Digital Forensics Ballistics
Reconstructing the source of an evidence exploiting multimedia data
Author:
OLIVER GIUDICE
XXIX Ciclo di Dottorato in Matematica e Informatica Department of Mathematics and Computer Science
UNIVERSITY OF CATANIA
A
BSTRACTThe Forensic Science (sometimes shortened to Forensics) is the application of technical and scientific methods to the justice, investigation and evidence discovery domain. Specifically finding evidences can be trivial and in many fields is achieved with methods that exploits manual processes and the experience of the forensics examiner. Though human factor can be often discussed and the evidences collected and found without repeatable and scientific methods could be of no use in tribunal. For these reasons this thesis focus on the investigation and development of classification engine able to uniquely identify and classify evidences in a scientific and repeatable way: each decision is driven by features and is associated by a confidence number that is the evidence itself. Two application in two different domains of Ballistics will be described: Image Ballistics, that is the reconstruction of the history of an image, and Fire Weapon Ballistics, that is the identification of the Weapon that fired an investigated bullet from the imprintings left on the bullet cartridge. To understand how to solve these two real in-the-field problems, multimedia-based novel techniques will be presented with promising results both in Image and Classic Ballistics domain.
D
EDICATION AND ACKNOWLEDGEMENTSDuring these long 3 years of PhD course, I have walked so many research paths that I do not remember all of them! I started from saliency detection techniques in video to identify human eye focus, passing through Computer Vision applications in traffic domain, passing then to techniques of Lossless compression of images finally landing to what was my love at first sight: the world of digital forensics.
Having changed frequently the research topic has definitely impacted on my final research results but has allowed me to enormously increase my cultural and scientific knowledge not only in the digital forensics field, but also in the image processing and Computer Vision applications. A first thanks goes to my supervisor: Prof. Sebastiano Battiato, who has followed me in these three years and has allowed me to complete the PhD course although compromised by numerous interruptions and obstacles.
Interruptions and obstacles that have mainly come from the recruitment in Banca d’Italia where I currently work as an IT research staff member. Actually, I must thank Banca d’Italia for allowing me to continue studying in my PhD course.
For Banca d’Italia my special thanks go to the Applied Research Team (Giuseppe Galano, Andre Gentili, Cecilia Vincenti et al.) of the IT department of Banca d’Italia, and specifically the coordinator dr. Marco Benedetti, who has been my source of inspiration and professional growth for these years.
I’d like to thank the "Reparto Investigazioni Scientifiche di Messina" (RIS) for providing data and domain-specific knowledge without which I would not be able to get the results presented in this thesis. Likewise, I would like to thank iCTLab for providing the data for the social image ballistics study and dr. Antonino Paratore for the help during the research activity.
A final thanks to the Image Processing LAB (IPLAB) reality from which I was born profes-sionally and whose members have accompanied me in these years.
Last but not least a thank you goes to my former girlfriend (three years ago) now my wife Cristina, to my parents and to everyone in someway has or had something to do with my life :D
T
ABLE OFC
ONTENTSPage
List of Tables vii
List of Figures ix
1 Introduction 1
2 Exploring the Multimedia Forensics Domain 3
2.1 Image Ballistics . . . 3
2.1.1 Lens Aberration Techniques . . . 4
2.1.2 CFA Interpolation Techniques . . . 5
2.1.3 Sensor Imperfections Techniques . . . 6
2.1.4 Techniques based on JPEG analysis . . . 6
2.1.5 Discussion . . . 7
2.2 Integrity and Authentication of Images . . . 8
2.2.1 Active Image Authentication Techniques . . . 9
2.2.2 Passive Image Authentication Techniques . . . 10
3 Evidences from the exploitation of JPEG compression 13 3.1 JPEG Compression Engine and DCT Transform . . . 15
3.2 Strengths and Utility of the Discrete Cosine Transform . . . 16
3.3 Statistical Distribution of the DCT Coefficients . . . 17
3.4 Sources of Error in the JPEG Algorithm: Definitions and Main Approaches . . . . 19
3.4.1 Quantization Error . . . 19
3.4.2 Rounding and Truncation Errors . . . 19
3.5 Methods for QSE in JPEG Images DCT Domain . . . 20
3.5.1 Methods based on Probability distributions on DCT coefficients . . . 21
3.5.2 Methods based on Benford’s Law . . . 23
3.5.3 Methods based on Benford’s Fourier Coefficients . . . 23
3.5.4 Methods based on Neural Networks encoding and classification . . . 24
TABLE OF CONTENTS
3.5.6 Methods based on Histograms and filtering . . . 26
3.6 Summary and Discussion on JPEG based Image Forensics Methods . . . 28
3.7 Boundary issues . . . 29
3.8 The Choice of the Right Dataset . . . 29
3.9 Computational Time . . . 30
3.10 Antiforensics . . . 31
4 Social Multimedia Image Forensics 33 4.1 A Dataset of Social Imagery . . . 34
4.2 Dataset Analysis . . . 35
4.2.1 Image Filename Alterations . . . 35
4.2.2 Image Size Alterations . . . 37
4.2.3 Meta-data Alterations . . . 37
4.2.4 Image JPEG Compression Alterations . . . 38
4.3 Image Ballistics of Social Data . . . 38
4.3.1 Implementing image ballistics: a classification engine . . . 40
4.3.2 Classification Results . . . 42
5 Enhancing Ballistics Analysis exploiting Multimedia Techniques 45 5.1 Weapon identification from cartridge imprintings . . . 45
5.1.1 Introduction to the problem . . . 45
5.1.2 How to address the comparison issue: shape analysis . . . 46
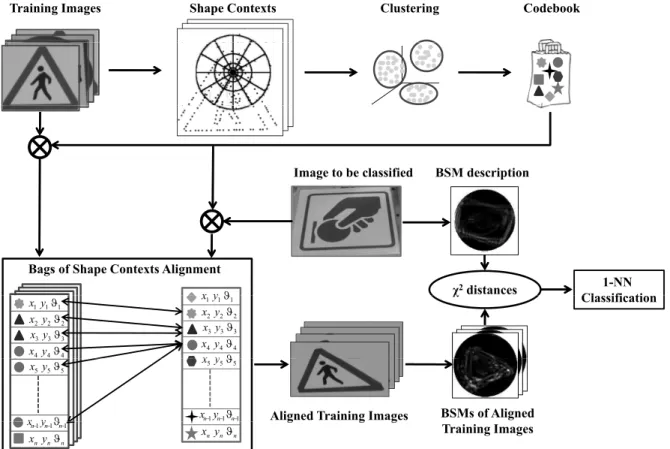
5.1.3 Aligning shapes . . . 47
5.1.4 A 3D approach to ballistics . . . 59
5.1.5 Firearm Serial Number Reconstruction . . . 63
6 Conclusions 69
Bibliography 71
L
IST OFT
ABLESTABLE Page
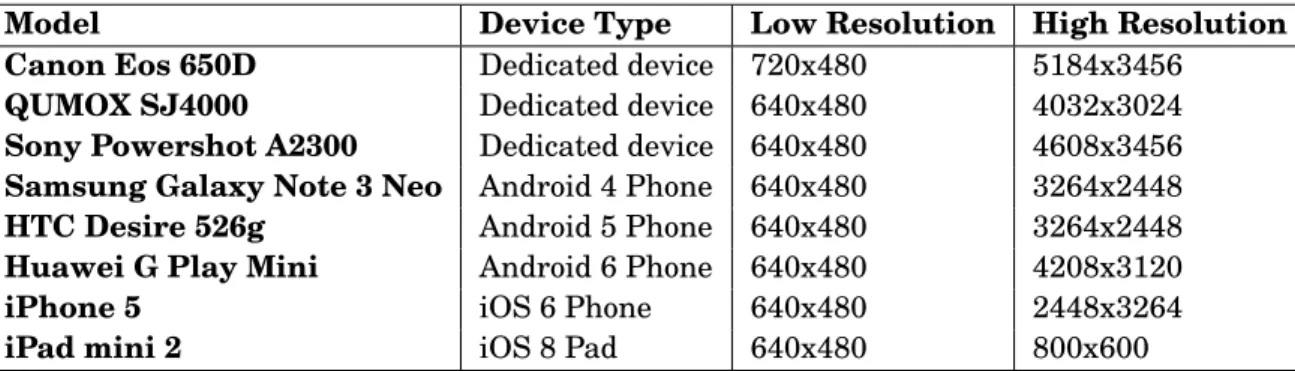
4.1 Devices used to carry out image collection. For each device the corresponding Low Quality (LQ) and High Quality (HQ) resolutions are reported. . . 36 4.2 Renaming scheme for an uploaded image with original filename IMG_2641.jpg. The
new file name for each platform is reported (Image IDs are marked in bold). . . 36 4.3 Alterations on JPEG files. The EXIF column reports how JPEG meta-data are edited:
maintained, modified or deleted. The File Size column reports if a resize is applied and the corresponding conditions. The JPEG compression column reports if a new JPEG compression is carried out and the corresponding conditions (if any). . . 36 5.1 Per-Class percentage of correct classified shapes obtained on the 70-class MPEG-7
dataset. The average accuracy of CBSM, SC, the combination of CBSM and SC and the proposed approach are respectively 67.43%, 63.79%, 59.36%, and 76.29%. . . 53 5.2 Per-Class percentage of correct classified shapes obtained on the 17-class Symbol
dataset. The average accuracy of CBSM, SC, the combination of CBSM and SC and the proposed approach are respectively 67.62%, 68.29%, 66.42% and 79.12%. . . 54 5.3 Precision/Recall values on the considered datasets. . . 57 5.4 Firearm classification results with different alignment and metric techniques. . . 63
L
IST OFF
IGURESFIGURE Page
2.1 Acquisition pipeline of a digital image. . . 5 2.2 An example of image forgery that changes the content in order to make the recipient
to believe that the objects in an image are something else from what they really are. In November 1997, after 58 tourists were killed in a terrorist attack at the temple of Hatshepsut in Luxor (Egypt), the swiss tabloid "Blick" digitally altered a puddle of water to appear as blood flowing from the temple. . . 9 3.1 When an image is analyzed for forensics purposes, the goal of the examiner can
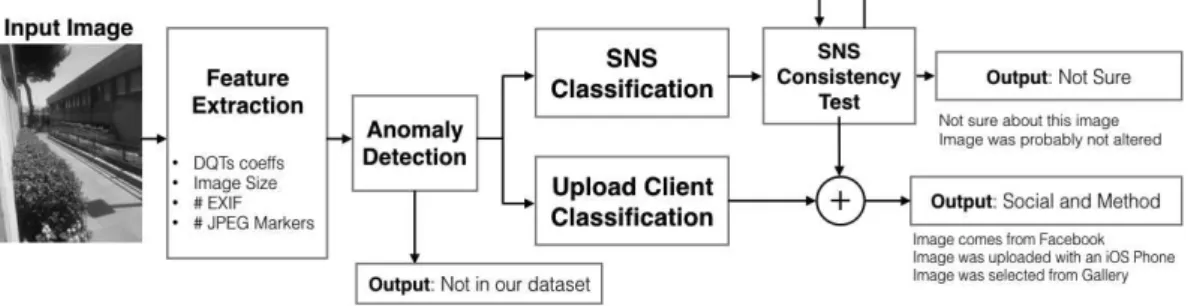
span from the (stand-alone) verification of its originality, up to the investigation of further and deeper details. He might have to ascertain which kind of devices took the image (Source Camera Identification), or/and which areas of the image have been manipulated (Forgery Localization). . . 21 4.1 Classification scheme for Image Ballistics in the era of Social Network Services. The
proposed approach encodes JPEG information from an input image into a feature vector. The obtained feature vector is evaluated through an Anomaly Detector that filters out images not processed by a SNS. If the input image is not an anomaly, the feature vector goes through other two classifiers: a SNS Classifier and an Upload Client Classifier. The output of the SNS Classifier is further processed through a SNS Consistency Test that checks if the features of the input image and the predicted SNS are consistent to re-compression and resizing conditions. The final output depends on this last stage: if all features are compatible with the classified SNS then the obtained prediction, joined with upload client prediction, is outputted. Otherwise the consistency test is repeated, for the next most probable predicted SNS, until it is satisfied or it stalls on the same predicted platform. In this case the overall output will be "Not Sure". . . 39 4.2 Confusion Matrices obtained from 5-cross validation on our dataset. The reported
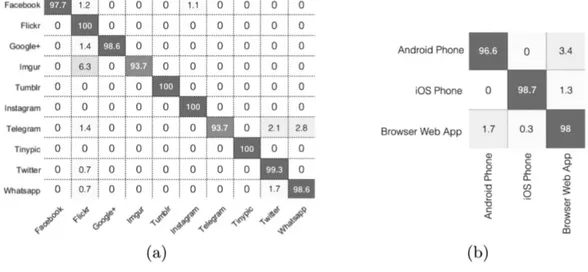
values, are the average accuracy values (%) in 5 runs of cross validation test. (a) Confusion Matrix for Social platform Classification, (b) Confusion Matrix for upload method classification. . . 43
LIST OFFIGURES
5.1 Simple combinations of SC [30] and BSM [63]. Shape Context with thin plate spline model transforms a shape in a very different one. Although belonging to different classes, the alignment procedure employed by SC transforms the test image in a novel image too similar to the target. Although the variability of the thin plane spline (TPS) model can be limited by modifying the standard parameter setting used in [30], the overall performance is not satisfactory (see Section 5.1.3.2). . . 50 5.2 Overall schema of the proposed approach. A Bag of Shape Contexts is built and
used in combination with BSM to properly classify the input image. A fundamental contribution is provided by the alignment process between Bags of Shape Contexts before exploiting the global BMS descriptor. . . 51 5.3 A slice of the 3D histogram representing the parameter space (α, Tx, Ty). Each pair
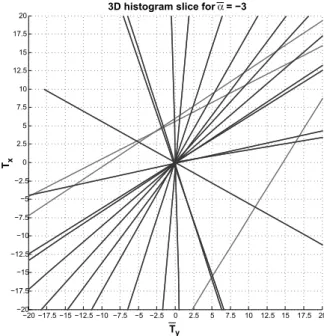
of coordinates (xtrainin g, ytrainin g) and (xtest, ytest) votes for a line in the quantized 2D parameter space (Tx, Ty). Lines corresponding to inliers (blue) intersect in the bin (Tx, Ty) = (0,0), whereas the remaining lines (red) are related to outliers. . . 52 5.4 Left: examples of eight over seventy different classes of the MPEG-7 dataset. Right:
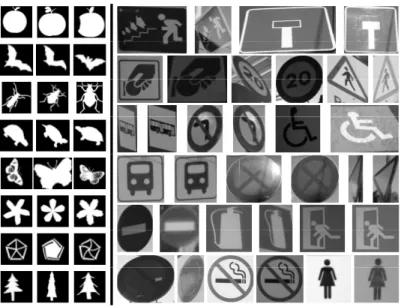
examples of the seventeen different classes of the Symbol dataset. . . 53 5.5 Performance evaluations at varying of the k parameter of k-NN classifier for MPEG-7
(a) and Symbol (b) datasets. . . 55 5.6 Performance evaluation with respect to rotational transformation. The proposed
approach outperforms the other methods both on the MPEG-7 CE Shape-1 Part-B dataset (a) and 17-class dataset of greylevel symbols (b). . . 55 5.7 Performance evaluation with respect to scale transformation. The proposed approach
outperforms the other methods both on the MPEG-7 CE Shape-1 Part-B dataset (a) and 17-class dataset of greylevel symbols (b). . . 56 5.8 Performance evaluation with respect to shear transformation. The proposed approach
outperforms the other methods both on the MPEG-7 CE Shape-1 Part-B dataset (a) and 17-class dataset of greylevel symbols (b). . . 56 5.9 Retrieval performance evaluation. The proposed approach achieves the best
perfor-mances both on the MPEG-7 CE Shape-1 Part-B dataset (a) and the 17-class dataset of greylevel symbols (b). . . 57 5.10 Examples of shapes of the hand sketch dataset [62]. Rows correspond to the following
ten categories: airplane, blimp, mug, cup, ice-cream-cone, human-skeleton, barn, bear, bicycle, bookshelf. The dataset presents high within variability (see 8throw) as well as contains classes with low between vaiability (see 2ndand 3rd rows). . . 58 5.11 Classification accuracy comparison between the proposed approach (Our) Vs. [62] in
both k-NN and SVM on growing data-set size. . . 59 x
LIST OFFIGURES
5.12 A point cloud representing the examined cartridge surface. A reference system is defined in the point cloud. In figure are shown areas identifiable on cartridges. The valid area (green) brings information for the ballistics task. The invalid one (red) presents noise and could reduce the accuracy of overall matching techniques. . . 61 5.13 Convolutional Neural Network architecture for the firearm classification task from
cartridges point clouds. . . 62 5.14 The Point cloud matching results. (a) and (b) are two point clouds representing a
cartridge fired from the same firearm. The orange triangle is one of the identified keypoints that is found as a match between the two point clouds. (c) shows the alignment result of the two point clouds. . . 63 5.15 Serial Number Recognition results on firearms. . . 67
C
H A P T E R1
I
NTRODUCTIONMany different fields of science are finding new application in the Forensic Science giving investigators more and more powerful tools. One of the Forensics fields that is having a lot of successful results is the Digital Forensics: Computer Science meets Forensics The earliest notion of digital forensics came when the Federal Rulers (US) first started to discuss about digital evidence in the 1970s. Real digital forensics investigations started 80s when federal agents started to take care of computers in search of digital evidences. This almost amateur approach continued until late 90s when academia researchers started to figure out that Digital Forensics is a field with problems and possibilities big enough to warrant investigation. In the final report of The first Digital Forensics Research Workshop (DFRWS), in 2001, there was a first definition of the Digital Forensic Science:
"The use of scientifically derived and proven methods toward the preservation, collection, validation, identification, analysis, interpretation, documentation and presentation of digital evidence derived from digital sources for the purpose of facilitating or furthering the reconstruc-tion of events found to be criminal, or helping to anticipate unauthorized acreconstruc-tions shown to be disruptive to planned operations".
Starting from this first definition, following the evolution of the digital world, Digital Forensics has developed into new specific fields:
• Multimedia Forensics: Analysis of digital images and videos from digital cameras, smart-phones, etc. or the web to solve a question;
• HW/SW Forensics: Analysis of hardware components and software applications for the detection of technical characteristics, operational potentials and operations carried out through them;
CHAPTER 1. INTRODUCTION
• Network Forensics: Analysis of internet data traffic flows and navigation meta-data and p2p platforms / systems for reconstruction of events;
• Audio Forensics: Voice speaker recognition, judicial transcripts. Audio enhancement; • Mobile Forensics: Mobile devices (smartphones, tablets, etc.) analysis;
• Disk Forensics: Analysis of mass storage media and reconstruction of events (timeline) for trial purposes;
The above-mentioned list is not exhaustive and much more new fields are emerging due to technology and scientific advance. Moreover some fields are dividing and specializing. For example in the Multimedia Forensics field now covers audio, video and image forensics each sub-field with its peculiarities and specializations. The introduction and wide-spread of digital sensors have made the scenario even more complex. Sensors can capture parts of the reality and transform it into digital representations, such as images or audio files, which are then stored and processed by computers. Such digital representations can be subject to forensic investigations, but they can only serve as probative facts if they are reliable and authentic.
In this thesis the Forensics Ballistics examination task will be covered in the most general way. Ballistics can be defined indeed as the reconstruction of the history of an evidence starting from the traces of the device that fired (acquired, produced, altered) the evidence itself. Starting from this definition Ballistics can be referred both to device source identification of images and Classic Ballistics examination of firearms traces on bullets and cartridges. This two parts of the meaning of Ballistics will be analysed. At first the Multimedia Forensics techniques will be surveyed starting with special dedication to JPEG traces and an novel application to Social Networks. Then classic ballistics examination of firearms proofs will be addressed with new multimedia-derived automatic techniques.
C
H A P T E R2
E
XPLORING THEM
ULTIMEDIAF
ORENSICSD
OMAINNowadays over 4.2m CCTV cameras are just in the UK, that achieved the first position in global league table for ratio of cameras to people. All those CCTVs record an huge amount of image data representing people in everyday life. Moreover the wide spread of Social Networks, with more than 1 billion images shared each day just on Facebook, produces what today we know as "Big Data". For these reasons, a new sector of Digital Forensics has born with the name of Multimedia Forensics. The term Multimedia Forensics appeared for the first time in early 2000 [149]. Over the past couple of years, the relatively young field of multimedia forensics has grown dynamically and now brings together researcher from different communities, such as multimedia security, computer forensics, imaging, and signal processing. Techniques from multimedia forensics provide ways to test the source of digital sensor data in order to authenticate an image and to test the integrity of the image itself in order to identify forgeries. Multimedia forensics covers images, video and audio contents. More specifically, Image Forensics analyses an image, by using image processing science and domain expertise, in order to reconstruct the history of an image since its acquisition (Image Ballistics), and to detect forgeries or manipulations (Image Integrity/Authenticity). A brief survey of the most efficient and recent approaches to solve the Image Ballistics task (Section 5.1) and the Image Authentication one (Section 2.2.1) will be presented in the remainder of this chapter.
2.1
Image Ballistics
Recent developments in Image Forensics have shown that the task of identifying the type of device, the model or even the sensor used to shot a photo or a video is possible. This can be done exploiting the traces left by the acquisition sensors as fingerprints. This discovery has attracted the interest of Law Enforcement Agencies (LEAs) for its potential usefulness for investigation
CHAPTER 2. EXPLORING THE MULTIMEDIA FORENSICS DOMAIN
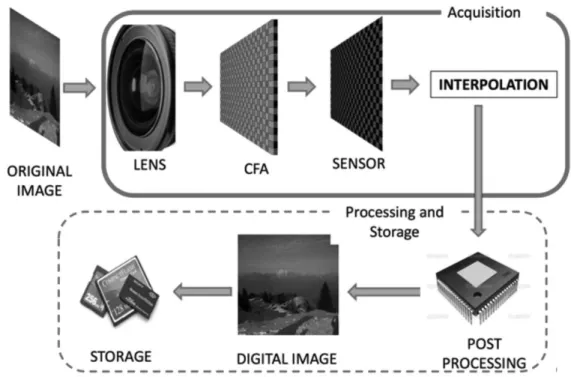
purposes. The possibility to establish a connection between a photo to a device can be used to trace the author of a digital document involved in criminal activities (like in the case of images and videos portraying child pornography or terroristic activity). The above concept, usually referred to as device fingerprinting, can be extended to a big variety of other traces embedded within digital contents, for instance, when an image is uploaded to a Social Network platform or when it is processed by means of a specific processing suite. Forensic analysis of these fingerprints may empower LEAs with a new class of investigative instruments, which can be extremely useful to combat cybercrimes and gather evidence in conventional investigations. The most effective techniques for image ballistics are intended to classify images acquired with scanner devices from those generated by a digital camera or those images altered with software processing. These techniques take into consideration the acquisition pipeline in a digital camera by considering traces left by each of the acquisition steps like the aberration introduced by the lens, the type of colour interpolation, the imperfections of the sensor that captures the scenes and the jpeg format used, in terms of image compression parameters. Figure 2.1 shows the acquisition pipeline for a digital image from its acquisition phase to the last storage step. In general, given an image, image ballistics aims to recognize the class and/or individual features of the device that generated the digital image showing the origin of the image. This can be done by exploiting different techniques that will be described in the next subsections.
2.1.1 Lens Aberration Techniques
The manufacturing process of lenses used in digital cameras produce different kinds of aberrations on images. Generally two kind of lens aberration are investigated to solve the problem of source camera identification: lens radial distortion [157] and chromatic aberration [101, 168]. Most of digital cameras are equipped with lenses having almost spherical surfaces that introduce radial distortions, this is done by manufacturers to reduce production costs, The radial distortion of spherical lenses causes straight lines in the object space rendered as curved lines on camera sensor and this occurs when there is a change in transverse magnification with increasing distance from the optical axis. The degree and the order of compensation of such a distortion vary from one manufacturer to another or even in different camera models. The goal in the method proposed in [157] is to find the distortion parameters that constitute the fingerprint to identify source camera following the Devernay’s straight line method [60]. However this method fails if there are no straight lines in the image and also if two cameras of the same model are compared. Besides it is also possible to operate a software correction in order to solve the radial distortion on an image. The second type of lens aberration is the chromatic aberration, that is the phenomenon where light of different wavelengths fail to converge to the same position of the focal plane. Specifically there are two kind of chromatic aberration: longitudinal aberration, that causes different wavelengths to focus at different distances from lens, and lateral aberration that is related to different positions on the sensor. In both cases, chromatic aberration leads to various
2.1. IMAGE BALLISTICS
Figure 2.1: Acquisition pipeline of a digital image.
forms of colour imperfections on the final image. Only lateral chromatic aberration is taken into consideration in [168] for source identification of cell phone devices by exploiting a SVM classifier.
2.1.2 CFA Interpolation Techniques
In the acquisition pipeline of digital images, the acquisition of colours is done by decomposing the visible light into three basic components corresponding to the wavelength of red, green and blue. In theory, a different sensor for each of the colours to be captured is needed but this would raise the of price camera devices exceedingly and introduces various technical complications. Commercial devices, instead, exploit another solution: in the acquisition pipeline, before light arrives to the sensor, a thin photosensitive layer is applied, known as CFA (Color Filter Array). The CFA filters the light by separating the three basic colours. In this way a grid of values is obtained, through which each pixel of the sensor, records the signal relating to a single colour component. The most popular type of CFA is the Bayer Pattern, represented by the multi-colour chessboard displayed in Figure 2.1. The use of the CFA reduces the number of sensors needed to one for coloured image acquisition. To do this reduction, a reconstruction of the two missing colour components by means of an algorithm of interpolation (demosaicing) is needed. Usually the processor of the acquisition device performs this process before the image is stored. As mentioned previously, it is necessary to reconstruct the signal captured by the CFA of the sensor in order to obtain an RGB image at full resolution. The brightness of missing values are obtained by
CHAPTER 2. EXPLORING THE MULTIMEDIA FORENSICS DOMAIN
applying a procedure of the image interpolation relative to each component of R, G and B that has been extracted by the CFA. There are several interpolation methods all of them estimate the values of the missing pixels by combining those of the neighbouring pixels using an interpolating function. Given an image I, the techniques for camera source identification are focused on finding the pattern of the CFA and the colour interpolation algorithm employed in internal processing blocks of a digital camera that acquired I [29]. One well-known approach, proposed by Bayram et al. [163], estimates the colour interpolation coefficients in different types of texture of the image (smooth, horizontal gradient and vertical gradient image regions) for every CFA pattern, through a linear approximation.
2.1.3 Sensor Imperfections Techniques
This class of approaches for camera source identification exploits systematic errors introduced by sensors that appear on all images acquired by that sensor. A way to observe these imperfections is by taking a picture of an absolutely evenly lit scene, the resulting digital image will exhibit small changes in intensity among individual pixels. These errors include sensor’s pixel defects and a pattern of noise. The noise pattern can be divided into two major components, namely, fixed pattern noise and photo response non-uniformity noise (PRNU). The noise is typically more prevalent in low-cost cameras and can be numerically evaluated through the analysis of multiple images obtained from the same camera. One example has been proposed by Lukas et al. [117]: for each camera under investigation, they first determine its reference pattern noise, which serves as a unique identification fingerprint. Thus to identify the camera from a given image, they considered the reference pattern noise as a spread-spectrum watermark, whose presence in the image is discovered by using a correlation detector. PRNU can be difficult to be evaluated due to image content and the number of images available from a specific camera device hence Lawgaly et al. [111] proposed a sharpening method to amplify the PRNU components for better estimation, thus enhancing the performance of camera source identification. Another recent technique of PRNU-enhancing has been proposed by Debiasi et al. [59] by parametrizing the enhancement of PRNU based on image contents.
2.1.4 Techniques based on JPEG analysis
Since the JPEG image format has emerged as a virtual standard, most devices and softwares encode images in this format. This lossy compression scheme allows for some flexibility in how much compression is achieved. Manufacturers typically configure their devices differently to balance compression and quality to their own needs and tastes [27]. This difference, embodied in the JPEG quantization tables, can be used to identify the source of image. The first work on image ballistics based on JPEG quantization tables has been proposed by Farid et al. [71] and the effectiveness of the idea was demonstrated in subsequent works like [105, 107]. Given the possibility to identify the acquisition device from JPEG quantization tables, new approaches
2.1. IMAGE BALLISTICS
emerged trying to estimate the original DQTs for multiple compressed JPEG images [82, 170]. Nowadays Social Networks allow their users to upload and share large amounts of images: just on Facebook about 1 billion images are shared every day. A Social Network is yet but another piece of software that alters images for bandwidth, storage and layout reasons. These alterations have been proved to make state-of-the-art approaches for camera identification less precise and reliable. Recent studies [46, 128] have shown that, although the platform heavily modifies an image, this processing leaves a sort of fingerprint on the JPEG image format. This evidence can be exploited to understand if the image has been actually uploaded to a particular social platform. Another big family of techniques based on JPEG standard are those that exploit the meta-data stored on JPEG files. The majority of modern cameras encapsulate meta-data in JPEG files, consisting in a format called EXIF [58]. An acquisition device can save within EXIF data information such as the producer and the model of the camera, information related to the date and time of image acquisition, information on characteristics of the image (pixel resolution, dpi, colour depth, etc.), shooting settings (shutter speed, aperture, flash, focus, etc.), GPS coordinates and others. While recording so many information, image ballistics based on EXIF very weak because it cannot guarantee that all information discovered are genuine. In fact it is very easy to alterate EXIF data. In order to discover image tampering, Kee et al. [105] proposed an image authentication approach based on EXIF data.
2.1.5 Discussion
The adoption of Forensic fingerprinting techniques in real investigative scenarios is problematic for a number of issues. First, the lack of robustness in realistic operating conditions. Existing techniques exhibit high accuracy when tested under controlled conditions. However, their use in a realistic setting is problematic, since the accuracy in such conditions is either unknown or known to drop dramatically [86]. This is particularly true for videos, since the adoption of video compression schemes usually inhibits the possibility of extracting the fingerprints [32, 33]. This problem is even more serious when the evidence gathered by forensic tools must be used as proof in court. In this case, in fact, the tools should be validated through properly defined procedures, and their accuracy established according to precise models, which, up to date, have not even been defined. Another big issue is the necessity of processing huge amount of data that is crucial in several investigative scenarios. In the case of child abuse or terrorism, for instance, seized hard drives may contain thousands of images and videos that must be processed in a timely fashion. A few approaches have been proposed so far to allow the extraction and analysis of device fingerprints contained in large amounts of images [90], however such techniques have not been extensively validated on real world data and there are still several open issues regarding their scalability to huge amounts of images and their robustness to simple processing operations [167]. Moreover, the above techniques have only been tested on images, so that their applicability to digital video has yet to be investigated. Real world investigations
CHAPTER 2. EXPLORING THE MULTIMEDIA FORENSICS DOMAIN
are characterized by the necessity of dealing with heterogeneous data stemming from diverse sources. As an example, textual metadata is often associated to multimedia contents, in the form of file headers, annotations or accompanying text, and should be used to complement the information inferable from the digital media itself. This is not an easy task since it entails a complex data fusion, multi-clue, process whose study has been undertaken only recently [53, 78]. As an additional difficulty, available information is often incomplete and unreliable. For instance, as opposed to laboratory conditions, the device classes that may have been used to produce an image are not fully known [16, 51, 97]. It is, then, necessary that proper tools to aggregate evidence obtained through different means and with different reliability, levels are developed. Finally the lack of reliability and countermeasures against deception attempts can be risky: it has been recently shown [39] that the adoption of simple counter-forensics strategies allows disabling most of the multimedia forensic techniques developed so far. Fake evidence can even be built if criminals have sufficient information about the forensic tools and the traces such tools look for. This raises several problems, especially when forensic evidence must be used in court. Anti-counter-forensics techniques developed so far are usually rather limited and address only one attack at a time, thus entering a typical cat-and-mouse loop in which attacks and countermeasures are developed in a greedy fashion. This naive approach slows down the development of general attacker-aware forensic techniques and impedes to evaluate the ultimate security of multimedia forensics tools [21].
2.2
Integrity and Authentication of Images
Back in 1946, making adjustments required a lot more than a computer, some software, and some pointing-and-clicking skills. Retouching required a whole box of tools, a very sharp eye, and an extremely steady hand. Nowadays, retouching and manipulating photographs is done with fancy photo-editing programs like Adobe Photoshop or GIMP or even in a more immediate and easy way through camera applications in mobile phones that offer capabilities of heavy image filtering, enhancing and editing. There are many modifications that can be applied to an image. They can be grouped into four categories: splicing, inpainting, enhancement and geometric transformations.
Given the huge amount of editing possibilities that can be done on an image, the question is: when retouching or image editing becomes a forgery? "Forgery" could be seen as a subjective word, an image can become a forgery based upon the context in which it is used. An image can be altered for fun or just for enhancing a bad photo. It is possible to agree that all editing that are applied to images in order to improve its appearance cannot be considered a forgery even though it has been altered from its original capture.
The detection and prevention of malicious forgeries on images, have focused the attention of Image Forensics researchers. It is possible to identify two different families of image
2.2. INTEGRITY AND AUTHENTICATION OF IMAGES
Figure 2.2: An example of image forgery that changes the content in order to make the recipient to believe that the objects in an image are something else from what they really are. In November 1997, after 58 tourists were killed in a terrorist attack at the temple of Hatshepsut in Luxor (Egypt), the swiss tabloid "Blick" digitally altered a puddle of water to appear as blood flowing from the temple.
cation approaches: active approaches, that insert or attach additional data on images in order to achieve the authentication of the image itself; passive approaches that exploit the intrinsic information of images to detect forgeries.
2.2.1 Active Image Authentication Techniques
Active image authentication approaches are based on traditional cryptography, watermarking and digital signatures based on image contents. Image authentication methods based on cryptography compute a message authentication code from images using an hash function. The resulting hash is further encrypted with a secret private key of the sender and then appended to the image. Techniques that are based on the hash computing of image lines and columns are known as line-column hash functions: separate hashes are obtained for each line and each column of an image. These hashes are stored and compared afterwards with those obtained for each line and each column of the image to be tested. If any change in the hashes is found, the image is declared manipulated and the tampered region is detected, otherwise the image is authentic [93]. Authentication methods based on watermarking consist in calculating a piece of data and hiding it in the image. The authentication is done by extracting it when it is necessary. The basic idea behind watermarking techniques is to generate a watermark and to insert it in the image in such a way that any modification made to the image is also reflected on the watermark. Simply verifying the presence of the inserted watermark allows the image authenticity verification and eventually localization of tampered regions. If the watermarking does not tolerate any image distortion it is fragile watermarking. In this case, the image is considered authentic if and only if all its pixels remain unchanged. The first algorithms of fragile watermarking has been computed from a set of image pixels. This set of pixels may be chosen with the help of a secret key. One of the first techniques that used image authentication though fragile watermarking was proposed
CHAPTER 2. EXPLORING THE MULTIMEDIA FORENSICS DOMAIN
by Walton [171]; it used only image information to generate the watermark. This technique is based on the insertion, in the least significant bits (LSB), the checksum calculated with the grey level of the seven most significant bits of pseudo-randomly selected pixels. This method was able to detect and localize manipulations but with no restoration capabilities. This method has the advantage of being very simple and fast. Moreover, it detects and localizes tampering. However, the algorithm cannot detect the manipulation if blocks from the same position of two different images, which are protected with the same key were exchanged. To avoid this type of attack, several improvements were made to this method by extracting more robust bits [52]. Other active techniques are based on the extraction and exploitation of image high level features like SIFT that can be encoded in a codebook and attached to an image. In this way the recipient can infer if any editing is done on receiving image just by extracting the features and comparing with the original attached codebook. Battiato et al. in [23] a SIFT-based robust image alignment tool for tampering detection.
2.2.2 Passive Image Authentication Techniques
The passive authentication methods can identify if an image suffered any kind of editing without the help of the additional information. In the process of a skilled forgery, besides changing the important region about the image content, there are lots of post-processing manners that can be used to remove the artificial trace. The post-processing will make the forensics approaches less effective, so how to deal with various post-processing and improve the robustness of forensics methods has become a very important subject. To achieve the best results, state-of-the-art approaches focus on detecting specific tampering according to specific image editing categories as listed in section 2.2. The majority of studies focus on the splicing detection, known also as copy-move forgery detection. [40] is a pixel-based approach that tries to identify the tampered region by analyzing specific and deterministic transformation done on pixel-blocks taken from the image itself (e.g., translations, rotations, scale transformations). Better results are obtained with approaches based on features extracted from different color spaces [187] and exploited with an SVM classifier. Other splicing detection methods are based on incoherences discoverable in frequency domain: [129] propose a method that exploits a shift-invariant version of the discrete wavelet transform for data analysis. Finally, [135] presents good results in detecting splicing tamperings by analyzing the intrinsic noise of an image. The task of detecting a forgery on image becomes increasingly difficult, as said before, if multiple post-processing are done on an image. In this case complex editing are applied to images and the only way to detect forgeries is by analyzing geometry and physical features in the contents of the image itself. Different approaches achieve good results by analyzing the contents of images based on scene illumination [153]. image edges distribution [44] and by comparing high level features (e.g., SIFT, SURF) of genuine images with tampered ones exploiting SVM classifiers [15, 38, 134, 159]. For most tampered images, in order to hide the tampering itself, median or blurring filters are applied to the image itself.
2.2. INTEGRITY AND AUTHENTICATION OF IMAGES
Understanding if an image has been blurred for malicious intent can be very interesting and for this purpose. [45] and [138] are two remarkable works for automatic detection of such forgeries. Last but not least, the JPEG format stores many information not only useful for Image Ballistics but also for forgery detection. Some approaches stand above the others: a group of them looks at the structure of the file: JPEG blocking artifacts analysis [41], [119], JPEG headers analysis [105], thumbnails [103] and EXIF analysis [85], DCT coefficient analysis [25, 27].
C
H A P T E R3
E
VIDENCES FROM THE EXPLOITATION OFJPEG
COMPRESSIONDue to the remarkable number of papers which over the past years covered these topics, the great variety of terms used to define the same components created some confusion. To standardize our exposure we provide a list containing the various features that will be considered. After discussing the different choices found in literature, in some cases we will propose our personal one, to be used in the rest of the paper:
• the terms “quantization" and “compression" lead to some misunderstanding in their in-terpretation. The core of JPEG algorithm is the reduction of size of the image file. This step is often called compression, with a clear figurative meaning, and is obtained with a mathematical operation called quantization which consists in dividing (and rounding) DCT coefficients for specific integer values. These divisors are coefficients of an 8 × 8 matrix, called quantization matrix, and are referred as quantization step or compression step. For these motivations, the two terms are often used indifferently. In this paper we adopt “com-pression" to indicate abstract concept, such as the kind of algorithm or its property, and “quantization" to refer to concrete numbers, so we will use “quantization step", “quantization
matrix", and so forth.
• In the world of photography, the “noise" is something that affects the image quality. As an example, the one known as Picture Response Non Uniformity (PRNU) [98] is inducted by imperfections on the sensor of the camera. Some other kinds of noise, which are of great importance for Image Forensics, are introduced during the quantization/dequantization phases of the JPEG algorithm, and since they derive from mathematical rounding opera-tions are frequently named as “errors".
CHAPTER 3. EVIDENCES FROM THE EXPLOITATION OF JPEG COMPRESSION
refer to it as q when it does not matter neither how many times the JPEG algorithm is applied, nor which is its position in the quantization matrix. If the number of JPEG compression matters, the quantization step of the n-th compression is denoted as qn, or qn. Instead, if the exact position (i, j) in the quantization matrix of a generic quantization step is important, the term mostly used is qi, j, or qi, j, with or without parenthesis. Finally, if the level of detail is so high that both the number of JPEG compression and the position of the quantization step inside the quantization matrix must be defined, in literature we can find indifferently qn
i, j, or qi, jn , again with or without parenthesis. We will denote the three conditions exposed above, respectively, q, qn, qi, j and qi, jn .
• The whole quantization table referred to the i-th compression is indicated as Qi.
• A gray-scale image before the JPEG compression can be thought as a 2-D matrix (in case of color images the approach is just a little bit complex), in which the numerical value of every single element is the luminance of the corresponding pixel. As we will illustrate in the next section, during the compression step the JPEG algorithm maps every element of the 2-D matrix from the spatial to the frequency domain, whereas in the decompression phase the values are casted back again in the spatial domain. Every step of the algorithm (during both the coding and the decoding phase) has its own characteristics, and the statistical distribution of the elements which characterizes a particular phase (that will be discussed in deep in Sect.3.3) needs to be examined separately. For this reason, the name of the terms in a same position varies with the step in which they are discussed (during the compression, the decompression, first or after the DCT), and every author made his own choices in this regard. Consequently, the terms and the related features are denoted in many different ways. Avoiding listing all the solutions adopted by the various authors through the years, we list the one we choosed:
– x(n)i, j indicates a single element in the spatial domain in position (i, j) of a certain
8 ×8 image block of an uncompressed image yet subjected to n JPEG compressions (n = 0 means that the image has never been compressed, n = 1 means that it has been compressed and decompressed, n = 2 means that the compression/decompression step has been applied for two times, and so on. . . );
– ˜x(n)i, j indicates a term (in the spatial domain of an image that has been compressed
ntimes) during the decompression phase, just after dequantization and IDCT steps mentioned in the following Sect. 3.1;
– y(n)i, j indicates a single element in the frequency domain in position (i, j) of a certain
8 ×8 image block of an uncompressed image yet subjected to n JPEG compressions, just after the DCT transform (n = 0 means that the image has never been compressed);
3.1. JPEG COMPRESSION ENGINE AND DCT TRANSFORM
– y(q)i, j(n) indicates a single element in the frequency domain in position (i, j) of a certain
8 ×8 image block of an uncompressed image yet subjected to n JPEG compressions, just after the quantization (n = 0 means that the image has never been compressed);
– j(n)i, j indicates a single element in the frequency domain in position (i, j) of the n-times
compressed JPEG image.
• With regard to the distributions of the terms in the various steps of the JPEG algorithm (both in the coding and in the decoding pipeline), we will use:
– dn is the distribution of the terms just after the DCT transform during the n-th encoding phase, and pn(x) its probability density (PDF) function;
– d′nis the distribution of the dequantized DCT terms just before the IDCT transform
during the n-th decoding phase, and p′
n(x) its PDF function;
• the rounding function is indicated either with the word round or with the square brackets [...];
• ǫq is the quantization error; • ǫr is the rounding error; • ǫtis the truncation error.
3.1
JPEG Compression Engine and DCT Transform
Starting from a RAW color image, the main steps of JPEG algorithm are the following: the lumi-nance component (also indicated as channel) is separated from the chromilumi-nance ones converting the input image from the RGB to Y CbCrspace. Later the two chroma channels are subsampled, every image referred to a channel is partitioned into 8 × 8 non-overlapping blocks and their values are converted from unsigned integer in the range [0,255] to signed values belonging to the range [-128,127]. At this point a DCT transform is applied to each one of them, followed by a deadzone quantization, using for each DCT coefficient of the 8 × 8 non-overlapping block a corresponding integer value1. This part of the algorithm is responsible, at the same time, for the powerful compression obtained by JPEG (because many DCT coefficients are reset) and for the loss of information, since the rounding function is not perfectly reversible. For this reason indeed, the entire procedure is said to be lossy. The quantized and rounded coefficients, obtained just rounding the results of the ratio between the original DCT coefficients and the corresponding quantization steps, are then transformed into a data stream by mean of a classic entropy coding whose parameters, together with metadata, are usually inserted in the header of the JPEG file to
1From here on indicated generically as q, or q
i jto indicate the specific quantization step in position (i, j) belonging
CHAPTER 3. EVIDENCES FROM THE EXPLOITATION OF JPEG COMPRESSION
allow a proper decoding.
In case of a forgery operation the entire process needs to be inverted, since to visualize the image it must be subjected to a IDCT (inverse DCT) transform, and then dequantized. Once visualized, the image can be manipulated and finally compressed again, most probably with a different quality factor (QF from here on) since it is unlikely that the editing software is set up with the same parameters as the inner software of the camera. The entire pipeline is exposed in Fig.3.1.
3.2
Strengths and Utility of the Discrete Cosine Transform
From the paper by Ahmed et al. that firstly developed the DCT [12], the increasingly rapid growth of image processing algorithms, and in particular of compression methods like JPEG for image or MPEG [144] for video, has led to the success of this transform. Many books [13], tutorials [10], papers [18, 27, 81, 154] defined the mathematical details concerned the DCT, and also its application to solve real problems [73]. This literature has been chosen as a main guideline to briefly summarize its intrinsic details.
From a mathematical point of view, the DCT block transform is a linear and invertible function belonging to the family of the Discrete Trigonometric Transforms (DTTS), that can be defined as a finite length mapping from a L2(R) space to another L2(R) space, and can be generally defined as:
(3.1) F: Rn−→ Rn, n ∈ N.
Some of the most important motivations for the use of DCT in image compression are the following:
• It decorrelates the image data: normally an image contains areas with uniform or slightly varying brightness, bounded from the so-called edges which instead cover a limited area. Therefore, neighboring pixels are strongly correlated. The idea is expressing the image values through a linear combination of coefficients that are (ideally) not correlated. This particular Fourier transform [68] is able to remove redundancy between neighboring pixels. The obtained uncorrelated coefficients can then be independently encoded, thus reducing the total entropy of the image data and allowing a higher compression efficiency. • It is an orthogonal transformation: this arises from the property of the transformation
matrix to be composed by orthogonal columns and so it is orthogonal itself [13, 81]. • Normalization: for each column vector vjof any discrete cosine transform kernel matrix
holds the following:
(3.2) kvjk = 1, i ∈ [1,...,8].
3.3. STATISTICAL DISTRIBUTION OF THE DCT COEFFICIENTS
• Orthonormalization: Since both the columns and the rows of the transformation kernel are orthogonal and normalized, this matrix is said to be orthonormal. This results in a significant decrease of the computational complexity, being the matrix inversion reduced to a matrix transpose.
• Efficient algorithms for its computation are available: the separability together with the symmetry and the orthogonality allows building a fixed transformation matrix that can be computed separately. Moreover it is not a complex transform, (compared i.e., with the Fourier Transform [13]) so there is no need to encode information about its phase.
3.3
Statistical Distribution of the DCT Coefficients
The first insight on the distribution of DCT coefficients was given in [142] and [131], even if until [152] substantially there were only a lot of proposals and hypotheses not supported by real scientific background. In their paper instead, Reininger and Gibson performed a set of Kolmogorov-Smirnov [99] goodness-of-fit tests to compare the various options: Gaussian, Laplacian, Gamma and Rayleigh distributions. Their results allowed concluding that:
• the distribution of the DC coefficients (the one in position (0,0) in every (8 ×8) block, which represents the average value of the input sequence in the corresponding block, follows a Gaussian law;
• the distributions of the AC coefficients (the remaining ones) follow a Laplacian law. For a complete and exhaustive analytical discussion about the topic we refer to [110]. In this paper, Lam and Goodman firstly pointed out that in every 8 × 8 image block pixel values can reasonably be thought as identically distributed random variables, generally with no (or with a weak) spatial correlation. They also hypothesized that, considering typical images, the variance σ2 of the Gaussian distribution of the terms through the 8 × 8 image blocks also varies as a random variable. This last distinction turns out to be the determining factor for the shape of the coefficients distributions, as we will see. Since the central limit theorem [76] states that the weighted summation of identically distributed random variables can be well approximated as having a Gaussian distribution2 with zero mean and variance proportional to the one of pixels in the block, and using conditional probability, they define:
(3.3) dn= pn(y(0)i, j) =
Z∞
0 pn(y (0)
i, j|σ2)pn(σ2)d(σ2).
They finally concluded that for these two reasons, the image can be represented with a doubly stochastic model and, since the probability density function (pdf from here on) ofσ2 in case of
2Note that the central limit theorem holds even when the image pixels are spatially correlated, as long as the
CHAPTER 3. EVIDENCES FROM THE EXPLOITATION OF JPEG COMPRESSION
natural images has been proved to be exponential with parameter λ, is possible to write the distribution of the coefficient as:
(3.4) p(y(0)i, j) = p 2λ 2 ex p{− p 2λ|y(0)i, j|}.
Recalling that the pdf of a Laplacian distribution is defined as:
(3.5) p(y) =µ
2ex p{−µ|y|}.
it is straightforward to conclude that the pdf in (3.4) is Laplacian with parameterµ=p2λ. As a corollary it is possible to state that, since the constant of proportionality which links the variance of the Gaussian distribution with the one of the block becomes smaller as we move to higher frequency, and since the quantization step typically increases with higher frequencies, producing that the DCT coefficients corresponding to those frequencies are very likely quantized to 0, the amount of DCT coefficients equal (or very near) to 0 increase as the positional index approaches to the high frequencies, i.e., the lower right part of the 8 ×8 block. Incidentally, this is the reason why in a context of First Quantization Step Estimation it will be almost impossible discover all the terms of the quantization matrix.
As an application of these results, a recent work by Raví et al. [148] analyzes DCT coefficients distribution to discover semantic patterns useful for scene classification. In these particular cases, it is observed that different scene context present differences in the Laplacian scales, and therefore the shape of the various Laplacian distributions can be used as an effective scene context descriptor.
For completeness it is necessary to cite also the papers by Muller [65] and Chang et al. [100], where (respectively) the Generalized Gaussian Model and the Generalized Gamma Model ap-proaches are proposed for better representing the statistical behavior of AC coefficients in case of images (about the DC one there is a general accordance). Even if the exposed results are to some extent remarkable, scientific community defining pdf of DCT terms is yet used to refer to Laplacian distribution, which in any case is a special case of the Generalized Gaussian distribu-tion. In our opinion this is justified from several reasons: the Generalized Gaussian Model, as exposed in [110], is a better model only when the kurtosis has a high value (that is not true for all kinds of images). Moreover, these models require in general more complex expressions and extra computational cost compared with the Laplacian one. Besides, these latter approaches are not based on mathematical analysis and empirical tests, thus having the drawback of a lack of robustness.
Finally, in 2004 Lam [178] pointed out that, in case of text documents, a Gaussian distribution is a more realistic model.
3.4. SOURCES OF ERROR IN THE JPEG ALGORITHM: DEFINITIONS AND MAIN APPROACHES
3.4
Sources of Error in the JPEG Algorithm: Definitions and
Main Approaches
The JPEG algorithm is classified as lossy because the compression process applied to the image is not fully reversible. Although this loss of information can be unpleasant, for Image Forensics it becomes useful for investigative purposes. Indeed, in analogy to the cues left by the criminal on the crime scene, some traces left in an image from JPEG compression algorithm, can be used to get useful information for reconstructing the history of the document. Cues or “evidences" are usually related upon the “difference between the image quality before and after the JPEG compression".
3.4.1 Quantization Error
This is the main source of error, and arises when a DCT coefficient is divided by the corresponding term of the quantization matrix, and the result is rounded to the nearest integer. It is formally defined as: (3.6) ǫq= yi, j− y(q)i, j× q = yi, j− round µy i, j q ¶ × q.
where i, j = (0...7), |...| is the abs function, q is the quantization step (i.e., the (i, j)thterm of the 8 ×8 quantization matrix), and yi, j is the (i, j)thDCT term of a generic 8 ×8 image block. Unlike rounding and truncation errors, whose definitions are globally accepted since in the various papers are always the ones that we show in the next subsection, in case of the quantization error the bibliography has shown different views. The only aspect with a general agreement is that quantization it is a non-linear operation and its output can be modeled as a random variable. The formula in (3.6), which represents the difference between the DCT terms in the same condition (i.e., dequantized) before and after the quantization step, represent our point of view. In our opinion, it better allows to highlight the joint effect of the quantization + rounding step in terms of information loss. In addition, and as further proof that this point of view is the most agreed, recent papers facing this kind of error [37, 175] made our same choice.
3.4.2 Rounding and Truncation Errors
Both these two sources of error arise after the IDCT, the inverse DCT transform that drives back the values from the frequency to the spatial domain once the image must be visualized. The output values of this operation (i.e., IDCT) must be transformed in format (from double to 8-bit unsigned integer) and range (from a larger range to [0,255]) to be correctly visualized. Despite they are generally discarded during mathematical modeling of the JPEG algorithm, their effects are not negligible. The formal definitions are as follows:
CHAPTER 3. EVIDENCES FROM THE EXPLOITATION OF JPEG COMPRESSION
• Rounding Error: The float numbers after the IDCT must be rounded to the nearest integer value to reconstruct the image in the spatial domain. The difference between the values before and after this process is called rounding error, and it is defined as:
(3.7) ǫr= | ˜xi, j− xi, j|.
As exposed in [177], it can be considered as a special kind of quantization with q = 1. Fan and de Queiroz in [70] model rounding errors as Gaussian distribution with zero-mean around each expected quantized histogram bin.
• Truncation Error: After the rounding step, always with the goal to reconstruct the image data, the values less than 0 need to be truncated to 0, whereas the ones larger than 255 are truncated to 255. The difference between the values before and after this cutoff is the truncation error. it is highly dependent on the QFs used in JPEG compression, and on the tested image dataset [64, 170]. More precisely, the smaller the QF (that means high quantization values), the higher the probability that it arises. Since nowadays the QFs are, by default, considerably high, this kind of error generally occurs with very low probability (less than 1%), and can be reasonably discarded during a mathematical modeling.
3.5
Methods for QSE in JPEG Images DCT Domain
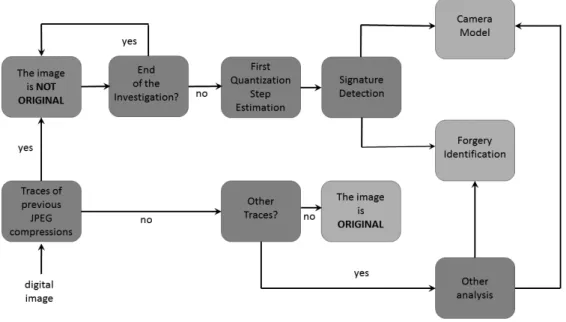
Image Forensics analysis is a process that aims to understand the history of a digital image. At first an image is investigated just to assess its originality: this can be done by figuring out if there are traces of previous JPEG compression(s) or by discovering other kind of alterations with methods that do not exploit JPEG compression (these methods will be not covered in this survey). If a previous JPEG compression is detected the image can be stated to be "not original" or altered in someway. Thus further analysis can be carried out to estimate the first Quantization Step and reconstruct the original JPEG compression parameters of the image in order to identify the source camera that acquired the analyzed image, the editing software that edited it or, as most recently debated, the Social Network Service from which it was last downloaded. Figure 3.1 schematizes the Image Forensics analysis pipeline described above. It is clear that the JPEG Double Quantization Detection (DQD) and the Quantization Step Estimation (QSE) are two fundamental steps in the overall process. Despite other possible criteria, we decided to survey DQD and QSE methods by dividing them into categories with names that recall what is exploited from image data. Thus the categories are for methods based on:
• Probability distributions on DCT coefficients; • Benford’s Law;
• Benford’s Fourier Coefficients;
3.5. METHODS FOR QSE IN JPEG IMAGES DCT DOMAIN
Figure 3.1: When an image is analyzed for forensics purposes, the goal of the examiner can span from the (stand-alone) verification of its originality, up to the investigation of further and deeper details. He might have to ascertain which kind of devices took the image (Source Camera Identification), or/and which areas of the image have been manipulated (Forgery Localization).
• Neural Networks encoding and classification; • DCT coefficients comparison;
• Histograms and filtering;
3.5.1 Methods based on Probability distributions on DCT coefficients
In [69] and [70], Fan and de Queiroz describe a method to determine if an image in bitmap format has been previously JPEG-compressed and further to estimate the quantization matrix used. They assume that if there is no compression, the pixel differences across 8 ×8 block boundaries should be similar to those within blocks, while they should be different if the image has been JPEG-compressed. The method first define two functions taking into account inter and intra-block pixel differences. The energy of the difference between histograms derived by these functions is then compared to a proper threshold, and the result allows highlighting the presence of prior compression (also with very high QFs). After detecting the compression signature, they present a method for the maximum likelihood estimation (MLE) of JPEG quantization steps and showed its reliability via experimental results. This work deserves to be quoted mainly because it proposes (for the first time in multimedia forensics) an estimation of the lattice structure in the DCT domain, even if limited on the case of quantization performed for a JPEG compressed image
CHAPTER 3. EVIDENCES FROM THE EXPLOITATION OF JPEG COMPRESSION
without downsampling of color components. As a critical remarks, we point out that both methods are limited to QF ≤ 95.
In [36], which in turn took the cue from [74], Bianchi et al. started to face with a particular scenario that they called Single Compression Forgery for JPEG images. This is the situation in which a part of a JPEG image is patched over an uncompressed image (copy-paste or cut/past operation) and the result is JPEG compressed. The core of the method is the use of Bayesian inference to assign to each DCT coefficient a probability of being double quantized, giving the possibility to build a probability map that for every part of the image tells if it is original or tampered. One of the parameters needed to calculate the probability is the quantization step of the first compression that, in this case, is iteratively estimated.
In [35], which is itself a refinement of [34], the authors build a likelihood map to find the regions that have undergone to a double JPEG compression. In particular they observe that the distribution of the DCT coefficients of a tampered image, considering the above scenario, can be modeled as:
(3.8) p(x; q1,α) =α· p (x|H0) +(1−α) · p(x|H1; q1).
whereαindicates how strong is the probability that the DCT coefficient has been single quantized (hypothesis H0, ⇒ it belong to a non-tampered part), or double quantized (hypothesis H1, ⇒ it belong to a tampered part). As can be seen, among the parameters required to correctly identify this likelihood map and modeling the double compressed regions, q1 (the quantization step of the primary compression) is crucial. The authors estimate q1 using the EM algorithm over a set of candidates. This procedure is replicated for each of the 64 DCT coefficients that composes the first-compression matrix. Besides its results, the method is important because it takes into account two kinds of traces left by tampering in double-compressed JPEG images: aligned and non-aligned, something that was considered, to the best of our knowledge, only few times before [20, 179] and never after. These two scenarios, respectively referred as A-DJPG and NA-JPG, arises depending if the DCT grid of the portion of image pasted in a splicing or cloning operation is (or not) aligned with the one of the original image. Also in these papers is underlined the difficulty to correctly estimate q1when it is ≤ q2. Indeed, their results are heavily affected from this problem, as they pointed out in their conclusions.
In [175], mainly dedicated to tampering detection by means of a proper comparison of the different distributions of DCT coefficients between tampered and non tampered regions, Wang et al. built up a mathematical model in which the knowledge of q1is required. For this reason, even indirectly, it provides a way to determinate the first quantization step in double compressed JPEG images. Indeed, starting from the expression of a generic double compressed DCT term without taking into consideration truncation and rounding errors, the authors model the probability distribution of the absolute values of the DCT coefficients in a tampered image. From this statistical model they define a likelihood function and use the EM algorithm for the estimation of the unknown parameters. In doing so, they also take into account the truncation and rounding
3.5. METHODS FOR QSE IN JPEG IMAGES DCT DOMAIN
errors, referring to the work of Bianchi et al. [36]. We want to point out that also in this work the case q1< q2 gives unsatisfactory results.
3.5.2 Methods based on Benford’s Law
In [80], the first digit law ([95]) is applied to estimate the JPEG-compression history for images in bitmap format, by means of a Support Vector Machine (SVM) based classifier. In particular, the provided results include the detection of JPEG single compressions and the estimation of JPEG compression factors even if limited to QFs ≤ 99. The authors demonstrated that the probability distribution of the first digit of the DCT coefficients in original JPEG images (single-compressed) follows this Benford-like logarithmic law:
(3.9) p(x) = Nlog10 µ 1 + 1 s + xq ¶ .
with x = 1,2,...,9, N is a normalization factor, and s, q are the model parameters.
Consequently, they proposed a generalized form of the Benford’s law to precisely describe the distributions of the original JPEG images with different Q-factors. Since the first digit of the DCT coefficients in double JPEG-compressed images does not follow the above mentioned law (in the paper is observed that the fitting provided by the generalized Benford’s law is decreasingly accurate with the number of compression steps), its presence (or absence) can be used as a signature in a double JPEG processing detection algorithm.
Like all the milestone papers, also this work has been deeply explored over the years. As an example, in [112] is discussed how the performances of this approach can be improved by examining the first digit distribution of each sub band of DCT coefficients independently, rather than analyzing the entire set at once. Again, Feng et al. in [75] outperformed the results given in the above paper with a multi-feature detection method using both linear and non-linear classifications, and in 2012 Li et al. in [114] proposed an approach that uses the Benford’s law to detect tampered areas in a JEPG image. One year after, Hou et al. extended the above results by including also zero in the set of possible digits for the statistics of the first digit distribution [96]. In the same year the authors of [125] exposed an Antiforensics method to fool the statistics connected to the Benford’s law in case of the detection of double compressed images. Another interesting question is answered by the application of this statistical rule in [126], where Milani et at. exposed a method able to detect how many JPEG compressions have been applied to the image.
3.5.3 Methods based on Benford’s Fourier Coefficients
At the same time, in a work by Pasquini et al. [137] is proposed a binary decision test, based upon the Benford-Fourier theory, to distinguish the images that was previously JPEG compressed starting from images stored in an uncompressed format. Always leveraging the same theory,

![Figure 5.1: Simple combinations of SC [30] and BSM [63]. Shape Context with thin plate spline model transforms a shape in a very different one](https://thumb-eu.123doks.com/thumbv2/123dokorg/4480997.32328/64.892.247.691.163.495/figure-simple-combinations-shape-context-spline-transforms-different.webp)