Indice analitico
Introduzione
11
Algoritmi di decodifica Turbo/LDPC
31.1 Codici convolutivi . . . 3 1.2 RSC encoders binari . . . 3 1.3 RSC encoders duo-binari . . . 6 1.4 Algoritmo BCJR . . . 6 1.5 Algoritmo log-MAP . . . 12 1.6 Algoritmo max-log-MAP . . . 15
1.7 Decodifica di codici convolutivi binari e duo-binari . . . 16
1.8 Codici Turbo . . . 16
1.8.1 PCCC e SCCC Turbo-encoders . . . 16
1.8.2 Algoritmi di decodifica di codici Turbo . . . 18
1.9 Codici LDPC . . . 20
1.9.1 Algoritmi di decodifica LDPC . . . 22
1.9.2 Algoritmo BPA . . . . 24
1.9.3 Algoritmo LDA . . . . 24
1.9.4 Algoritmo TDMP . . . . 27
1.9.5 Algoritmi lambda-min approssimati . . . 30
2 Standard di riferimento
352.1 UMTS /3GPP-HSDPA . . . 35
2.2 DVB-SH . . . . 36
2.3 IEEE 802.16e . . . 37
2.3.1 IEEE 802.16e LDPC . . . 37
2.3.2 IEEE 802.16e Turbo . . . 39
2.4 IEEE 802.11n . . . 41
2.5 Osservazioni . . . 42
3 Analisi degli aspetti implementativi pregressi
453.1 Rappresentazione dell’informazione . . . 45
3.2 Parallelizzazione della decodifica . . . 46
3.2.1 Strategia multi-MAP . . . 46
3.2.2 Strategia multi-SISO . . . 46
3.2.4 Sliding Window Algorithm . . . . 48
3.2.5 Paradigma Training Sequence Single Processor . . . 49
3.3 Parallelizzazione nell’architettura . . . 49
3.4 Processing building blocks . . . 51
3.4.1 Forward/Backward processor . . . 52
State metric array architecture . . . . . . . 55
3.4.2 Extrinsc reliabilities processor . . . . . . 56
3.4.3 Channel cumulative message processor . . . . . . 60
3.5 Considerazioni sulla mappatura degli stati afferenti . . . . . . 62
3.5.1 Mappatura min-feedback . . . . . . 64
3.5.2 Mappatura sistematica . . . . . . . 65
3.5.3 Mappatura semi-sistematica . . . . . . . . 66
3.5.4 Confronto tra i paradigmi di mappatura . . . 68
3.6 Tecniche low-power . . . . 69
3.6.1 Criterio di arresto per codici Turbo: tecnica MHDA . . . 69
3.6.2 Criteri di arresto per codici LDPC . . . 70
3.6.3 Confronto di TDMP e RLM . . . . . . 71
3.6.4 Tecniche low-power a livello hardware . . . . . . . 74
4 Architettura del decodificatore flessibile
75
4.1 Processo di decodifica Turbo . . . 75
4.2 Processo di decodifica LDPC . . . 77
4.3 Organizzazione delle memorie . . . . . 77
4.4 Reti di permutazione . . . . . . 78
4.4.1 Rete di permutazione estrinseca . . . . . 78
4.4.2 Rete di permutazione di canale . . . . . . . . . . 80
4.5 Rete di shifting circolare . . . . . . 81
4.4.1 QSN circular-shifter . . . . . . 82
5 Logica di controllo
855.1 Architettura orientata al controllo . . . 85
5.2 Gestione della configurabilità . . . . . . 87
5.3 Gestione dei processi iterativi e ricorsivi . . . . . . 88
5.3.1 Controllo delle fasi di processing Turbo . . . 88
5.3.2 Controllo delle fasi di processing LDPC . . . 91
5.4 Sincronizzazione delle elaborazioni parallele . . . 92
5.4.1 Elaborazioni parallele Turbo multi-MAP . . . 92
5.4.2 Elaborazioni parallele Turbo multi-SISO . . . 93
5.4.3 Elaborazioni parallele TDMP . . . 94
5.5 Gestione delle memorie . . . 94
6 Risultati implementativi
976.1 Occupazione di area . . . 97
6.2 Consumo di potenza . . . 98
6.3 Comparazione con lo stato dell’arte . . . 99
7 Conclusioni
101Bibliografia
102Ringraziamenti
107“Your life is the sum of a remainder of an
unbalanced equation inherent to the programming
of the matrix. You are the eventuality of an
anomaly, which despite my sincerest efforts I have
been unable to eliminate from what is otherwise a
harmony of mathematical precision. While it
remains a burden to sedulously avoid it, it is not
unexpected, and thus not beyond a measure of
control. Which has led you, inexorably, here..”
1
Introduzione
Negli ultimi anni, si è assistito all’integrazione sullo stesso dispositivo mobile di una notevole varietà di applicazioni. Esse richiedono data-rate sempre maggiori, ed una adeguata affidabilità nella trasmissione è indispensabile per garantire una qualità di servizi soddisfacente. In tal senso, la codifica di canale rappresenta una tecnica indispensabile per migliorare le performance delle comunicazioni.
La realizzazione di un sistema FEC avanzato, gioca un ruolo cruciale nell’economia di un sistema di comunicazione, visto che tale blocco richiede le maggiori computazioni all’interno dell’intero transceiver, e conseguentemente rappresenta il collo di bottiglia in termini di complessità dell’HW, data-rate e consumo di potenza. Nondimeno, il decodificatore deve essere in grado di soddisfare tutti gli standard di comunicazione richiesti da un particolare dispositivo, ed in particolare consentire la connessione a reti per mobile internet, reti WMAN e WLAN, e reti satellitari per la diffusione broadcast di contenuti multimediali.
In questo contesto, i codici Low-Density-Parity-Check (LDPC)[1] ed i Turbo [2] si fanno preferire per le loro ottime prestazioni di correzione d’errore e sono quindi inclusi in diversi standard. Citiamo i DVB-S2 [3], DVB-C2 [4], DVB-T2 [5], gli standard IEEE 802.11n [6], IEEE 802.16e [7] e IEEE 802.3an[8] per i primi, ed i 3GPP [9][10], DVB-SH [11], DVB-RCS [12] e lo IEEE 802.16e [7] per i secondi. La soluzione più banale per ottenere flessibilità, è data dalla predisposizione di un nucleo separato per ognuno dei diversi schemi di decodifica di cui si richiede il supporto. Se da un lato questo potrebbe fornire le prestazioni di correzione d’errore migliori ed i data-rate più spinti, dall’altro si accompagna a consumi di potenza ed ingombri di area che violano le limitate risorse dei dispositivi mobili. Come alternativa, si possono definire due core differenti, che implementino architetture di decodifica Turbo ed LDPC, separatamente incaricate di soddisfare in maniera flessibile le specificità delle varie sottoclassi di codice, ma per gli stessi motivi questa strategia potrebbe non essere del tutto soddisfacente.
La soluzione più promettente, si basa evidentemente sull’implementazione di un singolo core, capace di supportare la decodifica dei diversi standard, Turbo o LDPC. In questo caso, il nucleo della decodifica di canale è generalmente implementato su un Application-Specific-Instruction-set Processor (ASIP). Il maggior limite di questo genere di soluzioni risiede tuttavia nel throughput raggiungibile e nel consumo di potenza. A causa della complessità relativamente bassa dell’hardware, infatti, la frequenza operativa di clock è generalmente mantenuta piuttosto alta, al fine di ridurre i tempi di decodifica, e ciò comporta un notevole consumo di potenza.
Questi limiti, possono essere superati dalla definizione di una architettura Application Specific Integrated Circuit (ASIC). In questo caso, è di vitale importanza l’identificazione di sezioni comuni tra gli algoritmi di decodifica LDPC e Turbo, per la determinazione di comuni building blocks in vista di una riduzione
2
della complessità globale. Il punto di forza di un approccio di questo genere, risiede nel fatto che le comuni risorse HW possono essere facilmente parallelizzate, al fine di soddisfare gli stretti vincoli di data-rate, mantenendo così una frequenza operativa di clock relativamente bassa.
Un tale approccio progettuale, è relativamente inedito: Cavallaro et al. hanno per primi delineato una possibile architettura ASIC di decodificatore flessibile di codici LDPC e Turbo [13]. Gentile, in [14] ha indagato dettagliatamente l’efficacia di questo tipo di schema, definendo una architettura flessibile ed innovativa che supporta gli standard IEEE 802.11n (WLAN), IEEE 802.16e (WMAN), DVB-SH (diffusione broadcast di contenuti multimediali) e 3GPP (reti per mobile internet). La presente attività di tesi, si colloca come prosecuzione di tale lavoro.
Si procede con una analisi critica dello stato di avanzamento dell’architettura, con una esplorazione progettuale del paradigma di flessibilità a partire dal livello algoritmico. Si implementano alcune ottimizzazioni volte ad una riduzione della complessità globale e si procede quindi con la definizione di alcune interfacce e della glue logic necessaria a garantire flessibilità sopra ai vari standard di codifica. Si definisce quindi la logica di controllo necessaria a coordinare le elaborazioni globali del sistema e si implementano alcune misure volte a semplificare la comunicazione del sistema con il processore esterno.
L’architettura così delineata, è stata sintetizzata su tecnologia CMOS standard-cell a 45 nm, e si caratterizza per un’area di 0.94 mm2 ed un consumo massimo di potenza di 80.9 mW. I risultati di sintesi addebitano al blocco di controllo circa il 14% della complessità globale della logica. Grazie a queste proprietà, l’architettura proposta mostra performance superiori alle alternative presenti in letteratura.
3
Capitolo 1
Algoritmi di decodifica
Turbo ed LDPC
1.1 Codici convolutivi
1.1.1 RSC encoders binari
I Turbo codici sono generati a partire da recursive systematic convolutional encoders costruiti tramite linear feedback shift register (LFSR).
La figura 1.1. mostra la struttura di un semplice RSC-encoder, con costraint length L = 4 e rate R = ½.
Figura 1.1: RSC-encoder con L = 4 e R = ½
La costraint length si definisce come la lunghezza del registro a scorrimento più 1, mentre il rate è dato dal rapporto tra il numero di ingressi ed il numero di uscite del codificatore in un singolo slot temporale. Il valore di tali parametri, nonché i particolari collegamenti che implementano le catene di backward-adder e forward-adder sono riassunti nel cosiddetto generator vector, che nel nostro caso è:
4
[
] L’espressione 1.1, la quale è una trasposizione delle risposte impulsive nel dominio Z che legano le uscite agli ingressi, ci informa appunto che dei due output, il primo, è banalmente cortocircuitato con l’ingresso (questo indica l’ “1”), mentre il secondo è prodotto in uscita al forward-adder (le cui connessioni con il registro sono descritte dal numeratore del secondo termine tra parentesi) , ed è funzione del backward-adder (descritto al denominatore).
Il meccanismo di codifica di un RSC-encoder, può essere efficacemente esemplificato senza perdita di generalità riferendoci allo schema appena mostrato: entra in ingresso un bit di informazione alla volta, e ne escono due, combinazioni del bit attuale e dei precedenti, secondo quanto stabilito dal generator vector. Più propriamente, si dice che i bit in uscita sono funzione del dato attuale e dello stato del registro: per una costraint legth di L, il registro si può trovare in stati diversi (8 stati nel nostro caso). Lo stato al passo successivo, corrispondente all’ingresso di un nuovo bit di informazione, è anch’esso funzione del dato attuale e dello stato di partenza. Da ogni stato, se ne possono raggiungere solo due, corrispondenti ai due valori del bit di informazione che si sposta nella prima cella, così come ogni stato è raggiungibile solo da due, visto che viene scartato un solo bit dal registro a scorrimento. L’evoluzione degli stati del registro imposta dai bit di informazione in ingresso, può essere tracciata tramite un particolare diagramma detto trellis, o traliccio (figura 1.2).
Figura 1.2: diagramma trellis a 4 stati
Si noti che le possibili transizioni di stato mostrate nel diagramma, dipendono solo dalla specifica dimensione del registro a scorrimento (e quindi dal numero di stati possibili), e non dalle connessioni tra celle del registro e sommatori. In altre parole, tutti i codici RSC che presentano la stessa costraint length, sono accumunati da un medesimo trellis: dalla configurazione del backward-adder dipende infatti
5
l’associazione fra transizioni di stato e bit di informazione (percorsi in verde e rosso in figura 1.2), ma non la scelta dei possibili stati che si possono raggiungere. Essendo il registro resettato all’inizio della codifica, lo stato di partenza è sempre quello associato ad un vettore di soli zeri, S0. In base a quanto già spiegato, a seguito del primo bit di informazione in ingresso, il sistema si porterà in uno dei 2 possibili stati collegati, S0 o S1. Dopo un numero di passi uguale alla dimensione del registro (2 nella figura), possiamo trovarci, con la stessa probabilità, in uno qualsiasi dei 4 stati possibili ed a questo punto il trellis si ripeterà invariato. Quando eventualmente la sequenza di bit di informazione termina, risulta poi conveniente, per motivi che saranno chiariti in seguito, forzare lo stato finale ad uno noto, ad esempio proprio S0.
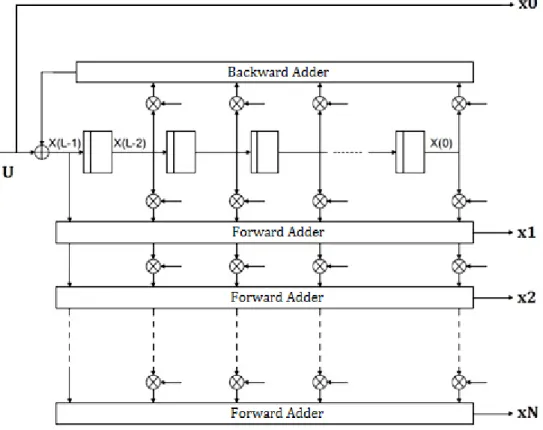
Nel caso più generale possibile, un RSC binary encoder può produrre in uscita, oltre al bit sistematico, più di un bit codificato, grazie alla presenza di più reti forward-adder, (chiaramente questo comporta una diminuzione del rate) come evidenziato dallo schema di figura 1.3.
Figura 1.3: schema generale di un RSC binary encoder
Nello schema sono evidenziati il bit di informazione in ingresso U, il bit sistematico x0, e gli altri N bit codificati x1 .. xN presentati come uscita di altrettanti forward-adder. Ciascuno di questi ultimi, in particolare, riceve in ingresso un sottoinsieme diverso dei bit di stato contenuti nel registro, grazie ad una ben precisa configurazione dei relativi “taps” (nel disegno rappresentati come collegamenti
6
programmabili tra i vari stadi del registro e le catene dei forward-adder e backward-adder).
1.1.2 RSC encoders duo-binari
Al fine di ottenere codici con robustezza e capacità di correzione d’errore maggiori, Berrou et all in [15] hanno introdotto i cosiddetti codificatori RSC M-binari (in funzione di un loro impiego nei Turbo codici che verrà chiarito più avanti). L’idea è quella di dare in ingresso al LFSR un simbolo composto da più di un bit. Il caso di maggior interesse pratico in tal senso è sicuramente quello degli RSC encoder duo-binari (M = 2), di cui la figura 1.4 propone uno schema generale.
Figura 1.4: schema generale di un RSC encoder duo-binario
1.1.3 L’algoritmo BCJR
Nel 1974 Bahl, Cocke, Jelinek e Raviv idearono un algoritmo di decodifica applicabile ai codici convoluzionali (ma non solo) basato sulla definizione di probabilità a posteriori e divenuto noto come BCJR, Maximum a Posteriori (MAP) o algoritmo forward-backward [16]. Di seguito introduciamo tale algoritmo nella sua forma originaria.
A-posteriori LLR reliability
Consideriamo un RSC encoder, e sia 1, …, i, …, k una information word al suo ingresso, dove ogni simbolo i si compone di M bit (M = 1 nel caso binario, M = 2 nel duo-binario) e sia 1, …, i, …, k la corrispondente sequenza in uscita, con i il simbolo prodotto dall’encoder all’istante i-esimo.
Per ogni “i” compreso tra 1 e k, l’algoritmo BCJR fornisce un set di quotazioni relative alle probabilità a posteriori (cioè condizionate dalla sequenza 1, …, i, …,
7
k ricevuta dal decodificatore) che il simbolo i coincida con i vari simboli . Tali stime sono presentate nella forma di Log-Likelihood-Ratio (LLR):
|
| Dove U è uno dei possibili simboli, rappresenta un simbolo scelto come riferime to ed y è ’i formazio e dispo ibi e a ricevitore dopo a trasmissio e dei simboli i sopra ad un canale rumoroso, come illustrato dalla seguente figura:
Figura 1.5: diagramma a blocchi semplificato del sistema in considerazione
L’algoritmo prevede il calcolo di a-posteriori LLR, cioè una per ciascun U (visto che in questo caso restituirebbe una quantità nulla). Nel caso binario, per questo motivo, vi è una sola quantità da calcolare per ciascun indice “i” e, ponendo = “0” , propenderemo per un “1” nel caso di positiva, per uno “0” altrimenti. Nel caso duo-binario, a fronte delle 3 a-posteriori LLR relative, stimeremo come corretto il simbolo associato al maggiore, nel caso che almeno una di tali quantità sia positiva, altrimenti sceglieremo .
Nell’analisi proposta di seguito, indicheremo con S i possibili stati raggiungibili procedendo nel trellis. Gli indici apposti a pedice, specificheranno lo stadio del trellis che si prende in considerazione, quelli ad apice, se presenti, individueranno poi un preciso stato all’interno dello stadio. Da questo punto di vista, quindi, il termine non indica solo lo stato “0”, ma anche l’evento associato alla ricorrenza dello stato “0” all’istante i-esimo. Con riferimento alla figura 1.6, indichiamo quindi con , indistintamente, ciascuno degli stati dello stadio i-1 del trellis, con quelli dello stadio i-esimo, ed analogamente definiamo ed . Prendendo adesso in considerazione l’espressione 1.2, si ha:
| | ∑ | → ∑ → | ∑ | → ∑ → | (1.3) Dove l’espressione → sta ad indicare che nella sommatoria si fa riferimento a coppie di stati contigue appartenenti ai due stage centrali del trellis ed associati ad una transizione (detta “edge”) consistente con il simbolo U. In
8
maniera del tutto analoga definiamo l’espressione al denominatore → . In rosso, nell’espressione 1.3 come di seguito, evidenziamo poi i termini che si possono eliminare (in questo caso perché si elidono vicendevolmente).
Figura 1.6: diagramma di riferimento per l’espressione della data dall’algoritmo BCJR. Il numero di collegamenti è relativo ad una L = 4.
Sviluppiamo ulteriormente l’espressione 1.3, in particolare andando a scomporre la sequenza dei k simboli y in 3 distinte parti: è naturalmente l’ i-esimo simbolo ricevuto dal decodificatore, si riferisce all’insieme dei simboli precedenti, ed
rappresenta l’insieme degli ultimi k-i simboli.
| | | I termini evidenziati in rosso nel lato condizionante delle probabilità, sono da considerarsi eliminabili in quanto ridondanti dal punto di vista del condizionamento (rispetto ai termini non evidenziati). Da 1.4, ricaviamo poi:
| | | | |
|
|
| | Nello specifico, i termini evidenziati in rosso in 1.5 si elidono, quelli contrassegnati in celeste sono altresì comuni a tutti gli addendi, sia a numeratore che a denominatore. Il termine evidenziato in verde, che rappresenta la generica probabilità di trovarsi nello stato in un qualsiasi stadio del trellis, è approssimabile a . Commettiamo cioè l’imprecisione di considerare i stati del tutto equiprobabili. Ciò, infatti, non è rigorosamente vero: lo stato , ad esempio, essendo quello di partenza, ed essendo l’unico associabile a qualsiasi stadio del trellis (gli altri, in generale sono sicuramente raggiungibile solo dopo un
9
numero minimo di passi come mostrato nella figura 1.2) è quello che ha la probabilità maggiore di essere rilevato. Questa approssimazione, il cui peso evidentemente diminuisce all’aumentare della lunghezza k della parola (visto che le sequenze di inizializzazione e di terminazione del trellis rappresenteranno una frazione sempre minore della sua lunghezza), ci consente tuttavia di poter elidere il termine evidenziato in verde nell’espressione 1.5, ottenendo quindi:
∑ → ∑ → Essendo:
= | la probabilità che l’i-esimo stato sia S’ conoscendo la sequenza iniziale 1, …, i 1
= | la probabilità che l’i+1-esimo stato sia S’’ conoscendo la sequenza finale i 1, …, k
= | la probabilità che la transizione produca a livello del ricevitore il simbolo . Ponendo che tali simboli siano composti da un numero n di bit, i 1,..,k possiamo porre = { }, e riscrivere quindi ∏ | , dove rappresenta il j-esimo bit associato all’edge
la probabilità a priori che l’i-esimo simbolo sia U. l’affidabilità estrinseca associata al simbolo U.
Per ciascuno stato di ogni livello del trellis, sono definite le relative metriche α e β, mentre ad ogni edge che collega due stati contigui, si associa uno specifico Ɣ. Tali parametri, che in ultima analisi dipendono esclusivamente dalla sequenza di simboli ricevuta, possono essere ricavati, grazie al BCJR, tramite un procedimento approssimato e ricorsivo, che in sostanza permette la decodifica della parola in tempi lineari con la lunghezza k della parola stessa.
Quest’ultima caratteristica, la complessità lineare, rende l’algoritmo di gran lunga preferibile rispetto alle alternative non approssimate, basate ad esempio su confronti a massima verosimiglianza, di complessità esponenziale con la lunghezza k. e quindi proibitive per la maggior parte dei codici.
10
Procediamo adesso dividendo numeratore e denominatore dell’espressione precedente per un comune fattore di normalizzazione, funzione solo dell’indice “i”, ottenendo: ∑ → ∑ →
dove il fattore indica la probabilità che l’i-esimo simbolo ricevuto sia stato prodotto dalla transizione con ciascun bit codificato = 0 (non vi è ambiguità, dato che c’è una sola transizione di questo tipo tra due stadi del trellis: quella “orizzontale” che collega due stati contigui).
Possiamo adesso ridefinire in forma normalizzata (o relativa) le metriche α, β e Ɣ viste sopra:
Questo ci permette di riportare l’espressione definitiva della a-posteriori LLR fornita dal metodo BCJR.
∑ →
∑ →
Forward e Backward Metrics
La trattazione dell’algoritmo si completa a questo punto con la descrizione di un procedimento ricorsivo per il calcolo delle state-metric e per il quale si fa riferimento alla figura 1.7. Definiamo anzitutto l’insieme A(S), il quale comprende tutti gli stati che nel trellis afferiscono in senso diretto (forward) ad S, e l’insieme B(S), che in maniera complementare include tutti gli stati che si possono raggiungere a partire da S. Entrambi gli insiemi constano di 2 elementi nel caso di un codice convolutivo binario e di 4 nel caso di un codice duo-binario. Per quanto detto possiamo scrivere:
| ( | ) ∑ | ∑ ( | )
11 ∑ ∑ ( )
Sviluppiamo l’espressione al numeratore di 1.12:
| |
| | I termini evidenziati sono eliminabili per motivi analoghi a quelli mostrati in precedenza. Aggiungendo un comune fattore normalizzante analogamente a quanto mostrato per il calcolo di , otteniamo quindi:
∑ ( ) ∑ ( )
che possiamo riscrivere come:
∑ ∑
In maniera del tutto analoga si ottiene:
∑ ∑
Tali espressioni, suggeriscono una procedura ricorsiva per il calcolo delle state metric. I parametri α del generico stadio i-esimo, sono infatti funzione di quelli associati allo stadio i-1-esimo, i quali a loro volta si ricavano a partire dai precedenti, e così via. Le metriche β, sono coinvolte in un procedimento ricorsivo analogo, ma di verso opposto. Dal punto di vista del decodificatore, le forward
12
metrics (backward metrics) saranno allora valutate inizializzandone opportunamente i valori all’inizio (fine) del trellis, e procedendo ricorsivamente attraverso il trellis stesso elaborando l’informazione riassunta nei parametri Ɣ. Integriamo quindi le espressioni relative al calcolo delle state metrics con le seguenti equazioni:
α
Figura 1.7: diagramma di riferimento per la definizione degli indici associati alle ricorsioni del metodo BCJR.
1.1.4 L’algoritmo log-MAP
L’algoritmo BCJR, soffre di un importante svantaggio: impone la computazione di un gran numero di moltiplicazioni. Senza soffermarci sui problemi che naturalmente questo comporta da un punto di vista architetturale, evidenziamo che numerose varianti meno complesse sono state proposte nel corso degli anni: l’algoritmo SOVA (Soft-Output Viterbi Algorith) nel 1989 [48], l’algoritmo ma -log-MAP nel 1990-1994 [18][19] ed il log--log-MAP nel 1995 [20], oggetto del presente paragrafo.
Come suggerisce il nome stesso, l’idea di base dell’algoritmo log-MAP, è quella di sostituire le metriche , e con delle corrispondenti quantità logaritmiche. Definiamo dunque:
13 ∑ → ∑ →
che può essere poi riscritta utilizzando l’operatore ma * e le sue proprietà: ma ma | | ma ma ( ma y z ) Ottenendo: → → (1.22) Channel reliabilities
Focalizziamoci adesso sul termine definito in 1.20: ∏ | ) ∏ | | | | | dove ,…, rappresentano il set di bit associati alla transizione , e sono le quantità soft di informazione corrispondenti ai bit del simbolo i ed a cui associamo le cosiddette channel reliabilities ,…, definite in forma LLR come segue:
( |
( | Osservando gli addendi logaritmici dell’espressione 1.24, notiamo che:
( |
( | se 1
( |
14
Questo ci permette infine di ottenere la seguente equazione:
∑
Forward e Backward Metrics
Applichiamo adesso le stesse elaborazioni alle equazioni 1.15 e 1.16 inerenti alle alpha e alle beta recursions.
∑ ∑
Definiamo a questo punto la seguente quantità:
dove lo “0” al denominatore deve intendersi come il simbolo costituito da un vettore di soli zeri. Possiamo a questo punto esporre le equazioni per il calcolo ricorsivo delle state metric in accordo al metodo log-MAP:
( )( ) ( )( ) ( )( ) ( )( )
Restano valide le considerazioni relative ai meccanismi ricorsivi alla base della computazione dei vari e
esposte per il BCJR. Anche in questo caso, il trellis è sottoposto alle doppie ricorsioni , forward e backward, che procedono dagli estremi opposti del diagramma a partire dai valori di inizializzazione. Nella pratica, le alpha-recursions avanzano parallelamente all’arrivo delle channel reliabilities e, quando si sono terminati i k passi necessari a percorrere il trellis in senso diretto, cominciano le beta recursions, nel verso opposto. Dopo 2*K passi, quindi, la doppia scansione del trellis termina, e con essa la decodifica del codice convolutivo a cui esso si riferisce. In giallo, nell’espressione 1.29, sono state
15
evidenziate le somme delle metriche beta con quelle gamma: ci riferiremo a tali quantità come metriche sigma. La sostanziale differenza che contraddistingue il MAP dal log-MAP, è la sostituzione delle innumerevoli moltiplicazioni definite per il primo, con le più agevoli somme di quantità logaritmiche introdotte dal secondo.
1.1.5 L’algoritmo max-log-MAP
L’algoritmo ma -log-MAP, rispetto al log-MAP, consente un ulteriore grado di semplificazione architetturale. Questo è ottenuto con la sostituzione dell’operatore max* con quello max (che banalmente restituisce in uscita il massimo tra gli input) nelle equazioni che coinvolgono , e , come illustrato nelle seguenti espressioni: → → (1.30) ( )( ) ( )( ) ( )( ) ( )( )
A differenza del log-MAP, che rispetto al BCJR presenta solo un diverso formalismo delle quantità in gioco, in questo caso introduciamo propriamente delle approssimazioni. Ciò è ben evidenziato dai grafici di figura 1.8, i quali rappresentano rispettivamente la funzione max*(x,y), quella max(x,y) e la relativa differenza.
Figura 1.8: rappresentazione tridimensionale rispettivamente delle funzioni binarie max*(x,y), max(x,y) e della loro differenza (terza colonna)
16
Come si vede, la funzione max*(x,y) è approssimata tanto meglio da quella max(x,y), tanto più gli operandi x ed y sono distanti tra loro. Il valore massimo della differenza, infatti, si ha nella bisettrice del primo e del terzo quadrante e vale 0.69. Nel caso più generale di operatori con un numero generico n di operandi, si ha:
ma ma ma
che vale appunto 0.69 nel caso binario, 1.39 per 4 operandi e circa 2.08 nel caso di otto operandi (come vedremo nel prossimo paragrafo, nel nostro caso non saranno contemplati operatori con un numero di ingressi diverso).
1.1.6 Decodifica di codici convolutivi binari e duo-binari
La maggior parte dei moderni standard di comunicazione, comprende codici convolutivi di tipo binario o duo-binario ad otto stati. A tal proposito, può essere utile soffermarsi su alcune generali proprietà relative a tali modelli e che saranno richiamate successivamente. Vediamo innanzitutto che agli otto stati, si associa un trellis strutturato su 8 livelli. Nel caso binario (duo-binario), poi, ciascuno di tali stati è collegato con 2 (4) stati dello stadio precedente e con 2 (4) stati di quello consecutivo, come già mostrato nella figura 1.2 (sarebbe poco pratico, in quanto poco leggibile, riportare un analogo diagramma riferito al caso duo-binario. Ci limitiamo ad evidenziare che 2 delle 4 connessioni afferenti o efferenti a ciascuno stato, sono le stesse del caso binario). Questo ci informa, con riferimento alle equazioni 1.28 e 1.29 (o 1.31 e 1.32 per il caso max-log-MAP), che gli operatori max* (o max) prevedono 2 ingressi per il caso binario, e 4 per quello duo-binario. Per quanto riguarda il calcolo delle a-posteriori LLR, nel caso binario dobbiamo ricavare una sola quantità , il cui segno ci informa se il corrispondente bit è valutato come 1 o 0. Nel caso duo-binario, a fronte dei 4 possibili simboli , , e all’ingresso del codificatore all’istante i-esimo, operiamo una valutazione
in tal senso in funzione delle 3 quantità (considerando i moduli oltreché i segni)
, , : scegliamo se le 3 a-posteriori LLR sono tutte
negative, altrimenti scegliamo il simbolo associato al maggiore. Notiamo infine che le transizioni (edge) da considerare tra gli stadi contigui associate a ciascun simbolo, sono sempre 8, sia per il caso binario che per il duo binario. Da questo consegue che, in entrambi i casi, gli operatori max* (o max) coinvolti nelle equazioni 1.22 o 1.30, hanno sempre 8 ingressi.
1.2 Codici Turbo
1.2.1
PCCC e SCCC Turbo encoders
La classe più popolare di codici Turbo, è quella dei Parallel Concatenated Convolutional Codes, la stessa introdotta dagli ideatori dei codici Turbo in [2]. La figura 1.9 mostra un classico esempio dell’architettura di questo tipo di
17
codificatori, composta di 2 RSC-encoders e di un interleaver. Quest’ultimo, in particolare, ha la funzione di dare in ingresso al secondo RSC-encoder una versione riordinata della sequenza di bit in ingresso, al fine di migliorare considerevolmente la capacità di correzione d’errore a livello del ricevitore.
Figura 1.9: PCCC encoder con rate R = 1/3
Uno schema del tutto analogo può essere proposto sostituendo agli RSC-encoder binari degli analoghi duo-binari, ottenendo così un Turbo codice duo-binario [33].
Figura 1.10: Esempio di PCCC duo-binary Turbo encoder
L’altra classe di Turbo codici, è quella dei Serial Concatenated Convolutional Codes (SCCC). La relativa architettura, complementare a quella precedente, è illustrata nella figura 1.11 e consta di due RSC-encoders interconnessi in serie per mezzo di un interleaver.
18
In quest’ultimo caso, l’interleaver si trova ad ordinare una quantità maggiore di bit, infatti, posta N la lunghezza della sequenza in ingresso, l’uscita del primo output conta N/R bit (>N, essendo R <1).
In generale, gli interleaver sono frequentemente utilizzati nelle comunicazioni digitali. Molti canali di comunicazione, infatti, non sono di tipo propriamente memoryless, visto che gli errori possono verificarsi in burst, piuttosto che indipendentemente. L’interleaving, di contro, attenua gli effetti di tale circostanza, mescolando i simboli da trasmettere e creando così una distribuzione degli errori più uniforme. L’efficacia di tale procedura, è intuitivamente presentata dall’esempio di figura 1.12. In essa si nota che nessuna parola dell’espressione originaria viene completamente cancellata, la quale conserva così la propria intelligibilità.
Figura 1.12: Rappresentazione schematica della procedura di interleaving
1.2.2
Algoritmi di decodifica di codici Turbo
L’algoritmo di decodifica turbo, e la sua implementazione fisica, riflette la struttura dell’encoder, ed è quindi composto di due parti, denominate SISO (Soft In Soft Out), le quali attuano la decodifica di un codice RSC attraverso uno degli algoritmi descritti (di solito log-MAP o max-log-MAP). A ciascun RSC encoder a livello del trasmettitore, corrisponde cioè un blocco SISO sul lato ricevitore: tali SISO, sono connessi secondo diverse possibilità, a seconda della particolare struttura del Turbo encoder (PCCC o SCCC), ed iterativamente si scambiano informazione estrinseca per affinare e rendere mutuamente più affidabile la rispettiva decodifica. Una giustificazione intuitiva di tale meccanismo è fornita in [21], ma può essere altresì presentata con il seguente esempio. Consideriamo dunque un cruciverba parzialmente completato. Due “risolutori” (i SISO), si apprestano a risolverlo: uno, gestisce le parole verticali (i bit codificati dal primo RSC), l’altro, quelle orizzontali (i bit codificati dal secondo SISO). Ciascuno di essi, per cominciare, basandosi sulle proprie informazioni suggerisce delle possibilità per le comuni lettere da individuare (i simboli U), registrando in aggiunta il proprio grado di confidenza con le varie lettere proposte (informazione estrinseca). Successivamente, essi confrontano le rispettive annotazioni, analizzando dove ed
19
in quale misura esse differiscono. Basandosi quindi sulle nuove conoscenze acquisite, modificano le proprie supposizioni e propongono nuove soluzioni. L’intero processo si ripete finché i due non convergono alle stesse conclusioni. E’ proprio questo tipo di scambio ciclico di informazione tra i due SISO che è all’origine del nome “Turbo”: il processo presenta infatti una analogo meccanico nel riciclo dei gas di scarico che avviene nei turbocompressori.
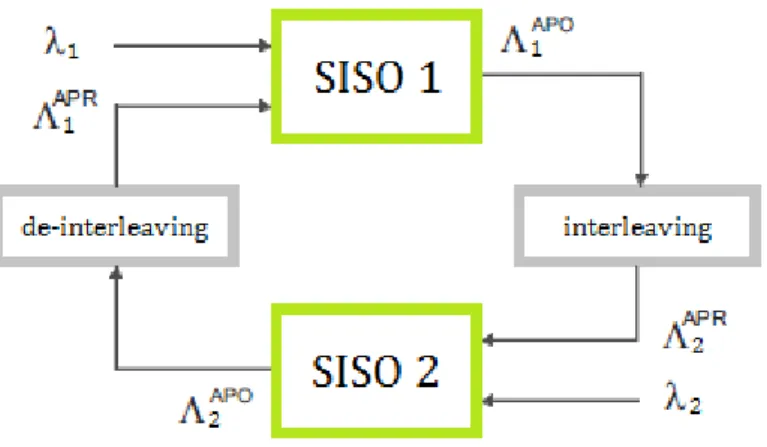
Decodifica di codici PCCC
L’architettura di un decodificatore PCCC è illustrata in figura 1.13. Lo scambio di informazione estrinseca è funzionale al raggiungimento della convergenza con un numero ragionevole di iterazioni. Come è mostrato, ciascun SISO riceve in ingresso le corrispondenti channel reliabilities (per SISO2 consideriamo nulle le sistematiche), e preleva, utilizzandole come informazione a-priori ( ) le extrinsic reliability prodotte dal SISO vicino. Ad ogni scambio di informazione, poi, i messaggi prodotti dai SISO necessitano di essere opportunamente permutati per mantenerne la consistenza, a causa della presenza dell’interleaver a livello dell’encoder. Il processo di decodifica procede quindi iterativamente, per un numero predefinito di iterazioni oppure fino al raggiungimento della convergenza: con questo intendiamo che le informazioni estrinseche prodotte da ciascun SISO sono concordi, e non cambiano con altre iterazioni.
Figura 1.13: Schema di riferimento per la decodifica PCCC
Decodifica dei codici SCCC
L’architettura di un decodificatore SCCC è illustrata in figura 1.14. Differentemente dallo schema del PCCC, il decoder SISO2 riceve solo le reliability relative alla codeword intermedia (intese come quantità a-priori), dato che il corrispondente RSC encoder non si interfaccia direttamente col canale (vedi figura 1.11). Tale blocco si occupa poi di aggiornare l’informazione estrinseca associata, che è a sua
20
volta trasmessa al SISO2, ed il processo di decodifica procede in maniera del tutto analoga a quanto esposto per i PCCC.
Figura 1.13: Schema di riferimento per la decodifica SCCC
1.3 Codici LDPC
I codici Low Density Parity Check, detti anche Gallagher Codes, rappresentano una classe di codici a blocco, non sistematici, proposti negli anni ’60 [1], [22]. Più in dettaglio, ciascuna delle parole di codice prodotte da un particolare LDPC encoder, deve appartenere allo spazio nullo di una corrispondente matrice di parità H: Quest’ultima è una matrice sparsa (cioè i cui valori sono quasi tutti nulli), con un numero di colonne (N) uguale al numero dei bit della parola di codice, ed un numero di righe (P) uguale ai soli bit di parità aggiunti dall’encoder LDPC. Un semplicissimo esempio di matrice di parità, di dimensione tuttavia troppo piccola per essere di interesse pratico, è il seguente:
21
Vi sono cinque uni in ogni riga e tre in ogni colonna. Ogni equazione di parità coinvolge quindi cinque bit di codice ed ogni bit interviene solo in tre regole di parità. I codici LDPC sono stati trascurati per decenni, probabilmente sia perché non sistematici (questo rende l’associazione tra parole di codice e bit d’informazione più complessa) sia perché con i valori della dimensione del blocco relativamente piccoli che era possibile simulare a quei tempi non risultavano evidenti le potenzialità per grandi valori di N. Questi codici sono stati infatti riscoperti solo dopo i Turbo codici, con cui ora rivaleggiano in prestazioni.
I codici LDPC possono essere equivalentemente descritti tramite uno speciale grafo bipartito, detto grafo di Tanner, composto da variable node (VN) e check node (CN). Ogni variable node corrisponde ad un bit della parola di codice trasmessa, e si associa quindi ad una colonna della matrice di parità. Di contro, i check node rappresentano la particolare condizione di parità imposta da una riga della matrice H. Ogni volta che un variable node è connesso ad un check node, ciò significa che il bit corrispondente al primo è coinvolto nella specifica relazione di parità stabilita dal secondo. Ogni collegamento del grafo corrisponde quindi ad un “1” della matrice di parità. Un esempio di grafo di Tanner è mostrato in figura 1.14, dove i variable node sono rappresentati da cerchi ed i check node da quadrati.
Figura 1.14: Esempio di grafo di Tanner
Ogni nodo del grafo è caratterizzato dal cosiddetto degree: il variable node degree rappresenta il numero di relazioni di parità in cui un particolare bit (variable node) è coinvolto, mentre il check node degree è il numero di variable node richiamati in uno vincolo di parità. In un codice LDPC regolare, indicato con C(i,j), tutti i variable node hanno degree “i” e tutti i check node hanno degree “j”. In molti altri casi, tuttavia, la convergenza dei codici LDPC è migliorata rendendo irregolare, in modo controllato, il numero di uni nelle equazioni di parità.
22
Le capacità di correzione d’errore di un codice LDPC, sono strettamente legate alla sua struttura e, in modo particolare, ai cosiddetti cicli. Un ciclo è un percorso chiuso tra variable e check node all’interno del grafo di Tanner, e la sua lunghezza è definita dal numero di VN e CN che vi si incontrano. Il grafo di figura 1.14, ad esempio, comprende un ciclo di lunghezza 4 tra i nodi , , e . Più avanti dimostreremo che in un codice LDPC, più lunghi sono i cicli e migliori sono le prestazioni di correzione d’errore. A tal proposito è utile definire un parametro, detto girth, che rappresenta la lunghezza minima associata ai cicli di un grafo. E’ stato provato che il minimo valore di girth che consente di ottenere performance soddisfacenti è 5, mentre le migliori prestazioni di correzione sono associate ai cosiddetti codici cycle-free (per i quale il girth può essere considerato infinito)
1.3.1
Algoritmi di decodifica LDPC
Ogni volta che una parola di codice rumorosa viene ricevuta, l’LDPC decoder ha il compito di recuperare la corretta informazione individuando e possibilmente rimuovendo gli errori introdotti dal canale. A tal fine, il decodificatore segue un particolare algoritmo di decodifica che iterativamente migliora l’attendibilità dei bit trasmessi. In particolare, ognuno dei bit trasmessi bi è caratterizzato dalla cosiddetta a-posteriori log-likelihood ratio (APO-LLR), data da:
ln |
| dove r rappresenta l’intera parola ricevuta. Il segno della APO-LLR, positivo o negativo, è evidentemente indicativo della valutazione, da parte del decodificatore, rispettivamente di un “1” oppure di uno “0”. Il modulo è altresì proporzionale al grado di affidabilità di tale stima. Sviluppiamo l’espressione come segue:
ln | | ln | | ln ln | | ln | | | | dove rappresenta l’i-esimo bit ricevuto, mentre indica l’insieme dei bit della parola escluso . Nei passaggi si è commessa l’approssimazione di considerare trascurabile il contributo condizionante della sezione evidenziata in giallo, e questo ci ha permesso di giungere all’espressione finale della APO-LLR. Essa si esprime nella somma di un contributo, detto intrinsic-LLR o channel-LLR, che dipende solo dalle caratteristiche del canale e da , e di un secondo, detto
23
extrinsic-LLR, che al contrario dipende da tutti gli altri bit ma non da , e che viene aggiornato iterazione dopo iterazione durante il processo di decodifica. Definiamo adesso:
il set dei CN a cui afferisce il VN corrispondente ad
un set in cui ciascun è definito come l’insieme degli e
4444444444che afferiscono a
Procediamo quindi sviluppando l’espressione della e trinsic-LLR in base alle seguenti considerazioni:
| ( | ) ( )
( ) Le espressioni evidenziate in giallo, qui come di seguito, si elidono tra numeratore e denominatore all’interno dell’espressione fratta della e trinsic-LLR e quindi non vengono prese in considerazione.
( ) ( | ) ( ) Possiamo adesso operare la seguente importante approssimazione:
( | ) ( | ) la cui ragionevolezza si evince dall’ammettere, come già anticipato, che il girth sia maggiore di 4. In questo caso, infatti, non può che essere l’unico bit in comune tra i check node e, per questo motivo, il condizionamento imposto dagli altri nei confronti di risulta essere più debole di quello diretto di
, e viene trascurato. Procedendo nello sviluppo dell’espressione abbiamo poi: ( ) ( | ) ( | ) ( | ) ( )
( | )
( )
Notando poi che , otteniamo infine:
ln |
| ln
| |
24
dove i vari rappresentano i cosiddetti check-to-variable message (λc2v), e rappresentano una stima che il generico offre del bit sulla base del vincolo di parità che coinvolge i soli .
Tutte le quantità definite fino a questo punto, possono essere valutate essenzialmente perseguendo due possibili algoritmi di decodifica: i cosiddetti Belief Propagation (BPA) e Layered Decoding Algorithm (LDA).
1.3.2
Algoritmo BPA
L’algoritmo BPA si basa su un continuo scambio di messaggi estrinseci (λc2v e λv2c) tra i check node ed i relativi variable node. All’inizio della decodifica, in particolare, le APO-LLR di ogni bit trasmesso sono inizializzate con le channel LLR ed ogni check node riceve questa informazione dai relativi variable node (variable to-check-message). Ogni check node, poi, in accordo con le relazioni di parità che lo definiscono, restituisce informazione estrinseca a ciascuno dei variable node connessi, per un totale di messaggi. Ogni variable node, di contro, riceve esattamente messaggi, ed è quindi in grado di calcolare la extrinsic LLR per la prossima iterazione. L’algoritmo, che quindi procede alternando check node phase e variable node phase, si ferma quando la condizione 1.33 è verificata (convergenza raggiunta), oppure dopo un numero predefinito di iterazioni. Definiamo quindi:
il messaggio dal variable node al check node il messaggio dal check node al variable node l’insieme dei variable node connessi al check node
l’insieme dei variable node connessi al check node escluso c( l’insieme dei check node connessi al variable node
c( l’insieme dei check node connessi al variable node escluso ta
L’algoritmo è quindi formalizzato nello pseudo codice di pagina 25.
1.3.3
Algoritmo LDA
Lo schema del belief propagation algorithm può essere convenientemente modificato per ridurre il numero di iterazioni necessarie ad ottenere la convergenza, e quindi il tempo complessivo della decodifica. A tal proposito, il layered decoding algorithm, prevede una sola fase, che può essere la check node phase oppure la variable node phase. In una soluzione CN-centrica, tutti i check node sonoaggiornati sequenzialmente, e le operazioni sui VN sono sparse sopra a ciascun CN, mentre in una soluzione VN-centrica tutti i VN sono aggiornati sequenzialmente, e le operazioni sui CN sono distribuite sopra a ciascun VN.
Quest’ultima soluzione, tuttavia, comporta alcuni problemi dal punto di vista della relativa implementazione VLSI, e per questo motivo non sarà approfondita.
26
Lo pseudo codice riportato sotto, mostra che anche la soluzione CN-centrica inizializza le APO-LLR con le channel LLR dei bit ricevuti. L’algoritmo procede poi check node per check node (o layer per layer), ed i messaggi variable to check sono calcolati immediatamente considerando che:
Di fatto, il generico viene calcolato una sola volta per ogni iterazione (esattamente come nel BPA), ed infatti le computazioni della check node phase sono le stesse del BPA. Al contrario, i vengono aggiornati, man mano che la check node phase procede, volte. In questo modo, la computazione dei messaggi variable to check può procedere considerando, di volta in volta, il valore più aggiornato delle APO-LLR, incrementando (fino quasi a raddoppiare), la velocità di convergenza del processo.
27
E’ per questo motivo che il LDA è particolarmente adatto per tutte quelle applicazioni che richiedono data rate molto spinti, come l’estensione ad alto throughput dello standard WLAN (IEEE 802.11n) o dello standard WMAN (IEEE 802.16e). Di contro, il LDA richiede l’osservanza di particolari misure nella sua implementazione, al fine di evitare possibili conflitti nell’accesso ai dati che darebbero luogo ad errori.
1.3.4
Algoritmo TDMP
Il primo passo per ottenere flessibilità nella decodifica di codici differenti, è quello di identificare un comune motore, che supporti la decodifica sia dei codici LDPC che di quelli Turbo. A tal proposito, una possibile opzione può essere ravvisata nell’algoritmo BCJR (nelle versioni modificata log-MAP e max-log-MAP), il quale, nel caso di trellis a due stati, si riduce al cosiddetto Turbo Decoding Message Passing [23].
Come già illustrato, la parola di codice prodotta dall’LDPC encoder, deve soddisfare un preciso set di vincoli di parità. In altre parole, le operazioni XOR dei bit coinvolti in un particolare check node, devono restituire 0 (condizione di even parity). Di fatto, è possibile descrivere tale condizione per mezzo di un trellis a due stati, in cui lo stato ad un generico stadio “i”, rappresenta la parità (even oppure odd) tra i primi “i” bit riferiti a quel check node. Un trellis di questo tipo, come quello mostrato in figura 1.16, ha una lunghezza uguale al check node degree , ed il primo e l’ultimo devono essere stati di even parit ( ). Tale diagramma, ammette la definizione di particolari forward e backward metrics, che possono essere impiegate per l’aggiornamento dei check-to-variable message. In questo modo è possibili definire delle semplici equazioni ricorsive che possono essere impiegate in sostituzione della funzione all’interno della check node phase descritta negli pseudocodici (che rappresenta la fase più complessa della decodifica LDC).
Figura 1.16: trellis a due stati per un LDPC check node
Di seguito, sviluppiamo le equazioni che definisco l’algoritmo TDMP. Definiamo innanzitutto i seguenti eventi:
= “lo stato all’arrivo del bit i-esimo è even”
= “lo stato successivo all’arrivo del bit i-esimo è even” = “lo stato all’arrivo del bit i-esimo è odd”
28
Si ha dunque:
ln |
| Sviluppiamo le espressioni all’interno del logaritmo:
| |
( | ( | | |
( | ( | Dove si sono indicati con i bit che afferiscono al nodo che vengono prima dell’i-esimo, e con quelli successivi. Consideriamo adesso le seguenti elaborazioni: ( | ( ) ( | ) ( ) ( | ( | ( | Dove sono stati evidenziati in giallo i termini che saranno semplificati tra i due termini della frazione del . In rosso indichiamo altresì i due fattori condizionanti che possono essere eliminati. I termini in celeste sono semplificabili in quanto probabilità approssimabili a 0.5 (questo non è del tutto vero per l’ultimo bit del trellis). La stessa notazione cromatica sarà adottata nei casi seguenti. In base a queste considerazioni possiamo porre:
ln ( |
( | ( | ( |
( | ( | ( | ( | Definiamo adesso le seguenti quantità:
( |
( | ( |
29
Per cui:
ln
Moltiplicando poi numeratore e denominatore dell’espressione precedente per
ed introducendo le seguenti metriche in forma LLR:
ci riconduciamo all’espressione definitiva del :
la quale presenta delle importanti analogie con l’equazione 1.22 relativa al calcolo della del caso Turbo e delle quali certamente si potrà tenere conto al fine della flessibilità. Come si può intuire, tali analogie si estendono anche alle equazioni ricorsive per il calcolo delle state metric e
: ( | ( | ( | ( | dove con si sono indicati i bit del trellis associato a con indice coerente con X. Si osserva che: ( | ( ) ( ) ( | ) ( ) ( | ) ( ) ( ) ( | ) ( | ) ( ) Per cui abbiamo:
( |
) ( | ) ( | ) ( | )
Dividendo poi numeratore e denominatore per la quantità ( | ), e considerando che:
30 ( | ) ( | ) Otteniamo quindi: dove l’espressione per si ottiene con passaggi analoghi a quelli per . Osserviamo infine che, in maniera del tutto simile a quanto già evidenziato in relazione all’algoritmo ma -log-MAP, anche in questo caso possiamo operare una sostituzione dell’operatore ma * con il più semplice ma , ottenendo una versione modificata, ed approssimata, del TDMP. Tale possibilità, la quale comporta degli sviluppi che non hanno un analogo nei codici associati a trellis con più di 2 stati, è approfondita nel seguente paragrafo.
1.3.5 Algoritmi Lambda-Min approssimati
Algoritmo min-TDMP
Consideriamo le equazioni relative al calcolo di , e in accordo al TDMP. Esse sono tutte nella generica forma:
Riconduciamoci adesso alla forma approssimata con l’operatore ma :
E’ facile osservare che da una funzione di questo tipo si possono ottenere solo 4 possibili risultati, che sono |x|, |y|, -|x| e -|y|. Questo, ci informa che la somma definita all’interno del secondo operatore è superflua, visto che possiamo riscrivere la 1.60 come:
| | | | | | ( ) Da un punto di vista architetturale, i vantaggi che l’adozione di tale forma comporta sono evidenti: al posto dei 2 operatori max richiesti per la computazione dei parametri , e , possiamo sfruttare la semplificazione offerta dall’uso di un solo blocco min (di complessità chiaramente paragonabile a quella di un solo blocco max). In generale, per una architettura che supporti un numero N di
31
check node update paralleli (N = 96 per una particolare classe dello standard LDPC IEEE 802.16e descritto dettagliatamente più avanti), in questo modo si risparmierebbero 2*N operatori max binari, vale a dire N per il blocco delle state metric computation, ed N per l’e trinsic computation. Per gli stessi motivi si evita altresì l’implementazione di 2*N sommatori ( 2*N = 192 nel caso sopracitato), e si evitano, conseguentemente, le eventuali saturazioni che i risultati di tali somme potenzialmente introducono nella precisione finita dell’aritmetica di macchina. Tale risparmio di logica e di potenza, potrebbe essere interessante anche in vista di un impiego dell’algoritmo nell’architettura flessibile. Di seguito, vengono sviluppate ulteriori possibilità che sono fornite dal paradigma “min” [24].
Algoritmo Two-Output-Lambda-Min
Tutte le procedure descritte fino ad ora per la fase di check node update, ovverosia l’impiego della funzione o gli algoritmi TDMP, max-TDMP e min-TDMP , presentano la stesso procedimento per il calcolo del segno del generico i-esimo check-to-variable message : lo XOR dei segni riferiti alle channel-LLR (o dei variable-to-check message per iterazioni successive alla prima) con indice diverso da “i”. In altre parole, il check node valuta se la condizione di parità sia o meno già rispettata tra gli altri : se si, propone un segno negativo (cioè uno 0) per il , altrimenti ne propone uno positivo (cioè un 1), per soddisfare il vincolo di parità. L’algoritmo two output lambda min non fa eccezione. Focalizziamoci quindi sul calcolo dei moduli dei check-to-variable message, e consideriamo la figura 1.17. In essa sono illustrati qualitativamente 2 possibili andamenti relativi ai moduli delle state metrics α e β. Nelle equazioni 1.61 e 1.62, si è mostrato come, nella procedura ricorsiva del calcolo di tali quantità, si possa impiegare un operatore min in sostituzione di quelli max. Questo, rende del tutto evidente come, man mano che si procede nel trellis (in senso forward per le alpha ed in senso inverso per le beta) , i moduli delle state metrics siano via via più piccoli. Infatti, dal valore di inizializzazione, che è ovviamente massimo visto che il trellis comincia e termina con certezza nello stato even, notiamo un andamento rigorosamente non crescente di |α| e |β|, in cui, agli eventuali scalini si associa la ricorrenza di un | | minore di quelli implicati nelle ricorsioni precedenti.
La conseguenza di questo è che, posta la lunghezza del trellis in considerazione (cioè il numero di edge, e non il numero di stadi), e ricordando che | | è calcolato come minimo tra le corrispondenti e , check-to-variable message avranno lo stesso modulo, che coincide col minore assoluto dei moduli dei in ingresso. Il | | rimanente, è invece proprio quello associato al minimo stesso , e corrisponderà al minimo di tutti gli altri | |. In formule:
( ) ∏
| | mi { | |
32
Figura 1.17: Trellis a due stati con esemplificazione qualitativa dell’andamento di forward e backward metrics
Jones et al. hanno proposto un algoritmo, detto A-min, che rappresenta una sorta di compromesso tra il two-output-lambda-min e la versione non approssimata con : la check node update procede in maniera approssimata in accordo al two-output-lambda-min per tutti i , eccetto che per quello col modulo minore, per il quale si utilizza la funzione .
Una eventuale architettura che supporti questi algoritmi non ricorsivi, deve comunque comprendere una rete per l’estrazione di minimo e quasi-minimo tra gli (massimo 22 nei casi contemplati in questo lavoro di tesi) , ed una rete di porte XOR per la computazione dei segni. Rispetto al min-TDMP, questo algoritmo si distingue soprattutto perché evita alpha-recursion e beta-recursion, e può quindi fornire i valori aggiornati di in un solo ciclo, anziché in 2* . D’altronde, i risultati che fornisce, sono esattamente gli stessi del min-TDMP, e conservano quindi alcuni vantaggi rispetto alla versione max-TDMP.
Nonostante alcuni meriti, tuttavia, non sarebbe pratico un impiego del two-output-lambda-min nella nostra architettura flessibile, intrinsecamente ricorsiva. Come sarà evidente più avanti, per ricavare in un solo ciclo il minore tra i potenziali 22 coinvolti in un check-node, occorrerebbe una configurazione completamente differente degli operatori max necessari alla state metric processing della decodifica Turbo. Nondimeno, l’algoritmo così come presentano, consente l’esecuzione di un solo check node update alla volta, in luogo del forte grado di parallelizzazione che invece consente una versione TDMP-centrica.
Tuttavia, quanto messo in evidenza dall’algoritmo two-output-lambda-min, può comunque essere utile anche in sede di decodifica max-TDMP o min-TDMP, visto che adesso sappiamo che degli che sono prodotti serialmente da tali procedimenti ricorsivi, hanno lo stesso modulo: questo potrebbe essere sfruttato per ridurre l’ingombro in memoria degli stessi (di circa la metà), oppure per interrompere le beta-recursion non appena si incontrano 2 con modulo sensibilmente diverso. In questo modo, mediamente, invece di calcolare tutti gli
33
Algoritmo Recursive Lambda Min
L’intrinseca incompatibilità architetturale che affligge gli algoritmi BCJR-like e two-output-lambda-min, dovuta alla sostanziale natura ricorsiva del primo non condivisa dal secondo, può essere superata nell’algoritmo RLM. Esso si basa sull’individuazione di minimo e quasi minimo come il two-output-lambda-min , ma è ricorsivo, come il TDMP, in modo da mantenere alcuni vantaggi del primo ed allo stesso tempo prestarsi come il secondo ad una implementazione flessibile pensata anche per i codici Turbo. L’idea di base è piuttosto semplice: l’identificazione dei due minimi avviene percorrendo in passi forward il trellis (fase delle pseudo alpha recursion), ed adoperando i successivi cicli, prima impiegati per le beta recursion, per invertire o meno il segno ai | | appena calcolati, senza particolari altre elaborazioni (fase delle pseudo beta recursion). La durata complessiva della check-node phase, in questo modo, è esattamente la stessa del TDMP, ovvero 2* cicli. Come sarà dimostrato in seguito, tuttavia, le computazioni in gioco in tale processo, sono pressoché dimezzate e, nondimeno, consente di evitare la definizione di alcuni buffer di memoria LIFO altrimenti indispensabili. Lo schema di riferimento dell’algoritmo RLM è riportato in figura 1.18