Capitolo 2
Progettazione e implementazione
Questo capitolo contiene la descrizione del lavoro svolto in termini di procedure programmate, con l’accento su aspetti non trattati nel lavoro teorico. Saranno inoltre definite le procedure per il preprocessing e le scelte effettuate per la simulazione.
2.1 L’ambiente di sviluppo
L’ambiente di sviluppo attraverso il quale la descrizione ad alto livello dell’algoritmo distribuito ALL-BRIDGE è stata trasformata in codice eseguibile è Eclipse, versione 3.0.1: questo ambiente, dotato di interfaccia utente a finestre, fornito sia di compilatore che di debugger, ha come proprio linguaggio base Java. In questo caso è
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
stato utilizzato Java 2 SDK versione 1.4.1. A corredo di Eclipse ci si è avvalsi della libreria JDSL 2.1, gratuitamente reperibile su internet, per la gestione di strutture dati complesse come gli alberi.
2.2 Scelte implementative
La codifica e conseguente simulazione di un algoritmo distribuito come quello oggetto del presente lavoro di tesi, ha imposto la creazione e la simulazione del comportamento di una rete virtuale all’interno di un computer stand-alone, formata da elementi che ne rappresentino i nodi e che siano capaci di elaborazioni autonome e di comunicare fra loro attraverso lo scambio di messaggi inviati su canali di comunicazione.
Per questo scopo è stato necessario studiare a fondo una possibile implementazione di una rete virtuale simulando il comportamento di ognuno dei suoi nodi. La scelta è caduta su un ambiente multithread creato ad-hoc in cui ogni thread si occupa di rappresentare un nodo della rete; tale scelta è stata guidata dalla struttura del problema
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
l’algoritmo andrà a lavorare, impone un modello di elaborazione potente come quello a processi concorrenti ma al tempo stesso leggero.
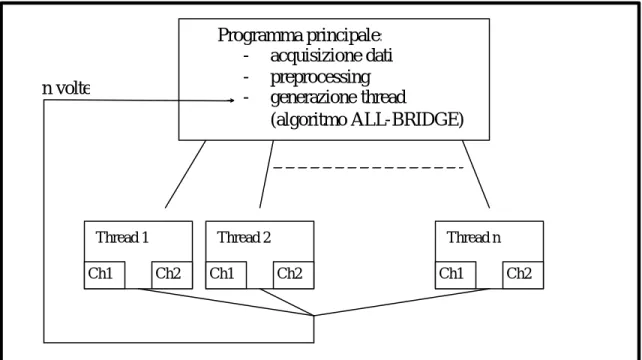
In linea di massima il codice è diviso in tre blocchi fondamentali: acquisizione dati, preprocessing dei nodi e corpo dell’algoritmo ALL-BRIDGE.
fig 1: architettura di massima del programma di simulazione Programma principale:
- acquisizione dati - preprocessing - generazione thread
(algoritmo ALL-BRIDGE)
Thread 1 Thread 2 Thread n
Ch1 Ch2 Ch1 Ch2 Ch1 Ch2
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
2.3 Acquisizione dati
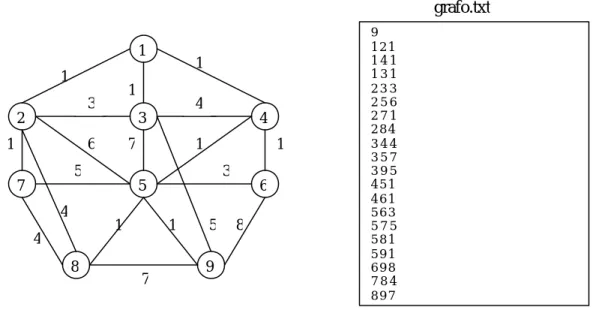
La rete virtuale può essere vista come un grafo i cui vertici corrispondono ai nodi e i cui archi corrispondono ai link di comunicazione.
Quindi il primo passo è stato quello di acquisire, attraverso una specifica procedura, il grafo associato alla rete, descritto in un file di testo, che poi sarà oggetto di rielaborazioni al fine di risalire alla struttura della rete.
fig 2: descrizione del grafo nel file grafo.txt
grafo.txt 4 5 7 8 7 6 5 4 3 1 1 1 1 1 1 1 1 3 2 4 5 6 7 1 8 9 3 4 9 1 2 1 1 4 1 1 3 1 2 3 3 2 5 6 2 7 1 2 8 4 3 4 4 3 5 7 3 9 5 4 5 1 4 6 1 5 6 3 5 7 5 5 8 1 5 9 1 6 9 8 7 8 4 8 9 7
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
Allo scopo è stata creata la funzione:
static grafo acquisisci_grafo(String file)
la quale, prendendo come input un file di testo contenente la descrizione del grafo, produce come output un elemento di tipo “grafo” costituito da una collezione di due tipi di elementi:
- tipo “nodo” che contiene al suo interno tutte le strutture dati necessarie alla memorizzazione delle informazioni relative al corrispondente nodo della rete, iniziando dal proprio nome, per passare alla lista degli archi incidenti, per poi continuare con gli alberi di copertura dei cammini di costo minimo, e le distanze del nodo da ogni possibile destinazione; contiene inoltre le posizioni del nodo all’interno di ogni SPT radicato in un nodo diverso e una serie di vettori che rappresentano le liste degli archi incidenti non appartenenti ai vari SPT. Infine il tipo “nodo” contiene anche la tabella di routing.
- tipo “arco”, il quale è costituito semplicemente dalla coppia di nomi dei nodi che mette in collegamento e dal suo peso.
Dal grafo implementato nella maniera descritta è stata possibile una ulteriore elaborazione per trasformarlo in una rete virtuale.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
2.4 Preprocessing
Questa fase è stata fondamentale per permettere il corretto svolgimento dell’algoritmo distribuito perché ogni nodo deve essere messo a conoscenza di determinate informazioni riguardanti la rete e i suoi vicini.
Il primo passo è stato quello di stilare le tabelle di routing per ogni nodo in modo da poter realizzare la comunicazione “shortest path” da un nodo a uno qualunque degli altri, registrando in ogni nodo il “next hop” per arrivare a tutti gli altri. Come detto un modo possibile è quello di calcolare tutti gli alberi di copertura dei cammini di costo minimo della rete, ognuno radicato in un nodo diverso e riportare le informazioni sui percorsi ottenuti nelle tabelle di routing. Per fare questo è stato utilizzato l’algoritmo di Dijkstra notoriamente utilizzato per grafi orientati, opportunamente rivisto in modo che sia applicabile al grafo in questione il quale possiede archi bidirezionali. A questo scopo è stata creata la funzione
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
che calcola l’albero di copertura dei cammini di costo minimo del grafo G radicato nel nodo “radice”, fornendo in output un elemento di tipo “Tree”.
Questo tipo fa parte della libreria JDSL che fornisce implementazioni per vari tipi di strutture dati complesse fra le quali gli alberi, inoltre, è corredato da metodi per diverse elaborazioni sugli alberi. All’interno di tale funzione vengono effettuate le visite preorder traversal e preorder traversal inverted dell’albero per generare le etichette alfa; infine sono aggiornate le tabelle di routing di ogni nodo, rispetto alla destinazione “radice dell’albero”.
In seguito, viste le condizioni imposte dall’algoritmo ALL-BRIDGE, è stato necessario calcolare per ogni nodo l’insieme degli archi incidenti che non fanno parte degli alberi SPT: essi rappresentano l’insieme di base per i possibili swap edge di un arco. Allo scopo è stata creata la procedura
public static void calcola_vicini_non_SPT(int nome_nodo)
che elabora rispetto al nodo “nome_nodo” un vettore contenente in ogni posizione la lista degli archi incidenti che non fanno parte dell’albero di copertura di costo minimo i-esimo.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
La procedura non ha output perché aggiorna la struttura dati Vector[] LL del nodo “nome_nodo”.
Per ultimo è necessario specificare che per ogni nodo, tutte le informazioni riguardanti i vicini, siano facilmente accessibili in quanto la variabile “grafo” è definita in modo globale ed è visibile da ogni thread in cui sarà in esecuzione uno specifico nodo.
2.5 Implementazione dell’algoritmo
L’operazione di implementazione dell’algoritmo ha rappresentato un passo critico che ha consentito di evidenziare alcuni punti non definiti dall’algoritmo ALL-BRIDGE.
Il primo punto riguarda il momento in cui si è passati a codificare, da pseudolinguaggio di alto livello a codice Java, la fase in cui un nodo interno deve effettuare una “richiesta” ad un figlio perché lo swap-edge ricevuto non è feasible con le proprie etichette alfa.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
Nella pratica, succede che la ricezione della risposta del figlio alla request va a mischiarsi e ad interferire con la fase di ricezione degli swap-edge “spontanei” dei figli, con uno squilibrio dell’algoritmo. Quindi è stato necessario memorizzare le richieste da effettuare ed eseguirle direttamente nello stato WAITING prima di mettersi in attesa delle risposte.
Il secondo punto si è presentato alla fine dell’implementazione dell’algoritmo dopo che tutti i nodi discendenti della radice hanno terminato la loro elaborazione ed inviato il loro swap-edge al genitore. Questa fase non prevede nessuna altra mossa per cui il nodo radice rimane in stato COMPUTING e tutti gli altri in stato SWAPPED senza essere a conoscenza del fatto che l’algoritmo sia effettivamente terminato.
Quindi è stato necessario aggiungere uno nuovo stato “DONE” all’insieme degli stati e inserire degli accorgimenti all’interno del codice per portare a terminazione l’algoritmo.
In effetti la fase è stata guidata anche dalla struttura stessa dell’algoritmo, perché la terminazione è determinata nel momento in cui il nodo radice riceve l’optimal swap edge dall’ultimo dei suoi figli.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
Infatti, la radice memorizza semplicemente gli swap edge ricevuti dai figli senza controllare la feasibility rispetto alle sue etichette (0,0) perché non deve calcolare uno swap edge proprio.
È stato sufficiente controllare il verificarsi dell’evento e di seguito inviare un messaggio “Done” ai propri figli, i quali poi lo devono propagare ai loro figli fino a coprire l’interno insieme dei nodi della rete. Una volta ricevuto il messaggio “Done”, tutti i nodi passano in stato DONE e sono a conoscenza del fatto che anche tutti gli altri si trovano in quel medesimo stato e che l’algoritmo distribuito ALL-BRIDGE è terminato.
2.6 Codifica dell’algoritmo ALL-BRIDGE in versione
definitiva
Come riportato in precedenza, la simulazione dell’esecuzione dell’algoritmo distribuito ALL-BRIDGE su una rete, presuppone il fatto che ogni nodo possa elaborare le sue funzioni in modo indipendente e riesca a comunicare con gli altri nodi attraverso canali
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
Un canale di comunicazione è costituito principalmente dalla struttura dati in cui i messaggi vengono memorizzati, dal mittente, e prelevati dal destinatario. Ovviamente queste operazioni devono essere protette per garantire la consistenza della struttura dati, e per questo il canale contiene al suo interno anche dei metodi sincronizzati che ne consentono un uso corretto.
class canaleC {
private Vector inputC = new Vector(10,2);
/* questo vettore funge da canale di */
/* comunicazione (per le scelte) quindi */
/* l'accesso deve essere fatto in modo */
/* Synchronized */
synchronized void send(elemento_canale e) { inputC.add(e);
notify(); }
synchronized elemento_canale receive() { if (inputC.isEmpty()) {
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
try {
wait();
/* se mi trovo qui vuol dire che */
/* qualcuno ha scritto nel canale */
}
catch (InterruptedException e) {} }
return (elemento_canale) inputC.remove(0); }
}
Nel caso specifico sono stati implementati due canali, uno per i messaggi “Choice” e l’altro per messaggi “Request” e “Done”.
Con l’obiettivo di creare un ambiente multithread, ad ogni nodo della rete è stato associato un thread che ne simuli l’elaborazione e in cui siano contenute tutte le strutture dati necessarie all’esecuzione dell’algoritmo ALL-BRIDGE, come i canali di comunicazione, la lista dei possibili swap edge e il vettore che contiene la lista delle eventuali richieste da inoltrare ai propri figli. Tale tipo di thread viene
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
public thread_nodo(nodo i, int albero) {....}
che accetta come argomento il nodo a cui il theard deve far riferimento e l’albero rispetto al quale eseguire l’algoritmo ALL-BRIDGE.
Il thread, oltre ad essere costituito da strutture dati, è formato anche da codice eseguibile che rappresenta il corpo dell’algoritmo distribuito ALL-BRIDGE. All’interno del run() del thread è contenuta la struttura dell’algoritmo. Esso è fondamentalmente è un loop al cui interno è richiamata la funzione corrispondente allo stato attuale del nodo, definito dalla variabile “stato”.
switch (this.stato) { /* struttura dell’algoritmo */
case 1: computing(); break; case 2: swapped(); break; case 3: waiting(); break;
case 4: { done(); cond=1; break; } }
Quindi a seconda dello stato del nodo, il thread esegue una delle quattro diverse procedure che costituiscono il corpo dell’algoritmo.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
La procedura “computing” è la codifica del primo stato in cui un nodo si può trovare. Per tale motivo al suo interno contiene i passi che un nodo deve effettuare, distinti a seconda che sia la radice, un nodo interno, oppure una foglia dell’albero di cui si stanno calcolando gli optimal swap edges.
La procedura “swapped” rappresenta lo stato in cui si trova un nodo interno, o una foglia, quando ha terminato la sua elaborazione locale ed attende richieste dal genitore oppure messaggi di terminazione.
La procedura “waiting” rappresenta invece lo stato in cui un nodo interno può trovarsi nel caso in cui deve fare richiesta ai propri figli di calcolare uno swap-edge rispetto a diverse etichette alfa.
La procedura che rappresenta lo stato Done si occupa solo di scegliere l’optimal swap edge nell’insieme degli archi incidenti unito l’insieme degli swap edge feasible ricevuti dai figli.
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
rispetto alle etichette alfa (a,b), la quale utilizza la funzione discende(alfa1,alfa2) che effettua il test sulla discendenza fra i nodi proprietari delle etichette alfa1 e alfa2
public boolean feasible(arco link, alfa label) { if (link == null) return true;
alfa primo = link.a.vect_alfa[this.n_alb-1]; alfa secondo = link.b.vect_alfa[this.n_alb-1];
if ( (discende(primo,label)) ^ (discende(secondo,label)) ) return true;
else
return false; }
public boolean discende(alfa primo, alfa secondo) {
if (( primo.a >= secondo.a ) & ( primo.b >= secondo.b )) return true;
else
return false; }
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
così come lo è anche la funzione chooseMin(a,b) che si occupa di scegliere l’optimal swap edge all’interno della lista ordinata L(x), rispetto alle etichette (a,b);
public elemento ChooseMin(alfa label) {
/* deve trovare il primo elemento all'interno di LX */
/* (che è ordinato per peso crescente) feasible con label */
boolean trovato = false;
elemento_canale estratto = null; for (int i=0; i<LX.size(); i++) {
estratto = (elemento_canale)LX.get(i); if (feasible(estratto.ele.link,label))
{ trovato = true; break; } }
if (trovato) return estratto.ele; else return null;
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
2.7 Esecuzione dell’algoritmo
Per ciò che riguarda l’esecuzione vera e propria dell’algoritmo, all’interno del main del programma principale in cui è già stato eseguito il preprocessing, sono stati creati n thread, ognuno istanziato con un diverso nodo della rete e con l’albero su cui deve essere eseguito l’algoritmo ALL-BRIDGE. In seguito i thread appena avviati, si mettono in attesa su una struttura condivisa creata per la sincronizzazione, e sono sbloccati dal main nel momento in cui anche l’ultimo thread è stato lanciato e possono iniziare la loro esecuzione.
È stato necessario introdurre la sincronizzazione iniziale perché nel caso di un numero elevato di nodi della rete, è possibile che alcuni thread debbano comunicare con altri che non sono ancora stati creati. Nel corso dell’esecuzione dell’algoritmo l’asincronia delle comunicazioni è gestita direttamente dai canali di comunicazione implementati. Quindi, il run() del thread, che come accennato in precedenza, rappresenta il codice dell’algoritmo distribuito, viene eseguito da ognuno dei nodi che compongono la rete virtuale. La loro collaborazione, ottenuta con lo scambio di messaggi, fa si che l’algoritmo distribuito sia portato avanti nella sua esecuzione, con la
CAPITOLO 2. PROGETTAZIONE E IMPLEMENTAZIONE
transizione dei vari nodi attraverso i possibili stati in cui un generico nodo si può trovare. Quando tutti i nodi si trovano nello stato DONE l’algoritmo è terminato.
Il procedimento appena descritto è stato eseguito n volte considerando, ad ogni iterazione, un diverso albero di copertura dei cammini di costo minimo radicato in un differente vertice del grafo, al fine di creare le tabelle di routing persistenti fault tollerant per ogni nodo.