Capitolo 4
All’interno di questo capitolo effettueremo la progettazione in linguaggio VHDL (Very High speed integrated circuits hardware Description Language) dello stimatore del moto proposto nel Capitolo 3. Riporteremo inoltre considerazioni sull’occupazione di area e sul tempo di latenza del circuito una volta effettuata la sintesi.
4.1
Descrizione dello schema generale
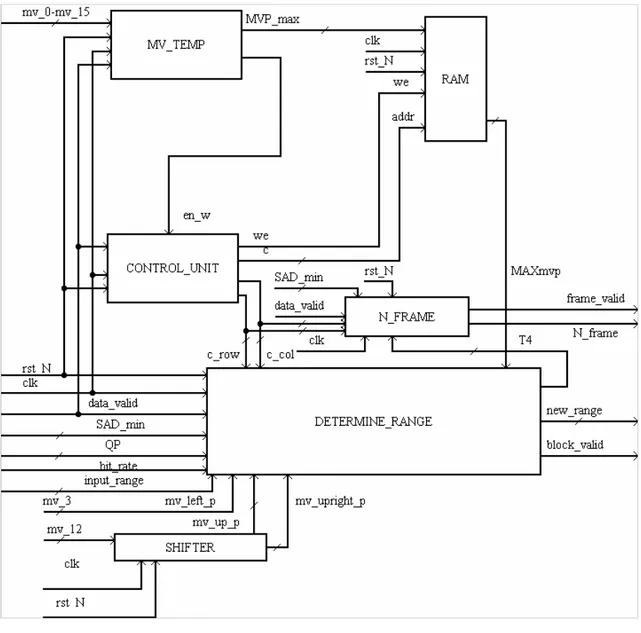
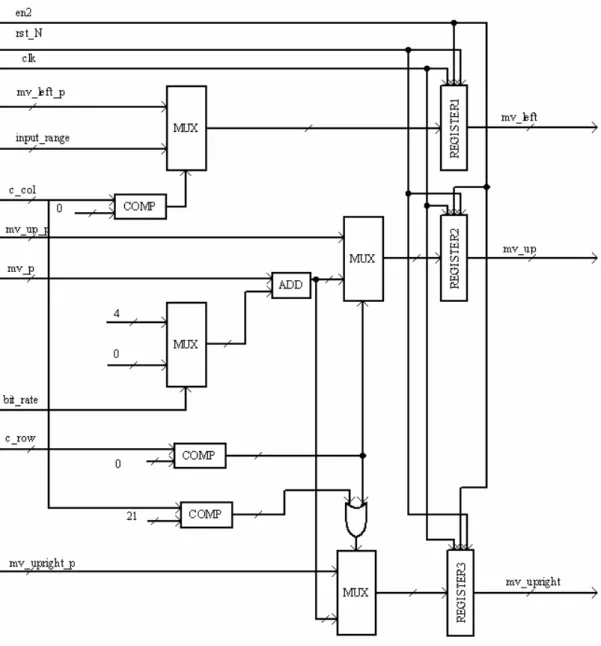
La stima del moto riveste nell’intero encoder il ruolo più delicato, essa infatti comporta notevoli computazioni che vengono iterate molteplici volte: è quindi opportuno adottare una realizzazione dedicata attraverso l’utilizzo di linguaggi di descrizione dell’hardware e programmi di sintesi logica. Concentriamo adesso la nostra attenzione sulla progettazione hardware della funzione che, all’interno dell’algoritmo di stima del moto, determina l’area di ricerca ( vedi paragrafo 3.4) e che stabilisce inoltre il numero di frames di riferimento che è opportuno utilizzare nella codifica di un frame (vedi paragrafo 3.6). Nella descrizione dell’algoritmo supporremo di codificare una sequenza video in formato CIF (352x288 pixels). Lo schema generale dei componenti che implementano le sopradette funzioni è riportato in Figura 4.1. Tale sistema è pensato per l’elaborazione di una delle due componenti (X o Y), l’altra viene elaborata successivamente dalla stessa struttura. Il circuito proposto opera sui valori assoluti dei vettori di moto, che si ipotizza siano espressi nel formato di modulo e segno, quindi per calcolarne il valore assoluto è sufficiente trascurare il bit del segno, senza compiere un’effettiva operazione di calcolo di modulo. Il blocco denominato determine_range è atto a determinare l’area di ricerca opportuna per ogni macroblocco del frame in esame. Tale blocco riceve in ingresso i segnali di clock (clk), di reset asincrono attivo basso (rst_N) e un segnale che permette l’inizio della computazione costituito da data_valid. Riceve in ingresso inoltre il fattore di quantizzazione QP (codificato su 5 bit), il valore dell’errore di predizione relativo all’ultimo macroblocco codificato SADmin (codificato su 16 bit), il segnale bit_rate che indica,quando assume valore pari ad 1, se il target bit_rate è superiore ai 500 Kbit/sec, e il valore del range di ricerca fornito nella configurazione, input_range, (codificato su 5 bit). Riceve inoltre i vettori di moto dei
blocchi 4x4 vicini denominati come mv_left_p, mv_up_p e mv_upright_p, e il vettore di moto che tiene conto delle correlazioni temporali indicato con MAXmvp memorizzato in una RAM il cui indirizzo corretto viene fornito da un contatore che scandisce i macroblocchi in esame.
Figura 4.1: schema generale
L’uso di una RAM è reso necessario in quanto si deve memorizzare il valore del massimo vettore di moto del macroblocco appartenente al frame precedente che occupava la stessa posizione di quello corrente. Si suppone di utilizzare direttamente i valori assoluti dei vettori di moto che così necessitano di essere espressi su 5 bit dato che essi assumono valori compresi tra -16 e +15 e quindi in valore assoluto tra 0 e 16; la RAM di cui avremo bisogno quindi è del tipo 396 locazioni di 5 bit ciascuna dato che
396 è il numero di macroblocchi in cui si divide un frame di una sequenza CIF. Il massimo valore dei vettori di moto di ogni macroblocco 16x16 è determinato dal blocco mv_temp che riceve in ingresso i valori dei 16 vettori di moto del macroblocco precedentemente codificato. I vettori di moto dei macroblocchi vicini sono presi rispettivamente: quello sinistro (mv_left) dai vettori dell’ultimo macroblocco codificato, quello in alto (mv_up) e in alto a destra (mv_upright) corrispondono ai vettori del ventunesimo e ventiduesimo blocco codificato in precedenza. Ottengo tali vettori memorizzando solamente gli ultimi 22 mv_12 codificati del frame corrente in uno shifter register (shifter), utilizzandone poi le uscite opportune. Oltre che fornire il nuovo valore dell’area di ricerca, new_range, il blocco indica quando tale valore è attendibile ponendo il segnale di block_valid ad 1, e passa al blocco che controlla il numero di frames di riferimento il valore della soglia T4, la cui funzione viene spiegata in 3.6. In Fig 4.1 si osserva inoltre la presenza di un blocco control_unit che riceve in ingresso i segnali di clk, rst_N, en_w e data_valid; tale blocco fornisce le coordinate del macroblocco in esame all’interno del frame, c_row e c_col, e inoltre fornisce per la memoria il segnale di abilitazione alla scrittura, we, e l’indirizzo, addr. Il blocco denominato con Nframe riceve in ingresso oltre al segnale di clock e al reset asincrono l’errore di predizione il quale verrà confrontato poi con T4 per decidere appunto sul numero di frames di riferimento. Nei prossimi paragrafi vedremo in dettaglio i blocchi di determine_range, di N_frame e di mv_temp; vedremo poi anche come è stato realizzato l’unità di controllo control_unit.
4.2
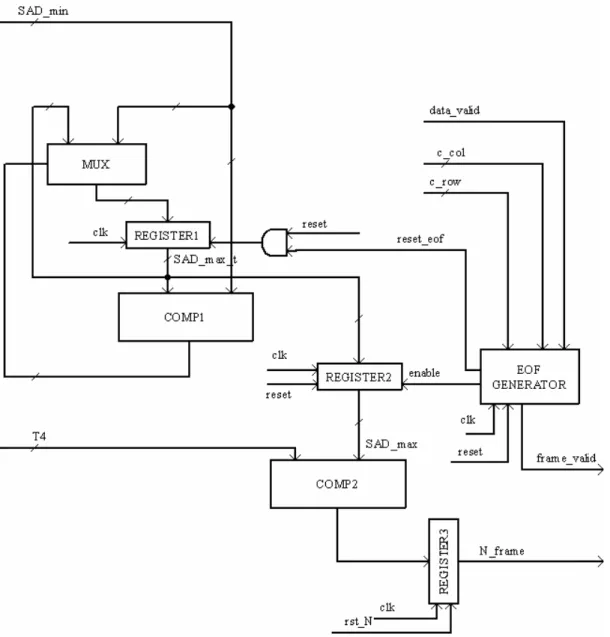
Descrizione di N_frame
In questo paragrafo prendiamo in esame il funzionamento del blocco che determina il numero opportuno di frames di riferimento che devono essere utilizzati nella codifica. L’idea di base (come visto in 3.6) consiste nel confrontare il massimo degli errori di predizione su un frame con una soglia che varia a seconda del QP. Questo confronto ci permette di decidere per il frame successivo se è opportuno utilizzare più frames di riferimento, nel caso in cui il massimo degli errori di predizione (in figura SAD_max) assuma un valore superiore alla soglia T4, oppure se è sufficiente prendere in esame un solo frame di riferimento. In Fig 4.2 si riporta lo schema circuitale. In alto a sinistra si
presente nel registro 1: se superiore viene memorizzato nel registro altrimenti il valore temporaneo del massimo errore di predizione resta invariato; il registro viene riportato a 0 dopo che è terminata l’analisi di ogni frame. Il valore così ottenuto viene registrato nel registro 2 abilitato solo alla fine del frame. Tale valore viene confrontato con quello di T4, e se risulta minore, il comparatore assume valore basso in uscita per segnalare che un solo frame di riferimento sarà sufficiente per l’analisi del frame successivo. Altrimenti il valore alto all’uscita del comparatore indica la necessità di un numero superiore ad uno per i frame di riferimento. Vale la pena notare che il valore dell’errore di predizione è espresso su 16 bit mentre quello di T4 solo su 13, questo ci permette di utilizzare un comparatore che prima analizza i 3 bit più significativi di SAD_max e solo se li trova tutti nulli continua a confrontare i 13 bit meno significativi con T4 effettuando così un efficiente comparazione.
Il blocco denominato con EOF Generator, implementa una macchina a stati sincrona che riceve in ingresso oltre al clock e al reset asincrono il segnale di data_valid, che informa che si inizia ad operare su un nuovo macroblocco, e il valore della riga e della colonna in cui si trova il macroblocco. Nello stato iniziale i segnali reset_EOF e frame_valid sono entrambi non attivi (tutti i reset si intendono attivi bassi) e si attende di trovarsi sull’ultimo blocco del frame. Si passa quindi allo stato successivo in cui si fornisce l’abilitazione, enable, per memorizzare il valore di SAD_max nel registro 2 poi si attendono due cicli di clock prima di asserire il segnale di frame_valid che indica che sono state compiute tutte le computazioni opportune sul frame in esame e che i dati possono essere prelevati. Si attende poi che il segnale di data_valid torni basso per indicare che i dati sono stati recepiti e si passa nello stato in cui si provvede a porre a 0 il contenuto del registro 1 per poi tornare nello stato iniziale in attesa di nuovi dati da calcolare.
4.3
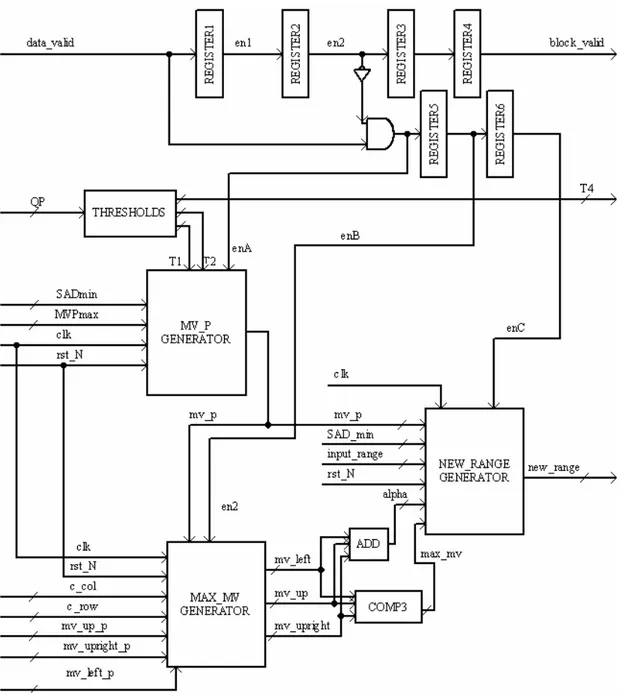
Descrizione di determine_range
In questo paragrafo descriveremo come viene realizzata la funzione determine_range che fornisce il valore dell’area di ricerca. Il segnale di data_valid serve per creare tre segnali di abilitazione che durano due cicli di clock e ritardati tra loro di un ciclo. Viene adottata questa soluzione perché i risultati dei blocchi che generano mv_p, max_mv e new_range devono essere calcolati in sequenza altrimenti potrei osservare in uscita segnali spuri. Abbiamo operato la scelta di utilizzare solo 6 registri e una porta AND invece che utilizzare una macchina a stati dato che in un ciclo di clock ogni blocco è in grado di fornire un corretto valore di uscita e non è necessario operare dei controlli per determinare se le uscite dei singoli blocchi sono stabili. Il blocco denominato come thresholds determina le soglie T1, T2 e T4 che poi sarà passata al sistema che decide il numero di frame di riferimento che devono essere utilizzati. Il blocco mv_p generator riceve in ingresso il segnale di clock e di reset asincrono, un segnale di abilitazione enA che permette la scrittura del vettore temporale mv_p in un registro interno al blocco. Riceve inoltre in ingresso il valore del vettore di moto appartenente al macroblocco che occupava, nel frame precedente, la stessa posizione di quello in esame (MVPmax); l’errore di predizione (SADmin) viene confrontato con le soglie T1 e T2 per determinare se effettivamente mv_p assumerà il valore del vettore di
minore delle soglie utilizzate. Quando mv_p assume valore nullo è indice che semplicemente non è necessario utilizzare anche dati temporali nella codifica dato che la predizione che stiamo operando è già molto buona. Il blocco MAX_MV generator riceve il segnale di abilitazione (enB) un ciclo di clock dopo il blocco che genera mv_p quindi tutti i segnali in ingresso hanno valore stabile. In uscita i mv_left, mv_up e mv_upright assumono i valori dei vettori di moto dei vicini temporali se essi sono effettivamente presenti oppure dei valori determinati da input_range e da mv_p. Si riesce a capire se i vicini spaziali sono effettivamente presenti dalla posizione del macroblocco nel frame, quindi da c_row e c_col, che sono rispettivamente l’indice di riga e di colonna del macroblocco se pensiamo il frame come una matrice i cui elementi sono appunto i macroblocchi. Viene poi determinato il massimo tra i vettori che comportano la correlazione spaziale tramite comp3 e vengono sommati tra loro per generare il segnale alpha che viene utilizzato dall’ultimo blocco all’interno di determine_range. Tale blocco, new_range generator viene attivato dopo ancora un ciclo di clock in modo tale che anche alpha e max_mv assumano valori congrui e stabili.
Figura 4.3: schema circuitale generale di determine_range.
Il blocco new_range generator presenta il valore di uscita dopo 1 ciclo di clock, quindi con una latenza di tre cicli di clock, rispetto a quando il segnale di data_valid provoca l’abilitazione del primo blocco tramite en1, troviamo in uscita il valore del nuovo range di ricerca indicato con new_range per garantire un margine di sicurezza aspettiamo un ulteriore ciclo di clock prima di asserire il segnale di block_valid che indica appunto che i dati sono attendibili.
4.3.1
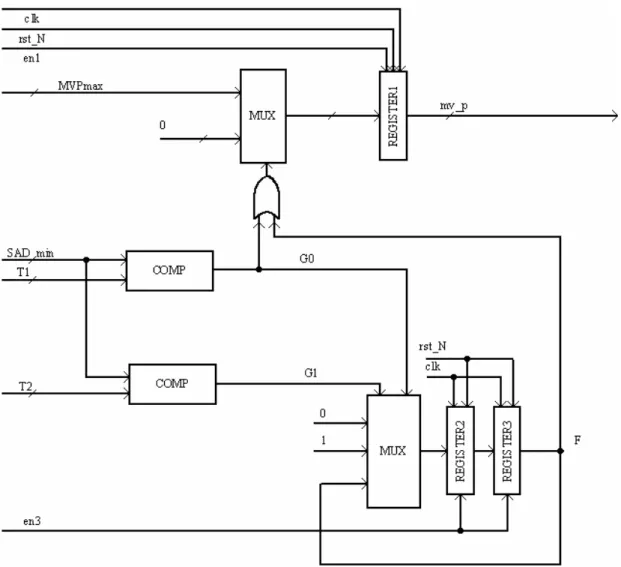
Descrizione di MV_P generator
In Fig 4.4 si riporta lo schema di funzionamento del blocco atto alla determinazione del vettore di moto che esplica le correlazioni temporali del macroblocco in esame con quello occupante la stessa posizione nel frame precedentemente codificato. Il vettore di moto, mv_p, viene determinato entro un ciclo di clock e sarà poi passato agli altri blocchi che si trovano in determine_range. Attraverso il multiplexer in alto in Fig 4.4 si osserva come mv_p possa assumere l’effettivo valore del vettore di moto del macroblocco del frame precedente oppure possa venire settato a 0, nel caso in cui non sia necessario sfruttare anche i dati derivanti dalla correlazione spaziale. Tale decisione viene effettuata comparando il valore dell’errore di predizione, SAD_min, con delle soglie: se esso è superiore al valore di T1 utilizziamo anche le correlazioni temporali per la predizione, altrimenti se è inferiore a T2 i dati derivanti da considerazioni temporali non sono necessari. Se il valore dell’errore di predizione assume valori intermedi, il comportamento del blocco dipende attraverso il valore del flag F dal macroblocco precedentemente codificato; un valore di F pari ad 1 indica che per il macroblocco precedente si era verificata un caso di elevato errore di predizione viceversa un valore pari a 0 indica che si era verificata un caso di basso errore, indice di una buona predizione. Il valore di F viene poi aggiornato, a seconda del valore assunto da SAD_min, in modo tale da non influenzare il macroblocco sotto analisi. Se il valore di SAD_min è tale da essere compreso tra quelli di T1 e T2 il valore di F non viene modificato.
Figura 4.4: schema circuitale di MV_P generator
4.3.2
Descrizione di max_mv generator
In Fig. 4.5 si mostra lo schema di funzionamento del blocco che calcola i vettori di moto dei blocchi 4x4 vicini al macroblocco in esame in accordo all’algoritmo trattato in 3.4.3. I registri presenti vengono abilitati dal segnale di en2 in modo tale che tutti i segnali in ingresso a tali registri assumano valori stabili, tenendo in considerazione che alcuni di essi provengono da altri blocchi. Si effettuano dei controlli su c_row e c_col per determinare la posizione del macroblocco all’interno del frame, se infatti esso costituisce parte del bordo del frame non tutti i vettori di moto dei vicini blocchi saranno disponibili; in tal caso tali vettori di moto assumono valori di default pari a
input_range per mv_left e a mv_p per mv_up e mv_upright aumentati di un fattore 4 se ci troviamo nelle condizioni di un elevato bit_rate (>500Kbit/sec).
Figura 4.5: schema circuitale di max_mv generator
4.3.3
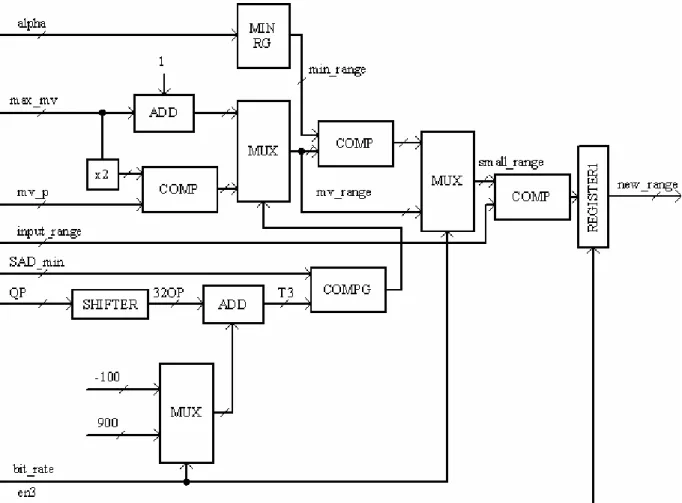
Descrizione di new_range generator
In figura 4.6 si riporta lo schema di funzionamento del blocco che determina il novo range di ricerca denominato come new_range. Il blocco riceve in ingresso alpha, che corrisponde alla somma dei tre vettori di moto dei vicini blocchi 4x4. Tale valore viene utilizzato per determinare un valore minimo del range di ricerca attraverso il blocco min_rg che in accordo all’algoritmo in 3.4.3 determina il valore min_range dal valore di alpha. Si osserva che nel caso di bassi bit_rate tale valore non è importante in quanto
comunque viene scelto per small_range il valore assunto da mv_range: esso viene determinato dal valore sia del vettore di moto che tiene conto delle correlazioni temporali, mv_p, sia dal massimo dei tre vettori di moto dei vicini blocchi, che quindi tiene conto delle correlazioni spaziali. Il valore di small_range viene poi confrontato con quello impostato nel file di configurazione e il minore tra i due costituirà il nuovo range di ricerca new_range; tale valore viene effettivamente aggiornato solo quando il segnale di abilitazione e3 lo permette, garantendo che si rispettino le precedenze nel calcolo dei segnali provenienti dai vari blocchi.
Figura 4.6: schema circuitale di new_range generator
E’ opportuno osservare il valore della soglia T3 viene determinato internamente al blocco dato e non dal blocco thresholds dato che essa si ottiene facilmente con un semplice shifter e con un adder. Si osserva inoltre che il comparatore utilizzato per determinare se il valore dell’errore di predizione è maggiore di T3 è meno complesso degli altri denominati come comp in quanto in uscita presenta solo un bit che indica il
4.3.4
Descrizione di thresholds
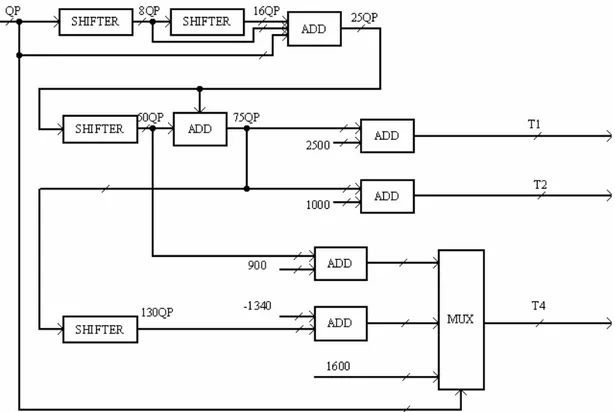
La Fig 4.7 riporta lo schema circuitale del blocco che riceve in ingresso il fattore di quantizzazione QP e fornisce il valore delle soglie T1, T2, T4 necessarie per la realizzazione dell’algoritmo proposto in 3.4.3. Si era posto infatti:
α + ⋅ = + ⋅ = + ⋅ = QP T QP T QP T1 75 2500, 2 75 1000, 3 35
Il valore di T3 si determina direttamente all’interno del blocco che la utilizza, come osservato nel precedente paragrafo. Si era poi riportato in 3.6:
) 28 ( 130 2300 4 52 28 ) 16 ( 50 1700 4 28 16 1700 4 16 1 − ⋅ + = → < ≤ − ⋅ + = → < ≤ = → < ≤ QP T QP QP T QP T QP
Nello schema si sono ottenute le varie soglie senza ricorrere a dei moltiplicatori, utilizzando solo sommatori e operando degli shift su QP.
Il blocco denominato come mux implementa la legge di decisione riportata per la determinazione di T4 utilizzando al suo interno dei comparatori che definiscono l’intervallo in cui è compreso il valore di QP e di conseguenza si seleziona l’uscita appropriata.
4.4
Descrizione di mv_temp
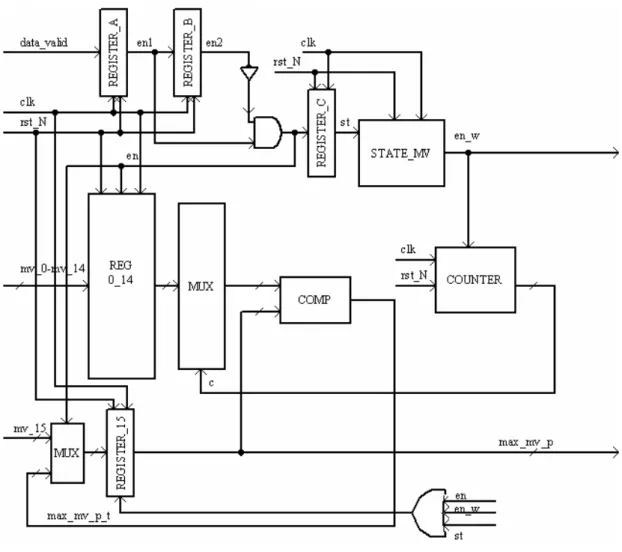
In Fig. 4.8 si presenta lo schema del blocco che determina il vettore di moto che ha valore assoluto massimo tra quelli dell’ultimo macroblocco 16x16 che è stato codificato. L’operazione di codifica di un macroblocco impiega molti cicli di clock e la determinazione di max_mv_p può essere operata in parallelo con tale codifica. Questo ci ha portato a progettare uno schema che si serve di un solo comparatore che opera il confronto su due vettori di moto, sceglie quello con valore più elevato (max_mv_p_t), lo memorizza in un registro e al ciclo di clock seguente ripete il confronto tra max_mv_p_t e un nuovo vettore di moto, quando tutti i confronti sono terminati avverte l’unità di controllo portando basso en_w che max_mv_p assume il valore del massimo vettore di moto del macroblocco precedentemente codificato e quindi si può procedere alla scrittura nella RAM. Questo approccio porta ad un’identificazione di max_mv_p che impiega un numero di cicli di clock maggiori rispetto ad un approccio in cui si eseguono più confronti in parallelo, consente, d’altra parte un risparmio in numero di comparatori utilizzati. Dato poi che questa operazione viene svolta in parallelo alla codifica di un macroblocco non è necessario fornire una veloce risposta dovendo comunque attendere la fine di questa ultima per impiegare nuovamente il blocco mv_temp (vedi 4.8). Quando il segnale di data_valid passa dal valore 0 ad 1 si ha dopo un ciclo di clock vengono caricati nei registri da reg0 a reg15 i valori dei vettori di moto, al clock successivo viene azionata una macchina a stati cha si porta da uno stato di riposo in cui ha l’uscita en_w bassa ad uno stato in cui en_w diviene alto; tale segnale attiva un contatore che conta fino a 15 cicli di clock al termine dei quali la macchina a stati si riporta nello stato di riposo, il contatore determina quale dei vettori di moto sarà in ingresso al comparatore. Il blocco in 17 cicli di clock fornisce quindi il valore del massimo vettore di moto del macroblocco precedentemente codificato. Possiamo osservare che utilizziamo reg_15 per accumulare il massimo parziale dei vettori di moto, per questo l’abilitazione di tale registro è alta per tutto il tempo necessario alla determinazione di max_mv_p .
Figura 4.8: schema circuitale di mv_temp
4.5
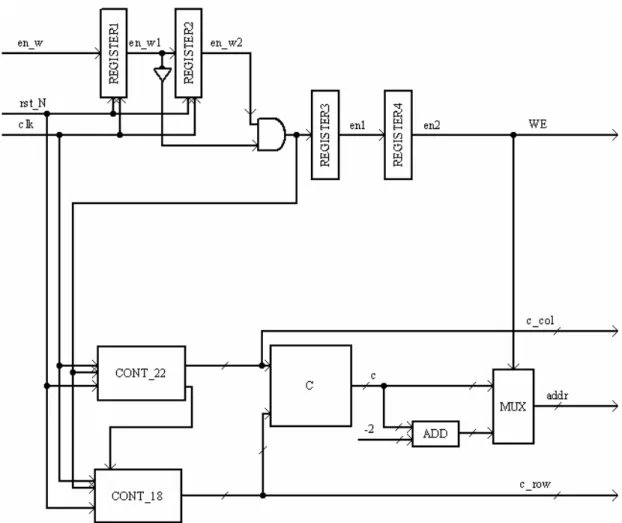
Descrizione di control_unit
In Fig. 4.9 si riporta lo schema circuitale dell’unità di controllo che fornisce i segnali di indirizzo, addr, e di abilitazione alla scrittura, WE, per la RAM. Tale unità fornisce inoltre le coordinate del macroblocco all’interno del frame, indicate come c_row e c_col. Il blocco viene attivato quando si verifica la transizione del segnale en_w dal valore1 a 0, questo attesta che è stato calcolato dal blocco sopra trattato il massimo vettore di moto del macroblocco precedentemente codificato. Vengono abilitati quindi due contatori modulo 22 (cont_22) e modulo 18 (cont_18) per un ciclo di clock ed essi incrementano il valore delle rispettive uscite che indicano appunto le coordinate in termini di colonna e riga del macroblocco in esame all’interno del frame. Si deve osservare che il contatore modulo 18 che indica la riga deve essere abilitato da cont_22 solo quando questo ultimo viene resettato, cioè quando ci troviamo nell’ultima
posizione di una riga. Il blocco indicato come C compone gli indirizzi di riga e di colonna in un unico indirizzo necessario per riferirsi alla RAM. L’indirizzo viene incrementato dopo l’analisi del blocco in modo tale che per la successiva analisi sia già caricato l’indirizzo corretto. L’operazione di scrittura viene effettuata dopo che si aggiorna l’indirizzo, dato che il massimo dei vettori di moto calcolato si riferisce al blocco precedente a quello di cui si è appena calcolata l’area di ricerca , si deve decrementare l’indirizzo di un valore pari a 2. è opportuno osservare che tale operazione è effettuata con un sommatore modulo 396 nel caso di un formato CIF di immagine, e comunque deve essere effettuata una somma algebrica modulo N in cui N è il numero di macroblocchi all’interno di un frame. Il segnale di WE viene ritardato di 2 clock rispetto a quello che abilita i contatori per essere sicuri che il nuovo indirizzo sia stabile.
4.6
Esempi di simulazione
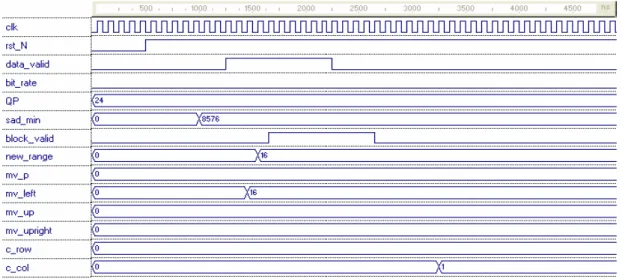
Si riportano adesso degli esempi di funzionamento del circuito in alcuni casi significativi. In Fig 4.10 si osserva come viene ottenuto il nuovo range di ricerca, denominato come “new_range” per il primo blocco di un frame. Supponiamo di trovarci in un caso di codifica di una sequenza che avviene a bassi bit-rate (<500Kbit/sec) e che inoltre ha registrato per il blocco codificato in precedenza un elevato valore dell’errore di predizione, indicato come “SAD_min”. Si nota inoltre che in questo caso il blocco inizialmente ha il segnale di reset attivo. Appena il segnale di data_valid passa dal valore 0 al valore 1, a indicare che i dati in ingresso al blocco sono stabili, si inizia a calcolare il nuovo range di ricerca. Per prima cosa viene aggiornato il valore di mv_p, che in questo caso si mantiene a 0, al clock seguente si aggiornano i valori dei vettori di moto dei vicini blocchi: essendo in analisi il primo macroblocco di un frame mv_left assume il valore di input_range, e quindi 16, e mv_up e mv_upright quello di mv_p, tale valore non viene aumentato di 4 dato che stiamo operando a basso bit_rate. Al clock successivo viene determinato il new_range, che così assume il valore di 16; si aspetta un ciclo di clock, dopo il quale viene asserito il segnale di block_valid che indica che il valore del range di ricerca è stato aggiornato. Tale segnale tornerà poi basso solo dopo qualche ciclo di clock quando data_valid torna basso, quando cioè l’encoder ha dato inizio alla ricerca utilizzando il nuovo range. Successivamente viene incrementato il valore di c_col per indirizzare correttamente il blocco seguente. Si osserva che il blocco impiega 4 cicli di clock da quando viene asserito il segnale di data_valid: la latenza è in effetti di 4 cicli di clock.
Figura 4.10: calcolo del range di ricerca per il primo macroblocco di un frame
In Fig 4.11 riportiamo invece il comportamento che si ottiene nel caso di basso valore di errore di predizione del blocco precedentemente codificato e in condizioni di elevati bit_rate. In questo caso, essendo il segnale di bit_rate pari ad 1, mv_up e mv_upright, che per il secondo blocco del frame non sono disponibili, assumono il valore di mv_p incrementato di 4. Supponiamo inoltre che il valore di mv_left sia 5, determinato dal quarto vettore di moto del macroblocco 16x16 precedentemente codificato. Sotto queste condizioni, in accordo all’algoritmo descritto in 3.4.3 il valore del nuovo range di ricerca viene determinato dal massimo tra i vettori di moto incrementato di 1. Si osserva come anche in questo caso i tempo di latenza è di 4 cicli di clock e di come di seguito si aggiorni i contatori c_col e c_row per identificare la posizione del macroblocco successivo.
Figura 4.11: calcolo del range di ricerca per il secondo macroblocco di un frame
Nella Fig 4.12 si osserva come varia il range di ricerca nel caso in cui l’unico valore che cambia rispetto al caso analizzato in Fig 4.11 è quello relativo all’errore di predizione. L’elevato valore di SAD_min ci porta ad operare in una zona diversa rispetto a quella utilizzata nel caso precedente in cui si determina il valore di new_range in modo più restrittivo (vedi 3.4.3): infatti adesso new_range si determina raddoppiando il valore del massimo dei vettori di moto.
In Fig. 4.13 si mostra come viene determinato il massimo tra i 16 vettori di moto di un macroblocco, MVP_max, che sarà poi memorizzato nella RAM e utilizzato per determinare la correlazione temporale adeguata per il calcolo di new_range per il macroblocco che occupa la stessa posizione nel frame successivo. Nell’esempio riportato si fa riferimento ai vettori di moto appartenenti all’ultimo macroblocco di un frame, il calcolo di MVP_max viene effettuato in parallelo alla determinazione di new_range per il macroblocco successivo, che in questo caso è il primo del frame successivo. Si osserva come il variare del valore assunto da MVP_max sia indice della modalità con cui vengono operati i confronti secondo lo schema circuitale mostrato in 4.4: il primo confronto viene effettuato tra il 16° e il 1° vettore di moto, poi si sceglie il massimo e si confronta col 2° vettore fino poi a compiere il confronto su tutti i vettori di moto; si compie un solo confronto per ciclo dato che si utilizza un solo comparatore, quindi il valore di MVP_max è significativo dopo 15 cicli di clock dal primo confronto. Si attende infatti un tempo sufficiente e fornendo un indirizzo appropriato (pari a 395 dato che esaminiamo l’ultimo macroblocco di un frame e gli indirizzi variano da 0 a 395) si va a scrivere il dato nella RAM. Tale dato sarà prelevato quando andremo a determinare new_range per il macroblocco che ha coordinate pari appunto a quelle che hanno formato l’indirizzo della locazione di RAM in cui abbiamo scritto. Vengono impiegati 21 cicli di clock dall’inizio dei confronti fino alla scrittura nella RAM ma il tempo impiegato non è un dato rilevante di per se in quanto i calcoli effettuati sono svolti in parallelo alla codifica del blocco corrente, infatti si nota che il calcolo e la scrittura di MVP_max non sono legati al fronte in discesa di data_valid che indica quando l’encoder inizia la stima del moto sul macroblocco in esame. Il tempo impiegato deve essere relazionato a quello necessario alla codifica del macroblocco, che superiore di due ordini di grandezza (vedi 4.7.2). Tale considerazione giustifica un approccio teso a minimizzare i componenti utilizzati a discapito del tempo impiegato per fornire i risultati.
Figura 4.13: determinazione del massimo vettore di moto di un macroblocco
4.7
Sintesi del circuito
In questo paragrafo descriveremo i risultati prodotti dalla sintesi del circuito, descritto nei paragrafi 4.1-4.6, in tecnologia CMOS standard cells HCMOS8 della ST Microelecttronics con una lunghezza di canale di 0,18µ e 6 livelli di metallizzazione per le interconnessioni. Abbiamo inoltre supposto di porre un’alimentazione per il core di 1,55V e di operare, per effettuare le simulazioni, alla temperatura di 125°C con la versione della libreria DLL (Device Low Leakage) e non con la versione della libreria DHS (Device High Speed) privilegiando la cura nel consumo in potenza a discapito della velocità dato che le specifiche temporali non sono risultate stringenti. Di seguito si riportano i risultati ottenuti in termini di area e di gates equivalenti; si riportano inoltre i tempi con cui si propagano i dati.
4.7.1
Risultati riguardanti occupazione di area
In Fig 4.14 si riporta l’occupazione di area in micron² considerando un tipico fattore di routing per questa tecnologia di 1,5 che tenga in considerazione lo spazio impiegato per realizzare i collegamenti necessari (le curva riportano l’area dovuta alla logica combinatoria, quella dovuta alla logica sequenziale e quella totale). Sono stati riportati i dati relativi a sintesi ottenute con circuiti operanti su diversi formati: 1)QCIF (176x144 pixels), 2)CIF (352x288 pixels), 3)4CIF (704x576 pixels), 4)16CIF (1408x1152 pixels); nel calcolo dell’area non viene considerata la RAM che si pensa di sintetizzare con tecnologia opportuna. Le dimensioni della RAM varieranno in seguito ai formati delle immagini trattate: nel caso di un formato QCIF le dimensioni della RAM saranno di 10bit per 99 locazioni, passando ai formati le locazioni quadruplicano di volta in volta.
0 20000 40000 60000 80000 100000 120000 1 2 3 4 formati Combinational area Noncombinational area
Total cell area
Figura 4.14: occupazione di area per vari formati
Riportiamo adesso in Fig 4.15 gli stessi dati della Fig 4.14 in termini di gates equivalenti considerando come riferimento una porta NAND a 2 ingressi che approssimativamente occupa un’area di 12,88 micron². Nel calcolo dei gates equivalenti non consideriamo il routing.
0 1000 2000 3000 4000 5000 6000 7000 1 2 3 4 formati gates eq. Combinational area Noncombinational area
Total cell area
Figura 4.15: occupazione di area per vari formati
Dalla Fig 4.15 si evince come all’aumentare delle dimensioni del formato dell’immagine aumenti la relativa occupazione dell’area. In Fig 4.16 si mostra la percentuale di occupazione di area per ogni componente e come essa varia per i diversi formati: mentre i blocchi atti a determinare il nuovo range di ricerca, il massimo dei vettori di moto di ogni blocco e il numero opportuno di frames di riferimento mantengono sostanzialmente invariate le proprie dimensioni il blocco che implementa l’unità di controllo ma soprattutto lo shift_register all’aumentare del formato necessitino di un’area maggiore: in particolare lo shift_register necessita di un’area ogni volta doppia passando da un formato al successivo, raddoppia infatti il numero di registri necessari per compiere l’operazione di shift.
Figura 4.16: percentuali di occupazione di area 1. MV_temp 2. N_frame 3. Control Unit 4. Determine_range 5. Shift_register
4.7.2
Risultati riguardanti tempo di propagazione dei dati
In Fig 4.17 si riporta il tempo massimo di propagazione dei dati registrato per i vari formati. Affinché il circuito proposto presenti il nuovo range per la componente X o Y della finestra di ricerca sono necessari 4 cicli di clock, quindi si osserva che il tempo speso dal circuito per presentare new_range varia da 200ns fino a 600ns. Se confrontiamo il tempo impiegato dal circuito nel caso di codifica di un’immagine in un frame di formato 4SIF con quello riportato in [1] necessario per la codifica di un macroblocco in un frame di uguale formato, pari a 16830ns, osserviamo che, anche ponendoci nell’eventualità di non poter eseguire nessuna delle operazioni necessarie alla determinazione del nuovo range di ricerca in parallelo alla codifica del macroblocco
QCIF 1 2 3 4 5 CIF 1 2 3 4 5 4CIF 1 2 3 4 5 16CIF 1 2 3 4 5
totale di codifica (essendo pochi punti percentuali). Non si è quindi ritenuto opportuno cercare di migliorare ancora la velocità di risposta a discapito di un maggiore consumo di potenza o di una maggiore occupazione di area.
0 10 20 30 40 50 60 70 80 1 2 3 4 formati ns time
Figura 4.17: tempo di propagazione dei dati
4.7.3
Dipendenza dei risultati dalle specifiche di sintesi
Riportiamo comunque in Fig 4.18 i risultati in termini di area espressa in micron² e in Fig 4.19 in termini di gates equivalenti, che si ottengono utilizzando delle specifiche temporali maggiormente stringenti: mentre in precedenza si era adottata una specifica temporale di 100ns come tempo di clock adesso utilizziamo 10ns per tempo di clock. Come si evidenzia nella Fig 4.18 l’occupazione di area è aumentata, dovuta principalmente all’utilizzo di buffer necessari per aumentare la velocità di propagazione dei dati. Si registra un comportamento del circuito in Fig 4.18 e in Fig 4.19 del tutto simile a quello visto in Fig 4.15 e in Fig 4.16.
0 20000 40000 60000 80000 100000 120000 140000 160000 180000 1 2 3 4 formati Combinational area Noncombinational area
Total cell area
Figura 4.18: occupazione di area per vari formati
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 1 2 3 4 formati gates e q . Combinational area Noncombinational area
Total cell area
Figura 4.19: occupazione di area per vari formati
Si riporta inoltro in Fig 4.20 le percentuali di occupazione di area per i vari blocchi, le osservazioni sono del tutto simili a quelle nel paragrafo 4.7.1, l’aumento di area anche sotto le specifiche prese adesso in esame è da attribuirsi principalmente allo shift_register. È infatti necessario un numero doppio di registri passando da un formato al successivo.
Figura 4.20: Percentuali di occupazione di area 1. MV_temp 2. N_frame 3. Control Unit 4. Determine_range 5. Shift_register
Si riportano poi in Fig 4.21 anche i tempi di propagazione dei dati per i vari formati: si osserva che tali tempi sono minori di quelli registrati adottando una specifica di clock di 100ns. Non si ritiene comunque opportuno spingerci oltre nella ricerca di una più rapida risposta del circuito dato che tale risposta si ottiene in un tempo molto minore di quello che comunque deve essere impiegato per la codifica di un macroblocco.
QCIF 1 2 3 4 5 CIF 1 2 3 4 5 4CIF 1 2 3 4 5 16CIF 1 2 3 4 5
0 10 20 30 40 50 60 70 1 2 3 4 formati ns time
Figura 4.21: tempo di propagazione dei dati
4.8
Considerazioni sulla potenza
L’introduzione di un controllo sul range di ricerca e sul numero di frame di riferimento implica un aumento dell’area totale dell’encoder e un overhead per la codifica di ogni macroblocco. L’utilizzo di tale controllo permette un notevole risparmio di tempo e di potenza, come osservato in 3.6 e 3.7. Dato che i calcoli effettuati nella codifica di un macroblocco sono proporzionali all’ampiezza dell’area di ricerca possiamo quantificare il risparmio di potenza ottenuto rapportando il valore del range di ricerca nel caso dell’encoder originale a quello ottenuto con l’introduzione del controllo proposto. In Tabella 4.1 si riportano i valori dei range di ricerca medi nei casi di alcune sequenze campione ottenuti esaminando la codifica di 250 frames. Si riportano inoltre i fattori di risparmio della potenza di calcolo.
Tabella 4.1Range medio e fattore di risparmio di potenza
M&D_QCIF FOR_QCIF M&D_CIF FOR_CIF SF_CIF M&C_SIF Range medio 3,79 7,2 3,57 7,98 8,38 5,06 Fattore di risparmio 17,8 4,9 20,07 4,04 3,65 10
L’aumento di efficienza (maggiore velocità nel caso di implementazione software) dello stimatore di moto proposto conduce ad un aumento di efficienza in termini energetici nel caso di implementazione hardware. Infatti la riduzione del tempo di elaborazione da un fattore 2 a un fattore 25, quando viene utilizzato un controllo per la dimensione dell’area di ricerca, è la conseguenza di una riduzione sia dei calcoli effettuati, sia degli accessi in memoria che dipendono in modo quadratico dalla dimensione della finestra di ricerca. Mentre l’algoritmo di FS utilizza sempre uno spiazzamento di 16 la tecnica da noi proposta adatta la dimensione dell’area di ricerca alla caratteristiche del segnale in ingresso. Nel caso di implementazione hardware dello stimatore di moto (un controllore inserito nel contesto più l’architettura sistolica convenzionale dell’ algoritmo di FS), la riduzione dell’area di ricerca permette una riduzione da un fattore 4 fino a un fattore 20 del numero di operazioni e accessi in memoria richiesti dalla architettura sistolica e quindi una diminuzione della potenza dissipata per elaborare un certo formato video.