1
”La bellezza del cosmo `e data non solo dalla unit`a nella variet`a, ma anche dalla variet`a nell’unit`a.”
(Umberto Eco - Il Nome Della Rosa)
Indice
Introduzione 9
1 XtreemOS: aspetti generali 13
1.1 Visione dell’architettura d’insieme. . . 14
1.2 Principi chiave di progettazione . . . 16
2 Scoperta e selezione delle risorse: SRDS 21 2.1 SRDS: aspetti generali . . . 21
2.2 Architettura di SRDS . . . 23
2.2.1 Application Directory Service . . . 26
2.2.2 Resource Selection Service . . . 26
3 Requisiti del sistema 27 3.1 Visione d’insieme . . . 27
3.2 Requisiti di progettazione . . . 29
3.2.1 Modularit`a . . . 29
3.2.2 Riusabilit`a . . . 29
3.3 Requisiti imposti dai clienti . . . 30
3.3.1 Affidabilit`a . . . 30
3.3.2 Consistenza dei dati . . . 30
3.3.3 Performance . . . 31
3.4 Req. delle direttive di progetto . . . 31 3
3.4.1 Requisiti generali[1] . . . 31
3.4.2 Req. per i servizi di griglia . . . 33
4 ADS: Application Directory Service 35 4.1 Architettura astratta di ADS . . . 35
4.1.1 I Namespace . . . 38
4.1.2 ADS Facade . . . 38
4.1.3 Module-specific API . . . 40
4.1.4 Query & Provide Interface . . . 41
4.1.5 Information Providers . . . 42
4.1.6 Information Management Layer . . . 43
4.1.7 DHT Implementation Layer . . . 44
4.2 Primo prototipo di ADS: implementazione. . . 47
4.2.1 Implementazione di Facade . . . 47
4.2.2 Moduli Query & Provide Interface . . . 49
4.2.3 Modulo Provide Interface . . . 51
4.2.4 DHT layer . . . 51 4.2.5 Implementazioni di DHT utilizzate . . . 52 4.2.5.1 Overlay Weaver . . . 52 4.2.5.2 Bamboo . . . 54 4.2.5.3 Chord# (Zib) . . . 56 4.2.6 Interazione con RSS . . . 56
4.3 Interazione con i clienti di SRDS . . . 57
4.3.1 Application Execution Management . . . 57
4.3.2 Job Directory Service . . . 60
4.3.3 Data Management System . . . 63
4.3.4 Altri clienti/funzionalit`a . . . 64
4.4 (NO!!)Interfacciamento verso le DHT . . . 68
4.4.1 Processo di traduzione delle Query . . . 68
INDICE 5
5 Protocolli di interazione con SRDS 71
5.1 Paradigmi di comunicazione . . . 72
5.1.1 RMI per i test . . . 72
5.1.2 DIXI framework . . . 73
5.1.2.1 Descrizione . . . 73
5.1.2.2 Creazione del Servizio SRDS in DIXI . . . 74
5.1.2.3 Problemi riscontrati nell’utilizzo di DIXI . . . 79
5.1.3 Java Message Service . . . 79
5.1.4 HyperText Transfert Protocol . . . 81
5.2 Formato delle richieste e delle risposte . . . 85
5.2.1 JSDL . . . 85 5.2.1.1 Descrizione del JSDL . . . 85 5.2.1.2 Struttura di un documento . . . 85 5.2.1.3 JDSL per AEM . . . 87 5.2.1.4 Estensioni al JSDL . . . 89 5.2.2 GLUE . . . 91
5.2.3 Passaggio di paramentri di tipo stringa . . . 94
5.2.4 JSON . . . 96
5.2.4.1 Descrizione . . . 96
5.2.4.2 Strutturazione e utilizzo nell’ambito di SRDS . 97 5.3 Conclusioni . . . 99
6 Test e Deployment 101 6.1 Testing . . . 101
6.1.1 Test delle funzionalit`a per AEM . . . 101
6.1.2 Test delle funzionalit`a per JDS . . . 103
6.1.3 Test sui livelli di Query & Provide Interface e su Informa-tion Management Layer . . . 106
6.1.4 Test di funzionalit`a su rete. . . 107
Conclusioni 113 Bibliografia . . . 116 Glossario . . . 116
Elenco delle figure
1.1 Architettura di XtreemOS . . . 15
2.1 Architettura di SRDS: interazione tra Application Directory Ser-vice e il Resource Selection SerSer-vice. . . 24
4.1 Architettura di ADS . . . 37
4.2 A sinistra esempio di allocazione di namespace su DHT singola, a destra allocazione su DHT multiple . . . 43
4.3 Primo prototipo di ADS . . . 50
4.4 Diagramma UML delle classi che fanno parte del DHT layer . . . 53
4.5 Interazione fra ADS e RSS . . . 58
4.6 AEM interazione client server (XOSD) . . . 60
4.7 Esempio di utilizzo della meta-dht . . . 65
5.1 Comunicazione tra servizi e clienti in DIXI . . . 74
5.2 Schema temporale della chiamata del servizio che fornisce SRDS 75 5.3 Flusso della chiamata di metodo da parte di AEM verso SRDS . . 77
5.4 Flusso di ritorno dalla chiamata . . . 78
5.5 RMI e JMS a confronto . . . 81
5.6 Listato JSDL . . . 90
5.7 Listato GLUE . . . 95
Introduzione
Questa tesi si inserisce nell’ambito del progetto europeo XtreemOS che ha come obiettivo la creazione di un sistema operativo per Griglie computazionali.
Essa propone SRDS (Service/Resource Discovery System), un modulo che trami-te l’utilizzo di trami-tecnologie basatrami-te sul paradigma Peer-to-Peer sia in grado di fornire meccanismi di directory service, una stretta integrazione verso gli altri moduli del sistema operativo. Esso devo inoltre garantire peformance che soddisfino le richieste dei clienti e della Qualit`a del Servizio.
Andy Oram nel suo libro[2], da una definizione base di Peer-To-Peer: un sistema autorganizzante di risorse in una rete evitando punti di centralizzazione.
L’approccio Peer-To-Peer e in particolare quello basato sulle DHT (Distributed Hash Table), come descrivono anche Ralf Steinmetz e Klaus Wehrle [3]nel loro libro, fornisce un sistema efficiente, scalabile e con un alto grado di tolleranza ai guasti a differenza di altri approcci gerarchici o centralizzati che sono stati usati in passato per l’organizzazione delle reti.
Le Hash Table distribuite sono un implementazione particolare del paradigma Peer-To-Peer; esse fanno uso di funzioni hash per la gestione di bilanciamento del carico, ai nodi vengono attribuiti degli identificatori appartenenti ad uno spazio uniformemente popolato. Un aspetto interessante delle DHT riguarda la comples-sit`a, generalmente logaritmica rispetto al numero di nodi, sia per le dimensioni della tabella di routing sia per i passi necessari a localizzare le risorse.
XtreemOS [4] mira a integrare all’interno del sistema operativo tutte le funzio-nalit`a che fanno parte solitamente dei middleware usati per le Griglie fornendo inoltre un supporto nativo alle organizzazioni virtuali. Installato su ogni mac-china della griglia (personal computers, cluster di workstation, dispositivi mobili)
XtreemOS fornisce tutto ci`o che un sistema operativo tradizionale fornisce per una singola macchina: astrazione dall’hardware e condivisione sicura delle risorse fra i diversi utenti. Inoltre dall’integrazione delle funzionalit`a della griglia all’interno del kernel linux. XtreemOS fornisce anche un metodo pi`u robusto e sicuro per la gestione dell’infrastruttura a livello amministrativo.
All’interno di XtreemOS, SRDS, come gi`a accennato, fornisce un meccanismo di directory service per gli altri moduli del sistema operativo. Tale meccanismo si basa sulla differenziazione delle DHT utilizzate, facendo uso per le diverse fun-zionalit`a di implementazioni che forniscono particolari caratteristiche, piuttosto che altre. Proprio per questo una delle funzionalit`a principali di SRDS `e fornire un meccanismo di adattamento a tali caratteristiche. Per esempio, in certi casi `e necessario fare uso di DHT con comportamenti transazionali, in altri `e necessario organizzare lo spazio degli indirizzi di una DHT in modo da avere due o pi`u aree con dati che abbiano valori semanticamente differenti tra di loro; SRDS fornisce un’interfaccia unificata per il reperimento e la memorizzazione dei dati all’interno delle diverse DHT.
Un altra importante caratteristica di SRDS `e la capacit`a di interfacciarsi ai moduli che ne fanno uso sfruttando protocolli di comunicazione e linguaggi di interroga-zione diversi.
Essendo XtreemOS un sistema progettato per griglie computazionali deve aderire a particolari requisiti che a sua volta si ripercuotono sulle caratteristiche di SRDS. Data la sua natura di servizio centrale nell’accesso alle informazioni da parte degli altri moduli, deve essere scalabile, ovvero in grado di garantire performance in relazione al numero di risorse, in modo da distribuire efficientemente il carico su tutte le macchine, essere tollerante ai guasti e tollerante ai continui e repentini cambiamenti nella topologia della griglia, ad esempio la dinamicit`a con la quale le risorse computazionali lasciano o vi rientrano.
Il Service/Resource Discovery System `e strutturato con due componenti principali che interoperano fra loro al fine di soddisfare le richieste dei clienti: su cui si focalizza questa tesi.
L’Application Directory Service `e stato pensato come un framework composto da una struttura a pi`u livelli, in cui ogni livello abbia un compito particolare. I
ELENCO DELLE FIGURE 11 livelli pi`u alti si occupano dell’interfacciamento verso i clienti e quelli pi`u bas-si bas-si occupano di mappare le funzionalit`a richieste dai clienti stesbas-si sulle varie DHT utilizzando la composizione di svariate implementazioni reali come Bam-boo, Owerlay Weaver, Chord#. ADS cura in particolare la gestione e la selezione delle risorse dinamiche.
Il compito del Resource Selection Service `e invece puramente incentrato sulla gestione e la selezione di risorse statiche.
Capitolo 1
XtreemOS: aspetti generali
Mentre molto `e stato fatto per costruire middleware orientati alle griglie, poco `e stato fatto per estendere le funzionalit`a del sistema operativo sottostante con lo scopo di fornire invece un supporto nativo, integrando alcuni importanti servizi base o funzionalit`a direttamente nel kernel di sistema operativo. Alla luce di tutto ci`o XtreemOS[4] si propone come il primo passo verso la creazione di un vero sistema operativo open source per griglie computazionali.
XtreemOS `e un sistema operativo Open Source basato su Linux, esteso per il supporto alle organizzazioni virtuali, che fornisce appropriate interfacce ai servizi OS di griglia.
A differenza dei classici approcci middleware che si appoggiano sulle funziona-lit`a di un sistema operativo preesistente, XtreemOS `e in grado di eseguire ogni tipo di applicazione, incluse primitive che fanno parte del sistema operativo stes-so. La realizzazione di questa nuova visione di griglia introduce nuove importati sfide come la trasparenza per gli utenti e gli sviluppatori delle applicazioni, la scalabilit`a, la gestibilit`a e la sicurezza.
Un tipico esempio di queste funzionalit`a pu`o essere considerato lo scheduling del-le risorse di una Griglia (Grid Resource Scheduling) che con XtreemOS diviene parte integrante del sistema operativo.
I principali obiettivi che il progetto XtreemOS si promette di raggiungere sono: • Fornire un sistema operativo per griglie computazionali basato su Linux
ed utilizzabile da svariati tipi di risorse quali PC, Cluster di Workstation, PDAs.
• Fornire un insieme di API compatibile con Posix insieme a nuove funzio-nalit`a e al supporto di applicazioni orientate alle griglie.
• Identificare le funzionalit`a fondamentali da integrare con Linux per l’ese-cuzione di applicazioni sicure all’interno di un ambiente per griglie.
• Sviluppare un insieme di servizi di sistema operativo performanti per la gestione delle risorse in griglie molto grandi e con alto tasso di dinamicit`a. • Aggregare risorse di cluster in una potente griglia di nodi integrando i
mec-canismi di Single System Image (SSI) all’interno di Linux.
• Fornire l’accesso condiviso a risorse fortemente dislocate nello spazio tra-mite l’utlizzo di device mobili.
• Validare il design e l’implementazione di XtreemOS con un insieme di casi d’uso reali in ambito scientifico e industriale.
• Promuovere la creazione di software e di comunit`a di utenti e sviluppatori, vista la sua natura Open Source.
1.1
Visione dell’architettura d’insieme.
Il progetto XtreemOS prevede diverse componenti che vanno dai moduli del ker-nel di Linux alle librerie di supporto alle applicazioni.
La stratificazione globale di questi package `e descritta in Figura 1.1, che ne da una descrizione ad un livello molto astratto. Ogni strato astrae dal livello sottostante e consiste generalmente in pi`u package. Un software package implementa uno o pi`u servizi di XtreemOS. Ogni servizio a sua volta implementa le sue funzionalit`a interagendo con gli altri servizi di uno stesso livello e quelli del livello sottostante.
1.1. VISIONE DELL’ARCHITETTURA D’INSIEME. 15
Figura 1.1: Architettura di XtreemOS
I servizi possono essere diversificati a seconda che siano servizi “classici” di griglia che risiedono all’interno del layer XtreemOS-G o estensioni di Linux (moduli del kernel etc.) che risiedono invece all’interno del layer XtreemOS-F. Tutti i servizi sono stati progettati all’interno di un singolo progetto in maniera cooperativa.
XtreemOS presenta inoltre due varianti realizzate per il suo utilizzo in un archi-tettura di tipo cluster e su device mobili:
XtreemOS Cluster Flavour La variante di XtreemOS per cluster `e basa-ta su LinuxSSI che implemenbasa-ta il Single System Image (SSI) un sistema operativo per cluster. SSI gestisce globalmente tutte le risorse dei nodi del cluster in maniera da permettere all’utente di utilizzare il Cluster come se fosse una singola macchina. L’interfaccia Posix `e a disposizione degli utenti per permettere l’esecuzione di applicazioni parallele o sequenziali e l’utiliz-zo degli strumenti di amministrazione.
XtreemOS Device Flavour fornisce anche un livello per device mobili cha-mato XtreemOS-MD, il quale integra la maggior parte delle funzionalit`a di XtreemOS dando agli utenti in movimento il pieno accesso alla Griglia di XtreemOS.
XtreemOS fornisce anche API che facilitano la creazione di nuovi servizi e l’in-terfacciamento verso quelli gi`a esistenti;
XtreemOS API In generale le API di XtreemOS servono 3 classi di appli-cazioni:
1. Applicazioni Linux gi`a esistenti, usando l’interfaccia standard Posix. 2. Applicazioni per Griglie computazionali gi`a esistenti.
3. Nuove applicazioni, usando funzionalit`a fornite unicamente da XtreemOS `
E stato scelto come standard OGF emergente SAGA ossia Simple API for Grid Application. All’interno del progetto `e presente un name space API chiamato XOSAGA (estensione per SAGA di XtreemOS). Esso contiene solo quei package, classi e interfacce che richiedono una specifica estensio-ne di SAGA in XtreemOS.
1.2
Principi chiave di progettazione
XtreemOS `e stato progettando perseguendo particolari principi chiave, in tali prin-cipi possiamo ritrovare un suddivisione logica delle funzionalit`a che vengono ga-rantite dal sistema operativo.
Organizzazioni Virtuali e Sicurezza. Con il termine Organizzazione Virtuale (VO) si intende un insieme di individui regole, che definisce:
• Quali risorse condividere.
• A quali utenti `e permesso di condividerle.
• Le condizione alle quali le risorse debbano essere condivise.
XtreemOS supporta diversi modelli di Organizzazioni Virtuali (VO). L’utente pu`o appartenere a diverse organizzazioni virtuali, inoltre una risorsa pu`o fornire potenza computazionale e servizi di memorizzazione per pi`u VO.
1.2. PRINCIPI CHIAVE DI PROGETTAZIONE 17 Quando un nuovo utente entra a far parte di una VO effettua una registrazione che gli garantisce l’accesso a tutte le risorse che fanno parte della stessa VO. Il “login” `e effettuato una volta sola. Il criterio di accesso alle risorse in XtreemOS `e guidato dalle credenziali dell’utente. Tali credenziali gestiscono la politica di utilizzo delle risorse della VO per quel determinato utente.
Application Execution Environment. (4.3.1) Il meccanismo di scoperta delle risorse all’interno di XtreemOS `e basato su un servizio di informazione distri-buita che si appoggia alla tecnologia Peer-to-Peer. Inoltre i servizi che prendono decisioni non hanno una visione di insieme ma si basano su informazioni locali. Per facilitare i servizi di griglia `e importante poter riprodurre tutte le funziona-lit`a ben conosciute di Linux per fornire diversi livelli di astrazione che siano pi`u orientati alle griglie. In questo caso, un sistema di monitoring affidabile che pu`o essere implementato tramite strumenti familiari per l’utente `e vitale nel fornire sicurezza sia agli utenti che agli amministratori.
Questa caratteristica solitamente non si trova negli ambienti per griglie.
Data Management. (4.3.3) La funzionalit`a di data management in XtreemOS `e fornita da XtreemFS. Con XtreemFS si `e scelto di implementare un file system che sia in grado di soddisfare tutte le aspettative che un sistema di gestione di dati di griglia dovrebbe avere, come la replicazione e l’accesso in parallelo. XtreemFS si integra pienamente con il concetto di VO e permette alle applicazioni di acce-dere in maniera trasparente all’intera griglia senza alcuna mediazione da parte di middleware intermedi.
Chiaramente un file system di questo tipo deve essere in grado di garantire anche l’accesso concorrente ai file, mantenendoli consistenti. L’Object Sharing Service (OSS) si occupa della condivisione dei dati volatili tramite la gestione di repliche che mantiene consistenti.
Infrastruttura per servizi scalabili ad alta disponibilit`a. L’infrastruttura per servizi scalabili ad alta disponibilit`a fornisce servizi generici che solitamente ven-gono utilizzati sia dai servizi XtreemOS-G sia dalle applicazioni che girano sopra
XtreemOS, rafforzano il sistema di gestione delle risorse all’interno di XtreemOS in maniera scalabile e trasparente. Di essa fanno parte:
• Server Distribuiti. Un server distribuito `e un’astrazione di processi server che i client vedono come singola entit`a. L’indirizzo del server distribuito rimane lo stesso anche se i nodi lasciano o si uniscono all’applicazione. • Nodi Virtuali. Un gruppo i nodi che fanno parte di un’applicazione
posso-no richidere di essere organizzati come un posso-nodo virtuale. Un posso-nodo virtuale `e un entit`a con tolleranza ai guasti in cui ogni membro pu`o prendersi carico dei task altrui in caso di fallimento degli altri nodi. Esistono diversi tipi di implementazione di nodi virtuali, basati su replicazione attiva o passiva, e meccanismi per il checkpointing e il restarting forniti dal sistema operativo XtreemOS.
• Servizio di Publish/Subscribe. Una forma comune di comunicazione tra un vasto numero di nodi che prendono parte ad un dato servizio o ad una applicazione `e il publish-subscribe. il servizio fornisce un sistema com-pletamente decentralizzato per la comunicazione di tipo pub/sub. L’imple-mentazione corrente `e basata su un approccio gerarchico mentre in futuro dovrebbe evolversi su un approcio basato sul contenuto.
• Resource Selection Service(2.2.2 ). Il Resource Selection Service (RSS) si occupa di effettuare una selezione preliminare dei nodi sui quali allocare un applicazione, selezione guidata da query effettuate su attributi statici. Sfrutta un approccio completamente decentralizzato basato su un overlay che `e costruita e mantenuta attraverso protocolli di tipo epidemico. Questo assicura scalabilit`a fino a centinai di migliaia di nodi e capacit`a di resistere a fallimenti e ad un alto grado di churning.1
• Application Directory Service(4). L’ Application Directory Service (ADS) gestisce il secondo livello di scoperta delle risorse, esso risponde alle query
1con churning si intende la modifica della topologia di una DHT dovuta all’inserimento o
all’uscita di nodi dalla rete. In presenza di churning la DHT deve sostenere degli overhead per la propria riorganizzazione.
1.2. PRINCIPI CHIAVE DI PROGETTAZIONE 19 espresse come predicati sopra gli attributi dinamici delle risorse. ADS crea uno specifico servizio di directory service usando gli ID dei nodi selezionati precedentemente da RSS, in relazione alle risorse coinvolte nell’esecuzione dell’applicazione. Per fornire scalabilit`a e affidabilit`a, sono usate tecniche che fanno uso di DHT e loro eventuali estensioni.
• Bootstraping delle applicazioni. Molte applicazioni richiedono nodi orga-nizzati sopra una specifica overlay network (torica, ad anello etc) per opera-re coropera-rettamente. Il bootstraping delle applicazioni `e un insieme di libopera-rerie che sfruttano protocolli di tipo epidemico per eseguire applicazioni che ri-chiedono ai nodi di autorganizzarsi dinamicamente a seconda dei requisiti imposti.
Capitolo 2
Scoperta e selezione delle risorse:
SRDS
In questo capitolo si descrive l’architettura e il funzionamento del Sistema per la scoperta delle Risorse e dei Servizi (SRDS). SRDS offre alle applicazioni ed agli altri componenti di XtreemOS la capacit`a di cercare e di selezionare servizi e risorse.
Si presenta un’architettura di massima del sistema con un livello di specifica astratto, basato sulla decomposizione di SRDS in due servizi: il Resource Se-lection Service (RSS) e l’Application Directory Service(ADS) includendo le loro interfacce e le loro interazioni.
2.1
SRDS: aspetti generali
SRDS riceve continuamente differenti tipi di dati, sia statici che dinamici associati a nodi, chiavi, applicazioni e servizi. Con lo scopo di fornire agli altri componenti di XtreemOS informazioni organizzate SRDS deve effettuare diverse operazio-ni, che riguardano sia query semplici, sia query complesse (basate su un range di vincoli ad esempio) a loro volta basate sia su attributi statici che dinamici, deve inoltre fornire un servizio di memorizzabile delle informazioni affidabile e customizzabile dagli utenti che lo richiedono.
Esempi di categorie di pseudo-query:
• query su attributo statico: SRDS-select-resources(”CPUArchitecture”, “i386”) in questo caso vengono selezionate tutte le risorse (workstation, cluster etc) che possiedono un processore del tipo Intel 386.
• query su attributo dinamico: SRDS-select-resource(“RAMFree”, “300 Mb”) in questo caso vengono selezionate le risorse che hanno almeno 300 Mb di memoria RAM non allocata.
• query multi-attributo: SRDS-select-resources(“CPUArchitecture”, “i386”, “RAMFree”, “300 Mb”)in questo caso si usano come discriminante due at-tributi uno dinamico e uno statico, chiaramente le risorse selezionate devono soddisfare entrambi.
• range query: SRDS-select-bounded-resources(“HardDiskSize”, “MaxVa-lue: 120 Gb”, “MinVa“MaxVa-lue: 15 Gb”) vengono selezionate le risorse che hanno una quantit`a di spazio totale su Hard Disk compresa tra i 15 e 120 Gb.
Chiaramente tutte queste funzionalit`a (come verr`a descritto nel capitolo 3 riguar-dante i requisiti dell’architettura) richiedono un implementazione che sia efficien-te, affidabile e scalabile. Il problema di controllare e organizzare un cos`ı vasto numero di risorse conduce di per se all’utilizzo di tecniche Peer-to-Peer. Infatti ol-tre ad essere intrinsecamente distribuita, l’architettura software di SRDS deve far fronte a diversi tipi di informazioni, ha compiti di elaborazione delle informazioni e di supporto alle diverse tipologie di semantica delle query.
Per soddisfare efficientemente tali requisiti sono stati seguiti dei semplici ed effi-caci principi di progettazione.
• La metafora del ”machete” e del ”bisturi” `e stata applicata per elaborare query complesse, a vantaggio delle soluzioni scalabili gi`a esistenti senza sacrificare funzionalit`a pi`u elaborate ed espansione futura con tecniche pi`u raffinate.
2.2. ARCHITETTURA DI SRDS 23 • Differenti problemi di implementazione (per esempio interfacciamento, ri-cerca di risorse, sicurezza e autenticazione) sono stati smembrati in sottosi-stemi separati in modo da migliorare la modularit`a e la futura integrazione con le caratteristiche avanzate di XtreemOS.
2.2
Architettura di SRDS
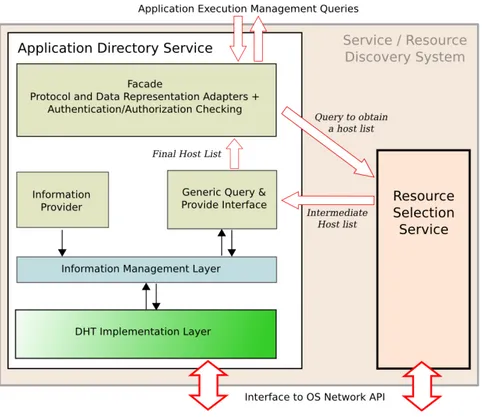
Come descritto in figura 2.2, SRDS include due componenti principali: il Resour-ce Selection ServiResour-ce (RSS) e l’Application Directory ServiResour-ce (ADS). RSS e ADS cooperano per soddisfare query complesse, nell’ottica di fornire sia un certo li-vello di flessibilit`a semantica per le query sia un sistema globale performante e scalabile.
Sia ADS che RSS utilizzano un implementazione distribuita, basata su reti di tipo Peer-to-Peer [5].
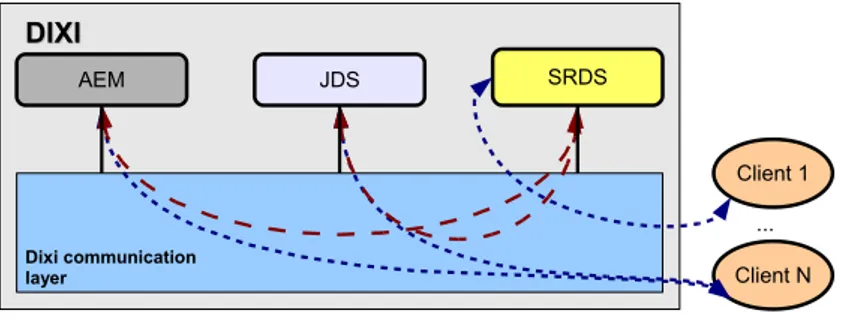
I clienti di SRDS sono altri moduli e servizi, cos`ıcome le applicazioni degli uten-ti. ADS fornisce la principale interfaccia di SRDS verso questi clienti tramite il modulo Facade.
A causa dei diversi tipi di clienti che si interfacciano a SRDS `e infatti necessario che un modulo che riesca a gestire comunicazioni che si basi sia su protocolli di-versi come RMI, JMS o framework come DIXI, sia su linguaggi di interrogazione e formati di rappresentazione diversi quali JSDL e JSON.
Un altro compito di Facade sar`a fornire autenticazione e sicurezza delle comu-nicazioni, questa implementazione pur non essendo ancora stata implementata dall’achitettura (`e richiesta l’interazione con il modulo che gestisce le Organizza-zioni Virtuali) `e tuttavia richiesta nei casi in cui il protocollo di comunicazione non la fornisca.
I moduli intermedi come Information Provider, Generic Query & Provide e Infor-mation e Interface Management Layer si occupano invece della gestione vera e propria delle query che pervengono dai clienti e della diversificazione semantica dei dati.
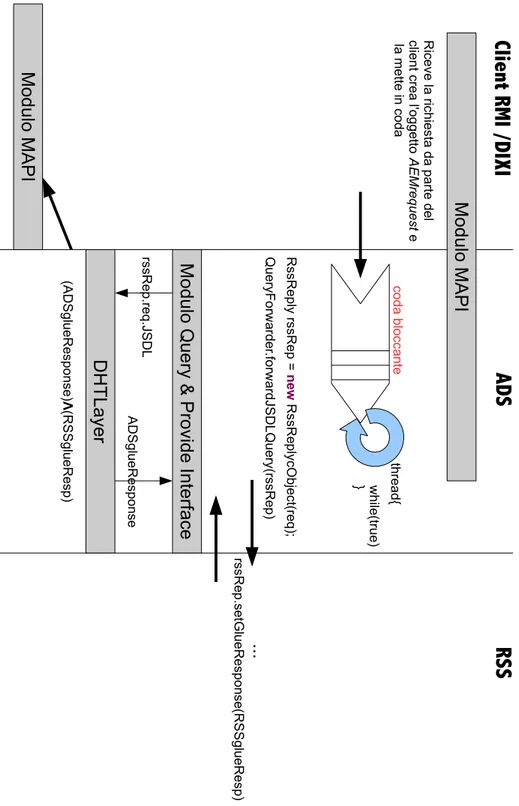
Figura 2.1: Architettura di SRDS: interazione tra Application Directory Service e il Resource Selection Service.
2.2. ARCHITETTURA DI SRDS 25 Il DHT Implementation Layer si occupa di fornire i proxy per l’interfacciamento verso le DHT che si utilizzano per la memorizzazione dei dati. Questo modulo `e necessario in quanto le diverse implementazioni di DHT quali Bamboo, Over-layWeaver piuttosto che Chord# pur avendo funzionalit`a semanticamente simili, come l’inserimento, la rimozione e l’interrogazione ne danno un implementazione diversa. Abbiamo bisogno quindi di un livello che generalizzi tali funzionlit`a ai livelli sovrastanti .
SRDS `e stato progettato prendendo in considerazione principalmente le richieste del modulo di XtreemOS AEM Application Execution Management. In partico-lare AEM chiede a SRDS di selezionare un insieme di risorse computazionali, in accordo ad alcuni vincoli e obiettivi che sono specificati dall’utente, per ren-dere possibile l’esecuzione di applicazioni da parte dell’utente stesso. Si consi-deri AEM come esempio chiarificante per descrivere in maniera efficace uno dei compiti principali di SRDS.
Le richieste dell’AEM arrivano a SRDS sotto forma di query che possono anche includere range di vincoli su attributi, informazioni dinamiche che riguardano le risorse espresse attraverso multipli criteri di ricerca. La complessit`a espressiva delle richieste pu`o risultare difficile da gestire, specialmente per le range query che tutt’ora costituiscono un campo di ricerca attivo all’interno degli studi sulle reti Peer-to-Peer [6].
Risulta complessa del resto anche la gestione delle query sopra un numero elevato di nodi P2P, specialmente quando si ha a che fare con informazioni altamente variabili.
Per cercare di ridurre tale complessit`a si `e cercato un tipo di approccio modulare che strutturi il processo di selezione delle informazioni in due fasi. Queste due fasi che corrispondono poi ai compiti di RSS e a quelli di ADS hanno funzionalit`a sostanzialmente diversi. RSS effettua una selezione grezza delle risorse, si com-porta esattamente come un ”machete” mentre ADS che si comcom-porta come ”bisturi” effettuando una selezione pi`u accurata. L’interazione fra queste due componenti risolve le richieste di AEM in maniera efficiente e scalabile. In particolare, quan-do SRDS deve soddisfare le richieste inizia un processo che restituisce la risposta
attraverso queste due fasi di ricerca. L’informazione raccolta alla fine di queste `e ritornata a AEM attraverso Facade di ADS.
2.2.1
Application Directory Service
L’ADS verr`a descritto e ampiamente trattato nel capitolo 3.
2.2.2
Resource Selection Service
In queste due fasi del processo di selezione L’RSS si comporta come un ”ma-chete” gestendo il primo livello di selezione delle risorse in una Organizzazione Virtuale (VO). RSS sfrutta una overlay che contiene le informazioni statiche ri-guardanti i nodi. L’RSS pu`o risolvere anche range query multidimensionali sopra attributi statici, ritornando all’ADS la lista degli identificatori dei nodi (IPs) che soddisfano la query. Questa operazione viene effettuata con poco overhead e con alta scalabilit`a grazie alla struttura di rete Peer-to-Peer sottostante. L’insieme dei nodi che soddisfano la query `e un sottoinsieme dei nodi totali che tuttavia dovr`a essere ulteriormente scremato dall ADS.
Capitolo 3
Requisiti del sistema
In questo capitolo vengono discussi i requisiti che il progetto impone, in parti-colare quelli in riferimento ad Application Directory Service dato che sono una parte significativa di tutto SRDS, oltre al fatto che per la tipologia di dati che ADS gestisce risultano i pi`u critici.
La suddivisione `e stata fatta sia in base ai clienti che si interfacciano ad ADS ognuno dei quali ha particolari esigenze, sia in base agli standard della Qos che il software dovrebbe garantire.
3.1
Visione d’insieme
All’ADS `e richiesto di fornire un servizio di directory service flessibile che sup-porti:
• query semplici: query base di tipo chiave-valore con un contenuto generico che provengono da altri moduli di XtreemOS e servono per il lancio di job o di altre applicazioni.
• query complesse: forme di interrogazione pi`u raffinata ( le range query sono un esempio) di alcuni moduli di XtreemOS.
• query dinamiche: query semplici e complesse che sono effettuate su cop-pie chiave valore che sono soggette ad aggiornamenti di tipo dinamico. In
modo da tener conto in tempo reale quantit`a misurata e propriet`a, sia per motivi di monitoraggio sia di supporto al processo decisionale.
ADS gestisce un numero elevato di nodi, tali nodi solitamente sono stabili, tutta-via non sono immuni da fallimenti o da churning in modo da rendere il sistema pratico, efficiente e scalabile l’overhead di ADS sopra i nodi fisici dovrebbe essere valutato e limitato.
`
E necessario tenere conto della scalabili`a dei servizi rispetto a:
• l’efficienza nell’esplorazione delle risorse, misurata eventualmente con la media e l’importo massimo delle risorse locali occupate, dal numero dei messaggi scambiati per nodo e dal volume del traffico di rete;
• tempo necessario di risposta alle query;
• il numero massimo di fallimenti e il livello di churning che ADS pu`o sop-portare prima di presentare degrado nelle prestazioni;
• il numero massimo di fallimenti e il livello di churning che ADS pu`o sop-portare prima della perdita di informazioni;
L’approccio maggiormente scalabile per soddisfare query semplici `e basato sulle Distribuited Hash Table (DHT)[7]. Algoritmi appropriati per DHT sono studiati da diversi anni nel settore e forniscono scalabilit`a e affidabilit`a, propriet`a neces-sarie per sistemi grandi, essendo logaritmiche nel numero di passi e di messaggi effettuati per singola query. `E tuttavia noto che le query complesse, come le ran-ge query[8] e le query su attributi dinamici sono pi`u complicate da ran-gestire, teorie recenti che sono tutt’ora oggetto di studio si occupano di algoritmi pi`u complessi che possano efficientemente risolvere tali query. Poich`e ADS `e destinato a sup-portare entrambe, una architettura generale `e stata elaborata al fine di suddividere il problema e di risolverlo fasi. Una specifica architettura `e stato progettata per eseguire una ricerca secondo i pi`u efficienti algoritmi a disposizione per questo tipo di ricerca.
3.2. REQUISITI DI PROGETTAZIONE 29
3.2
Requisiti di progettazione
3.2.1
Modularit`a
SRDS ha il compito di interfacciarsi a svariati tipi di servizi che utilizzano proto-colli e linguaggi diversi ai livelli pi`u alti, inoltre, ai livelli pi`u bassi richiede mec-canismi di traduzione delle query e di organizzazione semantica dei dati. Tutte queste caratteristiche risultano tra loro ortogonali oltre che indispensabili. Inoltre essendo SRDS parte di un progetto tutt’ora in fase di sviluppo, il rischio di cam-biamenti seppur minimali nei protocolli e nei linguaggi di interrogazione risultano assai probabili.
Infatti il numero di servizi che fa uso di SRDS `e destinato ad aumentare con il tem-po, dovranno essere quindi introdotti nuovi moduli di traduzione dei protocolli che devono a loro volta agganciarsi facilmente con i livelli sottostanti possibilmente introducendo il minor codice di interfacciamento possibile.
Per questo l’implementazione ha richiesto un certo grado di modularit`a del codice. Ogni modulo sia esso di aggancio ai protocolli piuttosto che di interfacciamento verso le DHT deve essere il pi`u possibile indipendente dagli altri.
3.2.2
Riusabilit`a
La parte di codice che si occupa della traduzione delle query deve essere progettata per poter essere riusabile di volta in volta da ognuno dei moduli che forniranno supporto di interfacciamento ai servizi (MAPI).
La natura delle richieste ci fornisce di per se un insieme ben definito di operazioni che vengono effettuate sulla DHT, in quanto i fruitori del servizio hanno sostan-zialmente la necessit`a di fare storing e retrieving di dati. La parte di codice che si occupa di implementare tali richieste risulta quindi ascrivibile a tutti i tipi di servizi che utilizzano SRDS.
3.3
Requisiti imposti dai clienti
3.3.1
Affidabilit`a
Una delle caratteristiche che vengono richieste a SRDS da parte dei servizi che ne fanno uso `e certamente l’affidabilit`a. Con tale termine intendiamo la tolleranza ai guasti e la tolleranza rispetto al churning.
Le Griglie Computazionali di dimensioni elevate sono soggette a repentini cam-biamenti nella topologia della rete con nodi che escono o che rientrano velocemen-te sulla griglia. `E necessario perci`o un meccanismo che sia in grado di mantenere affidabili i dati che i clienti necessitano di mantenere all’interno del Directory Ser-vice. Tale meccanismo `e fornito implicitamente dalle DHT che vengono usate per l’implementazione del servizio di Directory Service.
3.3.2
Consistenza dei dati
Un’altra caratteristica essenziale riguarda la consistenza dei dati. I servizi che fan-no uso di SRDS richiedofan-no un supporto che permetta una differenziazione seman-tica dei dati, sia che essi appartengono allo stesso servizio sia che appartengano a servizi diversi.
Questo meccanismo deve essere in grado di fornire un livello di traduzione del-le richieste che vengono di volta in volta effettuate dai servizi che permetta di usufruire della opportuna DHT con lo spazio di chiavi opportuno, inerente al significato semantico di quella richiesta.
Cos`ı avviene ad esempio nelle richieste che pervengono dal Job Directory Servi-ce, che possono avere come parametro di ricerca sia un attributo chiave che un attributo non chiave. Ad esempio la ricerca sull’attributo userId al quale sono associati tutti i job che appartengono ad un utente.
getJobIDByValue(“userID”, “the user 01”)⇒ [jobID002123, jobID002323, jo-bID052123, jobID006623]
Il layer che si occupa di tradurre le richieste sa di volta in volta lo spazio di chiavi sul quale effettuare la ricerca.
3.4. REQ. DELLE DIRETTIVE DI PROGETTO 31
3.3.3
Performance
Con performance intendiamo il grado di scalabilit`a del sistema rispetto al numero di nodi che ne fanno parte. Le DHT di per se garantiscono un tempo di ricerca logaritmico in base al numero di nodi dell’overlay.
Tuttavia SRDS `e composto da livelli che si appoggiano alle DHT e che forniscono i cosiddetti meccanismi di traduzione delle query e di gestione dello spazio di tutte le chiavi sulle DHT esistenti. Tali livelli pur aggiungendo un certo grado di degradazione nelle prestazioni risultano tuttavia indispensabili perch`e fanno parte del nucleo di funzionamento del servizio.
Si `e cercato quindi di inserire in SRDS meccanismi che non comportino cen-tralizzazioni nell’implementazione delle funzionalit`a del servizio garantendo tut-tavia consistenza e trasparenza delle informazioni, anche se ci`o ha comportato l’introduzione in determinati frangenti di meccanismi di mutua esclusione. L’introduzione di meccanismi di mutua esclusione `e tuttavia limitata a casi par-ticolari quali la creazione dinamica di nuovi namespace e non costituisce quindi un caso significativo di degradazione delle performance. Inoltre essa `e stata cir-coscritta introducendo sezioni critiche piccole e un certo grado di caching delle informazioni.
3.4
Requisiti che fanno parte delle direttive di
pro-getto di XtreemOS
3.4.1
Requisiti generali[1]
Nell’ambito dell’analisi dei casi d’uso di XtreemOS sono stati identificati i se-guenti requisiti. Anche se di natura generale sono tuttavia estendibili ai moduli che XtreemOS comprende e quindi anche a SRDS essendo esso un modulo fon-damentale all’interno del processo di scoperta e di selezione delle risorse a cui gli altri moduli del sistema operativo si appoggiano.
• XtreemOS deve supportare applicazioni intensive sui dati e a livello com-putazionale. Inerentemente alle applicazioni che sfruttano intensivamente i
dati `e essenziale che XtreemOS possa efficientemente gestire gli accessi a database centrali o distribuiti e alle applicazioni basate su file.
• XtreemOS deve supportare tipi di hardware eterogenei. XtreemOS deve poter essere eseguito su nodi eterogenei e con architetture molto diverse tra loro.
• XtreemOS deve supportare griglie con un numero variabile di nodi. XtreemOS deve essere capace di gestire da un numero esiguo di nodi fino ad un numero molto grande.
• XtreemOS deve supportare l’aggiunta o la rimozione dinamica di nodi. Du-rante l’esecuzione XtreemOS deve essere in grado do adattarsi alla quan-tit`a di risorse disponibili. Deve essere possibile l’aggiunta di nuovi nodi all’interno della griglia. Inoltre il sistema di scheduling deve considerare queste nuove risorse aggiunte dinamicamente. Se i nodi vengono rimos-si dalla griglia XtreemOS deve gestire la migrazione delle applicazioni in esecuzione.
• XtreemOS deve fornire comunicazioni veloci ed affidabili. Lo sfruttamento intensivo delle comunicazioni da parte dei servizi di XtreemOS deve essere garantito da connessioni veloci e latenze possibilmente basse. Inoltre di-verse applicazioni necessitano di connessioni di tipo permanente tra i nodi. Anche l’affidabilit`a delle connessioni `e un requisito cruciale per le appli-cazioni il cui funzionamento pu`o essere critico rispetto ai fallimenti della rete.
• XtreemOS deve fornire accessi a svariate tipologie di servizi di griglia. I principali servizi di griglia richiesti sono il trasferimento di file, la scoperta delle risorse e la sottomissione di Job. Pertanto, si deve garantire che que-sti servizi possano essere accessibili e eseguiti. I servizi e le risorse sono principalmente identificati da un URI - Uniform Resource Identifiers.
3.4. REQ. DELLE DIRETTIVE DI PROGETTO 33
3.4.2
Requisiti per i servizi di griglia ad alta disponibilit`a
• Garantire un certo numero di nodi per un tempo specifico. Per l’esecuzione di applicazioni parallele su XtreemOS `e necessario garantire che il numero di nodi allocati sia costante durante l’esecuzione di un Job. A questo fi-ne risulta fi-necessario un meccanismo di fault-tolerance per la replicaziofi-ne virtuale di nodi.
• Possibilit`a di avere un certo grado di banda garantita tra i nodi allocati durante l’intera esecuzione di un’applicazione.
Capitolo 4
ADS: Application Directory Service
In questo capitolo si affronta pi`u specificatamente l’architettura astratta che com-pone l’Application Directory Service, presentandone prima tutti i suoi livelli (4.1) per poi soffermarci sull’implementazione del prototipo dell’architettura (4.2). Si fornir`a poi (4.3)una descrizione dei principali clienti che interagiscono con SRDS e quindi con ADS.
4.1
Architettura astratta di ADS
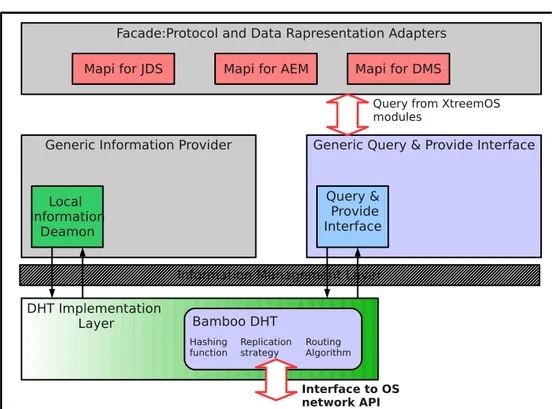
In questo paragrafo viene data una descrizione generale di tutti i componenti che fanno parte dell’archiettura di ADS come rappresentato in figura 4.1
Tali componenti verranno descritti pi`u accuratamente nelle sezioni successive (da 4.1.2 a 4.1.7). Da ora in poi, e se non diversamente indicato, si identificheranno come clienti di ADS tutti gli altri moduli o servizi di XtreemOS che hanno bisogno di interagire con esso.
Facade (4.1.2) Il modulo Facade `e un adattatore generico, che funge da interfac-cia verso i clienti di SRDS e fornisce l’incapsulamento delle richieste che da essi pervengono. Nell’ottica della sicurezza esso dovrebbe fornire anche un meccanismo per agganciarsi alle politiche che l’Organizzazione Virtuale, di cui il cliente che ne fa parte, necessita. `E importante notare che Facade `e il modulo che attualmente viene usato per raggiungere SRDS, cos`ı come la
definizione di interfaccia ADS `e fondamentale per definire il sistema per la scoperta di servizi e risorse SRDS.
Module-specific API (4.1.3) Questo modulo si occupa della comunicazione ver-so il cliente. Contiene tutte le API che forniscono la rappresentazione e la traduzione dei dati da e verso SRDS.
Generic Query & Provide Interfaces (4.1.4) Ogni interfaccia Query & Provide fornisce un algoritmo di traduzione dell’informazione richiesto su un insie-me di operazioni di interrogazione o di insie-memorizzazione di dati. Il noinsie-me doppio serve a ricordare che gli algoritmi di di traduzione devono essere implementati per tradurre in operazioni elementari tali operazioni in corri-spondenza della semantica e dell’uso che il cliente richiede. La traduzione permette alle informazioni dinamiche di essere efficientemente memorizza-te nel sottostanmemorizza-te livelli di informazione, inoltre permetmemorizza-te di sfruttare otti-mamente il livello DHT per le query complesse. Generalmente ai clienti possono essere associati moduli bidirezionali a seconda delle necessit`a. Generic Information Providers (4.1.5) Questi moduli sono intesi
esclusivamen-te per fornire informazioni al livello delle DHT. In particolare essi pren-dono le informazioni direttamente dall’host locale. Sono caratterizzati da un implementazione semplice in quanto non hanno il compito di restituire risultati.
Information Management Layer (4.1.6) Rappresenta l’interfaccia comune di tut-ta ADS verso tutte le funzionalit`a di gestione dell’implementut-tazione. E’ destinato a fornire un approccio comune di tipo put/get sopra coppie (chia-ve/valore) come implementazione e avanzamento della ricerca.
DHT Implementation Layer (4.1.7) Il DHT Implementation layer fornisce e ge-stisce il livello Peer-To-Peer dei nodi. I comportamenti della DHT possono essere customizzati a seconda delle necessit`a dei clienti per permettere a IML di selezionare le DHT in base a differenti poliche.
4.1. ARCHITETTURA ASTRATTA DI ADS 37
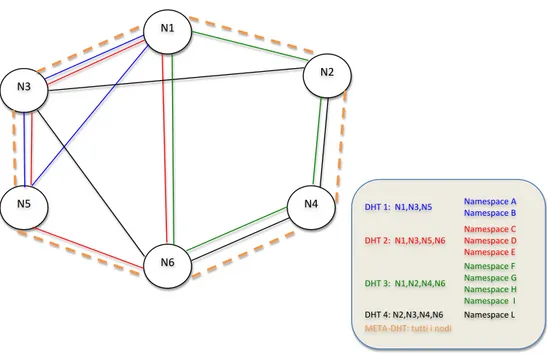
4.1.1
I Namespace
La gestione delle informazioni che verranno memorizzate da ADS j stata imple-mentata studiando un meccanismo semplice che ne permetta una diversificazione funzionale alle esigenze dei clienti. Le DHT per loro natura memorizzano infor-mazioni semanticamente uguali. Ad esempio una DHT dedicata al file sharing tiene informazioni che riguardano i file memorizzati dagli utenti, la ricerca all’in-terno di essa ´e effettuata chiamando la funzione di hashing sul nome del file da ricercare. Nel caso di ADS le informazioni da memorizzare nel Directory Service sono per loro natura diverse e indicizzabili in base a criteri fra loro differenti. Con il termine namespace intendiamo uno spazio riservato, all’interno di una DHT, alla memorizzazione di informazioni con un certo valore semantico. Le informazioni che appartengono a namespace differenti hanno un valore semantico differente in quanto possono o appartenere a clienti diversi oppure essere utilizzate in modo diverso dallo stesso cliente. Nel caso di ADS si utilizzano tre namespace: uno per la memorizzazione delle informazioni che riguardano AEM, due per quelle che ri-guardano JDS. I namespace vengono suddivisi all’interno della DHT in base alla lunghezza delle chiavi che vengono utilizzate per la memorizzazione. Cosm una DHT che abbia una lunghezza di chiavi pari a 160 bit pus essere suddivisa in 2 namespace da 80 bit, oppure uno da 100 e un altro da 60bit. In generale data L la lunghezza della chiave in bit della DHT e date l1, l2, ln le lunghezze delle chiavi
dei namespace attivi su di essa deve valere sempre la seguente relazione: L >=P
i=1..nli
Chiaramente non `e consigliato suddividere lo spazio delle chiavi di una DHT in maniera troppo frammentata in quanto in questo caso la lunghezza delle chiavi dei namespace diminuisce drasticamente e di conseguenza anche il numero di informazioni memorizzabili su ogni namespace.
4.1.2
ADS Facade
Il modulo Facade di ADS fornisce un framework per le funzionalit`a che sono comuni tra tutti i moduli MAPI, per facilitare la reimplementazione, al fine di
4.1. ARCHITETTURA ASTRATTA DI ADS 39 • permettere future evoluzioni per le funzionalit`a comuni con il minimo sfor-zo implementativo; ad esempio il miglioramento del monitoraggio e i cam-biamenti nelle API che forniscono il supporto alla sicurezza;
• facilitare la customizzazione di SRDS per scopi particolari; per esempio accettare/respingere le richieste degli host da parte di un proxy;
Il modulo Facade `e la classe contenente i moduli MAPI. In seguito verranno descritti i gruppi di funzionalit`a forniti ai moduli contenuti.
Incapsulamento L’incapsulamento dei messaggi con primitive per il boxing e l’unboxing dei dati. Viene utilizzato un formato comune di incapsulamento indipendente dal formato reale del messaggio.
• Il formato del contenuto del messaggio `e libero fino a quando `e possi-bile incapsularlo.
• Il contenitore del messaggio fornisce anche informazioni su l’intera-zione con ADS, che `e necessaria al fine di fornire un adeguato livello di sicurezza per l’interazione. Queste informazioni sono codificate nel contenitore, in modo da consentire alle routine di Facade di eseguire l’analisi del messaggio e di generare le operazioni adatte per tutti i tipi di messaggi,indipendentemente dai MAPI ai quali si riferiscono. Sicurezza Le primitive di sicurezza e di autorizzazione che vengono fornite si
basano sulle informazioni contenute nell’elemento contenitore in cui risie-de il messaggio. Esse effettuano le chiamate per l’autenticazione risie-della VO e dei meccanismi di autorizzazione. Generalmente questi meccanismi di au-torizzazione e controllo inerenti alla VO sono contenuti soltanto al livello di Facade, questo per minimizzare l’overhead per la gestione della sicurezza. Essi sono inoltre in grado di sfruttare le conoscenze circa il tipo di inte-razione in corso. Per esempio l’accesso alle funzionalit`a relativo ad AEM dovrebbe essere sottoposto alle politiche della VO di cui fa parte.
Routing esterno Facade fornisce funzionalit`a di routing tra i moduli MAPI e i clienti, per permettere a pi`u MAPI di utilizzare protocolli di trasporto comuni (ad es. HTTP).
Routing interno Facade pu`o anche fornire meccanismi di comunicazione omo-genei verso altri moduli all’interno di SRDS (ad esempio verso il Resource Selection Service - RSS).
Gestione delle comunicazioni `E comunque in corso di valutazione se Facade debba gestire un canale di comunicazione standard, che possa supportare SSL (Secure Sockets Layer), al fine di semplificare ulteriormente l’imple-mentazione dei moduli MAPI nei casi pi`u comuni.
4.1.3
Module-specific API
Module-specifiche API moduli forniscono funzionalit`a che sono personalizzati in base al cliente con il quale si tratta (modulo, il servizio di XtreemOS, o di applicazione). In particolare, un MAPI `e un end-point nella comunicazione tra i clienti di un determinato tipo e l’SRDS.
• Ogni MAPI comunica attraverso uno specifico canale, un protocollo e con uno specifico cliente. Si possono sfruttare queste assunzioni in ogni ope-razione richiesta. Di norma, un MAPI gestisce tutte le interazioni con un determinato cliente.
• Il MAPI fornisce funzionalit`a nel controllo degli accessi e sicurezza. • Un MAPI `e in grado di leggere e tradurre il formato del messaggio utilizzato
dal cliente e tradurre i dati in un formato adatto a tutti i moduli di livello inferiore.
• Il MAPI si occupa di spedire le richieste verso il modulo Query & Provide Interface adatto per quel cliente e di restituire le risposte dopo l’esecuzione della query al cliente stesso.
Traduzione dei namespace nei moduli MAPI. In questa parte viene data una definizione formale delle operazioni di traduzione, partendo dalla loro interfaccia esposta da ADS:
4.1. ARCHITETTURA ASTRATTA DI ADS 41
dove il primo livello di incapsulamento `e una struttura standard definita da SRDS .
I campi che contiene possono a loro volta essere descritti come: request = {op, key, value, parameters };
ClientInfo = {ClientType, ClientId };
XOSCert rappresenta il certificato collegato alle politiche di VO che autorizzano l’operazione definita dal campo op.
Un MAPI riceve tale operazione con relativi argomenti che integra con le informa-zioni ricevute da Facade, per ottenere una rappresentazione operationM AP I, dove
le informazioni sono implicitamente contenute nell’invlucro del messaggio, ad esempio i campi correlati alla sicurezza sono estratti direttamente dall’involucro che contiene il messaggio.
Il modulo MAPI produce a sua volta come output una descrizione dell’operazione per il modulo Query & Provide, contenente i seguenti campi:
operationQP = {op, keyM , valueM , Nspace, ClientType, ClientId }
Nspace = f ( key, value, parameters, ClientInfo );
dove il parametro Nspace specifica il namespace e deriva dai parametri dell’ope-razione e dalle informazioni che riguardano il cliente.
4.1.4
Query & Provide Interface
Query & Provide(QP) Interface `e un modulo che traduce le operazioni definite dall’interfaccia verso il cliente in quelle del livello IML, le quali sono presso-chi simili alle primitive delle DHT. Ogni interfaccia QP `e un implementazione separata, dipendente dal tipo di funzionalit`a che deve supportare.
I tratti comuni a tutti i QP sono invece i seguenti:
• Le operazioni di alto livello sono interpretate da algoritmi definiti sopra le funzionalit`a supportate da IML.
• Le funzionalit`a di traduzione non operano 1 ad 1, ognuna delle quali pu`o essere un algoritmo che opera sopra il livello DHT il quale `e composto da svariati step.
• Chiaramente, l’algoritmo che implementa ogni operazione `e dipendente dalla semantica dei dati, quindi un modulo QP `e fortemente legato al tipo di cliente.
• Le informazioni che riguardano il cliente devono quindi poter raggiungere il modulo QP, come d’altra parte un namespace separato pu`o essere usato per clienti diversi (per esempio applicazioni distribuite che utilizzano SRDS per la memorizzazione di dati possono voler creare uno spazio privato di chiavi).
• Un modulo QP collabora con l’IML nella gestione dell’astrazione del na-mespace (un implementazione semplice costituita da una concatenazione di chiavi uniche), aggiungendo le informazioni sul namespace ad ogni singo-la operazione richiesta all IML. QP assicura costantemente che le chiavi di clienti diversi siano tenute separate.
4.1.5
Information Providers
Il moduli Information Providers sfruttano interfacce e algoritmi semplici per for-nire informazioni all’IML. essi vengono usati quando non si ha la necessit`a di un supporto alla sicurezza e di gestire risultati da parte degli strati sottostanti.
• In casi semplici informazioni locali necessitano di essere inserite nella DHT (ad esempio il demone locale che fornisce informazioni sugli attributi dina-mici del nodo).
• Ogni qualvolta un cliente necessita di inserire informazioni che poi dovran-no essere reperite da altri un modulo Information Provider dedicato `e una soluzione pi`u semplice rispetto a quella di utilizzare un MAPI.
4.1. ARCHITETTURA ASTRATTA DI ADS 43
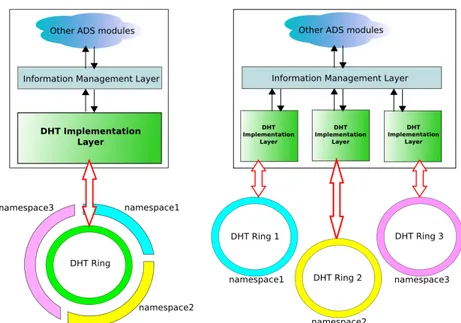
Figura 4.2: A sinistra esempio di allocazione di namespace su DHT singola, a destra allocazione su DHT multiple
4.1.6
Information Management Layer
L’interfaccia verso le primitive dell’Information Management Layer `e la base co-mune per tutte le operazioni di alto livello implementate in ADS. Fornisce un astrazione delle tipiche operazioni che avvengono sulle DHT (put/get/remove) con oggetto coppie chiave/valore. Si sono aggiunti esplicitamente alcuni parametri addizionali che semplificano la traduzione delle operazioni di ADS. Alcune fun-zionalit`a sono gi`a supportate dalle implementazioni di DHT esistenti (Bamboo) altre invece sono necessarie per assicurare flessibilit`a all’architettura stessa.
• le operazioni di put, get e remove;
• i parametri chiave e valore sono obbligatoriamente presenti;
• un supporto ai namespace, cio`e alla differenziazione semantica delle chiavi; • informazioni addizionali riguardano ad esempio l’expiring time di una chia-ve o il secret associato alla chiachia-ve stessa. Ad esempio Bamboo fornisce meccanismi di questo tipo.
Il livello IML attraverso l’utilizzo dei namespace mantiene tutte le informazioni che servono per discriminare le operazioni che vengono richieste ai livelli pi`u alti. Questo meccanismo permette di associare un significato particolare ad ogni operazione su una chiave, inoltre evita eventuali collisioni fra chiavi simili. Il namespace `e fornito dal livello QP, e pu`o essere usato per implementare spazi di chiavi separati in due differenti maniere come `e rappresentato in figura 5.2. Il namespace, che `e un id unico, viene concatenato con la chiave al fine di generare una chiave unica all’interno dell’anello della DHT. Come raffigurato in figura 5.2 le chiavi di differenti namespace (ad esempio clienti differenti di ADS) sono distribuite sopra una sola DHT.
Una seconda soluzione che comporta un overhead maggiore ma che risulta pi`u scalabile su griglie di grosse dimensioni `e quella di avere DHT separate, replican-do le istanze dei moduli del DHT Implementation layer.
4.1.7
DHT Implementation Layer
Il DHT Implementation Layer (DIL) fornisce le funzionalit`a di basso livello del-l’IML. Come `e stato accennato nella sezione precedente, l’ IML si occupa di sele-zionare un namespace per ogni operazione, e questo pu`o essere effettuato seguen-do due vie di implementazione diverse. In realt`a le due implementazioni non sono incompatibili, `e possono essere unite per raggiungere un tradeoff maggiore. Oltre a fornire le funzionalit`a supplementari, definite dall’IML (ad esempio, l’ex-piring delle richieste), il DIL deve poter permettere un certo grado di customizza-zione, concernente ad esempio il tipo di funzione hash che si vuole utilizzare, o il grado di replicazione dei dati. Questo `e necessario per poter abilitare la DHT a differenti tipi di utilizzo, inoltre pu`o risultare utile al fine di estendere ADS af-finchi fornisca supporto alle query complesse e sopra attributi dinamici. I due tipi principali di supporto a namespace separati che verranno descritti avranno un cer-to impatcer-to sopra le possibili adattamenti del livello DHT, e a come essi verranno eseguiti.
• Nell’implementazione in figura 5.2 (sx), una DHT singola `e usata per imple-mentare IML all’interno di ADS. Come conseguenza, tutti i nodi XtreemOS
4.1. ARCHITETTURA ASTRATTA DI ADS 45 devono far parte dell’anello della DHT fino a quando fanno parte della gri-glia. Si noti che fornire un istanza separata di ADS per ogni applicazione `e ancora possibile, come `e possibile che istanze multiple di ADS possano condividere l’istanza locale della DHT. In questo caso, le informazioni ri-guardanti il namespace sono utilizzate dinamicamente per selezionare il tipo di funzione hash e il grado di replicazione per un dato insieme di chiavi per esempio si pu`o mappare il namespace con parametri addizionali del livello DIL per ottimizzarne il comportamento.Un semplice esempio `e convertire la funzione hash in una funzione lineare affine o in una funzione per map-pare le space filling curve1, per favorire la localit`a per un dato insieme di chiavi sopra la DHT.
• Nell’implementazione di figura 5.2(dx), si dovrebbe poter customizzare tut-ti i parametri e le politut-tiche di una DHT per il suo uso specifico nel momen-to in cui viene creata, ossia al momenmomen-to della creazione di un overlay. Gli anelli dedicati a spazi di chiavi essenziali a XtreemOS rimarranno sempre attivi, mentre gli anelli pi`u piccoli supporteranno applicazioni specifiche, o VO temporanee, con un ciclo di vita pi`u corto e un costo di inizializzazione minore.
Traduzione dei namespace e interfaccia DHT. Iniziando dalle operazioni ri-cevute dai moduli QP, il livello IML si occupa di mapparle sopra il DIL. Come gi`a discusso nelle sezioni 5.1.5 e 5.1.6, questo richiede di mappare un concetto astratto di namespace (un separato spazio di chiavi) in una delle implementazioni di figura 5.2
Il formato astratto dell’operazione
operationQP = {op, keyM ,valueM , Nspace, ClientType, ClientId }
sar`a mappato in un operazione concreta sul DHT Implementation Layer operationDHT = {op, keyD ,valueD , auxInfo}
1Sono curve che permettono di raggiungere tutti i punti di una porzione di piano ad una certa
I campi dell’operazione sulla DHT sono funzioni dei campi a livello pi`u alto dell’operazione.
keyD = g(keyM, Nspace, ClientType, ClientId )
valueD =valueM
auxInfo= h( key, Nspace, ClientType, ClientId )
Non c’`e bisogno di assumere nessun cambiamento di valore al livello implemen-tazione DHT: i valori sono forniti dall’algoritmo di traduzione che `e incorporato all’interno del modulo QP, esso viene reinterpretato in questo passaggio. Si as-sume tuttavia che la traduzione delle chiavi sia il risultato dell’implementazione del namespace. In particolare, l’IML e il livelo DHT utilizzano le due funzioni di traduzione g() e h(). In una implementazione generica si ha che la funzione g() pu`o essere definita da una concatenazione di chiavi.
keyD = ()
dove: K1= Nspace K2= keyM
K3= marshall(ClientType, ClientId)
Che `e, l’effettiva chiave, e un ID univoco in funzione del cliente, al fine di garan-tire ai clienti separazione semantica quando necessario. Si noti che quando tale separazione non `e necessaria K3 pu`o non essere utilizzata. La lunghezza delle tre porzioni di chiave pu`o variare da caso a caso, a condizione che le informazioni fornite inizialmente dal namespace prevengano da collisioni di chiavi.
La funzione h() fornisce suggerimenti al livello DIL deducendo le informazioni dai namespace e da altri parametri per effettuare il tuning (adattamento) ideale della DHT (funzione hash appropriata e grado di replicazione ideale). Si noti che a seconda dell’implementazione scelta (figura ) la risultante chiave KD pu`o
4.2. PRIMO PROTOTIPO DI ADS: IMPLEMENTAZIONE. 47 essere divisa in due parti, una utilizzata per selezionare l’anello e l’altra come chiave DHT. La chiave che seleziona l’anello, in casi speciali pu`o essere vista come concatenazione di .
Inoltre, nelle implementazioni con multi-DHT nuovi overlay possono essere creati dinamicamente, di conseguenza, un analoga della funzione h() deve essere definita per poter fornire a tempo di creazione le informazioni per il tuning della DHT.
4.2
Primo prototipo di ADS: implementazione.
4.2.1
Implementazione di Facade
Facade si occupa principalmente dell’interfacciamento tra i clienti e SRDS. `
E stata implementata come insieme di classi che forniscono sia supporto alle co-municazioni: HTTPS, DIXI, JMS etc. sia che si occupano di caricare la configu-razione di tutto il sistema quando avviene il bootstrap del nodo.
Inoltre Facade ha anche il compito di creare le classi di aggancio per i client AEM, JDS e DMS i cosiddetti MAPI. Queste classi forniscono a loro volta il supporto per l’incapsulamento e la decodifica dei messaggi nel loro formato specifico. Caricamento configurazioni il caricamento delle configurazioni viene preso dal
file contenuto nella directory di installazione ADSConfig.xml il file `e in un formato xml e contiene le seguenti voci
• bootstraping: questo elemento contiene tutte le informazioni utili al momento del bootstraping del nodo esso contiene a sua volta:
– l’elemento namespace che contiene le informazioni riguardanti i namespace che devono essere creati al momento dell’avvio del nodo. Ogni elemento namespace ha come elementi sottostanti: name di tipo stringa, che identifica il nome con cui tale
name-space verr`aidentificato e che sar`a concatenato alla chiave uti-lizzata nelle richiesteverso la DHT
typeofdht di tipo intero, che indica il tipo di dht sulla quale verr`a inserito il namespace.
– l’elemento dht che contiene le caratteristiche proprie di ognuna delle implementazioni disponibili. Questo elemento contiene a sua volta i seguenti sottoelementi.
Name di tipo stringa che identifica il nome dell’implementazione scelta tra una delle tre disponibili (Bamboo, OverlayWeaver, Chord#).
Type di tipo intero che indica il tipo di dht, questo valore `e asso-ciato a quello che sta nell’elemento typeOfDht di namespace. Keylengthinbit di tipo intero, che indica la lunghezza delle
chia-vi che tale dht supporta. L’elemento
ReplicationDegreeMax di tipo intero, che indica il massimo gra-do di replicazione dei dati.
IsTransactional che indica se la dht `e di tipo transazionale o meno.
• scripts: dato che alcune implementazioni di dht come Bamboo e Chord# non possono essere lanciate all’interno della virtual machine sulla qua-le gira SRDS come istanze di classi, esse necessitano di script di co-mando assieme a particolari file di configurazione. Questo perch`e come Bamboo richiedono particolari configurazioni nel classpath e nelle librerie native o come Chord# non sono implementate in Java. L’elemento scripts contiene i seguenti sottoelementi:
type di tipo intero, che contiene il tipo della dht (la stessa che compare come elemento di namespace e di dht);
command di tipo stringa,che identifica il comando per lanciare la nuova dht;
configurationFile di tipo stringa, che contiene il path assoluto del file di configurazione eventualmente dal passare al comando.
• rss: questo elemento contiene le configurazioni che servono a lanciare il demone di Rss. I suoi elementi sono:
configDir di tipo stringa, che contiene il path assoluto della directory di configurazione di Rss;
4.2. PRIMO PROTOTIPO DI ADS: IMPLEMENTAZIONE. 49 configFile di tipo stringa, che contiene il nome del file di
configura-zione di Rss;
Creazione dei MAPI Facade provvede inoltre ad istanziare le classi che servono a interfacciare ADS verso i clienti.
• Nel caso di Dixi vengono istanziate le classi che eseguono il business code delle operazioni che il servizio SRDS fornisce.
• Nel caso di RMI viene lanciato il registro ed effettuato il binding al nome dei metodi remoti che SRDS espone.
Ognuna di queste classi fornisce un supporto orientato alla comunicazione, in genere sarebbe loro anche il compito di effettuare i controlli di sicurezza sui clienti che si interfacciano a noi. Ad esempio controllare se le operazioni che un cliente richiede siano permesse dalle politiche della sua Organizzazione Vir-tuale, piuttosto che non accettare richieste da clienti di cui non `e stata verificata l’identit`a.
4.2.2
Moduli Query & Provide Interface
I moduli Query & Provide Interface vengono implementati per i due principali client di SRDS, l’AEM e il JDS. Vengono identificati con le classi AemClientIm-plementation e JdsClientImAemClientIm-plementation. Tali classi contengono al loro interno i metodi che poi verranno esposti tramite i moduli MAPI verso l’esterno.
Essendo moduli chiave nell’utilizzo dell’architettura da parte del cliente essi ven-gono lanciati allo start-up dell’applicazione.
Questi due moduli una volta lanciati in una prima fase di start-up provvederanno a connettersi con i namespace che forniranno l’aggancio verso le DHT. Questo meccanismo `e realizzato tramite le feature fornite dal package dhtobject, in parti-colare la classe DhtObjectFactory si occupa di fornire le funzionalit`a di creazione e di associazione verso un namespace.
Hanno il compito oltre che di fornire l’interfacce per i metodi di connettersi ai namespace che dovranno contenere le informazioni dei clienti. Tale meccanismo `e
4.2. PRIMO PROTOTIPO DI ADS: IMPLEMENTAZIONE. 51 coadiuvato dalla classe DhtObjectFactory che si occupa di fornire il supporto alla creazione o all’aggancio verso i namespace e conseguentemente verso le DHT.
4.2.3
Modulo Provide Interface
Il modulo Provide Interface che viene inizializzato anch’esso allo start-up del do `e quello che si occupa della memorizzazione delle informazioni locali del no-do. Questo servizio `e utilizzato esclusivamente dal modulo che si occupa delle richieste del cliente AEM. Esso memorizza ogni 30 secondi le informazioni che riguardano gli attributi dinamici del nodo.
Le informazioni vengono inserite nella DHT tramite l’utilizzo del namespace as-sociato all’AEM. Questo modulo come quello descritto nella sezione precedente utilizza la classe DhtObjectFactory contenuta nel package dhtobject per associarsi al namespace.
4.2.4
DHT layer
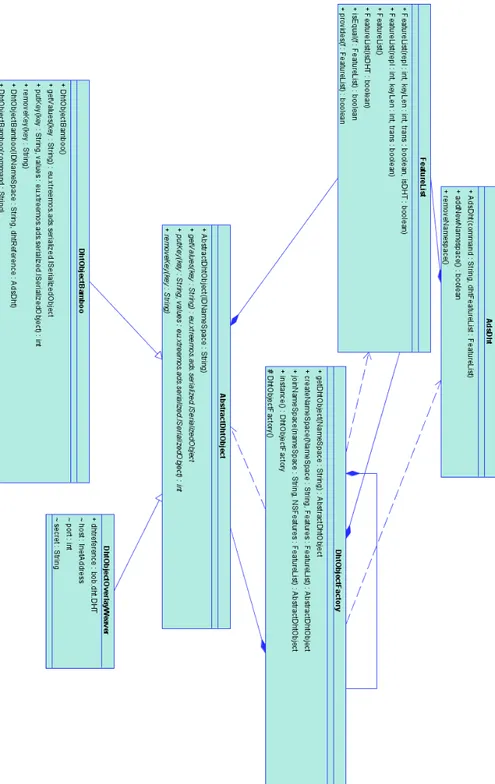
Nel primo prototipo di architettura non `e presente il livello IML, in quanto le ca-ratteristiche che dovrebbe implementare vengono gi`a fornite dai livelli di Query & Provide Interface. Per quanto riguarda la scelta del namespace infatti tali moduli effettuano gi`a l’aggancio passandone il nome alla classe DhtObjectFactory. Risulta invece essenziale la presenza di un livello che permetta di uniformare i comportamenti delle varie DHT, rispetto alle operazioni di put get e remove, verso i livelli pi`u alti dell’archittetura, fornendo un meccanismo che renda invisibili le varie differenti implementazioni tra tipi diversi di DHT.
Questo livello `e costituito principalmente dalle classi che estendono la classe astratta AbstractDhtObject. Una volta che il namespace `e stato creato esso `e as-sociato per tutta la sua durata ad un DHT particolare. In generale l’associazione viene fatta dalla classe DhtObjectFactory al momento della creazione del name-space. Tale operazione sceglie tra le DHT esistenti o tra quelle possibili una che soddisfi i criteri che il namespace impone attraverso delle feature list. Una vol-ta complevol-tato l’iter di creazione viene ritornato un oggetto che estende la classe
astratta AbstracDhtObject ma che al contempo `e il riferimento a quel tipo di DHT particolare.
Nel caso di AEM si ritorna un oggetto di tipo DhtObjectBamboo. Questa classe ha il compito di fornire un interfaccia comune per i metodi di put get e remove verso Bamboo. Infatti Bamboo utilizza una semantica particolare per tali operazioni che si differenzia da quelle utilizzate da altre implementazioni tipo Overlay Weaver ad esempio.
Un esempio tipico `e quello della remove. Nel caso di Bamboo infatti per effet-tuare la remove `e necessario fornire sia la chiave che il valore ad essa associato. Quando si utilizza tale operazione tuttavia non siamo a conoscenza dei valori a cui la chiave `e associata, di conseguenza la remove che la classe DhtObjectBamboo implementa in particolare effettua prima una get con la chiave da togliere, ed una volta reperito il valore effettua la remove. Nel caso di Overlay Weaver invece tale operazione non `e necessaria.
Quindi la gerarchia delle classi che ha come vertice la classe AbstractDhtObject fornisce un insieme di metodi che le classi che la estendono devono fornire tuttavia l’implementazione effettiva `e diversificata a seconda della DHT con la quale si interagisce.
4.2.5
Implementazioni di DHT utilizzate
4.2.5.1 Overlay Weaver
Descrizione. Overlay Weaver (OW)[9] `e l’implementazione di una DHT basata su Java che riesce a sfruttare diversi tipi di algoritmi di routing che appartengono ai pi`u comuni tipi di DHT quali Chord, Pastry, Tapestry, Kademlia e Koorde. Per questo OW viene anche definito “un toolkit per la creazione di overlay”.
L’idea centrale di Overlay Weaver `e stata quella di estrapolare dal livello di routing un livello comune a tutti questi algoritmi, in modo da poter permettere all’utiliz-zatore finale di poter combinare anche le caratteristiche di tali algoritmi.
OW non `e stato usato nel primo prototipo di ADS, tuttavia sono state predisposte le classi che si agganciano a tale DHT (DhtObjectOW), si prevede infatti che
4.2. PRIMO PROTOTIPO DI ADS: IMPLEMENTAZIONE. 53
nel successivo sviluppo del codice si possano sfruttare le caratteristiche di un architettura cos`ı versatile.
Operazioni. L’inserimento di un dato sulla DHT `e effettuato tramite l’operazio-ne di put. Sono presenti due metodi che svolgono questa funzionalit`a: put(ID key, V value, long ttl)`e il primo metodo e inserisce la coppia chiave-valore nella DHT. Esiste tuttavia la possibilit`a di associare pi`u valori alla stessa chiave, ma valori uguali sono unificati.
Il parametro ttl,espresso in millisecondi, rappresenta il periodo temporale in cui il dato `e valido ed `e a disposizione sulla rete. Passato il valore indicato dal ttl il dato viene rimosso.
Il parametro hashedSecret `e un oggetto che viene associato alla coppia chiave-valore per aspetti di sicurezza. In realt`a, la rimozione di una chiave `e permessa solo se all’operazione `e associato l’oggetto segreto corrispondente.
Per recuperare dati sulla DHT `e utilizzato il metodo get(ID key) il quale restituisce l’insieme di valori associati alla chiave (key) specificata. Se nessun valore `e stato trovato null `e restituito. Esistono due possibili metodi per la rimozione di un dato dalla DHT. Il metodo remove(ID key, V value, ByteArray hashedSecret) rimuove la coppia chiave-valore specificata. Se alla chiave `e associato pi`u di un valore, `e rimosso solo quello indicato dal metodo. Il metodo remove(ID key, ByteArray hashedSecret)rimuove tutti i valori associati alla chiave specificata (oltre che la chiave stessa).
4.2.5.2 Bamboo
Descrizione Bamboo[10] `e l’implementazione in parte in codice Java a e in par-te in codice C di una DHT basata su pastry. In realt`a il protocollo pastry `e stato reingegnerizzato da parte dei creatori. L’implementazione di Bamboo `e forte-mente basata sul modello SEDA[11]. Questo modello organizza il programma in blocchi logici che possono comunicare fra di loro tramite dei messaggi ai quali altri blocchi possono registrarsi per averne notifica. Ognuno di questi blocchi `e chiamato stage. Per compiere il lavoro necessario alla DHT sono necessari almeno i seguenti stages: