CAPITOLO V
VALIDAZIONE DEL CLASSIFICATORE E
APPLICAZIONE REAL-TIME
5.1 INTRODUZIONE.
Nella prima parte di quest’ultimo capitolo sono presentati i risultati del test di analisi delle prestazioni del classificatore CUBE costruito, e sono confrontati con quelle di due classificatori a reti neurali comunemente utilizzati in letteratura scientifica. La seconda parte riporta, invece, la descrizione dell’interfaccia real-time, implementata in Simulink col supporto delle GUI di Matlab, che realizza un’applicazione grafica del classificatore di segnali EMG, utilizzando i movimenti del polso come controlli per la guida di un cursore che si sposta in uno spazio bidimensionale sul monitor di un personal computer. Ciò rappresenta, in primo luogo, un intuitivo riscontro dell’efficacia del classificatore, in secondo luogo dà un’idea delle applicazioni più ampie e complesse che è possibile sviluppare partendo dal risultato di classificazione ottenuto.
5.2 VALIDAZIONE DEL CLASSIFICATORE CUBE.
5.2.1 Acquisizione dei dati.
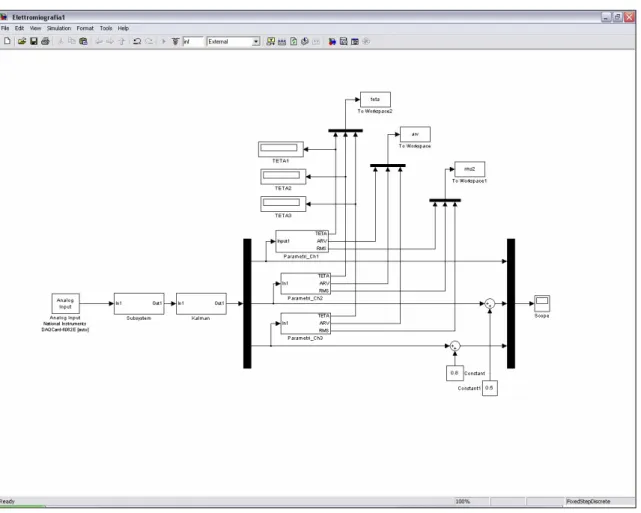
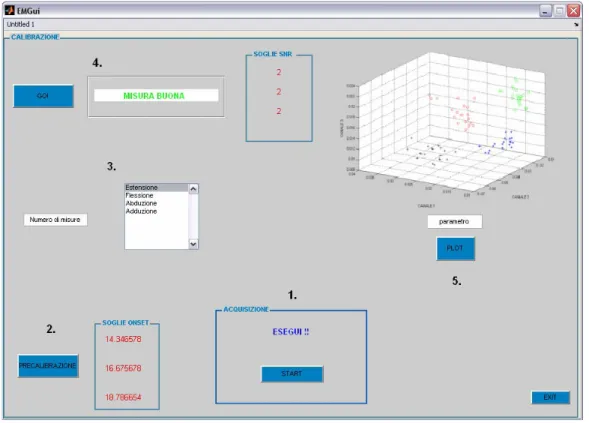
Per la validazione del classificatore sono stati acquisiti i dati provenienti da una serie di 20 ripetizioni dello stesso movimento, effettuata per ciascuno dei 4 movimenti investigati, secondo il protocollo sperimentale descritto nel capitolo precedente. Il procedimento di acquisizione e registrazione delle misure utili, è stato condotto mediante un modello Simulink (Fig. 1) e gestito da una Graphic User Interface (GUI) di Matlab appositamente programmata. Il modello registra i segnali EMG provenienti dal nostro hardware, condizionandoli come illustrato nel Capitolo IV, e in tempo reale calcola i parametri d’interesse (ARV, RMS e gli onsets) mediante delle embedded Matlab functions programmate ad hoc (Appendice B). La GUI è suddivisa in 5 sezioni (Fig. 2) deputate alle funzioni sotto elencate:
1. Inizio e termine dell’acquisizione del tracciato EMG.
2. Precalibrazione: calcolo della soglia di riferimento per l’onset di ogni canale, dall’acquisizione di un tracciato di solo rumore.
3. Selezione del numero di ripetizioni dello stesso movimento e del tipo di movimento.
4. Valutazione delle misure utili in base alla soglia di precalibrazione e all’SNR, quest’ultimo su valori di riferimento fissati da analisi offline condotte preventivamente (Capitolo IV). 5. Visualizzazione grafica delle distribuzioni dei parametri d’interesse, per i 4 movimenti,
nello spazio dei canali.
La prima fase della procedura è costituita dalla precalibrazione, in cui è acquisito un tracciato di solo rumore della durata di circa 5 s (Fig. 2 sezione 1) su cui viene calcolata la terna di soglie di
movimento e si seleziona, di volta in volta, il movimento che si intende registrare (Fig. 2 sezione 3), quindi comincia la vera e propria fase di calibrazione del classificatore, con la registrazione dei movimenti utilizzando la sezione 1, dove un messaggio “ESEGUI !!” compare dopo un intervallo di tempo fisso (3 s), a partire dall’inizio dell’acquisizione, per avere una sincronia di esecuzione da un tracciato all’altro. Nel display della sezione 4 è ritornato un messaggio sulla bontà o meno della misura corrente registrata. Nel caso questa soddisfi i requisiti di soglia e di SNR, viene immagazzinata, altrimenti si procederà ad un’ulteriore registrazione. Terminata la fase di calibrazione, è possibile visualizzare nella sezione 5 le distribuzioni dei valori di ciascun parametro calcolati sulle misure utili, per avere un immediato riscontro circa la separazione delle classi di discriminazione.
Figura 1. Modello Simulink per la calibrazione del classificatore CUBE. I blocchi “Parametri_Ch” sono le embedded functions che calcolano i parametri di interesse in tempo reale
Figura 2. La Matlab GUI programmata per gestire la fase di calibrazione del classificatore CUBE.
Ottenuti, a questo punto, i dati per la validazione, si è provveduto ad ordinarli in una matrice matdati 80×7, dove le righe sono i valori delle features, le prime 6 colonne sono le features (i 3 ARV e i 3 RMS rispettivamente), mentre l’ultima colonna è riservata alle classi di movimento, con la corrispondenza: Estensione Æ 1, Flessione Æ 2, Abduzione Æ 3 e Adduzione Æ 4.
arv1 arv2 arv3 rms1 rms2 rms3 class
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = 4 ... ... ... ... ... ... ... 4 3 ... ... ... ... ... ... ... 3 2 ... ... ... ... ... ... ... 2 1 ... ... ... ... ... ... ... 1 6 , 80 5 , 80 4 , 80 3 , 80 2 , 80 1 , 80 6 , 61 5 , 61 4 , 61 3 , 61 2 , 61 1 , 61 6 , 60 5 , 60 4 , 60 3 , 60 2 , 60 1 , 60 6 , 41 5 , 41 4 , 41 3 , 41 2 , 41 1 , 41 6 , 40 5 , 40 4 , 40 3 , 40 2 , 40 1 , 40 6 , 21 5 , 21 4 , 21 3 , 21 2 , 21 1 , 21 6 , 20 5 , 20 4 , 20 3 , 20 2 , 20 1 , 20 6 , 1 5 , 1 4 , 1 3 , 1 2 , 1 1 , 1 a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a matdati
5.2.2 Test di cross validation.
La matrice matdati è stata processata da un algoritmo implementato in una Matlab function (vedi Appendice B). All’interno di ogni gruppo di misure corrispondenti allo stesso movimento (ovvero righe della matrice), l’operatore ne stabilisce un sottoinsieme definito (datatraining), che sarà utilizzato per l’addestramento (training) del classificatore, mentre le restanti costituiranno il set dati per il test di classificazione (datatest). Per come è composta la matrice, il datatraining è preso all’interno di ogni gruppo di 20 righe cui corrisponde la stessa classe di movimento. La funzione restituisce la matrice di confusione relativa al test, normalizzata rispetto al datatest. La matrice di confusione è uno strumento ampiamente riconosciuto ed utilizzato per la rappresentazione dei risultati di classificazione e per la valutazione quantitativa della bontà del classificatore utilizzato. Si tratta di una matrice comunemente quadrata, dove le righe sono le classi corrette e le colonne le classi previste, ma può presentare una colonna ulteriore che riguarda i casi di non classificazione. Indicato con ni,j il valore booleano per cui ni,j= 1 se il dato n, appartenente alla classe i, è stato assegnato dal classificatore alla classe j e ni,j= 0 altrimenti, si definisce il generico elemento della matrice di confusione come:
∑
= n j i j i n c, ,Ne consegue che i valori presenti sulla diagonale principale della matrice di confusione (i = j) rappresentano i dati correttamente classificati, mentre quelli al di fuori (i ≠ j) sono i falsi riconoscimenti (o misclassificazioni). La matrice di confusione tipica del nostro studio è così strutturata:
ext flex add abd
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ 44 43 42 41 34 33 32 31 24 23 22 21 14 13 12 11 c c c c c c c c c c c c c c c c abd add flex ext
Per garantire risultati più attendibili di stima delle prestazioni del classificatore CUBE, è stata eseguita un’analisi di cross validation: fissato il datatraining in 15 righe su 20 per gruppo, l’istanza di test è stata ripetuta 5000 volte, dove, ogni volta, il training è stato eseguito su 15 righe diverse da quelle precedenti (ripermutando casualmente le 20 righe totali del gruppo). Questo ciclo di ripetizioni costituisce un sottoinsieme di tutte le possibili estrazioni di 15 righe sulle 20 del singolo gruppo, che sono state determinate mediante la formula del calcolo combinatorio:
(
)
! ! ! h h n n h n ⋅ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ,la quale indica quanti sono tutti i possibili sottoinsiemi di h elementi di un insieme di n elementi. Nel nostro caso si hanno 15504 sottoinsiemi di 15 righe su un totale di 20 (h = 15 e n = 20). Ad
ogni ripetizione l’algoritmo calcola la matrice di confusione e alla fine vengono restituite una matrice che è la media delle matrici di confusione sulle 5000 ripetizioni (con i valori espressi in percentuale) ed una matrice che è la deviazione standard. Le deviazioni standard sono importanti per valutare la robustezza dei risultati ricavabili dalla media delle matrici di confusione. Ricordiamo che la matrice media ideale è quella che ha tutti valori 100 sulla diagonale principale e 0 altrove, mentre la matrice delle deviazioni standard ideale è quella composta da tutti 0.
5.2.3 Risultati.
La cross validation è stata ripetuta al variare del parametro class i
k , che è il fattore intero di scala del parallelepipedo della generica classe lungo la dimensione (ossia il canale) i, come descritto nel Capitolo IV. Nella trattazione che segue tale parametro è stato fissato uguale per tutti e tre i canali di una stessa classe ( class class)
i k
k = , mentre è stato fatto variare solo per classi diverse. Di seguito
sono riportati i risultati dell’analisi per i casi esaminati:
1. kclass= 1 (class = ext, flex, add, abd).
La cross validation, in merito all’impostazione class
k = 1, ha fornito come matrice delle medie Cf e m matrice delle deviazioni standard Cf : st
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 98 . 52 0 0 0 0 44 . 47 0 0 0 0 66 . 63 0 0 0 0 04 , 41 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 03 . 24 0 0 0 0 55 . 23 0 0 0 0 38 . 26 0 0 0 0 88 , 19 st Cf .
Dall’ispezione visiva della matrice Cf , si vede come l’estensione è riconosciuta con un successo m del 41.04%, la flessione del 63.66%, l’adduzione del 47.44% e l’abduzione del 52.98%. Non risultano false classificazioni, ma le percentuali di riconoscimento corretto sono sensibilmente basse per un buon classificatore. La matrice Cf , inoltre, rivela delle percentuali di deviazioni standard st sulla diagonale principale molto elevate, indice di eccessiva rumorosità e scarsa incidenza dei dati provenienti dalla matriceCf . Questo test risulta, quindi, poco significativo. m
2. kclass= 2 (class = ext, flex, add, abd).
La matrice delle medie e la matrice delle deviazioni standard in questo caso sono:
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 34 . 89 48 . 9 0 0 9 . 4 4 . 82 0 0 0 0 85 0 0 0 0 10 . 91 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 82 . 15 98 . 11 0 0 29 . 8 17 0 0 0 0 29 . 16 0 0 0 0 08 . 13 st Cf .
Aumentando il valore di k aumenta il volume dei parallelepipedi delle classi di movimento nello spazio dei canali. Ciò, da un lato aumenta la possibilità di effettuare classificazioni corrette (coprendo, in parte, i casi di non classificazione), dall’altro, accrescendo la possibilità che le classi non siano più disgiunte, ma si intersechino parzialmente, può provocare la comparsa di falsi riconoscimenti. Difatti, nella matrice delle medie, si nota un aumento considerevole della percentuale di riconoscimenti corretti per tutti i movimenti, ma, per la prima volta, si manifestano anche delle errate classificazioni. Nel caso specifico, l’estensione è correttamente classificata per il 91.10%, la flessione per l’85%, l’adduzione per l’82.4% e l’abduzione per l’89.34%, mentre il 9.48% delle misure di abduzione presentate al classificatore sono state attribuite alla classe di adduzione e viceversa per il 4.9% delle misure di adduzione. La matrice delle deviazioni standard ha valori sulla diagonale principale più bassi rispetto al caso precedente, e ciò costituisce un miglioramento.
3. kclass= 3 (class = ext, flex, add, abd).
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 38 . 95 04 . 61 0 0 62 . 14 06 . 96 0 0 0 0 2 . 98 0 0 16 . 3 0 9 . 98 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 29 . 8 25 . 22 0 0 65 . 14 37 . 8 0 0 0 0 86 . 6 0 0 71 . 7 0 5 . 6 st Cf .
In questo caso si accentuano sia l’aspetto migliorativo dell’aumento di class
k , con valori percentuali
molto buoni di riconoscimento corretto, sia l’aspetto peggiorativo, con l’aumento delle percentuali di abduzioni scambiate per adduzioni (dal 9.48% precedente a ben il 61.04%) e di adduzioni classificate come abduzioni (dal 4.9% al 14.62%). In più, compare un nuovo falso riconoscimento, con un 3.16% di estensioni scambiate dal classificatore per adduzioni. I valori della matrice delle deviazioni standard sulla diagonale principale diminuiscono ulteriormente, ma aumentano quelli relativi ai falsi già precedentemente individuati ed in più compare un nuovo valore relativo alla nuova categoria di falsi rilevati.
4. kclass= 4 (class = ext, flex, add, abd).
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 100 28 . 79 0 0 84 . 52 92 . 99 7 . 2 0 0 6 . 7 94 . 99 56 . 2 14 . 7 8 . 37 0 88 . 99 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 63 . 0 36 . 16 0 0 54 . 25 26 . 1 84 . 5 0 0 3 . 12 0 95 . 6 8 . 11 95 , 25 0 89 . 0 st Cf
Questo caso è il peggiore tra quelli finora analizzati, in quanto, a fronte di valori sulla diagonale principale di Cf molto prossimi a quelli ideali, vi sono numerosi falsi riconoscimenti, alcuni anche m in percentuale rilevante: il 37.8% delle estensioni è classificato come adduzione, mentre il 7.14% come abduzioni, il 2.56% delle flessioni è riconosciuto come estensione e il 7.6% come adduzione, il 2.7% delle adduzioni è scambiato per flessione, mentre il 52,84% come abduzione, infine il 79.28% delle abduzioni il classificatore le riconosce come adduzioni. Per quanto riguarda la matrice
delle deviazioni standard, il discorso è analogo, con valori quasi ideali sulla diagonale principale ma alti sugli altri elementi non nulli.
Analizzando riga per riga la matrice delle medie sui 4 casi esaminati, si è osservato che l’estensione (prima riga) non viene mai erroneamente riconosciuta fino a class
k = 2, la flessione (seconda riga)
fino a class
k = 3, adduzione e abduzione (terza e quarta riga) per kclass= 2 hanno percentuali di falsa
classificazione sufficientemente basse (4.9% e 9.48%). Si è ritenuto pertanto di effettuare il test di cross validation del classificatore anche in un quinto caso.
5. kext= 2, kflex= 3, kadd= 2 e kabd= 2.
La matrice delle medie e quella delle deviazioni standard per questo ultimo caso sono risultate:
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 66 . 89 44 . 9 0 0 72 . 4 98 . 82 0 0 0 0 52 . 98 0 0 0 0 46 . 91 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 44 . 15 29 . 12 0 0 5 . 8 56 . 16 0 0 0 0 83 . 6 0 0 0 0 31 . 14 st Cf .
Questo caso costituisce un buon compromesso circa le percentuali di corretti riconoscimenti e quelle delle misclassificazioni, pertanto può considerarsi un caso significativo. Le deviazioni standard sono sempre valori grandi in assoluto, anche in considerazione del fatto che il campione di dati utilizzato per la validazione è ridotto e l’intera analisi meriterebbe di essere rifatta su un campione adeguatamente più grande. E’ importante fare una precisazione sulla matrice di confusione, osservando che la somma dei valori su ciascuna riga può fare esattamente 100 (100%), oppure esserne al di sotto o al di sopra. Questa caratteristica è legata alla natura del classificatore CUBE, il quale, per ogni ingresso di una classe corretta presentatogli, può fornire più di una risposta. Se l’ingresso è sempre associato ad un’unica classe prevista, allora la somma dei valori su ciascuna riga sarà pari a 100, se può essere associato a più classi previste contemporaneamente, la somma dei valori su ciascuna riga sarà maggiore di 100, se non è associato ad alcuna classe, la somma dei valori su ciascuna riga sarà minore di 100. Per riassumere in una maniera sintetica e facilmente interpretabile i dati appena riportati, è stata costruita una tabella (Tab. 1) nella quale sono riportati, per il classificatore CUBE impostato con i diversi valori di class
k , i valori medi delle
percentuali delle corrette classificazioni (CLASS) e delle misclassificazioni (MISCLASS). Questi si ottengono, rispettivamente, calcolando il valore medio degli elementi sulla diagonale principale della matrice di confusione restituita dalla cross validation, ed il valore medio di tutti gli altri elementi al di fuori della diagonale principale della stessa matrice.
Tabella 1. Valutazione comparativa del classificatore CUBE per diversi valori dikclass
CUBE class
k = 1 kclass= 2 kclass= 3 kclass= 4 kclass=
2-3-2-2
CLASS 51,28 86,96 97,14 99,94 90,66
Dalla tabella si evince che i primi due casi ( class
k = 1 e class
k = 2) hanno poca significatività, poiché
presentano percentuali medie di corretto riconoscimento basse. Per class
k =4 il classificatore CUBE
ha il massimo valore medio di classificazione, ma anche il più alto di misclassificazione. I casi 3 e 5 sono i più significativi in quanto, per class
k =3 il classificatore ha alta capacità di classificazione e
bassa percentuale media di misclassificazione, per l’impostazione 5 la classificazione è inferiore, ma comunque alta, e la misclassificazione sensibilmente più bassa.
5.2.4 Confronto con classificatori a reti neurali.
Il classificatore CUBE, per come progettato, in fase di addestramento necessita dell’intero datatrining, mentre, in fase di test, il volume di dati su cui lavora si riduce ai solo valori medi e alle deviazioni standard che forniscono le coordinate dei vertici su cui costruisce i parallelepipedi delle classi nello spazio dei canali sia per gli ARV che per gli RMS e rispetto alle quali verifica le condizioni di riconoscimento ogni volta che gli viene presentato un nuovo stato d’ingresso. Si tratta, pertanto, di un classificatore che richiede un ridotto impegno di memoria, oltre a non presentare un’eccessiva complessità di calcolo, dato che le condizioni di classificazione solo delle semplici disuguaglianze. Queste caratteristiche possono risultare importanti se se si pensa, ad esempio, all’implementazione in un microcontrollore all’interno di un dispositivo indossabile per il supporto funzionale, o per la sostituzione funzionale, dove sia necessario lavorare con un’elettronica on body e quindi in condizioni di dover ottimizzare l’occupazione di spazio sul chip integrato. In sostanza, sono anche le specifiche della particolare applicazione (integrazione, portabilità, complessità computazionale, ecc.) a condizionare il giudizio complessivo sull’efficacia di un classificatore. Come riferimento per la valutazione del nostro classificatore, è stato operato un confronto, a parità di datatraining, tra il classificatore CUBE e due tra i classificatori riconosciuti dalla comunità scientifica a livello internazionale ed appartenenti alla categoria delle reti neurali; si tratta del Multilayer Perceptron e della Mappa di Kohonen.
Il Multilayer Perceptron.
Per questo riconoscitore a rete neurale l’addestramento è condotto in maniera supervisionata, tramite un algoritmo di back propagation. Per il test di classificazione sono state utilizzate le seguenti specifiche sulla struttura della rete:
1. Neuroni di input = 6. 2. Neuroni nascosti = 3. 3. Neuroni di output = 4. 4. Neuroni di Bias = 1.
5. 1000 epoche di apprendimento.
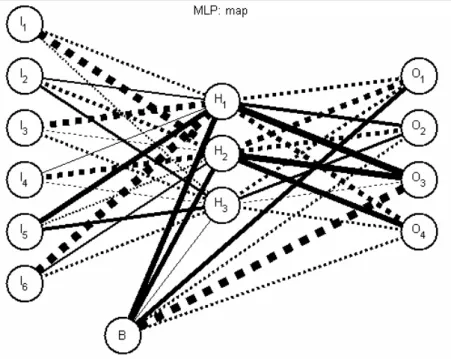
In Fig. 3 è rappresentata la mappa del Multilayer, ossia lo stato della rete dopo l’addestramento, con le relative connessioni tra gli strati, dove i pesi sinaptici sono evidenziati mediante lo spessore delle connessioni stesse e le connessioni tratteggiate corrispondono a pesi negativi.
Figura 3. La mappa del Multilayer Perceptron.
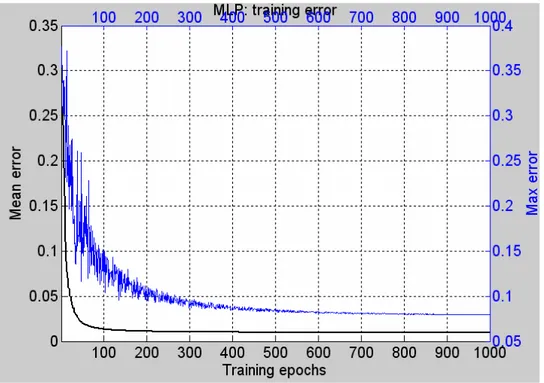
La cross validation è stata effettuata su un ciclo di 5000 ripetizioni del test di riconoscimento, con le stesse modalità di reclutamento del datatraining impiegate nella validazione del classificatore CUBE. I risultati sono riassumibili attraverso il grafico dell’andamento dell’errore medio durante il training (Fig. 4) e attraverso la matrice delle medie e quella delle deviazioni standard degli elementi delle matrici di confusione del test, che riportiamo di seguito:
⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 4 . 96 0 0 0 0 2 . 87 0 0 0 2 6 . 97 0 0 0 0 8 . 98 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 76 . 7 0 0 0 0 52 . 15 0 0 0 06 . 6 57 . 6 0 0 0 0 27 . 6 st Cf .
Con riferimento a Cf , le percentuali dei riconoscimenti corretti sono più elevate del caso del m classificatore CUBE, eccezion fatta per la flessione, per cui il nostro classificatore, al caso 5, fornisce un dato migliore. Non appaiono falsi riconoscimenti che interessano adduzione e abduzione, come nel CUBE, compare, per contro, un falso di tipo diverso, con una percentuale del 2% delle flessioni scambiate per adduzioni. La matrice delle deviazioni standard ha valori tutti inferiori di quelli dell’omologa del CUBE, e questo attesta una maggiore robustezza del classificatore a rete neurale. La somma dei valori presenti su ciascuna riga della matrice delle medie può essere minore o pari a 100.
Figura 4. Grafico dell’andamento dell’Errore Medio e dell’Errore Massimo durante il training.
Il Multilayer Perceptron cerca di minimizzare l’errore sull’uscita fornita, cioè lo scostamento dall’uscita attesa. Dal grafico di Fig. 4 si vede come il valore medio dell’errore durante l’addestramento diminuisca al passare delle epoche di training attestandosi su un valore prossimo a 0.0125 (1.25%), apprezzabilmente basso.
La mappa di Kohonen
La Mappa di Kohonen è un classificatore a rete neurale in cui la fase di addestramento è perfezionata sulla base di un decadimento esponenziale dei coefficienti di training. L’addestramento non è supervisionato e si basa sulla competizione fra neuroni (apprendimento hebbiano), ossia premia la somiglianza tra stato di ingresso e stato del neurone.
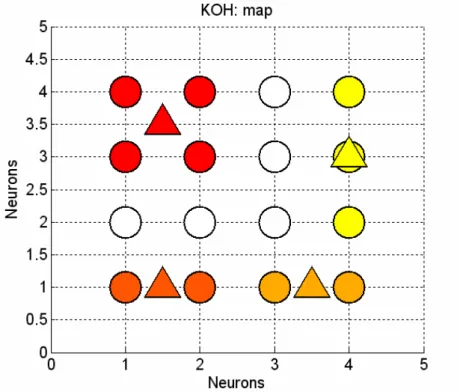
La Fig. 5 illustra la mappa bidimensionale dei neuroni artificiali di Kohonen per il nostro caso particolare, in cui ogni cerchio corrisponde ad un neurone artificiale. Si omettono, per la leggibilità del disegno, le connessioni sinaptiche. Nella prima fase, di addestramento, la rete riceve il set di dati per il training ed applica la legge di apprendimento in conseguenza della quale aggiorna i pesi sinaptici del neurone di volta in volta vincente e dei neuroni di un suo “vicinato”; la fase successiva, di etichettamento (labeling), attribuisce un colore diverso al neurone a seconda della classe cui viene associato. Un importante dato da rilevare, inerente la mappa è l’individuazione di un ordinamento dello spazio bidimensionale in regioni separate comprendenti neuroni associati ad una stessa classe (etichettati con lo stesso colore), il che è indice di una buona capacità discriminante dell’informazione associata al processo che si sta considerando. I triangoli rappresentati in figura, sono i centroidi costruiti sul baricentro geometrico della distribuzione di neuroni dello stesso colore e la fase di test della rete utilizzata come classificatore offre un’interpretazione sia basata sui neuroni, sia sui centroidi.
Figura 5. Mappa di Kohonen.
Nella pagina seguente sono riportate la matrice delle medie e quella delle deviazioni standard dei valori delle matrici di confusione per la cross validation del classificatore su 5000 iterazioni e sul solito campione di dati per il test, sia per il riconoscimento basato sui neuroni che per quello basato sui centroidi. Sui neuroni: ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 2 . 93 2 0 0 4 . 2 8 . 94 2 . 1 0 0 2 . 3 8 . 96 0 0 0 0 8 . 98 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 39 . 10 06 . 6 0 0 71 . 7 29 . 11 27 . 6 0 0 41 . 7 41 . 7 0 0 0 0 27 . 6 st Cf . Sui centroidi: ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 2 . 97 8 . 2 0 0 2 . 1 4 . 98 4 . 0 0 0 2 . 3 8 . 96 0 4 . 0 0 0 6 . 99 m Cf ; ⎟⎟ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎜ ⎜ ⎝ ⎛ = 01 . 7 01 . 7 0 0 27 . 6 81 . 6 83 . 2 0 0 41 . 7 41 . 7 0 83 . 2 0 0 83 . 2 st Cf .
Nel caso specifico, i risultati sui due metodi sono simili, con una prevalenza di percentuali migliori di riconoscimenti corretti da parte del metodo basato sui centroidi, che presenta però, seppur in percentuale molto bassa, un tipo di falso in più rispetto al metodo basato sui neuroni (lo 0.4% delle estensioni classificate come abduzioni). In relazione alle prestazioni del classificatore CUBE con le impostazioni ritenute migliori, invece, le percentuali sulla diagonale principale sono confrontabili per flessione e estensione, con percentuale migliore del CUBE per la flessione. Adduzione e abduzione sono riconosciute meglio dalla mappa di Kohonen, anche per quanto riguarda le percentuali relative ai falsi associati a questi due movimenti, ma la mappa presenta più categorie di misclassificazioni rispetto al classificatore CUBE: il nostro classificatore cade in errore solo per abduzione e adduzione, mentre la mappa anche per estensione e flessione. È opportuno riportare anche il grafico dell’andamento dell’errore durante l’addestramento, come fatto per il Multilayer Perceptron (Fig. 6), che diminuisce fino a circa 0.02 (2%), valore accettabilmente basso.
Figura 6. L’andamento dell’Errore Medio e Massimo durante il training.
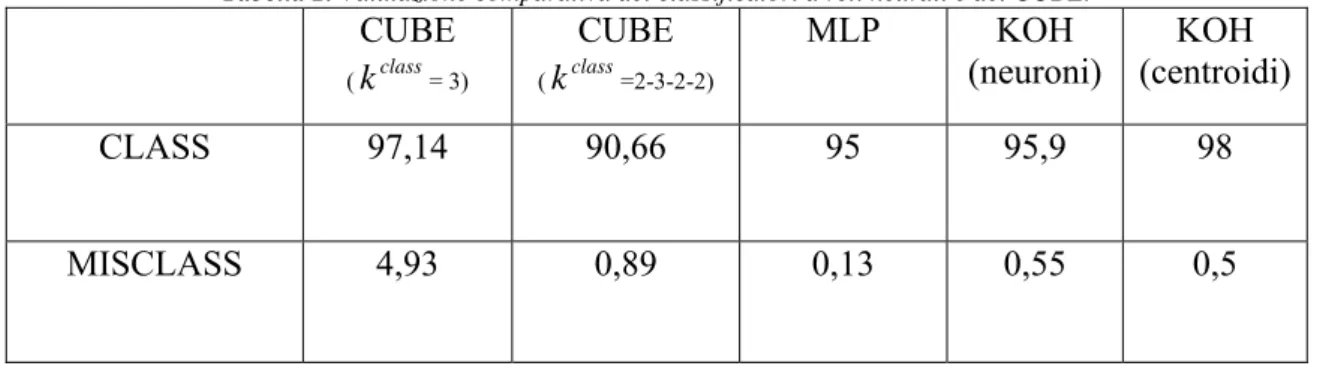
Costruiamo, infine, la tabella di valutazione comparata dei classificatori rispetto ai valori medi delle percentuali di classificazione e misclassificazione, considerando il classificatore CUBE nelle due impostazioni più significative, il classificatore Multilayer Perceptron (MLP), la Mappa di Kohonen sui neuroni e la Mappa di Kohonen sui centroidi:
Tabella 2. Valutazione comparativa dei classificatori a reti neurali e del CUBE. CUBE (kclass= 3) CUBE (kclass=2-3-2-2) MLP KOH (neuroni) KOH (centroidi) CLASS 97,14 90,66 95 95,9 98 MISCLASS 4,93 0,89 0,13 0,55 0,5
Dalla tabella risulta che i classificatori a rete neurale evidenziano valori di misclassificazione molto bassi, con i quali soltanto il classificatore CUBE nell’impostazione class
k =2-3-2-2 è confrontabile
come ordine di grandezza. Per quanto riguarda i valori medi di classificazione, il classificatore CUBE nell’impostazione class
k = 3 è secondo solo alla Mappa di Kohonen sui centroidi. In
definitiva, il nostro classificatore ha una percentuale media di classificazione che è confrontabile con quelle di classificatori a rete neurale, che hanno sicuramente una complessità di calcolo superiore. Questo, oltre al ridotto impegno di memoria per immagazzinare i dati necessari alla classificazione, depone a favore del nostro CUBE, considerando che si tratta di una prima versione sicuramente migliorabile.
5.3 INTERFACCIA GRAFICA REAL TIME BASATA SUL CLASSIFICATORE CUBE. 5.3.1 Introduzione.
Scopo ultimo della tesi, una volta progettato il classificatore di movimenti basato su segnali EMG, è stato quello di utilizzarlo in un’applicazione real-time, servendosi del riconoscimento come controllo per attuare un task. Nel caso specifico è stato scelto un feedback grafico, ossia l’utilizzatore esegue il movimento, l’hardware registra i segnali provenienti dal sistema indossabile ad elettrodi tessili, il classificatore CUBE, nel modo già visto, ha il compito di codificare l’intento dell’utente per il software real-time descritto in questa sezione, che controlla, in base al riconoscimento del set di 4 movimenti base, lo spostamento di un cursore in uno spazio di lavoro bidimensionale sul monitor di un personal computer. Il software di classificazione e controllo è stato realizzato implementando dei modelli Simulink, e la gestione dell’applicazione mediante lo sviluppo di una GUI di Matlab (Fig. 7), per il cui codice si rimanda all’Appendice B.
Le fasi in cui si articola l’applicazione sono 3:
precalibrazione calibrazione
esecuzione real-time.
Un modello Simulink è stato sviluppato per occuparsi delle prime due fasi, mentre un secondo realizza l’esecuzione.
5.3.2 La fase di precalibrazione.
Questa fase consiste nel calcolo delle tre soglie di riferimento (una per canale di acquisizione), in base alle quali saranno poi calcolati gli onsets sui segnali registrati nella fase di calibrazione del classificatore. Cliccando sul tasto “precalibration” della GUI di gestione, Il modello Simulink Calibrazione (Fig. 8) si connette al target esterno costituito dalla scheda d’acquisizione National Instruments DAQ 6062E a 12 bit e registra un tracciato di solo rumore per circa 8 secondi, dopodiché si disconnette e vengono calcolate le soglie in base alla già descritta formula ispirata all’algoritmo di Di Fabio (Capitolo IV):
threshold = mean( baseline reference) + 5dev.st(baseline reference).
Nel caso specifico la baseline reference è presa su un brano di 1.5 s di tracciato (3000 smps), escludendo i primi 1.5 s di registrazione, per evitare effetti indesiderati dovuti al transitorio di accensione del sistema di acquisizione. Il moltiplicatore della deviazione standard nel calcolo della soglia di ciascun canale è fissato ad un valore 5, maggiore del caso utilizzato per l’analisi offline (dove valeva 3), per compensare in parte fluttuazioni dovute alla variabilità dei segnali EMG rilevati e sveltire la procedura. Al termine dell’elaborazione i valori delle soglie di precalibrazione sono immessi nel blocco costante “soglie” del modello Simulink.
Figura 8. Il modello Simulink Calibrazione, che si occupa della fase di precalibrazione e di calibrazione.
5.3.3 La fase di calibrazione del classificatore.
Il tasto “start calibration” della GUI predispone nuovamente il modello Simulink Calibrazione alla registrazione dei segnali sui tre canali a disposizione; l’utente esegue, di seguito, ad intervalli di 3-4 s, una batteria di movimenti costituita da 5 ripetizioni di ognuno dei 4 movimenti del set di studio. Un tale numero ridotto di ripetizioni è stato scelto per snellire e velocizzare la procedura, che mira principalmente all’effetto grafico real-time della classificazione. Terminata l’acquisizione, premendo il tasto “stop calibration”, il modello si disconnette dal target e vengono calcolate le matrici dei valori medi e delle deviazioni standard dei parametri ARV e RMS calcolati sulle misure precedenti, da cui il classificatore trae le informazioni sui vertici dei parallelepipedi delle classi ed è, così, inizializzato. Tutta la parte di elaborazione del segnale è implementata in una S-function presente nel modello (Appendice B).
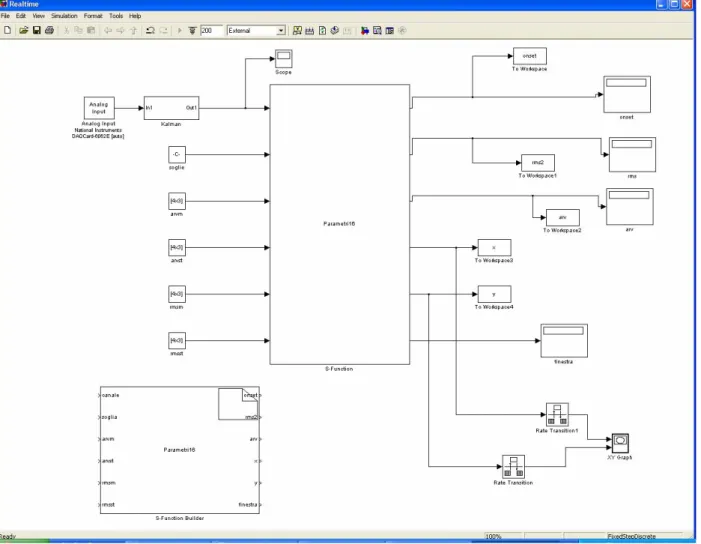
5.3.4 La fase di esecuzione real-time.
Il modello Simulink Realtime (Fig. 8), attivato dal tasto “start real time application” della GUI, è tutto incentrato sulla S-function (Appendice B) programmata per la classificazione dei movimenti in tempo reale e per il controllo, sempre in tempo reale dello spostamento conseguente del cursore.
Figura 9. Il modello Simulink Realtime, che realizza la fase di esecuzione in tempo reale.
Lo spazio bidimensionale in cui il cursore può muoversi è realizzato, all’interno del modello Realtime, mediante un blocco scope XY, dove le variabili X e Y, in uscita dalla S-function, fissano, le coordinate attuali del cursore. Gli spostamenti del cursore sono così codificati:
ESTENSIONE → CURSORE UP (↑); FLESSIONE → CURSORE DOWN (↓); ADDUZIONE → CURSORE RIGHT (→); ABDUZIONE → CURSORE LEFT (←).
La posizione iniziale del cursore è alle coordinate (0,0). Ogni volta che la S-function compie una classificazione, a seguito di un movimento eseguito dall’utilizzatore, aggiorna in tempo reale le uscite X e Y secondo le seguenti direttive:
Se viene riconosciuta un’estensione, la coordinata X non viene modificata, mentre viene incrementata la Y di un passo (fissato nel blocco scope XY di Simulink) nel verso positivo delle ordinate, come visibile in Fig.10.
Figura 10. Visualizzazione grafica dello spostamento del cursore nel piano di lavoro a seguito del riconoscimento di un’estensione.
Se viene riconosciuta una flessione, la variabile X non è modificata, mentre la Y è incrementata di un passo nel verso negativo delle ordinate (Fig. 11).
Figura 11. Visualizzazione grafica dello spostamento del cursore nel piano di lavoro a seguito del riconoscimento di una flessione.
Se viene riconosciuta un’abduzione, la variabile X è incrementata di un passo nel verso positivo delle ascisse, mentre la Y non è modificata (Fig. 12).
Se viene riconosciuta, infine, un’adduzione , la variabile X è incrementata di un passo nel verso negativo delle ascisse, mentre la Y rimane inalterata (Fig. 13)
Figura 13. Visualizzazione grafica dello spostamento del cursore nel piano di lavoro a seguito del riconoscimento di un’adduzione.
In condizioni di funzionamento corretto del sistema di classificazione in tempo reale, se viene eseguito un movimento diverso dai 4 su cui è addestrato il classificatore, il cursore non modifica la sua posizione (le coordinate X e Y rimangono inalterate). Nel caso di associazione del pattern di ingresso a due classi simultaneamente, il cursore non si sposta più in direzione parallela ad uno dei due assi di coordinate, bensì a 45°, in una direzione dipendente dalla coppia di classi di associazione. Di questo tipo di uscite spurie ne esistono 6 casi, combinazioni dei 4 movimenti presi a due a due. Nella Fig. 14 sono riportati i 4 casi che possono essere visti nel piano di lavoro, associati alle coppie (Ext, Add), (Ext, Abd), (Flex, Add) e (Flex Abd). I 2 casi associati alle restanti coppie (Ext, Flex) e (Add, Abd) non sono distinguibili visivamente, in quanto la coordinata da modificare è incrementata e decrementata dello stesso valore allo stesso tempo, annullando, di fatto, lo spostamento del cursore, che appare fermo nell’ultima posizione raggiunta.
Il tipo di controllo real-time descritto, basato sul particolare classificatore CUBE realizzato nel contesto di questo lavoro, si è rivelato un immediato ed intuitivo strumento di feedback, per l’operatore, sul comportamento del classificatore. Considerando un ulteriore perfezionamento dell’algoritmo, il riscontro grafico, e quindi visivo, potrebbe essere sfruttato per un intervento di modifica su particolari parametri del classificatore nell’ottica di migliorare la procedura di riconoscimento; in pratica una calibrazione in corsa. Nel nostro caso, ad esempio, tali parametri potrebbero essere i fattori di scala delle dimensioni dei parallelepipedi nello spazio dei canali (i
class i
k ). La Fig. 15 offre un’istantanea dell’interfaccia real-time nel caso in cui l’operatore è impegnato nell’esecuzione di un task motorio, costituito dalla ripetizione di un certo numero di movimenti tra quelli del set di base.
Figura 15. Interfaccia realtime EMG impiegata in un esercizio di esecuzione di un task motorio. La particolare traiettoria nello spazio di lavoro è la conseguenza della seguente successione di movimenti: EXT-ABD-ABD-EXT-ABD-ABD-FLEX-FLEX-FLEX-FLEX-FLEX-ADD-ADD-ADD-ADD.