UNIVERSITA DEGLI` STUDI DIPISA
D
IPARTIMENTO DII
NFORMATICAD
OTTORATO DIR
ICERCA INI
NFORMATICAP
H.D. T
HESISAn Integrated Environment For Automated
Benchmarking And Validation Of XML-Based
Applications
Jinghua Gao
SUPERVISORS Antonia Bertolino Eda Marchetti REFEREES Franco Turini Giorgio GhelliNovember 18, 2009
Acknowledgments
I would like to express my gratitude to all those who helped me during the writing of this thesis. Without their encouragement and assistance, this thesis would not have been completed.
My deepest gratitude goes first and foremost to Antonia Bertolino, my supervisor. She gave me much inspiration and encouragement during my academic studies. In this thesis year, she gave much time, and provided valuable guidance in every stage of thesis writing. Without her honest support, impressive kindness and patience, I could not have completed my thesis. Her hard-working attitude and optimistic spirit inspired me not only in this thesis but also for my future life and study.
My great gratitude also goes to Eda Marchetti, who is my minor advisor, and Andrea Polini. They offered great assistance in my research. When I doubted myself, they always brought confidence and great ideas to me. The completion of my research and this thesis can not be separated from their kindly supports.
I would like to thank Professor Pierpaolo Degano and Andrea Maggiolo Schettini who gave me a great and kindly help when I had a difficult time finishing the thesis. I wish to thank also Professor Giorgio Ghelli and his student Luca Pardini, who provided me with an useful case study. I also want to thank my dear colleagues in the Software Engineering lab, Antonino Sabetta, Francesca Lonetti, Guglielmo De Angelis, Cesare Bertolini, Daniela Mulas and Alberto Ribolini. They are my good friends; our lab was like a warm family. They always gave me a hand when I needed help, not only in academics, but also in my life. I enjoyed very much my time with them.
I thank my husband Yan He, he always supports me with his love, understanding and tolerance. Without his encouragement, I probably would never have reached this achievement.
Abstract
Testing is the dominant software verification technique used in industry; it is a critical and most expensive process during software development. Along with the increase in software complexity, the costs of testing are increasing rapidly. Faced with this problem, many researchers are working on automated testing, attempting to find methods that execute the processes of testing automatically and cut down the cost of testing.
Today, software systems are becoming complicated. Some of them are composed of several different components. Some projects even required different systems to work to-gether and support each other. The XML have been developed to facilitate data exchange and enhance interoperability among software systems. Along with the development of XML technologies, XML-based systems are used widely in many domains. In this thesis we will present a methodology for testing XML-based applications automatically.
In this thesis we present a methodology called XPT (XML-based Partition Testing) which is defined as deriving XML Instances from XML Schema automatically and sys-tematically. XPT methodology is inspired from the Category-partition method, which is a well-known approach to Black-box Test generation. We follow a similar idea of applying partitioning to an XML Schema in order to generate a suite of conforming instances; in addition, since the number of generated instances soon becomes unmanageable, we also introduce a set of heuristics for reducing the suite; while optimizing the XML Schema coverage. The aim of our research is not only to invent a technical method, but also to at-tempt to apply XPT methodology in real applications. We have created a proof-of-concept tool, TAXI, which is the implementation of XPT. This tool has a graphic user interface that can guide and help testers to use it easily. TAXI can also be customized for specific applications to build the test environment and automate the whole processes of testing.
The details of TAXI design and the case studies using TAXI in different domains are presented in this thesis. The case studies cover three test purposes. The first one is for functional correctness, specifically we apply the methodology to do the XSLT Testing, which uses TAXI to build an automatic environment for testing the XSLT transformation; the second is for robustness testing, we did the XML database mapping test which tests the data transformation tool for mapping and populate the data from XML Document to XML database; and the third one is for the performance testing, we show XML benchmark that uses TAXI to do the benchmarking of the XML-based applications.
Contents
1 Introduction 11
1.1 Motivations and Objectives . . . 12
1.2 Outline of The Thesis . . . 15
1.3 Publication List . . . 16
I Background and Related Work
19
2 Background 21 2.1 Software Testing And Related Concepts . . . 212.1.1 White-box Testing and Black-box Testing . . . 23
2.2 Category-Partition Methodology . . . 26
2.3 Pair-wise Testing . . . 27
2.4 XML Schema Fundamentals . . . 28
2.4.1 Brief Introduction of XML Language . . . 28
2.4.2 Document Type Definitions . . . 30
2.4.3 XML Schema . . . 31
2.4.4 Elements and Constraints of XML Schema . . . 32
2.4.5 XML Document Validation . . . 33
2.5 Summary . . . 34
3 Related Work 37 3.1 Related XML Testing . . . 37
3.1.1 XML and XML Schema Document Testing . . . 38
3.1.2 Conformance Testing . . . 38
3.1.3 Using Derived XML Document or XML Schema . . . 40
3.1.4 Adopting Perturbation Testing . . . 41
3.2 Syntax-based Testing . . . 41
3.3 XML Benchmarks . . . 42
II XML-based Partition Testing Methodology and
Implementa-tion
45
4 XML-based Partition Testing 47
4.1 Main Methodology of XPT . . . 47
4.1.1 XML Schema Analysis and Rewriting . . . 50
4.1.2 Subschema Derivation . . . 52
4.1.3 Element Identification . . . 54
4.1.4 Element Value Determination . . . 54
4.1.5 Constraint Determination . . . 55
4.1.6 Intermediate Instance Generation . . . 55
4.1.7 Test Case Generation . . . 59
4.2 XPT Test Strategy Selection . . . 61
4.2.1 Weight Assignment . . . 61
4.2.2 Test Strategies . . . 62
4.3 Summary . . . 64
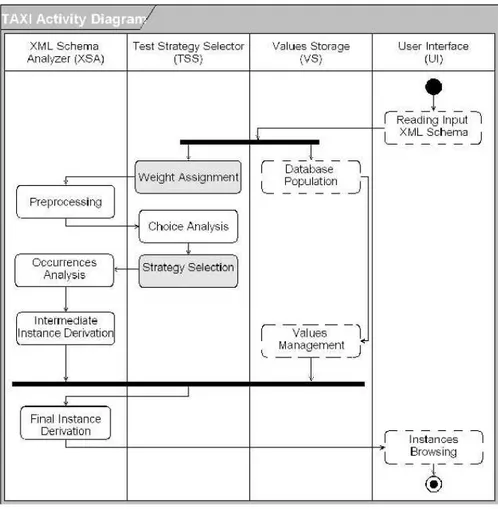
5 TAXI - The Implementation Of XPT 65 5.1 The Overview Of TAXI . . . 65
5.2 TAXI Components . . . 67
5.3 User interface . . . 68
5.3.1 XML Schema Input and Weight Assignment . . . 68
5.3.2 Database Population . . . 70 5.3.3 Instance Browsing . . . 71 5.4 Implementation of XSA . . . 71 5.4.1 Preprocessor . . . 73 5.4.2 Subschema Generation . . . 79 5.4.3 Occurrence Analysis . . . 81
5.4.4 Intermediate Instance Derivation . . . 83
5.4.5 Final Instance Derivation . . . 84
5.5 Implementation of TSS . . . 86
5.5.1 Application of Weights . . . 86
5.5.2 Strategy Selection . . . 87
5.6 Summary . . . 89
6 Cover Set Of TAXI 91 6.1 Test Cases of <element> . . . . 91
6.1.1 <element> . . . . 92
6.1.2 <element> With “default” Attribute . . . . 93
6.1.3 <element> With “fixed” Attribute . . . . 93
6.2 Test Cases of <SimpleType> . . . . 94
6.2.1 <simpleType> With Child <restriction> . . . . 94
0.0. CONTENTS 9
6.2.3 <simpleType> With Child “list” . . . . 95
6.3 Test Cases of <complexType> . . . . 96
6.3.1 <complexType> With Child <simpleContent> . . . . 97
6.3.2 <complexType> With Child <complexContent> . . . . 98
6.3.3 Test Cases of <sequence> . . . . 99
6.3.4 Test Cases of <all> Element . . . 103
6.3.5 Test Cases of <choice> Element . . . 105
6.4 Test Cases Of <Redefine> . . . 109
6.4.1 Redefine The <ComplexType> Element . . . 109
6.4.2 Redefine The <SimpleType> Element . . . 110
6.5 Test Cases Of <any> and <anyAttribute> . . . 110
6.5.1 Test Case Of <any> Element . . . 110
6.5.2 <anyAttribute> Element . . . 110
6.6 Summary . . . 110
III XPT Applications
115
7 XSLT Transformation Testing 117 7.1 Introduction . . . 1177.2 Automatic Validation of XSLT Stylesheet . . . 118
7.3 Case Study . . . 120
7.3.1 Marc21 and Dublin Core . . . 120
7.3.2 Driving the Generation Process . . . 123
7.3.3 Comparison of TAXI With Other Instance Generators . . . 127
7.4 Summary . . . 128
8 XML Database Mapping Test 129 8.1 Introduction . . . 129
8.2 Black-Box Testing For XML-database Mapping . . . 130
8.3 Case Study . . . 131
8.3.1 MySQL Database . . . 131
8.3.2 XML-database Mapper(myXDM) . . . 131
8.3.3 Testing myXDM Tool . . . 134
8.4 Summary . . . 137
9 The Application Of TAXI to XML Benchmarks 139 9.1 Introduction . . . 139
9.2 Benchmarks for XML-based Applications . . . 140
9.3 Case Study . . . 141
9.3.1 Background . . . 141
9.4 Advantages and Disadvantages of TAXI In Meeting The Requirements of
Benchmarks . . . 146
9.4.1 How TAXI Meets the Requirements of XML Benchmark . . . 146
9.4.2 Limitations of the TAXI tool for Benchmarking . . . 148
9.5 Summary . . . 148
10 Conclusion and Future Work 149
Chapter 1
Introduction
The computer is one of the greatest scientific inventions of the twentieth century. At the beginning, the computer was just used as a calculator to solve complex figures, and deci-pher code. As its use has developed, computer technologies have become more and more important in our lives. They are changing our daily life, the electric appliances running depend on computer technologies bring a lot of convenience and joy to our life. Advanced computer technologies are changing the way of people communicate. With development of the Internet, People can see each other with video cameras even though they are sepa-rated by thousands of miles. Computer technologies are also changing the ways we obtain information. Instead of book, now many people prefer to obtain information from the In-ternet or digital libraries, using one or more key words, search engines will list all related entries; it takes only seconds.
A reliable computer system requires not only the designed hardware; a well-functioning and robust software system is also indispensable. Along with widespread use of computer technologies, the concept of software engineering which is the application of a systematic, disciplined, quantifiable approach to development, operation, and mainte-nance of software [IEE90] has evolved steadily, and becomes more and more significant during computer system development.
In this thesis we concentrate on Software Testing, which is a process, or a series of processes, designed to make sure that computer code does what it was designed to do and that it does not do anything unintended [Mye04]. The activities of testing could run through the whole life cycle of software, and it is the most expensive part of software development. As experimentation, fifty percent or even more of development resources are spent on software testing [Bei90a]. The challenge of testing software adequately with minimal resources, as quickly and thoroughly as possible has become the goal and dream of testing. It has also become the drive of many researchers [Ber07]. To accomplish the goal of testing, people are turning to automated testing, which is “the management and performance of test activities, that include the development and execution of test scripts so as to verify test requirement, using an automated test tool” [ED00].
1.1 Motivations and Objectives
As already presented, during development process Software Testing is the most expensive part. But a system without testing is even more expensive. The further along in the development process an error is found, the more costly it is to correct it.
Unfortunately, the fact is that even with ample and proper testing, we can never en-sure that a software product is perfect, even if it has a simple structure. Along with development of computer science, instead of traditional manual testing, Automated Soft-ware Testing has become a new hot spot of research. People hope to reduce the costs and increase reliability by performing the analysis by computer, which in generally much quicker and more powerful than the human brain. This desire is good, but if Automated Testing is not developed in a proper manner, it brings higher risks, and becomes even more expensive than manual testing.
There are different methodologies of applying automated software testing. With the White-box Testing strategy, model-checking is a widely-used way for applying automated software testing; for Black-box Testing, deriving test cases from the system specifications is a useful and common way for automated testing. Formal standard organizations such as W3C, OMG and so on are developing standard software specifications; also there is much research focused on the formal description of system specifications.
Since software systems are turning out to be “more and more complicated with com-ponents developed by different vendors and using different techniques in different pro-gramming languages and even run on different platforms”, a concern that becomes creasingly crucial is interoperability. In the pursuit of working interoperability among in-dependently developed systems, industry is increasingly adopting open specifications and binding such specifications to standardised technologies. Such binding technologies must be open in nature, to allow for a wide range of diverse platforms, languages, and tools to be used, and still create compliant applications and content. The eXtensible Markup Language (XML) [Har99] is today the predominant format for data representation and is generally recognized as the standard way to exchange information between remote sys-tems and to bind the specifications [W3C05b]. In few years this language has established itself as the de facto standard form for specifying and exchanging data and documents between almost any digital or web application. Now XML applications are in widespread use for many areas, such as data and information preservation, data interchange, database population and for web applications. Therefore XML testing has become an interesting topic for many organizations and researchers. We are also enthusiastic about testing soft-ware systems based on XML. Considering the activities of automated testing, we would like to find a way for carrying out the testing of XML-based applications automatically.
Before starting methodology development, we first reviewed in depth the available literature, and found there are some systems taking XML Documents as input. Sometimes these documents must specially conform to specific rules.
The rules are usually defined by XML Schemas, which could be DTD [DTD96], RE-LAX NG [dV04], XML Schema, or other schemas. Among these schemas, currently XML Schema is the most powerful and flexible one. Along with the development of
1.1. MOTIVATIONS AND OBJECTIVES 13
XML, XML Schema has sprung up as a notation for formally describing what consti-tutes an agreed valid XML Document within an application domain. Compared with other schemas, XML Schema is more widely used by XML developers [Sri]. Also XML Schema actually conforms to the grammar of XML, so it is a well-structured language. XML Schema expresses the basic rules and constraints on data and parameters that di-verse classes of systems and web applications exchange; thus it provides an accurate and formalized representation of the input domain in a format suitable for automated process-ing, which clearly has big potential for test automation.
Based on the characters of XML and XML Schema, we have attempted to find a method that can automatically test XML-based systems. For systems that take XML doc-uments as input, the corresponding XML Schema can be considered as the specification of system input, or the grammar of system required data. Therefore, if we can get a set of XML documents that includes all possible or at least a portion of important derived XML documents from the XML Schema, these documents can be used as test cases to do the Black-box Testing to validate the behavior of XML-based systems.
The first aim of our methodology is “Automation”. With the increase in software complexity, testing needs more time to design and execute. But with the pressure of market competition, the cycle of software development is shortening. In this case, testing needs to be more efficient and execute within a shorter time frame.
To apply the Automation, first we need to know which activities of software test-ing those could be applied automatically. Accordtest-ing to the activities of normal software testing [Ber04], there are some test activities that could be automated. Those activities become the main activities of automated software testing [MF94].
The activities of automated testing include:
• Test Condition Identification: This activity determines the object that needs to be
tested, and the conditions of testing according to the test specification. It is the basis of the next steps of the testing.
• Test Case Design: Test cases are designed according to the test specification, by
determining test cases which comprise specific input values, expected outcomes, and any other information needed for testing.
• Test Case Generation: Test case generation builds the test cases by the conditions
and constraints of test case design; the test cases should cover the system input and output domains, or the paths on which the system could be run. To cover all values of these domains is difficult, but representative values should be included in the test cases;
• Test Case Execution: Test case execution is to run the software under testing with
the test cases;
• Test Result Analysis: Test result analysis is to check if the actual test outcomes
conform to the expected outcomes. The system passes the testing only if all the outcomes are consistent with the expected outcomes.
Based on these five activities of automated testing, the first step is “test condition identification”, we have already identified the XML-based applications as the test object; meanwhile the input domain of the application should be defined by an XML Schema. Then the main work is design and generate the test cases.
For testing purposes, only “Automation” is not enough; the derived test cases should be organized and must cover the representative possible inputs of the system, otherwise the result of testing is not reliable. Therefore the second aim of our methodology is “Systematization”.
Systematic testing is executed with a special purpose, it is ordered, planned, and test-ing designed to be purposefully methodical in its approach. Systematic testtest-ing is useful in initial examinations, where testing time is relatively brief, or when learning general soft-ware behavior. Systematic testing requires an in-depth analysis of the application and the application’s components at a very granular level. Some systematic testing approaches include equivalence class partitioning, boundary value analysis, combinatorial analysis, state transition testing, basis path testing, etc.
There are several tools that can generate XML Instances automatically, such as Sun XML Generator [XML99], XMLSpy [XML05b] and Stylus Studio [Cor08], but the XML Instances derived from these tools are not systematic. Sun XML Generator generates random instances, XMLSpy and Stylus Studio generate only the fix numbers of instances. It could be sufficient for some kind of testings, and for a lot of testing applications, random generations are not suitable and the test cases are not qualified enough.
There are tools such as [XML04], [tox05] that can derive XML documents from XML Schema systematically, but the generation is based on instructions that are designed and written by the user. The creation of instructions requires the user to have sufficient knowl-edge of specific XML Documents and the XML Schemas; it also depends greatly on the experience of the user. Our aim is to create a method that can analyse structure of the XML Schema and guide the generation totally automatically and systematically.
After the study, we found that XML Schema is well-structured with clear levels, since it is based on XML language. So it lends itself quite naturally to the application of parti-tion testing, in which a system is tested at its I/O interface by identifying relevant classes of input values, and by systematically choosing some representative test input values for each identified class. The basic assumption behind partition testing is that the input do-main can be divided into subdodo-mains, such that, for testing purposes, within each of them the program “behaves the same” (and then for every point within a subdomain the pro-gram either succeeds or fails). The subdivision of the input domain into subdomains, according to the basic principle of partition testing, can be done automatically by analyz-ing the XML Schema elements. By means of the elements, attributes and constraints of the XML Schema, we first divide the schema into a set of sub-schemas; we then gradually divide the sub-schema into sets of the elements that have the same properties of value and other constraints. The test cases actually are the XML Documents generated by combin-ing the values from these sets. If the values in the derived XML Documents are from the sets defined by the XML Schema, then these documents conform to the XML Schema, and we call them valid documents; otherwise the derived documents are invalid.
1.2. OUTLINE OF THE THESIS 15
The automation of test case execution and result analysis are not the same for different applications. Test execution takes the derived XML Documents as input to the system under testing; it is usually easily applied by some simple automatic file reading programs. The automatic tool for test result analysis must be designed specifically by the output of the applications. In our applications, which will be presented in Part III, we will show different ways for analysing the test result automatically according to the application.
As well as automatic testing, we have another goal for our approach, which is “Usability”. The method should be easily used in actual projects. To do this, we need not only to con-sider the technical problem of the methodology, but also to think about how to optimize the method and make it suitable for use in testing real software systems.
As presented before, we would like to apply partition testing to the XML Schema, and traditional partition testing usually creates a huge number of test cases. Along with the growth of system parameters, the test case number increases geometrically. For real applications, the number of test cases should match the requirements of the testing, other-wise it spends unnecessary time and resources, and increases the expense of the testing. In order to overcome this problem, we have developed the combinational method to reduce the number of derived test cases, and provide several strategies to make the generation more flexible.
Traditional partition testing does not allow the tester to focus on particular parts of the system, but in the real life testing, it is important to reduce the costs and time of testing. Sometimes selection of relevant test cases is done by the testers manually, and mainly depends on their intuition and experience. If they make the wrong decision, the testing will not get satisfactory results, and additional costs will be incurred for redoing the testing. Our goal is to provides some strategies that help the user to choose the critical parts for testing, and select a suitable set of test cases.
In this thesis we not only provide the theory of the methodology, but also the imple-mentation of the methodology; moreover we focus a lot on practical applications of the methodology. These applications make our method not only a concept, but also a tool that can readily be used to solve real problems.
1.2 Outline of The Thesis
This thesis is divided into three self-contained parts. The first part is the general intro-duction of background and related works; the second part focuses on the description of the approach; the third part gives case studies for our methodology; and the last part is a description of future work.
• Part I: In the first part, we present basic information regarding Software Testing,
XML Schema and others information used in our research. We want give the reader the basic information necessary for comprehending the approach presented in the thesis. We also outline related works in this part.
– Chapter 2 presents a brief introduction of Software Testing from different points of views, it also includs XML Schema fundamentals and the algorithms Category-partition and Pairwise Testing, which are used in this thesis.
– Chapter 3 presents related works from two aspects: first is the related XML based Testings, we classify these testing methods into different aspects. The seond is syntax based testing in which some works are similar to our research. In this chapter we introduce these methodologies and compare them with our approach briefly.
• Part II: This part is the description of our algorithm XML-based Partition
Test-ing in (XPT) and the implementation of a proof-of-concept tool TAXI (TestTest-ing by Automatically generated XML Instances).
– Chapter 4 proposes a practical and automatic approach to XPT, It applies the Category-partition method to the XML Schema, and generates XML Instances automatically and systematically.
– Chapter 5 presents the implementation of XPT. To verify the method XPT, we develop a proof-of-concept tool TAXI that implements the XPT method. TAXI has a graphic user interface, that allows the user to generate instances by different strategies. In this chapter we give the process of TAXI implemen-tation.
– Chapter 6 presents the cover set of the TAXI tool. The cover set is a part of test cases of TAXI.
• Part III: In this part we present three applications of XPT methodology. For each
application we give a case study and the comparison with other tools.
– Chapter 7 presents the environment for automatically testing XML Document transformation by XSLT.
– Chapter 8 shows the application of TAXI for doing Black-box Testing, specif-ically, we focus on XML database mapping and population.
– Chapter 9 presents the application and a case study using TAXI to do XML Benchmarking to evaluate the performance of XML-based systems.
Finally Chapter 10 presents the conclusion of the thesis, and the ongoing work of this topic in the future.
1.3 Publication List
• Antonia Bertolino, Jinghua Gao, Eda Marchetti, “XML Every-Flavor Testing”,
Proc. Web Information Systems and Technologies WEBIST 2006, Setubal, Portu-gal, April 11-13, 2006. This article is a survey of XML Testing. We summarized the
1.3. PUBLICATION LIST 17
existing XML Tests from different aspects, and organize them into a well-organized structure.
• Antonia Bertolino, Jinghua Gao, Eda Marchetti, Andrea Polini, “Systematic
Gen-eration of XML Instances to Test Complex Software Applications”, Proc. Rapid Integration in Software Engineering (RISE 2006) Geneve, Switzerland, September 13-15, 2006. This ariticle is the first publication about the XPT method. We de-scribed the idea of XPT method, and evaluate the possiblity of using it for testing complex software applications.
• Antonia Bertolino, Jinghua Gao, Eda Marchetti, Andrea Polini, “XModel-Based
Testing of XSLT Application”, Proc. Web Information Systems and Technologies, WEBIST 2007, Barcelona, Spain 3-6 March, 2007. In this article, we presented how to apply the XPT method for testing XSLT transformations.
• Antonia Bertolino, Jinghua Gao, Eda Marchetti, Andrea Polini, “TAXI - A Tool for
XML-based Testing”, Proc. 29th International Conference on Software Engineer-ing, ICSE 2007, Minneapolis, USA 20-26 May, 2007. This was a demonstration presented in the demo section of ICSE conference. It was the first time that we showed TAXI tool.
• Antonia Bertolino, Jinghua Gao, Eda Marchetti, Andrea Polini, “Automatic Test
Data Generation for XML Schema-based Partition Testing”, Proc. 29th Interna-tional Conference on Software Engineering, Second InternaInterna-tional workshop on Au-tomation of Software Testing (AST’07) at 29th International conference on Soft-ware Engineering (ICSE’07), Minneapolis, USA 26 May 2007. This article pre-sented the details of the proof-of-concept tool TAXI, its possible application do-mains, and the comparison between TAXI and other tools.
Part I
Chapter 2
Background
This chapter provides the background information used in this Thesis. At the beginning of the chapter is a comprehensive overview of software testing with basic concepts and the related methodologies that are used in the thesis. Since our research is focused on automatic testing of XML-based system, this chapter also includes a brief introduction of XML and XML Schema.
The chapter is structured as follows: Section 2.1 presents the concept of software testing and a brief description of software testing classifications. Section 2.2 and Section 2.3 introduce Category-partition methodology and Pair-wise Testing respectively. Section 2.4 describes fundamentals of XML and XML Schema.
2.1 Software Testing And Related Concepts
“Software Testing consists of the dynamic verification of the behavior of a program on a finite set of test cases, suitably selected from the usually infinite executions domain, against the specified expected behavior.” [Ber04].
In the software life cycle, testing is an important and critical process. In software engineering opinion, testing should start as early as possible, and continue throughout the entire software life cycle, but due to the limitation of time, cost and experience, much software is developed without testing, or is tested after the whole process of development is complete. This carries a big risk, because the earlier bugs are found in the system, the easier and cheaper it is to fix them. The costs to fix bugs rise logarithmically; they increase tenfold as time increases.
The activities of testing depend on the process of the software under testing. Accord-ing to [Ber04], software testAccord-ing includes seven main activities:
• Planning: As stated earlier Software Testing is a process or series of processes; it
must be planned and scheduled before being applied. The most important aspect of the test plan is the project management of testing, which includes planning for
equipment, managing personnel, setting the undesirable outcomes, and establishing the required costs in terms of time and effort to ensure the test environment and process run property.
• Test Case Generation: Test cases are generated by a particular test strategy;
more-over they should be appropriate to the test level and particular testing techniques. The derived test cases should include the expected results for testing.
• Test Environment Development: The test environment includes test equipment,
the control of test cases, analysis of results, scripts, and other materials for testing. It needs to be organized or created properly in preparation for future activities.
• Execution: In this active test cases are in the test environment. All actions
dur-ing testdur-ing should be documented clearly to guarantee the testdur-ing process is repro-ducible. If other people repeat testing, they should get the same result. This is essential for future defect correction and test result evaluation.
• Test Result Evaluation: The test result determines whether the test was successful.
It also indicates if performance of the software product conforms to the expected design, without any undesired outcomes.
• Problem Reporting/Test Log: The testing log should contain basic information
regarding the test, which includes the time of test execution, software environment configuration, the tester who performs the testing, and other related data. It should also include the record of unexpected outcomes during testing and the final result.
• Defect Tracking: The defects that are caught during testing should be analysed to
find what errors in the software caused those defects.
Test Planning should start at the early stages of a software project. Testing not only targets the code and the final product, but also analyzes the requirements, and the system design. Testing at the design stage can correct unsuitable parts of a project before they are implemented. This may save a lot of time in the future, since it avoids unnecessary implementation and saves the costs of finding bugs. During the code phase, tester and developer must cooperate properly to ensure that the behaviour of each release module strictly conforms to the specifications and is strong enough. Also the inter-operation between modules must execute correctly. In the software development process, the test phase sometimes is the most expensive part. The costs are mainly for:
• the design of the test plan and test cases. This must be done very carefully since the
correctness of the test plan and the quality of test cases are directly affect the results of testing;
• the execution of test cases. This also needs a considerable amount of time,
2.1. SOFTWARE TESTING AND RELATED CONCEPTS 23
• the test result evaluation. This needs not only time but also sufficiently experienced
of testers; and
• bug correction. This is costly because it requires not only the correction but also
needs to ensure that the modification corrects the bugs without causing other prob-lems.
Whatever testing does, the final goal is to find and fix the bugs in the software as early as possible and assure the effectiveness of software systems. Testers always want to do thorough testing, and find and fix all bugs to make the software perfect. Unfortunately this is only a dream. People can not fully test even very simple programs. Usually the set of inputs and outputs of software is very large or even unlimited; the number of possible paths through the software is very large, too. A full test suite would have to be huge enough to cover all cases that would occur during the software execution, but for most software, this test case set is unlimited. By current technology, it is impossible to gen-erate and execute unlimited test cases. So one key mission of testing is finding a way to reduce the huge number of possible test cases, and decide which test cases are important, and which are not. According to the software definition that is presented at the beginning of this section, software testing needs to select a finite set of test cases from the usually in-finite executions domain, and use dynamic verification to check the behavior of a program against the expected behaviors.
Since software can not be tested completely, and testers can only use finite test cases to find as many bugs as possible, how can it be done? There are two most classical test strategies that will be explained in the next section.
2.1.1 White-box Testing and Black-box Testing
There are different ways to classify software testing, Considering how to approach the testing for software, testing can be divided into Black-box Testing and White-box Testing. They are also the most popular strategies for testing.
White-box Testing
A software system can be regarded as a box. In White-box Testing (sometimes called clear-box testing) [Bei90b] [Mye04], the tester can see inside the box. Generally testing is done by accessing the program’s code to identify all paths through the software. Based on the paths of the software, the tester needs to choose test case inputs that ensure they can exercise paths through the code, and to determine what outputs are acceptable.
There are a lot of coverage standards in White-box Testing. These include:
• statement coverage, which requires each statement to be executed at least once; • decision coverage, which requires each decision branch to be executed at least one
time;
• condition coverage, which requires each condition of each decision in the software
• decision/condition coverage, which needs to satisfy both the requirements of
de-cision coverage condition coverage. In this case the dede-cision/condition coverage needs to execute each decision branch at least once, and all conditions of each de-cision branch must cover all possible values;
• condition combination coverage, which requires in each decision that all
combina-tions of the each condition must execute at least one time; and
• path coverage, which requires execution of all possible paths in the software.
White-box Testing strategy has lots of advantages. Firstly, with the knowledge of the internal software structure, it is easier to find out the types of input that can help in testing the application effectively. Also White-box Testing can check whether, within the software, the code executes according to specification, and it can help to optimize the code and removing extra lines to avoid bringing in hidden defects. However there are still some risks to use White-box Testing.
As presented in the previous phase, White-box Testing guarantees all independent paths within a module have been exercised at least once; it exercises all logical deci-sions on the true and false sides; it executes all loops at their boundaries and within their operational bounds; and exercises internal data structures to ensure their validity.
White-box Testing however, requires a considerable amount of time and effort. An-other factor that causes White-box Testing to become expensive is that the number of independent logic paths in software is often huge. To carry out test cases through each path is usually costly. However, even if all paths pass testing, it does not ensure that they are verified, because exhaustive path testing can not verify whether the code conforms to the software specification. Also it is nearly impossible to look into every bit of code, so some paths might be omitted and faults cause by these paths may not be found. Finally exhaustive path testing may not be able to find some bugs that are related to the data. Because of its characteristics, White-box Testing is mainly used in fields that require high reliability, such as war industry software, aerospace and industrial control systems.
Black-box Testing
In Black-box Testing [Mye04] [Bei95], the structure of the software is not shown to the tester, nor is it considered during testing. The tester only knows how the software is supposed to behave, he/she can not look inside the box to see how the software operates. The only thing the tester can do is type in certain inputs, and check if the output complies with the expected output. The tester doesn’t know how or why to get the output, they are only concerned with the results of comparison. Nevertheless, in order to implement Black-box Testing, the tester needs to read through the software specification, and clearly understand the expected behavior of the system.
The main methods of Black-box Testing includes: the equivalence class division
method, the boundary value analysis method, the wrong to speculate method, the cause-effect graph method, and the comprehensive strategy method.
Equivalence Class Division [RML05] [Bei95]
2.1. SOFTWARE TESTING AND RELATED CONCEPTS 25
Classes indicate a subset of an input domain in which each input value has an equal effect on debugging, using a select a representative value from each subset as a test case. This method can effectively reduce the quantity of test cases and reduce the costs of testing. When partitioning the classes, care must be taken to ensure that there are two kinds of equivalence classes: a valid equivalence class, which refers to sets that consist of valid and acceptable values of software; and an invalid
equivalence class, which denotes sets composed of invalid or insignificant values
of the system. Usually there will be one or more valid, and at least one invalid equivalence classes.
Boundary Value Analysis Method [Coe08] [Rei97]
The Boundary Value Analysis method takes boundary values from the input do-main, and input values that can cause the software to issue boundary output values as test cases. Long-term experience indicates that a high number of faults occur at the boundary values of inputs/outputs, so that test cases aimed at the boundary values can catch more bugs. Values that are equal or slightly greater or smaller than the boundary are suitable to be selected as test cases. The boundary Value Analysis method is often used as complementary to the Equivalence Class Division method. Wrong to Speculate Method [Mye04]
The Wrong to Speculate method depends on the use of experience and intuition to anticipate possible errors that could occur in the software system, and uses these supposed errors to make the test suite. The basic idea of the Wrong to Speculate method is first to list all situations that might cause errors in the software. The test cases should be designed specifically for each of these situations. The method is very dependent on people’s experience and could be an efficient testing method if the test group is well organized, and gathers enough error speculations.
Cause-effect Graph Method [Elm97] [AP97]
The Cause-effect Graph method is a supplement to the Equivalence Class Division method and the Boundary Value Analysis method, for overcoming the weakness of these two methods, which do not analyse combinations of software input condi-tions, so test cases for more input situations might be omitted. The adoption of the Cause-effect Graph method can help the tester to choose an efficient test suite by some specified steps. The Cause-effect Graph is a directed graph that maps a set of causes to a set of effects. The tester must draw a cause-effect graph according to the software specification, then add the constraints and conditions for the causes and ef-fects to the graph. He/she then transforms the cause-effect graph to a determinant form, and transforms the rows of the determinant form to test cases.
The Random method uses random data as test cases. This data can be generated automatically to reduce the cost of the testing. Also customers will have more con-fidence if the system passes the testing with sufficient random data. However, this is a high risk method, as it is difficult to determine what constitute an appropriate number of test cases that is sufficient but not too many; it is also not easy to guar-antee that the random data generated accurately represents probable actual inputs. Random testing may omit some parts of the system, or test some parts repeatedly. Black-box Testing is often used to find functional errors, the bugs of interface, data structure, system performance, and the fault of system initialization and termination. However, Black-box Testing is not a substitute for White-box Testing, although it can be used together with White-box Testing as an assistant to discover omitted faults.
The advantage of Black-box Testing is high automatization. The process of testing can be done automatically; for some software the results can even be analysed by Oracle automatically. For large software systems, it is more effective. Because the structure of code is not considered during testing, the tester tests the software from a user’s point of view; he/she does not need to have knowledge of implementation, and can be independent from the developer. But Black-box Testing depends highly on the software specification; if the specification is not clear and concise, the test cases can not be well designed. It is also difficult to test directly the specific parts of code that are very complex and have a higher possibility of containing errors. Another disadvantage is that Black-box Testing may leave many program paths untested, since test cases are not generated according to the structure of code. The final problem of Black-box Testing is bug shooting. If the software does not have well-designed exceptions, the causes of a fault are not easy to confirm.
While Black-box and White-box Testing are still in popular use, in order to overcome the disadvantages of these two strategies, people have attempted to combine them, and have invented the “gray-box testing”. Gray-box Testing is similar to Black-box Testing, which tests the software from outside, but the internal information of software is not strictly ”off limits”. The tester has some knowledge of the software’s internal structure, and he/she is required to design a limited number of test cases aimed at to the internal structures. The internal information can also helps the tester to choose appropriate test cases from the input domain.
Our methodology is inspired from famous method Category-partition [OB88], this method is based on Equivalence Class Division method in Black-box testing.
2.2 Category-Partition Methodology
Equivalence Class Division method is one of the most popular methods in Black-box test-ing. Category-partition (CP)[OB88] is a well-known method for applying the Equivalence Class Division.
Category-partition is used to create functional test suites. In this method a test engi-neer analyzes the system specification, writes a series of formal test specifications, and
2.3. PAIR-WISE TESTING 27
then uses a generator tool to produce test descriptions from which test scripts are written. It provides a formal way to partition the software specifications, and a method to gener-ated a test suite from the specification automatically and systematically. The advantages of this method are that the tester can easily modify the test specification when necessary, and can control the complexity and number of tests by annotating the test specifications with constraints. The Category Partition method has seven steps, the terms and the pur-pose of each step are explained below.
1. Analyze the specifications and identify the functional units (for instance, according to design decomposition). The functional units are the subsystems that can be tested independently.
2. Partition the functional specifications of a unit into categories: The categories are the environment conditions and parameters that are relevant for testing purposes.
3. Partition the categories into choices:1 these represent the significant values for each
category from the tester’s viewpoint. Choices are sets of values; that the values in each set have the same influence on the testing result.
4. Determine constraints among choices (either properties or special conditions), this prevents the construction of redundant, meaningless or or even contradictory combina-tions of choices.
5. Derive the test specification: categories, choices and constraints form a Test Speci-fication, suitable for automatic processing. It is not yet a list of test cases, but contains all the necessary information for substantiating them by unfolding the constraints.
6. Derive and evaluate the test frames: from the test specification, a set of test frames is derived by taking every allowable combination of categories, choices and constraints.
7. Generate the test scripts, i.e. the sequences of executable test cases.
The Category-partition method provides a great method for generating test cases from the system systematically and automatically. Since the test cases are generated by combin-ing the categories, the number of test cases are closely related to the number of categories. With this method, when the system is complex, the user often gets a huge number of test cases. Sometimes there are too many to be executed. To solve this problem, combina-tional methods are developed. Next section will present one of these methods, Pair-wise Testing, which is used in our methodology for test cases selection.
2.3 Pair-wise Testing
Testing approaches can be divided into two vast groups: stochastic testing (random test-ing) and combinatorial testing. Stochastic testing does not execute all test cases, but picks some of them randomly, The test case may locate a bug only by luck. Combinatorial test-ing generates all possible combinations of test data. Usually this set is too huge or even infinite, so that it can not be used to test software.
1Note the usage of the same term “choice” both in XML schema syntax (written as <choice>) and in
What the tester needs is a set of finite test data that includes the selected test cases, and is of a suitable size; the method to get this set of test data is “test case selection”. Pairwise testing is a well-known and important method for selecting the test cases. It is a widely popular approach to the combinatorial software testing method which for each pair of input parameters to a system, tests all possible discrete combinations of those parameters [THCS01]. As presented before, whether we do Black-box Testing or White-box Testing, the combinations of system parameters are usually very huge even for a simple system. For instance suppose a system have 3 parameters and each of them has 10 values, to do exhaustive testing all the values in the different parameters should be combined, and result in 310combinations. If the system is complicated, it is impossible to do exhaustive testing
because the number of test cases will be too huge to execute. In the history of software testing, people have found that in a software system, most of the errors are caused by the interactions of one or two parameters. Bugs involving interactions between three or more parameters are much less common, and it is very rare that an error is caused by the interaction of all parameters [YL02]. Therefore if we apply pair-wise testing to test the interaction of all pairs of parameters, we should catch most of the bugs at a greatly reduced cost.
2.4 XML Schema Fundamentals
As presented in Chapter 1, currently software is becomeing more and more complicated. Communication among different software components and different systems is becoming more and more frequent. The interoperability of software needs a standard format for data. XML [Har99] is the most popular and general standard for storing and exchanging data. It have been widely accepted for several years. We will focus on systems based on XML.
XML Schema is itself represented in XML, and can be easily extended. It defines the rules of the elements, attributes and other items of XML Documents.
In this section some basic concepts of XML and XML Schema are provided.
2.4.1 Brief Introduction of XML Language
“Extensible Markup Language (XML) is a simple, very flexible text format derived from
SGML (ISO 8879). Originally designed to meet the challenges of large-scale electronic publishing, XML is also playing an increasingly important role in the exchange of a wide variety of data on the Web and elsewhere.” [XML96]
XML is a set of rules for defining semantic tags that break a document into parts and identify the different parts of the document. It is a meta-markup language that defines a syntax used to define other domain-specific, semantic, structured markup languages [Har99].
XML language is the W3C endorsed standard for document mark-up; in simple terms, it defines a generic syntax used to mark up data with intuitive, human-readable tags. XML
2.4. XML SCHEMA FUNDAMENTALS 29
is a cross-platform, text-based and extensible language. As a meta-markup language, there are not any predefined tags in XML language; users make up the tags as required. Figure 2.1 shows a simple example of XML. As shown in the example, an XML Docu-ment must have one root eleDocu-ment, the content of root eleDocu-ment could be text-only or other elements. The XML Document in Figure 2.1 presents the structure and content of an email. All tags in the example are defined by the user. The content of the tags must ap-pear between the start tag that is written as <tag name> and close tag that is written as
</tag name>. < ? x m l v e r s i o n = " 1 . 0 " e n c o d i n g = " U T F - 8 " ? > < e m a i l > < t o > A n n i e < / t o > < f r o m > J a s e m i < / f r o m > < t i t l e > G r e e t i n g < / t i t l e > < b o d y > H i , h o w a r e y o u ? I m i s s y o u ! < / b o d y > < / e m a i l > Figure 2.1: A simple XML
XML can store and organize any kind of information in textual form. The information is represented as an hierarchy of elements with names, optional attributes and contents, which can be defined by the developers. XML Documents typically contain a structure that includes text, attributes, and other elements that, in turn, may include elements, text and attributes. This structure can be described as a tree, in which every item in the XML Document holds a position.
XML provides a standard format for storing and exchanging documents between com-puter applications (and not only), and it brings big advantages to the developers. XML language gives the possibility to the user to design the specific markup languages for different domains of the system, so that the developers can focus on the part they care about, and reduce the complexity of the system description during communication among developers. XML is a self-describing language; it can be written totally in ASCII text that is easily understood by computers, and is also easily read by a person, even if he/she does not have professional knowledge of XML. Since it is easy to read and write and it is non-proprietary, XML is an excellent format to interchange data among different applica-tions. The data of XML Document is well structured, so it is ideal for large and complex documents.
With Unicode as its standard character set, the XML supports many kinds of writing systems and symbols, and it can be edited with any kind of editor, from a standard text editor to a visual development environment. Besides, XML is easily combined with style sheets to create formatted documents in any desired style. Because of its many bene-fits, XML is fast becoming the most widely used format for data interchange between a system’s components, and on the Web.
2.4.2 Document Type Definitions
Besides XML Schema, Document Type Definition (DTD) is an other well-known XML Schema Language. Before XML Schema was developed, it was the most popular schema language. It is not XML based schema language; it specifies the tags used to define legal elements, attributes and constraints. Fig 2.2 shows a simple DTD example.
< ? x m l v e r s i o n = " 1 . 0 " e n c o d i n g = " U T F - 8 " ? > < ! E L E M E N T p e o p l e _ i n f o r m a t i o n ( p e r s o n * ) > < ! E L E M E N T p e r s o n ( n a m e , b i r t h d a t e ? , a d d r e s s ? , I D n u m b e r ? ) > < ! E L E M E N T n a m e ( # P C D A T A ) > < ! E L E M E N T b i r t h d a t e ( # P C D A T A ) > < ! E L E M E N T a d d r e s s ( # P C D A T A ) > < ! E L E M E N T I D n u m b e r ( # P C D A T A ) >
Figure 2.2: A simple example of DTD “People information”
By the specification of DTD in Figure 2.2, in the conformed XML Document, “peo-ple list” is a valid element, and it can contain any number of elements named “person”, because “person” is followed with *; and “person” is a valid element name, because it contains one element “name”, followed by three optional elements “birthday”, “address” and “IDnumber”. The “?” indicates these elements are optional. All these three optional elements should contain the parsed character data since they are followed with #PC-DATA. In Figure 2.3 we show an XML Document that conforms to the specification of DTD People information. < ? x m l v e r s i o n = " 1 . 0 " e n c o d i n g = " U T F - 8 " ? > < p e o p l e _ i n f o r m a t i o n > < p e r s o n > < n a m e > S a m B r o o k < / n a m e > < b i r t h d a y > 1 5 / 1 2 / 1 9 7 0 < / b i r t h d a y > < a d d r e s s > 2 3 E s t e r A v e N Y < / a d d r e s s > < / p e r s o n > < / p e o p l e _ i n f o r m a t i o n >
Figure 2.3: An XML Document conforms to DTD “People information”
In recent years, DTD has becomes very popular schema language in XML applica-tions, but it does not support communication between different modules. Also it has very basic content models that do not have enough capability to give a very clear description of XML Document structure, the element, attribute and constraints of data types. So in May of 2001, W3C recommended XML Schema as the standard mode of XML, and since then XML Schema has started to replace DTD gradually.
2.4. XML SCHEMA FUNDAMENTALS 31
2.4.3 XML Schema
An XML Schema language is a formalization of the constraints, expressed as rules or a model of structure, that applies to a class of XML Documents [vdV02]. Like other XML Schema languages (such as DTD), XML Schema expresses the rules that can determine whether an XML Document conforms to these rule. If it conforms, then it can be consid-ered as “valid” to that schema. When an XML Document has the structures or elements that are not defined in the XML Schema, then it does not conform and is invalid against the XML Schema.
When an XML document is validated against a schema (a process known as assess-ment), the schema to be used for validation can either be supplied as a parameter to the validation engine, or it can be referenced directly from the instance document using two special attributes; xsi:schemaLocation and xsi:noNamespaceSchemaLocation. (The lat-ter mechanism requires the client invoking validation to trust the document sufficiently to know that it is being validated against the correct schema.)
XML Schema offers a powerful set of tools for defining acceptable structures and content of XML Documents. Technically, an XML Schema is a collection of abstract metadata that resides within the XML format.
Schema documents are organized by namespace: all the named schema components belong to a target namespace, and the target namespace is a property of the schema doc-ument as a whole. A schema docdoc-ument may include other schema docdoc-uments with the same namespace, and may import schema documents with a different namespace.
XML Schema is based on the format of XML, and could extend and reuse the elements and types both inside the schema and also in the other namespaces. XML Schema is becoming more widely-used than other schemas because of its advantages:
First, XML Schema uses XML as the language to define the schema, so users who want to use XML Schema do not need to learn a new language. Also, it inherits the properties of XML, which is well structured and easily read both by humans and by computers.
Further, XML Schema defined more than 44 built-in datatypes. and each of these datatypes can be further refined for fine-grained validation of the character data in XML. The cardinality of the elements can be defined in a fine-grained manner using the minOccurs and maxOccurs attributes. This is a big improvement: DTD can not define the exact number of element occurrence. XML Schema makes the element definition more clear and conformed.
XML Schema also has other new features. It supports modularity and re-usability by extension, restriction, import, include, and redefine constructs. This brings great flexibil-ity in defining elements, and can also save time and avoid repeated definition of elements, types and attributes.
XML Schema supports identity constraints to ensure the uniqueness of a value in an XML Document, in the specified set, and it has an Abstract Data Model and therefore is not bound to XML representation only. While schemas are powerful, that power comes with substantial complexity.
In many ways, XML Schemas act as design tools to XML Documents. There are many uses of XML Schemas in the world of XML, but the most important and common usage is validation.
There are two significants uses of the XML validation. One is to check if the XML Document has the correct syntax conforming to the grammar of the XML specification; this validation is called “XML well formed”. Being well-formed is a basic requirement for an XML Document. Another validation is to check if the XML Document conforms to a DTD or an XML Schema. When the XML Document conforms to the criterion a defined in the XML Schema/DTD, then we call this XML Document valid for that schema; otherwise it is invalid. The validation against schemas takes place at several levels: The structural level checks if the XML element and attribute structures conform to the specification of the schema. Data level validation makes certain that the contents of the elements and attributes meet the rules made by the schema. In Section 2.4.5 we will give more details about XML validation against an XML Schema.
Besides validation, XML Schemas also are frequently used to do the documentation of XML. XML Schema provides a formal description of the structure and content of the XML Documents; usually when a new XML vocabulary is published, there will be XML Schemas attached to it. The XML Schema now become a part of the XML Documenta-tion. Because it is easily understood by people and machines, it is helpful in understanding the structure of the XML Documents.
2.4.4 Elements and Constraints of XML Schema
XML Schema is the description of a type of XML Document. It makes the rules for the syntax constraints of these XML Documents, and defines the elements, attributes that can appear in an XML Document, and their data types. Also it specifies the valid structure of the XML Document. This specification includes:
* The parent elements and their child elements; * The sequence in which the elements should appear;
* The occurrence times of the elements, and the appearance rules for attributes; * The context of the elements;
* The predefined values for the elements and attributes, specifically the fixed and default values.
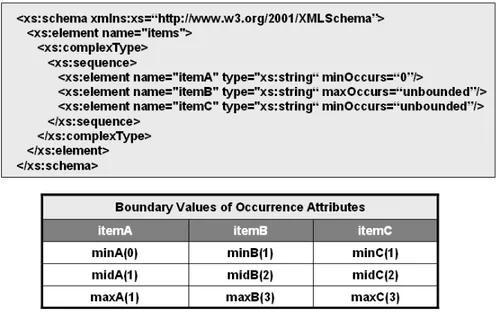
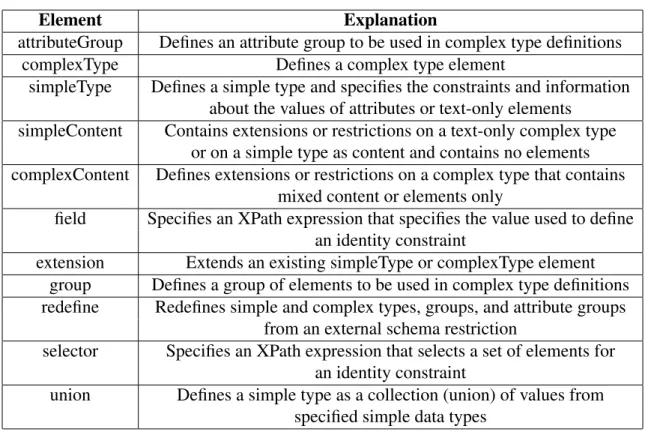
For this purpose, XML Schema specifies a set of elements and constraints. We list the elements that can affect and are significant to our work in Table 2.1, and give a simple explanation of each of them. This table is taken from [W3S05]. In Chapter 6 there are more explanations for each of the elements with a simple XML Schema as test case for TAXI tool.
2.4. XML SCHEMA FUNDAMENTALS 33
In order to define acceptable values for elements and attributes, XML Schema also defines a set of value restrictions. In XML Schema the restrictions for elements are called Facets. We list the Facets in Table 2.2 [W3S05].
2.4.5 XML Document Validation
As already presented in the previous section, XML validation is the most widely-used XML Schema application; also in our research it is an important concept. As presented before, XML Schema files define the structure of a class of XML Documents. The process for checking whether an XML Document matches the specification of a schema is called XML Validation. This validation is not the same as XML’s core concept of syntactic well-formedness. When an XML Document relates to a schema, it is considered “valid” when it is well-formed and conforms to the associated schema.
When XML Documents attach all of the specifications of XML Schema, we call the XML Documents conform to this XML Schema, and they are “valid” documents of this schema. The requirements typically include such constraints as:
Element and attribute, and time they are permitted to occur: XML Schema defines
the element and attribute by giving the name, structures, and rules for how they can be included in the XML Document. There are two attributes that restrict the element oc-currences in XML Document: “minOccurs” defines the minimum occurrence, and “max-Occurs” defines the maximum occurrence. When the “min“max-Occurs” of an element equals “0”, it means this element can be absent from the XML Document; otherwise it must be included in the XML Documents. Also the time that an element occurs must between the values of “minOccurs” and “maxOccurs”.
In contrast to elements, attributes can not appear more than once in an element, so in the schema, attributes have an attribute “use” to define the occurrences. This “use” has only three values: optional, required and prohibited. When the value equals optional, the attribute is not obliged to appear in XML Document; Required means the attribute must occur in XML Documents; while prohibited denotes that the attribute is forbidden to appear in XML Document.
The legal structure: The structure of elements and attributes is specified by a regular
expression syntax in specification of XML Schema. It defines the acceptable parent, child of each specific element, and their allowable attributes and constraints. All elements in the XML Document must be constructed according the rules, otherwise the element and the whole XML Document are considered to be “invalid”.
The data types of the elements and attributes: XML Schema defines the data types for
each of its elements and attributes. In the associated XML Documents the element data type must be interpreted strictly according to the XML Schema.
Along with the wide-used of XML Schema, there are many tools that can valid ate an XML Document against a schema automatically. For instance XMLSpy [XML05b] is a very well-known tool, that it offers a set of tools for XML applications; Stylus Studio [Cor08] is a powerful XML integrated development environment; also the Apache Xerces
Java XML Parser library provides a highly standards-conformance validator [Jav06]; it offers very good performance for validating.
2.5 Summary
In this chapter we presented the background for this thesis. We introduced some in-formation about Software Testing, especially Black-box Testing and White-box Testing. After that we included a brief introduction to the Category-partition method, which forms the basis method of our methodology and Pair-wise Testing which is also used in our approach for selecting the test cases. Simple introductions to XML and XML Schema foundations are also presented in this chapter as they are leading actors in our research. With the content of this chapter, it will be easier to follow and understand this thesis.
2.5. SUMMARY 35
Element Explanation
all Specifies that the child elements can appear in any order. Each child element can occur 0 or 1 time
any Enables the author to extend the XML Document with elements not specified by the schema
anyAttribute Enables the author to extend the XML Document with attributes not specified by the schema
attribute Defines an attribute
attributeGroup Defines an attribute group to be used in complex type definitions choice Allows only one of the elements contained in the <choice>
dec-laration to be present within the containing element
complexContent Defines extensions or restrictions on a complex type that contains mixed content or elements only
complexType Defines a complex type element element Defines an element
extension Extends an existing simpleType or complexType element
field Specifies an XPath expression that specifies the value used to define an identity constraint
group Defines a group of elements to be used in complex type definitions import Adds multiple schemas with different target namespace to a document include Adds multiple schemas with the same target namespace to a document key Specifies an attribute or element value as a key within the containing
element in an instance document
keyref Specifies that an attribute or element value correspond to those of the specified key or unique element
list Defines a simple type element as a list of values
redefine Redefines simple and complex types, groups, and attribute groups from an external schema restriction
restriction Defines restrictions on a simpleType, simpleContent, or a complex-Content
schema Defines the root element of a schema
selector Specifies an XPath expression that selects a set of elements for an identity constraint
sequence Specifies that the child elements must appear in a sequence. Each child element can occur from 0 to any number of times
simpleType Defines a simple type and specifies the constraints and information about the values of attributes or text-only elements
simpleContent Contains extensions or restrictions on a text-only complex type or on a simple type as content and contains no elements
union Defines a simple type as a collection (union) of values from specified simple data types
Constraint Description
enumeration Defines a list of acceptable values
fractionDigits Specifies the maximum number of decimal places allowed. Must be equal to or greater than zero
length Specifies the exact number of characters or list items allowed. Must be equal to or greater than zero
maxExclusive Specifies the upper bounds for numeric values (the value must be less than this value)
maxInclusive Specifies the upper bounds for numeric values (the value must be less than or equal to this value)
maxLength Specifies the maximum number of characters or list items allowed. Must be equal to or greater than zero
minExclusive Specifies the lower bounds for numeric values (the value must be greater than this value)
minInclusive Specifies the minimum number of characters or list items allowed. Must be equal to or greater than zero
pattern Defines the exact sequence of characters that are acceptable totalDigits Specifies the exact number of digits allowed. Must be greater
than zero
field Specifies an XPath expression that specifies the value used to define an identity constraint
whiteSpace Specifies how white space (line feeds, tabs, spaces, and carriage returns) is handled
Chapter 3
Related Work
Software testing is so important that there are many groups and organizations working on it, trying to find methods to reduce costs and improve the veracity of the testing. This chapter covers the research that is related to our work. During the process of our research we studied extensive literature, and conclude that the related works can be grouped into two aspects. One is from the view of XML based testing methods which will be presented in section 3.1. The other aspect is from the view of automatic XML generation methods, which will be presented in section 3.2.
3.1 Related XML Testing
During our research, we not only focused on our methodology, but also studied a wide area of literature about XML Testing. XML Testing can refer to verifying the adequacy of an XML Document with respect to the user’s exigencies; verifying the adequacy of an XML Instance with respect to a specific schema (DTD or XML Schema); verifying the wellformedness of a schema structure; or even for defining methodologies for merging or matching diverse XML Schemas.
As presented in Section 2, the DTDs and XML Schemas have largely evolved paired with XML diffusion. DTDs and XML Schemas are used for expressing basic structural rules and complex restrictions of the diverse data and parameters that units/components exchange with each other; both of them can be considered as the structuring schema of XML Documents.
The introduction of XML and XML Schemas paved the way for many tools and tech-niques devoted to checking the most varied aspects and concerns of the produced docu-ments. In next sections we will provide an overview of existing approaches, distinguish-ing between approaches that are applied to XML Documents, and approaches that start from the XML Schema. In this vast context of diverse interpretations, we have attempted to classify the various testing approaches and structure those methodologies, and to com-pare them with our methodology.