A
LMA MATER STUDIORUM
U
NIVERSITÀ DI BOLOGNA · SEDE DI CESENA
FACOLTÀ DI SCIENZE MATEMATICHE, FISICHE E NATURALI
Corso di Laurea Magistrale in Scienze e Tecnologie Informatiche
Analisi e integrazione dati finalizzate
alla lotta digitale all'evasione fiscale
Tesi di Laurea in Sistemi Informativi
Relatore:
Chiar.mo Prof.
Matteo Golfarelli
Correlatore:
Dott. Camillo Acerbi
Presentata da:
Enrico Gallinucci
III Sessione
2011/2012
Indice
1
Indice
INDICE DELLE FIGURE ... 3
INDICE DELLE TABELLE ... 5
INTRODUZIONE ... 7
1 IL SISTEMA INFORMATIVO DEL COMUNE DI CESENA ... 9
1.1 La problematica ... 9
1.2 La struttura del progetto ... 11
1.2.1 L’integrazione delle banche dati ... 11
1.2.2 L’obiettivo principale: la ricerca degli evasori ... 12
1.2.3 Gli utilizzi alternativi dello schema riconciliato ... 14
1.2.4 Le fasi del progetto ... 15
1.3 Le banche dati ... 16
1.3.1 Comune di Cesena ... 16
1.3.2 Agenzia delle Entrate ... 17
1.3.4 ISTAT ... 19
2 LE TECNOLOGIE ... 21
2.1 Pentaho Data Integration ... 21
2.2 MySQL ... 23
2.3 PHP e il framework interno ... 25
2.4 Javascript ... 26
3 IL PROGETTO DYNAMITE: IL BACK-END ... 29
3.1 Sintesi dei progetti precedenti ... 29
3.1.1 Anagrafe... 30
2
3.1.3 Catasto ... 31
3.1.4 Utenze dei consumi ... 33
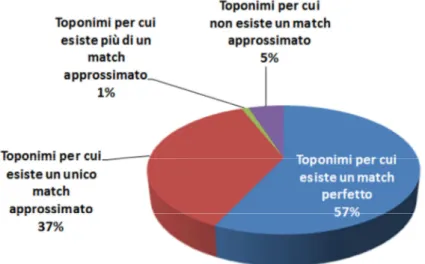
3.1.5 Schema dati ... 33
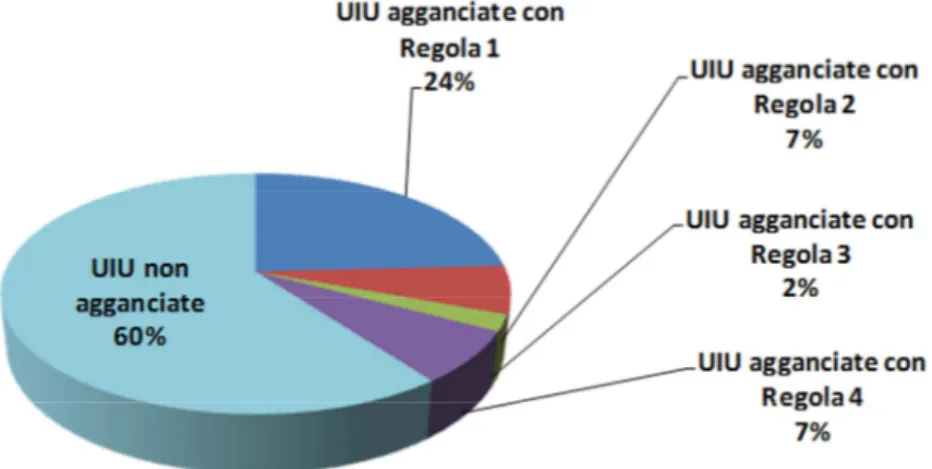
3.2 Match approssimati ... 34
3.2.1 Match tra residenti e titolari ... 37
3.2.2 Match tra toponimi... 40
3.2.3 Match tra coordinate catastali e indirizzi di residenza ... 44
3.3 Estensione del database ... 47
3.3.1 Indirizzi di residenza ... 47
3.3.2 Relazioni di parentela ... 49
3.3.3 Contratti d’affitto ... 51
3.3.4 Dichiarazioni dei redditi ... 57
3.3.5 Censimento ... 58
3.3.6 Schema dati finale ... 60
4 IL PROGETTO DYNAMITE: IL FRONT-END ... 63
4.1 I pattern di evasione ... 63
4.1.1 Consumi fuori soglia ... 64
4.1.2 Falsi separati ... 67
4.1.3 Analisi su patrimonio economico e immobiliare ... 73
4.2 L’interfaccia ... 77
4.2.1 La metafora adottata ... 77
4.2.2 Le funzionalità di navigazione ... 81
4.2.3 Il salvataggio dei dati ... 84
4.2.4 Gestione manuale dei match approssimati ... 85
4.3 Analisi what-if sull’equità fiscale ... 88
4.3.1 La realizzazione del modello previsionale ... 89
4.3.2 Analisi dei risultati ... 95
CONCLUSIONI ... 99
Indice delle figure
3
Indice delle figure
FIGURA 1 - UN ESEMPIO DI TRASFORMAZIONE PDI IMPLEMENTATA ... 23
FIGURA 2 - ARCHITETTURA INIZIALE DEL DATABASE RICONCILIATO ... 34
FIGURA 3 - FORMULA MATEMATICA DELLA DISTANZA DI LEVENSHTEIN TRA DUE STRINGHE ... 35
FIGURA 4 - PSEUDOCODICE PER IL CALCOLO DELLA DISTANZA COMPLESSIVA TRA RESIDENTE E TITOLARE ... 39
FIGURA 5 - STATISTICHE DEL MATCH TRA RESIDENTI E TITOLARI ... 39
FIGURA 6 - STATISTICHE SUL MATCH TRA I TOPONIMI NELLE UTENZE DEI CONSUMI D’ACQUA E QUELLI IN TOPONOMASTICA ... 43
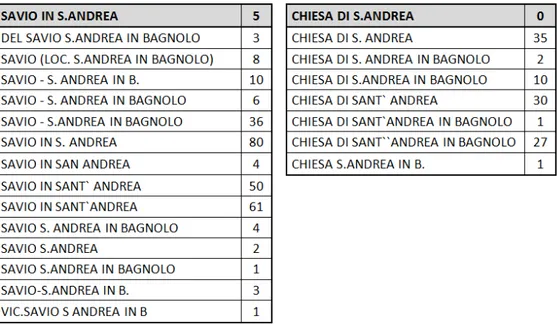
FIGURA 7 - ESEMPI DI TOPONIMI UTILIZZATI NEGLI INDIRIZZI CATASTALI ... 44
FIGURA 8 - STATISTICHE SUL MATCH TRA COORDINATE CATASTALI E INDIRIZZI DI RESIDENZA ... 46
FIGURA 9 - DIAGRAMMA ER FOCALIZZATO SUGLI INDIRIZZI DI RESIDENZA ... 48
FIGURA 10 - DIAGRAMMA ER FOCALIZZATO SULLE PARENTELE ... 50
FIGURA 11 - DIAGRAMMA ER FOCALIZZATO SUI CONTRATTI D'AFFITTO ... 55
FIGURA 12 - DIAGRAMMA ER FOCALIZZATO SULLE DICHIARAZIONI DEI REDDITI ... 57
FIGURA 13 - DIAGRAMMA ER FOCALIZZATO SUI DATI DEL CENSIMENTO... 59
FIGURA 14 - SCHEMA DATI DEL DATABASE RICONCILIATO ... 60
FIGURA 15 - PERCENTILI DELLE UTENZE ELETTRICHE ASSOCIATE AD UN’OCCUPAZIONE MEDIA DI DUE PERSONE ... 65
FIGURA 16 - IL PERCORSO DELLE RELAZIONI COINVOLTE NEL PATTERN DEI FALSI SEPARATI ... 68
FIGURA 17 - PSEUDOCODICE PER IL CALCOLO DEL PUNTEGGIO DI SOSPETTO DEI FALSI SEPARATI ... 70
FIGURA 18 - STATISTICHE SUL CAMPIONE DEI POTENZIALI FALSI SEPARATI ... 71
FIGURA 19 - FALSI SEPARATI: UN ESEMPIO (SITUAZIONE INIZIALE) ... 72
4
FIGURA 21 - ANALISI SU PATRIMONIO ECONOMICO ED IMMOBILIARE: UN ESEMPIO ... 75
FIGURA 22 - MECCANISMO DI NAVIGAZIONE DEI CONCETTI DELLO SCHEMA ... 78
FIGURA 23 - SCREEN DELL'INTERFACCIA: VISUALIZZAZIONE DELLA SCHEDA DI UN INDIRIZZO ... 79
FIGURA 24 - SCREEN DELL’INTERFACCIA: RICERCA INIZIALE PER AVVIARE LA LIBERA NAVIGAZIONE ... 81
FIGURA 25 - SCREEN DELL'INTERFACCIA: GESTIONE MANUALE DEI MATCH DEI TOPONIMI ... 87
FIGURA 26 - PSEUDOCODICE PER IL CALCOLO DEL REDDITO OCSE ... 89
FIGURA 27 - SUDDIVISIONE DELLE FAMIGLIE NEL COMUNE DI CESENA ... 89
FIGURA 28 - PSEUDOCODICE PER IL CALCOLO DELL'IMU ... 91
FIGURA 29 - DIAGRAMMA ER DELLE STRUTTURE DATI INTRODOTTE PER IL MODELLO PREVISIONALE ... 94
FIGURA 30 - CARICO FISCALE TOTALE MEDIO PER LE FAMIGLIE NELLA SITUAZIONE ATTUALE ... 95
FIGURA 31 - RAPPORTO TRA IL CFTM MEDIO E IL REDDITO OCSE MEDIO DELLA FAMIGLIE NELLA SITUAZIONE ATTUALE ... 96
FIGURA 32 - RAPPORTO TRA IL CFTM MEDIO E IL REDDITO OCSE MEDIO DELLA FAMIGLIE CON L’IMU SULLA PRIMA CASA ALLO 0.8%. ... 97
Indice delle tabelle
5
Indice delle tabelle
TABELLA 1 - CALCOLO DELLA SIMILARITÀ TRA I CAMPI DEI RESIDENTI E DEI TITOLARI ... 38
TABELLA 2 - REGOLE PROGRESSIVE PER I MATCH TRA RESIDENTI E TITOLARI ... 38
TABELLA 3 - REGOLE PROGRESSIVE PER I MATCH TRA TOPONIMI ... 42
TABELLA 4 - REGOLE PROGRESSIVE PER I MATCH TRA COORDINATE CATASTALI E INDIRIZZI DI RESIDENZA ... 45
TABELLA 5 - STRUTTURA DI BASE DEI TRACCIATI RELATIVI AI CONTRATTI D'ADDITTO ... 53
TABELLA 6 - DESCRIZIONE DELLE TABELLE DI MATCH PRINCIPALI COLLEGATE AI CONTRATTI D'AFFITTO ... 55
TABELLA 7 - DESCRIZIONE DELLE TABELLE DI MATCH SECONDARIE COLLEGATE AI CONTRATTI D'AFFITTO ... 56
TABELLA 8 - DESCRIZIONE DELLE CASISTICHE CONSIDERATE NEL PATTERN DEI FALSI SEPARATI ... 68
TABELLA 9 - DESCRIZIONE DEI COMPONENTI DELL'INTERFACCIA ... 79
TABELLA 10 - PARAMETRI RICHIESTI PER IL PATTERN DEI FALSI SEPARATI ... 82
TABELLA 11 - FORMATO DEI RISULTATI DEL PATTERN DEI FALSI SEPARATI ... 82
TABELLA 12 - PARAMETRI RICHIESTI PER IL PATTERN DEI CONSUMI FUORI SOGLIA ... 83
TABELLA 13 - FORMATO DEI SALVATAGGI MOSTRATI... 85
TABELLA 14 - DECODIFICA DEI VALORI UTILIZZATI PER DESCRIVERE IL LIVELLO DEI MATCH ... 86
TABELLA 15 - DESCRIZIONE DEI COMPONENTI DELL'INTERFACCIA PER LA GESTIONE MANUALE DEI MATCH ... 87
TABELLA 16 - PARAMETRI PER IL CALCOLO DELL'ADDIZIONALE IRPEF ... 90
TABELLA 17 - PARAMETRI PER IL CALCOLO DELL'IMU ... 91
TABELLA 18 - DESCRIZIONE DELLE SIMULAZIONI IMPLEMENTATE ... 92
TABELLA 19 - DESCRIZIONE DELLE TABELLE RELATIVE AL MODELLO PREVISIONALE ... 94
TABELLA 20 - DESCRIZIONE DEGLI SCENARI SIMULATI CON I RISPETTIVI GETTITI TOTALI RICAVATI ... 97
Introduzione
7
Introduzione
Negli ultimi anni, il problema dell’evasione fiscale è stato fortemente discusso sul territorio nazionale. I dati del 2012 mostrano come l’Italia sia il Paese con il mag-giore tasso di evasione in Europa, nonché tra i più alti dell’area OCSE. A risentire di questo problema non è solo lo Stato ma anche le amministrazioni comunali, alle quali spettano parte degli incassi ricavati dalla tassazione. Inoltre, la recente crisi economica e le conseguenti politiche di austerità adottate dal Governo hanno fat-to sentire il loro peso sui bilanci dei Comuni, che si trovano ad avere sempre meno risorse da destinare alle loro attività. In questo difficile scenario economico la ne-cessità di combattere efficacemente l’evasione fiscale è diventata più che mai im-portante. Grazie all’evoluzione tecnologica, questa problematica può essere oggi affrontata anche dal punto di vista informatico: incrociando le informazioni me-morizzate negli archivi digitali di vari enti è infatti possibile individuare compor-tamenti o situazioni che testimoniano un’evasione fiscale. In questa direzione si è già mossa l’Agenzia delle Entrate con la recente messa in opera di Serpico (“Servi-zio per i contribuenti”), un applicativo in grado di incrociare una moltitudine di da-ti per scovare gli evasori. Anche a livello locale cominciano a nascere iniziada-tive vol-te a combatvol-tere l’evasione fiscale. E’ in questo convol-testo che si è concretizzato il progetto su cui si focalizza questa tesi, denominato DyNamiTE (Digital fightiNg Tax Evasion) e svolto dall’Università di Bologna in collaborazione con il Comune di Ce-sena.
L’obiettivo principale di questo progetto è quello di sviluppare uno strumento informatico che consenta di individuare situazioni di sospetta evasione fiscale nel territorio di Cesena, con particolare attenzione alla casistica degli affitti in nero. Il primo passo necessario sarà quello di analizzare le banche dati e integrarle in un
8
unico schema. Successivamente bisognerà studiare i dati a disposizione per defini-re e implementadefini-re le tecniche di ricerca degli evasori; allo staff dell’Ufficio Tributi del Comune verrà inoltre richiesto un supporto nella verifica dei risultati e nella validazione delle tecniche implementate. Al fine di rendere disponibile lo stru-mento realizzato al personale del Comune sarà infine necessario lo sviluppo di un’interfaccia web, che permetta di consultare agevolmente i dati integrati e di applicare le tecniche di ricerca degli evasori.
La realizzazione di un nucleo informativo che racchiude e integra le informa-zioni di banche dati diverse non è necessariamente confinata alla lotta all’evasione fiscale, ma può essere sfruttata in diversi contesti. Un esempio ri-guarda la possibilità di eseguire analisi di tipo previsionale (what-if) in funzione di determinati scenari. Un ultimo obiettivo del progetto è quindi quello di concretiz-zare queste analisi e dimostrare il potenziale informativo della banca dati integra-ta.
L’esposizione del lavoro svolto in questa tesi viene suddivisa in quattro capitoli. Nel primo viene approfondita la problematica da affrontare e vengono descritte la struttura del progetto e le banche dati a disposizione. Nel secondo capitolo viene fornita una panoramica delle principali tecnologie utilizzate per la realizzazione del progetto. Nel terzo si entra invece nel vivo del progetto, con la documentazio-ne di tutte le attività svolte per lo sviluppo del back-end del sistema, costituito dalla banca dati riconciliata. Infine, il quarto e ultimo capitolo si focalizza sulla par-te di front-end: essa comprende l’implementazione dei patpar-tern di evasione, lo svi-luppo dell’interfaccia web e la realizzazione di un modello previsionale focalizzato sull’equità fiscale.
1. Il Sistema Informativo del Comune di Cesena
9
1 Il Sistema Informativo
del Comune di Cesena
La ricerca degli evasori fiscali parte dall’analisi complessiva del sistema informati-vo del Comune di Cesena; in primo luogo è necessario approfondire la problema-tica da affrontare, per capire qual è la situazione di partenza e da dove nasce la lotta digitale all’evasione. Successivamente si entra nel merito del progetto de-scrivendo tutte le attività previste, dalla costruzione dello schema riconciliato agli utilizzi che di esso si vuole fare. Un ultimo paragrafo viene infine dedicato alle sin-gole banche dati, con lo scopo di fornire una panoramica generale dei dati impie-gati nel corso del progetto.
1.1 La problematica
Il sistema informativo del Comune di Cesena dispone di una serie di banche dati, gestite internamente o importate da enti terzi, che spaziano su diverse aree di in-teresse. Sebbene queste banche dati siano fisicamente memorizzate nello stesso sistema informativo, i relativi schemi risultano sconnessi tra loro, indipendenti; in questo modo, i dati contenuti in schemi diversi - oltre a non essere consultabili contemporaneamente - non hanno alcun legame con i dati degli altri schemi. Teo-ricamente parlando, è però naturale che le varie banche dati presentino delle aree di sovrapposizione, dei concetti comuni in cui compaiono pressoché le stesse in-formazioni. Ad esempio, la banca dati dell’anagrafe e quella del catasto trovano un punto di intersezione nei soggetti memorizzati: l’elenco dei residenti e l’elenco dei titolari catastali, seppur presentino differenze dal punto di vista sintattico, condividono in gran parte gli stessi soggetti (i titolari degli immobili risiedono
mol-10
to spesso nello stesso comune in cui si trovano i rispettivi immobili). Se si unisco-no i due elenchi, le informazioni anagrafiche e catastali di ogni persona diventaunisco-no anch’esse unite tra loro e si stabilisce un vero e proprio legame tra le due banche dati.
La possibilità di integrare i dati di banche dati diverse fornisce due importanti vantaggi. Il primo riguarda la velocità delle operazioni di consultazione. Quando gli schemi sono integrati tra loro, la navigazione delle informazioni di banche dati di-verse diventa semplice e immediata; ad esempio, per conoscere l’indirizzo di resi-denza di un titolare catastale serve al massimo qualche secondo. Il secondo van-taggio riguarda invece il notevole potere informativo acquisito. All’interno delle singole banche dati, le informazioni sono limitate a un ruolo principalmente ope-rativo, di basso livello (registrazione e semplice consultazione di eventi o di pro-prietà). Quando invece si prendono tutte insieme, queste stesse informazioni ac-quisiscono un ruolo più strategico: esse diventano infatti parte di complessi profili, permettendo di disegnare storie o scenari da interpretare. Ad esempio, il titolare catastale può diventare un single di mezza età che, dopo la morte del padre, ha affittato la casa ereditata a una coppia di ragazzi stranieri, e così via. L’estrazione e l’interpretazione di queste storie può così essere sfruttata per individuare situa-zioni strane o apparentemente incongrue; un esempio volutamente banale consi-ste in una titolarità catastale valida per una persona che risulta deceduta. Le in-congruità nelle situazioni rilevate possono essere dovute a errori manuali o a se-gnalazioni tardive - come sarebbe probabile nell’esempio precedente. In altri casi, tuttavia, le incongruenze potrebbero essere reali e volontarie, ad indicare una possibile circostanza fraudolenta.
E’ in questo contesto che prende forma la lotta digitale all’evasione fiscale: essa ha infatti l’obiettivo di sfruttare l’unione dei dati per individuare le suddette circostanze fraudolente, in particolare quelle in cui emergono sufficienti dati per supporre che un determinato soggetto abbia perseguito un’evasione fiscale.
1. Il Sistema Informativo del Comune di Cesena
11
1.2 La struttura del progetto
In questo paragrafo si vuole delineare l’impostazione generale del progetto, dalla costruzione dello schema riconciliato agli utilizzi che di esso si vuole fare. Lo svol-gimento complessivo del progetto viene infine riassunto brevemente nell’ultimo paragrafo.
1.2.1 L’integrazione delle banche dati
Come anticipato nel paragrafo precedente, la maggior parte delle banche dati di cui dispone il Comune di Cesena gode di una propria indipendenza rispetto alle altre. Si tratta cioè di banche dati non integrate, separate tra loro e memorizzate in schemi diversi. Ad esempio, i dati gestiti e controllati dall’anagrafe comunale fanno riferimento a uno schema che non ha nulla a che vedere con quello del ca-tasto, nonostante esistano delle naturali sovrapposizioni nelle informazioni gesti-te.
La mancanza di integrazione delle banche dati comporta due problemi fonda-mentali. Il primo consiste nell’impossibilità di interrogare contemporaneamente banche dati diverse; in questo caso, la soluzione è piuttosto semplice: l’importazione di tutte le informazioni in un unico schema basterebbe per rendere i dati completamente disponibili. Tuttavia, il secondo problema risulta quello più complicato: assunto il fatto che nelle diverse banche dati siano presenti dei con-cetti comuni tra loro (come i soggetti, gli indirizzi, ecc.), l’indipendenza dei relativi schemi fa sì che tra tali concetti non ci sia alcuna relazione. Si riprenda l’esempio delle persone fisiche, per cui i soggetti che possiedono almeno una proprietà ca-tastale nel Comune di Cesena siano spesso residenti nello stesso Comune. Da que-sta relazione si intuisce come l’elenco dei titolari cataque-stali sia composto perlopiù da soggetti già presenti in anagrafe, ma la mancanza di integrazione degli schemi fa sì che le stesse informazioni risultino scollegate e ripetute sia nella banca dati dell’anagrafe che in quella del catasto.
Se quindi si riunissero tutte le informazioni dalle varie fonti in un unico sche-ma, mancherebbero comunque le relazioni tra i concetti comuni delle rispettive banche dati. Di conseguenza, non solo le informazioni risulterebbero duplicate, ma le stesse ripetizioni potrebbero risultare incongruenti tra loro: in assenza
vin-12
coli, elementi teoricamente identici tra loro (una stessa persona, o uno stesso in-dirizzo) possono essere espressi in maniera più o meno diversa nelle varie banche dati. Un indirizzo può essere scritto secondo formalismi diversi, o un errore ma-nuale può causare la memorizzazione di dati leggermente diversi per un soggetto, come una data di nascita diversa o - ancora peggio - un cognome diverso. La pre-senza di questo di tipo di differenze fa sì che l’individuazione delle associazioni tra le informazioni sia complicata: se si considerassero i soli match perfetti, una fetta rilevante delle associazioni reali andrebbe persa.
Per ovviare a questo tipo di problema si rende necessario l’utilizzo di tecniche di join approssimato, le quali permettono di riconoscere i collegamenti anche in assenza di corrispondenze perfette. Date due tabelle che esprimono un concetto comune, ogni record dell’una viene confrontata con i record dell’altra, calcolando una misura di distanza su uno o più campi; terminati i confronti, a ogni record del-la prima tabeldel-la viene associato il record dell’altra tabeldel-la con cui del-la distanza risul-ta minima. I risulrisul-tati di tutti le associazioni vengono quindi memorizzati in apposi-te strutture, detapposi-te tabelle di match. In questo modo si riescono a creare le con-nessioni tra i concetti comuni di schemi diversi, concretizzando l’integrazione del-le diverse banche dati e dando vita a un unico schema riconciliato su cui poter ef-fettuare le indagini richieste.
1.2.2 L’obiettivo principale: la ricerca degli evasori
Terminata l’integrazione delle banche dati a disposizione, lo schema riconciliato può essere sfruttato per attuare la lotta digitale all’evasione fiscale. L’attività prin-cipale consiste quindi nel definire i cosiddetti pattern di evasione, ossia i percorsi di navigazione dello schema riconciliato che, attraverso la selezione di dati con specifiche caratteristiche, restituiscano un elenco di situazioni sospette - ordinate, ove possibile, con un grado di sospetto decrescente.
In termini generali, l’evasione fiscale può spaziare su diversi settori, per cui è necessario stabilire innanzitutto su quale tipo di frode puntare. In seguito ad un’analisi delle banche dati a disposizione e a una valutazione delle attività di lotta all’evasione già portate avanti dall’Agenzia delle Entrate, si è deciso di
concentrar-1. Il Sistema Informativo del Comune di Cesena
13 si principalmente sulla lotta agli affitti in nero - senza comunque escludere la pos-sibilità di estendere la ricerca ad altri tipi di evasione.
Per la definizione di un pattern di evasione esistono fondamentalmente due ti-pi di approcci: il primo consiste nel definire i criteri titi-pici dello scenario legale e individuare i casi in cui questi criteri non sono rispettati. Un esempio semplificato potrebbe prevedere la rilevazione di un sospetto nei casi in cui un residente abiti in un appartamento non di sua proprietà (né di proprietà di un parente) e non sia registrato un contratto d’affitto tra il residente stesso e il proprietario dell’appartamento. Si tratta di casi teoricamente semplici da individuare, ma che richiedono un ottimo livello di qualità dei dati, in cui tutte le situazioni legali siano correttamente individuabili e in cui non ci siano problemi di dati mancanti. Un se-condo approccio consiste invece nel mettersi nei panni dell’evasore, capire quali siano gli escamotage tipicamente adottati per nascondere un affitto in nero e de-finire i criteri con cui tali situazioni possono essere rilevate nei dati a disposizione. Un esempio riguarda le false separazioni: due coniugi dichiarano residenze sepa-rate (due prime case), quando invece convivono in una di esse e sfruttano la se-conda casa per gli affitti. Si tratta di casi più complessi, in cui la difficoltà principale consiste nel definire in maniera corretta ed esaustiva il profilo dell’evasore, senza rischiare di includere situazioni con caratteristiche simili ma legalmente valide.
In entrambi i casi, è bene sottolineare come questo tipo di indagini non siano in grado di rilevare le irregolarità con certezza assoluta, ma permettano solamen-te di sollevare dei sospetti: possono essere svariati i motivi a giustificazione di si-tuazioni anomale, primo tra tutti l’errore umano nell’inserimento dei dati. Al fine di massimizzare le probabilità di correttezza al sollevamento di un sospetto, è im-portante che tali ricerche siano il più precise possibile. Tuttavia, ogni situazione di potenziale evasione rilevata deve essere manualmente controllata e validata, sia per verificare la correttezza del pattern utilizzato, sia per escludere eventuali falsi positivi. Solo al termine di questi controlli, i nominativi selezionati possono essere effettivamente segnalati alle autorità competenti per gli accertamenti - ed even-tualmente le sanzioni - del caso.
14
1.2.3 Gli utilizzi alternativi dello schema riconciliato
La ricerca degli evasori fiscali costituisce l’obiettivo principale di questo progetto, ma lo schema riconciliato dispone di potenzialità che vanno oltre questa singola attività; con i dovuti accorgimenti è possibile sfruttare in maniera alternativa lo schema riconciliato, in supporto a progetti già esistenti o programmati dal Comu-ne di Cesena, oppure individuando funzionalità completamente nuove. Per co-minciare, il Comune di Cesena ha in programma lo sviluppo del “Fascicolo del
cit-tadino”, ovvero uno strumento che riassuma tutte le informazioni sui residenti e
che metta a disposizione tali informazioni ai dipendenti comunali. In tale contesto, la banca dati integrata di questo progetto si inserirebbe molto facilmente, costi-tuendo essa stessa una buona parte del lavoro richiesto. Un esempio di nuova funzionalità lo si può invece trovare nella possibile applicazione di tecniche di data
mining. La vastità di informazioni messa insieme nello schema riconciliato può
es-sere sfruttata per ricercare caratteristiche comuni tra i cittadini; si potrebbe quin-di cercare quin-di raggruppare la popolazione in gruppi (detti cluster) in cui si possano evidenziare caratteristiche o comportamenti condivisi.
Per dimostrare le potenzialità della banca dati integrata, una parte del proget-to è stata dedicata allo sviluppo di una funzionalità alternativa alla lotta digitale all’evasione fiscale. La scelta è ricaduta nell’utilizzo della banca dati in senso pre-dittivo piuttosto che conoscitivo: ciò che si vuole fare è implementare un mecca-nismo in grado di simulare degli scenari futuri a partire dai dati attuali, per estrar-re informazioni che possano esseestrar-re di supporto al Comune nella scelta di politiche future. In particolare, le simulazioni si incentrano sul calcolo del carico fiscale dei residenti in termini di IMU e di addizionale IRPEF: modificando i parametri su cui il Comune ha facoltà di scelta, si vuole determinare il gettito totale previsto della tassazione e l’impatto che queste modifiche hanno sulle famiglie, opportunamen-te suddivise in caopportunamen-tegorie. L’obiettivo ultimo è quello di effettuare valutazioni sull’equità fiscale tra le tipologie di famiglie e di capire come le modifiche ai pa-rametri delle tasse possa far variare - ed eventualmente migliorare - il grado di equità. Di questo meccanismo previsionale verrà soltanto realizzato un prototipo dimostrativo, una proof-of-concept (POC): non si vuole implementare una vera e
1. Il Sistema Informativo del Comune di Cesena
15 propria funzionalità, quanto semplicemente dare dimostrazione concreta delle potenzialità della banca dati integrata.
1.2.4 Le fasi del progetto
La realizzazione del progetto DyNamITE si può essenzialmente suddividere in quattro fasi. La prima fase riguarda l’integrazione delle banche dati in un unico schema riconciliato. Si comincia quindi con la scelta dei dati da prelevare dalle sorgenti e con la progettazione dell’architettura dello schema, che deve poi essere popolato con una serie di operazioni ETL (Extraction, Transformation and Loa-ding). Successivamente vengono realizzati i join approssimati per agganciare le va-rie parti dello schema: si individuano i concetti comuni che richiedono il join ap-prossimato, si determinano le regole di match e si implementano le procedure.
Terminata l’integrazione dello schema, la seconda fase prevede l’implementazione dei pattern di evasione. Viene quindi studiato lo schema per capire quali percorsi possono essere perseguiti, dopodiché si eseguono dei test per valutare la bontà degli stessi. Per determinare la correttezza dei risultati, è ri-chiesto al personale dell’Ufficio Tributi del Comune di effettuare un riscontro ma-nuale, sulla base del quale validare il pattern o modificarne i parametri di ricerca.
Una terza fase prevede invece la realizzazione di un’interfaccia grafica da met-tere a disposizione dei dipendenti comunali. Le funzionalità dell’interfaccia consi-stono principalmente nella libera navigazione dello schema integrato, nell’esecuzione dei pattern validati nella fase precedente e nella possibilità di con-fermare manualmente i match approssimati determinati nella fase di integrazio-ne.
Nella quarta e ultima fase viene infine realizzato il POC sull’equità fiscale: viene quindi progettato il meccanismo previsionale e si implementano le procedure per il calcolo dei carichi e fiscali, dopodiché vengono simulati alcuni scenari su cui ese-guire una serie di analisi.
16
1.3 Le banche dati
In questo paragrafo vengono fornite informazioni generali sulle banche dati utiliz-zate e integrate in questo progetto, come la qualità dei dati e gli utilizzi previsti. Le banche dati vengono raggruppate in base alle rispettive fonti di provenienza.
1.3.1 Comune di Cesena
La principale fonte è ovviamente costituita dallo stesso Comune di Cesena, il quale detiene le banche dati primarie su cui basare la costruzione dello schema riconci-liato. La banca dati più importante viene sicuramente individuata nell’anagrafe, in cui sono contenute tutte le informazioni anagrafiche sui residenti a partire dal 1999 in poi. Importanti informazioni legate ai dati anagrafici sono anche gli indiriz-zi di residenza e i rapporti di parentela tra le persone. Qualitativamente parlando, i dati dell’Anagrafe godono di un buon livello; sono rari gli errori manuali e si pos-sono trovare alcune incongruenze tra le date di immigrazione/emigrazione, ma si tratta di una banca dati complessivamente affidabile. Per questo motivo, i dati anagrafici possono essere considerati come il fulcro dello schema riconciliato: le operazioni di integrazione delle altre banche dati considereranno sempre i dati anagrafici come il riferimento su cui basare le operazioni di match.
L’altra banca dati fondamentale è costituita dalla toponomastica, in cui è defi-nito il cosiddetto stradario: ogni via del Comune di Cesena viene definita con il suo toponimo ufficiale e associata ad un codice unico e ad un DUG (Denominativo Ur-banistico Geografico). Inoltre, la toponomastica specifica l’elenco di tutte le abita-zioni in termini di civico, civico-bis, interno e interno-bis. Nonostante il suo contri-buto informativo sia limitato, questa banca dati ha una grossa importanza nel de-finire ufficialmente e univocamente i toponimi delle strade, i quali vengono spes-so scritti secondo i più variegati formalismi. Il ruolo della toponomastica è quindi quello di rappresentare il punto di riferimento su cui basare i match sugli indirizzi stradali. L’unica banca dati che non ha bisogno di questa operazione è quella dell’anagrafe, in cui gli indirizzi di residenza sono già conformi alla codifica topo-nomastica.
1. Il Sistema Informativo del Comune di Cesena
17
1.3.2 Agenzia delle Entrate
Nella costruzione del database integrato, l’Agenzia delle Entrate ricopre un ruolo fondamentale in quanto fornitrice di un’ampia gamma di banche dati. La prima ad essere considerata in questo progetto è quella del catasto, di cui il Comune di Ce-sena dispone già da diverso tempo e che viene scaricata mensilmente dall’Agenzia del Territorio (oggi incorporata nell’Agenzia delle Entrate). In questa banca dati sono memorizzate tutte informazioni storicizzate sugli immobili posizionati all’interno dei confini comunali. Oltre ai dettagli sui singoli immobili (come la ca-tegoria di appartenenza e la superficie), essa specifica tutte le informazioni sulle titolarità catastali (come le quote e la durata del possesso) e sulle persone deten-trici di titolarità (sia fisiche che giuridiche). Inoltre, ad ogni immobile sono associa-te le coordinaassocia-te catastali e gli indirizzi stradali. Il ruolo di questa banca dati è di grande importanza per la lotta digitale all’evasione fiscale: i collegamenti con l’anagrafe per determinare proprietari e residenti di un dato immobile sono spes-so fondamentali. Purtroppo, i dati in essa contenuti spes-soffrono di uno scarspes-so livello qualitativo su diversi punti. Innanzitutto, le informazioni sui titolari catastali con-tengono spesso errori e uno stesso titolare può comparire più volte con alcuni dati leggermente diversi. Inoltre, le quote di possesso delle titolarità catastali non so-no spesso specificate e la somma delle stesse so-non corrisponde sempre al 100%. Le note più dolenti riguardano tuttavia gli indirizzi: innanzitutto, i toponimi delle strade sono scritti senza usare alcun formalismo, per cui i riscontri con la topono-mastica risultano difficili. In secondo luogo, non è prevista la memorizzazione dei civici interni degli immobili; questa grave mancanza fa sì che conoscere i residenti in un determinato appartamento risulta molto difficile, talvolta addirittura impos-sibile.
La seconda banca dati ricevuta è quella relativa alle utenze dei consumi, ossia le bollette di acqua, luce e gas, lei cui informazioni vengono inviate all’Agenzia del-le Entrate dai vari gestori deldel-le utenze (Enel, Hera, Edison, ecc.) e conglobate per tipologia di utenza (elettricità, acqua e gas). Richiesti dal Comune di Cesena speci-ficamente per questo progetto, i suddetti dati risultano già inseriti nel sistema in-formativo e parzialmente integrati, almeno per quanto concerne la riconciliazione tra gli intestatari delle utenze e i residenti anagrafici. Sebbene le utenze ricevute
18
siano relative solamente all’anno 2010, tali informazioni solo importanti per la possibilità di ricavare una stima del numero di occupanti effettivi rispetto ai resi-denti (o affittuari) dichiarati. Purtroppo, i dati ricevuti non risultano completi: le informazioni sugli intestatari delle utenze, i tipi di utenza ed i consumi fatturati sono qualitativamente buoni, ma - come per le titolarità catastali - l’indirizzo sui cui è attiva l’utenza risulta privo del civico interno. L’associazione di un’utenza ad un appartamento risulta pertanto possibile nei soli casi in cui l’intestatario dell’utenza risieda nello stesso stabile.
Un contributo importante arriva inoltre dai dati sulle dichiarazioni dei redditi, anch’essi già inseriti nel sistema informativo del Comune e relativi agli anni 2006, 2008, 2009 e 2010. Informazioni utili includono il reddito totale, il reddito da fab-bricati e il reddito imponibile. Tuttavia, si tratta di dichiarazioni solamente riassun-tive: i redditi sono espressi solo come totali, senza il livello di dettaglio che il sito dell’Agenzia delle Entrate offre per le ricerche puntuali da parte degli operatori comunali. Tali dettagli includono, ad esempio, le specifiche del reddito da fabbri-cati per ogni immobile: tipologia dell’immobile, rendita catastale, uso dell’immobile ed eventuale reddito da locazione. Queste informazioni sarebbero particolarmente utili, nonché in grado di sopperire alle mancanze del registro dei contratti d’affitto. Per questo motivo, il Comune ha sottoposto all’Agenzia delle Entrate la richiesta di ricevere i dati completi (come accade già per i maggiori Co-muni d’Italia); tuttavia, ad oggi tale richiesta non è stata ancora soddisfatta. Le di-chiarazioni riassuntive restano comunque valide ed utilizzabili; da esse è possibile sapere quale sia la ricchezza complessiva di una famiglia, oppure confrontare il reddito totale da fabbricati di una persona con la rendita catastale delle sue pro-prietà per effettuare dei controlli di congruenza.
L’ultima banca dati ricevuta dall’Agenzia delle Entrate è quella relativa ai
con-tratti d’affitto, contenente l’elenco dei concon-tratti depositati nell’ufficio di Cesena
(relativamente agli anno 2009 e 2010), insieme alle informazioni sui rispettivi lo-catari, affittuari ed immobili coinvolti. Diversamente dalle altre, questa banca dati non era ancora stata inserita nel sistema informativo del Comune, perciò le in-formazioni sono disponibili solamente nei tracciati testuali scaricati dall’Agenzia delle Entrate. L’apporto informativo dei contratti d’affitto nella lotta all’evasione
1. Il Sistema Informativo del Comune di Cesena
19 fiscale è sicuramente notevole, essendo quest’ultima principalmente focalizzata nel combattere gli affitti in nero. Tuttavia, si rilevano una serie di problemi che li-mitano fortemente l’utilizzo di questi dati. Innanzitutto, ai tre quarti dei contratti non è associato alcun immobile, per cui l’espressività di tali contratti si riduce di molto. Inoltre, i contratti possono essere consegnati in un qualunque Comune, che può non essere quello in cui si trova l’immobile; ne risulta che, dei contratti “sopravvissuti” al passo precedente, la metà di questi riguarda immobili che non si trovano a Cesena. Ipotizzando che le stesse percentuali si presentino negli altri comuni, si può simmetricamente stimare che la metà dei contratti relativi ad im-mobili di Cesena vengano depositati in comuni diversi. La somma di questi due fattori fa sì che i dati effettivamente utili siano solo una minima parte; di conse-guenza, i contratti d’affitto non possono essere usati per individuare attivamente delle evasioni (come veniva inizialmente ipotizzato), quanto solo per escludere eventuali falsi positivi.
1.3.4 ISTAT
In seguito al 21° censimento nazionale, avvenuto il 9 ottobre 2011, l’istituto na-zionale di statistica ha inviato ai Comuni d’Italia i tracciati dei dati raccolti; in par-ticolare, le persone censite sono state suddivise in 3 categorie: “residenti censiti”, “residenti non censiti” e “censiti non residenti”. Per la lotta all’evasione fiscale, la categoria dei “censiti non residenti” è stata valutata interessante: essa contiene infatti le persone (con i rispettivi domicili) che hanno dichiarato di abitare a Cese-na ma che non risultano residenti nel comune stesso - ossia potenziali affittuari su cui effettuare delle verifiche. Tuttavia, così come nel catasto e nelle utenze, gli in-dirizzi di residenza risultano senza interni e non conformi ai toponimi ufficiali; gli stessi problemi e le stesse operazioni di bonifica risultano necessarie anche in questa situazione.
2. Le tecnologie
21
2 Le tecnologie
La realizzazione del prototipo DyNamiTE ha richiesto l’adozione di diverse tecno-logie nelle varie fasi del progetto:
• Uno strumento ETL in grado di popolare lo schema integrato impor-tando i dati dalle varie sorgenti.
• Un RDBMS per ospitare la banca dati integrata.
• Un’interfaccia che consenta agli operatori comunali di usufruire delle funzionalità sviluppate.
I paragrafi seguenti descrivono in maniera dettagliata le caratteristiche e gli utilizzi di ciascuna tecnologia adottata.
2.1 Pentaho Data Integration
Pentaho Data Integration (PDI, conosciuto anche come Kettle) è un’applicazione client desktop dedicata precisamente all’integrazione dei dati, ossia all’esecuzione di operazioni ETL (Extraction, Transformation and Loading) [PEN13]. Realizzata dalla Pentaho Corporation, PDI fa parte di una suite di prodotti di Business Intelli-gence open-source chiamata Pentaho Business Analytics, la quale fornisce anche servizi OLAP, strumenti di reportistica e di data mining. I moduli della suite sono sviluppati in Java e sono disponibili per i tre principali sistemi operativi; inoltre, seppur integrati tra loro, i moduli della suite possono essere installati separata-mente, a seconda delle proprie necessità.
La versione utilizzata di PDI è la 4.2.0 (Community Edition), ovvero l’ultima di-sponibile al momento dell’installazione. L’impiego di questo software è stato
fon-22
damentale per la creazione della banca dati riconciliata; grazie a PDI è infatti pos-sibile eseguire le seguenti operazioni.
• Estrazione di dati da qualunque fonte (o sorgente): è possibile impor-tare tabelle da qualunque RDBMS (MySQL, Oracle, MS Access, ecc.) o leggere dati da fonti di altri tipi (come fogli Excel o tracciati testuali). Data l’eterogeneità delle banche dati che devono essere integrate, la possibilità di importare dati da diverse tipologie di sorgenti è sicura-mente importante.
• Trasformazione dei dati importati: una volta caricati, è possibile ese-guire sui dati una vasta serie di operazioni; esse possono spaziare dai classici operatori SQL (join, raggruppamenti, eliminazione di duplicati) all’esecuzione di codice procedurale scritto dall’utente. Queste opera-zioni permettono di selezionare i dati che devono essere portati sulla banca dati riconciliata e operare su di essi una serie di bonifiche.
• Caricamento dei dati: il passo conclusivo consiste nell’inserire (o ag-giornare) i dati in una banca dati di destinazione. Come per la lettura dei dati, anche la scrittura può avvenire sulle stesse tipologie di conte-nitori (tabelle, fogli Excel o file di testo). Nel nostro caso, le scritture avvengono esclusivamente sulla banca dati riconciliata in MySQL. L’interfaccia grafica di PDI (denominata Spoon) consente di organizzare le ope-razioni sopraelencate in procedure ETL, chiamate Trasformazioni ed espresse at-traverso dei grafici. Ogni tipologia di operazione è rappresentata da un’icona; tra-scinandola nell’area del grafico, essa può essere poi opportunamente configurata. Il flusso dei dati da un’operazione all’altra viene invece rappresentato da frecce direzionate, che collegano le varie icone posizionate.
2. Le tecnologie
23 Figura 1 - Un esempio di Trasformazione PDI implementata
Le Trasformazioni costruite possono essere salvate ed eseguite in qualunque mo-mento. Inoltre, due o più Trasformazioni possono essere collegate tra loro ed ese-guite in sequenza; tale costrutto viene definito come Job. Sebbene i Job non siano mai stati utilizzati nel progetto, il loro impiego potrebbe essere valutato nell’ottica di automatizzazione delle procedure di costruzione e aggiornamento della banca dati integrata.
2.2 MySQL
MySQL è un RDBMS (Relational DataBase Management System) open source, svi-luppato da Oracle Corporation e distribuito dalla stessa sotto licenza GPL (GNU General Public Licence). MySQL spicca per essere oggi l’RDBMS open source più diffuso al mondo [ORA13a], nonché adottato da famosi prodotti di calibro inter-nazionale quali Wikipedia, Google, Facebook e tanti altri [WIK13a]. Tra i motivi del successo di questo software va citata la sua ampia portabilità: essendo scritto in C e C++, MySQL è utilizzabile su tutti i sistemi operativi che dispongano di un compi-latore C++ [ORA13b]. Inoltre, MySQL è un componente fondamentale degli
am-24
piamente diffusi pacchetti software di tipo AMP (Apache, MySQL e PHP/Perl/Pyton), utilizzati per lo sviluppo di applicazioni web e disponibili per tutti i principali sistemi operativi (LAMP per Linux, WAMP per Windows, ecc.). Nel pro-getto DyNamiTE, MySQL - installato alla versione 5.5 Community Edition - è stato utilizzato per ospitare, manipolare ed interrogare la banca dati riconciliata. Cia-scuna di queste operazioni ha richiesto l’utilizzo della GUI (Graphic User Interface) ufficiale, denominata MySQL Workbench e solitamente integrata nell’installazione. Tale interfaccia si suddivide in 3 pannelli principali.
• SQL Development. Questo è il pannello principale di MySQL:
selezio-nando una delle connessioni disponibili (per collegarsi all’istanza server locale o ad un’istanza remota) si ha accesso ai database memorizzati sull’istanza selezionata. SQL Development è fondamentalmente dedi-cato all’esecuzione di codice SQL, sia attraverso la scrittura manuale del codice nelle schermate di editing, sia attraverso l’utilizzo di apposi-te maschere (le quali generano il codice corrispondenapposi-te in automati-co). L’utilizzo di questo pannello è stato intensivo fin dalle prime fasi del progetto. Durante l’integrazione delle banche dati è stato utilizzato per la creazione dei vincoli referenziali nello schema riconciliato, per la bonifica di alcuni dati e per l’esecuzione dei join approssimati. Nelle fa-si succesfa-sive è stato invece principalmente impiegato per l’esecuzione delle complesse interrogazioni elaborate (dai pattern di evasione al calcolo del carico fiscale) e per la definizione di statistiche sui dati a di-sposizione.
• Data Modeling. Il pannello di Data Modeling è un’interfaccia grafica
che mette a disposizione dell’utente le funzionalità di
forward-engineering e reverse-forward-engineering. La prima consiste nel definire i
mo-delli delle tabelle richieste e demandare ad una procedura automatica la creazione dello schema del database a partire dai modelli preceden-temente definiti. La seconda - al contrario - prevede di creare il model-lo model-logico di un database esistente. La funzionalità di back-engineering è stata l’unica utilizzata, con lo scopo di creare automaticamente lo schema ER del database.
2. Le tecnologie
25
• Server Administration. MySQL memorizza le banche dati su appositi
database server, detti anche istanze server, in modo che questi
possa-no essere acceduti anche da remoto. Il pannello Server Administration permette di gestire le suddette istanze: le operazioni più comuni sono la gestione degli utenti e dei rispettivi permessi, la modifica dei para-metri di configurazione del server e il controllo del file di log. In questo progetto, la presenza contemporanea di due sviluppatori (vedi para-grafo 3.1) ha richiesto di creare un’istanza server nella macchina di uno sviluppatore e di predisporre sull’altra un’istanza client che si collegas-se al collegas-server. Al termine della facollegas-se di co-sviluppo, la macchina ospitante il client è stata dismessa ed è rimasto operativo soltanto il server.
2.3 PHP e il framework interno
PHP è un linguaggio di scripting server-side e open-source, utilizzato principal-mente nello sviluppo web per la creazione di pagine dinamiche e di applicazioni web. Creato da Rasmus Lerdorf come semplice strumento di supporto alla sua homepage personale, PHP è oggi portato avanti dal PHP Group ed è il software open-source più utilizzato dalle aziende, nonché impiegato sul 75% dei siti web in cui il linguaggio server-side adottato viene specificato [W3T13a]. Insieme a MySQL, PHP costituisce un’importante componente nei pacchetti di tipo AMP (vedi paragrafo precedente) ed è anch’esso utilizzato da prodotti di fama interna-zionale, quali Wikipedia e Facebook. Sebbene esistano diversi editor per la scrittu-ra di codice PHP (quali Aptana, PHPEclipse o Netbeans, tutti gscrittu-ratuiti), si è deciso di utilizzare il classico Notepad++, soprattutto per la sua semplicità di utilizzo. PHP è stato utilizzato nel progetto per lo sviluppo dell’applicazione web da mettere a di-sposizione dei dipendenti comunali. In particolare, l’impiego di PHP riguarda le necessità di interagire con il database, di presentare a video i risultati delle inter-rogazioni e di mantenere in sessione alcune informazioni utili per l’utente.
La scelta di PHP rispetto a soluzioni alternative (come, ad esempio, JSP) è stata dettata dalla possibilità di utilizzare un framework sviluppato internamente ai Si-stemi Informativi del Comune e già utilizzato per la realizzazione di diversi applica-tivi ad uso interno. Tale framework utilizza PHP nella versione 5.2 e mette a
dispo-26
sizione una serie di funzionalità che semplificano e velocizzano lo sviluppo di un’applicazione web.
• Controllo centralizzato ed automatico degli accessi: il framework im-plementa un pannello amministrativo che consente di gestire i per-messi di accesso per ogni utente alle varie applicazioni del Sistema In-formativo. Grazie a questa gestione centralizzata, nella homepage di ogni utente vengono direttamente forniti i link alle applicazioni a cui egli ha accesso. Inoltre, il meccanismo di autenticazione degli utenti ri-sulta uniformato e viene automaticamente incluso nelle applicazioni all’atto della loro creazione.
• Standardizzazione degli accessi al database: oltre ad utilizzare lo stan-dard ODBC per garantire la connettività i più comuni DBMS, i risultati delle interrogazioni vengono automaticamente formattati in un array multidimensionale o in una tabella HTML personalizzabile.
• Layout predefinito: a tutti i componenti principali delle pagine HTML viene impostato un layout di base, in modo da uniformare il
look-and-feel delle applicazioni create.
Per utilizzare il framework in un’applicazione non sono richieste complicate configurazioni, ma risulta sufficiente includere alcuni file PHP nelle pagine dell’applicativo.
2.4 Javascript
Javascript è un linguaggio di scripting client-side, anch’esso utilizzato nello svilup-po web per la gestione dell’interazione dell’utente con la pagina e la modifica di-namica dei contenuti della pagina. Sviluppato dalla Netscape Communications Corporation e dalla Mozilla Foundation, Javascript ha conosciuto un largo succes-so con la diffusione delle tecniche AJAX (Asynchronous JavaScript and XML), le quali prevedono la comunicazione asincrona di dati tra client e server [MDN13]. L’utilizzo di Javascript si è oggi esteso anche al mondo non-web: diverse applica-zioni (quali Adobe Reader, Adobe Photoshop o la suite OpenOffice) consentono
2. Le tecnologie
27 infatti l’inserimento di script personalizzati grazie all’inclusione di un interprete Javascript.
Come PHP, anche Javascript è stato utilizzato per lo sviluppo dell’applicazione web, anche se con un ruolo di minore importanza. Il suo impiego è stato infatti mirato alla gestione delle comunicazioni asincrone (a rendere più piacevole la na-vigazione dell’utente) e per alcune semplici animazioni nei componenti delle pagi-ne. A supporto di quest’ultima necessità si è deciso di fare affidamento a JQuery, ovvero la libreria Javascript ad oggi maggiormente diffusa [W3T13b]. Open-source e già integrata nel framework interno, JQuery semplifica infatti l’esecuzione di co-dice Javascript, dal recupero di elementi del DOM all’applicazione di una vasta gamma di effetti grafici [TJF13].
3. Il progetto DyNamiTE: il back-end
29
3 Il progetto DyNamiTE:
il back-end
La prima parte del progetto è stata dedicata allo sviluppo del “cuore” del sistema, ossia la banca data riconciliata, attraverso l’integrazione delle banche dati d’origine. La prima parte del capitolo riassume le attività che sono state svolte nei progetti precedenti; una descrizione approfondita del loro lavoro è consultabile nei documenti di Tesi degli studenti che vi hanno preso parte [PAV12] [SOR12]. La seconda parte del capitolo è dedicata ai match approssimati, un’attività preceden-temente iniziata e conclusa insieme al mio contribuito. La terza e ultima parte, in-centrata sull’estensione del database riconciliato, è stata invece interamente svol-ta in autonomia dal sottoscritto.
3.1 Sintesi dei progetti precedenti
I progetti precedenti si sono concentrati principalmente sulla selezione, integra-zione e bonifica delle prime banche dati. Per la creaintegra-zione del database riconciliato (denominato “evasione”), la scelta delle fonti iniziali da cui estrarre i dati è ricadu-ta su quelle gestite dal Comune (anagrafe e toponomastica) e alcune di quelle fornite dall’Agenzia delle Entrate (catasto e utenze dei consumi). Tutte e quattro sono reperibili dal Sistema Informativo del Comune, il quale utilizza una piatta-forma Oracle per la memorizzazione dei dati.
Per ciascuna banca dati vengono forniti di seguito i dettagli sulla qualità dei dati, sulle informazioni effettivamente importate e sulle eventuali operazioni compiute su di essi.
30
3.1.1 Anagrafe
I dati anagrafici dei residenti del Comune di Cesena costituiscono il punto di par-tenza per la costruzione del database riconciliato, in quanto contengono informa-zioni qualitativamente buone su tutti i soggetti di interesse. In particolare, le in-formazioni importate sono le seguenti:
• Elenco dei residenti e dei relativi dati anagrafici. Si tratta di dati non storicizzati, perciò le informazioni specificate per un residente corri-spondono a quelle attuali e non c’è traccia delle eventuali precedenti modifiche.
• Gli indirizzi di residenza dei residenti. Sebbene esista uno storico com-pleto degli indirizzi di residenza (i quali sono maggiormente soggetti a variazioni rispetto ai dati anagrafici), i dati importati esprimono sola-mente la fotografia delle residenze al 31 dicembre 2010. Inoltre, gli in-dirizzi sono espressi secondo il formalismo della toponomastica, anche se manca il vincolo referenziale con gli indirizzi toponomastici.
Come detto più volte, i dati anagrafici dei residenti sono tra i migliori dal punto di vista qualitativo; per questo motivo, tali dati sono stati importati in maniera “grezza”, ossia senza apportare alcuna modifica. L’unica bonifica effettuata ha avuto luogo sugli indirizzi di residenza (per implementare il vincolo referenziale con gli indirizzi toponomastici), ma è stata applicata solo dopo l’introduzione degli indirizzi di residenza storicizzati (vedi paragrafo 3.3.1).
3.1.2 Toponomastica
Il compito fondamentale dei dati toponomastici è quello di rappresentare il punto di riferimento per la definizione dei toponimi ufficiali delle strade, ossia delle ri-spettive nomenclature corrette e univoche. Le informazioni importate corrispon-dono alle seguenti:
• Elenco e decodifica dei Denominatori Urbanistici Generici (DUG): ad esempio “VLE” per “viale”, “CSO” per “corso”, ecc.
• Elenco di tutte le strade del Comune di Cesena, con rispettivi toponimi e DUG.
3. Il progetto DyNamiTE: il back-end
31
• Elenco di tutti i possibili indirizzi, con le specifiche numerazioni civiche esterne ed interne in ogni strada del Comune.
Qualitativamente ottimi, i dati toponomastici sono stati importati senza essere minimamente modificati.
3.1.3 Catasto
Il catasto contiene informazioni di vario tipo riguardanti gli immobili siti nel Co-mune di Cesena: dalle semplici caratteristiche degli immobili, alle quote delle tilarità di possesso e alle coordinate catastali. A differenza dell’anagrafe e della to-ponomastica, le informazioni sono generalmente più complesse, per cui la loro comprensione può non essere immediata. Per questo motivo, la spiegazione dei dati importati viene trattata con maggior approfondimento.
• Elenco di tutte le Unità Immobiliari Urbanistiche (UIU) del territorio di Cesena e delle rispettive caratteristiche. Si tratta degli elementi di rife-rimento su cui si fonda il database del catasto e comprendono tutti i tipi di immobile: residenziali e commerciali, magazzini, capannoni e fabbricati in costruzione. Dal momento che le caratteristiche delle UIU possono essere soggette a diversi cambiamenti (aumento del numero di vani, rivalutazione della rendita catastale, ecc.), esse sono necessa-riamente storicizzate. Va inoltre citato il fatto che i terreni sono me-morizzati in una struttura a parte; esulando però dallo scope principale del progetto, si è deciso di non importarli e di mantenere le sole UIU.
• Elenco non storicizzato di tutti i titolari catastali. Così come per la di-stinzione UIU/terreni, anche la didi-stinzione tra persone fisiche e giuridi-che è materializzata nel database del catasto con l’utilizzo di due strut-ture separate. In maniera analoga, si è deciso di importare i soli dati delle persone fisiche, sulle quali si prevede di concentrare le analisi.
• Elenco storicizzato delle titolarità catastali, le quali associano i titolari (fisici e giuridici) alle proprietà (UIU e terreni) specificando la quota, la durata e la tipologia del possesso. Diversamente rispetto ai titolari e al-le proprietà, al-le titolarità sono memorizzate indistintamente in un’unica struttura e, in fase di importazione, si è deciso di mantenerle tutte: ad
32
esempio, può essere interessante sapere che un immobile è posseduto per metà da una persona fisica e per metà da una giuridica, oppure che una determinata persona possieda anche un certo numero di terreni.
• Elenco degli indirizzi in cui si trovano le UIU; tali indirizzi non sono as-sociati direttamente alle UIU ma alle rispettive versioni storiche. Il mo-tivo di questa particolarità risiede nel fatto che un immobile può subire un cambio di indirizzo: ad esempio, ad un appartamento situato all’angolo in un incrocio può essere spostato l’ingresso da una strada all’altra.
• Elenco delle coordinate catastali delle UIU; sebbene anch’esse siano associate alle singole versioni degli immobili, in fase di importazione si è deciso di associarle direttamente alle UIU. Il motivo risiede nel fatto che i cambiamenti di coordinate catastali sono molto meno frequenti; pertanto, per ogni immobile si è deciso di impostare come unicamente valida la coordinata catastale più recente.
Dal punto di vista qualitativo, i dati catastali presentano una serie di problemi che devono essere necessariamente trattati. In primo luogo, gli indirizzi degli im-mobili sono scritti secondo i più variegati formalismi, rispettando solo in pochi casi i toponimi ufficialmente dichiarati in toponomastica. Parallelamente, i dati dei ti-tolari presentano spesso degli errori di ortografia o di duplicazione di stesse per-sone. Questi problemi sono stato affrontati con l’applicazione delle tecniche di join approssimato (vedi paragrafo 3.3). In secondo luogo, l’assenza della numera-zione civica interna negli indirizzi limita notevolmente l’integranumera-zione della banca dati riconciliata, impedendo di associare con sicurezza un indirizzo di residenza ad un immobile. Per questo problema non esiste purtroppo una soluzione informati-ca o algoritmiinformati-ca: l’uniinformati-ca possibilità consiste in una bonifiinformati-ca manuale dei dati con l’aggiunta delle informazioni mancanti.
Un ultimo problema è quello della somma delle quote di possesso di un immo-bile (in determinati momenti o fasce temporali), la quale risulta spesso incongrua: può infatti capitare che essa sia diversa dal 100% (fenomeno causato il più delle volte dall’assenza delle quote di possesso nelle titolarità) o che non sia rispettata l’esatta corrispondenza tra le quote di nuda proprietà e quelle di usufrutto. In
3. Il progetto DyNamiTE: il back-end
33 questi casi, si è deciso di introdurre dei flag che indichino quando le due condizio-ni non sono rispettate, in modo da sapere se le quote di possesso di un determi-nato immobile siano o meno affidabili.
3.1.4 Utenze dei consumi
Provenienti dalle banche dati dei vari gestori sul territorio di Cesena, le utenze contengono informazioni sui consumi di elettricità, acqua e gas relativamente all’anno 2010. Memorizzate in tabelle separate a seconda del consumo, le infor-mazioni contenute risultano pressoché identiche: intestatario dell’utenza, consu-mo fatturato, importo dovuto e indirizzo dell’abitazione. Al consu-momento dell’importazione dei dati, l’integrazione tra gli intestatari delle utenze ed i resi-denti anagrafici era già stata implementata; rimane comunque necessaria l’integrazione tra gli indirizzi nelle utenze e gli indirizzi toponomastici, per la quale si rimanda al paragrafo 3.2.2. Tuttavia, similmente agli indirizzi catastali, anche gli indirizzi delle utenze risultano privi della numerazione civica interna, impedendo anche in questo caso la possibilità di associare un’utenza ad un indirizzo di resi-denza nel caso esistano più civici interni.
3.1.5 Schema dati
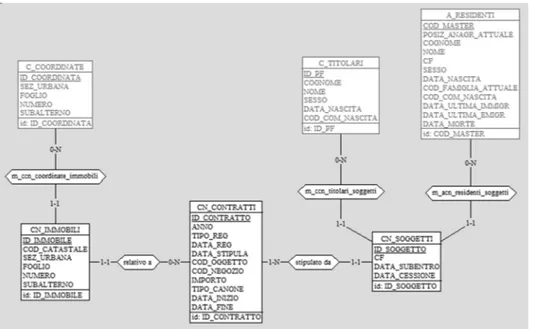
Al termine dei progetti precedenti, lo schema dati del database riconciliato era quello indicato in Figura 2. Nel modello logico sono riportate anche le tabelle di match (corrispondenti alle tabelle su sfondo bianco), di cui si parla nel paragrafo 3.2. Inoltre, per motivi di spazio, sono state omesse le tabelle che contengono so-lamente le decodifiche degli acronimi e delle sigle utilizzate in altre tabelle. Infine è necessario sottolineare che nello schema riconciliato è stata originariamente adottata la dicitura “enel” per contraddistinguere le utenze relative ai consumi di energia elettrica; sebbene i gestori delle utenze siano in verità diversi, tale dicitura è stata mantenuta negli sviluppi di questo progetto per mantenere l’uniformità dei formalismi utilizzati.
34
Figura 2 - Architettura iniziale del database riconciliato
3.2 Match approssimati
L’integrazione dei dati provenienti da banche dati diverse non si raggiunge con la semplice importazione delle informazioni in un unico database: un’operazione di fondamentale importanza consiste nell’applicazione delle tecniche di join appros-simato, grazie alle quali risulta possibile eseguire i collegamenti tra i concetti co-muni presenti. In questo progetto, sono due i concetti condivisi dalla maggior par-te delle banche dati e su cui è richiesta l’applicazione di quespar-te par-tecniche: le perso-ne fisiche e gli indirizzi.
Il problema di base consiste nell’individuare le associazioni tra i record di due tabelle i cui elementi sono concettualmente identici; ad esempio, la tabella dei ti-tolari catastali e quella dei residenti contengono entrambe persone fisiche, le qua-li risultano spesso ripetute sia nell’una che nell’altra tabella. L’individuazione delle associazioni è resa difficile dal fatto che, nelle diverse tabelle, una stessa persona può essere espressa in maniera diversa: che sia per un errore ortografico o per una comunicazione sbagliata, i valori dei campi nelle due tabelle potrebbero esse-re diversi; in questi casi, l’utilizzo dell’operatoesse-re di uguaglianza per il confronto dei
3. Il progetto DyNamiTE: il back-end
35 record non sarebbe in grado di effettuare il collegamento. Per risolvere questo problema è necessario fare affidamento a specifici algoritmi che permettano di riconoscere la similarità di due record attraverso l’utilizzo di misure di distanza (o di similarità).
Il meccanismo di join approssimato basa il confronto tra i record delle due ta-belle su una serie di regole progressive, le quali specificano diversi livelli di tolle-ranza sulla distanza tra i due record. La progressività delle regole indica una de-crescente rigidità: se i risultati del confronto rientrano nei parametri di una regola, l’associazione viene riconosciuta e memorizzata; in caso contrario si passa alla gola successiva, i cui parametri avranno una maggiore tolleranza. Terminate le re-gole, l’associazione viene naturalmente scartata. L’utilizzo di regole progressive permette inoltre di associare ai match individuati un diverso grado di certezza: minore è il numero della regola, maggiore è la sicurezza che il join individuato sia corretto. Tipicamente, la prima regola individua i match perfetti, per i quali è ri-chiesta una completa uguaglianza su tutti i campi. Le regole successive individua-no invece i match approssimati, per i quali vengoindividua-no indicati i valori massimi accet-tati nelle distanze tra i campi.
Per misurare la differenza tra campi numerici o booleani, il calcolo della distan-za è semplice: si considera una distandistan-za 0 se i valori sono uguali, 1 se sono diversi. Nel caso di confronti tra campi alfanumerici, invece, si è deciso di adottare la di-stanza di Levenshtein, nota anche come didi-stanza di edit [WIK13b]: date due strin-ghe a e b, la distanza è uguale a dove:
Figura 3 - Formula matematica della distanza di Levenshtein tra due stringhe In altre parole, la distanza si calcola come il numero di operazioni elementari necessarie per trasformare la stringa a in b; per “operazione elementare” si inten-de l’aggiunta o la rimozione di un carattere, oppure la sostituzione di un carattere con un altro). Una volta calcolata, la distanza di Levenshtein viene poi normalizza-ta, ovvero viene rapportata alla lunghezza della prima stringa, in modo che la
di-36
stanza rientri in un valore compreso tra 0 (uguaglianza) e 1 (massima disugua-glianza).
Il calcolo della distanza si complica se si considerano stringhe composte da una sequenza di parole. In questi casi, il mero confronto tra le due stringhe potrebbe dare risultati fuorvianti: ad esempio, se la stringa b contiene tutte le parole di a in ordine inverso, la distanza di Levenshtein risulterebbe molto alta nonostante l’errore sia sul solo ordinamento delle parole. Il meccanismo di confronto viene quindi maggiormente elaborato per evitare il suddetto problema. Dalle due strin-ghe vengono innanzitutto estratte le singole parole, separate tra loro dal carattere “ “ (spazio); questa operazione viene definita tokenizzazione, dove ad ogni parola estratta corrisponde un token. Successivamente, ogni token della stringa a viene associato al token della stringa b con cui la distanza è minima. La distanza totale viene quindi determinata come la somma pesata delle distanze tra i singoli token. Infine, lo stesso procedimento viene ripetuto invertendo le due stringhe e si de-termina la media delle due distanze calcolate.
L’implementazione degli algoritmi fin qui descritti non può essere frutto di pu-re query SQL, bensì è richiesto l’utilizzo di un linguaggio quantomeno procedurale. Tra le varie opzioni disponibili si è deciso di sfruttare il linguaggio C#, il cui compi-latore è integrato nel framework .NET, disponibile con Windows 7 e utilizzabile gratuitamente. Gli algoritmi di match approssimato sono stati pertanto imple-mentati in appositi programmi C# e compilati da linea di comando, in modo da creare un file eseguibile lanciabile in qualunque momento.
Un’ultima osservazione riguarda la memorizzazione dei match: tutti gli agganci riconosciuti devono infatti essere salvati in apposite tabelle, in modo da materia-lizzare e concretizzare l’integrazione dei due schemi di partenza. Seppur con qual-che differenza in base alle singole implementazioni, le tabelle di match presenta-no tutte la stessa struttura.
• Chiave primaria, composta dall’identificativo del record proveniente dalla prima tabella e dall’identificativo del record proveniente dalla se-conda tabella.
3. Il progetto DyNamiTE: il back-end
37
• Numero progressiva della regola che ha determinato l’aggancio tra i due record; si considerano le regole ordinate per importanza decre-scente, con la numero 1 ad indicare un match perfetto.
• Campo di validazione, ad indicare se l’associazione tra i due record è da considerarsi valida (1) o meno (0); valori tra 0 e 1 vengono usati nei casi in cui non ci siano elementi sufficienti per capire quale sia il match valido, ma tali elementi siano sufficienti a restringere la scelta tra due o più possibilità.
Le tabelle di match concretizzano quindi una relazione molti-a-molti tra i due concetti, in cui ogni record specifica la distanza e la validità tra ogni coppia di ele-menti.
3.2.1 Match tra residenti e titolari
Il primo concetto comune individuato nello schema riconciliato è quello delle per-sone, memorizzate in anagrafe come residenti e in catasto come titolari. Dato il contesto, è ragionevole pensare che la maggior parte dei titolari di proprietà sul suolo cesenate siano residenti nello stesso comune; per questo motivo si è deciso di realizzare il match approssimato tra le due entità. Trattandosi di concetti simili, è logico che i campi delle rispettive tabelle siano anch’essi condivisi: nome, co-gnome, codice fiscale, sesso, data di nascita e codice del comune di nascita sono infatti presenti in entrambe le strutture, pertanto sono questi i campi di riferimen-to utilizzariferimen-to.
Prima di procedere con l’implementazione del match è necessario capire quale sia la relazione tra le due entità. Da una parte si trova l’elenco dei residenti, il qua-le risulta qualitativamente buono e con pochi (e trascurabili) errori nei singoli re-cord. Dall’altra parte, l’elenco dei titolari catastali presenta diversi problemi: oltre ai singoli errori di ortografia, può capitare che una stessa persona sia elencata più volte ma con dati leggermente diversi (il cognome scritto diversamente, la data di nascita errata, ecc.). Questo significa che per ogni persona in anagrafe potrebbero corrispondere uno o più titolari (o anche nessuno); al contrario, per ogni persona in catasto può corrispondere al massimo un unico residente. Per questo motivo, si
38
decide di impostare il match approssimato partendo dai titolari catastali e cercan-do, per ciascuno di essi, quale sia il migliore (ed unico) aggancio tra i residenti.
Per eseguire il confronto tra i record dei residenti e quelli dei titolari è necessa-rio specificare il modo in cui deve essere calcolata la similarità tra i vari campi.
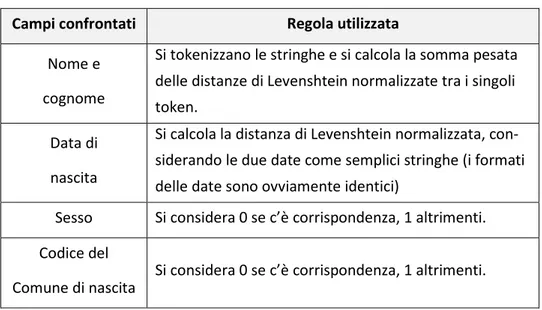
Tabella 1 - Calcolo della similarità tra i campi dei residenti e dei titolari
Campi confrontati Regola utilizzata
Nome e cognome
Si tokenizzano le stringhe e si calcola la somma pesata delle distanze di Levenshtein normalizzate tra i singoli token.
Data di nascita
Si calcola la distanza di Levenshtein normalizzata, con-siderando le due date come semplici stringhe (i formati delle date sono ovviamente identici)
Sesso Si considera 0 se c’è corrispondenza, 1 altrimenti. Codice del
Comune di nascita
Si considera 0 se c’è corrispondenza, 1 altrimenti.
In secondo luogo vengono definite le regole progressive per l’accettazione del-le associazioni individuate:
Tabella 2 - Regole progressive per i match tra residenti e titolari
Regola Descrizione
Regola 1
Match perfetti (uguaglianza su tutti i campi). Si è deciso di considerare perfetti anche i match in cui c'è corrispondenza sul solo codice fiscale (in quanto esso riassume i valori di tut-ti gli altri campi).
Regola 2 La distanza sul nome deve essere minore o uguale a 0.2 e le due data di nascita non devono essere nulle.
Regola 3
La distanza del nome deve essere minore o uguale a 0.3, le due data di nascita non devono essere nulle e deve esserci corrispondenza sul sesso e sul codice del comune di nascita. La regola 1 è stata implementata con una semplice query SQL; le associazioni individuate vengono inserite nella tabella di match col campo di validazione già impostato a 1. Le regole 2 e 3 sono state invece implementate con uno script C#,