5. ANALISI SIMULATIVA
In questo capitolo descriveremo lo studio simulativo che abbiamo condotto utilizzando RSVP-TE/ns (il modulo che abbiamo implementato).
Verificheremo dapprima il funzionamento dello scheduler WFQ in varie situazioni, e successivamente passeremo al vero scenario di simulazione, in cui abbiamo analizzato le strategie di allocazione di chiamate VoIP in reti con tecnologia MPLS: mostreremo gli script utilizzati, i risultati delle varie sessioni di simulazione e le conclusioni tratte.
5.1. Lo scheduler WFQ
Come detto nei capitoli precedenti, il modulo RSVP tratta i flussi di traffico separatamente, effettuando per ciascuno di essi una prenotazione isolata. L’algoritmo di scheduling del piano dati utilizzato è il WFQ (Weighted Fair Queuing), che permette
di creare una singola coda per ogni prenotazione RSVP, indicando la dimensione della banda da allocare e del buffer. Naturalmente se una richiesta eccede le risorse a disposizione il modulo di Admission Control lo segnala all’agent RSVP, che rifiuta la prenotazione.
Analizziamo nel dettaglio il comportamento dello scheduler WFQ implementato in RSVP/ns (e utilizzato anche nel nostro modulo), soprattutto per quanto riguarda la ridistribuzione della banda non allocata.
Partiamo dal caso in cui tutte le sorgenti che immettono traffico nella rete effettuino una richiesta di allocazione di risorse; supponiamo inoltre che il totale delle prenotazioni non raggiunga l’intera capacità disponibile nei link e che le varie sorgenti immettano un traffico maggiore di quello dichiarato (e per il quale hanno effettuato quindi la prenotazione). In questo caso la banda “libera” viene ridistribuita tra i flussi proporzionalmente all’allocazione effettuata per i flussi stessi: lo scheduler assume cioè come “pesi” per il suo algoritmo di ridistribuzione le quantità di banda allocata.
Mostriamo a tal proposito i grafici ottenuti dai dati raccolti effettuando delle simulazioni su Network Simulator. Abbiamo messo in “competizione” per le risorse due sorgenti CBR su link a 100Mbps (figura 5.1): la prima ha un rate medio di
80Mbps ed effettua una prenotazione di 50Mbps, la seconda ha un rate medio di 50Mbps ed effettua una prenotazione di 25Mbps; per entrambe la dimensione dei pacchetti è di 500 byte.
Come appare evidente dai dati, le due sorgenti dichiarano e prenotano meno di quanto poi trasmettono. Nel grafico in figura 5.2-a abbiamo i rate dei flussi trasmessi dalle sorgenti. Con un ammontare totale di 75Mbps di banda allocata, sono disponibili per i flussi ancora 25Mbps: lo scheduler li ridistribuisce secondo la regola enunciata prima, per cui conserva la proporzione di 2:1 che abbiamo nella prenotazione ed assegna 17Mbps alla prima sorgente e 8Mbps alla seconda. Il tutto è mostrato nel grafico in figura 5.2-b, dove abbiamo
l’andamento temporale dei rate di ricezione (misurati in ingresso all’ultimo router): la prima sorgente raggiunge un rate di circa 67Mbps e la seconda un rate di 33Mbps.
30 40 50 60 70 80 90 100 110 tempo (s) ra te di t ras m issi one (Mbps ) 1° sorgente CBR 2° sorgente CBR 20 30 40 50 60 70 80 90 tempo (s) ra te di r ic ez ione ( M bps ) 1° sorgente CBR 2° sorgente CBR 100
Figura 5.2-a: rate di trasmissione delle due sorgenti
Figura 5.2-b: rate di ricezione
100 0
Abbiamo ripetuto le stesse operazioni con delle sorgenti diverse, per dimostrare come la ridistribuzione della banda avvenga proprio secondo la prenotazione effettuata e non secondo il traffico immesso. Abbiamo infatti introdotto, nello scenario precedente, una prima sorgente con traffico pari a 80Mbps e una seconda sorgente con traffico pari a 120Mbps; abbiamo poi effettuato le stesse prenotazioni viste prima (50Mbps e 25Mbps) e abbiamo constatato come di nuovo lo scheduler distribuisca la banda libera secondo la proporzione delle prenotazioni (2:1) e non secondo la proporzione del traffico immesso (2:3). 60 70 80 90 100 110 120 130 140 150 tempo (s) ra te di tr as m iss ione (Mbps ) 1° sorgente CBR 2° sorgente CBR
Figura 5.3–a: rate di trasmissione delle due sorgenti
20 30 40 50 60 70 80 90 tempo (s) ra te di r ic e zi one (Mbp s) 1° sorgente CBR 2° sorgente CBR
Le figure 5.3-a e 5.3-b mostrano quanto detto, anche se bisogna sottolineare che quanto più link e buffer sono congestionati, tanto più il comportamento si discosta da quello ideale (come dimostra la parte finale del secondo grafico, in cui la sorgente a 120Mbps inizia a sfruttare più banda di quanta in effetti gliene spetti secondo l’algoritmo).
Abbiamo inoltre analizzato come avviene la ridistribuzione della banda libera da parte dello scheduler nel caso in cui solo alcune sorgenti effettuino la prenotazione delle risorse.
Utilizzando lo scenario in figura 5.4-a, abbiamo inserito due sorgenti che immettono in rete un traffico con rate medio pari
Figura 5.3–b: rate di ricezione
rispettivamente a 80Mbps e 60Mbps ed effettuano una prenotazione di banda pari a 50Mbps e 30Mbps. Inoltre stavolta abbiamo aggiunto due sorgenti che immettono un traffico pari a 30Mbps e 15Mbps senza effettuare però alcuna richiesta di banda (figura 5.4-b).
0 20 40 60 80 100 tempo (s) ra te di t rasmissione (M bp s) 1° sorgente CBR 2° sorgente CBR 3° sorgente CBR 4° sorgente CBR
Con una prenotazione totale pari a 80Mbps, lo scheduler ha la possibilità di ridistribuire 20Mbps: li assegna tutti alle sorgenti che non hanno effettuato prenotazioni (figura 5.5), secondo un rapporto 2:1 in favore della terza sorgente (14Mbps e 6Mbps), rapporto proporzionale quindi al traffico immesso in rete; questa modalità di ridistribuzione si ha perché le prime due sorgenti generano un traffico maggiore di quello dichiarato, non “rispettando” in un certo senso gli accordi presi con la rete, e quindi vengono penalizzate rispetto alle altre due sorgenti. Abbiamo modificato i rate diverse volte, ma i risultati sono gli stessi: in presenza di sorgenti che non effettuano prenotazioni
Figura 5.4-b: rate di trasmissione delle 4 sorgenti
(e che quindi non possono “violare” alcun accordo), lo scheduler assegna loro le risorse libere (in proporzione al traffico che immettono in rete), trascurando completamente le sorgenti che invece prenotano meno di quanto poi trasmettono.
0 10 20 30 40 50 60 70 80 tempo (s) ra te d i r ice zi o n e (M b p s) 1° sorgente CBR 2° sorgente CBR 3° sorgente CBR
Tutti i discorsi appena fatti valgono non solo per la banda non allocata, ma anche per la banda allocata e non utilizzata: anch’essa viene ridistribuita innanzitutto tra le sorgenti che non violano gli accordi presi (in proporzione al traffico generato), e, se non ci sono sorgenti di questo tipo, tra le sorgenti che riservano risorse (in proporzione alla banda allocata).
Infine abbiamo verificato il comportamento dello scheduler WFQ nel caso di rottura di un link e di setup di un LSP
Figura 5.5: rate di ricezione
alternativo. Come già sappiamo (cfr. paragrafo 4.5.), quando un collegamento non è più funzionante i nodi direttamente connessi al link immettono nella rete dei messaggi di notifica; non appena l’informazione giunge ai nodi d’ingresso e d’uscita dell’LSP, essi inviano dei messaggi di tear, che invitano i nodi interni a rilasciare le risorse allocate e a cancellare gli state relativi all’LSP. Una volta effettuate queste operazioni, è possibile settare un nuovo LSP lungo un percorso alternativo e reinstradare i pacchetti su di esso.
In figura 5.6 c’è la topologia usata per quest’ultima analisi sullo scheduler: abbiamo un path primario verso la destinazione 7 attraverso i nodi 3-4 e un path alternativo attraverso i nodi 3-5-6. I link hanno una capacità di 100Mbps.
3 7
4
5 6
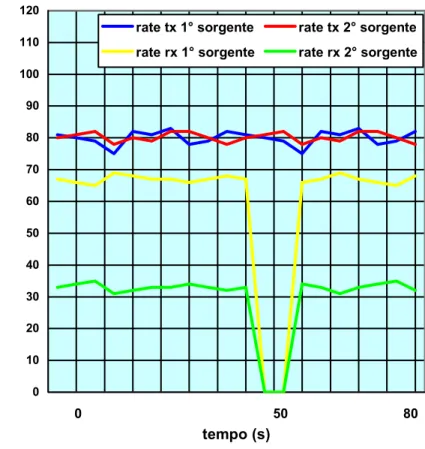
Le due sorgenti generano ciascuna un traffico pari a 80Mbps, ma la prima prenota 50Mbps e la seconda 25Mbps. Il percorso scelto da entrambe le sorgenti è quello più breve, che passa attraverso i nodi 3 e 4. Come già visto in precedenza, lo scheduler ridistribuisce i 25Mbps non allocati secondo la proporzione delle prenotazioni (2:1): la prima sorgente usufruisce quindi di 67Mbps e la seconda di 33Mbps (figura 5.7). 20 30 40 50 60 70 80 90 100 110 tempo (s) ra te (Mbp s )
rate tx 1° sorgente rate tx 2° sorgente rate rx 1° sorgente rate rx 2° sorgente
50 0
Al secondo 50 della simulazione si rompe però il link fra i nodi 3 e 4 (figura 5.8): parte subito il processo di segnalazione e di rilascio delle risorse e degli LSP, e già dopo qualche secondo le due sorgenti possono settare il path alternativo (attraverso i nodi 3-5-6), prenotando le stesse risorse (50 e 25 Mbps).
Anche in questo caso lo scheduler non cambia il suo comportamento nella distribuzione della banda non allocata, conservando la proporzione delle prenotazioni: come mostra la figura 5.9, dopo un piccolo intervallo temporale necessario alle operazioni di rerouting, in cui i pacchetti delle due sorgenti vengono persi, viene ristabilita la situazione precedente, con la
3 7
4
5 6
prima sorgente che di nuovo usufruisce di 67Mbps e la seconda che ne sfrutta 33.
Quindi anche per il path alternativo lo scheduler utilizza con le sorgenti di traffico le stesse modalità di distribuizione della banda non allocata.
0 10 20 30 40 50 60 70 80 90 100 110 120 tempo (s) ra te (Mbps )
rate tx 1° sorgente rate tx 2° sorgente rate rx 1° sorgente rate rx 2° sorgente
80 50
Figura 5.9: rate trasmessi e ricevuti prima e dopo la rottura
5.2. L’analisi simulativa
Dopo aver verificato le modalità di funzionamento dello scheduler WFQ, passiamo alla presentazione delle simulazioni volte all’analisi delle strategie di allocazione di chiamate VoIP in una rete con piano di controllo RSVP-TE e piano dati MPLS. Descriveremo lo scenario di simulazione, i vari script utilizzati e i risultati ottenuti.
5.2.1. Lo scenario di simulazione
La rete di telecomunicazioni su cui abbiamo lavorato ha una topologia abbastanza semplice, come mostra la figura 5.10: ci sono tre sorgenti di traffico e un unico destinatario, il nodo 5.
Figura 5.10: scenario di simulazione
3 2 BestEffort 1 FTP 5 Dest 0 VoIP 4 VoIP best effort Dest
Le prime due sorgenti di traffico rappresentano altrettanti operatori di rete, col primo che gestisce un servizio di chiamate VoIP (la telefonia su Internet) e il secondo che gestisce un servizio FTP. La terza sorgente rappresenta invece il traffico best effort della rete.
I comandi Tcl che servono a stabilire questa topologia di rete (e che fanno parte dello script di simulazione simul.tcl, mostrato interamente nell’Appendice C) sono i seguenti:
set n0 [$ns node] set n1 [$ns node] set n2 [$ns node] set n3 [$ns mpls-node] set n4 [$ns mpls-node] set n5 [$ns node] $ns duplex-rsvp-link $n0 $n3 100Mb 1ms 0.99 1000 50000 Param Null $ns duplex-rsvp-link $n1 $n3 100Mb 1ms 0.99 1000 50000 Param Null $ns duplex-rsvp-link $n2 $n3 100Mb 1ms 0.99 1000 50000 Param Null $ns duplex-rsvp-link $n3 $n4 100Mb 1ms 0.99 1000 50000 Param Null $ns duplex-rsvp-link $n4 $n5 100Mb 1ms 0.99 1000 50000 Param Null
set rsvp0 [$n0 add-rsvp-agent] set rsvp1 [$n1 add-rsvp-agent] set rsvp2 [$n2 add-rsvp-agent] set rsvp3 [$n3 add-rsvp-agent] set rsvp4 [$n4 add-rsvp-agent] set rsvp5 [$n5 add-rsvp-agent]
for {set i 3} {$i < 5} {incr i} { set a n$i
set m [eval $$a get-module "MPLS"] eval set LSRmpls$i $m}
Come risulta dai comandi, abbiamo caricato un agent RSVP su tutti i nodi della rete e il modulo MPLS sui nodi di backbone (3 e 4), in modo da poter utilizzare il protocollo RSVP-TE.
Abbiamo inoltre utilizzato i duplex-rsvp-link, come richiede RSVP-TE/ns, con capacità pari a 100 Mbit, ritardo di 1 ms, il 99% della banda prenotabile, 1 Kbps riservato ai messaggi di segnalazione e un buffer di 50000 byte.
5.2.2. Le sorgenti di traffico
Per quanto riguarda il traffico delle tre sorgenti, abbiamo utilizzati alcuni degli strumenti messi a disposizione da NS (tracce, simulatori di applicazioni e generatori di traffico).
Per la prima sorgente abbiamo utilizzato la classe TrafficTrace, che permette di generare pacchetti in base ai dati contenuti in un file di traccia costituito da due colonne: nella prima è indicato l’intervallo temporale che deve trascorrere prima della generazione del nuovo pacchetto e nella seconda la dimensione in byte del pacchetto stesso (figura 5.11).
0.000572 63 0.002945 63 0.064009 63 0.000683 63 0.000482 63 0.060400 63 0.128739 63 0.000567 63 0.000503 63 0.057445 63 0.000712 63 0.046931 63 0.127159 63 0.000560 63 0.000479 63 0.058675 63 0.030661 63 0.027312 63
Questa classe riveste un ruolo fondamentale nello studio di problematiche di rete, in quanto molto spesso le sorgenti di traffico non sono realmente modellabili con le classi messe a disposizione da NS; in questi casi quindi si possono acquisire dati di traffico effettuando delle sessioni di misura sulla rete, e da questi dati si generano poi i file di traccia: in questo modo il traffico prodotto dalla sorgente durante la simulazione non sarà più ottenuto da un modello matematico (quindi con le relative approssimazioni più o meno rilevanti), ma proprio dalla riproduzione del traffico osservato nel mondo reale durante la sessione di misura.
I comandi necessari all’utilizzo della classe TrafficTrace sono i seguenti:
set f5 [new Tracefile] $f5 filename traccia.dat
set app0 [new Application/Traffic/Trace] $app0 attach-tracefile $f5
In pratica si crea un oggetto della classe Tracefile (f5 in questo caso), lo si collega al file di traccia (traccia.dat) mediante il metodo filename e lo si associa ad una applicazione (app0) mediante il metodo attach-tracefile.
In realtà il file traccia.dat non è un semplice traccia ottenuta dalla misura di traffico reale; il file a nostra disposizione, dal nome audio.dat e mostrato in parte nella figura 5.11, è stato ricavato dalla “misurazione” di una singola chiamata VoIP, mentre per la nostra simulazione avevamo bisogno di un aggregato di tali chiamate. Ecco allora che abbiamo ideato uno script apposito, aggregato.tcl, che riceve da shell il numero di chiamate che si vogliono aggregare e, sfruttando la traccia audio.dat, realizza una nuova traccia aggregata (traccia.dat). Per realizzare tale aggregato abbiamo utilizzato la topologia mostrata in figura 5.12: abbiamo settato un numero di nodi pari al numero di chiamate da aggregare e abbiamo collegato ognuno di essi con link ad altissima velocità (10Gbps) al nodo Mux (che funge appunto da multiplatore), collegato a sua volta ad un ricevitore (Ric). Quindi abbiamo “attaccato” il file di traccia della chiamata VoIP ad ognuno dei nodi sorgente. C’è da sottolineare che per questa operazione sfruttiamo la proprietà di NS per cui ogni oggetto della classe TraceFile determina in maniera casuale il punto del file di traccia da cui iniziare a prendere le informazioni necessarie per la generazione del traffico, evitando in questo modo problemi di correlazione dei traffici derivanti dalla partenza sincronizzata di sorgenti che utilizzano lo stesso file di traccia.
Abbiamo quindi posto una sonda tra i nodi Mux e Ric, tramite il metodo trace-queue della classe Monitor, per monitorare gli arrivi dei pacchetti delle varie sorgenti e creare poi il file di traccia desiderato mediante la funzione tracciatura mostrata qui di seguito (al solito, per lo script completo si rimanda all’Appendice C):
set f4 [open sonda w]
$ns trace-queue $Mux $Ric $f4
proc tracciatura {} {
global ns sonda traccia.txt set f14 [open sonda r]
Mux Ric
set ft [open traccia.txt w] set vecchioarrivo 0
while { [gets $f14 pp] != -1 } { if {[lindex $pp 0] == "r" } { set nuovoarrivo [lindex $pp 1]
set intertempo [expr $nuovoarrivo –
$vecchioarrivo] set vecchioarrivo $nuovoarrivo
puts $ft "$intertempo [lindex $pp 5]" }
}
close $f14 close $ft }
Nella funzione tracciatura andiamo a leggere nel file di trace sonda gli istanti di arrivo dei pacchetti, calcoliamo gli intertempi (come richiesto dal formato dei file di traccia) e li andiamo a scrivere nel file traccia.txt, assieme alla dimensione dei pacchetti.
Bisogna aggiungere che il file così prodotto è naturalmente in caratteri ASCII, mentre la classe TrafficTrace utilizza file in formato binario (traccia.dat): si rende allora necessaria una conversione fra i formati, realizzata dal file convbinary.tcl (riportato nell’Appendice).
Nello script aggregato.tcl è inoltre presente una funzione per il calcolo del rate di traffico (record) che calcola e stampa a monitor il peak rate e il rate medio dell’aggregato di chiamate. Tutte le stesse operazioni appena descritte sono state ripetute per creare il traffico da utilizzare durante la simulazione per la sorgente 2, con l’unica differenza che nel nuovo file ftp.tcl il traffico delle singole sorgenti non viene da un file di traccia, bensì è stato ottenuto grazie ai simulatori di applicazioni di NS, e in particolare grazie alla classe Application/FTP. I comandi con i quali creiamo un’applicazione FTP per ognuno dei nodi sorgente sono i seguenti:
set sink0 [new Agent/TCPSink] $ns attach-agent $Ric $sink0
for {set i 1} {$i < ($numero_nodi + 1)} {incr i} { set app$i [new Application/FTP]
set tcp$i [new Agent/TCP] [set tcp$i] set fid_ $i
$ns attach-agent [set n$i] [set tcp$i] [set app$i] attach-agent [set tcp$i] $ns connect [set tcp$i] $sink0}
Infine per la terza sorgente (quella best effort) abbiamo usato la classe TrafficGenerator, alla quale appartengono tutti gli
oggetti che generano traffici con determinate caratteristiche statistiche e i cui parametri possono essere specificati attraverso le variabili membro della classe stessa. In particolare noi abbiamo utilizzato la classe CBR, come mostrano i seguenti comandi, che genera traffico a rate costante con pacchetti di dimensione fissa:
set udp2 [new Agent/UDP] $ns attach-agent $n2 $udp2 $udp2 set packetSize_ 500 $udp2 set fid_ 3
set cbr2 [new Application/Traffic/CBR] $cbr2 set packetSize_ 500
$cbr2 set rate_ 92Mb $cbr2 set random_ 1 $cbr2 attach-agent $udp2
5.2.3. La simulazione
In questa sezione analizzeremo nel dettaglio lo script utilizzato per le sessioni di simulazione.
Dopo aver creato la topologia della rete, abbiamo dimensionato il traffico delle sorgenti esaminate nella precedente sezione: 9 per la prima sorgente, abbiamo creato un aggregato di
chiamate VoIP con la traccia della chiamata a disposizione (il numero di chiamate è dipeso naturalmente dal tipo di
simulazione effettuata). In figura 5.13 è mostrato per esempio l’andamento dell’aggregato di 100 chiamate.
Aggregato VoIP 800000 900000 1000000 1100000 1200000 1300000 1400000 1500000 tempo (s) rate (b p s )
9 per la seconda sorgente abbiamo aggregato il traffico di vari utenti che effettuano sessioni FTP, ottenendo così un traffico totale con rate medio pari a 12Mbps, dall’andamento mostrato in figura 5.14;
9 per la terza sorgente abbiamo generato un traffico CBR con rate medio pari a 92Mbps e pacchetti di 500 byte (fig. 5.14).
Figura 5.13: andamento temporale del rate dell’aggregato VoIP
100 0
5000000 15000000 25000000 35000000 45000000 55000000 65000000 75000000 85000000 95000000 tempo (s) rate ( b p s) best effort FTP
Andiamo ad analizzare ora la lista degli eventi, partendo dalle righe dello script di simulazione:
$ns at 0.2 "$app0 start" $ns at 100.0 "$app0 stop" $ns at 0.2 "$app1 start" $ns at 100.0 "$app1 stop" $ns at 0.2 "$cbr2 start" $ns at 100.0 "$cbr2 stop"
Figura 5.14: andamento temporale delle sorgenti FTP e best effort
100 0
$ns at 0.5 "$LSRmpls3 create-crlsp $n0 $n5 0 1 0 +$banda $buffer 32 3_4_" $ns at 0.5 "$LSRmpls3 create-crlsp $n1 $n5 0 2 1 +10000000 5000 32 3_4_" $ns at 0.7 "$LSRmpls3 bind-flow-erlsp 5 1 0" $ns at 0.7 "$LSRmpls3 bind-flow-erlsp 5 2 1" $ns run
All’istante 0.2 facciamo partire contemporaneamente le tre sorgenti di traffico, come mostra l’immagine NAM in figura 5.15. 3 2 BestEffort 1 FTP 5 Dest 0 VoIP 4 VoIP dest 2 best effort
All’istante 0.5 facciamo inoltrare, per le prime due sorgenti, la richiesta di istaurazione dell’LSP con relativa prenotazione delle risorse, richiesta che comporta:
9 l’invio del Path message da parte delle sorgenti (figura 5.16-a) lungo il percorso indicato dall’ERO object;
9 la memorizzazione delle informazioni del Path message nei psb da parte dei nodi lungo il percorso;
9 l’invio del messaggio di Resv da parte del destinatario (figura 5.16-b) lungo il percorso inverso;
9 l’allocazione delle risorse e il setup delle tabelle per il label switching da parte dei nodi interni.
3 2 BestEffort 1 FTP 5 Dest 0 VoIP 4 Dest VoIP 2 best effort
3 7 Dest 2 BestEffort 6 1 FTP 5 0 4
All’istante 0.7 c’è il binding tra gli LSP e i flussi, e da questo momento in poi le prime due sorgenti sfruttano gli LSP settati con le relative risorse e i loro pacchetti vengono inoltrati secondo il label switching.
5.3. I risultati delle simulazioni
Prima di mostrare i risultati delle simulazioni, spieghiamo brevemente le procedure utilizzate per la raccolta dei vari dati. Anche queste funzioni, all’interno dello script utilizzato per la simulazione, sono riportate nell’appendice C.
4 5
Figura 5.16-b: invio dei Resv message
3 VoIP
Dest
Alcune procedure servono a calcolare i rate delle tre sorgenti, sia all’uscita delle sorgenti stesse che all’ingresso del nodo di destinazione, altre calcolano la percentuale di pacchetti persi per ogni flusso, altre ancora il ritardo sperimentato nella rete da parte dei pacchetti per andare dal mittente al destinatario; tutte riportano sia l’andamento temporale di queste grandezze che i valori medi e massimi. Esse utilizzano delle sonde che monitorizzano il comportamento dei pacchetti tra i nodi e che riportano le varie informazioni nei file di trace, dai quali le procedure vanno poi a leggerle ed elaborarle per calcolare le grandezze di interesse.
Naturalmente per ottenere risultati attendibili e “neutralizzare” la casualità delle simulazioni abbiamo effettuato tutta una serie di prove con semi diversi, dalle quali abbiamo poi ricavato i valori medi e gli intervalli di confidenza.
Nell’analisi dei vari parametri abbiamo inoltre trascurato la fase “transitoria” della simulazione in cui le sorgenti trasmettono ma non sono state ancora effettuate le prenotazioni di risorse (in pratica il primo secondo di simulazione).
Per quanto riguarda le sessioni di simulazione, possiamo dividerle in due tipologie:
9 nella prima abbiamo fissato il traffico delle tre sorgenti e la banda allocata per la sorgente FTP, e al variare della banda
allocata per la sorgente VoIP abbiamo ricavato i valori dei rate, dei pacchetti persi e dei ritardi;
9 nella seconda invece abbiamo fissato la banda allocata alla sorgente VoIP (oltre ai parametri delle altre due sorgenti), e al variare del numero di chiamate VoIP abbiamo calcolato le stesse grandezze.
Per entrambe le tipologie, le sorgenti VoIP e FTP prenotano risorse per un ammontare di traffico minore di quello che poi immettono nella rete, perciò, come visto nel paragrafo 5.1., lo scheduler non assegna loro alcuna risorsa aggiuntiva e riserva tutta la banda libera alla sorgente best effort.
100 1000 10000 100000 1000000 10000000 tempo (s) rate r icevu ti (K b p s) VoIP FTP best effort
Figura 5.17: rate ricevuti (in scala logaritmica)
In figura 5.17 sono riportati per esempio gli andamenti dei rate di ricezione delle tre sorgenti in una simulazione con prenotazione per la sorgente VoIP pari al 60% del peak rate: gli andamenti mostrano proprio come alle prime due sorgenti vengano riservate solo le risorse prenotate (il 60% del peak rate, e cioè 870Kbps, per la sorgente VoIP e 10Mbps per la sorgente FTP), mentre alla sorgente best effort venga assegnata tutta la restante banda libera (circa 89.1Mbps).
Nel grafico seguente c’è invece il confronto tra gli andamenti del rate del traffico VoIP trasmesso e ricevuto, nel caso sempre di prenotazione per il VoIP pari al 60% del rate di picco.
900000 950000 1000000 1050000 1100000 1150000 1200000 1250000 1300000 1350000 1400000 tempo (s) ra te (bps ) VoIP trasmesso VoIP ricevuto
Figura 5.18: rate di trasmissione e ricezione della sorgente VoIP
100 0
5.3.1. Prima tipologia: al variare della banda
Presentiamo i dati per la prima tipologia di simulazioni, in cui abbiamo supposto che il server VoIP gestisca fino a 100 chiamate contemporanee, e debba decidere di conseguenza quanta banda allocare per il suo servizio. Abbiamo così aggregato 100 chiamate VoIP con la traccia a disposizione (pacchetti di 63B, rate medio di 13Kbps e peak rate di 20Kbps), ottenendo un flusso con rate medio di 1.1Mbps e peak rate di 1.45Mbps. Abbiamo poi fatto variare la richiesta di allocazione della banda per la sorgente VoIP dall’80% al 100% del peak rate con passi di 5 punti percentuali, riservando a tale servizio dei buffer da 6000B. Per quanto riguarda gli altri mittenti, abbiamo sempre allocato 10Mbps per la sorgente FTP, mentre non c’è alcuna prenotazione per la terza sorgente. Per la definizione della QoS associata al servizio considerato, abbiamo fatto riferimento alle recommendation Y.1540 [14] e Y.1541 [15] dell’ITU-T: la prima definisce i parametri di QoS e come misurarli, la seconda introduce il concetto di Classe di Servizio (CoS) e definisce 6 differenti classi. Per ogni CoS la recommendation indica il valore massimo che i parametri di QoS non devono superare. I parametri sui quali si è incentrata la nostra analisi simulativa sono l’IPTD (IP Packet Transfer Delay) e l’IPLR (IP Packet Loss Ratio).
La tabella in figura 5.19-a riporta appunto i valori massimi relativi ai parametri di nostro interesse indicati dalla recommendation [15], mentre la tabella in figura 5.19-b presenta caratteristiche ed esempi dei servizi che possono essere supportati dalle classi definite.
Network performance Parameter Objective Class 0 Class 1 Class 2 Class 3 Class 4 Class 5 IPTD Upper bound 100 ms 400 ms 100 ms 400 ms 1 s Not spec. IPLR Upper bound 10-3 10-3 10-3 10-3 10-3 Not Spec.
Service Class Features and examples of services 0 Real time, sensitive to delay jitter, high interactivity
(Voice over IP, videoconference)
1 Real time, sensitive to delay jitter (videoconference)
2 Data transfer, high interactivity (signaling)
3 Data transfer, low interactivity (signaling)
4 Only data loss sensitive (data transfer, video streaming)
Figura 5.19-a: valori massimi dei parametri di QOS per ogni CoS
Dalle tabelle si ricava che per il servizio VoIP dobbiamo fare riferimento alla classe 0, e quindi abbiamo adottato per il parametro IPTD un upper bound 100ms e per il parametro IPLR un upper bound di 10-3.
Abbiamo inoltre assunto che i pacchetti che superano l’IPTD massimo vengano scartati dall’applicazione, quindi in realtà ciò che abbiamo calcolato per l’aggregato VoIP è un IPLR virtuale, dato appunto dal rapporto fra il numero di pacchetti persi o con ritardo maggiore di 100ms e il totale di pacchetti trasmessi.
Mostriamo i risultati delle simulazioni, partendo da un grafico congiunto della percentuale dei pacchetti persi e dei ritardi medi sperimentati per una specifica simulazione (fig. 5.20-a), che evidenzia come le due grandezze raggiungano i valori di picco negli stessi intervalli temporali: è chiaro d’altronde che quando la rete attraversa fasi di congestione i buffer sono molto pieni, e ciò comporta sia una maggiore probabilità di scarto che un maggiore ritardo di accodamento.
Nella tabella in figura 5.20-b elenchiamo i dati relativi al calcolo dell’IPLR virtuale al variare della banda prenotata, dati che andiamo poi a riportare nel grafico in figura 5.20-c (dove la linea tratteggiata rappresenta proprio il valore di 10-3 che l’IPLR non dovrebbe superare).
0 2 4 6 8 10 12 14 tempo (s)
ritardi (decimi di secondo) pacchetti persi
% di banda riservata IPLR virtuale
0.8 0.86637
0.85 0.78528
0.9 0.52747
0.95 0.03248
1 0.00627
Figura 5.20-b: tabella coi dati relativi all’IPLR virtuale Figura 5.20-a: confronto fra pacchetti persi e ritardi sperimentati
0,0001 0,001 0,01 0,1 1 0,8 0,85 0,9 0,95 1 % di banda allocata IP LR v ir tua le
Com’era facile prevedere, all’aumentare della banda prenotata diminuisce il valore dell’IPLR virtuale, così come il ritardo medio e i pacchetti persi (fig. 5.21).
% di banda % pacchetti persi ritardo medio (s)
0.8 0.04681 0.14687
0.85 0.01352 0.12448
0.9 0.00389 0.11389
0.95 0.00092 0.09128
1 0.00003 0.08233
Figura 5.20-c: IPLR virtuale al variare della banda (scala logaritmica)
Dai dati risulta evidente (fig. 5.20-c) che con questo dimensionamento del sistema (buffer di 6000B) il server VoIP non riesce a soddisfare i parametri di QoS nemmeno allocando una banda pari al peak rate dell’aggregato. Questo risultato non ci sorprende eccessivamente, poiché abbiamo calcolato il rate su intervalli temporali di 100ms, mentre utilizzando intervalli più piccoli avremmo ottenuto valori di picco molto più alti (per esempio, con finestre di 10ms il peak rate passa da 1.45Mbps a circa 2Mbps). Quindi quando parliamo di peak rate dobbiamo tener presente che in realtà abbiamo dei burst di traffico molto maggiori, e ciò spiega le perdite che si riscontrano anche con tale allocazione di banda. La scelta dell’intervallo temporale, e conseguentemente di un peak rate abbastanza basso, è stata fatta per evitare sprechi nell’allocazione di risorse.
Abbiamo ripetuto la stessa analisi simulativa utilizzando un IPTD di 150ms, un valore maggiore di quello della classe 0 ma ancora accettabile per un servizio sensibile ai ritardi e di alta interattività come la telefonia su Internet [16].
Dai dati in figura 5.22 si evince che questa volta il server riesce a soddisfare i parametri di QoS (IPLR minore di 10-3), sia con un’allocazione di banda pari al peak rate sia con un’allocazione pari al 95% del peak rate, visto che diminuiscono i pacchetti che sperimentano un ritardo maggiore dell’upper bound.
% di banda riservata IPLR virtuale 0.8 0.33637 0.85 0.04385 0.9 0.00947 0.95 0.00098 1 0.00005
Da un’analisi incrociata dei pacchetti persi e dei pacchetti che arrivano a destinazione dopo il limite massimo, si ricava che in entrambe le sessioni di simulazione (IPTD pari a 100ms o a 150 ms) il problema maggiore è dato dai ritardi sperimentati dai pacchetti (almeno per prenotazioni oltre il 90%), per cui una soluzione abbastanza intuitiva sembrerebbe essere l’utilizzo di buffer più piccoli per contenere i ritardi di accodamento, anche a costo di qualche pacchetto perso in più. Abbiamo allora effettuato delle simulazioni con buffer di 1000B, invece che di 6000B (tabella in figura 5.23).
% di banda IPLR virtuale % persi ritardi (s)
0.8 0.48955 0.05539 0.1073
0.85 0.15428 0.04228 0.0965
0.9 0.02817 0.02671 0.0797
0.95 0.00201 0.00103 0.0669
1 0.00096 0.00004 0.0512
Figura 5.23: IPLR virtuale con buffer di 1000B e IPTD di 100ms Figura 5.22: valori dell’IPLR misurati con un IPTD di 150ms
Confrontando questi risultati con quelli precedenti (buffer di 6000B), si nota, com’era facile prevedere, che al diminuire delle dimensioni del buffer le perdite aumentano, visto che c’è meno spazio disponibile nel buffer e i pacchetti vengono scartati, e i ritardi invece diminuiscono, visto che buffer più piccoli implicano tempi di accodamento minori (fig. 5.24).
0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,8 0,85 0,9 0,95 1 % di banda allocata % di pa c c h e tt i pe rs i con buffer di 1000B con buffer di 6000B 0,00 0,04 0,08 0,12 0,16 0,20 0,8 0,85 0,9 0,95 1 % di banda allocata rit a rdo m e dio ( s) con buffer di 6000B con buffer di 1000B
Per quanto riguarda invece il parametro IPLR virtuale, a differenza di quanto accadeva con buffer di 6000B questa volta il server riesce ad ottenere un IPLR minore di 10-3 se prenota una banda pari al peak rate dell’aggregato di chiamate (1.45Mbps). Diminuire le dimensioni dei buffer si è rivelata quindi una scelta oculata, poichè ci ha permesso di contenere i ritardi sperimentati dai pacchetti e di rientrare così, almeno con prenotazione pari al peak rate, nei limiti stabiliti dalla recommendation per la classe di servizio 0 (fig. 5.25).
0,0001 0,001 0,01 0,1 1 0,8 0,85 0,9 0,95 1 % di banda allocata IPL R v ir tu ale
Ripetendo invece i calcoli con una dimensione dei buffer pari a 1000B e un IPTD massimo di 150ms, abbiamo constatato che in questo caso la diminuzione del buffer non ha alcun senso e comporta anzi degli svantaggi: infatti già con un’allocazione pari al 95% del peak rate la percentuale di pacchetti persi è maggiore di 10-3 (fig. 5.23), quindi diminuire i ritardi ed aumentare le perdite non ha certo migliorato la situazione, perché ora l’IPLR supera l’upper bound solo con i pacchetti persi. Nel caso di buffer da 6000B e IPTD di 150ms era sufficiente riservare una banda pari al 95% del peak rate per soddisfare la QoS richiesta, mentre ora serve necessariamente il 100% (fig. 5.26).
In quest’ultimo caso quindi il dimensionamento dei buffer è molto complesso: sembra difficilissimo trovare il giusto compromesso tra i pacchetti persi e i ritardi sperimentati.
% di banda riservata IPLR virtuale
0.8 0.11219
0.85 0.05377
0.9 0.02731
0.95 0.00199
1 0.00048
5.3.2. Seconda tipologia: al variare delle chiamate
Nella seconda tipologia di simulazioni ci siamo messi in un’ottica diversa, chiedendoci quante chiamate possa accettare l’operatore che fornisce il servizio VoIP fissata la banda a disposizione, assicurando a ciascun utente il livello di QoS richiesto da un servizio di classe 0. Abbiamo stabilito che un nuovo utente non può essere accettato dal sistema se la sua attivazione implica che l’IPLR virtuale superi l’upper bound indicato per la CoS 0 (IPLR pari a 10-3).
Utilizzando lo stesso scenario di rete, abbiamo perciò prenotato 1Mbps per la prima sorgente con buffer da 5000B, e al variare del numero di chiamate VoIP da aggregare abbiamo appunto calcolato l’IPLR virtuale (che, ricordiamo, è uguale al rapporto fra i pacchetti persi o arrivati a destinazione con un ritardo superiore ai 100ms e il totale dei pacchetti trasmessi).
numero chiamate peak rate (Mbps) rate medio (Mbps) IPLR Virtuale 50 0.696 0.546 0.00034 60 0.880 0.678 0.00089 70 0.998 0.791 0.00363 80 1.101 0.907 0.01259 90 1.274 1.022 0.03827
Analizzando i dati a disposizione, emerge chiaramente (fig. 5.28) che nel nostro scenario di simulazione l’operatore non può accettare più di 60 chiamate VoIP contemporanee, se vuole assicurare loro un servizio di elevata qualità (CoS 0).
0,0001 0,001 0,01 0,1 50 60 70 80 90 numero di chiamate IPLR v ir tua le
Se rilassiamo il vincolo sull’IPTD (che anche questa volta è il parametro critico) e ci accontentiamo di un upper bound di 150ms, possiamo invece accettare anche 80 chiamate contemporanee (fig. 5.29).
numero chiamate peak rate (Mbps) rate medio (Mbps) IPLR Virtuale 50 0.696 0.546 0.00013 60 0.880 0.678 0.00047 70 0.998 0.791 0.00088 80 1.101 0.907 0.00095 90 1.274 1.022 0.00311
Anche questa volta quindi il parametro limitante è il ritardo sperimentato dai pacchetti per attraversare la rete, per cui proviamo di nuovo a ridurre le dimensioni del buffer, passando da 5000B a 1000B, in modo da contenere i ritardi ed essere costretti a scartare meno pacchetti a causa del loro eccessivo ritardo (figure 5.30-a e 5.30-b).
numero chiamate peak rate (Mbps) rate medio (Mbps) IPLR virtuale 50 0.696 0.546 0.00028 60 0.880 0.678 0.00077 70 0.998 0.791 0.00095 80 1.101 0.907 0.00396 90 1.274 1.022 0.01672
Figura 5.30-a: IPLR con banda di 1Mbps, buffer da 1000B e IPTD di 100ms Figura 5.29: IPLR con banda di 1Mbps, buffer da 5000B e IPTD di 150ms
0,0001 0,001 0,01 0,1 50 60 70 80 90 numero di chiamate IP LR v ir tual e
Ancora una volta la situazione è migliorata: l’operatore VoIP può accettare fino a 70 chiamate contemporanee, e quindi la scelta di buffer più piccoli si è rivelata di nuovo vincente. Se insieme a buffer di 1000B accettiamo anche un upper bound di 150ms per l’IPTD, possiamo arrivare addirittura fino a 100 chiamate contemporanee. numero chiamate peak rate (Mbps) rate medio (Mbps) IPLR virtuale 70 0.998 0.791 0.00066 80 1.101 0.907 0.00078 90 1.274 1.022 0.00083 100 1.356 1.144 0.00094 110 1.448 1.258 0.00253
Figura 5.30-b: IPLR virtuale al variare del numero di chiamate