4
4
La definizione e progettazione del
La definizione e progettazione del
Catalogo Impromtu “Statistiche Magazzino”
Catalogo Impromtu “Statistiche Magazzino”
In Figura 4.1 è rappresentata l'architettura utilizzata per il progetto. Nel seguito della trattazione, faremo sempre riferimento a questa rappresentazione.
Figura 4.1 Architettura COGNOS Impromptu/Power Play
Impromptu
Impromptu DatabaseDatabase
SQL / Data Retrieval
Catalogo
Input Query Definition Files Power Cube Power Play in ambiente Windows Transformer Data Retrieval Model Plan Transformer Analisi OLAP INFORMIX Database Cappi_su_aix
4.1 Analisi delle fonti dati sorgenti
4.1 Analisi delle fonti dati sorgenti
L'obbiettivo di questa seconda fase di progettazione è quello di determinare, sulla base degli obbiettivi strategici, dei fatti aziendali e delle relative prospettive di analisi (dimensioni), l'insieme delle fonti dati necessarie, cioè l'insieme delle tabelle (relazioni) del Database aziendale contenenti le informazioni utili per gli obbiettivi sopra mensionati. Data l'enorme quantità di tabelle di cui è costituito il Database, si è ricorso ad una stampa, ottenuta dal programma applicativo MITICO, per avere una descrizione di supporto del contenuto di ogni singola tabella.
Tabella 4.1 Tabelle scelte dal Database aziendale "Cappi_su_aix"
Nome tabella Descrizione
Mitico_clifor Dati anagrafici dei clienti,fornitori
Mitico_clfagg Informazioni aggiuntive sui clienti e fornitori
Mitico_magmov Informazioni sui documenti di vendita/acquisto(movimenti di magazzino)
Mitico_tbcama Informazioni sul tipo di documento di vendita/acquisto
Mitico_tbmaga Informazioni sulle agenzie periferiche
Mitico_magana Informazioni sui singoli articoli vendibili dal Consorzio Agrario
Mitico_Famiglia Informazioni sulle famiglie di prodotti disponibili
Mitico_Gruppo Informazioni relative ai gruppi (per ogni famiglia) di prodotti disponibili
Mitico_Sottogruppo Informazioni relative ai sottogruppi (per ogni gruppo) di prodotti disponibili
Mitico_tbprov Tabella di decodifica delle Provincie italiane
La nostra attenzione si è focalizzata sulle tabelle destinate a memorizzare i dati transazionali relativi alle operazioni di vendita e di acquisto; successivamente, sono state individuate le tabelle contenenti le informazioni anagrafiche dei clienti,
fornitori, quelle relative alle agenzie periferiche, ed infine quelle relative ai vari gruppi merceologici. Questo processo di indagine ha portato alla selezione del set
di tabelle riportate sopra in Tabella 4.1. Nel prossimo paragrafo, verrà discussa la procedura operativa di selezione delle tabelle candidate sopra elencate attraverso l'ambiente di reporting di COGNOS Impromptu Admin.
4.2 La creazione del Catalogo
4.2 La creazione del Catalogo
Un Catalogo è un file nel quale sono memorizzate le informazioni che necessita Impromptu per l'accesso al Database e per l'estrazione dei dati (data retrieval) e qualunque attività di reporting non può essere condotta senza la sua creazione. In particolare, le informazioni (metadati) associate alla struttura del Database includono il nome logico e fisico e la locazione del Database stesso, il nome delle colonne delle tabelle e la specifica delle struttura di join tra le tabelle stesse. La linea condotta per la creazione e messa a punto del nostro Catalogo è rappresentata dalle fasi seguenti:
➢ Impostazione della connessione al Database aziendale;
➢ Creazione di un nuovo Catalogo Impromptu;
➢ Selezione delle tabelle del Database che popoleranno il Catalogo;
➢ Sviluppo della strategia di join tra le tabelle del Catalogo;
➢ Analisi della strategia di join.
4.2.1 La definizione della connessione al Database
4.2.1 La definizione della connessione al Database
La connessione al Database relazionale è identificata da una serie di parametri che definiscono le modalità attraverso le quali COGNOS Impromptu estrae i dati, dati che verranno presentati in una determinata forma all'interno di un report. Il Sistema Informativo Aziendale del Consorzio Agrario è gestito, come discusso in precedenza durante la fase di collaborazione con i responsabili del CED, da un Database relazionale (INFORMIX DYNAMIC SERVER il cui nome logico è “Cappi_su_aix”) su un server IBM, dotato di un sistema operativo AIX. Sul terminale client su cui si è svolto il lavoro e sul quale si è provveduto all'installazione degli strumenti di COGNOS, i gestori del Database hanno provveduto alla fornitura dei drivers opportuni per la configurazione di una connessione ODBC (Open Database Connectivity) al server aziendale impostando opportunamente i parametri di sicurezza richiesti da COGNOS Impromptu. ODBC è un gataway standard che dispone di una serie molteplice di drivers per i più comuni sistemi di gestione di database.quando un utente (in attesa di risultati ed estraneo alla complessità del Database) lancia l'esecuzione della richiesta di dati corrispondente all'interrogazione formulata, Impromptu genera una query SQL che verrà successivamente tradotta (grazie al gataway) in un formato interpretabile dal Database. Il sistema di gestione del Database seleziona i dati corrispondenti allarichiesta e invia indietro i risultati che sono quindi visualizzati nel report
Impromptu dell'utente. Da quanto esposto, emerge che Impromptu sfrutta la capacità di processing del Database a cui è connesso attraverso il Catalogo il quale, puntando solo alle tabelle che contengono informazioni utili per l'area aziendale considerata, ha una dimensione contenuta che ne facilitano la portabilità e il mantenimento. Tali aspetti, legati alla performance del Catalogo Impromptu, sono rilevanti da un punto di vista informatico e saranno ripresi successivamente.
4.2.2 Il Catalogo “Statistiche Magazzino”
4.2.2 Il Catalogo “Statistiche Magazzino”
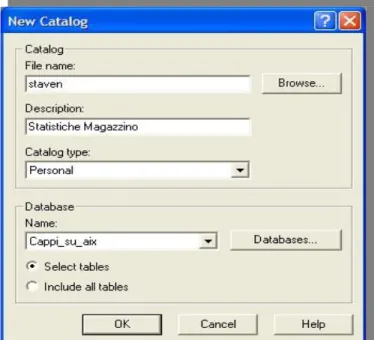
La procedura operativa per la creazione del Catalogo di questo lavoro ha inizio, come illustrato in Figura 4.2, con la definizione del nome del file del Catalogo (staven.cat), di una descrizione consona al suo contenuto, della tipologia di
Figura 4.2 Finestra di dialogo per la creazione di
Catalogo e del Database da cui selezionare le tabelle. Il nostro Catalogo verrà denominato “Statistiche Magazzino”, descrizione facilmente interpretabile ed in linea con il contenuto informativo del Catalogo: i dati delle tabelle che si sono scelte corrispondono ad operazioni di transazione che modificano dinamicamente lo “stato” del magazzino, o dei magazzini dell'azienda; poichè è possibile creare più di un Catalogo per rispondere ad esigenze diverse (non è il caso trattato in questa sede), si è ritenuto di scegliere la suddetta descrizione. La tipologia di Catalogo specifica nella pratica un parametro di configurazione per definire le modalità d'uso del Catalogo stesso da parte degli utenti. Per questo parametro si è scelto di mantenere la configurazione di default (personal) per esigenze di progettazione: la scelta di una delle altre possibili configurazioni (shared, distribuited, secured) avrebbe richiesto la definizione di opportune classi di utenti ognuna con esigenze di reporting differenti. Poiché, come verrà trattato successivamente, Impromptu è stato impiegato in modo sostanziale per la definizione dei dati di input (file .IQD) del modello multidimensionale e non per scopi reportistici, ci limitiamo, per completezza, a fornire solo ad una breve descrizione delle 4 tipologie possibili di Catalogo:
➢ Personal Catalog: si tratta di un Catalogo creato e gestito
dall'amministratore dell'applicazione, quindi il suo utilizzo è esclusivo e preclude aspetti legati alla sicurezza; nel contesto di una applicazione, può essere considerato un prototipo di catalogo condiviso tra più utenti;
➢ Secured Catalog: è un Catalogo accessibile in sola lettura da parte di un
utente e modificabile solamente dall'amministratore che lo ha creato; è impiegato tipicamente in situazioni dove l'utente non ha la necessità di
creare un report personale ma solo valutarne il contenuto (eventualmente esportando il report per successive letture, stampe, ecc.. .);
➢ Distribuited Catalog: l'amministratore crea, mantiene e controlla il
Catalogo originale (master distribuited catalog), che può essere accessibile all'utente il quale, per proprie esigenze di reporting, ne esegue una copia personale (personal master catalog) apportandone, eventualmente, le modifiche di cui ha bisogno. Il controllo degli accessi al catalogo master prevede l'aggiornamento automatico della lista degli utenti ai quali l'amministratore può assegnare una serie di privilegi definendo opportune classi di utenti;
➢ Shared Catalog: accessibile da tutti gli utenti connessi alla rete
aziendale,è una tipologia di Catalogo tipicamente impiegata nel caso in cui l'utente abbia necessità di creare il proprio report senza modificare il contenuto del Catalogo; gli utenti della rete dispongono di una copia equivalente del catalogo e l'amministratore può tuttavia concedere ad un utente specifico il privilegio di compiere alcune operazioni sul Catalogo come, ad esempio, la riorganizzazione del contenuto dello stesso (creazione di nuove cartelle, definizione di nuove variabili condizionali, prompting, funzioni di calcolo, ecc..).
Dal Database aziendale, “Cappi_su_aix”, verranno identificate le tabelle che faranno parte del nostro Catalogo personale “Statistiche Magazzino”. Nel prossimo paragrafo verrà descritta l'implementazione della strategia di join, procedura complessa che ha richiesto una indagine scrupolosa della struttura delle tabelle ed una serie di test di reporting per valutare il grado di conformità delle informazioni ottenute rispetto ai dati aziendali.
4.2.3 Selezione delle tabelle e sviluppo della stategia di join
4.2.3 Selezione delle tabelle e sviluppo della stategia di join
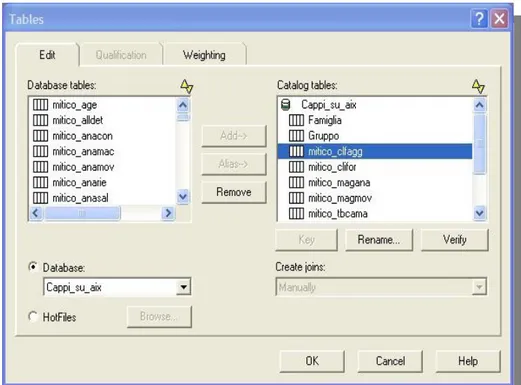
In Figura 4.3, è illustrata l'interfaccia di Impromptu per la selezione delle tabelle; le tabelle prescelte in questo lavoro sono quelle illustrate in Tabella 4.1 e verranno prese in esame a breve. Prima però, anticipiamo che a ciascuna tabella del Catalogo è associato un particolare parametro intero (weighting, peso), che sarà oggetto di ulteriore indagine nei principali aspetti legati alla performance del Catalogo.
Il passo successivo è stato quello di studiare e definire una strategia di join opportuna per le tabelle del nostro Catalogo. Un “join” definisce uno o più collegamenti relazionali (links) tra tabelle fisicamente residenti in un database. Un simile collegamento coinvolge due colonne delle tabelle aventi lo stesso nome identificativo o in altri termini, considerando le tabelle come la rappresentazione fisica di una relazione, gli attributi omonimi delle relazioni stesse. La definizione delle relazioni di join è una procedura integrante l'intero processo di creazione del Catalogo e, nel caso sia implementata in modo scorretto, compromette la consistenza dei dati generati dalle analisi di reporting dell'utente. Impromptu mette a disposizione essenzialmente due possibili scelte implementative:
➢ Creazione automatica : la strategia di join è eseguita dal programma in
modo automatico identificando le colonne delle tabelle attraverso gli attributi della chiave primaria, oppure effettuando un matching sintattico tra i nomi delle colonne;
➢ Creazione manuale: è la strategia di default del programma; il set delle
relazioni di join viene impostato manualmente dal progettista che, in questo caso, assume la completa responsabilità della strategia implementata.
La creazione automatica delle relazioni di join diminuisce sensibilmente il carico di lavoro del progettista ma, coinvolgendo generalmente molti attributi, produce una struttura complessa e talvolta non corretta. Dallo studio della semantica degli attributi delle relazioni del nostro Catalogo, è emersa infatti la presenza di campi
omonimi ma in taluni casi semanticamente differenti; tale aspetto non è risultato immediatamente a causa del ricco numero di campi da indagare, ma a seguito di alcune stampe ottenute attraverso la creazione di semplici report che hanno fornito risultati decisamente contrastanti; alla luce di questo, non potendo apportare modifiche strutturali alle tabelle del Database, e non potendo modificare manualmente la struttura del join generata automaticamente dal programma (l'eliminazione del link erroneo da un punto di vista semantico avrebbe arrecato benefici in termini di correttezza di risultati), la nostra attenzione si è rivolta alla strategia di join manuale, ritenuta anche più significativa da un punto di vista ingegneristico (Figura 4.4).
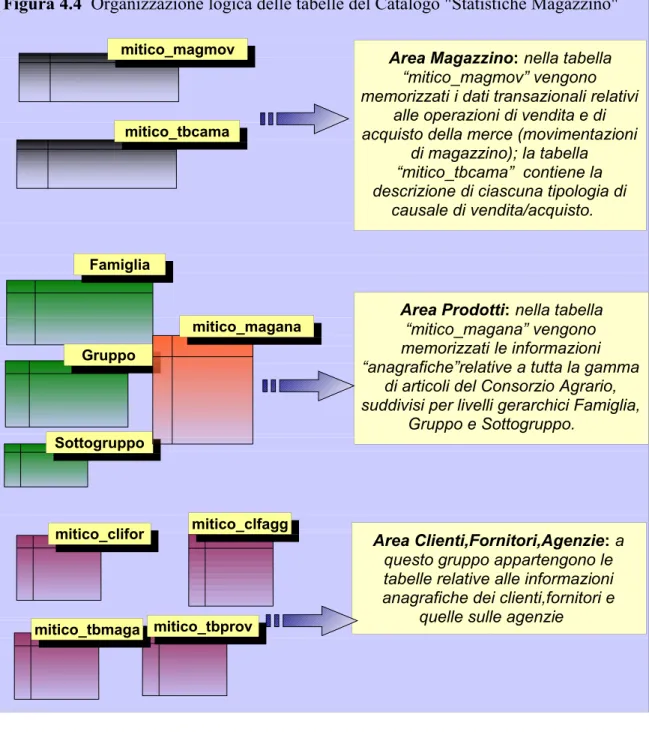
Per definire manualmente una buona strategia di join, si è ritenuto opportuno eseguire un'analisi preliminare del carico di lavoro allo scopo di gestire nel modo più efficace possibile l'esame della struttura delle tabelle e delle singole colonne componenti. Come prima operazione, le tabelle del nostro Catalogo sono state organizzate in gruppi logici secondo lo schema riportato di seguito (Figura 4.4);
Figura 4.4 Organizzazione logica delle tabelle del Catalogo "Statistiche Magazzino"
mitico_magmov
Famiglia
mitico_clifor
mitico_tbmaga
mitico_tbcama
Area Magazzino:nella tabella “mitico_magmov” vengono memorizzati i dati transazionali relativi
alle operazioni di vendita e di acquisto della merce (movimentazioni
di magazzino); la tabella “mitico_tbcama” contiene la descrizione di ciascuna tipologia di
causale di vendita/acquisto.
Gruppo
Sottogruppo
Area Prodotti:nella tabella “mitico_magana” vengono memorizzati le informazioni “anagrafiche”relative a tutta la gamma
di articoli del Consorzio Agrario, suddivisi per livelli gerarchici Famiglia,
Gruppo e Sottogruppo.
mitico_magana
Area Clienti,Fornitori,Agenzie:a questo gruppo appartengono le tabelle relative alle informazioni anagrafiche dei clienti,fornitori e
quelle sulle agenzie
mitico_clfagg
Successivamente, sono state analizzate le singole tabelle con l'obbiettivo di determinare le relazioni di join opportune limitatamente ad ogni singola area.
Per quanto rigurada il primo gruppo, ciascun record della tabella “mitico_magmov” contiene i dati relativi al documento di vendita o di acquisto; in particolare, il numero di registrazione (campo “numreg”), il numero di righe di cui è composto il documento (campo “numrig”), la data di registrazione del documento generato, il codice univoco del cliente che ha effettuato la vendita o del fornitore da cui è stata Figura 4.5 Relazione di join tra le tabelle "mitico_magmov" e "mitico_tbcama"
MITICO_MAGMOV
flgann codcma numreg numrig datare codart ... codmag codclf
U 50 200700189 5 12/01/04 45008 ... M50 116938
U 50 200700156 6 13/01/04 11478 ... M14 116938
R 03 200702021 3 24/11/06 30334 ... M50 116900
... ... ... ... ... ... ... ... ...
MITICO_TBCAMA
flgann codcma descri ... caurag ... flaggia flagneg
01 Carico da fornitore pianificato ... A ... + 1 50 DOCUMENTO TRASPORTO ... V ... - 1 03 Reso da clienti ... V ... + 0 ... ... ... ... ... ... ... ... Relazione di join : mitico_magmov.codcma = mitico_tbcama.codcma
acquistata la merce, il codice relativo all'articolo movimentato ed il codice magazzino (agenzia) presso cui è avvenuta la vendita o l'acquisto. La tabella “mitico_tbcama” è sostanzialmente una tabella di decodifica dei codici relativi ai tipi di operazioni di vendita o acquisto che sono riportati nel documento. Ciascuno codice (campo “codcma”) identifica una causale specifica, come evidenzia la Figura 4.5, a cui segue una descrizione esplicativa (campo “descri”); il campo “codcma” è presente anche nella tabella precedente ed è stato scelto come attributo candidato per la relazione di join tra le tabelle esaminate. Il link tra queste due tabelle coinvolge solamente il campo comune sopra descritto nonostante, nel seguito dell'analisi della struttura rimanente delle tabelle, siano stati identificati altri campi omonimi di potenziale interesse. Nel caso specifico però, prendendo ad esempio in considerazione il campo omonimo “datare” presente nelle due tabelle (non riportato in Figura 4.5 per esigenze di spazio), questo assume due significati completamente diversi: nella tabella “mitico_magmov” rappresenta la data di registrazione del documento di vendita/acquisto, mentre nell'altra tabella corrisponde alla data di aggiornamento dei codici; vista la discrepanza semantica, tale campo non è stato oggetto di interesse ulteriore. Da questo si è potuto comprendere come, nel caso in cui avessimo sfruttato Impromptu per la generazione automatica delle relazioni di join, avremmo ottenuto dati certamente inconsistenti.
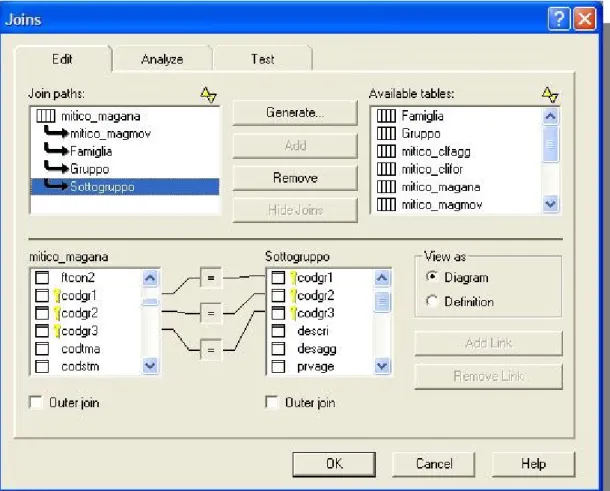
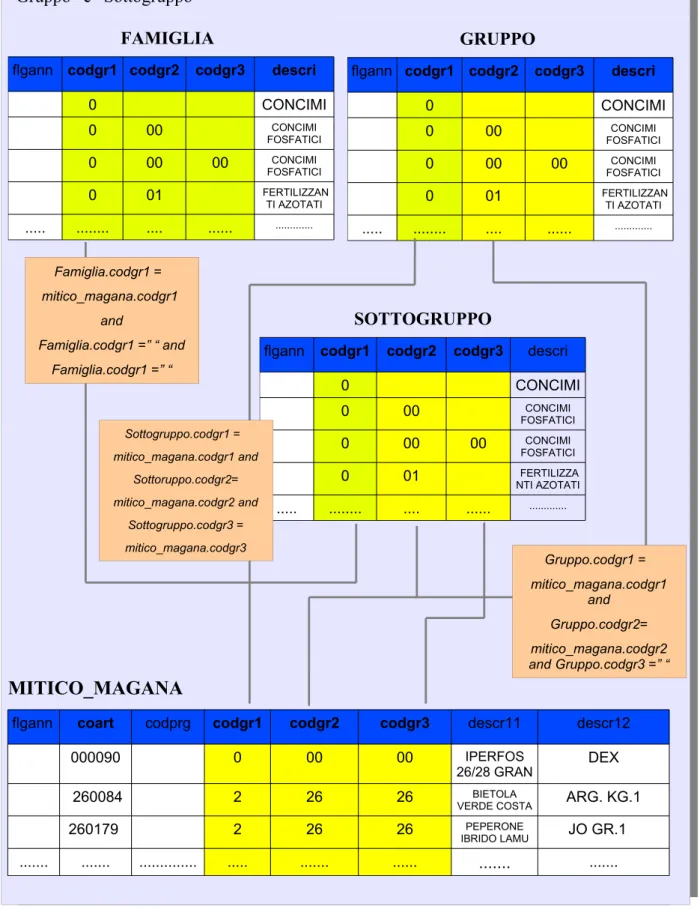
Questi aspetti sono stati affrontati similmente per determinare le relazioni di join tra le tabelle degli altri due gruppi. Tuttavia, per le tabelle relative ai gruppi merceologici, è stato opportuno definire delle relazioni di join più complesse che meritano un approfondimento particolare. Le tabelle “Famiglia”, “Gruppo” e “Sottogruppo” presenti nel nostro Catalogo hanno la medesima struttura e lo stesso contenuto della tabella “mitico_tbgrme” presente nel Database; si tratta quindi di 3 copie identiche (alias) di una stessa tabella, e la scelta di includerle
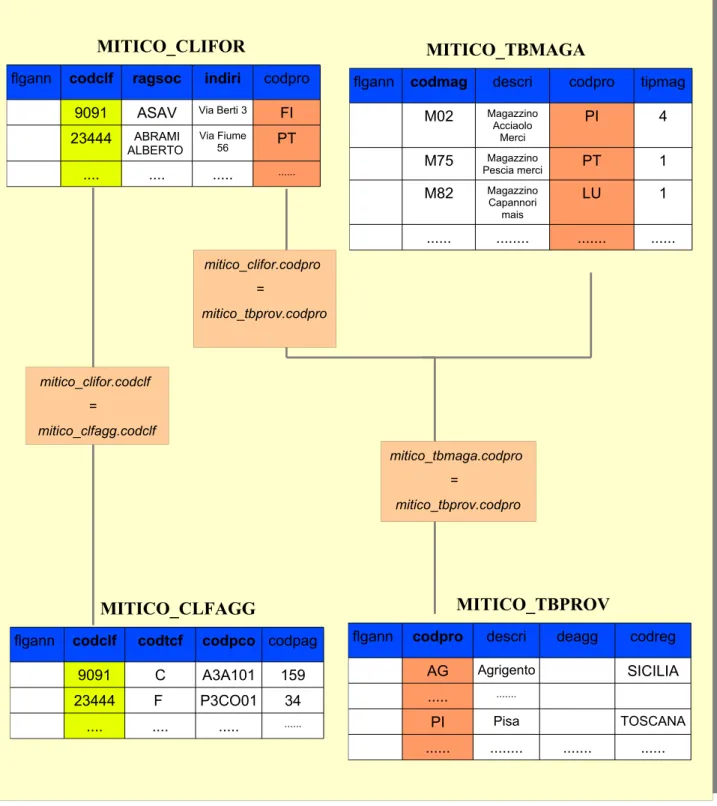
opportunamente nel Catalogo è stata raggiunta sulla base delle considerazioni seguenti. I gruppi merceologici dei prodotti dell'azienda sono organizzati in 3 livelli gerarchici opportunamente codificati dalla terna di attributi “codgr1”, “codgr2” e “codgr3”, che rappresentano rispettivamente la famiglia, il gruppo ed il sottogruppo di un articolo. A sua volta, ogni articolo ha un codice univoco corrispondente al campo “codart” presente nella tabella “mitico_magana”. In ogni record di questa tabella, il valore numerico assunto da ognuno dei 3 campi in esame è un intero positivo; scelta una particolare terna di valori interi, la descrizione ad essa associata in ogni tabella dei gruppi merceologici (campo “descri”) è sempre la medesima, è cioè quella del relativo sottogruppo a cui appartiene l'articolo. Il sottogruppo infatti è l'unico dei 3 attributi ad essere codificato con una terna di valori diversi dal carattere ' ' (stringa vuota). Questo ci ha permesso di capire come la sola tabella “mitico_tbgrme” non sarebbe sufficiente per recuperare correttamente la descrizione della famiglia, del gruppo e del sottogruppo in relazione ai dettagli dell'articolo corrispondente. Alla luce di questo, sono state introdotte opportune relazioni di join composte (complex join), inserendo i collegamenti necessari per recuperare senza ambiguità le informazioni sui singoli gruppi di prodotti e impostando opportune relazioni di equivalenza come mostrato in Figura 4.6. Per quanto concerne infine le tabelle dell'ultimo gruppo (area clienti, fornitori ed agenzie), le relazioni di join sono state ricavate senza particolari difficoltà ed in maniera abbastanza intuitiva come mostrato in Figura 4.7. A ciascun socio dell'azienda è associato un codice univoco, campo “codclf”, ed un campo per discriminare la tipologia di socio (“codtcf” : “C”, cliente “F”, fornitore). Infine, la tabella relativa ai clienti e fornitori e quella relativa alle agenzie condividono la tabella di decodifica delle provincie italiane “mitico_tbprov”.
La tipologia di join che è stata utilizzata in questa strategia parziale (che verrà completata per ottenere una strategia di join totale e conclusiva, cioè tra tutte le tabelle del Catalogo “Statistiche Magazzino”) è basata sulla relazione di equivalenza tra attributi omonimi delle relazioni (tabelle), quindi coincidenti a livello sintattico; questo tipo di join è quello implementato da Impromptu per default, ed è detto equijoin (o innerjoin, Figura 4.3). Il programma permette di realizzare altre tipologie di relazioni (non-equijoin) semplicemente selezionando l'operatore di disuguaglianza che si intende utilizzare, oppure ricorrendo ad istruzioni condizionali che permettono di formulare relazioni ancor più complesse. In generale infatti, Impromptu dispone di un insieme di funzioni piuttosto ampio che in taluni casi permettono di definire condizioni molto dettagliate per le relazioni di join. Le funzioni che operano su stringhe di caratteri sono, ad esempio, di grande supporto qualora si debbano relazionare due attributi di due tabelle coincidenti solo parzialmente a livello sintattico ma con le stesso contenuto informativo. In questo lavoro, situazioni di questo genere (diametralmente opposte a quelle descritte inizialmente relative a campi identici sintatticamente ma non a livello semantico) sono emerse solamente in pochissime occasioni peraltro non significative ai fini del completamento del nostro Catalogo. Nella definizione dei dati sorgenti del modello multidimensionale (file IQD, Impromtu Query
Definition), l'impiego di queste funzioni si è rivelato invece importante per
l'impostazione dei filtri opportuni per selezionare i dati necessari per un corretto popolamento della mappa delle dimensioni. Per il Catalogo definito infine, l'implementazione di una struttura di join semplice nel suo complesso ha risposto non solo alla nostre esigenza di progettazione, ma anche a quella di non degradare eccessivamente le prestazioni del Catalogo stesso, in modo da non compromettere la consistenza dei futuri report che possono essere creati e sfruttati anche per arricchire il contenuto del Power Cube.
Figura 4.6 Relazioni di join (complex join) tra le tabelle "mitico_magana", "Famiglia",
“Gruppo” e “Sottogruppo”
MITICO_MAGANA
flgann coart codprg codgr1 codgr2 codgr3 descr11 descr12
000090 0 00 00 IPERFOS
26/28 GRAN DEX
260084 2 26 26 BIETOLA
VERDE COSTA ARG. KG.1
260179 2 26 26 PEPERONE
IBRIDO LAMU JO GR.1 ... ... ... ... ... ... ... ...
FAMIGLIA
flgann codgr1 codgr2 codgr3 descri
0 CONCIMI 0 00 CONCIMI FOSFATICI 0 00 00 CONCIMI FOSFATICI 0 01 FERTILIZZAN TI AZOTATI ... ... .... ... ... SOTTOGRUPPO
flgann codgr1 codgr2 codgr3 descri
0 CONCIMI 0 00 CONCIMI FOSFATICI 0 00 00 CONCIMI FOSFATICI 0 01 FERTILIZZA NTI AZOTATI ... ... .... ... ... Famiglia.codgr1 = mitico_magana.codgr1 and Famiglia.codgr1 =” “ and Famiglia.codgr1 =” “ GRUPPO
flgann codgr1 codgr2 codgr3 descri
0 CONCIMI 0 00 CONCIMI FOSFATICI 0 00 00 CONCIMI FOSFATICI 0 01 FERTILIZZAN TI AZOTATI ... ... .... ... ... Sottogruppo.codgr1 = mitico_magana.codgr1 and Sottoruppo.codgr2= mitico_magana.codgr2 and Sottogruppo.codgr3 = mitico_magana.codgr3 Gruppo.codgr1 = mitico_magana.codgr1 and Gruppo.codgr2= mitico_magana.codgr2 and Gruppo.codgr3 =” “
Figura 4.7 Relazione di join tra le tabelle "mitico_clifor", "mitico_clfagg", “mitico_tbmaga” e
“mitico_tbprov”
MITICO_CLIFOR
flgann codclf ragsoc indiri codpro 9091 ASAV Via Berti 3 FI 23444 ABRAMI ALBERTO Via Fiume 56 PT .... .... ... ... MITICO_CLFAGG
flgann codclf codtcf codpco codpag
9091 C A3A101 159
23444 F P3CO01 34
.... .... ... ...
MITICO_TBPROV
flgann codpro descri deagg codreg
AG Agrigento SICILIA ... ... PI Pisa TOSCANA ... ... ... ... mitico_clifor.codpro = mitico_tbprov.codpro mitico_clifor.codclf = mitico_clfagg.codclf mitico_tbmaga.codpro = mitico_tbprov.codpro MITICO_TBMAGA
flgann codmag descri codpro tipmag
M02 Magazzino Acciaolo Merci PI 4 M75 Magazzino Pescia merci PT 1 M82 Magazzino Capannori mais LU 1 ... ... ... ...
La metodologia di realizzazione della strategia di join tra le tabelle di ogni singola area è stata reimpiegata per completare la strategia di join a livello dell'intero Catalogo, definendo cioè opportune relazioni tra le tabelle appartenenti a gruppi diversi. Come prima considerazione, la tabella “mitico_magmov” ha una importanza centrale dal punto di vista del contenuto informativo: essa infatti memorizza i dati operazionali relativi alle vendite, agli acquisti (fatti di interesse aziendale) relativamente ad ogni cliente, fornitore, e per ogni agenzia. Le colonne “codclf”, “codmag” e “codart” contengono queste informazioni che rappresenteranno le dimensioni più volte descritte, e sono altresì presenti rispettivamente nelle tabelle “mitico_clifor”, “mitico_tbmaga” e “mitico_magana”. Le nuove relazioni di equijoin che sono state introdotte tra le 3 tabelle sopra citate ed i 3 campi omonimi discussi, hanno portato ad un primo completamento della strategia di join del nostro Catalogo e sono raffigurate in Figura 4.10.
4.2.4 Analisi della stategia di join
4.2.4 Analisi della stategia di join
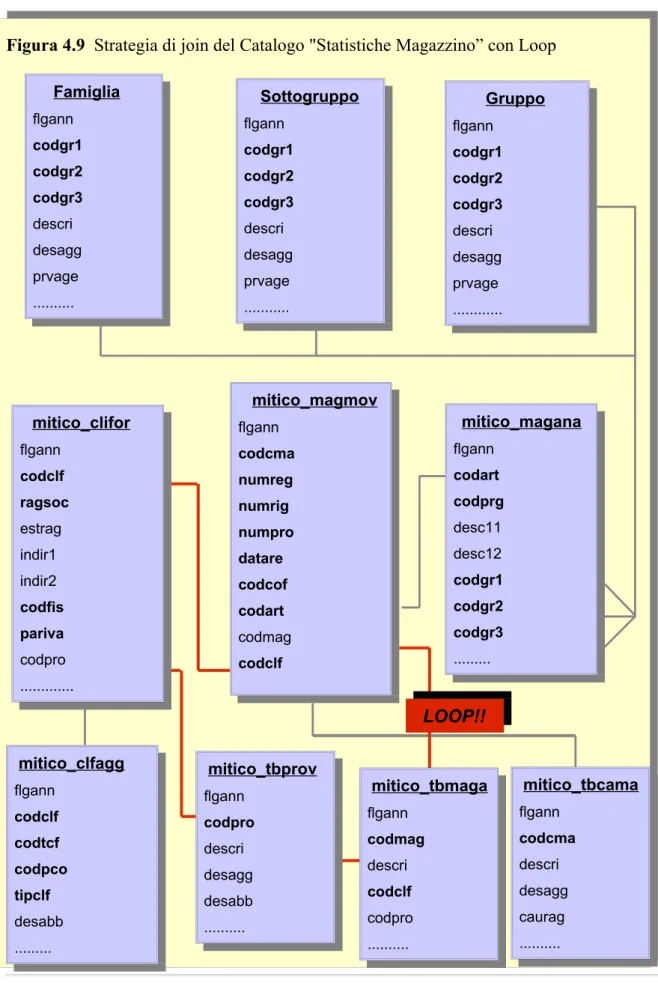
La strategia di join realizzata è stata successivamente sottoposta ad un processo di analisi, svolto in modo automatico da Impromptu con lo scopo di portare alla luce potenziali problemi che avrebbero potuto compromettere la funzionalità del nostro Catalogo. L'utilizzo di questo strumento di analisi è a discrezione del progettista il quale, in veste di amministratore esclusivo, potrebbe trascurarne l'uso tralasciando eventuali problemi latenti a scapito della performance del Catalogo. In generale, le situazioni di errore che il programma è in grado di diagnosticare sono la presenza di tabelle “orfane” (unjoined tables), la presenza di gruppi di tabelle non collegati da relazioni di join oppure l'esistenza di collegamenti circolari tra tabelle (loop). Le tabelle del nostro Catalogo sono state relazionate seguendo un certo criterio di
suddivisone logica che ha precluso a priori la possibilità di insorgere dei primi due problemi sopra elencati; tuttavia, l'esito dell'analisi condotta dal programma ha rilevato l'esistenza di un loop tra 4 tabelle, come mostrato in Figura 4.9; in Figura 4.8 invece è riportato il messaggio di eccezione sollevato da Impromptu al termine del processo di analisi.
La presenza di un loop all'interno della struttura di join può essere deleteria sia in termini di correttezza delle informazioni estrapolate dal Catalogo, sia in termini di performance. In un percorso circolare infatti, esistono links multipli tra due o più tabelle e quindi le informazioni che si possono ottenere da un percorso di join (join
path) possono essere diverse da quelle potrebbero ottenersi da un percorso
alternativo; l'efficienza nell'estrazione dei dati può essere notevolmente degradata Figura 4.8 Rilevazione di un loop da parte di Impromptu
qualora venga mantenuto un collegamento multiplo di questo tipo senza prendere alcuna azione correttiva. Una scelta simile può essere comunque accettabile se il percorso di join scelto da Impromptu nella formulazione della query SQL, che è quello “più breve”, risulta anche quello più efficiente per reperire le informazioni di cui si ha bisogno; in ogni caso, si tratta comunque di una scelta non ottimale perchè contrastante con il tipo di dati e l'utilizzo degli indici delle tabelle da parte del Database.
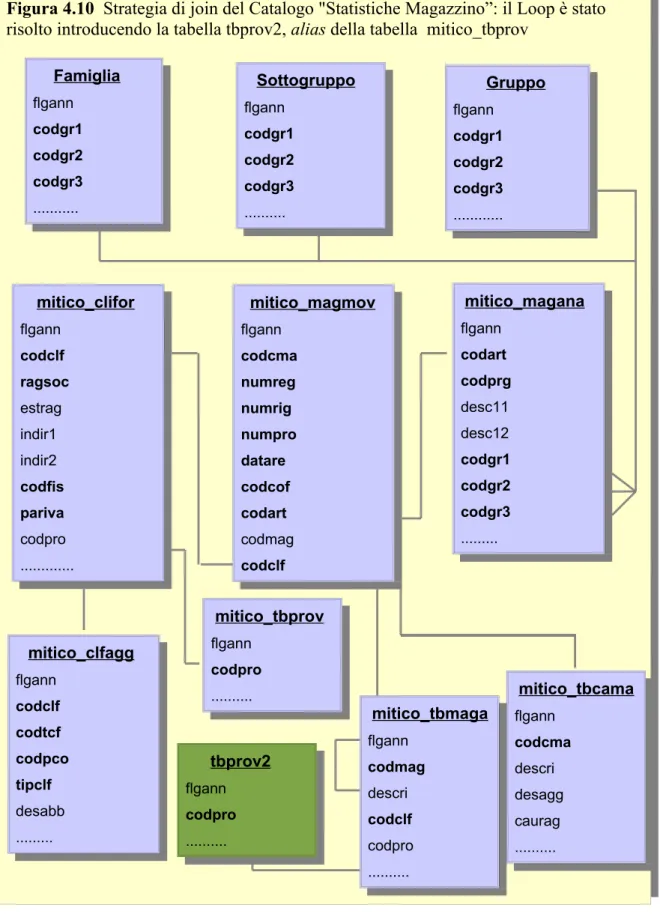
Il loop del nostro Catalogo (Figura 4.9) coinvolge la tabella di decodifica per i codici delle provincie italiane (“mitico_tbprov”) e le tabelle “mitico_clifor” e “mitico_tbmaga” non direttamente collegate ma entrambe relazionate con la tabella “mitico_tbprov”. Una tabella di decodifica comune (spesso chiamata lookup table), come quella del nostro Catalogo, ha portato a risultati scorretti, talvolta incomprensibili nei test di reporting effettuati, per esempio, per analizzare le vendite dei soci clienti per area geografica di appartenenza in relazione con quella delle agenzie periferiche. L'eliminazione della suddetta tabella avrebbe potuto risolvere il loop definitivamente ma avrebbe intaccato il contenuto informativo del nostro Catalogo; l'importanza delle informazioni geografiche per il modello da sviluppare non ha permesso quindi di intraprendere una scelta simile. La tecnica impiegata per risolvere il loop è stata quella di creare una copia (alias) della tabella individuata precedentemente, provvedendo alla definizione delle relazioni di join aggiuntive; l'introduzione di questa “nuova” tabella non ha alterato significativamente la struttura di join complessiva, e ha determinato un incremento della performance del programma sia in termini di consistenza di informazioni che in termini di tempi di risposta; infine, l'aumento contenuto della dimensione del Catalogo, la cui versione definitiva è illustrata in Figura 4.10, non è stato oggetto di analisi ulteriori alla luce dei miglioramenti ottenuti.
Figura 4.9 Strategia di join del Catalogo "Statistiche Magazzino” con Loop Famiglia flgann codgr1 codgr2 codgr3 descri desagg prvage ... Gruppo flgann codgr1 codgr2 codgr3 descri desagg prvage ... Sottogruppo flgann codgr1 codgr2 codgr3 descri desagg prvage ... mitico_magmov flgann codcma numreg numrig numpro datare codcof codart codmag codclf mitico_magana flgann codart codprg desc11 desc12 codgr1 codgr2 codgr3 ... mitico_clifor flgann codclf ragsoc estrag indir1 indir2 codfis pariva codpro ... mitico_clfagg flgann codclf codtcf codpco tipclf desabb mitico_tbprov flgann codpro descri desagg desabb ... mitico_tbcama flgann codcma descri desagg caurag ... mitico_tbmaga flgann codmag descri codclf codpro ... LOOP!!
Figura 4.10 Strategia di join del Catalogo "Statistiche Magazzino”: il Loop è stato
risolto introducendo la tabella tbprov2, alias della tabella mitico_tbprov
Famiglia flgann codgr1 codgr2 codgr3 ... Gruppo flgann codgr1 codgr2 codgr3 ... Sottogruppo flgann codgr1 codgr2 codgr3 ... mitico_clifor flgann codclf ragsoc estrag indir1 indir2 codfis pariva codpro ... mitico_magmov flgann codcma numreg numrig numpro datare codcof codart codmag codclf mitico_magana flgann codart codprg desc11 desc12 codgr1 codgr2 codgr3 ... mitico_tbprov flgann codpro ... mitico_clfagg flgann codclf codtcf codpco tipclf desabb ... mitico_tbcama flgann codcma descri desagg caurag ... mitico_tbmaga flgann codmag descri codclf codpro ... tbprov2 flgann codpro ...
4.3 La performance del Catalogo
4.3 La performance del Catalogo
Come già accennato più volte in questo lavoro di tesi, COGNOS Impromptu è stato impiegato per scopi di reportistica quasi esclusivamente nella fasi di testing, per valutare cioè la bontà e la consistenza delle informazioni ottenute rispetto ai dati aziendali. La presenza di un Catalogo performante è certamente un aspetto importante ma, nella visione globale di questo progetto, è legata ad aspetti che sono connessi solo parzialmente con quelli più caratterizzanti la performance del processo di creazione del Power Cube, oggetto principale di questo lavoro. Infatti, come verrà trattato successivamente, la tecniche di ottimizzazione attraverso cui è possibile ottenere un incremento importante della performance del cubo multidimensionale sono basate su fattori fondamentalmente differenti da quelli tipici dell'ambiente Impromptu. Tuttavia, in questa fase del progetto, gli aspetti di maggiore interesse che si è ritenuto opportuno valutare sono il grado di complessità delle relazioni di join e la specifica dei pesi associati alle tabelle del Catalogo (weighting). A ciascuna tabella del Catalogo è associato un particolare valore intero (peso), per default pari a 5. La priorità di accesso e recupero di dati risulta inversamente proporzionale al valore del peso settato dal progettista: in questo modo, Impromtu, nel momento in cui genera la query SQL, ordina le tabelle sulla base dei pesi assegnati, privilegiando le tabelle con peso minore. Le prove condotte utilizzando questa tecnica non hanno prodotto miglioramenti percettibili essenzialmente per due motivi: il Catalogo creato ha una dimensione contenuta per i nostri scopi, e la struttura di join implementata non presenta relazioni con un grado di complessità elevato; per questi motivi, si è scelto di mantenere l'assegnamento di deafult. Una scelta simile è risultata comunque opportuna considerando il fatto che il Database stesso può ottimizzare le query di input ignorando l'ordine di accesso delle tabelle imposto da Impromptu sulla base dei
pesi assegnati. La complessità delle relazioni di join è invece un aspetto importante che può incidere sulle prestazioni in modo più significativo; il mantenimento di una struttura di join “leggera” ed un numero di tabelle adeguato alle nostre esigenze è stato un obbiettivo importante perseguito con lo scopo non solo di ottenere tempi di risposta migliori (anche per scopi futuri di reporting), ma anche per valutarne i potenziali benefici nel processo di creazione del cubo nonostante, come già detto in precedenza, la sua performance dipenda da aspetti diversi che, in queste fasi iniziali del lavoro, non sono stati chiaramente affrontati.
4.4 Il Content Overview Report
4.4 Il Content Overview Report
del Catalogo “Statistiche Magazzino”
del Catalogo “Statistiche Magazzino”
Al termine della creazione del nostro Catalogo, si è ritenuto opportuno generare un report sul contenuto dello stesso per eventuali scopi analitici o amministrativi. Si tratta di un semplice file di testo ASCII articolato in diverse sezioni, ciascuna delle quali contiene le informazioni che sono state selezionate in precedenza dal menù di scelta di Impromptu; il programma infatti permette di personalizzare il contenuto del report in base alle proprie esigenze. Successivamente, il report è stato generato in modo automatico dal programma. Il contenuto del report informativo creato è riportato in Figura 4.11 ed in Figura 4.12 (la sezione relativa alle informazioni sulla struttura delle tabelle è solo parziale per motivi di spazio, mentre le altre sezioni sono riportate integralmente come presenti nel file di testo generato); si è provveduto infine ad effettuare alcune copie di buckup del file (“Cat_rep.icr”) per poter recuperare in ogni momento il contenuto del Catalogo creato.
Figura 4.11 Content Overview Report del Catalogo “Statistiche Magazzino” (parte I )
Impromptu Version 7.3.950.0 Catalog Content Report
Catalog Information
Catalog Name: C:\Programmi\Cognos\cer3\samples\Impromptu\reports\staven.cat Description: Statistiche Magazzino
Creation Date: giovedì, giugno 02, 2007
Database Information
Logical Name: Cappi_su_aix
Physical Name: DSN=Cappi_su_aix@ASYNC=0@0/0@COLSEQ=
Type: OD Database Structure Table : mitico_clifor Column : flgann Column : codclf ... Table : Famiglia Column : flgann Column : codgr1 Column : codgr2 Column : codgr3 Column : descri ... Table : mitico_magmov Column : flgann Column : codcma Column : numreg Column : numrig Column : numpro Column : datare ...
(...segue l'elenco completo, qui non riportato, delle tabelle del Catalogo “Statistiche Magazzino” )
Sezione 4
Elenco completo delle tabelle che compongono il Catalogo. Per ogni tabella sono indicate
le relative colonne.
Sezione 3Informazioni sul
Databese aziendale
Sezione 1 Informazioni sulla
versione Impromptu
Sezione 2 Informazioni
Figura 4.12 Content Overview Report del Catalogo “Statistiche Magazzino” (parte II)
Table Joins
mitico_clifor - mitico_clfagg : Inner Join mitico_clifor."codclf" = mitico_clfagg."codclf" mitico_clifor - mitico_magmov : Inner Join mitico_clifor."codclf" = mitico_magmov."codclf" mitico_clifor - mitico_tbprov : Inner Join
mitico_clifor."codpro" = mitico_tbprov."codpro" mitico_magana - mitico_magmov : Inner Join mitico_magana."codart" = mitico_magmov."codart" mitico_magana - Famiglia : Inner Join
Famiglia."codgr1" = mitico_magana."codgr1" and Famiglia."codgr2" = ' '
and Famiglia."codgr3" = ' ' Gruppo - mitico_magana : Inner Join
Gruppo."codgr1" = mitico_magana."codgr1"
and Gruppo."codgr2" = mitico_magana."codgr2" and Gruppo."codgr3" = ' '
Sottogruppo - mitico_magana : Inner Join
Sottogruppo."codgr1" = mitico_magana."codgr1"
and Sottogruppo."codgr2" = mitico_magana."codgr2" and Sottogruppo."codgr3" = mitico_magana."codgr3" mitico_tbcama - mitico_magmov : Inner Join
mitico_tbcama."codcma" = mitico_magmov."codcma" mitico_tbmaga - mitico_magmov : Inner Join
mitico_tbmaga."codmag" = mitico_magmov."codmag" tbprov2 (mitico_tbprov) - mitico_tbmaga : Inner Join
tbprov2 (mitico_tbprov)."codpro" = mitico_tbmaga."codpro"
Sezione 5
Elenco completo delle relazioni di join che
compongono la strategia implementata. Per ogni relazione è indicata la tipologia di join.