1
Le performance di un data warehouse sono un aspetto fondamentale per tutte le organizzazioni che utilizzano quotidianamente sistemi di Business Intelligence. Avere a disposizione informazioni in grado di aiutare i processi decisionali rappresenta al mondo d’oggi un vantaggio competitivo enorme nei confronti delle altre realtà concorrenti.
In questo elaborato di tesi viene presentato uno strumento software in grado di migliorare in maniera proattiva le performance di un data warehouse. Questo strumento consente a coloro che gestiscono il data warehouse, di individuare quali siano gli aggregati che devono essere costruiti in memoria, in modo tale da ottimizzare i tempi di risposta del data warehouse stesso.
L’efficacia delle indicazioni fornite da questo software è mostrata attraverso esperimenti, che sono stati effettuati su un data warehouse quotidianamente utilizzato da una grande azienda italiana.
2
Il capitolo 1 è un’introduzione alla Business Intelligence, in cui viene descritta l’importanza che sta sempre più assumendo all’interno delle organizzazioni sia pubbliche che private. Vengono inoltre descritti i metodi con cui vengono progettati e realizzati i data warehouse, infine viene approfondito il problema delle loro performance e sono presentati gli studi precedentemente effettuati.
Nel capitolo 2 è presentata la progettazione del sistema di Auto
Tuning, viene quindi descritta l’analisi dei requisiti e sono illustrate le scelte
progettuali adottate.
Nel capitolo 3 viene descritta l’implementazione dello strumento, viene illustrata l’architettura del sistema ed è analizzato lo sviluppo di ogni singolo componente.
Il capitolo 4 descrive la fase sperimentale che è stata condotta su un data warehouse appartenente ad una nota azienda italiana. Due test mostrano l’efficacia del sistema confrontando le performance del data warehouse prima e dopo l’utilizzo di Auto Tuning.
Infine nel capitolo 5 sono tracciate alcune conclusioni e sono discussi gli eventuali sviluppi futuri a cui il sistema potrà essere sottoposto.
3
Premessa
Il progetto realizzato e descritto in questo elaborato di tesi è stato reso possibile grazie alla disponibilità dell’azienda ICONSULTING S.p.A. presso la quale sono stato ospitato per 7 mesi in qualità di tesista.
Iconsulting è uno dei più grandi System Integrator indipendenti italiani specializzato unicamente in progetti di Data Warehouse, Business Intelligence e Corporate Performance Management. È l'unica azienda indipendente italiana ad essere partner di riferimento ed avere progetti in produzione con i più importanti vendor internazionali fra cui Oracle, IBM Cognos, Jaspersoft, Microstrategy, Microsoft, QlikView, SAP BusinessObjects, etc.
Il data warehouse su cui sono state effettuate le ricerche e le operazioni di testing appartiene ad una nota azienda italiana che opera nel settore Fashion & Retail. Questa Azienda produce, promuove e distribuisce i propri prodotti calzaturieri e di abbigliamento sia nel mercato italiano che in quello straniero.
4
Per motivi di privacy verrà omesso il nome di questa azienda, inoltre i dati visualizzati nelle immagini presenti all’interno di questo elaborato non sono da considerarsi reali in quanto sono stati volutamente modificati.
5
Capitolo 1
Introduzione alla Business Intelligence
Il termine Business Intelligence venne coniato per la prima volta nel 1958 da Hans Perter Luhn, ricercatore tedesco che all’epoca lavorava per IBM, durante i suoi studi volti alla realizzazione di un sistema automatico per diffondere le informazioni tra le varie sezioni di un’organizzazione.
L’evoluzione che ha avuto sia l’informatica che l’organizzazione all’interno delle aziende, ha fatto sì che anche la business intelligence si evolvesse cercando di soddisfare le sempre più esigenti richieste di cui le aziende necessitano per poter rimanere competitive sul mercato.
La Business Intelligence rappresenta lo strumento chiave dell’evoluzione verso una gestione sempre più efficace e strategica delle in-formazioni. Al giorno d’oggi le aziende non riescono a gestire efficientemen-te l’elevata mole di dati di cui sono in possesso e conseguenefficientemen-temenefficientemen-te hanno
6
difficoltà nel condurre il processo di estrazione della conoscenza che ha co-me punto di partenza i dati stessi.
Possedere una grande quantità di dati non implica necessariamente essere in possesso di un gran numero di informazioni. L’informazione è in-fatti un bene a valore crescente, necessario per pianificare e controllare con efficacia obiettivi, funzioni e processi di un’azienda. Attraverso la Business Intelligence si integra, centralizza, storicizza e certifica il patrimonio di in-formazioni generate quotidianamente all’interno di un’organizzazione ren-dendolo accessibile in maniera semplice ed immediata all’utente finale che può disporre così di sistemi di analisi, predizione, ottimizzazione e simula-zione. L’implementazione di un sistema di Business Intelligence rappresenta quindi il mezzo per raggiungere l’obiettivo di valorizzazione del patrimonio dei dati aziendali. Una definizione più accurata della moderna business in-telligence è quella fornita da [Rez12]:
La Business Intelligence è un sistema di modelli, metodi, processi, persone e strumenti che rendono possibile la raccolta regolare e orga-nizzata del patrimonio dati generato da un’azienda. Inoltre, attraverso elaborazioni, analisi o aggregazioni, ne permettono la trasformazione in informazioni, la loro conservazione, reperibilità e presentazione in una forma semplice, flessibile ed efficace, tale da costituire un supporto alle decisioni strategiche, tattiche e operative.
7
In un mercato globale in cui ormai oggi tutte le aziende, piccole o grandi che siano, si trovano ad affrontare ogni giorno, l’unico modo per po-ter rimanere competitivi è quello di rinnovare continuamente i loro prodotti ed i loro processi puntando quindi sulla loro continua innovazione. Tuttavia la velocità che caratterizza questo XXI secolo può indurre a compiere scelte sbagliate o comunque sia a non seguire la strada ottimale; per tale motivo la Business Intelligence ha acquisito un ruolo sempre più importante nel corso di questi ultimi anni, fornendo preziose informazioni in maniera sem-plice e tempestiva. I dati costituiscono infatti la vera ricchezza strategica di un qualunque tipo di ente sia pubblico che privato. Tuttavia, a causa dell'enorme quantità e dell'eccessivo livello di dettaglio che i dati fornisco-no, diventa necessario estrapolare informazioni aggregate e di sintesi, le quali costituiscono il vero valore aggiunto poiché focalizzano l'attenzione del management sulle sole informazioni rilevanti che consentono di prendere frequenti e rapide decisioni strategiche.
1.1 I Sistemi Informativi Aziendali
Per comprendere meglio le funzioni che sono ricoperte dalla business intelligence è necessario fare chiarezza su come le operazioni svolte dal si-stema informativo aziendale possono essere classificate in base alle attività dei diversi attori che ne fruiscono all’intero dell’organizzazione aziendale. Questa classificazione è stata effettuata nel 1965 da Robert Anthony ed è
8
tutt’oggi applicabile alle moderne aziende, nonostante la radicale innovazio-ne che l’Information and Communication Technology (ICT) ha avuto innovazio-nel corso di questi anni.
Essa è schematizzata nella piramide di figura 1.1 che prende il nome dal suo autore.
La piramide di Anthony individua tre categorie di attività all’interno di un’azienda:
1. Le attività strategiche, che consistono nella definizione della mission aziendale e dei conseguenti obiettivi strategici, non-ché della scelta delle risorse e delle politiche aziendali per conseguirli (scelta dei mercati, scelta dei prodotti…);
9
2. Le attività tattiche, che consistono nell’allocazione delle ri-sorse aziendali per poter raggiungere gli obiettivi posti dal management strategico e nel controllo dei corrispondenti ri-sultati in termini di efficienza ed efficacia (budgeting, pro-grammazione della produzione...);
3. Le attività operative, che rappresentano l’operatività cor-rente tipica dell’azienda (gestione ordini, magazzino, contabi-lità…).
Ciascuna delle precedenti attività è svolta dai diversi attori riportati nella colonna alla destra della piramide i quali si avvalgono di diverse cate-gorie di software per svolgere le loro attività.
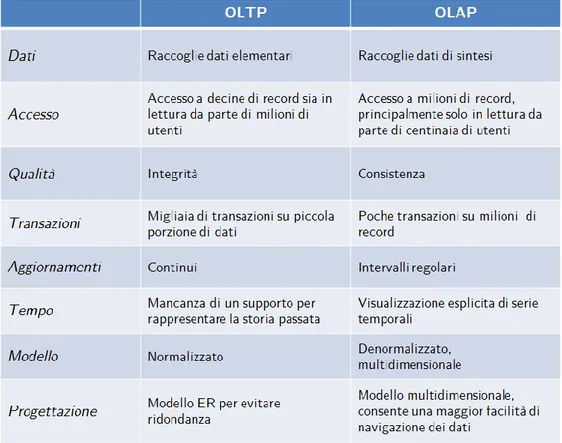
In generale, è possibile suddividere i sistemi informativi in due grandi gruppi:
On-Line Transaction Processing (OLTP): sistemi in grado di facilitare ed automatizzare la costruzione, l'esecuzione e l'amministrazione di applicazioni dedicate alla gestione di processi transazionali;
On-Line Analytical Processing (OLAP): sistemi di interro-gazione utili per ottenere in tempi ridotti informazioni di sin-tesi che permettono di effettuare analisi dei dati finalizzate
10
all'attuazione di processi decisionali e al miglioramento del patrimonio informativo.
La tabella in figura 1.2 mostra sinteticamente le principali differenze e le esigenze contrapposte che caratterizzano questi due tipi di sistemi.
11
1.1.1 Sistemi a Supporto delle Decisioni
I sistemi a supporto delle decisioni, oppure, utilizzando la terminologia inglese, Decision Support System (DSS) sono di ausilio al top management nei processi decisionali e in quelli di pianificazione. Una definizione formale di questa classe di sistemi è la seguente:
Un sistema di supporto alle decisioni è un sistema in grado di for-nire chiare informazioni agli utenti, in modo che essi possano analizza-re dettagliatamente una situazione e panalizza-rendeanalizza-re facilmente le opportune decisioni sulle azioni da intraprendere [PKB98].
In altre parole, un sistema DSS è un sistema informativo dedicato ad aiutare i responsabili del business in tutta la gestione d’impresa, in modo da permettere decisioni più veloci, più mirate e più efficaci. Questo sistema ha quindi l’obiettivo di contribuire ad incrementare le performance economiche di un’impresa, rendendo disponibili le informazioni strategiche in modo semplice e tempestivo.
12
1.2 Data Warehouse
Come si può evincere dalla definizione di Business Intelligence, ripor-tata al paragrafo 1.1, essa è un sistema molto complesso ed è composto da diverse tecnologie. La tecnologia che sta alla base della Business Intelligen-ce è il Data Warehouse (DW), che letteralmente significa “magazzino di dati”. Esso è il contenitore in cui vengono memorizzati i dati in maniera persistente. È bene mettere in evidenza che il data warehouse è diverso dal
Database, infatti quest’ultimo raccoglie i dati operazionali che derivano
dal-le attività operative di ciascuna azienda; quindi appartiene alla categoria dei sistemi transazionali OLTP. Il data warehouse invece, raccoglie i dati ag-gregati ed è quindi utilizzato nei sistemi di tipo OLAP.
1.2.1 Architettura del Data Warehouse
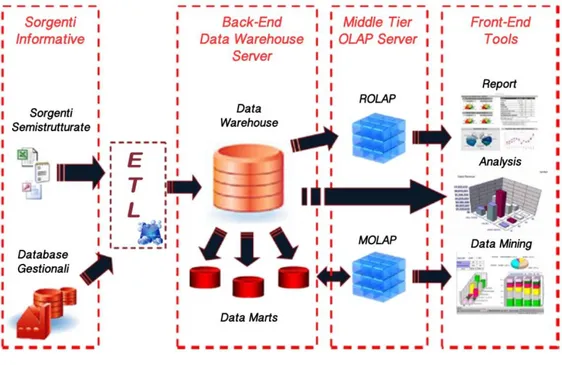
All’interno di un data warehouse i dati provenienti da sorgenti etero-genee sono integrati e riorganizzati in modo tale da rendere possibili analisi su di essi. Il processo di Data Integration si occupa di estrarre i dati dalle varie sorgenti OLTP, di trasformarli, organizzarli opportunamente secondo regole ben definite ed infine essi vengono caricati all’interno del data ware-house. Questo processo viene anche chiamato Extraction, Transformation
13
Il data warehouse rappresenta quindi una sorgente di dati secondaria, popolata dai sistemi OLTP esistenti e da altre fonti dati esterne, come per esempio fogli di calcolo, informazioni presenti su documenti cartacei etc.
Quella che a prima vista potrebbe sembrare una duplicazione delle formazioni, è invece una essenziale raccolta ben organizzata di tutte le in-formazioni presenti all’interno di una organizzazione, al fine di facilitare i processi di analisi e di pianificazione. L’organizzazione dei dati all’interno del data warehouse viene definita attraverso i data mart, i quali sono data-base analitici progettati per soddisfare le esigenze di una specifica funzione di business. In sostanza i data mart non sono altro che un sottoinsieme lo-gico dei dati presenti all’interno del data warehouse, da cui vengono diret-tamente alimentati.
Dopo che i dati sono stati trasformati, filtrati e riorganizzati nel data warehouse e nei vari data mart, viene definito il modello multidimensionale (ROLAP o MOLAP) sul quale verranno effettuate le varie analisi attraverso gli strumenti di reportistica front-end. Gli utenti hanno la possibilità di ef-fettuare le analisi utili per lo sviluppo del proprio business consultando da-shboard1 che mostrano dati consuntivi riguardanti per esempio il fatturato aziendale, budget, oppure possono essere effettuate analisi di data mining per estrarre informazioni “nascoste” all’interno dei propri dati.
1 Una dashboard (o cruscotto) è una collezione di oggetti che, organizzati per aree
14
La figura 1.3 mostra il flusso, l’organizzazione e l’utilizzo dei dati all’interno di un data warehouse.
1.2.2 Il Modello Multidimensionale
La modellazione multidimensionale dei dati consente di rappresentarli all'interno di un ipercubo, il quale permette di identificare immediatamente il raggio d'azione del data warehouse, evidenziando le dimensioni di analisi e le misure associate ai fatti di interesse. Tale concetto è rappresentato vi-sivamente in figura 1.4.
15
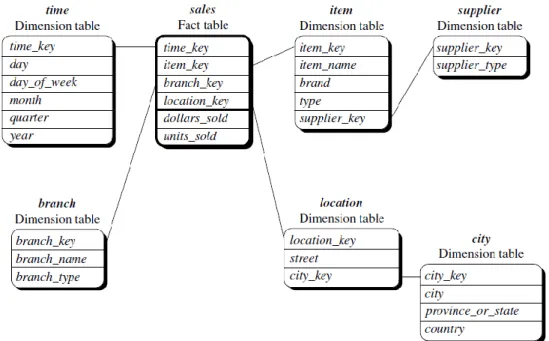
Le dimensioni sono le prospettive, o le entità, in base alle quali l’azienda vuol organizzare i propri dati. Esse rappresentano quindi i diversi punti di vista attraverso i quali effettuare le analisi all’interno di un oppor-tuno contesto. Ogni dimensione è associata ad una o più tabelle che pren-dono il nome di dimensional table o lookup table.
Un modello multidimensionale è costruito attorno ad un tema centrale che è rappresentato dalla fact table. La fact table contiene i fatti, o
misu-re, ovvero i concetti d’interesse per il processo decisionale dell’azienda.
Es-si sono valori numerici che descrivono un aspetto quantitativo tipico del bu-siness (quantitativo degli ordini, importo fatturazione, etc).
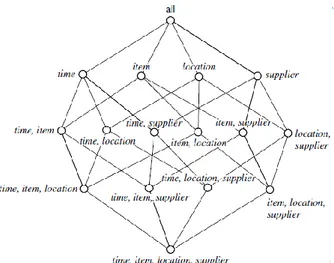
Solitamente all’interno di un contesto di un data warehouse si parla in maniera impropria di cubo. È bene sottolineare il fatto che le dimensioni associate ad un fatto sono molteplici all’interno di un data warehouse, quindi sarebbe più corretto parlare di ipercubo proprio perché si ha a che
16
fare con n-dimensioni. Ciascun livello dimensionale è costituito da diversi livelli di aggregazione che possono essere organizzati fra loro secondo un modello gerarchico.
Ciascun possibile sottoinsieme di dimensioni associato ad una fact ta-ble è detto cuboide, l’insieme di tutti i possibili cuboidi è chiamato lattice.
Figura 1.5 - Esempio di gerarchia di una dimensione relativa allo spazio (a) e al tempo (b)
17
Il lattice consente di visualizzare tutte le possibili combinazioni con cui è possibile sintetizzare le misure di una fact table.
In seguito alla definizione del modello multidimensionale del business, è necessario che esso venga implementato su un sistema fisico. In letteratu-ra esistono due possibili scelte contletteratu-rapposte in merito alla tipologia di data-base che si desidera utilizzare:
M ultidimensional OLAP (MOLAP): i dati sono memorizza-ti in strutture intrinsecamente mulmemorizza-tidimensionali (array, inol-tre è presente un motore OLAP all’interno del database;
Relational OLAP (ROLAP): i dati vengono memorizzati all'interno di un database relazionale ed un motore OLAP traduce le tipiche operazioni multidimensionali in query SQL, restituendo un risultato in formato multidimensionale. I dati sono raccolti all'interno di due diversi tipi di tabelle (fact
ta-ble e dimensional o lookup tata-ble), modellate all'interno di tre
possibili tipologie di schemi:
1. Star schema: vincola la presenza di un'unica tabella per ogni dimensione tutte collegate alla fact table che memorizza le istanze di un fatto;
18
2. Snowflake schema: le dimensional table sono norma-lizzate; conseguentemente la dimensione dello spazio occupato risulta minore poiché i dati non sono ridon-danti. Tuttavia è necessario effettuare un maggior numero di join per recuperare tutti i dettagli relativi ad un particolare fatto.
3. Fact Costellation schema: questa tipologia di model-lazione consente la condivisione delle dimensional table fra più fact table.
Figura 1.7 - Esempio di Star Schema Figura 1.8 - Esempio di Snowflake Schema
19
In un data warehouse sono collezionati tutti i dati relativi all’intera organizzazione aziendale, quindi viene comunemente adottato il modello constellation fact schema, poiché esso consente di collegare facilmente più fatti. Nei data mart, invece, vengono memorizzati sottoinsiemi di dati rela-tivi a specifiche aree dipartimentali dell’azienda; quindi, essendo inferiore la loro mole, solitamente viene adottato uno degli altri due modelli. La scelta più comunemente adottata è quella dello star schema, poiché il join è un’operazione computazionalmente pesante ed il guadagno che si ha sul minor spazio occupato solitamente non giustifica le peggiori performance che lo snowflake schema comporta. Tuttavia queste sono scelte progettuali che devo considerare altri fattori contingenti tipici di ogni sistema.
20
1.3 Performance di un Data Warehouse
Negli ultimi anni l’approccio adottato nell’implementazione di applica-zioni di Business Intelligence e nello sviluppo di un data warehouse è radi-calmente cambiato, passando da una visione di tipo dipartimentale ad una di tipo enterprise. Come conseguenza, la mole di dati da gestire è cresciuta notevolmente, così come è diventato sempre più complesso rispondere ai requisiti di business in maniera performante.
Le performance di un data warehouse sono un aspetto fondamentale che non può essere trascurato, poiché la tempestività con cui vengono for-nite le informazioni è uno dei punti di forza della Business Intelligence.
In questi ultimi anni l’affermarsi dei dispositivi mobili come smartpho-ne e tablet ha posto ulteriormente l’attenziosmartpho-ne su questo aspetto, infatti con questi dispositivi non si ha sempre la possibilità di essere collegati ad una rete Internet ad alta velocità proprio perché possono essere utilizzati ovunque. In questi casi si ha un ritardo nella consegna delle informazioni causato dalla scarsa velocità durante la trasmissione dei dati verso questi dispositivi. Quindi si rende ancor più necessario minimizzare i tempi di ela-borazione del data warehouse, in modo tale da non gravare troppo sui tempi di attesa complessivi. Questa difficoltà è alimentata anche dalla man-canza di strumenti di monitoraggio dell’utilizzo dei dati, strumenti che pos-sano dare indicazioni su quali misure e attributi sono maggiormente analiz-zati.
21
Tali aspetti, insieme al veloce cambiamento del business che richiede tipologie di analisi sempre diverse, fanno sorgere la necessità di sviluppare un sistema proattivo di tuning2 del data warehouse che fornisca informazio-ni circa l’utilizzo dei dati. Queste informazioinformazio-ni devono guidare la costruzio-ne di tabelle aggregate e devono suggerire un’eventualmente dismissiocostruzio-ne o modifica di aggregati esistenti.
1.3.1 Precedenti Studi
La finalità di questo lavoro di tesi è quella di realizzare uno strumento che sia in grado di suggerire ai tecnici del reparto BI, che si occupano della manutenzione del data warehouse, quali siano i cuboidi all’interno del latti-ce che è conveniente materializzare3 per migliorare le performance del data warehouse modellato su un database relazionale (ROLAP). Si tratta di ri-solvere un problema multi obiettivo che è stato dimostrato essere NP-completo [GuMu99], non è quindi possibile trovare una soluzione ottima bensì soltanto una ottimale.
Il primo obiettivo è la minimizzazione dei vincoli di sistema, relativo sia allo spazio che al tempo necessario alla creazione dell’aggregato.
2 Letteralmente significa “messa a punto”. In informatica il termine tuning indica
quell’insieme di attività di ottimizzazione effettuate al fine di migliorare le prestazioni di un sistema.
3
Con il termine materializzazione di un aggregato si intende il processo di creazione di una tabella ottenuta a partire dai dati contenuti nelle altre tabelle aggregandoli secondo una o più dimensioni.
22
Il secondo obiettivo è quello di soddisfare le esigenze degli utenti ridu-cendo i tempi di risposta delle interrogazioni e limitando i tempi necessari all’aggiornamento delle nuove tabelle.
Questi obiettivi sono in contrasto fra loro, pertanto la soluzione otti-male dovrà essere un compromesso tra i diversi requisiti.
Molti ricercatori hanno cercato di trovare una soluzione a questo pro-blema a partire dal 1996 quando il team dell’università di Stanford, compo-sto da Harinarayan, Rajaraman e Ullman [HRU96], ha propocompo-sto il “greedy
algorithm” che fornisce una soluzione facendo una serie di ottimizzazioni
locali considerando come vincolo principale quello dello spazio occupato dai vari aggregati. Questo vincolo era quello più stringente al tempo in cui ven-ne proposto questo algoritmo poiché i costi legati alla memoria erano eleva-ti; tuttavia oggi non è più così infatti i costi dei dispositivi hardware di memorizzazione sono diminuiti considerevolmente. Sono stati proposti an-che altri approcci an-che tengono in considerazione il tempo come vincolo [LWO01], oppure soluzioni ibride [ZXY01].
I tempi computazionali di tutti gli algoritmi che sono stati proposti nel corso di questi anni sono elevati poiché richiedono un gran dispendio di risorse computazionali. Questo può essere uno dei motivi per cui nessuna software house ha mai deciso di implementare un software in grado di for-nire queste informazioni su un data warehouse.
Esistono software che forniscono informazioni statistiche sui data warehouse, come per esempio quali sono le fact table più interrogate, il
23
tempo medio di risposta delle query etc. Un software commerciale che for-nisce questo tipo di informazioni è Data Warehouse Advisor4 della software house Informatica, tuttavia non viene fornito nessun suggerimento per mi-gliorare in maniera proattiva le performance del data warehouse.
La software house Infomix Corporation, che nel 2005 è stata acquisita da IBM, ha sviluppato un prodotto (MetaCube Aggregator5) in grado di offrire questa funzionalità; tuttavia questa analisi non viene fatta al livello fisico, bensì al livello logico del server OLAP. Quindi vi è una semplificazio-ne del livello logico che non comporta però ad un miglioramento delle per-formance del data warehouse installato nel livello fisico del sistema.
Il sistema di Auto Tuning, che verrà presentato nel seguente capitolo, si presenta quindi come il primo prodotto software in grado di fornire in maniera proattiva suggerimenti riguardo gli aggregati da materializzare in un data warehouse per migliorare le performance dello stesso.
4 www.informatica.com/us/products/application-ilm/data-warehouse-advisor 5
24
Progettazione del Sistema di
Auto Tuning
2.1 Analisi dei Requisiti
L’amministratore di un data warehouse e tutti coloro che sono addetti alla sua manutenzione hanno sia il compito di garantire la consistenza dei dati che quello di migliorare le performance del data warehouse stesso.
Uno degli strumenti per minimizzare i tempi di risposta di un data warehouse è quello di creare tabelle contenenti dati aggregati. L’individuazione degli aggregati che consentono di migliorare le performance di un data warehouse non è un processo semplice. Infatti è possibile aggregare i dati seguendo moltissime combinazioni, poiché
25
ciascuna dimensione è generalmente composta da più livelli di aggregazione organizzati secondo una precisa gerarchia.
La materializzazione di un numero elevato di aggregati è controproducente, specialmente in un data warehouse di grosse dimensioni. Tale materializzazione comporta infatti una grande occupazione di memoria, rallenta i processi di aggiornamento dei dati che vengono eseguiti quotidianamente ed aumenta inoltre la complessità del data warehouse stesso, rendendo ancora più difficile la sua manutenzione.
L’obiettivo che questo lavoro di tesi intende conseguire è quello di realizzare un sistema, chiamato Auto Tuning, il quale suggerisca l’individuazione di una tabella aggregata che, una volta materializzata, consentirà di migliorare le performance del data warehouse. Questo suggerimento viene fornito a seguito di analisi effettuate sul sistema che considerano le modalità con cui i dati vengono interrogati attraverso un’analisi dettagliata delle query lanciate su di esso.
Il sistema si occupa di fornire in output un numero limitato di aggregati candidati alla materializzazione, mentre sia il compito di scriverli in memoria che quello di effettuare il mapping all’interno del modello multidimensionale è lasciato all’amministratore del data warehouse o a coloro che sono autorizzati alla sua manutenzione. Questa scelta deriva dal fatto che essi sono responsabili di tutte le strutture dati presenti nel data warehouse, non è consigliato affidare un’operazione così delicata ad un
26
software poiché la scelta può essere dettata anche da altri fattori strategici dell’azienda.
Il sistema dovrà quindi rispondere, per esempio, a domande del tipo:
Dato un data warehouse ed un insieme di query, qual è la
percentuale di query coperte da ciascuna tabella?
Qual è l’insieme di misure e attributi maggiormente
interrogati?
Qual è l’aggregato che potrebbe essere materializzato per
rispondere più velocemente alle interrogazioni effettuate dagli utenti?
Su questi principi quindi, le principali funzionalità che lo strumento deve poter fornire sono le seguenti:
1. Diagnostica del sistema: analisi delle performance del data warehouse dettagliata per singolo fatto. Tale funzionalità deve considerare i seguenti aspetti:
Individuazione dei set di attributi e misure analizzate dalle query;
27
Definizione di un intervallo di monitoraggio con storicizzazione in tabelle opportune delle informazioni sulle performance.
2. Individuazione degli aggregati: attraverso l’identificazione dei campi maggiormente interrogati, il sistema dovrà suggerire possibili nuovi aggregati. Essi dovranno essere individuati attraverso un algoritmo di ricerca che consideri diversi fattori, come ad esempio:
Numero di query coperte;
Tempo necessario alla costruzione dell’aggregato;
28
2.2 Progettazione
Il sistema di Auto Tuning è stato concepito fin dalla sua progettazione come uno strumento stand-alone, basato su un proprio
repository in grado di supportare data warehouse di diverse tecnologie.
Questo è un aspetto fondamentale che consente di utilizzare questo strumento sui diversi data warehouse già esistenti nelle varie realtà aziendali. Inoltre non vincola la scelta di una tecnologia per poter sfruttare le sue funzionalità, poiché è in grado di connettersi ai data warehouse sviluppati dai vari vendor presenti sul mercato.
Il sistema di Auto Tuning deve operare a livello di tabelle fisiche di un data warehouse modellato secondo la tipologia ROLAP. Un’altra caratteristica fondamentale, che è stata tenuta in considerazione sin dalla fase di progettazione, è quella che Auto Tuning è in grado di funzionare sia sui data warehouse modellati come star schema che in quelli costruiti secondo il modello snowflake. Tale caratteristica amplia il campo di applicazione del sistema e soprattutto non influenza la scelta del modello da utilizzare durante la fase di progettazione di un nuovo data warehouse.
La tipologia di tuning che si intende realizzare è diversa dal tuning del database, non è definita quindi a livello di indici, partizioni o statistiche ma deve poter valutare il grado di copertura delle query. Il punto di partenza del sistema sarà quindi quello di analizzare le query che vengono effettuate
29
sul data warehouse, in modo tale da identificare a quale livello di aggregazione vengono interrogati più frequentemente i dati.
Una volta individuati i livelli di aggregazione più interrogati per ciascuna dimensione, il sistema deve proporre una serie di aggregati che saranno in grado di rispondere a tutte le query più frequentemente interrogate da parte dei sistemi di analisi front-end utilizzati degli utenti.
L’utente di Auto Tuning dovrà quindi valutare se è conveniente scrivere questa tabella aggregata in memoria oppure no. Questa decisione verrà presa tenendo in considerazione non solo la frequenza con cui l’aggregato verrebbe interrogato, ma verranno considerati anche altri fattori che caratterizzano l’intero sistema informativo in cui è presente il data warehouse. In particolare dev’essere valutato lo spazio di memoria libero presente nel data warehouse, poiché la dimensione delle tabelle aggregate varia in base al livello in cui sono stati aggregati i dati. Per esempio, la scelta potrebbe ricadere sulla materializzazione di un aggregato che viene interrogato con una frequenza minore ma che occupa minor spazio in memoria.
Un altro vincolo che l’amministratore del data warehouse deve considerare è quello relativo al tempo legato alla creazione di questa nuova tabella in memoria. Il processo ETL impiega generalmente un tempo molto lungo e rappresenta inoltre la fase più critica all’interno della manutenzione dell’intero data warehouse. Per questi motivi, uno degli obiettivi dell’amministratore del data warehouse è quello di minimizzare i suoi tempi,
30
cercando di limitare il più possibile sia il numero delle tabelle all’interno del data warehouse sia il numero degli attributi all’interno di ciascuna tabella. La criticità del processo ETL è data dal fatto che nel caso in cui esso fallisca, gli utenti finali degli strumenti di analisi front-end non hanno la possibilità di consultare i dati aggiornati. Inoltre è possibile visualizzare tali dati aggiornati soltanto al termine dell’intero processo di aggiornamento, che deve essere eseguito nel minor tempo possibile.
Dunque l’utente di Auto Tuning è tenuto a considerare anche quanto la costruzione dell’aggregato inciderà sulla durata temporale del processo ETL. Infatti, se il processo ETL già implementato sul data warehouse ha tempi di esecuzione molto lunghi, l’utente non potrà selezionare quegli aggregati che comportano un aumento significativo del tempo di tale processo.
Tutte queste considerazioni possono essere effettuate soltanto dall’amministratore del data warehouse o dagli addetti alla sua manutenzione, poiché devono essere considerati fattori relativi all’utilizzo che viene fatto del sistema Business Intelligence. Ci sono inoltre altre decisioni che possono essere prese congiuntamente a quella di costruire un nuovo aggregato in memoria, come per esempio quella di acquistare un nuovo componente hardware.
Il sistema di Auto Tuning è stato progettato considerando tutte queste esigenze che sono presenti all’interno di ciascun sistema di Business
31
Intelligence. Esso ha come obiettivo quello di fornire un supporto offrendo preziose informazioni in merito ai vincoli che devono essere considerati.
Per ciascun aggregato che il sistema genera dovranno essere fornite le seguenti informazioni:
Frequenza con cui l’aggregato viene interrogato;
Tempo necessario alla costruzione dell’aggregato;
Spazio occupato in memoria dall’aggregato.
Questi valori consentono all’utente di selezionare l’aggregato che più soddisfa le esigenze del data warehouse su cui viene effettuata l’analisi, tenendo in considerazione tutti i vincoli presenti sul sistema.
Nel data warehouse possono essere già presenti tabelle aggregate e attraverso questo strumento è possibile determinare la loro reale efficacia. Infatti possono essere state materializzate in memoria tabelle aggregate che in realtà non vengono consultate dagli utenti, pertanto è necessario individuare la causa del loro inutilizzo. Un errore sull’aggregazione anche di una singola dimensione può rendere inefficace la presenza dell’aggregato all’interno del data warehouse, peggiorando quindi le performance dell’intero sistema.
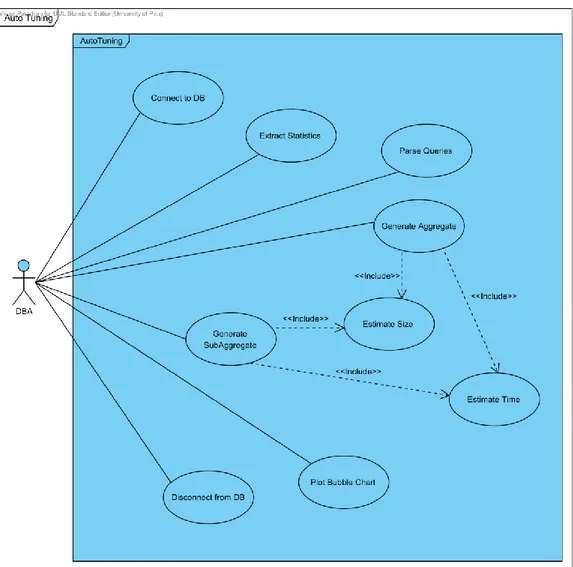
Tutte le funzionalità del sistema di Auto Tuning sono illustrate nel diagramma dei casi d’uso modellato attraverso il linguaggio UML (Unified
32
Il diagramma dei casi d’uso, riportato in figura 2.1, mostra le funzionalità offerte dall’intero sistema ad un alto livello di astrazione, non viene quindi tenuto in considerazione il linguaggio con cui verrà implementato il sistema.
33
38
Implementazione del Sistema di
Auto Tuning
3.1
Architettura
L’architettura del sistema di Auto Tuning si basa su tre livelli:
1. Livello Fisico;
2. Livello Logico;
39
Al livello fisico troviamo il data warehouse sul quale si vuole condurre l’analisi. È qui che vengono recuperate tutte le informazioni riguardo le query che sono state lanciate dagli utenti, ed i relativi dati statistici riguardanti i tempi necessari alle loro elaborazioni.
Il livello logico è composto dall’engine, il componente principale dell’applicazione. Esso individua gli aggregati candidati alla materializzazione, effettua la stima dello spazio che ciascuno di essi andrà ad occupare in memoria e la stima del tempo necessario alla loro creazione. All’interno dell’engine ci sono due sotto moduli: l’extractor ed il parser. Il primo ha il compito di estrarre i testi SQL delle query più lanciate sul data
40
warehouse e le relative informazioni statistiche, mentre il secondo ha il compito di analizzare ogni singola parola delle query individuando le fact table, le lookup, le misure, gli attributi su cui vengono fatti i join, quelli su cui vengono fatti i filtri ed i livelli di aggregazione di ogni dimensione interrogata.
Infine, il livello presentazione consente di visualizzare l’output fornito dal sistema sia attraverso tabelle numeriche che attraverso grafici, in modo tale da rendere più semplice la scelta dell’aggregato più conveniente da materializzare.
La figura 3.1 mostra il flusso di esecuzione del sistema fra i vari componenti. Si noti che l’engine interagisce con il data warehouse non solo nella fase iniziale in cui vengono estratte le informazioni circa le query che sono state lanciate dagli utenti, ma è necessario che vi interagisca nuovamente durante il processo di stima dello spazio e del tempo degli aggregati. Questo è necessario poiché l’engine deve tener conto dei molti fattori che dipendono sia dell’hardware su cui è installato il data warehouse, sia dal software.
3.2
Funzionamento
Il funzionamento dell’intero sistema è schematizzato nella figura 3.2, in cui è illustrata l’interazione fra i vari componenti, è specificata la
41
sequenza temporale con cui le varie operazioni vengono eseguite e sono indicate le tabelle che ciascuno di essi compila o consulta.
DW ESTRATTORE - connessione - testo SQL - n° esecuzioni - tempo esecuzioni PARSER
SQL_LOOKUP_METADATA - parametri riconoscimento
fact / lookup table - sogliaTempo
SQL_EXTRACT_AGGR_F
SQL_EXTRACT_AGGR_L SQL_EXTRACT_FM
ENGINE
gerarchie dimensioni e campi descrittivi delle chiavi
info relative alle query più interrogate con tempi di esecuzione > sogliaTempo
fact table top N parametri modello lineare -(stima tempo) numero righe da selezionare -dalla fact
info relative agli aggregati candidati alla materializzazione
- parametri connessione
SQL_EXTRACT_FULLTEXT
info recuperate dal dw
SQL_EXTRACT_FILTER
SQL_ENGINE_AGGR_F
SQL_ENGINE_AGGR_L SQL_ENGINE_M SQL_ENGINE_FILTER
42
Nei prossimi paragrafi viene presentato il funzionamento del sistema di Auto Tuning descrivendo tutti i livelli che compongono l’architettura. Essi sono descritti seguendo un approccio di tipo bottom-up, inizialmente verrà descritto quindi il livello fisico fino ad arrivare a quello di presentazione.
3.2.1 Livello Fisico
Una delle caratteristiche di Auto Tuning è quella di essere indipendente dalla tecnologia del data warehouse, per tale motivo è necessario che esso lavori su un proprio repository. Conseguentemente dev’essere definita la struttura di tutte le tabelle necessarie al suo corretto funzionamento. Tali tabelle devono essere create in fase di installazione sul data warehouse su cui dev’essere installato il sistema; in figura 3.3 è riportato lo schema completo di tutte le tabelle.
La tabella Sql_Lookup_Metadata è l’unica a non essere all’interno di un componente del sistema poiché è una tabella ausiliaria utilizzata da tutti. In questa tabella sono definite le gerarchie di tutte le dimensional table attraverso una struttura di tipo parent-child. Essa dev’essere generata a partire dal data warehouse su cui si vuol effettuare l’analisi e dev’essere aggiornata ogni volta che ci sono modifiche alle tabelle che compongono il data warehouse.
43
Nella tabella Sql_Extract_FullText viene memorizzato il testo completo delle query SQL che sono state lanciate più frequentemente dagli utenti, il numero di volte che sono state eseguite, il tempo totale necessario alla loro esecuzione ed il tempo medio per una singola esecuzione. Quest’ultimo valore non è esatto poiché i tempi di esecuzione di una query
44
dipendono da molti fattori contingenti, come per esempio il carico di lavoro sul server al momento in cui arriva la query, il traffico sulla rete, etc. quindi esso viene calcolato facendo un rapporto fra i primi due valori.
Il parser memorizza le informazioni relative agli aggregati candidati alla materializzazione nelle tabelle Sql_Extract_Aggr_F e
Sql_Extract_Aggr_L. In particolare, nella prima tabella viene
memorizzato il nome della fact table su cui si vuol costruire l’aggregato ed il numero di volte che è stata lanciata una query che interrogava questa fact table con l’insieme di lookup table, memorizzate nella tabella
Sql_Extract_Aggr_L, al livello di aggregazione specificato. Nella seconda
tabella viene specificato inoltre l’attributo della fact table su cui è stato fatto il join, infatti anch’esso differenzia due aggregati.
Nella tabella Sql_Extract_Aggr_Filter vengono inseriti gli attributi della fact table con cui sono stati effettuati i join con tutte le lookup table che, all’interno di una query, sono interrogate soltanto per effettuare dei filtri sui dati. Esse dovranno essere inserite nell’aggregato in maniera tale che esso possa effettuare il join con quella specifica dimensione. Si è deciso di distinguere queste dimensional table da quelle che hanno attributi all’interno del campo SELECT di una query SQL, poiché i filtri si limitano ad effettuare un partizionamento orizzontale dei dati riducendo quindi la copertura del numero di query a cui l’aggregato sarà in grado di rispondere.
La tabella Sql_Extract_F mantiene l’informazione statistica riguardante il numero di volte che ogni fact table è stata interrogata da una
45
query, invece nella tabella Sql_Extract_FL è tenuto aggiornato il numero di volte che ogni fact table è stata interrogata insieme ad una specifica lookup table. L’ultima tabella che viene compilata dal parser è la
Sql_Extract_Aggr_FM, in cui vengono inserite tutte le misure interrogate
per ogni fact table.
L’engine compila tabelle che hanno la stessa struttura di quelle del parser con la differenza che esse memorizzano soltanto le informazioni relative agli aggregati ed ai sotto aggregati generati dall’engine. Inoltre vengono memorizzate anche le stime relative allo spazio che verrà occupato in memoria ed il tempo necessario alla costruzione di ciascun aggregato.
3.2.2 Livello Logico
Il livello logico è quello in cui è definita sia la logica per l’individuazione degli aggregati che quella per la generazione dei sotto-aggregati. Nei seguenti paragrafi verranno analizzati i singoli componenti che formano il livello logico.
3.2.2.1 Estrattore
L’estrattore ha il compito di recuperare le informazioni riguardo il testo completo delle query che sono state lanciate dagli utenti, o dai software di reportistica che sono installati sul lato front-end del sistema di Business Intelligence.
46
L’estrattore deve estrarre inoltre i tempi e il numero di volte che una stessa query è stata eseguita. Tutte queste informazioni vengono inserite nella tabella Sql_Extract_FullText.
Poiché queste informazioni vengono memorizzate nelle tabelle di sistema interne al data warehouse, è necessario che questo componente venga definito in maniera custom per ciascun vendor.
3.2.2.2 Parser
Il compito del parser è quello di analizzare i testi delle query SQL che sono state recuperate dall’estrattore ed inserite nella tabella
Sql_Extract_FullText. Affinché il parser svolga correttamente il suo
compito, è necessario che l’utente specifichi preventivamente il nome di tutte fact table e di tutte le dimensional table presenti all’interno del data warehouse. Una possibile alternativa, nel caso in cui il data warehouse sia stato costruito seguendo una naming convention, è quella di fornire delle sequenze di caratteri per il riconoscimento della fact table e delle lookup table. Per esempio, tutte le fact table potrebbero iniziare con i caratteri ‘F_’ e tutte le lookup table con ‘L_’, tuttavia non è detto che tutti i data warehouse siano stati costruiti seguendo convenzioni sui nomi di tutte le tabelle.
Il parser ha il compito di esaminare soltanto le query che hanno un tempo di esecuzione superiore ad una soglia temporale, anch’essa fornita in input al sistema dall’utente.
47
Infatti l’obiettivo di Auto Tuning è quello di ridurre i tempi di esecuzione di queste query in particolare, poiché non ha senso condurre l’analisi su tutte quelle che rispondono già in maniera performante.
Partendo da questi input il parser deve compilare le tabelle
Sql_Extract_Aggr_F, Sql_Extract_Aggr_L, Sql_Extract_Aggr_Filter
e Sql_Extract_Aggr_M con le informazioni dell’aggregato in grado di rispondere alla query analizzata. Tipicamente ogni singola query va ad interrogare un’unica fact table, ciò è una diretta conseguenza della modellazione dei data warehouse (star schema, snowflake schema o constellation fact schema).
All’interno di ogni singola query devono essere individuate le seguenti informazioni:
Nome della fact table;
Misure interrogate;
Nome delle lookup table di cui vengono selezionate dimensioni;
Nome delle lookup table utilizzate solo per filtrare il risultato;
Livello di aggregazione di ciascuna dimensione;
Attributi delle fact table su cui viene fatto il join con tutte le lookup table.
48
L’analisi delle query deve tener conto dei costrutti proprietari di ogni vendor, infatti i software che generano la reportistica lato front-end non sempre utilizzano il linguaggio SQL standard. Per questo motivo anche il parser, così come l’estrattore, dovrà essere diverso per ciascuna tipologia di data warehouse. È bene notare che l’unica differenza fra i vari parser è quella nell’interpretazione del codice SQL, con particolare riferimento alle operazioni di join. Esistono infatti costrutti di join proprietari dei singoli vendor che non fanno parte del linguaggio SQL standard.
Per ciascuna query analizzata verrà inserita una nuova riga nella tabella Sql_Extract_Aggr_F, generando un nuovo identificatore per l’aggregato ed inserendo il valore della frequenza che è stato estratto dal data warehouse da parte dell’estrattore. Nel caso in cui la fact table in esame sia già presente nella tabella Sql_Extract_Aggr_F, e nella tabella
Sql_Extract_Aggr_L siano già presenti tutte le lookup table della query
con il medesimo livello di aggregazione e lo stesso attributo di join con la fact table, il parser deve aggiornare soltanto il valore della frequenza senza inserire alcuna nuova tupla nelle tabelle. Si noti che rispettando i vincoli di chiave primaria delle tabelle utilizzate dal sistema di Auto Tuning viene automaticamente soddisfatto questo requisito.
Lo stesso ragionamento è valido anche per l’inserimento della lista delle lookup table, interrogate soltanto per filtrare i dati nel risultato della query, nella tabella Sql_Extract_Filter.
49
Affinché vengano ridotte le operazioni di join con le lookup table, il parser inserisce nella tabella Sql_Extract_Aggr_L solo il livello di aggregazione più basso di una stessa dimensione interrogata dalla query.
Il parser ha inoltre il compito di aggiornare la tabella
Sql_Extract_FM con le misure selezionate dalla query. Per quanto
riguarda le misure, si è deciso di non tener traccia della lista di dimensional table con cui vengono interrogate, poiché la loro selezione per la materializzazione all’interno dell’aggregato è lasciata all’utente, il quale ha la possibilità di valutare la frequenza con cui ciascuna di esse è stata interrogata. Questo è il motivo per cui la tabella Sql_Extract_FM non è collegata alle altre attraverso vincoli di foreign key.
Nella figura 3.4 è riportato un esempio di tutte le informazioni che il parser deve estrapolare da una query. Tutte queste informazioni rappresentano l’output del parser verso l’engine, il quale, partendo da una struttura standard, potrà essere un unico componente indipendentemente dalla tecnologia utilizzata nei livelli inferiori.
50
Queste sono le specifiche implementative secondo cui il parser dovrà essere realizzato. Tuttavia l’attuale implementazione del sistema non include questo componente. Esso è l’unico componente che non è ancora stato completamente sviluppato.
51
3.2.2.3 Engine
L’engine rappresenta il componente core del sistema di Auto Tuning, infatti è questo il componente che genera gli aggregati che consentiranno al gestore del data warehouse di migliorare le performance dello stesso.
L’utente deve specificare la fact table su cui l’engine deve condurre l’analisi, questa selezione può essere guidata dalle informazioni raccolte nella tabella Sql_Extract_Aggr_F nella quale è indicata la frequenza con cui ciascuna fact table è interrogata dagli utenti. Verosimilmente l’analisi verrà condotta sulle fact table maggiormente interrogate, oppure su quelle fact table per le quali sono richiesti veloci tempi di risposta. Si noti che la scelta è lasciata all’utente, il quale ha la facoltà di selezionare una qualsiasi fact table.
La complessità del problema della selezione degli aggregati da materializzare deriva dalla dimensione dello spazio di ricerca della soluzione, la quale cresce esponenzialmente rispetto al numero di attributi dimensionali. Per questo motivo l’engine restringe lo spazio di ricerca concentrandosi su una singola fact table, e prende inoltre in considerazione soltanto le dimensioni maggiormente interrogate che gli vengono fornite dal parser. Per poter effettuare le stime e per fornire all’utente un numero ragionevole di alternative fra i possibili aggregati candidati alla materializzazione, deve essere specificato il parametro Top N, il quale indica il numero di query più interrogate che devono essere prese in esame durante l’analisi. Tale parametro può essere impostato dall’utente all’inizio
52
di ogni esecuzione di Auto Tuning, consentendo di prendere in considerazione soltanto le query maggiormente interrogate che hanno tempi di esecuzione non soddisfacenti.
3.2.2.3.1
Generazione Aggregati
La fase proattiva dell’engine inizia con la generazione di un aggregato per ciascuna delle Top N query analizzate dal parser. Ogni aggregato viene generato in modo tale che possa rispondere alla singola query, limitando il più possibile le operazione di join con le altre lookup table. Per far sì che questo accada vengono inserite tutte le lookup table, che hanno attributi selezionati dalla query al più basso livello di aggregazione interrogato per ciascuna dimensione. Vengono quindi selezionate tutte le informazioni presenti nella tabella Sql_Extract_Aggr_L precedentemente compilata dal parser. È bene sottolineare che per ogni dimensione vengono analizzati tutti i livelli di aggregazione presenti nell’intera query solo se essa ha almeno un attributo presente nel campo SELECT. Questa decisione deriva dal fatto che i filtri hanno il solo scopo di limitare il numero delle righe del risultato, attraverso un partizionamento orizzontale dei dati.
Per quanto riguarda invece le misure che l’engine inserisce nell’aggregato, la loro selezione non è ristretta a quelle presenti nella singola query analizzata, bensì vengono inserite tutte quelle che l’utente ritiene opportuno. La selezione delle misure può essere agevolata attraverso
53
la consultazione della tabella Sql_Extract_FM, nella quale è riportata la frequenza con cui ciascuna misura è stata richiesta dagli utenti.
Quindi l’engine genera n aggregati e ciascuno di essi, una volta materializzato, sarà in grado di fornire le stesse informazioni in un tempo più breve. Questo perché saranno ridotte sia le operazioni di join fra la fact table e le lookup table, indispensabili per analizzare i dati al livello di aggregazione richiesto, sia i calcoli computazionali necessari per avere i valori corretti per ciascun fatto.
3.2.2.3.2
Generazione Sotto Aggregati
Ciascun aggregato generato dall’engine è in grado di soddisfare soltanto una singola richiesta dell’utente; quindi per poter migliorare le performance di tutte le Top n query maggiormente lanciate dagli utenti sarebbe necessario creare altrettanti aggregati.
L’idea che sta alla base della generazione dei sotto aggregati è quella di generare un unico aggregato che sia in grado di rispondere a tutte le n query maggiormente effettuate sul data warehouse; ciò è possibile selezionando un nodo del lattice contenente tutte le dimensioni più interrogate. Si noti che, anche in questo caso, lo spazio delle soluzioni è ampio, quindi è doveroso ridurlo in modo tale da fornire all’utente, che utilizza Auto Tuning, un numero limitato di aggregati candidati alla materializzazione.
54
L’engine genera soltanto due aggregati fra tutti quelli presenti nel lattice:
1. Il primo sotto aggregato viene creato partendo dalla query più interrogata ed aggiungendo nell’aggregato le chiavi del massimo livello di dettaglio di tutte le altre dimensioni interrogate dalle altre n-1 query. La copertura delle query di questo sotto aggregato è pari alla sommatoria delle frequenze con cui tutte le top n query sono state eseguite. Infatti, facendo gli opportuni join con le altre dimensional table, è possibile recuperare le informazioni richieste da tutte le top n query.
2. Il secondo sotto aggregato viene creato analizzando tutte le top n query. Tutte le dimensioni interrogate vengono inserite nell’aggregato al minimo livello di aggregazione richiesto. Quindi considerando per esempio la dimensione temporale time se essa viene interrogata al livello di aggregazione month da una query e al livello year da un’altra, l’aggregato avrà come minimo livello di aggregazione month. Non sarà quindi possibile interrogarlo per avere informazioni ad un livello di aggregazione inferiore (day), tuttavia è bene osservare che l’obiettivo è quello di aggregare i dati in modo tale da ridurre i tempi computazionali necessari per averli al livello di
55
aggregazione richiesto dall’utente. Le seguenti figure mostrano un esempio di come viene generato il secondo sotto aggregato considerando due query che interrogano una fact table denominata F_ORDERS e tre dimensioni: L_PRODUCTS,
L_SALE_CHANNEL e L_CALENDAR.
56
57
Nelle figure 3.5 e 3.6 sono evidenziati in colore arancio i livelli di aggregazione delle dimensioni interrogati dalle due query; la figura 3.7 mostra invece la struttura del sotto aggregato generato a partire dalle due query in esame.
Si noti che per quanto riguarda la dimensione L_SALE_CHANNEL la prima query ha interrogato i dati al livello di aggregazione COMM_AREA_ID, mentre la seconda query ha richiesto i dati al livello MKT_ID. Poiché quest’ultimo è in una posizione gerarchica inferiore rispetto al primo, nell’aggregato è stato inserito il MKT_ID come livello
58
minimo di aggregazione di questa dimensione, in modo tale che il sotto aggregato sia in grado di rispondere ad entrambe le interrogazioni. Infatti l’obiettivo del sotto aggregato è quello di riuscire a rispondere a tutte le top
n query che vengono considerate durante l’analisi.
3.2.2.3.3
Stima dello Spazio degli Aggregati
La scelta dell’aggregato da materializzare nel data warehouse è lasciata all’utente, il quale seleziona quello che è più adatto all’esigenza del proprio sistema DSS. Questa scelta è basata sulla copertura che ciascun aggregato o sotto aggregato ha nei confronti delle query, nello spazio che occupa in memoria e nel tempo necessario alla sua costruzione. Per quanto riguarda lo spazio che esso andrà ad occupare in memoria, viene effettuata una stima da parte del sistema di Auto Tuning. Tale stima deve tener conto di molti fattori hardware e software tipici dell’ambiente su cui è installato l’intero sistema, come per esempio la dimensione di ciascun blocco di memoria ed il DBMS utilizzato. Per evitare l’inserimento di una serie di parametri in fase di installazione, si è deciso di materializzare una piccola porzione dell’intero aggregato, limitando il numero di righe della fact table. Questo processo deve essere un compromesso fra accuratezza della stima e tempo necessario alla materializzazione di una porzione di tutti gli aggregati. È ovvio che per avere una stima più precisa è necessario considerare un numero di righe maggiori nella fact table, viceversa per
59
ridurre i tempi necessari alle elaborazioni conviene ridurre il numero di righe.
L’algoritmo per stimare lo spazio di un aggregato è riportato nei seguenti step:
1. Contare numero di righe della fact table su cui deve essere costruito l’aggregato ROW_NUM_FACT;
2. Contare il numero di righe totali che avrà l’aggregato
ROW_NUM_AGGR_FULL;
3. Materializzare un aggregato con un numero di righe della fact table limitato (2% - 4%) memorizzando:
Spazio occupato SIZE_AGGR_PAR;
Numero di righe dell’aggregato parziale
ROW_NUM_AGGR_PAR;
4. Calcolare lo spazio medio occupato da ciascuna riga:
5. La stima dello spazio è data dalla seguente espressione:
60
3.2.2.3.4
Stima del Tempo di Costruzione degli
Aggregati
Un altro compito dell’engine è quello di effettuare la stima per il tempo necessario alla memorizzazione dell’aggregato in memoria. Anche in questo caso risulta difficile determinare con precisione questo valore, poiché il tempo necessario alla scrittura di una tabella in memoria è influenzato da molti fattori quali: l’hardware utilizzato, il carico di lavoro sul server e sulla rete al momento della scrittura, la velocità di scrittura sui dischi di memoria etc. Tener conto singolarmente di tutti questi parametri è impossibile, tuttavia l’obiettivo dell’engine è quello di dare un’indicazione temporale approssimativa con un’accuratezza relativa all’ordine di grandezza dei minuti.
La scelta adottata per stimare il tempo di ciascun aggregato e dei due sotto aggregati generati, è stata quella di utilizzare un modello di regressione lineare semplice. La variabile dipendente del modello è ovviamente il tempo necessario alla materializzazione dell’aggregato (TIME_AGGR_PAR), quelle indipendenti sono invece le seguenti:
SIZE_AGGR_PAR: dimensione in bytes dell’aggregato;
ROW_NUM_FACT: numero di righe della fact table su cui viene costruito l’aggregato.
61
L’efficacia di queste due variabili indipendenti verrà mostrata successivamente nel paragrafo 3.1.
Il valore della stima del tempo necessario alla scrittura in memoria dell’aggregato sarà dato dalla seguente espressione:
Per motivi statistici legati alla linearità e alla normalizzazione della distribuzione degli errori sperimentali, i valori delle variabili indipendenti sono stati corretti mediante la funzione del logaritmo naturale; pertanto, per ottenere il valore corretto del tempo, è doveroso applicare la funzione inversa dell’esponenziale.
Per far sì che questo modello tenga in considerazione la maggior parte dei fattori che influiscono sulla scrittura delle tabelle in memoria, è necessario che in fase di installazione venga costruito un dataset utilizzando tutti i componenti del sistema su cui vuol essere installato Auto Tuning. Verranno quindi materializzate delle tabelle fittizie, i dati relativi al numero di righe delle fact table di partenza e lo spazio (bytes) occupato dai vari aggregati. Tutte queste informazioni verranno utilizzate come input per avere i valori dei coefficienti del modello di regressione lineare.
Per semplificare questa operazione, verrà utilizzato un database appositamente creato e corredato dei necessari script attraverso i quali verranno effettuate tutte le operazioni opportune, quali la scrittura delle tabelle e la memorizzazione dei dati.
62
3.2.3 Livello Presentazione
L’interfaccia attraverso cui l’utente interagisce con il sitema di Auto
Tuning dev’essere in grado di visualizzare in maniera semplice ed intuitiva
tutte le informazioni necessarie per selezionare l’aggregato che consentirà un miglioramento delle performance del data warehouse in esame.
Innanzitutto devono essere visualizzate le informazioni relative alla situazione “as-is” del data warehouse, quindi dev’essere visualizzata all’utente la tabella Sql_Extract_F, nella quale sono memorizzate le frequenze di interrogazione di ciascuna fact table presente nel data warehouse. Consultando questa tabella, l’utente potrà quindi selezionare la fact table su cui effettuare l’analisi per individuare l’aggregato in grado di migliorare le performance del sistema. Verosimilmente la scelta ricadrà sulla fact table più interrogata, tuttavia sarà possibile scegliere una qualsiasi fact table infatti l’utente potrebbe essere interessato al miglioramento delle performance di una specifica area di business.
3.2.3.1 Bubble Chart
L’output finale fornito dal sistema di Auto Tuning è un bubble chart in cui ogni bubble rappresenta un aggregato e la sua grandezza è proporzionale alla copertura delle query che sono state effettuate sul data warehouse. Sull’asse delle ascisse è riportato il tempo, mentre in quello delle ordinate è riportato lo spazio.
63
Quindi ciascun aggregato sarà presente nel piano cartesiano con una bubble di grandezza proporzionale alla frequenza con cui sarà in grado di rispondere alle query, e sarà posizionata in corrispondenza dei valori stimati dall’engine. La figura 3.8 mostra un esempio di bubble chart fornito in output dal sistema.
L’aggregato ottimale, per migliorare le performance del data warehouse, è quello rappresentato dalla bubble con il diametro più grande che si trova il più vicino possibile all’origine. Questo significa che quell’aggregato sarà in grado di rispondere ad un elevato numero di query e
64
che sia lo spazio che il tempo necessario alla sua materializzazione non sono elevati.
È bene sottolineare che il sistema ha il solo scopo di suggerire in maniera proattiva la materializzazione di un aggregato, tuttavia la scelta finale e l’effettiva scrittura in memoria dell’aggregato è lasciata all’utente. La sua scelta sarà condizionata dai vincoli che dovrà rispettare sul proprio sistema che possono essere o relativi ad un limitato spazio libero in memoria, oppure all’impossibilità di attendere un tempo troppo elevato per la sua scrittura. Quest’ultimo caso si può verificare quando i tempi relativi ai processi ETL sono già molto elevati, infatti essi avvengono solitamente nel corso della notte ed in alcuni casi non è possibile prolungarli ulteriormente altrimenti gli utenti front-end non avrebbero la possibilità di consultare i dati aggiornati tempestivamente.
3.3
Informazioni Riguardanti lo Sviluppo
Durante questo progetto di tesi, l’implementazione ha riguardato il componente centrale del sistema di Auto Tuning, ovvero l’engine. Inoltre è stato sviluppato l’estrattore e la parte di interfaccia grafica riguardante la generazione del bubble chart in cui sono riportati gli aggregati ed i due sotto aggregati candidati alla materializzazione.
Il software è stato sviluppato con il linguaggio Java mediante l’utilizzo dell’editor NetBeans IDE 7.2.1.
65
Il livello fisico, che è stato utilizzato come riferimento durante tutto il processo di sviluppo, è stato il database Oracle DB 11g R2. Su di esso è stato creato il repository contenente tutte le tabelle necessarie al corretto funzionamento dell’intero sistema.
Oracle Database 11g R2 rappresenta il prodotto di Oracle più
conosciuto. Si tratta di un Object-Relational Database Management
System (ORDBMS) che negli anni è diventato una vera e propria
piattaforma arricchita da un esteso insieme di funzionalità di livello enterprise. Esse contribuiscono a creare un ambiente adatto per il data warehousing e la Business Intelligence, offrendo scalabilità, performance, security management, strumenti di analisi, integrazione, gestione della qualità dei dati e metodi di ottimizzazione come ad esempio partitioning, compression, in-memory parallel execution, cluster support, e cache management.
Per quanto riguarda l’implementazione dell’estrattore è stato preso come riferimento lo stesso database Oracle DB 11g R2, quindi il software utilizza il driver Oracle JDBC 1.5 per la connessione. L’estrattore preleva tutte le informazioni riguardanti le query che sono state lanciate sul database nell’ultimo mese e le memorizza nelle opportune tabelle descritte nel paragrafo 3.2.1.
Oracle DB è dotato di un meccanismo che consente di storicizzare automaticamente tutte le informazioni statistiche riguardanti le operazioni che avvengono sul database; questo componente si chiama Automatic
66
Workload Repository (AWR). Questo processo di memorizzazione dei dati
statistici viene ripetuto dall’AWR ad intervalli temporali regolari che prendono il nome di AWR snapshot. Il compito dell’estrattore per il data warehouse Oracle è quindi quello di recuperare queste informazioni dalle tabelle gestite dall’AWR ed inserirle nella tabella Sql_Extract_FullText.
Affinché l’AWR memorizzi tutte le query lanciate dagli utenti è necessario modificare i seguenti parametri di configurazione:
SNAP_INTERVAL
RETENTION
TOPNSQL
Il parametro SNAP_INTERVAL configura l’intervallo temporale con cui l’AWR aggiorna le tabelle con le informazioni del database. È consigliato lasciare le impostazioni di default che raccolgono le informazioni statistiche ogni ora.
Il parametro RETENTION configura il tempo di conservazione delle snapshots all’interno delle tabelle gestite dall’AWR. Anche per questo parametro è consigliato lasciare l’impostazione di default di 30 giorni poiché la sua variazione può avere ripercussioni su altri componenti di Oracle DB come per esempio il Query Optimizer, componente che consente di ottimizzare l’esecuzione delle query considerando l’attuale carico di lavoro sul server.