CAPITOLO 3
LE MISURE DI DISUGUAGLIANZA E POVERTA’
Dopo aver passato in rassegna i problemi metodologici che sorgono preliminarmente quando si misura la disuguaglianza o la povertà, si passa ora a descrivere i modi in cui la distribuzione del reddito, la disuguaglianza e la povertà possono essere rappresentate graficamente. Verranno introdotti i principali indici, sia statistici che normativi, utili per avere una corretta misurazione del grado di disuguaglianza e povertà esistente nel nostro paese.
3.1 RAPPRESENTAZIONI GRAFICHE DELLA DISTRIBUZIONE DEL REDDITO, DELLA DISUGUAGLIANZA E DELLA POVERTA’
La variabile economica di cui studiamo la distribuzione è il reddito familiare netto equivalente, ottenuto sommando i vari tipi di reddito di tutti i componenti di una famiglia, al netto delle imposte, e dividendo la somma per una scala di equivalenza pari alla radice quadrata del numero dei componenti. L’unità di analisi scelta per queste rappresentazioni è la famiglia, ad ognuna di essa viene attribuito un peso per rendere il campione rappresentativo della popolazione.
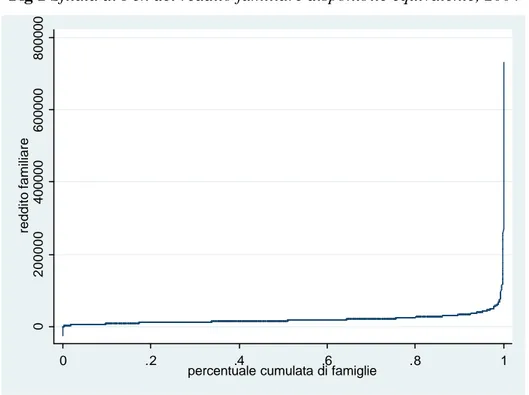
Nel 1971 Pen propose un grafico utile per rappresentare la distribuzione dei redditi tra gli individui o le famiglie. Immaginiamo, ad esempio, che tutte le persone/famiglie di un certo gruppo abbiano un’altezza proporzionale al proprio reddito e che esse, ordinate per reddito crescente, sfilino, prima passeranno davanti a noi le famiglie con reddito nullo o negativo (lavoratori autonomi in perdita), poi quelle con reddito basso, poi le tantissime famiglie che si addensano nella parte medio-bassa della distribuzione e infine, solo negli ultimissimi secondi, passerebbero degli autentici giganti, le famiglie più ricche13. Se rappresentiamo graficamente le famiglie, ordinate dalla più povera alla più ricca, con il valore del loro reddito, otteniamo la sfilata di Pen (fig. 1). Visto che le famiglie più ricche sono altissime, tutte le altre appaiono al loro confronto, come dei nani. La sfilata di Pen non è altro che l’inverso della funzione di densità cumulata.
13
Una famiglia che guadagna 700 mila euro all’anno sarebbe 10 volte più alta di una famiglia che percepisce un reddito annuo di 70 mila euro.
Questa andamento si ottiene infatti semplicemente invertendo gli assi del grafico della funzione di densità cumulata: F(y) sulle ascisse, y da 0 a ymax sulle ordinate.
A conferma di quanto appena detto facciamo un esempio: prendendo il campione delle famiglie italiane del 2004 e, ordinandole per reddito crescente, otteniamo la fig sottostante.
Fig 1 Sfilata di Pen del reddito familiare disponibile equivalente, 2004
0 200000 400000 600000 800000 reddito familiare 0 .2 .4 .6 .8 1
percentuale cumulata di famiglie
La figura 1 mostra che in Italia, nel 2004, un piccola percentuale di famiglie è molto ricca, ha un reddito annuo superiore ai 700 mila euro, mentre la maggior parte delle famiglie ha un reddito disponibile equivalente inferiore ai 50 mila euro. Quanto più la curva è alta, tanto più ricca è una popolazione, perché è piccola la quota di famiglie che possiede redditi inferiori o al massimo uguali ad un certo valore. Dal grafico è possibile inferire che l’Italia non è un paese eccessivamente ricco: ha molti redditi medio-bassi a fronte di un ristretto numero di famiglie con reddito molto elevati.
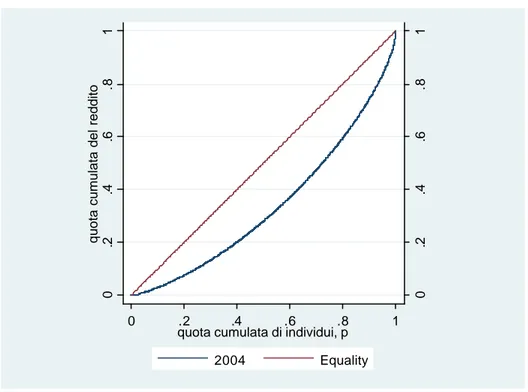
La figura 2 riporta invece la curva di Lorenz con riferimento alla distribuzione del reddito familiare disponibile equivalente. La curva di Lorenz venne introdotta dallo statistico americano M.O. Lorenz nel 1905. Tale curva è ottenuta ordinando gli n individui di una popolazione dal più povero al più ricco e riportando sull’asse orizzontale la quota cumulata della popolazione p e su quello verticale le quote cumulate del reddito totale. Se il reddito fosse distribuito in modo esattamente egualitario, allora ogni k % della popolazione possederebbe il k % del reddito totale e la
curva di Lorenz sarebbe inclinata di 45° (retta di equidistribuzione), in tutti gli altri casi la curva ha un andamento strettamente convesso e la convessità è tanto maggiore quanto più vi è disuguaglianza economica. Nel caso limite, in cui un solo individuo possiede tutto e N-1 individui non possiedono alcun reddito, la curva sarebbe una L rovesciata. La curva di Lorenz ci informa quindi sul grado di disuguaglianza della distribuzione: quanto più si avvicina alla bisettrice, tanto più egualitaria è la distribuzione. Inoltre, date due distribuzioni A e B, se la curva A giace sempre al di sopra della curva B, si dice che A domina B secondo Lorenz, cioè A è meno disuguale di B.
La curva non ci dice invece nulla circa il reddito medio della popolazione. Qualora infatti tutti i redditi vengano moltiplicati per una costante k, le quote relative dei redditi non varieranno.
Fig 2 Curva di Lorenz del reddito familiare disponibile equivalente
0 .2 .4 .6 .8 1 0 .2 .4 .6 .8 1
quota cumulata del reddito
0 .2 .4 .6 .8 1
quota cumulata di individui, p
2004 Equality
Così come esistono rappresentazioni grafiche della distribuzione del reddito e del grado di disuguaglianza, ne esistono altre relative alla dimensione della povertà.
Le cosiddette curve TIP (Three “I”s of Poverty) si basano sulla distribuzione del reddito e sono così chiamate per la loro capacità di rappresentare sinteticamente la
disuguaglianza, l’incidenza e l’intensità14 della povertà (S.P. Jenkins, P.J. Lambert
14
Per incidenza della povertà si intende la percentuale di famiglie povere calcolata sul totale della popolazione o sui diversi gruppi della popolazione, mentre l’intensità dice quanto è mediamente grave la
1997). Questi indici partono dall’assunto che un aumento del divario di povertà15 di un individuo comporta un aumento del divario della povertà in aggregato e sono derivati in maniera tale da rispettare questa proprietà. Tali curve sono utili nei confronti tra le popolazioni nel tempo e nello spazio.
I criteri circa l’ordinamento della povertà, proposti da Jenkins e Lambert, basati sul confronto delle curve TIP sulla distribuzione del divario di povertà piuttosto che sul confronto delle curve generalizzate16 di Lorenz, rispecchiano con maggior facilità e chiarezza la dimensione della povertà e della sua distribuzione.
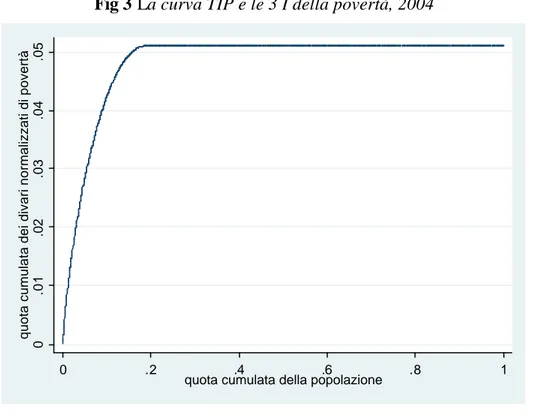
La fig 3 mostra un esempio della curva TIP17, ottenuta ordinando gli individui dal più povero al più ricco e cumulando i loro divari di povertà (o i divari normalizzati della povertà).
Fig 3 La curva TIP e le 3 I della povertà, 2004
0 .01 .02 .03 .04 .05
quota cumulata dei divari normalizzati di povertà
0 .2 .4 .6 .8 1
quota cumulata della popolazione
povertà per ogni indigente, ma non quanto lo è per la collettività perché non considera il numero dei poveri.
15 Il divario della povertà coincide con l’ammontare complessivo di reddito addizionale necessario ai
poveri per oltrepassare la soglia di povertà.
16
La curva di Lorenz generalizzata è ottenuta moltiplicando le ordinate della curva di Lorenz originaria per la media della distribuzione dei redditi.
17
In una prima versione del lavoro di Jenkins queste curve venivano etichettate come l’inverso della curva generalizzata di lorenz. Yitzhaki (1991) considera le curve come una “rotazione assoluta della curva di Lorenz”
Questa curva, usualmente indicata con TIP(?; p) dove 0≤ p≤1 e ? è il vettore dei divari di povertà normalizzati, è una funzione crescente della quota cumulata della popolazione (p), con pendenza uguale al divario di povertà calcolato per ciascun percentile/quantile della popolazione.
La pendenza della curva, ovvero il grado di concavità della parte non orizzontale, rappresenta la disuguaglianza, la lunghezza della sezione non orizzontale rappresenta l’incidenza, mentre l’altezza della curva rappresenta l’intensità della povertà. Il valore dell’ascissa in corrispondenza del quale la curva diviene orizzontale rappresenta la proporzione esatta dei poveri di una popolazione, mentre il valore dell’ordinata in corrispondenza del tratto orizzontale ci da l’indice proposto da Foster et al. (1984): FGT18(a) con il parametro a = 1. L’area al di sotto della TIP(?; p) è la metà dell’indice proposto da Shorrocks (1995) che altro non è che l’indice di Sen modificato.
Se i redditi percepiti dai poveri fossero uguali saremmo in presenza di perfetta uguaglianza dei divari di povertà e la curva diverrebbe una linea retta con pendenza uguale alla differenza tra la soglia di povertà (z) e il reddito medio dei poveri (?)19. Nel caso di massima povertà invece la cur va sarebbe inclinata di 45° e l’area al di sotto della retta sarebbe uguale a 0.5. Anche in questo caso, come per la curva di Lorenz, si può parlare di dominanza. Date due distribuzioni, A e B, qualora la curva associata alla distribuzione A fosse sempre al di sopra della curva associata alla distribuzione B, si potrebbe facilmente concludere che A domina B. Quindi la povertà in A sarebbe maggiore di quella in B.
Non esistono in letteratura altre rappresentazioni grafiche capaci di dare un quadro così completo e trasparente della povertà come fanno le curve TIP.
3.2 LA COSTRUZIONE DEGLI INDICI DI DISUGUAGLIANZA
Prima di introdurre i più importanti indici di disuguaglianza è necessario spiegare il significato di un indice sintetico. Esso è una funzione I:DN →R1 che associa ad ogni possibile distribuzione dei redditi un numero che ne misura il grado di concentrazione.
18 L’indice di Foster et al. è la media, calcolata su tutta la popolazione, di una misura individuale di
povertà. Il parametro a può assumere qualsiasi valore non negativo e misura l’avversione alla povertà, ovvero quanto maggiore è il valore di questo parametro, tanto più sensibile risulta questo indicatore al benessere delle persone più povere.
19
Se un paese ha dei programmi di assistenza sociale che prevedono un reddito minimo universale, la curva dovrebbe essere una linea retta con pendenza z- ? a partire dal punto che rappresenta la proporzione della popolazione che riceve il reddito minimo.
Un indice così concepito assicura sempre, per definizione, un ordinamento completo: dati due qualsiasi vettori di reddito, è possibile affermare, alternativamente, che il primo è più disuguale del secondo, o viceversa, o che la disuguaglianza è la stessa in entrambi. Tipicamente, il valore assunto da un indice sintetico varia nell’intervallo [0, 1] e seI
( )
y = 0 si ha una situazione in cui tutti i redditi sono uguali, mentre con I( )
y = 1si osserva massima disuguaglianza. In quest’ultimo caso N-1 redditi sono nulli ed un solo individuo possiede tutto il reddito della società.All’interno del metodo statistico rientrano quelle misure che, pur essendo di uso comune nell’analisi della disuguaglianza economica, hanno trovato frequente applicazione anche nello studio del grado di concentrazione di altre variabili: di qui la denominazione di misure statistiche (o oggettive) della disuguaglianza. Esempi di queste misure sono la varianza e il coefficiente di variazione.
Le misure di benessere sociale, invece, sono così definite perché la loro costruzione deriva da una impostazione in termini di funzioni di benessere sociale. Esse sono anche note con il termine di misure normative. Un esempio di queste misure è l’indice di Atkinson, la più nota misura ricavata a partire da un esplicito impianto normativo. Secondo gran parte degli studiosi un indice di disuguaglianza dovrebbe rispettare i seguenti assiomi:
-
Anonimità (o simmetria): l’indice deve essere insensibile a permutazioni del vettore dei redditi. In altre parole, se un ricco ed un povero si scambiano i redditi, il valore dell’indice non deve cambiare.-
Irrilevanza della scala: l’indice deve essere insensibile a variazioni equiproporzionali nei redditi (il concetto di disuguaglianza è inteso in senso relativo e non in senso assoluto). Kolm (1976) ha suggerito un assioma alternativo noto come indipendenza rispetto alle traslazioni: il valore dell’indice non varia se uno stesso ammontare se è sottratto o sommato a tutti i redditi.-
Principio del trasferimento di Pigou-Dalton20 : l’indice deve essere sensibile a trasferimenti di reddito (la disuguaglianza si riduce in presenza di un trasferimento dal più ricco al più povero poiché la distanza relativa -rapporto tra
20
i rispettivi redditi- si riduce). Viene implicitamente introdotto un concetto di “avversione alla disuguaglianza”21.
-
Normalizzazione : l’indice è uguale a zero nella perfetta eguaglianza nella distribuzione dei redditi.-
Principio di popolazione : il valore dell’indice non varia se ciascun individuo viene identicamente replicato K volte.-
Scomponibilità per gruppi: ripartendo la popolazione in sottogruppi (in base all’età, al sesso, alla regione di residenza, alla fonte di reddito ecc..); l’indice I è scomponibile per gruppi se può essere espresso come la somma ponderata dei valori che l’indice assume in ciascun sottogruppo (siano tali valori Ig) più un termine, IB, che misura la disuguaglianza tra i gruppi.L’indice complessivo aumenta se, a parità di reddito medio e di dimensione, cresce la disuguaglianza in un gruppo e non diminuisce nei restanti gruppi22
3.3 I PRINCIPALI INDICI STATISTICI
Consideriamo ora alcuni tra i più diffusi indici di disuguaglianza, e verifichiamo se essi rispettano gli assiomi prima enunciati.
-
Il coefficiente di variazione . E’ il rapporto tra lo scarto quadratico medio (σ ) (cioè la radice quadrata della varianza) e la media (µ); poiché numeratore e denominatore sono espressi nella stessa unità di misura, il rapporto è un numero puro, cioè indipendente dall’unità di misura, e quindi rispetta il principio dell’indipendenza di scala. µ σ µ = = V CIl coefficiente di variazione rispetta anche gli assiomi di simmetria, di indipendenza dalla popolazione e il principio di Pigou-Dalton. Si tratta di un indice molto usato perché è facile da calcolare e perché una sua semplice trasformazione è scomponibile
21
Il concetto di avversione alla disuguaglianza sarà spiegato nel paragrafo 3.4 con riferimento agli indici normativi di disuguaglianza.
22
per gruppi. Non attribuisce però ad un dato trasferimento di reddito un peso crescente quanto più povero è il beneficiario, ossia non rispetta il principio del trasferimento decrescente.
-
La varianza dei logaritmi. Si tratta di una misura molto diffusa della disuguaglianza, soprattutto negli studi relativi alla dispersione dei redditi da lavoro sui quali è molto frequente la trasformazione logaritmica nell’ambito della stima del rendimento dell’istruzione. La media dei logaritmi dei redditi (µg) è data da: g µ = = =∑
∏
∏
= = = N N i i N i i N i i y y N y N 1 1 1 1 ln ln 1 ln 1 23Conseguentemente la varianza dei logaritmi (VL ) è data dalla seguente espressione:
(
)
N y N y VL N i g i N i g i∑
∑
= = = − = 1 2 1 2 ln ln ln µ µQuesta misura, oltre al principio del trasferimento decrescente, soddisfa le proprietà di simmetria, indipendenza dalla media e indipendenza dalla popolazione. Ha uno svantaggio: non rispetta in generale il principio di trasferimento. La variazione dell’indice, in seguito a un trasferimento progressivo di reddito, è infatti del segno atteso (cioè negativo) solo in circostanze particolari; in tutti gli altri casi la variazione dell’indice è indeterminata, dipendendo dai livelli di reddito dei due soggetti.
-
La curva di Lorenz. Già introdotta nel paragrafo precedente, la curva di Lorenz non è un indice sintetico, ma una rappresentazione24 della disuguaglianza che individua la quota del reddito totale posseduta da frazioni cumulate della popolazione, una volta che questa sia stata ordinata per livelli non decrescenti del reddito. La curva è la relazione che lega ciascuna quota cumulata della popolazione con la corrispondente quota del reddito totale posseduta da queste persone. Se i redditi sono distribuiti in parti uguali, in modo che al 10% più23
Yi è il vettore dei redditi con i = 1…N di una popolazione N già resi equivalenti. 24
La curva di Lorenz, oltre ad essere una rappresentazione della disuguaglianza, può essere considerata una sua misura relativa.
povero della popolazione va il 10% del reddito complessivo, al 20% più povero va il 20% del reddito totale, e così via, la curva di Lorenz coincide con la retta di equiripartizione (la diagonale del quadrato). La convessità della curva rispetto all’asse orizzontale dipende dal fatto che le singole unità di analisi sono ordinate per valori crescenti del reddito. La curva di Lorenz incorpora gli assiomi di simmetria, indipendenza dalla scala e dalla popolazione e il principio del trasferimento di Pigou-Dalton. In quest’ultimo caso infatti, un trasferimento di reddito da un ricco a un povero, che non modifica l’ordinamento dei redditi, provoca sempre un innalzamento della curva in corrispondenza del beneficiario: la nuova curva rifletterà una distribuzione meno disuguale della precedente. Essa offre anche un criterio per ordinare in termini di disuguaglianza due ipotetiche distribuzioni di reddito, x e y. Se la curva associata alla distribuzione x giace sopra a quella di y per ogni percentile cumulato della popolazione, ossia è dominante in senso di Lorenz, è possibile affermare che la distribuzione x è meno disuguale della distribuzione y .
L’ordinamento stabilito dal criterio di dominanza di Lorenz ha la caratteristica di essere
incompleto. Se infatti due curve si intersecano tra loro almeno una volta, nulla può
essere detto sulla maggiore o minore eguaglianza di una distribuzione rispetto all’altra, ed il confronto rimane indeterminato. La possibile indeterminatezza del confronto tra curve di Lorenz rende evidente la difficoltà di imprigionare in un singolo valore numerico un fenomeno complesso come quello della disuguaglianza, di per sé difficile da misurare.
-
L’indice di Gini. Corrado Gini, nel 1912, propose una misura sintetica di disuguaglianza che divenne una delle più importanti e più diffuse negli studi sulla disuguaglianza nella distribuzione dei redditi. L’attrattiva maggiore di questo indice consiste nella sua immediata interpretazione geometrica in termini della curva di Lorenz. È infatti uguale al rapporto tra l’area compresa tra la retta a 45 gradi e la curva di Lorenz, e l’area del triangolo sottesa alla bisettrice stessa25.
25
Dato che l’area del triangolo sottesa alla bisettrice è uguale a ½, in termini geometrici si può affermare che l’indice di Gini è uguale al doppio dell’area compresa tra la bisettrice del quadrato e la curva di Lorenz.
Il coefficiente di Gini può anche essere interpretato come il gap di reddito atteso (in termini percentuali) tra due individui casualmente estratti da una popolazione ed è calcolato come:
(
)
∑
= − = N i i Gini i y N I 1 2 2 µ µdove i redditi yi sono ordinati in senso crescente e µ indica la media aritmetica del
reddito. L’indice varia tra 0 (massima uguaglianza) e 1 (massima disuguaglianza). Questo indice soddisfa le proprietà di simmetria, di indipendenza dalla scala, di indipendenza dalla popolazione e il principio del trasferimento, ma non quello del trasferimento decrescente.
Che esso soddisfi queste quattro proprietà lo si può dedurre direttamente dal fatto che l’indice è anche definibile in termini della curva di Lorenz .
L’indice di Gini presenta comunque un limite: non soddisfa la proprietà di scomponibilità esatta tra gruppi della popolazione. Se proviamo a scomporlo in una componente tra i gruppi e in una componente interna ai gruppi, emerge un residuo che non è facilmente razionalizzabile. Un’ulteriore limitazione dell’indice, peraltro comune a tutte le misure statistiche della dispersione, consiste nel fatto che esso non fornisce informazioni sul grado di asimmetria di una distribuzione. Ciò risulta evidente in riferimento alla relazione che lega tale indice alla curva di Lorenz. Dati due generici profili di reddito, valori differenti di IGini possono esprimere sia una relazione di dominanza tra curve di Lorenz sia il caso di uno o più incroci. Il coefficiente di Gini è, fra gli indici di disuguaglianza, il più sensibile alle differenze di reddito attorno alla moda.
-
Gli indici di entropia generalizzata (EG). Si tratta di una classe di indici che traggono ispirazione dalla teoria dell’informazione, in particolare dalla teoria che misura il valore informativo (entropia) di un sistema di eventi incerti26. La classe degli indici di entropia generalizzata è data dalle seguenti espressioni:(
)
− − =∑
= 1 1 1 ) ( 1 N i i y N EG α µ α α α α 1, ≠ α ≠0 26L’assunto su cui si basa la teoria è che quanto minore è la probabilità che l’evento incerto si verifichi, tanto maggiore è il valore informativo dell’evento stesso (e viceversa) (cfr. Cowell, 1995)
=
∑
= µ µ i N i i y y N EG(1) 1 log 1 α =1( )
∑
= = N i yi N EG 1 log 1 0 µ α =0Gli indici di entropia si differenziano per la sensibilità (rappresentata dal parametro α ) rispetto alle differenze di reddito in diverse parti della distribuzione. Più α è positivo (negativo), più EG(α) è sensibile alle differenze di reddito nella parte alta (bassa) della distribuzione. EG
( )
0 è la deviazione logaritmica media27 (DLM), EG(1) è noto con il nome di indice di Theil (1967), e EG(2) è metà del quadrato del coefficiente divariazione.
Tutti gli indici di entropia generalizzata soddisfano gli assiomi di simmetria, indipendenza dalla scala e indipendenza dalla popolazione.
Cons ideriamo in particolare il caso in cui α = 0, ovvero, la deviazione logaritmica media. La caratteristica peculiare di questo indice è quella di rispettare sia il principio di Pigou-Dalton sia il principio del trasferimento decrescente, ossia di essere maggiormente sensibile a trasferimenti che coinvolgono la parte inferiore della distribuzione, quella occupata dai soggetti più poveri.
La deviazione logaritmica media è un indice importante soprattutto perché gode (come tutti gli indici di entropia) della proprietà di scomponibilità tra gruppi: se si suddivide la popolazione in G gruppi omogenei rispetto a una data caratteristica socio-economica,
DLM è esattamente scomponibile in una disuguaglianza all’interno dei gruppi (within-groups), DLMW, e in una disuguaglianza tra i gruppi (between-groups), DLMB.
-
Il rapporto interdecilico. Una misura che, come l’indice di Gini, non comporta il calcolo di una somma ponderata di differenze rispetto al reddito medio è il rapporto interdecilico. Tale indice esprime il rapporto tra i redditi detenuti da individui che si trovano in diversi quantili della popolazione, ad esempio il decimo decile28, quello più ricco, e il primo decile, quello più povero.27
Se a è uguale a 0 o a 1, per trovare l’espressione dell’indice occorre applicare la regola di l’Hôpital.
28
I decili sono i dieci gruppi di uguale numerosità in cui può essere suddivisa una popolazione di individui, ordinati per valori non decrescenti del reddito. Il primo decile contiene quindi il 10% più
L’indice P90/P10 esprime il rapporto tra il reddito del soggetto che si trova al confine tra il nono e il decimo decile e il reddito del soggetto che si colloca tra il primo e il secondo decile. Spesso vengono calcolati anche i rapporti P90/P50 e
P50/P10, dove P50 è il reddito mediano.
Il limite di questa misura consiste nel non rispettare il principio del trasferimento; essa infatti si concentra su sezioni puntuali della distribuzione tralasciando completamente ciò che avviene in altre parti della stessa. Ha però il vantaggio di non essere influenzata dalla presenza di redditi eccezionali, sia molto elevati che molto bassi. Il rapporto interdecilico, anche in virtù della sua semplicità e facilità d’interpretazione, è frequentemente usato nelle analisi empiriche29.
Gli indici appena presentati costituiscono uno strumento essenziale nello studio della disuguaglianza. Se da un lato è importante avere una molteplicità di indici da poter usare, dall’altro lato però tale molteplicità pone un problema delicato: si può essere certi che l’impiego contemporaneo di due o più indici sintetici fornisca sempre lo stesso
ranking tra distribuzioni diverse in termini di maggiore o minore disuguaglianza?
Nel caso in cui due indicatori diano risultati diversi, verrebbe meno la caratteristica più importante degli indici sintetici, quella di assicurare un ordinamento completo. Non è un caso quindi che la maggior parte degli studi si sia concentrata sul criterio della dominanza di Lorenz e sulle sue possibili estensioni30, visto che, qualora tutti gli indici
di disuguaglianza soddisfino gli assiomi di indipendenza dalla popolazione, di simmetria, di indipendenza dalla scala e il principio del trasferimento, saranno coerenti con il criterio di dominanza di Lorenz.
3.4 I PRINCIPALI INDICI NORMATIVI
Una linea di ricerca innovativa, sviluppatasi nei primi anni 70 del secolo scorso, ha cercato di ricondurre il problema della costruzione degli indicatori distributivi all’interno dell’impianto normativo tipico dell’economia del benessere .
povero della popolazione, ecc. In generale, è sempre possibile suddividere la popolazione in altri tipi di quantili, ad esempio in quintili (5 gruppi, ognuno pari al 20% della popolazione totale) ecc.
29
Spesso per rapporto interdecilico si intende il rapporto non tra valori puntuali della distribuzione, ma tra valori totali (o medi) dei redditi di tutti gli individui appartenenti ai diversi quantili. In questo senso,
P90/P10 è il rapporto tra il reddito totale (o medio) del decimo decile e quello del primo decile. In questa
versione, l’indice è sensibile alla presenza di valori eccezionalmente elevati.
30
Il presupposto di tale impostazione è il seguente: date due distribuzioni di reddito x ed y e un qualunque indice di disuguaglianza, I(.), dire che una distribuzione è più disuguale dell’altra non ha solo un significato statistico, ma incorpora anche un giudizio di valore sulla desiderabilità di una distribuzione rispetto all’altra.
Nella scelta di una misura piuttosto che un’altra si cela quindi sempre un punto di vista etico.
Il modo classico che nell’economia del benessere viene seguito per introdurre giudizi di valore consiste nello specificare una funzione del benessere sociale. Una tipica espressione della funzione del benessere sociale (Fbs) è la seguente:
(1)
∑
( )
= = N i i y U W 1dove U
( )
yi viene interpretata come la valutazione sociale che una collettività attribuisce al reddito dell’individuo stesso. Da questa si ricava che la variazione (differenziale totale) del benessere sociale conseguente ad una variazione nella distribuzione dei redditi è:(2)
( )
i N i i i dy y y U dW∑
= ∂ ∂ = 1Se una politica produce le seguenti (piccole) variazioni nei redditi individuali:
N
y y
y ∆ ∆
∆ 1, 2,..., , la variazione nel benessere sociale è:
(3) dW =U1'∆y1+U2'∆y2 +...+UN'∆yN
dove U'indica la derivata prima del benessere sociale rispetto al reddito. La variazione del benessere sociale è quindi uguale alla somma delle variazioni dei redditi individuali, ciascuno pesato con il termine U’, che viene chiamato valutazione marginale sociale. La generica Fbs dell’equazione (1) è crescente nei redditi di ciascuno (derivata prima positiva); è simmetrica nei redditi individuali perché la forma della funzione U(.) è la stessa per tutti; ed è strettamente concava (derivata seconda negativa).
Quest’ultima è l’ipotesi chiave che incorpora la valutazione che la sociètà dà della disuguaglianza : dice che la valutazione marginale sociale del reddito di ciascun individuo è positiva, ma è tanto più bassa quanto più elevato è il reddito individuale, quindi implica una preferenza sociale per l’eguaglianza.
La forma della funzione del benessere riflette quindi il grado di avversione alla disuguaglianza espresso dalla società. Se ad esempio U(yi) = yi, allora il grado di avversione alla disuguaglianza è zero: conta solo la somma dei redditi e non come sono
distribuiti31. In tal caso la derivata prima è positiva (uguale a 1) ma la derivata seconda non è negativa, bensì zero. Affinché vi sia avversione alla disuguaglianza è necessario quindi che la funzione sia concava ed il grado di concavità esprime la misura di avversione; quanto maggiore è la concavità tanto maggiore è l’avversione alla disuguaglianza .
Data una funzione concava, se si effettua un trasferimento di reddito da un ricco ad un povero, il guadagno di utilità che la società ottiene dall’aumento di reddito del povero più che compensa la perdita di utilità derivante dalla riduzione del reddito del ricco e il benessere sociale aumenta.
A questo punto possiamo introdurre un primo importante risultato a cui è giunto l’approccio welfaristico allo studio della disuguaglianza, è noto come:
-
Teorema di Atkinson (1970). Date due distribuzioni generiche del reddito x ed y, e i corrispondenti livelli di benessere sociale W(x) e W(y), dove W(.) è una funzione del benessere sociale (Fbs) separabile in senso additivo, non decrescente e strettamente concava, µx = µy e Nx = Ny , allora Wx > Wy se e solo se x domina y in senso di Lorenz.Questo risultato è molto importante perché introduce un legame esplicito tra una misura molto usata per fare confronti di disuguaglianza tra distribuzioni diverse, la curva di Lorenz, e la valutazione sociale del benessere di una distribuzione: se la curva di Lorenz di una distribuzione sta sopra la curva di Lorenz di un’altra distribuzione con uguale reddito medio, allora non solo nella prima c’è meno disuguaglianza, ma in essa il benessere è superiore32. Il teorema vale per un’ampia gamma di Fbs, purchè siano additive, simmetriche e strettamente concave.
Qualora le distribuzioni present ino redditi medi diversi si potrebbe continuare a fare confronti solo in termini degli indici sintetici e della stessa curva di Lorenz poiché, essendo quest’ultime misure relative, prescindono dall’unità di misura del reddito. 31
∑
= = N i i y W 1 la Fbs è cioè utilitarista. 32Il teorema di Atkinson vale anche quando le popolazioni hanno numerosità campionaria diversa tra loro: in questo caso la funzione del benessere sociale deve essere espressa in termini pro capite:
). ( 1 1
∑
= = N I i y U N WUn approccio alternativo consiste nell’ordinare le distribuzioni tenendo conto non solo della disuguaglianza, ma anche nei livelli medi del reddito. In questo filone un importante risultato è stato presentato da Anthony Shorrocks nel 1983 con il concetto di curva di Lorenz generalizzata.
-
Curva di Lorenz generalizzata. Si ottiene moltiplicando le ordinate della curva di Lorenz originaria per la media della distribuzione.In termini formali, la curva di Lorenz generalizzata, GL (.), individua l’insieme dei punti di coordinate = =
∑
∑
∑
∑
= = = = N y N n N y N n y y N n n i i n i i N i i n i i 1 1 1 1 , , , µ µ µ con 1≤n≤NSull’asse delle ordinate non si misura, si noti, la proporzione del reddito totale detenuto da quote crescenti della popolazione (come avviene per la curva di Lorenz tradizionale), bensì l’ammontare cumulato di reddito, espresso in termini pro capite dell’intera
popolazione. È immedia to anche dedurre che i due valori estremi della curva sono,
rispettivamente, GL(0)=0e GL(1)=µ.
Dalla definizione di curva generalizzata si ricava il principio di dominanza che, a differenza di quello tradizionale, tiene conto della dimensione assoluta della distribuzione. Anche a tale criterio, noto come teorema di Shorrocks, si attribuisce un valore normativo.
-
Teorema di Shorrocks (1983). Date due curve di Lorenz generalizzate, quella che domina interamente l’altra è socialmente preferibile per tutte le funzioni del benessere sociale( )
N W o
simmetriche, non decrescenti e avverse alla disuguaglianza (cioè con U(.) strettamente concava)33.
Se la distribuzione x presenta una curva sempre superiore a quella della distribuzione y, per qualunque percentile cumulato della popolazione, si può affermare in termini equivalenti, che esiste dominanza stocastica del secondo ordine di x nei confronti di
33
Un’anticipazione sia del teorema di Atkinson che del teorema di Shorrocks è contenuta in Kolm (1969). (Baldini e Toso, 2004).
y. Il significato di questa espressione è in effetti lo stesso del teorema di Shorrocks: se c’è dominanza stocastica del secondo ordine allora il benessere sociale è superiore in x per tutte le Fbs considerate nel teorema34.
L’espressione “del secondo ordine ” implica ovviamente l’esistenza di una dominanza stocastica del primo ordine , che si verifica quando una distribuzione presenta una funzione di densità cumulata sempre inferiore ad un’altra, per qualsiasi livello di reddito35. La dominanza del primo ordine ha portata più generale rispetto a quella del secondo ordine, essa quindi implica quella del secondo ordine, ma non vale il contrario. La trasformazione delle curve generalizzate riduce l’incompletezza dell’ordinamento in quanto attribuisce un peso alla dimensione assoluta dei redditi. Non si può tuttavia escludere che anche due curve di Lorenz generalizzate si intersechino.
Oltre a chiarire il contenuto etico implicito nelle più note misure statistiche, l’altro importante contributo dell’approccio dell’economia del benessere consiste, come si è già detto, nell’aver proposto una serie di indici normativi. Tra questi merita particolare attenzione l’indice di Atkinson.
-
L’indice di Atkinson (1970). Si basa su una struttura delle preferenze collettive corrispondente ad una funzione del benessere sociale dove il grado di avversio ne (sociale) rispetto alla disuguaglianza è misurato da e, con e>0( )
ε µ ( ) ( )ε −ε = − − =∑
1 1 1 1 1 1 N i i y N AL’indice varia tra 0 (massima uguaglianza) e 1 (massima disuguaglianza). Più il parametro di avversione alla disuguaglianza, (e), è positivo, più l’indice è sensibile alle differenze di reddito nella parte bassa della distribuzione.
La Fbs incorporata nell’indice di Atkinson possiede, oltre alle proprietà di additività, non decrescenza e simmetria, anche un’altra proprietà, molto importante: essa presenta la caratteristica di elasticità dell’utilità marginale al reddito costante, cioè di
avversione relativa alla disuguaglianza costante. L’ipotesi di costanza dell’elasticità
34
Si noti che l’ordinamento di Lorenz generalizzato non è un ordinamento di disuguaglianza ma di benessere, perché affianca alle considerazioni distributive quelle di efficienza
35
Equivalentemente, si ha dominanza stocastica del primo ordine di x su y se la sfilata di Pen di x è sempre superiore alla sfilata di Pen di y
dell’utilità marginale sociale è necessaria affinché l’indice di Atkinson soddisfi la proprietà di indipendenza dalla scala.
L’indice di Atkinson, A
( )
ε , valuta in sostanza il grado di disuguaglianza di un insieme di redditi in termini del guadagno di benessere sociale che deriverebbe da un’ipotetica redistribuzione in senso egualitario. Più precisamente, esso esprime, come complemento ad 1, la proporzione di reddito complessivo necessario per godere dello stesso livello di benessere sociale della distribuzione effettiva, se tutti i redditi fossero equamente distribuiti. L’indice è quindi interpretabile come un indicatore di “inefficienza distributiva”, nel senso che misura la perdita di benessere indotta da una distribuzione diseguale. Di conseguenza, la scelta del valore numerico del parametro ε dipende dalle perdite di efficienza che il policy maker è disposto a sostenere e dalla distanza, in termini di reddito, che separa il povero dal ricco. A parità di distanza dai redditi, un valore più alto del parametro ε indica la disponibilità ad accettare una perdita più alta.3.5 I PRINCIPALI INDICI DI POVERTA’
Nella misurazione della povertà si presentano due problemi [Sen 1976]: a) l’identificazione delle persone povere nella popolazione; b) la derivazione di un indice di povertà che sintetizzi tutte le informazioni disponibili.
Il primo problema consiste essenzialmente nella definizione di una soglia di reddito che permetta di separare i poveri dai non poveri. Questa soglia può essere fissata con vari criteri: assoluti, relativi, soggettivi e pubblici.
-
Standard assoluti. La condizione di indigenza si presenta quando il consumo di una famiglia è inferiore a un paniere minimo di beni essenziali alla sopravvivenza o il reddito è insufficiente ad acquistarlo. Il limite di questo criterio consiste nello stabilire dei criteri oggettivi per definire cosa sia essenziale e cosa no per evitare l’indigenza, e nel capire cosa si intende per sopravvivenza. La soglia di povertà si ottiene sommando al costo di questo paniere una stima delle spese per gli altri beni e servizi necessari. Una soglia di tipo assoluto viene fatta variare nel tempo per tenere conto delle variazioni del livello dei prezzi.-
Standard relativi. Lo stato di povero viene identificato in relazione allo standard di vita medio della comunità, che determina quali sono i bisogni sociali essenzia li. La disponibilità di un certo reddito e di un certo paniere può permettere la sopravvivenza fisica ed essere quindi ritenuta adeguata in una società poco sviluppata, ma nello stesso tempo può risultare insufficiente in una società più avanzata.La conversione della nozione di povertà relativa in una soglia utilizzabile non è immediata, impone di caratterizzare precisamente lo standard di vita medio. In genere, si risolve il problema facendo coincidere quest’ultimo con il valore medio (o mediano) del reddito e fissando la soglia di povertà in rapporto a questo valore.
-
Standard soggettivi. Un modo alternativo di fissare la soglia di povertà è domandare ad un campione rappresentativo di famiglie quale sia il livello minimo di reddito per condurre una vita dignitosamente, senza lussi o eccessi. La soglia viene fissata in corrispondenza del livello di reddito in cui valore indicato e valore effettivo coincidono-
Standard pubblici. La soglia di povertà viene identificata con i livelli minimi di reddito fissati dagli interventi pubblici di assistenza sociale, che vengono quindi interpretati come l’ammontare di risorse che la società ritiene di dover garantire a ciascun individuo. In Italia, un esempio di queste soglie minime è rappresentato dall’assegno sociale per gli anziani, introdotto con la riforma pensionistica del 1995.Fissare la soglia di povertà sulla base dei livelli di assistenza pubblica è un criterio discutibile (Brandolini, 2001) perché sostanzialmente viene rimandato il problema, sarà infatti qualcun altro a dover stabilire la soglia di povertà.
La nozione di povertà relativa e quella di povertà assoluta prevedono dei limiti: la povertà relativa è un concetto molto simile a quello di disuguaglianza, ed è destinata a non scomparire mai, a meno che non si azzeri la disuguaglianza; la povertà relativa può avere un andamento pro ciclico: aumentare nelle fasi espansive del ciclo economiche (se la crescita avvantaggia soprattutto chi sta sopra la soglia di povertà) e diminuire in quelle recessive. Per quanto riguarda invece la povertà assoluta se la linea assoluta di
povertà è invariante nel tempo (a meno dell’aumento dell’inflazione), il numero di poveri assoluti tenderà necessariamente a ridursi nel corso degli anni se si assiste ad un aumento del reddito reale pro capite e della spesa.
In questo lavoro si farà riferimento al criterio relativo: la soglia di povertà verrà fatta coincidere con il 60% del valore mediano36 del reddito familiare equivalente. Ne discende che le variazioni nel tempo della linea riflettono non solo la dinamica dei prezzi, ma anche la crescita reale dell’economia.
Il secondo problema della misurazione della povertà è costituito dalla scelta di un indice che sintetizzi le informazioni disponibili.
Un primo strumento di misura è costituito dall’indice di diffusione o incidenza
(head-count ratio). Indicando con Z la soglia di povertà, esso è definito come:
( )
Z F n qH = =
dove F
( )
Z è la funzione di densità cumulata, n è il totale della popolazione, q rappresenta il numero di persone (famiglie) con reddito minore di Z, cioè Yq ≤ Z ≤Yq+1nella sequenza crescente dei redditi, e il reddito è “corretto” per tenere conto della composizione familiare con una scala di equivalenza (vedi par 2.4).
L’indice di diffusione è l’indice sintetico più semplice da usare ma presenta dei limiti poiché non descrive adeguatamente il fenomeno della povertà, non dicendo se i poveri si trovino molto al di sotto della soglia di povertà oppure poco.
Una seconda misura della povertà è il divario di povertà (poverty deficit) ovvero l’ammontare complessivo di reddito addizionale necessario ai poveri per oltrepassare la linea di povertà:
(
)
(
q)
q i i q Z Y Z D=∑
− = −µ =1dove µq è il reddito medio dei poveri. D misura l’entità del trasferimento aggregato che, ceteris paribus, consentirebbe di eliminare la povertà. Un modo alternativo per esprimere il divario di povertà è di normalizzarlo per la soglia di povertà moltiplicata per il numero di poveri:
∑
= − = = q i i Z Y Z q qZ D I 1 1 36Il valore mediano della distribuzione suddivide il totale delle famiglie, ordinate in base al reddito, in due parti eguali: la prima metà con redditi inferiori alla mediana, la seconda con redditi maggiori o uguali.
I è un indice di intensità (o income gap ratio) che misura di quanto il reddito dei poveri è mediamente al di sotto della soglie di povertà, in rapporto alla soglia stessa. Esso esprime quanto è mediamente grave la povertà per ogni indigente. Così come H
non è sensibile alla severità della povertà, I non dipende dal numero di poveri. Più in generale il problema è che questi due indici non danno alcuna informazione sulla distribuzione tra i poveri: una redistribuzione di reddito dal più ricco, tra i poveri, al più povero lascerebbe entrambi gli indici inalterati (Sen 1976). Mutuando il criterio di Pigou-Dalton dalla discussione sulle misure di disuguaglianza, si può argomentare che in questo caso la povertà è diminuita. Seguendo questa linea di ragionamento, Sen ha proposto il seguente indice:
(
1)
][I I Gq
H
S = + −
dove Gq è l’indice di Gini calcolato tra i poveri. Con tale indice, Sen introduce il concetto di “deprivazione” relativa: la povertà è tanto più intensa quanto più essa è avvertita dai poveri, ossia quanto più i poveri avvertono la distanza tra la loro condizione ed i gruppi sociali con cui si confrontano.
Un’altra classe di indici sensibili a trasferimenti di reddito tra i poveri è quella proposta da Foster, Greer e Thorbecke (1984):
α α
∑
= − = q i i Z Y Z n FGT 1 1dove a è un parametro che misura l’avversione alla povertà: quanto più è grande, tanto maggiore è il peso dei più poveri nell’indice.
Risultano particolarmente significativi due valori di questo parametro:
1. se a=0, FGT = H (indice di diffusione) 2. se a=1, FGT = I (indice di intensità)
Per valori del parametro, a, > 1 l’indice FGT diviene un indicatore della gravità della povertà e risente soprattutto della distribuzione dei redditi tra i più poveri perché attribuisce un peso maggiore a divari elevati. Si noti come i valori indicati ai punti 1,2 costituiscano gli estremi dell’intervallo dell’indice di Sen.