L
L’
’A
A
LG
L
GO
OR
RI
IT
TM
MO
O
D
DI
I
E
EL
LA
AB
BO
OR
R
AZ
A
ZI
IO
ON
NE
E
D
D
E
E
L
L
L
L
E
E
I
IM
M
MA
M
A
GI
G
IN
N
I
I
In questo capitolo vengono riportati, nella prima parte, alcuni concetti di base sull’elaborazione di immagini (image processing) utilizzati per lo sviluppo dell’algoritmo. Nella seconda parte, invece, viene descritto in dettaglio l’algoritmo utilizzato per l’elaborazione dei fotogrammi tratti dai filmati dell’induttore cavitante, registrati mediante la telecamera ad alta velocità
4.1 Fondamenti di elaborazione delle immagini
In questo paragrafo verranno trattati alcuni concetti di base della disciplina denominata “elaborazione delle immagini” (image processing). In particolare, dopo una breve introduzione all’argomento, verranno dapprima descritte le caratteristiche fondamentali delle immani digitali e, infine, verranno descritte le cosiddette tecniche di segmentazione con particolare attenzione a quella utilizzata nel presente lavoro di tesi.
4.1.1 Introduzione
Le moderne tecnologie digitali hanno reso possibile l’elaborazione di segnali multidimensionali (quali, ad esempio, le immagini che, come si vedrà possono essere considerate come segnali bidimensionali) grazie ad una serie di sistemi che vanno dal semplice circuito digitale al più complesso personal computer. L’elaborazione delle immagini viene talvolta definita [1] come quella disciplina in cui sia l’ingresso che l’uscita dell’elaborazione sono delle immagini. Tale definizione serve, soprattutto, a distinguerla da altre discipline, sempre legate alle immagini, quali, ad esempio, l’analisi delle immagini (image analysis) in cui le uscite sono una serie di misure (ovvero dei numeri).
Una delle prime applicazioni delle immagini digitali fu nell’industria editoriale, quando le immagini dovevano essere inviate da una parte all’altra dell’atlantico. Inizialmente, tutto ciò veniva fatto tramite un cavo sottomarino tra Londra e New York con un tempo di trasmissione di circa una settimana. Tale tempo di trasmissione fu ridotto a sole tre ore negli anni ’20 grazie all’introduzione del cosiddetto cavo “Bartlane”: le immagini venivano prima codificate in un nastro per la trasmissione via cavo e poi ricostruite una volta che venivano ricevute tramite una stampante telegrafica; un esempio di immagine inviata con questa tecnica è mostrato in Figura 4.1.
Figura 4.1 – Un immagine digitale prodotta nel 1921 da un nastro codificato [1]
I primi sistemi Bartlane erano capaci di codificare le immagini con cinque livelli di grigio. Tale capacità fu poi aumentata, nel 1929, a quindici livelli di grigio: la Figura 4.2 è un’immagine tipica con quindici livelli di grigio.
Figura 4.2 – Immagine tipica con quindici livelli di grigio [1]
Gli esempi appena citati non sono dei veri e propri risultati della disciplina dell’elaborazione di immagini in quanto, per produrre tali immagini non era stato utilizzato il calcolatore. Pertanto la storia dell’elaborazione di immagini digitali è strettamente legata allo sviluppo dei computer digitali.
I primi calcolatori potenti abbastanza da poter effettuare significative operazioni di elaborazione delle immagini comparvero negli anni ’60. La nascita di ciò che oggi chiamiamo elaborazione di immagini è legata, oltre che all’introduzione di queste macchine, anche allo sviluppo dei programmi spaziali di quegli anni. Infatti, i primi lavori sull’uso del calcolatore per il miglioramento delle immagini ottenute dalle sonde spaziali furono effettuati nel 1964 al JPL (Jet Propulsion Laboratory) quando alcune immagini della luna trasmesse dalla sonda Ranger 7 furono elaborate per eliminare alcuni errori di distorsione dovuti alla telecamera di bordo. La Figura 4.3 mostra una di queste immagini (la prima immagine della luna trasmessa da un veicolo spaziale americano), in cui sono visibili dei contrassegni utilizzati appunto per l’elaborazione.
Figura 4.3 – Prima immagine della luna trasmessa da un veicolo spaziale americano [1]
Oltre che in applicazioni spaziali, alla fine degli anni ’60 l’elaborazione delle immagini cominciò a essere usata anche in medicina, per l’osservazione terrestre e in astronomia. Uno degli eventi più importanti strettamente legato all’elaborazione di immagini in ambito medico fu, infatti, l’introduzione della TAC (Tomografia Assiale Computerizzata) nei primi anni ’70.
Dagli anni ’60 fino a oggi la disciplina dell’elaborazione delle immagini è cresciuta enormemente. Oltre che in medicina e nei programmi spaziali, le tecniche di elaborazione di immagini digitali sono utilizzate in una vasta gamma di applicazioni: dall’interpretazione di immagini ottenute ai raggi X a quella di immagini utilizzate in geografia per lo studio dell’inquinamento, dal miglioramento di immagini sfocate rappresentanti reperti archeologici alla fisica e tante altre discipline.
4.1.2 Le immagini digitali
Un’immagine è la rappresentazione di una scena su un piano prodotta tramite un opportuno dispositivo (macchina fotografica, telecamera, tomografo, ecc.).
Matematicamente, un’immagine può essere definita come una funzione (ovvero un segnale) di due variabili
f x y
( )
,
, dovex
e y sono le due coordinate spaziali, mentre il valore di f in un determinato punto( )
x y
,
è detto intensità dell’immagine in quel punto. Quandox
,y e f possono assumere solo un intervallo discreto di valori, l’immagine viene detta immagine digitale. Un’immagine digitale è, quindi, composta da un numero finito di elementi, ciascuno dei quali occupa una determinata posizione, che prendono il nome di pixels (picture elements).Grazie a questa proprietà, un’immagine digitale può essere considerata (Figura 4.4) come una matrice (che ha tante righe quanti sono i pixels in altezza e tante colonne quanti sono i pixels in larghezza dell’immagine) i cui elementi possono assumere un determinato numero di valori (intensità). Tutto ciò viene in particolare sfruttato da diversi linguaggi di programmazione per consentire l’elaborazione automatica dell’immagine.
Figura 4.4 – Tipica immagine digitale [2]
Una delle caratteristiche principali di un’immagine digitale è la cosiddetta risoluzione che altro non è che il numero di pixels presenti nell’immagine stessa. Essa è l’indice principale del grado di qualità di un’immagine (maggiore è la risoluzione, migliore è la qualità) e può essere espressa o da un solo numero (come per le moderne fotocamere digitali) o dal prodotto di due numeri che indicano il numero di pixels in larghezza e in altezza rispettivamente. Nel seguito del capitolo verrà utilizzata questa seconda forma.
L’intensità dell’immagine (f ) assume diverse forme a seconda del tipo di immagine: essa è un numero (ovvero uno scalare) nel caso di immagini monocromatiche, mentre è un vettore (generalmente a tre componenti) nel caso di immagini a colori. Il numero di valori (
N
) che può assumere f in un’immagine digitale dipende dal numero di bit ( ) utilizzati per definire ogni pixel e può essere facilmente determinato dalla seguente relazione:b
2b
N =
Come si è visto nel capitolo precedente, la telecamera utilizzata per effettuare le riprese dell’induttore cavitante è dotata di un sensore monocromatico; di conseguenza le immagini che saranno usate come input dell’algoritmo di elaborazione sono delle immagini monocromatiche dette anche immagini in “scala di grigio” (gray-scale). In particolare, le immagini in scala di grigio con cui si avrà a che fare nel seguito della trattazione sono di due tipi: immagini a 8 bit e immagini binarie.
Le immagini a 8 bit sono quelle riprese direttamente dalla videocamera (quindi sono quelle di ingresso dell’algoritmo) e, come si intuisce dal nome stesso, sono caratterizzate dal fatto che la f può assumere 256 (28) valori (da 0 a 255) che prendono il nome di “livelli di grigio” (gray-levels). L’intervallo 0-255 è quello più comunemente utilizzato e ciò è dovuto a due ragioni:
• l’occhio umano non è abbastanza sensibile alle differenze che si avrebbero utilizzando un range più ampio
• è conveniente in quanto le immagini occupano meno memoria quando vengono archiviate su un PC
Le immagini binarie, come si vedrà nel seguito del capitolo, sono, invece, quelle di output dell’algoritmo. Esse sono anche dette immagini B/W (Black/White) in quanto, in questo caso, la f può assumere solo due valori (0 o 1) e, quindi, i pixels costituenti l’immagine possono essere o bianchi o neri.
Per quanto riguarda, invece, le immagini a colori, la f è un vettore generalmente a tre componenti, ciascuna delle quali può assumere
N
(=
2
b) valori, che sintetizzano la decomposizione di un determinato colore in tre colori detti colori primari. A seconda dei colori primari utilizzati si hanno le diverse classi di immagini a colori. La classe più utilizzata è la cosiddetta RGB (Red Green Blue) che usa come colori primari, per l’appunto, il rosso, il verde e il blu. Questa classe è una delle più comunemente utilizzate e viene usata, per esempio, dai monitor dei PC. Un’altra classe di immagini a colori meno utilizzata è la cosiddetta CMYK (Cyan Magenta Yellow blacK) in cui la f è, chiaramente, un vettore a quattro componenti e che viene utilizzata, per esempio, dalle stampanti.4.1.3 Il problema della segmentazione
Il problema del rilevamento di oggetti all’interno di un’immagine è noto in letteratura con il nome di “segmentazione” di un’immagine (image segmentation) ed è, come si è visto nella Sezione 1.4 proprio quello che deve essere risolto dall’algoritmo di elaborazione delle immagini che vedremo nel prossimo paragrafo.
Generalmente, gli algoritmi di segmentazione di un’immagine sono basati su una delle due proprietà caratteristiche dei valori dell’intensità ( f ): discontinuità e similitudine. Nella prima categoria, l’approccio è quello di segmentare l’immagine sulla base delle improvvise variazioni di intensità che si hanno in alcune zone dell’immagine quali quelle che si hanno in corrispondenza dei contorni degli oggetti. Un esempio delle tecniche di segmentazione appartenenti a questa categoria è la cosiddetta “individuazione dei contorni” (edge detection).
Nella seconda categoria, invece, l’immagine viene suddivisa in regioni in cui l’intensità dei vari pixels è “simile” secondo un criterio prestabilito. Esempi di tecniche appartenenti a questa categoria sono quelle di “accrescimento di regioni” (region growing) e “del valore di soglia” (thresholding).
Grazie alla sua semplicità, sia dal punto di vista concettuale, sia di implementazione, la tecnica del valore di soglia è una delle più utilizzate ed è proprio quella utilizzata nel presente lavoro.
Essa è basata sulle proprietà del cosiddetto “istogramma” (histogram) di un immagine che è un diagramma che riporta in ascissa i livelli di grigio (che nel seguito saranno indicati con ) e in ordinata il numero di pixels che assumono un determinato livello di grigio nell’immagine ( ); un esempio di istogramma è mostrato in Figura 4.5. L’istogramma fornisce quindi una descrizione statistica dei livelli di grigio assunti dai vari pixels di un’immagine.
q
q
n
Figura 4.5 – Immagine in scala di grigio con relativo istogramma [2]
In particolare, per le immagini in cui si ha un oggetto molto luminoso su uno sfondo più scuro, l’istogramma ha la forma tipica mostrata in Figura 4.6. Gli istogrammi di questo tipo sono detti bimodali e hanno la seguente caratteristica: c’è un certo numero di pixels addensato attorno a un valore del livello di grigio relativamente basso (caratteristici dello sfondo scuro) e un altro gruppo di pixels addensati attorno a un valore più alto del livello di grigio (caratteristici dell’oggetto luminoso). In questo caso, il modo più intuitivo per estrarre l’oggetto è quello di selezionare un valore del livello di grigio (T in figura) mediante il quale il gruppo di pixels caratteristici della zona luminosa sono separati da quelli caratteristici della zona scura.
Figura 4.6 – Tipico istogramma “bimodale” [1]
Tutto ciò è esattamente quello che si fa mediante la tecnica del valore di soglia: l’immagine originale (in scala di grigio) viene trasformata in un’immagine binaria ponendo pari a zero l’intensità di tutti i pixels il cui livello di grigio è inferiore rispetto a un certo valore di soglia (ovvero colorandoli di nero) e pari a uno l’intensità di tutti gli altri(ovvero colorandoli di bianco).
Matematicamente, se
g x y
(
,
)
è la versione dif x y
( )
,
trasformata con questa tecnica rispetto ad un valore di soglia T, allora si ha:( )
, 0 se( )
( )
, 1 se , f x y T g x y f x y T ≤ ⎧⎪ = ⎨ > ⎪⎩Il valore di soglia non dipende solo dal livello di grigio (
f x y
( )
,
), ma, in generale, si ha:( ) ( )
(
, ,
,
,
,
)
T
=
T x y p x y
f x y
dove
p x y
(
,
)
può rappresentare una qualsiasi proprietà del pixel presente nel punto di coordinate(
x y
,
)
. Se T dipende solo daf x y
( )
,
allora è detto globale. Se T dipende sia daf x y
( )
,
che dap x y
(
,
)
è detto, invece, locale. Se T dipende anche dax
e da ysi parla, allora, di valore di soglia dinamico o adattativo.
Come detto in precedenza e come si è appena visto, la tecnica è concettualmente molto semplice; tuttavia il problema principale è rappresentato dalla scelta del valore di soglia. In letteratura si possono trovare diverse tecniche per determinare tale valore (vedi per esempio [1], [3], [4]). Il modo più semplice è, sicuramente, quello di applicare un singolo valore di soglia per tutta l’immagine (valore di soglia globale) scegliendo, nel caso di istogramma bimodale, un valore di livello di grigio in un intorno del minimo presente tra i due picchi caratteristici dell’istogramma. Un esempio in cui viene utilizzata tale tecnica è mostrato in Figura 4.7: a sinistra viene mostrata l’immagine originale, al centro l’istogramma e, a destra, l’immagine modificata.
Figura 4.7 – Esempio di determinazione del valore di soglia [1]
Tuttavia, oltre al fatto che l’istogramma non è sempre perfettamente bimodale, alcuni fattori (tra i quali soprattutto la presenza di un’illuminazione non uniforme) possono far si che un istogramma perfettamente bimodale non possa essere segmentato con un valore di soglia globale. Questo problema è mostrato nell’esempio di Figura 4.8 in cui è mostrata a sinistra l’immagine originale (è ben visibile il grado di illuminazione non uniforme), al centro l’istogramma e il valore di soglia scelto e, a destra, l’immagine modificata: come si può facilmente notare, il poligono non viene completamente separato dallo sfondo.
Figura 4.8 – Esempio di valore di soglia globale non utilizzabile [1]
Un metodo par risolvere tale problema (che, come si vedrà, è stato utilizzato anche nel presente lavoro) è quello di utilizzare un valore di soglia dinamico suddividendo l’immagine in sottoimmagini e usando un valore di soglia diverso per ciascuna sottoimmagine. In questo tipo di approccio, i punti chiave diventano, quindi, come suddividere l’immagine e come determinare il valore di soglia in ogni sottoimmagine. Per quanto riguarda la suddivisione dell’immagine, questa dipende dall’immagine in esame. Un esempio è mostrato in Figura 4.9 (a sinistra) in cui l’immagine di Figura 4.8 viene suddivisa in sedici rettangoli uguali. Nella stessa figura (a destra) è mostrato, invece, il risultato della segmentazione ottenuto dando un valore di soglia globale in ogni sottoimmagine: ad eccezione delle due sottoimmagini presenti nella parte centrale è ben visibile il miglioramento rispetto alla Figura 4.8. Un altro tipo di suddivisione verrà, invece, utilizzato nel presente lavoro e varrà mostrato nel seguito del capitolo.
Figura 4.9 – Esempio di suddivisione di un’immagine e risultato della relativa segmentazione [1]
Per quanto riguarda la determinazione del valore di soglia, oltre al metodo visto in precedenza (prendere il minimo presente tra i due picchi dell’istogramma) che può essere anche automatizzato mediante una procedura iterativa (vedi per esempio [1]), si possono trovare in letteratura diversi algoritmi per il calcolo ottimizzato di tale parametro (vedi per esempio [1] o [5]). Proprio uno di questi metodi e cioè il metodo di Otsu [5], che è uno di quelli più comunemente utilizzati, è stato utilizzato nel presente lavoro e sarà di seguito descritto.
Per comprendere meglio tale metodo bisogna pensare all’istogramma come se fosse una funzione di densità di probabilità (
p q
( )
). Tutto ciò può essere fatto semplicemente normalizzando l’ordinata dell’istogramma mediante il numero totale di pixels presenti nell’istogramma ( ):n
( )
n
qcon
0,1, 2,...,
p q
q
n
=
=
N
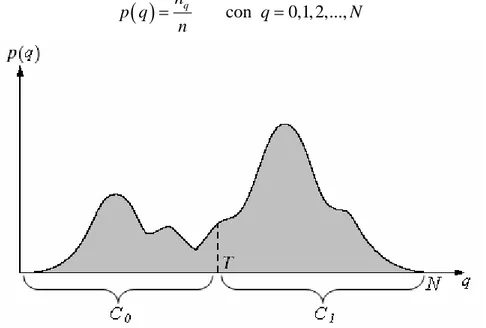
Figura 4.10 – Possibile istogramma bimodale
Senza perdere in generalità, supponiamo ora che l’istogramma di una certa immagine in cui è presente un oggetto scuro su uno sfondo luminoso sia quello mostrato in Figura 4.10. Scegliendo un certo valore di soglia (T in figura), l’istogramma viene diviso in due insiemi (o classi): la classe C0 che comprende tutti i livelli di grigio tra 0 e T (T non
compreso) e la classe C1 che comprende i livelli di grigio tra T (compreso) e . Con il
metodo di Otsu si cerca, quindi, il valore di T per cui è minima la “cosiddetta varianza interna alle classi” (within-class variance,
N
2W
σ
) che è così definita:( )
( ) ( )
( ) ( )
1T
2 2 2 0 0 1 WT
n T
T
n T
σ
=
σ
+
σ
i idove
n
0 en
1 sono le probabilità che un pixel appartenga alla classe C0 e C1rispettivamente; si ha infatti:
( )
1 0 0 T i n p − = =∑
e 1( )
N i T n p = =∑
mentreσ
02 e 2 1σ
sono la varianza della classe C0 e della classe C1 rispettivamente e sono,dunque, strettamente legate al livello di dispersione dei pixels presenti nelle due classi rispetto alla media.
La varianza interna alle classi è dunque una somma pesata delle varianze delle due classi in cui viene diviso l’istogramma. Al fatto che venga minimizzata tale grandezza può essere data la seguente spiegazione: se T è troppo basso, allora
σ
12 sarà alto (in quanto nella classe C1 ci saranno troppi pixels lontani dalla media di tale classe), il che implicache è alta la probabilità che un pixel, che dovrebbe essere incluso nella classe C0, venga
erroneamente incluso nella classe C1 e quindi
2
W
σ
sarà alto; il viceversa avviene se il valore di T è troppo alto, per cui anche in questo casoσ
W2 sarà alto. Quando, invece,2
W
σ
è in condizioni di minimo, le varianze delle due classi saranno paragonabili ed è pertanto minima la probabilità che un pixel venga erroneamente incluso in una qualsiasi delle due zone.Per velocizzare i tempi di calcolo, in realtà, più che minimizzare la varianza interna alle classi, generalmente si massimizza la cosiddetta “varianza tra le classi” (between-class variance,
σ
B2) che è definita nel modo seguente:( )
( )
2 2 2
B
T
WT
σ
=
σ
−
σ
dove
σ
2 è la varianza dell’intera distribuzione statistica. Come sottolineato nella definizione, la varianza totale non dipende dal valore di soglia, pertanto è facile constatare che i due procedimenti sono equivalenti.4.2 L’algoritmo di elaborazione delle immagini
Come è stato già accennato nella Sezione 1.4, tra gli obbiettivi del presente lavoro di tesi c’è anche quello di sviluppare un algoritmo, possibilmente automatico, con cui elaborare le immagini in modo tale da poter separare le zone cavitanti che si formano sulle pale dell’induttore dal resto dell’immagine. Tutto ciò richiede la trasformazione dell’immagine di partenza (in scala di grigio) in un’immagine binaria in cui le zone cavitanti sono bianche e tutto il resto è nero. Pertanto, ci si è trovati di fronte al problema della segmentazione di cui si è parlato nel paragrafo precedente.
Un simile problema è stato già affrontato in diversi lavori nell’ambito della cavitazione. In particolare in [6] la cavitazione viene estratta dall’immagine mediante un algoritmo di individuazione di contorni (edge detection). Come mostrato in Figura 4.11, dopo aver
estratto i contorni delle bolle con il suddetto algoritmo, questi vengono poi riempiti di nero ottenendo un immagine (Figura 4.10c) in cui, a differenza di quanto detto in precedenza, la cavitazione è nera e tutto il resto è bianco.
Figura 4.11 – Esempio di estrazione della cavitazione da un immagine: a) immagine originale, b) applicazione della tecnica di edge detection, c) immagine binaria finale [6]
Altro esempio di estrazione della cavitazione da un’immagine può essere trovato in [7]. In questo caso viene utilizzata, a differenza del precedente, la tecnica del valore di soglia effettuata tramite un valore di soglia globale (Figura 4.12).
Figura 4.12 – Esempio di estrazione della cavitazione da un’immagine mediante la tecnica del valore di soglia [7]
Uno dei pochi lavori reperibili in letteratura in cui la cavitazione viene estratta dalle immagini frontali di un induttore registrate mediante una telecamera (anche se non ad alta velocità) è [8]. L’elaborazione viene effettuata mediante un software sviluppato appositamente che estrae la cavitazione presente nella zona periferica dell’induttore in quattro passi (Figura 4.13): a) selezione dell’induttore senza il condotto che lo contiene, b) filtraggio dell’intera immagine sottraendo l’intensità media calcolata in zone con
risoluzione 16x16 dai valori caratteristici dei vari pixels, c) estrazione dei pixels bianchi, d) confronto con l’immagine originale.
Figura 4.13 – I quattro passi dell’algoritmo di elaborazione delle immagini utilizzato da Joussellin et al. [8]
Anche nel presente lavoro si è deciso di utilizzare la tecnica del valore di soglia in quanto, come già detto in precedenza, è una delle più semplici sia dal punto di vista concettuale, sia dal punto di vista dell’implementazione.
Nonostante la sua semplicità, questa tecnica ha comunque comportato alcuni dei problemi già accennati nel paragrafo precedente dovuti, soprattutto, al fatto che la maggior parte delle immagini a disposizione presentano (vedi Figura 4.14) un grado di illuminazione irregolare che dà luogo a effetti d’ombra e riflessi non rimuovibili mediante la semplice modifica delle posizione delle lampade alogene.
Figura 4.14 – Esempi di immagini in cui si hanno riflessi (sinistra) e luce non uniforme (destra)
Tutto ciò, in particolare, non ha reso possibile l’applicazione di un valore di soglia globale per effettuare la segmentazione dell’immagine. In Figura 4.15 viene infatti mostrato il risultato dell’applicazione di un valore di soglia globale (trovato mediante il metodo di Otsu) sia su un fotogramma tratto da un filmato laterale, sia su un fotogramma tratto da un filmato frontale (gli stessi fotogrammi non segmentati sono mostrati nelle Figure 4.14 (sinistra) e 4.18 (destra) rispettivamente).
Figura 4.15 – Esempi di applicazione di un valore di soglia globale: fotogramma di un filmato “laterale” (sinistra) e di un filmato “frontale” (destra)
Nel caso dei fotogrammi “frontali”, un leggero miglioramento nell’applicazione del valore di soglia globale si ottiene tagliando l’immagine in maniera tale da contenere il solo induttore. Applicando questa tecnica al fotogramma di Figura 4.18 (destra) si ha infatti il risultato mostrato in Figura 4.16 (sinistra). Questa tecnica si è però dimostrata poco versatile in quanto, come si vede nella stessa figura (a destra), il risultato peggiora in funzione del grado di illuminazione e del livello di cavitazione.
Figura 4.16 – Esempi di applicazione di un valore di soglia globale su fotogrammi “frontali” contenenti il solo induttore
Tale problema è stato dunque risolto con la tecnica vista nel paragrafo precedente: è stato cioè utilizzato un valore di soglia dinamico.
In particolare è stato dapprima creato un algoritmo che permette l’individuazione manuale delle zone in cui applicare il valore di soglia. Dal momento che tale algoritmo risulta molto lento se applicato ad un intero filmato composto da un gran numero di fotogrammi, si è deciso di adottare un algoritmo “semi-automatico” che ha permesso di ridurre i tempi necessari per l’elaborazione dei filmati.
E’ importante osservare che tutti gli algoritmi sono stato implementati in ambiente Matlab® in quanto in esso è presente un pacchetto, detto Image processing toolbox [2], nel quale sono presenti diversi programmi che permettono la manipolazione delle immagini digitali sia manualmente che automaticamente.
I codici Matlab che implementano gli algoritmi creati nell’ambito del presente lavoro sono presenti nell’Appendice B e sono di seguito descritti.
4.2.1 L’algoritmo manuale
Il diagramma di flusso dell’algoritmo “manuale” utilizzato per la modifica dei filmati frontali è mostrato in Figura 4.17. Questo stesso algoritmo, se privato del blocco relativo alla selezione dell’asse di rotazione dell’induttore, può essere utilizzato anche per la modifica dei filmati laterali.
Come si vede dal diagramma, l’algoritmo prende come ingresso il fotogramma di un filmato che non è altro che un’immagine in scala di grigio a 8 bit. Le immagini di ingresso tipiche per filmati frontali e laterali sono mostrate in Figura 4.18.
Figura 4.18 – Fotogrammi tipici di un filmato laterale (sinistra) e di un filmato frontale (destra)
Nel caso dei filmati frontali, la prima operazione da effettuare sull’immagine è quella di selezionare l’asse di rotazione dell’induttore. Questa è un’operazione molto importante, in quanto consente di ruotare l’immagine attorno a questo punto di un angolo tale da far si che l’induttore risulti fermo nella posizione occupata nel primo fotogramma del filmato. La selezione di questo punto avviene manualmente mediante un doppio click del mouse sul punto corrispondente all’asse di rotazione dell’induttore (Figura 4.19).
Figura 4.19 – Finestra di selezione dell’asse di rotazione dell’induttore
Dopo questa prima operazione, il programma consente di selezionare manualmente più zone poligonali nell’immagine all’interno delle quali viene usata la tecnica del valore di soglia risolvendo, così, il problema di non poter dare un unico valore di soglia per tutta l’immagine. Il valore di soglia in ogni zona, come si vede dal diagramma di flusso, viene
stabilito al termine di una procedura iterativa il cui valore iniziale viene calcolato automaticamente mediante il metodo di Otsu e che prosegue modificando manualmente tale valore a seconda che i risultati siano buoni o meno secondo il giudizio dell’operatore. A titolo di esempio vengono di seguito mostrati i risultati ottenuti durante la segmentazione dell’immagine di Figura 4.18 (destra) con questa tecnica. In particolare, nelle Figure 4.20 e 4.21 vengono mostrate alcune delle zone selezionate con i relativi istogrammi e valori di soglia impostati al termine della procedura iterativa. In Figura 4.22a viene mostrata l’immagine binaria finale e in Figura 4.22b viene mostrato un confronto tra l’immagine originale e quella modificata (la linea rossa non è altro che il contorno delle zone bianche di Figura 4.22a) dal quale si può vedere la bontà dei risultati ottenuti con l’algoritmo manuale. Infine, in Figura 4.23 vengono mostrati i risultati ottenuti per un fotogramma tratto da un filmato laterale.
Figura 4.20 – Selezione della prima zona dell’immagine (sinistra) con relativo istogramma e valore di soglia (destra)
Figura 4.21 – Selezione della seconda zona dell’immagine (sinistra) con relativo istogramma e valore di soglia (destra)
(a) (b)
Figura 4.22 – Risultato dell’elaborazione manuale (a) e confronto tra immagine originale e relativa immagine binaria (b)
Figura 4.23 – Esempio di applicazione dell’algoritmo manuale a un fotogramma tratto da un filmato laterale
4.2.2 L’algoritmo semi-automatico
Come accennato in precedenza, nonostante i buoni risultati prodotti, l’algoritmo manuale risulterebbe molto lento se venisse utilizzato per l’elaborazione di un intero filmato formato da un gran numero di fotogrammi. Perciò, per ridurre il tempo necessario ad elaborare un intero filmato è stato sviluppato un algoritmo che può essere definito “semi-automatico” in quanto produce automaticamente un immagine binaria di primo tentativo che può essere poi ritoccata manualmente mediante la procedura descritta nel paragrafo precedente.
In Figura 4.24 viene mostrato il diagramma di flusso di tale algoritmo, mentre il codice Matlab che implementa tale algoritmo è presente nell’Appendice B.
Come si vede dal diagramma, il primo passo della procedura è, come per l’algoritmo manuale, la selezione dell’asse di rotazione dell’induttore che viene effettuata in maniera identica a quella vista per l’algoritmo manuale (Figura 4.19).
Il passo successivo è la segmentazione automatica dell’immagine. Tale operazione può essere descritta facendo riferimento alla Figura 4.25.
Figura 4.24 – Diagramma di flusso per l’algoritmo semi-automatico
La segmentazione automatica consiste nel fare in maniera automatica ciò che si fa manualmente con la procedura vista in precedenza: anziché selezionare manualmente determinate zone nell’immagine, quest’ultima viene suddivisa in un certo numero di sottoimmagini. In particolare, come si vede in Figura 4.25, l’immagine viene suddivisa in un certo numero di settori circolari all’interno dei quali viene dato un valore di soglia calcolato automaticamente con il metodo di Otsu.
Per poter analizzare meglio le regioni cavitanti che si formano sulle pale dell’induttore, sia la parte centrale dell’immagine (dove, come si vedrà in seguito, spesso si manifestano altri fenomeni cavitanti), sia la regione esterna all’induttore sono state colorate di nero (vedi Figura 4.25).
Inoltre, come mostrato in Figura 4.26, analizzando l’istogramma di ciascuna immagine si è scoperto che la deviazione standard dei valori di luminosità nei settori circolari in cui non è presente la cavitazione è molto bassa (in quanto la luminosità di quelle zone è pressoché uniforme). Perciò anche i pixels presenti nei settori circolari con deviazione standard inferiore rispetto a un valore prefissato vengono colorati di nero senza impostare alcun valore di soglia.
Figura 4.26 – Andamento della deviazione standard dei vari settori circolari al variare di
θ
per due fotogrammi tipiciTramite questa procedura completamente automatica si ottiene un’immagine binaria di primo tentativo. Questa viene confrontata dal programma con l’immagine originale e, qualora i risultati di questa prima elaborazione non fossero buoni, il programma consente all’operatore di utilizzare la procedura manuale vista in precedenza per correggere eventuali errori presenti nell’immagine di primo tentativo.
Come esempio di applicazione di tale algoritmo, nelle seguenti figure vengono mostrati i risultati ottenuti sullo stesso fotogramma elaborato nel paragrafo precedente con la procedura manuale. In particolare, la Figura 4.27 (sinistra) mostra il risultato della procedura automatica applicata all’immagine originale. Nella stessa figura (destra) viene, invece, mostrato un confronto tra l’immagine originale e quella modificata. In quest’ultima immagine sono state sottolineate in blu le zone che in realtà non fanno parte della zona cavitante (e quindi da eliminare nell’immagine finale) e in verde la coda della stessa regione cavitante che, invece, non viene estratta dall’algoritmo.
Figura 4.27 – Risultato della segmentazione (sinistra) e confronto tra immagine originale e immagine modificata (destra)
Figura 4.28 – Esempio sul recupero di una zona cavitante non riconosciuta dall’algoritmo automatico
Come detto in precedenza, in questo caso, l’algoritmo permette di entrare nella modalità di elaborazione manuale consentendo innanzi tutto di eliminare eventuali zone non cavitanti estratte dall’algoritmo (zona blu in Figura 4.27) e, infine di riprendere manualmente solo la zona cavitante non estratta in precedenza (Figura 4.28).
Ultima operazione fatta dall’algoritmo è quella di mettere insieme l’immagine di primo tentativo e le zone eventualmente recuperate tramite l’algoritmo manuale in un’unica immagine. Per il caso visto nell’esempio precedente, il risultato di tale operazione con relativo confronto con l’immagine originale viene mostrato in Figura 4.29, dalla quale si può notare come i risultati ottenuti applicando l’uno o l’altro dei due algoritmi sviluppati siano analoghi.
Figura 4.29 - Risultato dell’elaborazione automatica (a) e confronto tra immagine originale e relativa immagine binaria (b)
Per concludere, la Figura 4.30 mostra i risultati ottenuti applicando l’algoritmo semi-automatico a quattro diversi fotogrammi tratti da filmati ottenuti in diverse condizioni flusso che dimostrano i buoni risultati forniti dall’algoritmo anche quando sull’induttore si hanno livelli di cavitazione maggiormente sviluppati che tendono ad alterare il livello di luminosità dell’immagine.
4.3 Note bibliografiche al Capitolo 4
[1] R.C. Gonzales, R.E. Woods, Digital image processing – 2nd edition, Prentice Hall, 2002.
[2] Aa. vv., Image processing toolbox for use with Matlab, The MathWorks Inc. [3] R.C. Gonzales, R.E. Woods, S.L. Eddins, Digital image processing using Matlab,
Prentice Hall, 2004.
[4] B. S. Morse, Thresholding, Brigham Young University, 2000.
[5] N. Otsu, A threshold selection method for gray-level histograms, IEEE Transaction on Systems, Man and Cybernetics, 1979.
[6] J.E. Hiscock, D. Mouland, G. Wang, C.Y. Ching, Gas bubble velocity measurements using high-speed images of gas-liquid flows, ASME FEDSM, 2000. [7] K. Kato, Y. Matudaira, H. Obara, Flow visualization of cavitation with particle and
bubble image processing, ASME FEDSM, 2003.
[8] F. Joussellin, Y. Courtot, O. Coutier-Delgosha, J.L. Reboud, Cavitating inducer instabilities: experimental analysis and 2D numerical simulation of unsteady flow in blade cascade, 4th International Symsposium on Cavitation, 2001.
![Figura 4.1 – Un immagine digitale prodotta nel 1921 da un nastro codificato [1]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/2.892.275.579.764.963/figura-immagine-digitale-prodotta-nastro-codificato.webp)
![Figura 4.2 – Immagine tipica con quindici livelli di grigio [1]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/3.892.338.600.105.334/figura-immagine-tipica-quindici-livelli-grigio.webp)
![Figura 4.4 – Tipica immagine digitale [2]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/4.892.183.675.660.944/figura-tipica-immagine-digitale.webp)
![Figura 4.5 – Immagine in scala di grigio con relativo istogramma [2]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/6.892.170.685.605.847/figura-immagine-scala-grigio-relativo-istogramma.webp)
![Figura 4.6 – Tipico istogramma “bimodale” [1]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/7.892.267.671.127.394/figura-tipico-istogramma-bimodale.webp)
![Figura 4.8 – Esempio di valore di soglia globale non utilizzabile [1]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/8.892.130.720.560.715/figura-esempio-valore-soglia-globale-utilizzabile.webp)
![Figura 4.12 – Esempio di estrazione della cavitazione da un’immagine mediante la tecnica del valore di soglia [7]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7247794.80397/11.892.196.739.736.909/figura-esempio-estrazione-cavitazione-immagine-mediante-tecnica-valore.webp)

