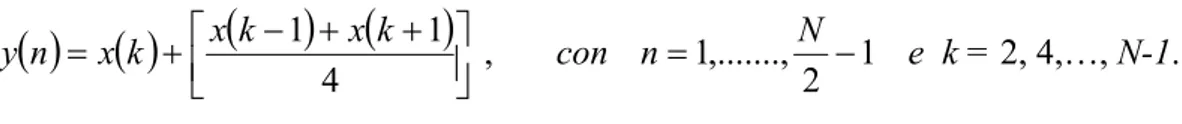C o r s o d i l a u r e a i n
I n g e g n e r i a E l e t t r o n i c a
T e s i d i l a u r e a
S
ISTEMA PER RICONOSCIMENTO
VOCALE PER APPLICAZIONI
INDUSTRIALI
Il candidato
Gaetano CutronaI relatori
Prof. Ing. R. Roncella Prof. Ing. P. Terreni
Dott. Ing. F. De Bernardinis
Sommario
Prefazione... 2
Capitolo I Introduzione al riconoscimento vocale automatico... 4
1.1 Caratteristiche del segnale vocale e blocco di pre-elaborazione ...7
1.2 Estrazione delle features...10
1.3 Train ...15
1.4 Specifiche tecniche del sistema per il riconoscimento vocale...22
Capitolo II Acquisizione ed estrazione delle features del comando vocale ... 24
2.1 Acquisizione del segnale...24
2.2 Suddivisione in frames ...27
2.3 MEL Cepstrum Analysis (MCA) ...29
Capitolo III Riconoscimento medianteSupport Vector Machines (SVM)... 37
3.1 Apprendimento e classificazione...38
3.2 Stima di un Classificatore Lineare Ottimale ...42
per gli Iperpiani ...42
3.3 Iperpiani classificatori non lineari...47
3.4 Processo di training delle SVM...49
3.5 Confronto con altre tecniche di apprendimento ...50
3.6 Software usato...51
Capitolo IV Embedded software in sistemi real-time di elaborazione dei segnali ... 53
4.2 Processori embedded...54
4.3 Embedded software...58
Capitolo V Risultati sperimentali ... 62
5.1 Preparazione del segnale vocale acquisito ...62
5.2 Esperimenti di estrazione delle features ...66
Conclusioni ... 70
Prefazione
Il processo cognitivo umano dei suoni è un fenomeno straordinariamente complesso sia per la molteplicità degli apparati che vi concorrono, sia per la loro modalità di funzionamento. Questi sono stati individuati e approfonditamente esaminati, in special modo, nel secolo appena trascorso, allorché, grazie alla crescita esponenziale verificatasi in ogni campo della ricerca scientifica, ci si è avvalsi, per gli studi del settore, di apparecchiature sofisticate, come, ad esempio, il microscopio elettronico a scansione. Così è stato possibile constatare tanto la ricchezza e la specificità delle strutture preposte alla ricezione e alla decodificazione dei suoni, quanto le peculiarità e le differenze fisiche dei segnali che arrivano ai nostri organi di senso (ad esempio: frequenza, energia, ecc.). Si è scoperto, altresì, che, fra tutte le stimolazioni che riceve, il nostro sistema uditivo si sintonizza, in maniera privilegiata, sulla voce umana, tramite l’attitudine propria del cervello ad analizzare ed elaborare qualsiasi suono che lo raggiunga, confrontandolo con quelli precedentemente acquisiti. In questo ambito, un risalto particolare assume la parola, elemento distintivo della specie umana, che rappresenta una risorsa estremamente immediata e versatile per comunicare ed esprimere idee.
Negli ultimi decenni la tecnologia ha permesso di utilizzare questo strumento, in modo automatizzato, anche nell’interfacciamento tra uomo e macchina. Per raggiungere un tale traguardo è stato necessario affrontare e risolvere una serie di problemi.
L’Uomo, infatti, è molto versatile nel riconoscimento dei suoni e le sue prestazioni sono pressoché stabili anche in avverse condizioni di ascolto, dal momento che egli riesce ad adattarsi facilmente allo speaker ed al canale. Ciò, invece, risulta difficile da ottenersi con i sistemi automatici, i quali non sono in grado di eguagliare le capacità naturali umane, data la varietà e la specializzazione che le contraddistingue. Per altro, al presente, disponiamo di sistemi di riconoscimento vocale automatico con cui un utente può interfacciarsi con il
sistema elettronico semplicemente usando la propria voce ed evitando, perciò, di servirsi di tastiere o di altri dispositivi di input che tengono occupati gli arti. L’evidente funzionalità assicurata dal ricorso a questa tecnologia ne fa ipotizzare, per l’avvenire, una diffusione sempre maggiore. Anche in questo lavoro viene presentato il progetto di un sistema di riconoscimento speaker dependent per applicazioni industriali, in grado di ricevere, mediante un microfono, comandi appartenenti ad un database predefinito, ma personalizzabile dall’utente.
Inoltre, perché la trattazione dell’argomento risulti più completa, essa si articola in cinque tappe che corrispondono ad altrettanti capitoli.
Nel primo, che funge da introduzione, si fa un quadro riassuntivo di quanto è attualmente disponibile per ciò che riguarda le tecniche di preparazione e di riconoscimento del segnale vocale e si riportano le specifiche tecniche del sistema che costituisce l’oggetto di questa tesi.
La descrizione del progetto vero e proprio avviene nei capitoli II e III dove si spiegano le tecniche di acquisizione, elaborazione e riconoscimento dei comandi vocali; inoltre le modificazioni che ne hanno permesso l’implementazione in un sistema embedded sono indicate nel capitolo IV.
Cap. I
Introduzione al riconoscimento vocale
automatico
L’informatica e l’elettronica hanno introdotto una vera e propria rivoluzione nel mondo moderno e, negli ultimi anni, si è assistito ad una accelerazione nella corsa all’automatizzazione, che in particolare ha avuto lo scopo di mettere a punto macchine atte a semplificare la vita umana.
Una di queste semplificazioni è permessa dai dispositivi di riconoscimento vocale, che in tempi recenti sono andati incontro a un largo sviluppo e ad una grandissima diffusione.
Si tratta di sistemi in grado di riconoscere il segnale vocale umano e di utilizzarlo per interfacciare un utente con vari dispositivi. I riconoscitori automatici sono oggetti molto versatili che si prestano ad una moltitudine di usi: dai macchinari industriali pilotati tramite la voce dell’operatore fino agli elettrodomestici, dai telefoni cellulari ai sistemi di dettatura automatica per personal computer. Il diffuso ricorso a questa tecnologia deriva dal fatto che risulta oggettivamente più immediato usare la voce per far fare qualcosa a chiunque.
I sistemi di riconoscimento possono raggrupparsi sostanzialmente in due classi: • Riconoscitori speaker independent (SI): Questi sistemi sono predisposti in
maniera che si prestino ad essere adoperati da più utenti e si basano su un database predefinito e non modificabile. Il numero di parole riconoscibili è elevato, in quanto la maggior parte di questi sistemi prevede la suddivisione in fonemi del segnale vocale e il successivo riconoscimento degli stessi in base a un confronto con quelli presenti nel database. Per altro, riuscire a interpretare l’insieme delle parole che costituiscono il linguaggio come una combinazione di suoni che possono essere isolati è una operazione mentale di straordinaria complessità, dal momento che, ad un esame strumentale, le singole parole che pronunciamo risultano formate da un’onda acustica continua e non da segmenti che corrispondano ai fonemi. Questi ultimi sono dunque non una realtà fisica, ma un’astrazione concettuale cui la mente umana è pervenuta
mediante un lungo processo evolutivo [1]. Dotare una macchina di circuiti che riproducano questa capacità del cervello dell’uomo comporta la creazione di oggetti molto complicati che necessitano di macchine potenti e veloci le quali non abbiano problemi di occupazione di memoria. Essi trovano applicazione soprattutto su personal computer in software per la digitazione sotto dettatura o simili. Il loro database è comunque limitato ma espandibile e può essere anche intercambiato acquistandone un altro predefinito dal fornitore (es. esistono sistemi che sono in grado di accettare vocabolari di lingue diverse). • Riconoscitori speaker dependent (SD): In questi sistemi le parole riconoscibili
sono direttamente definibili dall’utente, ma il loro numero è significativamente più ristretto se paragonato a quello del gruppo precedente. Oggetti di questo tipo trovano impiego in sistemi portatili (cellulari, ecc.) in quanto più semplici di quelli SI. Il presente lavoro prende in considerazione un sistema appartenente a questo secondo gruppo le cui specifiche formano il contenuto del paragrafo conclusivo di questo capitolo.
La maggior parte dei sistemi automatici di riconoscimento SD prevedono l’uso di un database di appoggio in cui è contenuto un numero finito di comandi riconoscibili dal sistema. Generalmente il database è personalizzabile dall’utente e il sistema funziona correttamente solamente con colui che lo ha definito (se si cambia utente, si deve ridefinire anche il database). Il sistema di riconoscimento si articola su due modalità distinte di funzionamento.
• Fase di train: L’utente deve letteralmente “allenare” il sistema, registrando i campioni, che vengono elaborati dal sistema stesso e immessi nel database, pronti per l’uso nella fase operativa vera e propria.
• Fase operativa: Il sistema funziona da riconoscitore vero e proprio: l’utente pronuncia un comando e il dispositivo, dopo aver ricercato nel database quello che più gli si avvicina, lo esegue.
Possiamo schematizzare la struttura del sistema, nella fase di train, con un diagramma a blocchi come quello rappresentato nella fig.1.1.
Database Train Estrazione delle features Pre elaborazione
Fig.1.1 Diagramma a blocchi della fase di train.
In figura sono evidenziate le diverse fasi che permettono il passaggio dalla registrazione all’immissione dei dati nel database:
1. Il comando pronunciato dall’utente viene acquisito tramite un microfono e pre-elaborato; il segnale vocale, infatti, registrato così come è, contiene dei disturbi e delle caratteristiche che non permetterebbero un corretto funzionamento del dispositivo.
2. Nella seconda fase, il sistema provvede ad individuare le caratteristiche comuni contenute nei campioni vocali registrati.
3. I dati raccolti nella fase precedente sono elaborati e raggruppati in classi differenti (una per ogni comando).
4. Le features che compongono le singole classi vengono immagazzinate, pronte per essere utilizzate nella fase di riconoscimento.
Passiamo ora ad esaminare le singole operazioni che, illustrate in modo dettagliato, costituiscono il contenuto dei paragrafi che seguono.
1.1 Caratteristiche del segnale vocale e blocco
di pre-elaborazione
Sebbene l’uomo riesca, senza fatica, a riconoscere il parlato anche in avverse condizioni di ascolto, ad esempio in ambienti rumorosi, i sistemi di riconoscimento automatico hanno prestazioni significativamente inferiori rispetto a quelle umane. Questa carenza è dovuta a diversi fattori, i più salienti sono:
1. Stile del parlato: Il parlato non è tutto uguale, esso differisce infatti per intonazione, pronuncia, cadenza, ecc. Questa caratteristica, per altro, influisce poco nel riconoscimento di parole isolate, mentre interferisce in modo più marcato nel riconoscimento di intere frasi.
2. Dipendenza dallo speaker: Un sistema SD è molto più semplice ed affidabile rispetto ad uno SI in quanto quest’ultimo presenta un problema di confusione del parlato poiché ogni individuo ha un proprio stile che differisce significativamente tra speaker e speaker (es. uomo, donna) ecco perché servono enormi quantità di campioni per il train di un sistema SI, con conseguente occupazione di memoria.
3. Condizioni di utilizzo: In un sistema di riconoscimento SD le condizioni in cui avviene la registrazione del segnale vengono scelte dall’utente in modo che esse siano le più funzionali possibili per l’ottimizzazione del processo; in quello SI, per contro, la componente SNR (rapporto segnale/rumore) del segnale in ingresso al sistema ha un peso ben maggiore nel determinare la bontà del risultato finale.
Inoltre il rumore può intervenire nel segnale a causa di diversi fattori, ad esempio esso può dipendere da disturbi presenti nel circuito durante l’acquisizione del comando (es. disturbi dovuti all’alimentazione da rete elettrica), oppure può derivare dall’ambiente esterno (conversazioni e rumori di sottofondo prodotti da macchinari, automobili, ecc.).
Al primo tipo di disturbi si può ovviare progettando il sistema con tecniche low noise, in modo da sopprimerli o attenuarli (es. inserendo dei condensatori
sulle alimentazioni, filtrando il segnale in ingresso in banda audio 100-8000 Hz, ecc.).
È, invece, più difficile eliminare le interferenze acustiche dell’ambiente esterno, esse infatti sono parte integrante del segnale sonoro: ad es. è praticamente impossibile cancellare del tutto i rumori del traffico cittadino nella registrazione di un discorso fatto per strada. Questo tipo di disturbo si trova soprattutto ad una frequenza che è ai limiti della banda audio, perciò un modo per smorzarlo sarebbe quello di filtrare il segnale con una banda che comprenda solamente il segnale audio vocale (300-3500 Hz (banda telefonica)); ricorrendo, però, a questa procedura si reiettano componenti frequenziali anche dal segnale utile; tuttavia questa perdita non è rilevante, in quanto il segnale può essere ugualmente discriminato, sia dal nostro orecchio sia dal sistema automatico di riconoscimento.
Nonostante questi accorgimenti, nulla può essere fatto per cancellare o limitare disturbi derivanti dalle voci di sottofondo di altri individui poiché si trovano alla stessa frequenza del segnale utile.
Tutti e tre questi problemi sono molto difficili da trattare nel progetto di sistemi SI mentre si possono facilmente eliminare o almeno ridurre nei sistemi SD; infatti, essendo l’utente stesso a personalizzare il sistema, cioè a definire e registrare il database nella fase di train, gli inconvenienti indicati al punto 1 e 2 risultano neutralizzati in partenza.
Riguardo alle condizioni di utilizzo, basterà adottare l’accorgimento di individuare a priori le caratteristiche di rumorosità proprie dell’ambiente in cui il sistema dovrà operare e quindi registrare in loco i campioni che faranno parte del database dei comandi (ad es. se il sistema si deve usare in una fabbrica conviene registrare il database proprio lì). In questo modo, sia il segnale campione inserito nel database, sia quello in ingresso nel normale utilizzo sono affetti dal medesimo disturbo, che viene trattato come se fosse in modo comune, motivo per cui risulta annullato. Nel caso in cui i luoghi di utilizzo del sistema fossero molteplici, può essere utile, in fase di registrazione, arricchire il database dei comandi, sommando, al campione originale, altri disturbi precedentemente registrati; con
questo accorgimento si ottengono dei campioni i quali contengono quei disturbi che più probabilmente si verificheranno durante il funzionamento vero e proprio. Passiamo ora ad analizzare le caratteristiche del blocco di pre-elaborazione.
I dispositivi fondamentali, di cui il blocco è formato, sono i seguenti: un filtro in banda telefonica e un convertitore A/D (analogico digitale), così che in uscita si ottiene una sequenza quantizzata del segnale in ingresso. Il passaggio al digitale è giustificato dal fatto che le odierne strutture digitali sono molto flessibili, dunque, volendo cambiare il tipo di elaborazione del segnale, basterebbe sostituire solo il software e non l’intero dispositivo, come avverrebbe in un improbabile sistema analogico.
Il funzionamento del dispositivo per il riconoscimento automatico si potrebbe schematizzare nel modo seguente:
Data la sequenza in ingresso (il segnale che si vuole riconoscere), trovare la più simile tra quelle presenti nel database.
Questa operazione, però, non è così semplice e lineare come potrebbe sembrare; infatti il segnale vocale, acquisito così come è, presenta una variabilità estremamente elevata, tanto che applicare direttamente un qualsiasi metodo discriminativo comporta una difficoltà non indifferente. Da ciò deriva la necessità di trasformare la sequenza in ingresso, estraendone delle features caratteristiche, le quali siano simili per ogni segnale dello stesso tipo. In questo modo, se il
segnale in ingresso si può assimilare ad una sequenza A = a1, a2,…, an , dopo
l’estrazione delle features si passa ad una nuova sequenza B = b1, b2,…, bm con
m<<n con conseguente semplificazione del problema. In figura 1.2 viene rappresentato, a mo’ d’esempio, l’andamento della sequenza in ingresso e in uscita al blocco di estrazione delle features corrispondente alla parola “uno”.
0 5 10 15 20 25 30 35 -2 0 2 4 6 nr. campione A m pi ez za 0 500 1000 1500 2000 2500 3000 3500 4000 -1.5 -1 -0.5 0 0.5 1 1.5x 10 4 nr. campione A m pi ez za Fig. 1.2.
In questo caso il segnale è stato campionato ad 8 kHz, perciò i 4000 punti in figura rappresentano 0.5 s di acquisizione. Lavorare con 4000 punti risulterebbe troppo complesso, se, invece, dal segnale vocale si estraggono delle features (in questo caso 35), si passa a operare invece che su 4000 su soli 35 punti, con notevole semplificazione del problema.
1.2 Estrazione delle features
Lo spazio delle features, in cui è necessario che il segnale sia trasformato, deve ottemperare alle seguenti proprietà fondamentali:
• Separabilità in classi: Da quando lo scopo dei sistemi di riconoscimento automatico è quello di classificare accuratamente il segnale vocale, l’unità
base per il riconoscimento deve essere ben separabile (e quindi discriminabile) in questo spazio delle features.
• Rappresentazione compatta: Come è già stato detto, lo spazio delle features deve avvalersi di una rappresentazione più compatta rispetto allo spazio di partenza. In tal modo si ottiene una minore complessità nella progettazione del classificatore, e di conseguenza anche una più accurata stima dei suoi parametri.
• Rappresentazione basata sui processi umani: Lo spazio delle features dove opera il classificatore necessita dell’applicazione delle conoscenze del
processo cognitivo umano dei suoni. Ad esempio, l’uso di una scala non
lineare di frequenze, adoperata in molti sistemi odierni, vuole riprodurre la
risposta logaritmica del sistema uditivo umano.
Esistono molti tipi di tecniche per l’estrazione delle features dal segnale vocale, le più famose, in letteratura, sono le seguenti:
1. Linear Predictive Coding (LPC).
2. Analisi basata sulla trasformata Wavelet. 3. Auditory Image Modelling (AIM). 4. Mel Cepstrum Analysis (MCA).
Delle prime tre tecniche ci occuperemo in questo paragrafo, mentre la quarta sarà ampiamente analizzata nel capitolo 2.
La tecnica LPC per l’estrazione di features è storicamente la più famosa: in essa, l’apparato vocale umano viene approssimato, in generale, ad un tubo eccitato dalle corde vocali; il sistema che simula il condotto è un filtro, con parametri
lentamente variabili (guadagno(G), e coefficienti del tratto vocale (ak )).
Il filtro ha una forma del tipo:
∑
= − − = = p k k kz a G z U z S z H 1 1 ) ( ) ( ) (L’idea base è di considerare il campione sonoro come combinazione lineare dei suoi predecessori e, quindi, di confrontare il campione originale con questa combinazione (campione stimato). In tal modo i coefficienti per la combinazione (predittori) possono essere determinati minimizzando la differenza.
Questo è un metodo molto robusto ed accurato per trattare segnali linearmente variabili nel tempo, ma la schematizzazione del tubo è un po’ troppo approssimata, in quanto una soluzione più precisa dovrebbe tenere conto anche della risposta della cavità nasale, tuttavia, ricorrendo ad un numero adeguato di parametri, questa tecnica fornisce delle buone features [2].
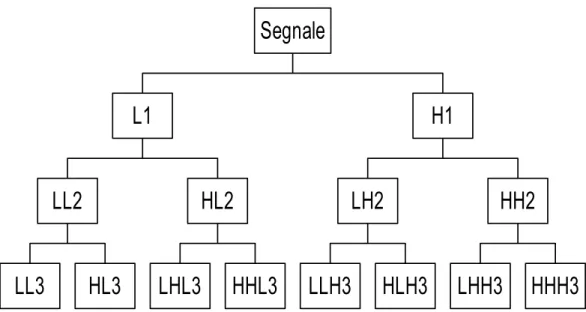
La trasformata Wavelet è una tecnica di analisi del segnale che consente di lavorare anche con quei segnali che, non presentando caratteristiche di stazionarietà, non possono essere analizzati mediante la consueta trasformata di Fourier. In particolare tale tecnica esamina, con diverse risoluzioni, le varie frequenze. Partendo dal segnale originale, si procede, in primo luogo, ad un suo sottocampionamento; si passa poi ad effettuare un filtraggio LP ed HP. Con questo procedimento si è ottenuta la suddivisione della banda di partenza in due metà uguali; le due sequenze (dette rispettivamente: di approssimazione e di dettaglio), le quali contengono la metà dei campioni del segnale di partenza, vengono successivamente sottoposte ad una ulteriore decomposizione LP e HP; l’operazione viene ripetuta fino ad ottenere una struttura ad albero come si vede in fig. 1.3 (decomposizione Wavelet completa). Il segnale di partenza può essere infine ricostruito, risalendo l’albero, attraverso una opportuna composizione dei coefficienti di approssimazione e di dettaglio.
LL3
HL3
LL2
LHL3
HHL3
HL2
L1
LLH3
HLH3
LH2
LHH3
HHH3
HH2
H1
Segnale
Fig. 1.3 Esempio di decomposizione wavelet a tre livelli.
Questa tecnica si può utilizzare nell’estrazione di features da un segnale vocale, come mostrato in [3], dove, partendo dal campionamento a 16 kHz di un segnale vocale suddiviso in frame, si opera una decomposizione Wavelet completa a tre livelli per ogni frame. La prima banda viene ulteriormente decomposta in tre livelli, la seconda in due, la terza una volta, la quarta due volte, la quinta una volta.
Come si osserva nella tabella 1.1 riportata, ai piedi dell’albero si hanno 24 bande di frequenza, per ognuna delle quali si calcola il logaritmo dell’energia e quindi la DCT (trasformata discreta del coseno vedi cap. II). Le features per ogni frame sono formate dai primi 13 coefficienti della DCT.
N.
filtro Frequenza di taglio bassa (Hz) Frequenza di taglio alta (Hz) Larghezza di banda (Hz) 1 0 125 125 2 125 250 125 3 250 375 125 4 375 500 125 5 500 625 125 6 625 750 125 7 750 875 125 8 875 1000 125 9 1000 1125 125 10 1125 1250 125 11 1250 1375 125 12 1375 1500 125 13 1500 1750 250 14 1750 2000 250 15 2000 2250 250 16 2250 2500 250 17 2500 2750 250 18 2750 3000 250 19 3000 3500 500 20 3500 4000 500 21 4000 5000 1000 22 5000 6000 1000 23 6000 7000 1000 24 7000 8000 1000 Tab. 1.1 Decomposizione wavelet per l’estrazione di features per il segnale sonoro.
La AIM (Auditory Image Modelling) è una tecnica che si discosta da tutte le altre, le quali sono accomunate dalla caratteristica di imitare, con una certa approssimazione, il sistema uditivo umano. La AIM, invece, si trova un passo avanti rispetto ad esse, perché, usando informazioni dettagliate sull’anatomia umana e sulla psicoacustica, segue il processo di percezione sonora alla lettera. L’estrazione delle features inizia con un filtraggio in banda audio del campione, dopo di che, l’onda acustica viene trasformata nel movimento basilare della membrana dell’orecchio interno. Questo è possibile grazie al filtraggio con un banco di filtri a risposta impulsiva simile a quella dei sistemi fisiologici. Contrariamente ai sistemi tradizionali, la successiva compressione dell’ampiezza del segnale è di tipo adattivo e ne enfatizza la natura dinamica piuttosto che le componenti stazionarie, riproducendo, perciò, il comportamento delle cellule uditive.
Questa tecnica è ancora in fase di sperimentazione, ma si è osservato che essa è caratterizzata da una elevata robustezza al rumore e assicura buone prestazioni in generale.
1.3 Train
Le features, una volta estratte, vengono inviate in questo blocco, dove entra in funzione un sistema in grado di classificarle (classificatore) e memorizzarle, separate in classi, nel database.
Esistono, in circolazione una infinità di classificatori, i più famosi sono quelli di tipo statistico e le cosiddette reti neurali.
Gli aspetti che devono necessariamente essere presi in considerazione, prima di scegliere il tipo di classificatore, sono:
• Generalizzazione: Nella maggior parte dei casi, per risolvere un problema di riconoscimento vocale abbiamo accesso solamente a un limitato numero di campioni nel database. Bisogna che il classificatore individui tutte le variabilità dai dati a disposizione, in modo da ottenere delle proprietà statistiche comuni con i dati da osservare. Si profilano così vari tipi di modelli: quelli parametrici che possono essere stimati con capacità di generalizzazione controllate, mentre le soluzioni non parametriche vanno incontro a problemi a livello di generalizzazione, e, dunque, devono essere forzate ricorrendo a una conoscenza significativa a priori dell’eventuale problema.
• Classificazione: A ogni modello parametrico è necessario aggiungere uno schema di classificazione perché si formi un sistema campione di riconoscimento; invece, con le tecniche non parametriche, si può saltare la stima della distribuzione dei dati e calcolare direttamente il classificatore (o la regione di decisione).
• Compattezza: La maggior parte dei sistemi di riconoscimento reali possono contare solo su un limitato numero sia di risorse computazionali sia di campioni nel database. Questo fa della compattezza, nella rappresentazione del classificatore, un importante aspetto da considerare. Per esempio, modellare la densità di probabilità come Gaussiana necessita di un minimo numero di parametri (la media e la varianza). Le rappresentazioni non parametriche, per contro, tipicamente basate sulle tecniche di quantizzazione vettoriale [4], hanno bisogno di un elevato numero di parametri.
Affrontare un problema di riconoscimento in modo statistico significa trovare nel database la sequenza più simile alla sequenza da riconoscere. Se A è la sequenza che si vuole riconoscere, in ingresso al sistema, e W è una delle tante sequenze inserite nel database, allora il sistema di riconoscimento deve trovare la sequenza W* la quale massimizza la probabilità che la sequenza A ascoltata corrisponda alla W: ). / ( max arg * pW A W W = (1)
p(W / A) è conosciuta come probabilità a posteriori, in quanto rappresenta la probabilità che si verifichi W dopo avere osservato A. È difficile, se non computazionalmente intrattabile, calcolare direttamente W* con la (1) a causa dell’infinito numero di sequenze tra le quali quella più simile ad A deve essere scelta. Questo problema può essere alquanto semplificato, applicando un approccio Bayesiano per trovare W*:
). ( ) / ( max arg * p A W pW W W = (2)
La probabilità, p(A / W), che il dato A sia stato osservato qualora una sequenza W sia stata pronunciata è tipicamente fornita da un modello acustico. La probabilità p(W) che dà le chances a priori che la sequenza W sia stata pronunciata è determinata usando un modello di linguaggio [5,6].
Il modello acustico, che è un classificatore, può essere di tipo parametrico o non parametrico. Un tipo di classificatori parametrici sono quelli basati sugli HMM (Hidden Markov Models). I parametri del modello, in questi sistemi, sono stimati ricorrendo a un database con un ragionevole numero di campioni. Un metodo molto famoso per la stima è quello basato sul principio della massima probabilità ML (Maximum Likelihood). Se assumiamo che i parametri di un HMM siano fissi ma sconosciuti, possiamo porre il problema della stima di essi come quello di massimizzare la probabilità che il modello generi i dati osservati (probabilità a posteriori). L’approccio per un tipico processo di calcolo dei parametri per un HMM, allora, risulta la massimizzazione della somiglianza dei dati una volta noto il modello, il processo tradizionalmente è conosciuto come calcolo del Maximum Likelihood [7]. Una delle ragioni più importanti che hanno portato al successo del ML e degli HMM è stata l’esistenza di metodi iterattivi convergenti per la stima dei parametri.
Per eseguire il calcolo del ML, l’algoritmo cui si ricorre più di frequente è quello dell’Expectation-Maximization (EM) (massimizzazione dell’aspettazione) [8,9]:
Supponiamo di avere uno spazio delle features Y di “dati completi” (i dati sono completi nel senso che non si è verificata perdita di informazione).
Supponiamo, inoltre, di avere una qualche funzione y → x di Y in uno
spazio osservabile X di “dati incompleti” (in questo caso c’è stata una perdita di informazione dovuta alla non perfetta conoscenza del processo). Lo spazio dei “dati incompleti” è praticamente quello con cui ci si confronta nei problemi reali.
Sia ƒ(y|Φ) una delle densità di probabilità definite in Y e g(x|Φ) la densità di probabilità in X indotta da ƒ(y|Φ). Il simbolo Φ rappresenta la parametrizzazione della funzione densità (es. la media e la varianza per un modello Gaussiano).
Per un dato x ∈ X lo scopo dell’EM è di trovare il massimo della funzione
L(Φ) = log(g(x|Φ)) usando la relazione tra f e g. In altre parole, invece di
ottimizzare direttamente nello spazio X, si cerca di ottimizzare nello spazio “completo” Y e utilizzare le relazioni tra i due spazi, per giungere alla soluzione ottimale. L’EM è molto efficace per questi problemi, in quanto
lavorare con f, è significativamente più semplice che lavorare con g. In realtà, il logaritmo non sarebbe necessario, ma per il fatto che la maggior parte delle parametrizzazioni delle densità sono di natura esponenziale, il logaritmo semplifica di molto l’analisi.
L’algoritmo EM è diventato una tecnica estremamente importante per la stima dei parametri in quanto, se nel processo di ottimizzazione si deve tener conto di dati mancanti, l’EM può arrivare elegantemente alla soluzione ottimale, senza doverli esplicitamente stimare; e poiché nel mondo reale si ha a che fare quasi sempre con dati insufficienti, questa proprietà dell’EM risulta rilevante in pratica.
Un altro tipo di classificatori, largamente usato nel riconoscimento vocale, è quello basato sull’architettura delle reti neurali. Negli anni 50 veniva progettato un modello di macchine, il percettrone, in grado di apprendere. Ciò creò non poche aspettative, specialmente tra i cultori del riconoscimento automatico, i quali pensavano di riuscire a raggiungere in breve tempo le prestazioni del sistema neuronale biologico. Infatti, tale macchina, opportunamente addestrata con un “training set” linearmente separabile, convergeva, con un numero finito di iterazioni, ad una soluzione che rappresentava i coefficienti degli iperpiani che separano le classi di addestramento. Sfortunatamente verifiche più approfondite hanno dimostrato che il percettrone ed alcune sue generalizzazioni erano inadeguati a risolvere molti problemi pratici di riconoscimento. E’ stato solo dal 1986, con l’introduzione dell’algoritmo di apprendimento mediante Back-Propagation, che questi sistemi hanno trovato un largo uso nella soluzione dei problemi di riconoscimento e classificazione [10,11]. Uno dei vantaggi principali delle reti neurali è la loro adattabilità: esse possono modificare automaticamente i propri parametri per ottimizzare il loro comportamento, anche nei confronti di sistemi tempo-varianti.
L’algoritmo di Back-Propagation è un semplice schema nel quale il gradiente dell’errore tra l’uscita della rete e l’uscita sperata è propagato indietro, dall’uscita all’ingresso, modificandone le connessioni [12,13] e ciò per soddisfare dei criteri di ottimizzazione, fra cui il più diffuso è quello del minimo errore quadratico medio.
E’ stato dimostrato che reti con un sufficiente numero di strati e nodi possono modellare zone di decisione e funzioni non lineari abbastanza complesse [12]. La stima dei parametri delle reti neurali può essere considerata di tipo discriminativo, i pesi delle connessioni sono aggiornati basandosi su esemplari appartenenti a tutte le classi del processo. In un HMM, la probabilità di generare un risultato dipende solamente dallo stato presente ed è indipendente da tutti gli altri stati. Questa non è una caratteristica positiva, in quanto il segnale vocale evolve continuamente durante l’osservazione, e tale evoluzione porta a osservazioni consecutive dipendenti l’una dall’altra.
Due tipi di rete neurale largamente usati nel riconoscimento vocale sono le Time-Delay Neural Network (TDNN) e le Recurrent Neural Network (RNN).
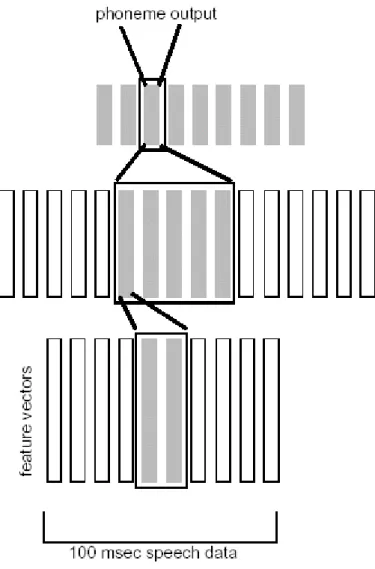
La prima architettura è stata sviluppata inizialmente per il riconoscimento di fonemi [12]. In questi sistemi le connessioni sono ritardate nel tempo per adattarsi alle segmentazioni varianti del segnale in arrivo, perciò non ci sono propagazioni istantanee dell’eccitazione dall’ingresso all’uscita (time-delayed). Ricorrendo a questo meccanismo si riescono ad accoppiare segmenti nel flusso di dati, in ingresso, senza curarsi della loro incidenza, la qual cosa ha lo scopo di potenziare la rete neurale. La fig. 1.4 mostra l’implementazione di una semplice TDNN:
L’ingresso della rete è esposto a 10 frame (es. 100 ms di segnale vocale). Il primo strato nascosto raggruppa 2 frame ogni 10 ms e passa queste features al successivo strato che ne raggruppa 5. Quest’ultimo è connesso ai nodi d’uscita che forniscono la classe del fonema. Il modo in cui sono disposte le connessioni forza la rete ad “apprendere” eventi del segnale vocale indipendenti dall’esatta locazione nel segnale stesso, ciò rende la rete invariante ai cambiamenti.
Fig. 1.4 Esempio di una time-delayed neural network.
Sebbene le TDNN siano state usate, con successo, in molte applicazioni, il loro impiego nel riconoscimento vocale è stato molto marginale. Ad esempio uno degli inconvenienti principali di queste reti è che il contesto temporale, utile per il classificatore, è predeterminato; c’è da aggiungere che la rete stessa non può trovare una finestra temporale ottimale per ottenere una informazione contestuale. Un ulteriore inconveniente deriva dalla necessità di sottoporre alla rete più frame alla volta, a differenza degli HMM, in cui il sistema riceve un frame alla volta e la segmentazione è dedotta dai dati. Questo problema può essere superato aggiungendo un feedback alla rete. La retroazione costituisce un metodo efficiente per aggiungere un contesto a una rete neurale, senza dover fornire dati multipli ai classificatori. Un secondo vantaggio è che si ottengono reti di dimensioni minori.
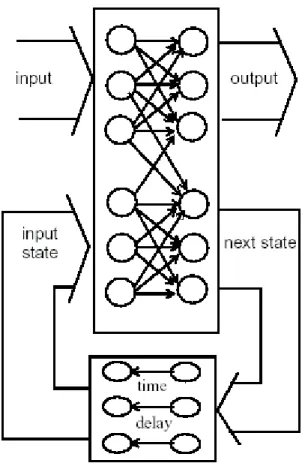
Le RNN sono esempi di reti a feedback [14,15]. La fig. 1.5 mostra una semplice struttura di RNN:
Fig. 1.5 Schema di una semplice RNN.
L’ingresso corrente e lo stato corrente formano l’ingresso alla rete, i due ingressi passano attraverso la rete per formare in uscita un vettore d’uscita e il prossimo stato corrente, che viene riportato in ingresso mediante una unità di ritardo. I parametri di una RNN sono stimati secondo un’efficiente procedura chiamata Back-Propagation Through Time (BPTT) [14].
Poiché le RNN processano un frame alla volta, esse sono spesso impiegate in sistemi ibridi di riconoscimento, dove la rete neurale funge da stimatore della probabilità a posteriori incorporata in sistemi con HMM [16].
L’ultimo tipo di classificatori da analizzare risulta essere quello basato sulle SVM, e la loro trattazione sarà fatta ampiamente nel capitolo III.
1.4 Specifiche tecniche del sistema per il
riconoscimento vocale
Le caratteristiche tecniche di un dispositivo di riconoscimento automatico sono scelte in funzione dell’uso che ne verrà fatto, perciò al sistema qui esaminato sono state attribuite determinate specifiche che ne permettessero un’utilizzazione proficua in ambito industriale. Per rispondere a questa esigenza il sistema si avvale dei requisiti qui di seguito elencati, per ciascuno dei quali sono stati anche evidenziati sia la peculiarità, sia i vantaggi che ne conseguono:
• Tipo di sistema speaker dipendente: per un database finito questi sistemi offrono prestazioni migliori rispetto a quelli SI. Gli aspetti positivi inerenti a questa opzione sono stati descritti nel primo paragrafo di questo stesso capitolo.
• Database finito anche se completamente definibile dall’utente: il sistema deve essere in grado di riconoscere, da un set finito, i singoli comandi senza la necessità di “legarli” insieme come nel riconoscimento di intere frasi.
• Tempo per il training breve: il sistema deve raggiungere la convergenza nel più breve tempo possibile, mantenendo comunque una buona accuratezza nel riconoscimento, inoltre l’utente deve poter fornire il minor numero di campioni originali per comando possibile in modo da non perdere molto tempo nella registrazione.
• Robustezza ai disturbi esterni: vista la necessità di applicazione del sistema in ambito industriale, esso deve essere in grado di effettuare un riconoscimento efficace anche in avverse condizioni di utilizzo (rumori di macchinari, voci di persone).
• Integrabilità in sistemi elettronici basati su DSP: per questa specifica si richiede una velocità di esecuzione elevata e una bassa occupazione di memoria sia di programma che di dati, a maggior ragione se il sistema deve essere integrato in un sistema portatile.
• Interfaccia semplice ed intuitiva che sia completamente attivabile con la voce. Tale caratteristica favorisce l’utilizzazione del dispositivo e di conseguenza crea i presupposti per una sua maggiore diffusione nel mercato.
Le prove effettuate per il raggiungimento delle suddette specifiche verranno descritte nel capitolo V, ma prima di fare ciò è opportuno analizzare le tecniche usate in tutto il processo di riconoscimento.
Cap. II
Acquisizione ed estrazione delle features del
comando vocale
In questo capitolo sarà affrontata la descrizione dettagliata del processo di acquisizione ed estrazione delle features dal segnale vocale relativamente al sistema di riconoscimento in oggetto.
2.1 Acquisizione del segnale
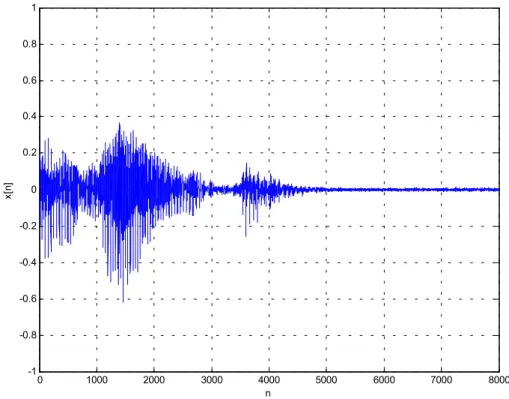
Come si verifica per ogni sistema di riconoscimento vocale, cui anche il nostro appartiene, il primo elemento da considerare riguarda l’acquisizione del segnale mediante un microfono. Nel nostro dispositivo il segnale in ingresso viene campionato tramite un convertitore A/D a 8 kHz. Per impedire che il sistema, una volta acceso, entri in funzione prima che sia sollecitato da un segnale utile, affinché venga evitata l’acquisizione di un campione che non corrisponda a nessun suono da riconoscere, è stato introdotto un comportamento a soglia, cioè se la tensione generata dal microfono per effetto del segnale audio in ingresso non supera i 0.2 V, allora l’acquisizione non parte. Se la soglia viene superata, il sistema registra 1 s di segnale che, campionato ad 8 kHz, corrisponde ad un vettore di 8000 punti. Riportando quest’ultimo in un grafico, dove in ordinata sia indicato il valore di questi punti e in ascissa la loro posizione, e unendo in seguito i punti adiacenti con una retta, si osserva qualitativamente l’andamento della
forma d’onda del segnale sonoro acquisito, come è mostrato in figura 2.1. 0 1000 2000 3000 4000 5000 6000 7000 8000 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 n x[n ]
Fig. 2.1 Forma d’onda qualitativa della parola “aumenta”.
La trattazione sulla durata temporale dei comandi sarà affrontata in modo particolareggiato nel capitolo V, ma già da ora anticipiamo che i comandi da riconoscere non hanno tutti la stessa durata, quindi, per la determinazione del corretto intervallo di appartenenza, viene applicata al segnale acquisito un’altra soglia. Essa agisce all’indietro, a partire dall’ultimo componente del vettore, fino a che non abbia raggiunto il punto in cui il segnale supera, per la prima volta, i 0.1 V. Il numero di punti tra le due soglie determina l’intervallo di appartenenza del comando. Pertanto l’applicazione della seconda soglia ha solo lo scopo di individuare la durata del segnale, infatti, per le successive elaborazioni del
campione sonoro, si utilizzeranno 5968 punti1, in modo da garantire una
uniformità sia nel numero di frame per singolo comando, sia nelle dimensioni dei frame stessi che debbono risultare tutti di uguale durata. Più avanti, nel cap. V,
1 Nella maggioranza dei casi i comandi non durano più di 75 ms e se eccedono tale misura
saranno elencate le prove effettuate per la determinazione della soglia ottimale, fissata a 0.1 V.
La figura 2.2 mostra l’andamento della parola “quattro” prima e dopo l’applicazione della seconda soglia.
500 1000 1500 2000 2500 3000 3500 4000 -1 -0.5 0 0.5 1 n x[ n] 0 1000 2000 3000 4000 5000 6000 7000 8000 -1 -0.5 0 0.5 1 n x[ n] Fig. 2.2.
2.2 Suddivisione in frame
Poiché elaborare direttamente un vettore di circa 6000 punti per estrarne delle caratteristiche significative non è semplice dal punto di vista computazionale, conviene suddividere il segnale in frame, magari sovrapposti (overlapping), in modo da attenuare eventuali brusche transizioni tra componenti adiacenti. Tale suddivisione, in questo lavoro, è attuata ricorrendo all’applicazione di finestre di Hamming di 1024 punti (128 ms), sovrapposte parzialmente di 100 punti (12.5 ms di overlapping). Si sono estratti quindi 7 frame per comando. I coefficienti di una finestra di Hamming possono essere calcolati secondo la formula:
(
)
, 1 2 cos 46 . 0 54 . 0 1 − − = + n k k w π k = 0,…., n-1.E’ stato preferito questo tipo di finestra per aggiungere una correlazione tra componenti spettrali adiacenti del frame stesso. Infatti se scegliamo la finestra rettangolare (il cui spettro è formato dal solo coefficiente in n = 0), questa non introdurrà alcuna modifica allo spettro del frame, invece, se si ricorre alla finestra di Hamming (il cui spettro (modulo) ha il primo, il secondo e l’ultimo coefficiente diversi da zero), modifichiamo lo spettro del frame, mediando il contributo di ogni campione dello spettro con i suoi vicini. Tuttavia, per maggiore completezza, nel cap. V saranno riportate anche le prestazioni che il sistema è in grado di fornire quando, al posto della finestra di Hamming, se ne usa una rettangolare.
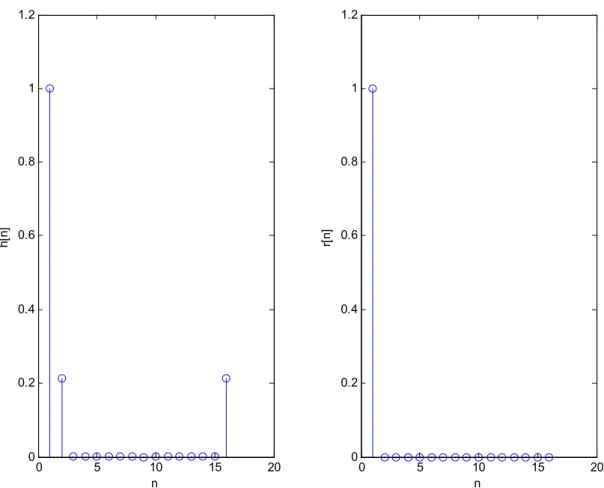
Nella figura 2.3 è illustrato l’andamento di una finestra di Hamming di 1024 punti, mentre nella figura 2.4 si può fare il confronto sull’andamento dello spettro di ampiezza della finestra di Hamming e di una finestra rettangolare, entrambe della stessa durata. Per una corretta interpretazione della figura 2.4 bisogna tener presente che è stato necessario ridurre drasticamente (da 1024 a 16) il numero dei punti delle finestre, per permettere una migliore visualizzazione degli andamenti spettrali rappresentati.
0 100 200 300 400 500 600 700 800 900 1000 0 0.2 0.4 0.6 0.8 1 n h[ n]
0 5 10 15 20 0 0.2 0.4 0.6 0.8 1 1.2 n r[ n] 0 5 10 15 20 0 0.2 0.4 0.6 0.8 1 1.2 n h[ n]
Fig. 2.4 Spettro di potenza normalizzato per una finestra di Hamming e una rettangolare di 16 punti.
2.3 MEL Cepstrum Analysis (MCA)
Per l’estrazione delle features dal frame è stata adoperata la tecnica MCA, che si compone dei seguenti passi di processo:
1. Calcolo della FFT (Fast Fourier Transform).
2. Filtraggio dello spettro di potenza con un banco di filtri a spaziatura logaritmica.
3. Costruzione della sequenza in uscita dai filtri, espressa in decibel. 4. Calcolo della DCT (Discrete Cosine Transform).
In particolare applicare al frame l’algoritmo FFT [17] su 1024 punti vuol dire calcolarne la DFT (Discrete Fourier Transform) che, per definizione, per una sequenza x(n), risulta:
( )
∑
= − − = N i k i N i x k X 1 ) 1 )( 1 ( , ) ( ω ω j N. N e / ) 2 (− π =Si noti che la lunghezza del frame (1024 punti) non è stata scelta a caso, infatti l’algoritmo della FFT può essere computato in modo ottimo solo con potenze di 2. Dunque adesso abbiamo a disposizione una sequenza di 1024 punti, questa volta non più reali, ma complessi. Moltiplicando questo vettore per il suo complesso coniugato, si ricava lo spettro di potenza del frame, come illustrato in figura 2.5.
0 50 100 150 200 250 300 350 400 450 500 0 0.2 0.4 0.6 0.8 1 1.1 Frequenza (Hz) P ot enz a no rm al iz za ta ( P (f) /m ax (P (f) ) Fig. 2.5.
Per semplificare questo spettro senza una significativa perdita di dati, è stato eseguito un filtraggio attraverso un set di 16 filtri BP (passa-banda). Le larghezze di banda e le frequenze centrali di questo banco sono state stabilite tenendo conto del funzionamento dell’udito umano che, come si evince da risultati sperimentali,
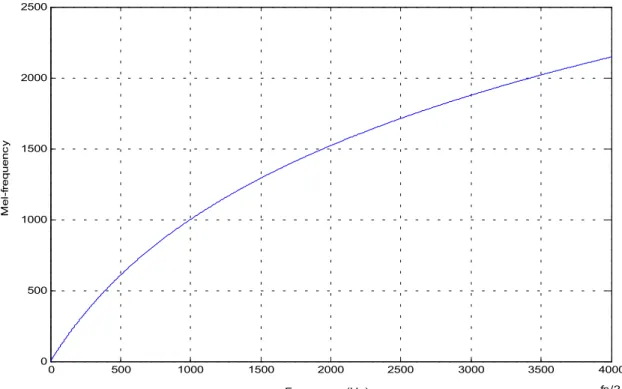
percepisce in modo non uniforme le diverse frequenze sonore. Una buona stima di questa risposta non lineare si può ottenere passando nel dominio di MEL (melodies) che si ricava dallo spazio delle frequenze tramite la formula [18]:
). 700 1 ln( 1127 ) 700 1000 1 ln( ) 700 1 ln( 100 f f m ≈ + + + =
Nella figura 2.6 è rappresentato l’andamento di m in funzione di f.
0 500 1000 1500 2000 2500 3000 3500 4000 0 500 1000 1500 2000 2500 Frequenza (Hz) M e l-fr eq ue n c y fs/2
Fig. 2.6 Relazione tra lo spazio di frequenze di Mel e le frequenze in Hz (fs è la frequenza di campionamento).
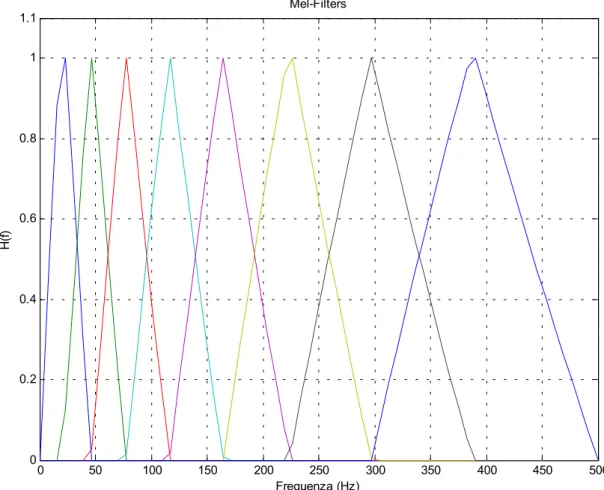
Un esempio della risposta del banco di filtri è schematizzato in figura 2.72.
2 Per maggiore chiarezza, nella rappresentazione il numero di bande è stato ridotto e la forma del
0 50 100 150 200 250 300 350 400 450 500 0 0.2 0.4 0.6 0.8 1 1.1 Mel-Filters Frequenza (Hz) H( f)
Il filtraggio in digitale, per questo banco di filtri, può essere agevolmente eseguito mediante la semplice moltiplicazione della matrice dei filtri per il vettore dello spettro di potenza del frame. Si è ottenuto così, in uscita da ogni filtro, un singolo valore che corrisponde alla somma delle potenze per una particolare banda, procedimento che riduce la precisione dello spettro fino al livello dell’orecchio
umano e a questo punto la sequenza ottenuta è stata espressa in decibel3. Il
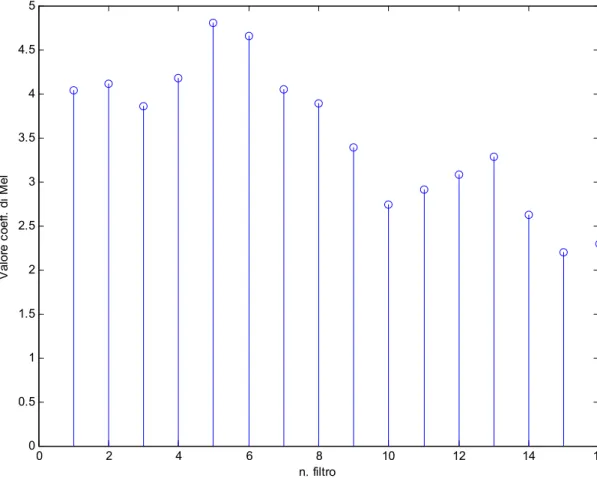
passaggio al logaritmo in base dieci risulta obbligatorio se si vuole rendere il sistema immune da eventuali differenze di volume dei campioni sonori. La figura 2.8 mostra i 16 coefficienti di Mel per la parola “quattro”.
0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 n. filtro Va lo re c oe ff. d i M el
Fig. 2.8 Coefficienti di Mel in uscita ad ogni filtro per la parola “quattro”.
3 In realtà non sono stati calcolati proprio i dB in quanto non è stata effettuata la moltiplicazione
L’aspetto più importante, quando si valuta uno spettro, è la sua forma. Essa è dovuta ai contenuti energetici delle varie armoniche. L’inviluppo dello spettro costituisce quindi un elemento per discriminare di che tipo di comando si tratti. Per enfatizzare questa forma si fa ricorso alla Cepstrum Analysis. Il cepstrum nella sua espressione più semplice è la trasformata inversa di Fourier (IDFT) dello spettro di frequenza in scala logaritmica di un segnale:
[
]
∫
− = π π ω ω ω π log ( ) . 2 1 ˆ X e e d x j j nPer segnali audio e nel riconoscimento vocale, in particolare, è conveniente utilizzare un cepstrum modificato. Una pratica procedura è quella di sostituire la IDFT con la trasformata discreta del coseno (DCT) che, per una sequenza x(n), si ricava mediante la formula:
( )
( )
∑
( )
(
)(
)
= − − = N n N k n n x k w k y 1 2 1 1 2 cosπ , con k = 1, ……, N e( )
N k w = 1 per k = 1; e( )
N k w = 2 per 2≤k≤ N.Questa alterazione abilita ad ulteriori future semplificazioni dei dati in uscita, inoltre la DCT è adoperata perché approssimazione della KLT (Karhunen Loèwe Transform) la quale è la trasformata che decorrela in modo ottimo una sequenza in ingresso [19].
Dopo avere trasformato con la DCT lo spettro semplificato, si è ottenuto il vettore delle features per il frame, come illustrato in figura 2.9.
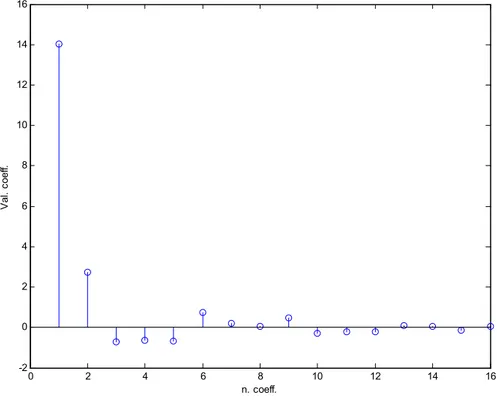
Di questi 16 coefficienti, il primo è il meno significativo, perché contiene informazioni sul valor medio e sulle bassissime frequenze del segnale in ingresso ed è variabile per ogni segnale, pertanto si può considerare disturbo e, come tale, di volta in volta viene scartato. Come appare in figura, l’ampiezza dei coefficienti diminuisce all’aumentare degli indici, di modo che gli ultimi coefficienti possono
essere trascurati in quanto danno poca informazione, gli altri, invece, sono relativi ai cambiamenti dell’inviluppo dello spettro.
0 2 4 6 8 10 12 14 16 -2 0 2 4 6 8 10 12 14 16 n. coeff. Va l. c oe ff.
Fig. 2.9 Features estratte dopo la DCT di un frame della parola “quattro”.
Il vettore definitivo delle features, per il frame, è formato dagli 8 coefficienti più rilevanti, cioè da quelli che vanno dal secondo al nono (figura 2.10).
Sono stati usati 16 filtri di Mel perché la DCT in molte implementazioni deriva dall’algoritmo della FFT [19] che, come già specificato, funziona in modo ottimizzato con potenze di 2.
Il procedimento descritto è stato scelto perché presenta notevoli vantaggi:
1. L’introduzione della scala di frequenze non lineare simula il funzionamento dell’orecchio umano.
2. La DCT viene eseguita in modo veloce perché il numero dei coefficienti è basso.
Se invece si fosse preferito non usare il banco di filtri e calcolare il cepstrum direttamente, si sarebbe ottenuto un numero rilevante di dati e computare la DCT su un elevato numero di campioni risulta molto costoso in termini di tempo.
Per ogni frame quindi si ottengono 8 coefficienti che moltiplicati per i 7 frame, forniscono un vettore di 56 elementi. Tale numero però è ancora troppo elevato visto che i sistemi di classificazione funzionano bene con un numero di features compreso tra 20 e 40. Si è deciso allora di operare un tipo di compressione dei dati tramite la formula:
( ) ( )
= +(
−) (
+ +)
4 1 1 x k k x k x n y , con 1 2 ,..., 1 − = N n e k = 2, 4,…, N-1.Le features definitive per il riconoscimento e la classificazione sono state ridotte a 27 per ogni comando.
Fig. 2.10 Features per il primo frame della parola “quattro”.
0 2 4 6 8 10 12 14 16 -1 -0.5 0 0.5 1 1.5 2 2.5 3 n. coeff. V al c oe ff.
Cap. III
Riconoscimento mediante
Support Vector Machines (SVM)
Una volta ottenute le features in base al procedimento esposto nel secondo capitolo, il sistema deve calcolare i parametri del modello per il riconoscimento, se sta operando nella fase di train, oppure classificare il segnale, se sta funzionando nella fase operativa. Tutto questo viene compiuto mediante l’utilizzo delle Support Vector Machines (SVM).
Nel capitolo I sono stati illustrati sistemi che modellavano il segnale vocale stimando una rappresentazione del segnale sonoro (HMM). Ad alto livello, però, il riconoscimento vocale può essere visto come un problema di classificazione, pertanto i classificatori che calcolano la regione di decisione, piuttosto che stimare una distribuzione di probabilità partendo dal database, dovrebbero fornire prestazioni migliori. Una SVM è una tecnica di apprendimento che calcola la regione di decisione attraverso un processo di discriminazione e presenta buone caratteristiche di generalizzazione [20]. Le SVM si sono dimostrate degli strumenti di gran lunga efficaci in molti classici problemi di riconoscimento [21]. Questo capitolo si occuperà sia dei fondamenti matematici alla base delle SVM sia delle loro applicazioni nei sistemi di riconoscimento in generale e in particolare in quello che costituisce l’oggetto di questa tesi.
3.1 Apprendimento e classificazione
Supponiamo che i dati nel database (training data) consistano in coppie, (x1, y1),
(x2, y2),… dove xi sono i campioni in ingresso e yi sono i risultati in uscita. Lo scopo di una macchina per l’apprendimento è di trovare la funzione y = f(x). Assumiamo che i dati siano stati forniti in modo casuale e indipendente secondo la distribuzione congiunta, ignota, P(x, y). Per “apprendere” la funzione sconosciuta, è opportuno stimarne una qualsiasi che sia “vicina” alla distribuzione congiunta oppure calcolare un predittore ottimo per l’uscita del sistema. Il processo, quindi, per la classificazione, deve trovare una legge, che, basandosi sui campioni esterni, assegni un oggetto alle varie classi. Per esempio, come si è visto nel paragrafo 1.3, in una rete neurale, il problema consiste esclusivamente nel trovare i pesi delle connessioni di una rete predefinita. Poiché la struttura della rete neurale è preimpostata, il set di reti tra le quali scegliere risulta finito. La rete ottimale viene stabilita basandosi su opportuni criteri che ne misurano la qualità. Definiamo un termine di qualità della funzione prescelta: il rischio. Lo spazio di
lavoro è un sottospazio Z di uno spazio n-dimensionale diℜ , che è l’unione dello
spazio dei vettori in ingresso e di quello dei vettori d’uscita. Assumiamo
l’esistenza di un set di funzioni
{
}
e di una funzione R, che misuri ilrischio come: n Z z z g( ), ∈
∫
= ( , ( )) ( ) )) ( (g z L z g z dP z R , (3)dove L è una funzione di perdita opportuna e P è la distribuzione di probabilità congiunta precedentemente citata. Il problema della minimizzazione del rischio è quello di minimizzare la funzione (3) per uno specifico training set. In realtà il processo di minimizzazione coinvolge la ricerca della parametrizzazione ottima della funzione g(z), che si può rappresentare parametricamente g(z, a); a questo punto è opportuno specificare che a non implica necessariamente che il problema
sia ristretto a una forma parametrica in quanto a può essere uno scalare, un vettore o un altro elemento funzionale astratto.
Con le modifiche alla funzione R di cui sopra, il rischio si può riscrivere come:
∫
= ( , ) ( )
)
(a Q z a dP z
R , dove Q(z,a)=L(z,g(z,a)).
La funzione Q è la funzione di perdita. Scegliere un appropriato valore da attribuire ad a per minimizzare R(a) comporta la minimizzazione del rischio; questa, però, non è un’operazione semplice da eseguire in quanto la distribuzione congiunta P non è nota a priori.
Il problema si può semplificare significativamente se si tenta di minimizzare una variante della R(a) che va sotto il nome di rischio empirico:
∑
=1 ( , ) ) ( Q z a l a Remp i .Remp è, perciò, l’errore medio computato sul numero fisso di campioni del
database assumendo che essi siano uniformemente distribuiti e considerando che
si prendono in esame un numero l di dati z1,z2,...,zl.
La Minimizzazione del Rischio Empirico (ERM) è una delle più comuni procedure di ottimizzazione nell’apprendimento automatizzato. L’ERM è computazionalmente più semplice da attuare che minimizzare direttamente la R(a), in quanto, così facendo, si aggira la necessità di stimare la P. Nella maggior parte dei casi l’ERM produce una buona macchina per l’apprendimento. Esistono una varietà di funzioni di perdita, un esempio è:
) , ( ) , (x y y f x a Q = − ,
dove y è l’uscita del classificatore, mentre x è il vettore in ingresso.
Esistono molte configurazioni di macchine per l’apprendimento che forniscono lo stesso rischio empirico. Per capire come scegliere la migliore configurazione si deve analizzare la relazione che intercorre tra il rischio attuale e quello empirico.
Per arrivare a questo risultato, è necessario prendere in considerazione i punti seguenti:
1. Si deve conoscere il minimo rischio ottenuto usando la Q , dove l è
uguale alla dimensione del campione.
) ,
(z al
2. Si deve considerare la differenza tra questo rischio e quello ottenuto con la (rischio minimo attuale).
) ,
(z a0
Q
Vapnik [21] provò che gli estremi per il rischio attuale esistono e sono: ). ( ) ( ) ( R f h Rα ≤ emp α + (4)
La quantità h è la Dimensione di Vapnik-Chervonenkis (VC) [20,22] ed è una misura della capacità di una macchina per l’apprendimento. Più formalmente, essa è definita come la massima lunghezza dei vettori ai quali si può applicare la funzione . Un campione X di dimensione m si può trattare con Q se Q permette di ottenere tutte le possibili classificazioni di X. Inoltre se f(h) è piccolo, la macchina generalizza bene, poiché è garantito che il rischio attuale sia prossimo al rischio empirico precedentemente minimizzato con il principio dell’ERM.
) ,
(z al
Q
Un’estensione dell’ERM è il principio della Minimizzazione Strutturale del Rischio (SRM). Si tratta di provare a identificare il punto ottimo sulla curva che descrive il limite sul rischio sperato. Il principio dell’SRM definisce un compromesso tra la qualità dell’approssimazione dei dati forniti e la complessità della funzione di approssimazione [22]; la dimensione VC viene usata come variabile di controllo per l’abilità di generalizzazione della macchina per l’apprendimento.
In pratica l’SRM può essere implementato in due modi distinti:
1. Per un intervallo di confidenza fisso, ottimizza il rischio empirico.
2. Per un rischio empirico fisso, ottimizza (o minimizza) l’intervallo di confidenza.
La decisione di usare l’una o l’altra implementazione dipende sia dal problema da risolvere sia dal classificatore. Infatti nell’apprendimento con reti neurali si usa la prima procedura, fissando preliminarmente la struttura della rete e minimizzando poi il rischio empirico. Le SVM implementano l’SRM usando il secondo approccio, dove il rischio empirico è fissato a un minimo (tipicamente zero per set di dati separabili) e il processo di apprendimento delle SVM ottimizza per un minimo dell’intervallo di confidenza. L’SRM si differenzia quindi dall’ERM in quanto introduce il vincolo che una struttura sia aggiunta allo spazio contenente la funzione ottima.
3.2 Stima di un Classificatore Lineare Ottimale
per gli Iperpiani
La seguente trattazione si basa sul fatto che, tra tutti gli iperpiani che separano i dati, esiste un unico iperpiano che massimizza il margine di separazione tra le classi [22]. La figura 3.1 illustra un tipico esempio di classificazione per un problema con due classi di dati dove i campioni sono perfettamente separabili mediante una regione di decisione lineare.
Fig. 3.1 Definizione di un classificatore lineare. Le SVM sono costruite massimizzando il margine.
H1 e H2 definiscono due iperpiani e la distanza tra essi viene chiamata margine. I campioni più vicini delle due classi giacciono su questi due iperpiani. Come è stato evidenziato nel paragrafo precedente, il principio dell’SRM impone una struttura al processo di ottimizzazione e, nel caso dell’ordinamento degli iperpiani, questo vincolo è dato proprio dal margine. L’iperpiano ottimo è quello che massimizza il margine minimizzando il rischio empirico.
In figura 3.2 sono mostrate le differenze nell’uso dell’ERM e dell’SRM nella stima di un semplice iperpiano classificatore. Usando l’SRM si ottiene l’iperpiano ottimo.
Fig. 3.2 Esempio delle differenze nell’uso dell’ERM e dell’SRM. Gli iperpiani C0, C1 e C2 compiono l’ottimizzazione perfetta così che il rischio empirico viene annullato. Comunque, C0 risulta essere l’iperpiano ottimo perché massimizza il margine.
Sia w il vettore normale alla regione di decisione. Se i campioni per il training si
rappresentano come l coppie {xi, yi}, i = 1, …, l e y = ± 1, i punti che stanno
sull’iperpiano che separa i dati soddisfano la relazione:
w · x + b = 0
dove b è la distanza dell’iperpiano dall’origine. Sia il margine delle SVM la distanza dall’iperpiano di separazione dei più vicini campioni tanto positivi che negativi: il processo di training delle SVM trova l’iperpiano di separazione che fornisce il margine massimo. Una volta ottenuto l’iperpiano, tutti i campioni soddisfano alle seguenti disuguaglianze:
xi · w + b + 1 per ≥ yi = +1 (5)
xi · w + b - 1 per ≤ yi = -1. (6)
Guardando queste relazioni si vede che nella figura 3.1 tutti i punti che le soddisfano si trovano sugli iperpiani H1 e H2 e il margine risulta essere di due unità, poiché la normale all’iperpiano non è vincolata ad essere di modulo
unitario, abbiamo bisogno di normalizzare questo margine con la norma del vettore perpendicolare all’iperpiano, w. Per massimizzare il margine si deve massimizzare perciò 1/||w||. Esistono tecniche eleganti per ottimizzare funzioni
convesse con vincoli [23], di conseguenza si preferisce minimizzare ||w||2 che è
una funzione convessa.
I vettori del training che rispettano la (5) e la (6) sono chiamati support vectors e, in figura 3.1, sono indicati con cerchi concentrici che stanno sugli iperpiani H1 e H2.
Per risolvere il problema di minimo vincolato, di solito si ricorre alla teoria dei moltiplicatori di Lagrange [24], che consente di ottenere una funzione di decisione del tipo: f(x) =
∑
xi · x + b (7) = N 1 i i iy αIl segno di f può essere usato per la classificazione dei campioni appartenenti alle due classi. In altre parole l’equazione (7) definisce il classificatore delle SVM. Si nota che esso è funzione dei campioni per il training. D’altronde non tutti questi ultimi contribuiscono alla definizione del classificatore, ma solamente i campioni con moltiplicatori non nulli e cioè i cosiddetti support vectors. Il set di dati fornisce, per così dire, l’entità di quanto complesso deve essere il classificatore. Per problemi di classificazione semplici, il numero di support vectors è piccolo e viceversa. Poiché ci sono M prodotti scalari nel calcolo del classificatore, dove M è il numero di support vectors, allora la complessità della classificazione cresce linearmente con il numero degli stessi.
Ci siamo posti il problema dei classificatori degli iperpiani come un problema di ottimizzazione, tuttavia, da una parte nulla fino ad ora ci ha condotto all’esistenza di un ottimo e, d’altro canto, se un tale punto ottimale esiste, niente ci assicura che esso sia unico. Questi due problemi vengono risolti dal teorema Karush-Kuhn-Tucker (KKT). Esso ha trovato largo uso nei problemi di ottimizzazione specificamente in quelli che trattano funzioni convesse. La definizione del teorema è la seguente:
siano f, h, g tre funzioni e sia x* un punto dei dati nonché un minimo locale per la
minimizzazione di f soggetto a h(x) = 0, g(x) 0. Allora esiste un e un
tali che: ≤ λ*∈ℜm p ℜ ∈ * µ . 0 *) ( * , 0 *) ( * *) ( * *) ( , 0 * = ∇ = ∇ + ∇ + ∇ ≥ x g x g x h x f T T T µ µ λ µ
Nell’enunciato di cui sopra, l’operatore ∇ rappresenta l’operazione di derivazione
rispetto alla variabile indipendente x, mentre λ e sono i moltiplicatori di
Lagrange associati ai vincoli.
µ
Nel processo di ottimizzazione delle SVM usando la terza delle condizioni del KKT con la (5) e la (6) si ottiene:
i
α (yi(xi · w + b) – 1) = 0
che è significativa solo se α è non nullo, quindi solo per quei campioni che soddisfano la relazione:
i
yi(xi · w + b) = 1.
Come evidenziato prima, questi campioni vengono chiamati support vectors. Fino ad ora abbiamo preso in considerazione il caso di dati per il train completamente separabili usando un margine lineare. I problemi di classificazione, tipicamente, presentano dati non separabili. L’ottimizzazione in tali situazioni è tipicamente compiuta tramite l’uso di classificatori di tipo soft decision con i quali la classificazione di un campione si associa alla probabilità. In figura 3.3 si vede un semplice iperpiano classificatore con due errori di training.
Fig. 3.3 Esempio di un classificatore soft margin che è robusto agli errori di training.
Nei casi di questo tipo i vincoli che devono essere soddisfatti dall’iperpiano diventano:
xi · w + b + 1 - ≥ ξi per yi = +1, (8)
xi · w + b - 1 + ≤ ξi per yi = -1, (9)
ξi ≥ 0 ∀ i.
Dove le ξ sono le variabili errore. Ora rimane il problema di trovare l’iperpiano con il minimo numero di errori ed esso si può risolvere minimizzando la funzione:
2 1 ) ( +
∑
i i C θ ξ ||w||2.Quest’ultima che è soggetta alle disuguaglianze (8) e (9), contiene θ che è una funzione la quale misura il costo di un errore di training e C che è la penalità associata a tale errore. Più alto è il valore di C, maggiori sono le difficoltà cui il processo di ottimizzazione andrà incontro per minimizzare gli errori di training. Questo può portare a un lungo tempo per la convergenza e a un elevato set di support vectors.
3.3 Iperpiani classificatori non lineari
Nel paragrafo precedente abbiamo visto la stima di classificatori lineari per casi in cui i dati erano separabili o non separabili. Ciò, comunque, non ci aiuta a risolvere molte situazioni reali dove si necessita di superfici non lineari per la separazione dei dati.
Il punto di forza delle SVM sta nella capacità di trasformare i dati in uno spazio multi dimensionale e costruire un classificatore binario lineare in questo spazio. Nelle formulazioni dell’ottimizzazione dei precedenti paragrafi si vede che i dati vengono trattati con il prodotto scalare. Supponiamo, allora, che i dati vengano
trasformati in una dimensione maggiore tramite una funzione Φ
dove n è la dimensione dello spazio di partenza e N è la dimensione del nuovo spazio delle features. In questo nuovo spazio possiamo ancora costruire un classificatore lineare ottimale con la sola differenza, rispetto al precedente, che
stavolta il prodotto scalare della (7) sarà il risultato di Φ . Può essere
vantaggioso definire allora una funzione “kernel” K,
, :ℜn →ℜN ) j x ( ) (xi ⋅Φ K(xi, xj) = Φ(xi)⋅Φ(xj),
che computa direttamente questo prodotto scalare senza che sia nota la forma esplicita di Φ. In questa nuova formulazione, la funzione decisione avrà la forma:
f(x) =
∑
K(x, xi) + b. = N 1 i i iy αPerché la funzione K sia un kernel valido, essa deve soddisfare a certe condizioni. La più importante proprietà è quella che K deve essere un prodotto scalare in qualche spazio delle features. Per affermare che una funzione rappresenti un prodotto scalare in uno spazio multidimensionale si ricorre al teorema di Mercer il
quale assicura che, per un dato kernel, esiste una coppia {H, Φ}, dove H definisce il nuovo spazio delle features [22,25].
Facciamo un esempio di quanto detto sopra: supponiamo che i nostri dati
appartengano a uno spazio a due dimensioni ℜ2 e che li vogliamo trasportare in
uno spazio ℜ3; possiamo scegliere un kernel K = (x ⋅ y)2. Per questo problema è
facile trovare una funzione, Φ, dallo spazio di partenza al nuovo spazio come:
(x ⋅ y)2 = Φ(x) ⋅ Φ(y).
Se si definisce x come {x1, x2} e y come {y1, y2}, allora:
(x ⋅ y)2 = x12y
12 + x22y22 + 2x1x2y1y2,
che è verificata se si definisce Φ come:
Φ(x) = 2 2 2 1 2 1 2 x x x x .
Questo esempio mostra che è possibile usare i kernel per trasformare implicitamente i dati in uno spazio di dimensioni maggiori.
Alcuni tra i kernel più usati sono:
K(x, y) = (x ⋅ y + 1)d (polinomiale di grado d), K(x, y) = Sigmoid[s(x ⋅ y) + c] (sigmoide),
K(x, y) = exp{-ϒ|x – y|2} (radial basis function (RBF)).
Si è scoperto che i kernel RBF sono i più potenti tra quelli sopra menzionati. Essi, a differenza di quelli polinomiali, possono trattare superfici di decisione molto