattori. F.3. Annulla le correnti di ricircolazione, dovute alla turbolenza ed impone che le portate in ingresso al sistema coincidano con le alimentazioni nominali dei reattori sorgente.
F.4. Alloca e carica il pointer P.
F.5. Alloca e carica il pointer PM con le portate medie dei reattori
F.6. Chiama la subroutine DLCONG per la risoluzione di problemi di minimo vincolato.
F.7. Correzione delle portate in SCAMBI in base alla soluzione data dalla funzione DLCONG.
G. Chiama la subroutine BILANCIO.
G.1. Alloca INGRESSI, USCITE e NETTO.
G.2. Carica INGRESSI ed USCITE con le portate totali in ingresso ed uscita dai reattori.
H. Chiama la subroutine SCRIVE.
H.1. Legge dal file sintesi.dat le proprietà operative dei singoli reattori (volume, temperatura e deviazione standard della temperatura).
H.2. Inizio ciclo: per ogni reattore
H.2.1. Calcola il numero delle correnti in uscita verso ogni altro reattore della rete e verso l’esterno del sistema.
H.3. Fine ciclo.
H.4. Apre Scamas.res e DSV64.RIC H.5. Inizio ciclo: per ogni reattore
H.4.1. Scrive in DSV64.RIC l’intestazione della sezione dedicata al reattore.
H.4.2. Apre il file DS#.dat H.4.3. Apre il file DS#.RIC
H.4.4. Scrive l’intestazione del file DS#.dat
H.4.5. Calcola il numero di splitter della corrente in uscita e le ricircolazioni verso ogni altro reattore della rete e l’esterno del sistema.
H.4.6. Scrive in Scamas.res gli ingressi, le uscite ed il netto verso gli altri reattori della rete e verso l’esterno, definendo, l’eventuale portata di alimentazione se è un reattore sorgente.
H.4.7. Scrive in DS#.dat:
H.4.7.1. Se il reattore è di alimentazione:
H.4.7.1.1 Scrive la portata di aria e di combustibile.
H.4.7.2. Scrive la sequenza di apparecchiature che simulano le caratteristiche del reattore.
H.4.7.3. Scrive la sezione del MIXER1 definendo le correnti di input ed output.
H.4.7.4. Scrive la sezione del REATTORE precisando i flussi di input, output e la temperatura del CSTR. Lo splitter, della corrente di output, deve dare somma unitaria.
H.4.7.5. Scrive il MIXER2
H.4.8. Scrive in DS#.RIC le correnti di riciclo al reattore dandone temperatura e portata.
H.4.9. Riassume in DSV64.RIC le correnti di riciclo al reattore e la loro provenienza.
H.6. Fine ciclo
H.7. Scrive in coda a Scamas.res il bilancio di massa sul sistema globale, riportando la portata uscente complessiva e l’alimentazione globale di aria e combustibili.
3.2.3.5 Modifiche al codice
La variazione principale, introdotta nel modulo Scamas, riguarda l’inserimento della subroutine CHIUDI_BILANCIO (F) per la correzione delle portate di scambio ed il raggiungimento della chiusura dei bilanci di materia sui reattori. La simulazione CFD calcola che in corrispondenza delle sezioni di ingresso ed uscita dal sistema, si vengono a creare delle correnti di ricircolazione dovute alla turbolenza; è stato necessario azzerare tali correnti per impedire che si possano avere portate uscenti dalla sezione di alimentazione e flussi in ingresso in corrispondenza dell’uscita dei fumi (F.3). Per quanto riguarda i reattori sorgente, si è imposto, che le portate in ingresso dall’esterno, fossero quelle nominali di aria e metano calcolate nella subroutine
SORGENTI (E) sostituendole a quelle valutate sulla base dei dati KIEN
(F.3).
Il file dello standard input è stato modificato per inserire un blocco di definizione delle sezioni e delle portate globali di alimentazione in maniera tale da valutare come si distribuiscano le correnti di aria e combustibile, tra le celle sorgente (C.7).
La ripartizione delle portate è stata effettuata in base alla determinazione della frazione volumetrica di una cella, riferita al volume globale che interessa la sezione (E.5).
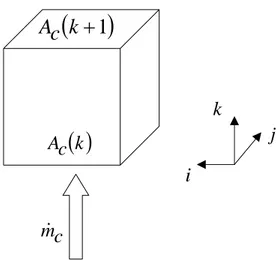
Fig. 3. 5 – Cella generica di una sezione di alimentazione
Il flusso massivo attraverso la superficie di alimentazione Ac
( )
k di una cella c è dato da m&c = Ac( )
k ⋅vc⋅ρc =Cost⋅Ac( )
kLa semistrutturazione della griglia di calcolo interessa solo la direzione
j , per cui si ha che in generale Ac
( )
k ≠ Ac(
k+1)
.Supponendo che Ac
( )
k ≅ Ac(
k+1)
≅ Ac e sapendo che il volume della cella può scriversi come Vc = Ac⋅h si può dire che Vc ≅ Ac( )
k ⋅h.Il volume globale delle celle di una sezione di alimentazione è dato da
h tot A c h c A tot V =∑ ⋅ = ⋅ e
( )
c A fr Cost tot A k c A Cost tot A c m ⋅ = ⋅ = & ; risulta quindi che c A fr Cost c m = ⋅ 1 & . Considerando che( )
c V fr tot V h h c V tot A c A tot A k c A c A fr = ≅ = ⋅ = si può concludere che c V fr Cost c m ≅ ⋅ 1 & .(
k
+
1
)
c
A
( )
k c A c m& i j kL’approssimazione della distribuzione delle portate globali, sulle celle sorgente, risulta tanto migliore quanto più dettagliata è la risoluzione spaziale della griglia del calcolo CFD.
Ulteriore modifica al modulo SCAMAS, riguarda l’eliminazione della valutazione dei flussi massivi a partire dalle portate areolari definite sulle facce delle celle; KIEN fornisce direttamente i campi suddetti nel file di interfaccia (B.2).