CAPITOLO 5
VERIFICA DEL PROGETTO
L’obiettivo di quest’ultimo capitolo è la verifica delle specifiche di progetto per il sistema che è stato fin qui descritto. In particolare, la maggior attenzione sarà riposta nel calcolo del grado di fedeltà raggiunto rispetto all’algoritmo di riferimento, quindi sarà stimata la velocità di elaborazione del sistema, ed infine la complessità circuitale ottenuta, per mezzo del tool di sintesi Xilinx Ise 6.2.
5.1 SIMULAZIONE FUNZIONALE
Il primo passo da compiere è la verifica della funzione logica implementata dalla descrizione operata in VHDL. Questo procedimento si dice simulazione funzionale. In questa fase si pone l’attenzione esclusivamente sulle funzioni sintetizzate dalle varie porte logiche, trascurando i ritardi ed i tempi caratteristici della tecnologia che sarà utilizzata per la sintesi finale. In altri termini, si suppone che tutte le porte logiche abbiano tempi di attraversamento nulli. E’ necessario sottolineare che il sistema vero e proprio acquisisce e salva i dati in apposite Ram
o Rom che potranno essere sintetizzate impiegando apposite risorse rese disponibili dalla FPGA di destinazione. Durante la simulazione funzionale, eseguita in ambiente VHDL, le fasi di acquisizione e salvataggio dati sono invece realizzate per mezzo di opportuni stream di dati su file di testo (.txt) al fine di simulare la presenza delle memorie, che sono vere e proprie entità fisiche. Quest’approccio è usuale nel caso della descrizione di sistemi in HDL e corrisponde a considerare l’hard disk del PC su cui opera il VHDL come area di memoria per la lettura e scrittura dei dati. Risulta quindi conveniente, per maggiore chiarezza, illustrare come sia possibile tradurre le immagini dal formato .img a quello di testo per poterle elaborare con la simulazione in VHDL, ed il viceversa, ovvero il passaggio dal formato .txt a quello .img per visualizzare i risultati in ambiente Matlab.
5.1.1 Flusso di test
La simulazione funzionale eseguita in ambiente VHDL è molto dispendiosa in termini di memoria richiesta sul PC e di tempo di elaborazione. Ad esempio, delle tre immagini disponibili (swan, bedroom e alpi), non è stato possibile effettuare un test completo per nessuna di esse. Anche nel caso dell’immagine più piccola, swan.img, le cui dimensioni sono 385 x 513, PC con ben 512 MB di Ram non sono in grado di gestirla a causa dell’insufficienza di memoria. Questo perché il progetto prevede la presenza di due ram di dimensione pari a quella delle immagini. Nel caso di swan, dunque, servirebbero due ram da 385 x 513 = 197505 locazioni, da 8 e da 18 bit. Questo problema è stato aggirato effettuando un sottocampionamento delle immagini per mezzo della funzione imresize disponibile nell’ambiente Matlab. Ad esempio, swan è stata ridotta alla dimensione 192 x 256 = 49152 pixel. Un sottocampionamento troppo spinto dell’immagine non può essere realizzato, pena la perdita di qualità dell’immagine stessa. Un altro problema è la distorsione delle immagini causato da una scelta di fattori di scala diversi per il sottocampionamento delle direzioni orizzontale e verticale, cosa permessa dalla funzione imresize. L’effetto è un cambio del rapporto tra le dimensioni, con ovvi problemi. Per evitare ciò, è necessario scegliere le due frequenze di sottocampionamento uguali. La riduzione delle
dimensioni è molto rapida. Ad esempio, scegliendo di campionare un pixel ogni 2 o 3, si ottengono immagini pari, rispettivamente, ad 1/4 ed 1/9 dell’originale. Un’alternativa al sottocampionamento è quella di effettuare test su porzioni limitate dell’immagine. Per quanto concerne la velocità di simulazione, si pensi che nel caso di processi che in realtà dovrebbero durare pochi decimi di secondo, tempo effettivo di elaborazione del sistema, l’ambiente VHDL ha richiesto tempi ben superiori, anche 20-30 minuti. La simulazione funzionale in Active è pertanto molto più lenta di quelle effettuate negli ambienti C e Matlab, dunque il rischio, in questa fase, è stato quello di rallentare notevolmente il flusso di progetto, specialmente nelle prime fasi di verifica del codice VHDL, dove inevitabilmente si presentano vari problemi. Si è pertanto scelto, al fine di velocizzare tutti i procedimenti di test, di operare le prime prove su immagini minime, come una matrice 4 x 4, che, escludendo la cornice esterna, non elaborata dal sistema, prevede solo 4 pixel da elaborare. Una volta raggiunti risultati soddisfacenti, è stato possibile estendere le simulazioni alle immagini complete, quando ormai tanti errori erano stati corretti. L’ambiente Matlab è utilizzato soprattutto per la verifica dei risultati ottenuti, per le sue qualità grafiche di rappresentazione e per l’efficienza in termini di velocità di elaborazione. In alcuni casi si è sfruttata questa qualità anche per effettuare delle simulazioni o studi particolari, come l’analisi statistica illustrata nel capitolo 2 a proposito della realizzazione della Lut per il calcolo dei coefficienti So e Sv. Si utilizzano, quindi, alcune funzioni in
ambiente Matlab, alcune già presenti come la già citata imresize, altre messe a punto dai ricercatori di Trieste come load_image.m per il caricamento dell’immagine .img in una matrice, display_image.m per la visualizzazione su video, save_image.m per il salvataggio di una matrice in formato immagine .img, ed altre sono state create ex-novo, avvalendosi della semplicità del linguaggio Matlab per la scrittura di funzioni. Per la conversione dell’immagine da formato .img al formato di testo .txt, necessario per poter lavorare nell’ambiente VHDL, è stata descritta la funzione save_image_txt.m (vedi appendice) che, ricevuta un immagine, ne converte i valori dei pixel dal formato decimale a quello binario su 8 bit, dato che si tratta di valori interi nel range [ 0 ; 255 ], e li scrive uno di seguito all’altro su righe successive, ottenendo una colonna di numeri ad 8 bit,
lunga quanto la dimensione della matrice di partenza. Una volta salvata l’immagine sotto forma di caratteri di testo, è possibile lanciare il test in ambiente VHDL indicando, nel testbench, il nome del file .txt appena creato come ingresso del sistema. Ogni riga del file corrisponderà ad una locazione della ram virtuale che si andrà a scrivere. Alla fine dell’elaborazione i dati sono stati sovrascritti nelle RAM X e Y e per una verifica dei risultati si deve prelevare il contenuto di quelle memorie. A tal fine, si esegue un nuovo stream di dati, che produrrà due files di uscita, sempre di tipo .txt, il cui nome può essere specificato a piacere nel codice VHDL. A questo punto si rende necessario il passaggio inverso di quello realizzato per l’ingresso dei dati: la conversione da formato .txt a formato .img. L’operazione viene realizzata da un’ulteriore funzione Matlab appositamente ideata, il cui nome è save_image_img.m. Quest’ultima ha bisogno in ingresso dei percorsi completi dei file .txt sorgente e destinatario .img, ed anche delle dimensioni dell’immagine che si deve creare, dato che queste informazioni sono state perse nel passaggio da .img a .txt. La funzione save_image_img.m costruisce una matrice di pixel leggendo un valore binario nel file di testo, convertendolo in decimale, e quindi posizionandolo nella posizione opportuna, secondo una scansione raster per colonna. Questa particolare scelta è in accordo con la modalità di creazione del file .txt eseguito dalla funzione save_image_txt.m. Anche in questo caso si è deciso di leggere le matrici per colonne, proprio come avviene nel primo ciclo di filtraggio del filtro RRF, al fine di semplificare la ricerca dei dati nelle ram virtuali. Nel caso in cui si effettuino i cicli successivi al primo, è necessario applicare alle uscite dei contatori di riga e colonna la semplice trasformazione descritta nel capitolo 4 per prelevare correttamente i dati. Una volta costruita, la matrice .img può essere salvata su file .img grazie alla funzione save_image.m. Per poter visualizzare l’immagine di riflettanza è invece stata scritta la funzione save_ref_img.m, analoga alla save_image_img.m, dato che differisce da questa solo per la dimensione della parte frazionaria dei valori.
Le simulazioni funzionali produrranno delle immagini di uscita che potranno essere confrontate per mezzo dei metodi del PSNR e dell’indagine visiva. Per il calcolo del rapporto segnale-rumore di picco, è stata descritta, sempre in ambiente
Matlab, la funzione psnr.m (vedi appendice) che, ricevuti i percorsi delle due immagini da confrontare, calcola il parametro richiesto.
Saranno effettuati vari confronti per valutare le prestazioni del sistema, in particolare:
• VHDL vs. ret_soft.c • VHDL vs. ret_soft_linear.c
dove si intende, se non diversamente specificato, il confronto tra le uscite globali dei sistemi, considerando ideali i blocchi che non interessano questo lavoro, i quali competono invece al sistema Retinex_B.
Riepiloghiamo in forma schematica il flusso da seguire per i test:
Preparazione ingressi: ambiente Matlab
• eventuale sottocampionamento dell’immagine o prelevamento di una porzione limitata (funzione imresize.m)
• conversione da formato .img a .txt (funzione save_image_txt.m)
Elaborazione in ambiente C
• elaborazione dell’immagine con gli algoritmi ret_soft.c e la sua versione approssimata ret_soft_linear.c
• salvataggio uscite parziali (luminanza, riflettanza) e globali.
Elaborazione in ambiente Active-HDL 4.2
• simulazione funzionale
• salvataggio immagini di luminanza e riflettanza in formato .txt
Verifica risultati VHDL vs. ret_soft.c: ambiente Matlab
• indagine oggettiva tra uscite di luminanza e riflettanza prodotte da Active e dall’algoritmo in C. (funzione psnr.m).
• indagine soggettiva tra le stesse immagini (funzioni save_image_img.m, load_image.m, display_image.m).
Verifica risultati VHDL vs. ret_soft_linear: ambiente Matlab
• indagine oggettiva tra uscite di luminanza e riflettanza prodotte da Active e dall’algoritmo in C. (funzione psnr.m),
• indagine soggettiva tra le stesse immagini (funzioni save_image_img.m, load_image.m, display_image.m).
5.1.2 Simulazione della descrizione VHDL
Sulla base del flusso di progetto appena schematizzato, sono state eseguite varie prove al fine di verificare tutte le funzionalità richieste al sistema progettato, al variare dei parametri programmabili Nc ed α, i cui range sono stati definiti nel cap. 2 ed in dipendenza da altre caratteristiche, quali il tipo e la dimensione dell’immagine, e la precisione dell’approssimazione dei dati in fixed point, in particolare nel dimensionamento della parte frazionaria dei valori rappresentati.
Per i motivi esposti in precedenza, due delle tre immagini del set di partenza, swan e bedroom sono state opportunamente ridotte per mezzo del sotto campionamento. Non é stato invece possibile effettuare alcuna prova su alpi.img, poiché un sottocampionamento che la riducesse a dimensioni accettabili per le simulazioni da effettuare ne causava un eccessivo deterioramento. Sarà invece possibile elaborarla, nel suo formato originale, nelle simulazioni in ambiente C.
In particolare:
• swan.img è stata trasformata per ottenere la versione ridotta swanrid.img, le cui dimensioni sono: 256 x 192.
• bedroom.img è stata ridotta alle dimensioni 256 x 256 ed il suo nuovo nome è bedroomrid.img
Le nuove immagini sono riportate nella figura 71.
Figura 71. Immagini swan.img e bedroom.img ridotte.
Sono stati eseguiti i seguenti test:
• elaborazione delle immagini con scelta dei valori ottimi per i parametri • elaborazione delle immagini al variare del parametro α con Nc fissato
al valore ottimo.
• elaborazione delle immagini al variare del parametro Nc con α fissato al valore ottimo.
• elaborazione di una delle immagini, per la precisione swanrid, con parametri fissati ai valori ottimi, variando la precisione dell’aritmetica di macchina, in particolare, a differenza dei 10 bit scelti per il parametro N definito nel cap. 3, si è provato a porre N pari prima a 7 e poi a 4, il che corrisponderebbe ad avere valori con numero di cifre decimali dopo la virgola pari rispettivamente a 2 ed a 1. Questo test è stato effettuato per mettere in luce il calo di prestazioni al diminuire della precisione dell’aritmetica di macchina.
• VHDL vs. ret_soft_linear.c
Valore dei parametri Swanrid.img PSNR (dB)
Bedroomrid.img PSNR (dB)
α=0.75; Nc=4 55.58 60.10
Tabella 24. Confronto tra VHDL e ret_soft_linear per le immagini di luminanza, con parametri di default.
Valore dei parametri Swanrid.img PSNR (dB)
Bedroomrid.img PSNR (dB)
α=0.75; Nc=4 46.79 49.03
Tabella 25. Confronto tra VHDL e ret_soft_linear per le immagini di riflettanza, con parametri di default.
Valore di α Swanrid.img PSNR (dB) Bedroomrid.img PSNR (dB) 0.500 56.70 61.56 0.750 55.58 60.10 0.900 54.20 59.88
Tabella 26. Luminanza vs. α per VHDL e ret_soft_linear
Valore di α Swanrid.img PSNR (dB) Bedroomrid.img PSNR (dB) 0.500 48.31 51.01 0.750 46.79 49.03 0.900 45.53 47.40
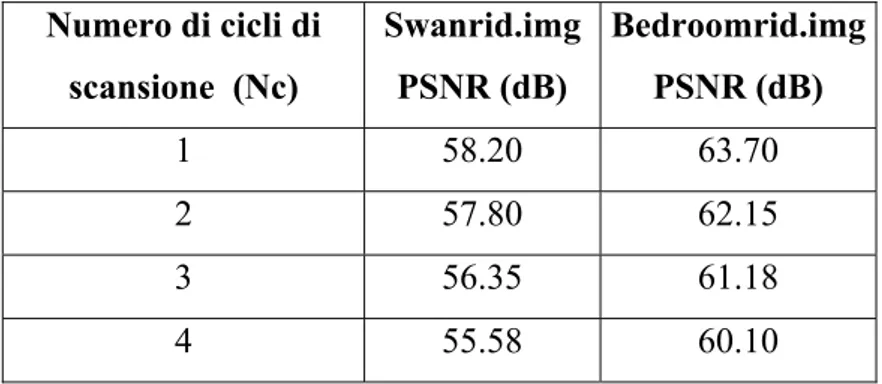
Numero di cicli di scansione (Nc) Swanrid.img PSNR (dB) Bedroomrid.img PSNR (dB) 1 58.20 63.70 2 57.80 62.15 3 56.35 61.18 4 55.58 60.10
Tabella 28. Luminanza vs. Nc per VHDL e ret_soft_linear.
Numero di cicli di scansione (Nc) Swanrid.img PSNR (dB) Bedroomrid.img PSNR (dB) 1 49.20 52.33 2 48.28 51.45 3 47.12 50.11 4 46.79 49.03
Tabella 29. Riflettanza vs. Nc per VHDL e ret_soft_linear.
Swanrid.img Dimensione parte
frazionaria (N) Lum. (dB) Ref. (dB)
7 53.10 44.11
4 51.12 43.29
Tabella 30. Luminanza e riflettanza vs. dimensione parte frazionaria per VHDL e ret_soft_linear.
Teoricamente avremmo dovuto ottenere valori di PSNR infiniti, poiché la descrizione VHDL non è altro che l’implementazione del codice C semplificato ret_soft_linear.c. In generale, invece, si sono ottenuti valori di PSNR molto elevati, ma mai infiniti. Ciò è dovuto alla simulazione dell’aritmetica fixed point per mezzo della funzione cutfloat, che si basa a sua volta sulla funzione floor. Utilizzando questo espediente, si introducono degli errori, in quanto il
troncamento dei bit della parte frazionaria non sarà mai ideale come lo vorremmo e perché tale operazione è stata effettuata sugli operandi e sulle uscite, mentre le computazioni intermedie effettuate dal processore tornano ad essere in aritmetica di tipo floating point.
Comunque, l’aver ottenuto valori di PSNR superiori a 50 dB nel confronto tra le immagini elaborate dalla versione C linearizzata e dalla sua implementazione VHDL, è sufficiente per concludere che l’implementazione hardware dell’algoritmo è fedele alla versione C e viceversa. Si tratta di un fatto di rilevante importanza: questo consentirà di effettuare ulteriori test operando in ambiente C, nettamente più veloce del VHDL. Un’elaborazione eseguita a livello software in ambiente C impiega infatti un tempo dell’ordine dei 10 secondi.
Nel caso in cui venga limitata la dimensione della parte frazionaria, come è stato fatto nell’ultimo test (tabella 30), le prestazioni calano come previsto.
In figura 72 sono riportate le uscite di luminanza e riflettanza prodotte dalle versioni C linearizzata e VHDL per un possibile confronto visivo, nei casi di swanrid.img e bedroomrid.img.
Ret_soft_linear VHDL
Figura 72. Immagini elaborate dall’algoritmo linearizzato e dall’implementazione VHDL.
• VHDL vs. ret_soft.c
Il confronto tra i risultati forniti dal sistema descritto in VHDL e dall’algoritmo ottimo ret_soft.c, modello del progetto, sancirà definitivamente la qualità del lavoro fin qui svolto. Questo test dovrebbe dare risultati molto vicini al confronto tra ret_soft.c e ret_soft_linear.c, con perdita di qualche dB a causa dell’errore introdotto dalla funzione che limita la dimensione della parte frazionaria.
Nelle tabelle da 31 a 34 si riportano i risultati delle prove, che sono analoghe a quelle realizzate per il confronto tra VHDL e ret_soft_linear.c, eseguite sia per l’uscita di luminanza che per quella di riflettanza.
Parametri di default α=0.75; Nc=4 Luminanza PSNR (dB) Riflettanza PSNR (dB) Swanrid.img 35.97 26.57 Bedroomrid.img 40.98 28.76 Valor medio 38.48 27.67
Tabella 31. Confronto tra uscite di luminanza e riflettanza tra VHDL e ret_soft.
Swanrid.img Bedroomrid.img Valore di α Lum. (dB) Ref. (dB) Lum. (dB) Ref. (dB) 0.500 39.30 28.86 42.20 29.11 0.750 35.97 26.57 40.98 28.76 0.900 31.18 25.44 39.99 27.88
Tabella 32. Luminanza e riflettanza vs. α per ret_soft e VHDL.
Swanrid.img Bedroomrid.img Numero di cicli di scansione (Nc) Lum. (dB) Ref. (dB) Lum. (dB) Ref. (dB) 1 38.51 29.52 43.55 29.55 2 37.77 28.37 42.25 29.40 3 35.92 26.94 41.12 28.91 4 35.97 26.57 40.98 28.76
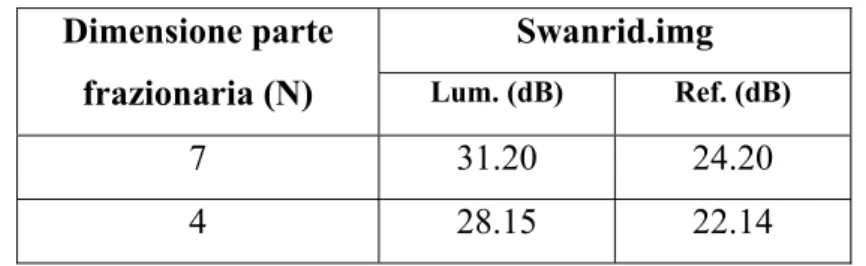
Swanrid.img Dimensione parte
frazionaria (N) Lum. (dB) Ref. (dB)
7 31.20 24.20
4 28.15 22.14
Tabella 34. Luminanza e riflettanza vs. dimensione parte frazionaria per ret_soft e versione VHDL.
Le prestazioni ottenute con i parametri programmabili fissati ai loro valori di default sono soddisfacenti, in quanto l’uscita di luminanza è sempre ben superiore al target di 30 dB di PSNR. L’immagine di riflettanza è invece, seppur di poco, inferiore a tale soglia, e questo è dovuto alla maggiore limitazione della parte frazionaria che è stata operata su tale segnale. Il grande margine ottenuto sulla luminanza consente però di ottenere un risultato finale, per quanto riguarda l’uscita globale del sistema, comunque superiore al limite minimo di prestazione richiesto dalle specifiche. Questo è stato verificato dal progettista del sistema Retinex_B, che ha effettuato simulazioni a partire dai segnali di luminanza e riflettanza generati da Retinex_A.
Una cosa da notare e facilmente giustificabile è la leggera perdita di prestazioni, quantificata da un valore di PSNR decrescente all’aumentare del valore di α o del numero di scansioni effettuate dal filtro RRF. Ciò è dovuto al fatto che nel caso in cui venga aumentato uno dei parametri, le computazioni svolte sono o più spinte, nel caso dell’aumento di α, o più numerose, nel caso dell’aumento di Nc. Dunque, al crescere di tali livelli di computazione ci si allontana sempre di più dall’algoritmo di riferimento. Le immagini ottenute sono in ogni modo di buona qualità, e non è detto, al solito, che un leggero peggioramento in termini di PSNR corrisponda ad un effetto realmente visibile.
Infine, il test in cui è stata variata la dimensione della parte frazionaria, ha messo in luce ancora una volta l’importanza della scelta sulla precisione dell’aritmetica di macchina, confermando le scelte operate nel capitolo 3.
Riportiamo infine nella figura 73, nella pagina seguente, le immagini fornite dal sistema implementato in VHDL a confronto con quelle elaborate con ret_soft.c, l’algoritmo ottimo.
Ret_soft VHDL
5.1.3 Esempi di forme d’onda
In questo paragrafo si riportano, per completezza e per esempio, alcune forme d’onda ottenute in ambiente Active-HDL 4.2 durante la sintesi logica.
Le figure 74,75 e 76 si riferiscono al caso di elaborazione di una matrice di dimensioni minime, 4 x 4, in cui i pixel da elaborare sono soltanto 4, poiché il sistema ignora il bordo esterno dell’immagine. Tale matrice è stata ideata per pura fantasia, in quanto date le sue dimensioni, non avrebbe senso estrarla da un’immagine tra quelle a disposizione. I parametri sono quelli di default, per cui α = 0.750 e Nc = 4. Nel waveform seguente si riportano i primi 35 ns di elaborazione, in cui il sistema inizia la fase di inizializzazione, dove l’immagine da processare viene caricata in memoria.
Figura 74. Waveform: inizio fase di acquisizione dati.
Come possiamo vedere dal segnale Sreg0, il sistema si trova inizialmente nello stato di reset (Sres). Il segnale di start è alto almeno fino all’arrivo del primo fronte di clock utile in seguito al rilascio del reset, segnale attivo alto. Impostate le dimensioni dell’immagine da elaborare (segnali lines_in e cols_in), ed il numero di cicli di scansione, qui definito dal segnale cycles, la macchina a stati enable_generator pone il sistema, una volta arrivato il primo fronte di clock in salita, nello stato S0, che perdurerà finché i dati d’ingresso non sono stati acquisiti completamente.
Enable è ovviamente sempre attivo, α è impostato al valore di default 0.750 che corrisponde al codice “10”, i segnali frame_y_valid e frame_r_valid all’inizio non sono specificati, poi assumono il valore logico basso, in attesa delle elaborazioni successive.
Nel waveform in figura 75 è possibile individuare l’istante in cui ha termine il calcolo della luminanza, segnalato dalla transizione del segnale frame_y_valid al valore logico alto.
Figura 75. Waveform: fine del calcolo della stima di luminanza.
Si noti un gate di ampiezza 1 Tclk sull’enable della rete pixel_address_conversion che corrisponde all’abilitazione del contatore per generare l’indirizzo dei pixel da prelevare dalle ram X ed Y per il calcolo della luminanza. Siccome si tratta dell’ultimo pixel da elaborare, pixel_address_conversion pone il segnale stop_out ad 1, e lo trasferisce alla macchina a stati, in modo tale che, alla fine dell’elaborazione del pixel corrente, il segnale frame_y_valid possa essere posto ad 1, al fine di segnalare la fine del calcolo di y(i,j). Frame_r_valid è ancora al livello logico basso, dato che il calcolo della riflettanza non è ancora stato iniziato. Nell’ultimo waveform, rappresentato in figura 76, possiamo invece vedere come si comporta il sistema nel momento in cui ha fine il calcolo della riflettanza.
Figura 76. Waveform: calcolo dell’ultimo pixel di riflettanza e raggiungimento dello stato di
Il segnale index_x_y, valore del contatore presente nella rete memory_address_generator, raggiunge il fondo scala, in questo caso 15, dato che si sta trattando un’immagine 4 x 4. Al clock successivo, il segnale di raggiunto fondo scala, stop_mag, passa al valore logico alto. In questo modo la macchina a stati è informata del fatto che il calcolo corrente di riflettanza è l’ultimo, e quindi, dopo che l’ultimo bit di riflettanza è stato computato, il segnale frame_r_valid viene posto ad 1 ed il sistema evolve fino allo stato di attesa S40, come possiamo vedere dal segnale Sreg0. A questo punto, per iniziare una nuova scansione, è necessario l’arrivo di un impulso su start, in corrispondenza di un fronte di clock utile.
5.2 SINTESI DEL SISTEMA
Dato che i test sulla funzionalità del sistema hanno fornito esiti positivi, è lecito passare all’ultima fase del flusso di progetto riportato in figura 7 nel cap.1, ovvero la sintesi logica.
In questo paragrafo ci proponiamo come obiettivo le stime della velocità di elaborazione del sistema in termini di frequenza massima raggiungibile e della complessità circuitale ottenuta in seguito alla descrizione eseguita nel cap. 4.
Si vuole, infatti, verificare la possibilità di implementazione del sistema su FPGA commerciali e valutare le prestazioni raggiungibili in termini di applicazioni statiche, ma anche per eventuali applicazioni dinamiche, che richiedono l’elaborazione di più frames al secondo. Vedremo quali siano i formati che potranno essere elaborati con questo sistema ed eventualmente studieremo delle alternative per migliorare le prestazioni, nel caso di possibili estensioni future di questo sistema per applicazioni del genere.
Per ottenere queste stime faremo uso del tool di sintesi logica Xilinx ISE 6, dell’omonimo produttore. Si tratta di un programma in grado, una volta scelta una FPGA, di simulare e di realizzare la sintesi logica su quel dispositivo, ed anche di fornire degli schemi circuitali semplificati, utili soprattutto nel caso in cui si sia utilizzata una descrizione HDL di tipo comportamentale, che lascia libertà al tool di sintesi per la scelta dell’architettura.
Tenendo conto delle caratteristiche e dei ritardi tipici della tecnologia e del dispositivo scelto, sono possibili anche delle stime in termini di massima frequenza raggiungibile, oltreché il calcolo delle risorse occupate sulla FPGA.
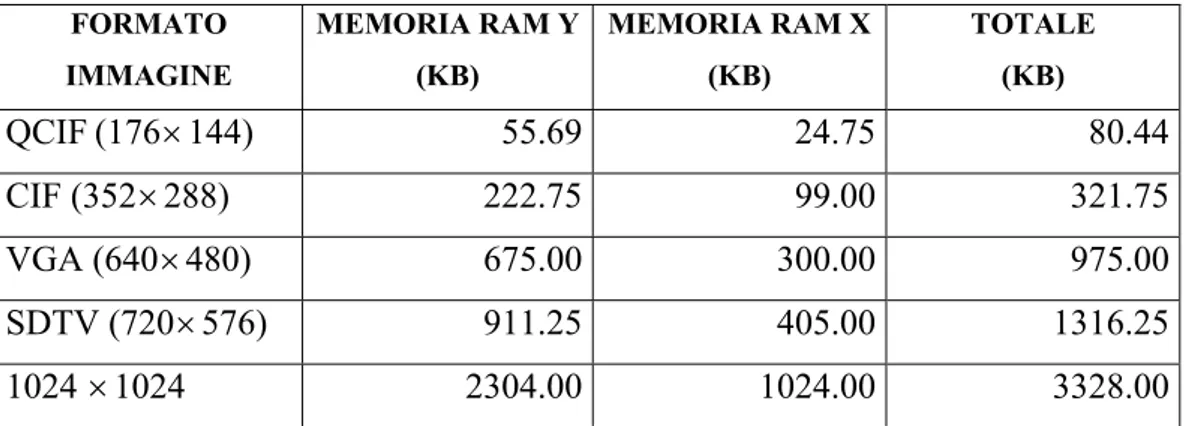
Possiamo però anticipare i risultati della sintesi, effettuando delle stime per quanto riguarda le risorse di memoria richieste, che sono facilmente calcolabili. In tabella 35 sono riportate delle stime di memoria richiesta per il sistema in due casi di dimensionamento e per diversi formati di immagine. In particolare, il QCIF, formato impiegato nelle moderne trasmissioni tra telefoni cellulari, è pari ad ¼ del CIF (Common Intermediate Format).
FORMATO IMMAGINE MEMORIA RAM Y (KB) MEMORIA RAM X (KB) TOTALE (KB) QCIF(176×144) 55.69 24.75 80.44 CIF (352×288) 222.75 99.00 321.75 VGA (640×480) 675.00 300.00 975.00 SDTV (720×576) 911.25 405.00 1316.25 1024 ×1024 2304.00 1024.00 3328.00
Tabella 35. Memoria richiesta nel caso in cui luminanza e riflettanza siano dimensionate su
18(8+10) e 8 (6+2) bit.
Proviamo a limitare il dimensionamento del sistema, riducendo il numero di bit della parte frazionaria di luminanza a 7. Il dimensionamento di Ram X non cambierà. FORMATO IMMAGINE MEMORIA RAM Y (KB) TOTALE (KB) VARIAZIONE (KB) QCIF(176×144) 46.41 71.16 -9.28 CIF (352×288) 185.63 284.63 -37.12 VGA (640×480) 562.50 862.50 -112.50 SDTV (720×576) 759.38 1164.38 -151.87 1024 ×1024 1920.00 2944.00 -384.00
Tabella 36. Memoria richiesta nel caso in cui luminanza e riflettanza siano dimensionate su
La situazione è leggermente migliorata, ma nel caso di immagini 1024 x 1024 la memoria richiesta è sempre dell’ordine del MB: il sistema in questione si definisce “memory-dominated”, nel senso che i requisiti di memoria sono più stringenti rispetto a quelli di complessità logica circuitale. Quest’aspetto costituisce, generalmente, un limite per i sistemi di elaborazione delle immagini.
5.2.1 Analisi di alcune famiglie di dispositivi Xilinx
Abbiamo detto che la prima cosa da fare nel condurre la sintesi logica è la scelta del dispositivo di arrivo. Tale scelta non deve essere fatta a caso, poiché esiste una miriade di FPGA disponibili ed in continuo aggiornamento. Esse si differenziano per molte caratteristiche, tra cui capacità (in termini di celle logiche), RAM on chip, numero di pin, ma anche per architettura e tecnologia. Dato che una stima della complessità circuitale sarebbe difficile da effettuare con precisione senza eseguire la sintesi, possiamo però ragionare sulla quantità di memoria richiesta.
Possiamo dunque scegliere la FPGA di destinazione confrontando la memoria disponibile on-chip con quella richiesta dal nostro sistema, anche se comunque è possibile concepire un sistema con RAM off-chip. E’ necessario, però, prestare attenzione al fatto che le FPGA con un maggior quantitativo di RAM a disposizione di solito sono anche quelle più grandi in termini di blocchi logici disponibili. Ciò significa che scegliendo la FPGA ragionando solo ed esclusivamente sulla memoria on board, si rischierebbe di ricadere su un dispositivo troppo grande e costoso per il sistema da implementare. La scelta dovrebbe essere quindi un trade-off tra costo e RAM fornita.
A titolo di esempio, verranno prese in analisi due famiglie di dispositivi FPGA della Xilinx: la famiglia Spartan-3 e la famiglia Virtex-4 [11]. Queste due famiglie hanno caratteristiche di tipo molto differente, non solo a livello architetturale, ma anche per quanto riguarda le risorse disponibili, dato che appartengono a due diverse generazioni di dispositivi. La famiglia Spartan-3 offre una quantità ben più ridotta di risorse logiche, variabili tra le 1780 celle logiche del componente xc3s50, cui corrisponde una Block RAM (BRAM)
disponibile on-chip pari a 72 Kbits, e le 74880 del componente xc3s5000 con BRAM on-chip di 1872 Kbits.
La famiglia Virtex-4 permette di realizzare sistemi ben più complessi, mettendo a disposizione risorse variabili tra un minimo di 12312 celle logiche per il componente FX12, avente BRAM di 648 Kbits, e un massimo di 141408 per il componente FX140 di BRAM pari a 10080 Kbits. I componenti di questa famiglia che sono marcati con la sigla FX possiedono una serie di caratteristiche che li rendono estremamente flessibili e di largo impiego per applicazioni anche piuttosto complesse. Si tratta di risorse come, ad esempio, uno o due processori PowerPC dedicati, che, nel caso in esame, costituiscono un vero e proprio eccesso che andrebbe sprecato e che ha come controindicazione quella di rendere tali componenti troppo costosi. Se si facesse attenzione soltanto ai requisiti di memoria, per consentire l’elaborazione di tutti i formati sopra elencati anche con il grado di precisione più alto, senza necessità di effettuare compressioni o sottocampionamenti e con tutte le RAM on-chip, la scelta ricadrebbe forzatamente sul più complesso dei componenti della famiglia Virtex-4.
Eseguendo una scelta un po’ più meditata, però, è facile rendersi conto che non è conveniente sobbarcarsi di un costo notevole per la realizzazione su un componente sofisticato, del quale, peraltro, le potenzialità più interessanti non sarebbero sfruttate, per avere il lusso di avere on-chip tutta la RAM che si vuole. Per ciò che riguarda la necessità di risorse logiche, una valutazione grossolana consente di affermare che la famiglia Spartan-3 offre già gates a sufficienza per la realizzazione del sistema, ma la RAM disponibile impone delle forti limitazioni di utilizzo.
Le possibilità a questo punto sono molteplici.
Si può decidere di scegliere il componente con massima quantità di RAM: xc3s5000. Esso offre 1872 Kbits di BRAM equivalenti a 234 Kbytes.
In questo caso si prospettano le seguenti possibilità d’impiego:
• elaborazione di formati QCIF, anche con precisione più alta e elaborazione di formati CIF con precisione limitata, oppure altri formati con RAM off-chip; • elaborazione di altri formati con salvataggio di informazioni sottocampionate
Stesse possibilità di impiego valgono per il componente xc3s4000, che conviene, in quanto, a parità di applicazioni possibili, limita maggiormente il costo e lo spreco di logica.
Si può decidere per un componente meno complesso limitando al massimo lo spreco di risorse logiche, ma saremmo obbligati ad utilizzare ram esterne.
Sono state effettuate varie prove di sintesi, a partire dal dispositivo xcv1000 disponibile nel laboratorio in cui è stato sviluppato questo lavoro di tesi.
In seguito è stata scelto la FPGA Xilinx xc3s1000 che fa parte della famiglia Spartan-3. La scelta è ricaduta su questo componente, poiché ha fornito i migliori risultati in termini di spazio occupato, ma soprattutto per quanto riguarda la massima frequenza raggiungibile, rendendo possibile una frequenza di clock pari a circa 20 MHz contro i 15 MHz nel caso della xcv1000.
Il dispositivo xc3s1000 ha a disposizione una quantità totale di RAM pari a 69 KB. Dalle tabelle 35 e 36 a pagina 160 si evince che, nel caso si desideri utilizzare la RAM on-chip, il massimo formato che si può elaborare è il QCIF. Per trattare immagini di maggiori dimensioni, si può scegliere o di utilizzare RAM esterna, oppure è possibile applicare delle tecniche di tipo lossy, come il sottocampionamento o la compressione delle immagini, con conseguente perdita di parte dell’informazione.
Nel prossimo paragrafo sono riportati i risultati delle sintesi logiche.
5.2.2 Report di sintesi
La sintesi effettuata in ambiente Xilinx ISE 6 fornisce i propri risultati sottoforma di un file di testo detto report, in cui vengono riportati svariati dati sulla complessità circuitale, sulle prestazioni raggiungibili in termini di massima frequenza di clock, ed altre informazioni interessanti come l’elenco dei componenti sintetizzati.
Riportiamo solo i dati salienti del report. La sintesi è stata effettuata nei casi N = 10 ed N = 6.
9 xcv1000 - N = 10.
================================================================= Final Report ================================================================= Device utilization summary:
--- Selected Device : v1000bg560-6
Number of Slices: 7121 out of 12288 57%
Number of Slice Flip Flops: 958 out of 24576 3%
Number of 4 input LUTs: 10192 out of 24576 41%
Number of bonded IOBs: 29 out of 408 7%
Number of TBUFs: 48 out of 12288 0%
Number of GCLKs: 1 out of 4 25% Design Statistics # IOs : 30 Macro Statistics : # Registers : 876 # 1-bit register : 860 # 16-bit register : 5 # 18-bit register : 3 # 2-bit register : 4 # 22-bit register : 1 # 5-bit register : 2 # 8-bit register : 1 # Counters : 1 # 10-bit up counter : 1 # Multiplexers : 2216
# 18-bit 4-to-1 multiplexer : 1 # 2-to-1 multiplexer : 2212
# 20-bit 4-to-1 multiplexer : 3 # Tristates : 4
# 10-bit tristate buffer : 1
# 18-bit tristate buffer : 2
# 2-bit tristate buffer : 1
# Adders/Subtractors : 183 # Multipliers : 5 # 10x10-bit multiplier : 1 # 11x10-bit multiplier : 1 # 11x11-bit multiplier : 2 # 11x4-bit multiplier : 1 # Comparators : 43 # FlipFlops/Latches : 958 ================================================================== Timing Summary: --- Speed Grade: -6
Per quanto riguarda la complessità circuitale, è richiesto il 57 % delle risorse disponibili sulla FPGA scelta, mentre la frequenza massima di clock possibile è circa 12 Mhz.
Provando a ridurre il dimensionamento del sistema, ad esempio riducendo la dimensione della parte frazionaria, si otterrebbe, il 43% in termini di risorse richieste e 14.6 Mhz per quanto riguarda la massima frequenza raggiungibile. Dunque, anche riducendo il dimensionamento dell’aritmetica, rinunciando a qualche dB di prestazione, il sistema diviene un po’ più veloce, ma non troppo. Ciò è causato dall’anello di reazione e dall’algoritmo, che non prevede il calcolo di nuovi pixel finché non si è finito di elaborare quello corrente.
Come già anticipato, l’implementazione sulla FPGA xc3s1000 ha fornito risultati migliori; riportiamo il report anche di questa sintesi:
9 xc3s1000 - N = 10
================================================================= Final Report =================================================================
Device utilization summary: ---
Selected Device : 3s1000fg320-5
Number of Slices: 7071 out of 7680 92% Number of Slice Flip Flops: 955 out of 15360 6% Number of 4 input LUTs: 10022 out of 15360 65% Number of bonded IOBs: 29 out of 221 13% Number of MULT18X18s: 4 out of 24 16% Number of GCLKs: 1 out of 8 12% ================================================================= TIMING REPORT Timing Summary: --- Speed Grade: -5
9 xc3s1000 - N = 6
================================================================= Final Report =================================================================
Device utilization summary: ---
Selected Device : 3s1000fg320-5
Number of Slices: 2068 out of 7680 26% Number of Slice Flip Flops: 721 out of 15360 4% Number of 4 input LUTs: 3735 out of 15360 24% Number of bonded IOBs: 29 out of 221 13% Number of BRAMs: 7 out of 24 29% Number of MULT18X18s: 4 out of 24 16% Number of GCLKs: 1 out of 8 12% ================================================================== TIMING REPORT Timing Summary: --- Speed Grade: -5
Minimum period: 48.496ns (Maximum Frequency: 20.620MHz)
Utilizzando la xc3s1000 scegliendo di riservare solo 6 bit alla parte frazionaria, si ottiene una frequenza massima di circa 20 MHz ed una bassa occupazione di area, il che consente di ottimizzare anche l’operazione di place and route al fine di ottenere prestazioni ancor più spinte. Una maggiore precisione nell’aritmetica di macchina si paga con una maggiore complessità circuitale, e quindi con una minore velocità di elaborazione. E’ ciò che è emerso dalle sintesi sulla stessa FPGA ma con diversi valori di N. Al solito, è necessario un trade-off velocità-complessità ed un’attenta analisi dello scenario in cui si intende utilizzare il sistema.
Per migliorare la velocità di elaborazione esistono comunque delle strategie, come cercare di modificare l’architettura aumentando il parallelismo, a scapito di una maggiore richiesta di risorse logiche, altrimenti si può far uso di sensori a dinamica logaritmica [9]. Tali dispositivi rispondono agli stimoli esterni con una dinamica in forma di logaritmo che dunque è compressa. Ciò permette innanzi
tutto di risparmiare sul dimensionamento del sistema, grazie alla riduzione della dinamica, ma la cosa veramente interessante è che sfruttando le note proprietà dei logaritmi, le operazioni di calcolo di riflettanza e di ricombinazione finale dell’immagine possono essere effettuate, rispettivamente, come differenza e somma pixel a pixel. A fronte di una maggiore spesa per i sensori, si ottiene dunque una semplificazione dell’architettura del sistema a valle.
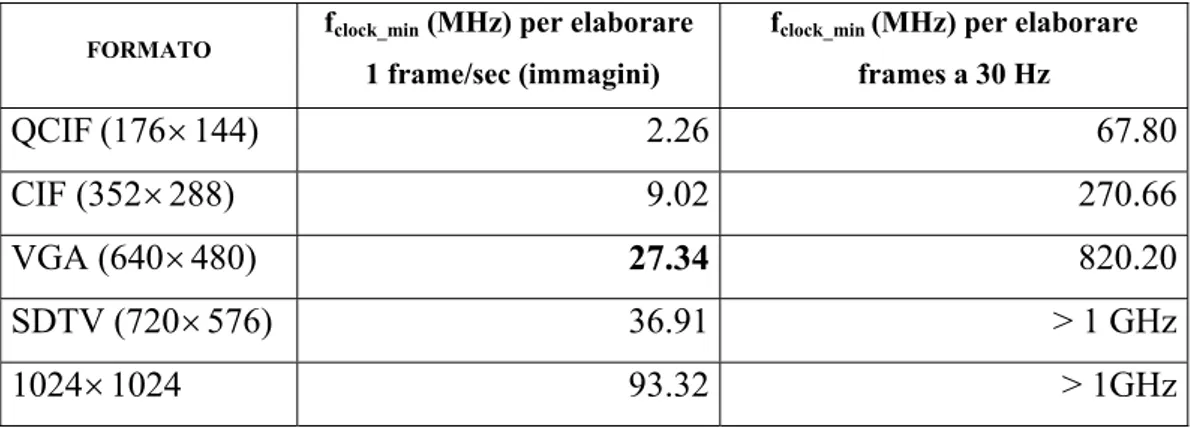
Questo approccio è tipicamente indicato nel caso di applicazioni dinamiche quali riprese video, pertanto i risultati ottenuti dal progetto del filtro RRF sono sicuramente validi per quanto riguarda le applicazioni statiche, e possono essere estese alle applicazioni video per qualche formato non troppo grande, quale il QCIF. Nella tabella 37 sono state calcolate le frequenze di clock necessarie per elaborare vari formati di immagine, staticamente e dinamicamente e sono state evidenziate le frequenze compatibili, almeno come ordine di grandezza, con i risultati forniti dalla sintesi.
FORMATO fclock_min (MHz) per elaborare
1 frame/sec (immagini)
fclock_min(MHz) per elaborare
frames a 30 Hz QCIF(176×144) 2.26 67.80 CIF (352×288) 9.02 270.66 VGA (640×480) 27.34 820.20 SDTV (720×576) 36.91 > 1 GHz 1024×1024 93.32 > 1GHz
Tabella 37. Frequenza di clock minima per elaborare vari formati nel caso statico e nel caso
dinamico, con parametri di default, in particolare Nc =4.
I dati riportati nella tabella precedente ci inducono a concludere che il sistema in esame non è adatto ad elaborare immagini dinamiche, specialmente per frequenze e formati troppo grandi, mentre nel caso delle applicazioni statiche, almeno per immagini non troppo estese, non ci sono problemi.
Nel caso si voglia estendere il sistema ad applicazioni video, si può pensare di rinunciare alle massime prestazioni offerte dal filtro riducendo il numero di scansioni, ad esempio effettuandone solo una. In tal caso si introdurrà del rumore
di fase, ma sarà possibile elaborare immagini in movimento. Nella tabella 38 si riportano le frequenze di clock richieste, per i vari formati, nel caso di video a 10 e a 30 Hz, con una sola scansione dell’immagine da elaborare. Ancora una volta sono state evidenziate le frequenze compatibili con le prestazioni di Retinex_A.
FORMATO fclock_min(MHz) per elaborare
frames a 10 Hz
fclock_min(MHz) per elaborare
frames a 30 Hz
125 X 86 3.44 10.32
QCIF(176×144) 8.11 24.33
CIF (352×288) 32.44 97.32
VGA (640×480) 98.30 294.9
Tabella 38. Frequenza di clock minima per elaborare vari formati nel caso statico e nel caso
dinamico, effettuando una sola scansione del frame sorgente (Nc =1).
Nel caso di un solo ciclo di scansione, le frequenze richieste, almeno fino a formati come il QCIF, sono compatibili con il filtro realizzato. Comunque, per applicazioni dinamiche, si tende a far uso di formati ancor più piccoli, come il 125 x 86, che per questo sistema permettono di elaborare anche video a 30 Hz con frequenze di clock dell’ordine dei 10 MHz, dunque in accordo con i limiti trovati per il filtro RRF.
Un ulteriore miglioramento della velocità di elaborazione, sebbene non elevato, può essere ottenuta implementando un’architettura in grado di realizzare il calcolo della riflettanza in pipeline con il calcolo della luminanza. Per fare un esempio, un filmato a 30 Hz in formato QCIF, richiederebbe una frequenza di clock pari a: 14.45 MHz.
Bisogna ricordare che il sistema implementato in questo lavoro fa parte di un progetto più complesso, che è stato diviso nel qui presente Retinex_A e nella parte Retinex_B, che prevede altri blocchi funzionali (vedi figura 1 cap.1), dunque è lecito chiedersi se le prestazioni appena stimate non siano da rivedere, considerando il sistema completo. Ragionando però sul fatto che i blocchi a valle del filtro RRF non prevedono un anello di reazione, possiamo ipotizzare che sia proprio il filtro RRF a limitare in basso le prestazioni in termini di velocità elaborazione. Questi ragionamenti sono stati confermati dal progettista dei blocchi
suddetti, il quale in fase di sintesi ha trovato una frequenza massima di clock per il suo sistema pari a circa 38 Mhz.
Come già anticipato, Xilinx ISE 6 permette di visualizzare lo schematico RTL (Register Transfer Level) in cui si parte dal top–level del sistema, rappresentato come blocco unico con rappresentati ingressi ed uscite, ed è poi possibile scendere sempre più di livello, aprendo i vari blocchi. Si può arrivare fino al livello delle porte logiche. Per quanto riguarda questo progetto, riportiamo per completezza, nella figura 77, il top-level e, in figura 78, un esempio di blocco a livello inferiore: il moltiplicatore di uscita del filtro RRF.
Figura 77. Top-level del sistema Retinex_A
Fedelmente alla descrizione VHDL operata per questo blocco, possiamo riconoscere, nella figura 78, tre registri a flip-flop, di cui due in ingresso ed uno in uscita per campionare gli operandi e registrare il risultato, ed il blocco moltiplicatore vero e proprio, che potrebbe essere a sua volta aperto per vederne la struttura interna.
5.3
DEFINIZIONE PIN DI I/O DEL SISTEMALa figura 77 relativa al top-level del sistema permette di individuare i pin di ingresso e uscita del chip che sarà realizzato. Ovviamente i segnali interni, ad esempio le uscite della macchina a stati finiti Enable_Generator non sono accessibili. L’utente può invece accedere ai pin d’ingresso clk, enable, reset, start, alfa (1…0), lines_in (9…0), cols_in (9…0), cycles (1…0).
Per quanto concerne i pin di uscita, ne abbiamo due: frame_y_valid e frame_r_valid e servono per informare il sistema Retinex_B del fatto che il calcolo dei segnali di luminanza e di riflettanza è stato ultimato, e quindi è possibile proseguire nelle elaborazioni fino ad ottenere l’immagine di uscita finale.
In questo capitolo sono state dunque verificate le specifiche di progetto proposte all’inizio di tutto il lavoro, sono state valutate le massime prestazioni raggiungibili, e si sono infine fornite delle alternative per l’adeguamento e l’aggiornamento del sistema, o per estenderlo ad altre applicazioni, allo scopo di fornire a tutta questa trattazione, se ce ne fosse bisogno, ancor più generalità e prospettive di sviluppo.