Indice
1.
Introduzione... 5
2.
Tecniche di ottimizzazione metaeuristiche ... 7
2.1 Algoritmi genetici ... 10
2.2 Ant colony system ... 13
2.2.1 ACO-CF ... 15
2.3 Harmony search optimization... 18
3.
Harmony search applicato al problema del group technology ... 23
3.1 Group technology problem ... 23
3.2 Harmony Search Optimization Modified ... 25
3.2.1 Procedura iterativa ... 28
4.
Problemi confrontati e risultati ... 36
4.1 Settaggio dei parametri ... 36
4.2 Confronto su problemi noti ... 38
4.3 Confronto su problemi random ... 41
5.
Conclusioni ... 47
6.
Bibliografia ... 49
7.
Ringraziamenti ... 51
1. I
NTRODUZIONENel campo della produzione si possono ottenere maggiori profitti abbassando i costi e aumentando la qualità dei prodotti. In ambito gestionale sono state sviluppate delle linee guida generali con l’obiettivo di ridurre i costi di produzione senza pregiudicare la qualità del prodotto finito. Queste includono metodi di produzione più efficienti, minimizzazione degli spostamenti durante le fasi di lavoro, riduzione di tempi morti e tempi di set-up. L’ingegneria applicata nell’ambito della Ricerca e Sviluppo (R&D) affronta in maniera diretta questa tipologia di problemi attraverso la progettazione di sistemi di miglioramento dell’efficienza produttiva.
Il processo di produzione richiede una varietà di macchine e spesso alcune procedure complesse. Frequentemente le parti devono essere spostate da un luogo ad un altro e ciò si traduce non solo in tempi di inattività del macchinario ma anche in manodopera necessaria allo spostamento fisico del componente.
D'altro canto, un numero sempre maggiore di imprese è soggetta ad ordini frequenti di piccola e media ampiezza. In questa situazione si verificano set-up più frequenti e maggiori spostamenti delle parti da una macchina all’altra.
Il Group Technology (GT) ha dimostrato di essere un modo utile per affrontare questo tipo di problemi, creando processi produttivi più flessibili.
Il GT può essere utilizzato sfruttando le somiglianze tra i componenti per ottenere una diminuzione dei costi aumentando la produttività senza pregiudicare la qualità del prodotto.
La formazione delle celle (CF) è un passo fondamentale del GT. Si tratta di uno strumento per la progettazione di sistemi di produzione per celle che utilizzano le somiglianze tra le parti e le macchine con lo scopo di raggruppare le macchine similari e creare famiglie di parti. Infatti le parti che hanno requisiti simili, se lavorate nel medesimo gruppo di macchine, permettono di ridurre notevolmente tempi di spostamento e di set-up.
In letteratura sono stati sviluppati molti metodi di cell formation, alcuni utilizzano algoritmi con funzioni di energia o particolari codici per ordinare macchine e parti come il Bond Energy Algorithm (BEA) (McCormick et al., 1972), il rank order clustering (ROC) (King, 1980), il rank order clustering modificato (MODROC) (Chandrasekaran and Rajagopalan,1986) ed il direct clustering algorithm (DCA)
(Chan and Milner, 1982). Altri utilizzano clustering gerarchicamente basati su similarità (Mosier, 1989; Wei and Kern, 1989; Gupta and Seifoddini, 1990; Shafer and Rogers, 1993) o approcci di tipo simulated annealing (vedi Xambre and Vilarinho, 2003). Uno degli algoritmi più recenti e performanti è l’ACO-CF [13] di tipo Ant Colony ed è proprio con questo che andremo a confrontare in maniera diretta i risultati ottenuti con il meta euristico implementato dal Dipartimento di Ingegneria Meccanica, Nucleare e della Produzione e denominato Modified Harmony Search Optimization (MHSO).
2. T
ECNICHE DI OTTIMIZZAZIONE METAEURISTICHENell'affrontare un problema di ottimizzazione, possono essere utilizzati vari approcci, a seconda sia delle difficoltà specifiche e delle dimensioni del problema in esame, sia degli obiettivi reali che si vogliono ottenere. Così, in quei casi in cui è necessario pervenire alla soluzione ottima di un certo problema, si utilizzerà un approccio di enumerazione implicita, sia esso basato su una formulazione di programmazione intera, o sullo sfruttamento delle proprietà combinatorie del problema. Se è invece sufficiente avere una garanzia sul massimo errore commesso, in termini relativi, si potrà far ricorso ad un algoritmo ρ-approssimato, ammesso che ve ne siano per il particolare problema in esame.
Infatti, mentre certi metodi esatti (come i piani di Gomory) possono applicarsi, almeno in linea di principio, a qualsiasi problema di programmazione lineare a numeri interi, per quanto riguarda gli algoritmi approssimati non esiste, per ora, un approccio sistematico allo stesso livello di generalità.
Una strada diversa, che può diventare l'unica percorribile se le dimensioni e/o la complessità del problema sono elevate, è quella che consiste nel cercare soluzioni di tipo euristico, ottenute cioè applicando un algoritmo concepito in modo da produrre soluzioni che si sperano buone, ma senza garanzia a priori sulla vicinanza all'ottimo. Un algoritmo euristico (o semplicemente un'euristica) deve essere in grado di produrre una soluzione in un tempo relativamente breve. Mentre chiaramente è possibile progettare euristiche specifiche per qualunque problema di ottimizzazione combinatoria, negli ultimi anni hanno acquisito importanza sempre maggiore alcuni approcci euristici di tipo generale, detti metaeuristiche. La struttura e l'idea di fondo di ciascuna metaeuristica sono sostanzialmente fissate, ma la realizzazione dei vari componenti dell'algoritmo dipende dai singoli problemi. Spesso peraltro queste metaeuristiche traggono ispirazione (se non legittimazione) da alcune analogie con la natura fisica. Ad esempio, nel simulated annealing si paragona il processo di soluzione di un problema di ottimizzazione combinatoria, in cui si passa iterativamente da una soluzione ammissibile a un'altra, sempre migliorando la funzione obiettivo, al processo con cui un solido, raffreddandosi, si porta in configurazioni con sempre minor contenuto di energia. Negli algoritmi genetici, un insieme di soluzioni ammissibili è visto come un insieme di individui di una popolazione che, accoppiandosi e combinandosi tra loro, danno vita a nuove
soluzioni che, se generate in base a criteri di miglioramento della specie, possono risultare migliori di quelle da cui sono state generate.
Gli approcci metaeuristici possono vedersi in realtà in modo omogeneo, come generalizzazioni di un unico approccio fondamentale, che è quello della ricerca locale.
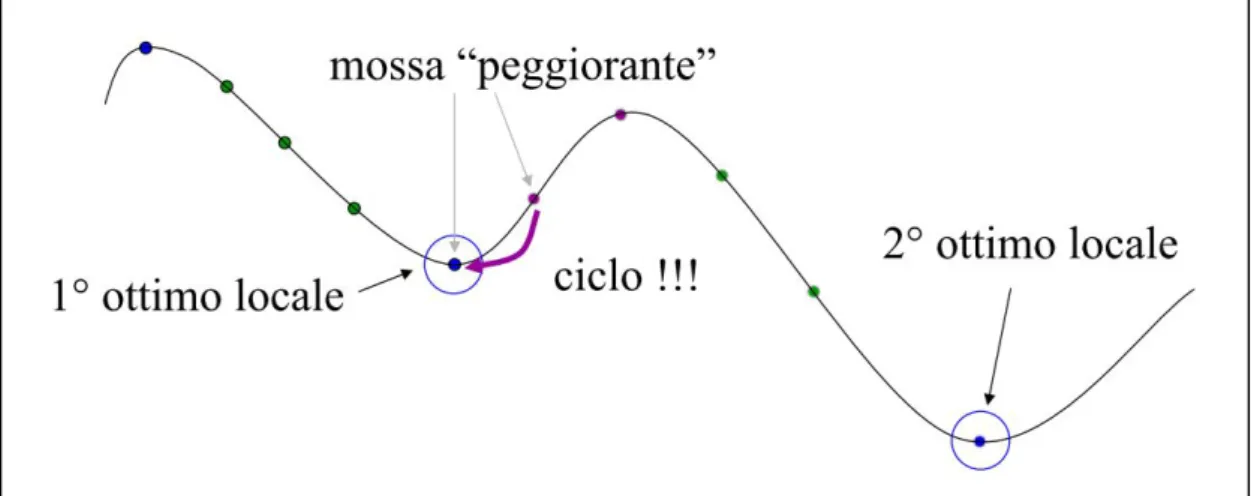
La ricerca locale si basa su quello che è, per certi versi, l'approccio più semplice e istintivo all'ottimizzazione: andare per tentativi. In effetti, l'idea di funzionamento della ricerca locale (come del resto quella delle varie metaeuristiche) è talmente elementare che è sorprendente constatare la sua relativa efficacia. Va tuttavia detto fin da ora che a fronte di questa relativa semplicità, l'applicazione di una qualunque metaeuristica a un problema di ottimizzazione combinatoria richiede comunque una messa a punto accurata e talvolta laboriosa.
Figura 1 Ricerca locale
Consideriamo un problema di minimizzazione, e una sua soluzione ammissibile x, con associato il valore della funzione obiettivo f(x). La ricerca locale consiste nel definire un intorno di x (detto, nella terminologia della ricerca locale, vicinato), e nell'esplorarlo in cerca di soluzioni migliori, se ve ne sono. Se, in questo vicinato di x, si scopre una soluzione y per cui f(y) < f(x), allora ci si sposta da x a y e si riparte da y con l'esplorazione del suo intorno. Se invece nel vicinato di x non si scopre nessuna soluzione migliore, allora vuol dire che x è un minimo locale. Nella ricerca locale classica, arrivati in un minimo locale, l'algoritmo si ferma e restituisce questo minimo come valore di output. Ovviamente, non si ha nessuna garanzia in generale che tale valore costituisca una soluzione ottima del problema; anzi, tipicamente esso può essere anche molto distante dall'ottimo globale. Le metaeuristiche, in effetti, sono
state concepite proprio per cercare di ovviare al problema di rimanere intrappolati in un minimo locale come mostrato in Fig. 1.
In base a quanto detto sopra, possiamo riassumere schematicamente l'algoritmo generale di ricerca locale come segue. Con x indichiamo una generica soluzione ammissibile del problema, N(x) il suo vicinato, e f(x) indica la funzione obiettivo.
Algoritmo di ricerca locale
a. Scegli una soluzione iniziale x; b. Genera le soluzioni nel vicinato N(x);
c. Se in N(x) c'è una soluzione y tale che f(y) < f(x), allora poni x := y d. e vai a 2, altrimenti STOP.
Lo spostamento da x a y al passo 3 viene spesso chiamato mossa. Nella ricerca locale, come si vede, si ha un miglioramento della funzione obiettivo in corrispondenza di una mossa.
Per applicare l'approccio della ricerca locale a un particolare problema, bisogna fare alcune scelte di fondo.
Occorre avere a disposizione una soluzione iniziale ammissibile. Questa può essere generata da un'euristica ad hoc per il particolare problema, o addirittura può essere generata casualmente. È possibile anche eseguire l'algoritmo a partire da diverse soluzioni iniziali, ottenendo così diverse soluzioni euristiche, e scegliere poi la migliore.
Bisogna definire in modo preciso e opportuno il vicinato di una soluzione. Definito il vicinato, occorre avere a disposizione un algoritmo efficiente per
esplorarlo. Non è utile definire il vicinato in un modo teoricamente potente ma non essere poi in grado di esplorarlo in un tempo di calcolo ragionevole. A seconda di come vengono fatte queste scelte, l'algoritmo risultante può
essere più o meno efficiente, e la soluzione proposta dalla ricerca locale risultare più o meno buona.
2.1 ALGORITMI GENETICI
Con il termine weak methods si indicano quei metodi di risoluzione di problemi che si basano su poche assunzioni (o conoscenze) relative alle particolari strutture e caratteristiche dei problemi stessi, motivo per il quale tali metodi sono applicabili ad una vasta classe di problemi. Gli Algoritmi Genetici rientrano pienamente in questa categoria, dal momento che essi sono in grado di compiere una efficiente ricerca anche quando tutta la conoscenza a priori è limitata alla sola procedura di valutazione che misura la qualità di ogni punto dello spazio di ricerca (misura data, ad esempio, dal valore della funzione obiettivo). Questa caratteristica conferisce a tali algoritmi una grande robustezza, ovvero una grande versatilità che li rende applicabili a diversi problemi, al contrario dei metodi convenzionali che, in genere, non trovano altra applicazione che quella relativa al problema per cui sono stati ideati.
Gli Algoritmi Genetici integrano l'abilità di semplici rappresentazioni (ad esempio stringhe di bit) a codificare strutture molto complicate con la potenza esibita da semplici trasformazioni che agendo su tali rappresentazioni migliorano significativamente queste strutture. Questo miglioramento è appunto l'obiettivo primario dell'ottimizzazione. Infatti, sotto l'azione di certe trasformazioni genetiche, si registrano miglioramenti, o, se si vuole, evoluzioni delle rappresentazioni in modo da imitare il processo di evoluzione di popolazioni di organismi viventi. In natura, il problema che ciascuna specie deve affrontare è quello della sopravvivenza, che coincide con il trovare un adattamento vantaggioso ad un ambiente mutevole e talvolta ostile. Le trasformazioni genetiche che consentono una evoluzione in tal senso sono quelle che alterano il patrimonio genetico della specie contenuto nei cromosomi di ciascun individuo: esse sono il crossover di gruppi di geni parentali e la mutazione. I cromosomi costituiscono l'equivalente delle stringhe di bit, in quanto codificano strutture biologiche molto complicate, mentre le trasformazioni genetiche costituiscono il mezzo attraverso il quale si generano nuove strutture biologiche più evolute delle precedenti.
L'idea di fondo degli algoritmi genetici è la seguente. Supponiamo di avere un certo insieme di soluzioni di un problema di ottimizzazione. Tra queste, ce ne saranno di più buone e di meno buone. La qualità di una soluzione è misurata da una funzione di merito, detta fitness function, che in genere coinciderà con la funzione obiettivo.
A questo punto, vogliamo generare nuove soluzioni, con la speranza ovviamente che fra queste ve ne siano sempre di migliori. L'idea è allora quella di "accoppiare" le soluzioni tra di loro in modo che "diano alla luce" nuove soluzioni. Allora, da una certa popolazione di individui (soluzioni), se ne ricava un'altra, che costituisce una nuova generazione, ossia quella dei figli della popolazione di partenza.
Questa nuova generazione potrebbe essere molto più numerosa della precedente, e allora quello che si fa è effettuare una selezione, cioè si escludono dalla popolazione tutte le soluzioni che hanno un valore di fitness function inferiore a una certa soglia. Con la popolazione così selezionata, si ricomincia, generando quindi i nipoti delle soluzioni di partenza e così via per un numero prefissato di generazioni.
Come si vede, in questo contesto così generale vi sono diverse scelte da fare. Anzitutto, negli algoritmi genetici gioca un ruolo fondamentale il modo in cui vengono rappresentate le soluzioni ammissibili. Tipicamente, una soluzione sarà rappresentata da un insieme di stringhe di interi o binarie, che sono i cromosomi. Ciascun cromosoma a sua volta è composto da geni (i singoli bit). Dalla combinazione di due individui (crossover) nascerà una nuova soluzione del problema. I geni nei cromosomi del nuovo individuo dovranno ovviamente provenire da quelli dei due genitori. Un semplice modo di realizzare questo è il seguente. Se indichiamo con e l'i-esimo gene di un certo cromosoma dei due genitori rispettivamente, il corrispondente gene nel cromosoma figlio può essere posto uguale all'uno o all'altro con probabilità p e (1 – p) rispettivamente. Si noti che in questo modo si introduce un elemento probabilistico nell'algoritmo. Peraltro, reiterando più volte il processo aleatorio di crossover, diverse soluzioni possono essere ottenute dalla stessa coppia di genitori.
È implicito in quanto detto finora che l'efficacia degli algoritmi genetici risiede nel fatto empirico che se si combinano soluzioni buone, si ottengono soluzioni ancora buone. Tuttavia, sperimentalmente si è potuto osservare che anche gli algoritmi genetici, dopo un certo numero di iterazioni, tendono a produrre soluzioni che non migliorano più. Per diversificare la ricerca, allora, si introduce un nuovo operatore, detto mutazione. Prima cioè di procedere alla successiva generazione, in alcuni degli individui della popolazione viene alterato un gene. Ovviamente, gli operatori di mutazione dipendono molto dal particolare problema in esame.
Da quanto detto, un algoritmo genetico è fondamentalmente caratterizzato da cinque componenti:
1. una rappresentazione delle soluzioni generalmente sotto forma di stringhe di bit;
2. un criterio per generare la popolazione iniziale di soluzioni;
3. una funzione di valutazione che misura la qualità di ciascuna soluzione;
4. un insieme di operatori genetici che trasformano punti-soluzione in altri punti;
5. un insieme di valori per i parametri di controllo dell'algoritmo. Lo schema di principio di un algoritmo genetico è quello che segue:
Generazione della popolazione iniziale While not (condizione di uscita) Do
begin
Selezione dei genitori Generazione dei figli Ricambio generazionale End
2.2 ANT COLONY SYSTEM
Questa tipologia di algoritmo fu inizialmente proposto da Marco Dorigo nel 1992 nella sua tesi di dottorato. L’obiettivo era cercare un percorso ottimale in un grafo, sulla base del comportamento delle formiche in cerca di un percorso tra le loro colonie e di una fonte di cibo . L'idea originale di allora è stata diversificata per risolvere una classe più ampia di problemi numerici, e di conseguenza, sono emersi nuovi problemi spesso connessi ai vari aspetti del comportamento delle formiche. Nel mondo reale, le formiche (inizialmente) vagano a caso, finché non trovano del cibo per poi tornare alla propria colonia rilasciando delle tracce di feromone. Se le altre formiche trovano il percorso della precedente, è probabile che smettano di viaggiare a caso, ma comincino invece a seguire tale percorso, e nel caso in cui trovino anche loro del cibo, tornano e rilasciano anche loro tracce di feromone rafforzando la dose già presente.
Col tempo, però, il feromone inizia ad evaporare, riducendo così la sua forza attrattiva. Più tempo ci vuole ad una formica per viaggiare lungo il sentiero per tornare nuovamente indietro, più i feromoni hanno luogo di evaporare. Un percorso breve, al confronto, viene marcato più velocemente, e la densità di feromone su di esso rimane alta poiché essendo parte di altri percorsi più lunghi è come dire, molto trafficato. L’evaporazione del feromone ha anche il vantaggio di evitare la convergenza verso una soluzione ottimale a livello locale. Se non ci fosse l’evaporazione tuttavia, i percorsi scelti dalle prime formiche tenderebbero ad essere eccessivamente attraenti per le successive. In tal caso, l'esplorazione dello spazio delle soluzioni risulterebbe vincolata.
Così, quando una formica trova un buon (breve) percorso che va dalla colonia ad una fonte di cibo, le altre formiche sono più propense a seguire questa strada, e il feedback positivo conduce tutte le formiche a seguire un percorso unico. L'idea dell'algoritmo Ant Colony è quella di imitare questo comportamento con delle "formiche virtuali" che passeggiano per il grafico rappresentante il problema da risolvere.
Figura 2 Comportamento di una colonia di formiche
L'idea originale viene osservando come le formiche sfruttino le loro capacità cognitive, che prese individualmente sono abbastanza limitate, ma messe a disposizione della collettività permettono loro di riuscire in una efficiente ricerca delle risorse necessarie alla colonia trovando il percorso più breve possibile come mostrato in Fig. 2.
1. La prima formica dopo aver trovato la fonte di cibo (F), in modo casuale (a), torna al nido (N), lasciandosi dietro una scia di feromoni (b).
2. Le formiche indifferentemente seguirebbero i quattro percorsi possibili, ma il rafforzamento della pista con il feromone rende più attraente il percorso più breve.
3. Sempre più formiche scelgono la via più breve, quindi le porzioni lunghe degli altri percorsi perdono i loro feromoni.
In una serie di esperimenti su di una colonia di formiche, dando loro la possibilità di scegliere tra due percorsi di lunghezza diversa che portano entrambi ad una fonte di cibo, i biologi hanno osservato che le formiche tendono ad utilizzare il percorso più breve. Se ci sono due strade per raggiungere la stessa fonte di cibo, alla lunga, quella più corta sarà percorsa da più formiche. La strada corta sarà sempre più rafforzata, e quindi diventerà più attraente.
Alla fine, tutte le formiche lavorando collettivamente determinano e, pertanto, "scelgono" la via più breve.
La filosofia di base dell'algoritmo comporta il movimento di una colonia di formiche attraverso i diversi stati del problema influenzato da due politiche di decisione locale: percorso e attrattività. In tal modo, ogni formica è come se costruisse gradualmente una soluzione al problema. Quando una formica completa una soluzione, o in fase di costruzione, la valuta, va a modificare il valore “percorso” dei componenti utilizzati per la sua soluzione. Queste informazioni sotto forma di feromone dirigeranno la ricerca delle formiche in futuro. Inoltre, l'algoritmo riprende il concetto di attrattività con il meccanismo di evaporazione e deposito del feromone sul sentiero evitando così ogni possibilità di rimanere intrappolati in ottimi locali.
2.2.1 ACO-CF
L’algoritmo ACO-CF[15] è stato sviluppato seguendo la logica degli Ant colony System infatti riesce a simulare il comportamento di una reale colonia di formiche. Il meccanismo principale che contraddistingue tale metodo è la sua abilità nel costruire delle soluzioni sempre migliori sfruttando una probabilità parametrizzata su di un modello rappresentante il percorso dei feromoni.
I valori del feromone vengono inizializzati prima di far partire il calcolo e successivamente aggiornati in funzione delle informazioni contenute nelle migliori soluzioni ottenute durante le iterazioni.
Le formiche virtuali comunicano in modo indiretto attraverso la lettura e l’aggiornamento di una matrice dei feromoni durante i loro percorsi, ed attraverso questo tipo di comunicazione riescono a cooperare nell’obiettivo di trovare le migliori soluzioni.
In Fig. 3 è rappresentata la struttura principale dell’ACO-CF.
Dati in ingresso il problema e la matrice τ dei feromoni inizializzata, dopo aver settato i tre parametri α β γ, utilizzati successivamente in fase di scelta delle operazioni da assegnare, comincia l’algoritmo.
Ogni formica “g” costruisce una soluzione sulla base del problema iniziale e della matrice dei feromoni. Una volta “costruita la soluzione” questa viene poi sottoposta ad una ricerca locale per migliorare il valore della funzione obiettivo “η”. Di tutte le soluzioni trovate, viene presa la migliore, o meglio quella che minimizza/massimizza la funzione obiettivo ( ), e la si confronta con la miglior soluzione ottenuta fino a quel momento ( ) aggiornandola in caso di miglioramento.
In ogni caso, e qui sta l’aspetto performante dell’algoritmo, la buona soluzione anche se non ottima, va a modificare quella che è la matrice dei feromoni.
In Fig. 4 è mostrata la procedura, denominata appunto SolutionConstruction che permette alla formica “g” di realizzare la sua personale soluzione in maniera costruttiva.
K = numero delle celle create
= insieme delle macchine inserite nella cella K = insieme delle parti inserite nella cella k
, = insieme iniziale rispettivamente di macchine e parti assegnate.
M, P = insieme delle macchine e parti da assegnare
Finché non sono assegnate tutte le operazioni, il ciclo While si ripete ed ogni volta, a seconda di quale operazione esce, c’è la possibilità di generare o no una nuova cella. Un passo molto performante è l’equazione 19 (per la cui consultazione rimandiamo all’articolo) che sceglie l’operazione “o” da assegnare nella cella “k” in funzione di una probabilità che dipende da i seguenti fattori:
matrice dei feromoni
similarità tra macchine e parti ammissibilità delle operazioni
Assegnate tutte le parti, la procedura rende già una buona soluzione con un numero di celle già determinato. Questa viene poi sottoposta ad una LocalSearch per andare alla ricerca di soluzioni migliori in un intorno dello spazio limitato.
Nella ricerca locale, l’algoritmo in un primo momento mantiene la disposizione delle macchine in uscita dal SolutionConstruction riassegnando tutte le parti con l’obiettivo di minimizzare i vuoti e le eccezioni eventualmente generate assegnando la parte nella cella k. Poi, una volta assegnate tutte le parti, è possibile che rimangano celle residue, ovvero delle celle composte da sole macchine senza alcuna parte. Ecco che le macchine presenti in tali celle vengono riassegnate in maniera ottimizzante, quindi sempre tenendo conto del minor numero di vuoti ed eccezioni che si vanno a creare qualora si assegni la macchina nella cella x piuttosto che nella y.
La LocalSearch prosegue poi con la valutazione della funzione obiettivo e con il riassegnamento di tutte le macchine in funzione delle famiglie delle parti già ottimizzate di nuovo sfruttando il criterio sopra descritto, e termina infine con la riassegnazione delle parti appartenenti ad eventuali celle residue generate nella ottimizzazione delle macchine. La procedura si ripete finché c’è un incremento della funzione obiettivo.
Questo algoritmo è stato testato dall’autore confrontandolo su una serie di problemi noti, con altri algoritmi molto performanti e secondo i risultati pubblicati è risultato essere il migliore (per i risultati si rimanda al cap. 5).
2.3 HARMONY SEARCH OPTIMIZATION
Dall’idea che gli attuali algoritmi metaeuristici tendono ad imitare fenomeni naturali, scientifici e comportamentali intorno a noi, un nuovo algoritmo può essere visto anche come un processo di creazione di nuove armonie musicali (ad esempio improvvisazioni jazz) alla ricerca di una musica migliore.
Proprio come l'improvvisazione musicale cerca una musica migliore rispetto alle precedenti (un’armonia fantastica) caratterizzata da una valutazione estetica molto buona, il processo di ottimizzazione cerca una soluzione migliore (Ottimo globale), andando a valutare una certa funzione obiettivo. Proprio come la valutazione dell’armonia è stabilita dall’insieme delle note suonate dai vari strumenti in contemporanea, la valutazione della funzione obiettivo è determinata sulla base dei valori assegnati alle variabili in gioco.
Come la qualità del suono può essere migliorata prova dopo prova, il valore della funzione obiettivo può essere migliorato iterazione dopo iterazione.
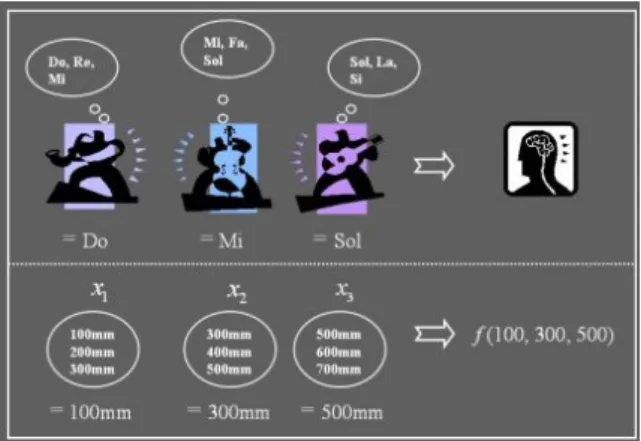
Figura 5 Analogie tra improvvisazione e ottimizzazione
L'analogia tra l'improvvisazione e ottimizzazione è mostrata in fig. 5. Ogni musicista (Sassofonista, contrabbassista e chitarrista) può essere visto come una variabile decisionale ( , , ), e la gamma di note che ogni strumento è in grado di suonare (sax ={Do, Re, Mi}; contrabbasso = {Mi, Fa, Sol}; e chitarra = {Sol, La, Si}) diventa il range di valori che una variabile può assumere = {100, 200, 300}; = {300, 400,500}; e = {500, 600, 700}). Se il sassofonista preme la nota “Do”, il contrabbassista pizzica il “Mi”, e il chitarrista il “Sol”, le tre note insieme formano una nuova armonia (Do, Mi, Sol). Se questa nuova armonia è migliore di un’armonia esistente, la nuova armonia viene mantenuta.
Allo stesso modo, il vettore di una nuova soluzione (100mm, 300mm, 500mm) generato nel processo di ottimizzazione è mantenuto se risulta migliore di un’armonia esistente, in termini di valore della funzione obiettivo. Proprio come la qualità della musica viene esaltata prova dopo prova, la qualità della soluzione sarà migliorata iterazione dopo iterazione.
Secondo il concetto espresso sopra, l’algoritmo Harmony search è costituito dalle seguenti quattro fasi:
a. Inizializzazione dei parametri
b. Inizializzazione della Harmony memory c. Generazione di una nuova armonia
d. Definizione dei criteri di terminazione dell’algoritmo
a. Inizializzazione dei parametri
In questa prima fase, il problema di ottimizzazione viene modellizzato come segue: max(min) ( )
∈ ∶ = 1, . . ,
Dove f(x) è la funzione obiettivo e X è un vettore soluzione composto da variabili , rappresenta i possibili valori che può assumere la variabile che solitamente per problemi a variabili discrete è
= 1,2, . . , In questo step si vanno anche ad inizializzare:
HMS (dimensione della harmony memory = numero di vettori soluzione simultanei presenti nella harmony memory )
PAR ( pitch adjusting rate) Questi parametri saranno spiegati nei prossimi steps.
b. Inizializzazione dell’harmony memory
Una volta che la dimensione della Harmony Memory (HMS) è definita, questa può essere rappresentata come una matrice di HMS vettori ammissibili (righe) costituiti da N+1 elementi (colonne) generati in maniera random, dove con N si intende il numero di note che vanno a comporre l’armonia, come mostrato in Fig. 6.
⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ … … … … … … … … … ( ) ( ) … ( ) ( ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
Figura 6 Modellizzazione della Harmony Memory
Solitamente la funzione obiettivo di ogni vettore viene espressa nell’ultima colonna della HM.
c. Generazione di una nuova armonia
Ad ogni iterazione una nuova armonia viene generata in n step successivi (cominciando dalla posizione 1 fino alla posizione N, dove N è il numero di variabili) attraverso tre meccanismi:
Random selection
Pitch selection dalla Harmony Memory Pitch adjusting (Mutazione)
Random selection:
Figura 7 range delle note
Come il musicista suona le note realizzabili con i vari strumenti (per esempio, , {Do, Re, Mi, Fa, Sol, La, Si} in Fig. 2) così il valore di una variabile ′ viene scelto in un certo range in maniera random.
Pitch selection
Figura 8 Note preferite
Come il musicista suona le sue note preferite a seconda della propria esperienza (per esempio , {Do, Mi, Do, Sol, Do} in Fig. 8) così il valore della variabile ′ è scelto in
funzione della Harmony Memory. Più precisamente andando a pescare da uno dei vettori il valore in posizione “i”.
Quindi con probabilità HMCR (Harmony memory random rate) si sceglierà una nota in maniera casuale, mentre con probabilità 1- HMCR si sceglierà sulla base dell’esperienza passata (della HM).
→ ( + ) . .
. . (1 − )
Pitch Adjustment
Una volta scelta la nota, il musicista può scegliere se cambiarla con una nota vicina o modificarne la tonalità (per esempio la nota Sol può essere cambiata in un Fa o in un
La come mostrato in Fig. 9) con una probabilità pari al HMCR × PAR (0 ≤ ≤ 0.1)
oppure mantenerla con probabilità pari a HMCR × (1-PAR).
Figura 9 Pitch Adjusting
′ è l’elemento non soggetto a Pitch Adjustment, mentre ( ) (con ∈ ) viene modificato di un fattore “m” vicino ad ( ) ( ∈ {… − 2, −1,1,2 … }) .
Aggiornamento della Harmony memory
Se un nuovo vettore = ( , . . . , ), valutando le rispettive funzioni obiettivo, è migliore della peggior soluzione presente nella Harmony memory, quest’ultima viene rimpiazzata dall’armonia migliore.
d. Definizione dei criteri di terminazione dell’algoritmo
Se un criterio di terminazione (numero di iterazioni piuttosto che funzione obiettivo x*) è raggiunto, allora STOP; altrimenti genera una nuova armonia e aggiorna la HM.
L’algoritmo HSO, modificato e implementato in molti modi, è stato applicato con successo su alcuni interessanti problemi ingegneristici come progettazioni strutturali (Lee and Geem, 2004), progettazioni di reti idriche (Geem, 2006), e rilevamento delle perdite in un fluido (Kim et al., 2001).