3.
PROGETTAZIONE DEL TAG.
3.1
INTRODUZIONE.
Un identificatore a Radio Frequenza, come già detto, è costituito da un lettore e da un tag. Il presente lavoro tratta la progettazione del tag, in particolare la parte digitale del tag.
Per la progettazione si sfrutta il linguaggio di programmazione VHDL.
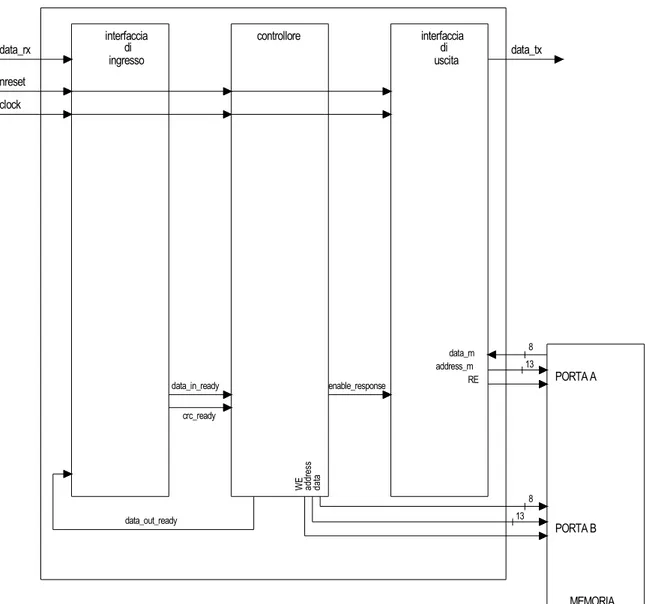
La parte digitale del dispositivo deve interagire sia con la memoria che con la parte a Radio Frequenza del dispositivo stesso tramite le variabili di ingresso nreset, clock, data_rx e la variabile di uscita data_tx.
Il problema della progettazione del tag si affronta dividendo il dispositivo in tre parti distinte: l’interfaccia d’ingresso, il controllore e l’interfaccia di uscita.
L’interfaccia d’ingresso si occupa di tutta la parte di acquisizione del segnale che arriva in ingresso e dell’estrazione dei dati trasmessi.
Il controllore gestisce l’elaborazione dei dati, l’esecuzione della richiesta da parte del lettore ed infine la preparazione dei dati in uscita.
L’interfaccia di uscita trasmette dunque la risposta alla richiesta del lettore.
Tutti i segnali dovranno, naturalmente, rispettare le norme ISO 15693 descritte in maniera dettagliata nel capitolo 2.
data_rx data_in_ready crc_ready nreset clock interfaccia di ingresso di uscita interfaccia controllore enable_response data_out_ready 8 13 8 13 data_tx MEMORIA d at a a dd re ss W E PORTA A PORTA B address_m data_m RE
Figura 3-1: Schema a blocchi del tag
3.2
INTERFACCIA DI INGRESSO.
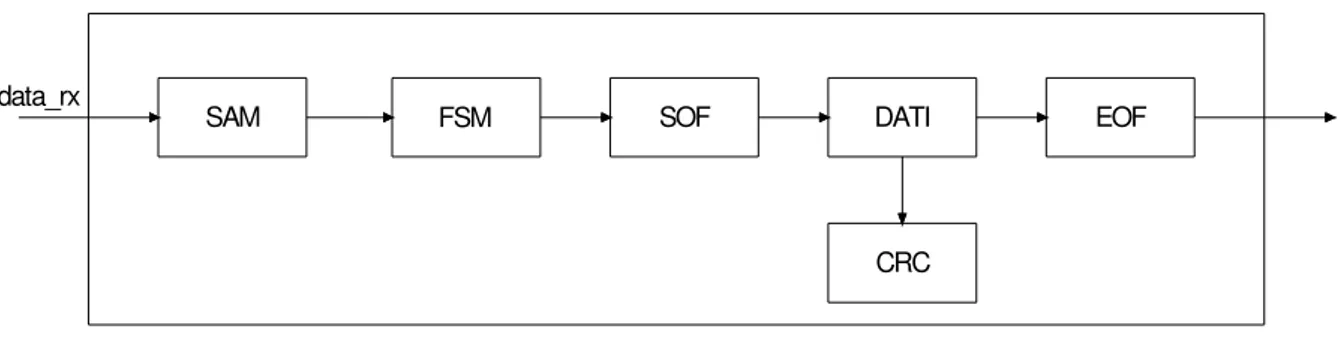
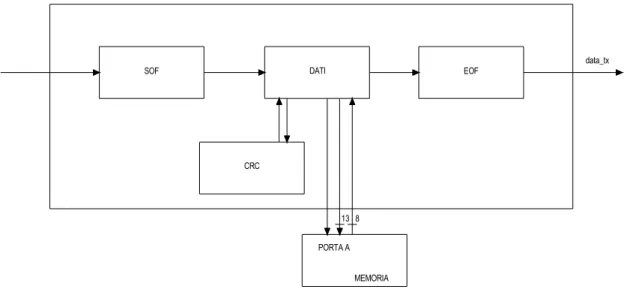
L’interfaccia di ingresso si occupa dell’acquisizione dei dati; deve cioè riconoscere il segnale utile, preceduto dal segnale di SOF (Start of Frame) e seguito dal segnale di EOF (End of Frame). I dati contenuti nel segnale utile sono poi immagazzinati in un apposito registro.
CRC
SAM FSM SOF DATI EOF
data_rx
Figura 3-2: Schema a blocchi dell’interfaccia di ingresso
3.2.1 Macchina a stati finiti e divisore.
Il segnale di ingresso, proveniente dalla parte a Radio Frequenza, viaggia ad una frequenza fc pari a 13,56MHz e può assumere un valore alto ed un valore basso.
Per riconoscere il dato, il segnale di ingresso deve essere quindi campionato. In realtà, il campionato deve essere effettuato più volte, con il clock proveniente dall’esterno alla frequenza fc, per diminuire la probabilità di errore, legato all’incertezza sul dato campionato,
nel caso in cui il campionamento del segnale viene fatto vicino al fronte.
Tutti i segnali presi in considerazione, SOF, segnale utile e EOF, sono multipli di un tempo elementare pari a 9,44µs=T=128/ fc, come si può vedere nel paragrafo 2.4. Per campionare i segnali quindi si può utilizzare un clock più lento rispetto al clock proveniente dall’esterno con frequenza fc, clock128, che può essere ottenuto tramite un divisore di
frequenza, ottenendo una frequenza 1/T= fc/128.
Il divisore di frequenza viene implementato grazie ad un contatore che incrementa il proprio valore sul fronte in salita del clock; a seconda del valore del bit più significativo del contatore, il segnale di uscita, clock128, vale 0 o 1. Si ottiene pertanto un segnale che per metà periodo vale 0 mentre per l’altra metà periodo vale 1.
Oltre al clock128 si genera anche un clock4, che viene utilizzano nella interfaccia di uscita, con una durata pari a quattro cicli di clock veloce quindi una frequenza fc/4.
Il clock lento, clock128, non è necessario però che sia sempre attivo ma si può attivare solo quando c’è il segnale esterno cioè quando il segnale di ingresso diventa non nullo.
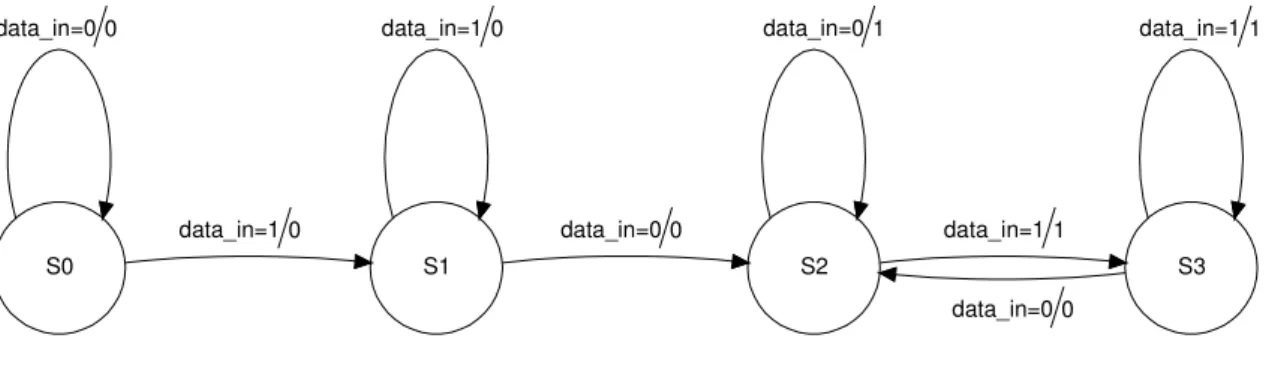
Si utilizza pertanto una macchina a stati finiti, che ha come ingresso il segnale di ingresso campionato, che abilita il divisore sul secondo fronte in salita del segnale di ingresso. La macchina a stati finiti ha 4 stati interni: S0, S1, S2, S3.
Figura 3-3: Macchina a stati finiti dell’interfaccia
Quando la macchina a stati finiti si trova nello stato interno S0 se l’ingresso è 0 resta in S0 con uscita nulla, se l’ingresso è 1 va invece nello stato interno S1 con uscita nulla. Quando lo stato interno è S1 se l’ingresso è 1 resta in S1, se l’ingresso è 0 va nello stato interno S2 e l’uscita rimane in entrambi i casi nulla. Quando lo stato interno è S2 se l’ingresso è 0 resta in S2 con uscita 1, se invece l’ingresso è 1, va nello stato interno S3 con uscita 1. Quando lo stato interno è S3 se l’ingresso è 1 resta in S3 con uscita 1, se l’ingresso è 0 torna nello stato interno S2 con uscita nulla.
Quando la macchina a stati finiti si trova per la prima volta nello stato interno S1, cioè quando il campo è diverso da zero, si attiva l’abilitazione field, che come vedremo servirà nel controllore.
È previsto inoltre un controllo sul segnale di ingresso, il segnale deve essere basso per un tempo né troppo breve né troppo lungo. Nel caso in cui ciò accade si provoca un reset di tutto il dispositivo.
Per il processo di generazione dell’errore si usa un contatore (count0) che conta i periodi di clock veloce in cui il segnale di ingresso è basso, a partire da quando è presente il campo cioè quando per la prima volta l’ingresso passa a 1, quindi la macchina a stati finiti iniziale è nello stato S1. Il segnale di ingresso deve essere basso per un tempo pari a 9,44µs=128T=128/ fc cioè per 1 periodo di clock lento o 128 periodi di clock veloce, come
visto nel paragrafo 2.4. Se l’ingresso è basso per un tempo inferiore a 96 cicli di clock o
S0 data_in=0
S1 S2 S3
0 data_in=1 0 data_in=0 1 data_in=1 1
data_in=1 0 data_in=0 0 data_in=1 1
superiore a 160 si segnala l’errore tramite il segnale nreset_with_error attivo basso, che fa ripartire tutti i processi. Il contatore si azzera ogni volta che l’ingresso diventa 1, per poi ricominciare il conteggio quando l’ingresso torna ad essere 0.
3.2.2 Riconoscimento della sequenza di SOF.
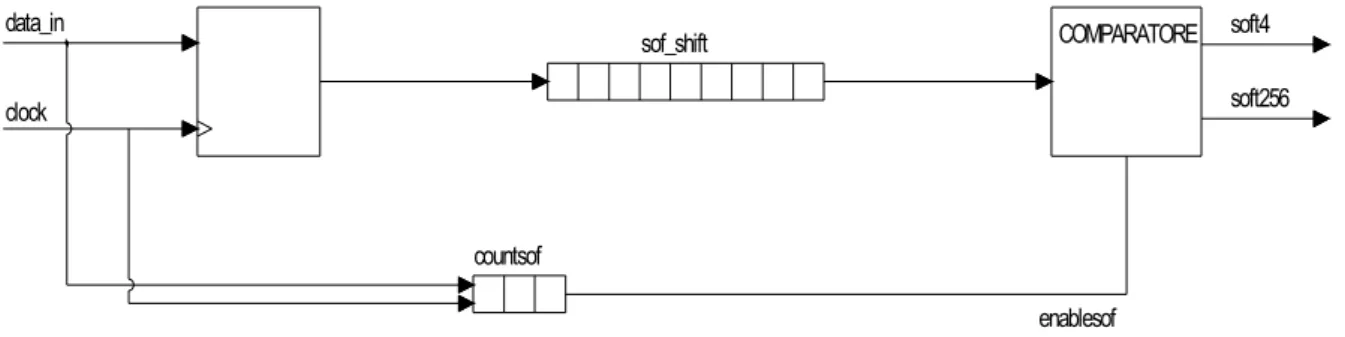
Il primo segnale che il tag deve riconoscere è la sequenza di Start of frame (SOF), che precede il segnale utile. È importante ricordare che lo SOF è diverso per le due codifiche: 1 out of 256 e 1 out of 4, come visto nel paragrafo 2.4.3.1. In entrambi i casi, però, la sequenza ha una durata pari a 8 periodi di clock128.
Il riconoscimento della sequenza di SOF è organizzato in due processi.
COMPARATORE enablesof data_in clock soft4 soft256 countsof sof_shift
Figura 3-4: Riconoscimento della sequenza di SOF
Per il primo processo è previsto l’utilizzo di uno shift register su 8 bit (sofshift) ed un contatore su 3 bit (countsof) che conta quindi da 0 a 7. Ogni dato, ottenuto dal campionamento del segnale sul fronte in salita del clock lento, è inserito nello shift register a partire dal bit meno significativo e trasla verso il bit più significativo ad ogni campionamento successivo. Nello shift register sono dunque memorizzati gli ultimi 8 valori campionati.
Il contatore incrementa il proprio valore sul fronte in salita del clock lento se il valore del segnale di ingresso campionato corrisponde alla sequenza del SOF: 01111110 per la codifica 1 out of 256 e 01111011 per la codifica 1 out of 4. Si può notare che le due sequenze differiscono per i bit in posizione 2 e 0, quando cioè il contatore assume i valori 101 e 111, in tal caso il contatore incrementa il proprio valore indipendentemente dal valore dell’ingresso.
Quando avviene il riconoscimento delle parti comuni alle sequenze di SOF nelle due diverse codifiche si attiva una abilitazione (enablesof = 1) al riconoscimento vero e proprio. La seconda parte del riconoscimento è fatta sul fronte in discesa del clock lento, per evitare di perdere un ciclo di clock. In particolare nel caso in cui si riconosca la sequenza di SOF nella codifica 1 out of 256 cioè nel caso in cui nello shift register sia memorizzato 01111110 si attiva il segnale sof256, invece in presenza della sequenza di SOF nella codifica 1 out of 4 cioè nel caso in cui nello shift register sia memorizzato 01111011 si attiva sof4.
Riconosciuta la sequenza di SOF va contemporaneamente resettato (nresetsof = 0) il primo processo; il segnale rimane basso durante il riconoscimento dei dati e dell’EOF altrimenti il processo resterebbe sempre attivo e continuerebbe a lavorare anche se non necessario. Il processo di riconoscimento del SOF riparte nel caso in cui si verifichino degli errori o nel caso in cui si riconosca l’EOF e si dovrà quindi ricominciare una nuova ricerca del SOF.
I due segnali sof4 e sof256 quando sono attivi alti attestano il riconoscimento della sequenza di SOF e la codifica con cui il lettore sta trasmettendo l’informazione, funzioneranno quindi come abilitazione per tutti i successivi processi.
3.2.3 Riconoscimento dei dati.
Il lettore trasmette la sequenza di SOF, seguita dalla sequenza dei dati. Il processo per il riconoscimento dei dati si differenzia per le codifiche 1 out of 4 e 1 out of 256, come si può vedere nel paragrafo 2.4.2. Nelle due codifiche il processo è attivato rispettivamente dai segnali sof4 o sof256 a seconda della codifica della codifica di SOF riconosciuta.
Si prenda in esame il caso della codifica 1 out of 256, la trasmissione di 1 byte ha la durata di 4,833ms pari a 512T (paragrafo 2.4.2.1). Si considera un contatore su 9 bit (count256) che incrementa il proprio valore sul fronte in salita del clock lento. Il byte è noto una volta individuata la posizione della pausa, che come si può notare coincide con un valore sempre dispari del contatore. Pertanto il byte è dato dagli 8 bit più significativi del contatore in corrispondenza dell’ingresso nullo, mentre il bit meno significativo è sicuramente 1. Il byte trovato si memorizza in un registro di appoggio e si attiva l’abilitazione enable256 per un periodo di clock lento. Abilitazione questa che servirà quando si memorizzeranno tutti i dati.
data_in 8 1 0 2 3 4 5 6 7 8 enable256 flagtemp
Figura 3-5: Riconoscimento dei dati nella codifica 1 di 256
Nel caso della codifica 1 out of 4 il byte che contiene l’informazione deve essere ricostruito (paragrafo 2.4.2.2). Il lettore trasmette infatti il byte dal bit meno significativo al più significativo codificando 2 bit alla volta. La trasmissione di 2 bit ha una durata di 75,52µs pari a 8 periodi di clock lento, per il riconoscimento si sfrutta lo stesso contatore utilizzato anche per l’altra codifica. In particolare la coppia di bit è uguale infatti ai bit in posizione 2 e 1 del contatore in corrispondenza dell’ingresso nullo, mentre il bit meno significativo del contatore è anche in questo caso 1. I 2 bit trovati sono memorizzati nei 2 bit più significativi del registro di appoggio e ad ogni successivo riconoscimento vengono traslati di 2 posizioni, quindi i primi 2 bit sono i bit meno significativi mentre gli ultimi 2 bit sono i bit più significativi. Memorizzati gli ultimi 2 bit dopo 32 cicli di clock lento, quando cioè i bit in
posizione 4 e 3 del contatore sono 11, si ottiene il byte completo e si attiva l’abilitazione enable4 per un periodo di clock lento. L’abilitazione servirà nel momento in cui si memorizzeranno tutti i dati.
enable4 data_in 0 flagtemp 1 2 3 4 5 6 7 8 8 2
3.2.4 Memorizzazione dei dati.
Il processo di memorizzazione dei dati è attivo quando una delle abilitazioni, enable4 o enable256, è alta cioè nel periodo di clock lento in cui nel registro di appoggio c’è esattamente il byte che contiene l’informazione. Qualora sia verificata la condizione, si incrementa il contatore (countbyte) su 6 bit e a seconda del valore del contatore si memorizza il byte di informazione nel registro dei flag di 8 bit (flag_sig) successivamente nel registro dei comandi di 8 bit (cmd_sig) per poi proseguire nel registro dei dati (reg336) di 336 bit a partire dal byte meno significativo. I comandi che necessitano la memorizzazione del maggior numero di bit sono i comandi di scrittura. Non considerando il comando di scrittura su più blocchi che sarà affrontato in maniera diversa, il comando di scrittura su un singolo blocco resta il comando più lungo da memorizzare. L’informazione viene memorizzata per evitare di soprascrivere un blocco nel caso in cui si verificassero degli errori, perdendo inesorabilmente l’informazione contenuta nel blocco stesso. Il comando di lettura su un singolo blocco, essendo il comando più lungo, stabilisce quindi la lunghezza del registro dei dati: 8 byte di UID, 1 byte di block number e 32 byte di dati quindi al massimo 41 byte. La richiesta del lettore ha il seguente formato: SOF, 8 bit di flag, il comando su 8 bit, UID su 64 bit, se è presente, e a seguire dati e EOF. L’UID, in particolare, è trasmesso a partire dagli 8 bit meno significativi per proseguire poi fino agli 8 più significativi. Per come abbiamo memorizzato i dati l’UID, se è presente, sarà posizionato nei 64 bit meno significativi del registro dei dati. Due dei comandi saranno trattati in maniera diversa rispetto agli altri comandi: scrittura su più blocchi e inventario. In tal caso, una volta trasmesso il comando si attivano le abilitazioni distinguendo per il comando di scrittura la presenza o l’assenza dell’UID. I dati sono comunque memorizzati nel registro dei dati e quando questo è pieno si soprascrive a partire dal byte successivo all’eventuale UID. Il processo è resettato dal reset globale (nreset) mentre un errore o il riconoscimento dell’EOF azzera solo il contatore infatti i registri e le abilitazioni serviranno poi in fase di elaborazione della richiesta, essendo le uscite dell’interfaccia di ingresso e gli ingressi del controllore.
3.2.5 Calcolo e verifica del CRC.
Il processo per il calcolo e la verifica del CRC, in accordo con quanto descritto nel paragrafo 2.6.1, è costituito da una parte combinatoria ed una parte sequenziale.
La parte combinatoria prepara di volta in volta il bit su cui effettuare il calcolo del CRC. La parte sequenziale effettua il vero e proprio calcolo del CRC, utilizzando uno shift register su 16 bit. Nello shift register viene memorizzato il nuovo valore del CRC, dopo opportune traslazioni e operatori logici di OR esclusivo. Il processo è scandito dal clock veloce, infatti una volta acquisiti i dati si conoscono già tutti gli otto bit di cui si vuole calcolare il CRC.
Il calcolo del CRC è necessario per verificare se il CRC inviato dal lettore nel comando è esatto. L’ulteriore calcolo del CRC sui sedici bit che costituiscono il CRC inviato dal lettore, nel caso in cui coincida con “F0B8” attiva l’abilitazione crc_ready_sig. L’abilitazione è quindi attiva quando il CRC mandato dal lettore è corretto, di conseguenza il comando mandato dal lettore può essere eseguito.
3.2.6 Riconoscimento della sequenza di EOF.
Non è possibile stabilire a priori la lunghezza della sequenza trasmessa, è certo, però, che questa è conclusa dall’EOF. È per questo che il processo parte quando sof4 o sof256 è attiva alta, cioè quando è stata riconosciuta la sequenza di SOF. Non è importante distinguere fra le due codifiche perché la sequenza di EOF è la stessa per le due codifiche.
Per il primo processo è previsto l’utilizzo di uno shift register su 4 bit (eofshift) ed un contatore su 2 bit (counteof). Ogni dato, ottenuto dal campionamento del segnale sul fronte in salita del clock lento, è inserito nello shift register a partire dal bit meno significativo e trasla verso il bit più significativo ad ogni campionamento successivo. Nello shift register sono dunque memorizzati gli ultimi 4 valori campionati.
Il contatore incrementa il proprio valore sul fronte in salita del clock lento.
Se il valore del segnale di ingresso campionato corrisponde alla sequenza di EOF si attiva una abilitazione.
3.3
IL CONTROLLORE.
Il controllore gestisce l’intera fase di esecuzione del comando, inviato dal lettore.
Il controllore è direttamente connesso con le interfacce di ingresso e di uscita. L’interfaccia di ingresso memorizza i dati acquisiti in un apposito registro. Il controllore riceve quindi dall’interfaccia di ingresso tutte le informazioni sul comando oltre ad un insieme di abilitazioni che permettono la corretta esecuzione del comando.
Il controllore è inoltre direttamente connesso alla memoria, per gestire i comandi di lettura e scrittura in memoria.
Il controllore deve inoltre preparare i dati, che costituiranno la risposta al comando, per l’interfaccia di uscita che la trasmetterà al lettore.
FSM 13 COMANDI ESECUZIONE MEMORIA PORTA B 8
Figura 3-7: Schema a blocchi del controllore
3.3.1 Generazione degli errori di trasmissione.
Al controllore arrivano i segnali data_in_ready e crc_ready, provenienti dall’interfaccia di ingresso. Il segnale data_in_ready attivo alto indica che è conclusa la fase di invio di un comando dal lettore al tag, quindi nel registro sono presenti i dati relativi al comando. Quando
il segnale crc_ready è attivo alto indica che il CRC inviato dal lettore è corretto; il segnale si attiva una volta calcolato il CRC sull’informazione inviata.
Una volta che il lettore ha inviato il comando, se il CRC non è corretto deve essere generato un errore (error_format), i dati inviati infatti non sono significativi.
Quando i dati sono significativi, quando cioè il CRC sui dati è corretto, si devono fare delle operazioni preliminari riguardanti tutti i possibili casi che coinvolgono l’UID, ricavando le relative informazioni dall’analisi del registro dei flag. L’UID può non essere presente nei dati inviati dal lettore, è obbligatorio infatti solo per alcuni comandi. Nel caso in cui l’UID è presente si deve verificare che l’UID trasmesso coincida con l’UID proprio del tag; infatti a seconda del caso che si è verificato il tag deve comportarsi in maniera diversa.
3.3.2 Macchina a stati finiti.
Quando i dati sono significativi, la richiesta arrivata è corretta e dunque pronta per essere analizzata. La figura 2-21 nel paragrafo 2.6.6 rappresenta la macchina a stati finiti del tag, il tag dunque si trova in uno dei possibili quattro stati.
Lo stato power-off è individuato dall’assenza del segnale esterno; è questo quindi lo stato in cui si trova inizialmente il tag.
Dallo stato power-off il tag passa nello stato ready quando arriva un segnale esterno. Come abilitazione si usa l’abilitazione (field), proveniente dall’interfaccia di ingresso, che si attiva quando la macchina a stati finiti dell’interfaccia di ingresso cambia per la prima volta stato, cioè quando il segnale di ingresso diventa per la prima volta alto (paragrafo 3.2.1).
In assenza di campo il tag torna nello stato di power-off, a partire da qualunque stato in cui si trovi in quel momento.
Il tag passa da uno stato all’altro solo quando arrivano dal lettore i particolari comandi select, reset to ready e stay quiet. Sia per il comando select che per il comando stay quiet l’UID è obbligatorio mentre per il comando stay quiet l’UID è opzionale. Nel caso in cui l’UID trasmesso coincide con l’UID proprio del tag, se il comando trasmesso è select, il tag passa nello stato selected, se il comando è reset to ready, il tag passa nello stato ready mentre se il comando è stay quiet, il tag passa nello stato quiet. Un caso particolare è quello del comando stay quiet senza l’UID, in tal caso il tag passa comunque nello stato quiet, infatti il lettore invia cosi lo stesso comando a tutti i ricevitori presenti nel raggio di azione. Nel caso
in cui l’UID trasmesso non coincide con l’UID proprio del tag, il tag non esegue il comando, quindi non cambia stato. Fa eccezione il caso in cui il tag si trova nello stato selected e il lettore seleziona un altro tag, in tal caso il tag passa nello stato ready.
Una volta arrivata una richiesta da parte del lettore il comando deve essere eseguito. Questa operazione può essere fatta quando il tag si trova in uno qualunque degli stati, ad eccezione dello stato power-off in cui il tag si trova solo nel caso di assenza del segnale di ingresso. Scendendo più in dettaglio ci sono comandi che possono essere eseguiti solo se il tag è nello stato selected, in caso contrario non sono eseguiti. Quando il tag è invece nello stato quiet esegue solo i comandi in cui è presente l’UID, gli altri comandi incluso il comando inventory non sono eseguiti. Tutte queste informazioni si ricavano semplicemente dall’analisi del registro di flag.
È a questo punto dunque che si prepara l’abilitazione all’esecuzione dei comandi, diversi dai comandi che fanno cambiare stato al tag, il tag infatti, come già detto, rimane nello stato in cui si trova, rispettando tuttavia le considerazioni fatte finora.
Si abilita inoltre anche la fine dell’esecuzione del comando per i comandi che non devono essere eseguiti, cioè i comandi per cui il tag deve rimanere in silenzio, e per i comandi di cambiamento di stato del tag stesso.
3.3.3 Fase di esecuzione dei comandi.
In questo processo si ha la vera e propria fase di esecuzione dei comandi, in maniera differenziata per ogni singolo comando, in particolare il processo parte quando riceve l’abilitazione all’esecuzione dei comandi. Si possono verificare degli errori in fase di esecuzione del comando, ogni qualvolta ciò accade il processo genera delle abilitazioni, diverse per ogni tipologia di errore, necessarie poi quando si invia la risposta al lettore.
In questa fase di esecuzione dei comandi si riconoscono anche gli errori dovuti all’invio da parte del lettore di un comando diverso da quelli previsti, si genera in tal caso l’abilitazione error02: il comando non è stato riconosciuto.
Passiamo all’analisi del processo che gestisce l’esecuzione dei comandi, presi singolarmente.
Stay quiet
In seguito alla trasmissione del comando stay quiet, con l’UID trasmesso coincidente con l’UID proprio del tag, il tag si sposta nello stato Quiet senza prevedere, però, alcuna risposta per il lettore. Il comando quindi non compare in fase di esecuzione.
Read single block
Il formato della richiesta da parte del lettore di un comando di lettura su di un singolo blocco prevede obbligatoriamente il numero del blocco, che darà l’indirizzo di memoria del blocco, mentre il campo UID è opzionale. Questa informazione è importante per risalire alla posizione del byte del numero del blocco nel registro dei dati che proviene dall’interfaccia di ingresso. Infatti in assenza dell’UID il byte di nostro interesse sarà il primo byte, mentre in presenza dell’UID sarà il byte successivo all’ultimo byte che contiene l’UID.
Per eseguire il comando di lettura su di un singolo blocco si fa quindi un accesso in memoria all’indirizzo di memoria i cui bit più significativi sono il byte del numero del blocco. La lettura in memoria è completa quando si legge tutto il blocco, quando cioè si leggono i 32 byte, scandita da un contatore che incrementa l’indirizzo di memoria ad ogni ciclo di clock.
L’esecuzione del comando di lettura avviene direttamente nell’interfaccia di uscita, il controllore però prepara in un registro di appoggio il numero del blocco.
Write single block
È importante tuttavia ricordare che è prevista la possibilità di bloccare la scrittura di un blocco, quindi il comando di scrittura su di un singolo blocco è eseguito solo quando il blocco stesso non è chiuso, altrimenti si verifica un errore che deve essere segnalato al lettore, con l’abilitazione error12: il blocco è chiuso e il contenuto non può essere modificato.
Nel formato della richiesta da parte del lettore di un comando di scrittura su di un singolo blocco oltre al numero del blocco, che darà l’indirizzo di memoria del blocco, ci sono anche i dati da inserire in memoria, mentre il campo UID è anche in questo caso opzionale.
Per eseguire quindi il comando di scrittura su di un singolo blocco si fa un accesso in memoria. I bit più significativi dell’indirizzo di memoria sono dati dal byte del numero del blocco, si tratta del primo byte del registro dei dati proveniente dall’interfaccia di ingresso, in assenza dell’UID, mentre in presenza dell’UID sarà il byte successivo all’ultimo byte che contiene l’UID. Un contatore incrementa l’indirizzo di memoria ad ogni ciclo di clock, per scrivere in tutto il blocco. Un secondo contatore permette di passare, ad ogni ciclo di clock, il
byte di dati, memorizzato nel registro dei dati proveniente dall’interfaccia di ingresso, a partire dal byte successivo al byte del numero del blocco. La scrittura in memoria è completa quando si scrivono i 32 byte che costituiscono il blocco.
Lock block
Per eseguire il comando di chiusura di un blocco è previsto l’utilizzo di un apposito registro da 256 bit, coincidente cioè con il numero di blocchi presenti in memoria, in modo tale che ogni bit del registro corrisponda ad un blocco di memoria. Quando si chiude il blocco il relativo bit del registro viene portato ad 1.
Il formato della richiesta da parte del lettore di un comando di chiusura di un blocco è costituito necessariamente dal numero del blocco, che darà l’indirizzo di memoria del blocco da chiudere e di conseguenza il bit del registro da mettere ad 1, mentre il campo UID è opzionale. La posizione del bit del registro è individuata dall’intero ottenuto dalla conversione del byte che costituisce il numero del blocco che, come già visto per i comandi precedenti, è il primo byte del registro dei dati proveniente dall’interfaccia di ingresso, in assenza dell’UID, mentre in presenza dell’UID sarà il byte successivo all’ultimo byte che contiene l’UID.
Nel caso in cui il lettore invia un comando di chiusura di un blocco già chiuso si verifica un errore, che deve essere segnalato, con l’abilitazione error11: il blocco è chiuso e non può essere chiuso ancora.
Read multiple block
Il formato della richiesta da parte del lettore di un comando di lettura di più blocchi si differenzia dal comando di lettura di un singolo blocco perché prevede obbligatoriamente oltre al numero del primo blocco, che darà l’indirizzo di memoria del primo blocco da leggere, il numero di blocchi da leggere, mentre il campo UID è ancora opzionale.
In assenza dell’UID il byte che contiene il numero del primo blocco da leggere sarà il primo byte del registro dei dati che proviene dall’interfaccia di ingresso, mentre in presenza dell’UID sarà il byte successivo all’ultimo byte che contiene l’UID; in entrambi i casi il byte contenente il numero di blocchi da leggere sarà il byte successivo.
Per eseguire il comando di lettura su più blocchi si fa quindi un accesso in memoria all’indirizzo di memoria i cui bit più significativi sono il byte del numero del primo blocco, la memoria è scandita da un contatore che incrementa l’indirizzo di memoria ad ogni ciclo di clock. La lettura in memoria è completa quando i bit più significativi dell’indirizzo sono
incrementati di un numero pari al numero di blocchi e sono stati letti i 32 byte relativi all’ultimo blocco.
L’esecuzione del comando viene fatta direttamente dall’interfaccia di uscita, il controllore invece prepara in due registri di appoggio il numero del blocco e il numero di blocchi da leggere.
Select
In seguito alla trasmissione del comando select, con l’UID trasmesso coincidente con l’UID proprio del tag, il tag si sposta nello stato selected. Al contrario del comando Stay quiet è prevista una risposta da parte del tag, anche in questo caso però il comando non compare in fase di esecuzione dei comandi.
Reset to ready
Quando il lettore invia il comando reset to ready, con l’UID trasmesso coincidente con l’UID proprio del tag oppure in assenza dell’UID, il tag si sposta nello stato ready. Come per il comando precedente, è prevista una risposta da parte del tag e, anche in questo caso, il comando non compare in fase di esecuzione dei comandi.
Write AFI
L’esecuzione del comando di scrittura dell’AFI consiste nel memorizzare il byte che contiene l’AFI all’interno di un apposito registro. Il byte di nostro interesse è il primo byte del registro dei dati proveniente dall’interfaccia di ingresso, in assenza dell’UID, mentre in presenza dell’UID è il byte successivo all’ultimo byte che contiene l’UID.
È previsto tuttavia anche un comando per bloccare la scrittura dell’AFI, quindi quando tale comando è stato inviato il comando di scrittura dell’AFI non può essere eseguito, si verifica un errore che deve essere segnalato al lettore, con l’abilitazione error12: il blocco è chiuso e il contenuto non può essere modificato.
Lock AFI
Per il comando di chiusura dell’AFI è previsto l’utilizzo di un segnale afi_l, che in fase di esecuzione del comando si porta al valore alto. Ogni successivo invio del comando per bloccare la scrittura dell’AFI non può essere eseguito, si verifica un errore che deve essere
segnalato al lettore con l’abilitazione error11: il blocco è chiuso e non può essere chiuso ancora.
Write DSFID
Come per il comando di scrittura dell’AFI, l’esecuzione del comando di scrittura del DSFID consiste nel memorizzare il byte che contiene il DSFID all’interno di un apposito registro. Il byte menzionato è il primo byte del registro dei dati proveniente dall’interfaccia di ingresso, in assenza dell’UID, mentre in presenza dell’UID è il byte successivo all’ultimo byte che contiene l’UID.
Allo stesso modo è previsto anche un comando per bloccare la scrittura del DSFID, quando tale comando è stato inviato, il comando di scrittura del DSFID non può essere eseguito, si verifica un errore che deve essere segnalato al lettore, con l’abilitazione error12: il blocco è chiuso e il contenuto non può essere modificato.
Lock DSFID
Per il comando di chiusura del DSFID, in analogia con il comando di chiusura dell’AFI, è previsto l’utilizzo di un segnale dsfid_l, che in fase di esecuzione del comando si porta al valore alto. Ogni successivo invio del comando per bloccare la scrittura del DSFID non può essere eseguito, si verifica un errore che deve essere segnalato al lettore, con l’abilitazione error11: il blocco è chiuso e non può essere chiuso ancora.
Get system information
Le informazioni richieste dal lettore con l’invio del comando get system information sono già presenti nel tag quindi il comando non compare nella fase di esecuzione dei comandi.
Get multiple block security status
Il formato della richiesta da parte del lettore di un comando get multiple block security status prevede obbligatoriamente un byte relativo al numero del primo blocco ed un byte relativo al numero di blocchi, mentre il campo UID è ancora opzionale.
In assenza dell’UID il byte che contiene il numero del primo blocco è il primo byte del registro dei dati che proviene dall’interfaccia di ingresso, mentre in presenza dell’UID è il
byte successivo all’ultimo byte che contiene l’UID; in entrambi i casi il byte contenente il numero di blocchi sarà il byte successivo.
Per eseguire il comando get multiple block security status si va a leggere i bit contenuti nel registro, a partire dal bit nella posizione individuata dall’intero ottenuto dalla conversione del byte che costituisce il numero del blocco, in numero pari al numero di blocchi.
Questa operazione viene fatta però direttamente dall’interfaccia di uscita, il controllore invece prepara in due registri di appoggio il numero del blocco ed il numero di blocchi di cui si vuole conoscere lo stato di sicurezza.
Gli ultimi due comandi rimasti sono trattati in maniera diversa rispetto alla totalità dei comandi visti, in cui il processo di esecuzione del comando avviene completamente all’interno del processo stesso.
Write multiple block
Nella fase di esecuzione dei comandi, il comando di scrittura su più blocchi non compare; è infatti necessario un processo dedicato per l’esecuzione del comando, come vedremo in seguito.
Inventory
L’esecuzione del comando di inventory è scissa in due fasi distinte, una fase di estrazione dei dati dal registro dei dati proveniente dall’interfaccia di ingresso, nel processo che esegue i comandi, ed una seconda fase che necessita invece di un processo a se stante.
Il formato della richiesta da parte del lettore di un comando di inventory prevede il campo AFI opzionale, la cui presenza si può rilevare dal registro dei flag, mentre sono obbligatori un byte relativo alla lunghezza della maschera e il valore della maschera, la cui lunghezza è estesa ad un multiplo di un byte fino ad un massimo di 64 bit.
In questa fase quindi, l’esecuzione del comando di inventario consiste nel memorizzare in appositi registri la lunghezza della maschera (mask_length) e il valore della maschera (mask_value). Il byte relativo alla lunghezza della maschera è il primo byte del registro dei dati proveniente dall’interfaccia di ingresso, in assenza del campo AFI, mentre in presenza del campo AFI è il secondo byte del registro dei dati. In entrambi i casi i byte successivi al byte menzionato nel registro dei dati proveniente dall’interfaccia di ingresso, si memorizzano nel
registro contenente la maschera, il cui numero di byte è pari alla lunghezza della maschera estesa però ad un numero multiplo di un byte.
Si abilita a questo punto il processo che viene eseguito solo nel caso del comando inventory.
In presenza del campo AFI nel comando il tag deve rispondere al lettore solo nel caso in cui il valore dell’AFI trasmesso coincide con l’AFI del tag, memorizzato nell’apposito registro.
Nel caso in cui si generano degli errori, durante l’esecuzione del comando di inventory, non è prevista una risposta del tag al lettore.
3.3.4 Processo per la gestione del comando Inventory.
Il processo viene eseguito quando si attiva l’abilitazione dal processo di esecuzione dei comandi. Ciò accade quando negli appositi registri sono memorizzati la lunghezza della maschera ed il valore della maschera stessa.
Il processo per la gestione del comando inventario differenzia i due casi possibili, cioè slot 1 o slot 16, ricavabili direttamente per ispezione dal registro dei flag.
Nel primo caso, slot 1, l’esecuzione del comando inventory prevede il confronto fra il valore della maschera e l’UID proprio del tag, a partire dai bit meno significativi, per un numero di bit pari alla lunghezza della maschera. Nel caso in cui coincidono il tag può rispondere al lettore, in accordo a quanto previsto nel paragrafo 2.6.7.
Nel secondo caso, slot 16, l’esecuzione del comando inventory diventa più complessa rispetto al caso precedente. Il processo sfrutta un contatore (slot_counter) su quattro bit che incrementa il proprio valore quando all’arrivo del segnale del clock è attiva l’abilitazione, proveniente dall’interfaccia di ingresso, che segnala il riconoscimento di una sequenza di EOF. L’esecuzione del comando inventory, in questo caso, prevede il confronto fra il valore della maschera e l’UID proprio del tag, a partire dai bit meno significativi, per un numero di bit pari alla lunghezza della maschera e, nel caso in cui coincidano, il confronto dei successivi quattro bit con il valore del contatore. Nel caso in cui coincidono il tag può rispondere al lettore, in accordo a quanto previsto nel paragrafo 2.6.7.
3.3.5 Processo per la gestione del comando write multiple block.
Il comando di scrittura su più blocchi è sicuramente il comando più complesso da trattare; i dati trasmessi infatti non possono essere memorizzati in registri di appoggio, ma devono essere scritti direttamente in memoria durante la trasmissione della richiesta di esecuzione del comando.
Il processo viene eseguito quando si attivano le abilitazioni provenienti dall’interfaccia di ingresso che segnalano l’arrivo del comando di scrittura su più blocchi in presenza o in assenza dell’UID.
Per questo processo si sfruttano altre abilitazioni provenienti dall’interfaccia di ingresso, utilizzate dall’interfaccia stessa nelle fasi di riconoscimento e memorizzazione di dati, per maggiori dettagli si vedano i paragrafi 3.2.3 e 3.2.4.
Il byte di informazione trasmesso è infatti prelevato direttamente dal registro di appoggio, utilizzato dall’interfaccia di ingresso, quando il byte è disponibile quando cioè sono attive le abilitazioni enable4 o enable256.
Si utilizza un contatore, il cui valore si incrementa al riconoscimento dei byte da memorizzare; a seconda del valore del contatore si memorizzano in due registri di appoggio le informazioni, prelevate dal registro di appoggio dell’interfaccia di ingresso, relative al numero del primo blocco, che da l’indirizzo di memoria, e il numero di blocchi su cui effettuare l’operazione di scrittura in memoria.
L’esecuzione del comando di scrittura su più blocchi consiste in un accesso in memoria all’indirizzo di memoria i cui bit più significativi sono il byte del numero del primo blocco e il byte da memorizzare è il byte disponibile nel registro di appoggio dell’interfaccia di ingresso. La memoria è scandita da un contatore che incrementa l’indirizzo di memoria ogni qualvolta sono attive le abilitazioni enable4 o enable256, quando cioè è disponibile il nuovo byte.
La scrittura in memoria è completa quando i bit più significativi dell’indirizzo sono incrementati di un numero pari al numero di blocchi e sono stati letti i 32 byte relativi all’ultimo blocco.
L’operazione preliminare consiste però nel controllare che i blocchi da scrivere non siano chiusi, informazioni prelevabili dall’apposito registro a partire dal bit nella posizione individuata dall’intero ottenuto dalla conversione del byte che costituisce il numero del primo blocco per un numero di bit pari al numero di blocchi. Nel caso in cui uno o più blocchi sono
chiusi viene segnalato l’errore con una abilitazione e non viene effettuata l’operazione di scrittura su nessun blocco.
3.3.6 Processo per la gestione della memoria.
Si può notare che gli accessi in memoria, in particolare le scritture in memoria, sono fatti in due processi distinti; è quindi necessario un processo a se stante che gestisca gli accessi in memoria.
Il processo quindi permette l’accesso in memoria quando uno dei due processi fa un accesso in memoria.
3.3.7 Processo per la gestione degli errori.
Il processo per la gestione degli errori prepara il flag di uscita nel caso in cui si siano verificati degli errori e il relativo codice dell’errore.
In tutti i processi descritti finora nel controllore, per ogni possibile errore previsto si sono attivate delle abilitazioni, ognuna relativa ad un errore. Quando è attiva una qualunque delle abilitazioni, a causa del verificarsi di un errore, il processo attiva il segnale error_command, che segnala all’interfaccia di uscita che durante l’esecuzione del comando si è verificato un errore e in più mette ad 1 il bit meno significativo del registro dei flag di uscita (flag_out), che normalmente, in assenza di errori, è 0. A seconda però dell’abilitazione che è stata attivata memorizza nel registro error_code il codice relativo all’errore che si è verificato, secondo quanto previsto nella tabella 9 (paragrafo 2.6.5.2).
3.4
INTERFACCIA DI USCITA.
L’interfaccia di uscita è quindi direttamente connessa al controllore per prelevare i dati necessari per gestire i dati da trasmettere.
Solo quando arriva l’abilitazione proveniente dal controllore, che denota la fine del comando in esecuzione, l’interfaccia si attiva.
MEMORIA PORTA A 8 13 SOF DATI CRC EOF data_tx
Figura 3-8: Schema a blocchi dell’interfaccia di uscita
3.4.1 Processo per la generazione del registro di uscita.
Il processo per la generazione del registro di uscita, attivo quando si è conclusa la fase di esecuzione del comando, memorizza a partire dal byte meno significativo tutte le informazioni necessarie alla risposta ad ogni comando, come previsto nel formato.
Nel caso in cui si sono verificati degli errori, cioè nel caso in cui è attiva l’abilitazione proveniente dal controllore, qualunque sia il comando si memorizzano nel registro di uscita nell’ordine: il byte del flag di uscita, il byte del codice dell’errore e, quando l’abilitazione crc_stop è alta, i 16 bit di CRC. L’abilitazione indica che il calcolo del CRC è concluso e può dunque essere memorizzato, per maggiori dettagli si veda il paragrafo 3.2.5.
Si procede allo stesso modo, nel caso in cui non si siano verificati errori, preparando la risposta ad ogni singolo comando.
Nel caso della risposta al comando inventory, i campi previsti nel formato della risposta sono memorizzati nel registro di uscita, a partire dal bit meno significativo, il byte dei flag di uscita, il byte del DSFID, i 64 bit di UID ed i 16 bit di CRC, quando è attiva l’abilitazione.
Nel caso della risposta al comando get system information nel registro di uscita, a partire dal bit meno significativo, sono memorizzati: il byte del flag di uscita, il byte di info flag, che contiene tutte le informazioni sui comandi supportati, i 64 bit di UID, il byte del DSFID, il byte dell’AFI ed i 16 bit di CRC, quando è attiva l’abilitazione. Il comando richiede la risposta più lunga quindi determina la lunghezza del registro cioè 112 bit.
Per i comandi di lettura in memoria e per il comando get multiple block security status, si memorizza nel registro di uscita il byte di interesse, una volta inviato il byte precedente.
La risposta al comando get multiple block security status (paragrafo 2.6.12.13) prevede il byte del flag di uscita, i byte relativi allo stato di sicurezza dei blocchi ed i 16 bit di CRC.
Il processo si attiva quindi alla conclusione dell’invio di ogni byte tramite un’abilitazione (byte_end) proveniente dal processo di generazione dei segnali, come si può vedere nel paragrafo 3.4.2.
Una volta memorizzato il byte del flag di uscita, nel registro di uscita sono quindi memorizzati i byte relativi allo stato di sicurezza dei blocchi ottenuti scorrendo l’apposito registro tramite un contatore, a partire dal bit nella posizione individuata dall’intero ottenuto dalla conversione del byte che costituisce il numero del blocco, in numero pari al numero di blocchi di cui si vuole conoscere lo stato di sicurezza. Queste informazioni sono dunque fornite dal controllore (paragrafo 3.3.3).
Il comando read single block prevede un accesso in memoria all’indirizzo, fornito dal controllore in un registro di appoggio (paragrafo 3.3.3). I bit più significativi dell’indirizzo di memoria sono il byte del numero del blocco. La lettura in memoria è completa quando si legge tutto il blocco, quando cioè si leggono i 32 byte.
La risposta al comando read single block (paragrafo 2.6.12.2) prevede il byte dei flag di uscita, il byte relativo allo stato di sicurezza del blocco, qualora fosse richiesto tramite il bit del registro del flag, i byte relativi al contenuto del blocco ed i 16 bit di CRC.
Ogni qualvolta si attiva l’abilitazione byte_end (paragrafo 3.4.2), cioè alla conclusione dell’invio di ogni byte, si memorizza nel registro di uscita il byte di interesse e si incrementa l’indirizzo di memoria.
Il comando read multiple block prevede un accesso in memoria, l’indirizzo ed il numero di blocchi sono forniti dal controllore in due registri di appoggio (paragrafo 3.3.3). I bit più
significativi sono il byte del numero del primo blocco. La lettura in memoria è completa quando i bit più significativi dell’indirizzo sono incrementati di un numero pari al numero di blocchi e sono stati letti i 32 byte relativi all’ultimo blocco.
La risposta al comando read multiple block (paragrafo 2.6.12.4) prevede il byte dei flag di uscita, il byte relativo allo stato di sicurezza del blocco, qualora fosse richiesto tramite il bit del registro del flag, i byte relativi al contenuto del blocco, ripetuti in numero pari al numero di blocchi ed i 16 bit di CRC.
Una volta concluso l’invio di un byte, cioè quando si attiva l’abilitazione byte_end (paragrafo 3.4.2), si memorizza nel registro di uscita il byte di interesse e si incrementa l’indirizzo per la scansione della memoria.
Per tutti gli altri comandi, nel caso in cui è prevista una risposta, il registro di uscita è dato dal byte del flag di uscita e dai 16 bit di CRC, quando è attiva l’abilitazione.
È stata menzionata l’abilitazione crc_stop che indica la fine del calcolo del CRC che può essere quindi memorizzato, come vedremo in seguito, ma per il calcolo del CRC sui dati da trasmettere è necessario conoscere l’ultimo bit su cui effettuare il calcolo del CRC. Per il calcolo del CRC si utilizza un registro, con la stessa lunghezza del registro di uscita, in cui l’unico bit diverso da 0 è il bit posizionato nella stessa posizione in cui si trova l’ultimo bit utile del registro di uscita.
3.4.2 Processo per la generazione dei segnali.
Il processo per la generazione dei segnali, attivo una volta conclusa la fase di esecuzione del comando, consiste nella generazione dei segnali relativi ai simboli logici 0 ed 1 nel caso di un’unica sottoportante e nel caso di due sottoportanti, vedi paragrafo 2.5.4. Si deve fare una ulteriore considerazione riguardante il data rate, che può essere alto o basso, vedi tabella 1 nel paragrafo 2.5.6.
Limitiamoci per ora al caso di un’unica sottoportante e data rate alto, vedi paragrafo 2.5.4.1, informazioni deducibili dal registro dei flag.
In questo caso si utilizza un unico contatore count_pulse su 13 bit, che incrementa il proprio valore sul fronte in salita del clock4, cioè con un periodo pari a quattro periodi di clock veloce. Con un unico contatore si riesce ad ottenere uno 0 logico, rappresentato nella
figura 2-10, dato da 8 impulsi a frequenza fC/32 seguito da un segnale non modulato per il successivo semiperiodo; e un 1 logico, rappresentato nella figura 2-11, dato da un segnale non modulato per un semiperiodo seguito da 8 impulsi a frequenza fC /32 per il successivo
semiperiodo.
Nel caso di un’unica sottoportante e data rate basso, la frequenza della sottoportante resta invariata ma il numero di impulsi deve essere incrementato di quattro.
Nel caso di due sottoportanti (paragrafo 2.5.4.2), informazioni deducibili dal registro dei flag, il processo è più complesso rispetto al caso di un’unica sottoportante e coinvolge un maggior numero di contatori.
Nel caso di data rate alto e due sottoportanti 0 logico, rappresentato nella figura 2-12, è dato da 8 impulsi a frequenza fC/32 seguito da 9 impulsi a frequenza fC/28; mentre un 1 logico, rappresentato nella figura 2-13, è invece dato 9 impulsi a frequenza fC/28, seguito da
8 impulsi a frequenza fC/32.
Nel caso di due sottoportanti e data rate basso, le frequenze delle sottoportanti restano invariate ma il numero di impulsi deve essere incrementato di quattro.
In tutti i casi visti finora una volta inviato un byte si attiva una abilitazione (byte_end) necessaria per memorizzare i dati nel registro di uscita (paragrafo 3.4.1).
3.4.3 Processo per la generazione dei segnali di SOF.
Il processo, attivo una volta conclusa la fase di esecuzione del comando, consiste nella generazione dei segnali di start of frame (SOF), nel caso di un’unica sottoportante (paragrafo 2.5.5.1) e nel caso di due sottoportanti (paragrafo 2.5.5.2); considerando come ulteriore variabile il data rate (tabella 1 nel paragrafo 2.5.6).
Una volta conclusa la sequenza il processo rimane inattivo fino alla conclusione dell’esecuzione del successivo comando arrivato dal lettore.
Nel caso di un’unica sottoportante si sfrutta il contatore utilizzato nel processo per la generazione dei segnali (paragrafo 3.4.2).
Nel caso di data rate alto e sottoportante unica la sequenza di SOF, rappresentata nella figura 2-14, è costituita da un segnale non modulato per un tempo 768/ fC, seguito da 24 impulsi a frequenza fC/32, seguito infine da un 1 logico.
Nel caso di data rate basso e sottoportante unica, la frequenza delle sottoportante resta invariata ma il numero di impulsi che da la sequenza di SOF deve essere incrementato di quattro.
Nel caso di due sottoportanti (paragrafo 2.5.5.2), informazioni deducibili dal registro dei flag, il processo è più complesso rispetto al caso di un’unica sottoportante e coinvolge un maggior numero di contatori.
Nel caso di data rate alto e due sottoportanti la sequenza di SOF, rappresentata nella figura 2-15, è costituita da 27 impulsi a frequenza fC/28, seguito da 24 impulsi a frequenza
C
f /32, seguito infine da un 1 logico.
Nel caso di data rate basso e due sottoportanti, la frequenza delle sottoportanti resta invariata ma il numero di impulsi che da la sequenza di SOF deve essere incrementato di quattro.
3.4.4 Processo per la generazione dei segnali di EOF.
Il processo per la generazione dei segnali di end of frame (EOF), nel caso di un’unica sottoportante (paragrafo 2.5.5.3) e nel caso di due sottoportanti (paragrafo 2.5.5.4), considerando come ulteriore variabile il data rate (tabella 1 nel paragrafo 2.5.6), si attiva una volta conclusa la fase di esecuzione del comando,
Nel caso di un’unica sottoportante), informazione deducibile dal registro dei flag, si sfrutta il contatore utilizzato nel processo per la generazione dei segnali (paragrafo 3.4.2).
Nel caso di data rate alto e sottoportante unica la sequenza di EOF, rappresentata nella figura 2-16, è costituita da uno 0 logico, seguito da 24 impulsi a frequenza fC/32, seguito infine da un segnale non modulato per un tempo 768/ fC.
Nel caso di data rate basso e sottoportante unica, la frequenza delle sottoportante resta invariata ma il numero di impulsi che da la sequenza di EOF deve essere incrementato di quattro.
Nel caso di due sottoportanti (paragrafo 2.5.5.4), il processo è più complesso rispetto al caso di un’unica sottoportante e coinvolge un maggior numero di contatori.
Nel caso di data rate alto e due sottoportanti la sequenza di EOF, rappresentata nella figura 2-17, è costituita da uno 0 logico, seguito da 24 impulsi a frequenza fC/32, seguito da
27 impulsi a frequenza fC/28.
Nel caso di data rate basso e due sottoportanti, la frequenza delle sottoportanti resta invariata ma il numero di impulsi che da la sequenza di EOF deve essere incrementato di quattro.
3.4.5 Processo per il calcolo del CRC.
La risposta al comando, oltre ai dati utili, contiene il CRC dei dati inviati. Anche nell’interfaccia di uscita deve essere calcolato quindi il CRC dei dati che vengono inviati al lettore.
Il calcolo del CRC è effettuato utilizzando uno shift register su 16 bit in cui si memorizza il nuovo valore del CRC, dopo opportune traslazioni e operatori logici di OR esclusivo. Il processo è scandito dal clock veloce, infatti una volta acquisiti i dati si conoscono già tutti gli otto bit di cui si vuole calcolare il CRC.