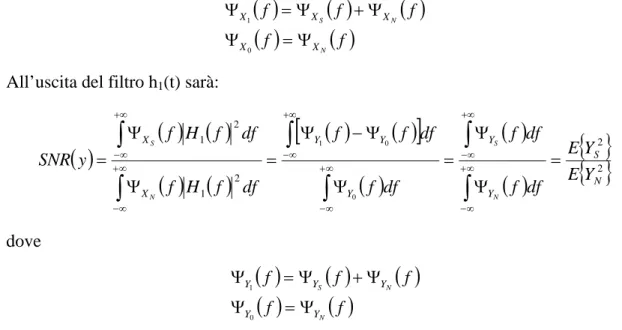2. CAPITOLO 2
T
OWEDA
RRAYIl termine towed array (o cortina idrofonica trainata, come è stato tradotto in italiano) indica un array di idrofoni disposti linearmente e rimorchiato mediante un apposito cavo a notevole distanza dall’unità trainante.
I towed arrays sono sensori che presentano una vasta possibilità di impiego, in ambito sia civile che militare, in configurazione principalmente passiva – solo ascolto, ma anche attiva – emissione acustica ed ascolto di eventuali eco di bersagli.
Nella configurazione passiva il towed array si presenta alla vista come un lungo tubo flessibile, di lunghezza variabile a seconda dell’utilizzo, dell’ordine comunque delle centinaia di metri, collegato all’unità trainante attraverso un cavo di traino, anch’esso di lunghezza variabile, da centinaia di metri, fino ad un migliaio. Nella configurazione attiva il towed array è ca-ratterizzato da una struttura bistatica, nella quale la trasmissione dell’impulso acustico av-viene mediante un emettitore anch’esso trainato a profondità variabile dalla stessa o da al-tra unità, mentre la ricezione avviene mediante un sensore dello stesso tipo di quello relati-vo alla configurazione passiva.
I Towed Arrays passivi sono quelli che interessano ai fini della presente trattazione. Nati per scopi bellici durante la Prima Guerra Mondiale, i Towed Arrays sono ancora impiegati in ambito militare per l’individuazione, la localizzazione e l’identificazione di unità navali (di superficie e sottomarine) e mine.
L’impiego in ambito civile ha potuto avere inizio solo quando la ricerca in campo elet-troacustico ha consentito di sviluppare sensori abbastanza sensibili da essere usati per
a-fig. 2.1 – Immagine subacquea di un towed array
scoltare i deboli suoni di origine naturale provenienti dai fondali marini. Negli anni Novan-ta ha avuto inizio così l’impiego dei Towed Arrays in ambito geofisico, per l’acquisizione di segnali prodotti da fenomeni sismici. Per
questo scopo vengono impiegate unità ap-positamente progettate, in grado di trainare numerosi towed arrays contemporaneamen-te, che formano sensori molto lunghi, pro-gettati per captare segnali a bassissima fre-quenza e debolissimi, come quelli prodotti dall’attività sismica della crosta terrestre (frequenza di circa 0,14 Hz [1, pag. 204]).
Dal 2000 si usa tale tipo di sensori passi-vi anche per l’indipassi-viduazione e la classifica-zione di cetacei tramite l’ascolto dei suoni
da essi emessi. L’impiego di sensori passivi di alta sensibilità in questo campo risulta par-ticolarmente importante in quanto, contrariamente ai sensori attivi, non risultano dannosi per i cetacei. Que-sto tipo di attività è colloca-ta all’interno del Marine Mammals Risk Mitigation Project, un progetto del NATO Undesea Research Centre, nato con lo scopo di analizzare l’impatto che i rumori prodotti dall’uomo (comprese le emissioni prodotte da sonar attivi) hanno sui ceta-cei.
I vantaggi che comporta l’impiego dei towed array systems sono dovuti alla loro natura di sistemi isolati, ovvero appendici, estensioni dell’unità trainante:
quando trainati da unità di superficie, hanno la possibilità di essere posizionati in profondità, in uno strato in cui la propagazione acustica risulta particolarmente fa-vorevole;
possono essere allontanati dalla piattaforma trainante, il che riduce il livello spettra-le di rumore autoindotto ricevuto;
la loro lunghezza è indipendente dalle dimensioni dell’unità che li traina, il che consente l’utilizzo di sensori con alto array gain e non limita il range di frequenze
fig. 2.3Stenella striata [29]
fig. 2.2 – Unità navale che traina towed ar-rays multipli per la ricezione di segnali pro-dotti da fenomeni sismici.
utilizzabili (spaziatura fra gli idrofoni), consentendo, come nel caso di utilizzo in campo geofisico, l’investigazione a frequenze estremamente basse;
interventi di manutenzione o riparazione non causano l’inutilizzabilità della piatta-forma a cui appartengono.
Per contro, il fatto di essere sistemi particolarmente ingombranti, richiede l’impiego di speciali apparecchiature per essere manovrati, come i winches e limita la manovrabilità dell’unità trainante.
fig. 2.4 – Towed Arrays avvolti su winches a bordo di un’unità navale.
2.1. Breve storia
Nella storia, lo sviluppo di strumenti e tecniche di prevenzione fa spesso seguito alla impellente necessità di contrastare una minaccia. Durante la Prima Guerra Mondiale il progresso della tecnica di ascolto passivo in acqua fu la risposta al massiccio impiego di sommergibili da parte della Germania.
L’attività degli U Boote tedeschi fu tale che dall’agosto 1914 all’ottobre 1918 portò all’affondamento di 5 234 navi mercantili alleate o neutrali [14, pag. 142].
All’interno di questo scenario venne impiegata per la prima volta la tecnica di traino di apparecchiature acustiche, che venivano in questo modo allontanate dalla sorgente di ru-more rappresentata dall’unità trainante. Il primo che studiò questa tecnica fu il Dr. Hayes [17], della U.S. Naval Station di New London, che tra il 1917 e il 1918 condusse una serie di prove, con lo scopo di trovare un sistema passivo di localizzazione subacquea che non risentisse di vibrazioni e rumore locale. Durante queste prove egli trainò alcune cortine i-drofoniche, che mostrarono di funzionare in maniera soddisfacente solo quando la nave procedeva a bassa velocità. A fronte dei risultati comunque positivi nella riduzione del ru-more, l’allontanamento dalla piattaforma attraverso il traino non si dimostrò nel complesso un successo, a causa dell’embrionale stato dell’arte dell’epoca nello sviluppo di sensori i-drofonici e delle tecniche di amplificazione del segnale, che non consentivano una raggio di scoperta maggiore di 2 km.
Dopo il 1918 non ci furono ulteriori progressi in questo tipo di tecnica fino alla Seconda Guerra Mondiale, all’inizio della quale erano in servizio nelle marine belligeranti o desti-nate a diventare tali, 635 sommergibili, di cui 165 sovietici, 113 italiani, 100 americani, 77 francesi, 65 giapponesi, 58 britannici e 57 appartenenti alla Germania di Hitler, che com-pletò, durante la guerra oltre 1000 U-boote [14, pagg. 164, 251, 309, 314].
La rinnovata esigenza di individuare i sommergibili spinse ad un nuovo impegno. Hor-ton ed altri [17] cercarono di sfruttare la tecnica del traino per fornire ai dirigibili la capaci-tà di detezione acustica in mare. Vennero costruiti così assemblaggi rigidi di idrofoni, trai-nati 15 metri dietro un “trattore” idrodinamico calato dal dirigibile. Il trattore serviva a se-parare l’idrofono dal rumore di scia nel punto in cui il cavo entrava in acqua. Nelle prove di valutazione, condotte a largo della Lakehurst Naval Air Station nell’estate del 1945, con una velocità di traino di 25 nodi, venne individuata una nave da carico a 5 miglia di distan-za.
Nonostante il successo iniziale, il progetto fu temporaneamente abbandonato perchè si scoprì che i cavi si rompevano dopo circa 8 ore di traino ad una velocità di 12 nodi.
Nell’ultimo anno di Guerra C. Holm sviluppò un progetto che prese il nome di Project General [18], volto ad equipaggiare le navi mercantili con due towed arrays, uno a dritta e
uno a sinistra, allo scopo di fornire loro un equipaggiamento che fosse in grado di proteg-gerli da attacchi di sommergibili.
Importanti miglioramenti nella progettazione dei cavi si ebbero negli ultimi anni Qua-ranta, quando vennero sviluppati cavi che erano sufficientemente robusti da essere trainati trasmettendo segnali e da resistere ad esplosioni. Si riaccese così l’interesse per i sistemi trainati da dirigibili. Ma alla nascita dei sistemi sonar attivi a profondità variabile (Variable Depth Sonar - VDS) il dirigibile perse di interesse come piattaforma per l’individuazione della minaccia proveniente dagli abissi, poiché non era in grado di sostenere sistemi pesan-ti ed ingombranpesan-ti quali i sonar atpesan-tivi.
Il programma VDS (negli Stati Uniti e in Canada), si basava sul concetto di trainare un apparato sonar ad alta frequenza, non tanto per allontanarlo dal rumore della piattaforma, quanto per portare l’apparato sonar in profondità, sotto il termoclino. Venne preferito il so-nar attivo ad alta frequenza per ottenere una buona direttività con un sensore di dimensioni ridotte.
Le prime esperienze di traino di sonar attivi condussero all’assemblaggio di sistemi pas-sivi trainati, che fossero in grado di misurare il rumore autoindotto dall’unità trainante e dal sensore attivo trainato. Questi
studi mostrarono che la sensibilità degli idrofoni veniva seriamente compromessa dal loro alloggia-mento (un contenitore che non consentisse le infiltrazioni di ac-qua) e che era necessario porre at-tenzione a posizionare gli idrofoni in profondità, lontano dallo strato di bolle superficiali, lontano dalla scia della nave e lontano da zone
di turbolenza in generale. La risposta alle vibrazioni, che causavano un’accelerazione degli idrofoni, venne notata non solo durante le prove con navi di superficie, ma anche in altri esperimenti, utilizzando simili assemblaggi di idrofoni, trainati da sommergibili.
Durante questi studi, vennero testati vari tipi di assemblaggi di idrofoni. Si notò che, quando gli idrofoni venivano accoppiati all’acqua di mare tramite un tubo di gomma dalle pareti sottili e flessibili, riempito di olio di ricino, si osservava un rumore inferiore ed una migliore risposta alle basse frequenze, rispetto all’uso di pareti rigide (metallo o plastica).
Nei primi anni Sessanta la Marina Americana si accorse che i sensori acustici montati sui suoi sottomarini erano ciechi in un settore di 70°-90° a cavallo della poppa; per questo sperimentò alcune cortine trainate, tra le quali la migliore risultò quella della ditta Bell
lephone Laboratories (BTL): il “Missile Tube Storage Array”, che fece misurare un target detection di 40.000 yards [18].
Tra il 1964 e il 1965 la Chesapeake Instruments Corporation (CIC) mise a punto una cortina trainata che prevedeva 2 array distanziati tra loro di 400 metri. Questa si dimostrò capace di scoprire un sommergibile a quota periscopica a una distanza di 67 miglia.
Nei primi anni Settanta furono im-barcati sulle fregate operanti in Medi-terraneo i primi sistemi Towed Array.
Durante gli anni Ottanta, in piena guerra fredda, quando il pericolo so-vietico era costantemente presente in Mediterraneo, numerosi furono i pro-getti di ricerca per la realizzazione di cortine idrofoniche, fra queste si ri-corda il “Project 20 LFAS” [23] dell’allora SACLANTCEN (l’attuale NURC).
A partire dagli anni Novanta si è notato come le cortine idrofoniche, sempre più perfe-zionate, complesse e sensibili, possano essere impiegate per scopi differenti da quelli più strettamente bellici. Infatti, allo stato attuale, i towed array risultano sempre di più impiegati per fini scientifici, come l’esplorazione e la mappatura dei fondali, la ricerca subacquea ed il monitoraggio dei mammiferi marini.
fig. 2.6 Esempio di profilo sottomarino ottenuto con la tecnica di riflessione dell’energia sismica [23].
2.2. Tecnologia
Un towed array è costituito da cinque segmenti: il cavo di traino, una prima sezione VIM, la sezione acustica, una seconda sezione VIM (Vibration Isolation Module) e la rope tail, come illustrato in fig. 2.8.
Il cavo di traino assolve al doppio scopo di trainare il sensore e di collegare elettrica-mente la sezione acustica all’unità trainante. Il collegamento elettrico serve sia per fornire la necessaria alimentazione
e-lettrica al sensore, sia per tra-sferire i segnali idrofonici rice-vuti alle apparecchiature di bordo, per consentirne la suc-cessiva processazione. Fra il cavo di traino e il tubo flessibi-le c’è una terminazione di rac-cordo detta Elettro Magnetic
Terminator, che congiunge
meccanicamente, elettricamente ed elettronicamente i due elementi.
Il Towed Array vero e proprio è composto, da prora verso poppa, da una sezione di as-sorbimento meccanico delle vibrazioni longitudinali indotte dal cavo di traino, una sezione acustica che contiene gli idrofoni ed una ulteriore sezione di assorbimento delle vibrazioni longitudinali indotte dalla Rope Tail.
La Rope Tail ha il duplice compito di fornire la necessaria forza di trazione iniziale in acqua per consentire il rilascio in mare dell’array e poi, una volta che il sensore sia in
fun-fig. 2.9 Electro Mechanical Terminator [24]
V.I.M.
Sezione acustica
V.I.M. Cavo di traino Rope Tail Unità Trainante HF HF HF HF MF LF VLF MF LF VLF V.I.M.
Sezione acustica
V.I.M. Cavo di traino Rope Tail Unità Trainante HF HF HF HF MF LF VLF MF LF VLF
zione, di contrastare l’effetto “scodinzolo” del tubo flessibile che può insorgere durante il traino. Per questo secondo scopo la Rope Tail crea una forza resistente a poppavia del tubo
flessibile, che contrasta la forza di traino. Le sezioni di assorbimento meccanico del-le vibrazioni sono dette VIM (Vibration
Isola-tion Module), rispettivamente Forward VIM
fra il cavo di traino e la sezione acustica e
Af-ter VIM fra la sezione acustica e la Rope Tail.
I VIM sono progettati per minimizzare il ru-more prodotto dal traino e sono composti da tubo molto flessibile nel senso longitudinale, della stessa sezione di quello della
se-zione acustica, la cui elasticità viene testata ad una lunghezza doppia di quella ef-fettiva [26, pag. 4];
spacers egualmente distanziati per mantenere la forma cilindrica regolare del tubo; cavi di nylon della stessa lunghezza del tubo;
cavi di Kevlar di lunghezza doppia di quella dei cavi di nylon;
cavi per il trasporto dell’alimentazione elettrica e per la trasmissione dei segnali, della stessa lunghezza dei cavi di Kevlar;
olio di riempimento, di densità minore di quella dell’acqua, per il raggiungimento dell’assetto di galleggiabilità neutro.
Ciascuno dei due VIM è in grado di attenuare le sollecitazioni prodotte rispettivamente dal cavo di traino e dallo scodinzolo della rope tail. Ma la presenza di due VIM rende ulte-riormente stabile la velocità in acqua della sezione acustica, che oscilla longitudinalmente comprimendo alternativamente i due VIM (uno si accorcia e l’altro si allunga), consenten-dole di procedere con moto piuttosto regolare. Un procedere a strappi troppo bruschi cau-serebbe infatti picchi di rumore dovuti al fatto che gli idrofoni sono sensibili alle accelera-zioni: producono segnali elettrici nella direzione dell’accelerazione1.
L’attrito fra l’acqua di mare e la superficie esterna del tubo flessibile causa una tensione longitudinale che produce una forza chiamata drag [24]. Questa forza provoca innanzitutto un piccolo allungamento del tubo di gomma e si trasmette ai cavi di nylon, che al loro volta possono allungarsi di circa il doppio [26, pag. 4] della loro lunghezza a riposo. Tale allun-gamento è funzione della velocità di traino. Se il drag aumenta (a causa, per esempio,
1
In un esperimento svolto presso il NURC, attraverso l’uso del Calibration Exciter Brüel&Kjær 4294 (caratteristiche tecniche reperibili all’indirizzo http://www.bksv.com/pdf/bp2101.pdf) è stata simulata l’accelerazione di 10 m/s2 ed applicata direttamente all’idrofono. L’idrofono di forma cilindrica ha risposto con una tensione di -68 dB//Vrms; l’idrofono di forma sferica ha risposto con una tensione di -48 dB//Vrms, misurate per mezzo di un Vector Signal Analizer (Agilent 89410A).
dell’aumento della velocità di traino), la forza causata dall’attrito viene trasmessa ai cavi di Kevlar, una fibra sintetica che ha una grande capacità di resistenza alla trazione ed una re-sistenza all’allungamento maggiore di quella dell’acciaio [30]. I cavi di Kevlar sono quindi i componenti che conferiscono al modulo VIM resistenza meccanica. Da questo momento, quindi, se la forza continua ad aumentare per ragioni impreviste, il tubo del modulo VIM non si allunga ulteriormente, fino al raggiungimento del carico di rottura dei cavi di Ke-vlar.
La sezione acustica è costituita da un tubo flessibile, con le stesse caratteristiche di quel-lo dei VIM, all’interno del quale sono presenti gli idrofoni, in numero e con spaziatura di-pendenti dall’applicazione. La sezione acustica è composta da:
idrofoni;
preamplificatori;
sensori di posizione (bussole, ac-celerometri, profondimetri, …); supporti meccanici (spacers); elementi di rinforzo (cavi di
Ke-vlar);
cavi conduttori; tubo flessibile;
connettore elettromagnetico; olio.
Come illustrato in fig. 2.8, la sezione acustica può essere costituta a sua volta da diffe-renti sezioni, ciascuna caratterizzata da una determinata densità di idrofoni. Array di questo tipo vengono detti Nested Arrays e consentono l’impiego di un singolo sensore per la rice-zione in differenti bande frequenziali.
Il principio dei Nested Arrays è che le frequenze limite superiore per ciascuna banda sono l’una multipla dell’altra, per poter rispettare la regola della spaziatura fra idrofoni di λ/2, riferito all’estremo superiore della banda di lavoro considerata. Nel caso illustrato in fig. 2.8 la sezione HF avrà un numero di idrofoni per esempio doppio rispetto alla sezione MF, che a sua volta ha un numero di idrofoni doppio rispetto alla sezione LF, che ha un numero di idrofoni doppio rispetto alla sezione VLF. Per l’ascolto nella banda HF, risulta-no attivi solo gli idrofoni appartenenti alla sezione HF, mentre per l’ascolto MF, LF e VLF sono attivi gli idrofoni della sezione di interesse più alcuni degli idrofoni delle sezioni a frequenza superiore, quelli spaziati della quantità λ/2.
fig. 2.11 – Elementi interni della sezione acustica di un Towed Array [23]
Gli idrofoni possono essere connessi in gruppi, che prendono il nome di staves o
stec-che. Scopo di questa composizione è la somma coerente dei segnali ricevuti dagli idrofoni
di ciascuna stecca, in modo da aumentare il rapporto segnale rumore. I campioni spaziali di rumore infatti possono essere considerati non correlati o molto poco correlati, mentre i campioni spaziali di segnale utile possono essere considerati completamente correlati. Da una somma coerente risulta quindi un aumento della potenza di segnale, mentre la densità spettrale di rumore rimane costante.
Nel caso di composizione degli idrofoni in staves, saranno questi ultimi a rappresentare le antenne elementari che compongono l’array e pertanto dovranno essere spaziati della quantità λ/2. Ne risulta che in questo tipo di configurazione gli idrofoni sono molto più vi-cini, con una spaziatura che può essere molto minore di λ/2.
Il preciso posizionamento degli idrofoni è assicurato dagli spacers, sistemi di supporto assicurati ai cavi di Kevlar ed al tubo flessibile. Gli spacers sono fatti di materiale a bassa densità, nell’ottica di ottimizzare l’assetto di galleggiabilità neutra del sensore, ed assicu-rano una buona protezione meccanica degli idrofoni e dei componenti elettrici quali i pre-amplificatori. Gli spacers garantiscono infine una minimizzazione del rumore meccanico, impedendo il movimento dei componenti in essi contenuti.
Per ogni idrofono c’è un preamplificatore, progettato in modo da amplificare quanto più possibile (valori di 20-30 dB2) il debole segnale elettrico in uscita dall’idrofono, posseden-do al contempo una cifra di rumore il più bassa possibile. I preamplificatori infatti rappre-sentano lo stadio di amplificazione di ingresso, che deve avere un guadagno quanto più possibile alto e cifra di rumore quanto più possibile bassa, in accordo con la formula di Friis3.
Tipicamente la rumorosità dei preamplificatori viene idealmente riportata con il livello del rumore prodotto da un particolare stato del mare (per esempio la rumorosità di tipo e-lettronico dei preamplificatori viene comparata con quella del mare a stato 0, delle curve di Knudsen ).
2
Dalle specifiche di un array Atlas usato al NURC
3
Ogni sistema di comunicazione può essere immaginato come una cascata di elementi. Ogni elemento è ca-ratterizzato da un certo guadagno di potenza disponibile e da una certa cifra di rumore. La cifra di rumore del sistema di comunicazione è data dalla formula di Friis:
) ( ... ) ( ) ( 1 ) ( ... ) ( ) ( 1 ) ( ) ( 1 ) ( ) ( ) ( 1 2 1 2 1 3 1 2 1 f G f G f G f F f G f G f F f G f F f F f F n n − ⋅ ⋅ − + + ⋅ − + − + =
Ovvero il rumore globalmente introdotto è sostanzialmente quello del primo elemento se il primo elemento ha un alto guadagno.
La preamplificazione in fase di assemblaggio dell’antenna viene usata anche per com-pensare le eventuali differenze di sensibilità4 fra gli idrofoni ed effettua inoltre un primo filtraggio passabanda, così da limitare la banda di ricezione alla banda prevista nella suc-cessiva processazione, operando in tal modo una riduzione della potenza di rumore prima della processazione.
I preamplificatori si usano anche per minimizzare l’attenuazione introdotta nel segnale dalle capacità parassite di-stribuite nei cavi di collegamento che trasportano i segnali di uscita. Il circui-to equivalente di fig. 2.12 rappresenta un idrofono collegato ad uno stadio di preamplificazione tramite cavo coassia-le o twistato ed è valido al di sotto della frequenza di risonanza dell’idrofono (gli idrofoni di un towed array vengono
utilizzati al di sotto della frequenza di risonanza per avere una risposta in frequenza costan-te). La risposta in tensione del circuito è data dalla seguente formula:
g a in a C C C C e e + + = (2. 1) dove ein rappresenta l tensione dovuta al rumore elettronico nel preamplificatore.
La capacità Ca è variabile con la
lunghezza del cavo, che è diversa per ogni idrofono, essendo questi distri-buiti longitudinalmente all’interno dell’array. Queste differenze negli elementi capacitivi causano sfasa-menti reciproci fra i segnali in in-gresso alla catena di signal processing, ovvero distorsioni dei segnali. Tale problema viene risolto agendo sui preamplificatori: vengo-no utilizzati amplificatori di corrente, di cui è riportato il circuito equivalente in fig. 2.13. Un tale schema circuitale mostra come la capacità del cavo si trovi ai capi di un
4
Con sensibilità di un idrofono si intende la sua sensibilità in spazio libero, ovvvero il rapporto, M, fra la tensione di uscita dell’idrofono e la pressione acustica misurata nel punto in cui si trova l’idrofono prima che questo fosse introdotto nel campo acustico. M [dB//V/μPa]
libero spazio in acustica pressione uscita di tensione = Idrofono Preamplificatore Cavo C Ca Cg ein ea
fig. 2.12 – Circuito equivalente di un idrofono che lavora lontano dalla frequenza di risonanza, colle-gato ad un preamplificatori e ad un cavo
C Ca Cg ein ea - +
fig. 2.13 – Circuito equivalente con amplificatore di corrente
cuito virtuale, il che rende la risposta in tensione del sistema indipendente dalla capacità del cavo stessa, eliminando contemporaneamente anche l’effetto di cross-talk dovuto ai ca-nali adiacenti.
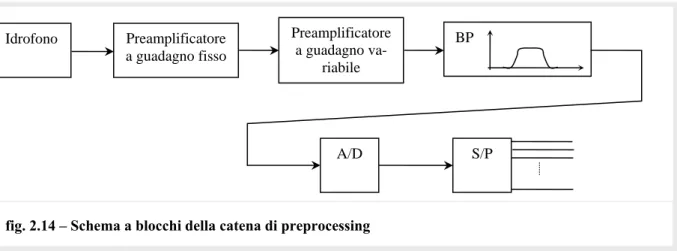
Ogni segnale in uscita dalla catena idrofono-preamplificatore rappresenta un canale del-la catena di preprocessing, il cui schema a blocchi è riportato in fig. 2.14
Dopo lo stadio di preamplificazione a guadagno fisso (stesso guadagno per tutti i cana-li), la catena di preprocessing prevede vari stadi di amplificazione con Automatic Gain
Control (AGC), un circuito che effettua una variazione automatica del guadagno (valori
ti-pici del guadagno totale variano da 0 a un centinaio di dB): se i livelli dei segnali prove-nienti da ciascun canale sono elevati, l’AGC tende ad abbassare il guadagno dell’amplificazione (uguale per tutti i canali), se invece sono bassi, aumenta il guadagno, questo allo scopo di normalizzare i segnali, ovvero di mantenere i segnali amplificati entro la dinamica di lavoro dei successivi circuiti di conversione analogico/digitale. Per non per-dere poi la possibilità di determinare il livello assoluto dell’intensità acustica ricevuta, l’informazione relativa al valore di guadagno imposto dal sistema AGC viene trasmesso alle unità di processazione successive.
Prima di entrare nella catena di processazione del segnale, i canali passano nei converti-tori A/D, campionaconverti-tori provvisti di filtro anti-aliazing, e nel convertitore S/P che consento-no la successiva trasmissione dei dati in parole composte mediamente da 16/24 bit alle uni-tà di processazione per la successiva trattazione del segnale.
Preamplificatore a guadagno fisso Preamplificatore a guadagno va-riabile BP A/D S/P Idrofono
2.3. Dall’antenna al display
La catena di processing nel corso del tempo ha subito varie modificazioni, soprattutto per quanto riguarda la digitalizzazione dei segnali, che ha preso piede solo negli ultimi an-ni.
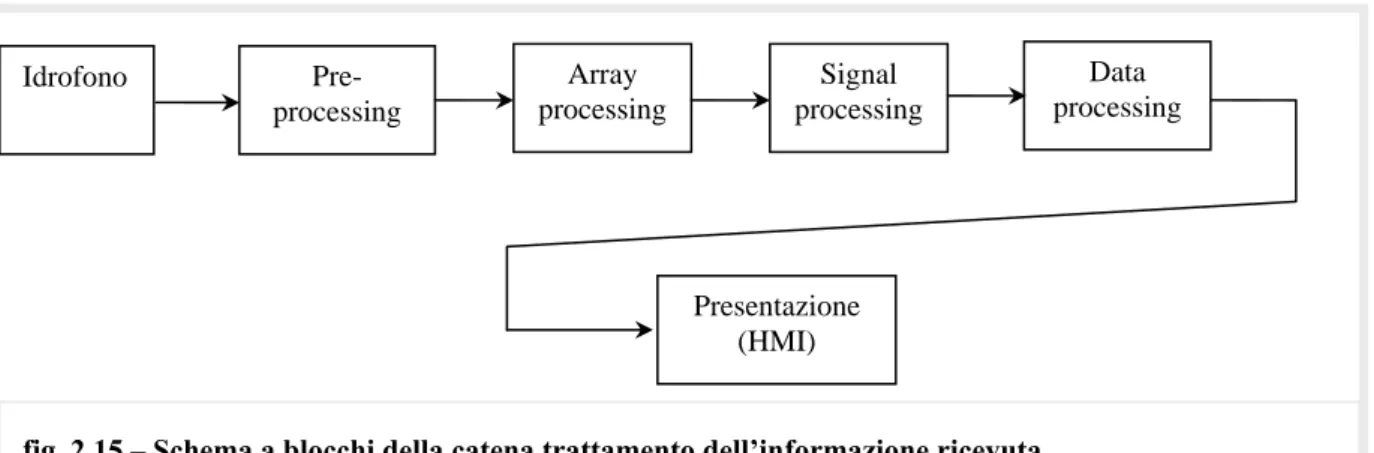
La tendenza nella costruzione dei nuovi sensori è di effettuare il preprocessing all’interno del sensore in acqua, in modo tale che a bordo dell’unità trainante vengano ese-guite esclusivamente le operazioni di array processing, signal processing e presentazione.
È necessario tenere ben presente la distinzione fra la parte tecnologica che effettua il preprocessing ed i successivi stadi di trattamento del segnale e di trattamento dei dati.
Il preprocessing ha il compito di preparare il segnale all’array processing. In questo sen-so la tecnologia impiegata nel preprocessing deve consentire di fornire al segnale la giusta amplificazione affinché l’informazione ricevuta non vada perduta prima di giungere agli stadi successivi; deve preparare il segnale ad essere quantizzato ai fini della digitalizzazio-ne, pertanto, successivamente ad una immediata amplificazione a guadagno costante, deve fornire una amplificazione a guadagno variabile che renda costante la dinamica del segna-le; deve far in modo, attraverso un opportuno filtraggio passa banda, che venga trasmesso solo il segnale nella banda di lavoro dell’antenna, per evitare la presenza di grating lobes nel diagramma d’antenna.
Nell’adempiere alle funzioni illustrate, la tecnologia fisica del blocco di preprocessing deve essere tale da preservare intatta l’informazione ricevuta, non introducendo rumore (si è detto della silenziosità dei preamplificatori) né distorsioni di fase dei segnali (si è detto della tecnologia che consente l’eliminazione delle capacità parassite nei cavi).
Dopo la parte tecnologica di preprocessing, ha luogo il trattamento del segnale vero e proprio, definito signal management [10, pag. 303], che include le elaborazioni associate al trattamento delle forme d’onda richiesto affinché il sistema sonar svolga il proprio lavoro di detezione e localizzazione di bersagli, determinando eventualmente la loro natura (come
Pre-processing Array processing Signal processing Presentazione (HMI) Idrofono
fig. 2.15 – Schema a blocchi della catena trattamento dell’informazione ricevuta
Data processing
accade nelle campagne di censimento di popolazioni di cetacei). Il signal management a sua volta si divide in tre parti: array processing, signal processing e data processing.
L’array processing è la tecnica di elaborazione dei segnali raccolti dai sensori, volta a ridurre il rumore ambientale nel quale è immerso il segnale da rilevare, permettere la di-scriminazione di onde piane provenienti da direzioni diverse e determinarne la loro dire-zione di provenienza.
I segnali in uscita dall’array processing entrano nel blocco di signal processing, che li elabora al fine di scoprire eventuali bersagli con vantaggiosi rapporti S/N e contemporane-amente determinarne la direzione di provenienza.
Dal blocco di signal processing non escono più segnali, ma dati costituiti dai bersagli scoperti. Questi dati vengono elaborati nel blocco di data processing al fine di offrire all’operatore una presentazione human-friendly dei dati ottenuti ed anche al fine di acquisi-re informazioni sui bersagli individuati.
2.3.1. Array Processing: Beamforming
Ciascun idrofono costituente l’array rappresenta un sensore che non è direttivo. L’omnidirezionalità è una proprietà che consegue dalla relazione tra le dimensioni dell’antenna e la lunghezza d’onda del segnale; se le dimensioni dell’antenna sono piccole rispetto alla lunghezza d’onda, l’antenna è omnidirezionale. Un’antenna omnidirezionale non consente di individuare la direzione di provenienza di un segnale.
Per le applicazioni dell’acustica subacquea, la direttività è una caratteristica desiderata, perché, nello specifico per i sonar passivi, consente di conseguire i seguenti vantaggi:
aprendo l’ascolto su settori limitati, consente di aumentare il rapporto segna-le/rumore riducendo ad un unico settore di ascolto il rumore in ingresso al ricevito-re, presente tutto intorno alla base acustica;
permette di discriminare un segnale utile proveniente da una certa direzione da se-gnali interferenti provenienti da altre direzioni;
consente di stimare la posizione angolare del bersaglio acquisendo l’informazione relativa alla direzione da cui proviene l’onda piana relativa al segnale.
Per ottenere un sensore direzionale è necessario rendere l’antenna direttiva. Per aumen-tare la direttività naturale di un’antenna è necessario aumentarne la dimensione geometrica D, in modo che risulti >1
λ
D
. Un tale risultato può essere raggiunto in elettromagnetismo costruendo antenne molto grandi, come le antenne a riflettore parabolico per le comunica-zioni satellitare, oppure tramite l’assemblaggio di antenne elementari (cioè piccole) in strutture ad array.
Per aumentare la direttività naturale delle antenne in campo acustico vengono utilizzate strutture ad array planare o lineare. I towed arrays sono strutture ad array lineare.
Con l’aumento della direttività di un allineamento di antenne, il valore dell’angolo a metà potenza (HPBW) diminuisce, viste le relazioni
D HPBW d N D λ ⋅ ≅ ⋅ ≅ 886 . 0
valide per qualsiasi allineamento lineare di antenne, dove N è il numero di elementi, d la spaziatura fra questi e λ la lunghezza d’onda.
L’assemblaggio degli idrofoni in array, presenta un ulteriore vantaggio: nel campo dell’elettromagnetismo applicato, cambiando opportunamente la fase della corrente di ali-mentazione alle antenne elementari costituenti l’array, è possibile modificare il diagramma d’antenna ed ottenere la cosiddetta scansione elettronica del fascio, la variazione della
di-rezione di puntamento del lobo principale del diagramma d’antenna; nel campo elettroacu-stico i segnali d’uscita di ciascun sensore vengono elaborati per ottenere lo stesso risultato, diagrammi d’antenna caratterizzati da particolari direzioni di puntamento del lobo princi-pale (detto beam), ovvero una direttività artificiale ottenuta per mezzo dell’array processing.
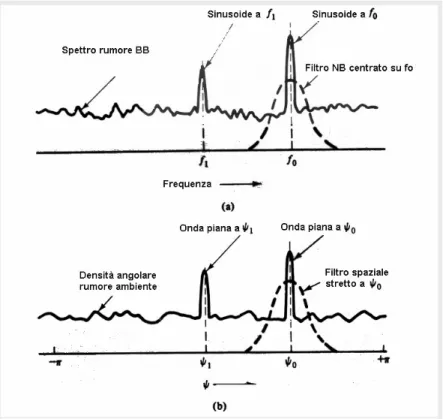
Facendo un’analogia fra il dominio della frequenza e il dominio dello spazio, un’antenna caratterizzata da una direttività nello spazio è considerata un filtro spaziale e il processo di filtraggio nel dominio dello spazio prende il nome di beamforming (formazione dei lobi).
La fig. 2.16 rappresenta un confronto tra la densità spettrale di potenza di un segnale sinusoidale in ru-more a larga banda (a) e la densità angolare di un’onda acustica piana nel rumore ambientale (b).
È possibile dimostrare che, similmente a quanto avviene nei processi di fil-traggio nel trattamento del segnale nel dominio della frequenza, il filtraggio spaziale incrementa il rap-porto segnale/rumore per segnali provenienti da di-rezioni distinte, in quanto l’SNR è inversamente
pro-porzionale all’apertura angolare del filtro.
fig. 2.16 – Confronto fra la densità spettrale di potenza di un se-gnale sinusoidale e densità angolare di un’onda acustica piana. [2, pag. 304].
Dominio della frequenza Dominio dello spazio
Densità spettrale di potenza del segnale ) ( 0 2 f f a δ −
Densità spettrale di potenza del rumore
0 2
) (f N
N =
Risposta in potenza del filtro ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = B f f rect f H 2 0 ) (
Potenza di segnale all’uscita del filtro
2 2 0 2 2 0 2 ) ( ) ( ) ( a f H a df f H f f a Ps = = = − =+∞
∫
∞ − δPotenza di rumore all’uscita del filtro
∫
∫
+∞ ∞ − +∞ ∞ − = = N f H f df N H f df Pn ( )2 ( )2 0 ( )2 Rapporto segnale/rumore B N a df B f f rect N a SNR ⋅ = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − =∫
∞ + ∞ − 0 2 0 0 2Densità di potenza angolare del segnale )
( 0 2δ ψ −ψ a
Densità di potenza angolare del rumore
K N(ψ)2 =
Risposta in potenza del filtro
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = B rect G ψ ψ ψ ψ 2 0 ) (
Potenza di segnale all’uscita del filtro
2 2 0 2 2 0 2 ) ( ) ( ) ( a G a d G a Ps = = = − =
∫
+ − ψ ψ ψ ψ ψ δ π πPotenza di rumore all’uscita del filtro
∫
∫
+∞ ∞ − + − = = π ψ ψ ψ ψ ψ π d G K d G N Pn ( )2 ( )2 ( )2 Rapporto segnale/rumore B B K a d rect K a SNR ψ ψ ψ ψ ψ π π ⋅ = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − =∫
+ − 2 0 2In generale, al diminuire dell’apertura angolare del filtro, aumentano le prestazioni del sistema:
aumenta il rapporto segnale/rumore;
aumenta la capacità di discriminare sorgenti angolarmente ravvicinate; aumenta l’accuratezza di stima di rilevamento del bersaglio.
G(ψ) n(x) s(x) H(f) n(t) s(t)
La direzione di puntamento del lobo principale del diagramma d’antenna viene a volte chiamata per semplicità main response axis (MRA), o direzione di puntamento dell’array. Tale direzione può essere ovviamente variata spostando meccanicamente l’antenna, oppu-re, come detto, attraverso l’elaborazione dei segnali. Tale procedura, meccanica o elettro-nica, prende il nome di beam steering e il sistema che la esegue è detto beam former.
Se il beam steering è fatto tramite array processing, allora il collegamento fra gli idro-foni che formano l’array avviene componenti circuitali chiamati reti di ritardo (se operano nel dominio temporale) o reti di sfasamento (se operano nel dominio frequenziale). Il beam
steering effettuato mediante l’array processing è particolarmente vantaggioso, perché con-sente di formare simultaneamente fasci di direttività in differenti direzioni.
Il beam forming tramite ritardi temporali è indipendente dalla frequenza, per questo è stato per lungo tempo preferito nei ricevitori passivi a banda larga; l’introduzione di un ri-tardo temporale Δn comporta l’introduzione di uno sfasamento Φ del segnale ricevuto n
proporzionale al ritardo indipendentemente dalla frequenza.
n n = fΔ
Φ 2π
Con l’introduzione della tecnologia digitale a livello hardware, c’è stata un’inversione di tendenza a favore del lavoro nel dominio della frequenza. I chip che calcolano la Fast Fourier Transform sono ormai materiale hardware a basso costo. È sufficiente quindi met-terne una batteria (un chip per ogni frequenza) per ogni beam, effettuare lo sfasamento in frequenza su ciascuna linea, quindi impiegare chip analoghi per antitrasformare. Il beam-forming temporale, invece, richiede l’impiego di una potenza di calcolo superiore, in quan-to i circuiti che creano ritardi temporali e che consenquan-tono l’interpolazione (di cui si dirà in seguito) sono strutture estremamente pesanti dal punto di vista computazionale, soprattutto per gli array di grandi dimensioni.
fig. 2.17 – Settori angolari dei fasci preformati per array lineari
Linear Array Linear Array Linear Array
Prima di passare alla descrizione delle due tecniche di beamforming nel dominio del tempo e nel dominio della frequenza, si dirà brevemente di come con l’array processing sia possibile influenzare anche il livello dei lobi laterali del diagramma di irradiazione (SLL – Side Lobe Level).
Si è detto che l’aumento delle dimensioni geometriche dell’antenna ne influenza la di-rettività e un’opportuna elaborazione dei segnali consente di modificare la direzione di puntamento; si dimostrerà ora come, pesando con opportuni coefficienti la tensione di usci-ta di ciascun canale dopo il beamforming sia possibile scegliere il numero di lobi secondari del diagramma d’antenna, la loro ampiezza ed influenzare ulteriormente l’HPBW [11, pag. 116-121].
Quando l’array è costituito da un elevato numero di elementi, si può dire che il suo dia-gramma di irradiazione sia determinato solamente dall’Array Factor5.
∑
− = = 1 0 ) ( ) ( N n j ne V AF θ χθdove θ è l’angolo di azimut in coordinate polari, Vn è la tensione di uscita di un particolare
canale e χ(θ) ingloba per semplicità di notazione la costante di fase e la dipendenza dalla
direzione della sorgente.
La tensione di uscita da ciascun canale avrà un termine di ampiezza e un termine di fa-se: α jn n n a e V = Quindi α θ χ ψ ψ θ χ θ − = ⋅ = − =
∑
∑
= = ( ) 1 0 1 0 ) ( ) ( N n jn n N n j ne a e V AFDa cui effettuando un cambiamento di variabile
ψ θ z ej N n n nz a AF = − =
∑
= 1 0 ) (l’array factor è esprimibile come una funzione polinomiale in z, il cui modulo sarà caratterizzato da un massimo assoluto (il lobo principale del diagramma di irradiazione) e da massimi relativi (i lobi secondari).
Scegliendo i coefficienti an (che costituiscono la funzione di ponderazione o smoothing
function), è possibile modificare l’andamento della funzione polinomiale AF e quindi
sce-gliere il numero di lobi secondari, la loro ampiezza e l’apertura del lobo principale.
5
Beamforming “Time delay”
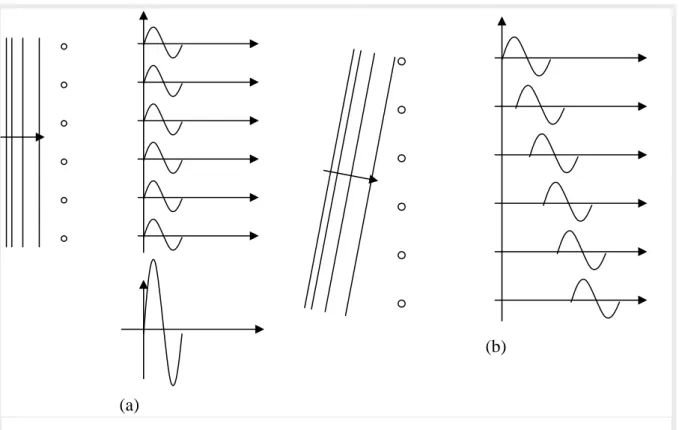
In fig. 2.18 viene rappresentato un fronte l’onda (localmente piana) che incide su un ar-ray di idrofoni, proveniente dalla direzione broadside (a) e da una qualsiasi altra direzione (b). I segnali in uscita dagli idrofoni vengono poi sommati in modo coerente.
La composizione dei segnali nel caso (b) darà luogo ad un segnale con ampiezza che potrebbe essere trascurabile o addirittura nulla (se la direzione di provenienza è tale da far sommare i segnali in controfase).
Il beamforming consiste nel fornire ai segnali ricevuti dagli idrofoni un ritardo tempora-le opportuno, tatempora-le da produrre una somma coerente. Il ritardo dipenderà ovviamente dalla direzione α che si vuole osservare e dalla distanza d fra gli idrofoni, secondo la seguente relazione, che fa riferimento alla fig. 2.19:
c
d α
τ = ⋅sin
dove c è la velocità del suono. Dalla pre-cedente eguaglianza, tramite relazioni in-verse, è possibile risalire all’angolo di provenienza del segnale conoscendo il ri-tardo:
(a)
(b)
fig. 2.18 – Ricezione di un’onda localmente piana da parte di un array di idrofoni dalla direzione bro-adside (a) e da una direzione qualsiasi (b)
α d
fig. 2.19 – Calcolo del ritardo da fornire ai se-gnali ricevuti dagli idrofoni
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⋅ = d c τ α arcsin
Il risultato finale sarà quello mostrato in rosso in fig. 2.20: una somma coerente come se il segnale provenisse dalla direzione broadside.
Da quanto detto sinora consegue facilmente che, introducendo per ogni canale idrofonico un set di ritardi temporali, possono essere formati simultaneamente dei fasci per diverse direzioni di provenienza del segnale (sistemi a fasci
pre-formati). In questo caso i ritardi temporali sono
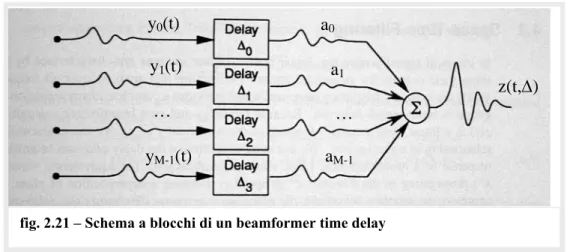
adattati alle differenti direzioni di interesse. I se-gnali corrispondenti vengono quindi sommati impiegando un sommatore per ogni direzione dei lobi preformati, secondo la formula:
∑
⋅ −Δ = Δ m m m m y t a t z(,θ ) ( )facente riferimento allo schema a blocchi di fig. 2.21.
Dopo i ritardi temporali, viene applicata una funzione di ponderazione (shading), rappresenta-ta dai am.
Quando in ingresso al beamformer ci sono se-gnali digitali, l’uscita di ogni canale viene ritardata di un multiplo intero del periodo di campionamento
c c
f
T = 1 , che dipende dal limite superiore della banda frequenziale per la quale l’array è stato progettato (teorema del campionamento). La struttura elementare di un beamformer digitale “time delay” è riportata in fig. 2.22.
fig. 2.20 – Somma coerente del segnale ritardato
fig. 2.21 – Schema a blocchi di un beamformer time delay
y0(t) y1(t) yM-1(t) … a0 a1 aM-1 … z(t,Δ)
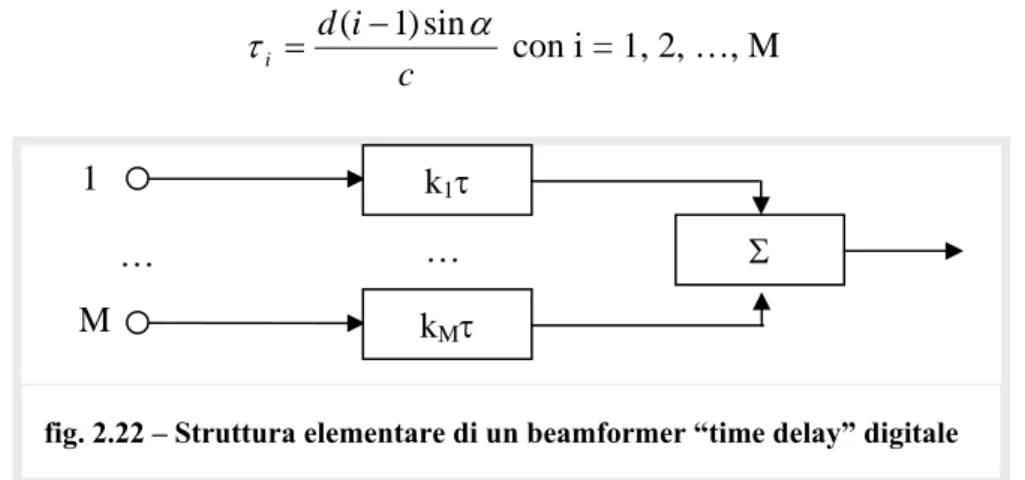
Per formare N fasci preformati, la struttura elementare deve essere ripetuta N volte. Ad ogni fascio, ad ogni direzione, corrisponde un set di numeri interi ki, con i = 1, 2, …, M. Se
si vuole formare un fascio nella direzione α per un array formato da M idrofoni spaziati u-niformemente a distanza d: c i d i α τ = ( −1)sin con i = 1, 2, …, M
Dal momento che i ritardi devono essere multipli interi del periodo di campionamento, le direzioni dei fasci che possono essere formate sono quelle per cui:
c d T
k⋅ C = sinα
ovvero solo per
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⋅ ⋅ = c f d c k arcsin α con k intero.
Non è detto che il ritardo da computare sia un multiplo intero del periodo di campionamento. Ta-le limitazione di impiego può esse-re facilmente eliminata tramite un’interpolazione dei dati. Al fine di poter applicare il ritardo effetti-vamente necessario, due campioni successivi relativi al medesimo ca-nale idrofonico vengono interpola-ti con opportuni coefficieninterpola-ti molinterpola-ti- molti-plicativi, che tengono anche conto della variazione della velocità del suono in acqua.
Operativamente i dati campionati ed interpolati vengono memorizzati in apposite celle di memoria denominate stave data RAM, la cui capacità totale dipende dal numero di
idro-k1τ kMτ Σ 1 M … …
fig. 2.22 – Struttura elementare di un beamformer “time delay” digitale
fig. 2.23 – Stave data RAM
Campioni temporali Idrofono 0 0 #idrofoni # campioni
foni componenti l’array, dal massimo ritardo che si deve realizzare e dall’indice di interpo-lazione.
In questo modo l’applicazione di un ritardo si traduce in un idoneo indirizzamento in lettura della RAM in celle di memoria che formano diagonali la cui inclinazione dipende dal particolare ritardo scelto, ovvero dalla direzione di puntamento del fascio.
Beamforming nel dominio della frequenza
Oltre al risparmio in termini di potenza di calcolo, il beamforming nel dominio della frequenza risulta di particolare utilità in quei sistemi sonar che consentono di rappresenta-re i dati in forma spettrale (lofar) e per i quali risulta indubbiamente comodo disporrappresenta-re dirappresenta-ret- diret-tamente dei vari fasci nel dominio della frequenza.
Dalle proprietà della trasformata di Fourier è noto che, se un segnale viene ritardato di Δ secondi, il suo spettro di ampiezza rimane invariato, mentre alla fase si aggiunge il termine lineare –ωΔ. Operando nel dominio della frequenza viene adoperato lo stesso principio ge-ometrico esposto nella trattazione del beamforming nel dominio del tempo, ma, anziché ri-tardare i segnali, questi vengono trasformati secondo Fourier nel dominio della frequenza, quindi vengono moltiplicati per opportuni esponenziali complessi −jωΔ
e ed inviati diretta-mente ad una elaborazione nel dominio frequenziale per la rappresentazione lofar, oppure antitraformati per tornare nel dominio del tempo.
Usando la stessa notazione della fig. 2.21, la Trasformata di Fourier del segnale relativo ad un generico lobo che punta della direzione α sarà:
(
)
∑
( )
− Δ Δ = ⋅ ⋅ m j m m m m a Y e Z ω,α ω ωove Ym
( )
ω rappresenta la trasformata dei segnali provenienti dai singoli idrofoni e am ilcoefficiente della funzione di ponderazione.
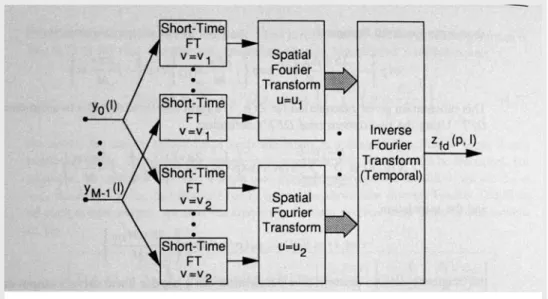
L’implementazione del beamforming nel dominio della frequenza è rappresentata nella fig. 2.24: ciascun segnale proveniente da un singolo canale passa in un banco di N blocchi hardware che effettuano la trasformata di Fourier, una per ciascuna frequenza di interesse, in modo da poter lavorare in banda larga; i campioni nel dominio della frequenza che risul-tano da questa operazione passano in N filtri spaziali.
Ogni filtro spaziale è in grado di effettuare il beamforming dei campioni frequenziali re-lativi ad una della frequenze di interesse, secondo lo schema a blocchi di fig. 2.25.
fig. 2.24 – Schema a blocchi del beamforming nel dominio della frequenza
Σ
1 Δ −jω eΣ
2 Δ −jω e(
ω
,α
Δ1)
Z(
ω
,
α
Δ2)
Z
Σ
M j e−ωΔ(
M)
Zω
,α
Δ( )
ω 1 Y( )
ω 2 Y( )
ω
N Yfig. 2.25 – Schema a blocchi di un filtro spaziale nel dominio della fre-quenza
2.3.2. Signal Processing
Lo scopo primario di un sistema acustico subacqueo passivo è di determinare la presen-za di segnali acustici emessi da semoventi marini, fornendo contemporaneamente la stima di parametri della sorgente che li ha generati.
Per la natura involontaria delle emissioni acustiche di interesse per un sistema sonar passivo, il segnale ricevuto è tipicamente un processo aleatorio, a banda larga e con una durata temporale data dalla geometria della propagazione dei raggi acustici e dal moto del-la piattaforma. Risulta chiaro quindi che è possibile fare solo delle supposizioni sulle pro-prietà statistiche del segnale.
Allo scopo di estrarre tutta l’informazione possibile contenuta nel segnale ricevuto, è essenziale combattere efficacemente la presenza del rumore. Quindi bisogna capire come deve essere fatta la risposta impulsiva del filtro di ricezione in modo tale che alla sua uscita il rapporto segnale rumore (SNR) sia il massimo possibile.
L’SNR è il principale parametro per la valutazione delle prestazioni di un ricevitore in tutte le applicazioni di scoperta di bersagli e di stima di parametri.
In fig. 2.26 è riportato lo schema a blocchi di un ricevitore sonar passivo. All’ingresso della catena ricevente il rapporto segnale rumore sarà pertanto dato da6:
( )
( )
( )
( )
[
]
( )
∫
∫
∫
∫
∞ + ∞ − +∞ ∞ − ∞ + ∞ − +∞ ∞ − Ψ Ψ − Ψ = Ψ Ψ = df f df f f df f df f SNR X X X X X in N S 0 0 1 Dove( )
f S XΨ rappresenta la densità spettrale di potenza del processo di segnale utile,
( )
fN
X
Ψ la densità spettrale di potenza del processo di rumore e
6
Gli integrali al numeratore ed al denominatore rappresentano la potenza statistica del processo, ovvero il valor quadratico medio del processo, che equivale all’integrale della densità spettrale di potenza ed al valore dell’autocorrelazione del processo nell’origine:
( )
{
2}
( )
( )
0 x X f df r t X E =∫
Ψ = +∞ ∞ − h1(t) 2 ⋅ comparatore x(t) y(t) 2 (t) y z(t) Decisionefig. 2.26 – Schema a blocchi del ricevitore di un sonar passivo
-T/2 T/2 1/T
( )
( )
( )
( )
f( )
f f f f N N S X X X X X Ψ = Ψ Ψ + Ψ = Ψ 0 1All’uscita del filtro h1(t) sarà:
( )
( ) ( )
( ) ( )
( )
( )
[
]
( )
( )
( )
{ }
{ }
2 2 2 1 2 1 0 0 1 N S Y Y Y Y Y X X Y E Y E df f df f df f df f f df f H f df f H f y SNR N S N S = Ψ Ψ = Ψ Ψ − Ψ = Ψ Ψ =∫
∫
∫
∫
∫
∫
∞ + ∞ − +∞ ∞ − ∞ + ∞ − +∞ ∞ − ∞ + ∞ − +∞ ∞ − dove( )
( )
( )
( )
f( )
f f f f N N S Y Y Y Y Y Ψ = Ψ Ψ + Ψ = Ψ 0 1Richiamando la (1.14), e facendo riferimento alla fig. 2.27, in ingresso al decisore si ha [2, pag. 366]:
{
} {
}
(
)
} | { | | ) ( 0 2 0 1 H z Var H z E H z E z SNR = −All’uscita del quadratore sarà pertanto:
{ } { }
(
)
} { ) ( 2 0 2 2 0 2 1 2 y Var y E y E y SNR = −Dalla nota formula [8, pag. 68] che consente di esprimere la varianza in termini di valor quadratico medio e valor medio:
{ } { }
2 0 2 4 0 2 0 } {y E y E y Var = −Si assume ora che il segnale ed il rumore siano processi gaussiani a media nulla, fra loro indipendenti. In questo modo il momento del quarto ordine E
{ }
y04 può essere espresso come funzione dei momenti di primo e secondo ordine, secondo la formula [8, pag. 135]:{ }
{ }
{ }
(
) (
)
⎩ ⎨ ⎧ − ⋅ − ⋅ ⋅ ⋅ = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ =∑
= − pari k per 1 3 ... 3 1 dispari k per 0 dove 0 k k Z E Z E i k X E i k i i i k X i X k σ ηConsiderando che ηy =0 per ipotesi e che il modulo quadro può essere visto come un quadratore seguito da un filtro passa basso, che elimina le componenti a frequenza doppia, risulta che:
{ }
{ }
2 0 2 4 0 2E y y E = Allora{ }
{ } { } { }
2 0 2 2 0 2 2 0 2 2 0 2E y E y E y y Var = − = Quindi{ } { }
(
)
{ }
) ( } { } { ) ( 2 2 0 2 2 2 2 0 2 2 2 0 2 1 2 y SNR y E y E y E y E y E y SNR = − = S =All’ingresso del decisore il rapporto segnale rumore sarà:
{ } { }
(
)
{ }
} { } { ) ( 0 2 0 2 0 1 z Var z E z Var z E z E z SNR = − = SPer il calcolo della varianza di z0 si procede come segue:
{ }
{ }
0 2 2 0 0} {z E z E z Var = − (2.2) Per la definizione di potenza statistica del processo7 e per il teorema fondamentale del filtraggio [9, pag. 496]:{ }
z( ) ( )
f H f df E y∫
+∞ ∞ − Ψ = 2 2 2 0 2 0 (2.3)Per il teorema di Wiener-Khintchine8, antitrasformando si ottiene:
{ }
z R( ) ( )
τ R τ dτ E h y∫
+∞ ∞ − = 2 2 0 2 0 Dove 7 Si veda nota 6 8La densità spettrale di potenza per segnali determinati è calcolabile come trasformata di Fourier della fun-zione di autocorrelafun-zione. Tale teorema è estendibile al caso di processi aleatori stazionari [9, pag. 495].
( )
E{
Y(
t) (
Y t) ( ) ( )
Y t Y t}
R y * 0 0 * 0 0 2 0 τ τ τ = + +Per la proprietà dell’apettazione del prodotto di 4 variabili aleatorie gaussiane a media nulla [2, pag. 273]9 e per il fatto che il modulo quadro può essere visto come un quadratore seguito da un filtro passa basso, che elimina le componenti a frequenza doppia, risulta che:
( )
E{
Y(
t) (
Y t)
}
E{
Y( ) ( )
t Y t}
E{
Y(
t) ( )
Y t}
E{
Y(
t) ( )
Y t}
R y 0 * 0 * 0 0 * 0 0 * 0 0 2 0 τ τ τ τ τ = + + + + +Scrivendo le aspettazioni come autocorrelazioni, quindi applicando la definizione di po-tenza statistica del processo10:
( )
τ( )
( )
τ{ }
2 2( )
τ 0 2 2 2 0 0 0 2 0 0 y y y y R R E y R R = + = +Infine, come si nota dalla fig. 2.26 la risposta del filtro che segue il quadratore (che per semplicità di notazione verrà indicato con h2(t)) è normalizzata:
( )
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = T t rect T t h2 1Questo consente ai processi y2 e z di avere il medesimo valor medio. Quindi:
( )
τ{ }
2( )
τ 0 2 0 2 0 y y E z R R = +Pertanto, sostituendo la (2.3) nella (2.2), la varianza di z0 risulta:
{ }
z[
E{ }
z R( )
τ]
R( )
τ dτ E{ }
z E{ }
z E{ }
z R( ) ( )
τ R τ dτ Var∫
y h∫
y h +∞ ∞ − +∞ ∞ − + − = − + = 2 0 2 0 2 0 2 0 2 0 2 2 0 2 0( ) ( )
∫
+∞ ∞ − = R τ R τ dτ z Var y h 2 0 2 0} { (2.4)La funzione di autocorrelazione del filtro h2(t) sarà una funzione triangolare di durata
2T:
( )
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = T rect T T Rh 2 1 1 2 τ τ τ pertanto( )
∫
+ − ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ − = T T y d R T T z Var 0 τ 2 τ τ 0 1 1 } { 9{
} { } { } { } { } { } { }
3 2 4 1 4 2 3 1 4 3 2 1 4 3 2 1x x x E xx E x x E xx E x x E xx E x x x E = + + 10 Si veda. nota 6Il tempo T, larghezza del filtro h2(t) viene preso molto maggiore del tempo di
correla-zione, ovvero dell’inverso della banda equivalente di rumore [2, pag. 218].
) 0 ( ) ( 1 2 2 0 0 y y eq cor R d R B T
∫
+∞ ∞ − = = τ τ (2.5) La funzione di autocorrelazione 2( )
τ 0 yR all’interno dell’integrale ha pertanto una durata molto inferiore a quella della funzione triangolare per la quale è moltiplicata. È pertanto lecito scrivere:
( )
∫
+∞ ∞ − ≈ R τ dτ T z Var 0 2y 0 1 } { (2.6)Sostituendo la (2.5) nella (2.6) si ottiene:
( )
{ }
eq eq y TB y E TB R z Var 2 0 2 2 0 0 } { ≈ 0 =Pertanto il rapporto segnale rumore all’ingresso del decisore è:
{ } { }
(
)
{ }
{ }
2 0 2 2 0 2 0 1 } { ) ( y E z E TB z Var z E z E z SNR = eq S − =Ma dal momento che i processi y e z di hanno il medesimo valor medio: 2
{ }
{ }
( ) ) ( 2 2 0 2 2 2 y SNR TB y E y E TB z SNR = eq S = eqFinora non si è data alcuna descrizione del filtro h1(t) e neppure si è data alcuna
indica-zione per l’ottimizzaindica-zione del sistema nel senso del rapporto segnale rumore di uscita. Per ottimizzare il sistema massimizzando il rapporto segnale rumore di uscita è necessa-rio scegliere opportunamente il filtro h1(t).
Esprimendo il rapporto segnale rumore di uscita in termini di densità spettrali di potenza e sfruttando la definizione di banda equivalente di rumore nel dominio della frequenza:
( ) ( )
( ) ( )
( ) ( )
( ) ( )
⎪⎪ ⎭ ⎪ ⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ Ψ Ψ ⋅ Ψ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ Ψ =∫
∫
∫
∫
∞ + ∞ − ∞ + ∞ − ∞ + ∞ − ∞ + ∞ − 2 2 1 2 1 4 1 2 2 2 1 2 ) ( df f H f df f H f df f H f df f H f T z SNR N S N N X X X X( ) ( )
( ) ( )
∫
∫
∞ + ∞ − +∞ ∞ − Ψ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ Ψ = df f H f df f H f T z SNR N S X X 4 1 2 2 2 1 2 ) (si può applicare la disuguaglianza di Schwarz:
( )
( )
( ) ( )
∫
( )
( )
∫
( ) ( )
∫
+∞ ∞ − ∞ + ∞ − ∞ + ∞ − Ψ Ψ Ψ ≤ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ Ψ Ψ Ψ df f H f df f f df f H f f f N N S N N S X X X X X X 4 1 2 2 2 2 2 1 ottenendo che:( )
( )
∫
+∞ ∞ − Ψ Ψ ≤ df f f T z SNR N S X X 2 2 2 ) ( (2.7)Il rapporto segnale rumore massimo in uscita si ha quando vale l’eguaglianza fra il membro di destra e di sinistra della (2.7), ovvero quando:
( )
( )
( )
f f f H N S X X 2 2 1 Ψ Ψ =Le relazione precedente descrive il filtro di Eckart, ottimo nel caso di rumore bianco e la cui risposta tende ad essere inferiore nelle porzioni di spettro in cui la densità spettrale di potenza di rumore non è bianca.
In fig. 2.28 è riportato lo schema a blocchi di un ricevitore sonar passivo:
Il filtraggio passabanda ha lo scopo di limitare la banda di ricezione alla banda prevista nella successiva processazione, operando in tal modo una riduzione della potenza di rumo-re prima della processazione.
Il blocco tratteggiato in fig. 2.28 rappresenta, per sensori passivi, ciò che il filtro adatta-to rappresenta per sensori attivi, il filtro che rende massimo il rapporadatta-to segnale rumore di uscita. 2 ⋅ NORMALIZZATORE DECISORE A SOGLIA BP
fig. 2.28 – Schema a blocchi della catena di trattamento del segnale
h1(t)
-T/2 T/2 1/T
Il normalizzatore effettua la normalizzazione del processo di rumore.
Per ogni elemento dello schema a blocchi di fig. 2.28 viene proposta la rappresentazione del segnale in uscita. I dati analizzati provengono da uno studio del Nato Undersea Rese-arch Centre relativo alla sperimentazione di un sonar attivo multistatico. I segnali ricevuti da tale sensore sono stati processati tramite un apposito software Matlab sviluppato dai ri-cercatori del Centro. Il software replica la catena di signal processing di un ricevitore di da-ti sonar, consentendo l’analisi a posteriori dei dada-ti raccolda-ti.
Nello specifico è stato analizzato il segnale ricevuto da un sensore-boa ricevente, della durata di 35 secondi. Il segnale è stato fornito in ingresso al programma di calcolo, che è stato interrotto dopo ciascuno step del signal processing ed i dati così forniti sono stati gra-ficati.
Vengono riportati in questo paragrafo i dati relativi a tutta la catena di processazione, compresi quelli riguardanti il processo di beamforming.
Trattandosi di un sensore facente parte di un sistema attivo multistatico, oltre al rumore di fondo, viene ricevuto (intorno al secondo 5) l’impulso acustico trasmesso da un trasdut-tore in zona di campo lontano e ricevuto dalla propagazione diretta (direct blast).
In fig. 2.29 sono rappresentati i dati in uscita da ciascun canale (idrofono più preampli-ficatore). Questo tipo di rappresentazione consente di dare una prima stima della integrità del sensore. È chiaro che i livelli di segnale o rumore ricevuto dagli idrofoni dovrebbero risultare simili per tutti gli idrofoni. Bassi livelli come quelli rappresentati dalle linee oriz-zontali azzurre indicano un malfunzionamento dello specifico canale.
fig. 2.29 – Rappresentazione dei dati in uscita da ciascun canale (idrofono più preamplificatore)
L’applicazione dell’amplificazion e con AGC con-sente una norma-lizzazione della dinamica. Ne ri-sulta un appiatti-mento dei segnali provenienti dai singoli canali, che nasconde gli ef-fetti negativi deri-vanti dal cattivo funzionamento di alcuni elementi dell’array. Come
si nota dalla fig. 2.30, non sono più presenti infatti, dopo il passaggio nell’amplificatore a guadagno variabile, le righe azzurre di fig. 2.29. La riga verticale in corrispondenza del se-condo 12 potrebbe indicare l’eco di un bersaglio, oppure un disturbo, od un errore del si-stema. La sua natura sarà chiara dopo il filtro adattato: se non verranno rilevati contatti in corrispondenza del secondo 12, sarà evidente che si trattava di un disturbo.
Con il beamforming si passa dalla visualizzazione tempo-canale alla visualizzazione tempo-angolo ri-portata in fig. 2.31. Si perde
l’informazione sulla bontà dei canali e si passa
l’informazione sulla posizione dei contatti.
Al posto di ri-ghe verticali più scure presenti nella visualizza-zione tempo-canale, indicanti un contatto, ci si aspetta di trovare zone più scure in corrispondenza dello stesso tempo e di
fig. 2.30 – Ampiezza dei singoli canali dopo amplificazione variabile
un dato angolo. È evidente da questa rappresentazione che il trasduttore attivo usato per l’esperimento si tro-vava sul bearing 140° del ricevitore.
La stessa informa-zione si ottiene con un diagramma bidimen-sionale di fig. 2.32, nel quale ogni curva (ogni colore) rappre-senta un particolare rilevamento. Si nota come segnali molto forti come quello del direct blast vengano ricevuti da tutte le di-rezioni.
I dati in uscita dal beamformer vanno in ingresso al filtro adattato, che ha il compito di massimizzare il rapporto segnale/rumore ad istanti ti prefissati, in presenza di rumore
bian-co.
Dalla fig. 2.33 si nota immedia-tamente che non è presente più al-cun segnale al secondo 12, mentre invece all’uscita del be-amforming si sa-rebbe detto che fosse identifica-bile una forte sorgente di se-gnale, addirittura
di ampiezza in media maggiore di quella del direct blast. Si trattava quindi di un disturbo.
fig. 2.32 – Rappresentazione bidimensionale dei segnali in uscita dal beamforming
La fig. 2.34 fornisce lo stesso tipo di rappre-sentazione bidimensio-nale di fig. 2.32.
Prima di entrare nel decisore a soglia av-viene la cosiddetta normalizzazione del rumore, ovvero viene effettuata una stima della varianza del pro-cesso di rumore, per sottrarre quest’ultimo al segnale uscito dal filtro adattato,
ottenen-do il risultato illu-strato nella fig. 2.35.
Dopo il filtro adattato e la nor-malizzazione, il segnale passa nel decisore a soglia, la cui uscita è vi-sualizzabile in fig. 2.36 ed è rap-presentata da dati di tipo 0/1.
Per le succes-sive fasi di pre-sentazione e di analisi dei bersa-gli, può essere utile mantenere
l’informazione relativa all’energia dei segnali. Questo è facilmente ottenibile impiegando lo schema a blocchi di fig. 2.37.
fig. 2.34 – Rappresentazione bidimensionale dei segnali in uscita dal filtro adattato
fig. 2.35 – Uscita del normalizzatore Matched Filter
Questa operazione corrisponde a moltipli-care la fig. 2.36 per la fig. 2.33. I valori 0 (blu) rimarranno nulli, mentre i valori 1 (rosso) acquisteranno il valore dell’energia dei segnali. Il risultato di questa o-perazione è riportato in fig. 2.38.
fig. 2.38 – Distribuzione di energia sui contatti fig. 2.36 – Uscita del decisore a soglia
MF NORM DET
Distribuzione di ener-gia su ciascun contatto
2.3.3. Presentazione
I risultati della processazione del segnale devono poi essere interpretati da un operatore. Si rende pertanto necessario un collegamento fra operatore e sistema sonar, noto con il nome di Human-Machine Interface (HMI). Un tale tipo di interfaccia riveste un ruolo de-terminante: qualora l’operatore non si trovasse nelle condizioni di poter interpretare effica-cemente le informazioni elaborate dal sistema, la tecnologia che lo compone risulterebbe inutilizzabile.
Lo stesso acronimo sonar suggerisce l’impiego del senso umano dell’udito per la lettura dei risultati acquisiti dal sistema. Storicamente si ricordano infatti uomini in cuffia per l’ascolto dei segnali captati dagli idrofoni. Alle loro orecchie giungevano segnali immersi in rumore ambientale, che si presentava in forme diverse: un tono sordo alle basse frequen-ze; alle alte frequenze un fischio nitido.
Il funzionamento dell’orecchio umano è stato alla base del progetto di alcuni sistemi impiegati nel passato. Ad esempio, la determinazione della direzione orizzontale di prove-nienza di un suono o di un rumore viene effettuata dall’udito prevalentemente in base alla differenza di tempo con il quale il suono incide sui due orecchi; sulla base di tale principio si è pensato di dividere la base ricevente subacquea in due semibasi uguali e distinte, cia-scuna delle quali fornisce i segnali che vengono ricevuti dai due orecchi [3, pag. 323].
Tuttavia l’orecchio umano presenta dei limiti e, con l’introduzione delle tecniche di cor-relazione, si è successivamente preferito affiancare la presentazione visiva alla presenta-zione uditiva. Infatti l’orecchio umano è limitato inferiormente e superiormente nelle fre-quenze sonore udibili. Il limite inferiore è generalmente ritenu-to 20 Hz; il limite superiore va-ria da soggetto a soggetto, sog-getti giovani possono ascoltare suoni, se sufficientemente in-tensi, fino alla frequenza di 20.000 Hz; soggetti di media età possono invece ascoltare suoni la cui frequenza non supera ge-neralmente i 12.000-16.000 Hz [3, pag. 326].
La fig. 2.39 rappresenta il
fig. 2.39 Soglia di udibilità, di dolore e campo della musica [3, pag. 325]

![fig. 2.11 – Elementi interni della sezione acustica di un Towed Array [23]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7329907.90666/9.892.131.791.399.757/fig-elementi-interni-sezione-acustica-towed-array.webp)