4. MISURE DI LOCALIZZAZIONE NEL CASSETTO
In questo capitolo finale, tutte le conoscenze accumulate vengono ora impiegate in modo da implementare un algoritmo di localizzazione per Tag RFID nel cassetto; grazie agli esperimenti del capitolo precedente sono state apprese molte informazioni riguardanti il parametro RSSI a disposizione, la prima delle quali riguarda due errori intrinseci dai quali esso è affetto:
l’RSSI non è stabile nel tempo, bensì è caratterizzato da un’oscillazione nel tempo quantificabile in circa 1-2dBm rispetto al un valor medio;
Tag dello stesso modello e a parità di condizioni rispondono in generale con livelli di potenza differente: nel peggiore dei casi, vale a dire per l’Impinj Satellite, le discrepanze rispetto ad un riferimento di 100% si estendono dal 70% fino al 130%, mentre per il Tag Lab-ID UH414 si riscontra la variazione meno gravosa, che si assesta dal 92% al 102%.
Per quanto riguarda invece l’andamento delle caratteristiche dell’RSSI in distanza, nelle migliori condizioni di lavoro (vale a dire orientazione, modello del Tag, tipo e posizionamento dell’antenna) si riscontra una tendenza delle curve del parametro verso la linearità (nel caso di scale logaritmiche degli assi cartesiani) ma solo a tratte ed in ogni caso ampiamente affette da fluttuazioni dovute al multipath, quantificabili in vari dBm (1÷3 dBm), che in generale rendono l’andamento abbastanza lontano da quello idealmente desiderato di una funzione monotona (fortemente) decrescente.
Per tutti questi motivi si è ritenuto sconsigliabile l’utilizzo di algoritmi basati su un andamento della potenza ricevuta del tipo “1 r⁄ ”, con α ≥1 (in scala lineare per gli assi α cartesiani) ed è stato deciso di orientarsi invece verso un algoritmo basato sulle variazioni, il k-Nearest Neighbor (k-NN), per poi andarlo ad applicare nello scenario di misura.
4.1 Algoritmo k-Nearest Neighbor
In base alla classificazione affrontata nel secondo capitolo, il k-NN [20]-[21] è catalogabile come algoritmo della famiglia di Scene Analysis, infatti è caratterizzato dalla presenza di Tag di riferimento posizionati nello scenario in punti strategici valutati attentamente, inoltre la localizzazione è basata sulle variazioni o, entrando nello specifico, sul confronto dell’RSSI tra i Tag di riferimento stessi ed i Tag incogniti che vogliamo stimare. La metodologia è stata ereditata pressoché senza variazioni da Landmarc [19], un algoritmo molto noto in letteratura il quale sfrutta il k-NN con Tag RFID di tipo attivo.
Stima della posizione con il k-NN. La stima della posizione di un Tag incognito
è effettuata basandosi sulle caratteristiche dei Tag vicini a quello considerato: i livelli di potenza (RSSI) che l’antenna Reader riceve da un Tag incognito, vengono comparati con quelli ricevuti da tutti i Tag di riferimento dislocati nella scena. Questi ultimi i quali, in termini di valore assoluto della differenza, forniscono i valori più simili di RSSI, sono stimati essere i più vicini fisicamente al Tag incognito e le loro coordinate note sono dunque utilizzate per predirne la posizione.
Un fattore estremamente interessante è l’assenza di una calibrazione preventiva: la stima delle distanze è effettuata mediante confronti degli RSSI ricevuti “in diretta” dallo scenario.
Altra caratteristica da apprezzare è la semplicità della matematica implicata, la quale presenta calcoli intuitivi quanto efficienti. Le coordinate di un Tag incognito (𝑥𝑥𝑒𝑒, 𝑦𝑦𝑒𝑒) vengono stimate pesando le coordinate (𝑥𝑥𝑖𝑖, 𝑦𝑦𝑖𝑖) di tutti i Tag di riferimento :
(𝑥𝑥
𝑒𝑒, 𝑦𝑦
𝑒𝑒) = ∑ 𝑊𝑊
𝑘𝑘𝑖𝑖=1 𝑖𝑖(𝑥𝑥
𝑖𝑖, 𝑦𝑦
𝑖𝑖)
(4.1)in cui “i” è l’indice del Tag di riferimento i-esimo, “k” è il numero totale dei Tag di riferimento utilizzati e “𝑊𝑊𝑖𝑖” è il fattore di pesaggio relativo al Tag di riferimento i-esimo, che viene calcolato in base alla differenza “𝐸𝐸𝑖𝑖” tra il valore dell’RSSI (in scala lineare [Watt]) del Tag incognito in esame con quello di tutti i “k” Tag di riferimento presenti nella scena.
Questi fattori di peso sono calcolati tramite (4.2):
𝑊𝑊
𝑖𝑖=
1 𝐸𝐸𝑖𝑖2 � ∑ 1 𝐸𝐸 𝑗𝑗2 � 𝑘𝑘 𝑗𝑗=1=
1 𝐸𝐸𝑖𝑖2�∑
𝑘𝑘𝑗𝑗 =1𝐸𝐸
𝑗𝑗2�
, � 0 ≤ 𝑊𝑊𝑖𝑖 ≤ 1 𝑒𝑒 ∑𝑘𝑘𝑗𝑗 =1𝑊𝑊𝑗𝑗 = 1� (4.2)dove “j” è l’indice di variazione di tutti i Tag di riferimento, compreso l’ i-esimo (j=1…i…k), mentre “𝐸𝐸𝑖𝑖” si calcola tramite la relazione (4.3):
𝐸𝐸
𝑖𝑖= �𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖[𝑊𝑊] − 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅
𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖[𝑊𝑊]�
(4.3)In pratica i Tag di riferimento con valori di RSSI simili al Tag incognito (e quindi almeno in teoria fisicamente vicini), produrranno una differenza “𝐸𝐸𝑖𝑖” piccola comparata alla somma di tutte le differenze �∑𝑘𝑘𝑗𝑗 =1𝐸𝐸𝑗𝑗2� e di conseguenza un fattore di pesaggio “Wi” grande (vicino all’unità) per le proprie coordinate. Viceversa il fattore tenderà a zero nel caso in cui la differenza tra gli RSSI sia grande rispetto alla sommatoria di tutte quante (indice di Tag fisicamente distanti, almeno in teoria), e le coordinate di un tale Tag di riferimento non sarebbero considerate nella stima.
Scelta del k-NN come algoritmo di stima. A questo punto appare chiara la
decisione della scelta del k-NN per uno scenario come quello esaminato nel capitolo precedente: l’algoritmo è basato sulle differenze, di conseguenza l’unico fattore vincolante è che Tag in posizioni distinte rispondano con valori di RSSI il più possibile diversi, in modo da riuscire a discriminarli l’uno dall’altro. Un altro punto di forza legato a questo principio è il discreto livello di immunità al rumore ed alle interferenze: infatti se un Tag incognito si trovasse in una zona caratterizzata da alti livelli di multipath o interferenze di altro tipo, i Tag di riferimento ad esso vicino sarebbero influenzati dallo stesso fenomeno e verosimilmente risponderebbero con valori simili di RSSI.
Accuratezza del metodo. In figura 4.1 si da un’idea degli errori di misura
riscontrati in letteratura [20] con questo algoritmo, quello riportato si tratta di un esempio di localizzazione in ambiente indoor per distanze fino a 3 metri circa, con l’utilizzo di 13 Tag passivi di riferimento; la media dell’errore in questo caso si aggira intorno ai 30cm con una deviazione standard di 25cm.
(a) (b)
Figura 4.1 - Accuratezza dell’algoritmo k-NN: errore medio (a) e set-up di misura (b)
Un altro fattore molto importante correlato al livello di accuratezza ottenibile è il numero “k” di Tag di riferimento utilizzati nella formula di pesaggio: ipotizzando uno scenario nel quale sia presente una buona densità di Tag di riferimento (Tag per unità di area) il senso sarebbe quello di selezionare, in base al particolare Tag incognito da stimare, solo alcuni dei Tag di riferimento tra quelli presenti, tipicamente un gruppo di quelli più vicini, argomento già affrontato nel capitolo precedente, vale a dire l’algoritmo di miglioramento che prevede la selezione dei Tag migliori.
E’ inoltre possibile confermare sperimentalmente che esiste un limite (dipendente ovviamente dallo scenario di misura) del numero di Tag di riferimento per unità di area, oltre al quale non si apprezza un ulteriore miglioramento dell’errore di stima [19]-[20].
Errore sistematico4. Purtroppo l’algoritmo del k-NN incorre in un errore
sistematico che dipende fortemente dalla disposizione dei Tag di riferimento ed incogniti, è un errore sulla stima misurabile in metri, intrinseco nel principio di funzionamento.
4Un errore è detto sistematico quando risulta costante al ripetersi della misura e per questo non può essere
eliminato con la ripetizione della misurazione, come avviene invece per l'errore statistico: nel nostro caso specifico dipende fortemente dalla disposizione dei Tag di riferimento e dei Tag incogniti.
Viene di seguito descritto questo fenomeno per le due modalità di disposizione dei Tag che verranno utilizzate nei test successivi.
Caso di Tag di riferimento disposti in linea con conseguente perdita di una coordinata. Nel caso in cui si decida di optare per un posizionamento dei Tag di
riferimento in linea (ad esempio in direzione del lato lungo del cassetto), per questioni prettamente matematiche insite nell’algoritmo viene persa la stima della coordinata che non varia (nell’esempio, quella del lato corto): infatti, essendo tale coordinata sempre la stessa per ogni Tag di riferimento, non ci sono informazioni da utilizzare e l’unico dato da poter associare alle stime (4.1) è l’esatto valore della coordinata comune in tutti i Tag. Il problema è presentato in figura 4.2 dove è mostrata la migliore delle ipotesi, vale a dire il caso in cui la posizione stimata (Stima1) del Tag incognito vada a trovarsi proprio in corrispondenza del Tag di riferimento R#1, annullando l’errore di localizzazione per l’asse “x”: rimane comunque un errore sistematico riguardante l’asse “y” esattamente pari alla distanza tra i due Tag. Dunque in questo caso l’errore sistematico nello scenario completo sarà pari alla minima distanza, relativa all’asse “y”, tra Tag incogniti e di riferimento.
Figura 4.2 – Errore sistematico nell’algoritmo del k-NN per Tag disposti in linea
Per concludere, nel caso in cui il Tag incognito venga stimato nella posizione “Stima2” (sempre figura 4.2), allora sarebbe presente sia l’errore sistematico ineliminabile sull’asse “y” appena descritto, che un ulteriore errore relativo all’asse “x”. Si fa presente infine che il numero di Tag di riferimento non modifica il valore assunto dall’errore: esso dipende solo dalla disposizione in linea.
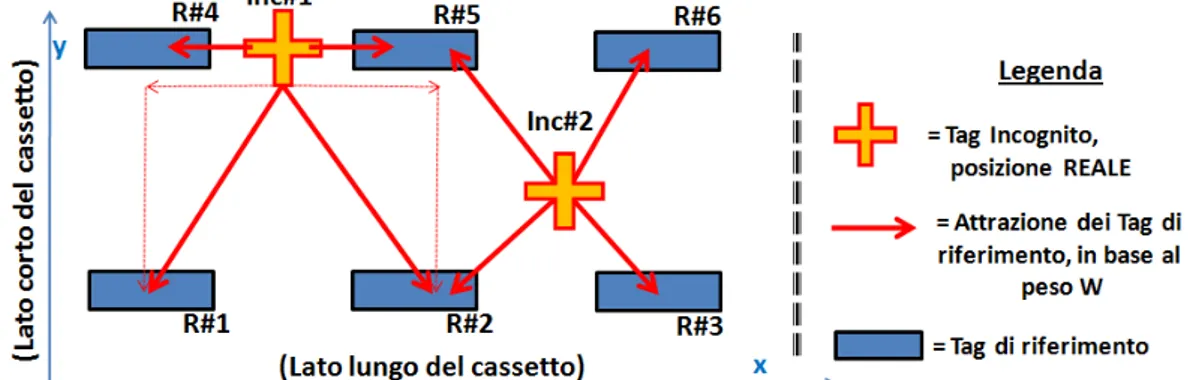
Caso di Tag di riferimento disposti a griglia. Per una disposizione del Tag di
riferimento su entrambe le coordinate in teoria l’errore sistematico non dovrebbe presentarsi, ma in alcune delle misure effettuate, verrà comunque rilevato sulla coordinata del lato corto (“y”). Cerchiamo di capirne il motivo: nel caso in cui il fenomeno si presenti, esso sarebbe dovuto alla sfortunata posizione eventualmente scelta per i Tag incogniti, corrispondente a quella di “Inc#1” in figura 4.3. In questo caso per il principio del k-NN, ognuno dei Tag di riferimento attira verso la propria posizione la stima del Tag incognito, con una efficacia tanto maggiore quanto più grande è il fattore di pesaggio: tale forza di attrazione è schematizzata dalle frecce rosse in figura 4.3 (dove la lunghezza non è proporzionale alla forza). Nel caso del Tag incognito Inc#1 dunque, rispetto all’asse delle “x” non si rileverà alcun errore sistematico per lo stesso motivo riscontrabile nella disposizione in linea, vale a dire che tutti i Tag di riferimento attirano la stima sia verso destra che verso sinistra e potrà dunque accadere di incorrere in una stima perfetta. Riguardo all’asse “y” invece si nota che, a causa della sfortunata posizione del Tag Inc#1, sono presenti vari Tag (R#1 ed R#2 in figura) che attirano la stima verso il basso, ma nessun Tag ad attirarla verso l’alto. Sarà dunque impossibile, a meno di pesi nulli dei Tag R#1 ed R#2, che la coordinata “y” venga stimata all’altezza corretta, infatti pensando al cassetto ed al comportamento pressoché costante dell’RSSI lungo l’asse y, i pesi associati a tali Tag di riferimento saranno considerevoli, piuttosto che nulli. Si fa presente che per una disposizione dei Tag incogniti più casuale, come accade ad “Inc#2”, l’errore sistematico non si presenta in nessun caso, dal momento che la stima è attratta verso qualunque direzione del piano (in base ai pesi).
4.2 Applicazione del k-NN nel cassetto
Nella prima sezione a seguire verranno descritti dettagliatamente i set-up di misura e le idee architettate per studiare l’algoritmo di localizzazione, mentre i risultati saranno presentati nei paragrafi successivi. Si commenteranno inoltre la scelta di parametri quali la potenza, i Tag, le orientazioni scelte, le modalità di disporre i Tag di riferimento, i metodi adottati per il calcolo delle stime, nonché l’esecuzione di alcune misure preliminari utili alla decisione di suddetti parametri.
4.2.1 Set-up di misura
In base ai risultati ottenuti nel capitolo precedente, sono state fatte alcune scelte dei parametri, che verranno portati avanti nelle esecuzioni di tutte le misure di localizzazione qui presentate.
Tag. Per ridurre la quantità di dati che sarà necessario elaborare in questa fase si è deciso di utilizzare un unico Tag, l’UPM Raflatac Rafsec G2, ampiamente testato con ottimi risultati. Un’alternativa altrettanto valida sarebbe stato il LAB-ID UH414, scartato con l’idea magari di considerarlo in uno sviluppo futuro come scenari che richiedano un funzionamento anche per distanze maggiori, grazie ai discreti livelli di potenza che è in grado di riflettere al trasmettitore.
Orientazioni. E’ stata considerata un’unica orientazione per i Tag, la 1_V, ponendosi quindi nelle condizioni migliori, osservate proprio in quella circostanza. L’idea è quella di portare avanti questo studio preliminare di smart shelves iniziando a valutare la bontà dell’algoritmo del k-NN in un caso favorevole e qualora si riscontrassero risultati accettabili, provare a porsi in scenari più complicati.
Antenna: tipo, posizione, potenza. Nell’unica orientazione 1_V disponibile per i Tag la polarizzazione lineare sarebbe stata una scelta sensata da un certo punto di vista, ma dal momento che i Tag in uno scenario realistico avrebbero probabilmente orientazioni arbitrarie, oltre a considerare che la maggior parte dei test precedenti
sono stati eseguiti con l’antenna in polarizzazione circolare, con visione al futuro di una smart shelf è stata ovviamente selezionata quest’ultima. Per quanto riguarda il posizionamento, i test con antenna sul lato lungo oppure sotto al cassetto hanno fornito risultati insoddisfacenti, mentre i migliori successi sono stati riscontrati con l’antenna sul lato corto dove il Tag si allontanava longitudinalmente dall’antenna e di conseguenza questa è stata la posizione scelta. La potenza utilizzata, salvo casi descritti separatamente, è stata confermata a 300mW.
Infine, per l’applicazione dei Tag in qualunque posizione desiderabile, sono stati inseriti nel cassetto dei divisori in cartone, materiale praticamente trasparente alle onde elettromagnetiche, installati in questo caso per permettere l’orientazione 1_V come si vede da figura 4.4 sotto.
Figura 4.4 – Set-up per l’algoritmo k-NN:antenna sul lato corto del cassetto,
divisori in cartone.
Problematiche dovute alla presenza di più Tag. Quando per la prima volta è
stato effettuato un test con l’inserzione contemporanea di più Tag ravvicinati nel cassetto è stata riscontrata la possibilità che alcuni di essi non venissero letti dal Reader a causa delle interferenze reciproche: nel caso di un numero complessivamente limitato di Tag (meno di 20) tale problema si presenta raramente ed in tali remote eventualità è stato risolto riposizionando i Tag più sfortunati di pochi centimetri rispetto alla postazione originaria, evitando di modificare in modo consistente lo scenario.
Come si vedrà nella presentazione dei risultati, sono state eseguite anche misure con un numero contemporaneo di Tag più elevato, arrivando ad un massimo di 42 (una densità nel cassetto di circa 130 𝑇𝑇𝑇𝑇𝑖𝑖 𝑟𝑟⁄ ), nel qual caso a parità di condizioni (𝑃𝑃𝑇𝑇2 = 300𝑟𝑟𝑊𝑊), mediamente si riusciva a leggere il 90% dei Tag nell’area di misura: questi sono gli unici casi che hanno richiesto un incremento della potenza fino a 𝑃𝑃𝑖𝑖′ = 450𝑟𝑟𝑊𝑊, o alternativamente, considerando che tutti i Tag sono disposti in polarizzazione verticale, il passaggio dall’antenna in polarizzazione circolare a quella in polarizzazione lineare, riuscendo così a mantenere la 𝑃𝑃𝑇𝑇 = 300𝑟𝑟𝑊𝑊: ciò ha reso possibile l’incremento della percentuale di letture positive di Tag fino al 98÷100%. Questo conferma che il problema riscontrato è dovuto all’interferenza tra i vari Tag ed al fatto che il Reader deve essere in grado di fornire una potenza sufficiente ad alimentare tutti i Tag, in modo che riescano a rispondere adeguatamente in backscattering. In generale quindi si può supporre che tale problema sia facilmente risolvibile incrementando il livello di potenza con la quale vengono investiti ed eventualmente, in caso di necessità, ricorrendo ad un Reader dalle specifiche in potenza meno restrittive.
Calcolo delle stime: media rispetto a varie realizzazioni dell’algoritmo. A causa
dell’aleatorietà dello scenario e dei valori di RSSI restituiti dal Reader, durante le prime prove è stato appurato che eseguendo varie realizzazioni successive dell’algoritmo ad istanti temporali differenti, ogni volta si ottengono, come prevedibile, corrispondenti realizzazioni differenti delle coordinate stimate per ognuno dei Tag incogniti: l’errore di localizzazione presenta delle oscillazioni temporali in funzione di ogni particolare realizzazione dell’algoritmo. Questo fatto del tutto prevedibile in uno scenario reale piuttosto che ideale, ha posto le basi per una nuova idea, vale a dire quella di effettuare una media delle coordinate stimate per varie realizzazioni temporali dell’algoritmo, riducendo così la aleatorietà delle stime per svincolare l’errore dalla particolare realizzazione acquisita in un certo istante: così facendo l’errore presenterà sempre uno stesso valor medio stabile, caratteristico di ogni particolare scenario e che potrà anche essere utilizzato per valutare la bontà dell’algoritmo.
Ci sono due metodi possibili di implementare una tale media, anche se dai primi test eseguiti ci si è resi conto che i risultati ottenuti sono molto simili (questo fatto viene illustrato esplicitamente nel paragrafo 4.2.2).
Primo metodo: media delle stime ottenute;
1) si acquisiscono in contemporanea i valori istantanei di RSSI da ogni Tag nel cassetto;
2) si procede con l’esecuzione dell’algoritmo k-NN utilizzando tali valori acquisiti ed ottenendo le stime delle coordinate per ognuno dei Tag incogniti;
3) a questo punto si ripetono i passi 1 e 2 per varie volte (ad esempio 10 volte), in modo da ottenere varie (dieci) stime delle coordinate per ognuno dei Tag incogniti;
4) a parità di Tag incognito, si calcola infine la media di tutte le (dieci) coordinate ottenute nella ripetizione dei passaggi precedenti.
Secondo metodo: media preventiva dei valori di RSSI;
1) si acquisiscono contemporaneamente i valori istantanei di RSSI da tutti i Tag nello scenario e si ripete nel tempo questa acquisizione per varie volte (ad esempio 10 volte);
2) per ogni Tag si calcola il proprio valore di RSSI medio dalle dieci realizzazioni acquisite;
3) si esegue un’unica volta l’algoritmo del k-NN utilizzando le medie degli RSSI associate ad ogni Tag e si ottengono così le stime delle coordinate.
Riportando i risultati del capitolo precedente riguardo alla variazione del parametro RSSI come fenomeno intrinseco del Reader, si era appreso che per ottenere una stima delle caratteristiche del segnale era necessaria e sufficiente l’acquisizione di un numero compreso tra 8 e 10 valori di RSSI: da questo si comprende che anche le medie sopra riportate, per lo stesso motivo produrranno risultati ottimali con un numero equivalente di realizzazioni. Un valore eccessivo non apporterebbe miglioramenti, mentre un numero inferiore non ottimizzerebbe al meglio l’algoritmo di riduzione dell’errore con le medie.
Metodo utilizzato per la media ed istogrammi dell’errore. Si fa presente che
l’esecuzione del primo metodo aggiunge la possibilità di creare un valido istogramma contenente il numero di presentazioni degli errori di misura riscontrati nel cassetto: avendo a disposizione dieci stime e dunque dieci realizzazioni dell’errore per ognuno dei Tag incogniti (12), saranno disponibili 120 dati per creare l’istogramma. Adottando invece il secondo metodo gli unici dati a disposizione sarebbero una sola stima media e di conseguenza solamente una realizzazione dell’errore per ogni Tag, con le quali non è possibile creare un istogramma che riporti informazioni utili.
Conclusioni ed inizio misure. Le misure presentate nel paragrafo successivo
saranno svolte in base a tutte le considerazioni riportate fino a questo momento; per quanto riguarda la disposizione dei Tag di riferimento si anticipa che sono stati eseguiti test con le seguenti configurazioni:
3 Tag in linea 6 Tag in linea 9 Tag in linea; 6 Tag a griglia 9 Tag a griglia.
Riguardo al problema già descritto ed insito nell’algoritmo del k-NN riguardante la perdita della coordinata relativa al lato corto, è giusto chiarire fin da adesso che sebbene questo fatto possa apparire come una grave mancanza, in realtà, pensando ad un cassetto lungo e stretto come quello in uso, il fatto di non avere a disposizione l’informazione del posizionamento rispetto al lato corto potrebbe essere accettabile a seconda dell’applicazione. Se inoltre si riflette sul fatto che in direzione del lato corto ci si aspettano stime poco accurate a causa del comportamento dell’RSSI scarsamente utilizzabile, si capisce che in base allo scenario potrebbe anche essere una buona idea quella di abbandonare tale coordinata per ridurre l’errore medio.
Tag incogniti. Inizialmente è stato deciso di utilizzare solamente 12 Tag
incogniti, contemporaneamente presenti nello scenario a prescindere dal numero di Tag di riferimento (con una 𝑃𝑃𝑇𝑇= 300mW): le coordinate sono rimaste inalterate in tutti i test. Per validare in modo generale i risultati ottenuti sono stati poi inseriti contemporaneamente 36 Tag incogniti, numero che ne ha permesso una dislocazione uniforme all’interno del cassetto (con aumento della potenza 𝑃𝑃𝑇𝑇 a 450mW): i test ad alta densità di Tag sono risultati necessari dopo aver verificato che nel caso di pochi Tag
incogniti si presentano comportamenti dipendenti dalla loro particolare disposizione e dunque era necessario svincolarsi da questo fenomeno per ottenere dei parametri di valutazione veritieri. Inoltre, è lecito porsi in una tale condizione visto che un cassetto intelligente in applicazioni reali come ad esempio un cassetto per medicinali, è molto probabile che debba contenere al suo interno un numero elevato di Tag per unità di area.
4.2.2 Disposizione dei Tag di riferimento
Per decidere in che modo disporre i Tag di riferimento, in numero e posizione, sono stati eseguiti dei test preliminari i quali, insieme a tutte le indicazioni ricavate nelle misure del capitolo precedente, hanno permesso di decidere quali fossero i set-up dei Tag di riferimento più interessanti da dover approfondire. Dalle informazioni già in possesso possiamo innanzitutto trarre le seguenti considerazioni:
a causa delle variazioni di RSSI scarsamente apprezzabili nei 40cm a disposizione sul lato corto, per tale direzione probabilmente ha senso l’impiego massimo di due Tag di riferimento distanziati adeguatamente, sperando di poter apprezzare variazioni sufficienti di RSSI;
negli 80cm a disposizione per il lato lungo invece, grazie ai buoni risultati ottenuti con antenna sul lato corto, si proveranno ad utilizzare vari Tag, in numero da testare accuratamente, così da individuare il limite superiore che massimizzi l’accuratezza della localizzazione (in termini di densità di Tag, in modo tale da fornire un parametro generico e non specifico dello scenario del nostro cassetto 40x80 cm2). Appurato questo, sono stati eseguiti due test di acquisizione di RSSI, disponendo i Tag nello scenario a certe distanze prestabilite, per verificare in prima approssimazione il livello di differenza reciproca in termini di potenza ricevuta: si eseguiranno i confronti in scala lineare, in quanto i valori di RSSI da inserire nelle formule del k-NN (4.3) devono essere espressi in Watt
Test 1) 5 Tag (denominati rispettivamente come T#1,T#2,….T#5) sono stati disposti in
linea, centrati sul lato corto (dunque a 20cm) e alle seguenti distanze sul lato lungo: 13cm, 21cm, 40cm, 63cm, 69cm, vedi figura 4.5 e tabella relativa (4.1)
Figura 4.5 – Test preliminari per la disposizione dei Tag di riferimento: Tag in linea
Test 1: RSSI [µW] e [%] T#1=100%
Tag T#1 T#2 T#3 T#4 T#5
Coordinate[cm] (13,20) (21,20) (40,20) (63,20) (69,20)
RSSI [µW] 646 372 148 5,3 4,5
RSSI (%) 100% 57% 22% 8% 6%
Tabella 4.1 – Risultati dei test per la disposizione dei Tag di riferimento in linea Test 2) 6 Tag (denominati come T#1,T#2,….T#6) sono stati posizionati a formare una
griglia, alle coordinate di 9 e 30cm rispetto al lato corto e alle seguenti distanze sul lato lungo: 21cm, 40cm, 63cm, disposti come mostrato in figura 4.6 e tabella relativa (4.2).
Figura 4.6 – Test preliminari per la disposizione dei Tag di riferimento: Tag a griglia
Test 2: RSSI e [%] T#1=100% Tag T#1 T#2 T#3 T#4 T#5 T#6 Coordinate[cm] (21,9) (21,30) (40,9) (40,30) (63,9) (63,30) RSSI [µW] 372 178 71 123 28 13 RSSI (%) 100% 47% 19% 33% 7% 3%
Per un riscontro dall’impatto immediato, in tabella 4.1 sono stati riportati anche i valori in percentuale rispetto all’RSSI in µW del T#1 preso come 100% in ognuno dei test: questo è lecito tenendo presente che non sono importanti i livelli assoluti di potenza ricevuta, quanto le differenze relative tra i vari Tag.
In conclusione si può affermare quanto segue:
5 Tag in linea. Fino a 63cm dall’antenna si apprezzano variazioni relative dell’RSSI importanti e sicuramente sufficienti per pensare ad un’applicazione del k-NN con i riferimenti in tali posizioni. Oltre ai 63cm la variazione percentuale tra gli ultimi due Tag è praticamente nulla, anche se in parte questo è dovuto al fatto che sono stati posti a soli 6cm di distanza. In base a questi risultati è possibile pensare all’utilizzo di un ulteriore Tag, arrivando così a 6 Tag di riferimento in linea, cercando di incrementarne la densità nella la parte iniziale dove le variazioni relative sono molto forti e ridurla invece nella parte finale. Molto interessante potrebbe rivelarsi il posizionamento di soli tre Tag, i quali fornirebbero variazioni relative ancora più sostenute e valutare quale delle due configurazioni possa portare risultati migliori. 6 Tag a griglia. In direzione del lato corto le variazioni relative di RSSI sono
evidenti solamente in prossimità dell’antenna Reader (con riduzione del 47% in 21cm), mentre in direzione del lato lungo, a parità di posizione si apprezzano variazioni simili al caso dei Tag in linea. Con questa configurazione tra l’altro si nota una evidente asimmetria nel diagramma di irradiazione in campo vicino dell’antenna, il quale è maggiormente direzionato verso i Tag di indice pari (ovvero a destra nel campo visivo dell’antenna).
Risulta dunque che le differenze sono sufficientemente evidenti in direzione del lato lungo e scarsamente distinguibili a distanza dall’antenna sul lato corto: sono entrambe configurazioni di interesse per un’analisi approfondita.
4.2.3. Tre Tag di riferimento in linea
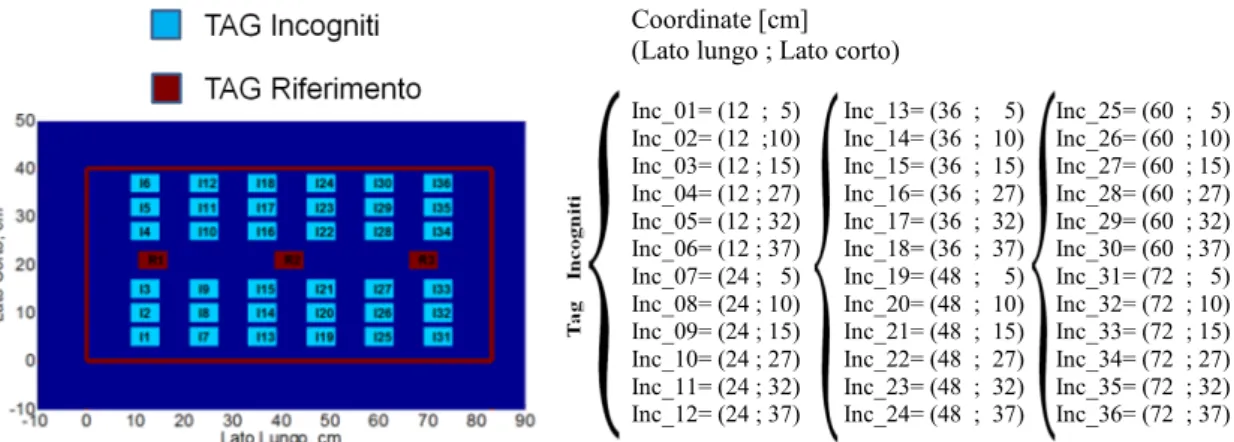
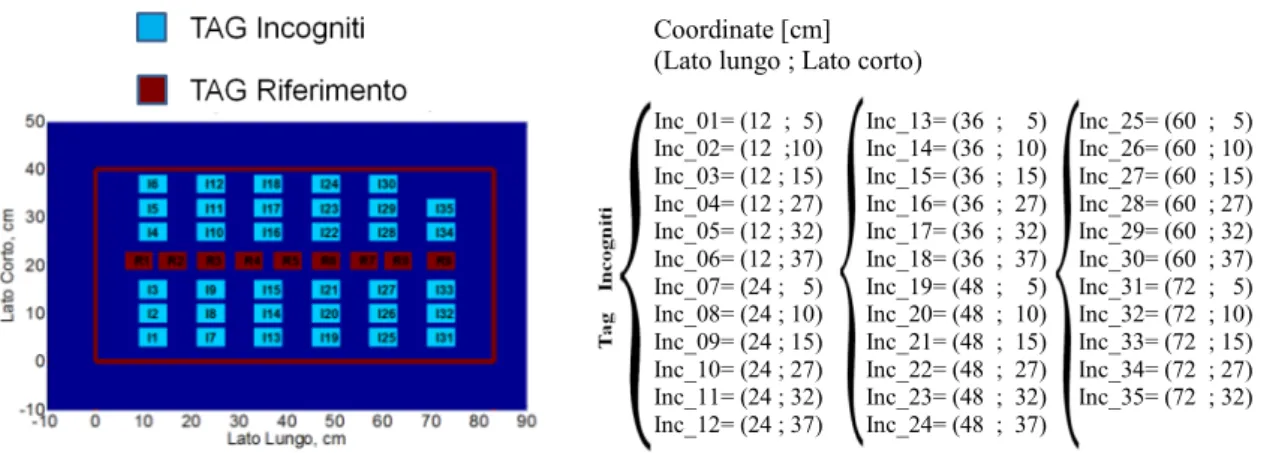
I Tag di riferimento sono stati inseriti tenendo conto dei risultati discussi nel paragrafo precedente, in modo da assicurare differenze relative considerevoli nell’RSSI ricevuto, compatibilmente ad una disposizione il più possibile uniforme rispetto alla lunghezza del cassetto; tutto ciò è mostrato nelle seguenti figure dove si può visualizzare il set-up di misura che sarà sempre presentato in questo modo anche nelle prove a seguire: in figura 4.7, a sinistra è visualizzata un’immagine schematica della disposizione di tutti i Tag all’interno del cassetto nel caso del set-up che prevede 12 Tag incogniti, mentre a destra sono elencate le coordinate di tali Tag rispetto ai due lati dello stesso (espresse in centimetri).
Figura 4.7 – Set-up di misura: 3 Tag di riferimento in linea, 12 Tag incogniti
Come già accennato, gli scenari di misura sono stati riproposti aumentando il numero di Tag incogniti fino ad un massimo di 36 unità, sia per capire quanto l’algoritmo risenta di una densità maggiore di Tag incogniti, che per valutare l’errore medio nel caso di una distribuzione più uniforme all’interno dell’area di misura, dal momento che con solamente 12 elementi i Tag risultano abbastanza concentrati in punti ben precisi. In questo caso la potenza è stata aumentata a 450mW per i motivi già discussi (essenzialmente per permettere al Reader di alimentare tutti i Tag). Salvo casi particolari (caratterizzati da modifiche comunque minime), la disposizione dei Tag incogniti in
Coordinate [cm] (Lato lungo ; Lato corto)
Ref_1 = (13.5 ; 21) Ref_2 = (41.5 ; 21) Ref_3 = (69 ; 21) Inc_01 = (9 ; 9) Inc_02 = (9 ; 30) Inc_03 = (18 ; 9) Inc_04 = (18 ; 30) Inc_05 = (36 ; 9) Inc_06 = (36 ; 30) Inc_07 = (45 ; 9) Inc_08 = (45 ; 30) Inc_09 = (63 ; 9) Inc_10 = (63 ; 30) Inc_11 = (72 ; 9) Inc 12 = (72 ; 30)
entrambi gli scenari a 12 o 36 è rimasta pressoché inalterata in tutti i test che seguiranno. Il set-up è presentato in figura 4.8, comprensivo delle coordinate di tutti i 36 Tag incogniti (si nota chiaramente la distribuzione più uniforme rispetto al caso di 12 Tag).
Figura 4.8 – Set-up di misura: 3 Tag di riferimento in linea, 36 Tag incogniti Risultati. Si tenga presente che solamente per questo primo caso verranno presentate ed
ampiamente descritte tutte le tipologie di risultati e di grafici che sono a disposizione, mentre a partire dal test successivo e per tutti i seguenti si riporteranno solamente quelli più interessanti ed informativi, scartando i risultati meno significativi a seconda del caso.
Calcolo dell’errore medio delle stime. L’errore totale corrisponde alla distanza
euclidea (in due dimensioni) tra la posizione reale (𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 , 𝑦𝑦𝑖𝑖𝑖𝑖𝑖𝑖) e quella stimata (𝑥𝑥𝑠𝑠𝑖𝑖𝑖𝑖𝑟𝑟𝑇𝑇, 𝑦𝑦𝑠𝑠𝑖𝑖𝑖𝑖𝑟𝑟𝑇𝑇) per ogni Tag, come in formula (4.4)
𝐸𝐸𝑟𝑟𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒 𝑖𝑖𝑖𝑖𝑖𝑖𝑇𝑇𝑜𝑜𝑒𝑒 = �(𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 − 𝑥𝑥𝑠𝑠𝑖𝑖𝑖𝑖𝑟𝑟𝑇𝑇)2+ (𝑦𝑦𝑖𝑖𝑖𝑖𝑖𝑖 − 𝑦𝑦𝑠𝑠𝑖𝑖𝑖𝑖𝑟𝑟𝑇𝑇)2 (4.4)
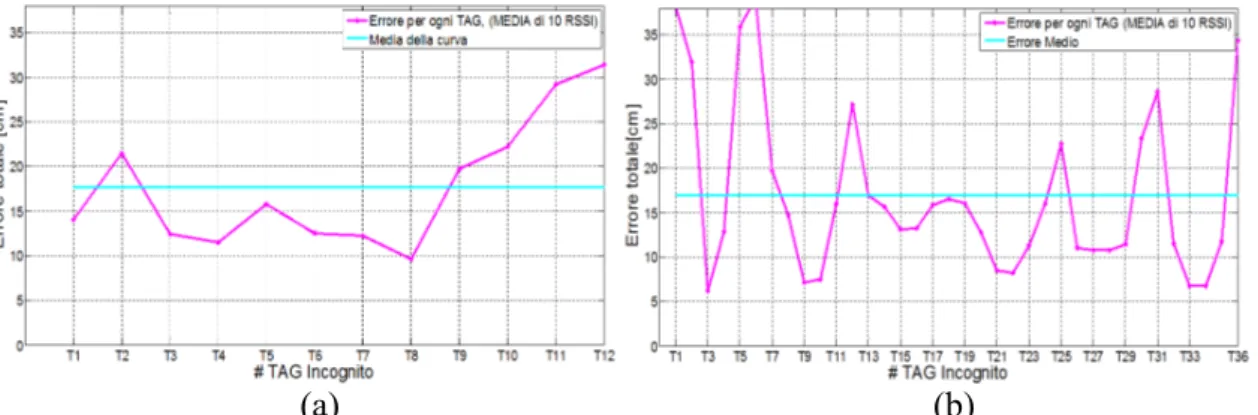
In figura 4.9 a pagina seguente sono presentati quattro grafici dell’errore totale nei confronti della stima delle coordinate per ognuno dei Tag incogniti, i quali sono elencati sull’asse delle ascisse (36 Tag incogniti nei grafici a,c e 12 Tag incogniti nei grafici b,d). Considerando di utilizzare il primo metodo (Metodo#1) esposto nel paragrafo 4.2.1, per calcolo delle medie dei risultati, nelle figure 4.9-a e 4.9-c sono riportate le dieci realizzazioni dell’errore totale per tutti i Tag incogniti, dopodiché è stata eseguita per ciascun Tag incognito la media di tali realizzazioni: i risultati sono visibili in blu nelle figure 4.9-b e 4.9-d in cui a parità di Tag incognito è stata eseguita la media dei dieci errori, quindi eseguendo una media di queste ultime curve (i cui risultati sono nelle
Coordinate [cm] (Lato lungo ; Lato corto)
Inc_01= (12 ; 5) Inc_13= (36 ; 5) Inc_25= (60 ; 5) Inc_02= (12 ;10) Inc_14= (36 ; 10) Inc_26= (60 ; 10) Inc_03= (12 ; 15) Inc_15= (36 ; 15) Inc_27= (60 ; 15) Inc_04= (12 ; 27) Inc_16= (36 ; 27) Inc_28= (60 ; 27) Inc_05= (12 ; 32) Inc_17= (36 ; 32) Inc_29= (60 ; 32) Inc_06= (12 ; 37) Inc_18= (36 ; 37) Inc_30= (60 ; 37) Inc_07= (24 ; 5) Inc_19= (48 ; 5) Inc_31= (72 ; 5) Inc_08= (24 ; 10) Inc_20= (48 ; 10) Inc_32= (72 ; 10) Inc_09= (24 ; 15) Inc_21= (48 ; 15) Inc_33= (72 ; 15) Inc_10= (24 ; 27) Inc_22= (48 ; 27) Inc_34= (72 ; 27) Inc_11= (24 ; 32) Inc_23= (48 ; 32) Inc_35= (72 ; 32) Inc_12= (24 ; 37) Inc_24= (48 ; 37) Inc_36= (72 ; 37)
curve in rosso), si può attendere un valore di circa 18cm e 17cm di errore totale medio nel cassetto rispettivamente per la disposizione di 12 e 36 Tag incogniti.
(a) (b)
(c) (d)
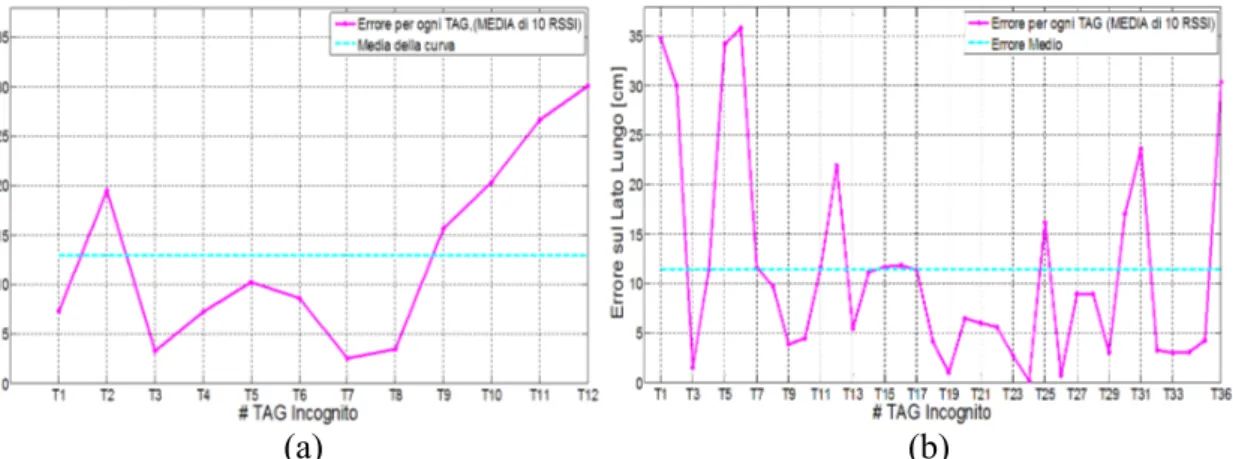
Figura 4.9 – Errore totale di stima sulle due coordinate: 3 Tag di riferimento in linea e
12 o 36 Tag incogniti. 10 realizzazioni dell’errore per ogni Tag (Metodo#1) (a)(c); Media delle precedenti 10 realizzazioni (Metodo#1) (b)(d);
Concludendo, nelle figura 4.10-a e 4.10-b (12 e 36 Tag incogniti) sono presentati i medesimi risultati nel caso in cui si utilizzi il secondo metodo (Metodo #2, vedi sempre paragrafo 4.2.1) per il calcolo delle stime medie.
(a) (b)
Figura 4.10 – Errore totale di stima sulle due coordinate: 3 Tag di riferimento in linea.
Per ogni grafico è presente una sola curva (in rosa), la quale è il risultato dell’unica esecuzione dell’algoritmo k-NN sfruttando i valori medi di 10 realizzazioni dell’RSSI per ognuno dei Tag incogniti. Si vede chiaramente che tale modo di procedere comporta, a meno di variazioni dell’ordine di 1cm, risultati coincidenti al Metodo#1 mostrato in figura 4.9-b e 4.9-d. Per tale motivo d’ora in poi verrà adottato esclusivamente il Metodo#1 il quale permetterà, come già affermato, di avere a disposizione dati sufficienti per la creazione di un istogramma.
Proseguendo con l’analisi dei risultati, nelle figure 4.11 sono presentati quattro grafici, concettualmente equivalenti ai precedenti di figura 4.9, nei quali però si riporta solamente l’errore commesso rispetto alla coordinata del lato lungo del cassetto, definito di seguito nella formula (4.5) dove “x” identifica la coordinata relativa al lato lungo: 𝐸𝐸𝑟𝑟𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒 𝑠𝑠𝑠𝑠𝑜𝑜 𝐿𝐿𝑇𝑇𝑖𝑖𝑖𝑖 𝐿𝐿𝑠𝑠𝑖𝑖𝑖𝑖𝑖𝑖 = |𝑥𝑥𝑖𝑖𝑖𝑖𝑖𝑖 − 𝑥𝑥𝑠𝑠𝑖𝑖𝑖𝑖𝑟𝑟𝑇𝑇| (4.5)
(a) (b)
(c) (d)
Figura 4.11 – Errore di stima sul lato lungo: 3 Tag di riferimento in linea e 12 o 36 Tag
incogniti. 10 realizzazioni dell’errore per ogni Tag (Metodo#1) (a)(c); Media delle precedenti 10 realizzazioni (Metodo#1) (b)(d);
Infine, grazie ai grafici riportati in figura 4.12-a e 4.12-b, si fa presente che anche considerando solamente la coordinata relativa al lato lungo, adottare il Metodo#2 per la media delle stime non apporta vantaggi rispetto al Metodo#1, ciò risulta chiaro confrontando con le precedenti figure 4.9-b e 4.9-d.
(a) (b)
Figura 4.12 – Errore di stima sul lato lungo: 3 Tag di riferimento in linea.
Errore calcolato con media preventiva di 10 RSSI (Metodo#2): 12 (a) e 36 (b) Tag incogniti.
Commenti ai risultati. Innanzitutto si nota in tutti i grafici che la dislocazione di un
numero maggiore e più uniforme di Tag incogniti produce in generale risultati differenti (non necessariamente migliori, come vedremo nei test che seguiranno) e sicuramente più veritieri, per il fatto che in questo modi ci svincoliamo da comportamenti (favorevoli o meno) dovuti ad una disposizione particolare come quella di 12 Tag incogniti mostrata precedentemente in figura 4.7.
Entrando nei particolari della disposizione con 3 Tag di riferimento in linea, si vede chiaramente come evitando di considerare la coordinata relativa al lato corto, l’errore mediamente commesso si riduce drasticamente: considerando la disposizione di 36 Tag incogniti si riporta in questo caso un valore di circa 12 cm sul lato lungo (figure 4.11-d e 4.12-b ) contro i 17cm dell’errore totale (figure 4.9-d e 4.10-b). Questo era auspicabile, dal momento che i Tag sono disposti in linea e dunque la coordinata non stimata sull’altro lato subisce costantemente un errore sistematico che si somma al totale (analizzeremo questo aspetto con l’istogramma). Dunque risulta chiaro che, optando per
una disposizione dei Tag in linea, conviene abbandonare l’altra coordinata per stimare la posizione esclusivamente rispetto al lato lungo (quindi un algoritmo 1-D), ma con conseguente riduzione dell’errore commesso.
Si noti infine che nella regione centrale del cassetto, a circa 30-50 cm sul lato lungo, gli errori commessi sono generalmente inferiori rispetto alle zone esterne: ciò è una conferma di quanto è stato appurato nel capitolo precedente (vedi paragrafo 3.5.1), vale a dire il fatto che le curve di RSSI in quel tratto possiedono le caratteristiche migliori (andamento decrescente, quasi lineare e con fluttuazioni poco accentuate); la zona maggiormente affetta da errore riguarda tutti i Tag incogniti sulla prima linea, in prossimità dell’antenna: dal momento che tale fenomeno verrà confermato nella zona iniziale del cassetto anche nelle prove successive, si arriva a capire che, almeno in parte, ciò è dovuto a maggiori interferenze causate dal fenomeno del multipath che evidentemente in quella particolare regione è molto consistente.
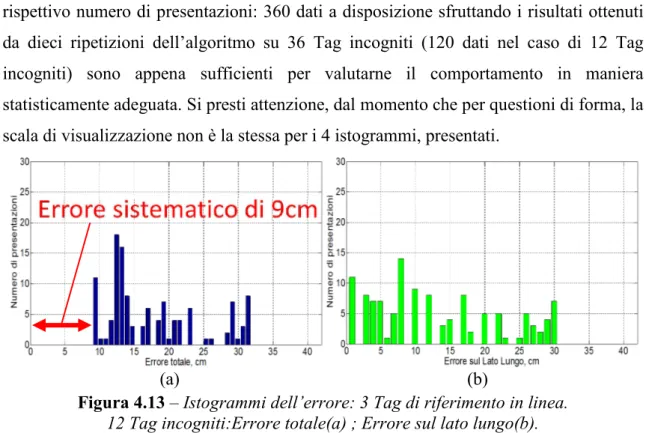
Istogrammi. In conclusione di questa prima analisi si riportano in figura 4.13 e 4.14 (12
o 36 Tag incogniti) gli istogrammi dell’errore per ogni valore dell’errore in centimetri, il rispettivo numero di presentazioni: 360 dati a disposizione sfruttando i risultati ottenuti da dieci ripetizioni dell’algoritmo su 36 Tag incogniti (120 dati nel caso di 12 Tag incogniti) sono appena sufficienti per valutarne il comportamento in maniera statisticamente adeguata. Si presti attenzione, dal momento che per questioni di forma, la scala di visualizzazione non è la stessa per i 4 istogrammi, presentati.
(a) (b)
Figura 4.13 – Istogrammi dell’errore: 3 Tag di riferimento in linea.
(a) (b)
Figura 4.14 – Istogrammi dell’errore: 3 Tag di riferimento in linea.
36 Tag incogniti: Errore totale(c) ; Errore sul lato lungo (d).
Le informazioni che si possono estrarre sono molto interessanti, innanzitutto in figura 4.13-a (con 12 Tag incogniti) si apprende che l’errore totale non scende mai sotto ai 9cm mentre in figura 4.14-a (36 Tag incogniti) non scende sotto i 6cm: si tratta dell’errore sistematico ampiamente discusso nell’introduzione al k-NN, dovuto al fatto che i Tag di riferimento sono disposti in linea e dunque le stime saranno tutte distribuite lungo tale linea, commettendo un errore costante sulla coordinata del lato corto: a conferma di questo, 9cm e 6cm equivalgono esattamente alla minima distanza relativa al lato corto tra un Tag incognito ed uno di riferimento (nei due scenari comprensivi rispettivamente 12 e 36 Tag incogniti). Si conferma poi dalle figure 4.13-b e 4.14-b che tale errore non è presente se consideriamo solamente la coordinata del lato lungo: ad esempio in 4.14-b si vede che con una probabilità di circa il 10% la stima è prodotta con solo 1cm di errore (35 presentazioni su un totale di 360 prove). Questa è l’ulteriore conferma che l’abbandono di una coordinata, se permesso dallo scenario dello smart shelf, apporta esclusivamente benefici in termini di errore medio. L’ultima informazione estrapolabile dagli algoritmi riguarda il fatto che l’errore nel cassetto nel caso di 12 Tag incogniti è distribuito nel range 0-30 cm decisamente molto esteso senza alcun valore dominante, mentre nel test più veritiero ad alta densità di Tag, gli errori si concentrano nel range 0-15 cm dove sono compresi circa il 75% dei valori.
In figura 4.15 infine, si riporta un’immagine che rappresenta la distribuzione delle stime (con 12 Tag incogniti per una miglior visualizzazione), la quale conferma quanto affermato poco fa riguardo agli andamento degli istogrammi ed all’errore sistematico, infatti si nota che le stime sono disposte lungo la linea dei Tag di riferimento ed inoltre risultano tutte concentrate nella zona centrale del cassetto.
Figura 4.15 – Risultato della localizzazione con 3 Tag di riferimento in linea e 12 Tag
4.2.4. Sei Tag di riferimento in linea
In base ai risultati ottenuti con tre Tag in linea, il passo successivo è quello di inserirne almeno sei: le prove preliminari confermavano che fino a sei Tag disposti in linea ed in maniera corretta sono in grado di fornire risposte con livelli di RSSI sufficientemente distinguibili; il primo set-up di misura è riportato in figura 4.16 dove si nota la disposizione dei 12 Tag incogniti, mentre quelli di riferimento sono posti in maniera uniforme ad esclusione dei primi due, i quali sono stati avvicinati dal momento che la variazione di RSSI in prossimità dell’antenna, analizzata nel capitolo precedente, era risultata più sostenuta a parità di distanza tra i Tag stessi.
Figura 4.16 – Set-up di misura: 6 Tag di riferimento in linea, 12 Tag incogniti.
In figura 4.17 invece si riporta il set-up di misura relativo alla dislocazione di 36 Tag incogniti: le posizioni dei Tag di riferimento sono state modificate di qualche centimetro per assicurarsi che venissero letti tutti quanti. In entrambi i set-up le coordinate dei Tag incogniti non vengono riportate di nuovo in quanto le stesse del caso precedente.
Figura 4.17 – Set-up di misura: 6 Tag di riferimento in linea, 36 Tag incogniti.
Coordinate [cm]
(Lato lungo ; Lato corto) Ref_1= (9 ; 21 ) Ref_2= (13.5 ; 21 ) Ref_3= (27 ; 21 ) Ref_4= (41.5 ; 21 ) Ref_5= (54 ; 21 ) Ref_6= (69 ; 21 ) Coordinate [cm]
(Lato lungo ; Lato corto)
Ref_01 = (12 ; 21) Ref_02 = (24 ; 21) Ref_03 = (36 ; 21) Ref_04 = (48 ; 21) Ref_05 = (60 ; 21 Ref 06 = (75 ; 21)
Risultati. Essendo i Tag di riferimento disposti in linea vengono riportati solamente i
risultati dell’errore relativo (4.5) che si ha sul lato lungo del cassetto, si veda figura 4.18:
(a) (b)
Figura 4.18 – Grafici dell’errore di stima sul lato lungo: 6 Tag di riferimento in linea.
12 Tag incogniti (a); 36 Tag incogniti (b)
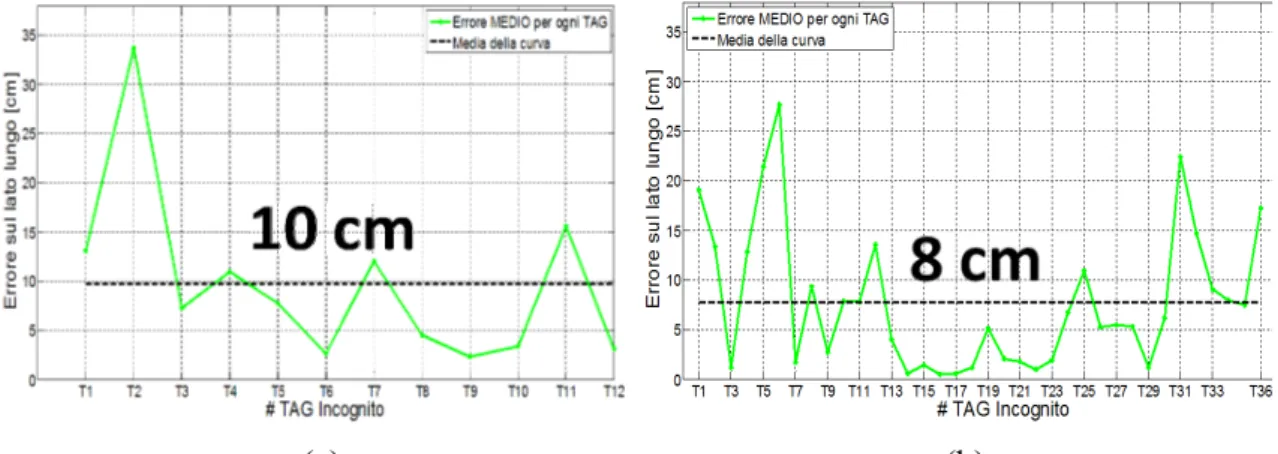
in entrambe le figure si nota un chiaro incremento dell’accuratezza nelle stime rispetto al caso di soli 3 Tag di riferimento, sia per la riduzione dell’errore medio che passa a 10cm nel caso di 12 Tag incogniti ed a 8cm nel caso di 36 Tag incogniti, che anche per un livellamento delle prestazioni le quali migliorano anche per i Tag nelle zone esterne del cassetto; un commento a parte è necessario per i Tag in vicinanza dell’antenna Reader e in particolare nei pressi delle coordinate (10, 30) cm, i quali presentano errori piuttosto consistenti e molto discordanti dal resto dei Tag vicini e per questo motivo tale fenomeno può essere attribuito ad un caso sfortunato di interferenza da multipath in quella particolare posizione: il fenomeno si riscontra in entrambe le configurazioni di Tag incogniti e come si ricorda, era causa di un incremento dell’errore anche nello scenario di 3 Tag di riferimento (figura 4.11-d, pag. 150 e 4.12-b, pag.151).
La prova generale con 36 Tag incogniti visibile in figura 4.18-b fornisce in generale un risultato più affidabile in quanto la maggior densità ed uniformità della loro disposizione riduce la possibilità di incorrere in risultati più o meno favorevoli a seconda del posizionamento nei confronti dei Tag di riferimento. Inoltre la curva dell’errore rispecchia l’andamento del caso a minor densità, con due vantaggi : l’errore medio cala a
circa 8cm e per i Tag da #13 a #24 (36-48cm sul lato lungo) le stime sono quasi perfette: questo dato può considerarsi più accurato del precedente, in quanto mediato come detto, in uno scenario ben distribuito di Tag.
Istogrammi. Sono presentati in figura 4.19.
(a) (b)
(c) (d)
Figura 4.19 – Istogrammi dell’errore: 6 Tag di riferimento in linea.
12 Tag incogniti:Errore totale(a) ; Errore sul lato lungo(b). 36 Tag incogniti: Errore totale(c) ; Errore sul lato lungo (d).
In questo caso si riporta anche il risultato dell’errore totale (figura 4.19-a e 4.19-c) , in quanto fornisce una utile indicazione riguardo l’errore sistematico che, a parità di condizioni del caso con 3 Tag di riferimento, rimane inalterato nelle due configurazioni e sempre pari a 9cm (per lo scenario a 12 Tag incogniti) oppure a 6cm (con 36 Tag incogniti) per il fatto che la distanza dei Tag incogniti rispetto a quelli di riferimento sulla coordinata del lato corto non è variata. Considerando il caso precedente (3 Tag di riferimento), l’istogramma relativo al lato lungo (figura 4.19-b), mostra che adesso
l’errore è maggiormente concentrato a valori bassi, altro indice della bontà di questa disposizione: circa l’85% degli errori rientra tra 0 e 15cm. Tale fenomeno è confermato ed ulteriormente enfatizzato dall’inserzione di 36 Tag (figura 4.19-d) in cui tra l’altro si apprezza un picco (35% delle presentazioni totali) vicino allo zero, causato dalle stime a bassissimo errore per i Tag incogniti da #13 a #24.
Per concludere, in figura 4.20 si riporta l’immagine del risultato ottenuto con 6 Tag di riferimento e 12 Tag incogniti: si vede bene l’allineamento delle stime lungo una sola coordinata come nel caso precedente, ma a differenza dei 3 Tag in linea si apprezza una miglior distribuzione lungo tutto il cassetto.
Figura 4.20 – Risultato della localizzazione con 6 Tag di riferimento in linea (e 12
4.2.5. Nove Tag di riferimento in linea
Quest’ultima prova con i Tag di riferimento in linea è necessaria per valutare quale sia il limite massimo numero di Tag oltre il quale non si ottengono miglioramenti nella stima delle coordinate, fornendo così una specifica molto importante di valutazione, vale a dire la densità di Tag per unità di area (o di lunghezza rispetto al lato lungo) che massimizzi l’accuratezza delle stime nel cassetto. In figura 4.21 è presentato il set-up di misura relativo a 12 Tag incogniti posti alle stesse coordinate già utilizzate in precedenza, mentre quelle per i Tag di riferimento sono state selezionate per una distribuzione uniforme lungo tutto il cassetto.
Figura 4.21 – Set-up di misura: 9 Tag di riferimento in linea, 12 Tag incogniti
Si riporta anche il set-up di misura con 36 Tag incogniti, mostrato in figura 4.22. In questo caso si riportano per correttezza le coordinate dei Tag incogniti in quanto in realtà ne sono effettivamente stati utilizzati solamente 35 per problemi logistici.
Figura 4.22 – Set-up di misura: 9 Tag di riferimento in linea, 35 Tag incogniti
Coordinate [cm] (Lato lungo ; Lato corto) Ref_1= (9 ; 21 ) Ref_2= (16 ; 21 ) Ref_3= (24 ; 21 ) Ref_4= (32 ; 21 ) Ref_5= (40 ; 21 ) Ref_6= (48 ; 21 ) Ref_7= (56 ; 21 ) Ref_8= (63 ; 21 ) Ref_9= (72 ; 21 ) Coordinate [cm] (Lato lungo ; Lato corto)
Inc_01= (12 ; 5) Inc_13= (36 ; 5) Inc_25= (60 ; 5) Inc_02= (12 ;10) Inc_14= (36 ; 10) Inc_26= (60 ; 10) Inc_03= (12 ; 15) Inc_15= (36 ; 15) Inc_27= (60 ; 15) Inc_04= (12 ; 27) Inc_16= (36 ; 27) Inc_28= (60 ; 27) Inc_05= (12 ; 32) Inc_17= (36 ; 32) Inc_29= (60 ; 32) Inc_06= (12 ; 37) Inc_18= (36 ; 37) Inc_30= (60 ; 37) Inc_07= (24 ; 5) Inc_19= (48 ; 5) Inc_31= (72 ; 5) Inc_08= (24 ; 10) Inc_20= (48 ; 10) Inc_32= (72 ; 10) Inc_09= (24 ; 15) Inc_21= (48 ; 15) Inc_33= (72 ; 15) Inc_10= (24 ; 27) Inc_22= (48 ; 27) Inc_34= (72 ; 27) Inc_11= (24 ; 32) Inc_23= (48 ; 32) Inc_35= (72 ; 32) Inc_12= (24 ; 37) Inc_24= (48 ; 37)
Risultati. Analizzando i grafici dell’errore relativo al lato lungo del cassetto presentati
in figura 4.23-a e 4.23-b si apprende che l’utilizzo di 9 Tag di riferimento non apporta ulteriori miglioramenti ed anzi, l’errore medio nel caso più significativo di 35 Tag incogniti sale da 8 a 10cm (rispetto al caso con sei Tag di riferimento) ed anche l’andamento della curva di errore al variare dei Tag incogniti è sicuramente più accentuata e frastagliata del caso precedente in ogni posizione; anche il confronto con soli 12 Tag incogniti, seppur meno affidabile, conferma il miglior comportamento di sei riferimenti. In entrambi i grafici si conferma anche in questo caso la forte interferenza da multipath presente nella zona iniziale del cassetto, con errori più alti intorno alle coordinate (10, 30).
(a) (b)
Figura 4.23 – Grafici dell’errore di stima sul lato lungo: 9 Tag di riferimento in linea.
Istogrammi. L’errore sistematico per la stima delle coordinate in entrambe le
dimensioni si mantiene ancora esattamente a 6cm (con 35 Tag incogniti, figura 4.24-a) o 9cm (con 12 Tag incogniti, figura 4.24-c) per gli stessi motivi già esposti in precedenza. L’istogramma rispetto al lato lungo, presentato in figura 4.24-d nel caso di 35 Tag incogniti risulta abbastanza buono con errori concentrati a livelli bassi (l’80% dei valori rientra nel range da 0 a 15cm), in ogni caso non raggiunge la bontà del caso con sei Tag di riferimento mostrata in figura 4.19-d a pag 157, nel quale i valori risultavano ancora più condensati verso il basso. L’andamento dell’istogramma nel caso di soli 12 Tag incogniti mostrato in figura 4.24-b conferma che tale disposizione non è adatta per una corretta analisi, fornendo risultati molto diversi e di conseguenza poco veritieri.
(a) (b)
(c) (d)
Figura 4.24 – Istogrammi dell’errore: 9 Tag di riferimento in linea.
12 Tag incogniti:Errore totale(a) ; Errore sul lato lungo(b) 35 Tag incogniti: Errore totale(c) ; Errore sul lato lungo (d)
4.2.6. Sei Tag di riferimento a Griglia
Dopo un’ampia valutazione dell’algoritmo mediante disposizione dei Tag di riferimento lungo una linea, se ne considera ora una diversa disposizione, quella a griglia: in questo modo sarà possibile fornire un valore di stima anche per la coordinata del lato corto e dunque bidimensionale, per capire se sia possibile e con quale accuratezza discriminare una posizione rispetto ad entrambi i lati.
Figura 4.25 – Set-up di misura: 6 Tag di riferimento a griglia, 12 Tag incogniti
In figura 4.25 è mostrato il set-up di misura con 12 Tag incogniti posizionati nelle stesse coordinate già adottate: si tenga presente però che questa scelta è risultata fin da subito poco fortunata per due motivi, l’uno che avvantaggia il lato lungo e l’altro che peggiora le prestazioni rispetto al lato corto:
come spiegato nell’introduzione al k-NN, si presenta un errore sistematico rispetto al lato corto (dunque uno svantaggio), il quale si annullerebbe nel caso di una disposizione più casuale e/o più densa dei Tag incogniti. Si rimanda al paragrafo 4.1 per i dettagli;
la posizione è invece privilegiata rispetto alle stime sul lato lungo, per il fatto che Tag incogniti e di riferimento si trovano reciprocamente molto ravvicinati in
Coordinate [cm]
(Lato lungo ; Lato corto) Ref_1 = (13.5 ; 9) Ref_2 = (13.5 ; 30) Ref_3 = (41.5 ; 9) Ref_4 = (41.5 ; 30) Ref_5 = (69 ; 9) Ref_6 = (69 ; 30)
allineamento rispetto proprio a questo lato (figura 4.25) e questo aiuta il funzionamento di un algoritmo come il k-NN.
Proprio per questi motivi, per cercare di fare un confronto più veritiero con i set-up di Tag in linea, è stata eseguito anche un necessario test aggiuntivo comprendente l’utilizzo di 36 Tag incogniti, in modo da svincolarsi dai due problemi discussi: il nuovo set-up di misura è presentato in figura 4.26 dove si riportano anche le coordinate dei Tag incogniti, che in questo caso sono cambiate per permettere di ricoprire anche la zona centrale prima occupata dai Tag disposti in linea. Entrambi i set-up verranno esaminati, in quanto un loro confronto diretto mostrerà risultati decisamente interessanti, come la scomparsa dell’errore sistematico nel secondo caso).
Figura 4.26 – Set-up di misura: 6 Tag di riferimento a griglia, 12 Tag incogniti Risultati. In figura 4.27 (a pagina seguente), a causa della disposizione che permette
adesso di stimare entrambe le coordinate, tornano ad acquistare un significato i grafici dell’errore completo, valutato appunto sulle due coordinate, dai quali si evince un comportamento relativamente buono con una media di circa 16cm (figura 4.27-c) nel caso di 36 Tag incogniti, con valori però non molto uniformi in tutta l’area.
Ref_01= (12 ; 10) Ref_02= (12 ; 32) Ref_03= (36 ; 10) Ref_04= (36 ; 32) Ref_05= (60 ; 10) Ref_06= (32 ; 32)
Inc_01=(12; 5) Inc_13=(36 ; 5) Inc_25=(60; 5) Inc_02=(12; 21) Inc_14=(36 ; 21) Inc_26=(60;21) Inc_03=(12; 15) Inc_15=(36 ; 15) Inc_27=(60;15) Inc_04=(12; 27) Inc_16=(36 ; 27) Inc_28=(60;27) Inc_05=(24; 12) Inc_17=(48 ; 21) Inc_29=(75;21) Inc_06=(12; 37) Inc_18=(36 ; 37) Inc_30=(60;37) Inc_07=(24; 5) Inc_19=(48 ; 5) Inc_31=(72; 5) Inc_08=(24; 10) Inc_20=(48 ; 10) Inc_32=(72;10) Inc_09=(24; 15) Inc_21=(48 ; 15) Inc_33=(72;15) Inc_10=(24; 27) Inc_22=(48 ; 27) Inc_34=(72;27) Inc_11=(24; 32) Inc_23=(48 ; 32) Inc_35=(7 ; 32) Inc_12=(24; 37) Inc_24=(48 ; 37) Inc_36=(72;37)
(a) (b)
(c) (d)
Figura 4.27 – Grafici dell’errore di stima: 6 Tag di riferimento a griglia.
12 Tag incogniti: Errore totale (a) ; Errore sul lato lungo (b) 36 Tag incogniti: Errore totale (c) ; Errore sul lato lungo (d)
L’informazione molto più interessante riguarda il fatto che sebbene la coordinata sul lato corto possa essere teoricamente stimata con i Tag di riferimento disposti a griglia, dal confronto tra i grafici 4.27-a-b e 4.27-c-d si conferma come la stima migliore si ottiene considerando il solo lato lungo: è un chiaro indice di quanto la stima sul lato corto sia poco affidabile e ciò è una conferma dei risultati preliminari in cui si erano trovati andamenti delle curve di RSSI scarsamente utilizzabili in un algoritmo generico di localizzazione.
Passando dunque alle prestazioni relative al lato lungo, si nota un valore medio di soli 8cm con 12 Tag incogniti (figura 4.27-b) che non deve però trarre in inganno, essendo questa una disposizione privilegiata per la localizzazione. A conferma di ciò, con l’inserzione di 36 Tag incogniti e dunque per una valutazione più concreta
dell’algoritmo e svincolata da situazioni particolari, si riscontra in figura 4.27-d un errore medio più veritiero che sale a 10,5cm: effettuando dunque un confronto diretto con la figura 4.18-b di pag 156 riguardante un’equivalente scenario però con sei Tag disposti in linea, si comprende che i Tag a griglia su questa coordinata riportano sia un errore medio più grande (superiore di circa 2,5cm) che anche una maggiore fluttuazione di tali errori rispetto al valor medio, al variare della posizione (e cioè del Tag incognito). Se ne deduce dunque che la disposizione con 6 Tag di riferimento in linea è in generale una miglior soluzione.
Istogrammi. Sono presentati nelle quattro figure 4.28 a pagina seguente. In figura
4.28-a (risult4.28-ati dell’errore tot4.28-ale per 12 T4.28-ag incogniti) si not4.28-a un4.28-a riduzione dell’errore sistematico totale rispetto ai casi di Tag in linea, il quale scende a circa 3cm; la causa di tale errore è stata ampiamente descritta nel paragrafo 4.1, mentre risulta difficile fare un’ipotesi circa il valore esatto che dovrebbe riportare in via teorica in questo caso, in quanto dipende molto dal fattore di pesaggio insito nei Tag di riferimento che si trovino nella linea al di sotto o al di sopra della posizione da stimare: si può dire con certezza però che, considerate le coordinate dei 12 Tag incogniti rispetto a quelli di riferimento, debba essere compreso nel range 0-9cm, con 9cm caso più sfavorevole che si presenta quando un Tag incognito sulla linea superiore viene stimato esattamente su quella opposta; in ogni caso il valore riscontrato di 3cm risulta sensato, in quanto è auspicabile che i Tag di riferimento più vicini a quello incognito riportano un peso (e dunque un’attrazione) maggiore di quelli più distanti.
Si noti infine in figura 4.28-c che l’errore sistematico nel caso di una disposizione più uniforme e densa dei Tag incogniti scompare: si tratta di un risultato atteso, alla luce di quanto emerso nei paragrafi precedenti (vedi 4.1).
(a) (b)
(c) (d)
Figura 4.28 – Istogrammi dell’errore: 6 Tag di riferimento a griglia
12 Tag incogniti Errore totale (a) ; Errore sul lato lungo (b) 36 Tag incogniti Errore totale (c) ; Errore sul lato lungo (d)
Analizzando gli istogrammi dell’errore relativo al lato lungo (figura 4.28-b e 4.28-d), nel caso “b” si nota un valido comportamento, con una netta predominanza di errori piccoli (il 66% rientra nei primi 6cm), ma questo di nuovo non deve trarre in inganno, in quanto dovuto alla disposizione particolare dei Tag incogniti, infatti analizzando il caso più generale di figura 4.28-d per 36 Tag incogniti, si nota una distribuzione dell’errore decisamente meno accurata: c’è un picco di circa il 20% di valori a livelli bassi, ma circa il 75% degli errori rimanenti rientra nella fascia 5-15cm. Interessante il confronto diretto anche in questo caso con l’immagine 4.19-d di pag. 157 relativa all’istogramma con 6 Tag in linea: ciò conferma la migliore accuratezza raggiunta dalla disposizione in linea, con errori distribuiti su valori decisamente più piccoli.
La figura 4.29 è un riscontro di quanto affermato per gli istogrammi relativi a 12 Tag incogniti: si vede come in nessun caso i Tag incogniti vengano stimati correttamente lungo la direzione del lato corto e come siano invece tutti concentrati verso il centro per via dell’attrazione combinata dovuta ai Tag di riferimento sulle due linee superore ed inferiore.
Figura 4.29 – Risultato della localizzazione con 6 Tag di riferimento a griglia (e 12
incogniti) 4.2.7 Nove Tag di riferimento a griglia
Si tratta dell’ultimo caso analizzato, per cercare di dare, anche per la disposizione a griglia, un limite all’accuratezza in funzione del numero massimo o densità di Tag di riferimento impiegati. Il set-up è mostrato in figura 4.30. I Tag incogniti sono 12 e di nuovo nella stessa posizione, dunque sono affetti dagli stessi due fenomeni di vantaggio per il lato lungo e svantaggio per quello corto.
Figura 4.30 – Set-up di misura:9 Tag di riferimento a griglia, 12 Tag incogniti
Coordinate [cm]
(Lato lungo ; Lato corto) Ref_1 = (13.5 ; 30) Ref_2 = (13.5 ; 21) Ref_3 = (13.5 ; 9) Ref_4 = (41.5 ; 30) Ref_5 = (41.5 ; 21) Ref_6 = (41.5 ; 9) Ref_7 = (69 ; 30) Ref_8 = (69 ; 21) Ref 9 = (69 ; 9)
Risultati. In base ai risultati ottenuti si apprende che la soluzione con 9 Tag di
riferimento risulta in un accuratezza nettamente inferiore al caso precedente: effettuando confronti a parità di Tag incogniti (12) l’errore totale, che tra l’altro raggiunge un picco di quasi 35cm ha un valor medio di 5cm superiore al caso di soli sei Tag di riferimento a griglia, mentre l’errore relativo al lato lungo riporta il livello medio più alto riscontrato in tutte le prove. Si è quindi reputato non necessario procedere con il set-up di misura a maggior densità di Tag incogniti in quanto, almeno relativamente alla coordinata del lato corto, lo scenario attuale risulta avvantaggiato dalla favorevole disposizione dei Tag incogniti, molto ravvicinati ad i riferimenti, come già notato nel caso precedente. Motivo per il quale, con l’esperienza del caso precedente si comprende che il nuovo set-up porterebbe a risultati ancor più scadenti: è dunque lecito affermare che con nove Tag di riferimento a griglia è stato ampiamente superato il limite di Tag necessario e sufficiente all’esecuzione di una localizzazione accurata. In figura 4.29-a e 4.29-b vengono mostrate le curve acquisite con tale configurazione.
(a) (b)
Figura 4.31 – Grafici dell’errore di stima: 9 Tag di riferimento a griglia.
Istogrammi. L’errore totale sistematico (figura 4.32-a) si mantiene ai livelli del caso
precedente, infatti le stime si concentrano nella parte centrale del cassetto per gli stessi motivi. L’errore sul lato lungo (figura 4.32-b) è distribuito in maniera pressoché uniforme in range piuttosto grande 0-25 cm che lo rende uno dei casi peggiori analizzati.
(a) (b)
Figura 4.32 – Istogrammi dell’errore: 9 Tag di riferimento a griglia
Errore totale(a) ; Errore sul lato lungo (b)
4.2.8 Conclusione preliminare per la disposizione dei Tag di riferimento
In generale tutti i risultati riportati confermano che in un cassetto come quello adottato, il numero ideale di Tag di riferimento per cercare di ridurre al minimo gli errori è 6. Inoltre, fare un confronto diretto tra le due migliori configurazioni in linea ed a griglia è facilmente eseguibile proprio grazie ai risultati ottenuti con i 36 Tag incogniti e 6 di riferimento: risulta chiaro che la disposizione dei Tag in linea, seppur porti alla perdita di una coordinata, è sempre da preferire per un cassetto dalla forma lunga e stretta come quello utilizzato in questo contesto; supponendo invece che la lunghezza del lato “secondario” sia tale da rendere necessaria una stima adeguata per entrambe le coordinate, allora scartando l’idea di una configurazione a griglia, il modo migliore sarebbe quello di inserire una seconda antenna sull’altro lato del cassetto, abbinata ad una seconda linea di Tag di riferimento lungo l’altro asse che, se di lunghezza adeguata
(sicuramente maggiore di 50cm), può portare a risultati dall’accuratezza dai valori già sperimentati in queste prove per il lato lungo.
In tabella 4.3 viene riporta un riepilogo dei risultati ottenuti per la disposizione di riferimenti in linea, nel caso di una disposizione uniforme e sufficientemente densa di Tag incogniti, in numero di 36.
# Tag di riferimento Densità [𝑻𝑻𝑻𝑻𝑻𝑻/𝒎𝒎] Densità [𝑻𝑻𝑻𝑻𝑻𝑻/𝒎𝒎𝟐𝟐] Errore medio [cm] (36 Tag inc.) Note 3 in linea
3,75
9,4
12
Andamento della curva dell’errore molto frastagliato. Errori molto alti ai due estremi, soprattutto nella parte iniziale (dovuto anche a multipath più consistente in quella zona)
6 in linea
7,5
18,8
8
Errori bassi ed equamente distribuiti per tutta la lunghezza. Risultati anomali con errori molto sopra la media, nei pressi delle coordinate (10, 30) (multipath)
9 in linea
11,25
28,1
10
Curva dell’errore al variare dei Tag incogniti molto frastagliata. Ancora errori molto sopra la media nei pressi delle coordinate (10, 30) (multipath)
Tabella 4.3 – Riepilogo risultati di localizzazione per Tag di riferimento in linea
Per ogni prova analizzata è stata riportata la densità dei Tag di riferimento all’interno del cassetto, calcolata nei due modi riportati in formula (4.6) e (4.7) :
𝑁𝑁𝑠𝑠𝑟𝑟 𝑒𝑒𝑟𝑟𝑖𝑖 𝑑𝑑𝑖𝑖 𝑇𝑇𝑇𝑇𝑖𝑖 𝐿𝐿𝑠𝑠𝑖𝑖𝑖𝑖 ℎ𝑒𝑒𝑒𝑒𝑒𝑒𝑇𝑇 𝑖𝑖𝑇𝑇𝑠𝑠𝑠𝑠𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖 [𝑟𝑟] � 𝑇𝑇𝑇𝑇𝑖𝑖 𝑟𝑟 � (4.6) 𝑁𝑁𝑠𝑠𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖 𝑑𝑑𝑖𝑖 𝑇𝑇𝑇𝑇𝑖𝑖 𝐴𝐴𝑟𝑟𝑒𝑒𝑇𝑇 𝑖𝑖𝑇𝑇𝑠𝑠𝑠𝑠𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖 [𝑟𝑟2] [ 𝑇𝑇𝑇𝑇𝑖𝑖 𝑟𝑟2] (4.7)
La (4.6) è una densità di Tag per unità di lunghezza, dunque è un parametro generalmente utilizzabile in qualunque tipo di scenario, mentre la (4.7) calcola una densità per unità di area, appositamente misurata nel cassetto 40x80 cm2 di queste prove e confrontabile con qualunque altro scenario che preveda una disposizione dei Tag di riferimento su di un'unica linea.
Si comprende dunque che un valore adeguato per la densità dei Tag di riferimento in linea può approssimarsi come in 4.8 o 4.9 (dati estratti da Tabella 4.2) a seconda che si decida di ragionare in termini di lunghezza del cassetto oppure di area:
𝐷𝐷𝑒𝑒𝑖𝑖𝑠𝑠𝑖𝑖𝑖𝑖à 𝑑𝑑𝑖𝑖 𝑇𝑇𝑇𝑇𝑖𝑖 𝑑𝑑𝑖𝑖 𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖 𝑝𝑝𝑒𝑒𝑟𝑟 𝑠𝑠𝑖𝑖𝑖𝑖𝑖𝑖à 𝑑𝑑𝑖𝑖 𝑜𝑜𝑠𝑠𝑖𝑖𝑖𝑖ℎ𝑒𝑒𝑒𝑒𝑒𝑒𝑇𝑇 ≈ 8 [𝑇𝑇𝑇𝑇𝑖𝑖/𝑟𝑟] (4.8) 𝐷𝐷𝑒𝑒𝑖𝑖𝑠𝑠𝑖𝑖𝑖𝑖à 𝑑𝑑𝑖𝑖 𝑇𝑇𝑇𝑇𝑖𝑖 𝑑𝑑𝑖𝑖 𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖 𝑝𝑝𝑒𝑒𝑟𝑟 𝑠𝑠𝑖𝑖𝑖𝑖𝑖𝑖à 𝑑𝑑𝑖𝑖 𝑇𝑇𝑟𝑟𝑒𝑒𝑇𝑇 ≈ 20 [𝑇𝑇𝑇𝑇𝑖𝑖/𝑟𝑟2] (4.9)
4.3 Revisione dei dati
Come già esposto (paragrafo 2.2.1 e figura 2.4), il parametro RSSI restituito dai Tag soffre di due problemi intrinseci, uno riguardante la varianza del dato dovuta all’oscillazione dei valori durante la finestra temporale di acquisizione e l’altro insito nel fatto che Tag dello stesso modello ed a parità di condizioni rispondono in generale in modo diverso. Se il primo è un problema intrinseco ed ineliminabile della strumentazione utilizzata (Tag e Reader), riguardo al secondo è teoricamente possibile eseguire una revisione per cercare di annullarne l’effetto (paragrafo 2.3.6).
In pratica l’idea è quella di prendere ogni valore di RSSI acquisito dai Tag di riferimento e, prima di inserirlo nell’algoritmo di localizzazione, pre-moltiplicarlo per una costante 𝐾𝐾𝑖𝑖 preventivamente trovata tramite calibrazione, in modo da normalizzare le risposte di tutti i Tag: se si pensa all’impiego finale in uno scenario di smart shelf, questa procedura è comodamente applicabile ad i Tag di riferimento in quanto pochi e soprattutto fissi, mentre è praticamente impensabile proporla per i Tag incogniti che, oltre ad essere
generalmente molti, possono anche cambiare in tempi brevi sia in posizione che in numero (si pensi alle medicine disponibili in una farmacia).
In formule dunque, abbiamo la revisione effettuata mediante una semplice moltiplicazione (4.10):
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑒𝑒𝑅𝑅𝑖𝑖 = 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 ∗ 𝐾𝐾𝑖𝑖 (4.10)
dove i è l’indice dei Tag di riferimento e quindi la costante è diversa per ognuno di essi ed è calcolata mediante l’espressione 4.11 dove si è scelto il Tag di riferimento #1 come elemento di default per la revisione (qualunque altro sarebbe stato ugualmente valido): 𝐾𝐾𝑖𝑖 = 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖1 �𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 (4.11)
Questo fa sì che, dopo la revisione, ogni Tag risponda con un livello identico a quello del Tag preso come fattore di default; ad esempio in 4.12 è riportata la revisione per il Tag di riferimento #2:
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑒𝑒𝑅𝑅2 = 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖2 ∗ 𝐾𝐾2= 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖2 ∗ 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖
1
𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖2 = 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑟𝑟𝑒𝑒𝑟𝑟𝑖𝑖𝑟𝑟𝑒𝑒𝑖𝑖𝑖𝑖𝑖𝑖1 (4.12) In conclusione, tali valori revisionati verranno inseriti nelle formule relative al k-NN (4.13) o (4.3) il quale calcolerà le stime con lo stesso principio dei pesaggi di coordinate: 𝐸𝐸𝑖𝑖,𝑅𝑅𝑒𝑒𝑅𝑅 = �𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 [𝑊𝑊] − 𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑅𝑒𝑒𝑅𝑅𝑖𝑖 [𝑊𝑊]� (4.13)
Metodo di acquisizione delle costanti 𝑲𝑲𝒊𝒊. La revisione dei dati è stata testata solamente per il miglior set-up di misura riscontrato, vale a dire quello relativo a 6 Tag di riferimento disposti in linea. Entrando nei dettagli della calibrazione, a differenza di quanto riportato in letteratura [20], anziché eseguire un’unica calibrazione a distanza fissa dall’antenna Reader, si è deciso di calcolare specificatamente le costanti 𝐾𝐾𝑖𝑖 per ogni Tag di riferimento alla propria distanza alla quale sarà utilizzato (R#1 @ 9cm,
R#2 @ 13.5cm, R#3 @ 27cm, R#4 @ 41.5cm, R#5 @ 54cm, R#6 @ 69cm), in base alla seguente modalità:
1) Il Tag di riferimento i-esimo ed il Tag di riferimento #1 (quest’ultimo sempre utilizzato come default per il calcolo delle costanti) sono stati posti alla distanza corrispondente al Tag di riferimento i-esimo stesso: per entrambi i Tag si è ottenuto il valore di RSSI mediato su 10 acquisizioni successive in modo da ridurre l’errore dovuto alla varianza del dato.
2) La costante 𝐾𝐾𝑖𝑖 specifica per una sola distanza ed un solo Tag (l’i-esimo) è stata calcolata mediante la formula (4.9)
Il tutto è stato ripetuto per i sei Tag di riferimento, ognuno alla propria specifica distanza, in modo che all’interno dello scenario, dopo la revisione tutti rispondano con gli stessi livelli che si sarebbero riscontrati impiegando il Tag #1 nelle varie posizioni (il quale ha costante 𝐾𝐾1 = 1).
Risultati. Teoricamente l’idea di una tale revisione, effettuata tra l’altro con grande
accuratezza, sembrava valida ma i risultati affermano, contrariamente alle aspettative, che questa correzione non apporta miglioramenti nella stima. I grafici sono esposti nelle figure 4.33 insieme ad i risultati non revisionati (già analizzati) per un confronto diretto, mediante il quale si vede chiaramente che le curve sottoposte a revisione dell’errore rispetto al lato lungo (figure 4.33-a-c a pagina seguente) hanno un andamento quasi coincidente alle stesse non revisionate (figure 4.33-b e 4.33-d sempre a pagina seguente) ed anzi, nel primo caso i valori medi peggiorano leggermente.