Capitolo 1: Modelli in biologia e medicina
1.1
INTRODUZIONE: COS’E’ UN MODELLO?
Dare una definizione esauriente e semplice del concetto di modello è difficile in quanto, spesso, a questo termine sono attribuiti significati diversi.
In generale, un modello è uno schema elaborato in molte discipline per rappresentare gli elementi fondamentali di fenomeni o enti e descrivere quindi quanto osservato. E’ la rappresentazione matematica semplificata di un sistema. In un modello molte caratteristiche sono importanti, ma non tutte sono incluse nel modello. Appartengono ad esso solo quelle caratteristiche che giocano un ruolo essenziale nell’interpretazione del fenomeno osservato.
Molto noti sono i modelli in scala ridotta, che riproducono qualitativamente un sistema pur riducendone proporzionalmente la dimensione.
Soffermandoci sui modelli teorici, questi sono distinti in:
- modelli descrittivi o statici
:
riproducono con eventuali semplificazioni la realtà, sintetizzando in un meccanismo o in un algoritmo i dati osservati relativi ad un fenomeno senza presupporre l’uso che ne sarà fatto e quindi senza tentare di spiegare il meccanismo su cui il fenomeno osservato è basato;- modelli interpretativi : cercano di spiegare il comportamento di un fenomeno e la sua evoluzione formulando ipotesi ricorrendo a leggi generali; quindi vengono ipotizzate le strutture interne che giustifichino il comportamento esterno e le conseguenza logiche di tali ipotesi;
- modelli predittivi : si propongono di prevedere l'andamento futuro di un fenomeno, almeno entro un dato orizzonte temporale, lasciando spazio ad eventuali scelte.
1.2
MODELLI MATEMATICI
Tra tutti i tipi di modelli predittivi, utili nello sviluppo della conoscenza scientifica, un ruolo fondamentale, sia per quanto riguarda la crescita delle capacità esplicative e del potere previsionale dei fenomeni oggetto della ricerca scientifica, che per lo sviluppo delle applicazioni tecnologiche della scienza contemporanea, spetta sicuramente alla famiglia dei modelli simbolici o matematici, che danno una rappresentazione astratta della realtà cui si riferiscono, mediante un insieme di equazioni e/o disequazioni che legano le grandezze coinvolte.
I modelli matematici costituiscono quindi un sottoinsieme proprio dei modelli teorici, caratterizzato dal fatto che le proprietà e le relazioni di una teoria sono espresse nel linguaggio, e seguendo la logica, della matematica.
Ciò equivale a dire che, mentre ci sono molte teorie che non si possono tradurre in modelli matematici, al contrario tutti i modelli matematici sono anche, o meglio prima, modelli teorici. È questa la ragione del processo accelerato di matematizzazione della scienza che, a partire dalla fisica, ha interessato la chimica, la biologia pura e le varie biologie applicate, ma anche le cosiddette scienze umane, dalla logica alla sociologia, dall’economia alla scienze dell’informazione. L’economista matematico E. Malinvaud nel libro Méthodes statistiques de l'économetrie (Parigi, 1964) dà la seguente definizione:
“Un modello matematico è la rappresentazione formale di idee o conoscenze relative ad un fenomeno”.
Questa definizione contiene una descrizione completa delle caratteristiche di un modello matematico, che possono essere raccolte in tre punti fondamentali, non separabili l'uno dall'altro. Precisamente:
a) un modello matematico è la rappresentazione di un fenomeno. Non si tratta però di una semplice descrizione verbale, ma di una descrizione che mette in luce determinati aspetti caratteristici di un fenomeno in termini formali: è la logica del processo che viene analizzata;
b) tale rappresentazione non è discorsiva o a parole, ma formale, ossia espressa in linguaggio matematico, il linguaggio formale e astratto per eccellenza;
c) non esiste una via diretta dalla realtà alla matematica. In altri termini il fenomeno specifico studiato non determina la “sua” rappresentazione matematica; ciò che invece si fa è di tradurre in formule idee e conoscenze relative al fenomeno.
Perché Malinvaud dice che un modello matematico è la rappresentazione formale di “idee o conoscenze relative a un fenomeno” e non dice semplicemente che è la rappresentazione formale di un fenomeno?
L'esame di un aspetto della realtà non suggerisce in alcun modo come esso debba essere descritto matematicamente, ossia non esiste una “via diretta” che porta dalla realtà alla “sua” descrizione matematica, in modo univoco. E questo per tante ragioni.
In primo luogo perché la realtà è costituita da un intrico talmente complesso e inestricabile di fenomeni, da impedire una descrizione relativamente semplice e schematica qual è quella matematica. Una descrizione della realtà perfettamente aderente a essa sarebbe non soltanto impossibile, perché troppo complicata, ma anche inutile: il contrario esatto della rappresentazione formale cui aspiriamo.
Per descrivere un fenomeno dobbiamo quindi fare delle scelte, selezionarne degli aspetti e questa scelta richiede di mettere in campo le nostre idee.
Le idee che entrano in gioco sono in primo luogo relative a cosa si vuole descrivere.
Nello scegliere questo aspetto da descrivere, nell'isolarlo dai tanti altri che compongono l'intreccio in cui ci si presenta il fenomeno, dobbiamo procedere in modo corretto senza considerare come secondari aspetti che sono invece fondamentali per l'oggetto che ci proponiamo di studiare o viceversa. Infatti il primo passo nello sviluppo di un modello è sempre un processo di astrazione, tramite il quale alcune proprietà e relazioni di un settore della realtà vengono isolate come fondamentali mentre altri aspetti sono giudicati inessenziali, almeno riguardo al contesto prescelto, e conseguentemente trascurati dal modello. Ma non è sufficiente fare in modo corretto questa operazione di isolamento. Infatti, il fenomeno non contiene la legge, come una scatola contiene un oggetto, e il nostro compito non può ridursi quindi allo sforzo di aprire la scatola per scoprirne il contenuto.
La conoscenza non inizia dal vedere bensì dal guardare: interviene qui in modo decisivo l'osservazione empirica e l'esperimento per formarci un'idea e costruire un'ipotesi circa la legge che dovrebbe governare il processo in esame. Quel che noi facciamo quindi è mettere insieme tutte le conoscenze empiriche e le idee che ci siamo fatti del fenomeno, per costruirne una rappresentazione matematica, che si tradurrà per lo più in formule o equazioni di vario tipo.
Abbiamo così ottenuto un modello matematico del processo reale in oggetto.
Migliorare un modello significa renderlo sempre più simile alla realtà ma, d’altra parte, come osservato in precedenza, se un modello si complica oltre un certo limite, perde la sua capacità esplicativa ed ogni funzione conoscitiva. Questa proprietà è all’origine di una sorta di contraddizione intrinseca nell’utilizzazione dei modelli, che possiamo indicare come il paradosso
della modellizzazione. Se è vero infatti che un modello è, nel senso che deve essere, diverso dalla
realtà, è però altrettanto vero, ovviamente, che un modello è tanto più valido quanto più numerosi sono gli elementi della sua struttura che sono invece aderenti alla realtà modellizzata.
Il paradosso dei modelli ha una conseguenza fondamentale, che riguarda il contenuto di verità dei modelli stessi. La proprietà sopra ricordata, per cui un modello è sempre per alcuni aspetti simile ma, per altri aspetti, diverso dalla realtà a cui si riferisce, mostra, per un verso, che il medesimo settore della realtà può essere modellizzato in una infinità di modi diversi a seconda delle proprietà e delle relazioni che, di volta in volta, si astraggono dalla realtà; ma, per l’altro, forza anche alla conclusione, certamente non facile da accettare, che un modello non può essere valutato in base ad un criterio di verità, cioè di una sua corrispondenza o perfetta sovrapponibilità alla realtà modellizzata.
Questo modo di procedere non è però sufficiente a garantire la validità del modello e cioè la sua adeguatezza a descrivere il fenomeno studiato e a prevedere certi effetti, visto che tutte le idee e le conoscenze che noi abbiamo utilizzato per costruirlo possono aver introdotto delle discrepanze dalla realtà più o meno accettabili. È indispensabile allora la fase di verifica del modello. Per verificare il modello occorrerà dedurre dalla sua struttura matematica la previsione che esso fornisce circa il comportamento del fenomeno; poi confrontare queste previsioni con i dati reali, sia che si tratti di dati statistici, sia che si tratti di un esperimento eseguito appositamente per verificare la bontà del modello.
1.3
MODELLI MATEMATICI IN BIOLOGIA : UN PO’ DI STORIA
I primi esempi di applicazione del metodo quantitativo alla biologia risalgono al Seicento quando si cominciarono a stilare le tavole di mortalità e si tentò di trarre alcune considerazioni di tipo statistico. Ma la prima volta che i matematici entrarono in campo su una questione “molto umana” fu nel Settecento, in occasione dell'inoculazione del vaccino del vaiolo. Come è noto, l'inoculazione del siero attivo provoca una leggera forma della stessa malattia. Rispetto all'opportunità o meno di operare una tale scelta, si crearono presto due fronti opposti. I sostenitori del vaccino si dichiaravano favorevoli al progresso della scienza al di là dei rischi che questo poteva comportare, mentre i contrari sostenevano che inoculare il vaccino rappresentava un'azione contro natura.
Nel 1760 il matematico svizzero Daniel Bernoulli cercò di dimostrare matematicamente che la vaccinazione era necessaria, calcolando i vantaggi (in termini di vite salvate) dell'essere inoculati rispetto alla probabilità di morire nel caso non si venisse inoculati.
Dunque l'inoculazione andava fatta per il bene dell'umanità e per l'interesse dello Stato.
Uno dei primi a sollevare obiezioni fu Jean d'Alembert che dedicò a questo argomento addirittura quattro Memorie. D'Alembert sosteneva che i fenomeni umani sono troppo variabili per essere ridotti a formule ed equazioni. Si aggiunga che i calcoli fatti da Bernoulli erano per lo più di carattere statistico e probabilistico e, a quel tempo, queste due discipline non avevano ancora raggiunto lo status di "scienze matematiche".
Ma per avere dei modelli deterministici (anziché probabilistici alla Beronoulli) bisogna aspettare
Thomas Malthus e Pierre François Verhulst, il primo, economista e pastore anglicano e il secondo
considerato uno dei fondatori della moderna statistica. Entrambi si occuparono di dinamica delle popolazioni (all'epoca, Malthus e Verhulst ragionavano in termini di popolazioni umane), che sarebbe diventato in seguito uno dei più importanti campi di applicazione della matematica alla biologia.
Il primo arrivò a determinare nel 1798 la famosa legge che da lui prese il nome, ma che in seguito si rivelò poco realistica, e questo portò Verhulst nel 1845 a trovare un nuovo più sofisticato modello oggi noto come applicazione logistica.
A parte gli studi di tipo statistico, questi furono gli unici due modelli matematici applicati alla biologia di tutto il diciannovesimo secolo. Sarà il matematico Vito Volterra, all'inizio del ventesimo secolo, a spingere perché la biologia accettasse al suo interno l'uso di strumenti di tipo quantitativo. Già nel 1900, in occasione dell'inaugurazione dell'anno accademico dell'Università di Roma, aveva esordito con una conferenza dal titolo Sui tentativi di applicazione delle matematiche alle scienze
biologiche e sociali, ma solo nel 1925 entrò nel vivo della questione creando un modello
A partire dagli anni '20, la matematizzazione dei fenomeni non fisici e in particolare di quelli biologici subisce un'improvvisa accelerata e nuovi campi di ricerca (come la dinamica delle popolazioni, lo studio dei sistemi dinamici, la teoria dei giochi, etc.) diventano discipline autonome. Ma ancora una volta la biomatematica si distingue per una certa resistenza alle novità.
Il ventesimo secolo è, dal punto di vista scientifico, il secolo dei modelli. La scienza non vuole più spiegare e nemmeno interpretare, vuole risolvere dei problemi e creare delle teorie che si basino su modelli applicabili e predittivi che saranno giudicati per la loro efficacia.
Volterra, e in generale i biologi fra le due guerre, vorrebbero costruire una meccanica analitica dei fenomeni biologici e il loro punto di vista è strettamente sperimentalista.
La matematizzazione della biologia dovrebbe avvenire sulla falsariga della matematizzazione della fisica classica avvenuta nei secoli precedenti. Occorrerà aspettare la fine della seconda guerra mondiale perché l'approccio modellistico si faccia definitivamente strada in biologia, dando vita ad applicazioni che vanno dalle reazioni enzimatiche alle oscillazioni dei sistemi biochimici, dalla morfogenesi alle neuroscienze.
1.3.1 MODELLISTICA MATEMATICA
"Una disciplina ha tanto più la dignità della scienza quanto più fa uso dello strumento matematico", scriveva Galileo Galilei. In biologia trovare delle connessioni e dei legami di tipo matematico è certamente difficile, molto più difficile che in altre scienze come la fisica o l'astronomia, perché descrivere l'essere vivente è molto più complesso che definire la materia.
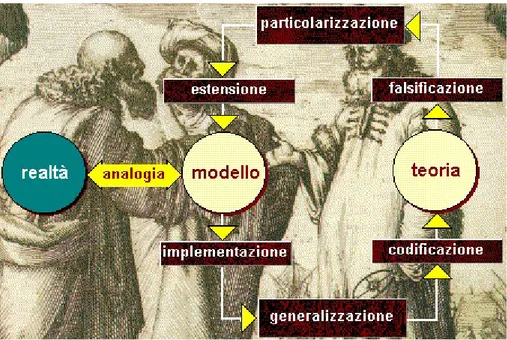
Col termine modellistica matematica si intende il processo che si sviluppa attraverso l'interpretazione di un problema originato dalle discipline fisiche, chimiche, biologiche, ingegneristiche, mediche, economiche, etc., la rappresentazione dello stesso problema mediante il linguaggio e/o le equazioni della matematica, l'analisi di tali equazioni, nonchè l'individuazione di metodi idonei ad approssimarle, ed infine, l'implementazione di tali metodi su calcolatore, dopo averli tradotti in opportuni algoritmi. Tutto ciò è schematizzato in figura 1.1.
Figura 1.1- Schema della modellistica matematica
I problemi matematici creati nell'ambito della modellistica non sempre sono risolubili per via analitica. I teoremi dell'analisi matematica e della geometria, se pur fondamentali per stabilire l'esistenza e l'unicità della soluzione, spesso non hanno natura costruttiva atta ad indicare un processo di rappresentazione esplicita della soluzione.
Spesso, perciò, è necessario sviluppare metodologie di approssimazione che conducono ad algoritmi tali da rendere possibile la risoluzione su calcolatore. È anche grazie all’uso di strumenti di calcolo elettronici e l’impiego di softwares capaci di fornire risposte adeguate in tempi brevi che si è sviluppata la modellizzazione matematica.
1.4
LA MATEMATICA IN MEDICINA
Un aspetto sempre più evidente in vari settori delle scienze biologiche è la crescente disponibilità di dati e di nuove sorgenti di dati ottenute dallo sviluppo scientifico e tecnologico. Le nuove tecniche di indagine e la necessità di organizzare e interpretare una quantità crescente di dati e di informazioni biologiche rappresentano un’opportunità notevole per il coinvolgimento della matematica, inclusi i metodi computazionali e statistici, nella ricerca biologica e biomedica e nella comprensione dei problemi medici (diagnostica, epidemiologia, medicina clinica,…).
I rapporti tra matematica e biologia hanno in realtà una lunga storia (storia a cui hanno partecipato, tra gli altri: G. Galilei, W. Harvey, R. Boyle, R. Hooke, L. Euler, T. Young, J. Poiseuille, H. von Helmholtz, D. Bernoulli, N. Wiener, J. Von Neumann, V. Volterra ...). Certamente questi rapporti non sono, per vari motivi, tuttora facili anche se lo sviluppo, l’analisi e la simulazione numerica di modelli matematici nell’ambito più generale delle scienze della vita si sta lentamente affermando come ulteriore strumento investigativo da affiancare ad altre metodologie sperimentali o teoriche. In un modello matematico il fenomeno reale che si vuole indagare viene rappresentato da quantità tipiche della matematica (funzioni, equazioni, …) che vengono poste in relazione tra di loro sulla base di ipotesi e nozioni note per il fenomeno.
Tra i vantaggi che un modello matematico in biologia o medicina dovrebbe avere possiamo ricordare:
- predire l’evoluzione di un sistema biologico in condizioni differenti senza rifare esperienze o in situazioni non verificabili sperimentalmente;
- convalidare quantitativamente ipotesi biologiche; - indagare proprietà di materiali biologici;
- suggerire esperimenti;
- evidenziare legami sottostanti tra vari enti biologici attraverso l'analisi dei dati sperimentali e di eventuali fenomeni soggiacenti.
Oltre a questo va ricordato l’apporto delle scienze matematiche allo sviluppo dei metodi di indagine, basti pensare ai metodi di ricostruzione e rappresentazione di immagini biomediche
per tecniche non invasive (per esempio la TAC, Tomografia Assiale Computerizzata, o la RM, Risonanza Magnetica). Difficile descrivere gli sbocchi occupazionali dei matematici in questi ambiti multidisciplinari in continua evoluzione e non ancora, potremmo dire, stabilizzati anche se nuove possibilità sembrano profilarsi.
1.4.1 SETTORI BIOMEDICI D’INTERESSE PER I MATEMATICI
Vediamo alcuni settori biomedici potenzialmente di interesse per i matematici. I settori citati nel breve elenco che segue possono comunque interagire tra di loro e non sono da considerare completamente separati tra di loro.
- Epidemiologia e ricerca clinica. Uno dei primi campi applicativi della matematica in ambito biomedico ha riguardato lo sviluppo e l’analisi di modelli per popolazioni. Un esempio notevole coinvolge il lavoro di R.A. Fisher all’inizio del ventesimo secolo che ha portato allo sviluppo sia delle basi teoriche della statistica matematica sia all’introduzione di strumenti quali l’analisi della varianza (ANOVA) o il progetto di esperimenti. Attualmente vi sono necessità riguardanti l’applicazione di tecniche dell’epidemiologia nella ricerca e nella pratica clinica, per esempio per impostare correttamente uno studio caso-controllo, per metanalisi, per la valutazione di interventi complessi o la pianificazione dei servizi. Modelli dinamici di epidemie fanno invece intervenire sistemi di equazioni differenziali o integro differenziali.
- “Scienze omiche”. L’analisi delle informazioni biologiche legate alla valutazione della diversità genetica e all’esecuzione del programma genetico ha portato allo sviluppo delle cosiddette scienze omiche (genomica, proteomica, farmacogenomica, metabolomica, …), tutte caratterizzate dalla necessità di elaborare una enorme quantità di dati per lo sviluppo di modelli interpretativi e statistici. Spesso sorge il problema di avere a disposizione pochi esperimenti a fronte di una grande quantità di variabili. La genomica, per esempio, si occupa della mappatura, del sequenziamento e dell’analisi dei genomi mentre la proteomica riguarda lo studio del corredo di proteine in una cellula, tessuto o un organismo. Le applicazioni sono molte e importanti, le competenze devono riguardare conoscenze di statistica, di informatica, tecniche di classificazione e cluster analysis, metodi di apprendimento automatico.
- Modellistica matematica. Una ulteriore illustrazione delle interazioni tra matematica e biologia riguarda la possibilità di costruire, validare e simulare opportuni modelli matematici con particolare riguardo ai modelli differenziali. Un esempio storico di grande successo in questo ambito è il modello di Hodgkin-Huxley che descrive la dinamica del potenziale d’azione che si propaga lungo una membrana cellulare. Questo modello è ormai generalmente utilizzato negli studi di elettrofisiologia cellulare. Lo sviluppo di un modello matematico segue un lungo cammino che vede l’analisi in vitro, lo sviluppo, l’identificazione del modello stesso, l’analisi dei dati, metodi numerici di simulazione, tecniche di programmazione e visualizzazione. La complessità dei fenomeni coinvolge spesso diverse scale spaziali e temporali rendendo difficile lo sviluppo di un modello appropriato. Questo avviene sia quando si analizza un sistema o sottosistema (per esempio parte dell'apparato cardiocircolatorio oppure un organo) sia quando si studia un ente apparentemente piu' semplice come una singola specie cellulare. Inoltre osserviamo che, oltre che allo studio di modelli di singoli enti (per esempio cellule) è ormai di interesse analizzare il comportamento di reti di oggetti che rappresentino le interazioni tra le singole componenti (esempi tipici sono le reti biochimiche o le reti neurali). Lo sviluppo di modelli interagisce con altri ambiti di interazione matematica/biologia soprattutto quando il tema di studio è particolarmente complesso e importante, basti citare, per esempio, la dinamica e la cura dei tumori.
- Analisi di segnali e immagini biomediche. Esistono diverse tecniche non invasive capaci di fornire immagini dell’interno del corpo umano (TAC, MRI, PET,…) o di fornire dati relativi al funzionamento di apparati od organi (elettrocardiogramma, ECG; elettroencefalogramma EEG, …). Questi segnali sono ampiamente utilizzati per diagnosi o valutazioni di funzionalità di apparati biologici.
I settori sopra indicati non esauriscono certamente le possibilità nell’ambito biomedico, occorre anche osservare che sono previsti nel prossimo futuro ulteriori sviluppi. Per esempio la rappresentazione e la visualizzazione di immagini biomediche potrà essere utilizzata all’interno di sistemi virtuali altamente interattivi e sistemi avanzati per la diagnosi, il trattamento e la pianificazione chirurgica. Inoltre bioimmagini differenti saranno integrate per avere una visione piu' approfondita e completa di patologie nella pratica clinica. Altro esempio riguarda i modelli matematici che stanno apportando contributi significativi allo sviluppo di protesi artificiali avanzate.
Sottolineiamo che un matematico dovrà necessariamente lavorare in un gruppo multidisciplinare con persone con competenze differenti. Questo comporta un problema di linguaggio che si deve
acquisire. Il matematico deve poter anche riuscire ad esemplificare eventuali approcci metodologici. Solitamente il problema centrale dell’attività in un tale gruppo di lavoro resta il particolare problema biologico o il particolare problema medico. È quindi importante che il matematico abbia la capacità di affrontare un problema concreto e abbia le conoscenze di base di carattere informatico e delle metodologie computazionali per metere in opera un proprio modello.
1.5
LA COMPLESSITA’
La realtà in cui siamo immersi è formata da molti sistemi complessi caratterizzati dalla convivenza di tanti fattori eterogenei che, con la loro interazione, creano dinamiche di vario tipo. Le relazioni presenti in questi sistemi, spesso sono caratterizzate da non linearità, per cui risulta molto difficile, se non impossibile, spiegare l’effetto finale partendo dalla conoscenza delle singole cause.
È fondamentale non confondere il termine “complesso” con “complicato”: ciò che è complesso non è scomponibile e deve essere considerato nella sua interezza essendo composto da una fitta rete di relazioni che si condizionano a vicenda; complicato invece è qualcosa che può essere scisso nelle sue parti essenziali e dalla somma di queste è possibile capire e prevedere ciò che si ottiene.
Negli ultimi anni lo studio della complessità si è sviluppato maggiormente anche grazie alla grossa spinta impressa dall’evoluzione tecnologica: le innovazioni hanno dato ai ricercatori strumenti più adeguati alla rappresentazione e alla comprensione di fenomeni complessi che interessano varie discipline tra cui anche l’economia.
Col passare del tempo la complessità è stata definita in diversi modi tra cui quella di Richard H. Day (1994) che definisce complesso “un sistema dinamico se da un punto di vista endogeno non tende asintoticamente ad un punto fisso, a un ciclo limitato o a un’esplosione.” Nella sua visione un fenomeno di questo tipo può avere comportamenti discontinui e può essere descritto da equazioni differenziali o equazioni alle differenze finite, possibilmente comprendendo anche elementi stocastici.
Barckley e Rosser (1999), argomentando su questa definizione, mettono in luce come sia difficile associare le parole di Day alla complessità riferita all’economia, in quanto in questo ambito l’interazione tra gli individui crea complicazioni non prevedibili e quindi difficilmente rappresentabili attraverso una metodologia puramente matematico-statistica.
Questo porta ad una visione completamente innovativa dello studio di molte discipline (dalla matematica, alla biologia, dalla medicina all’economia), che passano da quella classica, in cui per giungere a delle conclusioni è necessario fare determinate semplificazioni (sotto forma di ipotesi che allontanano dalla realtà ), ad una più innovativa che tende a modellizzare la realtà individuando regole base degli elementi costitutivi del modello. Questo secondo metodo di studio punta, attraverso l’interazione delle parti che compongono il modello, all’osservazione delle dinamiche che si creano e non alla loro comprensione puntuale. Se così fosse cadrebbe la definizione di complessità. Come accade nella realtà, a volte, si ottengono risultati inspiegabili dovuti all’incorporazione della componente non lineare di cui si è parlato prima.
1.5.1 SISTEMI COMPLESSI
Un sistema non è altro che un insieme di elementi che interagiscono per un unico scopo. Molti sistemi possono essere complicati, ma non necessariamente sono considerati complessi. Non c’è una definizione precisa di sistemi complessi; tuttavia molti autori sono d’accordo su una serie di proprietà che un sistema deve avere per essere considerato tale.
Tutti gli esempi di sistemi complessi esibiscono alcune caratteristiche comuni: - hanno una serie di agenti che interagiscono;
- esibiscono un comportamento emergente, ciò sta a significare un comportamento collettivo autorganizzativo difficile da prevedere dallla conoscenza del comportamento dell’agente;
- il loro comportamento emergente non ha un controllo centrale.
Chiariamo brevemente il concetto di ‘emergente’ per sapere i motivi per cui le caratteristiche e le propietà dei sistemi si possono ritenere ‘emergenti’.
Il concetto di emergenza, introdotto per la prima volta da C.L. Morgan nel libro Emergent
Evolution nel 1923, fu ritenuto per parecchi anni di pertinenza principalmente nel contesto della
biologia. In relazione al fatto che all’interno dell’evoluzione biologica è spesso possibile osservare l’apparire di alcune caratteristiche in modo discontinuo , imprevedibili sulla base di quelle precedentemente esistenti, l’attributo ‘emergente’ fu considerato sinonimo di ‘nuovo’, ‘imprevedibile’. Solo successivamente e in differenti contesti disciplinari, anche se principalmente in fisica, si realizzò che questa grossolana concezione di emergenza era implicita nella Teoria Generale dei Sistemi proposta da Von Bertalanffy (che era lui stesso un biologo): da un insieme di elementi interagenti possono emergere comportamenti e propietà del tutto imprevedibili considerando quelle degli elementi.
Un modello di comportamento è dunque detto emergente se non rientra nella categoria di quelli che erano gli obiettivi del progettista del modello stesso.
Tornando al concetto di sistema complesso, esso comporta più componenti, fra loro interagenti (elementi, insieme, insieme strutturato, sistema, sottosistema).
Il passaggio da un insieme strutturato ad un sistema può essere temporaneo o stabile, prevedibile o imprevedibile, reversibile o irreversibile.
Anche se, come abbiamo detto, non esiste una definizione universalmente accettata di Sistema Complesso, si possono elencare alcune proprietà, spesso fra loro correlate, che caratterizzano la complessità di un sistema o la cui mancanza nega la complessità dello stesso.
Se da una parte i sistemi semplici o lineari sono costituiti da elementi che interagiscono tra loro secondo relazioni lineari e hanno comportamenti fortemente prevedibile nel tempo, d’altrocanto i Sistemi Complessi manifestano proprietà opposte che rendono inefficace un’analisi di tipo riduzionista:
1) gli elementi del sistema interagiscono in modo non-lineare, il che significa che è impossibile stabilire in modo standard il ruolo che un singolo elemento ha giocato in un processo. Per analogia con l'algebra ordinaria ricordiamo che ci sono molti modi per un sistema di essere non-lineare(le curve studiate in geometria, ossia, non proporzionalità tra "causa" ed "effetto"), ma un solo modo di essere lineare (la retta, proporzionalità "classica" causa-effetto);
2) un sistema complesso può dunque produrre dei comportamenti impredicibili, che non possono essere dedotti sulla base della conoscenza delle proprietà dei costituenti e delle interazioni di questi considerati a coppie isolate. Questi comportamenti globali non-prevedibili appartengono a classi molto diverse tra loro, sia in relazione all'ambiente che al tempo: possono aversi piccole perturbazioni che modificano in modo drastico l'assetto del sistema e forti perturbazioni che invece vengono "assorbite" in tempi più o meno rapidi; a periodi di stasi si alternano rapidi cambiamenti. Molti sistemi del mondo fisico, socioeconomico, urbanistico e biologico sono definibili come sistemi complessi. Sono sistemi complessi ad esempio il moto dei fluidi, la trasformazione economica di una regione, la crescita di un centro urbano, la vita di un organismo, e molti altri. Gli strumenti matematici classici per la descrizione dei fenomeni fisici si basano sul calcolo infinitesimale di Newton e Leibnitz, ma questi strumenti sembrano non essere particolarmente adatti per descrivere i sistemi complessi, poiché, da un lato, la descrizione approfondita di questi sistemi può condurre ad equazioni eccessivamente complicate, mentre, dall’altro lato, l’approssimazione nelle computazioni, altrove controllabile, può in questi casi divenire importante e influire fortemente sullo sviluppo del sistema. A volte non è neppure possibile formalizzare un fenomeno attraverso un sistema di equazioni a causa della sua caoticità.
Alcuni sistemi fisici, infatti, raggiungono una soglia talmente alta di complessità che in essi sorge il fenomeno del caos, definibile come l’incapacità di prevedere il comportamento di un sistema in
maniera esatta nel corso del tempo (ad esempio nel caso di un fluido turbolento o del moto delle palle di un biliardo).
I fenomeni caotici presentano due aspetti fondamentali: l’irreversibilità del moto e la perdita irreversibile di informazioni sullo stato iniziale.
Tra gli strumenti alternativi alla tradizionale matematica, idonei al trattamento di questo tipo di sistemi e fenomeni e che consentono di ovviare a questo tipo di problemi, possono essere situati gli automi cellulari.
1.5.2 AUTOMI CELLULARI
COS’E’ UN AUTOMA CELLULARE?
Il concetto di automa cellulare (o di automa in senso più generale) è stato introdotto nel 1947 da Von Neumann nel corso dei suoi studi sui fenomeni biologici, che egli descriveva come modalità di mutua interazione tra entità elementari, chiamate appunto “automi”, le cui proprietà verranno in seguito descritte.
L’idea guida di Von Neumann era la seguente: considerato un insieme di molti automi dotati della capacità di interagire in maniera opportuna, il sistema, nella sua globalità, si mostrerà capace di comportamenti complessi e differenti, come se fossero finalizzati ad un obiettivo globale.
Un sistema complesso può quindi essere pensato come composto da entità semplici (gli automi appunto), in cui vi è una mutua interazione tra queste entità: questa mutua interazione dà luogo, nell’insieme, al comportamento globale del sistema complesso.
Una delle idee fondamentali del concetto di automa cellulare è quella di riuscire a ricostruire il comportamento complesso di un sistema a partire da semplici regole che descrivono l’interazione dei “micro-componenti” in cui si pensa suddiviso il sistema stesso.
Si potrebbe quindi affermare che l’idea di base degli automi cellulari è di tentare di descrivere un sistema complesso non “dall’alto”, usando complesse equazioni, bensì simulandolo mediante interazioni di celle che seguono semplici regole, e lasciare così che la complessità emerga da tali interazioni.
UN PO’ DI STORIA
Gli automi cellulari, come accennato prima, sono nati alla fine degli anni ’40 grazie al lavoro dei matematici Stanislaw Ulam e John von Neumann; il loro iniziale scopo era di studiare macchine in grado di autoriprodursi e in grado di computare un qualsiasi algoritmo se opportunamente inizializzate (le cosiddette “macchine universali”).
Un successivo importante sviluppo, anche con particolare attenzione alle possibili applicazioni, si è poi avuto a partire dagli anni ’80 grazie ai lavori di Stephen Wolfram e di altri.
Gli automi cellulari hanno avuto applicazioni in fisica, chimica, biologia, ecologia e, a partire proprio dalla fine degli anni ’80, nello studio della morfologia urbana e territoriale.
Essi sono stati adoperati per simulare i processi più diversi: dalla percolazione del caffè, al procedere delle colate laviche, alle inondazioni, alla diffusione degli inquinanti, al procedere dei pedoni o all’aggirarsi di visitatori in un museo, senza dimenticare l’evoluzione di sistemi urbani. Negli anni sono stati quindi affrontati problemi di varia natura mediante modelli basati su automi cellulari.
Gli automi cellulari sono quindi adatti, in definitiva, per descrivere dinamiche globali che scaturiscono da elaborazioni locali uguali tra loro. Essi hanno riscosso molto successo perché, nonostante la semplicità, sono adatti a esprimere un gran numero di fenomeni “naturali” e a mettere in rilievo il ruolo dell’interazione tra le diverse componenti di un processo.
AUTOMI E RETI DI AUTOMI
Prima di fare esempi pratici è opportuno trattare alcune questioni riguardo al più generale concetto di automa. In matematica e logica un automa è un formalismo che consente di descrivere il comportamento di una “macchina”; esso può essere descritto dai seguenti elementi:
− un insieme di informazioni (dati, comportamenti, stimoli) in ingresso; − un insieme di informazioni in uscita;
− un insieme di stati interni.
Un automa è quindi una sorta di “scatola chiusa” che riceve informazioni dall’esterno, compie alcune azioni, e restituisce altre informazioni. Le azioni si basano sulle regole che definiscono le relazioni tra ingresso, stato interno e uscita. Gli stati interni rappresentano la situazione del sistema
ad un dato istante, e costituiscono la “memoria” dell’automa, consentendo ad esso di “ricordare” la risposta da fornire a determinati ingressi.
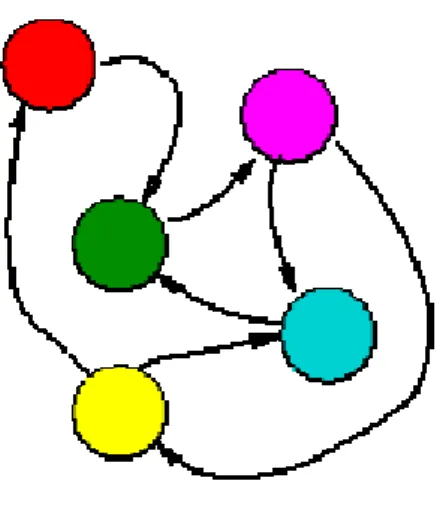
Un automa è dunque un oggetto con un input ed un output. Dato un certo input dà sempre lo stesso output, che viene anche detto stato dell'automa. Al suo interno ha delle regole che gli permettono di associare input e output (Fig.1.2).
Figura 1.2 - Automa: le regole trasformano l’imput in output.
Più automi possono essere connessi in modo che l'output di un automa sia l'input di un altro automa. Si forma in questo modo una rete di automi (Fig. 1.3). La dinamica della rete viene descritta dallo stato di ogni automa in ciascun periodo di tempo.
Figura 1.3 – Rete di atomi.
L’idea base del concetto di automa cellulare è, come già accennato prima, quella che da interazioni semplici scaturiscono comportamenti complessi.
Un automa può essere definito come una struttura topologica costituita da una griglia e da un intorno.
1.5.3 INFORMATICA E COMPLESSITA’
“La complessità è quasi un concetto teologico, molta gente ne parla, ma nessuno sa cosa realmente sia. Certamente ci sono alcuni temi comuni, da cui è caratterizzata una ricerca attinente la complessità: un approccio sintetico ai problemi come opposto a quello riduzionistico, una forte enfasi trans-disciplinare ed una scelta delle problematiche, che include alcune delle più conosciute tematiche “intrattabili” della scienza.
In molte di queste ricerche, le simulazioni al computer son risultate più importanti dell’analisi, ed in molti campi la simulazione rappresenta la sola via percorribile per la quale finora si son fatti progressi.
Non vi è un accordo generale su cosa costituisca un “sistema complesso”; lo stesso termine è stato usato in diverso modo da gente diversa. Alcuni lo usano per significare sistemi con comportamenti caotici, altri si riferiscono agli automi cellulari, sistemi disordinati a molti-corpi, reti neurali, algoritmi adattivi, e così via. ... In superficie questi (sistemi complessi) appaiono avere poco in comune fra loro e sono originati da diverse aree scientifiche: fisica, chimica, biologia, matematica, informatica, psicologia ed economia. In quanto non esiste una definizione generalmente accettata di complessità, abbiamo bisogno almeno di chiederci quali proprietà questi sistemi condividono, come primo passo alla comprensione di ciò che li rende complessi.”
Questo brano di Daniel Stein nella prefazione di “Lectures in the Sciences of Complexity” introduce a quella che possiamo considerare una delle più significative frontiere della Scienza oggi. L’Informatica gioca un ruolo determinante in questa crisi, non solo perché la disponibilità di potenza di calcolo sempre più crescente risulta essere una condizione necessaria per le simulazioni al computer, ma sopratutto perché questa disponibilità di nuovi e potenti strumenti di calcolo e di elaborazione pone tutta una serie di prospettive di indagine impensabili fino a pochi anni fa, introducendo delle metodologie in grado per la prima volta di aggredire problematiche concernenti fenomeni altamente complessi nei sistemi naturali ed artificiali.
Si evidenzia a questo punto la questione, forse non sufficientemente meditata, dei rapporti fra strumenti computazionali e sviluppo della scienza. Non è un caso che si è assistito, per quanto riguarda lo studio dei sistemi naturali, ad un "imperialismo" della Fisica la quale si è fatta forte dello strumento del calcolo differenziale per descrivere le proprietà globali dei processi fisici. Altre discipline scientifiche, come ad esempio la Biologia, si sono attestate ad un "livello di scientificità"
inferiore, per mancanza di strumenti altrettanto potenti. In modo grossolano si rimarca qui la differenza fra scienza predittiva e scienza descrittiva, che molto spesso è tale proprio per la complessità dei fenomeni che studia. Nuove prospettive vengono aperte dalla simulazione di sistemi complessi tramite modelli, che intrinsecamente posseggono strutture complesse similari per certi aspetti ai sistemi, a cui essi sono applicati.
Lo sviluppo dell'Informatica in questi ultimi anni sembra quindi destinato a stravolgere in un modo, che ancora si presenta poco chiaro nella sua dinamica, il quadro presentato; anzitutto notiamo l’emergere di nuovi modelli computazionali come ad esempio gli Automi Cellulari, le Reti Neurali e gli Algoritmi Genetici che rappresentano nuovi strumenti formali di crescente importanza nell'explicatum delle problematiche concernenti i Sistemi Complessi.
1.6
FISIOLOGIA COMPUTAZIONALE E “PHISIOME PROJECT”
Le scienze fisiche, negli ultimi 200 anni, hanno confrontato la complessità della natura con lo sviluppo di modelli matematici dei fenomeni naturali.
La nostra abilità ed accortezza nel capire i complessi flussi dei fluidi, per esempio, con lo scopo di progettare aerei o prevedere le condizioni metereologiche, è un testamento per i fisici ed i matematici del diciannovesimo e ventesimo secolo, che identifica le leggi di conservazione della fisica per la natura e sviluppa strutture matematiche per descriverle.
L’applicazione di queste leggi per la soluzione di problemi ingegneristici si è estremamente sviluppata negli ultimi 50 anni per la messa a punto dei computer e delle analisi numeriche ( ogni nuovo dispositivo ingegneristico è oggi giorno progettato con lo scopo di fare modelli matematici e analisi agli elementi finiti).
L’uso della modellistica matematica in fisiologia ha ottenuto rilievo negli anni ’50 con la previsione da parte di Hodgkin e Huxley della velocità di propagazione del potenziale d’azione lungo una fibra nervosa grazie ai modelli sulla conduzione dei canali ionici.
Altri successi nell’applicare tecniche delle scienze fisiche ai sistemi fisiologici sono stati l’analisi ingegneristica del flusso sanguigno nelle arterie usando la fluidodinamica computazionale, e l’analisi ortopedica sforzo-deformazione usando la teoria dell’elasticità lineare e l’analisi agli elementi finiti.
Dunque la disciplina della fisiologia sposa in un certo senso la nuova branca che si sta formando della “fisiologia computazionale” in cui matematici e bioingegneri lavoreranno fianco a fianco con fisiologi e biologi molecolari per creare un legame stretto tra la fisiologia delle cellule, dei tessuti e degli organi con i database sempre più in crescita della proteomica e della genomica. Tuttavia, gli strumenti richiesti per questo così detto “Physiome Project” sono significativamente differenti da quelli delle analisi ingegneristiche standard per un numero di ragioni. Prima di tutto i materiali biologici sono quasi tutti inomogenei, anisotropi ed esibiscono un comportamento non lineare, bensì queste caratteristiche non siano insolite neppure nei materiali ingegneristici. Inoltre i processi biologici esibiscono un’enorme complessità, come può essere quella della trasduzione di un segnale. Ad ogni modo la caratteristica unica e realmente significatica dei materiali biologici è la loro abilità di crescere e rimodellarsi in risposta ai cambiamenti dell’ambiente, determinati in parte dai geni e in parte dal loro ambiente fisico.
Un’importante conseguenza è che la struttura e la funzione sono intimamente collegate in un modo che nessun materiale ingegneristico o sistema può emulare. Catturare queste relazioni struttura-funzione in una maniera computazionalmente efficiente è la chiave di successo della fisiologia
computazionale e richiede modelli e software che sono differenti da quelli che si trovano nel mondo ingengeristico standard.
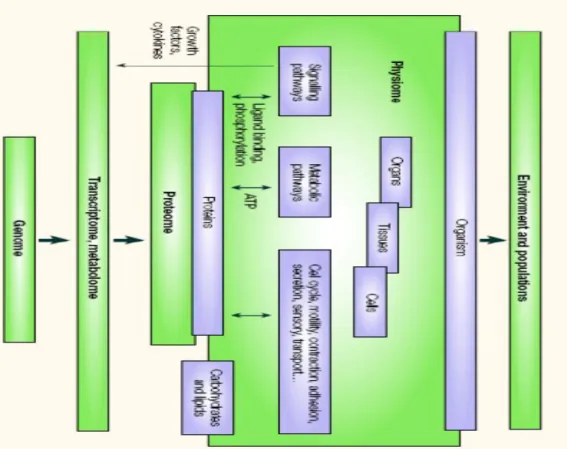
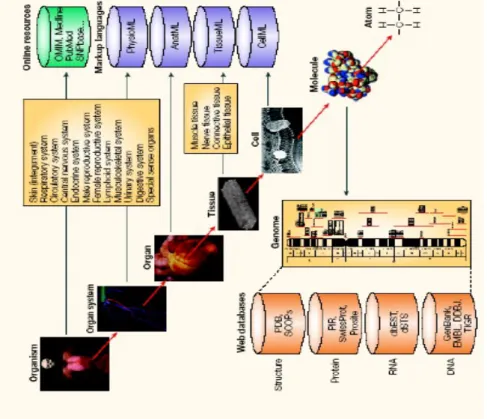
Dunque l’obiettivo del “Physiome Project” è quello di provvedere una struttura per modellare il corpo umano usando metodi computazionali che possono incorporare la biochimica, la biofisica e l’anatomia delle cellule, dei tessuti e degli organi (fig. 1.4 ). Per supportare questo obiettivo, il progetto sta sviluppando dei linguaggi XML e strumenti software per creare, eseguire e visualizzare l’uscita al computer dei modelli a livello cellulare, tissutale e di organi. Sono anche disponibili database accessibili via web che danno le informazioni fisiologiche necessarie per supportare questi modelli.
I maggiori sviluppo nella scienza e nella medicina sono le recenti esplosioni di informazioni della genomica e proteomica; d’altro canto gli sviluppi nell’imaging stanno provvedendo molte informazioni sulle funzioni degli organi.
Figura 1.4 – Relazioni tra fisioma e altre aree dell’organizzazione biologica. Le altre aree dell’organizzazione biologica includono il genoma (i geni codificati in DNA), il trascrittoma , metaboloma e il proteoma. C’è un altro livello di organizzazione sul fisioma, che tratta di popolazioni e interazioni con l’ambiente.
PHYSIOME PROJECT
Il fisioma è la descrizione quantitativa e integrata del comportamento funzionale dello stato fisiologico di un individuo o di una specie. Il fisioma descrive le dinamiche fisiologiche dell’organismo normale e intatto ed è basato su informazioni di struttura e funzione (genoma, proteoma e morfoma).
Il termine deriva da ‘physio’ (vita) e ome(integro). Esso definisce le relazioni tra genoma e organismo dal comportamento funzionale alla regolazione genica. Nel contesto del progetto fisioma, esso include modelli integrati di componenti di organismi, come organi particolari o sistemi cellulari, sistemi biochimici o endocrini.
Le finalità del “Physiome Project” sono il coordinamento di informazioni di natura molecolare, cellulare e fisiologica su organismi viventi all’interno di un database accessibile a tutti. Tra gli obiettivi invece del progetto ci sono:
la creazione di farmaci migliori;
terapie genetiche finalizzate alla cura e alla prevenzione delle malattie; modelli matematici per spiegare il funzionamento dell’organismo; migliore comprensione dei complessi processi vitali.
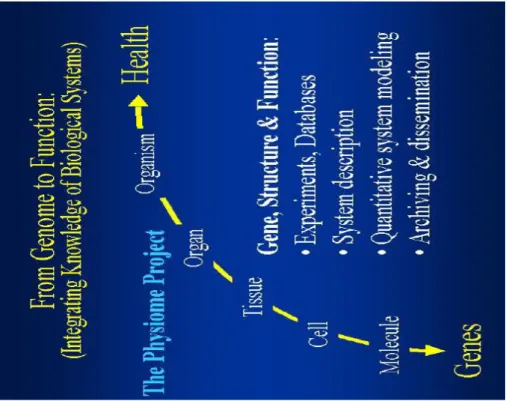
Il “Progetto Fisioma” è un programma internazionale per definire il fisioma tramite lo sviluppo di database e modelli che faciliteranno la comprensione della funzione integrata di cellule, organi e organismi (Fig. 1.5). Il progetto è focalizzato nella compilazione e nella predisposizione di uno schedario centrale di database, collegando informazioni sperimentali e modelli computazionali da molti laboratori in una singola, cornice auto-consistente. L’unione degli sforzi di ricerca promuoverà lo sviluppo di complessi database e un integrativo, analitico approccio allo studio della medicina e della fisiologia.
Figura 1.5 – “Physiome Project”, l’integrazione della conoscenza sui sistemi biologici
Principale obiettivo del progetto fisioma è comprendere e descrivere l’organismo umano, la sua fisiologia e lo stato fisiopatologico in maniera quantitativa; dunque utilizzare questa comprensione per migliorare la salute umana.
Il progetto darà informazioni alla comunità internazionale di scienziati, medici, docenti e aziende sotto forma di descrizione funzionale dell’uomo e altri sistemi biologici nello stato di salute e di malattia. Il progetto fisioma non si limita agli aspetti scientifici:esso comprende formazione, ricerca, archiviazione dei dati, disseminazione e creazione di banche dati. Inseriti nel progetto sono le nozioni di collaborazione effettiva e libero scambio di informazioni: i dati, i concetti e la descrizione degli elementi biologici, processi e modelli saranno accessibili pubblicamente via internet.
Il progetto fisioma intende sviluppare, collezionare, preservare e disseminare informazioni e conoscenze integrate del funzionamento dei sistemi biologici. Gli elementi chiave del progetto sono la creazione di banche dati di informazioni fisiologiche, farmacologiche e patofisiologiche sull’uomo e su altri organismi e la loro integrazione tramite modelli computazionali. I modelli includono qualsiasi degli schemi posti in diagramma, suggerendo le relazioni tra elementi che compongono il sistema, a modelli computazionali quantitativi che descrivono il comportamento di sistemi fisiologici e la risposta degli organismi a modificazioni ambientali. Ciascun modello matematico è un sommario di informazioni ottenibili ed è in grado di definire una ipotesi di lavoro circa l’operatività del sistema. Le ipotesi che derivano da questo sistema sono sottoposte a test di
verifica ottenendo nuovi risultati che conducono a nuovi modelli. Il comportamento complesso dei sistemi biologici sarà gradualmente rilevato attraverso questo processo step-by-step di costruzione e ulteriori rifiniture.
Le aspettative basilari del progetto Fisioma sono di migliorare la comprensione della biologia e sviluppare tipi specifici di miglioramenti nella salute umana. Al fine di definire ogni specifica entità patologica attraverso interventi terapeutici, si dovrebbero individuare targets che forniscono un risultato effettivo senza causare effetti collaterali sotto forma di side effects o effetti a lungo termine. Un approccio sistematico a questi targets lavorerà solo quando dati a sufficienza saranno stati integrati in una descrizione comprensibile, schematica e corretta dal punto di vista computazionale capace di predirre gli effetti degli interventi. Interventi farmaceutici e genomici non sono prevedibili con affidabilità sia dal genoma che dal proteoma, ma richiedono la comprensione del fenotipo intatto in un ambiente conosciuto.
Un network di centri del progetto fisioma sta sviluppando e muovendosi attraverso una risorsa internazionale adattabile per collezionare dati e modelli degli aspetti funzionali dei sistemi biologici. I databases generati da questi centri danno informazioni sperimentali che devono essere integrate attraverso modelli fisiologici. I centri mantengono i loro database individuali di informazioni e modelli per il reperimento pubblico tramite Internet. I database e modelli di questi centri accoglieranno dati da molte specie. Il progetto fisioma è attualmente nella posizione del progetto genoma 20 anni fa. Vi sono molti ricercatori che lavorano su diversi progetti, gli sforzi sono generalmente individuali non ci sono localizzazioni centrali che mettono in collegamento i dati ottenuti dai progetti. Ciascun progetto fisioma, dovrebbe comunque essere considerato come un progetto pilota e esaminato rispetto al suo contributo scientifico, tanto quanto esso rafforza il suo spirito collaborativo.
Gruppi di lavoro scientifici individuano aree particolari nella fisiologia dell’uomo e degli altri organismi e sono focalizzati sulla fisiologia dell’uomo e degli altri organismi, su osservazioni sperimentali e modelli computazionali, modelli integrativi per la valutazione. Gruppi di lavoro scientifici dovrebbero ambire a disegnare, sviluppare, implementare, testare, documentare, archiviare e disseminare informazioni quantitative e modelli integrativi del comportamento funzionale di molecole, organelli, cellule, tessuti, organi e organismi intatti dai batteri all’uomo. Le funzioni dei gruppi di lavoro scientifici dovrebbero essere:
inserire informazioni sperimentali in database; definire la biologia che deve essere modellata;
disegnare e sviluppare modelli computazionali; implementare, testare e modellare documenti; archiviare e disseminare database e modelli;
sviluppare web-tutoriali e materiale per la formazione.
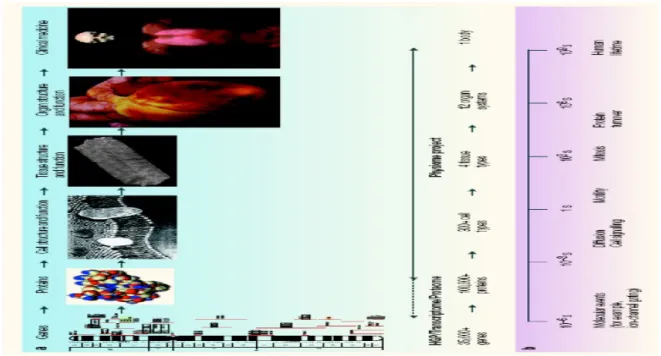
Il bisogno di fare modelli matematici dovrebbe richiedre delle giustificazioni: la matematica è il linguaggio per descrivere processi fisici e chimici, e fare modelli matematici è l’unico mezzo per avere una struttura quantificabile per integrare numerosi processi lungo scale spaziali e temporali. Ogni tentativo di unire eventi molecolari e cellulari con funzioni fisiologiche si deve occupare di scale che spaziano dalla lunghezza di 1 nm, lunghezza tipica delle proteine, a 1m, lunghezza di un corpo ( Fig. 1.6 a ).
In maniera simile il range della scala dei tempi deve coprire da 1 μs, che è caratteristico del moto Browniano, fino a 70 anni, che è il tempo di vita medio dell’uomo (Fig.1.6 b )
Figura 1.6 – Relazionare eventi molecolari e cellulari con funzioni fisiologiche significa trattare con grandi range di scale spaziali e temporali. a Livelli di organizzazione biologica dai geni alle proteine, cellule, tessuti, organi ed infine l’intero organismo. Il range di scala spaziale, da 1 nm delle proteine a circa 1 m dell’ntero corpo, richiede una gerarchia di modelli. Differenti tipi di modelli sono appropiati per ogni livello. I modelli a livello di organo e di corpo intero qui mostrati sono modelli del cuore e del torso dell Istituto di Bioingegneria di Auckland, Nuova Zelanda. b Il range di scale temporali come mostrato qui è ancora più scoraggiant e richiama ancora una gerarchia di modelli.
E’ evidente che nessun singolo modello può coprire un fattore di 109 in una scala spaziale e un
fattore di 1015 in scala temporale.
Un approccio più ragionevole è sviluppare modelli per un range più limitato di scale spaziali e temporali e sviluppare tecniche per relazionare i parametri di questa gerarchia di modelli ( vedi, per esempio, i recenti testi sulla biologia computazionale). Questo significa che, ad ogni livello, c’è un ‘black box’ che raggruppa tutti i dettagli al livello sotto ( sia in senso spaziale che temporale ) in una espressione matematica. I parametri di questa espressione sono determinati direttamente dagli esperimenti, ma possono essere correlati ad un altro modello più dettagliato, ad un livello spaziale e temporale più affine.
Per accedere ai database di informazioni che sono rilevanti per fare modelli, c’è bisono di ontologie per l’anatomia e la funzione che, dai più alti livelli di organizzazione biologica, iniziano con i sistemi di organi e progressivamente accedono ai tessuti, cellule, organelli cellulari, proteine e domini di proteine ( Fig. 1.7 ).
Per concludere, la complessità dei sistemi biologici, e la vasta quantità di informazioni adesso disponibile a livello di geni, proteine, cellule, tessuti e organi, richiede lo sviluppo di modelli matematici che possano definire la relazione tra la struttura e la funzione a tutti i livelli di organizzazione biologica.
1.7
MODELLISTICA E SIMULAZIONE AD AGENTI
Uno degli approcci più promettenti per l’analisi delle interdipendenze tra reti complesse è quello della così detta modellistica ad agenti (Agent-based modeling).
L’idea fondamentale che guida questi modelli è che comportamenti complessi possano essere il frutto delle interazioni tra agenti che operano sulla base di regole semplici che, nel loro interagire fanno emergere quelle proprietà che caratterizzano il comportamento collettivo del sistema. Ciò non è altro che la trasposizione degli approcci comportamentali biologici e sociologici che enfatizzano come l’aggregazione ordinata di individui di una determinata specie comporta l’insorgenza di comportamenti non prevedibili a partire dallo studio del singolo individuo isolato, ad esempio si pensi a come l’aggregazione di milioni di api comporti la creazione del soggetto alveare con dinamiche e propietà non derivabili dalla semplice aggregazione.
L’idea è quella di studiare le infrastrutture critiche utilizzando un approccio bottom-up: ciò sta a dire modellare l’intero sistema partendo dalle componenti individuali (modellate mediante agenti) . Un modello dell’intero sistema è quindi ottenuto inter-connettendo agenti, ossia sistemi indipendenti che elaborano, autonomamente, risorse e informazioni, producendo degli output, i quali a loro volta diventano imput per gli altri, e così via.
Per l’implementazione del modello di interazione si farà uso di ambienti di modellazione e simulazione ad agenti, come ad esempio NetLogo, SWARM e RePast.
Di questo modo di fare modelli e degli strumenti di programmazione ad esso correlati si farà riferimento nei prossimi capitoli.
1.7.1 MODELLI BASATI SU AGENTI VS. MODELLI BASATI SU EQUAZIONI
In molti ambiti, tra cui quelli biologici e medici, i modelli basati su agenti concorrono con quelli basati su equazioni che identificano le variabili del sistema e valutano o integrano set di equazioni che relazionano queste variabili. Scopo di questo paragrafo è illustrare le somiglianze e le differenze tra queste due classi di modelli, e sviluppare dei criteri in base ai quali si è portati a selezionare l’uno o l’altro approccio.
Entrambi gli approcci simulano il sistema sia costruendo il modello sia facendolo eseguire tramite il computer. Le differenze stanno nella forma del modello e nel come esso viene eseguito.
Nella modellistica ABM ( Agent based modeling ), il modello consiste in un set di agenti che incapsulano i comportamenti dei vari individui che formano il sistema e l’esecuzione consiste nell’emulare questi comportamenti.
Nella modellistica EBM ( Equation based modeling ), il modello consiste invece in un set di equazioni, mentre l’esecuzione consiste nel valutarle. Così la “simulazione” è il termine generale che si applica ad entrambi i modelli, che sono distinti come emulazione (basata su agenti) e valutazione (basata sulle equazioni).
Capire le relative possibilità di questi due approcci è di grande interesse sia etico che pratico per i modellatori di sistemi e i simulatori.
Le due diverse tipologie condividono alcuni temi comuni, ma differiscono per due motivi: le relazioni fondamentali tra le entità che vengono modellate, ed il livello al quale queste relazioni concentrano la loro attenzione.
Entrambi gli approcci riconoscono che il mondo include due tipi di entità: individuali e osservabili, ognuno con un aspetto temporale.
La prima differenza fondamentale tra ABM ed EBM sta nelle relazioni sulle quali uno focalizza la sua attenzione.
Un modello basato sulle equazioni inizia con un set di equazioni che esprimono le relazioni tra le entità osservabili. La valutazione di queste equazioni produce un’evoluzione delle entità osservabili nel tempo. Le equazioni possono essere algebriche, o possono essere variabili nel tempo ( le equazioni differenziali o ODE, usate nei sistemi dinamici ) oppure sia nel tempo che nello spazio ( equazioni differenziali parziali, o PDE ).
Al contrario un modello basato su agenti inizia, non con equazioni che relazionano entità osservabili l’una all’altra, ma con comportamenti attraverso i quali le entità individuali interagiscono l’una con l’altra. Questi comportamenti possono coinvolgere molte entità individuali
direttamente (ad esempio le volpi che mangiano i conigli) o indirettamente attraverso un ambiente condiviso ( i cavalli e le mucche che competono per l’erba).
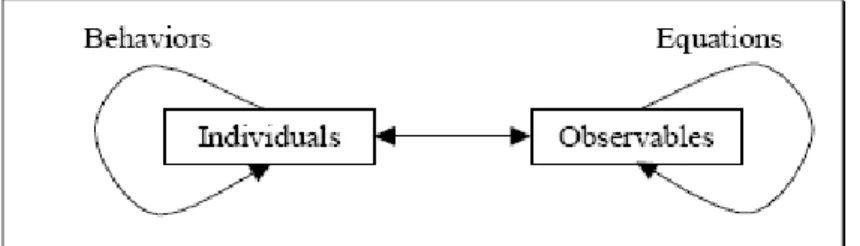
Chi fa il modello inizia rappresentando i comportamenti di ogni individuo, poi li lascia liberi di interagire. Relazioni dirette tra le entità osservabili sono un’uscita del processo, non il suo ingresso. La figura 1.8 riassume le relazioni critiche:
le entità individuali sono caratterizzate, separatamente o in aggregati, da entità osservabili, e influiscono sui valori di queste ultime con le loro azioni;
le entità osservabili sono correlate una all’altra tramite equazioni;
le entità individuali interagiscono una con l’altra attraverso i loro comportamenti.
Figura 1.8 – Relazioni tra entità individuali e osservabili.
Una seconda differenza fondamentale tra gli ABM e gli EBM è il livello al quale il modello si focalizza. Un sistema è composto da una serie di entità individuali interagenti. Alcune entità osservabili di interesse possono essere definite solamente a livello di sistema, mentre altre possono essere espresse sia a livello individuale che come aggregati. Un modello basato su equazioni tende a fare un uso estensivo delle entità osservabili a livello di sistema, poichè è spesso più facile formulare delle equazioni usando queste quantità.
In contrasto, la naturale tendenza dei modelli ABM è quella di definire i comportamenti degli agenti in termini di entità osservabili accessibili all’agente individuale.
Queste due distinzioni sono comunque delle tendenze, non regole. I due approcci possono infatti essere combinati e la scelta tra i due deve essere fatta caso per caso sulle basi di considerazioni pratiche e su tre raccomandazioni generali:
- ABM è più appropriato per domini caratterizzati da un alto grado di localizzazione e distribuzione. EBM è applicato maggiormente a sistemi che possono essere modellati centralmente, ed in cui le dinamiche sono dominate da leggi fisiche più che da processi d’informazione;
- i ricercatori che fanno modelli ad agenti sono consapevoli della lunga storia dei modelli basati sulle equazioni e dovrebbero fare verificare il loro modello ad agenti con quello esistente ad equazioni. Queste comparazioni sono particolarmente valutabili in sistemi semplici in cui si può tracciare le cause della divergenza tra i modelli. In ogni caso i vantaggi e gli svantaggi dell’uno o dell’altro approccio sono valutabili da caso a caso; è per questo che la scelta nell’adottare l’uno o l’altro modello per un dato problema dipende dallo sviluppare una propria casistica che dimostra le rispettive forze e debolezze dei due approcci;
- l’enorme popolarità dei modelli basati sulle equazioni è dovuta in larga misura alla disponibilità di strumenti “drag and drop” per costruire e analizzare modelli di sistemi dinamici. I vantaggi della modellistica ad agenti dipenderà invece sulla disponibilità di strumenti comparabili per questo approccio, e tutti coloro che credono in questo metodo dovrebbero incoraggiare lo sviluppo e il miglioramento di questi strumenti.