CAPITOLO 3: Web Mining
Le tecniche di mining forniscono la possibilità di capire meglio tutti i dati che l’azienda ha a disposizione, dando la possibilità di riassumere dati storici per capire il passato e prendere decisioni brillanti sul futuro, di segmentare il mercato per ottenere programmi più specifici, di assegnare uno score ai clienti per valutare i clienti potenziali ed ottenere un ritorno sugli investimenti. Con i dati storici è possibile stabilire un benchmarks per valutare le performance e verificare il raggiungimento degli obiettivi.
Gli algoritmi di Data mining applicati a soluzioni web permettono di rilevare i modelli comportamentali dei visitatori generando report o implementare azioni in base ai modelli rilevanti.
Lo scopo di questo capitolo è quello di far capire al lettore che cos’è il Web Mining e come è possibile utilizzare questa tecnica per risolvere i problemi causati dall’eccesso di informazioni disponibili su Internet. In particolare mostrando, senza entrare in dettagli tecnici, come le informazioni, riguardanti l’ordine nel quale le pagine di un sito web sono visitate, possono essere utilmente utilizzate per prevedere il comportamento di visita ad un sito.
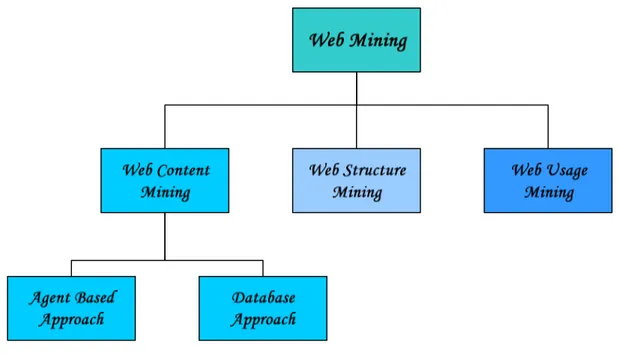
1 Tassonomia del web mining
In analogia con il termine Data Mining, l’espressione Web Mining si riferisce all’applicazione di tecniche di Data Mining a dati provenienti dal web, per estrarre automaticamente informazioni dalle risorse (sia documenti che servizi) presenti sul web.
I dati che possono essere usati nel processo di Web Mining sono: il contenuto delle pagine web, struttura della pagina (HTML o XML tags), struttura sito (hyperlink tra le pagine), dati di uso (Web log) descriventi come le pagine sono accedute, profili utenti includenti informazioni demografiche o di registrazione.
Figura 1 Tassonomia Web Mining
1.1 Web content mining
Il Web Content Mining indica il processo di scoperta di informazioni utili all’analisi del contenuto del web. Tale contenuto può essere non-strutturato, semi-strutturato (documenti HTML o XML) o più strutturato (tabelle, database). Una tassonomia del Web Mining divide il Web content mining in due classi:
♦ Agent Based Approach, che prevede l’uso di agenti che possono operare
autonomamente o semiautonomamente per scoprire e organizzare informazioni dal web. Gli agenti in questa classe si dividono in:
o Intelligence search agent:
vanno oltre i semplici motori di ricerca (search engines), usano, ad esempio, informazioni descriventi il profilo di un utente o altre specifiche informazioni per interpretare e organizzare le informazioni scoperte.
o Information filtering:
utilizzano tecniche di Information Retrieval, informazioni sui hyperlink in uso ed eventuali altri approcci per classificare i documenti.
o Personalization Web Agent:i quali a sua volta si dividono in:
collaborative filtering raccomanda pagine che sono state prima richieste da
User registration preference raccomandazioni basate sul profilo o
informazioni demografiche dell’utente;
Content-based filtering raccomanda pagine che risultano in base a qualche
criterio, simili al profilo dell’utente.
♦ Database Approach: questo approccio del Web mining è generalmente concentrato
sulle tecniche per integrare e organizzare dati web eterogenei e semi strutturati all’interno di database relazionali, usando meccanismi di query su database standard e tecniche di data mining per accedere a queste informazioni e analizzarle.
o Multilevel Databases:
Molti ricercatori, per organizzare le informazioni basate sul web hanno proposto un database multilivello (multilevel database). L’idea principale che si nasconde dietro a questa proposta è che il livello più basso del database contiene le informazioni primitive semistrutturate memorizzate in vari depositi web, come documenti ipertestuali. A più alto livello i meta dati o le generalizzazioni sono estratte dai più bassi livelli e sono organizzati in collezioni strutturate come database relazionali o object-oriented.
o Web Query Systems:
Ci sono stati molti sistemi basati su meccanismi di query e linguaggi sviluppati recentemente che tentano di utilizzare linguaggi come l’SQL per fare query su database standard. Facciamo un esempio di Web-base query
systems. W3QL, combina la struttura delle query, basandosi sull’organizzazione di documenti ipertestuali, e contenuti di query che si basano su tecniche di Information Retrival.
Queste tecniche, grazie all’analisi del contenuto di documenti, aiutano l’utente, a ricercare nella vastità dei documenti web, quelli che ne soddisfano il suo bisogno informativo.
1.2 Web structure mining
Il Web Structure Mining è il processo di scoperta di informazioni utili all’analisi della struttura del sito (hyperlink) e/o delle pagine (tags HTML o XML). L’informazione sulla struttura del sito web può essere usata per classificare le pagine e creare misure di
similarità tra i documenti. Un esempio di questo tipo di approccio è dato da Google che da un misura di bontà alla pagina in proporzione al numero di link che puntano ad essa.
Il Web Structure Mining cerca di scoprire i modelli sottostanti alla struttura del web. Il modello è basato sulla topologia dell’hyperlink con o senza la descrizione del link. Questo modello può essere utilizzato per categorizzare le pagine web e è utile per generare informazioni di similitudine e di relazione tra le pagine web.
1.3 Web usage mining
Web usage mining è un ramo specifico del Web mining, definito per la prima volta nel
1996 da Etzioni come l'utilizzo di tecniche di data mining per scoprire automaticamente ed estrarre informazioni da documenti e servizi sul World Wide Web.
Il termine Web usage mining è invece comparso nel 1997, quando Cooley et al. fornirono il primo tentativo di tassonomia della disciplina di Web Mining. Da allora, per
Web usage mining si intende l'applicazione di tecniche di data mining a dati provenienti
dal web è perciò un processo di scoperta e analisi di modelli (pattern) che concentra l'attenzione sui dati relativi agli accessi effettuati dagli utenti (Web usage data).
Il Web Usage Mining indica l’insieme complessivo dei processi, delle tecniche e delle tecnologie di data analysis, finalizzato alla scoperta di significativi schemi di comportamento (pattern) dai log file descriventi la navigazione degli utenti in uno o più siti Web. Quindi in questo caso le informazioni che ci interessano riguardano il comportamento dell’utente.
I log file possono essere analizzati sia dal lato client sia dal lato server. Dal lato server permettono di scoprire informazioni sui siti su cui il servizio risiede, che possono essere usate ad esempio per migliorare la struttura del sito. Dal lato client permettono di individuare informazioni su sequenze di click (clickstream), sul singolo utente o su gruppi di utenti, che possono essere usate, ad esempio, per la personalizzazione delle pagine web.
C’è da notare come in questo caso l’informazione estratta non si basa sul contenuto dei documenti, ma viene estratta, attraverso il log file del web server, l’intelligenza dell’utente, ovvero vengono scoperte le associazioni mentali che un navigatore compie durante la ricerca di una informazione in un sito web.
Lo scopo del Web Mining è quello di analizzare il comportamento di navigazione degli utenti per capirne le preferenze e quindi massimizzare l’attività commerciale, capire i pattern di navigazione per migliorare la struttura del sito e personalizzare la navigazione ed
Il Web Mining dovrebbe quindi permettere di mettere a punto una metodologia che a partire dall’osservazione e dalla corretta analisi statistica dei dati consenta di influenzare il comportamento dell’utente, provocando decisioni di acquisto oppure fornendo in generale maggiore soddisfazione dell’utente del sito.
In questo capitolo ci concentreremo sul Web usage mining e in particolare sull’analisi dei clickstream; con lo scopo di dare al lettore un’idea di quelle che sono le principali tecniche senza scendere nei particolari.
2 Analisi clickstream
Ogni iterazione tra utente Internet e la rete genera una traccia che, se tratta in modo opportuno, offre l’opportunità di fornire informazioni sempre più interessanti.
Cliccando con il mouse il visitatore di un sito, esprime in modo inconsapevole le sue preferenze e attua un suo individuale modello di comportamento.
Ogni volta che un utente si collega ad un sito web, il server tiene traccia di tutte le azioni compiute in un log file. Ciò che viene catturato è il “flusso di click” (clickstream) del mouse e le chiavi usate dall’utente durante la navigazione all’interno del sito.
Attraverso l’analisi delle sequenze di click (clickstream analysis), accompagnate da opportune elaborazioni delle tracce lasciate da chi visita i loro siti, le aziende presenti nella rete sono già in grado di accumulare una tale quantità di informazioni da consentire la gestione delle attività on line in cui sono impegnate. La capacità infatti di prevedere il comportamento futuro dei propri clienti secondo le analisi effettuate sul loro comportamento passato, o quello di riuscire a capire quello che i potenziali clienti di un sito vorrebbero venisse loro offerto dà alle aziende che si sono attrezzate per raggiungere questi risultati, un reale e consistente vantaggio competitivo su tutti i concorrenti che non sono in grado o che non ritengono opportuno farlo.
Nasce così l’e-intelligence, ovvero quel processo di gestione di grandi masse di dati web per estrarre informazioni di supporto ai sistemi decisionali per il Web Marketing, che è a tutti gli effetti un’applicazione di DataWarehousing dove i dati da memorizzare, analizzare e su cui fare Data Mining allo scopo di scoprire relazioni non ovvie e potenzialmente utili, provengono da file di log dei server Internet che gestiscono le applicazioni on-line e da altre sorgenti di informazioni a esse correlate, integrati da dati esterni riguardanti essenzialmente prodotti e clienti
office o da fonti esterne, vengono memorizzati per essere sottoposti a diversi tipi di analisi con lo scopo di migliorare i processi decisionali) estraendo gli ambiti di utilizzo e introducendo varianti alle tecniche abituali: il marketing, continuerà ad avere tra i suoi obiettivi quello di personalizzare e adattare al tipo di canale i messaggi, i servizi e i prodotti proposti al cliente, o campagne per migliorare la profittabilità o la fidelizzazione; per far questo però dovrà disporre di nuovi strumenti che permettono di analizzare i modi con cui questi clienti si muovono nei siti web e come li usano per fare eventuali acquisti.
Da qui lo sviluppo delle tecniche di clickstream analysis, dall’analisi cioè della sequenza di click legati ad ogni sessione di chi entra in un sito per giungere a una certa pagina o acquistare un particolare prodotto. Per inciso, i dati di clickstream, che sono di grande valore per l’e-intelligence, costituiscono una caratteristica unica ed esclusiva del canale elettronico, il solo che consente di individuare con precisione la sequenza degli eventi che portano un cliente potenziale a scegliere un determinato prodotto.
L’utilità dei dati di clickstream (che a livello grezzo, ovvero così come vengono estratti dai file di log dei server sono sostanzialmente privi di significato e fanno emergere informazioni valide solo dopo essere stati posti in sequenza logica) aumenta in modo sensibile se si riesce ad abbinarli ai dati anagrafici dei visitatori che li hanno generati.
L’integrazione dei due tipi di informazione consente infatti di sviluppare modelli più completi che tengono conto delle caratteristiche dei visitatori, soprattutto se i nuovi dati aggiuntivi derivano da altri canali da essi ugualmente utilizzati. In questo modo diventa possibile per l’aziende sviluppare strategie di marketing specifiche per il cliente multicanale e la pubblicità, gli incentivi e il posizionamento dei prodotti possono essere personalizzati e distribuiti utilizzando i canali preferiti da ciascun cliente.
L’obiettivo principale dell’analisi è quello di mostrare come i dati della web
clickstream possono essere utilizzati per capire quali sono i percorsi di navigazione più
probabili, con lo scopo di prevedere, possibilmente on-line, quali pagine saranno osservate, avendo visto uno specifico percorso di altre pagine precedentemente. Tale analisi possono essere utilizzate per capire, per esempio, qual è la probabilità di vedere una pagina di interesse (come la pagina degli acquisti di un sito e-commerce) provenendo da un'altra pagina.
Per condurre un’analisi di tipo clickstream è necessario avere a disposizione un data set , che si ricava dall’elaborazione di un log file. I file di log standard posseggono al loro interno informazioni su:
• Access log file: dati relativi alle richieste effettuate dagli utenti. Memorizzati in vari
formati, i più comuni CLF (Common Log Format) o ECLF (Extended CLF) • Error log file: dati relativi ad errori incorsi durante l’invio delle pagine richieste.
• Referrer log file: memorizza lo URL della pagina dalla quale è stata effettuata la
richiesta al sito.
• Agent log file: memorizza il nome ed il numero della versione del browser usato
dall’utente per fare la richiesta.
Se prendiamo, ad esempio, un file di log di un sito di e-commerce un possibile dataset, ottenuto dall’elaborazione del file di log, potrebbe essere quello riportato nella tabella 1.
c_value c_time c_caller
70ee683a6df…… 70ee683a6df…… 70ee683a6df…… 70ee683a6df…… 70ee683a6df…… 14OCT05:11:09:01 14OCT05:11:09:08 14OCT05:11:09:14 14OCT05:11:09:23 14OCT05:11:09:24 home catalog program product program
Tabella 1 Dataset considerato nell'esempio
Tale dataset contiene lo userid (c_value), una variabile con la data e l’istante in cui il visitatore si è collegato ad una specifica pagina (c_time) e la pagina web vista (c_caller). La tabella descrive il fatto che il visitatore corrispondente all’identificatore (cookie)
70ee683a6df…è entrato nel sito il 14 ottobre del 2005 alle ora 11:09:01 e ha visitato in
sequenza le pagine: home, catalog, program, product, program, lasciando il sito alle 11:09:24
L’intero dataset, dell’esempio riportato, contiene 250711 osservazioni, ciascuno corrispondente a un click che descrivono il percorso di navigazione di 22527 visitatori tra le 36 pagine che compongono il sito di e-commerce. I visitatori sono considerati come unici, ovvero nessun visitatore appare in più di una sessione.
Questo dataset è un classico esempio di dataset transazionale. Questo può essere utilizzato direttamente in formato simile a quello della Tab. 1, con tante righe quanto il numero totale di click, per determinare le associazioni e le regole sequenziali. Alternativamente può essere utilizzato il data set derivato, chiamato “visitatori”. Esso è organizzato per sessioni e contiene variabili che possono caratterizzare ciascuna di queste sessioni. Le variabili contenute sono anche di tipo qualitativo, come la durata della
in cui la sessione inizia (start). Ma elemento più importante per la nostra analisi è che, tale
dataset, contiene variabili binarie che descrivono se ciascuna pagina è visitata almeno una
volta (modalità 1) o no (modalità 0). La Tabella 2, sotto riportata mostra un estratto della tabella visitatori; ogni riga corrisponde alle sessioni (o equivalente mente, ai visitatori, dal momento che sono unici. Vi sono tante righe quanto il numero totale di visite al sito.
c_value c_time lenght clicks time Home catalog Addcart program product
70ee683a 6df……
14OCT05 :11:09:01
24 5 11:09:01 1 1 0 1 1
Tabella 2 Dataset derivato
Quello riportato è un esempio di come è possibile ricavare un data set da un file di log. L’obiettivo dell’analisi è quello di tracciare i pattern di visita più importanti, dove un partner significa una sequenza di pagine ordinate nel tempo, possibilmente ripetuta. La misura dell’importanza adottata determina i risultati dell’analisi. Le misure più comuni si riferiscono sia alla probabilità di visita di una certa sequenza (supporto) sia alla probabilità condizionale di vedere una certa pagina, avendo visto le altre nel passato (confidenza).
Una volta organizzati i dati si procede con la fase di esplorazione, questa fase è necessaria per derivare conclusioni valide. A tal fine i dati considerati devono essere omogenei.
Una volta conclusa la fase di esplorazione si passa alla costruzione del modello. Una delle tecniche più usate riguarda l’analisi di pattern frequenti in un set di dati (Market
Basket Analysis). La Market Basket Analysis, o analisi del carrello, è una metodologia che
mira ad identificare delle regole ricorrenti all’interno di un certo insieme di transazioni. Nello specifico della grande distribuzione essa è orientata all’identificazione delle relazioni esistenti tra un vasto numero di prodotti acquistati da differenti consumatori in un particolare luogo (il punto vendita, il supermercato).
La Market Basket Analysis applicata al commercio elettronico prende il nome di
Analisi clickstream. In questo caso l’analisi delle sequenze e delle associazioni
(clickstream) tra le pagine visitate e le transazioni effettuate fornisce utili indicazioni per il lay-out dei siti web e per il marketing dei prodotti o servizi forniti.
L’associazione identifica gli articoli che verranno probabilmente acquistati o visti nella stessa sessione. Se si inseriscono dei riferimenti a tali articoli sulla stessa pagina in un
prodotto dimenticato. Se si definisce una promozione su un prodotto in un gruppo omogeneo, si potranno probabilmente incrementare gli acquisti di altri prodotti dello stesso gruppo. L'associazione può essere utilizzata anche in situazioni in cui si dispone di pagine statiche di catalogo. In questo caso, ci si basa sul visitatore per selezionare la prima pagina del catalogo da visualizzare e quindi si presentano gli articoli associati come vendite incrociate. L'associazione è la soluzione di data mining utilizzata da molti siti fra i quali Amazon.com.
Un'altra tecnica utilizzata è la Link Analysis che consiste nell’applicazione della teoria dei grafi al Data Mining Il grafo contiene tutte le possibili combinazioni: ogni nodo rappresenta una pagina vista ed assume dimensioni maggiori al crescere del numero di visite; la presenza di un arco identifica una situazione di dipendenza tra i nodi, la sua dimensione maggiore al crescere del numero delle visite; la presenza di un arco identifica una situazione di dipendenza tra i nodi, la sua dimensione indica invece il livello dell’associazione mentre la sua direzione, indicata dal senso della freccia, definisce la sequenza delle pagine viste.
Sotto è riportato un esempio di grafo ottenuto con la Link Analysis applicata ai dati dell’esempio del sito di e-commerce.
Figura 2 Grafo Link Analysis
Anche il Clustering fa parte delle tecniche di mining che vengono utilizzate sul web. L'analisi cluster permette di raggruppare utenti con caratteristiche simili in base ai diversi percorsi di navigazione.
i clienti, consentono di implementare dei processi di gestione dell’e-business che possono essere definiti e-Intelligence.
Grandi masse di dati diventano così un potente supporto alle decisioni a livello di Web Marketing e non solo.
3 Considerazioni conclusive
Gli algoritmi di Data mining applicati a soluzioni web permettono di rilevare i modelli comportamentali dei visitatori e di implementare azioni in base ai modelli rilevanti.
L’obiettivo del Web Mining trova giustificazione nell’opinione diffusa che l’informazione presente nel Web è sufficientemente strutturata da consentire una efficace applicazione di tecniche statistiche e di apprendimento automatico.