Capitolo 3
Linguaggi di Querying Visuali
Introduzione
In questo capitolo verranno mostrate le analogie e le differenze tra i linguaggi di query per DBMS (Data Base Management System) e un linguaggio visuale adatto a manipolare il processo di Knowledge Dyscovery. La parte conclusiva del capitolo sarà poi dedicata alla stesura dei requisiti [TESI_2] per un linguaggio visuale adatto per l’interazione con KDDML procedendo poi nel capitolo successivo con una definizione formale del linguaggio.
Il processo di sottomissione di query ad un motore di estrazione di conoscenza, da alcuni punti di vista può essere paragonato al mondo delle basi di dati. Nel corso degli anni infatti, sono stati sviluppati molti linguaggi visuali per interrogare i database e per permettere a un numero maggiore di utenti di rivolgere query anche di una certa complessità ai database. Una componente importante, quando si parla di query per sistemi di KDD, è la natura delle query per l’estrazione di conoscenza (KDD). Da ciò nasce l’esigenza di ottenere una costruzione delle richieste al sistema KDD in base a metodi di analisi nuovi o già esistenti. La direzione verso cui si muovono gli odierni sistemi di basi di dati è rivolta principalmente a sostenere applicazioni commerciali/gestionali. Il successo del linguaggio di query strutturato (SQL) è basato sulla presenza di un piccolo numero di primitive sufficienti per descrivere e rendere utilizzabili una vasta gamma di applicazioni di questo genere. Purtroppo, queste primitive non sono sufficientemente espressive per permettere l’interazione con nuove applicazioni nell’ambito della knowledge discovery. Attualmente la maggior parte dei sistemi di KDD offrono caratteristiche isolate di analisi dei dati usando gli alberi di classificazione, le reti neurali e le procedure di scoperta di regole
associative. Tali sistemi non possono essere inclusi in applicazioni molto grandi e tipicamente offrono soltanto una modalità di analisi dei dati.
Quello a cui siamo interessati, è la formulazione di un linguaggio strutturato che possa esprimere l’intero processo di KDD e non solo una parte di esso.
3.1 KDD e DBMS
Il processo di KDD dovrebbe trarre sicuramente uno spunto dal campo dei DBMS e seguire uno dei paradigmi proprio di questo campo: ottimizzazione delle query e una interazione attraverso le interfacce grafiche. Quindi lo scopo principale dovrebbe essere quello di migliorare l’ambiente di sviluppo per i programmatori che desiderano realizzare applicazioni KDD. Infatti, c’è un bisogno crescente KDDMS, o sistemi di database mining di seconda generazione, per avere un maggior controllo sulle applicazioni di KDD proprio come succede per DBMS (gestiscono con successo le applicazioni commerciali/gestionali).
Le queries in KDDMS, tuttavia, devono essere molto più generali rispetto ad SQL; parallelamente, gli oggetti interrogati devono essere molto più complessi rispetto ai records (tuples) nelle basi di dati relazionali. Per realizzare questo tipo di filosofia, definiamo degli oggetti relativi al mondo del KDD e delle query fatte su misura per il KDD. Naturalmente questo nuovo linguaggio introdotto deve rispettare il principio di chiusura. Come abbiamo già analizzato nel capitolo precedente, KDDML rispetta in pieno questa regola e allo stesso modo anche il linguaggio grafico che definiremo conserva questa legge. Da una query KDD viene “ritornato” un attributo che restituisce un insieme di oggetti che possono essere KDD objects o oggetti della base di dati quali record o tuple. Infine si può dire che un KDDMS dovrebbe potere immagazzinare in maniera persistente gli oggetti e controllarli in modo da fornire gli strumenti necessari per interrogare il sistema stesso. Quindi, il processo di querying ha due ruoli
importanti: generazione di nuovi oggetti di KDD e recupero di quegli oggetti che sono stati generati già. Nelle basi di dati relazionali, il risultato di una query è una relazione che può essere interrogata ulteriormente. Infatti, una query relazionale “non si preoccupa” se i propri argomenti sono relativi alla base di dati originale o se sono un risultato di un'altra query. Tipicamente la regola precedente è conosciuta come principio di chiusura e rappresenta uno dei pilastri portanti nel disegno di un linguaggio di KDD (anche se SQL non lo segue completamente). Quindi quello che vorremmo è un linguaggio di querying che possa soddisfare il principio di chiusura. Quindi il risultato di una query KDD Q1 può essere un argomento di un'altra query KDD Q2 che prende come argomento il tipo restituito dalla query Q1.
3.2 Verso un Linguaggio Visuale
Lo sviluppo sempre più rapido nell’ambito dell’information tecnology, l’evoluzione dell’hardware e del software e l'uso molto diffuso di automazione sia nelle postazioni multimediali di casa o negli uffici, hanno alterato considerevolmente la richiesta ed i requisiti del software.
L'efficienza, non molti anni fa era l'obiettivo principale degli sviluppatori; ora, dato lo sviluppo del potere di calcolo dei computer, l’usabilità è diventata un parametro critico per tutti software commerciali. In effetti, ci è prova empirica notevole che l'attenzione usabilità fa diminuire drasticamente i costi ed aumenta la produttività. D'altra parte, gli utenti stanno diventando più esperti e sempre più esigenti: non desiderano sprecare tempo per leggere i manuali e vogliono un prodotto che si possa imparare in maniera rapida utilizzando i tool sfruttandone in pieno le potenzialità. Le metafore grafiche per le interfacce utente puntano a migliorare l’usabilità dei programmi senza intaccarne le potenzialità ed il potere espressivo. In questo senso la presentazione grafica delle informazioni è di primaria importanza, poiché un'illustrazione efficace
trasporta spesso più immediatamente, più chiaramente, e più intuitivamente un concetto rispetto ad una spiegazione in forma testuale molto lunga.
Buoni risultati di usabilità sono stati raggiunti dalle applicazioni quali i word-processor, tool di disegno e, generalmente, da quelle applicazioni che non richiedono la conoscenza teorica specifica per essere usate. Purtroppo, i linguaggi di querying per i sistemi di gestione delle basi di dati (DBMS) difettano sia per ciò che riguarda l’intuitività che negli aiuti visivi forniti all’utente. Ciò preclude agli utenti inesperti di trarre massimo vantaggio dal prodotto utilizzato.
Infatti, un utente inesperto che vuole interrogare un DBMS per mezzo di un linguaggio di query (es. SQL) tradizionale deve affrontare un certo numero di problemi :
Apprendimento: acquistare padronanza dei principi di base della teoria relazionale richiede molto tempo e uno studio intenso per chi non ha già conoscenze di base.
Difficile da usare: un utente che interroga un DBMS deve attenersi ad una sintassi rigida, che è difficile da ricordare ed ha un sussidio visivo minimo.
Pochi feedback dal sistema: l'utente riceve poche risposte circa la semantica della domanda che sta formulando.
Poca interazione: il processo di interrogazione-costruzione è solitamente basato su comandi specifici e questo meccanismo non prevede nessuna forma di dialogo con l'utente.
Un’interfaccia visiva può aiutare efficacemente il processo di costruzione di una query: anche se le difficoltà oggettive non possono completamente essere
superate, se gli utenti interagiscono con un ambiente amichevole facile da usare la formulazione di query diventa in questo modo più facile.
Molte volte i sistemi DBMS sono forniti con dei veri e propri linguaggi visuali, che sono generalmente ricondotti ad un grafico per la rappresentazione delle tabelle che appartengono alla base di dati (nella maggior parte dei casi un form) e un processo visuale per la definizione del join. Queste caratteristiche permettono all'utente di formulare le query senza dover scrivere istruzioni SQL, ma richiedono una buona conoscenza della teoria relazionale quando deve essere costruita una nuova query. Si può dire che possono essere seguiti nello sviluppo dell'interfaccia visiva per un DBMS quattro paradigmi visivi: tabulare, a diagrammi, ad icone ed ibrido.
Fra i metodi tabulari ricordiamo QBE, il primo tentativo riuscito di sviluppare un'interfaccia utente grafica per un RDBMS, i cui principi di base ancora sono usati da molti prodotti commerciali. Un metodo con costruzione di diagramma è seguito in GUIDE [WK82] ed in SUPER [DAAS95], (con il quale è possibile formulare le domande manipolando direttamente lo schema concettuale) e in QBD* [ACS90], dove l'utente sviluppa un grafico che rappresenta la query.
Alcuni linguaggi che utilizzano la costruzione dei diagrammi adottano una rappresentazione 3-D per i dati ed i risultati. Nei metodi chiamati iconici, le query sono formulate selezionando ed unendo le icone e generandone nuove. Un metodo iconico 3-D può essere trovato in [COO93], dove sono usate tecniche di realtà virtuale per interrogare le basi di dati. Il paradigma iconico è molto intuitivo ed ha un grande potere espressivo. Tuttavia, la possibilità di distinguere un'icona da un’altra diminuisce con l'aumento del numero totale di icone; inoltre, le icone che rappresentano le azioni o i concetti astratti sono molto difficili da progettare, nel senso che è complicato “pensare” un modo per far capire all’utente che tipo di operatore rappresenta quella data icona.
I paradigmi ibridi tentano di superare questo problema unendo l'immediatezza delle icone con la potenza espressiva del testo.
3.3 Visual Query System
3.3.1 Introduzione
I sistemi con metafora grafica per la sottomissione di query (VQS) sono sistemi di querying che usano le rappresentazioni visive per descrivere il dominio di interesse e ed esprimere delle richieste. I VQS possono essere visti come un’evoluzione dei linguaggi di querying adottati nei sistemi di gestione di database; sono stati progettati per migliorare la comunicazione uomo-macchina. Quindi, le loro caratteristiche più importanti sono quelle che determinano le modalità di comunicazione uomo ⇔ calcolatore.
Per per esaminare un VQS e poter così porre le basi per realizzarne uno specifico per KDDML, in primo luogo introduciamo una classificazione basata sulle caratteristiche principali che un linguaggio di questo tipo deve avere per permettere una agevole comunicazione tra GUI,utente e sistema. Questa classificazione si basa sulla rappresentazione visuale adottata e sulle strategie di interazione.
Allora, a questo scopo, identifichiamo differenti tipi di utenti per capire quale genere di sistema può essere adatto ad ogni genere di utente.
I sistemi visivi di querying (VQS) sono definiti come sistemi per interrogare database o sistemi di KDD (come nel nostro caso), che usano una rappresentazione visiva per descrivere il dominio di interesse ed esprimere delle interrogazioni su tale sistema.
Tali sistemi sfruttano la larghezza di banda ben nota del canale di comunicazione uomo-vista, permettendo sia il riconoscimento che la manipolazione di grandi quantità di informazioni così come la possibilità di usare le risposte visive per migliorare la comunicazione uomo macchina. Un VQS, quindi, fornisce sia il linguaggio per esprimere le query da un punto di vista visivo sia una varietà di funzionalità per facilitare interazione utente-sistema. Questi linguaggi quindi, sono orientati verso un ampio dominio di
utenti, in particolar modo inesperti che hanno difficoltà nell’utilizzo dei computer e generalmente ignorano la struttura interna del sistema. Negli ultimi anni, molti VQS sono stati proposti in letteratura.
Adottano una gamma di rappresentazioni e di strategie visive e di interazione. Il numero enorme di proposte testimonia l'interesse crescente nel campo. Molto spesso infatti, prodotti che hanno un approccio grafico nell’interazione con gli utenti riscuotono maggior successo con alcune tipologie di utenti. I feedback visivi, un'altra caratteristica delle interfacce con manipolazione diretta, forniscono le informazioni che permettono di valutare il lavoro che si sta facendo per ogni azione eseguita dell'utente.
In letteratura sono state elencate un certo numero di caratteristiche di usabilità che possono essere ottenute con tecniche di manipolazione diretta (a livello grafico):
i. riduzione della distanza fra il modello mentale di realtà concepito dall’utente e la rappresentazione di tale realtà proposta dal calcolatore; ii. riduzione della dipendenza dalla lingua madre dell'utente;
iii. facilità nell'imparare funzionalità di base nell’interazione con il sistema; iv. tasso di efficienza elevato ottenuto anche dagli utenti esperti, con la
possibilità di definire funzioni e caratteristiche nuove; v. riduzione significativa del tasso di errore.
La manipolazione diretta è effettuata molto spesso attraverso una serie di primitive grafiche come le finestre, le icone, i menu e puntatori nelle cosiddette interfacce di WIMP (window, icon, menu, pointer) [DFAB93], dove sono adottate le metafore grafiche per aiutare l’utente ad acquisire familiarità con le
applicazioni. Una volta che le interfacce WIMP sono state progettate per interrogare sistemi di Knowledge discovery, gli operatori dei linguaggi di querying devono essere espressi in termini di sequenze dirette adatte alla manipolazione. Tali sequenze non possono basarsi sugli oggetti convenzionali del modello di dati, ma su una rappresentazione esterna adeguata in modo da poter essere percepiti facilmente dall'utente (vedere [HIL95]). Una volta che abbiamo scelto un tipo di rappresentazione visiva, possiamo dire che siamo in presenza di un VQL. I VQL possono essere visti come sottoclassi particolari di una categoria più generale di linguaggi visivi. Più precisamente, i linguaggi di querying visivi sono una sottoclasse dei linguaggi di programmazione visivi, cioè linguaggi i cui costrutti sono completamente visuali, ma che agiscono su oggetti che non hanno necessariamente una rappresentazione visiva intrinseca (per esempio, dati alfanumerici nelle basi di dati tradizionali).
3.3.2 Formalismo grafico
Un sistema interattivo, se ha l’obiettivo di immagazzinare, comunicare e percepire le informazioni importanti, può avere un certo successo con gli utenti, se è basato su segnali visivi bidimensionali quali schemi, immagini, fotografie e mappe geografiche. I segnali visivi sono caratterizzati da un alto numero di variabili sensitive: formato, intensità, struttura, texture, orientamento e colore. Per esempio, si possono identificare molte situazioni differenti in cui il
colore può essere valido: “… per identificare (colore come nome), misurare
(colore come quantità), rappresentare o riprodurre la realtà (colore come rappresentazione) e per animare o decorare (colore come bellezza). Molte volte le costruzioni visive permettono in maniera più immediata di afferrare un concetto. In altri casi invece, per esempio nel caso di un testo lineare, non si riesce ad avere la stessa immediatezza poiché l'insieme delle corrispondenze può essere ricostruito soltanto nella mente dell'utente.
Lo scopo principale dell’adozione di una rappresentazione visiva in un sistema di querying è comunicare chiaramente all'utente il contenuto di informazioni delle basi di dati (se siamo nell’ambito DB), concentrandosi sulle caratteristiche principali ed omettendo i particolari inutili, e informazioni per la modellazione del flusso del processo di Knowledge Discovery (se siamo in ambito KDD), ponendo l’accento sulla divisione in fasi e permettendo una manipolazione degli operatori ad alto livello. Tali informazioni internamente sono strutturate in parecchi modi che principalmente dipendono dalle caratteristiche del modello di dati, ma devono essere resi al livello di interfaccia in modo tale che l'utente possa facilmente comprenderle e modificarle. Tuttavia, la rappresentazione visiva dell'interfaccia deve essere pensata tenendo ben presenti i concetti interni al sistema di querying (o linguaggio di programmazione). Per fornire questa natura doppia, una rappresentazione visiva deve essere basata su un cosiddetto formalismo visivo, un termine introdotto da David Harel come segue [HAR88]: “L’intricata natura dei sistemi computer-related può e a parer nostro dovrebbe, essere rappresentata attraverso formalismi visivi: visuale poiché essa deve essere generata, compresa dagli esseri umani e comunicare con essi; formale, perché deve essere gestita, manipolata ed analizzata dai calcolatori”.
I formalismi visivi includono gli oggetti “semplici” quali le tabelle, gli schemi, le icone, ecc. Questi sono i componenti delle rappresentazioni visive come proposto in questo lavoro. È abbastanza evidente che l'importanza di una rappresentazione fatta in questo modo diminuisce con il crescere dell'esperienza dell'utente, poiché una base fortemente tecnica dell'utente permette un apprendimento con uno sforzo abbastanza ragionevole rispetto ad un utente completamente privo di esperienza. Considerando che, quando l'utente è inesperto, rappresentazioni semplici sono sempre un punto di forza di una applicazione, poiché egli preferisce interagire con qualche cosa di simile alla “realtà in cui vive”, senza considerare il modello astratto di fondo.
3.3.3 Criteri di Classificazione per VQL
Tutti i linguaggi di querying sono valutati in base a due dimensioni: funzionalità ed usabilità. Il primo è collegato con sia con il potere espressivo del linguaggio (quante cose un utente può fare con il linguaggio) che con le alternative che l'utente ha per la presentazione dell’output. L’ultimo è collegato con lo sforzo che bisogna fare per formulare una query; ciò rappresenta lo sforzo necessario all'utente per interagire con il sistema.
Per classificare questi sistemi, il primo test di verifica che consideriamo è la rappresentazione visiva adottata per presentare il dominio di interesse, gli operatori del linguaggio applicabili ed il risultato delle query presentate. La rappresentazione della query dipende generalmente dal tipo di metafora grafica che si sceglie per il proprio sistema e allo stesso tempo dal modo con cui si sceglie di rappresentare ogni operatore del linguaggio. Nei paragrafi seguenti verrà descritto in maniera più formale questo concetto, poiché nella nostro studio di linguaggio visuale bisogna tenere presente che il sistema sottostante è già definito e realizzato ed è necessario fornire differenti rappresentazioni grafiche a seconda degli operatori di tale sistema.
Di conseguenza, considereremo uno schema unico di classificazione sia per il sistema sottostante che per le query. I sistemi possono essere differenziati a seconda del formalismo visivo adottato, cioè form, diagramma (o schema), icona o una loro combinazione. D'altra parte, la rappresentazione visiva usata per visualizzare il risultato di query può portare ad una classificazione differente. Ma questo va oltre allo scopo di questo lavoro di tesi che, come evidenziato precedentemente, si propone di definire e realizzare un sistema di input al motore KDDML, lasciando a futuri aggiornamenti la parte relativa alla presentazione dell’output all’utente.
L'obiettivo di un utente che ha a che fare con un VQS è quello di recuperare i dati o i modelli che si ha in mente. Questo processo di solito può essere spezzato in due passi principali:
1. Capire il dominio di interesse. L'obiettivo di questa attività è la definizione precisa del sottoinsieme del sistema coinvolto nella query. Generalmente, lo schema è molto più ricco del sottoinsieme dei concetti che sono coinvolti nella domanda. Il primo punto corrisponde all'identificazione dei concetti che sono utili per la query ed il risultato è uno schema, cioè la rappresentazione statica di tali concetti.
Ad esempio se vogliamo estrarre delle regole di associazione da un datset iniziale bisogna avere presente che bisogna fornire un input al sistema (ad esempio un file .arff), eventualmente passare da una fase di data cleaning e poi applicare un algoritmo per l’estrazione di regole di associazione ottenere il risultato richiesto.
2. Formulare la query. La query può essere manipolata in vari modi, secondo gli operatori di querying disponibili. L'obiettivo della formulazione della query è di esprimere formalmente gli operandi coinvolti nella query con i rispettivi parametri. Ad esempio se vogliamo estrarre dei cluster da un determinato dataset, nel sistema KDDML si deve fornire come parametro all’operatore <CLUSTER_MINER> l’algoritmo utilizzato per estrarre il modello (es. K-Means) che a sua volta prevede degli ulteriori parametri ( numero di centroidi, posizione iniziale dei centroidi, ecc.).
3.3.4 Rappresentazione della Query
In questo paragrafo verranno trattati sostanzialmente tre differenti modelli per la visualizzazione delle query. Il modello cosiddetto “form-based“ non verrà trattato poiché non lo consideriamo adatto agli scopi di questo lavoro essendo stato utilizzato maggiormente in ambiente database.
I diagrammi sono adottati frequentemente nei VQS come componenti (visivi) di base o figure geometriche semplici (quadrato, rettangolo, cerchio, ecc.). Generalmente, un diagramma usa componenti visivi che hanno una corrispondenza uno-a-uno con i concetti specifici. Le linee spesso stanno ad indicare delle relazioni tra gli oggetti del diagramma. A volte sono incluse le etichette negli schemi semplicemente per facilitarne la comprensione. In un diagramma, se modifichiamo il layout secondo alcune regole, logicamente si ottengono delle nuove relazioni tra gli oggetti grafici rappresentati.
La metafora a diagrammi emerge quindi come il formalismo visivo più popolare usato nei VQS esistenti. Consideriamo ad esempio SUPER [DAAS95], che visualizza lo schema della base di dati usando un'estensione E-R degli schemi ben noti. I rettangoli sono usati per le entità, diamanti per i rapporti, frecce per le relazioni speciali IS-A, ed etichette, collegate all'entità o alla relazione, usate per rappresentare gli attributi.
Tutte le rappresentazioni prese in considerazione, e fanno uso di sistemi 2D anche se negli ultimi anni sono state proposte alcuni linguaggi visuali che fanno uso di una rappresentazione 3D.
Questi sistemi sono basati sull'idea che l'introduzione di una terza dimensione può aumentare potenza espressiva, secondo le indicazioni di alcuni precursori sugli ambienti interattivi 3D sviluppati negli anni passati.
Rappresentazione icon-based
In informatica, un'icona può essere definita come un’immagine fatta da una serie di segmenti e stilizzata. La segmentazione di immagine implica l'estrazione di un singolo componente dallo sfondo mentre la stilizzazione si riferisce ad una rappresentazione fatta da un piccolo numero di linee significative che tutti insieme costituiscono l'icona. Ogni linguaggio di querying visuale, necessita non solo di una rappresentazione delle immagini degli oggetti reali, ma anche di concetti astratti , di azioni o dei processi. Se desideriamo
rappresentare processi (in relazione ai calcolatori) , siamo costretti ad estendere lo scopo rappresentativo dell'icona, poiché non abbiamo controparti visive naturali e non possiamo sfruttare la somiglianza “pittorica” tra icona ed concetto astratto.
In breve, possiamo riassumere con la seguente definizione, il significato di un'icona nel nostro contesto: “l'icona è un oggetto fatto da elementi primitivi che comunica a chi lo guarda la propria funzione o informazioni interne (concetti, funzioni, dichiarazioni, modalità, ecc.) assegnate dal progettista. Lo scopo di un'icona è rappresentare (o ricordare) un determinato concetto, mentre gli schemi favoriscono la visualizzazione dei rapporti fra i concetti (denotati per mezzo di etichette). Inoltre, negli schemi la descrizione dei rapporti non usa i simboli ma piuttosto si collega fra i simboli e la descrizione dei collegamenti è fornita senza ambiguità. L'icona ha un potere metaforico significativo, cioè può essere interpretata come metafora visiva, come quando una croce rossa su uno sfondo bianco si riferisce alla disponibilità di cura medica.
Nel nostro sistema grafico le icone denotano sia le entità (o gli operatori) dell'ambiente, che delle funzioni messe a disposizione dal sistema. Una query è espressa quindi unendo le icone secondo una certa sintassi spaziale. Da questo punto di vista le icone ci permettono di migliorare l’interazione tra uomo e macchina. Infatti, le icone permettono agli utenti di comprendere facilmente come procedere nella manipolazione e nella stesura di una query.
Questi tipi di linguaggi naturalmente sono indirizzati ad utenti che non sono a conoscenza del modello dei dati che il sistema nasconde, e vogliono utilizzarne tutte le potenzialità.
3.4 Linguaggi visuali per KD
Negli ultimi anni si è registrato un aumento crescente di software dedicati al KDD e in generale al Data Mining. Molto spesso una caratteristica fondamentale di tali software è quella di raggruppare insieme tool ed algoritmi conosciuti da tempo permettendo all’utente di utilizzarli in un ambiente creato su misura.
Chiaramente l’obiettivo principale di questi sistemi è quello di fornire i mezzi per l’estrazione di conoscenza attraverso un’interfaccia abbastanza amichevole ma allo stesso tempo con un alto potere espressivo .
Una breve analisi dei sistemi presi in considerazione (per maggiori dettagli vedi [TESI_2]) può aiutare in maniera significativa a comprendere le problematiche che stanno dietro alla realizzazione del linguaggio visuale per KDDML e allo stesso tempo è possibile prendere degli spunti importanti per rendere il sistema più efficiente e semplice da usare.
Bisogna notare che il DM è considerato un processo esplorativo.
Come tale, un’idonea interfaccia grafica, fortemente interattiva e facile da usare, è essenziale per promuovere al meglio tale processo. È da evidenziare, comunque, che a differenza dei sistemi sviluppati per i database relazionali, dove la maggior parte delle interfacce è costruita sulla base di SQL, i sistemi per il DM non condividono alcun sottostante data mining query language. La mancanza di tale standard rende complessa la standardizzazione di prodotti sviluppati in tale settore, e limita fortemente l’inter-operabilità tra i sistemi stessi.
Nel seguito vengono presentati alcuni sistemi che permettono una interazione grafica nel processo di estrazione di conoscenza soffermando la nostra attenzione maggiormente sugli aspetti di interazione tra utente e sistema considerando il potere espressivo dell’input grafico.
Si noti inoltre che i sistemi presentati in seguito sono stati scelti poiché le funzionalità principali ed il modello di rappresentazione delle query si
avvicinano e hanno dato spunto alla realizzazione del linguaggio grafico per KDDML.
3.4.1 Yale
YALE viene applicato per risolvere compiti di machine learning e knowledge discovery in una serie di domini come: il preprocessing, il clustering, il text processing e la classificazione.
Esistono inoltre alcuni plug-in che forniscono operatori non presenti nella versione standard del sistema, che aggiungono funzionalità per specifici compiti di apprendimento.
I processi KDD sono spesso visti come una concatenazione sequenziale di operatori. In molte applicazioni, questa visione non è sufficiente a modellare il processo, e di conseguenza vi è la necessità di poter annidare le varie catene di operatori, che si presentano essenzialmente come alberi.
Questa osservazione è la base concettuale di YALE, il quale prevede che le foglie dell’albero di un processo KDD corrispondano a semplici passi nel processo modellato. I nodi interni invece corrispondono a passi più complessi o astratti del processo, mentre la radice dell’albero rappresenta l’intero processo KDD. Questi alberi in YALE si chiamano esperimenti, e sono costituiti da una catena di operatori in alcuni casi annidati, in cui ogni operatore consuma una serie di oggetti in input e produce alcuni oggetti in output.
Gli operatori definiscono gli input richiesti, gli output forniti e i parametri, sia obbligatori sia opzionali, permettendo in questo modo a YALE di controllare automaticamente l’annidamento ed i tipi di oggetti che vengono scambiati.
3.4.2 La gui di Yale
andare a manipolare direttamente i file XML (figura 15).
supponiamo di far partire la GUI con un esperimento vuoto. Ci troviamo di fronte ad una finestra principalmente divisa in due parti, e nella cui parte bassa è presente un message box, che registra l’attività del sistema.
Attraverso il box, infatti, è possibile seguire l’evoluzione dell’esperimento, osservando i messaggi in output visualizzati nel message box.
Gran parte della GUI è lasciata invece ad una serie di tab, grazie ai quali è possibile avere viste differenti della stessa query, vedere i risultati, sia intermedi che finali e monitorare l’attività del sistema e lo stato di avanzamento dell’esperimento.
Per la costruzione dell’esperimento Yale mette a disposizione una serie di tab in cui vi è la possibilità di settare varie opzioni:
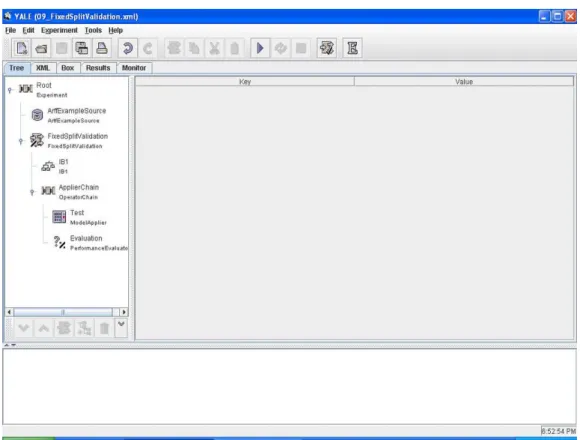
• Tree. In Yale un esperimento è visto come un albero (figura 16). Attraverso questa vista è possibile costruire tale albero, inserendo i vari operatori. Partendo dal nodo Root, sempre presente, semplicemente cliccando sul nodo, si accede ad un menù a tendina che permette l’inserimento, la sostituzione, la cancellazione e la disabilitazione di un operatore. La costruzione dell’albero risulta quindi piuttosto intuitiva: si decide il nodo padre dell’operatore da inserire e si procede ad inserirlo. Nel caso si voglia eliminare un nodo, è necessario selezionare il nodo da eliminare e cancellarlo, considerando però che l’eliminazione di un nodo comporta la necessaria eliminazione dell’intero sottoalbero ad esso associato.
Lo stesso procedimento vale nel caso si tenti di disabilitare l’operatore, mentre in quello della sostituzione, il sottoalbero rimane immutato. Naturalmente se si cerca di sostituire un nodo con un altro non compatibile l’esperimento non verrà validato e non sarà possibile eseguire la query.
figura 15 : Gerarchia YALE
Come ultima caratteristica, vorremmo sottolineare la possibilità di rinominare i nodi dell’albero a proprio piacimento, rendendo ancora più chiari i vari compiti associati ai nodi (l’algoritmo associato al nodo ovviamente resta immutato). • XML. Ogni esperimento in YALE è rappresentato da un file, opportunamente redatto in XML. Questa vista non fa altro che mostrare il file XML, che sarà quello effettivamente utilizzato dal sistema. L’utente può modificare o scrivere l’esperimento, direttamente maneggiando il file XML attraverso questa vista. Le modifiche apportate al file si ripercuotono immediatamente anche sulle altre due viste presenti.
Dopo aver costruito l’esperimento si può :
• Validare l’esperimento (Validate Experiment). Questa funzione controlla se tutti gli operatori sono annidati correttamente ed hanno tutti i loro parametri corretti. In caso contrario, la presenza di eventuali errori viene
segnalata nel message box.
figura 16 : rappresentazione di un esperimento con un albero
Questa possibilità di controllo statico risulta utile, perchè evita di eseguire l’esperimento, e ciò in caso di esperimenti complessi potrebbe comportare una notevole perdita di tempo. Bisogna precisare che tale controllo, essendo statico, garantisce solo la correttezza dell’esperimento relativamente ai tipi e la sintassi, ma non dà garanzie sulla semantica. • Eseguire (Run). Tale funzione permette di eseguire l’esperimento. Anche in questo caso, il sistema effettua la fase di validazione anticipatamente all’esecuzione.
Per quanto riguarda la metafora grafica utilizzata, YALE ha una concezione molto simile a quella di KDDML, infatti il processo KDD, rappresentato attraverso il file XML, può essere visto come un albero di operatori. In realtà YALE estende tale concetto, aggiungendo anche la visualizzazione
dell’annidamento degli operatori. Un utente potrebbe perdere molto tempo, nel caso di alberi complessi, per riuscire a capire il grado di annidamento di un certo operatore.
Senza ripeterci troppo, YALE permette di salvare, modificare, caricare esperimenti, modelli e risultati. Tranne che per gli esperimenti, non si rileva l’utilizzo di file in formati di interscambio o leggibili anche al di fuori del sistema.
Un caso interessante è che YALE al suo interno permette di utilizzare tutti gli algoritmi WEKA. Il modello generato da un algoritmo WEKA può essere anche salvato in YALE, ma in questo caso non può essere più ricaricato da WEKA (almeno non nell’ultima versione).
Per quanto riguarda il delicato problema dell’estensione del sistema, YALE supporta l’implementazione di operatori definiti dall’utente. Per implementare un operatore, l’utente deve semplicemente definire gli input richiesti, l’output generato, i parametri obbligatori e opzionali ed il core funzionale dell’operatore. Inoltre Yale, dopo aver dato la descrizione dell’operatore inserito in un opportuno file XML, creerà automaticamente tutti gli elementi grafici corrispondenti nella GUI, grazie ai quali sarà possibile inserire l’operatore appena definito nei propri esperimenti.
Questo rappresenta senza dubbio un punto di forza del sistema, in quanto, oltre ad avere una facile espandibilità a livello più basso, permette all’utente di personalizzare anche la GUI con i propri operatori.
Concludendo, possiamo affermare che la GUI di YALE, pur essendo un sistema molto complesso, grazie al tutorial on-line ed al Wizard, permette di essere sfruttata in breve tempo anche da chi non ha molta familiarità con questi sistemi, mentre un utente già esperto può manipolare direttamente il file XML ed avere al tempo stesso una serie di utili informazioni su ciò che sta costruendo.
Pertanto, in questo caso siamo in presenza di una vera e propria metafora grafica, che non incrementa, né limita le funzionalità del sistema, ma
rappresenta solo una visione diversa, ad un livello superiore, di ciò che è la costruzione e la visualizzazione di una query, o in questo caso un esperimento di knowledge discovery.
3.5 Orange
Il sistema offre una serie di funzionalità che includono una larga varietà di algoritmi per il machine learning ed il DM, in più comprende una serie di routine per la manipolazione e l’input dei dati ed ha la caratteristica si supportare delle query scritte nel linguaggio di scripting Python.
3.5.1 La GUI di Orange
Orange permette all’utente di formulare una query attraverso un tool chiamato Orange Canvas (figura 17).
Nella GUI sono infatti presenti dei widget per Data entry, preprocessing , Data visualization, classificazione, regressione, costruzione di regole di associazione, clustering, modelli di valutazione .
I widget, che non sono altro che wrapper comunicano e si passano token attraverso canali di comunicazione per interagire con altri widget.
Generalmente supportano un numero di segnali standardizzati che possono essere creativamente combinati, per costruire l’applicazione desiderata.
L’utente può scrivere tale applicazione a mano, utilizzando script Python, o utilizzare ORANGE Canvas per costruire incrementalmente lo schema. ORANGE Canvas è costituito principalmente da una finestra, su cui costruire lo schema del nostro esperimento di DM o machine learning.
figura 17. Canvas Orange con collegamenti tra widgets
Lo schema, infatti, non è altro che un grafo, i cui nodi sono ORANGE Widget, e gli archi sono i canali di comunicazione tra i nodi.
Nella parte alta dell’applicazione è presente la lista di tali widget divisi per categoria.
Per ciò che riguarda l’ultilizzo e in particolar modo l’inserimento dei widgets nel flusso di lavoro basta fare click sull’operatore da inserire, ed il sistema lo fa comparire nello schema. Una volta presente, lo si può trascinare ovunque e lo si può collegare ad altri widget eventualmente presenti.
La connessione dei widget risulta quindi il passo più delicato del procedimento, in quanto le connessioni non sono altro che dei canali di comunicazione, attraverso i quali i componenti si scambiano oggetti.
Il tutto è complicato dal fatto che ogni ORANGE Widget molto spesso supporta diversi input e fornisce diversi output, quindi, in accordo con questa caratteristica, è in grado di ricevere e spedire token di tipi differenti. Pertanto, al fine di distinguerli, è stato necessario tipare i canali input-output previsti per ciascun operatore-widget.
La filosofia costruttiva permette di costruire gli schemi in maniera chiara e leggibile, vincolando la posizione dei widget all’interno del form di disegno, e ben evidenziando i canali di comunicazione, sia attivi che non attivi.
Il suo utilizzo è piuttosto semplice, ed anche la presenza di un help sia in locale che in remoto aiuta l’utente nel prendere confidenza con il tool.
In futuro è previsto l’inserimento di un wizard, attualmente presente solo come voce nel menù file, ma non ancora implementato.
Una piccola nota dolente riguarda l’esecuzione della query. Questa viene eseguita di pari passo con la costruzione dello schema, in maniera trasparente all’utente, che quindi non ha il totale controllo su ciò che il sistema sta effettivamente eseguendo.
Una volta raggiunto un buon grado di familiarità con il sistema, si riesce comunque attraverso la disabilitazione dei canali, anche ad avere un’esecuzione parziale, come in YALE.
Un vantaggio di questo approccio risiede nel fatto che durante la composizione dello schema, il sistema, attraverso la finestra di output, informa l’utente di eventuali errori presenti. Questi errori non riguardano la sintassi, ma rappresentano errori rilevabili solo a run-time, riguardanti ad esempio caratteristiche richieste da un determinato operatore su un file di training set in input.
Una caratteristica molto particolare di questo sistema è data dal fatto di poter salvare il processo che si sta realizzando graficamente sotto forma di uno script Python. In questo modo il Canvas di Orange può essere considerato come un vero e proprio strumento di programmazione visuale che può guidare l’utente nella stesura della query anche non conoscendo alcun linguaggio di
programmazione.
3.6 Weka
WEKA fornisce l’implementazione di algoritmi di machine learning, che possono essere applicati ad un dato insieme di dati da riga di comando. Il sistema si avvale di una grande quantità di strumenti utili a trasformare i dati da un insieme di valori ad un altro.
Il sistema permette di essere utilizzato in maniere differenti. Ad esempio, è possibile utilizzare WEKA prima per applicare un metodo di apprendimento ad un insieme di dati, ed analizzare il suo output per estrarre informazioni riguardanti i dati. Un altro metodo possibile è quello di applicare alcuni algoritmi di learning e confrontare le loro performance, in modo da sceglierne uno per fare delle previsioni.
Ad esempio, i classificatori hanno tutti la stessa interfaccia command-line, ma si distinguono per le varie opzioni specifiche che ogni classificatore offre. Analogo discorso può essere fatto per gli altri componenti del sistema come ad esempio i filtri (filters), attraverso i quali è possibile ridurre, filtrare i dati in input, come ad esempio rimuovere dal data set tutte le tuple con valori mancanti.
WEKA permette anche, in qualche misura, di essere visto come un middleware, attraverso il quale è possibile risolvere sottoproblemi di machine learning e DM della propria applicazione con un minimo di programmazione aggiuntiva, semplicemente accedendo ai veri metodi forniti dall’interno del proprio codice. 3.6.1 La Gui di Weka
Quando si avvia Weka si può optare tra differenti modalità di compilazione di query e più in particolare:
• Simple CLI: è un ambiente a riga di comando, attraverso il quale è possibile invocare le varie funzionalità di cui WEKA è composto.
• Explorer: è l’ambiente in genere più usato, infatti, con esso è possibile caricare insiemi di dati, visualizzare graficamente la distribuzione dei valori degli attributi, fare statistiche su di essi, effettuare preprocessing, eseguire algoritmi di estrazione di RdA, clustering, etc. e visualizzare i risultati.
Sostanzialmente copre tutte le funzionalità, e per quanto riguarda la visualizzazione dei risultati, espande le potenzialità di WEKA rispetto alla versione priva di GUI.
• Experimenter: è una versione batch dell’Explorer, e consente di impostare veri e propri esperimenti di DM. Ad esempio, è possibile effettuare una serie di analisi su vari insiemi di dati e con svariati algoritmi, ed eseguirle alla fine tutte insieme, rendendo attuabile un confronto tra i vari tipi di algoritmi, per determinare qual è il più adatto a risolvere uno specifico problema.
• Knowledge Flow: è una variante dell’Explorer, in cui le operazioni da eseguire si esprimono in ambiente grafico, disegnando un diagramma che indica il flusso della conoscenza(figura 18). È infatti possibile selezionare varie componenti da una tavolozza, collegarle tra loro e creare quello che in genere viene detto data-flow, in quanto mostra il flusso di dati attraverso le varie componenti che abbiamo inserito nel sistema.
Il Knowledge Flow è stato l’ultimo ambiente ad essere inserito, e non tutte le funzionalità presenti nell’Explorer sono ancora disponibili.
La modalità di inserimento dei widgets è molto semplice ed intuitiva.
L’utente infatti, può selezionare i componenti WEKA da una toolbar posta in alto, posizionarli in un layout, che ricopre gran parte della GUI, e connetterli insieme per creare un “knowledge flow” per processare ed analizzare i dati.
Questa interfaccia permette di inserire qualsiasi tipo di operatore senza alcun vincolo riguardo alla connessione tra gli operatori.
I widgets sono raggruppati per tipo :
Data Sources: in cui l’utente può scegliere vari formati di file sorgente, ad esempio l’operatore ArffLoader, che permette di leggere in input un file arff.
• Data Sinks: in cui l’utente può scegliere vari formati di file di destinazione, ad esempio ArffSaver.
• Visualization: dà la possibilità di scegliere il tipo di visualizzazione che si desidera per il tipo di conoscenza estratta.
• Filters: qui sono presenti una gran quantità di filtri, sia “supervised” che “unsupervised”, caratteristica fondamentale in sistemi di knowledge discovery, attraverso cui si riduce la quantità di dati da analizzare, rendendo talvolta fattibili analisi altrimenti di difficile attuazione. Non meraviglia, quindi, il gran numero di operatori a nostra disposizione.
• Evaluation: qui sono presenti una serie di operatori che permettono di valutare le performance di un learner, definire training set, test set, ed attuare operazioni ad essi associate.
• Classifiers-Clusterers: dà la possibilità di inserire una serie impressionante di algoritmi per il mining. Solo per citarne alcuni, abbiamo algoritmi per costruire alberi di decisione, cluster, etc.
figura 18 : (Weka knowledge Flow)
In maniera molto semplice è possibile interagire con il sistema infatti il processo di costruzione di un knowledge flow si compone di :
- Selezionare l’oggetto (operatore-algoritmo), cliccandoci col mouse. - Inserirlo nel layout.
- Configurarlo (cliccando col tasto destro sull’oggetto, appare un menù a tendina, attraverso il quale è possibile vedere le opzioni previste per l’oggetto).
- Connetterlo ad altri oggetti presenti nel layout.
Tale costruzione viene in parte guidata dal sistema, per evitare situazioni incongruenti. Il software infatti evita la possibilità di connettere tra loro due nodi incompatibili.
nodi sono operatori-algoritmi, e gli archi, etichettati, rappresentano il flusso dei dati tra i vari nodi del grafo.
A questo punto si può far partire l’esecuzione facendo partire il flusso di dati dal nodo radice (ad esempio un Data Source). Dal punto di vista della rappresentazione, questa sembra essere una metafora piuttosto potente. Il grafo suddetto, infatti, rappresenta in modo molto chiaro e potente una query per un sistema di estrazione di conoscenza.
Osservando il flusso dei dati, ci si rende conto di quanto un processo KDD possa essere complesso, e di come sia importante garantire la composizionalità, intesa sia a livello delle fasi, dove l’output della fase di preprocessing può rappresentare ad esempio l’input della fase di mining, sia a livello di algoritmo, ed in questo caso l’output di un algoritmo può diventare l’input di quello da applicare successivamente.
La GUI permette, oltre alla visualizzazione e/o al salvataggio dei risultati intermedi del flusso, per eventuali utilizzi futuri, anche di salvare/caricare (e quindi successivamente modificare) un intero grafo.
Il file rappresentante il grafo che viene salvato non contiene la query in un formato cosiddetto “di scambio”, ad esempio KDDML utilizza XML come rappresentazione della query KDD.
Questo è dovuto soprattutto al fatto che nel file salvato in formato proprietario, sono contenute anche informazioni a livello grafico, come le posizioni degli oggetti nel layout. Per il resto, essendo la GUI un’estensione del sistema WEKA, la parte di applicazione di algoritmi si riduce a chiamate ai moduli JAVA che li implementano.
Un punto di forza di qualsiasi sistema di DM dovrebbe essere l’espandibilità, ottenuta senza dover andare a toccare il core del sistema.
Per quanto riguarda WEKA utilizzato senza GUI, l’espandibilità è ottenuta aggiungendo al sistema una nuova classe JAVA, che prevede di essere inserita in package già esistenti, e con interfacce e metodi predefiniti .
[KDDML].
3.7 Rappresentazione di una query KDD
In base alle metafore grafiche esistenti nei tool più utilizzati per la sottomissione di query, tra cui ci sono quelli analizzati brevemente in precedenza, possiamo dire che ci sono due “filosofie” differenti che brevemente cercheremo di analizzare mettendo in evidenza soprattutto gli aspetti legati alla formulazione delle query.
3.7.1 Grafo
Il grafo è una metafora molto utilizzata nei tool che hanno un’interfaccia grafica per la sottomissione delle query.
Come abbiamo visto in precedenza, sia Weka che Orange utilizzano la metafora a grafo che sicuramente permette una maggiore flessibilità da un punto di vista grafico. Per quanto riguarda la stesura di una query l’utente infatti può inizialmente inserire tutti gli operatori necessari per l’estrazione di conoscenza e poi interconneterli tra di loro.
Si intuisce molto bene come questa caratteristica rappresenti una lama a doppio taglio. Infatti, se da un punto di vista della libertà lasciata all’utente sull’inserimento degli operatori si può dire che soddisfi a pieno i requisiti, da un punto di vista dell’usabilità può rivelarsi molto faticoso da parte di un utente poco esperto. Questo poiché dopo l’inserimento dello schema generale della query bisogna procedere a collegare i nodi del grafo in modo che lo schema risultante rappresenti una query valida.
stesura del progetto altrimenti si corre il rischio di consumare del tempo a compilare una query non valida.
Sotto questo punto di vista si deve dire che Weka non guida molto l’utente nella stesura della query ,infatti si possono creare degli schemi con delle connessioni generiche e ci si accorge di avere una processo non “funzionante” solo quando si tenta di eseguire la query.
In modo differente si comporta Orange. Infatti questo tool permette di interconnettere due nodi A,B solo se il segnale di output di A è compatibile con uno dei segnali di input di B. In questo modo chi sta formulando la query non può connettere a caso i nodi del grafo e almeno i vincoli relativi ai segnali degli operatori vengono rispettati.
Anche in questo caso però non esiste una sorta di linea guida per la stesura della query seguendo il processo di KD nel senso che widgets che appartengono a fasi non compatibili del processo di KDD possono essere inseriti senza alcun vincolo. Questo infatti rappresenta un punto fondamentale su cui si fonda lo sviluppo dell’interfaccia grafica di KDDML.
Questo concetto verrà approfondito maggiormente nel capitolo successivo, quando si discuteranno le scelte effettuate da un punto di vista realizzativo. Per concludere si può dire che la caratteristica oggettiva della “costruzione a grafo” è la maggiore complessità rispetto a quella ad albero. In questo caso infatti , l’utente non solo deve inserire gli operatori, ma deve anche connetterli. Pertanto, dal punto di vista della costruzione, vi è la necessità di un passo ulteriore rispetto alla metafora ad albero.
È chiaro che questa maggiore difficoltà può influire sull’usabilità e sull’immediatezza della GUI stessa.
3.7.2 Albero
La metafora ad albero come nel caso di quella a grafo presenta alcuni aspetti positivi ed altri negativi per ciò che riguarda il processo di compilazione di una query.
Quando in questo contesto si parla di albero si sottintende una certa gerarchia tra gli operatori del sistema. Infatti, senza una sorgente di dati come input non si avrebbe la possibilità di eseguire una query per mancanza di dati oggettivi e quindi di conseguenza si può pensare all’operatore di Data Input come al nodo di grado maggiore poiché senza di esso non si possono inserire altri nodi.
Questo è il caso del tool YALE descritto in precedenza che prevede una modalità di inserimento degli operatori ad albero consentendo una vista anche a Box in cui è più semplice capire come sono annidati gli operatori.
Quindi, la costruzione della query in questi tool richiede all’utente solo l’inserimento dell’operatore, e non necessita dell’introduzione di connessioni tra gli operatori. La posizione dell’operatore inserito all’interno dell’albero mostra il tipo di dato che lo attraversa, e la gerarchia prevista tra questi evita l’inserimento di operatori incompatibili in alcuni punti dell’albero.
Questa visione conduce ad una costruzione più ordinata, ed a nostro avviso più intuitiva, rispetto a quella a grafo, in cui un utente può, in una prima fase introdurre tutti gli operatori, e solo alla fine connetterli.
Bisogna dire però che per un’utente più esperto questo modo di vedere la query potrebbe rappresentare in qualche modo troppo vincolante. Infatti consideriamo ad esempio il caso in cui l’utente voglia estrarre da un dataset regole di associazione e poi in seguito applicare ai dati ottenuti un operatore di preprocessing. In questo caso se si utilizza il paradigma ad albero si è costretti ad inserire necessariamente prima l’operatore di input, poi quello per l’estrazione di regole associative e solo alla fine quello di preprocessing. In questo modo se si procede all’eliminazione del nodo intermedio anche il figlio
verrà eliminato dalla rappresentazione della query perdendo così parte dello schema.
Se si utilizzasse invece una rappresentazione a grafo, l’utente esperto avrebbe maggiore possibilità di interagire con il sistema cancellando e inserendo operatori a proprio piacimento. Questo, come precedentemente accennato, è un punto cardine da cui partire per pensare una interfaccia grafica per KDDML. Inoltre è da evidenziare il fatto che i tool che utilizzano il grafo prevedono l’inserimento (e la successiva connessione) in modo esplicito da parte dell’utente, di nodi per la visualizzazione delle informazioni ritenute importanti. Questo fatto può rappresentare un’ulteriore difficoltà, sia per capire l’operatore più adatto al tipo di informazione da visualizzare, sia per la maggiore complessità del grafo risultante,mentre col tempo garantisce comunque maggiore libertà e permette all’utente di scegliere solo le informazioni che ritiene realmente rilevanti.
3.7.8 Ulteriori Problematiche di rappresentazione
Fino ad ora ci siamo posti il problema di valutare la metafora grafica solo dal punto di vista della costruzione degli esperimenti, ma tale discorso deve essere necessariamente integrato con quello che riguarda l’espressività generale di tutta la rappresentazione, intesa anche come immediatezza e facilità di lettura di ciò che viene prodotto, o ci troviamo ad analizzare.
Sotto questo punto di vista, la situazione si complica, in quanto, se da una parte l’albero risulta più semplice e più intuitivo, dall’altra il grafo sembra fornire maggiori caratteristiche di espressività ed immediatezza.
Infatti, se consideriamo la rappresentazione della query con un grafo, risulta molto più semplice intuire in che direzione si evolve il processo di estrazione di conoscenza poiché quest’ultimo può essere visto come un flusso di dati che da
un nodo (operatore) di input passa attraverso varie fasi fino a raggiungere il risultato voluto. Nell’albero, in caso di esperimenti complessi, con un elevato annidamento degli operatori, risulta più difficile, o per meglio dire, meno immediato capire che tipo di informazione attraversa i vari operatori.
In generale, si può dire che la maggiore chiarezza espressiva del grafo dipende dal fatto che la costruzione di un grafo è un procedimento che permette maggiori libertà individuali da parte dell’utente, rispetto alla costruzione di un albero, nel quale l’inserimento degli oggetti grafici avviene in maniera ordinata e completamente assistita dal sistema.
Quando costruiamo il grafo, il sistema non ci vincola minimamente rispetto alla disposizione dei nodi nello spazio. Risulta evidente che un grafo può venir costruito in maniera leggibile, distribuendo bene i nodi ed evitando intersezioni tra le connessioni, ma anche in maniera disordinata, senza una logica all’apparenza ben precisa, che limita considerevolmente la facilità di lettura. Anche in questo caso queste osservazioni hanno rappresentato un un notevole spunto per realizzare la metafora grafica per KDDML e in tal senso maggiori dettagli verranno mostrati nel capitolo successivo.
Al fine di migliorarne la lettura, è utile la possibilità, offerta anche da ORANGE, di rinominare i vari nodi presenti, utilizzabile insieme ad un operatore di visualizzazione che permette di rendersi conto dei dati analizzati fino a quel momento.
Concludendo questa parte possiamo dire che il tipo di metafora scelta, oltre ad influire sull’aspetto grafico dell’applicazione, influisce particolarmente sulla costruzione della query, e di conseguenza sull’usabilità e sul potere espressivo del software stesso. Sotto certi punti di vista, la struttura ad albero risulta sicuramente quella che offre il miglior connubio tra espressività e facilità d’uso, mentre sotto altri, tale struttura, se intesa in maniera troppo rigida può limitare eccessivamente sia il sistema, che non viene sfruttato in maniera completa, sia l’utente, che può trovarsi ad essere “schiacciato” in schemi troppo rigidi e poco espressivi.