Corso di laurea in
Ingegneria Elettronica
Tesi di laurea
Il candidato I relatori
Daniele De Marco Prof. Ing. R. Saletti
Prof. Ing. R. Roncella
Ai miei genitori
ed ai miei nonni.
Sommario
Prefazione ...5
Capitolo I
Introduzione al problema...7
1.1 Un primo approccio: confronto nel dominio del tempo dei campioni del segnale. ...8
1.2 Variabilità del segnale vocale...11
1.3 Confronto tra fonemi estratti dai campioni del segnale ...11
1.4 Confronto nel dominio della frequenza ...13
1.5 Come fa l’uomo ...14
1.5.1 Struttura dell’apparato uditivo ...14
1.5.2 Processo Buttom-Up ...17
1.6 Linee guida nella progettazione di un ASR ...19
Capitolo II
Tecniche di implementazione di un ASR...21
2.1 Struttura di principio di un ASR...21
2.2 I tradizionali approcci al problema dell’estrazione delle features ...23
2.2.1 Approccio basato su caratteristiche fisiche: potenza e zero-crossing. ...24
2.2.2 Approccio basato sulla modellizzazione dell’apparato vocale: LPC ...24
2.2.3 Approccio basato sulla modellizzazione apparato uditivo: AIM ...25
2.2.4 Mel Cepstral Analysis...25
2.3 Algoritmi di training e riconoscimento ...27
2.3.1 Neural Networks ...27
2.3.2 Support Vector Machines ...28
2.3.3 Hidden Markov Models...32
2.3.3.1 Algoritmo di Baum Welch ...34
2.3.3.2 Algoritmo di Viterbi ...36
2.3.4 Dynamic Time Warping...37
2.4 HTK...39
Capitolo III
Trattazione del rumore ...46
3.1 Training in presenza di disturbi. ...46
3.2 Tecniche per l’estrazione delle features in presenza di rumore. ...48
3.2.1 ZCPA...48
3.2.2 ASBF ...49
3.2.3 SMACHER ...50
Capitolo IV
Realizzazione...53
4.1 Descrizione del database. ...53
4.2 Proposta di una tecnica per misurare la distanza tra frames...56
4.2.1 Idea di base ...56
4.2.2 Descrizione dell'algoritmo utilizzato. ...58
4.2.3 Analisi dei risultati e possibili migliorie...61
4.3 SMACHER per HTK. ...63
4.4 Mel Cepstral Analysis per HTK ...66
4.5 Analisi dei risultati...67
Conclusioni...71
Prefazione
Lo scopo principale della tecnologia è fornire all’uomo degli strumenti che gli permettano di svolgere delle attività in modo più efficace ed efficiente, eliminando quindi la perdita di tempo e di energie dovuta all’esecuzione di operazioni meccaniche. Naturalmente anche i sistemi di riconoscimento vocale hanno questo scopo, e risultano particolarmente utili in caso di necessità di un canale di input aggiuntivo o alternativo rispetto all’uso delle mani, come ad esempio per cambiare impostazioni ad alcuni macchinari industriali che richiedono l’uso di entrambe le mani, o a bordo di motoveicoli, alla guida dei quali può essere molto pericoloso staccare le mani dal manubrio per svolgere altre attività. Un altro campo di applicazione dell’ASR (Automatic Speech Recognition) potrebbe essere quello della costruzione di sistemi per l’aiuto di disabili che non abbiano il completo utilizzo degli arti, soprattutto delle mani. La voce è comunque lo strumento che l'uomo utilizza in modo più spontaneo e naturale per comunicare, e dunque un riconoscitore vocale potrà essere utile montato su praticamente ogni macchinario che abbia bisogno di essere impostato da un utente.
Allo stato dell'arte sono disponibili dei sistemi di ASR che hanno percentuali di corretto riconoscimento vicine al 100%, tuttavia è possibile ottenere queste prestazioni solo in condizioni molto particolari, ossia su piattaforme potenti ed in ambienti molto silenziosi. Naturalmente grande disponibilità di potenza di calcolo
ed assenza di disturbi sono condizioni ideali in cui la maggior parte dei sistemi non potranno andare a lavorare: nei casi reali dovremo fare i conti con piattaforme a potenza di calcolo limitata per ragioni di economicità e di spazio disponibile, e soprattutto con una gamma di disturbi ampia e molto variabile.
Lo scopo della presente tesi è lo studio delle tecniche di implementazione di un sistema di riconoscimento di parole isolate speaker dependent e resistente al rumore.
Restringendo l’ambito di interesse della tesi a sistemi di riconoscimento di parole isolate speaker dependent diminuisce infatti il carico computazionale: un sistema che debba riconoscere i comandi da una sola persona avrà inevitabilmente una complessità molto inferiore rispetto ad un sistema che debba riconoscere parole pronunciate da un generico parlatore, allo stesso modo diminuirà la complessità del sistema la corrispondenza biunivoca tra parole riconoscibili e comandi da eseguire.
Per ridurre i disturbi derivanti dal rumore verrà presentato un metodo sviluppato nel corso della realizzazione della presente tesi e verrà illustrata l’implementazione di una tecnica sviluppata presso i laboratori della Motorola.
La tesi è suddivisa in quattro capitoli: nel primo verranno introdotte le principali difficoltà legate alla realizzazione di un sistema di riconoscimento vocale, e verrà mostrato come degli approcci ingenui sono inevitabilmente destinati a non portare risultati utili. Nel secondo capitolo saranno illustrate le principali tecniche di implementazione attualmente disponibili, valutandone pro e contro. Nel terzo capitolo sarà affrontato il problema del rumore, e verranno riportate alcune tecniche ideate per ridurne gli effetti negativi sul corretto riconoscimento. Nel quarto capitolo, infine, verranno descritte le tecniche implementate e verranno riportati i risultati ottenuti.
Cap. I
Introduzione al problema
I segnali sonori, tra cui il parlato, si propagano nell’aria come una perturbazione della pressione. Vengono acquisiti da un sistema digitale grazie ad un trasduttore che trasforma la pressione in un segnale elettrico continuo e ad un convertitore analogico-digitale che permette di trattare il segnale come un’opportuna sequenza di campioni.
Fig. 1.1
L’audio viene catturato da un microfono in modo analogico e quindi convertito in digitale da un convertitore A/D
.
Se si assume che sul sistema siano presenti un pulsante in grado di far iniziare l’acquisizione del segnale vocale ed uno in grado di farla terminare, il riconoscitore vocale consisterà in un’opportuna elaborazione dei campioni così
ottenuti. Sarà necessario in un primo tempo addestrare il sistema fornendogli un insieme di segnali esempi di ciascuna parola che dovrà in seguito essere riconosciuta, poi il sistema potrà essere utilizzato dandogli in ingresso una sequenza di campioni di una parola che esso dovrà provvedere ad associare ad uno solo dei gruppi di esempi in memoria.
Il sistema dovrà dunque soddisfare le seguenti specifiche:
• dovrà riconoscere parole isolate: dovrà cioè riconoscere delle brevi espressioni individualmente e non una combinazione di esse, come in genere fa ad esempio l’uomo;
• dovrà essere speaker dependent: dovrà cioè essere capace di identificare i comandi forniti dalla stessa persona che lo ha addestrato;
• dovrà avere un insieme di parole esempio finito e completamente definibile dall’utente;
• dovrà dimostrare una certa robustezza ai disturbi esterni.
E’ da notare che nei grafici che seguono il segnale vocale è visualizzato come un segnale continuo, per una maggiore intelligibilità.
1.1 Un primo approccio: confronto nel dominio del tempo dei
campioni del segnale.
L’algoritmo più intuitivo per effettuare un confronto è il seguente:
1. sottrarre campione a campione alla stringa in ingresso X tutte le stringhe memorizzate Y ; i
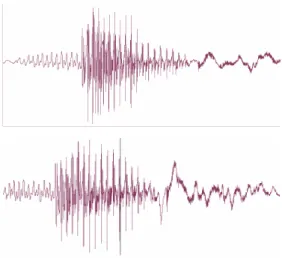
Questo metodo risulta del tutto inefficace. In figura 1.2 sono riportate le forme d’onda della parola “Bar” pronunciata da due diverse persone.
Si supponga che la prima forma d’onda sia quella in ingresso e la seconda sia quella memorizzata da riconoscere.
speaker 1
speaker 2
Fig. 1.2: La parola “bar” pronunciata da due differenti speakers
E’ evidente come il procedimento proposto non porterà ad alcun risultato apprezzabile: le forme d’onda della parola pronunciate da speakers differenti sono
diverse tra loro come possono esserlo le forme d’onda di due parole distinte: a colpo d’occhio non si può individuare alcuna regolarità..
Si potrebbe pensare che queste differenze siano dovute alla diversità dei timbri degli speakers.
Si confrontino dunque le forme d’onda della parola “bar” pronunciata due volte dallo stesso speaker:
Fig. 1.3: la parola “bar” pronunciata due vlte dallo stesso speaker
In questo caso sono riconoscibili le zone corrispondenti a ciascuna delle tre lettere, ma un confronto punto a punto sarebbe ancora improduttivo.
Si può a questo punto pensare di normalizzare le durate delle singole lettere che compongono la parola, ma anche in questo caso il risultato non sarebbe soddisfacente, infatti il segnale vocale ha ampi margini di variabilità.
1.2 Variabilità del segnale vocale
L’apparato vocale, attraverso il quale sono emessi i suoni del parlato, è un sistema molto complesso che coinvolge la laringe, le corde vocali, la faringe e la bocca. Questo sistema varia da persona a persona, in base alla conformazione fisica, ed è principalmente questa variabilità che causa le differenze di pronuncia della stessa parola che abbiamo visto in precedenza.
A peggiorare le cose contribuiscono dialetti e particolari intonazioni prosodiche, che rendono la voce di ognuno un fenomeno praticamente unico.
Tuttavia anche la stessa persona non può pronunciare la stessa parola due volte in modo perfettamente uguale: l’emissione di una parola è influenzata da innumerevoli fattori, tra cui la particolare postura che assunta, lo stato emotivo, il particolare tono che dato alla parola.
1.3 Confronto tra fonemi estratti dai campioni del segnale
Per riuscire a costruire un buon riconoscitore vocale sarà necessario dunque fare in modo di ottenere dalla forma d’onda della parola gli elementi che la contraddistinguono e trascurare quelli soggetti a variabilità.
Le persone alfabetizzate associano automaticamente alla pronuncia di una parola la forma scritta corrispondente. E’ dunque intuitivo pensare di ridurre una parola ad una sequenza di lettere: questo modo di procedere porterebbe molti vantaggi: tutte le parole da riconoscere occuperebbero uno spazio di memoria esiguo, e potrebbero essere confrontate con quelle in ingresso con algoritmi molto semplici quindi poco dispendiosi dal punto di vista computazionale.
Purtroppo questo metodo è praticamente inapplicabile: infatti le lettere non corrispondono in modo biunivoco a precisi suoni: una stessa lettera, anche all’interno della stessa parola, può essere pronunciata in modo differente, in base alla posizione dell’accento all’interno della parola, o anche in base alle lettere che la precedono o la seguono: l’apparato vocale umano, come tutti i sistemi macroscopici, non può variare che con continuità tra un suono ed un altro, rendendo dunque la forma d’onda di una lettera funzione di quelle vicine: fenomeno detto coarticolazione.
L’IPA (International Phonetic Association) ha stabilito un insieme di simboli che cercano di rappresentare tutti i suoni di tutte le lingue: l’intenzione dei ricercatori dell’IPA era di creare un livello intermedio tra i suoni della lingua parlata e le lettere della lingua scritta.
Tuttavia anche questo tentativo non è stato risolutivo: i suoni producibili dall’apparato vocale umano non sono discretizzabili: si possono emettere un’infinità di sfumature per ogni fonema.
Si confrontino le forme d’onda delle “a” della Fig.1.3:
Fig. 1.4 : forme d’onda delle “a”della stessa parola pronunciata 2 volte dallo stesso speaker
Si può notare come pur essendo le due forme d’onda simili una sottrazione punto a punto non darebbe come risultato zero: picchi e valli del segnale non coincidono perfettamente.
1.4 Confronto nel dominio della frequenza
Un potente strumento di analisi dei segnali è la Fast Fourier Transform. Trattare un segnale nel dominio della frequenza presenta numerosi vantaggi, tra cui sicuramente la facilità di elaborazione.
In particolare se un segnale presenta delle regolarità nel dominio del tempo, queste regolarità si traducono in picchi frequenziali, aumentando sicuramente la leggibilità del segnale.
E’ dunque un’idea feconda quella di utilizzare la FFT per estrarre dal segnale quelle informazioni che si è visto essere difficilmente reperibili nel dominio del tempo.
Un problema è dato dalla variabilità della portante attorno alla quale viene a trovarsi il segnale, soprattutto per i riconoscitori speaker independent. Lo stesso problema potrebbe in realtà manifestarsi per i riconoscitori speaker dependent: si può facilmente notare come la voce di ognuno non abbia una tonalità fissa, e soprattutto che è facile cambiarla, anche involontariamente. Comunque a meno di canticchiare la frequenza principale di ognuno rimane abbastanza stabile, come anche le armoniche superiori.
Una strada sicuramente sbagliata di trattare il segnale è quella di calcolare la FFT di tutta la sequenza della parola: in questo modo si avrebbero troppi picchi frequenziali e non si saprebbe a quale parte del segnale attribuirli: si perderebbero
preziose informazioni riguardo l’evoluzione nel tempo del segnale. Il costo computazionale sarebbe poi notevole.
Questi problemi sono di facile soluzione e sarà chiaro in seguito come la FFT, pur non essendo risolutiva, sia lo strumento di analisi privilegiato di tutti gli attuali riconoscitore vocali.
1.5 Come fa l’uomo
Si è visto come il segnale vocale sia un fenomeno che sfugge a rigide categorizzazioni: una grande quantità di fattori vi influiscono e lo rendono non completamente deterministico, tanto che nonostante i notevoli sforzi compiuti dalla comunità scientifica ancora non si è giunti a realizzare un riconoscitore vocale che sia completamente affidabile.
A questo punto è inevitabile porsi una domanda: se riconoscere le parole presenta queste enormi difficoltà come mai la stragrande maggioranza delle persone vi riesce in modo naturale, senza alcuno sforzo?
Se l’uomo riesce a risolvere i problemi del riconoscimento vocale con naturalezza i motivi sono essenzialmente due:
• La struttura dell’apparato uditivo • Processo Buttom-Up
1.5.1 Struttura dell’apparato uditivo
L’orecchio umano ha il compito di amplificare il segnale proveniente dall’esterno e di trasformarlo in impulsi elettrici che siano fruibili dal cervello. Nel compiere queste operazioni l’orecchio condiziona il segnale in modo tale che sia più
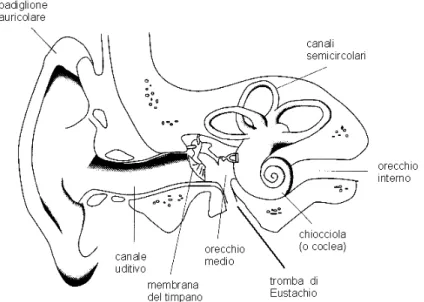
facilmente intelligibile da parte dell’uomo e lo arricchisce inoltre di alcune informazioni non direttamente collegabili alla variazione di pressione dell’aria. In figura si può vedere lo schema di un orecchio.
Fig. 1.5 : Struttura dell’orecchio umano.
L’intero orecchio è divisibile in tre parti:l’orecchio esterno,quello medio e quello interno.
L’orecchio esterno è composto dal padiglione auricolare e dal canale uditivo. Il padiglione auricolare raccoglie il suono e lo modifica per aggiungervi informazioni riguardanti la direzionalità: degli esperimenti hanno dimostrato che persone che ascoltavano dei suoni con degli auricolari, neutralizzando così il padiglione auricolare, attribuivano variazioni di frequenza a variazioni di posizione della sorgente. Il canale uditivo ha una forma assimilabile ad un cilindro ed avendo una lunghezza di circa 3 cm funziona da risonatore ad una frequenza di circa 3kHz, frequenza attorno alla quale si addensano le informazioni del parlato.
L’orecchio medio ha un funzionamento assimilabile a quello di un adattatore di impedenze: trasforma la variazione di pressione dell’aria, di per sé insufficiente a causare una variazione nel fluido dell’orecchio interno,in una variazione meccanica molto più efficace. Assolvono allo scopo i tre ossicini martello, incudine e staffa, i quali, con un complesso gioco di leve meccaniche, compensano la situazione di partenza sfavorevole, adottando cioè un sistema di trasmissione vantaggiosa.
L’orecchio interno ha un funzionamento assimilabile ad un trasduttore: è costituito da una cavità chiamata chiocciola, al cui interno è presente un liquido che riceve il suono sotto forma di impulsi meccanici da parte della staffa che batte sulla membrana basilare, la quale si trova tra l’orecchio medio e quello interno. All’interno del fluido si creano delle onde stazionarie proporzionali al suono percepito, ogni onda avrà un picco in corrispondenza di una particolare zona della chiocciola, in dipendenza dalla frequenza dell’onda stessa. A questo punto delle terminazioni nervose trasmetteranno intensità e frequenza al cervello. La risposta dell’orecchio non è lineare, e tende ad essere più fine in corrispondenza delle frequenze che interessano il parlato: lo studio della percezione è oggetto della Psicoacustica.
La scala di Mel è stata concepita per tracciare una corrispondenza tra altezza in frequenza ed altezza percepita: fissando l’ampiezza otteniamo un grafico del tipo:
in cui è possibile apprezzare un pendenza maggiore per frequenze comprese tra i 200 Hz ed i 5 kHz. I fenomeni psicoacustici sono molteplici e si può citare ancora la dipendenza dell’altezza di un suono percepito dalla sua ampiezza, ed ancora il mascheramento di componenti frequenziali vicine ad altre a potenza maggiore. Tutte queste caratteristiche si sono sviluppate nel corso di millenni ed hanno reso l’orecchio umano uno strumento privilegiato per l’ascolto del parlato, tanto che le tecniche per l’ASR che danno i risultati migliori trattano il segnale imitando il comportamento del nostro orecchio.
1.5.2 Processo Buttom-Up
Quando si riconosce una parola pronunciata da un interlocutore non ci si basa sul solo dato acustico: si mettono in moto spontaneamente dei meccanismi che sfruttano tutte le informazioni che è possibile reperire al riguardo, si elaborano queste informazioni e poi si effettua una sorta di “verifica” con il dato acustico.
Le informazioni che si utilizzano in questo processo provengono essenzialmente da:
1. La vista. La lettura del labiale è molto importante per la comprensione del linguaggio soprattutto da parte dei bambini. Gli adulti riescono a farne a meno: basti pensare all’efficacia di strumenti quali telefono o radio. Tuttavia quando ne hanno la possibilità tutti si aiutano guardando i movimenti della bocca. Un interessante esperimento di McCrurk ha mostrato come una forma d’onda che se solamente ascoltata veniva interpretata dalla maggioranza delle persone come la sillaba /ba/, nel caso fosse ascoltata da un apparecchio televisivo che mostrava una persona che riproducesse il labiale della sillaba /ga/ era riconosciuto come /da/.
2. Le regole della sintassi. Comunemente è molto raro ascoltare una parola isolata: solitamente una parola farà parte di un discorso, e questo discorso obbedisce a delle precise regole che lo strutturano in tutte le sue parti fino ad arrivare all’unità elementare che è la parola. Dunque in una determinata posizione all’interno del discorso vi si potrà trovare un solo o tutt’al più un ristretto numero di parole (nomi, aggettivi, ecc.)
3. Il contesto. A restringere in maniera definitiva il ventaglio di possibilità tra cui una persona si trova a dover scegliere c’è il contesto nel quale la parola è stata pronunciata: il contesto è costituito principalmente dal tema del discorso, ma non solo: considerando anche il livello culturale del parlante, le sue opinioni riguardo l’argomento trattato, l’ambiente in cui la conversazione ha luogo, si riesce in pratica a quasi “prevedere” la parola che l’interlocutore sta per pronunciare.
E’ bene notare come queste capacità proprie dell’uomo non si possano implementare su una macchina allo stato dell’arte, e anche se si potesse
richiederebbero una quantità di risorse impensabile per un sistema portatile quale quello oggetto di questa tesi. Quello che in realtà si fa è cercare di utilizzare la conoscenza, seppure approssimativa, di questi modi di procedere dell’uomo per migliorare i sistemi di riconoscimento automatico.
1.6 Linee guida nella progettazione di un ASR
Pur nella sua grande variabilità il parlato mantiene molte caratteristiche costanti, lo dimostra il fatto che una parola isolata pronunciata da chiunque, se ben scandita, è facilmente riconoscibile da tutti.
Il parlato è dunque un fenomeno né completamente deterministico né completamente aleatorio: all’interno di una parola acquisita un riconoscitore vocale ottimo dovrebbe essere in grado di individuare:
• Gli elementi invarianti: quelle caratteristiche della parola che rimangono costanti al variare dello speaker.
• Gli elementi caratteristici dello speaker, che insieme agli elementi invarianti dovrebbero essere acquisiti dal sistema.
• Gli elementi insignificanti, che non portano nessuna informazione utile al nostro scopo e dovrebbero dunque essere ignorati.
Per poter realizzare un sistema di questo tipo sarebbe necessario avere una teoria esaustiva sul parlato, cosa di cui bisogna ancora fare a meno, non essendo ancora stata elaborata.
Il nostro dovrà dunque essere un ibrido: dovrà:
• estrarre gli elementi che sappiamo di sicuro essere significativi,
• trattare il segnale secondo una nostra particolare ipotesi sul fenomeno fonatorio
Non è un caso che tradizionalmente il campo del riconoscimento vocale sia banco di prova per sistemi di apprendimento artificiali.
Cap. II
Tecniche di implementazione di un ASR
2.1 Struttura di principio di un ASR
Esiste un modo di procedere tradizionale nel riconoscimento vocale che consiste nel suddividere tutto il processo in tre parti:
• Estrazione delle features • Fase di training
• Confronto
Estrazione delle features. Definiamo come features di un segnale l’insieme degli
elementi che lo caratterizzano. Per estrarre le features si divide la stringa in ingresso costituita dai campioni del segnale vocale, che sia da riconoscere o da classificare, in più parti anche parzialmente sovrapposte.
Tutte le informazioni vengono estratte separatamente da ogni sottosequenza. Questo procedimento si basa sul fatto che il segnale vocale ha un’evoluzione nel tempo e questa evoluzione è basata su unità costitutive di durata diversa ma per lo più di poco inferiore al centinaio di msec.
La sovrapposizione di ogni finestra sulla precedente è decisa in fase di progetto come quella che minimizza l’errore nei dati sperimentali, ma in genere si fa in modo che sia comunque possibile prendere la parte centrale della forma d’onda corrispondente ai “fonemi” tralasciando i bordi affetti da fenomeni coarticolatori. Trattando opportunamente ognuna di queste sequenze di campioni, otteniamo un insieme di vettori di features; l’insieme dei vettori di features caratterizza il segnale.
E’ opportuno che i vettori di features abbiano un numero di elementi minore del numero di campioni della finestra, innanzitutto perché in questo modo l’elaborazione del segnale risulterà più leggera da un punto di vista computazionale, poi perché un numero limitato di elementi indica una capacità da parte delle features di sintetizzare le informazioni contenute nel dominio del tempo, di prelevare cioè gli elementi significativi.
Naturalmente è molto importante che le features siano passate alle fasi successive mantenendo l’ordine con cui sono state estratte all’interno del segnale: anche la precisa sequenza di features rappresenta a sua volta una caratteristica importante del segnale vocale.
Fase di training. Se una parola è immessa per la prima volta nel nostro sistema,
abbiamo la cosiddetta fase di training: il riconoscitore vocale provvede ad allocare in memoria le features degli esempi forniti o a creare dei modelli per il nuovo dato. Questi modelli sono già preimpostati dal progettista ed il sistema dovrà provvedere solo a calcolare opportuni parametri che caratterizzino i dati ricevuti e permettano un efficace .
Confronto. Se una parola è immessa per richiamare un comando si è nella fase di
confronto ed il sistema sceglie tra i modelli memorizzati quello che più si addice alle features in ingresso.
E’ da notare che questa suddivisione in fasi è basata su un’imitazione del modo di procedere dell’uomo: le fasi di estrazione delle features, di training e di riconoscimento corrispondono rispettivamente all’ascolto, l’apprendimento ed il riconoscimento de parte dell’uomo.
2.2 I tradizionali approcci al problema dell’estrazione delle
features
Come più volte detto nei precedenti capitoli non esiste una teoria sul parlato che permetta di estrarre tutte e sole le caratteristiche essenziali da esso, dunque sono stati proposti vari metodi basati su approcci differenti al problema. Di seguito ne
riportiamo solo quattro che sono quelli “storici”: quelli cioè che hanno goduto di successo per un lungo periodo di tempo.
2.2.1 Approccio basato su caratteristiche fisiche: potenza e zero-crossing.
Uno dei primi metodi per l’estrazione delle features era basato su osservazioni di carattere sperimentale sul segnale vocale: è stato dimostrato che alcuni parametri facilmente calcolabili potevano essere messi in correlazione con alcune caratteristiche della fonazione, almeno di quella di origine indoeuropea:
• Potenza: i suoni vocalizzati hanno generalmente una potenza maggiore delle consonanti.
• Zero-Crossing: i diversi valori di attraversamento dell’asse delle ascisse in una rappresentazione tempo-ampiezza permettono di discriminare le consonanti fricative da quelle occlusive
Naturalmente questi parametri sono insufficienti per ottenere delle ottime features, sia perché la caratterizzazione mantiene sempre un margine di incertezza, sia perché è facile trovare parole diverse composte da una sequenza di vocali e consonanti di stesso tipo combinate in modo identico.
2.2.2 Approccio basato sulla modellizzazione dell’apparato vocale: LPC
La tecnica dell’LPC (Linear Predictive Coding) è stata per molto tempo la più usata per estrarre features. L’idea alla base della tecnica è questa: non essendo possibile caratterizzare il segnale vocale come fenomeno a sé stante si studia ciò che lo produce. I ricercatori che svilupparono l’LPC assimilarono l’apparato vocale umano ad un tubo modellizzabile matematicamente con un filtro applicato alle corde vocali.
La FDT del filtro è: = − = p i i iz a z H 0 1 ) (
A seconda della sequenza ricevuta si andava a studiare la configurazione del filtro che più verosimilmente la aveva generata: i parametri ai costituivano il vettore delle features. Questa tecnica ha dato buoni risultati ma è ormai obsoleta.
2.2.3 Approccio basato sulla modellizzazione apparato uditivo: AIM
L’Auditory Image Modeling individua nella struttura dell’apparato uditivo umano il motivo dell’efficacia con la quale gli uomini riescono a riconoscere le parole. Questa tecnica tenta di riprodurre in tutte le sue parti il comportamento delle componenti fisiologiche dell’orecchio: banchi di filtri a risposta impulsiva simulano i movimenti basilari delle membrane.
Nel trattamento del segnale si fa in modo di simulare anche i fenomeni psicoacustici, come il mascheramento delle componenti frequenziali vicine ad altre a potenza maggiore, o la compressione della scala delle frequenze. Questa tecnica è ancora in continua evoluzione e per ora risulta molto impegnativa da un punto di vista computazionale.
2.2.4 Mel Cepstral Analysis
I coefficienti MC (Mel Cepstral) sono attualmente tra i più usati e danno ottimi risultati in ambienti non rumorosi.
L’algoritmo per calcolarli consiste essenzialmente in tre passi: 1. calcolo della FFT;
2. filtraggio tramite un banco di filtri di Mel (Fig. 2.2);
3. calcolo dell’antitrasformata del logaritmo della sequenza precedentemente ottenuta.
In questo modo si otteniene un numero di coefficienti prestabilito, che costituiscono il cosiddetto cepstrum del segnale.
I coefficienti ricavati possono essere in parte essere messi in relazione con dei fenomeni fisici: il primo coefficiente rappresenta l’energia del segnale, che permette di rilevare le vocali; il secondo coefficiente è in relazione alla distribuzione dell’energia sullo spettro. Gli altri coefficienti non hanno particolari significati fisici individuali, ma dalla loro configurazione si ottiene un miglioramento delle prestazioni del sistema, sicuramente dovuto al fatto che tutti assieme riescono a caratterizzare il segnale.
E’ da notare che questa tecnica riproduce alcuni comportamenti dell’orecchio umano: il numero di filtri è maggiore alle basse frequenze e minore alle alte, infatti l’uomo è più sensibile ai suoni medio-bassi.
L’elevata sensibilità ai disturbi di questa tecnica è da attribuire essenzialmente al fatto che ognuno dei coefficienti risente di ogni modifica in ogni regione dello spettro: in questo modo qualsiasi rumore di qualsiasi tipo modifica tutti i coefficienti, risultando praticamente ineliminabile.
!
2.3 Algoritmi di training e riconoscimento
2.3.1 Neural Networks
Come accennato in precedenza, se l’uomo riconosce con facilità le parole è soprattutto grazie alla sua capacità di formulare ipotesi, dunque è naturale che molti ricercatori abbiano tentato la strada dell’intelligenza artificiale, ed in particolare delle reti neurali (Neural Network), per aumentare le prestazioni degli ASR.
Le NN nascono come un’imitazione del cervello animale, infatti quest’ultimo è formato da un insieme di unità fondamentali, chiamati neuroni, e da collegamenti tra i neuroni, le sinapsi.
Secondo le ipotesi dei neurofisiologi queste reti sarebbero capaci di elaborare segnali elettrici, presentando un comportamento “a soglia”: emettono cioè un segnale elettrico dopo averne ricevuti una quantità fissata. Le sinapsi farebbero in modo di ostacolare o di favorire il passaggio degli impulsi da un neurone ad un altro in base alla minore o maggiore frequenza con cui i due neuroni risultano attivi contemporaneamente. Imparare vorrebbe dire dunque modificare opportunamente le sinapsi, strutturare le reti di neuroni.
Nella trasposizione artificiale delle reti neuronali ad ogni neurone si fa corrispondere un nodo, e ad ogni sinapsi un peso. Ogni nodo ha uno stato di attivazione (acceso-spento) che dipende dagli input che riceve.
Se si organizza una rete neurale come una successione di vari livelli di nodi otteniamo una topologia detta “a strati”: ogni nodo facente parte di uno strato ha connessioni solo con i nodi dello strato precedente (che fungono da ingressi) e con quelli dello strato successivo (uscite).
A questo punto imparare per una rete neurale vorrà dire in sostanza determinare l’influenza che ogni nodo dello strato precedente avrà su quelli dello strato successivo, cosa che può essere fatta mediante l’algoritmo di back-propagation, che nella fase di training valuta l’errore dell’uscita della rete e lo propaga all’indietro modificando i pesi della rete.
Dunque nelle applicazioni di ASR il modello di una parola consisterà essenzialmente nel vettore dei pesi di una rete. In realtà volendo utilizzare con profitto le NN in questo campo è necessari adottare strutture opportune per fenomeni che si evolvono nel tempo[16]
2.3.2 Support Vector Machines
Quella delle Support Vector Machines è una tecnica da poco sviluppata. Trae origine da uno studio analitico dei sistemi di apprendimento automatico. Infatti in un generico problema di classificazione avremo in ingresso dei dati x∈X, e degli elementi y∈Y che rappresentano l’esatta classificazione degli x. La variabile x
può essere considerata aleatoria, di conseguenza anche y lo sarà, e sarà legata alla x mediante una probabilità condizionata P(y|x) fissata ma sconosciuta.
Una macchina per l’apprendimento dovrà dunque implementare un insieme di funzioni f(x, ) in y che minimizzino l’errore su un training set T={(x1,y1),(x2,y2),….,(xn,yn)}, cioè su un insieme di dati di cui si conosce l’esatta classificazione.
A questo punto la capacità di generalizzazione di una macchina, intesa come la capacità di fornire classificazioni corrette, sarà quantificabile mediante una funzione
R(α)= L(y,f(x,α) dP(x,y)
dove L è una generica funzione di perdita. R(α) è convenzionalmente chiamato Funzionale di Rischio. L’obiettivo di una macchina per l’apprendimento diventa quello di minimizzare il funzionale di rischio.
Le reti neurali seguono il principio di minimizzazione del rischio empirico (ERM): chiamando
(
)
(
)
= = l i i i EMP L y f x l R 1 , , 1 αle NN cercano l’insieme degli α tali che f(x,α) minimizzi la funzione REMP per i dati appartenenti al training set.
Tuttavia il rischio empirico non è uguale al funzionale di rischio: si dimostra che R(α)≤ REMP + Ω(h). Il parametro h è la cosiddetta dimensione di Vapnik-Chervonenkis (VC), che rappresenta il massimo numero di elementi separabili in ogni modo da una macchina per l’apprendimento.
E’ possibile per esempio come una rete neurale a singolo strato (Single Layer Perceptron) può classificare un input bidimensionale in modo binario, ossia come
può dividere il piano in modo tale da individuare due regioni: una di appartenenza e una di non appartenenza.
G(l) è la funzione che associa ad l (numero di input) il numero di modi in cui l input possono essere classificati, dunque la dimensione VC è la l* tale che G(l*)=l* e G(l*+1)=l*.
Dunque per avere un basso R(α), e dunque una alta capacità di generalizzazione, si deve minimizzare oltre all’ERM anche Ω : questo modo di procedere si chiama Minimizzazione del Rischio Strutturale (SRM).
Si dimostra che per qualsiasi spazio di funzioni implementabile da una macchina per l’apprendimento, il principio di SRM converge alla migliore soluzione possibile con probabilità unitaria.
La funzione Ω , detta intervallo di confidenza, è direttamente proporzionale alla dimensione VC.
Nelle reti neurali, quando è fissata l’architettura, è fissata anche la dimensione VC. In questo modo se si tiene VC basso, non si può abbassare sotto una certa soglia il Rischio Empirico; per abbassare il valore del Rischio Empirico si deve tenere la dimensione VC alta, e dunque il funzionale di rischio rimarrà alto.
Le Support Vector Machines sono una macchina per l’apprendimento che ha la capacità di modificare la dimensione VC durante la fase di addestramento, permettendo in questo modo di minimizzare contemporaneamente sia il Rischio Empirico sia l’intervallo di fiducia.
Per ottenere questo le SVM cercano l’iperpiano di separazione ottimale, che si dimostra minimizzare la dimensione VC.
In figura è riportato l’iperpiano di separazione ottimale per un SLP binario bidimensionale.
" # $
Un’altra proprietà interessante delle SVM è la loro capacità di condensare l’informazione del training set in pochi punti, i support vectors, che genereranno poi gli iperpiani classificatori.
2.3.3 Hidden Markov Models
Gli HMM (Hidden Markov Models) sono lo strumento attualmente più usato per la creazione di modelli del parlato.
Questo metodo, per sua natura, si adatta molto bene al fenomeno del parlato. Gli HMM, infatti, partono dal presupposto che l’oggetto della modellizzazione, in sé, non è conoscibile: possiamo conoscerlo solo attraverso delle osservazioni legate all’oggetto stesso in modo non deterministico. In base a questo assunto vengono determinati con opportune tecniche dei coefficienti che legano in modo probabilistico le osservazioni a presunti stati dell’oggetto della nostra modellizzazione: questi coefficienti costituiscono il modello.
Se questa tecnica viene applicata con successo all’ASR è perché,come sappiamo, la parola, oggetto da modellizzare, è di per sé solo un’astrazione e le sue riproduzioni sono legate ad essa in modo di certo non biunivoco.
Saranno descritti adesso i principi matematici della tecnica che implementano le osservazioni teoriche fatte.
Si ipotizzi che una parola sia formata da una sequenza q={q0,q1,q2… qN} di stati Sj, con j=0,1,2…M , e che si disponga di una sequenza di osservazioni Oi con i=0,1,2…N.
Un modello di Markov è formato a questo punto da tre famiglie di coefficienti:
• bj(Oi): è la probabilità che data l’osservazione Oi mi trovi nello stato qt=Sj. L’insieme di questi coefficienti è detto Matrice Di Confusione, e si indica con B.
• ajk : rappresenta la probabilità che avvenga una transizione dallo stato Sj allo stato Sk, ossia P(qt=Sk|qt-1=Sj). L’insieme di questi coefficienti è detto matrice di transizione e si indica con A.
• cr , che è la probabilità che il primo stato della sequenza sia Sr: P(q0=Sr).
Attualmente la forma più diffusa dei coefficienti bj(Ot) è quella di una mistura di Gaussiane, quindi ci calcoliamo la matrice di confusione come:
( )
(
)
= Σ = M m jm jm t jm t j O c N O b 1 , ;µdove M è il numero di gaussiane e cjm è il peso dell’m-esima Gaussiana: deve
essere verificata la condizione = = M m jm c 1 1. Ogni Gaussiana ha la forma:
(
)
( µ) ( µ) π µ − − Σ− − Σ = Σ O O n e O N 1 | 2 1 | | ) 2 ( 1 , ;dove è il vettore media e la matrice di covarianza.
In linea di principio P(O | λ) sarà stimata come cqo
Π
t aqt qt-1 bqt(Ot).2.3.3.1 Algoritmo di Baum Welch
L’algoritmo di Baum Welch è utilizzato per addestrare il sistema, dovrà dunque stimare i coefficienti bj(Ot) ed ajk.
Si supponga di avere un modello ad N stati ed una sequenza di T osservazioni. Se il sistema è a singola Gaussiana, i coefficienti bj(Ot) avranno la forma:
( )
( µ) ( µ) π − Σ − − − Σ = O O n t j O e b 1 | 2 1 | | ) 2 ( 1Dunque se ci fosse un solo stato si potrebbero stimare la media e la covarianza semplicemente come: = = T t t j o T 1 1 µ
(
) (
)
= − ′ − = Σ T t j t j t j o o T 1 1 µ µPassando alla rappresentazione in più stati tuttavia ogni vettore di osservazione potrà trovarsi in linea di principio in ogni stato.
Si procede dunque in questo modo: si inizializzano tutti i parametri con valori non significativi, e anziché assegnare ogni vettore di osservazione ad uno specifico stato, lo si assegna a ciascuno stato in proporzione alla probabilità che il vettore stesso vi si trovi. A questo punto j e j saranno dunque calcolabili come:
( )
( )
= = = T t j T t t j j t L o t L 1 1 µ( )
(
)(
)
( )
= = ′ − − = Σ T t j T t j t j t j j t L o o t L 1 1 µ µdove Lj(t) è la probabilità di trovarsi nello stato j in corrispondenza del t-esimo vettore di osservazione, calcolato con i precedenti parametri.
Questo algoritmo è ripetuto finché la variazione dei parametri tra due sue applicazioni successive non è minore di una certa soglia.
Per il calcolo di Lj(t) si usa di solito l’algoritmo Forward-Backward, in cui vengono stimati i coefficienti j (forward probability) e j (backward probability), definiti rispettivamente come:
( )
t P(
o ot x( )
t j M)
j = 1,..., , = | α( )
t P(
ot oT x( )
t j M)
j = ,..., | = , βI coefficienti rappresentano rispettivamente la probabilità di osservare i primi t vettori e di trovarsi nello stato j, dato il modello M, e la probabilità di osservare i restanti T-t vettori qualora ci si trovi nello stato j del modello M. Dunque
( ) ( )
t j t P(
O x( )
t j M)
j β = , = |
α .
Dalla definizione inoltre N(T)=P(O|M).
A questo punto si può calcolare Lj(t):
(
)
(
(
)
)
( ) ( )
) ( | | ) ( , , | ) ( ) ( T t t M O P m j t x O P M O j t x P t L N j j j α β α = = = = =I coefficienti della matrice di transizione si calcolano invece mediante la seguente formula: dato un training set di R sequenze Or 1 r R di osservazione
= = = − = + + = R r T t r i r i r R r r j T t r t j ij r i r ij r r t t P i t o b a t P a 1 1 1 1 1 1 ) ( ) ( ) 1 ( ) ( ) ( 1 β α β α Dove Pr=prob(Or| ).
Il coefficiente di transizione dal primo stato si calcola invece come:
= = R r r j r j r j P R a 1 1 (1) (1) 1 1 α β
Mentre il coefficiente di transizione verso l’ultimo stato come:
= = = = R r T t r i r i r R r r i r i r iN r t t P T T P a 1 1 1 ) ( ) ( 1 ) ( ) ( 1 β α β α . 2.3.3.2 Algoritmo di Viterbi
L’algoritmo di Viterbi serve per stimare la probabilità di una sequenza di osservazioni dato un modello M. E’ utilizzato infatti per il riconoscimento.
Se si chiama j(t) la massima probabilità di trovarsi nello stato j avendo osservato i primi t vettori ot, questa sarà data da:
{
i ij}
j( )
t ij(t)=
max
ϕ (t−1)a b oϕ
Con 1<j<N. Naturalmente N(T)=P(O|M).
Si può calcolare efficientemente j(t) utilizzando una ricorsione che sfrutti il fatto che 1 ) 1 ( 1 = ϕ e ) ( ) 1 ( a1jbj o1 j = ϕ .
2.3.4 Dynamic Time Warping
L’algoritmo del DTW (Dynamic Time Warping) propone una definizione del concetto di “distanza” tra parole: prende in ingresso la sequenza Ga di features corrispondenti alla parola da riconoscere e misura la distanza con ciascun gruppo di features Gk in memoria: sarà riconosciuta la parola k le cui features hanno distanza minima con quelle da riconoscere.
Per misurare la distanza si procede in questo modo: si supponga che dist(fx,fy) sia un metodo per calcolare la distanza tra due features: si costruisce una matrice delle distanze d(j,i) in cui ogni elemento ji è dist(faj,fki) con faj∈ Ga; fki∈Gk .
A questo punto ci si calcola una nuova matrice D in cui il valore di ogni elemento è calcolabile mediante l’espressione:
% & ' ()* +
,' ()*
In questo modo sarà possibile individuare il percorso che minimizza la distanza tra le parole, deformando gli assi temporali (time warping) a seconda del numero di features associate ad ogni suono.
Per misurare la distanza tra le features sono stati proposti molti metodi, ad esempio: Chebychev: maxj(|xj-yj|) Euclidea:
(
)
2 1 j j N j y x − = Minkowski:λ(
)
λ = − N j j j y x 1 Camberra: = + − N j j j j j y x y x 1| | | |Mahalanobis: (x-y)TM-1(x-y)
Dove xj indica la j-esima componente del vettore x ed il grassetto invece indica il vettore stesso. M è un’opportuna matrice.
Il metodo del DTW ha il vantaggio di essere molto leggero dal punto di vista computazionale, e di rimanere legato al fenomeno fisico della parola, non addestrandone modelli. Tuttavia i risultati ottenuti con questo metodo sono certamente inferiori rispetto a quelli ottenuti con i metodi precedentemente illustrati.
2.4 HTK
HTK è un toolkit sviluppato dall’Università di Cambridge per la costruzione di sistemi basati sui modelli di Markov nascosti. HTK costituisce un prezioso ausilio
alla progettazione in quanto provvede all’esecuzione degli algoritmi relativi agli HMM in modo totalmente settabile dall’utente.
L’HTK si presenta come un insieme di applicazioni eseguibili a riga di comando su un qualsiasi PC, ogni applicazione implementa un determinato passo dell’algoritmo e possono essere editati con facilità dei files che svolgono le operazioni desiderate in successione, ad esempio dei files batch sotto Windows.
I comandi principali sono HRest ed HVite, che eseguono rispettivamente l’algoritmo di Baum-Welch e quello di Viterbi.
HRest prende in ingresso un file contenente il percorso con il quale sono rintracciabili i files delle features per il training ed un altro file che contiene la topologia scelta per gli HMM, descritta mediante un semplice linguaggio di programmazione. Di seguito si riporta a titolo di esempio la descrizione di una topologia a cinque stati left-right, a singola gaussiana, con vettore delle features a cinque componenti:
!
" ! # $$%&!
' ! (
!
! #
) & ) & ) & ) &
" ! #
) & ) & ) & ) & ! *
! #
) & ) & ) & ) &
" ! #
) & ) & ) & ) & ! #
! #
) & ) & ) & ) &
" ! #
) & ) & ) & ) &
+ ,! (
& & & ( & ( & & & & & & & * & * & # & & & & & & & * & * & # & & & & & & & * & -& -& -& -& -& -& -& -& -& -&
. !
-/ 0 +1
I numeri inseriti nel modello non sono significativi, a meno che non siano pari a zero, infatti se HRest trova un parametro uguale a zero lo lascia inalterato, interpretandolo dunque come un’impostazione.
HVite riceve in ingresso le features del segnale da riconoscere e tutti i modelli stimati da HRest, eseguendo l’algoritmo di Viterbi su ognuno di essi, e indicandoci il più probabile.
E’ possibile inoltre configurare gli HMM su tutte le topologie più diffuse, incluse le Gaussiane Tied-Mixture, ossia un modello in cui tutti gli stati condividono lo stesso ampio set di Gaussiane.
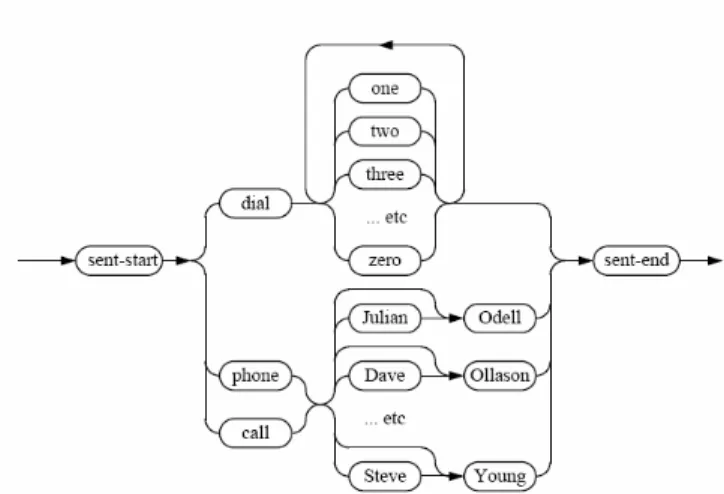
Accanto a questi due tools principali ve ne sono moltissimi che eseguono altre operazioni collaterali, tra cui molti pensati specificatamente per il riconoscimento vocale: è infatti possibile definire delle catene di parole con ordine intercambiabile, come ad esempio in figura:
Fig. 2.8: Una catena di parole descrivibile mediante un tool di HTK.
o anche estrarre i principale tipi di features impostando solamente i principali parametri, utilizzando ad esempio HCopy.
Accanto alle operazioni classiche legate agli HMM, HTK fornisce altri tools che possono rendere il sistema più efficiente, come HInit, che esegue una prima inizializzazione dei parametri dei modelli HMM prima che vengano passati ad HRest. HInit applica l’algoritmo di Viterbi per compiere una prima stima dei valori degli HMM, poi in base a quella stima applica nuovamente Viterbi, trovando una successione di stati più probabile, e stima nuovamente gli aij ed i bk( ): ripete queste operazioni iterativamente fino a quando un’ulteriore ripetizione non modificherebbe nulla, ossia fino a quando l’algoritmo converge.
Il sistema permette inoltre di mantenere un contatto abbastanza stretto con le operazioni svolte, essendo necessario impostare i parametri quasi totalmente a mano.
L’Università di Cambridge fornisce un toolkit chiamato ATK (Application Toolkit for HTK). ATK consiste in un layer C++ che permette di utilizzare i tools di HTK come librerie, permettendo dunque alle applicazioni realizzate con HTK di essere portate su svariati sistemi.
2.5 Modulo Voice Extreme
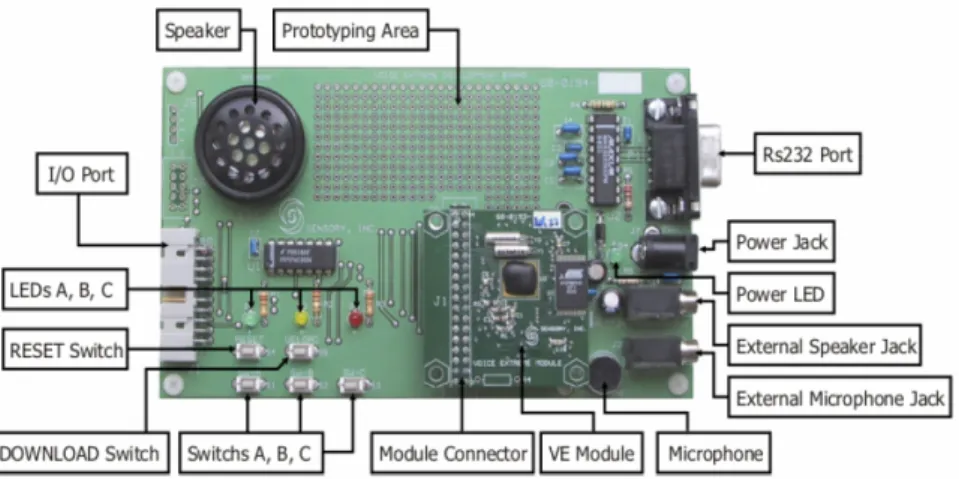
Esistono in commercio dei sistemi embedded che condensano su un unico stampato tutti i circuiti necessari per effettuare sintesi e riconoscimento vocale. Tra i più significativi possiamo sicuramente citare il Voice Extreme Module, della ditta Sensory , che offre buone prestazioni a prezzi abbastanza contenuti.
Fig. 2.9: Modulo Voice Estreme
Per essere programmato il modulo è montato su una piattaforma dotata di piena connettività con il PC grazie alla porta seriale Rs232, di un microfono integrato e di un Jack che può essere utilizzato per collegare al modulo un microfono esterno.
La Sensory fornisce un ambiente di programmazione simile all’ANSI C standard, chiamato VE C, che permette di programmare il modulo secondo le specifiche
desiderate dall’utente. Questo ambiente di programmazione è dotato di interfaccia grafica e vi si possono trovare delle funzioni ideate appositamente per il riconoscimento vocale, sia speaker dependent sia speaker independent .
Il modulo è composto principalmente da una memoria Flash da 2 Mb, e da un unico chip (VE IC) contenente una Rom da 64 KB con l’interprete VE C, un processore centrale ad 8 bit ed a 4MIPS che effettua le operazioni vere e proprie sul segnale vocale ed un firmware contenente l’applicazione per il riconoscimento. Sono poi presenti sul chip un convertitore A/D ed uno D/A, che gli permettono di gestire i flussi di segnale da e verso il mondo esterno ed un bus I/O che si affianca ai pin della porta RS232.
Sullo stampato sono presenti inoltre due oscillatori, uno a 14,32 MHz, utilizzato per ottenere il clock necessario per compiere le operazioni sul segnale, ed uno a 32,768 KHz, utilizzato per le acquisizioni.
0 1 1 2#
Per rendere operativo il modulo, è necessario non solo configurarlo tramite il software, ma anche sviluppare opportune circuiterie che gli permettano un interfacciamento corretto verso l’esterno. Nel caso in cui si desideri utilizzare il modulo per effettuare sintesi vocale bisogna inoltre fornirgli opportuni files.
Il sistema può lavorare con valori di tensione di alimentazione compresi tra 2,85 V e 5,25 V, dissipando in corrispondenza di una tensione di alimentazione di 3 V una corrente di circa 10 mA.
La tecnologia di riconoscimento del modulo è basata sulle reti neurali.
Tra i vantaggi di una soluzione del genere troviamo sicuramente l’affidabilità garantita dall’azienda. In figura 2.11 è possibile vedere come la percentuale di corretto riconoscimento dichiarata rimane sempre molto vicina al 100%. L’ampiezza del rumore è fissa ad 80db e l’ampiezza del segnale è data in relazione alla massima ampiezza che non provoca saturazione, posta a 0dbS . Quando il segnale giunge a -36dbS l’ampiezza del rumore e quella del segnale sono all’incirca uguali.
Sempre nella stessa figura sono riportati i valori del corretto riconoscimento in assenza di rumore.
Cap. III
Trattazione del rumore
Finora si è supposto che i dati da trattare fossero esclusivamente quelli del parlato. In realtà questa non è che un’astrazione teorica: in tutti i casi pratici il riconoscitore vocale sarà utilizzato in un luogo che presenterà inevitabilmente dei rumori ambientali.
L’aggiunta di rumore fa decadere decisamente le prestazioni di tutti i sistemi di ASR , soprattutto per dei valori di rapporto segnale-rumore bassi.
Ancora non sono stati trovati strumenti che risolvono il problema del riconoscimento in ambiente rumoroso in modo soddisfacente. I ricercatori hanno proposto molte tecniche che riescono anche ad abbassare di qualche punto la percentuale di errore, ma nessuna assicura al sistema la robustezza ai disturbi che dimostra l’uomo.
In questo capitolo saranno illustrate brevemente le principali tra queste tecniche.
3.1 Training in presenza di disturbi.
Una delle strategie più comunemente adottate per ridurre gli effetti del rumore è allenare il sistema nelle stesse condizioni di rumore in cui sarà utilizzato.
Questo semplice accorgimento può effettivamente dare discreti risultati, tuttavia le condizioni in cui ciò può accadere sono poche infatti:
• solitamente la principale fonte di rumore è il macchinario che l’ASR deve pilotare e dunque non può funzionare durante la fase di training.
• è impossibile assumere il rumore come qualcosa di costante: in generale è variabile e soggetto ad addizione di sorgenti indesiderate. Ad esempio se ci si trova su un’automobile non si può considerare come causa di disturbo il solo rombo del motore: potranno aggiungersi i rumori del traffico, i tintinnii della carrozzeria, la pioggia, ecc. Lo stesso rumore del motore ha un intervallo di variabilità alto e non rimane a lungo costante.
Inoltre avendo a disposizione dei comandi registrati in ambiente silenzioso sarà possibile applicare tecniche di de-noising che altrimenti avrebbero effetto nocivo sul riconoscitore.
Un ultimo problema può provenire dalla creazione di modelli sbagliati da parte dell’ASR in particolare con le HMM.
E’ dunque chiaro come questa tecnica sia solo un palliativo e difficilmente potrà dare buoni risultati in applicazioni reali.
3.2 Tecniche per l’estrazione delle features in presenza di rumore.
3.2.1 ZCPA
La tecnica dello Zero Crossing with Peak Amplitude è un algoritmo che si articola in 4 passi:
1. si fa passare il frame attraverso un banco di filtri passa banda 2. si trovano gli attraversamenti dello zero dal semipiano superiore
3. si calcola l’inverso della distanza tra gli attraversamenti successivi e il picco raggiunto dal segnale nell’intervallo
4. ci si costruisce un istogramma che associa ad ogni inverso della distanza la somma dei logaritmi dei picchi associati.
5. si applica la Discrete Cosine Transform all’istogramma così ottenuto. Questo algoritmo per dati puliti ha prestazioni peggiori dell’MCA, ma in ambiente rumoroso ha un aumento di percentuale di corretto riconoscimento anche del 40%.
Il punto di forza di questo algoritmo è l’esaltazione dei picchi frequenziali dello spettro e l’attenuazione delle valli solitamente affette da rumore.
Infatti l’inverso della lunghezza prima calcolato può essere associato alla frequenza dell’oscillazione mentre il picco alla potenza ad essa associata. Le componenti a potenza minore non riescono a provocare oscillazioni sufficienti a causare un attraversamento dello zero.
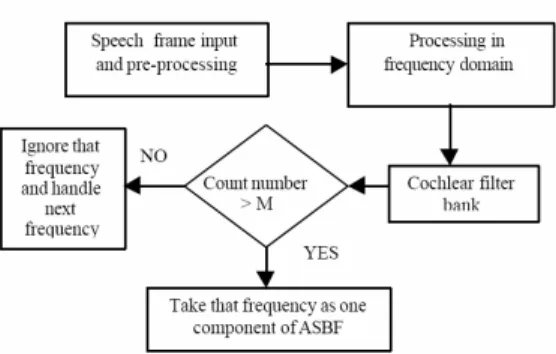
3.2.2 ASBF
Le Auditory Spectrum Based Features sono ricavate da una modellizzazione dell’orecchio umano come una serie di filtri:
Fig. 5.1: banco di filtri per ASBF
I passi dell’algoritmo si possono sintetizzare in 5 punti: 1. si calcola la FFT di ciascun frame;
2. si fa passare la FFT nel banco di filtri di fig. 5.1 di equazione:
( )
(
)
2 2 1 1 2 0 1 1 − − − + + − = z b z b z a A z H k k k k k ;3. dall’uscita di ogni filtro vengono selezionate le M frequenze a cui sono associate le potenze maggiori e trascurate le altre;
4. si conta all’uscita di quanti filtri una frequenza è stata scelta tra le più significative e si incrementa un contatore di conseguenza;
5. siccome il numero delle frequenze può essere variabile se ne scartano N-N0 (N0 il numero prefissato) utilizzando come criterio di minore interesse la vicinanza a componenti a maggiore potenza.
Fig. 5.2 Schematizzazione dell’algoritmo
Questo modo di procedere cerca di simulare il comportamento dell’orecchio umano che, tende a mascherare le componenti frequenziali vicine ad una componente a potenza maggiore,esaltando le armoniche isolate anche se più deboli.
Dal punto di vista del risultato finale si ottiene qualcosa di molto simile alle ZPCA, ma più radicali: prendiamo in considerazione esclusivamente picchi frequenziali e trascuriamo totalmente le valli.
Un altro vantaggio di questo algoritmo è l’esiguo numero di features estratte, che lo rende poco dispendioso computazionalmente.
3.2.3 SMACHER
Questa strategia per l’estrazione delle features si compone di tre tecniche sostanzialmente indipendenti fra loro che sommate danno apprezzabili risultati:
1. Spectral Masking: si fa passare la FFT del frame in un filtro yn=Cyn-1+xn con C variabile che tende a “riempire” le valli frequenziali, al contrario di altre tecniche che tendono ad eliminarle, rivelando una sorta di “inviluppo spettrale”.
2. Si effettua una trasformata wavelet-like che ha il pregio di mantenere la potenza corrispondente alle varie parti del segnale localizzata nelle features. Assumendo che lo spettro sia su 8 componenti la trasformata sarebbe equivalente ad una trasformazione mediante una matrice:
− + − + − + − + − − + + − − + + − − − − + + + + + + + + + + + + 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Fig. 5.3: Esempio di una matrice per una trasformata wavelet-like
In cui gli elementi con il + si sommano tra loro, così come quelli con il segno -, poi viene calcolato il loro rapporto riga per riga.
3. Energy Conditioning: è stato notato che la parte silenziosa della stringa acquisita risente in modo particolare del rumore, causando la gran parte degli errori del sistema. Questa tecnica riesce a ridurre questo effetto calcolando dai primi N frames (presumibilmente silenziosi) l’energia media e quella massima del disturbo ambientale ( m ed M rispettivamente) e moltiplicando i successivi frames per un coefficiente
s E m f b= 1− + se E>m e E<M s se E<=m 1 se E>=M
dove f è una funzione monotona crescente ed E è l’energia del frame da moltiplicare.
Questo sistema è stato ideato espressamente per operare su veicoli. E’ interessante soprattutto la terza tecnica che cerca di sopprimere il rumore direttamente nel dominio del tempo. Infatti in alcune parole, soprattutto quelle che presentano doppie consonanti, ci sono dei frames silenziosi anche all’interno della parola stessa: in questo modo il loro effetto nocivo è attenuato.
Cap. IV
Realizzazione
4.1 Descrizione del database.
Per gli esperimenti è stato utilizzato un database costituto da venti parole pronunciate da uno speaker. Ogni parola è stata pronunciata 10 volte. Dei 10 campioni ottenuti per ciascuna parola sei sono stati utilizzati per il training del sistema; quattro per il riconoscimento.
Alle parole possono essere aggiunti alcuni campioni di rumore ad SNR settabile mediante un semplice programma che moltiplica opportunamente i campioni del rumore prima di sommarli a quelli della voce.
I dati sono stati acquisiti nel formato Wav, con 16 bit per campione ed un sample rate di 8ksamples/sec, un filtraggio a 4kHz del segnale non comporta significative perdite di informazioni.
Uno Due Tre Quattro Cinque Sei Sette Otto Nove Zero Chiama Soccorso stradale Accendi i fari Radio on Radio off Parla con il passeggero Interrompi comunicazione Fendinebbia Freccia destra Freccia sinistra % Automobile Sinusoide Rumore bianco %
I files wav sono divisi in due parti: una parte iniziale, chiamata header, ed il campo dei dati vero e proprio. L’header contiene le informazioni sulla codifica del file.
‘RIFF’ Nei primi byte il file viene dichiarato di tipo multimediale. 4 bytes –ASCII Lunghezza Viene dichiarata la lunghezza del file compreso l’header 4 bytes-integer
‘WAVE’ Formato del file 4 bytes-ASCII
‘fmt ‘ Formato dei chunk 4 bytes-ASCII flength Lunghezza dei chunk 4 bytes-integer format Tipo di file wave 2 bytes-integer chans Numero di canali 2 bytes-integer sampsRate Sample rate in Hz 4 bytes-integer bpsec Numero di byte al secondo 4 bytes-integer bpsample Numero di byte per ogni sample 2 bytes-integer bpchan Numero di bit per ogni canale 2 bytes-integer ‘data’ Viene dichiarato l’inizio della sezione con i dati 4 bytes-ASCII dlength Lunghezza della sezione con i dati 4 bytes-integer
% " ! 4
Nella sezione con i dati vi sono i campioni del segnale. Nel caso della codifica ad un canale e 16 bit i campioni sono messi uno di seguito all’altro. I sedici bit sono poi scritti secondo la codifica Big Endian, ossia è riportato prima il byte meno significativo e poi quello più significativo.
Nello sviluppo della tesi è stato poi necessario codificare dei files nel formato HTK. Anche i files HTK si dividono in una sezione header ed una sezione dati. E’ da notare che i files HTK utilizzano la codifica Little Endian, in cui i bytes sono scritti a partire dal più significativo fino al meno significativo. Volendo dunque assicurare la compatibilità con i files prodotti dalla maggior parte dei software è necessario ricodificare opportunamente i dati.
nSamples Numero di campioni nel file 4 bytes-integer sampPeriod Tempo tra un campione e l’altro in unità di 100 ns 4 bytes-integer sampSize Numero di bytes per sample 2 bytes-integer parmKind Tipo di dato 2 bytes-integer
% % $1 ! 5.6
4.2 Proposta di una tecnica per misurare la distanza tra frames
4.2.1 Idea di base
Qui di seguito è riportata una nuova tecnica proposta durante lo sviluppo della presente tesi. I risultati a cui l'implementazione di questa tecnica ha portato non la rendono al momento preferibile ai sistemi correntemente disponibili, ma è stato ritenuto opportuno riportarla perché introduce un nuovo approccio al problema del rumore, approccio che sfrutta l'assenza di rumore nei dati in memoria, e lascia aperte numerose possibilità di miglioramento.
Questa tecnica presuppone un'ipotesi sul fenomeno del rumore: supponiamo infatti di poter considerare lo spettro del rumore la somma di una componente a banda larga che mantenga una differenza tra Pmin e Pmax limitata ed una componente limitata in banda ma non in ampiezza.
%
-Se dunque si estraggono come features da ogni frame di segnale gli N picchi ad ampiezza maggiore, si neutralizza automaticamente l'influenza del rumore a banda larga sul corretto riconoscimento. L'eliminazione del rumore a banda stretta avviene poi mediante il confronto delle features in memoria con quelle da riconoscere.
Questo modo di procedere presuppone l’ipotesi che il segnale vocale sia descrivibile dai 4 picchi ad ampiezza maggiore.
E’ stato scelto come algoritmo di riconoscimento il DTW perché per sua natura conserva i dati del training set non utilizzandoli per addestrare modelli.
Dunque l'eliminazione del rumore a banda stretta avviene con la misura della distanza tra features. Si supponga di dover misurare la distanza tra una feature a ed una feature b.
Innanzitutto è necessario definire una quantificazione della distanza tra picchi frequenziali, poi, nell’ordine:
1. si lega ad ogni armonica della feature a una della feature b in modo tale da minimizzare la somma di N-1 distanze.
2. si sommano le N-1 distanze minori.
Fig. 4.6: Ogni armonica è relazionata in modo biunivoco ad un’altra in modo da minimizzare la somma delle distanze.
In questo modo si suppone che il confronto di un eventuale picco di rumore farà registrare la distanza più grande tra tutte, e non inficerà dunque il calcolo della distanza tra le features.
4.2.2 Descrizione dell'algoritmo utilizzato.
I campioni acquisiti dal sistema vengono suddivisi in sequenze da 32 ms, ad ogni sequenza è poi applicata una finestra di Hamming, moltiplicando l’i-esimo campione della sequenza per un coefficiente h(i) calcolato come:
− − − = 1 1 2 cos 46 . 0 54 . 0 ) ( n i i h π
dove n è il numero di campioni di ciascuna finestra, in questo caso dunque n vale 256.
Ad i campioni così calcolati è applicata la FFT.
Si ottiene dunque un vettore complesso; per ottenere lo spettro si moltiplica il vettore per il suo complesso coniugato.
% 7 ! 5
Il vettore viene quindi analizzato punto per punto, poi vengono scelti i massimi locali dei quali sono memorizzati solo i quattro ad ampiezza maggiore.
Dunque ogni vettore feature sarà composto da otto elementi: le quattro ampiezze dei picchi e le quattro frequenze corrispondenti.