Facoltà di Ingegneria Industriale e dell'Informazione
Corso di Laurea Magistrale in Ingegneria Informatica
Aggregatori di informazioni
Relatore:Chiara Francalanci
Correlatore: Francesco Merlo
Autore: Simone De Luca
Matricola:764635
Simone De Luca
Indice
1 Stato dell’arte 11 1.1 Definizione ed esempi . . . 12 1.1.1 Motori di ricerca . . . 13 1.1.2 Motori di confronto . . . 17 1.1.3 Aggregatori di notizie . . . 19 1.1.4 Social media . . . 22 1.1.5 Mash-up . . . 24 1.1.6 Magazzini online . . . 26 1.1.7 Gestori e profitti . . . 28 1.1.8 Volume utenti . . . 281.2 Valutazione delle fonti . . . 28
1.2.1 Valutazione delle fonti nei motori di ricerca . . . 28
1.2.2 Algoritmi di valutazione . . . 31 1.2.3 Tabella comparativa . . . 33 1.3 Considerazioni generali . . . 33 1.3.1 Motori di ricerca . . . 33 1.3.2 Motori di confronto . . . 35 1.3.3 Aggregatori di notizie . . . 35 2 Classificazione 37 2.1 Classificazione in base allo scopo . . . 38
2.2 Classificazione in base alla selezione delle fonti . . . 39
2.3 Classificazione in base alla valutazione delle fonti . . . 40
2.4 Classificazione per funzionalit`a . . . 41
2.5 Classificazione degli esempi proposti . . . 42
2.6 Altri criteri di classificazione . . . 42
2.6.1 Criterio di localit`a(o diffusione) . . . 42
2.6.2 Classificazione per modalit`a di guadagno . . . 44
2.6.3 Classificazione in base alle dimensioni . . . 44
3 Test di FourSquare 47 3.1 Visione generale . . . 47
3.1.1 Interfaccia e ricerca . . . 48
3.1.2 Valutazioni dell’utente . . . 50 3
3.2 Test dell’applicazione . . . 50
3.3 Conclusioni . . . 50
4 Android App: Ville e Giardini toscani 53 4.1 Introduzione . . . 53
4.1.1 La piattaforma di sviluppo: Android e Eclipse . . . 53
4.1.2 Obiettivi e motivazioni del progetto . . . 54
4.2 Analisi dei Requisiti . . . 56
4.2.1 Visione generale del progetto . . . 56
4.2.2 Dominio applicativo . . . 57
4.2.3 Use Case Diagram . . . 57
4.3 Progettazione del sistema . . . 58
4.3.1 Progettazione del database . . . 58
4.3.2 Progettazione dell’app . . . 60
4.4 Screenshot dell’applicazione . . . 64 5 Sviluppi futuri 73
Elenco delle figure
1.1 Esempio di ricerca con Google . . . 15
1.2 Google Now . . . 16
1.3 Flipboard . . . 20
2.1 Classificazione per scopo . . . 39
2.2 Classificazione per selezione . . . 40
2.3 Classificazione per valutazione . . . 41
2.4 Classificazione per funzionalita . . . 42
2.5 Classificazione per diffusione . . . 44
2.6 Classificazione per guadagni . . . 46
2.7 Classificazione per dimensioni . . . 46
3.1 Interfaccia Foursquare per Android . . . 49
4.1 Overview del sistema . . . 56
4.2 Approccio Jackson-Zave . . . 57
4.3 Use Case Diagram . . . 59
4.4 Diagramma Entit`a-Relazione . . . 61
4.5 Package Diagram . . . 62 4.6 Class Diagram . . . 65 4.7 SearchVillaActivity . . . 66 4.8 SearchVillaActivity . . . 67 4.9 VillaActivity . . . 68 4.10 VillaActivity . . . 69 4.11 VillaActivity . . . 70 4.12 VillaActivity . . . 71 4.13 VillaActivity . . . 72 5
Elenco delle tabelle
1.1 Motori di ricerca . . . 17
1.2 Motori di confronto . . . 19
1.3 Aggregatori di notizie . . . 21
1.4 Aggregatori di social media . . . 23
1.5 Siti mash-up . . . 26
1.6 Magazzini online . . . 27
1.7 Gestori e profitti . . . 29
1.8 Volume utenti mensile . . . 30
1.9 Valutazioni delle fonti . . . 34
2.1 Classificazione degli esempi . . . 43
2.2 Localit`a degli esempi . . . 45
Abstract
Al giorno d’oggi gli aggregatori svolgono un ruolo fondamentale per la ricer-ca di informazioni nel Web. Basti pensare ai motori di ricerricer-ca: senza di essi sarebbe impossibile orientarsi nella marea di informazioni disponibili sul Web. In questa tesi si cercer`a di fare un punto sullo stato dell’arte di questo genere di applicazioni, presentandone anche una classificazione. Come conclusione si `
e sviluppato un aggregatore di informazioni di ville e giardini, nell’ambito del turismo in Toscana.
Capitolo 1
Stato dell’arte
Quando cominciai a trafficare con il programma che avrebbe poi fatto nascere l’idea del World Wide Web, lo chiamai Enquire, da Enquire Within upon Everything, entrate pure per avere
informazioni su ogni argomento. Tim Berners-Lee, L’architettura
del nuovo Web, 1999
Al giorno d’oggi il Web `e uno dei principali e pi`u usati canali per il veicolo di qualsiasi tipo di informazione; viene consultato per conoscere le notizie del giorno, per conoscere le previsioni del tempo, per consultare voci su Wikipedia, per cercare un locale in cui passare la serata ecc. Non esiste oggi nessuna azien-da rilevante che non sia dotata di un WIS (Web Information System) attraverso il quale espone al resto della rete informazioni su di essa, talora vendendo anche beni e servizi. Accanto ai classici WIS si sono diffusi esponenzialmente negli ultimi anni i social media, ovvero siti Web il cui contenuto `e principalmente user driven quali blog, wiki, forum,siti di media sharing e social network (come Facebook e Twitter). Nei social media gli utenti collaborano a creare, valutare e distribuire informazione. Pensiamo ad esempio al portale TripAdvisor dove gli utenti pubblicano recensioni e valutazioni di hotel ristoranti e attrazioni tu-ristiche.
Con l’avvento delle nuove tecnologie portatili come smartphone e tablet, i con-tenuti presenti sul Web sono diventati fruibili pressoch´e ovunque, grazie alle
connessioni Wi-Fi e GSM. Si stima che il numero di persone che abbiano acces-so oggi al World Wide Web siano circa 2,4 miliardi [1].
Con la crescita della fruibilit`a del Web e del numero di utenti che potevano ave-re accesso ad esso, `e cresciuto esponenzialmente anche il numero delle pagine Web esistenti; secondo una stima effettuata da Google nel 2008, il numero delle pagine Web ammonta ad oltre 1000 miliardi[2]. E’ chiaro che di fronte ad un universo cos`ı sterminato di pagine, all’utente della rete si pongono due problemi fondamentali:
1. dove trovare l’informazione: come `e possibile orientarsi e trovare ci`o di cui si ha bisogno all’interno della rete Web? ;
2. capire dove l’informazione `e affidabile: una volta che si trova ci`o che si `
e cercato, come `e possibile capire se l’informazione a cui si `e arrivati `e affidabile?.
Trovare l’informazione di cui si ha bisogno coinvolge l’utente in una fase di ricerca; `e chiaro che districarsi tra miliardi di pagine senza meccanismi che vengano in aiuto dell’utente `e praticamente impossibile e diventa un fattore time-consuming.
Il secondo problema riguarda invece l’affidabilit`a dell’informazione: come `e pos-sibile sapere tra le varie fonti trovate quali sono affidabili e quali no? A queste problematiche di frammentazione e di affidabilit`a delle fonti provano a dare una soluzione i cosiddetti aggregatori di informazione che verranno approfonditi nei paragrafi seguenti e di cui si prover`a a dare una classificazione.
1.1
Definizione ed esempi
Prima di cercare di delineare cosa siano gli aggregatori di informazioni, speci-fichiamo meglio alcune definizioni preliminari. In particolare, nel contesto che stiamo trattando definiamo come:
• utente: un utilizzatore del Web, che pu`o accedervi da una qualsiasi piattaforma, desktop o mobile;
• informazione: tutto ci`o che `e contenuto in una pagina Web; pu`o essere in un qualsiasi formato supportato (testo, video, immagine ecc..) e pu`o rappresentare di tutto (una descrizione, una notizia , una coordinata su una mappa ecc..);
• content provider o fonte: un fornitore di contenuti che siano accessibile tramite il Web; i contenuti possono essere resi disponibili sia sotto forma di pagina Web che di web-service;
• Pagina Web: documento digitale accessibile all’utente attraverso la re-te Inre-ternet e l’utilizzo di applicazioni denominare-te web-browser(Firefox, Chrome, Internet explorer, ecc..);
• Web services: secondo la definizione del W3C i web-services sono sistemi software in grado di garantire un alto grado di interoperativit`a in un con-testo distribuito come il Web [3]; essi espongo servizi tramite interfacce, definite attraverso documenti in formato XML.
Il concetto di aggregatore di informazione racchiude al suo interno un’ampia gamma di applicazioni software e Web. Secondo Wikipedia un aggregatore `
e un qualsiasi software o applicazione web che abbia il compito di ricercare informazioni o contenuti frammentati sul web e riproporli in forma aggregata per una migliore fruizione.[4]. Lo scopo di un aggregatore `e quello di riunire materiale informativo proveniente da fonti diverse in un unico contenitore in modo da ridurre il tempo e lo sforzo necessario all’utente per la fruizione dei contenuti. In questo modo l’utente avr`a uno spazio di informazione nuovo, completamente personalizzato e dinamico.
Esistono oggi numerosi esempi di aggregatori che si diversificano uno dall’altro per diversi fattori. Nei paragrafi seguenti si fornir`a una rassegna di esempi significativi cercando di focalizzare l’analisi su due fattori,:
1. quali sono i criteri di scelta delle fonti da parte dell’aggregatore; 2. quali sono i criteri di valutazione delle fonti da parte dell’aggregatore. Questi due criteri vanno a rispondere alle due problematiche precedentemente espresse, ovvero come l’utente pu`o reperire l’informazione e come pu`o fidarsi o meno di una determinata fonte. Nei paragrafi seguenti si trover`a una carrellata di esempi di aggregatori rilevanti che si possono trovare sul Web. Nel Capitolo 2 si prover`a poi a dare una classificazione degli aggregatori di informazioni tenendo conto delle caratteristiche emerse dai vari esempi qui di seguito esposti.
1.1.1
Motori di ricerca
Un tipo fondamentale di aggregatori di informazione sul Web sono sicuramente i motori di ricerca: essi sono fondamentali per potersi orientare nello sterminato
mondo del Web. Il loro ruolo `e talmente fondamentale che spesso, come home-page quando si apre un browser. Spesso funzionalit`a di ricerca sono integrate all’interno del browser stesso: basti pensare alla barra degli indirizzi di Chrome che mostra suggerimenti all’utente in base alla stringa che viene man mano in-serita.
I motori di ricerca sono quindi pagine Web che permettono all’utente di svolgere operazioni di search di altre pagine; essi prendono in input una serie di parole che l’utente ritiene significative e restituiscono ad esso una serie di link a pagine, ordinate sulla base di uno score a loro assegnato.
Un primo problema che appare chiaro `e la mole infinita di informazione su cui i motori devono effettuare la ricerca: come detto in precedenza il numero totale delle pagine Web totali stimate supera i mille miliardi, e per qualsiasi motore di ricerca sarebbe impossibile percorrere in tempi accettabili per l’utente un nume-ro cos`ı elevato di link; il motore di ricerca scandaglia quindi non tutte le pagine Web esistenti, ma solo un loro sottoinsieme che viene chiamato directory[5]. Un sito Web entra a far parte della directory di un motore di ricerca tramite un processo di indicizzazione: una volta che un sito Web viene indicizzato da un motore di ricerca potr`a poi comparire tra i risultati che il motore restituisce all’utente. L’operazione di indicizzazione pu`o essere svolta in proprio oppure esistono aziende di Web Hosting che la effettuano a pagamento[6].
Un altro aspetto fondamentale nell’analisi dei motori di ricerca `e capire il mec-canismo con cui vengono ordinati i risultati restituiti all’utente. L’importanza dell’algoritmo di ordinamento `e lampante: l’utente privileger`a le pagine Web presenti tra i primi risultati, e difficilmente `e disposto a scorrere troppo la lista dei risultati proposti. L’operazione attraverso la quale i siti Web vengono ot-timizzati affinch´e essi possano comparire il pi`u in alto possibile nei risultati di ricerca `e detta posizionamento. Possiamo vedere il meccanismo di ordinamento dei risultati come il modo in cui un motore di ricerca valuta le proprie fonti, che sono le pagine Web che indicizza. I risultati sono ordinati non solo in ba-se all’algoritmo di ordinamento proprio del motore di ricerca; possono ottenere posizioni migliori infatti dei link sponsorizzati cio`e inserzioni a pagamento per le quali l’inserzionista acquista le parole per le quali vuole comparire[6]. Questa tecnica viene anche chiamata pay-for-placement e permette alle aziende proprie-tarie del sito Web di ottenere un posizionamento privilegiato sui risultati forniti quando l’utente inserisce certe parole chiave.
Oltre i normali motori di ricerca esistono anche i motori di metaricerca che in seguito ad una query da parte dell’utente utilizzano diversi motori di ricerca e
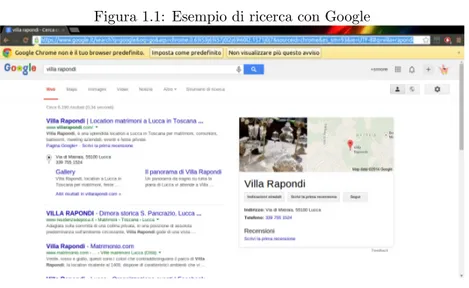
Figura 1.1: Esempio di ricerca con Google
aggregano i risultati in un unico elenco; in questo modo si cerca di ovviare all’ impossibilit`a di un motore di ricerca di indicizzare l’intero universo delle pagine Web e quindi offrire una prospettiva di ricerca pi`u ampia senza dover compiere la stessa ricerca pi`u volte su diversi motori.
Il pi`u famoso motore di ricerca al giorno d’oggi `e sicuramente Google.Fondato da Larry Page e Sergey Brinn nel 1997, oggi Google non `e solo un semplice mo-tore di ricerca ma un aggregamo-tore di numerosi servizi: fornisce mappe di tutto il mondo tramite Google Maps, ha un proprio social network(Google Plus), un proprio sistema operativo che funziona su smartphone e tablet(Android) e anche un proprio browser (Google Chrome). Dalla pagina web di Google l’utente ha la possibilit`a di effettuare diverse tipologie di query: si possono cercare pagine Web, notizie, foto, video, prodotti acquistabili su tantissimi e-store.
Google restituisce all’utente i risultati ordinati secondo il suo algoritmo proprie-tario chiamato PageRank. Il PageRank `e un algoritmo di analisi che assegna un peso numerico ad ogni elemento di un collegamento ipertestuale, d’un insieme di documenti, come ad esempio il World Wide Web, con lo scopo di quantificare la sua importanza relativa all’interno della serie[7].Il concetto di PageRank ‘e legato a quello di popolarit‘a: lo scopo che si prefigge ‘e quello di indicare le pagine o i siti di maggiore rilevanza in relazione ai termini ricercati. Questo metodo pu`o esser descritto come analogo ad una elezione nella quale ha diritto al voto chi pu`o pubblicare una pagina web, e il voto viene espresso attraverso i collegamenti in essa presenti. I voti non hanno tutti lo stesso peso: le pagine web pi‘ u popolari esprimeranno, coi propri link, voti di valore maggiore.
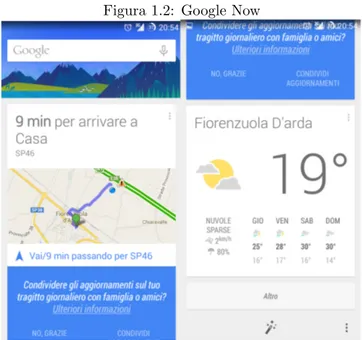
L’in-Figura 1.2: Google Now
terpretazione e la definizione della popolarit`a di un sito non sono per‘o legate soltanto a queste votazioni, ma tengono conto anche della pertinenza del con-tenuto di una pagina, nonch´e delle pagine correlate, con i termini ed i criteri della ricerca effettuata. Altro importante elemento che lega un sito alla sua popolarit`a `e relativo alla diffusione, alla popolarit`a dell’argomento trattato in esso. Per argomenti poco richiesti i siti raggiungono facilmente le prime posi-zioni nelle ricerche, ma altrettanto verosimilmente posseggono e mantengono un page rank che potrebbe essere bassissimo. Tutto questo permette, o perlomeno ha lo scopo, di attuare un controllo incrociato che garantisca la validit`a dei ri-sultati di ricerca.
Uno degli strumenti di aggregazione pi`u interessanti di Google `e sicuramente la mobile app Google Now: disponibile su Android e IOS essa fornisce all’utente un homepage creata dinamicamente in base alla posizione in cui l’utente si trova (sfruttando i meccanismi di geolocalizzazione disponibili sui dispositivi mobile), alle preferenze dell’utente e alle sue ultime ricerche. Un esempio di schermata fornita da Google Now `e nella figura seguente.
Come `e possibile vedere esso fornisce automaticamente diverse informazioni all’utente (previsioni meteo del luogo in cui si trova, tragitto per tornare a casa e informazioni sul traffico). Tutto questo viene fatti automaticamente senza
nessuna query da parte dell’utente. Altri esempi di informazioni che fornisce Google Now sono:
• informazioni sui risultati delle partite della squadra/e del cuore dell’utente, sulla base di ricerche effettuate in precedenza da esso;
• informazioni sull’andamento in borsa delle azioni di interesse per l’utente; • informazioni su luoghi turistici che si trovano nelle vicinanze dell’utente. • segnalazione di nuovi articoli e notizie su pagine che l’utente ha visitato
recentemente.
Riassumendo quindi i motori di ricerca cercano l’informazione tra le pagine indicizzate nel proprio database;inoltre il meccanismo di page ranking fornisce dei risultati che vengono ritenuti affidabili rispetto alle parole chiave fornite dall’utente.
Nome Descrizione Selezione delle fonti
Valutazione delle fonti
Google Motore di ricerca di pagine Web
Tramite indicizza-zione
Tramite algoritmo (PageRank) Tabella 1.1: Motori di ricerca
Link utili:www.google.it
1.1.2
Motori di confronto
Accanto ai classici motori di ricerca, un’ altra tipologia di aggregatori che sta prendendo sempre pi`u piede sono i cosiddetti motori di confronto; essi sono tipi-camente delle web-application che a fronte di informazioni ricevute dagli utenti, effettuano delle ricerche sul Web finalizzate al recupero di offerte relative a de-terminati prodotti o servizi in modo tale da riportare sulle proprie pagine, in forma aggregata i migliori risultati individuati.
Un esempio di motore di confronto `e il sito Indeed, un motore di metaricerca di annunci di lavoro. Il sito raccoglie annunci di lavoro da migliaia di siti web, incluso bacheche di lavoro, quotidiani, associazioni, e pagine d’impiego di com-pagnie private. Indeed aggiunge su richiesta gratuitamente qualsiasi bacheca di lavoro online che rispetti le linee guida dettate nel sito.
questo motore `e trovare le tariffe telefoniche offerte dai vari operatori del settore che sono pi`u convenienti per l’utente sulla base dell’analisi del traffico reale del-l’utente. MobiSave effettua il confronto con oltre 50 mila piani tariffari possibili recuperando i dati dell’utente direttamente dal portale del suo attuale operato-re e fornisce due tipi di risultati in forma aggoperato-regata: spesa mensile e risparmio annuale.
Interessante `e anche il caso del sito Ciao.it : Ciao `e un sito web di propriet`a dell’azienda Ciao GmbH su cui `e basata una comunit`a virtuale di consumatori. Si tratta di portale d’opinione, ovvero un servizio d’opinione sugli acquisti, dove gli utenti possono pubblicare le proprie recensioni su diversi prodotti e servizi. L’inserimento dei prodotti e servizi commerciali da recensire `e controllato dal-l’azienda; le valutazioni dei vari prodotti sono ottenute attraverso la media dei punteggi dati dagli iscritti. Il sito permette di confrontare i prezzi di prodotti e servizi provenienti da vari negozi online; il sito offre inoltre una funzione di comparazione avanzata che consente di ottenere una tabella di confronto pro-dotti che illustra le principali caratteristiche dei propro-dotti scelti.
Un’altro motore di comparazione `e il portale Kelkoo , un sito focalizzato al confronto di prezzi di beni e servizi; Kelkoo permette di confrontare i prezzi di diversi negozi online passando in rassegna ogni giorno circa 3 milioni di offerte. Kelkoo effettua la comparazione tra l’insieme dei negozi online con cui collabo-ra; un utente che effettua la ricerca e seleziona un offerta viene reindirizzato al sito del negozio online che propone quell’offerta.
Simile a Kelkoo `e il sito TrovaPrezzi.it, un motore di ricerca per acquisti online che ricerca nei vari negozi online affiliati al sito; `e possibile per tutti i possessori di siti di e-commerce diventare inserzionisti del sito e vedere indicizzati i propri prodotti nelle ricerche effettuate su Trovaprezzi. I prodotti trovati vengono re-stituiti in ordine crescente di prezzo.
Link utili: Indeed: www.indeed.com MobiSave: www.mobisave.it Ciao: www.ciao.it Kelkoo: www.kelkoo.it TrovaPrezzi: www.trovaprezzi.it
Nome Descrizione Selezione delle fonti
Valutazione delle fonti
Indeed Portale per la ri-cerca di annunci di lavoro
Aggiunte su richie-sta dall’operatore
Tramite algoritmo MobiSave Sito per la
compa-razione di tariffe di telefonia mobile Selezionate dall’o-peratore Tramite algoritmo di comparazione Ciao.it Comunit`a virtuale
di consumatori con opinioni su acquisti Selezionate dall’o-pertatore Valutate dall’uten-te
Kelkoo Motore di confronto di beni e servizi Selezionate dall’o-peratore e tramite iscrizione Tramite algoritmo di comparazione TrovaPrezzi Motore di confronto
di beni e servizi Selezionate dall’o-peratore e tramite iscrizione Tramite algoritmo di comparazione Tabella 1.2: Motori di confronto
1.1.3
Aggregatori di notizie
Sicuramente gli aggregatori Web pi`u conosciuti e diffusi sono le applicazioni feed-reader, che possono essere applicazioni sia software che Web che raccoglie contenuti dal Web (come news, blog, podcast..)tramite Web-feed e li espone all’utente in un unico spazio di informazione riducendo il tempo e gli sforzi ne-cessari per seguire regolarmente gli aggiornamenti di un sito Web.
Il Web-feed, detto anche semplicemente feed, `e un unit`a di informazioni for-mattata secondo determinate specifiche (solitamente XML)[8]. Un feed fornisce all’utente un contenuto aggiornato di frequente; un feed-reader effettua il par-sing di un feed e ne incorpora il contenuto (o comunque parte di esso) in una pagina HTML che l’utente pu`o visualizzare tramite browser web. Solitamen-te un lettore di feed `e in grado di svolgere funzioni avanzate come rilevare gli aggiornamenti automaticamente. La fruizione del feed da parte dell’utente `e molto semplice in quanto basta aggiungere il feed al proprio lettore. Esempi di lettori di feed sono Google Reader, RSSOwl, Akregator ecc..
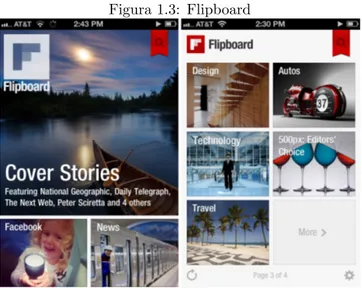
Un altro esempio di aggregatore di notizie `e Flipboard che `e una applicazione per smartphone e tablet disponibile su varie piattaforme. Lo scopo di Flipboard `
e quello di consentire all’utente di crearsi un vero e proprio magazine personale. L’utente pu`o scegliere di includere fonti tra varie testate e inoltre pu`o scegliere di aggiungere anche sezioni social in cui scorrono post dei propri account di
Figura 1.3: Flipboard
Twitter e Facebook.
Altri tipi di aggregatori di news sono quelli in cui gli utenti suggeriscono le notizie all’aggregatore come TzeTze e Digg.
TzeTze (www.tzetze.it) `e un aggregatore che pubblica in tempo reale le notizie dalla rete che vengono scelte dagli utenti. `E un palinsesto dinamico originato dagli utenti, aggiornato ogni mezz’ora, che seleziona da siti rigorosamente solo on line, che non hanno quindi una derivazione cartacea o televisiva, le informa-zioni in base alla loro popolarit`a e attualit`a. L’inserimento del simbolo della mosca () a margine della notizia pubblicata nel proprio sito o blog consente di farla votare ed essere visibile nel portale tzetze. Questo bottone consente agli utenti di segnalare il contenuto del blog. Il bottone TzeTze [] nel tuo blog con-sente ai tuoi utenti di segnalare il contenuto del tuo blog perch´e sia pubblicato su www.tzetze.it.Quando un utente clicca il bottone TzeTze nel tuo blog, un estratto dell’articolo segnalato viene inserito per la pubblicazione nell’homepa-ge di TzeTze, accompagnato da una immagine e da un link che riporta al sito. Quando un utente clicca nel blog il bottone TzeTze associato a un post gi`a pubblicato, aumenter`a il numero di voti associato all’articolo.
Digg `e un sito Web di social news; esso permette agli utenti del sito di votare i contenuti web verso l’alto o verso il basso. Creato nel 2004 da Kevin Rose , Owen Byrne, Ron Gorodetzky e Jay Adelson, la funzione principale del sito `e quello di consentire agli utenti di scoprire, condividere e raccomandare
conte-nuti web. I membri della comunit`a possono segnalare una notizia proveniente da una qualsiasi pagina Web e gli altri utenti possono votare la pagina verso l’alto (digg) oppure verso il basso (bury) direttamente su digg.com. Il prodotto finale `e una serie di contenuti popolari e di trending provenienti da tutta la rete Internet, aggregati da un social network.
Un altro aggregatore di notizie `e Liquida: Liquida aggrega e rende maggior-mente fruibili, tramite le sue tecnologie di ricerca, i migliori contenuti User Generated e i pi`u interessanti articoli presenti in Rete. Gli articoli contenuti in Liquida provengono esclusivamente da blog, che vengono inseriti nel directory del sito o in seguito ad una segnalazione oppure direttamente per mano della redazione di Liquida. Periodicamente il sistema di Liquida scandaglia i blog presenti nella sua directory per accertarsi dell’esistenza di nuovi post. Questa operazione viene effettuata con un programma “sentinella” scritto in Python che viene eseguito contemporaneamente su macchine diverse. Con la funzione vota e condividi i contenuti possono essere valutati dagli utenti e condivisi sui principali social network.
Link utili:
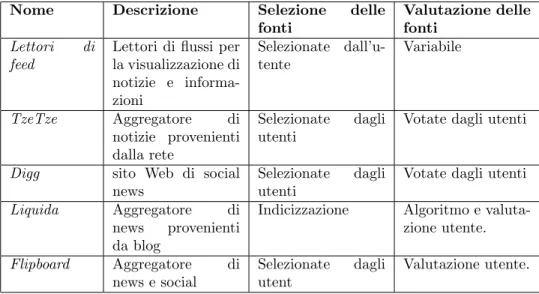
Nome Descrizione Selezione delle fonti
Valutazione delle fonti
Lettori di feed
Lettori di flussi per la visualizzazione di notizie e informa-zioni Selezionate dall’u-tente Variabile TzeTze Aggregatore di notizie provenienti dalla rete Selezionate dagli utenti
Votate dagli utenti Digg sito Web di social
news
Selezionate dagli utenti
Votate dagli utenti Liquida Aggregatore di
news provenienti da blog
Indicizzazione Algoritmo e valuta-zione utente. Flipboard Aggregatore di news e social Selezionate dagli utent Valutazione utente. Tabella 1.3: Aggregatori di notizie
Tzetze: www.tzetze.it Digg: www.digg.com Liquida: www.liquida.it
1.1.4
Social media
Con il termine di social media si intendono siti Web 2.0 che supportano for-me di pubblicazione e condivisione di contenuti generati dagli utenti sfruttando relazioni sociali tra gli utenti. L’esplosione del numero di social network quali Facebook,Foursquare, Twitter, Google+ ecc.., ha portato alla nascita di aggre-gatori di social media che permettano di gestire contemporaneamente pi`u profili online.
Esistono numerosi esempi di aggregatori di questo tipo; uno di questi `e Timeki-wi sviluppato da Overblog. TimekiTimeki-wi `e un servizio online che consente di creare una propria timeline personale, aggregando i contenuti condivisi pubblicamente da diverse piattaforme social.
Un altro esempio di aggregatore di social network `e Storify: Storify `e un sito Web che consente la creazione e il salvataggio di storie o timeline utilizzando social media come Facebook e Twitter. Gli utenti possono effettuare ricerche fra multipli social network e poi trascinare gli elementi dentro storie individuali; successivamente possono poi riordinare gli elementi e aggiungere del testo che aiuti la contestualizzazione della storia.
I social network stessi si stanno muovendo in un’ottica di aggregazione; Face-book ad esempio ha estensioni che gli permettono di integrarsi perfettamente con altre piattaforme come Wordpress, Instagram e FourSquare. Analizzando il concetto che sta alla base di Facebook, esso stesso `e un aggregatore di di-verse fonti(gli utenti che si iscrivono), in cui ogni utente seleziona le proprie fonti(tramite richiesta di amicizia), pubblica contenuti provenienti da qualsiasi pagina web e valuta i contenuti che le fonti propongono(tramite il tasto di like); .
Un altro social network che incorpora funzioni di aggregazione `e Twitter ; questo social network, lanciato nel luglio del 2006, `e fondamentalmente un servizio di microblogging in cui ogni utente pu`o pubblicare messaggi di al massimo 140 caratteri. A differenza di Facebook, che basa la propria rete social sul concet-to di friendship, esso si basa sul concetconcet-to di seguire; ogni utente pu`o seguire (diventate cio`e follower) altri utenti e leggere i contenuti da loro pubblicati e a sua volta essere seguito da altri utenti interessati ai contenuti da lui pubblicati. I contenuti che vengono pubblicati dagli utenti vengono chiamati tweet ; ogni utente pu`o inserire i tweet degli utenti che segue in una lista di preferiti e anche
ritwittare tra i propri contenuti i tweet di altri. I messaggi brevi di Twitter pos-sono essere etichettati con l’uso di uno o pi`u hashtag: parole o combinazioni di parole concatenate precedute dal simbolo cancelletto. Etichettando un messag-gio con un hashtag si crea un collegamento ipertestuale a tutti i messaggi recenti che citano lo stesso hashtag. Nell’aprile del 2009 `e stata aggiunta all’interfaccia del social network una barra di ricerca e un riassunto dei temi pi`u attuali, che vengono chiamati Trending Topics, ovvero le frasi pi`u comuni che ricorrono nei contenuti pubblicati. Secondo quanto dice Biz Stone, uno dei proprietari della piattaforma, Ogni aggiornamento pubblico inviato a Twitter da qualsiasi parte
del mondo pu`o essere immediatamente indicizzato e utilizzato per la ricerca in tempo reale (da Wikipedia).Come Facebook, esso si integra perfettamente con
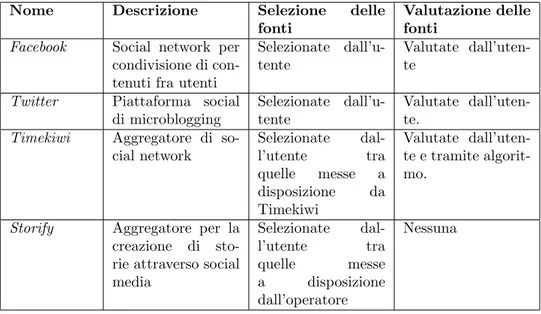
le pi`u importanti piattaforme social come Instagram, Bling, etc. Nome Descrizione Selezione delle
fonti
Valutazione delle fonti
Facebook Social network per condivisione di con-tenuti fra utenti
Selezionate dall’u-tente
Valutate dall’uten-te
Twitter Piattaforma social di microblogging
Selezionate dall’u-tente
Valutate dall’uten-te.
Timekiwi Aggregatore di so-cial network Selezionate dal-l’utente tra quelle messe a disposizione da Timekiwi Valutate dall’uten-te e tramidall’uten-te algorit-mo.
Storify Aggregatore per la creazione di sto-rie attraverso social media Selezionate dal-l’utente tra quelle messe a disposizione dall’operatore Nessuna
Tabella 1.4: Aggregatori di social media Link utili:
Timekiwi: timekiwi.com Storify: storify.com Facebook: www.facebook.it Twitter: www.twitter.com
1.1.5
Mash-up
Un’altro caso di aggregazione di informazione sul Web sono i cosiddetti siti o applicazioni Web mash-up, ovvero siti ibridi che raccolgono in modo dinami-co informazioni e dinami-contenuti provenienti da pi`u fonti. In pratica questo tipo di applicazioni usano contenuti da pi`u sorgenti per creare un servizio totalmente nuovo; il contenuto dei siti mash-up `e normalmente preso da terzi via API, tra-mite feed o Javascript.
Uno degli esempi pi`u diffusi di questo tipo di applicazioni sono quelle che sfrut-tano i meccanismi di geolocalizzazione e le mappe (come Google Maps), soprat-tutto su dispositivi mobili,sempre pi`u spesso dotati di GPS, per trovare posti come negozi, locali, hotel ecc: uno di questi `e Foursquare. Foursquare `e un social network basato su geolocalizzazione disponibile tramite Web e applica-zioni mobili; questo social network permette di condividere e salvare i luoghi visitati dall’utente e si integra perfettamente con gli altri social network come Facebook e Twitter. Fondata nel 2008 da Dennis Crowley e Naveen Selvadurai, Foursquare `e un’applicazione mobile e web che permette agli utenti registrati di condividere la propria posizione con i propri contatti. Il check-in nei luoghi permette di ottenere punti necessari a scalare una classifica settimanale, basa-ta sugli ultimi 7 giorni, della quale fanno parte i conbasa-tatti della propria stessa citt`a. I check-in possono inoltre essere condivisi, insieme ad un breve status, collegando Foursquare ai propri profili Facebook e Twitter. Gli utenti ricevono inoltre dei badge, dei riconoscimenti per aver raggiunto certi obiettivi, eseguen-do il check-in in certi luoghi, a una certa frequenza o trovaneseguen-dosi in una certa categoria di luoghi. L’applicazione permette di ricercare posti vicini a dove ci si trova, tramite meccanismi di geolocalizzazione; gli utenti possono poi lascia-re delle lascia-recensioni sui vari posti che vengono poi visualizzate dagli altri utenti. Una delle funzionalit`a pi`u utili `e che si possono poi ottenere indicazioni stradali e visualizzare i vari locali direttamente su Google Maps, il servizio di mappe fornito da Google.
Un altro esempio di applicazione mash-up `e SongBird, che fonde insieme due servizi: quello di lettore multimediale e quello di browser Web; `e una alterna-tiva open source ad altri programmi proprietari, come Itunes, da cui prende parzialmente spunto per l’interfaccia ed `e disponibile su piattaforma Web, su PC e per dispotivi mobili. La particolarit`a di SongBird `e che oltre ad essere un lettore multimediale dedicato principalmente alla riproduzione di file musicali, esso recupera informazioni dal Web per offrire un’esperienza di fruizione della
musica completa e con aggiornamenti real-time. Ad esempio quando si ascolta un brano, Songbird recupera la biografia dell’artista da Wikipedia, da aggiorna-menti a tempo reale su quest’ultimo, mostra una galleria fotografica e una serie di video da Youtube correlati al brano in riproduzione.
Sul Web esistono inoltre siti che permettono la creazione di applicazioni mash-up Web-based, come ad esempio il servizio di Yahoo chiamato Pipes; Pipes `e un potente strumento di composizione per aggregare, manipolare, e fare mashup di contenuti da tutto il Web. Yahoo Pipes `e un ambiente di sviluppo semplicissimo. Utilizzando un editor visuale nel proprio browser `e possibile pubblicare e condi-videre servizi senza essere necessariamente dei programmatori. Per costruire il proprio mashup `e sufficiente trascinare i differenti moduli messi a disposizione e disporne le connessioni. Ogni modulo `e specializzato nel reperire informa-zioni su Internet da una particolare fonte o con una particolare tecnologia, o nell’elaborare le informazioni in ingresso con certe modalit`a. I moduli hanno dei connettori in ingresso ed in uscita per poterli collegare tra di loro e creare un pipe completo. Una volta completato un pipe `e possibile salvarlo sul ser-ver e richiamarlo per ottenere in output un feed in uno dei seguenti formati: RSS, RDF, JSON o Atom. `E anche possibile pubblicare il proprio mashup cos`ı costruito e condividerlo su Internet, permettendo ad altri utenti di crearne dei cloni, aggiungervi ulteriori funzionalit`a o utilizzarlo come componente di un al-tro ”pipe” da loro creato. Sono disponibili svariati moduli, dal Fetch Data che consente di recuperare dati da fonti web in Xml o Json (Javascript Object Nota-tion), a funzionalit`a gi`a implementate per ottenere informazioni da applicazioni come Flickr o Google, ai moduli per l’elaborazione dei dati, fino a pacchetti per la rappresentazione cartografica di oggetti. Il risultato di questo stream di dati rappresenta un completo mashup realizzato in brevissimo tempo (nell’ordine di qualche minuto) e senza aver scritto una sola linea di codice.
Un ultimo caso di mash-up che prendiamo in considerazione `e quello di sFinder, un sito Web che fa uso di diversi servizi quali Yahoo, Google, Word-tracker e Wikipedia. Ci`o che fa WordsFinder `e estrapolare le parole chiave, in diverse lingue, che sono essenziali per una indicizzazione ottimale dei propri siti internet e delle proprie campagne promozionali; facendo copia incolla di un documento su WordFinder, il sito prover`a ad estrarre da esso le parole chia-ve, scegliendole allo stesso tempo n´e troppo articolate n´e troppo generiche. In pratica WordsFinder genera automaticamente i meta-tag che sono fondamentali per rendere un sito individuabile dai motori di ricerca.
Nome Descrizione Selezione delle fonti
Valutazione delle fonti
Foursquare Social network ba-sato su geolocaliz-zazione Selezionate dall’o-peratore Valutate dall’uten-te e tramidall’uten-te algorit-mo di geolocalizza-zione
Songbird Lettore multime-diale con funzioni di browsing
Selezionate dall’o-peratore
Nessuna. Pipes Web application
per la creazione di siti mash-up Selezionate dal-l’utente tra quelle messe a disposizione dall’operatore Nessuna
Wordsfinder Estrattore di paro-le chiave dai docu-menti
Selezionate dall’o-peratore
Tramite algoritmo.
Tabella 1.5: Siti mash-up Link utili: Foursquare: www.foursquare.com SongBird: www.getsongbird.com Pipes: pipes.yahoo.com Wordsfinder: www.wordsfinder.com
1.1.6
Magazzini online
In ultima istanza analizziamo il caso dei mall elettronici che vendono beni e servizi online. Sono oggi innumerevoli i siti che offrono queste opportunit`a, ma sicuramente il caso pi`u famoso e di maggior successo `e Amazon.
Amazon.com, fondata dal 1995 da Jeffrey Bezos, `e stata tra le prime grandi compagnie a vendere merci su Internet; Amazon.com oggi vende prodotti di qualsiasi genere, dall’elettronica agli articoli per la casa ma inizialmente era na-ta come libreria online. Quesna-ta scelna-ta `e ben spiegata dalle parole dello stesso fondatore:E’ chiaro che realizzare una libreria che abbia a magazzino tre milioni di libri non `e pensabile, poich´e non esisterebbe un’area metropolitana sufficien-temente estesa da renderla economicamente vantaggiosa. Ma implementare una base di dati con tre milioni di titoli accessibile via Internet non mi `e sembrato impossibile, anzi, mi `e sembrato il modo migliore per sfruttare le potenzialit`a
dei computer e di Internet.
Una delle opportunit`a che offre Amazon `e quella di diventare Associati e di guadagnare pubblicando inserzioni di Amazon sui propri siti. Su Amazon `e possibile anche diventare venditori dei propri prodotti; grazie a questa funzione gli utenti venditori possono far si che i propri prodotti siano rintracciabili attra-verso le ricerche dai visitatori del sito. Tutti i beni venduti su Amazon possono poi essere valutati dagli acquirenti e la recensione pubblicata nella pagina del prodotto.
Oltre ai magazzini online esistono siti Web che consentono la vendita dei propri contemporaneamente su diverse piattaforme Web, particolarmente utilizzati so-prattutto per la distribuzione di musica digitale. Un esempio `e il sito Cd Baby, un negozio di musica online specializzato in artisti indipendenti; esso `e anche un aggregatore digitale di musica indipendente e consente agli artisti di distribuire i propri album e le proprie canzoni su i pi`u importanti negozi musicali online come ITunes, Napster, Amazon ecc. Rispetto ad altri servizi di distribuzione musicali online, CD Baby `e un vero e prorio servizio integrato di promozione e vendita musicale, in quanto ti permette di vendere direttamente la tua mu-sica in formato vinile, Cd o Mp3 all’interno del CD Baby Store. Interessanti sono le funzionalit`a aggiuntive come la possibilit`a di creare un sito internet, la vendita attraverso il widget personalizzabile da embeddare sul tuo sito web o sulla Pagina Facebook, la stampa dei Cd e i servizi partner a pagamento come la possibilit`a di far recensire i propri lavori da agenzie specializzate e consulenze tecniche sulla strumentazione usata o da utilizzare per i prossimi lavori.
Nome Descrizione Selezione delle fonti
Valutazione delle fonti
Amazon Mall online per la vendita di prodotti Selezionate dall’o-peratore Valutate dall’uten-te Cd Baby Distribuzione di musica sui principali canali online Selezionate dall’o-peratore Nessuna.
Tabella 1.6: Magazzini online Link utili:
Amazon: www.amazon.com CD Baby: www.cdbaby.com
1.1.7
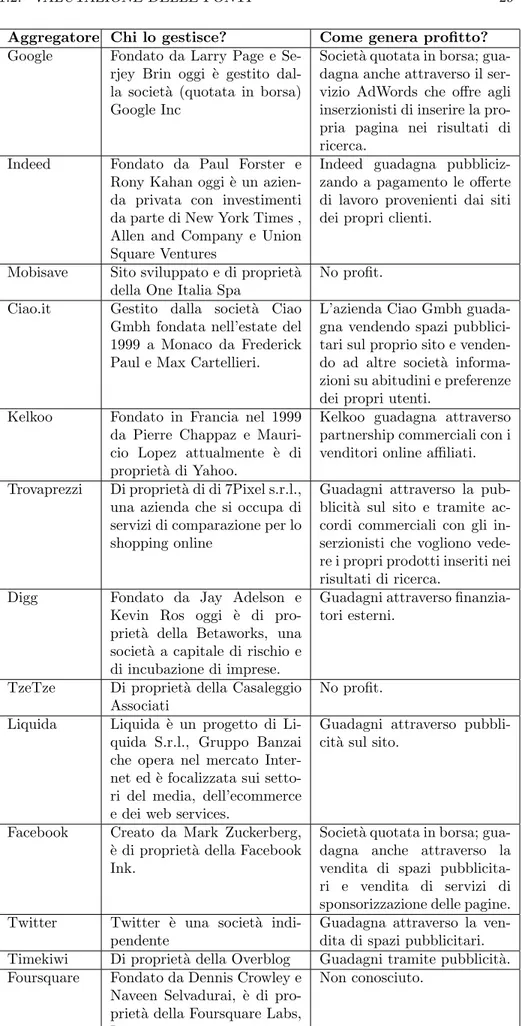
Gestori e profitti
In questa sezione vengono riassunte informazione riguardo chi gestisce gli ag-gregatori presi in esame e come fanno a generare profitto.
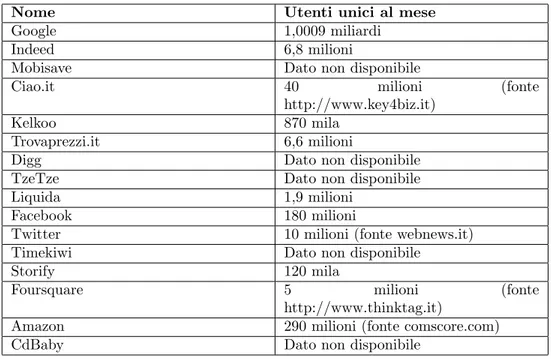
1.1.8
Volume utenti
In questa sezione vengono indicate informazione sul volume di utenti unici men-sili (a livello mondiale) degli aggregatori considerati nei vari esempi. Queste
sta-tistiche sono state ottenute tramite il servizio AdPlanner di Google (www.google.com/adplanner) e fanno riferimento al periodo dall’8 novembre 2012 al 7 dicembre 2012. I
risul-tati non forniti da AdPlanner sono esplicitamente indicati con la fonte da cui `e stato preso il dato.
1.2
Valutazione delle fonti
In questa sezione si vuole approfondire il concetto di valutazione delle fonti. Una fonte viene valutata quando le si assegna un punteggio od una votazione; que-sta votazione o punteggio pu`o essere calcolato tramite un algoritmo oppure pu`o venire assegnato dirette dagli utenti oppure pu`o essere un misto di entrambe le cose. La valutazione di una fonte pu`o incidere o meno in fase di presentazione all’utente: ad esempio quando si effettua una ricerca su Google le fonti vengo-no restituite in ordine decrescente, da quella che ha ricevuto il punteggio pi`u alto a quella che ha ricevuto il punteggio pi`u basso dall’algoritmo di PageRank; nei motori di confronto come TrovaPrezzi e Kelkoo invece i prodotti vengono presentati in ordine crescente di prezzo. Al contrario in certi aggregatori la va-lutazione non incide: ad esempio in Facebook i post vengono mostrati in egual modo, sia che essi abbiano pochi like sia che ne abbiano pochi. Altri aggregatori ancora non effettuano nessuna valutazione della fonte, come nel caso dei lettori di feed.
1.2.1
Valutazione delle fonti nei motori di ricerca
La valutazione della fonte `e un fattore cruciale soprattutto nei motori di ricer-ca; infatti `e fondamentale riuscire ad ottenere un buon punteggio per avere un
Aggregatore Chi lo gestisce? Come genera profitto? Google Fondato da Larry Page e
Se-rjey Brin oggi `e gestito dal-la societ`a (quotata in borsa) Google Inc
Societ`a quotata in borsa; gua-dagna anche attraverso il ser-vizio AdWords che offre agli inserzionisti di inserire la pro-pria pagina nei risultati di ricerca.
Indeed Fondato da Paul Forster e Rony Kahan oggi `e un azien-da privata con investimenti da parte di New York Times , Allen and Company e Union Square Ventures
Indeed guadagna pubbliciz-zando a pagamento le offerte di lavoro provenienti dai siti dei propri clienti.
Mobisave Sito sviluppato e di propriet`a della One Italia Spa
No profit. Ciao.it Gestito dalla societ`a Ciao
Gmbh fondata nell’estate del 1999 a Monaco da Frederick Paul e Max Cartellieri.
L’azienda Ciao Gmbh guada-gna vendendo spazi pubblici-tari sul proprio sito e venden-do ad altre societ`a informa-zioni su abitudini e preferenze dei propri utenti.
Kelkoo Fondato in Francia nel 1999 da Pierre Chappaz e Mauri-cio Lopez attualmente `e di propriet`a di Yahoo.
Kelkoo guadagna attraverso partnership commerciali con i venditori online affiliati. Trovaprezzi Di propriet`a di di 7Pixel s.r.l.,
una azienda che si occupa di servizi di comparazione per lo shopping online
Guadagni attraverso la pub-blicit`a sul sito e tramite ac-cordi commerciali con gli in-serzionisti che vogliono vede-re i propri prodotti inseriti nei risultati di ricerca.
Digg Fondato da Jay Adelson e Kevin Ros oggi `e di pro-priet`a della Betaworks, una societ`a a capitale di rischio e di incubazione di imprese.
Guadagni attraverso finanzia-tori esterni.
TzeTze Di propriet`a della Casaleggio Associati
No profit. Liquida Liquida `e un progetto di
Li-quida S.r.l., Gruppo Banzai che opera nel mercato Inter-net ed `e focalizzata sui setto-ri del media, dell’ecommerce e dei web services.
Guadagni attraverso pubbli-cit`a sul sito.
Facebook Creato da Mark Zuckerberg, `
e di propriet`a della Facebook Ink.
Societ`a quotata in borsa; gua-dagna anche attraverso la vendita di spazi pubblicita-ri e vendita di servizi di sponsorizzazione delle pagine. Twitter Twitter `e una societ`a
indi-pendente
Guadagna attraverso la ven-dita di spazi pubblicitari. Timekiwi Di propriet`a della Overblog Guadagni tramite pubblicit`a. Foursquare Fondato da Dennis Crowley e
Naveen Selvadurai, `e di pro-priet`a della Foursquare Labs, Inc.
Non conosciuto.
Storify Sito fondato da Xavier Dam-man e Burt HerDam-man
No profit, riceve finanziamen-ti da terze parfinanziamen-ti.
Songbird Software open-source svilup-pato da Pioneers of the Inevitable
No profit
Pipes Di propriet`a di Yahoo.com Guadagni attraverso la vendi-ta di servizi.
Wordsfinder Non trovato Il servizio che offre `e a pagamento.
Amazon Fondato da James Bezos, `e di propriet`a della Amazon.com Inc.
Societ`a quotata in borsa, gua-dagna attraverso la vendita di beni e servizi.
Nome Utenti unici al mese Google 1,0009 miliardi
Indeed 6,8 milioni
Mobisave Dato non disponibile
Ciao.it 40 milioni (fonte http://www.key4biz.it)
Kelkoo 870 mila Trovaprezzi.it 6,6 milioni
Digg Dato non disponibile TzeTze Dato non disponibile Liquida 1,9 milioni
Facebook 180 milioni
Twitter 10 milioni (fonte webnews.it) Timekiwi Dato non disponibile
Storify 120 mila
Foursquare 5 milioni (fonte http://www.thinktag.it)
Amazon 290 milioni (fonte comscore.com) CdBaby Dato non disponibile
Tabella 1.8: Volume utenti mensile
posizionamento importante nei risultati di ricerca; si `e visto che esistono aggre-gatori come Wordsfinder che aiutano i gestori di siti a trovare le migliori parole chiave utili ad indicizzare il sito al meglio. Le tecniche di ottimizzazione per aumentare i volumi di traffico grazie ai motori di ricerca vengono chiamate SEO (Search Engine Optimization).Ci sono per`o due fenomeni che possono alterare i risultati delle ricerche nei motori come Google sono due: lo spamdexing e i risultati sponsorizzati.
Con il termine di spamdexing si intendono tutte quelle tecniche tese ad alterare i risultati delle ricerche al fine di ottenere un miglior posizionamente in questi ultimi; queste tecniche hanno la caratteristica di ottenere risultati soddisfacenti per i gestori di siti che le utilizzano ma allo stesso tempo di portare a risultati di ricerca insoddisfacenti sia per i fornitori dei motori di ricerca sia per gli utenti che li utilizzano. Alcuni esempi di spamdexing sono:
• utilizzare informazioni estranee al sito nella sezione meta-tag di una pagi-na; questo tipo di operazione viene chiamata overstuffing. Ad esempio un sito potrebbe cercare di accaparrarsi traffico internet di una azienda rivale inserendo nei meta-tag il nome o i marchi dei prodotti di questa azienda; • utilizzare del testo nascosto all’interno di una pagina ai fini di alterare i
risultati della ricerca;
• utilizzare molte volte una stessa keyword all’interno di una pagina in modo che il motore di ricerca pesi questa parola in maniera pi`u rilevante che per altri siti.
I link sponsorizzati sono invece una soluzione lecita per aumentare il proprio traffico nel sito e per lanciare campagne pubblicitarie sul Web. Tutti i princi-pali motori di ricerca e anche i social network come Facebook, vendono spazi pubblicitari che in un certo senso alterano e gonfiano il posizionamento delle pagine che gli acquistano; ad esempio pu`o comparire all’inizio della lista di ri-sultati con un colore diverso dagli altri e una dicitura che indica che il risultato `e sponsorizzato oppure comparire in una barra laterale del sito. Ci`o che `e impor-tante nel rapporto con l’utente `e che sia correttamente segnalato che in questi casi si tratta di risultati pubblicitari.
1.2.2
Algoritmi di valutazione
In questa sezione verranno approfonditi alcuni degli algoritmi di valutazione che vengono utilizzati da certi aggregatori per assegnare un punteggio alle proprie fonti.
PageRank
Nei motori di ricerca sono due gli algoritmi principali che ne garantiscono il successo e il funzionamento: l’indicizzazione e il pagerank. Il primo permette di inserire il sito nel database del motore di ricerca mentre il secondo ne definisce la posizione nella pagina dei risultati della ricerca.
Il PageRank `e l’algoritmo che utilizza il motore di ricerca Google per assegnare un peso alle proprie fonti. Grazie a questo algoritmo Google pu`o restituire all’utente i risultati della ricerca, in ordine decrescente di rilevanza.
Il principio base di questo algoritmo `e quello di assegnare un valore numerico ad ogni elemento di un collegamento ipertestuale all’interno del World Wide Web; questo valore rispecchia l’importanza del collegamento ipertestuale all’interno della serie in cui si trova. Ci`o che si propone di fare questo algoritmo `e quello di assegnare un grado di popolarit`a al sito rispetto ai termini inseriti in fase di ricerca. Il principio di funzionamento di questo algoritmo `e assimilabile ad un meccanismo elettivo: ogni pagina Web indicizzata `e un elettore ed esprime il proprio voto attraverso i collegamenti ipertestuali in essa presente;le pagine
esprimono un voto che `e proporzionale alla popolarit`a. Oltre a queste votazioni altri elementi che concorrono a definire la popolarit`a del sito secondo questo algoritmo sono la pertinenza del contenuto della pagine, le pagine correlate, la diffusione dell’argomento trattato.
Algoritmi di geolocalizzazione
Tra gli esempi mostrati in precedenza abbiamo Foursquare che utilizza un algo-ritmo di geolocalizzazione per ricercare negozi e locali nelle vicinanze della zona in cui ci troviamo. Grazie a questo algoritmo verranno restituiti come risultati solo dei places entro un range che pu`o essere stabilito dall’utente.
Le tecniche di geolocalizzazione permettono di determinare la posizione nel mon-do reale, di un determinato device; questi algoritmi si rivelano particolarmente utili sui dispositivi mobili, come smartphone e tablet, sempre pi`u spesso dotati di GPS e che permettono quindi di essere utilizzati anche come navigatori. I meccanismi di geolocalizzazione pi`u utilizzati sono:
• tramite tecnologia GPS che sfrutta i satelliti artificiali che orbitano intorno alla Terra;
• tramite l’indirizzo IP assegnato al device;
• tramite le celle telefoniche a cui il cellulare si collega; • tramite WiFi o WLAN.
Tra i meccanismi elencati il pi`u preciso `e sicuramente quello che si basa sulla tecnologia GPS, ancor meglio se `e utilizzato in tandem con localizzazione tra-mite WiFi.
Oltre a Foursquare, tra gli esempi proposti, ci sono altri aggregatori che uti-lizzano algoritmi di geolocalizzazione. Ad esempio Facebook utilizza la geolo-calizzazione per assegnare un tag agli stati o alle foto pubblicate dagli utenti; Google invece utilizza la geolocalizzazione nel servizio Google Maps, che fornisce all’utente mappe di tutto il mondo. La geolocalizzazione pu`o essere utilizzata inoltre per campagne di marketing mirate rispetto al luogo nel quale ci si trova (viene anche definito geomarketing).
Motori semantici
Secondo la definizione del suo ideatore, Tim Berners-Lee il Web semantico `e un’estensione del Web corrente in cui le informazioni hanno un ben preciso
significato e in cui computer e utenti lavorano in cooperazione(Scientific Ame-rican, Maggio 2001). Ci`o significa che i documenti pubblicati sul Web sono insertiti in un contesto semantico che viene specificato dalle informazioni e dai dati e i meta-dati[9].
La ricerca semantica `e un metodo di ricerca che tenta di provare ad avvicinarsi ai meccanismi cognitivi dell’uomo, ovvero il motore di ricerca tenta di estra-polare il contesto e il significato delle parole che sta leggendo. Tra gli esempi che sono stati analizzati in questo capitolo abbiamo Liquida che fa uso di un motore semantico per classificare gli articoli che propone. L’algoritmo utilizzato da Liquida autocompone i contenuti selezionati dalla redazione di Liquida e li raggruppa a seconda delle tematiche che trattano grazie ad un sistema di analisi dei contenuti. Come dichiarato da Liquida, l’algoritmo per ogni tema seleziona-to propone ai letseleziona-tori un occhiello redazionale, l’articolo ritenuseleziona-to pi`u rilevante, i tag relativi, altri post inerenti e quattro contenuti multimediali (immagini e vi-deo)(Liquida.it). Liquida utilizza tecnologie semantiche per indicizzare i propri post e che permettono di effettuare ricerche per categoria. Questo sistema, svi-luppato da Expert System in collaborazione con Liquida, cataloga il materiale informativo in base all’argomento trattato e genera metadati che permettono di recuperarli in fase di ricerca.
1.2.3
Tabella comparativa
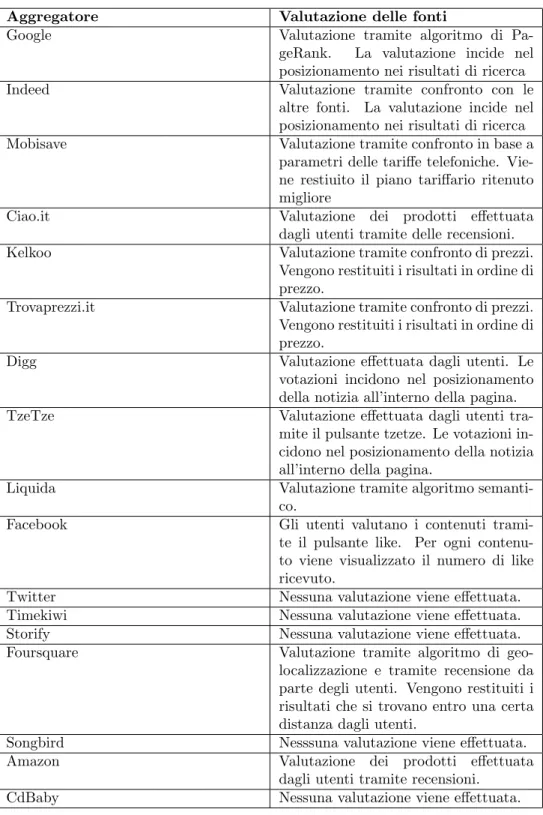
La tabella seguente riassume, per ogni esempio preso in considerazione in questo capitolo, come viene espressa la valutazione della fonte e come questa valutazione incide nell’economia dell’aggregatore.
1.3
Considerazioni generali
In questa sezione verranno fatte alcune considerazioni di carattere generale sugli aggregatori analizzati nei precedenti capitoli; in particolare verranno espressi quali sono i punti forti e quelli deboli degli aggregatori considerati.
1.3.1
Motori di ricerca
Come gi`a approfonditamente spiegato nel capitolo 1, la funzione dei motori di ricerca `e quella di scandagliare il Web alla ricerca di pagine coerenti ad un input (solitamente una stringa di caratteri) inserita dall’utente. Il problema
princi-Aggregatore Valutazione delle fonti
Google Valutazione tramite algoritmo di Pa-geRank. La valutazione incide nel posizionamento nei risultati di ricerca Indeed Valutazione tramite confronto con le
altre fonti. La valutazione incide nel posizionamento nei risultati di ricerca Mobisave Valutazione tramite confronto in base a
parametri delle tariffe telefoniche. Vie-ne restiuito il piano tariffario ritenuto migliore
Ciao.it Valutazione dei prodotti effettuata dagli utenti tramite delle recensioni. Kelkoo Valutazione tramite confronto di prezzi.
Vengono restituiti i risultati in ordine di prezzo.
Trovaprezzi.it Valutazione tramite confronto di prezzi. Vengono restituiti i risultati in ordine di prezzo.
Digg Valutazione effettuata dagli utenti. Le votazioni incidono nel posizionamento della notizia all’interno della pagina. TzeTze Valutazione effettuata dagli utenti
tra-mite il pulsante tzetze. Le votazioni in-cidono nel posizionamento della notizia all’interno della pagina.
Liquida Valutazione tramite algoritmo semanti-co.
Facebook Gli utenti valutano i contenuti trami-te il pulsantrami-te like. Per ogni contrami-tenu- contenu-to viene visualizzacontenu-to il numero di like ricevuto.
Twitter Nessuna valutazione viene effettuata. Timekiwi Nessuna valutazione viene effettuata. Storify Nessuna valutazione viene effettuata. Foursquare Valutazione tramite algoritmo di
geo-localizzazione e tramite recensione da parte degli utenti. Vengono restituiti i risultati che si trovano entro una certa distanza dagli utenti.
Songbird Nesssuna valutazione viene effettuata. Amazon Valutazione dei prodotti effettuata
dagli utenti tramite recensioni. CdBaby Nessuna valutazione viene effettuata.
pale di questo tipo di aggregatore `e che devono scorrere milardi di pagine in tempi molto brevi; `e ovvio quindi che non potranno mai essere prese in consi-derazione la totalit`a delle pagine Web. Secondo alcune stime, il numero totale di pagine Web supera i mille miliardi; se prendiamo in considerazione Google, il suo database di pagine indicizzate consta di circa 25 miliardi di pagine. Quindi `
e praticamente impossibile effettuare una ricerca che prenda in considerazione tutto il materiale presente sul Web.
Un’altra problematica, che ricorrer`a anche per gli altri tipi di aggregatori, `e il grado di fiducia che ha l’utente nei risultati proposti dal motore di ricerca; `e im-portante quindi che gli algoritmi di ricerca siano in grado di eliminare risultati di spam (nel capitolo 1 `e stato affrontato il problema del cosiddetto spamindexing).
1.3.2
Motori di confronto
Le problematiche relative ai motori di confronto sono pi`u o meno le stesse di quelle dei motori di ricerca, ovvero quantit`a di pagine indicizzate e fiducia del-l’utente nei risultati proposti dall’aggregatore.
Prendiamo in considerazione aggregatori come Kelkoo oppure Ciao.it: essi si propongono di effettuare una ricerca su prodotti venduti in rete, cercando di restituire all’utente le offerte migliori presenti fra le pagine indicizzate; `e ov-vio che maggiore sar`a la fiducia dell’utente quanto pi`u ampio sar`a lo spettro della ricerca dell’aggregatore. Infatti un utente potrebbe chiedersi se le offerte presentate da questi aggregatori siano effettivamente le migliori oppure se altre offerte siano state trascurate; siccome la maggior parte di essi opera solo su un certo numero di Web-store con cui stipula accordi commerciali, l’utente si pu`o porre effettivamente il dubbio che le offerte non siano in realt`a le migliori ma che i risultati delle ricerche siano in qualche modo delle inserzioni pubblicitarie. A questo riguardo bene si comporta Ciao.it, che ha una community di utenti che recensisce e assegna dei punteggi sia ai prodotti che ai negozi online. Un altro punto a sfavore di questi aggregatori `e che prendono in considerazione solo un limitato numero di negozi e le offerte considerate sono esclusivamente di prodotti venduti online.
1.3.3
Aggregatori di notizie
Per gli aggregatori di notizie `e pi`u che mai fondamentale la fiducia che gli utenti hanno nell’aggregatore e nelle fonti che prende in considerazione; infatti tanto pi`u l’utente non si fida delle fonti che l’aggregatore utilizza per reperire le notizie,
tanto pi`u non prender`a in considerazione tale aggregatore. Da questo punto di vista, gli aggregatori che meglio rispondono a questa esigenza di affidabilit`a sono i lettori di feed; essi infatti permettono all’utente di selezionare personalmente le fonti, permettendogli di creare una sorta di notiziario personalizzato. Altri aggregatori come Digg e TzeTze invece permetto agli utenti di valutare gli articoli; gli articoli con pi`u valutazioni positive occuperanno posti di maggior rilievo nella pagina.
Un’altro tipo di problematica che si pone con questo tipo di aggregatori `e di natura prettamente legale: infatti ci possono essere problemi di copyright nella pubblicazione di notizie pubblicate da altri siti; deve esserci quindi l’assenso dei siti sorgenti, che in cambio ottengono visibilit`a su questi aggregatori; `e quindi fondamentale che l’aggregatore sia di successo in modo che i siti sorgenti abbiano un guadagno a permettere la pubblicazione delle proprie notizie. Una soluzione adottata da questi aggregatori `e che per leggere l’intera notizia, l’utente sia reindirizzato alla pagina originale del sito sorgente.
Capitolo 2
Classificazione
Non classificato non omologato, Indesiderato, non obliterato, Non idoneo, non ammesso, Non allineato,assente sempre ingiustificato.
Subsonica-Non identificato
Alla luce degli esempi mostrati nel capitolo precedente, si prova qui a dare una classificazione degli aggregatori Web. Questo tentativo di classificazione tiene conto di tutte le caratteristiche emerse dall’analisi dei vari aggregatori, cercando di cogliere gli aspetti che li caratterizzano.
Come gi`a emerge dalle tabelle comparative del capitolo precedente, due criteri imprescindibili per la classificazione sono il modo in cui gli aggregatori selezio-nano le fonti e come esse vengono valutate; un altro criterio `e sicuramente lo scopo per cui viene usato un aggregatore e le funzionalit`a di cui esso dispone. Alla luce di tutto ci`o i criteri di classificazione utilizzati sono i seguenti:
• classificazione in base allo scopo dell’aggregatore; • classificazione in base alla selezione delle fonti ; • classificazione in base alla valutazione delle fonti ; • classificazione in base alle funzionalit`a.
Nei prossimi paragrafi verranno esposti e giustificati questi criteri e alla fine si effettuer`a una classificazione di tutti gli esempi mostrati nel capitolo precedente.
2.1
Classificazione in base allo scopo
Il principio base di questo criterio `e quello di classificare gli aggregatori sulla base dello scopo di utilizzazione; ad esempio un motore di ricerca come Google viene utilizzato dagli utenti per effettuare una ricerca sul Web mentre ad esem-pio un aggregatore di notizie viene utilizzato per leggere contenuti provenienti da pi`u fonti. Sulla base di queste considerazioni e sull’analisi dei casi presi pre-cedentemente in considerazione le classi di aggregatori individuate per questo criterio sono:
• Ricerca: la funzione primaria degli aggregatori appartenenti a questa classe `e quella di effettuare una ricerca tra le fonti che appartengono al proprio database e restituirle all’utente ordinate dalla pi`u coerente alla meno coerente a seconda del criterio di ricerca e dall’algoritmo di valuta-zione utilizzato; solitamente viene fornita un’anteprima per ogni risultato nella lista che viene restituita all’utente. Rientrano in questa classe di aggregatori tutti i motori di ricerca (Google, Yahoo ecc.); possiamo ve-dere come motore di ricerca anche il mall online di Amazon, in quanto dal punto di vista di aggregatore ci`o che compie `e quello di effettuare una ricerca all’interno del proprio database dei prodotti.
• Comparazione: questo tipo di aggregatori a fronte di un input ricevuto dall’utente (tipicamente una stringa che rappresenta l’oggetto della ricer-ca) effettuano una ricerca di beni o servizi all’interno delle proprie fonti e restituiscono all’utente i migliori risultati, secondo un determinato pa-rametro, in forma aggregata. Questo parametro varia da aggregatore ad aggregatore; solitamente se la ricerca riguarda prodotti in vendita questo parametro pu`o essere il prezzo del prodotto oppure il voto delle recen-sioni effettuate dagli utenti. Ne sono esempi di questa classe i motori di confronto come Kelkoo, Ciao, Indeed.
• Lettura: la caratteristica di questa classe di aggregatori `e quella di offrire all’utente la possibilit`a di leggere materiale informativo proveniente da pi`u fonti; in questo caso le fonti possono essere selezionate dall’utente (come nel caso dei lettori di feed) che decide quali fonti inserire nel proprio aggregatore. Tipicamente fanno parte di questa categoria di aggregatori tutti i servizi di aggregazione di news come i lettori di feed, Liquida e TzeTze e gli aggregatori di social network come Storify e TimeKiwi.
Figura 2.1: Classificazione per scopo
• Pubblicazione: lo scopo principale di questo tipo di aggregatori `e la pub-blicazione di informazione; l’informazione pu`o provenire da fonti diverse, come nel caso di Pipes che crea mash-up con informazioni provenienti da siti diverse, oppure l’informazione pu`o essere pubblicata su diverse fonti come nel caso di Timekiwi (uno stesso post pu`o essere pubblicato contem-poraneamente su Facebook e su Twitter) e di CdBaby che distribuisce le proprie canzoni su diversi market online.
• Misto: sono gli aggregatori che per loro natura possono rientrare in pi`u di una delle classi sopraccitate. Se prendiamo ad esempio Timeki-wi, esso permette la lettura di contenuti provenienti da fonti diverse e allo stesso tempo permette la pubblicazione di post su pi`u social network contemporaneamente; esso `e quindi un aggregatore sia di lettura che di pubblicazione.
2.2
Classificazione in base alla selezione delle
fonti
Il principio base di questo criterio di classificazione `e quello di suddividere gli aggregatori in base alle modalit`a di selezione delle fonti. Quando un aggregatore seleziona una fonte essa entra a far parte del database dell’aggregatore e da essa l’aggregatore pu`o recuperare contenuti. Le classi individuate per questo criterio sono le seguenti:
• Selezione dell’utente: in questa classe le fonti vengono selezionate diret-tamente dall’utente che utilizza l’aggregatore. All’interno di questa classe `e possibile individuare due sottoclassi: selezione possibile tra tutte le fonti
Figura 2.2: Classificazione per selezione
disponibili e selezione possibile fra un sottoinsieme di fonti selezionate dal-l’operatore. Ad esempio, nei lettori di feed l’utente pu`o scegliere fra tutte le fonti che dispongono di questa tecnologia; al contrario in aggregatore di social network come TimeKiwi l’utente pu`o scegliere solo tra quelle messe a disposizione dal sito;
• Selezione dell’operatore: in questa classe le fonti vengono selezionate direttamente dagli operatori degli aggregatori, secondo criteri discrezionali o a seguito di accordi commerciali; sono un esempio di questa classe di aggregatori Mobisave e Kelkoo.
• Selezione tramite iscrizione (o indicizzazione): a questa classe ap-partengono gli aggregatori nei quali vengono selezionate le fonti che si iscrivono al database (o directory).Ad esempio Google seleziona le proprie fonti tra i siti Web indicizzati.
2.3
Classificazione in base alla valutazione delle
fonti
In questo criterio di classificazione si prendono in considerazione i meccanismi di valutazione delle fonti che implementano i vari aggregatori. Questi meccanismi sono stati trattati approfonditamente nel paragrafo 2.2 del capitolo precedente. Le classi individuate per questo criterio sono le seguenti
• Valutazione utente: in questa categoria di aggregatori le fonti subiscono una valutazione da parte dell’utente; in alcuni casi la valutazione delle
Figura 2.3: Classificazione per valutazione
fonti pu`o avere ripercussioni sulla stessa (ad esempio pu`o essere inserita pi`u o meno in basso nei risultati di una ricerca, come in Digg) oppure no(ad esempio il numero di like su Facebook non ha ripercussioni sul posizionamento della fonte). Ne sono un esempio Digg, TzeTze, Facebook e Amazon.
• Valutazione tramite algoritmo: le fonti sono valutate tramite un algo-ritmo,che pu`o basarsi su diversi criteri; ne sono un esempio Google tramite il suo algoritmo PageRank e gli algoritmi di comparazione dei motori di confronto.
• Nessuna: le fonti non sono oggetto di valutazione, come ad esempio capita in CdBaby e nei lettori di feed.
2.4
Classificazione per funzionalit`
a
In quest’ultimo criterio di classificazione si suddividono gli aggregatori che per-mettono solo la visualizzazione di contenuti a quelli che perper-mettono la pubblica-zione di contenuto e l’acquisto di beni o servizi. Le classi individuate per questo criterio sono:
• Informativo: rientrano in questa classe tutti gli aggregatori che hanno solo funzionalit`a informativa, ovvero permettono la visualizzazione di con-tenuti all’utente ma non la pubblicazione di concon-tenuti ne l’acquisto di beni o servizi. Esempi ne sono Google, Ciao.it e i lettori di feed.
Figura 2.4: Classificazione per funzionalita
• Dispositivo: sono gli aggregatori che permettono di pubblicare contenuti (come Facebook e Timekiwi) e di acquistare direttamente dal sito beni e servizi(Amazon e Cdbaby); non sono inclusi in questa classe aggregatori come Kelkoo e Trovaprezzi che non vendono direttamente i prodotti ma rimandano ai siti di e-commerce che effettivamente vendono i prodotti.
2.5
Classificazione degli esempi proposti
Nella tabella qui di seguito vengono classificati secondo i 4 criteri proposti tutti gli aggregatori presi in considerazione nel capitolo precedente.
2.6
Altri criteri di classificazione
In questa sezione verranno presi considerati criteri di classificazione secondari rispetto a quelli pubblicati in precedenza.
2.6.1
Criterio di localit`
a(o diffusione)
Questo criterio classifica gli aggregatori in base al bacino geografico a cui sono rivolti. Le classi individuate sono due:
• Locali: l’aggregatore opera in un contesto nazionale; ad esempio Mobi-Save analizza offerte di telefonia mobile presenti esclusivamente in Italia; • Globali: l’aggregatore opera in un contesto nazionale; social network quali Facebook e Twitter raggruppano utenti provenienti da qualsiasi parte del mondo.
Nome Scopo Selezione delle fonti Valutazione fonti Funzionalit`a Google Ricerca Tramite iscrizione Tramite algoritmo:
viene utilizzato al-goritmo PageRank
Informativo Indeed Comparazione Selezione dell’ operatore Algoritmo Informativo Mobisave Comparazione Selezione dell’ operatore Algoritmo Informativo Ciao.it Comparazione Selezione dell’operatore Algoritmo Informativo Kelkoo Comparazione Selezione dell’operatore e
iscrizione
Algoritmo Informativo TrovaPrezzi Comparazione Selezione dell’operatore e
iscrizione
Algoritmo Informativo Lettore di
Feed
Lettura Selezione dell’utente Nessuno Informativo Digg Lettura Selezione dell’ utente Utente Informativo TzeTze Lettura Selezione dell’utente Utente Informativo Liquida Lettura Iscrizione Tramite algoritmo e
utente
Informativo Facebook Misto:lettura
e pubblica-zione
Selezionate dall’utente Utente Dispositivo Twitter Misto:
lettu-ra e pubbli-cazione
Selezionate dall’utente Utente e tramite algoritmo
Dispositivo Timekiwi Misto:lettura
e pubblica-zione
Selezionate dall’utente tra quelle scelte dall’operato-re
Utente Dispositivo Storify Lettura Selezionate dall’utente Nessuna Informativo FourSquare Lettura Selezionate dall’operatore Algoritmo Informativo Songbird Lettura Selezionate dall’operatore Nessuna Informativo Pipes Pubblicazione Selezionate dall’utente tra
quelle selezionate dall’o-peratore
Nessuna Dispositivo Wordsfinder Ricerca Selezione dell’operatore Algoritmo Informativo Amazon Ricerca Selezione dell’operatore Utente Dispositivo CdBaby Pubblicazione Selezionate dall’utente tra
quelle selezionate dall’o-peratore
Nessuna Dispositivo
Figura 2.5: Classificazione per diffusione
Nella tabella seguente vengono classificati gli esempi proposti secondo questo criterio di localit`a.
2.6.2
Classificazione per modalit`
a di guadagno
Questo criterio classifica gli aggregatori in base alle modalit`a con le quali questi guadagnano. In base a quanto emerso le classi identificate sono:
• Guadagni tramite pubblicit`a: la fonte di guadagno dell’aggregatore proviene dalla vendita di spazi pubblicitari;
• Guadagni tramite vendita di beni o servizi: l’aggregatore guadagna attraverso la vendita di beni (come Amazon e CdBaby) e servizi (come Wordsfinder);
• Quotazione in borsa: rientrano in questa classe tutti gli aggregatori le cui societ`a sono state quotate in borsa(come Facebook);
• Guadagni tramite finanziamenti esterni: i guadagni avvengono tramite l’investimento di terze parti nell’aggregatore;
• No profit: sono quegli aggregatori senza scopo di lucro; • Misti: aggregatori che mixano pi`u modelli di guadagno.
2.6.3
Classificazione in base alle dimensioni
In questo criterio vengono presi in considerazione i volumi di traffico mensile degli aggregatori. In base a questo criterio le classi individuate sono: