2
Preamble Acquisition
su segnale Spread Aloha
In questo capitolo viene trattato il problema dell'acquisizione di preambolo in E-SSA. Dopo una introduzione sull'importanza dell'acquisizione nei sistemi spread spectrum, vengono presentate le tecniche classiche solitamente usate oggi e le loro prestazioni teoriche in presenza di disturbo AWGN. Successivamente viene presentato un modello per l'interferenza multi utente su segnale E-SSA e attraverso un'approssimazione gaussiana vengono valutate le prestazioni previste. Tali prestazioni risultano insoddisfacenti, e quindi a conclusione del capitolo viene presentata la ricerca bidimensionale come possibile soluzione al problema della rivelazione di preambolo in questo scenario.
2.1 Acquisizione in sistemi DS/SS
La sincronizzazione di codice nei sistemi DS/SS è il problema della stima del ritardo della sequenza di spreading nel segnale ricevuto. Tradizionalmente essa si divide in due fasi: acquisizione di codice, che fornisce una stima grossolana con precisione dell'ordine del tempo di chip, e successivo tracking che affina la stima e la aggiorna periodicamente. Un ricevitore che non effettua una corretta sincronizzazione
va a buon fine è possibile generare localmente una replica della sequenza di codice per effettuare il de-spreading. La difficoltà è data dal fatto che la stima deve avvenire quando non è possibile avere altre informazioni sulla trasmissione. Il SINR (Signal to Interference + Noise Ratio) prima del de-spreading è infatti tipicamente molto basso, dell'ordine di –20 dB e oltre,e non è possibile valutare le condizioni di propagazione sul canale o i parametri di fase e frequenza della portante ricevuta.
Nelle trasmissioni a pacchetto come E-SSA, il processo di acquisizione deve iniziare e concludersi indipendentemente per ciascun pacchetto. Per facilitare ciò viene inserito un preambolo prima dei dati utili e quindi la fase di acquisizione coincide con la ricerca della presenza di tale preambolo. Si parla anche di data-aided acquisition poiché il preambolo è perfettamente noto al ricevitore. Il suo dimensionamento deve essere inoltre valutato attentamente nei confronti del payload: un preambolo lungo rende più facile la sua rivelazione, ma al tempo stesso rappresenta un maggiore overhead che non trasporta dati utili. Una ulteriore complicazione è data dal fatto che trattiamo un sistema unslotted per cui i preamboli vanno cercati su tutto il tempo in maniera continuativa.
E' noto che il criterio Maximum Likelihood applicato alla stima del ritardo richiederebbe la costruzione di un rivelatore estremamente complesso, perché dovrebbe eseguire una correlazione continua sul segnale in modo da trovare quel valore che massimizzi la funzione di verosimiglianza f :
= arg max f r t ; (2.1)
La formula ci dice che, dato il segnale osservato r(t), deve essere calcolato il valore assunto da f in corrispondenza di un infinito numero di ritardi di tentativo. Nei sistemi reali ciò non è ovviamente possibile, e ci si riduce allora a considerare il tempo come suddiviso in un numero finito di celle di ricerca della dimensione di un chip o frazione di chip. Se indichiamo con H1 l'ipotesi di “inizio di preambolo” e con H0 quella di
“assenza di inizio di preambolo”, il problema diviene quello di una decisione binaria da effettuarsi cella per cella cercando di limitare gli eventi di falso allarme e mancata rivelazione. Deve essere evidenziato il fatto che si tratta di un problema di decisione
fortemente sbilanciato: il numero di celle H0 è di gran lunga superiore al numero di
celle H1.
Il sistema di acquisizione di codice può in generale essere scomposto nelle seguenti due funzioni, eseguite su una certa cella in esame:
• Una tecnica di rivelazione (detection scheme), che osserva il segnale ricevuto sui Tpr secondi disponibili ed esegue certe operazioni in modo da restituire una
variabile di decisione Z;
• Un criterio di decisione (decision criteria), che nel nostro caso è il threshold crossing (TC) ovvero: a seconda che il valore di Z superi o meno una certa soglia, si decide per l'ipotesi H1 o H0.
Nei sistemi hardware l'acquisizione può essere di tipo serial search o parallel search a seconda di come vengano scelte le celle di ritardo da esaminare, ed opera nel dominio del tempo avvalendosi tipicamente di correlatori basati su filtri FIR. Un'acquisizione realizzata in software-radio conviene invece implementarla sfruttando l'efficienza computazionale della FFT, ovvero lavorando nel dominio delle frequenze. A rigore, essa rientra dunque nella categoria parallel search perché, data una certa finestra di tempo, effettua la ricerca su tutte le celle in essa contenute. Inoltre non è più necessaria una distinzione netta fra acquisizione e tracking: quando viene trovato il picco di correlazione di un preambolo, si ritiene conclusa con successo la sincronizzazione di codice per quel pacchetto.
Il principale riferimento prestazionale del sistema di acquisizione sono le Receiver Operating Characteristics (ROC), cioè l'andamento della probabilità di mancato avvistamento PMD nei confronti della probabilità di falso allarme PFA al
variare della soglia di decisione. Se sono disponibili le funzioni densità di probabilità condizionate della variabile Z, e se indichiamo con ζ la soglia, tali probabilità corrispondono a: PFA= Pr
{
Z | H0}
=∫
∞ f Z | H0d Z (2.2) P = 1−P =Pr{
Z | H}
=∫
f Z | H d Z (2.3)In Fig. 2.1 è mostrata la relazione fra le densità di probabilità condizionate e i valori PFA e PMD. La distribuzione della variabile Z dipende dal particolare detection scheme
impiegato. La scelta della soglia è invece legata al compromesso che si vuole raggiungere fra le due probabilità ed è un punto critico, per una serie di motivi:
• una soglia bassa abbassa la PMD ma alza la PFA, e viceversa;
• il riconoscimento di preambolo non deve diventare il collo di bottiglia del sistema: la PMD deve essere sufficientemente inferiore al PLR dovuto agli errori
riscontrati nel payload o alle perdite per collisione sul canale; • una PFA elevata induce uno spreco di risorse di calcolo nel Gateway;
• E-SSA non prevede la ritrasmissione dei pacchetti, nel caso questi andassero perduti. La ROC deve essere in generale “buona”.
Un criterio di scelta della soglia che viene spesso adottato è il Constant False Alarm Rate (CFAR). Tale criterio consente di lavorare con una PFA ad un certo valore
prefissato, indipendentemente dalle condizioni di rumore e interferenza che possono cambiare nel corso del tempo. Per poter funzionare, CFAR necessita di una stima del livello di disturbo istantaneo, costituito dal rumore termico più l'intensità degli arrivi λo del momento. Fissata PFA, la soglia viene adattata in maniera dinamica e la PMD si
modifica di conseguenza.
Quando si verifica un evento di falso allarme, il sistema entra nello stato di verifica: l'intero sistema di decodifica entra in funzione e viene tentata la ricezione del
payload, per poi arrestarsi quando il Cyclic Redundancy Check fallisce. Per questo è utile tenere presente anche un altro valore, indicativo (direttamente proporzionale) della quota di tempo sprecata in ricezione per il tentativo di decodifica di arrivi inesistenti. Per distinguerlo dalla PFA viene indicato con il nome di Effective False
Alarm Rate ed equivale a:
EFAR= # false alarms
# arrivals found (2.4)
Nei seguenti sottoparagrafi sarà trattato il caso ideale di segnale utile disturbato da rumore AWGN e sotto ipotesi di perfetto allineamento fra il codice locale e quello in arrivo.
2.1.1 Correlatore non coerente
Se vi fosse corretto recupero di frequenza e fase il detection scheme ottimo per il riconoscimento del preambolo sarebbe il correlatore coerente. Nel nostro caso, come già detto sopra, non è possibile una correzione della fase perché il segnale in arrivo ha un SINR troppo basso per potervi eseguire accurate stime. In tale situazione è possibile dimostrare che il nuovo schema da impiegare è il correlatore non coerente, detto anche energy detector.
Riprendendo l'espressione 1.23, considerando un singolo preambolo disturbato da rumore AWGN, ponendo offset di frequenza nullo e osservando il segnale ricevuto nell'intervallo [0, Tpr], le ipotesi H1 e H0 fra le quali deve essere fatta la decisione
divengono:
H1: rRFt =ℜ
{
A pt ej ej 2 f0t}
wt , 0tTpr (2.5)H0: rRFt =w t ,0tTpr (2.6)
Dove A è l'ampiezza del preambolo ricevuto e supposta nota, θ è variabile aleatoria uniforme in [–π, π], e w(t) è rumore AWGN avente dsp bilatera pari a N0/2.
Scomponendo il segnale utile nelle due componenti in fase e quadratura e raccogliendo Acosθ e –Asinθ si ha:
ℜ
{
A pt ej ej 2 f0t}
= A pRt cos − pItsin
I t
cos 2 f0t − A p
Rt sin pIt cos Q t
sin 2 f0t = A cos[ pRt cos 2 f0t − pIt sin 2 f 0t]
−Asin [ pIt cos 2 f0t pRt sin 2 f0t ] . (2.7)
Andiamo a fissare le prime due funzioni di una base di rappresentazione del segnale:
0t=2[ pRt cos2 f0t − pIt sin 2 f 0t ] (2.8)
1t =−2[ pIt cos2 f0t pRt sin 2 f0t] (2.9)
Tali funzioni risultano ortogonali in quanto è verficata la condizione f0Tpr>>1. Il
segnale utile può così essere espresso come ℜ
{
A pt ej ej 2 f0t}=
Acos 2 0t
Asin
2 1t . (2.10)
I coefficienti dello sviluppo di Karhunen-Loeve relativi a queste due funzioni della base sono: X0=
{
∫
0 Tpr rRFt 0t d t=W0 ip. H0∫
0 Tpr rRFt0t d t= Acos EpW0 ip. H1 (2.11) X1={
∫
0 Tpr rRFt 0t d t=W1 ip. H0∫
0 Tpr rRFt 0t d t= Asin EpW1 ip. H1 (2.12)Dove Ep è l'energia di preambolo che, con impulso di trasmissione a energia unitaria,
vale: Ep=
∫
0 Tpr ∣p t∣2d t=∫
0 Tpr pR2t p I 2t d t=2 N pr (2.13)W0 e W1 sono invece variabili gaussiane incorrelate, a media nulla e varianza
w2=E
{
∫
0 Tpr w t10t1d t1⋅∫
0 Tpr w t20t2d t2}
==
∫
0 Tpr∫
0 Tpr E{
w t1wt2}
0t1 0t2d t1d t2=N0 2∫
0 Tpr 02t d t≃N0Ep . (2.14) Comunque si scelgano le rimanenti funzioni della base, i coefficienti che ne risultano sono irrilevanti ai fini della decisione. Il problema è allora di tipo bidimensionale e si basa sui valori X0 e X1 osservati. Poiché essi sono indipendenti (sono variabiligaussiane e incorrelate), le densità di probabilità del vettore (X0, X1) osservato nelle
due ipotesi e condizionate alla conoscenza di θ sono: f X0, X1| , H0= 1 2 w 2 e −X0 2X 1 2 2 w2 ≡f X0, X1| H0 (2.15) f X0, X1| , H1= 1 2 w2 e −X0−A cos Ep 2 X1−A sin Ep 2 2w 2 (2.16)
Prima di scrivere il rapporto di verosimiglianza deve essere tolta la dipendenza dalla fase nella seconda, per cui:
f X0, X1| H1=
∫
− 1 2 f X0, X1| , H1d = = 1 2 w2 e −X0 2 X1 2 A2 Ep 2 2 w 2 ⋅∫
− 1 2 e AEp w 2 X0cos X1sin d . (2.17) Effettuando adesso la sostituzioneX0cos X1sin =
X02X12cos −0 con 0=−tg −1
X1X0
(2.18) ed il successivo cambio di variabile β=θ–θ0, l'integrale da risolvere diviene:
∫
−−0 −0 1 2e AEp w 2 X0 2 X1 2 cos d =I0
AEp
X02X12 w2
(2.19)dove si è tenuto conto che l'integrando è una funzione periodica di β con periodo 2π, e si è introdotta la funzione di Bessel modificata di prima specie di ordine zero definita da
I0x = 1 2
∫
−
Adesso è possibile scrivere il rapporto di verosimiglianza: X0, X1= f X0, X1| H1 f X0, X1| H0 =e− A2 Ep 2 2 w 2 I0
A Ep
X0 2 X12 w2
≷ (2.21) Dove ξ è una soglia opportuna che, scelta in base alla PFA di obiettivo, ottimizza la PMDche può essere ottenuta. Poiché la funzione di Bessel è una funzione monotona crescente il test di decisione può essere ridotto a:
H1 H1
X02 X12 ≷
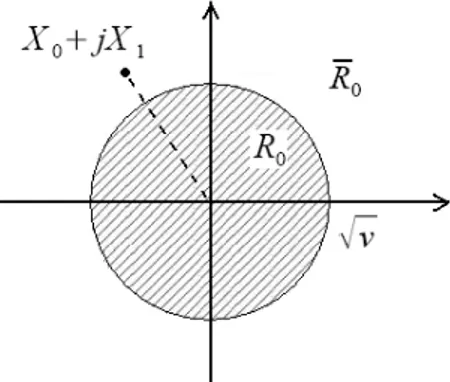
v oppure X0 2 X1 2 ≷ v (2.22) H0 H0Il modulo del vettore degli osservati (il modulo quadro) deve essere confrontato con la nuova soglia
v (v), che dipende strettamente dalla precedente ξ. In altri termini, guardando al piano bidimensionale definito da (X0, X1) la regione di decisione per H0 èun cerchio di raggio
v , indicato con R0 , mentre la regione di decisione per H1 èla parte esterna ad esso R0 (Fig. 2.2).
Lo studio è stato fatto a partire dal segnale a radiofrequenza ma si ottiene lo stesso risultato se si elabora il segnale direttamente in banda base. A tale scopo deve essere eseguita la correlazione, complessa, fra l'inviluppo complesso del ricevuto e il preambolo
∫
0 Tpr rBBt p*t d t= X 0jX1 (2.23)seguita da un blocco che ne estrae il modulo (o modulo quadro) e va a confrontare con
Fig. 2.2 - Regioni di decisione per il
la soglia
v (v). Nelle Figg. 2.3 e 2.4 è mostrato il passaggio al segnale in banda base e l'applicazione del correlatore all'inviluppo complesso. Il processo di rumore w(t), portato in banda base, è:
w t=wRt j wIt (2.24)
in cui wR(t) e wI(t) sono processi incorrelati, ciascuno avente dsp bilatera piatta pari a
N0 sulla banda di interesse. Dato che questo schema equivalente è più sintetico da
trattare, nel seguito lavoreremo direttamente in banda base.
E' utile a questo punto ricavare le prestazioni cercate, cioè i valori di falso allarme e mancato avvistamento che possono essere raggiunti. Le due densità di probabilità condizionate ad H0 e H1 devono essere integrate, rispettivamente, sulle
regioni di decisione R0 e R0 . Data la simmetria circolare di tali regioni è
necessario nel corso del calcolo il passaggio a coordinate polari (Z,θ) con
Z =
X02X12 per risalire così alla funzione f(Z|H
i), che corrisponde alla ddp della
sola variabile di decisione, e poi integrare. Si ottiene: PFA=
∬
X0, X1∈ R0 f X0, X1| H0d X0d X1=∬
X0, X1∈ R0 1 2 w2 e −X0 2X 1 2 2 w 2 d X0d X1 =Figg. 2.3 e 2.4 - Estrazione dell'inviluppo complesso e correlazione con il
=
∫
v ∞∫
− 1 2 w2 e− Z 2 2 w 2 Z d d Z =∫
v ∞ Z w2 e− Z 2 2 w 2 d Z =e− v2 w 2 . (2.25)L'ultimo integrando è la ben nota funzione di Rayleigh. La probabilità ottenuta, come era prevedibile, dipende dal rapporto fra la soglia e il livello di rumore. Per quanto riguarda la PMD: PMD=
∬
X0, X1∈R0 f X0, X1| H1d X0d X1 = =∬
X0, X1∈R0 1 2 w2 e −X0 2 X1 2 A2 Ep 2 2 w 2 I0
A Ep
X0 2 X1 2 w2
d X0d X1 =∫
0 v∫
− 1 2 w2 e −Z 2 A2 Ep 2 2 w 2 I0
A EpZ w2
Z d d Z =∫
0 v Z w2 e −Z 2 A2 Ep 2 2 w 2 I0
A EpZ w2
d Z (2.26) L'ultimo integrando è la ben nota funzione di Rice. Purtroppo non esiste una forma chiusa per risolverlo e quindi il risultato viene espresso tramite la cosiddetta funzione Q di Marcum:PMD=1−Q
A Ep w ,
vw
. (2.27)Della funzione di Marcum esistono tabulati e funzioni approssimate pronte su calcolatore. Ad esempio in Matlab è disponibile la funzione marcumq(a,b). Si può notare che, oltre che dal livello di rumore e dalla soglia, adesso c'è una chiara dipendenza dalla particolare ampiezza A del preambolo.
2.1.2 Offset di frequenza e NCPDI
Nel paragrafo 1.3.2 è stata evidenziata la necessità di tenere conto di un offset di frequenza di ±1 KHz, derivante da errori negli oscillatori, nella conversione di banda, oppure da effetto Doppler dovuto al movimento relativo fra satellite e terminale. L'offset tende ad alzare la PMD perché è causa di una degradazione del picco
utile di correlazione, mentre lascia invariata la PFA. Vediamo più in dettaglio il perché
Seguendo lo schema del ricevitore in banda base (Fig. 2.4), l'inviluppo complesso del segnale ricevuto può essere scritto come:
H1: rBBt=A p t ej 2 f t w t ,0tTpr (2.28)
H0: rBBt= w t , 0tTpr (2.29)
In ipotesi H0 non vi sono cioè modifiche, mentre in ipotesi H1 la coppia di variabili X0,
X1 diventa: X0jX1=
∫
0 Tpr rBBt p*t d t=A ej ∫
0 Tpr | p t |2ej 2 f tdtW 0jW1 (2.30)Essendo p(t) limitato sul tempo [0,Tpr], l'integrale corrisponde ad una trasformata di
Fourier:
∫
−∞ ∞
| p t|2ej 2 f tdt=TF
{
| p t|2}
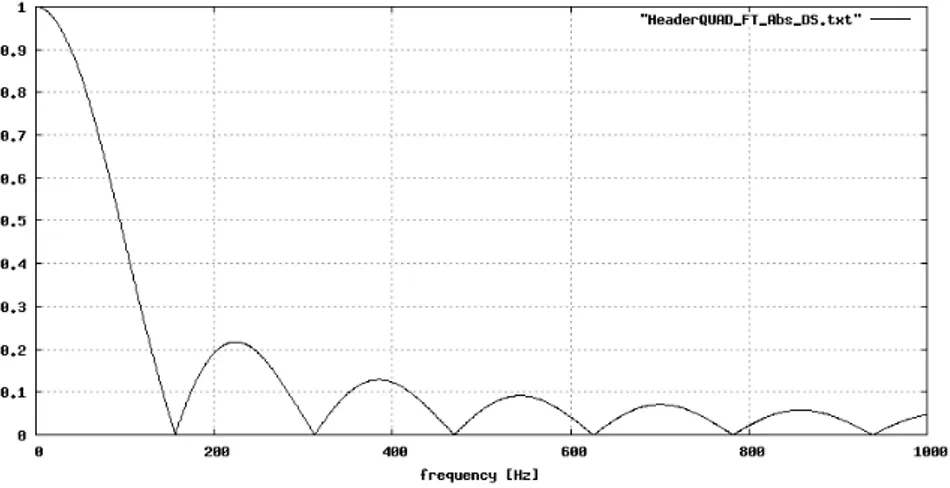
@ f =− f . (2.31)Tale trasformata, nota in tecnica radar come zero-delay Ambiguity function, presenta un andamento del modulo di tipo sinc(ΔfTpr). Nelle Figg. 2.5 e 2.6 sono mostrate la
Ambiguity Function e la sezione lungo t=0, calcolate con il preambolo E-SSA.
Si può concludere che il contributo utile si abbassa del fattore sinc(ΔfTpr) e la PMD (eq.
2.27) al variare del particolare Δf diviene: PMDf =1−Q
A Epsinc f Tpr
w ,
v
w
(2.32)Il primo nullo della sinc si trova a Δf=1/Tpr, che nel nostro caso è pari a circa 156.2
Hz: pacchetti che arrivassero con tali offset verrebbero perduti!
E' immediato notare che un correlatore più corto allontanerebbe il nullo della sinc, tuttavia non sfrutterebbe l'intera energia presente nel preambolo. Una soluzione pratica ormai usata da molti anni, che consente un tempo di osservazione lungo quanto il preambolo ma mantiene la stessa robustezza all'offset di una correlazione corta, è la combinazione non coerente NCPDI (Non Coherent Post Detection Integration). Essa consiste nel suddividere il tempo Tpr in M intervalli, eseguire in successione altrettante
correlazioni parziali, e poi andare a sommare le uscite in modulo quadro (Fig. 2.7). Fig. 2.6 – Zero-delay Ambiguity Function.
Riprendendo la stessa notazione usata precedentemente, nel caso NCPDI abbiamo 2M variabili reali (ovvero M variabili complesse) esprimibili come:
X0,m=
{
ℜ{
∫
mTpr/M m 1 Tpr/M rBBt p * t d t}
=W0, m ip. H0 ℜ{
∫
mTpr/M m1Tpr/M rBBt p * t d t}
≃Acos Epsinc f Tpr/M M W0, m ip. H1 X1, m={
ℑ{
∫
mTpr/M m1Tpr/M rBBt p*t d t}
=W1, m ip. H0 ℑ{
∫
mTpr/M m1Tpr/M rBBt p*t d t}
≃Asin Epsinc f Tpr/M M W1,m ip. H1dove m=0,1,2,..,M-1 ed è stato sottinteso il fatto che l'energia del preambolo sia equamente distribuita su tutta la durata Tpr. W0,m e W1,m sono variabili gaussiane tutte
dello stesso tipo, incorrelate, a media nulla e varianza
2w , m=E
{
∫
mTpr/M m1Tpr/M ℜ{
w t 1p *t 1}
d t1∫
mTpr/M m1Tpr/M ℜ{
w t 1p *t 1}
d t2}
≈ ≈ N0Ep M = w , M 2 . (2.35)La variabile di decisione Y proviene dalla somma di 2M variabili gaussiane al quadrato: Y =
∑
m=0 M −1 | X0, mjX1,m|2 =∑
m=0 M −1 X0,m2 X1,m2 (2.36)Nell'ipotesi H0 si tratta di variabili gaussiane a media nulla e stessa varianza per cui si
dimostra che la densità di probabilità f(Y|H0), funzione della sola Y, è una Chi-quadro
centrale con 2M gradi di libertà: f Y | H0= Y M −1 2 w , M2 M⋅M −1!e − Y 2 w ,M 2 , Y ≥0 (2.37)
Nell'ipotesi H1 la media delle variabili non è nulla e si ha una Chi-quadro non centrale
f Y | H1, f = 1 2 w , M2
Y s f
M −1 2 e− Y s f 2 w ,M 2 IM −1
Y
s f w , M2
,Y ≥0 (2.38) dove s(Δf) , che dipende dall'offset di frequenza, è detto parametro di non centralitàs f =
∑
m=0 2M −1 m2=A 2E p 2sinc2 f Tpr/M M (2.39)e IM-1(x) è la funzione di Bessel modificata di prima specie di ordine (M-1). E' facile
verificare che se si pone M=1 e si effettua il cambio di variabile Z =
Y , si ottengono esattamente le funzioni f(Z) di Rayleigh e Rice trovate nel correlatore non coerente (2.25, 2.26). La regola di decisione si basa ora sul superamento della soglia v', per cui le prestazioni cercate risultano:PFA=
∫
v' ∞ f Y | H0dY =e − v' 2 w ,M 2∑
m=0 M −1 1 m!
v ' 2 w , M2
m (2.40) e PMDf =∫
0 v' f Y | H1, f dY =1−QM
s f w , M ,
v ' w , M
(2.41)dove QM è adesso la funzione di Marcum generalizzata di grado M. Anche di essa
esistono tabulati e funzioni pronte su calcolatore, ad esempio in Matlab è disponibile la funzione marcumq(a,b,M).
Per risalire alla PMD generale bisogna trovare e integrare la f(Y|H1) che non è
più condizionata ad un particolare Δf : PMD=
∫
0 v '{
∫
−1 KHz 1 KHz f Y , f | H1d f}
dY =∫
0 v '{
∫
−1 KHz 1 KHz f f f Y | H1, f d f}
= =∫
0 v '∫
−1 KHz 1 KHz 1 2 KHz f Y | H1, f d f dY ≡∫
−1 KHz 1 KHz 1 2 KHzPMD f d f (2.42)in cui l'offset è stato considerato come variabile aleatoria uniforme in [–1 KHz, +1 KHz]. Il calcolo della probabilità può essere approssimato tramite integrazione numerica al calcolatore.
Una questione rimasta irrisolta è come debba essere fissato M. Un valore basso favorisce infatti la rivelazione di arrivi con offset piccoli penalizzando però quelli con
offset più elevati, e viceversa. In [15] viene presentato il criterio CHILD (Coherent Integration Length Dimensioning) che suggerisce di scegliere un M tale che:
Npr M ≃ 3 8 1 f Tc . (2.43)
Il criterio si basa sull'analisi dell'uscita del singolo correlatore parziale, e quindi non tiene conto dell'effetto dovuto alla successiva somma dei quadrati. Inoltre suppone un errore di frequenza Δf noto, che nei casi pratici andrà sostituito con il worst case Δfmax.
Per questi motivi la regola CHILD non è da considerarsi come ottima a priori, ma viene indicata dagli autori come un buon punto di partenza per l'ottimizzazione del sistema. Nel caso con Npr=24576 si trova un valore di circa M=17.
Il punto debole della NCPDI è il fatto che introduce delle non linearità (i moduli quadro) provocando un effetto di noise-enhancement. Normalmente nei sistemi DS/SS questa perdita è modesta e comunque accettabile, perché ampiamente ripagata dalla robustezza nei confronti dell'offset. Nel caso E-SSA la situazione invece è molto più critica e, come vedremo nei prossimi paragrafi, l'applicazione di una NCPDI non è consigliabile.
2.2 Processo MAI in E-SSA
Nello studio delle prestazioni è necessario tenere soprattutto conto della degradazione dovuta alla presenza di segnali in arrivo sovrapposti al pacchetto di cui viene tentata l'acquisizione di codice. Questi segnali generano un contributo di disturbo aggiuntivo sulle variabili in uscita al correlatore (eq. 2.11, 2.12) o ai correlatori parziali del rivelatore di preambolo. Tale disturbo è anche legato alla funzione di autocorrelazione del codice impiegato, e questo spiega l'importanza in fase di progetto di una scelta attenta della sequenza di spreading.
Nel caso di sistemi Spread Aloha come E-SSA, una trattazione accurata del processo di interferenza, e quindi delle variabili di decisione, è complicata per via della caratteristica unslotted della trasmissione. Il numero di pacchetti che in ogni
istante appaiono sovrapposti nel tempo è a tutti gli effetti un processo stocastico discreto (Fig. 2.8). Nel paragrafo 2.2.1 viene modellata tale interferenza attraverso un'approssimazione gaussiana, così da avere delle curve prestazionali analitiche (par 2.2.2) da poter confrontare con i risultati sperimentali del Capitolo 4.
2.2.1 Approssimazione Gaussiana
Indicato con u=0 il preambolo (utente) utile che inizia in t=0 e indicato con U il numero di pacchetti interferenti, la componente di segnale che disturba la rivelazione del preambolo è data da:
iBBt=
∑
u≠0 U Ausu t−uej 2 fut u , 0tT pr . (2.44)Riportiamoci per adesso al caso di perfect power control (Au=A) e di assenza di offset
di frequenza (Δfu=0). Nel caso di rivelatore a correlatore, tale disturbo viene correlato
con il preambolo e dà un contributo
∫
0 Tpr∑
u ≠0 U A su t−up*t ej ud t= A∑
u≠0 U ej u∫
0 Tpr s t−up*t d t= MAI0j MAI1 . Le variabili in uscita X0, X1 sono dunque esprimibili come somma di due o trecomponenti, a seconda che ci si trovi nell'ipotesi H0 o H1 :
X0=
{
W0MAI0 ip. H0A cos EpW0MAI0 ip. H1 (2.46) X1=
{
W1MAI1 ip. H0Asin EpW1MAI1 ip. H1 (2.47)
L'Approssimazione Gaussiana Standard consiste nel modellare iBB(t) come un
processo complesso di tipo AWGN, con parti in fase e quadratura a dsp piatta I0
almeno sulla banda stretta del filtro integratore (che è dell'ordine di 1/Tpr), e si basa su
due considerazioni:
• I pacchetti sono statisticamente indipendenti fra loro;
• U è una variabile aleatoria, che però tende ad assumere valori elevati a causa dell'elevata intensità di traffico λo (ad es. 8000 pkt/s).
Questi fatti consentono l'applicazione del Teorema del Limite Centrale per caratterizzare le variabili MAI0 e MAI1 con una opportuna densità di probabilità
gaussiana. Per quanto riguarda la media, si ha:
E
{
MAI0}
=E{
MAI1}
=0 (2.48)Se il numero di pacchetti U fosse deterministico e tutti i pacchetti si sovrapponessero completamente, un buon valore per la varianza sarebbe quello già noto per le reti A-CDMA: i2=E
{
MAI02}
=E{
MAI12}
≃I0Ep=∑
u=1 U PRF u 1/Tc EP=U PRFTcEp (2.49) dove si è tenuto conto che gli utenti trasmettono con continuità per cui PRF(u)=PRF.Nel caso di E-SSA però, non solo U è variabile ma la potenza media interferente, dovuta all'utente u, dipende da quanto è sovrapposto il pacchetto u-esimo. E' necessario quindi introdurre ulteriori approssimazioni. E' possibile innanzitutto suddividere i pacchetti interferenti in tre diverse categorie (Fig. 2.9):
U =U1U2U3
(–Tpl –Tpr, –Tpl);
• U2 pacchetti totalmente sovrapposti al preambolo di interesse, ovvero il loro
inizio cade nell'intervallo [–Tpl, 0);
• U3 pacchetti che giungono in ritardo, ovvero il cui inizio cade nell'intervallo
(0, Tpr).
La variabile U2 ha distribuzione di Poisson con parametro λoTpl. Dato che essa indica
quei pacchetti che interferiscono completamente col preambolo utile, il loro contributo nella 2.49 può essere approssimato come:
PU2=E
{
PU2}
=E{
∑
u=1 U2PRFu
}
=E{
U2}
PRF=oTplPRF (2.50)I pacchetti U1 e U3 sono invece quelli che si sovrappongono parzialmente. Le variabili
hanno distribuzione di Poisson con parametro λoTpr e l'unica differenza che distingue le
due categorie è che la prima porta chip di payload interferenti mentre la seconda porta chip di preambolo interferenti. Nel caso U1, la potenza media di disturbo da essi
portata deve essere valutata mediando rispetto alla variabile U1 e al tempo τu:
PU1=E
{
PU1}
=E{
∑
u=1 U1 Pinterfu }
=∑
U1=0 ∞{
∫
o Tpr 1 Tpr∑
u=1 U1 Pinterfu |ud u}
e −oTpr oTpr U1 U1!dove Pinterf(u) è la quota di potenza dell'utente u che interferisce col preambolo utile,
sempre minore o uguale alla PRF(u) che invece indica l'intera potenza dell'utente.
Considerando adesso che:
Pinterfu | u≃PRFuTpr−u
Tpr
=PRFTpr−u Tpr
(2.52)
e inserendo questo valore nella formula si ottiene:
∑
U1=0 ∞{
∑
u=1 U1 P RF T2pr∫
o Tpr Tpr−ud u}
e −oTpr oTpr U1 U1! = =∑
U1=0 ∞ P RF 2 U1 e−oTpr oTprU1 U1! = PRF 2 E{
U1}
= PRF 2 0Tpr . (2.53)Dal momento che Tpl>>Tpr, U2 assume valori molto più grandi di U1 e U3 per cui
possiamo ritenere trascurabile il contributo di potenza interferente dato da questi ultimi. Con questo modello per l'interferenza, le formule 2.25 e 2.27 sono ancora valide perché le varianze delle gaussiane si sommano:
PFA=e− v 2w 2 i 2 (2.54) PMD=1−Q
A Ep
w2i2,
v
w2i2
. (2.55)Nel caso di rivelatore NCPDI le conclusioni sono simili. Infatti le variabili in uscita ai correlatori parziali adesso sono:
X0,m=
{
W0,mMAI0, m ip. H0 A cos Ep M W0, mMAI0,m ip. H1 (2.56) X1, m={
W1, mMAI1,m ip. H0 A sin Ep M W1, mMAI1, m ip. H1 (2.57)con m=0,1,..,M-1. Il numero medio di pacchetti U2 che interferiscono totalmente con
la m-esima porzione di preambolo è
E
{
U2}
=o
TplTprM −1M
(2.58)cioè un poco superiore rispetto al caso di correlatore completo, e la varianza approssimata è la stessa per ogni m e diviene
i , m2 ≃I0Ep
M =E
{
U2}
PRFTcEp
M = i , M
2 . (2.59)
somma: PFA=e − v ' 2w ,M 2 i, M 2
∑
m=0 M −1 1 m!
v ' 2 w , M2 i , M2
m (2.60) PMD=1−QM
s
w , M2 i , M2 ,
v '
w , M2 i , M2
(2.61) dove s=A 2 E2p M . (2.62)I precedenti risultati sono stati trovati considerando offset di frequenza nullo. In realtà possiamo pensare di estenderli al caso di offset non nullo, ma ancora in condizioni ideali di perfect power control. Infatti l'effetto dell'offset è quello di traslare leggermente lo spettro di un pacchetto interferente ricevuto senza però modificare la potenza media statistica ad esso associata, cioè la potenza del processo di disturbo MAI. Nel prossimo paragrafo questa estensione sarà effettuata per la tecnica NCPDI.
2.2.2 Prestazioni teoriche
Per tracciare le ROC teoriche deve essere per prima cosa valutato il primo argomento delle funzioni di Marcum, si deve quindi far variare il secondo argomento e graficare la variazione di PMD (o PD=1-PMD) in funzione di PFA.
Il segnale ricevuto così come definito in (eq. 2.5) ha potenza PRF=PBB
2 =
A2 Tc
. (2.63)
Nel caso del correlatore completo e in assenza di rumore (σW=0) si ha
I0=oTpl A2 (2.64)
e il rapporto da inserire nella PMD risulta:
A Ep i = A Ep
I0Ep=A
2 Npr oTplA2 =
2 Npr oTpl . (2.65) Nel caso NCPDI e sempre in assenza di rumore si haI0=o
TplTprM −1M
A2
(2.66) e il rapporto da inserire nella PMD risulta:
A Ep/
M i , M = A Ep
I0Ep=
2 Npr o
TplTpr M −1 M
. (2.67)In Tab. 2.1 sono riportati tali valori a seconda dell'intensità degli arrivi, e calcolati in base ai parametri di riferimento E-SSA. In particolare il valore di M che al momento è stato fissato è 24, e sarà considerato tale anche nel Capitolo 4.
Tab. 2.1 – Valori inseriti nelle funzioni di Marcum, al variare di λo.
λo E{U2} Corr. Q(arg1, -) E{U2} NCPDI QM(arg1, -)
2000 160 17.53 172 16.91
4000 320 12.39 345 11.94
6000 480 10.12 517 9.75
8000 640 8.76 689 8.45
10000 800 7.84 861 7.56
In generale ci attendiamo dei risultati ottimistici rispetto alla realtà, per almeno tre motivi:
• SGA è adatta per codici PN diversi da utente a utente, e inoltre è noto il suo comportamento ottimista quando il numero di chip è elevato. Qui il codice è unico;
• Abbiamo trascurato i contributi di interferenza dovuti alle sovrapposizioni parziali;
• La probabilità di collisione a livello di chip non è stata mai inclusa nel calcolo. Le ROC qui trovate non tengono conto di questo, per cui in molti test di cui al Capitolo 4 si è evitato di generare nel segnale la collisione.
Le ROC sono riportate nelle Figg. 2.10, 2.11 e sono state tracciate su MATLAB impiegando le funzioni marcumq(a,b) e marcumq(a,b,M).
Fig. 2.10 - ROC nel caso di correlatore e assenza di Doppler shift, su segnali a 6k, 8k, 10k pkt/s
con perfect power control e assenza di chip level collision.
Fig. 2.11 - ROC nel caso NCPDI e assenza di Doppler shift, su segnali a 4k, 6k, 8k pkt/s con
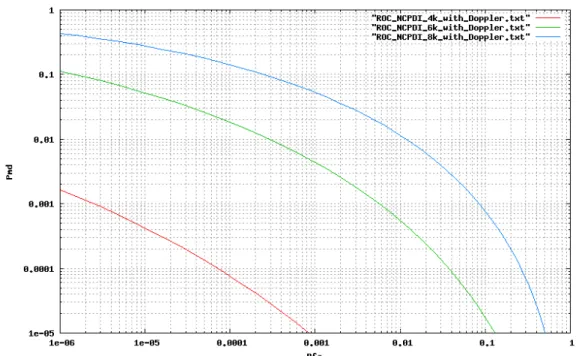
In Fig. 2.12 è invece riportata la ROC semi-analitica per il caso NCPDI. Essa è stata ricavata integrando al calcolatore la probabilità di mancato avvistamento al variare dell'offset (eq. 2.42).
In E-SSA è prevista da progetto una PLR<10-3 perché il sistema non prevede la
ritrasmissione in caso di perdita del pacchetto. Un Preamble Searcher deve quindi garantire una PMD<10-4, cioè un ordine di grandezza inferiore, in modo che non
rappresenti il collo di bottiglia del sistema. La PFA, d'altra parte, deve essere bassa
anch'essa altrimenti il valore di EFAR diviene ingestibile. Come sarà più chiaro dai risultati del Cap.4, le prestazioni ottenibili con NCPDI non sono soddisfacenti, oltre al fatto che non tengono conto dell'ulteriore perdita dovuta al fenomeno di chip collision. In un modello più realistico, inoltre, bisogna tenere in conto di una dispersione in potenza dei pacchetti ricevuti. Le prestazioni in tale caso peggiorano perché si è costretti ad applicare soglie più basse, rischiose in termini di PFA.
Fig. 2.12 - ROC nel caso NCPDI e presenza di Doppler shift, su segnali a 4k, 6k, 8k pkt/s con
2.3 Ricerca bidimensionale ritardo/frequenza
In E-SSA una curva ROC migliore sarebbe fortemente auspicabile. Essa potrebbe abbassare fortemente il numero di cicli eseguiti dal cancellatore iterativo di interferenza (SIC) previsto per il sistema, con un notevole alleggerimento dei requisiti di calcolo imposti al Gateway software-radio, nonché permettendo una corretta rilevazione dei preamboli anche nelle configurazioni di canale che risultano difficili da trattare per la SIC.
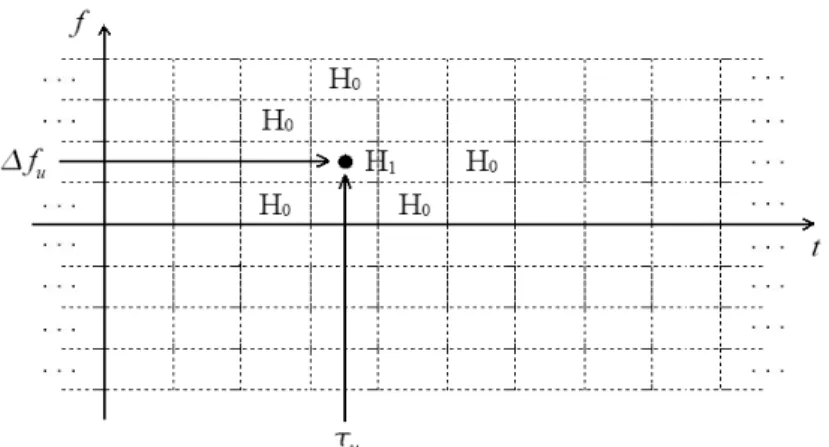
L'offset di frequenza incognito negli arrivi introduce a tutti gli effetti una seconda dimensione in cui deve essere cercato il preambolo: se prima consideravamo il tempo diviso in celle, adesso possiamo pensare ad un'area bidimensionale di ricerca ancora divisa, per comodità, in celle rettangolari. A ciascuna cella corrisponde una coppia di valori (ritardo, offset di frequenza) quantizzata, in cui l'estensione sull'asse delle frequenze è limitata a ±1KHz, mentre l'estensione sull'asse dei tempi idealmente non è limitata (Fig. 2.13). Tutta l'area deve essere analizzata, perché qualunque cella rappresenta un potenziale candidato all'evento H1. Il vantaggio che si ottiene è che è
possibile tornare ad eseguire correlazioni sull'intero preambolo, evitando la degradazione dovuta alle correlazioni parziali. Attraverso un uso intenso al calcolatore di tecniche veloci di trasformata di Fourier (FFT) è possibile effettuare in parallelo la ricerca sia nel tempo che in frequenza che sarà argomento centrale del prossimo Capitolo.