Risorse Linguistiche
Ogni applicazione di NLP richiede ingenti risorse linguistiche in quanto il trattamento del linguaggio naturale necessita di materiale e strumenti adatti alla sua gestione e analisi.
La progettazione e l’implementazione del sistema studiato e sviluppato per questo lavoro di tesi sono basati su tecnologia Synthema per il tratta-mento del linguaggio naturale (Lexical System TechnologyTM
o LST). In particolare `e stato utilizzato l’ambiente Synthema Lexical Studio capace di integrare al suo interno un sistema di gestione di basi di dati lessicali, un analizzatore (parser) sintattico, un editor di dizionari e di grammatiche e un lemmatizzatore per effettuare la disambiguazione lessicale. Lexical Stu-dio possiede dizionari generali monolingue o bilingue e dizionari di sinonimi, risorse contenenti importanti definizioni morfologiche, sintattiche e seman-tiche per la lingua italiana. Con Lexical Studio abbiamo avuto a
ne uno strumento per modificare e controllare le risorse come il linguaggio (che raccoglie morfologia, sintassi e semantica), il lessico (monolingue, bilin-gue, sinonimi e contrari) e la grammatica (adatta per la comprensione della struttura della frase, per l’analisi degli errori e per la lemmatizzazione).
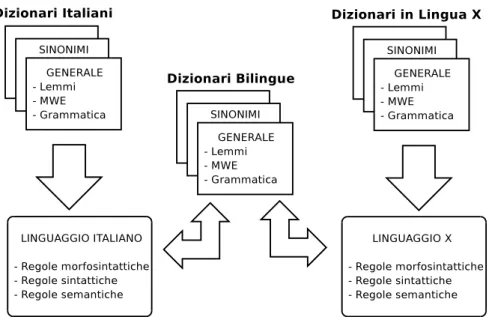
Figura 3.1: Dizionari e Linguaggi.
3.1
Il Sistema di Gestione di Basi di Dati Lessicali
Un modulo fonamentale di Lexical Studio per il controllo delle risorse `e il Si-stema di Gestione di Basi di Dati Lessicali(Lexical Data Base Management System, LDBMS), originariamente creato presso il Centro Ricerca IBM poi perfezionato e ampliato da Synthema [17]. Con tale modulo `e possibile ge-stire contemporaneamente i dizionari (monolingue, bilingue o sinonimi) per diverse lingue.
Le caratteristiche principali del LDBMS sono le seguenti:
• indipendenza tra il sistema, l’applicazione e il linguaggio;
• indipendenza tra il numero dei dizionari e la dimensione dei lessici;
• capacit`a di memorizzare relazioni tra unit`a lessicali ed informazioni sia sintattiche che semantiche;
• ottimizzazione dei tempi di accesso alle strutture.
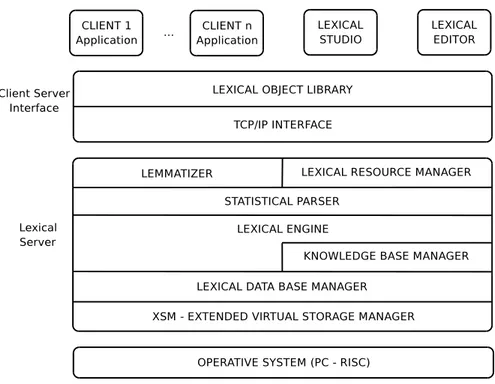
Figura 3.2: L’architettura del sistema.
LDBMS `e basato su un’architettura ABCD (A Basic Computer Dictio-nary) [33] che garantisce tempi brevi per l’accesso alle informazioni
lessi-cali. Inoltre vengono garantite una buona flessibilit`a e la trasportabilit`a in ambienti e piattaforme differenti.
L’elemento pi`u importante del LDBMS `e il dizionario, per questo l’ar-chitettura ABCD `e opportunamente organizzata allo scopo di permettere sia la descrizione logica dell’intero dizionario sia i pr`ıncipi di memorizzazio-ne. Inoltre le procedure di ricerca delle informazioni nei vocabolari devono essere tali da mantenere tempi di risposta contenuti.
La struttura del sistema `e tale da prevedere la massima indipendenza tra l’organizzazione delle parole e le regole che le governano. Ci`o `e possi-bile mantenendo distinte due entit`a: il dizionario e il linguaggio. Il primo oggetto rappresenta l’insieme di tutte le parole (quindi il lessico), mentre il secondo `e formato da tutte le regole che consentono la generazione di una lingua. Questo genere di suddivisione `e giustificabile tenendo presente che tipicamente lessici differenti di uno stesso linguaggio (ad esempio un lessico medico ed uno matematico) fanno riferimento allo stesso insieme di regole, che non avrebbe senso duplicare. Grazie a questa distinzione `e possibile mantenere nel sistema pi`u dizionari regolati da uno stesso linguaggio.
3.2
Il Dizionario
Il dizionario `e un risorsa molto importante per uno strumento di predizione e, in generale, per ogni sistema per il trattamento automatico del linguaggio naturale.
Il vasto dizionario Synthema della lingua italiana `e formato da circa 43.800 lemmi, 876.000 forme e 1.165.000 classificazioni; inoltre sono dispo-nibili alcuni dizionari specialistici o tematici (come quello geografico o dei cognomi).
3.2.1
Organizzazione Logica del Dizionario
Le informazioni incluse nel dizionario sono rappresentabili logicamente nel seguente formato tabellare:
lemma: (POS, Features, Regole di Flessione, Regole di Alterazione)
Qualora si presentassero casi omografi, i lemmi inseriti saranno replica-ti tante volte quante sono le possibili accezioni, come mostra l’esempio in Tabella 3.1.
Forma Classificazione
la Articolo Determinativo Femminile Singolare la Sostantivo Maschile Singolare
la Pronome Personale Femminile di Terza Persona Tabella 3.1: Possibili classificazioni della forma “la”.
La POS (Part-of-Speech) indica la categoria grammaticale, nelle nove forme previste per l’italiano (si veda in proposito l’Appendice B). Di seguito alla categoria sintattica viene inserito un elenco di caratteristiche (featu-res) ovvero una serie di attributi che classificano il lemma secondo aspetti
specifici: qualit`a sintattiche (verbo transitivo, intransitivo, ausiliare), forma grafica (tutto maiuscolo o solo l’iniziale) ed altre informazioni funzionali utili alla grammatica per la costruzione della frase.
Le regole di flessione e di alterazione rappresentano le modalit`a con cui il lemma in questione pu`o essere flesso e alterato. Nel caso in cui vi siano pi`u paradigmi di flessione e di alterazione, il lemma sar`a ripetuto in tutte le sue possibili forme.
Lemma POS Features IRULE ARULE
certamente ADV FREQ, MODAL — 92
raccolto ADJ EVAL, PASTPART 1 62
abolizionista NOUN RARE, CONC, ANIM, HUM 9 — Tabella 3.2: Alcune voci del dizionario.
La Tabella 3.2 mostra un esempio di alcuni elementi presenti nel dizio-nario1
. Da questa tabella possiamo notare che il lemma “abolizionista”: • `e un sostantivo (NOUN);
• `e classificato come parola poco usata (RARE), concreta (CONC), con soggetto animato (ANIM) e umano (HUM);
• segue la flessione associata alla regola con codice 9: quella di “artista”,
1I campi “IRULE” (Inflection Rule) e “ARULE” (Alteration Rule) identificano codici
che fanno riferimento a regole rispettivamente di flessione e di alterazione del lemma, si veda la Sezione 3.3.
che flette in “artisti ”e “artiste” (come `e possibile vedere nella Sezione 3.3.1);
• non `e presente alcuna regola di alterazione.
3.2.2
La Struttura del Dizionario
Come gi`a detto, il dizionario `e la componente del LDBMS maggiormen-te utilizzata. Per questo la sua struttura e le sue propriet`a acquisiscono grande attenzione poich´e incidono pesantemente su tutto il sistema. L’ar-chitettura ABCD descrive sia l’intera struttura logica del dizionario che le tecniche di memorizzazione virtuale. Inoltre essa permette l’ottimizzazione della velocit`a di accesso alle informazioni lessicali.
I meccanismi utilizzati per la ricerca delle informazioni all’interno del di-zionario sono stati scelti ed implementati al fine di ottenere tempi di risposta efficienti. A tal proposito, le ricerche devono essere tali da minimizzare il numero di passi logici massimizzando, allo stesso momento, la quantit`a di dati reperiti.
Come riportato nell’Appendice B, viene definito lemma la parola di cui tratta ciascuna entrata di un dizionario. Mentre con il termine forma si intende un aspetto morfologico della parola, ovvero una sua variante lessicale (come la forma femminile, la forma plurale o la forma attiva e passiva del verbo). Prendendo, per esempio, il lemma coraggioso, una sua possibile
forma pu`o essere coraggiosi (forma maschile plurale) o coraggiosa (forma femminile singolare).
Il dizionario `e di tipo non generativo, ovvero formato da tutte e sole le forme ammesse dal lessico (il dizionario `e completo). I dizionari non gene-rativi possono essere creati attraverso una fase di generazione che permette la produzione delle forme. Al contrario, i dizionari generativi sono composti esclusivamente dai lemmi di origine e sono caratterizzati da complesse fun-zioni di ricerca che, data una forma, tentano di risalire al lemma tramite le regole di flessione e di alterazione.
La completezza di un dizionario cos`ı strutturato consente di evitare le diverse fasi di analisi morfologica ed inoltre garantisce la massima correttezza dato che sono memorizzate solo le parole valide. Per contro vi `e la necessit`a di memorizzare una vasta quantit`a di informazioni.
`
E possibile fare, a priori, una considerazione riguardo la lingua italiana e, in genere, le altre lingue indoeuropee: dato un lemma, vi `e un’alta probabi-lit`a che le sue forme possano variare solo nella parte finale. In altri termini, si pu`o pensare alle parole come composte da una prima parte collegata al significato semantico e da una seconda che identifica gli attributi morfologici e grammaticali.
In seguito ad un’analisi morfologica accurata ed alquanto complessa `e stata studiata la lunghezza media delle parole, considerando forme flesse e alterate [3]. Ne `e risultato che mediamente una parola in lingua italiana `e
composta da dieci caratteri, e inoltre, limitando la lunghezza massima dei suffissi, `e possibile formare un gruppo ristretto di tutti i possibili suffissi flessi e/o alterati in tutte le forme.
Per le motivazioni sopra descritte e per sfruttare al meglio le operazioni di consultazione delle informazioni, per la memorizzazione `e stata adottata una struttura ad albero: Tree Word List (TWL). Detta struttura `e formata da un doppio albero che consente di identificare una parola come la com-posizione di una parte sinistra iniziale detta radice (che non corrisponde al concetto linguistico di tema) ed una parte destra finale detta suffisso. L’organizzazione logica appena presentata, rispecchia quella fisica in quanto l’albero delle radici (Lexicon TWL) e quello dei suffissi (Language TWL) determinano due strutture distinte ma altamente collegate, appartenenti rispettivamente al dizionario e al linguaggio.
La condivisione delle componenti della TWL generale `e massima, tale da mantenere compatto l’albero di tutte le forme. Attualmente l’intero dizio-nario italiano comprende circa 43.000 lemmi per 800.000 forme ed occupa meno di 14Mb.
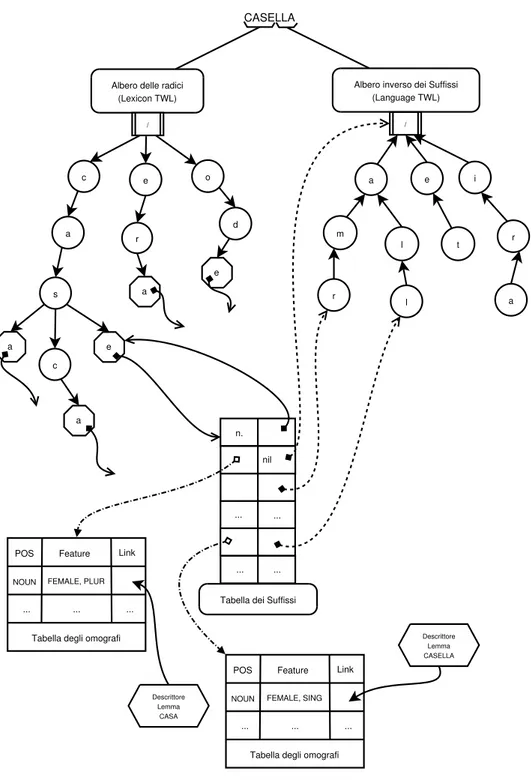
Come possiamo vedere in Figura 3.3, l’albero delle radici (Lexicon TWL) `e formato da nodi terminali (raffigurati a forma ottagonale) e non terminali (a forma circolare). I nodi terminali sono collegati anche ad una struttura detta Tabella dei Suffissi la quale rappresenta la connessione delle due TWL e consente il formarsi della parola come successione di una radice e di un
CASELLA
Albero delle radici (Lexicon TWL)
/
Albero inverso dei Suffissi (Language TWL) / c e o a a s i l r a d c t l e r a m r a a e
Tabella dei Suffissi n.
... ...
... ... nil e
POS Feature Link
NOUN FEMALE, PLUR
... ... ...
Tabella degli omografi
Descrittore Lemma CASA Descrittore Lemma CASELLA POS Feature Link
NOUN FEMALE, SING
... ... ...
Tabella degli omografi
suffisso. La Tabella dei Suffissi, infatti, contiene un legame tra la radice e tutti i possibili suffissi connessi cos`ı da ottenere tutte le forme. Inoltre, tale tabella possiede altri collegamenti tra cui la Tabella degli omografi di ogni forma per determinare la classificazione2
.
La struttura cos`ı organizzata permette una ricerca delle parole in modo semplice e ricorsivo. Oltre a ci`o `e minimizzata la duplicazione dei dati.
3.2.3
Generazione e Gestione dei Dizionari
I dizionari utilizzati da Lexical Studio devono sottoporsi ad una precedente fase di “generazione”. Un’operazione di questo tipo consente di espandere i lemmi attraverso le regole previste nel linguaggio (flessione, alterazione ed uso di enclitici, come vedremo nello specifico nella sezione successiva) per poter disporre di tutte le parole.
La generazione del dizionario avviene una tantum ed `e legata alle regole grammaticali definite nel linguaggio di riferimento. L’analizzatore sintatti-co di Lexical Studio effettuer`a il riconoscimento e il confronto delle parole esaminate con quelle generate. Al momento dell’analisi, le parole sono tut-te presenti nei dizionari che il parser utilizza, garantut-tendo, cos`ı, prestazioni non ottenibili con motori di riconoscimento morfologico operanti a tempo di esecuzione.
Per la fase di test `e stato scelto di implementare e usare un dizionario
2Classificare una forma significa specificare la categoria grammaticale, il lemma di
di dimensioni limitate: una raccolta di parole italiane pi`u frequenti (circa 2.400 lemmi).
3.3
Il Linguaggio
Come accennato in precedenza, il sistema utilizzato distingue due entit`a di-verse: il dizionario e il linguaggio. Nella seconda entit`a vengono considerate tutte le modalit`a di variazione del lemma, di coniugazione, uso degli encliti-ci, le informazioni di tipo sintattico e semantico e le regole grammaticali di una lingua. Una parte di questi concetti servono occasionalmente alla gene-razione del dizionario, mentre altri (come la grammatica) rappresentano la parte centrale della fase di analisi sintattica di una frase.
Vedremo, in seguito, una panoramica sulle principali regole utilizzate nel linguaggio per la creazione dei dizionari e per l’analisi del testo.
3.3.1
Modalit`
a di Flessione: Declinazione e Coniugazione
Le regole che governano le condizioni di flessione (spesso citate come Inflec-tion Rule, IRULE) per aggettivi e sostantivi sono memorizzate in strutture apposite ed organizzate per ogni categoria in modo da far riferimento ad un lemma-tipo. Per esso viene esplicitata la completa flessione e associata ad un codice identificativo. In Tabella 3.3 `e mostrato un esempio di Inflection Ru-le per la declinazione dei sostantivi singolari sia maschili che femminili che seguono il lemma-tipo “artista” (ne `e un esempio il sostantivo “corista”).
IRULE: CODE 9
MALE FEMALE SING (artista) MALE PLUR (artisti )
FEMALE PLUR (artiste)
Tabella 3.3: Regola di flessione per i sostantivi.
Le regole per la coniugazione dei verbi sono riportate in strutture simili, organizzate in forma tabellare e numerata per la determinazione di un verbo-tipo. Riportiamo nella Tabella 3.4 un esempio di modalit`a di coniugazione del verbo “amare”, ovvero un verbo appartenente alla prima forma (-are) e in assenza di consonanti gutturali (come “ch” e “gh”) o palatali (come “ci”, “ce”, “gi” e “ge”). In tale tabella sono riportati i modi di coniugazione e, per ognuno di essi, le forme in ogni persona ammessa. I tempi composti con i verbi ausiliari saranno verificati con la grammatica, ma comunque riconducibili alle forme qui presenti.
3.3.2
Modalit`
a di Alterazione
I meccanismi che regolano le capacit`a di alterazione (riportate in seguito come ARULE, da Alteration Rule), sono strutturate similmente alle regole di flessione. In una struttura tabellare vengono riportate, a capo di ogni co-dice identificativo, tutte le possibili tipologie di alterazione previste da uno specifico lemma preso come modello base. Attraverso l’espansione di questo lemma vengono create le forme alterate, come il diminutivo, il
vezzeggiati-CODE 001 amare
Indicativo Presente
amo ami ama amiamo amate amano
Indicativo Imperfetto
amavo amavi amava amavamo amavate amavano
Passato Remoto
amai amasti am`o amammo amaste amarono
Futuro Semplice
amer`o amerai amer`a ameremo amerete ameranno
Congiuntivo Presente
ami ami ami amiamo amiate amino
Congiuntivo Imperfetto
amassi amassi amasse amassimo amaste amassero
Condizionale Presente
amerei ameresti amerebbe ameremmo amereste amerebbero
Imperativo
— ama ami amiamo amate amino
Participio Presente Infinito
amante amanti amare amar
Participio Passato Gerundio
amato amata amati amate amando Tabella 3.4: Regola di coniugazione per i verbi.
vo o il superlativo. Cos`ı facendo l’alterazione viene descritta in tutte le sue possibili circostanze, ma solo al momento della generazione vengono costrui-te solo le forme plausibili: ad esempio il diminutivo dell’aggettivo “bello” ammette “bellino”, “bellina”, “bellini” e “belline”, ma applicando la regola del diminutivo al sostantivo “macchina” vengono generate soltanto le forme corrette “macchinina” e “macchinine”, ma non le due forme maschili.
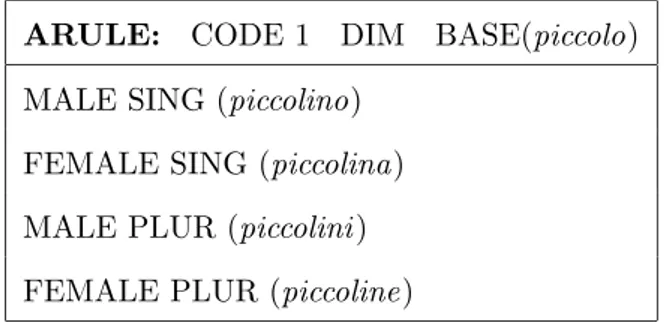
ARULE: CODE 1 DIM BASE(piccolo) MALE SING (piccolino)
FEMALE SING (piccolina) MALE PLUR (piccolini ) FEMALE PLUR (piccoline)
Tabella 3.5: Regola di alterazione.
La Tabella 3.5 mostra un esempio di schema di alterazione, in partico-lare la formazione del diminutivo di tutte le parole che si declinano come l’aggettivo “piccolo”.
3.3.3
Enclitici
In fase di generazione, vengono costruite le opportune forme enclitiche di ogni verbo sulla base delle propriet`a sintattiche che gli vengono attribui-te nella fase di definizione. Con tali propriet`a si accede alla tabella di definizione degli enclitici e il sistema genera la forma corrispondente.
IMP PRES PERS2 SING, IMP PRES PERS1 PLUR, IMP PRES PERS2 PLUR, GERUND,
PART PAST MALE SING, INF
FEAT(TRAN)
lo ECLIT(OBJ PERS3 MALE SING) Tabella 3.6: Esempio di enclitico.
Per comprendere l’esempio in Tabella 3.6 `e necessario una sua lettura dal basso verso l’alto: qui viene mostrato l’uso di “lo”, enclitico accusativo di terza persona maschile singolare. Da tale definizione `e ricavabile che “lo” si applica ai verbi transitivi, nello specifico alle sei forme flesse indicate nella tabella. Ad esempio dal verbo “mangiare” vengono generati nell’ordine: “mangiarlo”, “mangiatolo”, “mangiandolo”, “mangiatelo”, “mangiamolo” e “mangialo”.
3.3.4
Propriet`
a Sintattiche e Semantiche
Per concludere le propriet`a del linguaggio, citiamo l’utilit`a di informazio-ni aggiuntive che possono essere attribuite ad ognuna delle nove categorie grammaticali. Ciascun lemma possiede, dunque, caratteristiche esplicite in-cluse nel dizionario (RARE, CONC, ANIM, ecc.) o individuate al momento della generazione della forma flessa (FEMALE, PLUR, SUPR, GERUND,
PERSn, ecc.).
Le propriet`a sintattiche sono presentate in una tabella e possono descri-vere, al momento, fino a 128 informazioni diverse per ogni part-of-speech per un totale di circa 300 attributi.
Attualmente non sono previste molte indicazioni a livello semantico, ma l’ampliamento in questa direzione pu`o essere realizzato e gestito impiegando, anche in questo contesto, opportune informazioni da utilizzare assieme alle regole della grammatica.
3.3.5
La Grammatica
I soli dizionari non sono sufficienti ad individuare univocamente il ruolo di una parola all’interno della frase poich´e con essi `e solo possibile disporre di tutte le classificazioni sintattiche (POS) dei termini omografi ma non ag-giungono criteri per la discriminazione tra le varie scelte. L’eliminazione di queste ambiguit`a `e dunque possibile grazie all’insieme delle regole gramma-ticali, definite secondo la sintassi del Linguaggio per la Scrittura di Regole (LSR).
Le regole grammaticali scritte con LSR deveno essere compilate (per va-lutare la correttezza formale delle regole) e caricate in uno spazio di memoria opportuno. Solo a questo punto il parser pu`o utilizzarle per l’analisi della frase.
tipologie: la grammatica del dizionario (ogni dizionario pu`o avere la propria per l’individuazione delle espressioni polilessicali tipiche) e la grammatica del linguaggio, per l’individuazione delle strutture sintattiche proprie del linguaggio stesso.
Partendo dalla grammatica del dizionario, scendiamo nel particolare per darne una descrizione esplicativa.
La Grammatica del Dizionario
L’insieme delle regole grammaticali appartenenti a ciascun dizionario com-prende vincoli specialistici legati ad esso e non al linguaggio. Si tratta di una grammatica specialistica capace di raggruppare le espressioni composte (come “Banca d’Italia” o “bacino idrografico”), le locuzioni (come “stanco morto” o “a quattr’occhi”) e le espressioni idiomatiche appartenenti ad una particolare lingua o dialetto (come “fare la cresta” o “prendere un gran-chio”). Il significato complessivo di queste espressioni non corrisponde spes-so alla semplice composizione del significato letterale delle singole parti: si parla di Multi Word Expressions (MWE) da cui il nome di Grammatica MWE.
La grammatica MWE ha lo stesso formalismo delle regole del linguaggio e considera una sequenza di unit`a lessicali, che verifica particolari condizioni, raggruppata in un singolo token. `E il caso di molte espressioni composte come quelle viste in precedenza, che occorrono molto spesso in relazione al
dizionario di riferimento, come anche in ambito geografico (si pensi a “Emilia Romagna”, “La Spezia”, “Las Vegas” o “New York City”).
CODE <0731>
PREP(BASE==‘‘in ’’, TYPE==ARTFORM) NOUN(BASE==‘‘caso ’’, NUMB==SING) CONJ(BASE==‘‘che ’’)
=⇒ CONJ(=:(CONJ))
Tabella 3.7: Una particolare Multi Word Expression (MWE).
Nella Tabella 3.7 `e riportato l’esempio di espressione “in caso che”: essa viene trasformata, in seguito a questa regola, in un’unica entit`a (una con-giunzione). Il perno della regola `e “che”; la regola controlla che l’elemento perno sia preceduto dal sostantivo singolare “caso” e prima ancora dalla preposizione semplice “in”. Se il pattern si verifica allora viene prodotto un nuovo token CONJ (congiunzione) a cui viene associata tutta la sequenza.
La Grammatica Generale
L’altra tipologia di grammatica `e quella appartenente al linguaggio, definita grammatica generale. Le sue regole sono suddivisibili in due gruppi: le regole positive, per il riconoscimento della struttura della frase, e le regole negative, per l’individuazione degli errori. In Tabella 3.8 e in Tabella 3.9 sono riportati due esempi di regole, la prima positiva e la seconda negativa.
CODE <P0015>
ADJ(GEND==GEND(NOUN), NUMB==NUMB(NOUN), ALTC==GOW||CASE(NOUN))
NOUN() =⇒
CNOUN(=:(ADJ), PERS=PERS3, HEAD (NOUN), DET=(ADJ)) Tabella 3.8: Esempio di regola positiva.
Nella regola presentata in Tabella 3.8 il perno `e rappresentato da NOUN(); l’aggettivo che precede il sostantivo perno deve concordare con esso in ge-nere e in numero, ed inoltre deve esserci concordanza in alterazione (ALTC). In questa notazione, la virgola indica l’AND mentre l’operatore || rappre-senta la concatenazione. La funzione CASE(NOUN) pu`o essere VOWEL, CONS o SPUR a seconda che l’iniziale del sostantivo base sia rispettivamente una vocale (“albero”), consonante pura (“ragazzo”) o consonante spuria (“scali-no”). Quindi il pattern specifica che l’aggettivo dovr`a avere l’attributo ALTC uguale GOWVOWEL (go with vowel, ad esempio bell’ ), GOWCONS (bel ) o GOWSPUR (bello) in concordanza con l’iniziale del sostantivo: in caso di “s” o “g”, ven-gono considerate le prime due lettere (“il sole”, “il gatto”, “lo stadio”, “lo gnomo”). Se il pattern viene verificato, si produce un nuovo token CNOUN (Composite NOUN) di livello pi`u alto, che specifica il ruolo di terza persona del sintagma.
CODE <p0090>
CONJ(ID=MAIN, BASE==‘‘ma ’’) CONJ(BASE==‘‘per`o’’)
=⇒ ECONJ(ERR==24)
Tabella 3.9: Esempio di regola negativa.
presenti la costruzione “ma per`o”. La congiunzione “per`o” `e il perno e, se `e preceduto dalla congiunzione “ma”, si verifica il pattern segnalando il particolare errore.
3.4
Il Parser Sintattico
Il modulo per la gestione delle risorse `e composto da due elementi principali:
- il gestore dei dizionari, - il parser sintattico.
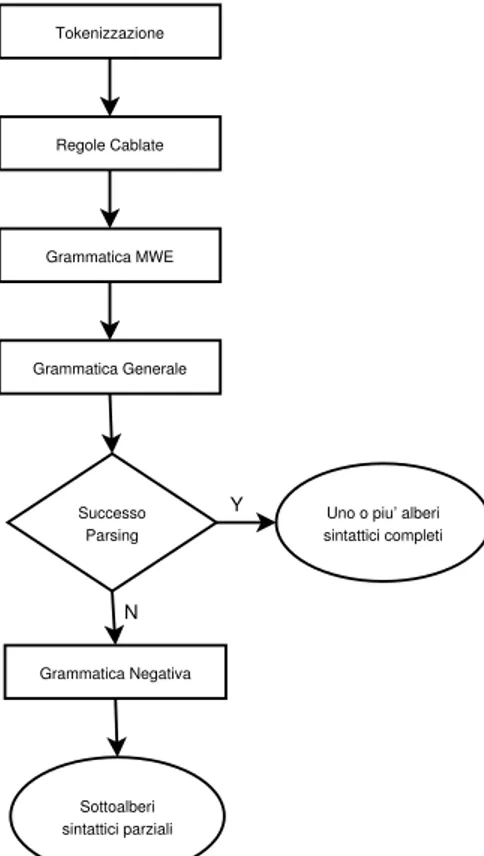
Il parser sintattico (o analizzatore) esegue diverse fasi di analisi della frase ed `e basato sul linguaggio. In Figura 3.4 sono riportate le fasi che comprendono l’operato del parser.
1. Tokenizzazione: tutte le frasi in ingresso al parser vengono scandi-te e suddivise in token (ovvero unit`a lessicali minime), che poi sono classificati attraverso l’uso del dizionario. Da questa operazione se-gue la costruzione di una catena di token formata da tutte le possibili
Grammatica Generale Grammatica Negativa Grammatica MWE Tokenizzazione Regole Cablate Successo Parsing
Uno o piu’ alberi sintattici completi
Sottoalberi sintattici parziali
Y
N
Figura 3.4: Fasi principali del Parser Synthema.
classificazioni (anche molteplici per un’unica parola) dei termini che compongono la frase.
2. Regole Cablate: attraverso regole scritte appositamente, `e possibile ottimizzare l’accesso alle strutture dati del sistema. Fanno parte di questa categoria i pr`ıncipi “deterministici” che permettono la costru-zione o l’esclusione di un singolo token. Ad esempio, il pronome di prima persona singolare “mio” ha valenza nel ruolo di aggettivo pos-sessivo: un’opportuna regola pu`o verificare il ruolo della parola rispet-to a quelle adiacenti e discriminare tra pronome e aggettivo (infatti
se seguita da un sostantivo essa non pu`o essere un pronome). Cos`ı“ facendo viene ridotto il numero di possibili classificazioni per il singolo token.
3. Grammatica MWE: la catena di token viene successivamente analiz-zata dalla grammatica del dizionario per individuare le espressioni po-lilessicali (MWE), realizzando in questo modo, una seconda riduzione del numero degli elementi.
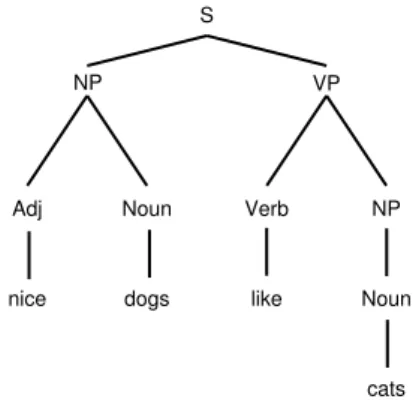
4. Grammatica Generale: in seguito viene applicata la grammatica gene-rale del linguaggio che consente la disambiguazione delle classificazioni. Dunque viene prodotto l’albero sintattico risultante (ne `e un esempio quello in Figura 3.5), cercando di riportare tutte le foglie ad un’unica radice. La chiusura dell’albero rappresenta la corretta individuazione dei legami tra token e quindi il riconoscimento della struttura gram-maticale ammessa da ogni frase nel testo analizzato. Se la frase `e ambigua, allora si possono produrre pi`u alberi sintattici.
5. Grammatica Negativa: nel caso in cui la finalit`a del parsing sia l’indi-viduazione o la correzione degli errori, l’analizzatore prevede la possi-bilit`a di attivare la grammatica negativa la quale produrr`a segnalazioni per i token ritenuti discordanti e per le costruzioni risultate errate.
S
NP VP
Adj Noun Verb NP
Noun
nice dogs like
cats
Figura 3.5: Albero sintattico per la frase “nice dogs like cats”.
3.4.1
Caratteristiche del Parser Synthema
Riassumendo i concetti sopra descritti e volendo fornire osservazioni da un punto di vista tecnico, il parser Synthema presenta le seguenti caratteristi-che:
• scansione del testo da sinistra a destra con assenza di look-ahead; • analisi di tipo bottom-up e depth-first: in particolare la scansione della
grammatica e il reperimento delle regole avviene dal caso specifico al caso generale, e le scelte alternative vengono provate, in successione, una dopo l’altra;
• suddivisione dell’intero testo in frasi poich´e la frase `e considerata come unit`a di analisi;
• parsing con grammatiche multiple prodotte con il linguaggio LSR, presentato nella Sezione 3.3.5;
• restituzione, in caso di successo, di una struttura del testo in uno o pi`u alberi sintattici completi. Qualora si presenti il caso di mancata chiusura del parsing, la struttura prodotta contiene diversi sottoalberi parziali con l’eventuale indicazione degli errori individuati.
3.5
Il Lemmatizzatore
La lemmatizzazione `e quel complesso di operazioni svolte per riuscire a con-durre tutte le forme sotto il rispettivo lemma [12]. Con il termine “lem-ma” si intende ciascuna parola-tipo o parola-chiave di un dizionario, mentre “forma” indica ogni possibile diversa realizzazione grafica di un lemma. La lemmatizzazione, quindi, consiste nell’attribuire alle varianti flesse (uomini ), alterate (ometto) o grafiche (omo) la sua forma base (uomo), che ricopre il ruolo del lemma.
`
E possibile fare delle prime considerazioni:
• esistono delle convenzioni di lemmatizzazione intrinseche in ciascuna lingua (specialmente per una lingua ricca come l’italiano);
• il lemma `e anche una forma (non vale per`o il contrario): mangiare `e sia un lemma che una forma.
Le operazioni di lemmatizzazione risultano apparentemente facili: `e ov-vio per ogni essere umano effettuare tali compiti quotidianamente esercitan-do la differenza tra lemma e forma. Tuttavia la lemmatizzazione effettuata
da una macchina `e un processo complesso, poich´e si devono formalizzare tutti gli automatismi che l’uomo mette inconsciamente in atto ogni volta che vuole parlare o scrivere.
La lemmatizzazione acquisisce interesse se si pensa ad essa come ad una forma di organizzazione del materiale lessicale di un testo. La maggior parte delle ricerche testuali, infatti, sono concentrate a reperire tutte le occorrenze di un dato lemma sotto qualsiasi forma esso si presenti, mentre `e certamente pi`u raro il caso che si miri all’indagine di una particolare forma.
All’interno dell’ambiente di Lexical Studio, la lemmatizzazione `e effet-tuata esaminando l’albero sintattico prodotto dal parser. In pratica, con questo meccanismo si vuole associare ad ogni forma flessa una coppia cos`ı formata:
[(sestupla), (lemma di origine)]
L’elemento denominato “sestupla” identifica una rappresentazione di una serie di informazioni, tra cui la part-of-speech (che `e la stessa del lemma). Un esempio di risultato della lemmatizzazione `e riportato in Figura 3.6: viene presentata la parola “bambina” come forma flessa del lemma “bambino”. La sestupla indicata denota che la forma `e rispettivamente un sostantivo (POS = S), comune (C), di genere femminile (F) e singolare (S). Le ultime due informazioni nella sestupla appartengono al lemma di origine (in questo caso “bambino”), che infatti `e di genere maschile (M) e singolare (S).
bambina [(S C F S
| {z } f ormaM S), (bambino)]
| {z } lemmaFigura 3.6: Classificazione del sostantivo “bambina”.
ragazza [(S C F S M S), (ragazzo)] donna [(S C F S F S), (donna)] `
e [(V E N 3 I N), (essere)] aveva [(V A N 3 I I), (avere)] entrato [(V F M S P P), (entrare)] Tabella 3.10: Classificazioni di sostantivi e verbi.
Altri esempi sono mostrati nella Tabella 3.10, dove sono riportati due sostantivi e tre verbi. Nello specifico caso delle classificazioni dei verbi si ha che:
• “`e” risulta un verbo (POS = V), ausiliare essere (E), neutro (N), ter-za persona singolare (3), indicativo (I), presente (N), avente lemma “essere”;
• “aveva” `e un verbo (POS = V), ausiliare avere (A), neutro (N), ter-za persona singolare (3), indicativo (I), imperfetto (I), avente lemma “avere”;
• anche “entrato” `e un verbo (POS = V), intransitivo con ausiliare essere (F), maschile (M), singolare (S), participio (P), passato (P), con lemma “entrare”.
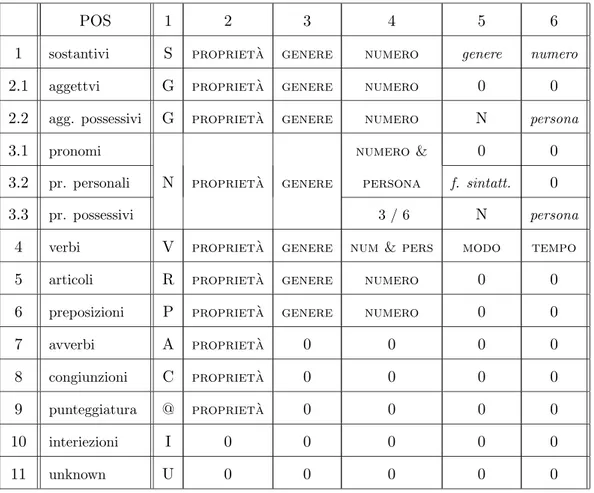
Lo schema generale delle informazioni contenute nelle sestuple per le diverse POS, `e riassunto nella Tabella 3.11. Il significato dei valori in essa contenuti `e il seguente:
• propriet`a: indica un’informazione aggiuntiva della forma che speci-fica ulteriormente la categoria (ad esempio la propriet`a “comune” per i sostantivi);
• genere: pu`o assumere valori uguali a M, F o N nel caso in cui la forma sia, rispettivamente, maschile, femminile o neutra (valida cio`e sia per il femminile che per il maschile);
• numero: viene specificato S, P o I a seconda che la forma sia singolare, plurale o indefinita;
• numero & persona: oltre agli elementi previsti nel campo numero, alcuni pronomi e i verbi possono assumere un valore compreso tra 1 e 6 che corrisponde ad una combinazione di persona e numero (1 indica la prima persona singolare e 6 la terza plurale);
• genere (del lemma): nel caso di sostantivi e aggettivi, questo campo pu`o assumere gli stessi valori del campo genere, mentre per i pronomi `e prevista una diversa tipologia a seconda del caso;
• numero (del lemma): ultimo elemento dei sostantivi che esprime la stessa modalit`a del campo numero ma per il lemma;
• persona (del lemma): comprende un valore tra 1 e 6 a seconda della persona del lemma (come nel caso precedente, 1 rappresenta la prima persona singolare e 6 la terza plurale);
• funzioni sintattiche: contiene valori per classificare la funzione della forma all’interno della frase: soggetto, oggetto, complemento indiretto, ecc.;
• modo e tempo: nel caso di verbi, gli ultimi due elementi della sestupla possono denotare la categoria della coniugazione verbale (il modo: in-dicativo, congiuntivo, condizionale, imperativo, participio, gerundio o infinito) e il sistema dei suffissi e delle desinenze che indica il momento e le modalit`a (il tempo: presente, futuro, passato e imperfetto).
POS 1 2 3 4 5 6 1 sostantivi S propriet`a genere numero genere numero
2.1 aggettvi G propriet`a genere numero 0 0
2.2 agg. possessivi G propriet`a genere numero N persona
3.1 pronomi numero & 0 0
3.2 pr. personali N propriet`a genere persona f. sintatt. 0 3.3 pr. possessivi 3 / 6 N persona
4 verbi V propriet`a genere num & pers modo tempo
5 articoli R propriet`a genere numero 0 0
6 preposizioni P propriet`a genere numero 0 0
7 avverbi A propriet`a 0 0 0 0
8 congiunzioni C propriet`a 0 0 0 0
9 punteggiatura @ propriet`a 0 0 0 0
10 interiezioni I 0 0 0 0 0
11 unknown U 0 0 0 0 0
Tabella 3.11: Schema di corrispondenza “POS / sestupla”.
Si noti che nella lingua italiana gli aggettivi e i pronomi possessivi non contengono informazioni di genere relative al riferente (N sta per neutro), a differenza, ad esempio, della lingua inglere (“his”, “her”).
Nel caso di pronome possessivo che funge da soggetto, il campo “3/6” in-dica la persona del verbo che deve essere terza, se il pronome `e singolare, altrimenti `e la sesta.
Si pu`o dedurre, quindi, che il significato degli ultimi due elementi della sestupla sono legati al primo. Infatti questi due dati:
• per sostantivi, aggettivi possessivi e pronomi possessivi indicano infor-mazioni sull’origine del lemma;
• per i pronomi personali il quinto elemento esprime la funzione sintat-tica, mentre il sesto `e nullo;
• per i verbi, il quinto e il sesto carattere rappresentano nell’ordine il modo e il tempo della coniugazione verbale;
• per le altre categorie, i due elementi sono nulli.
In Tabella 3.12 `e mostrata la Tabella di Lemmatizzazione estratta dal-l’analisi di alcuni testi precedentemente lemmatizzati.
3.5.1
La Grammatica Statistica
Ispirato al modello teorico delle Catene di Markov (viste nella Sezione 2.3.3), la grammatica statistica rappresenta un’altra importante componente a di-sposizione in Lexical Studio. Parte integrante della grammatica statistica `e il concetto di “tripla” (detta per questo Grammatica a Triple), corri-spondente alla definizione di “trigram”, ovvero una sequenza di tre sestuple che identificano la part-of-speech. Le triple risulteranno particolarmente significative all’interno del progetto realizzato per questa tesi.
Categoria Grammaticale
Informazione Aggiuntiva
Esempi
1 S = sostantivo C = default mano, vita, macchine H = persona Mario, Giorgio, Monica T = citt`a Londra, Bologna, Siena ecc.
2 V = verbo T = transitivo scrivere, vedere, misurare I = intransitivo arrivare, esistere, andare E = “essere” sono, sarai, essendo ecc.
3 R = articolo D = determinativo il, la, lo, l’ I = indeterminativo un, una, un’
4 G = aggettivo G = possessivo sua, loro, vostri N = numerale sette, milioni, 1975 I = indefinito molto, tante, certo ecc.
5 A = avverbio T = temporale ora, subito, dopo L = di luogo l`a, ovunque, qui C = comparativo meno, pi`u, cos`ı ecc.
6 C = congiunzione C = coordinativa e, ma, anche, ed S = subordinativa che, quando, infatti
Categoria Grammaticale
Informazione Aggiuntiva
Esempi
7 P = preposizione S = semplice di, a, da, in, con, su C = default alla, sul, nell’
8 N = pronome P = personale ci, lei, mi R = relativo che, quale, chi ecc.
9 I = interiezione 0 = default bene, brava, grazie
10 @ = punteggiatura 0 = default “!”, “;”, “.”
11 U = unknown 0 = default parole sconosciute non trattabili
Tabella 3.12: Tabella di lemmatizzazione.
Inizialmente, la grammatica a triple `e stata un prototipo capace di ve-locizzare il processo di lemmatizzazione sfruttando informazioni statistiche derivate dall’osservazione dello stile di composizione di testi.
Le triple, cos`ı come originariamente pensate, sono state ottenute at-traverso lo studio di un corpus giornalistico. L’estrazione delle triple ha previsto, infatti, una selezione di testi tali da trattare argomenti diversi, ma anche scritti da autori differenti e di varie testate editoriali (quotidiani, settimanali di attualit`a, periodici specialistici). Il corpus cos`ı ottenuto `e sufficientemente vario da poter costituire la base per l’analisi di documenti non vincolati ad un particolare ambito semantico. I testi selezionati sono stati lemmatizzati utilizzando una grammatica formale (scritta con il lin-guaggio LSR) e successivamente `e stata effettuata una revisione manuale
del risultato. Tale revisione risulta indispensabile (e onerosa) al fine di otte-nere corpora correttamente lemmatizzati e senza la presenza di ambiguit`a. Disporre di corpora corretti `e indispensabile per il successivo processo di generazione delle triple.
Il risultato della lemmatizzazione `e stato analizzato per individuare gli “oggetti lessicali” che occorrono spesso insieme, in modo da capire come ven-gono pi`u frequentemente costruite le frasi. Le tecniche utilizzate in questa fase di analisi seguono i fondamenti teorici presentati nella Sezione 2.4. In particolare sono state estratte le sestuple e aggregate in gruppi di tre rispet-tando l’unit`a sintattica minima (la frase). Supponiamo, ad esempio, di avere una frase di cinque parole (la quinta `e il simbolo di fine frase). Indicando con wi la i-esima parola e con P OS(wi) la corrispondente classificazione (o
meglio, la sestupla), possiamo ottenere le seguenti triple: [P OS(w1), P OS(w2), P OS(w3)]
[P OS(w2), P OS(w3), P OS(w4)]
[P OS(w3), P OS(w4), P OS(w5)]
Ad ogni tripla estratta `e stata, in seguito, attribuito un valore statistico in base alla frequenza con cui i tre elementi lessicali comparivano assieme. Le triple sono memorizzate in una struttura dati ad albero (simile a quella per il dizionario) in modo da ottimizzare le operazioni di ricerca. L’inserimento di una tripla avviene seguendo un algoritmo che ottimizza lo spazio di memoria e i tempi di accesso. In Tabella 3.13 sono riportati due esempi di triple.
[(verbo intransitivo), (preposizione), (sostantivo)]
dormire sul letto
restare a casa
[(pronome personale), (verbo transitivo), (articolo)]
io vedo la...(luna)
lei ama il...(ragazzo)
Tabella 3.13: Due esempi di tripla.
La grammatica a triple permette, dunque, di lemmatizzare un testo tra-mite l’analisi dell’occorrenza delle sequenze di parole all’interno di un certo corpus linguistico e non mediante un’analisi grammaticale e ad alcun rife-rimento alla sintassi. A parit`a di efficienza dell’analisi, il metodo statistico migliora i tempi di lemmatizzazione. Come ogni sistema probabilistico, per`o, questo sistema non `e del tutto corretto in quanto approssima la realt`a. Per-ci`o `e stato creato un sistema ibrido che prevede la coesistenza di entrambe le versioni di grammatiche. L’alternativa pu`o essere determinata in quel-le situazioni in cui sono significative quel-le prestazioni nell’ordine del tempo di esecuzione, mentre risulta irrilevante la corretta costruzione dell’albero sintattico della frase.
Infine, `e importante sottolineare, inoltre, che il corpus scelto per la crea-zione di questo tipo di grammatica statistica, `e legato al contesto tempo-rale. Pertanto, in linea di principio, il processo di estrazione delle triple (e l’attribuzione delle probabilit`a) deve essere ripetuto periodicamente.