CAPITOLO 4
CONSIDERAZIONI FINALI E CONCLUSIONI
Il problema clinico affrontato in questo studio nasce dall’interesse rivolto alla miocardite, una infiammazione del muscolo cardiaco che può essere causata da molteplici fattori. Escludendo la biopsia endomiocardica, che permette una diagnosi definitiva ma in maniera altamente invasiva, non esiste attualmente alcun esame che confermi la prognosi con assoluta certezza. Tuttavia la Risonanza Magnetica Cardiaca si è rivelata uno strumento importante per aiutare a diagnosticare la miocardite, in particolare in questo studio è stata delineata come soluzione ottimale, poiché offre la possibilità di visualizzare i tessuti sulla base delle proprietà magnetiche dei protoni che li compongono, permettendo di effettuare una indagine del miocardio attraverso la valutazione del tempo di rilassamento longitudinale.
L’interesse nei confronti del tempo di rilassamento T1, come tecnica di indagine in ambito
cardiaco, è relativamente recente. In questo lavoro di tesi è stato fatto riferimento proprio all’utilità di tale tempo T1, affrontandone una quantificazione sia prima che dopo
l’infusione dell’agente di contrasto, come previsto dalla misura dell’ECV.
L’idea di questo studio è nata dalla considerazione che il mercato richiede costantemente un elevato livello di qualità delle immagini digitali fornite dai moderni sistemi di diagnostica medica e dall’esigenza di prestazioni ad alta risoluzione e tempistiche sempre più rapide.
Prendendo spunto da ciò e partendo dall’osservazione che le mappe parametriche solitamente generate nella pratica clinica vantano un’elevata performance nella quantificazione diretta delle variazioni miocardiche, ma si basano su una lenta procedura di acquisizione, in questo lavoro è stato scelto di simulare la realizzazione di tali mappe T1
cercando di superare questo aspetto negativo dovuto al fatto che l’acquisizione dell’intero segnale di rilassamento aumenta fortemente il tempo di misura totale a causa di un lungo tempo di inversione TI.
A livello pratico questo è stato concretizzato realizzando un fantoccio, ovvero un simulatore di immagini di risonanza magnetica capace di restituire in uscita, per ogni pixel, delle curve di decadimento T1 con una certa evoluzione temporale. Gli esperimenti fatti
hanno permesso di costruire e campionare la curva di rilassamento con cui la magnetizzazione longitudinale ritorna al suo livello originale; la curva campionata è stata fittata e sono stati estratti i valori del T1 del miocardio e del ventricolo sinistro. L’utilizzo
del modello non lineare a tre parametri, basato sull’algoritmo di minimizzazione dei quadrati di Levenberg-Marquardt (eq. 1) ha influenzato tutto il resto del lavoro. Infatti, trattandosi di un modello esponenziale difficile da linearizzare, è stato fatto un fitting non lineare.
Il risultato ottenuto in questa prima fase è stato usato come punto di riferimento e confronto per le elaborazioni successive; le diverse modalità di ottimizzazione del codice originale sono state ideate con l’intento di apportare delle modifiche capaci di gestire, nel modo più efficiente possibile, l’obiettivo di velocizzare la procedura inziale ed aumentare l’accuratezza del risultato finale. In ultimo, il codice con l’ottimizzazione ritenuta migliore è stato adattato alle reali immagini di risonanza magnetica, in modo da ottenere un risultato più realistico.
Quanto appena descritto ripercorre brevemente il lavoro svolto ma, analizzandolo più nel dettaglio, è possibile riuscire ad individuare alcune considerazioni che possono rappresentare eventuali limiti o spunti per sviluppi futuri.
A livello di implementazione pratica dell’algoritmo, tutte le immagini RM reali, le mappe riprodotte e le prove effettuate sul fantoccio sono state processate con dei programmi sviluppati tramite l’uso online di IDL che, se da un lato vanta facilità di apprendimento e la possibilità di interpretare il formato DICOM, la versione qui utilizzata, proprio per il fatto di poter lavorare solo in presenza di connessione ad internet costituisce un punto a sfavore. Per quanto riguarda la Risonanza Magnetica Cardiaca, i risultati raggiunti in questo lavoro confermano il vantaggio di prediligere tale tecnica non invasiva, che si dimostra un eccellente metodo clinico nella diagnosi di una patologia di difficile interpretazione come la miocardite, pur tenendo conto della sua complessa modellizzazione cinetica che impedisce di rimuovere completamente fattori di confondimento come: la frequenza cardiaca, la composizione corporea e la variabilità della clearance renale.
La necessità di misurare il tempo di rilassamento T1 sia prima che dopo l’iniezione del
bolo, come previsto dalla misura dell’ECV, trova qui una ulteriore conferma, perché le differenze numeriche ottenute nei due diversi contesti implicano il grado di diffusione
dell’agente di contrasto e questo aiuta a distinguere un tessuto sano da uno malato, anche perché sarebbe difficile basarsi sul solo valore del T1 assoluto.
Sul piano numerico, poiché nella realtà il valore del T1 non si conosce a priori e non può
essere calcolato esplicitamente, si è consapevoli che le prove effettuate sul fantoccio sono servite unicamente a convalidare la metodologia di stima dell’errore commesso sul rilassamento T1. Inoltre, qui non è stato tenuto conto dell’influenza che il valore del tempo
T1 subisce al variare dei parametri fisiologici dei pazienti coinvolti e né di eventuali
artefatti da movimento verificatisi durante l’acquisizione, perciò tutti i risultati ottenuti sono da valutare in relazione a tale precisazione.
Un’altra puntualizzazione di cui tener conto è che le mappe parametriche create, la Fitting Error Map, la T1 Map e la T1 Phantom Map, sono state realizzate ponendosi nella
condizione peggiore, ovvero considerando un numero di frames molto più grande di quello effettivamente usato nella realtà e questo incide sulle tempistiche coinvolte.
Sempre nell’analisi dei risultati, va sottolineato che in questo lavoro il punto di inversione preso in considerazione è, tra i campioni analizzati, quello che registrava il minimo errore %. Nella realtà, però, può capitare che il T0 appartenga ad una curva non ben definita,
perciò il minimo non si vede bene in quanto “coperto” dal rumore. La scelta del T0 tra uno
dei campioni qui effettuata è giustificabile dall’avere una sequenza ad alta risoluzione; ma se si considerasse una curva a bassa risoluzione, come le vere sequenze T1, si troverebbe
una approssimazione del punto di inversione.
Quest’ultima affermazione ha lasciato dedurre che il tempo di calcolo e il numero di iterazioni sono legate più al numero di frames su cui si lavora, che non all’entità del rumore. Infatti, la velocità di IDL, come di qualsiasi altro software simile, di interagire con i vettori, prescinde dal valore dei singoli elementi contenuti nel vettore.
È emerso appunto, che il tempo di calcolo in pre-contrast è nettamente superiore a quello impiegato in post-contrast, proprio perché il numero di frames con cui si lavora nel primo caso è pari a 180, rispetto ai 60 in post-contrasto.
Con lo scopo di ridurre l’elevato tempo di calcolo iniziale impiegato per la realizzazione del fantoccio (dell’ordine delle ore), sono state proposte varie ottimizzazioni. Analizzandole più in dettaglio è possibile riportare le seguenti considerazioni:
• La modifica iniziale apportata con successo è stata l’eliminazione del background (caratterizzato dall’assenza di segnale utile), che ha comportato una netta riduzione del tempo di calcolo, passando da un certo numero di ore per il conseguimento dell’output del programma a pochi minuti.
Questi dati hanno portato a concludere che nel fondo sono presenti errori alti che non danno alcun contributo informativo utile, per questo è risultato fondamentale il filtraggio del background.
• Anche l’idea di utilizzare l’alto grado di correlazione dei pixel tra loro adiacenti ha dato ottimi risultati; l’unico neo è dovuto al fatto che tale ottimizzazione può risultare fallimentare in corrispondenza delle zone di confine tra un tessuto e l’altro. • Il tentativo di lavorare in un ristretto intervallo Δt ha confermato che, non conoscendo a priori il miglior range Δt per l’algoritmo, la procedura è più veloce in corrispondenza di un intervallo Δt minore. Nonostante la netta differenza tra l’errore e il tempo presentati per Δt=1 e per il Δt massimo, si nota che l’andamento decrescente dell’errore T1 si assesta comunque su un plateau dopo un certo valore
di Δt.
• L’esperimento di sottocampionare la curva di decadimento assegnando un diverso peso ai campioni è risultato fallimentare, infatti i risultati raccolti hanno dato modo di constatare che azzerare il peso di alcuni campioni non implica che questi non vengano del tutto analizzati, bensì sono solo considerati con un valore diverso; perciò non è stato registrato alcun risparmio in termini di tempo di calcolo rispetto all’ottimizzazione precedente, né c’è stato un guadagno in termini di errore percentuale.
• Il tentativo di linearizzazione del fitting è stato sfruttato per ricavare il valore del tempo T0 di ogni singolo pixel in tempi brevi, evitando così sia di ricorrere al
metodo di Nekolla e alla sua procedura iterativa alquanto dispendiosa in termini di tempo di calcolo, sia è stata accantonata l’idea di limitare la ricerca del miglior tempo T0 all’interno dell’intervallo Δt. Se da un lato si è rivelato altamente
soddisfacente il ridotto tempo di calcolo impiegato per il conseguimento dei risultati, d’altro canto è vero anche che gli errori percentuali ottenuti sul T1 non si
sono apprezzati allo stesso modo. Tale risultato poco incoraggiante però non è del tutto invalidante perché se ne può comunque apprezzare il tempo di lavoro così veloce ed essere considerato un metodo vantaggioso per applicazioni temporanee che possono servire per una stima iniziale della mappa T1.
Maggiori conferme di tali considerazioni sono emerse dal confronto dei risultati ottenuti relativi sia ad uno stesso paziente che tra pazienti diversi. La scelta di quale algoritmo
proporre come migliore per essere adattato al caso delle immagini RM reali è strettamente legata alle richieste mediche e agli utilizzi futuri. Infatti, in alcuni contesti potrebbe risultare vincolante la durata del tempo di calcolo, mentre in altri casi potrebbero dover essere rispettati dei precisi limiti inerenti le percentuali d’errore.
Questo è il motivo per cui è stato pensato che la scelta migliore dovrebbe cadere sull’algoritmo capace di soddisfare il miglior compromesso tra un rapido tempo di calcolo ed una soddisfacente percentuale d’errore.
Limitando le considerazioni all’errore percentuale commesso sul T1, la scelta potrebbe
cadere sull’ottimizzazione 6, che è quella che presenta una notevole riduzione dell’errore percentuale sul T1, però la sua validità è limitata a sequenza molto lunghe.
Per le considerazioni relative all’errore percentuale di fitting, bisogna tener conto che lo scopo del fitting eseguito con MPFIT (e con LINFIT nel caso dell’ottimizzazione 7) è stato quello di cercare il set di parametri che meglio fitta i dati. Tutte le ottimizzazioni hanno riportato un errore percentuale di fitting inferiore rispetto al caso del fantoccio base, proprio perché in tutte è stato rimosso il fondo.
L’altro parametro che può influenzare la scelta del migliore algoritmo è la durata del tempo di calcolo. È risultato che le ottimizzazioni più rapide si sono rivelate essere quelle con un errore percentuale maggiore. Ad ogni modo, ciascuna ottimizzazione proposta ha raggiunto l’obiettivo iniziale di velocizzare la procedura di realizzazione delle mappe, perché ciascuna riesce a conquistare una riduzione temporale superiore all’89%, passando da un certo numero di ore richieste in fase iniziale a pochi minuti impiegati nelle ottimizzazioni, e questo può considerarsi un ottimo risultato. Ovviamente, le tempistiche impiegate cambiano a seconda che si stiano facendo delle misurazioni in pre- o in post-contrasto.
Volendo trovare un compromesso e scegliere una procedura che abbia in sé la facoltà di produrre una mappa con un errore percentuale sul T1 accettabile e con tempistiche
soddisfacenti, sono state selezionate l’ottimizzazione 6 e la numero 5, in quanto entrambe rispondono in maniera positiva alle richieste sollevate ed hanno il valore Δt che si assesta più velocemente sul plateau (rispetto alle altre procedure che seguivano la logica della finestra di ampiezza Δt). Tuttavia, la 6 è valida solo per sequenze molto lunghe, con numerosi intervalli RR; per tale motivo la scelta potrebbe ripiegare sull’accoppiata 7+8.
Fig. 4.1: Grafici in cui è possibile osservare come variano gli errori % commessi sul T1 (in alto), gli errori % di fitting (al
centro) e i tempi di calcolo (in basso) in pre-contrasto (a sinistra) e in post-contrasto (a destra) nelle diverse procedure di ottimizzazione rispetto al fantoccio di partenza (in rosso). Sono stati rappresentati i valori medi±SD dei diversi rumori σ appartenenti al data-set VAR. Gli output dell’ottimizzazione 7 (“linearization”), non sono qui riportati in quanto utilizzati solo per il conseguimento di dati utili alla realizzazione dell’ottimizzazione 8.
0 1 2 3 4 5 Errore % T1 %
Pre-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom 0 0 1 2 3 4 5 Errore % T1 %Post-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom 0 0 1 2 3 4 5 Errore % Ditting %Pre-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom 0 0 1 2 3 4 5 Errore % Ditting %Post-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom ≈370 0 10 20 30 40 50 60Tempo di calcolo
m in
Pre-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom 0 ≈150 0 10 20 30 40 50 60Tempo di calcolo
m in
Post-contrasto
No BK Neighbors Δt range Diff. weight Flett method 2P Dit T0 lin Phantom 0I risultati ottenuti adattando il codice scritto in IDL al caso delle immagini di risonanza magnetica vere hanno dato conferma delle valutazioni riguardanti le procedure di ottimizzazione e dei tempi di calcolo impiegati.
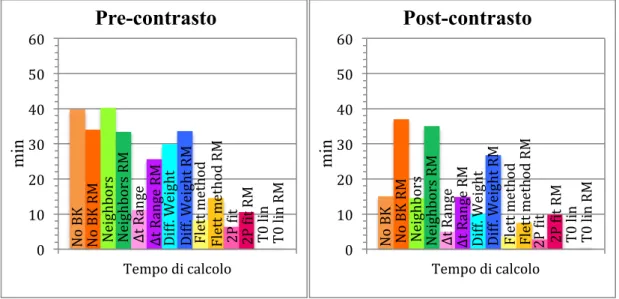
Fig. 4.2: Grafici in cui è possibile osservare come variano i tempi di calcolo in pre-contrasto (a sinistra) e in post-contrasto (a destra) nelle diverse procedure di ottimizzazione del fantoccio rispetto al codice adattato al caso delle immagini RM reali. La differenza tra i due casi è che nel fantoccio c’era un minor numero di tessuti da discriminare e, dunque, le tempistiche erano più rapide; nonostante le misure non coincidano perfettamente, si può dire che le simulazioni non si distinguono troppo dalle tempistiche reali. Sono stati rappresentati i valori medi±SD dei tempi di calcolo impiegati nei diversi pazienti. Gli output dell’ottimizzazione 7 (“linearization”), non sono qui riportati in quanto utilizzati solo per il conseguimento di dati utili alla realizzazione dell’ottimizzazione 8.
Dunque, l’intento di dar vita ad una procedura intelligente di elaborazione delle immagini in tempi rapidi e con errori percentuali bassi è stato pienamente raggiunto.
Gli obiettivi futuri comprendono la volontà di proseguire il percorso intrapreso in questo studio nella speranza che tale tecnica, con le ulteriori opportune modifiche, possa trovare effettiva applicazione in ambito biomedico, sia per scopi diagnostici sia per fornire al medico le informazioni necessarie in fase pre-operatoria. Il lavoro potrebbe essere approfondito concentrandosi sull’eliminazione del background, in particolare riadattandola in maniera tale da isolare il solo oggetto sotto indagine. Le principali aree di interesse in tale categoria riguardano i tessuti inerenti il cuore.
No B K No B K RM Neighb ors Neighb ors RM Δt Ra nge Δt Ra nge RM Diff. W eig ht Diff. W eig ht R M Fl et t me th od Fl et t me th od R M 2P Dit 2P Dit RM T0 l in T0 l in RM 0 10 20 30 40 50 60
Tempo di calcolo
m in
Pre-contrasto
No B K No B K RM Neighb ors Neighb ors RM Δt Ra nge Δt Ra nge RM Diff. W eig ht Diff. W eig ht R M Fl et t me th od Fl et t me th od R M 2P Dit 2P Dit RM T0 l in T0 l in RM 0 10 20 30 40 50 60Tempo di calcolo
m
in