V Facolt`a di Ingegneria
Corso di Laurea Specialistica in Ingegneria Informatica
Dipartimento di di Elettronica e Informazione
Analisi, progettazione e sviluppo di contromisure
per vulnerabilit`a basate su
alterazioni del flusso di controllo
LibDefender: una libreria dinamica per garantire
l’integrit`a del flusso di esecuzione
Relatore: Prof. Gerardo PELOSI Correlatore: Ing. Alessandro BARENGHI
Tesi di Laurea di:
Abstract 1
Introduzione 3
1 Vulnerabilit`a: stato dell’Arte 7
1.1 Organizzazione della memoria virtuale di un processo . . . 7
1.2 Chiamate a funzione . . . 9
1.2.1 Record di attivazione . . . 9
1.2.2 Esempio di chiamata a funzione . . . 10
1.3 Allocazione dinamica della memoria . . . 12
1.4 Classi di vulnerabilit`a . . . 14
1.4.1 Buffer overflows . . . 14
1.4.2 Stack smashing . . . 15
1.4.3 Off-by-one e sovrascrittura frame-pointer . . . 17
1.4.4 Uncontrolled Format string . . . 19
1.4.5 Return-to-library . . . 22
1.5 Tecniche avanzate di attacco . . . 27
1.5.1 Evoluzione return-to-library . . . 27
1.5.2 Return oriented programming . . . 32
1.5.3 Aggirare ASLR e W⊕X . . . 35
1.6 Heap overflow . . . 38
1.6.1 Sovrascrittura puntatori a funzione sull’heap . . . 38
1.6.2 Heap overflow . . . 38
1.6.3 dlmalloc . . . 39
2 Contromisure: stato dell’Arte 43 2.1 Protezione a livello kernel . . . 44
2.1.1 Stack Patch . . . 44
2.1.2 PaX . . . 44
2.1.3 W⊕X . . . 47
2.2 Protezione tramite modifiche al compilatore . . . 48
2.2.1 Stack Guard . . . 48
2.2.2 StackShield . . . 49
2.2.3 ProPolice . . . 49
2.3 Protezioni integrate in librerie . . . 50
2.3.1 Libsafe . . . 51
2.3.2 Guarded Memory Move . . . 52
2.4 Altri metodi di protezione integrati nel kernel . . . 53
2.4.1 AppArmor . . . 54
2.4.2 Tomoyo . . . 54
2.5 Riepilogo . . . 55
3 LibDefender: una libreria per garantire l’integrit`a del flusso di esecuzione 57 3.1 LibDefender . . . 57
3.1.1 Libunwind . . . 58
3.1.2 Implementazione . . . 61
3.1.3 Protezione funzioni elaborazione stringhe e memoria . 61 3.1.4 Prevenzione format string . . . 63
3.2 Caratteristiche innovative . . . 64
3.3 Limitazioni . . . 65
3.3.1 Librerie statiche . . . 65
3.4 Protezione da heap overflow . . . 66
3.4.1 Aggiungere funzione alla lista delle system call . . . . 67
3.4.2 Implementazione delle syscall di salvataggio e controllo 68 4 Risultati sperimentali 73 4.1 Funzionalit`a . . . 73
4.1.1 Test buffer overflow e return-to-libc . . . 74
4.1.2 Test format string . . . 75
4.1.3 Verifica individuazione e blocco attacchi . . . 76
4.1.4 Valutazione Prestazioni . . . 77
Conclusioni 85
Appendice A 87
4.3 Specificatori format string . . . 87 4.4 Principali registri architetture Intel . . . 88
1.1 Layout memoria processo . . . 9
1.2 Evoluzione stack durante l’esecuzione del programma . . . 13
1.3 Stack smashing . . . 17
1.4 Frame pointer overwrite . . . 19
1.5 Uno schema esemplificativo per la vulnerabilit`a return-to-library . . . 23
1.6 Stringa di overflow utile per un attacco return-to-library mul-tiplo . . . 28
1.7 Uno schema della tecnica esp lifting . . . 29
1.8 Uno schema della tecnica di frame faking . . . 30
1.9 Uno schema della tecnica di Return Oriented Programming . 34 1.10 Uno schema della struttura dello heap . . . 39
1.11 Un blocco di memoria nello heap dopo la deallocazione . . . . 40
4.1 Esempio output tentativo di buffer overflow bloccato da lib-Defender . . . 77
4.2 Esempio output tentativo di format string bloccato da libDe-fender . . . 77
4.3 Test di durata inferiore ai 100 secondi . . . 78
4.4 Test di durata superiore ai 100 secondi . . . 79
4.5 Benchmark filesystem: threaded I/O, dbench e Postmark . . 80
4.6 Test GraphicsMagick . . . 81
4.7 Test PostgreSQL TPS-b . . . 82
4.8 Test su crittografia e librerie matematiche . . . 82
2.1 Tabella riepilogativa delle tipologie di vulnerabilit`a e del gra-do di protezione offerto dalle contromisure . . . 56 4.1 Tabella riepilogativa dell’indagine empirica sull’uso di
punta-tori a funzione e virtual in C e C++ . . . 83 4.2 Tabella riepilogativa dei principali specificatori di formato . . 87 4.3 Registri ad uso generico . . . 88 4.4 Registri usati per l’indirizzamento . . . 88 4.5 Registri di segmento . . . 88
Questo elaborato di tesi si inserisce nel contesto della sicurezza infor-matica e dei sistemi operativi, in particolare nell’ambito dello sviluppo di misure per la protezione da attacchi informatici per il sistema operativo Linux. L’obiettivo della tesi `e quello di progettare e implementare contro-misure che prevengano attacchi volti ad alterare il flusso di esecuzione di un processo. Le contromisure implementate sono due e vanno a proteggere due differenti aree della memoria virtuale di un processo. La prima contro-misura `e costituita da una libreria dinamica in grado di prevenire attacchi che interessano lo stack : buffer overflow, frame pointer overwrite, format string e return oriented programming. Questa libreria `e stata progettata in modo da essere indipendente dall’architettura hardware del sistema, oltre a minimizzare l’impatto sulle prestazioni. La seconda contromisura consiste in una modifica al kernel Linux propedeutica a una modifica del compi-latore C/C++ che permetta di prevenire attacchi di tipo heap overflow. La campagna sperimentale ha fatto uso della Phoronix Test Suite su un sistema operativo Ubuntu GNU/Linux 11.04 (architettura AMD64), ed `e stata condotta per confrontare i risultati dei benchmarks con quelli ottenuti sullo stesso sistema protetto con le contromisure sviluppate. I risultati spe-rimentali hanno evidenziato un impatto sulle prestazioni inferiore al 10%, dimostrando un’ampia efficacia e applicabilit`a delle soluzioni sviluppate.
Introduzione
Gli errori di programmazione relativi alla gestione della memoria sono i pi`u frequentemente sfruttati per attaccare programmi scritti nei linguaggi C e C++. La classe di vulnerabilit`a dei buffer overflow che deriva da tali errori di programmazione `e stata per anni la pi`u diffusa e dunque la pi`u sfruttata a causa dei numerosi bug individuati in software di uso comune su desktop e server. Con il passare degli anni numerose contromisure sono state svilup-pate sia per prevenire lo sfruttamento di tali vulnerabilit`a, sia per rendere pi`u difficile l’implementazione di attacchi di questo tipo, senza giungere ad una soluzione definitiva. Le pi`u recenti metodologie d’attacco sono in grado di essere attuate con successo aggirando molte delle contromisure preceden-temente sviluppate e riproponendo il problema della protezione da questi attacchi. Negli ultimi anni anche la categoria degli heap overflow ha assun-to un ruolo sempre pi`u rilevante all’interno del panorama delle vulnerabilit`a note.
Questo elaborato di tesi si concentra sul sistema operativo Linux e si pone come obiettivo quello di progettare ed implementare contromisure che impediscano alterazioni del flusso di esecuzione di un programma. L’imple-mentazione si basa su di una libreria dinamica in grado di impedire attacchi di tipo buffer overflow, return-to-libc, format string e su di una modifica al kernel Linux che, accompagnata da una modifica al compilatore permetta di prevenire attacchi di tipo heap overflow. La tesi si struttura in quattro capitoli, la cui struttura andremo ad illustrare di seguito.
Nel primo capitolo si andranno a descrivere innanzitutto alcuni concetti teorici indispensabili per comprendere il funzionamento delle varie tecniche
di attacco. Successivamente si andranno a presentare gli errori di program-mazione che danno origine alle vulnerabilit`a che possiamo raccogliere nelle categorie di buffer overflow, format string ed heap overflow, oltre a descri-vere nel dettaglio le tecniche di attacco stesse. La descrizione delle varie tecniche partir`a dalle tecniche di base fino ad arrivare alle pi`u recenti e complesse. Nella secondo capitolo verr`a presentata una panoramica del-le varie contromisure sviluppate nel tempo con l’obiettivo di impedire lo sfruttamento di alcune delle tecniche di attacco precedentemente descritte, o a renderne pi`u difficile lo sfruttamento. Si conclude il secondo capitolo con una comparazione riassuntiva delle diverse contromisure sottolineando-ne pregi e mancanze, individuando il contesto in cui si va a collocare la soluzione sviluppata nell’elaborato e descritta nel capitolo seguente.
Nel terzo capitolo si descrive nel dettaglio libDefender, la contromisura sviluppata con l’obiettivo di prevenire gli attacchi che mirano alla deviazione del flusso di controllo dell’applicazione. Si inizia con una descrizione det-tagliata di libunwind, una libreria multipiattaforma che permette lo stack unwinding che `e sfruttata durante l’implementazione della contromisura. Il capitolo si sviluppa poi con una descrizione dettagliata delle caratteristiche di libDefender, a partire dai concetti teorici che ne hanno ispirato lo sviluppo per poi descriverne le funzionalit`a e l’implementazione pratica delle stesse. Si passa poi ad un’analisi critica dei limiti dell’approccio per valutarne la rilevanza e le possibili soluzioni. Infine si procede a descrivere l’implementa-zione in kernelspace del meccanismo di protel’implementa-zione contro gli heap overflow propedeutico alla modifica del compilatore C/C++, il quale permette di completare le misure di protezione contro le principali categorie di attacchi noti.
Nella prima parte del quarto capitolo si andr`a ad illustrare il funzio-namento di alcuni dei programmi di test sfruttati per dimostrare l’efficacia di libDefender nel bloccare attacchi ed i risultati di questi test. Si proce-de poi ad illustrare i risultati proce-dei test prestazionali eseguiti per valutare le prestazioni di libDefender per poi commentare i risultati dei test stessi. In-fine si passa ad un riepilogo e commento pi`u generale sui risultati raggiunti dall’elaborato, illustrando i possibili sviluppi futuri.
Vulnerabilit`
a: stato dell’Arte
Per poter comprendere al meglio il funzionamento delle tecniche di attac-co appartenenti alle categorie di vulnerabilit`a quali buffer overflow, format string ed heap overflow e le contromisure relative `e utile avere una buona conoscenza di quale sia la disposizione della memoria e di come essa venga utilizzata da parte dei processi durante la loro esecuzione. A tal fine pri-ma di entrare nel dettaglio riepilogheremo alcuni concetti teorici relativi ai sistemi operativi.
1.1
Organizzazione della memoria virtuale di un
processo
La struttura della memoria virtuale del processo `e suddivisa in pi`u seg-menti, i quali identificano delle aree di memoria dedicate ognuna ad un particolare scopo. Tra le principali informazioni relative ad un processo che possiamo trovare in memoria durante la sua esecuzione abbiamo:
• il codice del programma stesso • variabili d’ambiente
• variabili statiche • variabili globali • stack
• librerie dinamiche
Prendendo come riferimento l’architettura IA-32 ed entrando maggior-mente nel dettaglio possiamo identificare i seguenti segmenti:
Text contiene le istruzioni vere e proprie, il codice che viene effettivamen-te eseguito dalla CPU. Questo segmento `e accessibile in sola lettura, ogni tentativo di scrittura in questa sezione causa la terminazione del processo.
Data contiene i dati globali e statici, ovvero tutte le dichiarazioni di varia-bili globali o statiche che vengono immediatamente inizializzate. Es: static int foo = 0;
BSS acronimo di block started by symbol; questa sezione contiene tutte le variabili globali o statiche non inizializzate.
Heap in questa parte della memoria vengono inserite le aree di memoria allocate dinamicamente ( per esempio tramite funzioni quali: malloc, realloc, calloc ).
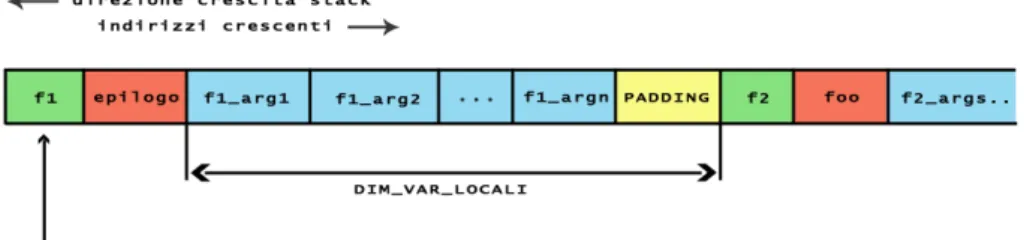
Stack in questa parte della memoria di processo vengono inserite variabili locali e dinamiche, oltre ai parametri di funzione ed alle informazioni di controllo. Come evidenziato nella figura 1.1 lo stack parte da indi-rizzi alti e “cresce” verso indiindi-rizzi minori, mentre lo heap “cresce” in direzione contraria.
Memory Mapping in questa parte dello spazio di indirizzamento vengono inserite le librerie dinamiche utilizzate dal processo ed i file mappati in memoria tramite chiamate ad mmap()
Figura 1.1: Layout memoria processo
1.2
Chiamate a funzione
Una funzione rappresenta una sezione di codice parzialmente isolata dal resto del programma che implementa un sottoprogramma; il suo scopo `e quello di consentire il riuso di una porzione di codice.
Per eseguire una funzione `e necessario quindi deviare il flusso di esecuzio-ne e passare al codice della funzioesecuzio-ne stessa, per poi riprendere l’esecuzioesecuzio-ne dal punto in cui il flusso `e stato deviato. `E dunque necessario salvare tutte le informazioni necessarie a ripristinare il contesto di esecuzione prima di passare ad eseguire la funzione tramite l’istruzione call. Queste informa-zioni vanno a costituire un blocco dati contiguo detto record di attivazione o frame, che viene salvato (tutto o in parte a seconda della calling conven-tion) sullo stack prima dell’ingresso nella funzione chiamata, e ripristinato all’uscita dalla stessa.
1.2.1 Record di attivazione
Il record di attivazione include l’intero contesto di esecuzione ovvero: parametri della funzione i parametri della funzione invocata vengono
indirizzo di ritorno rappresenta il valore dell’indirizzo dell’istruzione suc-cessiva alla call che verr`a usato dall’istruzione ret per ripristinare l’e-secuzione al termine della funzione. Viene quindi salvato al momento dell’esecuzione dell’istruzione call.
frame pointer quando presente contiene l’indirizzo della base del record di attivazione precedente, ovvero il contenuto del registro %ebp al momento della chiamata a funzione. Questo valore non viene sem-pre salvato sullo stack, ad esempio l’opzione di compilazione di gcc -fomit-frame-pointer evita il salvataggio di questo valore con lo sco-po di rimuovere l’overhead computazionale ascrivibile al salvataggio ed al ripristino di questo valore sullo stack.
variabili locali lo spazio per le variabili locali della funzione chiamata viene allocato sullo stack nel prologo della funzione stessa
1.2.2 Esempio di chiamata a funzione
Analizziamo passo per passo la struttura di una chiamata a funzione, partendo dal codice in figura 1.1 che fa ancora riferimento per semplicit`a al-l’architettura IA-32 e ad un programma compilato senza opzioni che vadano a modificare la struttura del record di attivazione:
Listing 1.1: Esempio di chiamata a funzione
1 void foo( int a, int b, int c ) { 2 int buf[2]; 3 char test[3]; 4 buf[0] = 1; 5 test[0] = ’A’; 6 } 7 8 int main(void) { 9 int i = 9; 10 foo(1, 2, 3); 11 return 0; 12 }
Listing 1.2: Assembly generato dalla chiamata a funzione
1 main:
2 push %ebp
3 mov %esp, %ebp
4 sub $4, %esp 5 movl $9, -4(%ebp) 6 push $3 7 push $2 8 push $1 9 call foo 10 mov $0, %eax 11 leave 12 ret 13 foo: 14 push %ebp
15 movl %esp, %ebp
16 sub $12, %esp
17 movl %1, -8(%ebp)
18 movb $41, -12(%ebp)
19 leave
20 ret
Possiamo subito notare che in generale, ogni funzione guardata a livello di codice macchina 1.2 inizia con una sequenza di istruzioni detta prologo. Tale sequenza ha l’obiettivo di salvare sullo stack l’attuale frame pointer, al-lineare il base pointer con la cima dello stack, ed infine riservare la quantit`a di memoria necessaria ad allocare le variabili locali decrementando %esp. Prima della chiamata a funzione, nell’architettura IA-32, i parametri della funzione devono essere salvati sullo stack in ordine inverso rispetto alla loro posizione nel prototipo di funzione (operazione effettuata dalla sequenza di push alle righe 6–9). Nel caso dell’architettura AMD64 invece solo i para-metri di dimensione minore di 64bit o che rappresentano dati non allineati rispetto a multipli di 64bit vengono passati alla funzione chiamata per mez-zo dello stack, tutti gli altri vengono memorizzati all’interno di registri della CPU, fino ad un massimo di 6 valori. Infine all’esecuzione dell’istruzione call 1.2(b), anche l’instruction pointer verr`a salvato sullo stack, andando a comporre il record di attivazione del processo assieme al frame pointer (se presente). Dopo l’esecuzione delle istruzioni che compongono il corpo della funzione verr`a eseguito l’epilogo della funzione, ovvero le istruzioni leave e ret, nel caso in cui il frame pointer sia stato salvato sullo stack, addl e ret
in caso contrario. L’istruzione leave infatti serve a riallineare stack pointer con frame pointer (equivale infatti alle istruzioni movl %ebp, %esp; popl %ebp ) ripristinando il base pointer che andr`a ora a puntare alla base del frame precedente. Nel caso in cui il frame pointer non sia stato salvato sullo stack l’istruzione addl va invece ad incrementare il valore dello stack pointer del numero di bytes necessario a riallinearlo con il return address. In en-trambi i casi a questo punto la cima dello stack punta all’indirizzo del return address. Successivamente viene eseguita la ret, che non fa altro che sosti-tuire il valore attuale dell’istruction pointer con quello in cima allo stack. A questo punto `e compito del chiamante rimuovere dallo stack gli eventuali parametri della funzione chiamata, incrementando %esp.
1.3
Allocazione dinamica della memoria
Il meccanismo di allocazione dinamica della memoria permette di allo-care esplicitamente blocchi di memoria di dimensione arbitraria in un’area dedicata (detta heap) (con delle ovvie limitazioni di dimensione massima che variano a seconda dell’implementazione dell’allocatore di memoria). Tale meccanismo permette di risolvere alcune problematiche legate alla gestione della memoria che non possono essere gestite in modo adeguato tramite l’al-locazione statica o automatica della memoria. La memoria allocata statica-mente persiste per l’intera vita del programma ma deve essere dimensionata al momento della compilazione. Il meccanismo di allocazione automatica della memoria rappresenta il modo in cui viene gestita l’allocazione delle variabili locali. Esse vengono infatti allocate al momento in cui il flusso di esecuzione raggiunge lo scope delle variabili locali stesse, ad esempio al mo-mento dell’esecuzione della funzione in cui esse sono visibili. Quando il flusso di esecuzione lascia lo scope di tali variabili esse vengono deallocate. Dunque non `e possibile controllare contemporaneamente la visibilit`a e la dimensione delle variabili senza sfruttare il meccanismo di allocazione dinamica della memoria. Il programmatore ha quindi la possibilit`a di allocare un’area di memoria, utilizzarla per poi liberarla, rendendola di nuovo disponibile per altre operazioni di allocazione dinamica. Di solito una libreria di sistema mappata nello spazio di indirizzamento del processo si incarica di gestire le operazioni di allocazione e di deallocazione della memoria.
Figura 1.2: Evoluzione stack durante l’esecuzione del programma
Come lo stack, anche lo heap contiene anche informazioni di gestione insieme ai dati stessi. Come risultato abbiamo che gli attacchi di buffer overflow sullo heap hanno lo stesso principio di base dei buffer overflow sullo stack, ovvero sovrascrivere informazioni di gestione specifiche per deviare il flusso di esecuzione del programma con l’obiettivo di eseguire codice arbi-trario. Le modalit`a con cui la vulnerabilit`a viene sfruttata, come vedremo, sono significativamente diverse.
1.4
Classi di vulnerabilit`
a
Questa sezione conterr`a una breve descrizione delle principali classi di vulnerabilit`a correlate con iniezione ed esecuzione di codice in applicazioni C o C++. Per ogni classe di vulnerabilit`a andremo anche a descrivere quale errore di programmazione causa la vulnerabilit`a, per poi passare a descrivere nel dettaglio la tecnica di base con cui un attaccante pu`o sfruttare tale vulnerabilit`a [12, 35] .
1.4.1 Buffer overflows
La classe di vulnerabilit`a andremo a descrivere racchiude tutte le vul-nerabilit`a che conseguono da una operazione di scrittura in memoria che prosegua oltre i confini di un buffer. Con buffer facciamo riferimento ad un blocco di memoria contiguo, che possa contenere pi`u istanze di variabili dello stesso tipo. Un esempio di buffer per il linguaggio C `e ad esempio un semplice array di caratteri.
Come sappiamo le variabili possono essere dichiarate come statiche o posso-no essere allocate dinamicamente. Nel primo caso lo spazio necessario verr`a allocato alla creazione del processo, nel secondo caso lo spazio verr`a allocato a runtime. Questa differenza determina in quale area di memoria riservata verranno allocate le variabili.
Le variabili globali statiche sono difatti allocate nel segmento data che fa parte dell’eseguibile stesso, mentre le variabili locali vengono, al contrario, allocate all’interno dell’area di memoria riservata al processo detta stack in cui i dati vengono gestiti secondo una politica LIFO.
L’esistenza stessa della vulnerabilit`a detta buffer overflow `e dovuta ad alcune caratteristiche intrinseche del linguaggio C e della libreria standard. Buona parte delle funzioni di manipolazione di memoria o stringhe offerte dalla libreria standard C (detta anche libc) non implementano infatti al-cun tipo di validazione degli argomenti con i quali esse vengono invocate. E’ dunque possibile che il buffer sorgente abbia dimensione maggiore del buffer destinazione. Una qualsiasi operazione di copia tra i due buffer ha come conseguenza un overflow : l’operazione di copia del buffer sorgente non termina una volta raggiunto il limite del buffer destinazione, ma prosegue sovrascrivendo le locazioni di memoria adiacenti.
Nel caso il buffer destinazione sia stato allocato nello stack l’operazione di copia pu`o quindi sovrascrivere anche informazioni relative al flusso di controllo del programma quali l’indirizzo del frame pointer precedente o l’indirizzo dell’istruzione successiva da eseguire al termine della procedura corrente.
Le modalit`a con cui l’attacco viene implementato dipendono dall’errore di programmazione che crea la vulnerabilit`a e dai dati iniettati dall’attaccante. Possiamo dunque dividere l’attacco in due fasi distinte, le quali vanno a co-stituire anche due parti distinte del cosiddetto vettore di attacco.
La prima parte, detta injection vector (IV) ha lo scopo di deviare il flusso di esecuzione sfruttando la vulnerabilit`a creata dall’errore di programmazione. La seconda parte viene invece detta payload e costituisce il vero e proprio corpo dell’attacco che causa la compromissione del sistema.
Sovrascrivere semplicemente le locazioni adiacenti con dati casuali comporta spesso il crash del processo, configurando quindi un caso di Denial-of-Service (DoS). Pi`u significativo `e il caso in cui l’attaccante inietti nella memoria del processo del codice e riesca poi a deviare il flusso di esecuzione in modo da eseguirlo, come illustreremo nella sezione successiva andando a descrivere lo stack smashing, la prima tecnica con cui vennero sfruttate le vulnerabilit`a di questa classe.
1.4.2 Stack smashing
La prima tecnica sviluppata per sfruttare questa classe di vulnerabilit`a fu lo stack smashing. [16, 18]
Questo tipo di attacco impone all’attaccante di:
• sovrascrivere il return address di modo che punti ad una locazione arbitraria e non pi`u al codice della funzione chiamante.
• iniettare codice valido nella memoria del processo, in una locazione raggiungibile dal punto di arrivo del salto precedente, di modo che ese-guendo tale salto possa prendere il controllo del sistema o raggiungere lo scopo dell’attacco.
Descriviamo nel dettaglio come sia possibile attuare questa tecnica con un esempio. Nel codice in figura 1.3, la funzione bar copia una stringa
all’in-terno del buffer locale c, usando l’istruzione strcpy() offerta dalla libreria standard C.
Listing 1.3: Esempio di programma vulnerabile rispetto allo stack smashing
1 void bar (char *buf) { 2 char c[12];
3 strcpy(c, buf); 4 }
5 int main (int argc, char **argv) { 6 bar(argv[1]);
7 }
A causa dell’implementazione delle funzioni di manipolazione per le stringhe in C, in cui il valore nullo rappresenta il terminatore di stringa, il codice iniettato non potr`a contenere byte nulli, che causerebbero la terminazione dell’operazione di copia.
Dato che nell’esempio il contenuto della stringa copiata `e controllato dall’utente l’attaccante pu`o facilmente causare la sovrascrittura dell’area di memoria adiacente al buffer destinazione dell’operazione alterando quindi il contenuto del record di attivazione.
Come possiamo vedere in figura 1.3a, la memoria adiacente al buffer contiene l’indirizzo del frame pointer salvato e l’indirizzo di ritorno salvato che corrisponde all’indirizzo dell’istruzione da eseguire subito dopo il termine della funzione corrente.
E’ quindi possibile per l’attaccante sovrascrivere il return address di mo-do che all’esecuzione dell’istruzione ret il flusso di esecuzione venga deviato ad un indirizzo appartenente allo stesso stack sovrascritto dall’attaccante, come possiamo vedere in figura 1.3b. In questa locazione di destinazione sar`a stata inserita una sequenza di istruzioni assembly in grado di compro-mettere il sistema, ad esempio lanciando una shell comandabile da remoto (da cui il nome shellcode con cui vengono comunemente identificate queste sequenze di istruzioni).
(a) Layout stack prima dell’attacco (b) Layout stack dopo l’attacco Figura 1.3: Stack smashing
1.4.3 Off-by-one e sovrascrittura frame-pointer
Questa classe di vulnerabilit`a `e dovuta quasi sempre ad due errori ap-parentemente banali nell’espressione di un ciclo di istruzioni:
• inizio di un ciclo a partire dalla seconda posizione (Alg. 1.4)
• criterio di terminazione errato ( ad esempio ≤ invece di < ) (Alg. 1.5)
Listing 1.4: Errore di programmazione 1
1 void bar(char *foo, int foo_size) { 2 char tmp[foo_size];
3 int i;
4 for( i = 0; i <= foo_size; i++ ){ 5 // operazioni su foo e tmp 6 }
Listing 1.5: Errore di programmazione 2
1 void bar(char *foo, int foo_size) { 2 char tmp[foo_size];
3 int i;
4 for( i = 1; i < foo_size; i++ ){ 5 // operazioni su foo e tmp
6 } 7 }
Questi due errori permettono un overflow di un solo byte, che per`o pu`o essere sufficiente per deviare il flusso di esecuzione. Se infatti l’array `e adiacente al record di attivazione l’attaccante avr`a la possibilit`a di sovrascrivere un byte del frame pointer salvato. La differenza fondamentale rispetto ai precedenti attacchi risiede nel fatto che il return pointer non viene modificato ma viene alterato solo il frame pointer salvato.
In figura 1.4 possiamo osservare la sequenza di passi che portano alla realizzazione di un attacco di tipo off-by-one, un caso specifico di vulnera-bilit`a frame pointer overwrite che ne conserva la logica di funzionamento. Come possiamo vedere la struttura della stringa di overflow `e costituita dal cosiddetto payload ovvero l’insieme di una sequenza di istruzioni nop seguite dallo shellcode. Le istruzioni nop non hanno alcun effetto a parte quello di causare l’incremento dell’istruction pointer e sono quindi usate dall’attac-cante come riempitivo cos`ı da non dover calcolare con assoluta precisione l’indirizzo a cui deviare il flusso di esecuzione, il quale potrebbe variare leg-germente ad ogni esecuzione dell’attacco o su host diversi. Subito dopo il payload troviamo il byte che va a sovrascrivere il byte meno significativo del frame pointer salvato del processo vulnerabile in questo caso di off-by-one, mentre nel caso pi`u generico di frame pointer overwrite troveremmo il valore che andrebbe a sovrascrivere l’intero frame pointer.
L’attacco quindi fa si che durante l’esecuzione dell’epilogo della funzione, il valore di %ebp divenga quello controllato dall’attaccante, facendolo pun-tare il registro ai primi byte dello shellcode (figura 1.4a). Successivamente verr`a eseguita l’istruzione ret, che acceder`a alla parola salvata nei 4 byte precedenti, che verranno interpretati come un indirizzo di ritorno. Questo porter`a l’indirizzo del payload, ovvero un indirizzo che l’attaccante stima sia
contenuto all’interno della sequenza di istruzioni nop, ad essere assegnato ad %eip, deviando il flusso di esecuzione del programma (figura 1.4c). A questo punto verranno eseguite le istruzioni nop che porteranno poi all’esecuzione dello shellcode.
(a) (b) (c)
Figura 1.4: Frame pointer overwrite
1.4.4 Uncontrolled Format string
L’attacco di tipo uncontrolled format string detto anche comunemen-te format string [15, 17] si rende possibile quando una stringa controllata dall’utente viene valutata come argomento di una funzione di stampa for-mattata. A causa di questo errore di programmazione un attaccante `e in grado di leggere valori dallo stack o di scrivere ad indirizzi arbitrari.
Prima di entrare nei dettagli della tecnica andiamo a descrivere il mec-canismo alla base della stampa formattata. Le format function sono una classe di funzioni di conversione (quali ad esempio printf o fprintf che trasformano gli argomenti della funzione in una stringa formattata. Tali fun-zioni possono venire invocate con un numero variabile di argomenti, uno dei quali dovrebbe essere la stringa di formato. La stringa di formato `e quindi una stringa contenente testo e parametri di formattazione, che rappresenta uno degli argomenti tipici di una format function. I sopracitati parametri di formattazione sono delle particolari stringhe, costituite dal carattere % e alcune lettere successive (es %d, %ld ), che identificano il tipo del dato ed il formato con cui inserire l’argomento associato nella stringa risultante.
L’attacco pu`o quindi essere eseguito quando l’applicazione non valida l’input ottenuto dall’utente. Dunque l’attaccante `e in grado di inserire, nel-la funzione che viene interpretata come format string, dei parametri quali %x o %n ai quali non corrisponde alcun argomento della funzione, e che quindi causano la lettura o anche la scrittura di valori in memoria. Il particolare parametro %n infatti non inserisce alcun valore nella stringa risultato, ma causa la scrittura del numero di caratteri formattati fino a quel punto al-l’indirizzo a cui fa riferimento l’argomento corrispondente (di tipo puntatore ad intero). Vi `e un’altro dettaglio legato ai parametri di formattazione che ci pu`o essere molto utile. Inserendo un parametro del tipo %[n]$s avremo la possibilit`a di accedere alla n-esima parola sullo stack senza modificare il contenuto dello stack.
Possiamo utilizzare questa caratteristica per scrivere ad un arbitrario indi-rizzo di memoria inserendo un parametro del tipo %[n]$n. Una generica stringa adatta per eseguire un attacco di tipo format string potr`a quindi essere simile a quella mostrata di seguito:
[address+3][address+2][address+1][address] %1$[n1-16]x %[m+1]$n %1$[n2-n1]x %[m+2]$n
%1$[n3-n2]x %[m+3]$n %1$[n4-n3]x %[m+4]$n[padding]
Di cui andremo a spiegare nel dettaglio la struttura blocco per blocco: • %1$[n1-16]x : stampa n1 - 16 caratteri (il numero 16 deriva dal fatto
che i primi quattro indirizzi occupano esattamente 16 byte e quindi il numero totale di byte da stampare deve essere compensato
• %[m+1]$n : scrive il numero di caratteri stampati fino ad ora (n1) all’indirizzo trovato alla parola m+1esima dello stack ([address+3]) • %1$[n2-n1]x : stampa n2 - n1 caratteri. Il numero n2 indica i
caratteri stampati fino ad ora.
• %[m+2]$n : scrive il numero di caratteri stampati fino ad ora (n2) all’indirizzo trovato alla parola m+2esima dello stack ([address+2]) • %1$[n3-n2]x : stampa n3 - n2 caratteri. Il numero n3 indica i
caratteri stampati fino ad ora.
• %[m+3]$n : scrive il numero di caratteri stampati fino ad ora (n3) all’indirizzo trovato alla parola m+3esima dello stack ([address+1])
• %1$[n4-n3]x : stampa n4 - n3 caratteri. Il numero n3 indica i caratteri stampati fino ad ora.
• %[m+4]$n scrive il numero di caratteri stampati fino ad ora (n4) all’indirizzo trovato alla parola m+4esima dello stack ([address]) • padding composto da 0 a 3 caratteri permette di allineare gli indirizzi
[address+k] che verranno inseriti sullo stack prima dell’esecuzione della funzione.
Durante l’esecuzione di una format string ci `e possibile sovrascrivere solo un byte alla volta. E’ qundi necessario sovrascrivere byte per byte l’indi-rizzo in memoria, partendo dai byte meno significativi che andranno quindi scritti in fondo all’indirizzo di memoria da sovrascrivere. Dunque se as-sumiamo che l’indirizzo che vogliamo scrivere sia 0x12345678 all’indirizzo ind=0x08048412 dovremo scrivere
• il byte 0x78 all’indirizzo ind+3 • il byte 0x56 all’indirizzo ind+2 • il byte 0x34 all’indirizzo ind+1 • il byte 0x12 all’indirizzo ind
Il motivo per cui iniziamo a sovrascrivere l’ultimo byte e non partiamo dai byte pi`u significativi `e dovuto al particolare meccanismo del parametro %n. Dato che questo parametro permette di scrivere all’indirizzo da noi indicato il numero di byte stampati fino a quel momento (e come possiamo vedere nella spiegazione) `e chiaro che i valori che andiamo a scrivere in memoria essere sempre maggiori, ovvero
n4 > n3 > n2 > n1
Per rispettare questo vincolo andremo a sovrascrivere in realt`a tre byte dell’indirizzo, partire dai byte meno significativi ci permette di ottenere al termine delle scritture il giusto indirizzo in memoria. Sceglieremo quindi i valori in questo modo:
• n2 = 0x156 = 342 • n3 = 0x234 = 564 • n4 = 0x312 = 786
Quando questi verrano scritti in memoria il risultato delle operazioni sar`a: 0x00000078
0x00015678 0x02345678 0x12345678
Il valore 0x3 verr`a scritto nella parola successiva in memoria, mentre l’indi-rizzo da noi scelto sar`a stato correttamente sovrascritto.
1.4.5 Return-to-library
L’evoluzione successiva degli attacchi fu quella di riusare del codice gi`a presente nella memoria del processo vulnerabile. Il primo a suggerire tale approccio nel 1997 fu Solar Designer, con una mail alla lista Bugtraq [4]. L’attacco return-to-library ha quindi in comune con il classico buffer overflow l’uso di un Injection Vector per deviare il flusso di esecuzione, ma differisce nei passi successivi. Questa tecnica difatti prevede la sostituzione dell’indirizzo di ritorno con l’indirizzo di una funzione di libreria arbitraria, consentendone l’esecuzione al termine della funzione corrente.
La libreria C standard, viene usata praticamente da tutti i programmi scritti nel linguaggio C ed `e quindi molto probabile che essa sia presente in memo-ria. Se a questo uniamo il fatto che essa offre alcune funzioni che possono essere sfruttate dall’attaccante per eseguire codice arbitrario (system()) o per elevare i propri permessi (setuid()), possiamo dedurre che questa sia quasi sempre sfruttata per portare a termine questo genere di attacco, ma in teoria l’attacco pu`o essere condotto invocando poi funzioni appartenenti ad una qualsiasi libreria gi`a presente in memoria. Uno schema dello stato dello stack durante l’esecuzione di questo tipo di attacco `e mostrato in figura 1.5. Illustriamo il funzionamento dell’attacco nel dettaglio con un esempio che andremo a sviluppare passo per passo.
Figura 1.5: Uno schema esemplificativo per la vulnerabilit`a return-to-library
Listing 1.6: Un banale programma vulnerabile ad un attacco return-to-library
1 #include <stdio.h> 2 #include <string.h>
3 int main( int argc, char **argv ) {
4 char buff[5];
5 if(argc != 2) {
6 puts("I need one and only one argument!\n");
7 return(1);
8 }
9 printf("exploiting return to libc\n");
10 strcpy(buff, argv[1]);
11 printf("\n you typed: [%s]\n", buff);
12 return(0);
13 }
Supponiamo di voler eseguire la syscall system(), cos`ı da poter eseguire un comando arbitrario, ad esempio una shell come /bin/sh. Dunque l’unico argomento da inserire sullo stack sar`a l’indirizzo della stringa che indica il path del comando da eseguire.
Prima di poter sfruttare la vulnerabilit`a dobbiamo per`o: • trovare l’indirizzo della funzione system()
• inserire in memoria ed avere il relativo indirizzo dell’argomento /bin/sh Per trovare l’indirizzo della funzione ci baster`a usare gdb interrompendo il programma nel main ed eseguendo
(gdb) p system
$1 = {<text variable, no debug info>} 0xb7ece180 <system> mentre per inserire in memoria la stringa abbiamo due possibilit`a:
• cercare in memoria una stringa gi`a esistente • sfruttare una variabile d’ambiente ad hoc
In questo esempio useremo l’approccio pi`u rapido che sfrutta una variabile d’ambiente.
Prima di eseguire il codice andremo quindi ad eseguire $> export SHELL=/bin/sh
per esportare la variabile d’ambiente contenente la stringa contenente il comando da invocare.
Sfrutteremo poi un breve programma per ricavare l’indirizzo in memo-ria della vamemo-riabile d’ambiente appena esportata, facendo uso della funzione getenv(SHELL)
Listing 1.7: Un esempio di programma in grado di recuperare l’indirizzo di una variabile d’ambiente
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<string.h>
4 int main(int argc, char **argv){
5 char *ptr;
6 ptr = getenv(argv[1]);
7 if( ptr == NULL )
8 printf("%s not found\n", argv[1]); 9 else
10 printf("%s found at %08x\n", argv[1], (unsigned
int)ptr);
11 return 0;
12 }
Lanciandolo otterremo: SHELL found at bfffffe0
Una volta ottenuto l’indirizzo sappiamo che a causa dell’endianness la strin-ga da inserire conterr`a i byte in ordine inverso, ovvero
\xE0\xFF\xFF\xBF
Sar`a dunque necessario sfruttare un buffer overflow, sovrascrivendo poi il return address con l’indirizzo della funzione di libreria da chiamare. Ora abbiamo tutte le informazioni necessarie, possiamo cercare di indovinare quale sia il numero di bytes da riempire prima di poter sovrascrivere il return address, ad esempio eseguendo:
$> ./retlib ` perl -e ’printf ‘‘A’’ x 23’` Exploiting via returning into libc function You typed [AAAAAAAAAAAAAAAAAAAAAAA]
Segmentation fault (core dumped)
$> gdb -c ./core
Core was generated by ’retlib’.
Program terminated with signal 11, Segmentation fault. #0 0x08004141 in ?? ()
(gdb)
Il messaggio d’errore estratto dal core dump ci mostra che nell’indirizzo a cui il programma `e ritornato compaiono due 0x41, la codifica ASCII della ’A’. Questo fatto ci permette di capire che siamo gi`a arrivati a sovrascri-vere il return address, quindi possiamo dedurre dal fatto che , che dopo 21 bytes di padding possiamo poi inserire l’indirizzo della system(). I 4 byte successivi rappresentano invece l’indirizzo dell’istruzione da eseguire subito dopo ritorno dalla funzione: potremmo sfruttare questo campo per concate-nare pi`u funzioni (ad esempio setuid(0); system(/bin/sh);, oppure per eseguire una exit() per evitare di causare la terminazione del programma, lasciando possibilmente tracce nei log di sistema.
Infine vengono inseriti gli argomenti della funzione invocata; ad esempio il puntatore alla stringa contenente il comando da eseguire nel caso della system().
Un esempio di comando che potremmo eseguire per sfruttare la vulne-rabilit`a potrebbe essere quello mostrato di seguito:
$>./retlib‘perl -e
1.5
Tecniche avanzate di attacco
1.5.1 Evoluzione return-to-libraryIl principale sviluppo successivo della tecnica ’return-to-library’ fu quello di sfruttare un buffer overflow per permettere l’esecuzione di pi`u funzioni in sequenza [33]. L’idea alla base di questa tecnica `e quella di sfruttare delle brevi sequenze di istruzioni terminate da un’istruzione ret gi`a presenti in memoria, che consentano il riallineamento dello stack di modo da rende-re possibile l’esecuzione di pi`u funzioni in successione. Esempi notevoli di queste sequenze di istruzioni sono elencati nel listato 1.8
Listing 1.8: Sequenze di istruzioni assembly utili all’esecuzione di attacchi return-to-library 1 popret: 2 pop %eax 3 ret 4 5 leaveret: 6 leave 7 ret 8 9 addret: 10 add $immediate,%esp 11 ret
Quindi una possibile stringa di overflow per un attacco di return-to-library multiplo avr`a una struttura simile a quella mostrata in figura 1.6: La strin-ga di overflow `e quindi costituita da una serie di caratteri di riempimento che servono da padding per raggiungere la posizione del return address. Questo verr`a sostituito dall’indirizzo della prima funzione da eseguire, su-bito dopo dovremo inserire l’indirizzo di una sequenza popret. L’esecuzione di una popret ci permette di rimuovere dallo stack i parametri passati alla prima funzione cos`ı che al ritorno dalla sequenza l’esecuzione possa passa-re dipassa-rettamente alla seconda funzione, concatenando quindi l’esecuzione di due funzioni appartenenti alla libreria standard C. Ovviamente `e necessario conoscere l’indirizzo in memoria di una sequenza contenente un numero di
Figura 1.6: Stringa di overflow utile per un attacco return-to-library multiplo
pop pari al numero dei parametri passati alla funzione precedente, e questo costituisce uno dei limiti di questa tecnica di attacco. Ci`o che rende mol-to importante quesmol-to contribumol-to `e l’idea di riutilizzare non solo delle intere funzioni presenti in memoria ma anche delle brevi sequenze di istruzioni terminate da una ret, idea che `e alla base anche di altre tecniche di attac-co sviluppate successivamente attac-come il Return Oriented Programming, che descriveremo nel prosieguo del capitolo.
ESP lifting
Il concetto alla base di questa tecnica `e lo stesso di quello descritto nella precedente sezione, cos`ı come l’obiettivo finale della tecnica. Ci`o che diffe-renzia questa tecnica dalla precedente `e il contesto in cui questa pu`o essere applicata, oltre ad imporre meno vincoli al tipo funzioni che `e possibile inse-rire nella stringa di overflow. Poniamoci dunque nel caso in cui il programma vulnerabile non salvi sullo stack il valore del frame pointer. Analizzando le istruzioni assembly generate dal compilatore notiamo che l’epilogo delle fun-zioni sar`a del tipo addret gi`a riportato nel listato 1.8. Tale sequenza va ad incrementare direttamente il valore di %esp dato che il frame pointer non `e stato salvato sullo stack. Il registro %esp viene incrementato di un numero di byte pari allo spazio occupato sullo stack dalle variabili locali della fun-zione tramite l’istrufun-zione addl che va quindi a riallineare il valore di %esp
all’indirizzo del return address, cos`ı che la successiva ret termini la funzio-ne. Questa caratteristica pu`o essere sfruttata durante un attacco di tipo return-to-libc per riallineare lo stack pointer e rimuovere gli eventuali parametri passati alla funzione precedentemente invocata, realizzando una funzione analoga a quella delle sequenze popret gi`a descritte nella precedente sezione.
Figura 1.7: Uno schema della tecnica esp lifting
Questo tipo di sequenze impongono per`o meno vincoli rispetto alle se-quenze popret. dato che una volta individuato l’epilogo di una funzione che abbia fatto uso di sufficienti variabili locali `e possibile sfruttare l’epilogo di tale funzione per rimuovere dallo stack un numero maggiore di parametri appartenenti alla funzione precedente rispetto a quanto sarebbe possibile con l’uso di popret.
Nel caso in cui si ricorra all’uso di popret si `e invece vincolati dal fatto che `e spesso difficile trovare sequenze di istruzioni terminate da una ret che contengano pi`u di due istruzioni pop, il che significa che usando tali sequenze non `e possibile eseguire tramite return-to-libc chiamate a funzione che facciano uso di pi`u di due parametri.
Per sfruttare questa tecnica `e quindi necessario strutturare la stringa di overflow come mostrato in figura 1.7, aggiungendo del padding al termine dell’elenco dei parametri della funzione f1 di modo che lo spazio occupato dalle variabili locali e dal padding sia pari al numero di byte sommati ad %esp dalla sequenza addret da noi scelta.
A questo punto inserendo l’indirizzo della sequenza addret subito dopo l’indirizzo della funzione f1 riusciremo ad incrementare il valore di %esp allineandolo all’indirizzo della funzione successiva per poi eseguirla.
Frame Faking
La tecnica illustrata precedentemente non `e per`o applicabile in ogni si-tuazione. Nel contesto di una normale applicazione a 32 bit, compilata senza l’opzione -fomit-frame-pointer noteremo che la maggior parte delle fun-zioni saranno terminate da una diversa sequenza di funfun-zioni che potremo chiamare leaveret 1.8.
Indipendentemente dal livello di ottimizzazione il compilatore inserir`a sempre le due istruzioni leave e ret in sequenza. Dunque non avremo la possibilit`a di attuare un attacco del tipo esp lifting.
In questi casi dovremo sfruttare a nostro vantaggio le sequenze leaveret 1.8, adattando la strategia d’attacco, sfruttando un meccanismo simile a quello della tecnica frame pointer overwrite.
Facendo riferimento alla figura 1.8, il valore denominato finto ebp0 dovrebbe rappresentare l’indirizzo del primo finto frame mentre finto ebp1 l’indirizzo del secondo e cos`ı via.
Figura 1.8: Uno schema della tecnica di frame faking
• l’epilogo della funzione vulnerabile pone finto ebp0 in %ebp e passa ad eseguire una sequenza leaveret.
• l’istruzione leave che fa parte della sequenza leaveret causer`a la copia di finto ebp1 in %ebp per poi portare all’esecuzione della funzione f1 il cui indirizzo `e stato appoistamente inserito nei 4 byte precedenti sullo stack.
• f1 inizia l’esecuzione trovando sullo stack i giusti argomenti, viene quindi eseguita normalmente e la catena pu`o proseguire
Un problema di questo approccio `e che `e necessario conoscere la posizione precisa dei frame finti dato che devono essere assegnati con precisione gli indirizzi dei “finti ebp”. Se ad esempio tutti i frame sono collocati all’in-terno della stringa di overflow `e necessario conoscere il valore di %esp dopo l’overflow per poter calcolare le posizioni relative dei vari elementi. Se invece si `e in grado di posizionare questi falsi frame ad un indirizzo noto e fissato non abbiamo pi`u la necessit`a di ricavare il valore di %esp, ma tutto ci`o non `
e sempre fattibile.
Borrowed code chunks
Come abbiamo illustrato precedentemente la tecnica return-to-libc si ba-sava originariamente sull’esecuzione di funzioni appartenenti alla libreria standard per eseguire le operazioni necessarie a portare a termine l’attacco. Per aggirare alcune limitazioni causate dal passaggio dei parametri nello stack stesso queste modalit`a di attacco sono state sviluppate facendo uso, come abbiamo gi`a descritto, di brevi sequenze di istruzioni dette popret per riallineare correttamente lo stack.
L’idea di sfruttare delle brevi sequenze di istruzioni `e stata sfruttata da Krahmer anche per rendere applicabile la tecnica return-to-libc su ar-chitetture come AMD64 [10] . Tale piattaforma adotta infatti una diversa convenzione di chiamata per le funzioni che prevede il passaggio di alcuni tipi di parametri tramite registri e non con l’uso dello stack [14]. Questo fatto ha spinto Krahmer a sfruttare delle sequenze di popret allo scopo di poter continuare a passare i parametri all’interno della stringa di overflow, copiando poi i valori dei parametri nei registri opportuni appena prima di eseguire la chiamata a funzione.
1.5.2 Return oriented programming
Con il nome di Return Oriented Programming si fa riferimento ad una modalit`a di attacco che pu`o essere considerata come un’evoluzione della categoria degli attacchi return-into-libc e borrowed-code-chunks [23] . La tecnica sviluppata da Shacham si basa sull’idea di combinare alcune sequen-ze di istruzioni terminate da una ret fino ad ottenere una funzione di base, come ad esempio lo spostamento di un valore dalla memoria ad un registro o un’operazione aritmetica come xor o and. Ognuna di queste sequenze viene denominata gadget. La tesi dell’articolo [23] `e che concatenando una appropriata sequenza di gadget sia possibile eseguire una qualsiasi sequen-za di operazioni. Le sequenze di istruzioni necessarie alla costruzione dei gadget possono essere individuate all’interno dei programmi disponibili tra-mite l’analisi del codice binario del programma. L’articolo illustra come sia possibile costruire dei gadget sfruttando la libreria standard C come base di codice da analizzare, ma si ipotizza che a partire da una qualsiasi base di codice sufficientemente estesa sia possibile recuperare le sequenze necessarie a costruire tali gadget. Le fasi necessarie a condurre l’attacco, che andremo di seguito a descrivere nel dettaglio sono:
• individuare le sequenze di istruzioni utili allo scopo
• assemblare tali sequenze in gadget che, se concatenati, permettano l’esecuzione della funzionalit`a desiderata
Come individuare le sequenze
Prima di entrare nel dettaglio di come sono state recuperate le sequenze di istruzioni necessarie alla costruzione dei ’gadget ’ definiremo in modo pi`u preciso cosa intendiamo per ’sequenza utile’ di istruzioni. Una sequenza di istruzioni pu`o essere considerata utile se gli elementi della sequenza sono istruzioni valide che non deviano il flusso di esecuzione (ad esempio salti condizionati e non). Inoltre l’ultima istruzione della sequenza deve essere una ret. Le sequenze che possono essere usate per la costruzione dei gadget possono essere ottenute a partire dall’analisi statica degli eseguibili. Nel caso dell’ISA Intel IA-32 vi `e inoltre la possibilit`a di sfruttare il fatto che le istruzioni abbiano lunghezza variabile per estrarre sequenze interpretando
solo parti di istruzioni. Possiamo difatti interpretare una sequenza di bytes qualsiasi come un opcode, dunque partendo da un certo offset rispetto al-l’inizio dell’istruzione originaria c’`e la possibilit`a di ottenere comunque un opcode valido. Con questa procedura ci `e possibile individuare sequenze che non avremmo potuto individuare in altro modo dato che non sono sta-te inserista-te insta-tenzionalmensta-te nel programma. Quanto frequensta-te si verifichi questo fenomeno `e un fattore che dipende dalle caratteristiche dell’ISA su cui stiamo lavorando, ovvero da quanto `e probabile che una sequenza di by-te scelta nel modo sopra descritto possa rappresentare un’istruzione valida. L’Instruction Set IA-32 `e molto denso, ovvero un flusso di byte casuale pu`o essere interpretato come una serie di istruzioni valide con una probabilit`a sufficientemente alta da rendere fattibile questo tipo di approccio.
L’algoritmo usato per popolare l’albero delle sequenze valide, chiamato Galileo, si basa sull’assunzione tale per cui `e pi`u semplice cercare all’indie-tro a partire da una sequenza valida, piuttosto che il contrario. Le sequenze trovate inizieranno quindi tutte a partire dalle occorrenze di istruzioni ret presenti all’interno della base di codice scelta per l’analisi. Il procedimento scelto per la ricerca `e ricorsivo e parte dal byte immediatamente precedente alla sequenza valida attuale. Ci si chiede se questo byte rappresenta un’istru-zione valida, nel caso lo sia si crea un nuovo nodo dell’albero e si continua leggendo il byte precedente. A questo punto si controlla se la concatenazione di questi due ultimi byte costituisca un’istruzione valida. Se lo `e si aggiunge un altro nodo allo stesso livello del precedente e si itera fino a raggiungere il numero massimo di byte consentiti per un’istruzione IA-32 valida. A questo punto si discende di un livello nell’esplorazione dell’albero e si considera co-me sequenza valida anche l’istruzione riconosciuta con le iterazioni appena completate e si ricomincia l’analisi a partire da questo punto. Una volta co-struiti gli alberi delle possibili sequenze valide contenute nella base di codice considerata il passo successivo `e quello della costruzione dei gadgets.
Assemblare ed eseguire gadgets
L’articolo mostra inoltre come a partire dalle sequenze valide individuate con l’algoritmo Galileo sia possibile costruire gadgets che implementino le funzioni essenziali per la computazione che vengono raggruppate in quattro categorie:
• load/store
• aritmetica e logica • flusso di controllo
• syscalls e funzioni di libreria
E’ dunque possibile costruire un’insieme di gadgets tale da poter affermare che tale insieme sia Turing-completo e permetta l’esecuzione di funzioni ar-bitrariamente complesse. Dal punto di vista pratico le limitazioni principali sono quelle dello spazio disponibile dove inserire la sequenza di indirizzi e parametri che permettono l’esecuzione dei gadget. Andiamo ora a descrivere nel dettaglio la struttura di una stringa di overflow in grado di implementare un attacco di tipo ROP prendendo ad esempio l’attacco descritto in figura 1.9 La figura ci mostra lo stato dello stack al momento in cui uno stack
Figura 1.9: Uno schema della tecnica di Return Oriented Programming overflow ha avuto successo. La prima cella di memoria alla base della figura contiene il valore deadbeef che `e andato a sovrascrivere il frame pointer salvato della funzione originaria. L’attaccante ha inoltre deviato con suc-cesso il flusso di esecuzione del programma sovrascrivendo anche il return address. L’esecuzione ora passer`a quindi al primo gadget che consiste in una sequenza popret che permette di assegnare ai registri %eax ed %edx i va-lori 08049167 e 080491a1 assegnati durante l’overflow alle celle dello stack immediatamente precedenti.
A questo punto viene eseguito il gadget successivo che far`a uso di questi valori e cos`ı via.
Come abbiamo visto `e quindi necessario costruire la stringa di overflow tenendo conto dell’endianness dell’architettura e poi collocare in ordine la sequenza di indirizzi a cui si trovano i gadget che vogliamo vengano eseguiti, sfruttando sequenze di popret per assegnare i valori da elaborare nei registri opportuni.
1.5.3 Aggirare ASLR e W⊕X
Sfruttando una variante della tecnica di return oriented programming appena descritta `e possibile sfruttare buffer overflow anche nel caso siano attive misure di protezione quali W⊕X ed ASLR. L’attacco descritto nel-l’articolo di Roglia et al. [22] consiste nella costruzione ed esecuzione di alcuni gadget che permettono di ottenere informazioni sull’indirizzo di base a partire dal quale sia stata allocata la libreria standard C. Grazie a queste informazioni `e dunque possibile ricavare l’indirizzo di ogni altra funzione della libreria ed eseguire con successo un attacco return-to-libc aggirando di fatto la randomizzazione della memoria virtuale.
Prima di spiegare nel dettaglio il funzionamento dell’attacco riepiloghia-mo alcuni concetti che ci saranno utili per comprenderne il funzionamento. Le funzioni appartenenti a librerie condivise (shared library) non vengo-no invocate come delle vengo-normali funzioni, con una singola istruzione call. L’invocazione di una funzione di libreria dinamica passa prima attraverso l’esecuzione di alcuni salti indiretti che permettono di raggiungere infine la funzione chiamata. Ogni programma contiene infatti due strutture dati che sono dedicate allo scopo di gestire queste chiamate:
Global Offset Table - GOT un array contenente gli indirizzi in memo-ria virtuale effettivi delle funzioni appartenenti alle librerie dinamiche usate dal programma.
Procedure Linkage Table - PLT una struttura dati contenente salti in-diretti facenti riferimento ad elementi della GOT.
La struttura denominata Procedure Linkage Table `e costruita in modo che l’i-esimo elemento della tabella contenga un’istruzione di salto indiretto al-l’indirizzo dell’i-esimo elemento della Global Offset Table. Al momento della
compilazione tutte le chiamate a funzione faranno quindi riferimento agli elementi della PLT per eseguire le chiamate a funzioni appartenenti alle librerie dinamiche. Disassemblando il codice di un eseguibile che sia linka-to dinamicamente potremo quindi ritrovare esempi di chiamata come call strcpy@plt
In questi casi il debugger riconosce che l’indirizzo della funzione chiamata `
e corrispondente al record nella PLT che porter`a, tramite la GOT, ad esegui-re la vera funzione di libesegui-reria strcpy. Nel momento in cui viene eseguito il collegamento tra le librerie dinamiche e l’eseguibile infatti il linker si occupa di inserire gli indirizzi corretti delle funzioni di libreria nei record della GOT. Tali indirizzi non sono noti al momento della compilazione dato che con la randomizzazione della disposizione in memoria virtuale dei vari elementi, ad ogni esecuzione del processo le librerie dinamiche verranno mappate nello spazio di indirizzamento del processo ad un indirizzo differente, noto solo a partire dal momento in cui viene eseguito il linking dinamico. Questo processo di compilazione della GOT pu`o avvenire in realt`a al momento del-l’esecuzione del programma (preemptive binding) o pu`o essere ritardato fino all’occorrenza della prima chiamata ad ognuna delle funzioni di libreria (lazy binding).
L’ attacco sfrutta quindi le informazioni presenti all’interno della GOT per calcolare l’indirizzo di base della libreria, cos`ı da poter ricavare l’indirizzo assoluto di una funzione arbitraria della libreria stessa. Entriamo pi`u nel dettaglio delle operazioni eseguite per ricavare l’indirizzo di partenza della libreria standard C. Scegliamo una funzione dalla libreria standard C, ad esempio open e ricaviamone l’indirizzo in memoria virtuale a cui `e stata mappata, tramite la funzione address of. Abbiamo ora la necessit`a di una funzione che chiameremo got base offset(foo) in grado di restituire l’offset rispetto alla base della Global Offset Table del record contenente l’indirizzo della funzione open. A questo punto possiamo ricavare l’indirizzo di base della libreria standard eseguendo il calcolo
libc_base_address = address_of(open) - got_base_offset(open) A questo punto possiamo ricavare l’indirizzo in memoria di una qualsiasi funzione foo() appartenente alla libreria standard eseguendo
Questo calcolo deve per`o essere eseguito nel contesto del processo vulne-rabile, sfruttando il Return Oriented Programming dato che non `e possibile eseguire codice iniettato in memoria.
L’attacco `e stato implementato in due varianti leggermente diverse, che andremo a descrivere di seguito.
GOT dereferencing
Questa modalit`a di attacco implementa la tecnica di base che calcola l’indirizzo della funzione foo() desiderato tramite Return Oriented Pro-gramming per poi deviare il flusso di esecuzione alla funzione foo() Per implementare questo attacco sono dunque necessari anche solo tre gadgets. L’articolo cita, come uno dei gadget necessari ad eseguire il calcolo, una sequenza come add 0x5dc4(%ebx), %eax; pop %edi; ret. Questo gadget ci permette infatti di leggere un valore arbitrario dallo spazio di indirizza-mento del processo. Sfrutteremo quindi la sequenza per leggere l’indirizzo del record della GOT della funzione open. Per fare ci`o dovremo prima pre-disporre i valori di %eax e %ebx tramite un’altra sequenza che imposti i seguenti valori nei registri:
%eax = got_base_offset(foo) - got_base_offset(open) %ebx = got_base_offset(open) - 0x5dc4
A questo punto, dopo l’esecuzione di questi gadget, %eax conterr`a l’indi-rizzo della funzione foo e ci baster`a un terzo ed ultimo gadget del tipo jmp *%eax per trasferire il controllo alla funzione da noi scelta.
GOT overwriting
La seconda variante ha l’obiettivo di sovrascrivere uno degli elementi della Global Offset Table (ad es. quello della funzione open) con l’indirizzo di una funzione a nostra scelta per poi invocare la funzione sfruttando il record appena modificato. Questo attacco `e possibile dato che il binding tra libreria e processo viene eseguito ”on demand” dal linker, dunque la pagi-na di memoria contenente la GOT `e scrivibile. Le principali operazioni da eseguire tramite gadgets sono la lettura di una locazione di memoria, una somma ed una successiva scrittura. Per fare questo `e sufficiente un’operazio-ne di somma con operando di destinazioun’operazio-ne un indirizzo di memoria. Infiun’operazio-ne
per trasferire il controllo alla funzione da noi scelta ci baster`a sfruttare una chiamata alla funzione di cui abbiamo sovrascritto il record nella Global Offset Table.
1.6
Heap overflow
L’area di memoria denominata heap viene allocata dinamicamente a run-time dall’applicazione. Come per i buffer allocati sullo stack anche nel caso di array allocati sull’heap `e possibile scrivere oltre il limite del buffer, dando luogo ad un overflow. Il concetto alla base della tecnica di overflow `e lo stes-so dei buffer overflow, con la differenza che l’heap cresce verstes-so indirizzi pi`u alti e non viceversa come accade per lo stack. In ogni caso nessun indirizzo di ritorno viene memorizzato sullo heap quindi l’attaccante dovr`a sfruttare altre tecniche per guadagnare il controllo del flusso di esecuzione.
1.6.1 Sovrascrittura puntatori a funzione sull’heap
Uno dei modi di sfruttare un heap overflow `e di sovrascrivere puntatori a funzione memorizzati nello heap subito dopo il buffer in opera la funzione vulnerabile. I puntatori a funzione non sono per`o sempre disponibili, quindi altri modi di sfruttare heap overflow consistono nel sovrascrivere un punta-tore ad una tabella funzioni virtuale e fare in modo che faccia riferimento ad una tabella generata dall’attaccante. A questo punto quando l’applicazione cerca di eseguire uno di questi metodi virtuali eseguir`a il codice a cui fa riferimento il puntatore controllato dall’attaccante.
1.6.2 Heap overflow
I puntatori a funzione oppure i puntatori a funzioni virtuali non sono sempre disponibili quando un attaccante scopre una vulnerabilit`a di tipo heap overflow. Una tecnica pi`u generica per sfruttare heap overflow pu`o essere quella di sovrascrivere le informazioni di gestione della memoria as-sociate ad un blocco di memoria allocato. Per descrivere la vulnerabilit`a ci baseremo su di una specifica implementazione di un allocatore dinami-co di memoria: la versione inclusa nella GNU C library, originariamente sviluppata da Doug Lea, da cui il nome alternativo di dlmalloc [1, 11].
1.6.3 dlmalloc
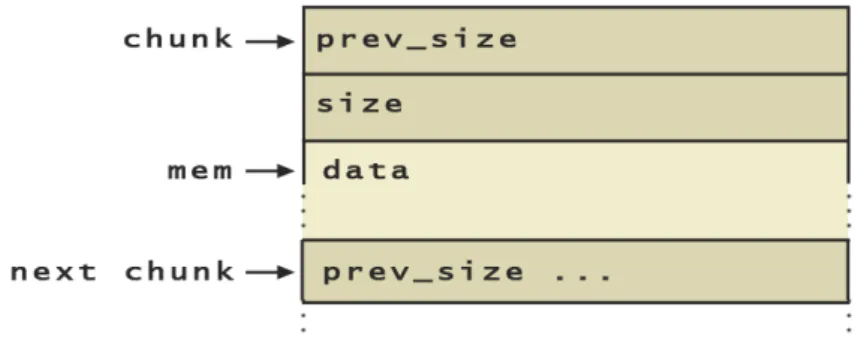
La libreria standard C memorizza le informazioni riguardanti le aree di memoria che un’applicazione richiede in una struttura dati strutturata come segue in figura 1.10
Figura 1.10: Uno schema della struttura dello heap
In cui mem rappresenta il puntatore che viene restituito da una chiamata a malloc(). Una volta che il blocco `e stato usato, questo va deallocato tramite una chiamata a free(mem). La funzione esegue alcuni controlli e l’area di memoria viene rilasciata. Se almeno uno dei blocchi adiacenti `e libero, i due verranno fusi con il blocco corrente per minimizzare il numero di blocchi massimizzando la dimensione dei blocchi stessi. La struttura del blocco di memoria dopo la deallocazione sar`a quella mostrata in figura 1.11 Come possiamo vedere ci sono due nuovi valori aggiunti alle informazio-ni di gestione: fd e bk. Questi due valori sono puntatori che permettono di inserire il blocco nella lista doppiamente collegata dei blocchi di memo-ria libera. La necessit`a di poter inserire dopo la deallocazione questi due puntatori fa si che anche il tentativo di allocazione di una quantit`a nulla di memoria risulter`a nell’allocazione di un numero di byte pari al doppio della dimensione di un puntatore sulla macchina. Il punto fondamentale `e che queste informazioni sono all’interno della stessa struttura che contiene anche i dati, creando la potenziale vulnerabilit`a, proprio come nel caso dello
Figura 1.11: Un blocco di memoria nello heap dopo la deallocazione
stack che contiene al suo interno dati ed informazioni di gestione (indirizzo di ritorno, frame pointer).
Il passo successivo `e quello di sovrascrivere queste informazioni di con-trollo e poi fare in modo che dlmalloc vada ad elaborare queste informa-zioni modficate. Una delle operazioni che potrebbe essere sfruttata per sovrascrivere un’indirizzo arbitrario di memoria `e list unlink().
Listing 1.9: Struttura della macro unlink
1 #define list_unlink(P, BK, FD){ 2 BK = P->bk; 3 FD = P->fd; 4 FD->bk = BK; 5 BK->fd = FD; 6 }
Questa funzione prende come argomento un puntatore ad un’area libera e due puntatori temporanei, chiamati bk e fd. In pratica l’elemento prece-dente a quello attuale ed il successivo vengono collegati, in questo modo l’area corrente viene sganciata dalla lista degli elementi in uso. Dunque per sfruttare un heap overflow una tecnica possibile `e quella di sovrascrivere i
valori del puntatore bk e fd del blocco successivo in modo che vengano usa-ti durante la free() per sovrascrivere un indirizzo di memoria controllato dall’attaccante.
Contromisure: stato
dell’Arte
I primi tentativi di difesa cercarono di impedire lo sfruttamento delle tecniche di stack smashing: l’idea era quella di impedire l’esecuzione del co-dice iniettato nello stack. Dato che negli attacchi di stack-smashing classico lo shellcode veniva iniettato nello stack, tali misure erano utili ad impedire gli attacchi.
Con l’evoluzione delle tecniche queste protezioni non erano pi`u efficaci dato che il codice da eseguire poteva essere nascosto in aree di memoria diverse dallo stack, oppure perch`e con lo sviluppo delle tecniche return-to-library non era pi`u necessario iniettare dello shellcode per poter prendere il controllo del sistema.
Una possibile distinzione che possiamo operare per classificare le varie modalit`a di protezione sviluppate `e distinguere in quale componente del sistema `e implementato il meccanismo di controllo o di protezione definito dalla contromisura:
• protezioni a livello kernel
• protezioni integrate nel compilatore
2.1
Protezione a livello kernel
2.1.1 Stack PatchI primi tentativi di impedire lo sfruttamento di buffer overflow furono delle patch per il Linux kernel denominate Stack Patch [5] . Queste patch avevano lo scopo di impedire l’esecuzione di codice contenuto all’interno dell’area di memoria che costituiva lo stack di un processo. In questo modo si cercava di ostacolare la semplice esecuzione di codice iniettato in memoria durante la sovrascrittura del buffer vulnerabile.
Queste modifiche non furono risolutive, dato che lo shellcode poteva esse-re iniettato in aesse-ree di memoria diverse dallo stack ma che fossero comunque accessibili in scrittura, per poi eseguirlo [32]. L’intera classe degli attacchi return-to-libc non era difatti bloccata o influenzata da questa protezione, che difatti non `e stata integrata nel linux kernel ed `e stata rapidamente sostituita da altre contromisure.
2.1.2 PaX
Il progetto PaX consiste in una serie di patch per il Linux kernel che permettono di rendere lo stack e lo heap non eseguibili, oltre ad offrire la possibilit`a di randomizzare lo spazio di indirizzamento dei processi. Queste funzionalit`a vennero poi incluse all’interno di un progetto pi`u ampio, GR-Security [25], che integra anche un’architettura RBAC di controllo degli accessi.
NOEXEC
NOEXEC rappresenta un componente del progetto PaX sviluppato con l’obiettivo di impedire l’iniezione e la successiva esecuzione di codice all’in-terno dello spazio di indirizzamento di un processo.
Vi sono due modi di introdurre nuovo codice eseguibile all’interno dello spazio di indirizzamento di un processo:
• creare un’area di memoria ed iniettare il codice
Per poter gestire queste situazioni `e necessario poter gestire il permesso di esecuzione di una pagina in modo indipendente rispetto al permesso di lettura. Tale funzionalit`a viene implementata da NOEXEC, introducendo quindi una migliore gestione dei permessi a livello di pagina.
Se guardiamo al progetto da un altro punto di vista possiamo considerare NOEXEC come una forma di implementazione del ’principio del privilegio minimo’.
In questo contesto l’idea `e che se dei dati all’interno di uno spazio di indi-rizzamento non hanno bisogno di essere eseguibili allora non dovrebbero es-serlo, dunque la possibilit`a di rendere una pagina di memoria non-eseguibile diviene importante. Estendendo questa idea, se un’applicazione non ha la necessit`a di generare codice a runtime non dovrebbe poterlo fare, quindi PaX si incarica di impedire modifiche che facciano passare una pagina da ’scrivibile’ ad ’eseguibile’.
La prima funzionalit`a implementata da NOEXEC `e dunque aggiunge-re la gestione dei permessi di esecuzione delle pagine di memoria. Nelle architetture in cui la MMU supporta questa funzione, ad esempio AMD64 ed ARMv6, questa verr`a utilizzata. La principale architettura in cui tale funzione non `e supportata `e IA-32, in questo caso PaX sfrutta due diver-se tecniche per ottenere pagine non ediver-seguibili. La prima tecnica si basa sulla logica di paginazione, mentre l’altra va a modificare il meccanismo di segmentazione di IA-32.
La seconda funzionalit`a di NOEXEC permette al kernel di fare uso della possibilit`a di gestire il permesso di esecuzione per pagina. In particolare lo stack e lo heap vengono resi non eseguibili. Inoltre tutti i file ELF vengo-no mappati in memoria dal kernel con i diritti di accesso corretti, ovvero rendendo eseguibili solo i segmenti contenenti codice.
L’ultima funzionalit`a di NOEXEC `e il blocco dei permessi sulle pagine di memoria a cui accennavamo precedentemente. Questo significa che viene inibita la possibilit`a di trasformare una pagina di memoria da scrivibile ad eseguibile e viceversa. Questa funzionalit`a pu`o essere disattivata per gli eseguibili che abbiano la necessit`a di generare codice a runtime, al prezzo di inserire una possibile via per lo sfruttamento del cambio di permessi al fine di rendere praticabili le tecniche di iniezione del codice gi`a descritte nel