CAPITOLO 4
PROGRAMMAZIONE IN SIMULINK
_______________________________________________________________________________
In questo capitolo esamineremo i caratteri generali del programma SIMULINK, soffermandoci soprattutto sugli aspetti di maggiore interesse, o almeno su quelli che, durante la realizzazione del progetto, ci sono apparsi tali.
4.1 Caratteri generali
Il SIMULINK è un ambiente di programmazione grafico associato alla shell di MATLAB. Sembra, quindi, opportuno fornire una descrizione generale di quest’ultimo linguaggio. MATLAB (MatrixLaboratory) è un linguaggio di programmazione ad alto livello ed insieme un ambiente interattivo per lo sviluppo di algoritmi, per la visualizzazione e l’analisi dati, per il calcolo numerico e per la prototipazione rapida. E’ uno strumento software molto diffuso nella ricerca scientifica e trova applicazione in diversi campi che vanno dall’ingegneria, alle scienze matematiche e fisiche, alla chimica, alla biologia e alle scienze finanziarie. Una caratteristica fondamentale del codice è la semplicità di utilizzo in quanto il suo costituente principale è la matrice e la sua algebra. MATLAB utilizza librerie per l’algebra matriciale sviluppate nei progetti LAPACK and ARPACK che rappresentano lo stato dell’arte del calcolo matriciale. E’ un software molto duttile in quanto dotato di un insieme di funzionalità, denominate Toolbox che rappresentano un set di soluzioni e applicazioni dedicate ad una classe specifica di problemi. I più diffusi sono: il Control System Toolbox per l’analisi e la sintesi dei sistemi di controllo, il Comunication Toolbox per l’analisi e il progetto dei sistemi di comunicazione, il Data Acquisition Toolbox per
ricorrere all’utilizzo dei tradizionali linguaggi di programmazione C/C++ offrendo un’interfaccia grafica sviluppata e un’ampia gamma di algoritmi risolutivi.
Vediamo più approfonditamente alcuni aspetti del SIMULINK.
Si tratta di un pacchetto software per la modellizzazione, simulazione e analisi di sistemi dinamici. Supporta sistemi lineari e non-lineari, modellati in tempo continuo, campionato, o un ibrido dei due; i sistemi possono anche essere multirate, cioè differenti parti possono operare a velocità diverse. Per la costruzione dei modelli, SIMULINK usa un’interfaccia grafica (GUI GraficalUserInterface) molto intuitiva che si basa sull’assemblaggio di blocchi predefiniti o costruiti dall’utente presenti nelle varie e numerose librerie con semplici operazioni del mouse (click-and-drag).
Dopo la costruzione del modello è possibile effettuare la sua simulazione, scegliendo tra una serie di metodi integrativi, direttamente dal menù di SIMULINK o similmente dalla shell di MATLAB con l’utilizzo di particolari comandi. Questo è un fattore chiave del SIMULINK: i suoi utenti hanno accesso alla vasta gamma di applicazioni presenti in MATLAB.
L’integrazione tra SIMULINK e MATLAB è stata da noi sperimentata durante tutta la fase di progetto, dandoci la possibilità di caricare sul nostro modello dati salvati su MATLAB e, viceversa, di poter salvare i risultati delle nostre simulazioni sul workspace, per poter essere usati successivamente per grafici ed ulteriori verifiche.
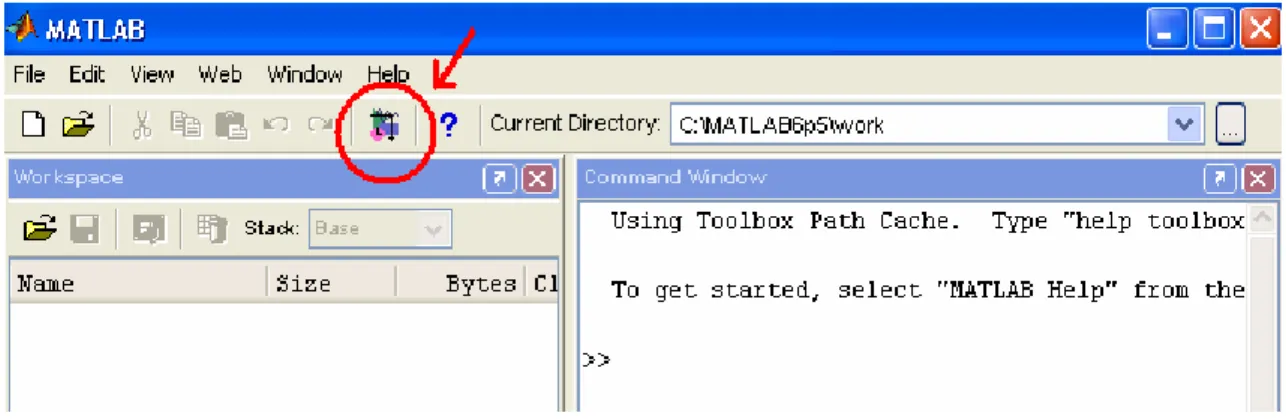
Vediamo brevemente i comandi per accedere al programma: cliccando sul’icona (mostrata in fig.4.1) presente sul MATLAB toolbar compare il Simulink Library Browser, cioè una finestra ad icone, che raggruppano i blocchi della libreria in classi di appartenenza.
Figura 4.2 La libreria di SIMULINK
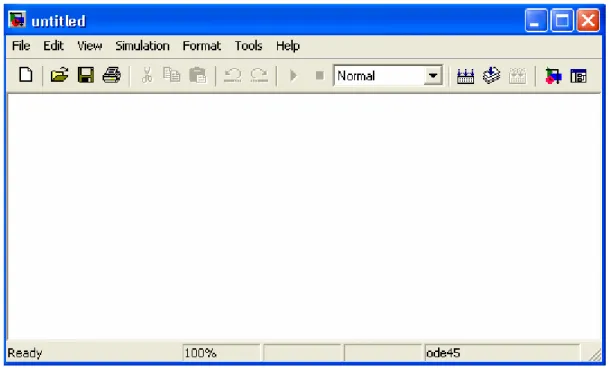
Scegliendo dal menù file l’opzione New si apre una finestra vuota che conterrà il nostro modello (fig. 4.3).
Figura 4.3 Il modello
A questo punto basta trascinare all’interno della finestra i blocchi che ci interessano collegandoli con delle linee che stabiliscono le relazione matematiche che intercorrono tra essi ed infine settare il valore dei parametri.
4.2 Uso del SIMULINK
La simulazione in SIMULINK avviene, come già detto, in due fasi: la prima riguarda la costruzione grafica del progetto, la seconda, la simulazione vera e propria del comportamento del modello costruito.
Analizzeremo in questi paragrafi le due fasi: in quella di modellizzazione ci soffermeremo sulla descrizione dei blocchi, che rappresentano l’elemento base del modello, dei sottosistemi (subsystems) e delle relative maschere (masks), in quella di simulazione illustreremo più propriamente gli elementi fondamentali del processing.
4.2.1 I blocchi
Ogni blocco rappresenta un sistema dinamico elementare che produce un’uscita continuamente (blocco continuo) o a specifici istanti di tempo (blocco discreto).
Ognuno di essi contiene un vettore di ingressi, stati e uscite:
u y
( input )
( output )
Gli stati, se presenti, sono delle variabili che determinano l’uscita del blocco e il cui attuale valore è una funzione di quello precedente e/o degli ingressi.
Il Simulink Memory Block è un esempio di blocco con stati, infatti, l’uscita attuale non è altro che l’ingresso precedente, mentre il Gain Block è un esempio di blocco senza stati poiché l’uscita attuale è l’ingresso attuale moltiplicato per una costante.
Gli stati possono essere discreti, continui o una combinazione di essi.
Possiamo riassumere quanto detto mostrando simbolicamente le relazioni tra ingressi, stati e uscite: ( , , ) o y= f t x u Uscite 1 ( , , ) k u d x f t x u + = Aggiornamento ' ( , , ) c d x = f t x u Derivata
dove x=
[
xc xd]
è il vettore degli stati; la prima componente è quella relativa agli stati continui, la seconda a quelli discreti.E’ opportuno soffermarsi sulle due tipologie di blocchi che abbiamo a disposizione: i
x
fissato, chiamato il tempo di campionamento del blocco; i blocchi discreti mantengono la loro uscita costante tra due successivi istanti di campionamento e contengono un parametro settabile dall’utente che permette di fissare il suo sampling rate.
Altri blocchi possono essere o continui o discreti, a seconda del tipo di blocchi da cui sono pilotati e si dice che questi hanno un implicit sampling rate; se uno qualsiasi degli ingressi è continuo allora anche l’implicit sampling rate sarà continuo; nel caso discreto, il tempo di campionamento del blocco coincide con il più piccolo sampling rate dei suoi ingressi solo se questi sono suoi multipli interi, altrimenti coincide con il fundamental sampling time degli ingressi, il quale è definito come il più grande intero divisore di tutti i tempi di campionamento.
In fig.4.4 sono mostrate due situazioni in cui sono presenti due ingressi che hanno instanti di campionamento differenti ed i relativi fundamental sampling rate.
1) Ts1 = 0.25
fundamental sampling rate = 0.25 Ts2 = 0.50
2) Ts1 = 0.50
fundamental sampling rate = 0.25 Ts2 = 0.75
4.2.2 I subsystems
Durante la costruzione del modello, molto spesso ci siamo trovati a lavorare con un numero di blocchi elevato che aumentava eccessivamente le dimensioni e la complessità del sistema. L’unica soluzione è stata quella di raggruppare in modo "gerarchico" blocchi “logicamente” connessi all’interno di questi sottosistemi. I vantaggi che derivano dal loro utilizzo sono quindi:
• la diminuzione delle dimensioni del modello
• la costruzione di un diagramma a blocchi gerarchico dove il Subsystem block è ad un livello superiore, mentre i blocchi che lo costituiscono appartengono ad un livello inferiore.
Di seguito sono riportati i passi che bisogna seguire per la costruzione di un sottosistema:
1) Con il mouse si devono selezionare i blocchi e le linee di connessione che si vogliono inserire all’interno del sottosistema.
Per esempio la figura sottostante mostra un modello che rappresenta un contatore. Vogliamo inserire nel sottosistema l’Unit Delay e il Sum Block
2) Dal menù Edit si deve selezionare Create Subsystem
Figura 4.6
Questo è ciò che appare nel modello: i due blocchi selezionati sono “scomparsi” all’interno del Subsystem; in realtà basta cliccare per due volte sul sottosistema per ritrovare gli oggetti selezionati. E’ possibile fare anche delle modifiche: per esempio cambiare il tipo di blocchi, aggiungerne di nuovi ecc. In definitiva all’interno del Subsystem si possono effettuare tutte le operazioni eseguibili nel modello principale.
Figura 4.7
4.2.3 Le maschere
I sottosistemi appena descritti diventano degli strumenti ancora più interessanti se vengono “mascherati”. Una maschera è un’interfaccia utente che ha lo scopo di nascondere i contenuti del subsystem (cioè cliccandoci due volte sopra non si vedono più i blocchi che lo costituiscono) e quello di farlo apparire come un “atomic block”, cioè un blocco preesistente con la sua propria icona e con la sua finestra di dialogo in cui settare i parametri degli oggetti in esso contenuti.
Mostreremo, con un semplice esempio, come funzionano le maschere e come sono create.
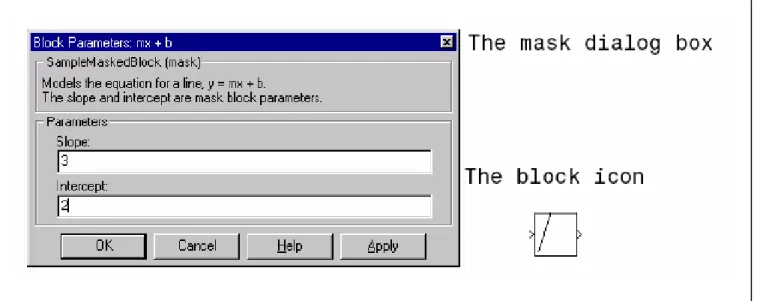
Prendiamo un sottosistema che modelli l’equazione di una retta, y = mx + b.
Figura 4.8
Cliccando due volte sul sottosistema si apre una finestra che contiene i blocchi; nel nostro esempio i blocchi presenti sono: Gain Block, chiamato Slope, il cui parametro è specificato come m, e un Constant Block, chiamato Intercept, il cui parametro è indicato con b.
Dopo aver creato la maschera, avremo una nuova icona ed un dialog block che contiene i prompt per Slope e per Intercept.
Figura 4.9 Dialog box e icona del sistema mascherato
L’utente attraverso la finestra setta i valori dei due parametri, che poi SIMULINK passa ai blocchi contenuti all’interno del sottosistema.
Per creare la maschera è necessario:
• Specificare i prompt per i parametri del dialog box.
• Specificare il nome delle variabili usati per immagazzinare il valore di ogni parametro.
• Inserire la documentazione, composta dalla descrizione del blocco e dall’ help. • Specificare i comandi grafici per la creazione dell’icona.
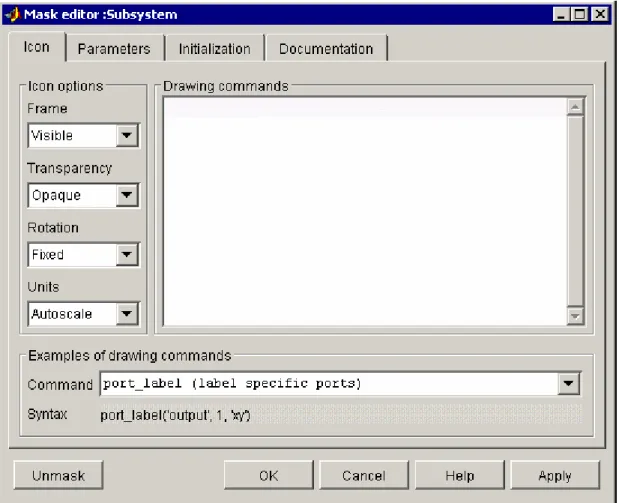
Dopo aver selezionato il sottosistema si sceglie Edit Mask; a questo punto compare il Mask Editor.
Sono presenti quattro pannelli che permettono di costruire la maschera:
• Icon Panel: crea l’icona.
• Parameters Panel: permette di definire il prompt dei parametri e il nome delle variabili ad essi associati.
• Initialization Panel: permette di inserire i comandi di MATLAB che inizializzano il sottosistema.
• Documentation Panel: permette di inserire la documentazione del blocco.
Icon Panel
Vogliamo costruire un’icona adatta al tipo di operazione svolta dal sottosistema; nel nostro caso si è deciso di mostrare la pendenza della retta. Con un valore di slope pari a tre l’icona appare in questo modo:
Dobbiamo inserire questi comandi :
L’inserimento di quei comandi ha l’effetto di disegnare una retta che parte dal punto [0,0], che corrisponde all’angolo in basso a sinistra, fino al punto [1,m], sapendo che il punto [1,1] corrisponde all’angolo in alto a destra. Se lo slope è negativo, SIMULINK sposta la retta in alto di uno.
Parameters Panel
Qui vengono settati il prompt, cioè il “ text label ” che descrive il parametro, e il nome delle variabili associate ai parametri.
Figura. 4.13 Parameter Panel
Figura4.14 Il prompt dei parametri
Initialization Panel
E’ possibile inizializzare il sottosistema introducendo dei comandi MATLAB costituiti da funzioni, operatori e dalle variabili definite nella maschera.
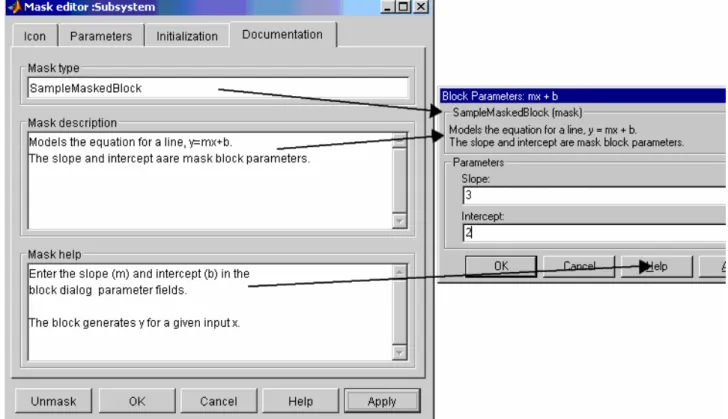
Documentation Panel Mostrato in fig.4.16
Figura 4.16 Documentation Panel
Quelli che abbiamo mostrato sono gli aspetti più interessanti della fase di modellizzazione; ora analizzeremo quelli relativi alla simulazione, cioè illustreremo i processi di calcolo degli stati e delle uscite del sistema all’interno di un certo intervallo di tempo.
4.2.4 La simulazione
La simulazione avviene in due fasi: l’inizializzazione del modello e la sua esecuzione.
Model Initialization Phase
Durante questa fase il SIMULINK:
1) Calcola le espressioni che determinano il valore dei parametri dei blocchi.
2) Determina le caratteristiche dei segnali, come il nome, il data type, il numeric type, la dimensione ecc.
3) Determina la dimensione dei vettori degli stati e dei parametri. 4) Effettua delle ottimizzazioni sui blocchi.
5) Elimina la gerarchia del modello con la sostituzione dei sottosistemi virtuali con i blocchi che li costituiscono.
6) Calcola l’ordine con cui i blocchi devono essere eseguiti nella fase di esecuzione. 7) Determina il tempo di campionamento di quei blocchi in cui non è stato
esplicitamente indicato.
8) Alloca e inizializza la memoria usata per immagazzinare i valori correnti degli stati e delle uscite di ogni blocco.
Model Execution Phase
In questa fase SIMULINK calcola gli stati e le uscite del sistema ad istanti precisi chiamati time-step, la cui lunghezza dipende da quale tipo di metodo di integrazione (Solver) è stato scelto.
Ad ogni time-step il SIMULINK:
1) Aggiorna le uscite dei blocchi nell’ordine stabilito. Prende i valori correnti degli ingressi e degli stati e calcola le uscite.
2) Aggiorna gli stati dei blocchi nell’ordine stabilito richiamando le funzioni che calcolano le derivate (per i blocchi continui) o gli aggiornamenti (per i blocchi discreti). Sono le funzioni viste nel paragrafo 4.2.1.
3) Cerca le discontinuità degli stati continui. Quando SIMULINK individua una discontinuità all’interno di un time step, determina l’istante preciso in cui essa
avviene e prende due intervalli addizionali uno precedente e l’altro successivo alla discontinuità. Cerchiamo di capire perché l’individuazione delle discontinuità (zero-crossing detection) è così importante. Le discontinuità in uno stato variabile coincidono spesso con eventi significativi dell’evoluzione dinamica di un sistema, quindi è necessario simulare precisamente quei punti. Prendiamo, per esempio, una palla che rimbalza sul pavimento: l’istante in cui colpisce il suolo rappresenta una discontinuità; è facile intuire che se questo avvenisse nel mezzo di un time step la simulazione risulterebbe approssimativa, poiché l’utente “crederebbe” che la palla avesse cambiato la sua direzione in aria.
4) Calcola l’istante del successivo time step.
SIMULINK ripete i passi dall’1 al 4 fino alla fine della simulazione.
Solvers
Il processo di calcolo degli stati successivi di un sistema viene implementato dal SIMULINK con una serie di programmi, detti solvers, i quali si dividono in alcune categorie.
Fixed-step Solvers: eseguono il modello ad intervalli di tempo regolari dall’inizio alla fine
della simulazione. E’ possibile settare la lunghezza del time step, sapendo che diminuirla significa incrementare l’accuratezza dei risultati ma anche aumentare il tempo richiesto per la simulazione.
Variable-step Solvers: variano lo step size in maniera adattativa durante la simulazione;
lo diminuiscono per incrementare l’accuratezza quando gli stati cambiano velocemente, mentre lo aumentano quando gli stati variano lentamente. Risulta un buon compromesso tra accuratezza dei risultati e velocità di simulazione.
Facciamo un semplice esempio per mostrare la differenza tra i due tipi di solver. Prendiamo un sistema in cui si trovano due sampling time, uno pari a 0.50 e l’altro a 0.75. Il fundamental sampling time di questo sistema discreto è 0.25.
Figura 4.17 Confronto tra Fixed e Variable Step Solvers
Nella fig.4.17 le linee rappresentano i passi della simulazione mentre i cerchi gli istanti in cui è presente un’uscita.
Continuos Solvers: usano delle tecniche di integrazione numerica per risolvere le
equazioni differenziali (ODE) che rappresentano gli stati continui di un sistema dinamico. SIMULINK fornisce una grande varietà di fixed-step e variable-step solvers ognuno dei quali utilizza uno specifico ODE-solution-method.
Discrete solvers: sono usati nei sistemi puramente discreti. Calcolano il successivo
passo di simulazione e niente altro.
E’ da notare che un sistema dove sono presenti contemporaneamente stati continui e stati discreti può essere risolto solo con solver di tipo continuo.
Adesso possiamo settare i parametri più importanti della simulazione; scegliendo Parameters dal Simulation menù si apre il Solver Panel.
Figura 4.18 Solver Panel
Su questo pannello è possibile effettuare le seguenti operazioni:
• Settare gli istanti di inizio e fine simulazione. • Scegliere il solver e settare i suoi parametri.
Abbiamo a disposizioni i seguenti tipi di solver: 1) Fixed-step continuos solvers.
2) Variable-step continuos solvers. 3) Fixed-step discrete solvers. 4) Variable-step discrete solvers.
Si noti come scegliendo un fixed-step solver sia possibile settare solo il passo fisso di simulazione, mentre se si sceglie un variable- step solver possiamo settare il massimo ed
4.3 Le S - FUNCTIONS
Una S-Function è una descrizione, mediante linguaggio di programmazione, di un sistema dinamico, il cui codice può essere scritto utilizzando i linguaggi MATLAB, Fortran, Ada, C/C++; ad eccezione di quelle scritte in MATLAB, le altre S-Function sono compilate come MEX-file (Memory Executable) utilizzando il comando mex disponibile all’interno dell’ ambiente MATLAB. Le S-Function utilizzano una sintassi particolare che permette loro di interagire con i solvers di SIMULINK nello stesso modo in cui i solvers interagiscono con i blocchi; la forma di una S-Function è molto generale e può descrivere sistemi continui, discreti e ibridi. Quasi tutti i modelli SIMULINK possono essere realizzati, quindi, come S-Function.
L’utilizzo più comune di una S-Function è come blocco utente. E’ possibile utilizzarle in svariate situazioni tra cui:
• Aggiungere blocchi di utilità generale nella libreria di SIMULINK. • Inserire un codice C già presente in una simulazione.
• Descrivere un sistema come una serie di istruzioni. • Utilizzare animazioni grafiche.
• Velocizzare notevolmente la simulazione integrando codice C.
Dopo aver creato una S-Function, basta inserire nel nostro modello il blocco S- Function che si trova nella libreria e inserire nella finestra di dialogo il nome della funzione e i parametri necessari.
Figura 4.19
La funzione limintm in fig.4.19 richiede tre parametri: il limite inferiore, superiore e la condizione iniziale.
Cerchiamo di capire come lavora una S – Function.
Le S- Function sono dei veri e propri blocchi costruiti dall’utente, e come tali hanno le stesse caratteristiche presentate nel paragrafo 4.2.1 valide per qualsiasi blocco, cioè sono descritte da un vettore degli ingressi, delle uscite e degli stati .
Come già detto SIMULINK lavora in due fasi. Per prima cosa avviene l’inizializzazione del modello, durante la quale vengono caricate le librerie, determinate le caratteristiche dei segnali (nome, dimensione, tipo), allocata memoria, stabilito l’ordine d’esecuzione dei blocchi ecc. Successivamente SIMULINK entra nella fase vera e propria di simulazione detta simulation loop che viene attraversato ad ogni passo di simulazione; ad ogni simulation step, SIMULINK esegue tutti i blocchi del modello secondo l’ordine stabilito nella fase di inizializzazione, chiamando delle funzioni che calcolano le uscite, le derivate,
S I M U L A T I O N L O O P
Figura 4.20 I passi di simulazione in SIMULINK
Inizializzazione modello
Calcolo del prossimo istante di campionamento. ( solo per i blocchi con tempo di campionamento
variabile )
Calcolo uscite
Aggiornamento degli stati discreti
Calcolo derivate
Calcolo uscite
Calcolo derivate
Individuazione degli attraversamenti per lo zero
(solo per stati continui e/o con attraversamento dello zero) I N T E G R A Z I O N E
Vediamo meglio le funzioni (chiamate routines) che vengono “chiamate” dal SIMULINK ad ogni passo di simulazione (si parla di S-Function Callback Methods). Queste funzioni si possono classificare come:
• Inizializzazione: durante questo stadio SIMULINK esegue le seguenti operazioni:
1. Inizializza SimStruct, una struttura che contiene informazioni sulla S- Function.
2. Definisce numero e dimensione delle porte di ingresso e di uscita. 3. Definisce gli istanti di campionamento.
4. Predispone aree di memorizzazione e l’array size.
• Calcolo del prossimo istante di campionamento: questo viene calcolato se si sta utilizzando un blocco con passo variabile.
• Calcolo dell’uscita nell’istante di campionamento: al completamento di questa fase le uscite del blocco saranno disponibili nell’istante di tempo attuale.
• Aggiornamento degli stati discreti: ciascun blocco esegue l’aggiornamento degli stati discreti per il prossimo istante.
• Integrazione: questa si applica a modelli con stati continui e/o con attraversamenti dello zero non campionati.
Le C-MEX S-Function sono realizzate come funzioni in linguaggio C. Esiste un set di routine per le S-Function le quali vengono chiamate direttamente da SIMULINK per eseguire il loro compito e possono essere utilizzate nella scrittura delle S-Function.
Nella tabella sono mostrate le routine più importanti:
Stadio della simulazione Routine S –Function
Inizializzazione mdlInitializeSizes
Calcolo istante campion.succ. (facoltativo) mdlGetTimeOfNetxVarHit
Calcolo uscite mdlOutpus
Aggiornamento stati discreti mdlUpdate
Calcolo derivate mdlDerivaties
Mostriamo in fig.4.21 un semplice esempio di scrittura di C-MEX S-Function:
Figura 4.21
Il seguente modello è costituito dalla S-Function timestwo che raddoppia l’ampiezza dell’onda sinusoidale in ingresso e da uno Scope che grafica l’uscita.
Nel dialog box della funzione timestwo non bisogna settare alcun parametro. Il codice che è stato scritto per la S- Function rispetta il seguente schema:
Figura 4.22
Inizio delle simulazione
mdlInitializeSampleTimes mdlInitializeSizes
mdlOutputs
La scrittura del codice è abbastanza complicata; possiamo comunque individuare le seguenti routines:
• MdlInitializeSizes informa che non ci sono parametri da settare e che ci sono un input ed un output.
• MdlInitializeSampleTimes: specifica il tempo di campionamento della S-Function.
Possiamo scegliere tra tre opzioni:
1. Discrete: la S-Function aggiorna le sue uscite ad intervalli fissati specificati dall’utente.
2. Continuos: la S-Function aggiorna le sue uscite ad ogni passo di simulazione.
3. Inherit: la S-Function eredita il tempo di campionamento dei blocchi che in qualche modo ne influenzano il comportamento, come il blocco connesso all’ingresso, il blocco di
destinazione e il tempo di campionamento più veloce nel sistema.
• MdlOutputs: effettua il calcolo numerico per determinare l’uscita. • MdlTerminate: termina il programma.
Dobbiamo dire che il SIMULINK permette di creare una S-Function evitando all’utente di scrivere “a mano” il codice, che come abbiamo potuto constatare, risulta molto complicato anche per un esempio relativamente semplice. Lo strumento che ci permette di fare questo è il S- Function Builder Block.
Basta prendere questo blocco dalla libreria e portarlo all’interno del modello; cliccandoci sopra due volte si apre un pannello; dopo aver inserito i parametri, il blocco stesso penserà automaticamente alla generazione del codice C attraverso le appropriate routines e alla sua compilazione.
Il dialog box contiene i seguenti pannelli:
Initialization Panel
In questo pannello l’utente specifica le informazioni riguardanti gli stati iniziali ed il sampling time (fig.4.23).
Figura 4.23 Initialization Panel
Nell’ Initialization Panel sono presenti i seguenti campi:
- Number of discrete states: indica il numero degli stati discreti presenti nella S-Function.
- Discret states IC: qui si inseriscono i valori iniziali degli stati discreti; i valori vanno passati separati da una virgola.
- Number of continuous states: indica il numero di stati continui.
- Continuous states IC: qui si inseriscono le condizioni iniziali degli stati continui. - Number of parameters: indica il numero dei parametri che sono accettati dal blocco. - Sample mode: determina la lunghezza dell’intervallo tra gli istanti in cui la
S-Function aggiorna le sue uscite. Possiamo scegliere tra continuous, inherit e discrete mode; se si seleziona quest’ultimo l’utente deve settare il valore del sample
Data Properties Panel
In questo pannello l’utente inserisce le informazioni riguardanti gli ingressi, le uscite e i parametri come nome, dimensione, tipo ecc.
Figura 4.24 Data Properties Panel
Libraries Panel
In questo pannello l’utente inserisce le librerie e la locazione di file e funzioni che vengono utilizzati dall’utente in altri pannelli.
Outputs Panel
In questo pannello l’utente inserisce il codice che calcola l’uscita della S- Function ad ogni passo di simulazione.
Figura 4.26 Outputs Panel
All’interno del codice possiamo trovare (in riferimento alla fig.4.26): - il vettore delle uscite; nel nostro caso y0[0].
- Il vettore degli ingressi; nel nostro caso u0[0].
- Il vettore che rappresenta gli stati discreti indicato con xD[ ]. - Il vettore che rappresenta gli stati continui indicato con xC[ ]. - Il vettore dei parametri.
Continuous Derivates Panel
Se la S-Function ha stati continui, l’utente inserisce in questo pannello il codice per il calcolo delle derivate.
Gli stati e le derivate si indicano rispettivamente con xC[ ] e dx[ ] (vedi fig.4.27).
Figura 4.27 Continuous Derivates Panel
Discrete Update Panel
Se la S-Function ha stati discreti, l’utente inserisce in questo pannello il codice che calcola nell’intervallo attuale i valori che gli stati discreti avranno al passo successivo .
Gli stati discreti si indicano con XD[ ] (vedi fig.4.28).
Build Info Panel
L’utente può scegliere alcune opzioni riguardanti la costruzione del MEX file (fig.4.30).
Figura 4.30 Build Info Panel
4.3.1 Un esempio di S- FUNCTION
Di seguito illustreremo un esempio, che abbiamo utilizzato nel nostro progetto.
Si tratta della simulazione di un filtro IIR passa basso dell’ottavo ordine con frequenza di campionamento pari a 93.333 MHz e frequenza di cut-off pari a 20 MHz.
Utilizzando il FilterDesignTool di MATLAB abbiamo calcolato i coefficienti a[i] e b[i] dell’espressione che dovevamo simulare:
8 8 0 0 ( ) ( ) i i i i b y n i a x n i = = ⋅ − = ⋅ −
∑
∑
(4.1)Intialization Panel
In riferimento alla fig.4.31.
Figura 4.31 Initialization Panel
Si tratta di un blocco discreto.
I 16 stati iniziali sono per noi i valori di x(n-i) e di y(n-i) (con i = 1,2,3,4,5,6,7,8) che all’inizio abbiamo fissato a zero.
Data Properties Panel
In riferimento a fig.4.32 e fig.4.33
Figura 4.32 Data Properties Panel - Input ports
Figura 4.33 Data Properties Panel - Output ports
Abbiamo un solo ingresso in, di dimensione pari a 1; rappresenta x(n). Abbiamo una sola uscita out, di dimensione pari a 1; rappresenta y(n).
Outputs Panel
In riferimento a fig.4.34.
Figura 4.34 Outputs Panel
Abbiamo inizializzato i coefficienti a[i] e b[i] e abbiamo scritto il codice che calcola l’uscita secondo l’equazione (4.1).
Discrete Update
In riferimento a fig.4.35.
Figura 4.35 Discrete Update Panel
Abbiamo inserito due cicli for; il primo per gli aggiornamenti di x(), il secondo per quelli di y().