!" ___________________________
# ## ___________________________
R
INGRAZIAMENTIQuesto lavoro di tesi è stato un lavoro di team: infatti raccoglie i contributi di tante persone che durante il lavoro hanno collaborato dandomi consigli e pareri o che mi hanno sostenuto e spronato affinché raggiungessi questo traguardo nella maniera migliore.
In primo luogo intendo ringraziare il Prof. Gianluca Dini per l’impegno e la costante presenza e collaborazione con cui ha accompagnato il mio lavoro. Per le stesse motivazioni intendo ringraziare l’Ing. Nicola Provenzano che mi ha affiancato e con la sua esperienza e i suoi suggerimenti mi ha consentito di concentrare il mio lavoro consentendomi di giungere nel modo più diretto a conclusione. I miei ringraziamenti vanno anche a tutti coloro che all’interno del Dipartimento di Ingegneria dell’Informazione hanno collaborato e mi hanno stimolato facendo sì che il mio obiettivo venisse raggiunto con la massima determinazione. In particolare voglio ringraziare il Prof. Alessio Bechini, l’Ing. Mario Cimino e l’Ing. Ida Savino. Ringrazio infine Luca Merloni per la collaborazione durante le fasi in cui abbiamo lavorato sull’interazione dei nostri lavori.
Questo lavoro non sarebbe tuttavia stato possibile senza la collaborazione e la disponibilità dell’azienda Bassnet s.r.l. presso cui è stato sviluppato. I miei ringraziamenti vanno a Mauro Felici, Project Manager del progetto al quale ho dato il mio contributo con questo lavoro: lo ringrazio per la fiducia concessami, per il tempo che mi ha dedicato nonostante i pressanti impegni e per tutti i consigli che mi hanno permesso di indirizzare da subito gli sforzi nella giusta direzione. Ringrazio inoltre tutti coloro che all’interno dell’azienda mi hanno supportato e consentendomi di integrarmi rapidamente
hanno fatto in modo che potessi dare da subito il mio contributo al progetto. In particolare intendo ringraziare Roberto Carbonari (Direttore Sviluppo e Program Management) per il materiale messomi a disposizione e per i suggerimenti che mi ha dato nelle fasi iniziali del lavoro.
Anche se probabilmente non avranno mai modo di leggere queste note, intendo ringraziare Seth Proctor, capo progetto presso la Sun Microsystems Laboratories del gruppo di sviluppo della Sun XACML, per la disponibilità a valutare le mie proposte e a chiarire i miei dubbi e l’Ing. Andreas Matheus della facoltà di Informatica della Technischen Universität München per avermi aiutato a chiarire alcune problematiche relative alla Sun XACML implementation.
Le persone che ho nominato finora, sono coloro che hanno dato il loro contributo diretto al lavoro di tesi, ma questo lavoro è solo il punto conclusivo di un lungo e difficile cammino. Non posso non ricordare tutti coloro che mi sono stati vicini sostenendomi e spronandomi affinché portassi a frutto il lavoro di questi anni, superando ogni difficoltà o intralcio.
Il primo e mai sufficiente ringraziamento va a mia madre per la fiducia che mi ha concesso consentendomi di crescere e di rafforzare lo spirito di responsabilità e per la grande pazienza con cui ha atteso il raggiungimento di questo obiettivo. Ringrazio tutti i colleghi con cui ho condiviso questi anni di università: sono tanti quelli che vorrei ringraziare, per tutti ringrazio Marco, Alfio e Salvo per il sostegno e l’esempio che mi hanno offerto fin dai primi anni.
Ringrazio infine gli amici e tutti coloro che in ambiente lavorativo mi hanno dato la loro fiducia, consentendomi contemporaneamente di acquisire competenze nel gestire la responsabilità e di affiancare l’attività lavorativa al percorso universitario: senza la presenza e la vicinanza di tanti colleghi difficilmente sarei riuscito a conciliare le due attività.
L’ultimo ringraziamento va agli amici di sempre che nonostante la forzata lontananza di questi anni, nei brevi periodi di incontro mi hanno fatto sempre sentire la loro vicinanza e il loro sostegno.
INTRODUZIONE...3
CAPITOLO 1 DESCRIZIONE DEL PROGETTO CMOS...6
ARCHITETTURA DELLA PIATTAFORMA CMOS ...7
LA BASE DI DATI GENERALE DI CMOS...8
La modellazione concettuale dei dati per una applicazione in CMOS ...9
Esempio di modello dei dati. ... 10
Rappresentazione di un modello dei dati. ... 11
Struttura della base di dati ...13
Schema relativo alla gestione dei modelli dei dati. ... 13
Schema relativo alla memorizzazione dei dati... 16
ASPETTI RELATIVI ALLA PRESENTAZIONE E NAVIGAZIONE DEI DATI. ...18
CONTROLLO DEGLI ACCESSI...21
Classificazione degli utenti delle applicazioni CMOS...21
Amministratore dell’applicazione... 22
Designer del modello dei dati. ... 23
Redattore dei dati... 23
Verificatore dei dati. ... 23
Utenti finali... 24
Controllo degli accessi in CMOS ...24
Politiche di controllo degli accessi... 25
SCENARIO...31
DESCRIZIONE DELLA RICHIESTA XACML...35
Esempio di Request. ... 37
Elemento ResourceContent... 40
DESCRIZIONE DELLA RISPOSTA XACML. ...41
Esempio di Response. ... 43
CLASSIFICAZIONE DELLE POLITICHE IN XACML. ...44
Elemento Target nelle politiche...45
Identificazione e reperimento degli attributi. ...46
XACML Rule...48
La Condizione nelle Regole... 49
XACML Policy...49
XACML Policy-Set...51
Algoritmi di combinazione...53
Algoritmo di combinazione “Permit-Overrides”. ... 54
Algoritmo di combinazione “First-Applicable”. ... 55
CAPITOLO 3 SPECIFICHE DI PROGETTO E IMPLEMENTAZIONE...56
LA SUN'S XACMLIMPLEMENTATION VERSION 1.2...56
LA PIATTAFORMA J2EE...59
Tipologie di Enterprise Java Beans...60
J2EE Container ...61
Confezionamento dei componenti J2EE. ...62
IL REPOSITORY LDAP DEGLI UTENTI. ...63
VARIAZIONI IN CMOS LEGATE AL CONTROLLO DEGLI ACCESSI...64
LA SOLUZIONE ARCHITETTURALE REALIZZATA...66
Il CMOSPEPBean . ...67
Attività del metodo “evaluate”... 68
Il CMOSPDPBean ...69
Attività del metodo “ejbCreate”... 70
Utilizzo del package LOG4J. ...71
DESCRIZIONE DEL CLIENT DI TEST PER IL PEP. ...72
APPLICAZIONE DEL CONTROLLO DEGLI ACCESSI A UN CASO REALE. ...75
Descrizione dell’ambito applicativo...76
Modello degli utenti...77
Dizionario degli attributi degli utenti...79
Modello dei dati...80
Dizionario dei dati...82
Classificazione delle operazioni. ...85
Dizionario delle operazioni. ...86
Specifiche per le politiche...87
Struttura delle politiche XACML. ...89
Alternative alla struttura proposta... 91
Esempio di Policy. ...92
Esempio di Target della Policy. ... 94
Esempio di Regola. ...95
Esempio di Target della Regola. ... 96
CAPITOLO 5 MISURA DELLE PRESTAZIONI ...98
CLASSIFICAZIONE DEI TEMPI DI RISPOSTA...98
METODOLOGIA DI MISURAZIONE...99
Tempi di costruzione di una Request ...100
Tempi di costruzione del PDP ...101
Tempi di valutazione delle politiche. ...102
CAPITOLO 6 CONCLUSIONI E SVILUPPI FUTURI. ...106
INTEGRAZIONE NELLA PIATTAFORMA E SVILUPPI FUTURI. ...107
Realizzazione di un editor delle politiche. ...108
Realizzazione di uno strato per la gestione degli attributi utente...108
APPENDICE A - POLITICHE UTILIZZATE NEI TEST...110
POLITICA PER RICHIESTE SULLA CLASSE LIBRO...110
POLITICA PER RICHIESTE SULLA CLASSE PRESTITO...120
POLITICA PER RICHIESTE SULLA CLASSE CD-ROM...124
APPENDICE B – ESTRATTO DEI FILE DI LOG...127
ESEMPIO DI LOG DEL CMOSPEPCLIENT...127
I
NDICE DELLE FIGURE
FIGURA 1STRUTTURA DELLA PIATTAFORMA CMOS. 8
FIGURA 2ESEMPIO DI MODELLO DEI DATI. 11
FIGURA 3ESEMPIO DI VARIAZIONE DI MODELLO. 12
FIGURA 4SCHEMA DELLA BASE DI DATI PER LA GESTIONE DEI MODELLI DEI DATI.
14
FIGURA 5SCHEMA DELLA BASE DI DATI UTILIZZATO PER LA MEMORIZZAZIONE DEI DATI.
16
FIGURA 6 ESEMPIO DI STRUTTURA DI PAGINA PER LE APPLICAZIONI. 19
FIGURA 7CLASSIFICAZIONE DEGLI UTENTI. 21
FIGURA 8CONTESTO DI LAVORO DEL POLICY DECISION POINT. 32
FIGURA 9FLUSSO DI DATI SCAMBIATO TRA I COMPONENTI PREVISTI DALL'XACML.
34
FIGURA 10RAPPRESENTAZIONE DELLO SCHEMA DI UNA REQUEST. 36
FIGURA 11ESTRATTO DALLO SCHEMA XSD RELATIVO ALLA
REQUEST.
37
FIGURA 12ESEMPIO DI REQUEST XACML. 38
FIGURA 13ESEMPIO DI ELEMENTO RESOURCECONTENT. 40
FIGURA 15ESTRATTO DALLO SCHEMA XSD RELATIVO ALLA
RESPONSE.
43
FIGURA 16ESEMPIO DI RESPONSE XACML. 44
FIGURA 17MODELLO DEL LINGUAGGIO PER LE POLITICHE. 52
FIGURA 18STRUTTURA PREVISTA DALLA SUN'S XACML
IMPLEMENTATION VERSION 1.2
57
FIGURA 19STRUTTURA DI UN'APPLICAZIONE J2EE 60
FIGURA 20ARCHITETTURA FUNZIONALE PER I CONTAINER J2EE 62
FIGURA 21AAAPULL SEQUENCE 64
FIGURA 22INTEGRAZIONE DEL CONTROLLO DEGLI ACCESSI IN CMOS 65
FIGURA 23SCHEMA DEL PROTOTIPO REALIZZATO. 74
FIGURA 24MODELLO DEGLI UTENTI DELL'APPLICAZIONE "SERVIZIO
PRESTITI"
78
FIGURA 25MODELLO DEI DATI DELL'APPLICAZIONE "SERVIZIO
PRESTITI"
82
FIGURA 26REQUEST UTILIZZATA PER LE MISURAZIONI 100
I
NTRODUZIONE
Il lavoro che viene presentato in questa tesi è stato sviluppato nell’ambito del progetto CMOS presso l’azienda Bassnet s.r.l. di Firenze [ 1], una società che ha tra i propri obiettivi lo sviluppo di soluzioni innovative ad alto contenuto tecnologico e che ricopre il ruolo di Laboratorio Nazionale di Ricerca riconosciuto dal Ministero dell’Istruzione.
Il progetto CMOS (“Nuova piattaforma in ambiente Open Source per la realizzazione di sistemi di Content Management”) è un progetto approvato e finanziato dal Ministero delle Attività Produttive che prevede la progettazione e l’implementazione di una piattaforma di servizi legati al mondo del content, document e workflow management.
Con questo lavoro è stata individuata e sviluppata una soluzione volta a integrare nella piattaforma un modulo per il controllo degli accessi ai dati. Lo scopo del controllo degli accessi è di sottoporre ogni richiesta dell’utente di accedere ai dati a un insieme di politiche di accesso. Le politiche di accesso impongono delle condizioni che devono essere verificate affinché l’azione dell’utente venga autorizzata.
Le applicazioni Web basate sui dati sono attualmente le più diffuse: esempi possono essere siti istituzionali di organizzazioni pubbliche e private, siti per il commercio elettronico, siti di comunità virtuali. Lo sviluppo di queste applicazioni coinvolge competenze multidisciplinari necessarie per affrontare compiti eterogenei che vanno dalla progettazione delle strutture dati relative ai
contenuti, alla realizzazione di interfacce ipertestuali per la gestione e la navigazione delle informazioni.
CMOS vuole essere una soluzione per chi ha le conoscenze del dominio informativo su cui deve essere sviluppata un’applicazione, ma non ha sufficienti competenze informatiche per affrontare i vari aspetti legati allo sviluppo: il progetto CMOS intende fornire uno strumento che consenta di produrre una applicazione Web senza approfondite competenze informatiche, attraverso l’utilizzo di un’interfaccia grafica che guidi nel processo di sviluppo, mettendo in evidenza gli aspetti logici dell’applicazione e mascherando tutti gli aspetti implementativi.
Nelle applicazioni di Content Management la sicurezza dei dati è un aspetto particolarmente rilevante, in particolar modo deve essere garantito che chiunque voglia accedere ai dati messi a disposizione dall’applicazione abbia sufficienti diritti. In quest’ottica in CMOS si è sentita l’esigenza di consentire allo sviluppatore dell’applicazione di definire delle politiche di accesso ai dati: ogni sviluppatore potrà individuare delle categorie di dati sensibili e per ognuna di esse potrà specificare quali caratteristiche dovrà avere l’utente per poter accedere ai dati, intendendo con tale termine qualsiasi azione che possa avere a che fare con i dati, dalla visualizzazione, alla modifica, alla cancellazione o all’inserimento. In particolare nello sviluppo del progetto CMOS si è fatta la scelta di esprimere le politiche in modo molto flessibile, facendo riferimento agli attributi caratterizzanti sia l’utente che i dati coinvolti in una richiesta di accesso.
Il lavoro che viene qui presentato è partito da questa esigenza di sicurezza: si è individuata una possibile soluzione ed è stato sviluppato un prototipo compatibilmente con i criteri di progetto imposti dalla integrazione con la piattaforma CMOS e dalla sua fase di sviluppo attuale.
Questo documento illustra l’evoluzione del lavoro:
– nel primo capitolo viene presentato il progetto CMOS con particolare
riferimento agli aspetti relativi al controllo degli accessi;
– nel secondo capitolo viene presentata descritto lo standard XACML
che è alla base della soluzione individuata per la realizzazione del modulo di controllo degli accessi;
– nel terzo capitolo viene descritta l’integrazione della soluzione
adottata nella struttura di base prevista per il CMOS e viene presentato il prototipo realizzato;
– nel quarto capitolo viene presentato un caso applicativo con
l’introduzione di un formalismo per l’applicazione dello standard XACML a applicazioni generiche di Content Management.
– nel quinto capitolo vengono presentate una serie di misurazioni
rilevate durante l’esecuzione di alcuni componenti del prototipo realizzato, con lo scopo di individuare i principali fattori che ne influenzano le prestazioni;
– nel sesto capitolo vengono indicate delle possibili modifiche e
sviluppi che sono stati individuati durante la realizzazione di questo lavoro e che si ritengono necessari per completare l’integrazione del modulo del controllo degli accessi con il progetto CMOS.
CAPITOLO 1
D
ESCRIZIONE DEL PROGETTO
CMOS
Il progetto è legato all’uso di piattaforme di sviluppo e di linguaggi Open Source e prevede la realizzazione di diversi moduli interagenti, ognuno relativo a una specifica funzionalità.
I moduli attualmente previsti sono relativi alla realizzazione dei modelli dei dati, al supporto di più dispositivi di accesso, con particolare attenzione alla accessibilità e alla usabilità, alla gestione dei flussi di lavoro e alla gestione dei profili utente e dei privilegi per l’accesso ai dati.
È previsto che i vari moduli comunichino tra di loro scambiandosi messaggi in XML: questa scelta lascerà libero l’utente di utilizzare tutti i moduli previsti dalla piattaforma o di sostituirne alcuni con altri equivalenti, già presenti tra i prodotti Open Source in circolazione. Questa caratteristica è stata utilizzata anche in fase di test di alcuni prototipi: ad esempio durante lo sviluppo del modulo per la modellazione dei dati, la sua funzione è stata realizzata tramite il programma di modellazione UML ArgoUML [ 2].
A
RCHITETTURA DELLA PIATTAFORMACMOS
Il progetto CMOS è basato su un’architettura in cui sono gestiti, in maniera completamente separata, gli aspetti relativi ai contenuti e gli aspetti relativi alla loro presentazione.
La gestione degli aspetti relativi alla presentazione è affidata a un modulo che si occupa di adeguare la presentazione dei contenuti al particolare dispositivo di navigazione utilizzato dall’utente; infatti le potenzialità rappresentative dei dispositivi previsti sono particolarmente variabili: nell’ambito dell’utilizzo di un browser visuale su un personal computer le capacità di presentazione sono eterogenee al variare delle caratteristiche dell’hardware e del tipo di browser utilizzato, ma le potenzialità variano notevolmente se si passa a browser presenti su dispositivi palmari, siano essi telefoni cellulari o Pda, o a dispositivi browser per utenti disabili che possono spaziare dai lettori di schermo ai browser vocali.
Il compito del modulo di presentazione è di individuare le caratteristiche della tecnologia utilizzata dall’utente e di adattare la presentazione in modo da sfruttare al meglio le capacità del dispositivo senza influenzare gli aspetti relativi alla gestione dei contenuti.
Il modulo per la gestione dei contenuti si appoggia a una base di dati sviluppata in CMOS, ma è previsto lo sviluppo di un modulo in grado di interfacciarsi con basi di dati preesistenti.
In Figura 1 è contenuta una rappresentazione dell’architettura appena descritta.
L
A BASE DI DATI GENERALE DICMOS
La base di dati utilizzata in CMOS ha il compito di contenere i dati delle applicazioni che saranno sviluppate con la piattaforma CMOS; poiché ogni applicazione sarà basata su un modello concettuale dei dati Figura 1 Struttura della piattaforma CMOS
specifico dell’applicazione, la base di dati di CMOS è stata realizzata in modo tale da poter contenere qualsiasi modello dei dati.
La modellazione dei dati da parte dell’utente segue il modello Entity-Relationship, ma la piattaforma utilizza un proprio modello di rappresentazione e memorizzazione fisica dei dati.
Nello sviluppo di un’applicazione con CMOS la base di dati modellata dall’utente viene destrutturata e mappata nella base di dati utilizzata dalla piattaforma. Quest’ultima è organizzata in modo da poter contenere, oltre ai dati destinati a stare nella base di dati definita dall’utente, anche una rappresentazione del modello Entità-Relationship.
I vantaggi che si ottengono con questa impostazione della base di dati della piattaforma sono collegati sia alla grande flessibilità che viene resa disponibile (l’utente può definire il modello della base di dati che intende utilizzare), ma anche ai benefici che derivano dalla ottimizzazione nella disposizione dei dati (la piattaforma rappresenta e memorizza i dati secondo un proprio modello) che risulta essere orientata alle attività che i moduli di CMOS compiono su di essi.
La modellazione concettuale dei dati per una applicazione in
CMOS
Alla base di una applicazione di Content Managent vi sono i dati gestiti dall’applicazione. Chi sviluppa l’applicazione deve individuare e realizzare un modello concettuale dei dati relativi alla realtà che deve essere rappresentata.
In particolare, in CMOS un modello dei dati è composto da un insieme di Classi e da un insieme di Relazioni tra le classi. Ogni classe è caratterizzata da un insieme di Elementi.
Esempio di modello dei dati.
Per rendere più chiaro questa definizione di modello, consideriamo un esempio esplicativo: in un contesto universitario si vogliono gestire le informazioni relative agli studenti e alla loro carriera, indicando per ogni studente i seguenti dati: un Nome, una Matricola, la Media dei voti, il numero Esami sostenuti e un elenco relativo ai dati caratterizzanti ogni esame sostenuto. Ogni Esame è caratterizzato da: un Codice, la Data in cui è stato sostenuto e il Voto riportato. Inoltre si vuole indicare per ogni esame quali sono i testi di riferimento suggeriti dal docente. Ogni testo è caratterizzato da: un Titolo, un Autore e un Editore.
In tale realtà, possono essere individuate tre classi: Studente, Esame e Testo; la classe Studente ha un insieme di elementi composto da: Nome, Matricola, Media, Esami sostenuti; la classe Esame ha un insieme di elementi composto da: Codice, Data, Voto; la classe Testo ha un insieme di elementi composto da: Titolo, Autore, Editore. Sono inoltre individuabili, una relazione tra Studente e Esame e una relazione tra Esame e Testo. In generale le relazioni sono considerate bidirezionali, ma allo stato attuale dei lavori non è stata ancora preso in esame l’aspetto della cardinalità delle relazioni.
Rappresentazione di un modello dei dati.
In accordo con lo spirito di CMOS è previsto che la modellazione venga effettuata attraverso una interfaccia grafica che rende disponibile un sottoinsieme dell’UML [ 3] adeguato a definire le rappresentazioni di realtà previste nel progetto CMOS. Tramite questa interfaccia grafica il modello appena descritto, può essere schematizzato come in Figura 2.
È previsto che una applicazione possa fare riferimento a più modelli di dati: mantenendo inalterato l’insieme delle classi, è sufficiente aggiungere o togliere delle relazioni per ottenere dei modelli diversi.
Ad esempio, nel caso precedente relativo alle classi Studente, Esame, Testo, si può fare riferimento a una realtà differente mettendo in relazione lo studente con gli esami e lo studente con i testi, intendendo visualizzare per ogni studente sia gli esami sostenuti che i libri presi in prestito in biblioteca e ottenendo la rappresentazione di Figura 3.
I modelli, le classi, gli elementi e le relazioni sono tutti caratterizzati da un insieme di attributi impliciti che non hanno a che fare con la realtà rappresentata, ma che vengono utilizzati dall’applicazione per
le loro gestione. Gli attributi impliciti sono delle proprietà (talvolta chiamate
tagged values) che vengono associate ai modelli, alle classi, agli elementi e
alle relazioni; possono essere legati ad aspetti relativi alla presentazione, alla archiviazione e ad altre funzionalità della piattaforma, sono estendibili e configurabili: nella fase attuale dello sviluppo del progetto, gli attributi impliciti non sono ancora del tutto definiti e sono oggetto di progettazione.
Struttura della base di dati
Come evidenziato in precedenza, la base di dati utilizzata in CMOS ha uno schema che è invariante al variare dell’applicazione sviluppata. Tale schema può essere visto come composto da due sezioni: la prima che esamineremo è quella relativa alla rappresentazione dei modelli dei dati definiti dall’utente, la seconda è dedicata a contenere i dati che appariranno all’utente come se fossero contenuti in una base di dati avente uno schema originato dai modelli dei dati definiti per l’applicazione.
Nella fase attuale del progetto, la struttura della base di dati è soggetta a cambiamenti, ma per gli obiettivi di questo lavoro faremo riferimento alla versione che viene qui presentata.
Schema relativo alla gestione dei modelli dei dati.
La parte dello schema destinata alla gestione dei modelli dei dati è rappresentata in Figura 4.
Figura 4 Schema della base di dati per la gestione dei modelli dei dati
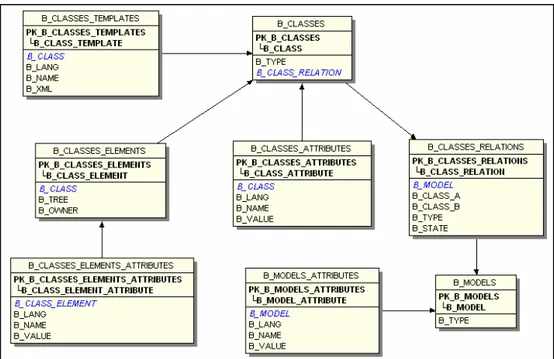
La tabella B_MODELS consente di accedere a tutti i modelli contenuti nella base di dati: ogni modello dei dati viene individuato per mezzo della chiave b_model.
Ad ogni modello è associato un insieme di attributi e un insieme di relazioni tra classi: gli attributi del modello sono contenuti nella tabella
B_MODELS_ATTRIBUTES, le relazioni tra le classi sono contenute nella tabella B_CLASSES_RELATIONS.
La tabella B_MODELS_ATTRIBUTES contiene gli attributi dei modelli dei dati: ogni attributo è individuato dalla chiave b_model_attribute e può essere associato al modello di appartenenza per mezzo della chiave esterna b_model; ad ogni attributo, oltre al nome b_name e al valore b_value è associato anche un campo b_lang: tale campo è presente anche tra gli attributi delle classi e degli elementi ed è legato alla caratteristica prevista per la piattaforma CMOS di realizzare applicazioni “localizzabili” con supporto a più lingue.
La tabella B_CLASSES_RELATIONS descrive le relazioni tra le classi. Ogni relazione è individuata attraverso la chiave b_classes_relation ed è legata a uno specifico modello di dati per mezzo della chiave esterna
b_model. Ogni relazione ha associate le due classi del modello che mette in
relazione (b_class_A e b_class_B ); essendo le relazioni bidirezionali, ogni relazione prevede due entry nella tabella, una per ogni verso di navigazione: per distinguere le due entry, si usa il campo b_type che indica una gerarchia tra le classi A e B e può assumere il valore Padre/Figlio. Il rimanente campo
b_state viene utilizzato per indicare se la relazione è attiva, cioè navigabile.
La tabella B_CLASSES consente di individuare le classi
contenute nei modelli dei dati. Ogni classe è individuata per mezzo della chiave b_class e viene collegata alle relazioni che la riguardano per mezzo del campo b_class_relation. Inoltre alle classi sono associati gli attributi contenuti nella tabella b_classes_attributes e gli elementi descritti nella tabella b_classes_elements.
La tabella B_CLASSES_ATTRIBUTES descrive gli attributi associati alle classi e ha una struttura simile alla tabella
B_MODELS_ATTRIBUTES.
La tabella B_CLASSES_ELEMENTS descrive gli elementi delle classi che risultano individuabili tramite la chiave b_class_element. A ogni elemento è associata la classe di appartenenza tramite la chiave esterna
b_class e un campo b_tree che verrà descritto successivamente durante la
descrizione dello schema relativo alla memorizzazione dei dati.
La tabella B_CLASSES_ELEMENTS_ATTRIBUTES è del tutto simile alle tabelle B_CLASSES_ATTRIBUTES e B_MODELS_ATTRIBUTES.
Schema relativo alla memorizzazione dei dati.
In Figura 5 è descritto lo schema delle tabelle presenti nella base di dati utilizzate per la memorizzazione dei dati. I dati verranno immessi secondo i modelli dei dati che dovranno essere definiti dagli utenti che utilizzeranno la piattaforma CMOS per sviluppare applicazioni. Una volta che una applicazione sviluppata con CMOS sarà a regime, saranno utilizzate solo le tabelle contenute in questo schema. Infatti, esse riassumono tutte le informazioni che sono contenute nello schema precedentemente esposto relativo al modello dei dati.
I dati che vengono memorizzati in CMOS secondo un modello dei dati definito dall’utente, vengono completamente destrutturati: infatti non vengono memorizzati secondo la gerarchia modello, classe, elemento. Figura 5 Schema della base di dati utilizzato per la memorizzazione dei dati
Vengono memorizzati gli elementi all’interno di un struttura reticolare che ricalca il modello concettuale definito dall’utente ereditando i riferimenti alle classi e alle relazioni.
Il meccanismo realizzato prevede che l’istanza di una classe definita dall’utente, che in CMOS viene chiamata scheda, venga identificata attraverso una coppia di valori (b_class, b_code): tutti gli elementi che compongono l’istanza della classe sono identificati tramite la suddetta coppia di valori.
Durante la navigazione, per indicare una scheda viene utilizzato un GUID (Globally Unique IDentifier), detto b_key, che la identifica univocamente: per risalire dal b_key alla coppia (b_class, b_code) che viene utilizzata per individuare gli elementi della scheda nella base di dati.
La tabella B_KEYS contiene le informazioni per operare la conversione citata; oltre a tale funzionalità, la tabella B_KEYS contiene anche informazioni che vengono utilizzate per limitare temporalmente la validità dei dati: infatti è previsto che dei dati presenti nella base di dati vengano mascherati al di fuori dei vincoli temporali associati.
La tabella B_ELEMENTS viene acceduta attraverso la coppia ricavata tramite la tabella B_KEYS. Ogni elemento è caratterizzato da un tipo che può appartenere a un insieme configurabile di tipi definiti dalla piattaforma: al momento sono previsti i tipi B_VCHAR, B_TEXT, B_NUMBER,
B_DATETIME e B_OBJECT. A seconda del tipo di un elemento, nella entry della tabella B_ELEMENTS ad esso associato, verrà istanziato l’opportuno identificatore che verrà utilizzato per individuare il valore dell’elemento all’interno delle tabelle che contengono i dati. È presente un ulteriore campo che individua un collegamento tra schede: il suo valore viene utilizzato come chiave nella tabella B_TREES.
Le tabelle per la memorizzazione dei valori dei dati sono una per ognuno dei tipi citati; oltre al valore dell’elemento contengono le indicazioni necessarie per il supporto alle lingue.
La tabella B_ATTRIBUTES contiene gli attributi necessari per la gestione (visualizzazione, ecc.) di ogni elemento.
La tabella B_TREES contiene le informazioni relative alle relazioni tra le schede: partendo dal modello dei dati (tabella
B_CLASSES_RELATION) mantiene tra le schede i collegamenti che replicano le relazioni tra le classi presenti nel modello dei dati. A questa tabella fanno e faranno riferimento delle informazioni accessorie, necessarie per il rapido accesso ad alcuni aspetti dei dati, utili per applicare funzionalità particolari alle schede.
A
SPETTI RELATIVI ALLA PRESENTAZIONE E NAVIGAZIONE DEI DATI.
La presentazione dei dati, pur essendo variabile a seconda della tecnologia utilizzata dall’utente, mantiene delle caratteristiche strutturali che si ripercuotono nell’accesso ai dati.
In particolare, i dati verranno acceduti raggruppati per pagine: dal punto di vista dei contenuti, in generale ogni pagina contiene una o più schede, ricordando che in CMOS per scheda si intende l’istanza di una classe del modello concettuale dei dati. Nell’ambito di una pagina, le schede possono essere appartenenti alla stessa classe o eterogenee.
L’approccio generale che è stato seguito nell’individuare le caratteristiche strutturali delle pagine è basato su considerazioni di usabilità che devono essere soddisfate dalle applicazioni generate tramite CMOS
Ogni pagina deve contenere, indipendentemente da come verrà presentata all’utente, delle caratteristiche funzionali che rispondano alle esigenze di usabilità; queste ultime prevedono che l’utente di una applicazione venga messo in grado di individuare in ogni momento in che pagina si trova, quali sono le sezioni principali dell’applicazione, quali sono le opzioni disponibili nel livello attivo, capire se è disponibile la possibilità di fare una ricerca tra i dati. Queste funzionalità vengono fornite tramite un menù indicante le sezioni principali e le opzioni disponibili nel livello attivo, un percorso di contesto che identifica la pagina all’interno della struttura dell’applicazione.
Un esempio di pagina conforme alla struttura prevista, con evidenziate le caratteristiche funzionali, è riprodotta in Figura 6.
Gli elementi strutturali menzionati sono costituti da link di navigazione che una volta selezionati provocano la presentazione di una nuova pagina. Ogni link è un riferimento al GUID di una scheda e innesca la modifica della pagina con la presentazione della scheda puntata dal link.
In alcuni casi, come nel caso dei link componenti il percorso di contesto, o come nel caso dei titoli di schede che vengono presentati in elenchi generati da operazioni di ricerca, i link sono costituiti da concatenazioni di elementi delle schede riferite dai link stessi: questo fa sì che in ogni pagina siano presentate più schede, siano esse presentate integralmente o in maniera concisa attraverso pochi elementi che le compongono. La piattaforma prevede che l’utente nella fase di definizione di un modello dei dati indichi, quali elementi della scheda debbano essere utilizzati per comporre il titolo della scheda o i link che la riferiscono.
C
ONTROLLO DEGLI ACCESSIClassificazione degli utenti delle applicazioni CMOS
Le caratteristiche delle applicazioni che potranno essere sviluppate con il CMOS saranno particolarmente variabili e fortemente dipendenti dalla realtà cui faranno riferimento; tutte le applicazioni hanno il comune denominatore di essere applicazioni di Content Management e sulla base di tale peculiarità, si può delineare una prima caratterizzazione e classificazione degli utenti che in linea del tutto generale interagiranno con l’applicazione.
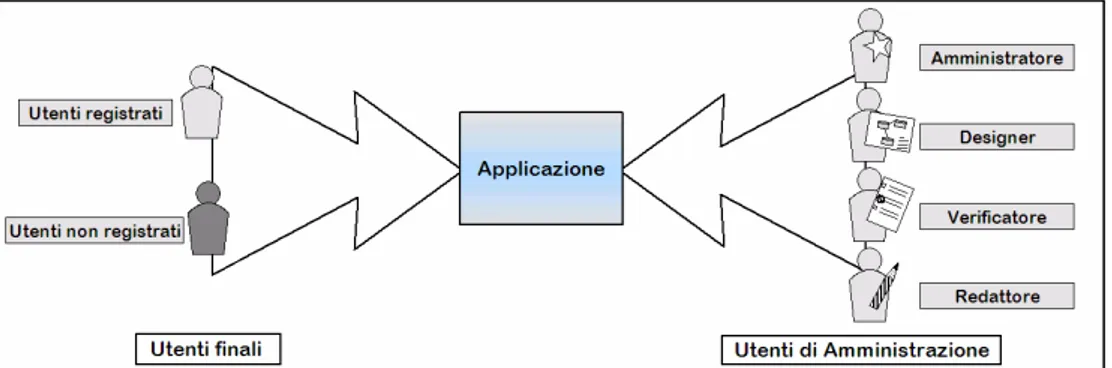
In prima analisi occorre differenziare gli utenti delle applicazioni di Content Management in due grosse categorie: alla prima appartengono quelli utenti che interagiscono con l’applicazione ai fini dell’amministrazione dell’applicazione stessa, alla seconda appartengono gli utenti che intendono fruire dei dati gestiti dall’applicazione.
In Figura 7 è data una rappresentazione schematica della classificazione degli utenti. Esaminiamo in maniera più dettagliata queste due macrocategorie:
– alla prima categoria appartengono l’amministratore dell’applicazione, i designer dei dati, i redattori e i verificatori; – nella seconda categoria è possibile individuare una ripartizione tra
utenti registrati e autenticati e utenti non registrati.
A seconda della complessità dell’applicazione, queste tipologie di utenti possono essere accorpate o ulteriormente dettagliate sulla base del modello dei dati gestito dall’applicazione, ma a livello funzionale esse sono sempre presenti. Descriviamo ora le funzionalità che devono essere previste per ognuna delle categorie di utenti menzionate.
Amministratore dell’applicazione.
Questo utente deve poter agire sullo stato dell’applicazione e deve poter accedere a statistiche relative all’attività dell’applicazione. Ha il compito di amministrare gli utenti: deve individuare una classificazione degli utenti adeguata per la realtà su cui sarà basata l’applicazione e in base ad essa deve distribuire dei privilegi a tutti gli utenti; può inserire nuovi utenti o eliminarne tra quelli inseriti, inoltre può modificarne il profilo. Deve autorizzare e verificare l’attività dei designer dei dati.
Designer del modello dei dati.
Questo utente è esperto della realtà su cui sarà basata l’applicazione. Sotto autorizzazione dell’amministratore deve poter inserire nuovi modelli di dati o modificare quelli presenti. Ha un ruolo molto delicato perché tutta l’attività dell’applicazione è basata sul modello dei dati.
Redattore dei dati.
Questo utente ha il compito di inserire, modificare o cancellare i dati gestiti dall’applicazione: a seconda delle competenze, può essere un redattore dei dati relativi alla presentazione (grafico, esperto di accessibilità, esperto di tecnologie di accesso ai dati) o un redattore dei contenuti. In relazione alla complessità dell’applicazione o della realtà da essa gestita si può prevedere una sottoclassificazione dei redattori rispetto alla porzione di dati o alle operazioni sui dati di loro competenza. I dati che subiscono l’attività dei redattori, non sono immediatamente disponibili per l’utente finale, ma devono essere prima verificati e autorizzati dai verificatori.
Verificatore dei dati.
Questo utente è responsabile per la pubblicazione dei dati gestiti dall’applicazione, intendendo per pubblicazione l’operazione attraverso cui i dati vengono resi disponibili all’utente finale. Deve convalidare l’operato dei redattori e amministrare i dati pubblicati. Come per i redattori, si può prevedere una sottoclassificazione dei verificatori rispetto alla porzione di dati di loro competenza.
Utenti finali.
Questi utenti sono i fruitori principali dell’applicazione di Content Management: utilizzano l’applicazione perché hanno l’obiettivo di accedere ai dati gestiti dall’applicazione. Si può immaginare una ripartizione di base tra utenti registrati e autenticati e utenti non registrati o anonimi. La visione dei contenuti che l’applicazione fornisce agli utenti finali deve essere filtrata in relazione ai privilegi posseduti dall’utente finale: gli utenti anonimi possono accedere solo alle pagine che non contengono dati sensibili, mentre gli utenti autenticati fruiranno dei dati sottostando al controllo degli accessi adottato nell’applicazione che consentirà di realizzare viste dei dati personalizzate in base ai privilegi.
Controllo degli accessi in CMOS
Prima di descrivere quali sono state le scelte relative al controllo degli accessi che sono state fatte nell’ambito del progetto CMOS, esaminiamo che cosa si intende per controllo degli accessi e quali sono le scelte disponibili.
Alla base dello sviluppo di un sistema per il controllo degli accessi vi è la definizione di regole secondo cui consentire o negare l'accesso alle risorse, intendendo per accesso qualunque tipo di operazione si voglia compiere sulla risorsa; successivamente si definisce un meccanismo in base al quale si fa in modo che le regole vengano rispettate. In altri termini, inizialmente si definisce la politica di sicurezza alla base del controllo degli accessi; poi si definiscono i meccanismi software e hardware che implementano la politica di sicurezza scelta.
Politiche di controllo degli accessi
Le politiche di controllo degli accessi possono essere divise in tre classi principali: discrezionali (Discretionary Access Control, DAC), obbligatorie (Mandatory Access Control, MAC) e basate sui ruoli (Role-based Access Control, RBAC).
Le politiche discrezionali (DAC) basano il controllo degli accessi sull'identità del richiedente e su insiemi di regole che stabiliscono chi può, o non può, eseguire determinate azioni su determinate risorse. Sono chiamate discrezionali in quanto prevedono la possibilità che gli utenti trasferiscano i loro diritti ad altre entità a loro discrezione.
Le politiche obbligatorie (MAC) gestiscono il controllo degli accessi in conformità ad un insieme di regole definite ed imposte da un’autorità centrale. La forma più comune di politica di questo tipo è chiamata multi-livello. Essa si basa sulla classificazione di soggetti ed oggetti nel sistema: gli oggetti sono entità passive che memorizzano informazioni; i soggetti sono invece entità attive che richiedono l’accesso agli oggetti. A differenza delle politiche discrezionali, gli utenti non si identificano direttamente con i soggetti. Nelle politiche obbligatorie infatti, gli utenti sono le persone fisiche che accedono al sistema, mentre i soggetti sono i processi (i programmi in esecuzione) che operano per conto degli utenti.
Le politiche basate sui ruoli (RBAC) sono state introdotte nei primi anni ‘90 per la gestione del controllo nell’ambito di applicazioni commerciali. La motivazione principale dietro a questo tipo di politica è la necessità di specificare ed imporre politiche di controllo degli accessi strettamente legate alla struttura dell’organizzazione aziendale. Questa scelta è giustificata dal fatto che, in un numero consistente di
organizzazioni, l'identità di un soggetto è rilevante solo dal punto di vista delle sue responsabilità civili o penali. Ai fini del controllo degli accessi, piuttosto che conoscere l’identità di un soggetto, è invece molto più importante conoscere i ruoli e le funzioni che tale soggetto svolge nell’ambito dell’organizzazione.
La politica RBAC soddisfa tale esigenza assegnando i permessi di accesso ai ruoli ed assegnando questi ultimi agli utenti in base alle loro responsabilità e qualifiche all’interno dell’organizzazione. Nel caso più generale, l’assegnazione dei permessi ai ruoli e dei ruoli agli utenti può essere modificata dinamicamente per soddisfare le mutate esigenze dell’organizzazione.
La politica RBAC supporta, inoltre, i principi di minimo privilegio e di separazione delle responsabilità. Il principio del minimo privilegio è rispettato dal momento che RBAC può essere configurato in maniera tale che i permessi siano assegnati esclusivamente ai ruoli richiesti per portare a termine una determinata attività. La separazione delle responsabilità viene rispettata assicurando che solo ruoli mutuamente esclusivi possano essere richiesti per completare una attività sensibile.
Riassumendo, da questa breve digressione si può evincere che, rispetto alle politiche DAC e MAC, la politica RBAC si caratterizza per il fatto che la decisione di autorizzare una certa azione si basa non solo sull’identità del soggetto che ha richiesto l’operazione ma anche su altre caratteristiche possedute da tale soggetto come ad esempio il ruolo che esso riveste nell’ambito dell’organizzazione o le funzioni che in tale ambito svolge. Questo approccio permette quindi una gestione più flessibile delle politiche di controllo degli accessi e dà supporto a importanti principi di sicurezza come il principio di minimo privilegio ed il principio di separazione delle responsabilità.
L’approccio RBAC può essere considerato come un caso particolare della politica di controllo degli accessi basata sugli attributi (Attributes-based Access Control, ABAC) in cui la decisione di autorizzare o meno l’azione richiesta da un soggetto su di una particolare risorsa dipende dalle caratteristiche, o attributi, del soggetto (subject attributes) nonché dagli attributi della risorsa stessa (resource attributes). Ne segue quindi che la politica ABAC generalizza la politica RBAC per quanto riguarda sia i soggetti sia le risorse. Mentre nella politica RBAC un soggetto è essenzialmente caratterizzato da due attributi predefiniti, l’identità ed il ruolo, nella politica ABAC l’insieme di attributi che caratterizza un soggetto non è definito a priori e può essere specificato in base alle esigenze del contesto applicativo. Inoltre, mentre nella politica RBAC, ad eccezione dell’identità, nessun attributo della risorsa (ad esempio il suo stato interno) influenza la decisione sull’autorizzazione, nella politica ABAC qualunque attributo della risorsa può influenzare tale decisione.
Scelte sul controllo degli accessi nel progetto CMOS
Poiché uno degli aspetti principali che caratterizzano il progetto CMOS è la flessibilità offerta all’utente per la realizzazione di applicazioni di gestione dei contenuti, per mantenere questo alto grado di flessibilità anche nella politica per il controllo degli accessi, si è fatta la scelta della politica basata sugli attributi (ABAC).
La scelta di questa politica prevede che il CMOS sia dotato di un meccanismo per la gestione degli attributi e di un linguaggio per la definizione delle politiche (policy language), nonché di un supporto a tempo di esecuzione che garantisca l’applicazione delle politiche.
In pratica, nello sviluppo di una applicazione con il CMOS, si dovranno definire uno o più modelli concettuali dei dati, si dovrà individuare una serie di attributi che caratterizzeranno gli utenti (template degli utenti) e si dovranno descrivere le politiche tramite le quali il CMOS autorizzerà o meno l’accesso ai dati da parte degli utenti.
La descrizione delle politiche dovrà essere effettuata mediante l’uso di un linguaggio che consenta di esprimere politiche ABAC. Poiché il CMOS è destinato al mondo Open Source, è stata scartata l’ipotesi di sviluppare un linguaggio proprietario e la scelta si è orientata verso uno standard emergente che sembra destinato a divenire lo standard di fatto per il controllo degli accessi nelle applicazioni distribuite: tale standard è l’XACML proposto da OASIS che verrà ampiamente descritto nel capitolo successivo.
CAPITOLO 2
L
O STANDARD
OASIS
XACML.
Nella realizzazione della piattaforma CMOS è stata fatta la scelta di effettuare il controllo degli accessi utilizzando politiche basate sugli attributi (ABAC); questa scelta è motivata dall’esigenza di mantenere un elevato grado di flessibilità nella definizione delle politiche adeguatamente al grado di flessibilità che la piattaforma offre negli altri aspetti relativi allo sviluppo di applicazioni di Content Management distribuite.
Un sistema di controllo degli accessi necessità di un meccanismo che a livello di esecuzione autorizzi l’accesso ai dati nel rispetto delle politiche definite; l’attività di tale meccanismo richiede che venga definito un linguaggio con cui esprimere le richieste di accesso e un linguaggio che consenta di definire le politiche.
La risposta a tali esigenze è stata individuata nello standard XACML [ 5] [6] (eXtensible Access Control Markup Language) proposto da OASIS (Organization for the Advancement of Structured Information
Standards).
Lo standard XACML fornisce un linguaggio per la definizione delle politiche (policy language) e un linguaggio di interfaccia per la interrogazione del sistema che applica le politiche (context language). Entrambi i linguaggi indicati sono espressi in XML nel rispetto di opportuni XSD [7] [8] (XML Schema Definition) definiti nello standard. La scelta
dell’XML è stata fondata sulla facilità con cui ne può essere estesa la sintassi e la semantica per adattarla alle esigenze dell’XACML e sull’ampio supporto da parte di piattaforme e produttori di cui gode.
Sebbene esistano già linguaggi sia proprietari sia application-specific che permettono di esprimere tali politiche, XACML presenta i seguenti vantaggi:
• è standard ed Open Source: è supportato da una ampia comunità di esperti e di utenti e ci si aspetta quindi che abbia una diffusione tale da rendere più facile la comunicazione con applicazioni che utilizzano lo stesso standard;
• è generico: questo significa che piuttosto che tentare di fornire un controllo degli accessi per un ambiente specifico o per uno specifico tipo di risorse, XACML può essere utilizzato per scrivere delle politiche che poi possono essere utilizzate da differenti tipi di applicazioni agevolando così la gestione stessa delle politiche;
• è estendibile: XACML è stato concepito per essere integrato nei più disparati ambienti applicativi ed operativi andando ad adattare l’implementazione di alcune componenti “di interfaccia” a tali ambienti;
• è distribuito: le politiche possono essere definite ed amministrate da gruppi differenti e localizzate in siti differenti; XACML è in grado di recuperarle e di combinare le decisioni delle varie politiche in un'unica decisione;
• è potente: nonostante sia estendibile, XACML dà supporto ad una grande varietà di tipi, funzioni e regole per la scrittura delle politiche (vale la pena osservare che, a livello internazionale, si sta lavorando per estendere XACML in modo da renderlo interoperabile con altri standard come SAML e LDAP).
Un aspetto che rende XACML particolarmente potente è la naturalezza con cui si possono definire le politiche senza preoccuparsi di eventuali conflitti tra di esse: in ogni caso sarà possibile individuare un metodo per combinare i risultati e prendere una decisione.
S
CENARIOPer comprendere come funziona in concreto questo standard, occorre analizzare come viene integrato il meccanismo di controllo degli accessi in uno scenario tipico in cui un soggetto richiede l’autorizzazione ad eseguire una particolare azione/operazione su di una determinata risorsa.
La descrizione dei componenti previsti e delle loro interazioni che viene qui presentata è contenuta nelle specifiche dell’XACML, ma non ha carattere normativo e viene fornita per indicare la struttura funzionale prevista dallo standard. Le implementazioni dello standard possono differire da tale descrizione essendo vincolate a rispettare solo gli aspetti normativi definiti dallo stesso.
La richiesta di autorizzazione deve essere indirizzata a uno specifico componente del meccanismo di controllo degli accessi denominato Policy Enforcement Point (PEP). Tale componente costituisce il punto di contatto tra il mondo esterno e il controllo degli accessi: dal punto di vista del richiedente è come se a tutti gli effetti la decisione sulla autorizzazione venga presa dal PEP, in realtà tramite in PEP si attiva un complesso procedimento che mette il PEP nella condizione di produrre una risposta alla
richiesta di autorizzazione. Sia la richiesta che la risposta devono essere prodotte nel rispetto di una sintassi e di una semantica concordate tra il richiedente e il PEP; in genere l’interfaccia del PEP viene realizzata nel rispetto del linguaggio appartenente al richiedente.
Il compito del PEP è di adattare l’interrogazione del richiedente al linguaggio di richiesta previsto dall’XACML e di inoltrarla verso il Policy Decision Point (PDP): questo è il componente del meccanismo che sottopone la richiesta alle politiche, prende una decisione e la inoltra al PEP utilizzando il linguaggio di risposta previsto dall’XACML. La richiesta ricevuta dal PDP e la risposta da esso prodotta costituiscono il contesto
XACML.
Come indicato in Figura 8, dal punto di vista del PDP la decisione viene presa in relazione a un contesto XACML: infatti il PDP interagisce con richieste e politiche XACML e produce risposte XACML.
In pratica il PEP fornisce uno strato di astrazione e indipendentemente dallo specifico contesto esterno con cui è a contatto, confeziona una richiesta che deve essere sottoposta alle politiche: in base a questa considerazione si può affermare che in linea di principio le stesse politiche possono essere applicate a contesti diversi se dai PEP relativi a tali contesti pervengono richieste simili. Se le richieste indirizzate al PEP dal Figura 8 Contesto di lavoro del Policy Decision Point
richiedente e le risposte attese da esso sono espresse in XML si può ipotizzare che in generale l’attività del PEP possa essere realizzata per mezzo di una trasformazione XSLT.
Le richieste XACML contengono una descrizione della richiesta ricevuta dal PEP: viene descritto il soggetto richiedente, la risorsa su cui il soggetto intende agire e l’azione che il soggetto intende effettuare sulla risorsa.
All’arrivo di una richiesta, il PDP la sottopone alle politiche definite nel sistema: tali politiche contengono un Target che descrive le caratteristiche che devono avere il soggetto, la risorsa e l’azione inerenti a una richiesta affinché la politica possa essere applicata. Per individuare le politiche applicabili alla richiesta, il PDP può operare in due modi alternativi:
– può utilizzare la richiesta come chiave di accesso a un
repository delle politiche opportunamente strutturato rispetto a caratteristiche dell’utente, della risorsa e delle azioni: all’arrivo di una richiesta, tramite una ricerca nel repository, vengono individuate le politiche applicabili;
– può valutare i target di tutte le politiche rispetto alle
caratteristiche descritte nella richiesta e in base a tali valutazioni ricavare quali politiche sono applicabili.
La decisione su una richiesta può richiedere la conoscenza di attributi caratterizzanti il soggetto richiedente, la risorsa e in generale ulteriori attributi d’ambiente. Nel caso in cui tali attributi non siano resi disponibili direttamente dal PEP, il contesto di valutazione viene completato per mezzo dell’attività di un ulteriore componente denominato Policy Information Point (PIP).
Similarmente si presuppone che le politiche siano gestite da un ulteriore componente detto Policy Administration Point (PAP).
Il sistema ora descritto e il flusso dei dati scambiati tra i vari componenti è rappresentato in Figura 9.
All’arrivo di una richiesta del richiedente al PEP, questa viene propagata verso il PDP corredata dagli attributi necessari alla decisione che vengono resi disponibili tramite il PIP. Il PDP facendo riferimento al solo contesto e supportato dalle politiche predisposte dal PAP è in grado di Figura 9 Flusso di dati scambiato tra i componenti previsti dall'XACML
prendere una decisione: questo aspetto viene evidenziato dal fatto che il PDP è l’unico elemento del controllo degli accessi che non ha contatti con l’esterno. Nel diagramma non vengono indicate le obligations: con tale termine si indicano quelle operazioni che il PEP deve svolgere in relazione a una risposta del PDP affinché quest’ultima possa essere considerata valida. Un altro aspetto che risulta evidente dal diagramma è il posizionamento dei vari componenti rispetto al mondo esterno al controllo degli accessi: il PEP costituisce l’unico punto di contatto con il richiedente, il PIP è in grado di reperire dall’esterno i dati necessari al completamento del contesto, il PAP e le politiche possono essere gestiti internamente, ma in alcuni casi possono derivare dall’esterno, mentre il PDP opera in contatto con il solo contesto XACML.
D
ESCRIZIONE DELLA RICHIESTAXACML.
Il PEP interroga il PDP inviandogli una richiesta costruita nel rispetto dello standard: tale richiesta è un documento XML valido secondo lo schema stabilito dallo standard. Tale schema prevede che l’elemento principale del documento sia “Request”; tale elemento contiene una
rappresentazione del soggetto, della risorsa e dell’azione coinvolti nella richiesta, negli elementi denominati “Subject”, “Resource” e “Action”.
Ciascuno di questi elementi è costituito da un insieme di descrizioni di attributi denominati “Attribute”. L’elemento “Attribute” è
“AttributeValue” e da un insieme di metadati che vengono utilizzati per
identificare l’attributo. I metadati previsti sono: un identificatore obbligatorio “AttributeID” e due opzionali “Issuer” e “IssueInstant”
che contengono informazioni su chi ha emesso l’attributo e sul momento dell’emissione. Per gli attributi più comunemente utilizzati sono stati riservati dei valori di “AttributeID”.
Un attributo è caratterizzato da un tipo “DataType” che descrive
il tipo di dato che costituisce il valore dell’attributo: tale tipo può appartenere a un insieme di tipi primitivi predefiniti o a dei tipi dichiarati nell’ambito del contesto XACML.
Una rappresentazione schematica della struttura di una richiesta XACML è data in Figura 10, mentre in Figura 11 è contenuto un estratto dello schema XSD relativo a una Request.
Esempio di Request.
Per capire meglio come viene espressa una richiesta in XACML esaminiamo l’esempio di Request raffigurato in Figura 12.
Questa Request riferisce che un soggetto caratterizzato da quattro attributi (“ urn:oasis:names:tc:xacml:1.0:subject:subject-id”, “Corso_di_laurea”, “Nome” e “Media_voti”) intende effettuare una
azione caratterizzata da un unico attributo
(“urn:oasis:names:tc:xacml:1.0:action:action-id”) su una risorsa
caratterizzata da cinque attributi
(“urn:oasis:names:tc:xacml:1.0:resource:resource-id”, “Titolo”,
“Autore”, “Classificazione”, “Costo”).
Questo esempio potrebbe essere immaginato nel contesto di una biblioteca universitaria in cui gli utenti sono degli studenti, le risorse sono libri e le azioni consentite potrebbero essere “Prestito” e
“Restituzione”. Nel caso in cui i soggetti o le risorse potessero
appartenere a più categorie, sarebbe necessario indicare anche la categoria per individuare univocamente l’entità: con riferimento alla risorsa dell’esempio, se oltre ai libri ci fossero anche dei CD-ROM, la rappresentazione andrebbe ulteriormente dettagliata indicando “Libro” o
“CD-ROM” come “ urn:oasis:names:tc:xacml:1.0:resource:resource-id”.
I nomi di attributo possono essere basati direttamente sull’entità cui si riferiscono, ma quelli relativi a entità comunemente utilizzate sono stati fissati dallo standard; nell’esempio abbiamo “urn:oasis:names:tc:xacml:1.0:resource:resource-id”,
“urn:oasis:names:tc:xacml:1.0:subject:subject-id” e
“urn:oasis:names:tc:xacml:1.0:action:action-id”.
In particolare la richiesta di Figura 12 comunica che l’utente caratterizzato come in Tabella 1, intende effettuare un’operazione di “Prestito” sulla risorsa caratterizzata come in Tabella 2:
Tabella 1
Attributo
Valore
Tipo
subject-id “123456” String
Corso di Laurea “Ingegneria Informatica” String
Nome “Mario Rossi” String
Media Voti “24.35” Double
Tabella 2
Attributo
Valore
Tipo
resource-id “0201730383” String
Titolo “Building web applications” String
Autore “Jim Conallen” String
Classificazione “005.72” String
Elemento ResourceContent.
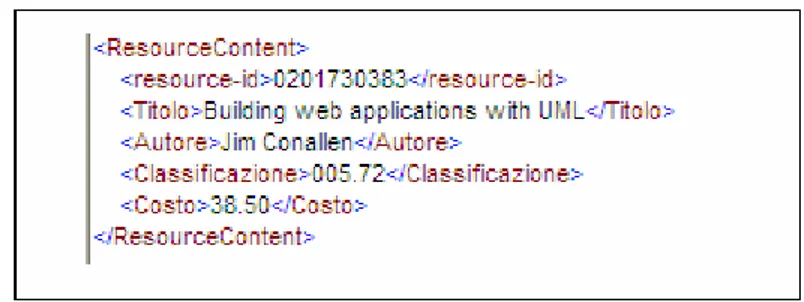
Nella descrizione della risorsa presente nella richiesta, oltre alla sequenza di elementi “Attribute” è previsto un ulteriore elemento
opzionale denominato “ResourceContent”. Tale elemento può contenere
una qualsivoglia rappresentazione XML della risorsa che sarà resa disponibile al PDP per l’applicazione delle politiche: questo elemento non ha alcuna funzione predefinita, a seconda dei casi può essere utilizzato per contenere una rappresentazione alternativa o complementare della risorsa.
In Figura 13 è presente una possibile struttura dell’elemento “ResourceContent”associabile alla richiesta di Figura 12: è evidente che in
una simile rappresentazione si perdono informazioni relative al tipo dei dati, ma in compenso si ha la possibilità di rappresentare elementi gerarchici, possibilità non prevista dal solo uso degli attributi.
D
ESCRIZIONE DELLA RISPOSTAXACML.
Una volta che il PDP ha preso una decisione sulla richiesta ricevuta, confeziona una risposta e la invia al PEP. Tale richiesta è un documento XML valido secondo lo schema stabilito dallo standard che prevede che l’elemento principale del documento sia “Response”.
Una rappresentazione di un elemento “Response” è contenuta in
Figura 14: contiene di norma un elemento “Result”, ma dipendentemente dalla richiesta ricevuta tale elemento può essere multiplo.
Un elemento “Result” è costituito da un elemento “Decision”,
un elemento “Status” e eventualmente una o più elementi “Obligation” . Figura 14Rappresentazione dello schema di una Response
Un elemento “Decision” deve contenere un valore tra
“Permit”, “Deny”, “NotApplicable” e “Indeterminate”: il meccanismo
in base al quale il PDP perviene alla decisione verrà spiegato dettagliatamente nei paragrafi successivi. Se l’elemento “Decision”
assume il valore “Permit”, il PEP deve autorizzare la richiesta di accesso
sottoposta a valutazione, in tutti gli altri casi l’autorizzazione deve essere negata: nel caso del valore “Deny” la negazione è frutto della decisione del
PDP, negli altri casi (“NotApplicable” e “Indeterminate”) il PDP non è
stato in grado di individuare una politica applicabile alla richiesta o di individuare una decisione non ambigua.
Un elemento “Status” contiene informazioni su eventuali errori
verificatisi nell’ambito dell’attività del PDP per il calcolo della decisione oppure assume il valore “urn:oasis:names:tc:xacml:1.0:status:ok”.
L’elemento “Obligation” non ha alcun vincolo di cardinalità:
può non essere presente o essere presente in più copie. Contiene delle indicazioni su operazioni che il PEP deve capire e deve eseguire per poter considerare valida la decisione del PDP: se il PEP non può eseguire una “Obligation”, deve compiere le stesse azione previste per una
“Decision” di valore “Deny”.
Opzionalmente l’elemento “Response” contiene un attributo
““ResourceID”” che indica quale è la risorsa per la quale è stata presa una
decisione di controllo degli accessi.
In Figura 15 è contenuto un estratto dello schema XSD relativo a un elemento “Response”.
Esempio di Response.
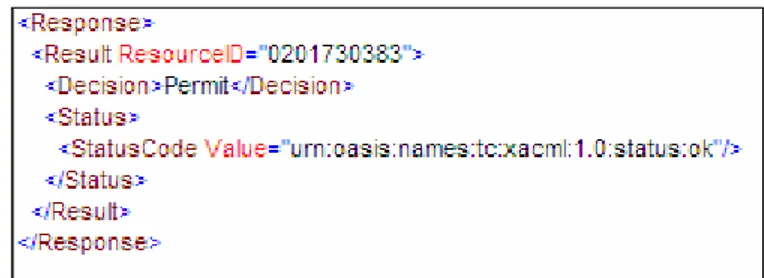
Per capire meglio come viene prodotto una risposta del PDP esaminiamo l’esempio di elemento “Response” raffigurato in Figura 16.
L’elemento “Response” contiene l’attributo “ResourceID” che
fa riferimento alla specifica risorsa oggetto della decisione che risulta essere “Permit”; l’elemento “Status” indica che non si è verificato alcun errore.
C
LASSIFICAZIONE DELLE POLITICHE INXACML.
La descrizione delle politiche prevista dall’XACML consente di organizzare e strutturare al meglio le politiche in base alla loro applicabilità e alle possibilità di combinarne i risultati. Le politiche sono organizzabili gerarchicamente secondo tre livelli: l’unità più elementare delle politiche è la Regola (“Rule”); più Regole possono essere raggruppate in una Politica
(“Policy”); più Politiche possono essere raggruppate in Set di Politiche
(“PolicySet”).
Ogni livello di politica è caratterizzato da un elemento “Target”
e da un risultato che viene utilizzato dal PDP per stabilire la decisione sulla Richiesta.
L’elemento “Target” identifica quali devono essere le
caratteristiche necessarie del Soggetto, della Risorsa e dell’Azione contenuti in una Richiesta affinché la Richiesta possa essere sottoposta alla politica.
Il risultato di una Regola è fissato da un attributo obbligatorio dell’elemento “Rule” detto Effetto (“Effect”): tramite tale attributo, chi
scrive la politica, stabilisce il risultato della Regola nel caso in cui venga applicata con successo a una Richiesta.
Diversamente dalla Regola, il risultato degli altri tipi di politiche (“Policy” e “PolicySet”), non viene fissato a priori da chi scrive la
politica, ma viene derivato dai risultati delle politiche componenti mediante opportuni algoritmi di combinazione.
Elemento Target nelle politiche.
L’elemento “Target” ha una funzione molto importante nelle
politiche XACML, in quanto tramite la sua valutazione si determina l’applicabilità di una politica condizionando fortemente l’attività del PDP.
Esaminando la struttura di un elemento “Target” si identificano
tre sequenze di descrizioni associate rispettivamente ai Soggetti (“Subjects”), alle Risorse (“Resources”) e alle Azioni (“Actions”):
affinché una politica possa essere applicabile a una Richiesta è necessario che il Soggetto, la Risorsa e l’Azione specificati nella Richiesta siano corrispondenti con la descrizione di un Soggetto, di una Risorsa e di un’Azione tra quelli presenti nell’elemento “Target”.
In dettaglio, la descrizione di un Soggetto, di una Risorsa o di un’Azione è costituita da una sequenza di corrispondenze (“Match”) che
devono essere tutte verificate affinché ci sia corrispondenza tra l’elemento indicato nella richiesta e l’elemento specificato nel Target.
Le corrispondenze vengono valutate tramite opportune funzioni di match che producono un valore booleano: tali funzioni prevedono come parametri un elemento “AttributeValue” e un elemento relativo al
Soggetto, alla Risorsa o all’Azione che viene estratto dal contesto di valutazione per mezzo di due meccanismi di reperimento previsti dall’XACML: il “AttributeDesignator” e il “AttributeSelector”. Un
ulteriore vincolo riguarda i “DataType” dei due parametri passati alla
funzione che devono rispettare quelli previsti per la funzione.
Le funzioni previste per l’uso nella valutazione di corrispondenze, vi sono tutte le funzioni che fanno confronti di disuguaglianza tra elementi dello stesso tipo, più un set di funzioni speciali che verificano che l’elemento recuperato dagli “AttributeDesignator” e
dagli “AttributeSelector” presenti le caratteristiche richieste da certi
standard: “x500Name-match”, “rfc822Name-match” e “ regexp-String-match”.
Identificazione e reperimento degli attributi.
Gli attributi relativi al Soggetto, alla Risorsa e all’Azione componenti una richiesta vengono considerati come parte del contesto relativo alla richiesta indipendentemente dalla loro presenza effettiva nella richiesta di decisione.
Essi vengono riferiti nelle politiche per mezzo degli
“AttributeDesignator” (che sono differenziati in
“ResourceAttributeDesignator”, “SubjectAttributeDesignator” e
“ActionAttributeDesignator”) e tramite l’elemento
“AttributeSelector”.
Gli “AttributeDesignator” identificano gli attributi per
mezzo del nome “AttributeID” e del tipo “DataType” (opzionalmente può
essere utilizzato anche l’attributo “Issuer”). Per reperire attributi relativi
alla risorsa occorre utilizzare il “ResourceAttributeDesignator”, per
reperire attributi relativi al soggetto occorre utilizzare il “SubjectAttributeDesignator”, per reperire attributi relativi all’azione
occorre utilizzare il “ActionAttributeDesignator”.
L’elemento “AttributeSelector” identifica gli attributi per
mezzo di una espressione XPath che fa riferimento all’attributo come elemento XML nel request contest.
In definitiva il PDP fa riferimento agli attributi come se fossero presenti nella richiesta di decisione, ma è compito degli “AttributeDesignator” e degli “AttributeSelector” recuperare gli
attributi e renderli disponibili al PDP.
Questi meccanismi danno come risultato delle collezioni (Bag)
di elementi del tipo specificato. Se non viene individuato alcun elemento “Attribute” corrispondente a quello ricercato, se tale elemento è indicato
come necessario (“MustBePresent”) viene restituito il valore
“Indeterminate”, altrimenti viene semplicemente restituita una collezione