2. Materiali e Metodi
2.1. Sito di studio
La prateria di Posidonia oceanica in cui è stato effettuato lo studio si estende dalla città di Livorno fino al centro abitato di Quercianella verso sud. Il sito di studio si trova presso la località di Antignano (43° 29’ N, 10° 19’ E) a sud di Livorno. All’interno della prateria è stata presa in esame un’area ad una profondità compresa tra 4 e 6 metri, scelta al fine di evitare artefatti dovuti alla profondità sulla distribuzione delle specie analizzate. L’estensione dell’area di studio è pari a 500 metri circa.
All’interno di questa zona sono state selezionate aree sufficientemente estese entro cui ospitare le unità sperimentali, costituite da transetti della lunghezza di 32 metri, composti da 64 quadrati contigui di 50 centimetri di lato, con una copertura iniziale di P.
oceanica pari al 100%. I transetti sono stati marcati durante l’estate dell’anno 2006, mediante l’utilizzo di paletti di ferro lunghi 80 cm e con diametro pari ad 1 cm. Tali paletti sono stati fissati al substrato con un martello e marcati con un sottile strato di stucco epossidico (Veneziani Subcoat “S”) nella parte emergente dalla strato di foglie. Per facilitare ulteriormente il riconoscimento dei transetti sono state utilizzate targhette di plastica di diversi colori.I paletti sono stati collocati a distanze fisse (4, 8, 16, 32 metri) rispetto al primo paletto di ogni transetto utilizzando una cordella metrica. Nella collocazione delle unità sperimentali i margini della prateria sono stati mantenuti ad una distanza minima di 1 m dal transetto, al fine di evitare artefatti dovuti ad esempio ad erosione del substrato o ad un diverso idrodinamismo.
Per stimare l’abbondanza delle specie epifite dei rizomi di P. oceanica è stato eseguito un campionamento fotografico. I transetti sono stati campionati tra febbraio e aprile 2007. Prima di eseguire le fotografie è stato necessario tagliare le foglie di P.
oceanica all’interno di rettangoli della dimensione di 17 x 24 centimetri, situati al centro di ogni quadrato da 50 x 50 centimetri. Qualora fossero presenti rizomi ortotropi, le fotografie sono state scattate dopo averli adagiati, al fine di osservare il popolamento epifita proiettato su una superficie orizzontale. Il campionamento fotografico è stato eseguito utilizzando una macchina fotografica (Canon WP-DC40), protetta da una custodia
resistente all’acqua, ed equipaggiata con un supporto metallico allo scopo di mantenere costante l’ingrandimento.
La stima della copertura percentuale relativa ai principali gruppi algali e di invertebrati è stata ottenuta sovrapponendo una griglia ad ogni immagine (in formato JPEG) tramite PC. Tale griglia è composta da 25 quadrati di uguale misura, ai quali è stato assegnato un valore tra 0 (assenza della specie) e 4 (copertura totale del quadrato da parte della specie campionata). Sommando i valori assegnati ai 25 quadrati si ottiene la stima della copertura percentuale della specie in esame all’interno della fotografia campionata (Dethier et al. 1993).
A causa delle difficoltà intrinseche al campionamento di tipo fotografico nelle praterie di P. oceanica, alcune fotografie presentano piccole aree in cui non è possibile riconoscere gli organismi presenti. La copertura di tali aree è stata stimata ed utilizzata per correggere la copertura percentuale di tutti i taxa. Qualora non fosse possibile riconoscere gli organismi a livello di specie attraverso il campionamento fotografico essi sono stati descritti con minore dettaglio tassonomico o raggruppati in categorie morfo-funzionali.
Per il Phylum Chlorophyta sono state rilevate le specie Caulerpa racemosa,
Cladophora spp. e Flabellia petiolata. Per il Phylum Rhodophyta sono state rilevate
Rhodymenia spp., Sphaerococcus coronopifolius e Peyssonnelia spp. Inoltre sono presenti alghe a tallo laminare, alghe a tallo cilindro-corticato, alghe corallinacee a tallo articolato ed alghe corallinacee incrostanti. Il campionamento fotografico ha permesso infine di identificare alcuni Phyla di invertebrati: Porifera, Cnidaria della Classe Hydrozoa, Bryozoa, Mollusca come Pinna nobilis appartenente alla Classe Bivalvia, Anellida della Classe Polychaeta ed Echinodermata appartenenti alla Classe Echionoidea, in particolare
Paracentrotus lividus e Arbacia lixula.
Per ogni quadrato è stato conteggiato il numero di taxa presenti. Sono state analizzate solo le specie più abbondanti, ovvero Rhodymenia spp., Peyssonnelia spp., alghe filamentose e il numero di taxa.
2.2 Analisi dei Dati
2.2.1 Analisi della varianza
I dati sono stati analizzati per mezzo dell’ analisi della varianza.
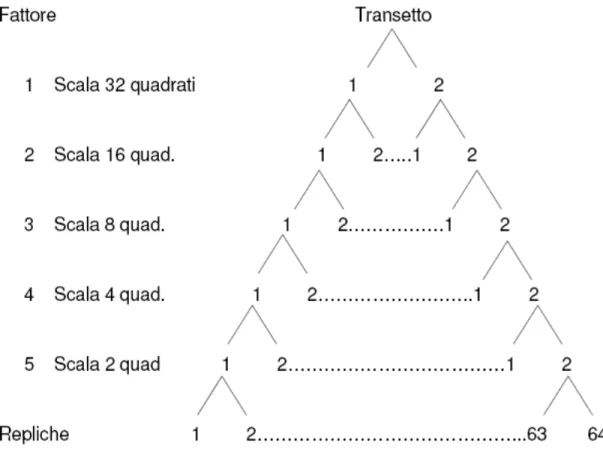
Il disegno sperimentale comprende 5 scale spaziali (2, 4, 8, 16, 32 quadrati) considerate come fattori gerarchizzati (Fig. 5). Sono presenti due livelli del fattore 1 (scala spaziale di 32 quadrati, ovvero le due metà del transetto) e comprendono ognuno due livelli della scala spaziale inferiore (fattore 2, scala di 16 quadrati). Procedendo verso i fattori inferiori nella gerarchia del disegno, ognuno comprende due livelli del fattore sottostante. Infine, ogni livello del fattore 5 (scala spaziale 2 quadrati) comprende due repliche. Le repliche sono quadrati di 50 x 50 cm lungo il transetto di 32 metri, per un totale di 64 quadrati.
Figura 5. Disegno sperimentale comprendente i 5 fattori random, ovvero cinque scale spaziali all’interno di ogni transetto. Ogni scala spaziale è gerchizzata in quella più grande, ad esempio il fattore 3 è gerarchizzato in 2 e in 1.
L’analisi della varianza è stata eseguita secondo il suddetto disegno gerarchizzato (Fig. 5) per ogni transetto su ciascuna variabile misurata. Tale analisi presuppone che i dati rispettino l’assunto di indipendenza, quindi non permette di analizzare potenziali pattern di correlazione nei dati. Questo tipo di analisi permette invece di individuare le scale spaziali a cui si osserva una maggiore variabilità, sebbene ciò possa avvenire esclusivamente alle scale spaziali selezionate per il campionamento. Utilizzando le varianze derivanti dal disegno gerarchizzato sono state calcolate le componenti di varianza relative ad ognuna delle 5 scale spaziali. Qualora si siano ottenuti valori di componenti di varianza negativi essi sono stati posti uguali a zero, poiché rappresentano sottostime di variabilità nulla. E’ stata utilizzata la tecnica del calcolo delle componenti di varianza perché permette di stimare i valori di varianza associati alle cinque scale spaziali considerate. Il vantaggio di tale tecnica risiede nel confronto tra valori assoluti di varianza relativi alle singole scale spaziali. Uno svantaggio di questa tecnica risiede nel calcolo delle varianze alle scale più estese. Tali varianze sono calcolate da un numero di repliche inferiore rispetto alle varianze calcolate per le scale spaziali ridotte. In particolare la varianza associata alla scala spaziale di 32 quadrati è calcolata utilizzando solamente 2 repliche. Le analisi della varianza sono state effettuate utilizzando il programma GMAV5 (Università di Sydney, Autralia).
2.2.2 Variogrammi
Il semivariogramma è un metodo che viene impiegato per valutare l’autocorrelazione spaziale di dati osservati in punti a distribuzione spaziale nota. Esso è la funzione che interpola la semivarianza dei valori osservati in gruppi di coppie di punte a determinate distanze. La semivarianza è pari a:
n (h) ( z ( x + d ) – z ( x ) )2
γ
(d)=
Σ
i = 1 n ( h )
Con
γ
(d) : Semivarianza alla distanza dz : valore della variabile in esame in un particolare punto n : numero di coppie di osservazioni effettuate alla distanza d xi : posizione spaziale di z lungo il transetto
d : lag o distanza
Tale analisi assume che la variabile considerata soddisfi la condizione di stazionarietà di secondo ordine (Legendre & Legendre 1998). Il semivariogramma è il grafico che rappresenta l’andamento della semivarianza rispetto alla distanza tra i dati, che normalmente viene interpolato con diverse funzioni in modo da determinare la tipologia di autocorrelazione spaziale della variabile misurata (Shine & Wakefield 1999).
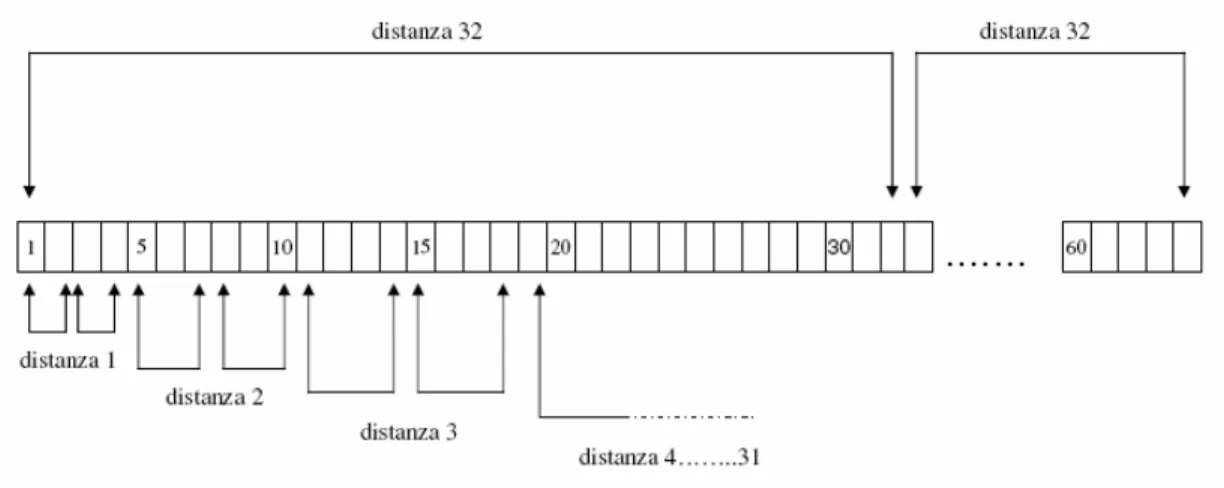
Nel presente lavoro tali osservazioni sono rappresentate dalla stima della copertura percentuale, per una data specie, nei singoli quadrati lungo i transetti. Le classi di distanza sono le distanze tra quadrati alle quali vengono effettuati i confronti tra coppie di repliche. Nel presente studio sono stati eseguiti confronti tra repliche a partire dalla distanza di un quadrato (quadrati adiacenti), fino a distanze di 32 quadrati, comprendendo tutti i confronti alle distanze intermedie (Fig. 6).
Figura 6. Rappresentazione schematica dei confronti tra coppie di quadrati per ottenere il variogramma. Nel calcolo della semivarianza sono state incluse tutte le distanze tra quadrati, da 1 a 32 quadrati di distanza.
In situazioni ideali ai grafici che rappresentano la relazione tra la semivarianza e le classi di distanza di un processo stazionario di secondo ordine viene fittato uno dei modelli standard. Esistono numerosi modelli che rappresentano differenti andamenti, e permettono di stimare parametri caratteristici. Uno dei modelli più diffusi è il modello sferico (Fig. 7). La semivarianza aumenta gradualmente all’aumentare della distanza (lag) fino ad un livello di variabilità spaziale oltre cui si mantiene costante. Tale valore è definito sill e rappresenta la varianza della variabile presa in esame. La distanza alla quale la semivarianza diventa stabile è chiamato range (a, Fig. 7), e rappresenta la distanza entro cui le unità di campionamento sono correlate spazialmente, a distanze maggiori i dati risultano indipendenti. L’intercetta sull’asse delle ascisse descrive l’effetto nugget, e corrisponde alla variabilità locale che si osserva a scale minori dell’intervallo di campionamento, ad esempio per effetto dell’errore di campionamento, o per effetto della variabilità a piccola scala (Legendre & Legendre 1998). Infine la porzione di variabilità che risulta spazialmente autocorrelata è misurata dal valore C1.
Possono essere fittati differenti modelli con diverse strutture di autocorrelazione spaziale utilizzando least square o maximum likelihood criteria. In particolare il modello
Fig. 7: Variogramma rappresentante il modello sferico. C0 rappresenta l’effetto nugget. C1 rappresenta la componente di semivarianza spazialmente strutturata. C rappresenta la sill (C = C0 + C1). Il range (a) rappresenta la distanza a cui la variabile non mostra correlazione spaziale.
sferico descrive dati autocorrelati entro un certo lag (range-a), e indipendenti oltre tale distanza.
Una serie di dati che mostra un andamento di tipo periodico è fittata dal modello periodico, nel quale la semivarianza cresce e decresce ciclicamente a distanze caratteristiche.
Infine, serie di dati che non mostrano correlazione spaziale, portano ad un variogramma in cui i valori di semivarianza a tutte le scale possono essere rappresentati da una semplice intercetta. Tale variogramma è caratterizzato completamente dall’effetto
nugget, ovvero non emergono strutture di correlazione alla scala di campionamento. Per eliminare la variabilità su ampie scale spaziali che potrebbero rappresentare dei gradienti, i dati sono stati sottoposti ad una procedura di detrendizzazione, ovvero ai valori di ogni quadrato è stata sottratta la media della categoria. I semivariogrammi sono stati calcolati utilizzando il programma R: A Language environment for Statistical Computing (R Foundation for Statistical Computing, Vienna, 2004).
2.2.3 Analisi multilivello
L’analisi multilivello (HLM) descrive le relazioni di una o più variabili all’interno di un set di dati gerarchizzato. Una caratteristica dell’HLM è che le variabili possono essere incorporate ad ogni livello del modello utilizzato, in modo tale che le stesse osservazioni possono essere utilizzate per indagare diversi meccanismi a differenti scale spaziali (McMahon & Diez 2007). I dati relativi alle alghe filamentose, Peyssonnelia spp.,
Rhodymenia spp. e numero di taxa sono stati detrendizzati con la stessa procedura utilizzata prima di realizzare i semivariogrammi. Dai dati detrendizzati sono state calcolate le densità spettrali per le quattro categorie lungo ciascuno dei tre transetti.
Sono stati utilizzati due modelli per effettuare la HLM, il modello A e il modello B, (Tab. 1). Le rette di regressione di questa analisi utilizzano l’approccio della verosimiglianza (likelihood).
Il primo livello del modello B dell’HML è rappresentato da una equazione di regressione.
y
ij= п
oi+ п
1iFreq+ ε
ij(B.1) In tale equazione Yij misura la variabile di risposta, nel nostro caso la densità
spettrale del livello i (transetto) del gruppo j (frequenza). L’equazione B.1 (modello B, livello 1) comprende una distribuzione di intercette пoi, ed una distribuzione di coefficienti
di regressione п1i legata ai valori della variabile indipendente (Frequenza). Nel modello
sono comprese delle distribuzioni di intercette e coefficienti angolari per correggere la non-indipendenza dell’errore residuo εij.
Idealmente si assume che l’errore residuo εij, associato alla stima della relazione tra
la densità spettrale e la frequenza nell’equazione di regressione lineare B.1, sia caratterizzato da indipendenza, media zero e varianza σ2ε. Siccome la densità spettrale
(variabile di risposta) è relativa all’i-esima osservazione e gerarchizzata nel j-esimo gruppo, il termine di errore residuo risulta correlato, quindi non si può verificare l’assunto di indipendenza. A causa di questa correzione, il primo livello del modello B non comprende un’intercetta e un coefficiente di regressione, bensì tutte le intercette e i coefficienti angolari di ciascuna delle j equazioni di regressione, che consistono nelle equazioni di regressione di livello 2 del modello B:
п
1i =γ
1o+ Φ
1i (B.2.2) Nelle equazioni (B.2.1 e B.2.2) i termini γoo e γ1o sono i parametri che descrivono ivalori medi delle intercette e dei coefficienti angolari delle equazioni di regressione di secondo livello. Φoi e Φ1i misurano invece le deviazioni tra le intercette ed i coefficienti
angolari di ciascuna retta di regressione ed i rispettivi valori medi. Si assume che Φoi e Φ1i
abbiano distribuzione normale multivariata, con medie zero e con varianze di σ20 e σ21
rispettivamente. La covarianza tra questi effetti random è descritta da σ01. Sostituendo le
equazioni B.2.1 e B.2.2 all’interno dell’equazione B.2, si ottiene il modello combinato che descrive le relazioni tra la densità spettrale e la frequenza, includendo i termini di errore dei due livelli del modello B.
y
ij= (γ
oo+ γ
1o Freq)
+ (ε
ij+ Φ
oi+ Φ
1i Freq)
(Mod. B)Per valutare la relazione tra densità spettrale e frequenza, sono stati comparati modelli di complessità crescente. Il modello più semplice (A) è un modello ‘incondizionato’ che include solo l’intercetta. Si tratta quindi di una versione ridotta del modello B, ottenuto ponendo la frequenza uguale a zero. Nel primo livello del modello ridotto (equazione A.1), la densità spettrale comprende due parametri di variabilità.
y
ij= п
oi+ ε
ij (A.1) Il primo parametro (пoi) spiega la variabilità dovuta all’intercetta, mentre il secondoparametro (εij) spiega lo scostamento dall’intercetta. Il primo parametro (пoi) è
ulteriormente scomposto nel secondo livello del modello A (equazione A.2), che descrive l’effetto medio della distribuzione di intercette (γoo) e i termini di scostamento (Φoi) di ogni
intercetta, appartenente a tale distribuzione, dalla media.
п
oi =γ
oo+ Φ
oi (A.2) Sostituendo l’equazione A.2 nell’equazione del primo livello del modello A (equazione A.1) si ottiene il modello combinato (Mod. A).Modello A
y
ij= γ
oo+ ε
ij+ Φ
oi Livello 1 :y
ij= п
oi+ ε
ij Livello 2 :п
oi =γ
oo+ Φ
oi Modello By
ij= (γ
oo+ γ
1o Freq)
+ (ε
ij+ Φ
oi+ Φ
1i Freq)
Livello 1 :y
ij= п
oi+ п
1i Freq+ ε
ij Livello 2 :п
oi =γ
oo+ Φ
oiп
1i =γ
1o+ Φ
1i Parametri Descrizioney
ij Variabile dipendente: log (Densità Spettrale) Freq Variabile indipendente: log (Frequenza)п
oi Intercetta, misura l’entità della densità spettraleп
1iCoefficiente angolare della retta di regressione, identifica il coefficiente spettrale β della funzione 1/f-noise.
γ
oo Effetto medio della distribuzione di intercetteγ
1o Effetto medio della distribuzione di coefficienti angolariΦ
oi Termine di errore associato alla distribuzione di intercetteΦ
1iTermine di errore associato alla distribuzione dei coefficienti angolari
ε
ijTermine di errore associato alla i-esima osservazione della j-esima densità spettrale
Tabella 1. Tabella riassuntiva dei modelli utilizzati per la HLM. Il modello A e il modello B risultano dalla risoluzione del sistema comprendente le equazioni dei livelli 1 e 2 dei rispettivi modelli. Nella seconda parte della tabella sono descritti i singoli parametri.
I due modelli applicati ai dati di densità spettrale sono spiegati nelle figure 8 e 9.
Fig. 8 Spiegazione grafica del modello A:
y
ij= γ
oo+ ε
ij+ Φ
oiγ
oo è rappresentato dalla linea tratteggiata rossa, ovvero l’effettomedio dell’intercetta
ε
ij è rappresentato dalla differenza tra la densità spettrale allafrequenza j dell’i-esimo transetto (circoli colorati) e la media della densità spettrale all’interno dell’i-esimo transetto (trattini colorati)
Φ
oi è rappresentato dalla differenza tra la densità spettrale media deltransetto (trattini colorati) i e l’effetto medio dell’intercetta (linea tratteggiata rossa)
Se il modello il confronto tra il modello A e il modello B, indica che il primo spiega la maggior parte della variabilità nei dati di densità spettrale, non verrà dimostrata correlazione spaziale per la categoria in esame. Viceversa se il modello B mostra una maggiore bontà di adattamento ai dati di densità spettrale, nella categoria in esame si potrà identificare il grado di correlazione spaziale, sia essa negativa o positiva. Le analisi multilivello sono state effettuate utilizzando il programma R: A Language environment for Statistical Computing (R Foundation for Statistical Computing, Vienna, 2004).
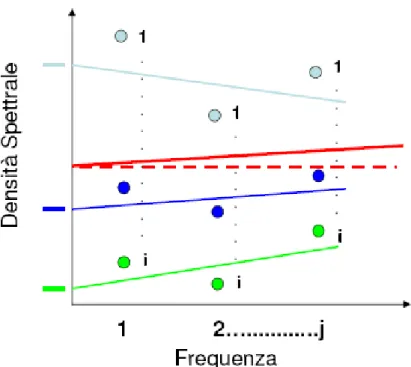
Figura 9 Spiegazione grafica del modello B:
y
ij= (γ
oo+ γ
1oFreq) + (ε
ij+ Φ
oi+ Φ
1iFreq)
γ
oo è rappresentato dalla linea tratteggiata rossa, ovvero l’effetto mediodell’intercetta
γ
1o Freq è rappresentato da dalla linea continua rossa, ovvero l’effetto medio delcoefficiente angolare
ε
ij è rappresentato dalla differenza della densità spettrale del transetto i allaj-esima frequenza (pallini colorati) e l’effetto del coefficiente angolare della retta di regressione del transetto i (linee continue colorate)
Φ
oi è rappresentato dalla differenza tra la densità spettrale media del transetto(trattini colorati) i e l’effetto medio dell’intercetta (linea tratteggiata rossa)
Φ
1i Freq è rappresentato dalla differenza tra l’effetto del coefficiente angolaredelle rette di regressione di ogni transetto (linee continue colorate) e l’effetto medio del coefficiente angolare (linea continua rossa)