34
Capitolo 3 – Il Cocktail Party Effect
3.1- Il Cocktail Party Effect nella storia
L’“effetto cocktail party”, (la capacità di concentrare l’attenzione dell’ascolto su un unico parlatore tra una molteplicità di conversazioni e rumori di fondo) è stato riconosciuto da tempo. Questa capacità di ascolto può essere associata alle caratteristiche del sistema di produzione del linguaggio umano, al sistema uditivo, o all’alto livello di percezione ed elaborazione del linguaggio stesso. Edward Colin Cherry, nei suoi studi sulla scienza cognitiva, sostenne che:”uno dei fatti più impressionanti riguardanti le nostre orecchie è che ne abbiamo due, eppure si sente un solo mondo acustico; una sola voce per parlatore” È interessante, quindi, analizzare gli aspetti di attenzione selettiva nel sistema uditivo: sotto quali condizioni un ascoltatore può prestare attenzione solamente ad uno dei diversi messaggi concomitanti?
Gli esseri umani sono abili ad ascoltare una sola voce pur ricadendo nel mezzo di altre conversazioni e rumori, ma non tutti i meccanismi di questo processo sono del tutto chiari. Il fenomeno cocktail party può essere visto in molti modi. Dal punto di vista di un ascoltatore, il compito è intuitivo e semplice, mentre da una prospettiva psicologica e fisiologica, vi è una vasta e complessa matrice di elementi da utilizzare per spiegare l’effetto: ci sono molte interazioni tra il segnale, il sistema uditivo, e il sistema nervoso centrale.
35 3.1.1- I Primi lavori
Gran parte dei primi lavori in questo settore possono essere ricondotti ai problemi incontrati dai controllori del traffico aereo nei primi anni ‘50: a quel tempo, i controllori ricevevano i messaggi dai piloti attraverso gli altoparlanti presenti nella torre di controllo, ma l’ascolto delle voci miscelate dei vari piloti provenienti da un singolo altoparlante rendeva molto difficile il compito dei controllori stessi.
Nel 1953, E. C. Cherry eseguì numerosi esperimenti presso il MIT (Massachusetts Institute of Technology) riguardanti il riconoscimento di messaggi ricevuti da uno e due orecchie. Questo fu il primo lavoro tecnico riguardante il “Cocktail Party Effect”. Da questi esperimenti, Cherry ricavò alcuni fattori che avrebbero potuto facilitare la progettazione di un “filtro” finalizzato alla separazione delle varie voci miscelate:
1) Separazione spaziale delle voci; 2) Lettura delle labbra, dei gesti, e simili;
3) Differenti caratteristiche vocali fra le varie voci simultanee: tono, velocità di esposizione, sesso, etc…;
4) Accenti diversi;
5) Probabilità di transizione (basata sul significato, la dinamica vocale e la sintassi del discorso)
Tutti i fattori, tranne l’ultimo, potevano, però, essere rimossi registrando due messaggi dello stesso parlatore. L’autore affermò che “il risultato è una babele, ma comunque i messaggi possono essere separati”. Cherry suggerì, infatti, che gli esseri umani hanno una vasta memoria di probabilità di transizione che rende facile il compito di prevedere gruppi di parole.
Una serie successiva di esperimenti fecero uso di “shadowing” di registrazioni, in cui il soggetto sperimentale doveva seguire un messaggio vocale e ripeterlo, ignorandone altri, dopo averli ascoltati da una registrazione su nastro. In questi esperimenti il contenuto delle registrazioni erano spesso correlate, per
36 esempio, selezionando paragrafi adiacenti dello stesso libro. Il riconoscimento fu spesso effettuato a frasi, ed i soggetti trovarono il compito molto difficile pur avendo avuto la possibilità di ripetere l’esperimento un numero illimitato di volte. In tutti i casi, però, le frasi “di media o lunga durata” (più di 2-3 parole) furono correttamente identificate e gli errori commessi in genere sintatticamente corretti. In una leggera variazione del test, al soggetto fu permesso di prendere appunti con carta e matita; questo aiuto alla memoria a lungo termine rese il compito molto più facile ed accorciò il tempo necessario ad eseguirlo.
I soggetti ascoltarono anche diversi messaggi vocali presentati a ciascun orecchio attraverso l’uso di cuffie. In questa configurazione non era presente il contributo offerto dalla direzionalità: si trattava, semplicemente, di un segnale dicotico (in cui al soggetto sperimentale venivano fatti ascoltare due messaggi diversi da un orecchio all’altro). I soggetti non ebbero difficoltà ad ascoltare uno solo dei due messaggi presentati, escludendo l’altro, ma non riuscirono, però, a ricordare nulla, riguardo al messaggio scartato, se non le caratteristiche dei suoni che erano presenti. Solitamente i soggetti eseguivano molto rapidamente il compito di shadowing, anche se con un leggero ritardo.
Norman, nei suoi studi, affermò che “maggiore è il ritardo, e maggiormente si può sfruttare la struttura del linguaggio. Questo è ciò che potrebbe essere chiamato il fenomeno «what-did-you-say (quello che hai detto)». Spesso, quando qualcuno a cui non presti attenzione ti fa una domanda, la tua prima reazione è quella di dire «uh, che cosa hai detto?» Eppure, prima che la domanda venga ripetuta, è possibile rivangare nella memoria. Quando questo esperimento è stato effettivamente provato nel mio laboratorio, abbiamo ottenuto dei risultati in accordo con le nostre intuizioni: c’è una memoria temporanea per gli elementi di cui non siamo interessati, ma come Cherry, James, e Moray sottolineano, nessuna memoria a lungo termine.”
In una variante interessante di questi studi, la stessa registrazione fu inviata ad entrambe le orecchie, con un ritardo variabile tra le due ed, ai soggetti, veniva richiesto di seguire (shadowing) una sola registrazione. Il ritardo veniva poi lentamente diminuito, fino ad un punto in cui le registrazioni erano inviate
37 entro 2-6 secondi l’una dall’altra. Quasi tutti i soggetti dichiararono di aver riconosciuto, ad un certo punto del test, la coincidenza fra le registrazioni presentate alle orecchie. Questo risultato fu sorprendente, alla luce delle prove precedenti in cui i soggetti risultavano incapaci di individuare anche una sola parola del messaggio inviato all’orecchio respinto. Dal passaggio periodico del messaggio tra le orecchie, fu determinato l’intervallo di tempo necessario per trasferire l’attenzione: per la maggior parte dei soggetti questo intervallo fu di circa 170 ms.
38 3.1.2- Probabilità di transizione e ascolto di due messaggi simultanei
Spieth. presso il Laboratorio di elettronica della Marina di San Diego eseguì una serie di esperimenti, indagando le risposte alla presentazione di messaggi simultanei. Egli relazionò il fenomeno di attenzione selettiva al lavoro di Cherry sulla probabilità di transizione: “questo suggerisce la possibilità che tutto ciò che aumenta la prevedibilità (element-to-element) all’interno di ciascuno dei due messaggi concorrenti, diminuisce la prevedibilità dell’elemento nell’altro messaggio rendendo, quindi, più facile l’ascolto di uno dei due”.
Infine, nel 1958, Broadbent stabilì sperimentalmente che la probabilità di un ascoltatore di sentire correttamente una parola varia con la probabilità che la parola stessa ha di essere presente in un particolare contesto. Ad esempio, dopo aver sentito la parola “pane”, la presenza successiva di “coltello”, o”burro” è più probabile che “gomma da cancellare” o “carburatore”. Le prestazioni di ascolto selettivo sembravano, quindi, variare con le informazioni, come definito dalla “teoria della comunicazione”, piuttosto che con la quantità di stimolazione fisica.
39 3.1.3- Smascheramento binaurale
Rispetto al caso monoaurale, la nostra capacità di rilevare un segnale presentato in concomitanza ad un segnale di fondo mascherante è notevolmente migliorata nel caso di ascolto binaurale. In condizioni ideali, la soglia di rilevamento per l’ascolto binaurale supera l’ascolto monoaurale di 25 dB. Si consideri, ad esempio, una condizione di controllo in cui il segnale ed il rumore sono inviati ad un orecchio solo. Se il segnale venisse poi inviato contemporaneamente ad entrambe le orecchie, ma la fase del rumore su un orecchio fosse spostata di 180° rispetto all’altro, vi sarebbe un miglioramento di 6 dB nella rilevazione del segnale. Questo miglioramento rispetto alla condizione di controllo viene chiamato “binaural masking level difference BMLD (differenza binaurale di livello di mascheramento)”. Inoltre se il rumore venisse inviato ad entrambe le orecchie, ma il segnale fra le orecchie fosse fuori fase di 180°, vi sarebbero 15 dB di BMLD. Tale tecnica viene spesso sfruttata nelle cuffie dei piloti da caccia per aiutarli nella separazione dei segnali vocali dall’alto livello di rumore presente nella cabina di pilotaggio. Le cuffie sono semplicemente cablate in modo che il segnale presentato su un orecchio sia in antifase (180° fuori fase) rispetto al segnale presentato all’altro orecchio
Durante l’ascolto binaurale, inoltre, un segnale proveniente da una determinata direzione viene meno efficacemente mascherato da un segnale interferente se proveniente da una diversa direzione..
40 3.2-
Ascolto dicotico e memoria di lavoro
Wood e Cowan nel 1995 hanno replicato ed esteso l’indagine di Moray (1959) riguardante un aspetto importante del fenomeno cocktail party, riferendosi ad una situazione in cui pur essendo in presenza di un ambiente rumoroso, gli stimoli fortemente pertinenti, come il proprio nome, possono improvvisamente catturare la nostra attenzione. Entrambe le indagini hanno documentato che circa il 33% dei soggetti si accorgono della presenza del proprio nome all’interno di un messaggio trascurato ed irrilevante. È stato dimostrato che i soggetti che rilevano il loro nome in un messaggio irrilevante hanno relativamente basse capacità di memoria di lavoro e, quindi, difficoltà ad inibire le informazioni di distrazione.
Lo scopo dell’esperimento è stato quello di spiegare perché alcuni soggetti, ma non tutti, dimostrano l’effetto cocktail party, ponendosi, così, di fronte ad alcune interessanti possibilità: da un lato, era possibile che i soggetti più capaci notassero i loro nomi perché in grado di monitorare i messaggi irrilevanti, senza danni per le prestazioni di shadowing; dall’altra parte, era possibile che solo i soggetti meno capaci notassero i loro nomi perché non in grado di mantenere l’attenzione sul messaggio in questione in presenza di distrazione. Per eseguire l’esperimento è stata misurata la capacità dei soggetti usando la memoria di lavoro, considerata come un sistema cognitivo costituito da memorie di archiviazione, nonché da un meccanismo centrale di controllo esecutivo. La funzione della memoria di lavoro è quella di mantenere attivamente le “informazioni obiettivo rilevanti” al servizio della conoscenza complessa. La limitata capacità della memoria di lavoro limita probabilmente le prestazioni cognitive. Questa capacità è stata misurata con il compito “operation span” (si veda il paragrafo successivo) in modo tale da assegnare ad ogni soggetto un punteggio. In questo modo è stato possibile suddividere i vari soggetti in gruppi ad alta e bassa capacità di memoria di lavoro; successivamente questi soggetti hanno dovuto svolgere un compito di ascolto dicotico in cui veniva presentato loro il proprio nome nel messaggio irrilevante.
41 3.2.1- Procedura del compito “operation span”
Al soggetto è stata presentata una serie di visualizzazioni sullo schermo di un computer. Ogni visualizzazione conteneva un’operazione matematica ed una parola non correlata (ad esempio, [è (6 + 4) / 2 = 5? Dog]). Il compito del soggetto, per ogni visualizzazione, è stato quello di dire ad alta voce l’equazione, rispondere “sì” o “no” in base al risultato dell’equazione stessa, e poi dire ogni parola. Quando la serie di esposizioni era conclusa, il compito era di scrivere tutte le parole su un foglio. Il numero di visualizzazioni in una serie variava da 2 a 6 e sono state presentate 3 serie di ogni lunghezza per un totale di 15 serie, con lunghezza di serie casuale e non prevedibile da parte del soggetto. Il punteggio span è stato valutato come il numero cumulativo di parole della serie ricordate che sono state perfettamente scritte nell’ordine di serie corretto. Il punteggio medio era di 24,85 per i soggetti ad alto span e 8,22 per i soggetti a basso span. I soggetti ricadenti nei due quartili di mezzo dell’intervallo dei punteggi span sono stati omessi dallo studio.
3.2.2- Procedura di ascolto selettivo
Il campione comprendeva 40 studenti universitari (17 maschi, 23 femmine) di lingua inglese con un udito normale. Tutti i soggetti dovevano ripetere lo stesso messaggio rilevante, ma ogni “gruppo span” è stato diviso in due sottogruppi di egual numero: al primo veniva presentato un messaggio irrilevante che conteneva, dopo 4 minuti di shadowing, il nome proprio del soggetto e dopo 5 minuti il nome proprio di un altro soggetto, mentre al secondo veniva presentato un messaggio irrilevante con il nome proprio del soggetto dopo 5 minuti di shadowing ed il nome proprio di un altro soggetto dopo 4 minuti.
Il messaggio rilevante conteneva 330 parole monosillabiche registrate da una voce monotona femminile al ritmo di 60 parole al minuto e durata di 5,5 min. Il messaggio irrilevante conteneva 300 parole monosillabiche registrate da una voce monotona maschile. L’inizio del messaggio irrilevante cominciava 30
42 secondi dopo il messaggio rilevante, consentendo un breve periodo di pratica senza distrazioni. L’ordine delle parole era identico tra i soggetti, tranne per i nomi, che sono stati digitalmente inseriti nel messaggio irrilevante al posto di una parola dopo 4 o 5 minuti di shadowing, come precedentemente sottolineato. I soggetti sono stati incaricati di ascoltare il messaggio presentato all’orecchio destro e ripetere ogni parola, non appena fosse stata presentata, facendo meno errori possibile ed ignorando le distrazioni che venivano dall’orecchio sinistro. Durante il compito di shadowing, lo sperimentatore era seduto ad un tavolo separato nella stessa stanza, in modo tale da poter registrare gli errori dei vari soggetti. Alla fine dell’esperimento ad ogni soggetto è stato chiesto se durante il compito di shadowing fosse stato udito qualcosa di particolare riguardo al messaggio irrilevante e tutti coloro che hanno risposto affermativamente hanno dichiarato di aver udito il proprio nome.
3.2.3- Risultati e discussioni
Controllando i risultati subito dopo il compito di shadowing, è stato scoperto che il 20% dei soggetti ad alto span e il 65% dei soggetti a basso span hanno riportato l’ascolto del loro nome nel messaggio irrilevante.
Successive analisi di Fisher hanno indicato che la probabilità di ottenere queste proporzioni per pura casualità (in base al presupposto che i soggetti a basso e alto span, in realtà, sono ugualmente portati a rivelare il loro nome nel messaggio irrilevante) è solo p = 0,005. Nessun soggetto ha riferito, invece, l’audizione del nome proprio dell’altro soggetto che era stato ugualmente presentato. I soggetti a basso span hanno anche incontrato maggiori difficoltà a svolgere il compito di shadowing. Dato questo risultato, è stato verificato che la differenza di rilevamento del nome tra i soggetti ad alto e basso span non era semplicemente il risultato di un maggiore cambiamento di attenzione da parte dei soggetti a basso span. Pertanto, sono stati esaminati gli errori di shadowing per le due parole nel messaggio rilevante che precedevano il nome proprio del soggetto. Per queste due parole non ci sono state differenze di gruppo nello
43 shadowing, escludendo, pertanto, la possibilità che i soggetti a basso span avessero rilevato i loro nomi più frequentemente rispetto ai soggetti ad alto span, semplicemente perché la loro attenzione vagava nel messaggio non pertinente al momento opportuno. Vi è stata, invece, una differenza tra i soggetti ad alto e basso span in errori di shadowing commessi in concomitanza con la presentazione del nome, la quale ha comportato, quindi, una distrazione maggiore per i soggetti a basso span. Sono stati infine esaminati gli errori di shadowing dopo la presentazione del nome ed è stato notato che, indipendentemente dal valore di span, i soggetti che hanno rilevato la presenza del proprio nome all’interno del messaggio irrilevante, hanno commesso maggiori errori nelle due parole successive alla presentazione del nome. Comunque, questa distrazione non persiste per più di due parole. La maggiore incidenza di rilevamento del nome in soggetti a basso span è particolarmente sorprendente dato che era preventivabile il risultato completamente opposto. Teoricamente i soggetti ad alto span, grazie alla loro maggiore capacità, dovevano monitorare più accuratamente i messaggi non pertinenti in modo da sentire i loro nomi. Il fattore critico sembra essere la capacità di bloccare le informazioni dal messaggio irrilevante. Soggetti ad alto span sono più capaci di questo e sono stati, quindi, meno propensi a sentire i loro nomi, e anche meno suscettibili ad una conseguente interruzione delle prestazioni di shadowing dei messaggi pertinenti. Infine, il risultato attuale non risponde alla domanda se la capacità di memoria di lavoro guida la capacità inibitoria o viceversa. Una possibile interpretazione è che la capacità di lavoro della memoria è una “risorsa” che alimenta l’esecutivo centrale, che è responsabile di mantenere l’attivazione per le informazioni pertinenti e di sopprimere le informazioni di distrazione (Conway & Engle, 1994).
44
3.3- Intelligibilità del parlato
3.3.1- Analisi della scena uditiva
I suoni o eventi acustici presenti in un determinato ambiente vengono creati quando accadono fenomeni fisici dovuti ai più svariati motivi. L’unità percettiva che rappresenta un singolo evento acustico viene definito flusso uditivo. In una serie di passi, per esempio, ciascuno rappresenta un singolo suono separato, ma usualmente noi percepiamo la serie come un unico evento percettivo. Una grande varietà di ricerche riguardanti il raggruppamento percettivo di stimoli nei flussi uditivi sono state recentemente effettuate e riassunte da Bregman. Nell’introduzione al suo libro, egli parla delle costanze percettive di audizione; la costanza di percezione può essere definita come la tendenza della percezione a conservare caratteristiche costanti nel tempo e nello spazio, entro certi limiti, pur al variare oggettivo delle situazioni di stimolazione (il nostro corpo mantiene una temperatura superiore di poco ai 36o pur variando delle condizioni climatiche): la voce di un amico viene
normalmente percepita sia in una stanza silenziosa che in un cocktail party; eppure, all’interno di quest’ultimo, l’insieme delle componenti di frequenza derivanti da tale voce si mescolano nell’orecchio dell’ascoltatore con le componenti di frequenza provenienti dalle altre fonti. Lo spettro totale di energia che raggiunge l’orecchio può, quindi, essere significativamente differente in ambienti diversi. Per riconoscere il timbro unico della voce dobbiamo isolare le componenti di frequenza, responsabili di quella voce, dalle altre, che sono presenti nello stesso momento. Una scelta sbagliata di componenti di frequenza cambierebbe il timbro e, di conseguenza, la percezione della voce. Il fatto di riuscire costantemente a riconoscere il timbro di una voce “amica” implica, quindi, che l’essere umano è in grado di scegliere selettivamente le giuste componenti di frequenza in contesti diversi.
L’analisi della scena uditiva si occupa della questione percettiva riguardante la decisione di quante sorgenti sonore sono presenti in un determinato ambiente, quali sono le loro caratteristiche e dove sono localizzate. Un bambino, per
45 esempio, imitando la voce di sua madre, non inserisce di certo i cigolii della culla che si sono verificati contemporaneamente al discorso della madre stessa; il bambino, quindi, rifiuta i cigolii come non facenti parte dell’oggetto percettivo formato dalla voce della madre.
Molte delle idee sull’analisi della scena uditiva possono essere fatte risalire al lavoro svolto dai gestaltisti dei primi anni del 1900 secondo cui eventi visivi ed uditivi sono combinati per rendere gli oggetti il più intuitivi possibile. Elementi che appartengono ad un flusso sono simili e prevedibili, mentre gli elementi appartenenti a diversi flussi sono dissimili ed imprevedibili. Per gli psicologi della Gestalt, con particolare riferimento alle percezioni visive, le regole principali di organizzazione dei dati percepiti sono:
1) prossimità (gli elementi sono raggruppati in funzione delle distanze spaziali e temporali);
2) somiglianza (tendenza a raggruppare gli elementi simili);
3) buona continuità (tutti gli elementi che sono percepiti come appartenenti ad un insieme coerente e continuo vengono raggruppati); 4) destino comune (se gli elementi sono in movimento, vengono
raggruppati quelli con uno spostamento coerente);
5) Simmetria e chiusura (elementi che formano oggetti simmetrici e racchiusi tendono ad essere raggruppati);
Da questa prospettiva, possiamo considerare che i singoli eventi acustici vengano raggruppati in un unico flusso percettivo in base alla loro somiglianza (per esempio, in frequenza, timbro, intensità), alla loro prossimità spaziale o temporale, al loro andamento temporale in termini di frequenza, intensità , posizione, ritmo, ecc.
46 3.3.2- Analisi del linguaggio
Oltre ai processi di raggruppamento sopra citati, anche le caratteristiche del linguaggio giocano un ruolo fondamentale nel riunire i singoli eventi acustici in un unico flusso uditivo tra le quali:
• Andamento del tono: in generale, il tono della voce di un parlatore cambia lentamente, e segue le melodie che fanno parte della grammatica e del significato di una particolare lingua;
• Continuità spettrale: poiché il tratto vocale non passa istantaneamente da una posizione articolatoria all’altra, le frequenze fondamentali di suoni successivi tendono ad essere continue. Queste caratteristiche spettrali danno continuità al flusso uditivo;
• Segregazione basata sul tono: è più difficile separare due racconti detti se entrambi hanno lo stesso tono. È stato affermato che con zero semitoni di separazione, viene sentito un singolo flusso uditivo incomprensibile ma, con un solo quarto di tono di differenza vengono sentite molto chiaramente due voci, ed è possibile passare la propria attenzione da una all’altra.
• Armoniche: su una scala logaritmica, le armoniche della parola si muovono su e giù in parallelo quando il tono di una parola cambia. Armoniche che mantengono tale rapporto sono probabilmente percepite come collegate alla stessa sorgente sonora.
47
3.4- Il Cocktail Party Effect nelle colonie di pinguini
Tutti gli uccelli marini sono monogami per diverse ragioni, tra le quali i continui viaggi per la ricerca di cibo fra mare e luoghi di riproduzione, ed il fatto che entrambi i sessi covino ed allevino i pulcini. Nella famiglia del pinguino, un problema particolarmente complesso sembra essere il riconoscimento individuale tra i due partner e tra genitori e pulcino, dato che spesso queste colonie sono formate da diverse migliaia di individui. Inoltre, l’identificazione avviene in un ambiente particolarmente rumoroso, con indizi vocali, ma non visivi od olfattivi.
Nella specie del pinguino reale la difficoltà è maggiore dato che la riproduzione avviene senza l’utilizzo di un nido, pertanto, questi pinguini hanno pochissimi aiuti per trovare, all’interno della colonia, il proprio partner o il proprio pulcino costituendo, così, un buon modello per lo studio del cocktail party effect.
Il pinguino reale, Aptenodytes patagonicus, si riproduce in dense colonie formate da un numero elevatissimo di coppie (fino a 300000), sulle piane litorali delle isole subantartiche. Questo uccello di grandi dimensioni, 0.9 m di altezza e 12 kg di peso corporeo, cova le singole uova in piedi. L’uovo continua ad essere covato da uno dei genitori fino a quando è sufficientemente grande per essere lasciato da solo nella colonia. In questa fase del ciclo di allevamento, entrambi i genitori sono in mare in cerca di cibo fino a 500 km di distanza dalla colonia. Durante il periodo di cova, che si estende per quasi sei mesi, i pulcini vengono spinti, a poco a poco, al di fuori della zona in cui sono nati a causa del movimento continuo degli adulti appena arrivati che covano le proprie uova.
L’adulto proveniente dal mare, per sfamare il suo pulcino, si fa strada nella zona della colonia, verso il luogo dove si trovava il pulcino (luogo d’incontro) e, a piedi, lo chiama ad intervalli regolari. Il pulcino nella colonia chiama in risposta e corre verso suo padre per chiedere il cibo. Pertanto la richiesta dei genitori deve essere distinta dalle chiamate di altri genitori e degli altri pulcini, e dalle chiamate dei vari pinguini in accoppiamento. Questo processo di
48 riconoscimento è reso ancor più difficile non solo da questi rumori estranei, ma anche da problemi di propagazione a causa della distanza tra genitori e pulcino e per il fenomeno di schermatura causata dai corpi dei volatili (screening). In termini fisici, i segnali acustici che si propagano all’interno della colonia vengono degradati, in qualche misura, dalla confusione dei parametri di ampiezza e frequenza indotta dalle frequenze di filtraggio selettivo, dal riverbero e dalla turbolenza atmosferica ed, inoltre, dalle attenuazioni prodotte dall’assorbimento e dalla diffrazione dovuta ai moltissimi pinguini presenti. Di conseguenza, la degradazione del segnale aumenta con la distanza di propagazione.
Inoltre, quando aumenta la distanza tra emettitore e ricevitore, aumenta anche il numero di corpi che il segnale deve attraversare; questo effetto di screening dei corpi, spesso trascurato o sottovalutato negli studi che si occupano di uccelli marini coloniali, dovrebbe effettivamente essere preso in considerazione.
A questo proposito sono stati condotti alcuni esperimenti all’interno delle colonie per determinare le distanze medie e massime di rilevazione della chiamata dei genitori, e per testare la capacità dei pulcini di discriminare le chiamate dei genitori in una situazione d’interferenza, ovvero tra più chiamate simultanee di adulti.
3.4.1- Soggetti ed area di studio
Lo studio sul campo è stato condotto da Thierry Aubin e e Pierre Jouventin alla fine degli anni ‘90 nel sud dell’Oceano Indiano, a Possession Island, arcipelago di Crozet dal 11 dicembre 1995 al 16 gennaio 1996, in una colonia di 10 ettari con circa 40000 coppie di pinguini reali adulti e circa 1500 pulcini (equivalente a 0,8 uccelli per m2 circa).
Con le dimensioni, il numero e la densità degli uccelli, la colonia studiata è sufficientemente rappresentativa delle altre colonie esistenti nelle isole subantartiche.
49 3.4.2- Procedura sperimentale: analisi della chiamata dei genitori adulti Per misurare l’ampiezza alla quale viene prodotta una chiamata dei genitori, sono state eseguite le misure di SPL durante le chiamate di 11 uccelli nelle quali il microfono è stato posto ad una distanza dal becco dei pinguini di 1 m. Le registrazioni delle chiamate dei genitori sono stateanalizzate al fine di rivelare le loro caratteristiche principali (composizione spettrale, andamento dell’ampiezza nel tempo e parametri di frequenza).
3.4.3- Misurazioni del rumore ambientale
Per determinare il livello medio del rumore di fondo della colonia, sono state effettuate 20 misure di SPL ad intervalli di 15 s in una zona di alimentazione al centro della colonia. Inoltre, il rumore ambientale è stato anche registrato per una durata di 4 min. In queste misurazioni il fonometro è stato posto ad un’altezza di 0,9 m (altezza della testa del pinguino adulto).
La registrazione è stata poi esaminata per determinare la composizione spettrale del rumore ambientale e la durata dei periodi di silenzio misurati in funzione dell’ampiezza nel periodo di 4 min Questa funzione, espressa in dB, è stata calcolata mediante la trasformata di Hilbert.
Ogni periodo con un livello di oltre 30 dB al di sotto del livello medio del rumore ambientale calcolato in precedenza è stato considerato come un periodo di silenzio. Tutte le misurazioni e le registrazioni sono state prese dalle 11:00 alle 12:00, nei periodi di calma, con una velocità del vento inferiore a 10 km/h, umidità relativa dell’83% e temperatura di 6-8 °C.
3.4.4- Test di propagazione delle chiamate dei genitori
Per stimare la distanza massima alla quale la chiamata dei genitori possa essere differenziata dal rumore di fondo, è stata trasmessa ripetutamente al centro della zona di alimentazione della colonia una chiamata precedentemente registrata. Un altoparlante ed un microfono sono stati montati su un cavalletto
50 ad una altezza di 0,9 m e sono stati posizionati a distanze di 1 m (riferimento), 7 m e 14 m. Queste posizioni di altoparlante e microfono sono state scelte per simulare alcune tipiche situazioni di chiamata fra adulti e pulcino dentro l’area di alimentazione di una colonia. Per quantificare l’effetto di screening dei corpi degli uccelli, le registrazioni sono state confrontate con quelle eseguite con la stessa altezza di microfoni ed altoparlanti e le stesse distanze, ma senza alcun pinguino presente.
3.4.5- Test di rilevamento della chiamata dei genitori da parte del pulcino. I pulcini sono stati esaminati con dei segnali sperimentali durante l’assenza dei loro genitori. Ogni segnale in esame è stato ripetuto due volte ad un intervallo di 5 s l’uno dall’altro. L’SPL dei segnali di trasmissione era di circa 95 dB ad 1 metro di distanza dall’altoparlante. In condizioni naturali, il processo di riconoscimento della chiamata dei genitori è stato determinato da un’evidente alterazione del comportamento del pulcino: si è notato, infatti, che il pulcino dopo l’emissione del segnale sperimentale girava il capo in direzione della sorgente, rispondeva alla chiamata, e poi si avvicinava (spesso correndo) direttamente verso l’altoparlante. Si è notato inoltre che gli altri pulcini presenti nelle vicinanze, mentre si pavoneggiavano, non reagivano alla chiamata estranea (cioè non è stato osservato nessun cambiamento del loro comportamento). L’intensità della risposta dei pulcini è stata valutata da una scala a cinque punti classificati come segue:
• classe 0 (nessuno) = nessuna reazione; • classe 1 (debole) = testa girata;
• classe 2 (medio) = chiamata di risposta dopo la seconda trasmissione di segnale;
• classe 3 (forte) = chiamata di risposta dopo la prima trasmissione; • classe 4 (molto forte) = chiamata di risposta dopo la prima trasmissione,
il pulcino si avvicina in direzione dell’altoparlante e si ferma in prossimità (meno di 2 m).
51 3.4.6- Test di rilevamento in funzione della distanza
Sono state trasmesse al pulcino due chiamate dei genitori identiche, separate da un intervallo di 5 s, a distanze pulcino-altoparlante diverse, in una zona di alimentazione con densità normale di uccelli. L’esperimento è iniziato con una distanza di 20 m successivamente ridotta via via di 1 metro, spostando l’altoparlante e, ad ogni distanza, è stato osservato il comportamento del pulcino. Durante gli spostamenti dell’altoparlante, alcuni uccelli situati tra il pulcino e la sorgente si sono allontanati e per dare loro il tempo di tornare in vicinanza dell’altoparlante, è stata osservata una pausa di 6 minuti. L’esperimento è terminato nel momento in cui veniva osservata una alterazione nel comportamento del pulcino (risposta dalla classe 1 alla classe 4). In totale sono stati esaminati 30 pulcini e per ogni distanza testata, è stato rilevato il numero di uccelli tra il pulcino e l’altoparlante.
3.4.7- Test di rilevamento in funzione del disturbo
Per stimare la soglia minima di discriminazione della chiamata dei genitori in una situazione d’interferenza, sono stati trasmessi al pulcino una serie di segnali misti. Sono state sovrapposte sei chiamate di adulti, utilizzando una semplice aggiunta di ampiezza, delle quali, una corrispondeva alla chiamata dei genitori (PC), mentre le altre cinque corrispondevano alle chiamate di adulti estranei (EC). Le cinque EC avevano lo stesso livello sonoro medio e la loro durata era sempre superiore alla durata di ciascun PC testato. La sovrapposizione ha portato ad un segnale miscelato con una totale mancanza di silenzi. Inoltre, le caratteristiche spettrali delle EC scelte sono state molto vicine a quelle del PC testato (differenza non superiore a circa 15Hz per le frequenze fondamentali). In queste condizioni, si è potuto ritenere che il PC fosse quasi completamente mascherato dalle CE, sia in ambiti di tempo che di frequenza.
Per misurare la soglia di rilevazione del PC da parte del pulcino, sono stati testati i segnali con diversi rapporti di livello di intensità fra i PC e le EC.
52 Questi rapporti sono stati definiti come E = 20 log (APC / AEC), dove E
rappresenta il livello di comparsa del PC in dB, AEC l’ampiezza assoluta delle
EC miscelate e APC l’ampiezza assoluta del PC. Sono stati testati 15 pulcini
con valori di E pari a: -9, -6, -3, 0, +3 dB. La distanza tra altoparlante e l’uccello era circa 7 m.
3.4.8- Risultati
Chiamate dei genitori
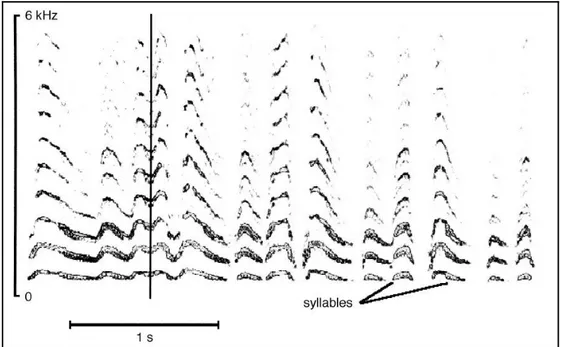
La misura dell’SPL delle chiamate dei genitori registrate ad 1 metro hanno dato un valore medio di 95,4 ± 0,4dB. Le componenti sonore della chiamata tra due frequenze e due ampiezze minime sono state denominate “sillabe”da Jouventin e Robisson . La durata della chiamata varia da 3 a 6 s e la prima sillaba è generalmente la più lunga (Figura 3.1). La composizione spettrale di una sillaba è caratterizzata da due bande di frequenza (fenomeno delle due voci) con le loro armoniche rispettive. Per ogni serie armonica, la maggior parte dell’energia è concentrata tra i 500 e 2500Hz, per la fondamentale (f0) e
le prime tre armoniche superiori, con un livello massimo corrispondente alla seconda armonica (2f0).
53
Rumore di fondo
Il valore medio dell’SPL del rumore ambientale misurato ad una distanza di 2 m dai margini della colonia è stato 74,1 ± 3,4 dB. L’analisi dei silenzi nel corso della registrazione dei 4 minuti ha dato i seguenti risultati: sono stati rilevati 57 silenzi, con una durata minima di 0,03 s, una durata massima di 3,60 s ed una durata media di 0,64 s. La somma sei silenzi durante il periodo di registrazione è stata 36,46 s, cioè solo il 15% del periodo di osservazione. Il rumore ambientale ha un ampio spettro che varia da 100-150 a 5000-6000Hz, con distinti picchi principali. Sopra i 5000-6000Hz, il rumore della colonia è stato di almeno 30 dB inferiore al picchi principali ed è stato quindi considerato trascurabile.
Il vento (debole durante l’esperimento) e, in particolare, il rumore del movimento delle pinne hanno generato un picco marcato a 200Hz. Le altre vette principali che vanno da 500 alla 1800Hz corrispondono alle frequenze delle diverse chiamate degli adulti. La parte successiva ai 2200Hz corrisponde principalmente alle frequenze delle risposte dei pulcini (Fig. 2).
54
Rilevamento delle chiamate dei genitori da parte dei pulcini, in relazione alla distanza
Gli esperimenti hanno dimostrato che i pulcini individuano, riconoscono e localizzano la chiamata dei genitori, senza ambiguità (risposta di classe 4) ad una distanza relativamente breve (circa 11 m, con un numero medio di 10 uccelli attraversati). Tuttavia, l’orientamento della testa verso l’altoparlante (risposta di classe 1) si è osservata ad una distanza maggiore (circa 14 m, con un massimo rilevato a 18 m, e con un numero medio di 15 uccelli attraversati).
Rilevamento delle chiamate dei genitori da parte dei pulcini, nel caso di interferenza
Gli esperimenti hanno indicato che il pulcino riesce comunque a rilevare la chiamata dei genitori in una situazione di estrema interferenza. Il processo di riconoscimento si è verificato sempre con un livello di comparsa della chiamata dei genitori (rispetto alle chiamate estranee) di -6 dB, ossia ben al di sotto del livello di rumore (derivante dalle cinque chiamate estranee). Ciò ha dimostrato che i pulcini sono in grado di riconoscere i loro genitori nonostante un forte effetto di mascheramento nel dominio del tempo e della frequenza. Il riconoscimento non è avvenuto, però, con un livello di comparsa di -9 dB. 3.4.9- Discussione dei risultati
Rilevabilità della chiamata dei genitori in relazione all’ampiezza di comparsa
La chiamata è emessa da un adulto con un SPL di circa 95 dB, un valore relativamente elevato, ma non eccezionale, rispetto ad altri tipi di uccelli. L’acustica tecnica impone che l’SPL debba diminuire con la distanza secondo la legge dell’inverso del quadrato (6 dB per il raddoppio della distanza); in questa maniera l’SPL di chiamata dei genitori calcolato ad 1 km dovrebbe essere 35 dB, sempre abbastanza forte da essere sentito, ma non in ambiente rumoroso come una colonia di pinguini. La chiamata viene prodotta e trasmessa in un contesto coloniale che coinvolge il rumore di fondo e la propagazione tra i corpi, anche riducendo la distanza di trasmissione.
55 l livello medio del rumore di fondo misurato è stato di circa 74 dB. Considerando che la chiamata degli adulti del pinguino reale viene emessa con un’ampiezza di 95 dB, il livello di comparsa della chiamata degli adulti sarebbe 95-74 = 21dB. Se si considera che la distanza di riconoscibilità di un segnale corrisponde alla distanza dalla fonte alla quale l’ampiezza del segnale è pari a quella del rumore di fondo (segnale/rumore = 1), la distanza massima di trasmissione della chiamata, dedotta dalla legge dell’inverso del quadrato, sarebbe dovuta essere di circa 11m (il riferimento è 1 metro quindi 20 log r1/r2
= 20 log 11 = 21dB).
Inoltre nel caso reale, a causa della presenza di numerosi pinguini fra il trasmettitore ed il ricevitore, si è verificato un eccesso di attenuazione (EA) di 1,5 dB a una distanza di 6 m, e di 3 dB ad una distanza di 13 m. EA è causato dalla porosità dei corpi dei pinguini che contribuiscono all’assorbimento dei suoni. Maggiore è la distanza, maggiore è il numero di corpi attraversati, tanto più diminuisce l’SPL. A causa dell’EA, la massima distanza prevista di trasmissione della chiamata degli adulti non avrebbe dovuto superare gli 8-9 m, distanza particolarmente breve. Al contrario, gli esperimenti con gli uccelli hanno dimostrato che i pulcini riconoscono la chiamata dei loro genitori ad una distanza maggiore (in media 14.43 m di distanza per una risposta di classe 1 e 10.58 m per una risposta di classe 4). Una possibile spiegazione di questo fenomeno potrebbe essere che i pulcini sono in grado di rilevare la chiamata del genitore, anche se il rapporto segnale-rumore è inferiore a 1. In effetti, dall’esperimento eseguito con l’utilizzo di rumore interferente si è notato che, anche se il livello di chiamata dei genitori è di 6 dB al di sotto del livello del rumore di fondo, il pulcino è in grado di discriminare la chiamata. In questo modo, la distanza di riconoscimento di chiamata del genitore da parte del pulcino è più grande della distanza alla quale il segnale non può essere differenziato in ampiezza dal rumore di fondo.
56
Rilevabilità della chiamata dei genitori in relazione alla frequenza di comparsa
La chiamata dei genitori è un suono complesso basato su serie armoniche da 400 Hz a più di 5000 Hz, con l’80% dell’energia concentrata in una banda di frequenza da 400 a 2000 Hz. Durante la propagazione a breve distanza in campo libero (meno di 15 m), all’aumentare della distanza stessa, il livello di intensità dei picchi diminuisce, ma i livelli relativi di ogni picco vengono mantenuti. In effetti, a breve distanza e ad un’altezza di 1 metro, gli effetti di assorbimento atmosferici e del suolo non sono sufficienti ad attenuare le frequenze alte e basse, così, quando la chiamata si propaga in un campo libero, ad una altezza di 1 m su una superficie piana, la forma complessiva dello spettro è mantenuta. Per questo motivo gli spettri di segnali a 1 m, 7 m e 14 m sono fortemente correlati.
Questo non avviene, però, quando i corpi dei pinguini sono presenti fra sorgente e ricevitore, in quanto, alcune delle vette più importanti (tra cui quella a 1000 Hz), sono più gravemente attenuate rispetto alle altre. La forma dello spettro è fortemente modificata rispetto alle registrazione fatta ad 1 m, e, a 14 m, le cime tendono addirittura a scomparire nel rumore di fondo. Inoltre tutte le analisi spettrali corrispondono a periodi di quiete, cioè con gli uccelli nelle immediate vicinanze che rimangono in silenzio. Presumibilmente, in situazioni più normali questa tendenza ad appiattire lo spettro sarebbe più forte.
Nonostante queste alterazioni i pulcini dei pinguini reali riescono a discriminare le chiamate dei loro genitori dal rumore di fondo.
57 3.5- Il Cocktail party effect nelle sale ristoranti
Il fenomeno acustico del Cocktail Party Effect assume,come già sottolineato in precedenza, un ruolo fondamentale in ambienti caratterizzati dalla presenza di diversi gruppi di parlatori, come ad esempio una sala ristorante.
Se un cliente seduto ad un tavolo, nel parlare con i propri commensali, viene infastidito da un suono disturbante (campo sonoro riverberante), dovuto ai parlatori seduti negli altri tavoli, automaticamente cercherà di alzare il tono della propria voce quanto basta per superare il rumore di fondo.
Se ogni parlatore, seguendo tale comportamento, alzasse il tono della propria voce, il rumore di fondo aumenterebbe progressivamente inducendo ogni altro parlatore ad aumentare nuovamente il proprio tono di voce instaurando, così, un effetto a catena, chiamato per l’appunto “Cocktail Party Effect”.
Si può facilmente dimostrare che la differenza di intensità ΔL fra il campo sonoro diretto e quello riverberato non dipenda dalla potenza emessa dal singolo parlatore; aumentando quindi il tono della voce non si aumenta il grado di intelligibilità del parlato ma solo il rumore di fondo della sala. Per aumentare questa differenza di intensità è necessario diminuire la distanza d fra il parlatore e gli ascoltatori, diminuire il numero N complessivo dei parlatori ed aumentare il potere fonoassorbente A della sala.
In una data sala, con A dato ed N fissato, l’unico modo per poter incrementare ΔL è quello di ridurre la distanza d fra parlatore ed ascoltatori, seduti al medesimo tavolo. In sede di progetto, invece, si dovrà prevedere una sala con un elevato potere fonoassorbente, per ottenere bassi valori del tempo di riverberazione diminuendo, così, il rumore di fondo. Va notato come, per valore eccessivamente bassi del tempo di riverberazione, si possa creare l’effetto opposto al rumore di fondo, ovvero la mancanza di privacy fra i diversi gruppi di conversazione; come ogni parametro, anche il tempo di riverberazione va, quindi, scelto con criterio per non infastidire in nessun modo le conversazioni dei clienti.
58 3.5.1- Densità di energia del campo riverberante
Si consideri un ambiente confinato di volume V contenente una sorgente sonora di potenza W. Per effettuare il calcolo della densità di energia sonora D del campo riverberante si fa riferimento alla teoria di Sabine che si basa su tre ipotesi:
1. la densità D è uniformemente distribuita nell’ambiente;
2. il processo di assorbimento dell’energia sonora da parte delle pareti e degli oggetti contenuti nell’ambiente è regolare e continuo;
3. l’assorbimento dell’energia sonora da parte dell’aria è trascurabile. L’i-esima parete delimitante l’ambiente abbia:
• area = Si;
• coefficiente di riflessione = ri;
• coefficiente apparente di assorbimento acustico αi = 1 – ri;
Sia
∑
→ = n 1 i i SS l’area totale delle pareti; ed Ii l’intensità sonora incidente
sull’i-esima parete. Con ciò, il coefficiente medio di riflessione e il coefficiente medio apparente di assorbimento sono dati da:
(3.1) S r S r n 1 i i i
∑
→ = ; S α S α n 1 i i i∑
→ =In condizioni di regime la potenza disponibile per il campo riverberante r⋅W
dovrà essere assorbita dalle pareti o trasmessa all’esterno per cui dovrà sussistere la relazione: (3.2)
∑
→ = ⋅ n 1 i i i iαI S W rPer l’ipotesi 1) le intensità Ii sono tutte uguali fra loro per cui sostituendo I = Ii
nella formula (3.2)e combinandola, poi, con la seconda delle (3.1) si ottiene:
(3.3) (1−α)W=SIα
La densità sonora per incidenza caotica si può scrivere: (3.4)
4 Dc I=
59 con c velocità del suono nell’aria. Dalla formula (3.3) ne consegue:
(3.5) α α − = cS W ) 1 4( D
che fornisce l’energia sonora del campo riverberante. E’ utile introdurre la costante della sala H [m2] definita come:
(3.6) S r 1 S H = α⋅ α − α =
Si nota che per piccoli valori di α si può considerare H = αS. Utilizzando la (3.6), la (3.5) si può scrivere nella forma: (3.7)
cH 4W D=
e l’intensità associata al campo riverberante, per la (3.4) sarà: (3.8)
H W I=
L’intensità del campo sonoro diretto ad una distanza d dalla sorgente è, per definizione, data da:
(3.9) d 2 d 4 QW I π =
con Q fattore di direzionalità caratteristico della sorgente. Alla intensità Id è
associata una densità di energia del campo diretto Dd pari a:
(3.10) d 2 d cd 4 QW c I D π = =
Si noti la differenza fra il campo sonoro diretto e quello riverberante: nel campo diretto la densità di energia e l’intensità variano inversamente al quadrato della distanza dalla sorgente (quindi la pressione acustica varia inversamente alla distanza), mentre, nel campo riverberante, la densità di energia e l’intensità risultano costanti su tutta la sale (quindi anche la pressione acustica rimane costante).
L’intensità totale del campo acustico è data dalla formula:
(3.11) It = I + Id
Sostituendo le (3.8) e (3.9) nella (3.11) si ottiene:
(3.12) ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ π + ⋅ = 2 t d 4 Q H 4 W I
60 cui corrisponde un livello:
(3.13) ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ π + + ⋅ = W 2 d 4 Q H 4 log 10 L L
con LW livello di potenza della sorgente definito come:
0 W W W log 10 L =
riferito a W0 = 10-12 watt. Per ambienti poco assorbenti, con piccoli valori di H
(α << 1), prevale nell’argomento del logaritmo al secondo membro della (3.13) il termine
H 4
e la diminuzione del livello con la distanza è trascurabile per cui vi è prevalenza di campo riverberante. Per ambienti fortemente assorbenti, con grandi valori di H (α ≅1) il contributo di
H 4
è trascurabile e dalla formula (3.13) consegue:
(3.14) 20logd 4 Q log 10 L L W ⎟− ⎠ ⎞ ⎜ ⎝ ⎛ π ≅ −
In queste condizioni il livello L diminuisce con la distanza con un decremento di 6 dB per ogni raddoppio della distanza, tipico della propagazione in campo libero.
In Figura 3 è riportato l’andamento di L – LW in funzione della distanza dalla
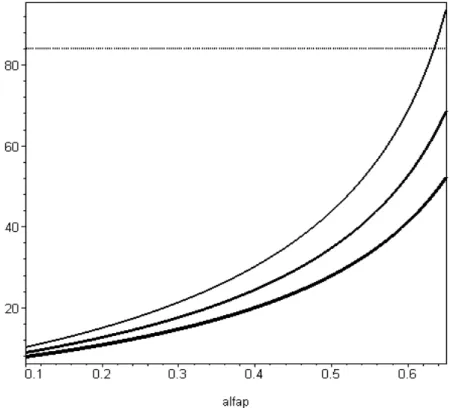
sorgente, con fattore di direzionalità caratteristico della sorgente Q = 1 e per vari valori di costante della sala H. La retta più a sinistra (H = ∞) rappresenta il caso limite in cui l’energia incidente viene assorbita completamente dalle pareti e il campo sonoro è solo diretto.
61
Figura 3.3- Livello di pressione sonora in funzione della distanza in ambiente semiriverberante
3.5.2- Distanza critica
La distanza dalla sorgente alla quale la densità di energia del campo riverberante eguaglia quella del campo diretto è definita distanza critica dc.
Imponendo: D = Dc dalle (3.7) e (3.10) di ottiene: (3.15) π = 16 QH dc
Si noti che la distanza critica è indipendente dalla potenza W della sorgente sonora; per d < dc, prevale il campo riverberante.
Sempre dalle (3.9) e (3.10) si può ottenere che: 2 d d 1 16 QH D D ⋅ π = da cui per la (3.15) si consegue: (3.16) 2 c d d d D D ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ =
62 che esprime il rapporto fra la densità di energia del campo sonoro diretto e quella del campo riverberante in funzione del rapporto fra la distanza dalla sorgente sonora d e la distanza critica dc.
Se α << 1 si può considerare H = αS e la (3.15) diviene: (3.17) π α ≅ 16 QS dc
Ricavando dalla formula del tempo di riverberazione di Sabine (2.1), il prodotto αS e sostituendolo nella (3.17) si ottiene:
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ϑ ⋅ π = 0,01 QV dc
che esprime la distanza critica in funzione del volume della sala, del tempo di riverberazione di Sabine, e del fattore di direzionalità della sorgente. Per una sorgente panoramica (Q = 1) e per una sala con Ԃ = 1 risulta:
V 8 , 31 10 d 2 c = ⋅ −
e quindi, per esempio: con una sala di V = 1000 m3 si ottiene una d
c = 1,8 m e
con un V = 2000 m3 si ottiene una d
c = 2,5 m.
3.5.3- Considerazioni analitiche sul Cocktail Party Effect
In una sala ristorante, di volume V e superficie dell’i-esima parete Si, sono
presenti z tavoli e M clienti distribuiti in vari tavoli in ciascuno dei quali sono mediamente sedute m persone. Si avranno, quindi,
m M
N= tavoli occupati e, ipotizzando un solo parlatore per ciascun tavolo, si avranno anche N parlatori. Sia poi r la distanza media fra un parlatore ed i suoi ascoltatori seduti allo stesso tavolo.
Se nella sala è presente un solo gruppo di conversazione il disturbo è nullo e la densità di energia sonora utile Du [J/m3] è data:
(3.18) Du =Dd+Dr
avendo indicato con Dd e Dr, rispettivamente la densità del campo sonoro
63 In presenza, invece, di più gruppi di conversazione, il suono utile per gli ascoltatori di ciascun tavolo è ancora dato dalla formula (3.18), mentre la densità Dn del disturbo risulta:
(3.19) Dn =
(
N−1)
⋅Dravendo supposto per tutti i parlatori la stessa potenza di fonazione w [W] e che la distanza tra i tavoli sia maggiore della distanza critica. Sia ΔL la differenza di livello tra il suono utile e quello disturbante, il rapporto
n u D D = η è dato da: (3.20) 10 L 10 Δ = η
Per Dd e Dr si possono usare le (3.7) e (3.10):
2 d cd 4 Qw D π = ; cH 4w Dr =
con H [m2] costante della sala, Q fattore di direzionalità della sorgente e c
[m/s] velocità del suono nell’aria. Il rapporto η si può scrivere nella forma:
(3.21) ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + − = η o22 r r 1 1 N 1 avendo posto: π = 16 QH r02 ; per la costante della sala si può considerare:
) 1 ( S H α − α ⋅ = dove S V 4 S zu p μ + + α = α avendo indicato con:
p
α il coefficiente medio di assorbimento delle pareti; u [m2]l’assorbimento acustico dovuto ad un tavolo;
μ [m-1] il coefficiente di estinzione dovuto all’aria.
Si può anche scrivere, combinando la (3.20) con la (3.21):
(3.22) 10log(N 1) r r 1 log 10 L 2 2 o − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + ⋅ = Δ
64 che fornisce la differenza di livello tra il campo dovuto ad un singolo parlatore ed il campo riverberante dovuto a tutti gli altri parlatori. Si noti che ΔL non dipende dalla potenza di fonazione del singolo parlatore. Dalla formula (3.22) consegue che per poter aumentare ΔL è necessario: diminuire la distanza fra parlatore e ascoltatori, diminuire il numero di parlatori, aumentare r0 e quindi
aumentare Q e H. In una data sala con N fissato (Q dato o comunque non modificabile) l’unico modo per aumentare ΔL è ridurre la distanza r; ovviamente al di sotto di un certo valore di r risulterà scomodo mantenere una normale conversazione. Dalla formula (3.21) consegue che ΔL = 0 per :
2 N r r 0 c − =
che fornisce la distanza dal singolo parlatore alla quale il campo sonoro diretto eguaglia quello riverberante dovuto a tutti gli altri parlatori. Si indichi con ηm il
rapporto minimo fra la densità del suono utile e quella del disturbo massimo che possa comunque garantire una buona intelligibilità in ciascun gruppo di conversazione; con ciò per avere una chiara conversazione ad ogni tavolo deve essere soddisfatta la condizione:
(3.23) η ≥ ηm
Per η < ηm in ciascun gruppo di conversazione l’audizione diventa difficoltosa,
i parlatori per farsi sentire meglio sono istintivamente portati ad aumentare la potenza della propria voce aumentando notevolmente la densità del campo riverberante (proporzionale a N - 1) lasciando comunque costante il rapporto η; la sala diventa rumorosa e non è più garantita una chiara intelligibilità delle conversazioni portando un notevole fastidio alle persone presenti.
Dalle formule (3.21) e (3.22) consegue che per assicurare una buona audizione è necessario che il numero di parlatori soddisfi la relazione:
N ≤ NMAX con: (3.24) ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + ⋅ η + = 022 m MAX r r 1 1 1 N
65 Considerando anche l’assorbimento acustico dovuto alle persone l’espressione (3.6) della costante della sala si scrive:
(3.25) ) N ( 1 ) N ( S H β + α − β + α = con S mU =
β , avendo indicato con U l’assorbimento acustico dovuto ad una persona. Con ciò dalla (3.21) si ha:
(3.26) ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ β − α − β + α γ + − = η N 1 N 1 1 N 1 avendo posto 2 r 16 QS π = γ .
Il numero massimo di parlatori si ottiene risolvendo, rispetto ad N, la (3.26) con η = ηm. In ogni caso, ovviamente, MMAX dovrà essere inferiore al numero
massimo di persone consentito in relazione all’indice di affollamento previsto per la destinazione d’uso del locale in esame.
69
Piano primo: ristorante
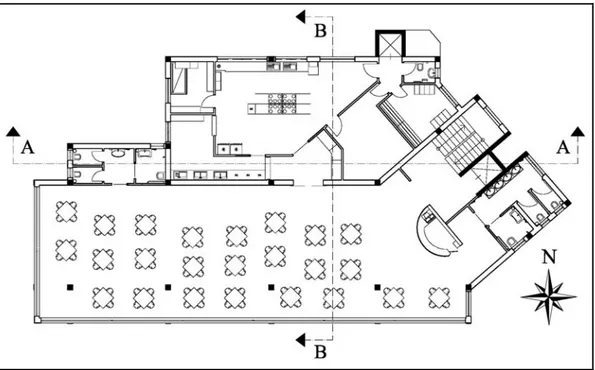
Il secondo piano è raggiungibile attraverso i collegamenti verticali, scale ed ascensore, ben visibili sia dalla strada che dalla piazza. Il piano è sostanzialmente diviso in due parti: a nord si trova la cucina con tutti gli opportuni locali, dotata di entrata principale (ascensore di servizio), mentre a sud si colloca la sala ospitante ben 108 posti (Figura 3.8).
Figura 3.8- Pianta piano primo
La sala non è un volume unico ma si sviluppa in due altezze diverse: una parte più bassa che corrisponde all’aggetto della sala, coperta da soffitto intonacato, mentre la parte rimanente, ben più alta, è caratterizzata da una copertura in legno lamellare leggermente ricurva con nervature in entrambe le direzioni che la sorreggono; è dotata, inoltre, di un angolo bar e di due zone distinte per i servizi igienici (Figure 3.9).
72 3.6.2- Il modello Raynoise 3.0
Per lo studio della sala è stato impiegato il software Raynoise 3.0.
Questo è un programma dedicato alla modulazione acustica, realizzato attraverso l’applicazione di algoritmi in grado di simulare il comportamento acustico di predefiniti volumi. Grazie alla versatilità degli algoritmi utilizzati, è possibile l’analisi sia di volumi chiusi (sale per conferenze, auditorium, sale di registrazione) che aperti (effetti acustici del traffico stradale, impatto acustico ambientale) ed anche di situazioni di inquinamento acustico da rumore ambientale. Il software è fornito in lingua inglese, nella versione 3.0, dalla Numerical Integration Tecnologies - NIT di Leuven (Belgio).
Le principali applicazioni di Raynoise sono di natura architettonica, ambientale ed industriale:
a) Acustica architettonica: Riguarda gli aspetti tipici della progettazione e della valutazione delle prestazioni acustiche di uno spazio confinato; in tal caso assume rilevante importanza il transitorio acustico ed, attraverso la risposta all’impulso, è possibile individuare alcuni indicatori della qualità acustica di una sala, come:
1) Tempo di riverberazione (Reverberation Time) RT; 2) Tempo di decadimento (Early Decay Time) EDT; 3) Definizione (Definition) DEF;
4) Indice STI (Speech Trasmission Index) STI, RASTI; 5) Chiarezza (Clarity) C;
6) Rapporto segnare-rumore (signal to noise ratio) NC, NR; 7) Efficienza laterale (Lateral Efficiency) LE.
Per rendere più intuitiva l’analisi dei risultati, Raynoise è in grado di produrre risposte grafiche qualitative come mappe iso-contorno, riflettogrammi e percorso di raggi sonori;
73 b) Acustica ambientale: In relazione alla crescente sensibilità legislativa verso problematiche di natura ambientale, Raynoise è un valido aiuto per quanto riguarda l’analisi di studi preventivi di impatto generato da sorgenti di rumore poste in campo aperto. In tal senso sono possibili simulazioni di sorgenti puntuali come dispositivi industriali, di sorgenti lineari come infrastrutture di viabilità (strade ed autostrade), di trasporto (ferrovie e tram) ed infine di sorgenti aerali come aree di parcheggio o aree pubbliche; c) Acustica industriale: Per l’analisi acustica di un ambiente industriale è
necessario conoscere il livello di potenza sonora dei macchinari presenti in termini di banda di ottava, la disposizione dei macchinari stessi in relazione all’edificio e le caratteristiche acustiche di assorbimento dell’intera struttura. Ogni sorgente è considerata come elemento a se stante oppure interagente con altre sorgenti ed è possibile l’analisi del singolo contributo di ogni sorgente, rispetto al livello di pressione finale. Una volta completato l’inserimento dei dati, Raynoise permette di analizzare diverse configurazioni e di apportare in sede di analisi dei risultati modifiche relative al livello di potenza e alla ridistribuzione dei macchinari, alla geometria dell’edificio ed ai coefficienti di assorbimento dei vari materiali.
74 3.6.3- Situazione attuale
La sala ristorante oggetto dell’esempio di calcolo vede la presenza di 24 tavoli (90 x 90 cm) occupati ognuno da K = 4 persone per un totale di N = 96 posti a sedere (Figura 3.8). La sala presenta una volumetria di 740 m3, una superficie
calpestabile di 202 m2, una superficie intonacata di 190 m2, una copertura in
legno lamellare di 110 m2, un soffitto intonacato di 92 m2 ed infine una superficie finestrata di 80 m2.
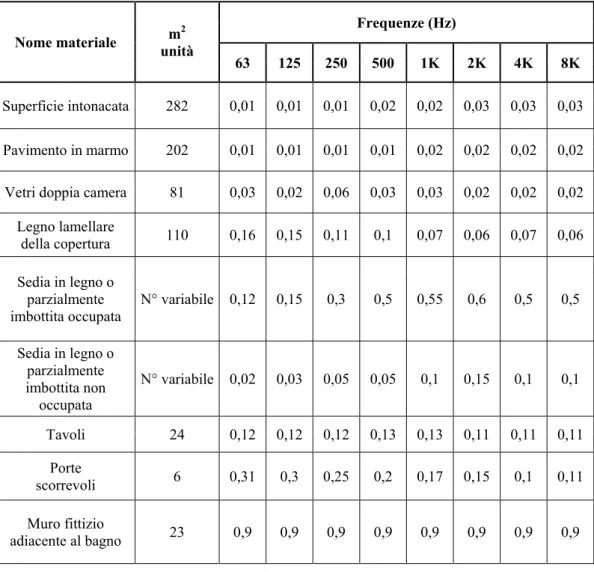
In Tabella 3.12 sono riportati i valori del coefficiente di assorbimento di tutti i materiali presenti nella sala (per la presenza del vano scale e dei bagni schermati dal bar è stato introdotto nel software, ai fini della simulazione acustica, un muro fittizio con coefficiente di assorbimento molto alto)
Tabella 3.12- Coefficienti di assorbimento dei vari materiali
Nome materiale unità m2
Frequenze (Hz)
63 125 250 500 1K 2K 4K 8K
Superficie intonacata 282 0,01 0,01 0,01 0,02 0,02 0,03 0,03 0,03 Pavimento in marmo 202 0,01 0,01 0,01 0,01 0,02 0,02 0,02 0,02 Vetri doppia camera 81 0,03 0,02 0,06 0,03 0,03 0,02 0,02 0,02
Legno lamellare
della copertura 110 0,16 0,15 0,11 0,1 0,07 0,06 0,07 0,06 Sedia in legno o
parzialmente
imbottita occupata N° variabile 0,12 0,15 0,3 0,5 0,55 0,6 0,5 0,5 Sedia in legno o parzialmente imbottita non occupata N° variabile 0,02 0,03 0,05 0,05 0,1 0,15 0,1 0,1 Tavoli 24 0,12 0,12 0,12 0,13 0,13 0,11 0,11 0,11 Porte scorrevoli 6 0,31 0,3 0,25 0,2 0,17 0,15 0,1 0,11 Muro fittizio adiacente al bagno 23 0,9 0,9 0,9 0,9 0,9 0,9 0,9 0,9
75 In questa configurazione, come primo tentativo, si è calcolato il tempo di riverberazione ottimale a 500 Hz della sala considerata come auditorium (con un solo parlatore) attraverso la Formula 2.29:
n 1 V k θ≅ ⋅
che pertanto risulta essere ϑ = 0.57 s e ciò trova corrispondenza con la
Figura 2.2. Dalla formula di Sabine del tempo di riverberazione si ha, sostituendo a ϑ il suo valore ottimale a 500 Hz:
= ϑ ⋅ = α ⋅ 0,16 V S 208 m2
da cui α = 0,3 e la costante della sala H risulta = − = α − α ⋅ = 3 , 0 1 208 ) 1 ( S H 297 m2
Dalla Tabella 3.12 si nota, invece, che il coefficiente di assorbimento medio nel caso in esame è pari a α = 0.13, cui corrisponde un tempo di riverberazione abbastanza elevato e pari a ϑ = 1.24 s.
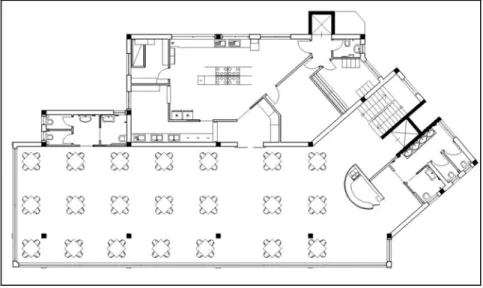
Si rende quindi necessario un primo intervento di correzione acustica che permetta di ridurre il tempo di riverberazione. Inoltre la distanza “d”, fra due tavolini adiacenti, è, in media, di circa 80 cm, valore necessario a far fluire la clientela ed il personale addetto alla sala; utilizzando la Formula 3.15, con Q = 1, si ottiene un valore di dc = 2.4 m. Per non stravolgere la fisionomia della sala e per raggiungere una distanza parlatore – ascoltatore pari al valore trovato di dc, è stato ridotto il numero dei tavoli da 24 a 21 (Figura 3.13)
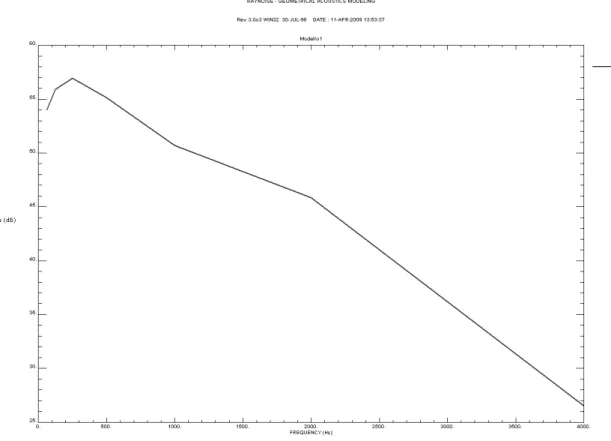
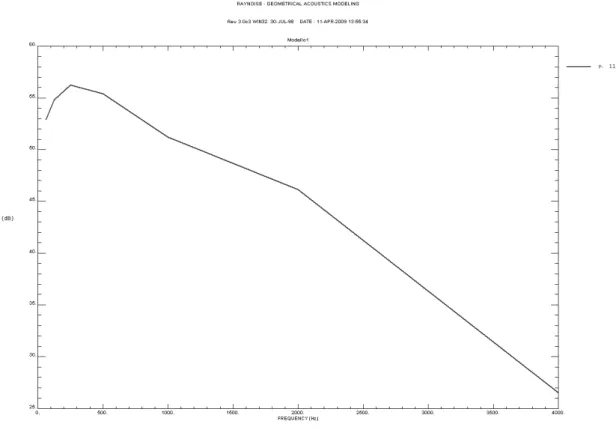
76 Dopo questo primo intervento è stato calcolato il tempo di riverberazione con l’uso del software Raynoise ed, in Tabella 3.14, vengono riportati i valori dell’area e volume del locale, oltre che del tempo di riverberazione secondo la teoria di Sabine e di Eyring.
Tabella 3.14 REVERBERATION --- Total Area (m2) : 759.2 Volume (m3) : 740.4 HZ 63 - 125 - 250 - 500 - 1K - 2K - 4K - 8K RT(Sabine) : 2.01 1.97 1.59
1.27
1.22 1.16 1.28 1.29 RT(Eyring) : 1.93 1.89 1.51 1.19 1.14 1.08 1.20 1.21 --- I valore del tempo di riverberazione a 500 Hz calcolato con Raynoise risulta in ottimo accordo con quello calcolato direttamente con la formula di Sabine. Il θ60 risulta decisamente elevato ed è, quindi, necessario un notevole79
Figura 3.18- Vari combinazioni di foratura e fresatura
In Figura 3.19 è riportato il grafico dell’andamento del coefficiente di assorbimento per le quattro diverse combinazioni contenuto nella scheda tecnica del pannello.
Figura 3.19- Andamento del coefficiente di assorbimento per le quattro combinazioni
Dietro i pannelli si può avere spazio libero o spazio libero con materassino in lana di roccia (a diverso spessore da 200 a 10 mm), questo per aumentarne il grado si fono assorbenza.
80 Limitando l’utilizzo di questi pannelli altamente fonoassorbenti alle sole pareti intonacate, il valore del coefficiente di assorbimento medio risulta pari a α = 0.30, ottenendo una riduzione del tempo di riverberazione a 500 Hz da ϑ = 1.24 s a ϑ = 0.58 s. Con questo intervento acustico il tempo di riverberazione si è avvicinato notevolmente al suo valore ottimale per sala intesa come auditorium (un solo parlatore); ai fini dell’analisi del Cocktail Party Effect, però, è stato necessario intervenire ulteriormente sulla sala rivestendo con i pannelli Topakustik anche il soffitto intonacato e schermando le finestre con tendaggi di velluto pesante fortemente drappeggiati. In queste condizioni, il coefficiente di assorbimento medio risulta pari a α = 0.58 ed il tempo di riverberazione a 500 Hz pari a ϑ = 0.32 s.
Successivamente, assumendo il coefficiente di assorbimento da parte di una persona U = 0.40, il coefficiente di assorbimento di un tavolo u = 0.20, la distanza tra parlatore e ascoltatore r = 0.80 m e Q = 1, dalla teoria del Paragrafo 3.5.3 è stato possibile creare il grafico di Figura 3.20, in cui è riportato l’andamento del numero massimo di persone (MMAX) in funzione del
valor medio del coefficiente di assorbimento α , per valori di ΔL = 3, 4, 5 dB.
Figura 3.20- Numero massimo di persone presenti nella sala in funzione di α per vari valori di ΔL:ΔL = 3 linea sottile; ΔL = 4 linea media; ΔL = 5 dB linea grossa
82
Figura 3.22a- Tavolo N°1. Andamento di Lu in funzione della frequenza: Lu = a 500 Hz
83
Figura 3.23a- Tavolo N°11. Andamento di Lu in funzione della frequenza: Lu = a 500 Hz
84
Figura 3.24a- Tavolo N°21. Andamento di Lu in funzione della frequenza: Lu = a 500 Hz
85 In Tabella 3.25 sono riportati i valori di Lu e Ld a 500 Hz per ogni ricevitore
analizzato; nelle posizioni 5 e 7 il livello disturbante Ld può risultare
addirittura superiore al segnale utile. I valori di ΔL corrispondenti (ovviamente negativi) non sono stati riportati.
Tabella 3.25- Sala con 21 tavoli
Ricevitore
α
Lu (dB) Ld (dB) ΔL = Lu – Ld (dB) 1 0,58 55,2 54,9 0,3 5 54,8 56,2 - 7 53,8 54,5 - 9 55,6 54,5 1,1 11 55,4 55,3 1,1 13 55,8 55,4 0,4 17 55,5 54,1 1,3 21 55,3 52,5 2,8Dalla tabella appare evidente come, nel caso di sala piena, la differenza tra il suono utile ed il suono di disturbo sia bassa in tutta la sala ed addirittura negativa in alcuni punti. Ciò significa che il suono utile prodotto dal parlatore seduto vicino all’ascoltatore viene quasi completamente coperto dal suono di disturbo prodotto da tutti gli altri parlatori presenti nella sala.
Si è ritenuto necessario abbassare il numero di tavoli occupati da 21 a 16 pari al 75% dei tavoli presenti; in Tabella 3.26 sono stati riportati i valori ottenuti.
Tabella 3.26- Sala con 16 tavoli
Ricevitore
α
Lu (dB) Ld (dB) ΔL = Lu – Ld (dB) 1 0,58 55,2 51,8 3,4 5 54,8 53,2 1,6 7 53,8 53,0 0,8 9 55,6 53,8 1,8 11 55,4 53,4 2,0 13 55,8 53,1 2,7 17 55,5 53,2 2,3 21 55,3 51,2 4.186 La differenza di livello sonoro nella sala, seppur nettamente migliorata, è ancora bassa, soprattutto in alcuni punti; ciò comporta un ulteriore abbassamento del numero dei tavoli occupati: da 16 a 12 pari al 60% dei tavoli presenti. In Tabella 3.27 sono riportati i valori ottenuti dall’analisi.
Tabella 3-27- Sala con 12 tavoli
Ricevitore
α
Lu (dB) Ld (dB) ΔL = Lu – Ld (dB) 1 0,58 55,2 48,4 6,8 5 54,8 49,7 5,1 7 53,8 47,3 6,5 9 55,6 50,5 5,1 11 55,4 51,2 4,1 13 55,8 48,8 7,0 17 55,5 46,8 8,7 21 55,3 46,2 9,1Dalle tabelle precedenti si deduce che nella sala si ha un buon valore di ΔL, in tutte le posizioni, solo per 12 tavoli su 21, ossia quasi il 60% dei tavoli presenti (48 persone su 84), risultato in ottimo accordo con il grafico di Figura 3.20. Nella situazione di sala piena è stato studiato un caso aggiuntivo, sia analiticamente che con il software Raynoise: la sala è stata divisa in due parti da un sistema di pannellatura scorrevole rivestita da pannelli Topakustik (Figura 3.28).
87 Nel grafico di Figura 3.29 è stato riportato l’andamento del numero massimo di persone (MMAX) in funzione del valor medio del coefficiente di
assorbimento α , per valori di ΔL = 3, 4, 5 dB per la sala 1.
La sala 1 ha un interesse maggiore dal punto di vista dell’analisi del Cocktail Party Effect per il fatto che presenta un volume minore ma un numero di tavoli maggiore rispetto alla sala 2.
Figura 3.29- Numero massimo di persone presenti nella sala in funzione di α per vari valori di ΔL:ΔL = 3 linea sottile; ΔL = 4 linea media; ΔL = 5 dB linea grossa
Dal grafico si nota come sia possibile soddisfare una buona acustica (ΔL > 4), assumendo un coefficiente di assorbimento medio α = 0.6, in presenza di un numero massimo di persone MMAX = 30 (7÷8 tavoli pari al 60% dei tavoli
presenti). In Figura 3.30 sono evidenziate le postazioni della sala 1 per le quali è stato analizzato il valore di ΔL da Raynoise nel caso di sala piena.
88
Tabella 3.30- Posizioni analizzate della Sala 1
Nella Tabella 3.31 sono riportati i valori ottenuti dall’analisi. Nella posizione 7 il livello disturbante Ld può risultare addirittura superiore al segnale utile. Il
valore di ΔL corrispondente (ovviamente negativo) non è stato riportato.
Tabella 3.31- Sala 1 piena
Ricevitore
Lu (dB) Ld (dB) ΔL = Lu – Ld (dB) 1 55,2 54,8 0,4 9 55,6 54,7 0,9 11 55,4 55,3 1,1 17 55,5 54,0 1,5Appare evidente come i valori di ΔL nei tavoli analizzati non si discostino da quelli ottenuti nell’analisi della sala intera con tutti i tavoli occupati (si veda Tabella 3.25).
A titolo informativo si riporta che la divisione della sala non è stata del tutto inutile, poiché ha comunque portato un lieve miglioramento nella sala 2.
91 I pannelli devono essere stoccati in ambiente asciutto, a temperatura ambiente almeno 24 ore prima dell’installazione, devono essere protetti dall’umidità, dai raggi di sole, e da qualsiasi alterazione della superficie. Nei locali in cui vengono installati, inoltre, non vi devono essere né polvere né residui. Ultima Canopy non è utilizzabile in esterni o interni in cui l’acqua ristagni e dove l’umidità potrebbe essere in contatto diretto con il pannello. La posa non dovrà essere effettuata in un ambiente con umidità relativa superiore al 90%, né in presenza di esalazioni chimiche che richiedano la protezione delle persone, né con temperature inferiori allo 0°C. Le condizioni idonee di installazione sono comprese tra i 16 e i 23°C con un’umidità relativa inferiore al 70%. Il sistema di ancoraggio è costituito da cavi metallici di 4,88 m di lunghezza, vari accessori di fissaggio del pannello alla copertura esistente ed un manicotto per la regolazione dell’altezza (Figura 3.34).
Figura 3.34-Kit di ancoraggio del pannello
Dal punto di vista acustico Ultima Canopy è fortemente vantaggioso in quanto è possibile installare ulteriormente su esso materiali fortemente fonoassorbenti, garantendo così un elevato confort acustico. In Tabella 6.27 si riportano i coefficienti di assorbimento del pannello alle varie frequenze.
Tabella 3.35 Materiale 63 Hz 125 Hz 250 Hz 500 Hz 1K Hz 2K Hz 4K Hz 8K Hz Ultima Canopy 0,20 0,27 0,70 0,96 0,98 0,89 0,760 0,64