11
2 Reti Neurali
2.1 Introduzione
Il calcolo che permette di ottenere i parametri di volo a partire dalle misure di pressione viene effettuato per mezzo di reti neurali.
Una rete neurale artificiale, Artificial Neural Network, ANN, o più spesso Neural
Network, NN, è un modello matematico-informatico di calcolo nato come forma
semplificata del modo in cui in natura si comportano le reti neurali biologiche. Formato da unità elementari: neuroni artificiali, celle o nodi, connesse tra loro (principalmente in parallelo), ha la peculiarità di essere un sistema adattativo: cambia la sua struttura in base alle informazioni, esterne o interne, che riceve durante la fase d’apprendimento [3].
2.2 Storia
Il neurone artificiale fu proposto da W. S. McCulloch e W. Pitts ne "A logical
calculus of the ideas immanent in nervous activity", del 1943. Nel testo venne illustrata
la schematizzazione del neurone artificiale: un combinatore lineare a soglia con dati binari multipli in entrata e un singolo dato binario in uscita. Un numero opportuno di tali elementi, connessi in modo da formare una rete, è in grado di calcolare semplici funzioni booleane. Le prime ipotesi d’apprendimento furono introdotte da D. O. Hebb nel libro del 1949 "The organization of behavior". Nel ’58 F. Rosenblatt propose nel libro "Phychological review" lo schema di rete neurale, detto Perceptron (percettrone). Aveva lo scopo di riconoscere e classificare le forme per fornire un'interpretazione dell'organizzazione generale dei sistemi biologici e lo faceva attraverso i pesi sinaptici variabili che permettevano al percettrone di apprendere. Nel 1969 Marvin Minsky e Seymour A. Papert, in "An introduction to computational geometry", mostrarono i limiti operativi delle semplici reti a due strati basate sul percettrone. Dimostrarono l'impossibilità di risolvere per questa via molte classi di problemi, ossia tutti quelli non caratterizzati da separabilità lineare delle soluzioni (tra cui per esempio l’or esclusivo, XOR). Un matematico americano Paul Werbos nella sua tesi di dottorato del 1974
12 rispose a queste considerazioni con le reti MLP (Multi-Layers Perceptron, ossia percettrone multistrato), ma non fu dato molto peso al suo lavoro. Ci fu poi un periodo di stasi che terminò nel 1982 quando J. J. Hopfield riprese lo studio in quella direzione. Poco dopo, nell’86, David E. Rumelhart, G. Hinton e R. J. Williams crearono l’algoritmo di retropropagazione dell'errore (error backpropagation). Un sistema in grado di modificare sistematicamente i pesi delle connessioni tra i nodi così che la risposta della rete si avvicina sempre di più a quella desiderata [3].
2.3 Funzionamento delle reti neurali
Lo schema di funzionamento del neurone artificiale ricalca quello del neurone biologico. Dai dendriti le informazioni arrivano al nucleo. Nel caso artificiale la j-esima unità riceve gli input: gli stimoli della rete, da strati precedenti o direttamente dall’esterno. Ogni connessione ha un’importanza diversa in base alla quale varia il peso associato allo stimolo. La somma di questi stimoli pesati e del bias, che rappresenta la soglia interna del neurone, è detta net. L’output del neurone è generato dalla funzione di trasferimento f(net), che rappresenta, per il neurone biologico, il segnale trasportato
dall’assone. Considerando un neurone Y che riceve in ingresso i segnali dai neuroni X1,
X2, …, Xn:
y
IN=
w
1⋅
x
1+
w
2⋅
x
2+
⋅
⋅⋅
+
w
n⋅
x
n+
y
BIAS (Eq. 2.1)I termini w1, w2, …, wn sono i pesi sinaptici e YBIAS è la soglia d’ingresso del
neurone. Ad YIN viene applicata la funzione di trasferimento ottenendo il segnale
d’uscita che verrà inviato a tutti i neuroni dello strato successivo. Il numero di parametri di una rete neurale è uguale al numero di pesi più il numero di soglie d’attivazione dei neuroni.
I neuroni vengono organizzati in strati o layer. Si possono utilizzare reti a singolo strato o multistrato, se sono presenti più strati interni, detti strati nascosti,
hidden layer. In questa configurazione i neuroni d’ingresso non sono considerati uno
strato perché non eseguono alcuna elaborazione a differenza dello strato formato dai neuroni di output. Ogni neurone di uno strato è collegato a tutti quelli dello strato successivo e il collegamento è caratterizzato dal proprio peso sinaptico. Il numero di neuroni per ogni strato, i pesi, le soglie d’ingresso e le funzioni di trasferimento costituiscono l’architettura di una rete e ne determinano la capacità di adattarsi. Esistono
13 in letteratura delle metodologie, chiamate di pruning o surgerying, che permettono di migliorare le prestazioni della rete eliminando alcune delle connessioni interne ma riducendone l’adattabilità.
La fase d’apprendimento è fondamentale perché è il momento in cui vengono impostati i pesi sinaptici. Il corretto funzionamento di una rete neurale sull’insieme d’apprendimento non offre però una garanzia di un altrettanto corretto funzionamento sui dati relativi allo stesso concetto ma non appartenenti al database di training. Quando il numero delle unità cresce, aumenta in corrispondenza anche il potere computazionale, ma la capacità di generalizzare su nuovi esempi diminuisce perché ha luogo in uno spazio di parametri enorme ma vincolati da pochi esempi.
I paradigmi d’apprendimento principali sono tre: supervisionato, non supervisionato e per rinforzo.
L’apprendimento supervisionato (supervised learning), richiede di un insieme di dati per l'addestramento (training set): esempi tipici d'ingressi con le uscite corrispondenti. In questo modo la rete può imparare la relazione che li lega. Successivamente, la rete è addestrata mediante un opportuno algoritmo (tipicamente, la
backpropagation che è appunto un algoritmo d'apprendimento supervisionato), il quale
usa i dati allo scopo di modificare i pesi ed altri parametri della rete in modo da minimizzare l'errore di previsione relativo all'insieme d'addestramento. Se l'addestramento ha successo la rete impara a riconoscere la relazione incognita che lega le variabili d'ingresso a quelle d'uscita e sarà capace di fare previsioni anche nei casi in cui l’uscita non è nota a priori. L'obiettivo dell'apprendimento supervisionato è la previsione del valore dell'uscita per ogni valore valido dell'ingresso, basandosi soltanto su un numero limitato d’esempi di corrispondenza, cioè, coppie di valori input-output. La rete deve essere dotata di un'adeguata capacità di generalizzazione, con riferimento a casi ignoti. Ciò consente di risolvere problemi di regressione o classificazione.
L’apprendimento non supervisionato (unsupervised learning) è basato su algoritmi d'addestramento che modificano i pesi della rete facendo esclusivamente riferimento ad un insieme di dati che include le sole variabili d'ingresso. Questi algoritmi tentano di raggruppare i dati d'ingresso e di individuare dei cluster rappresentativi dei dati facendo solitamente uso di metodi topologici o probabilistici. L'apprendimento non supervisionato è anche impiegato per sviluppare tecniche di compressione dei dati. Le reti Kohonen o Self Organizing Map (SOM) sono addestrate in questa modalità.
14 L’apprendimento per rinforzo (reinforcement learning) prevede che un opportuno algoritmo cerchi un modus operandi a partire da un processo d'osservazione dell'ambiente esterno. Ogni azione ha un impatto sull'ambiente e l'ambiente produce una retroazione che guida l'algoritmo stesso nel processo d'apprendimento. Questa classe di problemi prevede un agente, dotato di capacità di percezione, che esplora un ambiente nel quale intraprende una serie d’azioni. L'ambiente stesso fornisce in risposta un incentivo o un disincentivo, secondo i casi. Gli algoritmi per il reinforcement learning tentano in definitiva di determinare una politica tesa a massimizzare gli incentivi cumulati ricevuti dall'agente nel corso della sua esplorazione del problema. L'apprendimento con rinforzo differisce da quello supervisionato perché non sono mai presentate delle coppie input-output d’esempi noti. Inoltre l'algoritmo è indirizzato ad una prestazione in linea che implica un bilanciamento tra esplorazione di situazioni ignote e sfruttamento della conoscenza corrente.
Le reti neurali statiche descrivono il comportamento di sistemi statici, in altre parole il vettore d’uscita, in un determinato istante, dipende unicamente dal valore in quell’istante del vettore d’ingresso. L’architettura più comune di una rete statica è il percettrone multi-strato (Multi-Layer Perceptron, MLP), che presenta uno strato d’ingresso, uno o più strati intermedi e uno strato d’uscita.
Il vettore degli ingressi p è costituito da un numero R d’elementi e ad ogni strato di neuroni nascosto verrà associata una matrice, costituita dai pesi delle connessioni, di dimensioni RxS, con S il numero di neuroni dello strato. Questa matrice è costituita
dagli elementi wij che rappresentano i pesi della connessione fra il neurone i-esimo dello
strato nascosto e l’ingresso j-esimo. Ogni strato, inoltre presenta un vettore b, di lunghezza S, costituito dalle soglie d’attivazione dei neuroni formanti quello strato.
L’addestramento è un procedimento iterativo in cui i valori dei pesi e delle soglie d’attivazione vengono riaggiornati, passo dopo passo, fino a quando una funzione differenza degli errori fra l’uscita della rete e l’uscita del sistema reale è minore di un certo valore (goal). Tale funzione, anche chiamata cifra di merito C, è espressa da:
( )
=
(
( )
−
NN(
i,
Θ
)
)
i i i iC
a
p
a
p
E
C
(Eq. 2.2)con pi ingresso i-esimo, ai risposta del sistema reale all’i-esimo ingresso, aiNN risposta
della rete all’i-esimo ingresso, Θ vettore dei parametri della rete neurale.
La cifra di merito è dunque elaborabile come somma degli errori quadratici (Sum
15
Sum of Squared Error, NSSE) oppure come media degli errori quadratici (Mean of Squared Error, MSE).
L’obiettivo dell’addestramento è trovare i parametri della rete che minimizzano il valore della cifra di merito. Il vettore Θ viene quindi riaggiornato per ogni iterazione durante l’addestramento attraverso la relazione:
( )i
=
Θ
( )i+
( )i⋅
f
( )iΘ
+1µ
(Eq. 2.3)
dove con i è indicata i-esima iterazione o epoca, f(i) è il parametro di direzione di ricerca
e µ(i) è il passo (learning rate) dell’algoritmo iterativo. Durante l’addestramento di una
rete viene cercato il punto di minimo della superficie che rappresenta l’andamento dell’errore nello spazio dei pesi, eseguendo la ricerca nella direzione dell’opposto del gradiente, valutato alla i-esima epoca d’addestramento.
Questa forma di ricerca dell’errore usata negli algoritmi d’addestramento viene chiamata discesa del gradiente. Per reti ad un solo strato, che utilizzano questo algoritmo, l’aggiornamento dei pesi e del gradiente è immediato: ciò non accade nelle reti multi-strato in cui l’aggiornamento del gradiente implica una procedura di propagazione all’indietro dell’errore, dato che la cifra di merito è calcolata solo con le uscite della rete. In questo caso si parla di algoritmi d’addestramento backpropagation. Dal punto di vista metodologico si procede in due fasi, nella prima si procede dagli ingressi verso le uscite calcolando le attivazioni di tutti i neuroni; nella seconda, al contrario, si procede a ritroso calcolando di quanto debbano essere modificati i pesi uno per uno. Un’inconveniente a cui si può andare incontro nella backpropagation è quello di avere delle superfici dell’errore con minimi locali che inevitabilmente bloccherebbero l’addestramento impedendo alla rete la ricerca del minimo assoluto. Per risolvere questo problema può essere utilizzata una regola di learning che cambia la direzione di ricerca.
Uno degli algoritmi principali d’addestramento è l’algoritmo di Newton che utilizza come matrice per cambiare la direzione di ricerca l’inversa dell’hessiano della cifra di merito.
In alcuni casi la matrice H è singolare, non invertibile. Viene allora scomposta nel prodotto di tre matrici:
T
V
U
H
=
⋅
Σ
⋅
(Eq. 2.4) dove Σ è la matrice diagonale degli autovalori di H. Invece di calcolare l’inversa di H si calcola l’inversa della matrice[
I
]
V
TU
I
16 Questo metodo è chiamato metodo di Levenberg-Marquardt ed uno dei metodi di addestramento più usati nonostante sia meno preciso e veloce del metodo di Newton.
La capacità di generalizzare è la caratteristica principale che una rete deve possedere, e si è verificato che, aumentando il numero di epoche d’addestramento, l’errore sul training set diminuisce; questo tuttavia non vuol dire che la rete possiede una buona capacità di generalizzazione che deve essere misurata su un insieme di dati di validazione.
La complessità, intesa come numero di neuroni e numero di layer, di una rete svolge, in questo problema, un ruolo importante. Aumentando il numero dei parametri aumentano i gradi di libertà del modello. E’ possibile modificare i parametri in modo da far aderire maggiormente il comportamento del modello a quello del sistema. Questo però accade fino ad un certo valore della complessità, in cui gli errori sul training set e sul validation set diminuiscono di pari passo, dopodiché l’errore sul validation set inizia ad aumentare nonostante la contemporanea diminuzione dell’errore sul training set. Il fenomeno prende il nome di overfitting o overlearning e si verifica dal momento in cui il modello scelto aderisce troppo ai dati d’addestramento.
I metodi utilizzati per evitare questo problema sono gli algoritmi Early Stopping (ES) e Bayesian Regularization (BR). Con il primo l’addestramento viene arrestato quando si arriva in prossimità del minimo dell’errore su un set di validazione. Ai dati di addestramento vengono affiancati i dati di validazione che la rete usa contemporaneamente all’addestramento per testare la rete ed avere una stima dell’errore che questa commetterebbe su dati diversi da quelli del training set. Per questo metodo il numero dei dati d’allenamento e validazione è importante perché il loro variare può influire sui risultati. Il secondo metodo migliora la generalizzazione delle reti durante l’addestramento. La cifra di merito, che viene minimizzata per aggiornare i pesi delle connessioni, è pesata attraverso un parametro γ:
(
)
MSW
MSE
C
=
γ
⋅
+
1
−
γ
⋅
(Eq. 2.6) con MSW media dei pesi quadratici (Mean Squared Weight, MSW). Il metodo tratta l’addestramento e la generalizzazione in modo statistico, cioè, le soluzioni vengono combinate insieme per trovare quella che produce la generalizzazione migliore a differenza dell’altro metodo per cui l’inizializzazione dei pesi è del tutto casuale.Il metodo BR fornisce solitamente risultati migliori, ma richiede tempi di calcolo d’apprendimento superiori al metodo ES. E’ stata questa la motivazione che ha condotto
17 alla scelta del metodo BR per le reti neurali che sono state impiegate nella computazione dei dati provenienti dalla sonda.
L’individuazione dei parametri principali delle reti si è svolta analizzando tutte le possibili architetture delle reti e cercando di valutare al meglio quelli che potevano essere i parametri in gioco per un corretto funzionamento sia nella fase d’addestramento che di test.
La rete neurale che è stata realizzata ha utilizzato un paradigma d’apprendimento supervisionato (supervised learning). Sono stati necessari quindi i dati in ingresso ed in uscita per l’allenamento (training set), per la validazione (validation
set) e per verificarne l’errore una volta allenata la rete (testing set). Il database di
pressioni trovate attraverso il CFD è stato ampliato attraverso interpolazioni fino a 10000 punti che poi sono stati suddivisi in maniera uniforme nello spazio in 1010 punti per il training set, 8450 punti per testing set e 540 punti per validation set [1].
Sono state prese in esame alcune possibili architetture neurali, differenti per: • il numero di layer,
• il numero di neuroni in ogni strato,
• le funzioni di trasferimento da attribuire ad ogni neurone, • il tipo e il numero di ingressi da assegnare alla rete.
Per quanto riguarda quest’ultimo aspetto in primo luogo sono stati individuati, tra gli 85 a disposizione sulla calotta sferica, i punti che rendono la rete sensibile alla ricostruzione dei parametri di volo. Successivamente è stato fatto uno studio d’ottimizzazione della posizione delle prese di misura, monitorando il valore della pressione in ognuno dei sensori al variare di α e di β.
Scelti i punti i cui valori di pressione vengono utilizzati come input alle reti, si è passati a definire l’architettura delle reti. La scelta del numero di layer e del numero di neuroni per ogni layer è stata fatta in base alle esperienze maturate in precedenza. La scelta finale è ricaduta su un’architettura a due layer nascosti da 10 neuroni ciascuno, illustrata in figura 2.1 della pagina successiva.
Naturalmente le reti presentano anche un layer di uscita che avrà un numero di neuroni uguale al numero di output scelto per la rete [1].
18
Fig. 2.1 Architettura della Rete Neurale Artificiale
Per quanto riguarda la funzione di trasferimento da assegnare ai nodi la scelta è stata più delicata. Le principali funzioni di trasferimento (F.d.T.) prese in esame sono state: a gradino con soglia θ, lineare, lineare a tratti, sigmoide, iperbolica.
In base alle prove effettuate è stata scelta la funzione sigmoide. A differenza delle funzioni di soglia, che assumono solo i valori 0 e 1, la funzione sigmoide può assumere tutti i valori compresi in questo intervallo e per questo è la più utilizzata.
(
e
Ta)
a
f
y
=
(
)
=
1
1
+
− ⋅ (Eq. 2.7) Si noti inoltre che nella funzione sigmoide compare il parametro T detto “Parametro di temperatura”, che per lo studio condotto in questo lavoro di tesi è stato scelto pari a 4 [5].19
2.4 Prove effettuate
Le prove effettuate nella precedente attività di tesi hanno abbracciato una tipologia di reti molto ampia, fornendo precise indicazioni sulle architetture e modalità verso le quali avrei dovuto indirizzarmi. Le reti sperimentate erano di tipo MLP con due strati nascosti da 10, 13, 15, 18 neuroni per strato. Sono state scelte le reti con 10 neuroni perché anche se presentavano un errore leggermente più alto rispetto a quelle con un numero maggiore di neuroni, avevano stabilità e velocità di computazione superiore. L’addestramento si è basato sull’algoritmo di tipo Backpropagation - feed
forward con modalità BR ed ES. L’errore però è stato calcolato in maniera differente
nei due casi: nel primo il parametro da ottimizzare nel processo di addestramento era la somma dei quadrati degli errori commessi in ogni punto d’addestramento, SSE, nel secondo il MSE. E’ risultata migliore la metodologia BR per un errore medio e massimo inferiore sia in allenamento sia nel test e per le eccedenze (numero di volte in cui l’errore supera il 50%) di un ordine di grandezza inferiore rispetto all’altra metodologia. La funzione di trasferimento utilizzata è stata la sigmoide logaritmica con parametro di temperatura T = 4. Per le reti è stata sperimentata una vasta gamma d’ingressi variando il numero di input e la modalità in cui questi venivano forniti. L’orientamento finale si è indirizzato verso reti a 5 input aventi come segnale d’ingresso il valore della pressione locale in 5 prese differenti. Gli ingressi provati potevano essere Simple Input, SI, cioè, inseriti nella rete così come sono presenti nel database aerodinamico oppure
normalizzati, NSI, attraverso max(i(P0)) e min(i(P0)), il valore massimo e minimo della
pressione riferita al punto centrale 0 secondo la formula:
0 0 0
min( ( ))
max( ( )) min( ( ))
Ni
i P
i
i P
i P
−
=
−
(Eq. 2.9)Sulla base di precedenti attività di ricerca condotte dal Dipartimento d’Ingegneria Aerospaziale sono stati fissati alcuni parametri del processo di addestramento:
• il numero massimo di epoche (cicli iterativi dei pesi sinaptici) pari a 3000,
• il goal (valore della cifra di merito sotto del quale si deve fermare l’addestramento) di 10-5,
20 Lo strato finale della rete prevedeva uno, due o tre neuroni in base al numero di output richiesto, in un intervallo di [-5, 15] gradi per l’angolo d’incidenza, [-15, 15] gradi per l’angolo di derapata e [20, 70] metri al secondo per la velocità.
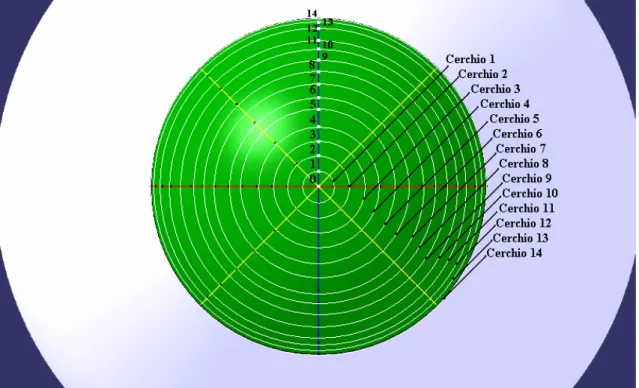
Fig. 2.2 Vista della calotta emisferica frontale della sonda
La calotta frontale dove sono state calcolate le misure di pressione e dove sono posti i punti di controllo è stata suddivisa, in cerchi con origine nel punto centrale 0. La schematizzazione dei cerchi è realizzata in modo da far coincidere il punto di controllo sull’arco superiore col numero della cerchio. Nella figura 2.2 sono visibili i cerchi e i punti di controllo da 1 a 14 disposti sull’arco longitudinale superiore (in blu). In questo lavoro le reti sono state addestrate utilizzando le misure di pressione relative ai cerchi 3, 4, 5 ,6 [1].