Scuola di Ingegneria Industriale e dell’Informazione
Corso di Laurea Magistrale in Computer Science & Engineering
AN APPROACH FOR EVALUATING
THE REPUTATION OF DATA SERVICES
Relatore: Prof. Cinzia CAPPIELLO Correlatore: Prof. Pierluigi PLEBANI
Tesi di Laurea di: Roberto Procaccianti, matricola 875883
Ringraziamenti
Vorrei ringraziare prima di tutto la mia relatrice Cinzia Cappiello e il cor-relatore Pierluigi Plebani per il tempo che hanno dedicato ad aiutarmi a scrivere questa tesi.
Un grazie speciale va alla mia famiglia per avermi supportato (e soppor-tato) durante questi lunghi anni al Politecnico di Milano.
Un ringraziamento ai compagni di sventura al Politecnico, in particolare a Fabio, Federico ed Alessandro, con cui ho condiviso la maggior parte del momenti della triennale. Ringrazio anche Sara e Alessandro per avermi fatto compagnia durante questi due anni di magistrale.
Infine ringrazio tutti i miei amici di sempre, che nonostante tutto sono al mio fianco.
Indice
Elenco delle figure V
Elenco delle tabelle VII
1 Introduzione 1 2 Stato dell’arte 3 2.1 Reputation . . . 3 2.2 Data Quality . . . 14 2.2.1 Accuracy . . . 14 2.2.2 Consistency . . . 14 2.2.3 Completeness . . . 15 2.2.4 Timeliness . . . 16 2.3 Service Quality . . . 17 2.3.1 Performance . . . 18 2.3.2 Dependability . . . 18 2.3.3 Security . . . 18 2.3.4 Usability . . . 19 2.4 Conclusioni . . . 19 3 Contesto e Metodologia 20 3.1 Data Utility . . . 21 3.2 Fog Computing . . . 23 3.3 DITAS . . . 24 3.4 Reputation model . . . 27
3.4.1 Reputation registrazione sorgenti Rini . . . 29
3.4.2 Reputation legata alla scelta del data set Rchoice . . . 31
3.5 Test di Validazione del modello . . . 39
3.5.1 Descrizione simulazioni query . . . 40
3.5.2 Metodologia del test . . . 45
3.5.3 Discussione risultati validazione utenti . . . 47
3.5.4 Modifica dei pesi di Cu e Fv . . . 49
3.5.5 Nuovo confronto con valori degli utenti . . . 51
3.6 Conclusioni . . . 58
4 Realizzazioni Sperimentali 60 4.1 Descrizione della metodologia . . . 60
4.2 Descrizione prove e risultati . . . 62
4.3 Analisi risultati . . . 77
5 Conclusioni 79 5.1 Direzioni future . . . 80
Elenco delle figure
3.1 Modello delle componenti della Data Utility . . . 22
3.2 Schema Fog Computing, tratto da vanrish.com/blog/2017/12/03/fog-computing-and-edge-computing . . . 23
3.3 DITAS cloud platform architecture, tratta da [1] . . . 25
3.4 Interazione tra utente, DITAS e data owner . . . 26
3.5 Componenti della reputation . . . 29
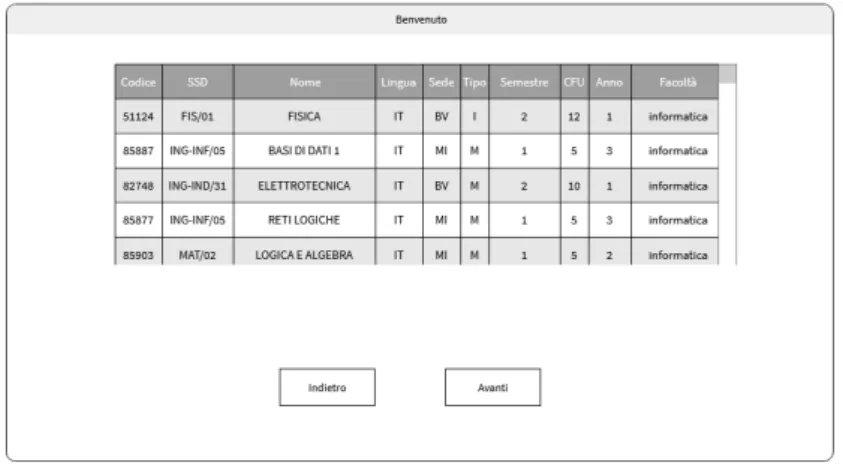
3.6 Schermata di benvenuto dell’applicazione . . . 42
3.7 Risultati Query corretta . . . 43
3.8 Reminder all’utente delle regole . . . 43
3.9 Visualizzazione risultato query alterato . . . 44
3.10 Pagina di uscita dell’applicazione . . . 44
4.1 Simulazione 1% di errore, Cu = 0.7 . . . 64 4.2 Simulazione 1% di errore, Cu=1.5 . . . 65 4.3 Simulazione 2% di errore, Cu=0.7 . . . 67 4.4 Simulazione 2% di errore, Cu=1.5 . . . 68 4.5 Simulazione 5% di errore, Cu=0.7 . . . 69 4.6 Simulazione 5% di errore, Cu=1.5 . . . 70 4.7 Simulazione 10% di errore, Cu=0.7 . . . 71 4.8 Simulazione 10% di errore, Cu=1.5 . . . 72 4.9 Simulazione 25% di errore, Cu=0.7 . . . 73 4.10 Simulazione 25% di errore, Cu=1.5 . . . 74 4.11 Simulazione 50% di errore, Cu=0.7 . . . 75 4.12 Simulazione 50% di errore, Cu=1.5 . . . 76
Elenco delle tabelle
3.1 Risultati test con modifica alla accuratezza . . . 46
3.2 Risultati test con modifica alla completezza . . . 46
3.3 Risultati test con modifiche al response time . . . 46
3.4 Risultati test con modifiche ad accuratezza e completezza . . 47
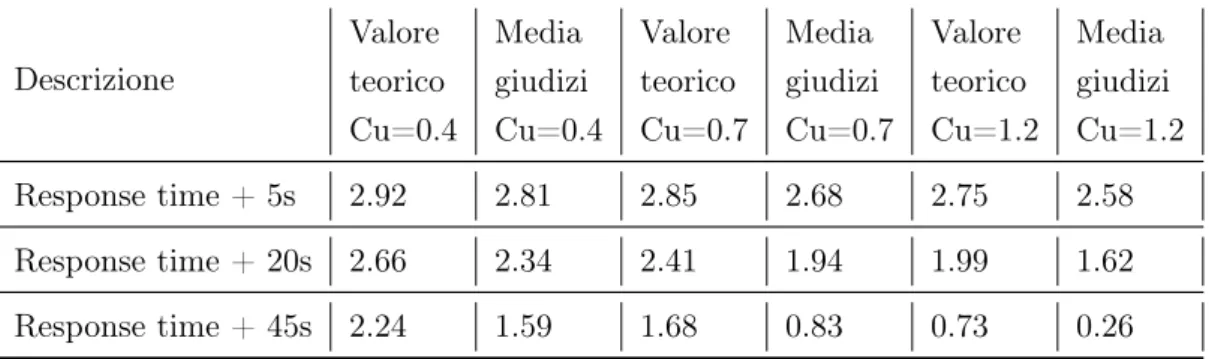
3.5 Nuovo confronto tra risultati teorici e giudizio degli utenti, accuratezza . . . 52
3.6 Nuovo confronto tra risultati teorici e giudizio degli utenti, completezza . . . 54
3.7 Nuovo confronto tra risultati teorici e giudizio degli utenti, response time . . . 55
3.8 Nuovo confronto tra risultati teorici e giudizio degli utenti, accuratezza e completezza . . . 57 4.1 Simulazione 1% di errore, Cu=0.7 . . . 64 4.2 Simulazione 1% di errore, Cu=1.5 . . . 65 4.3 Simulazione 2% di errore, Cu=0.7 . . . 66 4.4 Simulazione 2% di errore, Cu=1.5 . . . 67 4.5 Simulazione 5% di errore, Cu=0.7 . . . 69 4.6 Simulazione 5% di errore, Cu=1.5 . . . 70 4.7 Simulazione 10% di errore, Cu=0.7 . . . 71 4.8 Simulazione 10% di errore, Cu=1.5 . . . 72 4.9 Simulazione 25% di errore, Cu=0.7 . . . 73 4.10 Simulazione 25% di errore, Cu=1.5 . . . 74 4.11 Simulazione 50% di errore, Cu=0.7 . . . 75 4.12 Simulazione 50% di errore, Cu=1.5 . . . 76
Sommario
Negli ultimi anni il volume di dati scambiati è aumentato in maniera con-siderevole, favorendo lo sviluppo di applicazioni atte a sfruttare questa im-provvisa abbondanza di dati. Una delle principali cause si può attribuire al fenomeno dell’Internet of Things (IoT). Questo però comporta la difficoltà a trovare la fonte di dati adatta alle proprie esigenze e agli scopi delle appli-cazioni. In suddetto contesto si inserisce DITAS, un progetto il cui scopo è aiutare gli sviluppatori di applicazioni data-intensive nel definire ed eseguire le proprie applicazioni. Il seguente lavoro di tesi si inquadra all’interno di codesto progetto, più nello specifico ampliando la definizione di Data Utility. Questa è definita come la rilevanza dei dati considerando il contesto d’uso, cioè le finalità dell’utente e le caratteristiche del sistema. É composizione di tre elementi principali, nello specifico la Data Quality (Qualità dei Dati), la Service Quality (Qualità del Servizio) e la Reputation.
Nel corso di questa tesi si andrà ad approfondire solo quest’ultima com-ponente, ampliandone il raggio d’azione dalla qualità dei dati alla qualità del servizio, rendendola utile a tutti gli utenti che vorranno utilizzare la piatta-forma in futuro. L’aspetto innovativo consta nel considerare non solo i vari parametri di Data Quality ma prendendo in esame gli aspetti tipici della qualità del servizio, cioè di quei valori che normalmente sono esterni alla sorgente di dati. L’insieme di questi valori andrà a costituire il coefficiente della reputation come variabile atta ad aiutare un utente nella scelta di una sorgente di dati. A seguito della registrazione, scelta ed utilizzo di un data set il valore della reputazione verrà aggiornato, rendendolo un metro di giu-dizio impattante sulla scelta da un determinato set di dati da parte di un utente.
Abstract
In the last years the volume of data has increased considerably, helping the development of applications who exploit this amount of data. One of the main causes is the rising of Internet of Things (IoT). The abundance of data however leads to the increasing difficulty of finding the data source suitable for own needs and the purposes of the applications.
Within this context is defined DITAS, a project whose purpose is to help the developers of data-intensive application to define and execute their own applications. The following thesis work will be arranged within DITAS project, more specifically expanding the definition of Data Utility. This is defined as the relevance of data considering the context of use, that is the user’s purpose and system’s characteristics. It is the composition of three main components, Data Quality (DQ), Service Quality and reputation.
This thesis will only elaborate on the last component, expanding his range of action from Data Quality to Service Quality and make it useful for all the user that will use this platform in the future. The innovative aspect consist of considering not only the various dimensions of Data Quality but to take into consideration all the aspects typical of the Service Quality, that is all the values that are normally external to the data source.
All of this values will constitute the reputation value, as a variable which purpose is to help the choice of a data set by the users. Following the re-gistration, choice and utilisation of a data set the reputation value will be updated, making it a variable for the choice of data set by an user.
Capitolo 1
Introduzione
Negli ultimi anni si è assistito ad un aumento esponenziale della quantità di dati generati dai più svariati tipi di sorgenti. Uno dei problemi derivanti da tale abbondanza è riuscire a trovare dati che abbiano elevati parametri di qualità e che siano rilevanti ai fini del compito assegnato.
Per valutare la bontà delle sorgenti di dati, tra gli aspetti che si possono considerare spicca il concetto di Data Utility. Questa è definita come la rilevanza dei dati considerando il contesto d’uso, cioè le finalità dell’utente e le caratteristiche del sistema. É composta da tre punti di vista: Service Quality, Data Quality e Reputation. Quest’ultimo è un concetto abbastanza recente nel campo, ed è legato agli altri due aspetti nel fornire un metro di valutazione della qualità complessiva di una sorgente di dati agli utenti.
Come per Data Quality e Service Quality, anche la reputation di una sorgente di dati è legata al contesto in cui tale data set viene utilizzato. Lo scopo di questo elaborato è quello di dotare gli sviluppatori di applicazio-ni data-intensive di uno strumento atto ad assegnare un giudizio ai data set; suddetta valutazione verrà in aiuto nel momento della ricerca e nella scelta della sorgente di dati da adoperare, limitando i possibili risultati e rendendo la fase di selezione del data set più semplice anche per chi magari non ha gli strumenti adeguati per capire le varie sfaccettature della qualità dei dati.
In particolare, la reputation non è solo un metro di giudizio della qualità complessiva del data set, ma anche di tutti quegli aspetti tipici del Qua-lity of Service, come possono essere l’accessibilità, il tempo di risposta e l’affidabilità, portando un approccio innovativo rispetto allo stato dell’arte.
Il valore della reputation calcolato si andrà a combinare con quello della Data Quality e della Service Quality andando a formare la Data Utility.
Inoltre, dopo aver paragonato il modulo proposto con il metro di giudizio degli utenti, esso verrà testato con un algoritmo allo scopo di verificare il suo funzionamento su vasta scala.
La struttura di questo elaborato si sviluppa nel seguente modo:
Nel Capitolo 2, Stato dell’arte, viene analizzata la situazione attuale della ricerca descrivendo i concetti di Data Quality, di Reputation e di Service Quality.
Nel Capitolo 3, Contesto e Metodologia, viene introdotto il contesto in cui è inserito il lavoro, il Fog Computing e in particolare DITAS. Successivamen-te, viene esposto il modello teorico proposto con le sue componenti. Inoltre, verranno messi a confronto i valori ottenuti tramite il modello proposto con le valutazioni proposte dagli utenti.
Nel Capitolo 4, Realizzazioni Sperimentali, viene esposto un test riguar-dante la valutazione della correttezza del modulo proposto utilizzando un algoritmo che simula l’esecuzione del modulo per un elevato numero di volte. Nel Capitolo 5, Conclusioni, vengono esposte le conclusioni sul lavoro effettuato e mostrate le prospettive future.
Capitolo 2
Stato dell’arte
In questo capitolo vengono introdotte tutte le nozioni necessarie a compren-dere l’oggetto di questa tesi. In particolare, verranno trattate la Reputation, fulcro del presente lavoro. Inoltre, si descriverà il concetto di qualità dei dati, le sue numerose definizioni e verranno esposte le varie dimensioni che la compongono.
Infine, dato il contesto in cui si inserisce questo lavoro di tesi, si darà spa-zio alla definispa-zione del concetto di qualità del servispa-zio e delle cinque categorie in cui essa è suddivisa.
Nella Sezione 2.1 verrà definita la reputation. Successivamente, nella Sezione 2.2 si tratterà di Data Quality. Infine, nella Sezione 2.3 si parlerà di Service Quality.
2.1
Reputation
La reputation (o reputazione) è un concetto legato alla fiducia che l’utente di un servizio ha nei confronti di un provider o di una sorgente di dati in generale. La reputation non è una qualità tipica solamente del campo infor-matico, ma si può trovare in statistica, come nel marketing e nella finanza, e per ciascun campo di azione ha una definizione differente.
Nel marketing la reputazione di una azienda viene definita come la per-sonificazione dell’effetto cumulativo di tutte le attività di marketing passate e presenti. Inoltre, è una delle caratteristiche tipiche di un prodotto che i po-tenziali compratori utilizzano per fronteggiare l’incertezza nel loro processi decisionali [2].
Hess Jr. [3] la definisce come la percezione dei clienti di quanto be-ne l’azienda si prenda cura di loro e abbia riguardo be-nei confronti del loro benessere.
Passando al contesto preso in esame dalla tesi, in [4] viene descritta come "la misura nella quale i dati sono considerati attendibili considerando la loro sorgente e il loro contenuto"
Nonostante sia una dimensione abbastanza recente, in letteratura esi-stono diversi metodi affermati per il calcolo della reputation, considerando ambiti di azione differenti tra loro.
Huang, Kanhere e Hu [5] partendo da un esperimento legato al rumore ambientale usano la funzione di Gompertz per ridurre l’influenza che gli smartphone con valori alterati hanno sul valore finale del rumore ambientale. In questo modello, la reputazione viene legata al peso associato al valore inviato al server centrale: se il valore, paragonato a quello inviato dagli altri smartphone, viene considerato errato, la reputazione di tale smartphone si riduce e al successivo invio i suoi dati avranno meno peso.
Nello specifico, l’uso della funzione di Gompertz serve a rendere l’anda-mento della reputazione similare al corrispettivo "umano"; nelle situazioni sociali, la reputazione viene costruita gradualmente nel corso del tempo ma tende ad essere persa molto velocemente in caso di comportamenti disonesti.
Uno dei più importanti modelli è la beta reputation, introdotta da Joe-sang e Ismail [6]. La base su cui poggia è la distribuzione beta, usata per rappresentare una distribuzione di probabilità nel caso di eventi dal risultato binario.
La funzione beta prende in esame il numero di osservazioni dei due pos-sibili risultati (outcome) per fornire una stima del prossimo risultato. Nel caso di feedback provenienti, ad esempio, da una transazione e-commerce il risultato non è del tipo binario.
Questo problema viene risolto dando alla valutazione una coppia (r,s) di valori continui, dei quali r riflette il grado di soddisfazione mentre s il grado di insoddisfazione. Tali valori andranno a creare la funzione di soddisfazione riguardante l’entità target T da parte di un agente (o un insieme di agenti) X. Il reputation rating trasforma la funzione di soddisfazione in un valore nell’intervallo [-1,1], così da risultare più chiaro per gli utenti.
Inoltre, la beta reputation deve essere in grado di combinare i feedback ricevuti da sorgenti multiple; tale obiettivo è ottenuto combinando tutte le coppie (r,s) provenienti da diversi agenti in un unico paio di valori.
Successivamente, questo modello di reputation è in grado di attribuire un peso maggiore ai feedback provenienti da agenti con alto valore di repu-tation, associando al giudizio di un agente una tupla di valori rappresentanti l’opinione a proposito di tale valutazione.
Questa tupla è composta da 3 valori (b,d,u), dei quali il primo rappresenta la probabilità che un giudizio sia vero, il parametro d quella che tale giudizio sia falso e l’ultimo elemento è l’incertezza. La somma di b,d e u deve essere pari ad uno.
Infine, questo modello introduce un "forgetting factor", un parametro che assegna un peso minore alle valutazioni passate rispetto a quelle più recenti. Il ragionamento alla base è quello che un agente potrebbe cambiare compor-tamento nel corso del tempo, e di conseguenza falsare il giudizio attuale.
Un altro modello [7] considera la reputazione come una composizione di diversi indici, in modo da ottenere un valore il più possibile oggettivo. In particolare, gli elementi che compongono il valore della reputation sono i seguenti:
• Una serie di indici basati sugli SLA (Service Level Agreement) per diverse dimensioni di Data Quality, cioè il livello medio della qualità dei dati che il provider riesce a garantire per una determinata dimensione • Un valore soggettivo, basato sul rapporto tra provider e utente • Un valore "istituzionale" basato sulla reputazione che il provider ha
nel contesto di appartenenza
• Indice di affidabilità, inizialmente ad 1, che diminuisce se la media dei valori delle varie dimensioni di Data Quality utilizzate differiscono dai valori concordati.
Quest’ultimo modello è importante perché costituisce la base di partenza per la costruzione del modulo per il calcolo della reputation di un data set, come si vedrà nel capitolo 3.
Michiardi e Molva [8] propongono un meccanismo, chiamato CORE, per regolare la collaborazione tra nodi in una rete ed evitare eventuali attacchi di tipo DoS (Denial of Service). In questo modello, la reputazione di un nodo viene calcolata sulla base di alcune informazioni del nodo stesso e da altre che invece provengono dagli altri nodi.
Tale valore è composto da tre componenti: • Reputazione soggettiva
• Reputazione indiretta • Reputazione funzionale
Il termine reputazione soggettiva si riferisce alla componente calcolata dopo un’osservazione, cioè l’incontro di un soggetto con un altro soggetto, valu-tando una certa metrica. Questo valore viene calcolato usando una media pesata delle valutazione degli incontri passati e di quello presente, dando maggiore peso alle esperienze passate.
La seconda componente aggiunge alle esperienze personali anche il parere degli altri nodi nei confronti del nodo valutato.
Infine con la reputazione funzionale si aggiunge la possibilità di calcola-re il valocalcola-re della calcola-reputazione pcalcola-rendendo in considerazione diversi criteri di valutazione, ad esempio Routing o Packet Forwarding. Ogni criterio di va-lutazione avrà il suo peso nella formula finale.
Sempre nell’ambito del peer-to-peer è definito PeerTrust [9], un modello di fiducia dinamico che valuta e quantifica l’attendibilità di utenti nell’ambito degli e-commerce. La caratteristica fondamentale di questo modello di fidu-cia è l’identificazione di 5 elememnti fondamentali per la valutazione della reputazione di un peer in una comunità e-commerce P2P (Peer to Peer).
Tali elementi sono riportati di seguito:
• Il feedback ottenuto che un utente ottiene da altri utenti
• L’ambito in cui tale utente ottiene il feedback, come ad esempio quante transazioni ha un utente con altri peer
• Il parametro di credibilità della sorgente del feedback
• Il contesto in cui avviene la transazione, allo scopo di distinguere tran-sazioni mission critical (essenziali) da trantran-sazioni non indispensabili
• La comunità in cui avvengono tali transazioni, per evidenziare eventuali caratteristiche particolari di tale comunità ed eventuali vulnerabilità
Tutti questi elementi convergono in una formula, che calcola il valore di fi-ducia (trust) che un peer possiede durante un determinato lasso di tempo. TRAVOS [10], descrive l’interazione tra due agenti un sistema multi-agente (MAS), con il coefficiente di fiducia che è calcolato come l’aggregazione di due componenti. La prima parte di tale valore è composta dall’insieme delle valutazioni che un agente (truster ) ha nei confronti di un secondo agente (trustee); la seconda calcola un valore di fiducia sulla base della reputazione che ha l’agente valutato.
Ogni interazione tra truster e trustee è considerata avente successo dal truster se il trustee adempie ai suoi doveri. L’insieme delle interazioni tra due agenti è registrato in una tupla, al cui interno troviamo il numero di interazioni positive e il numero di interazioni con esito negativo.
Il rapporto tra questi due parametri crea un seconda variabile, B, la quale rappresenta la probabilità che il secondo agente soddisfi i doveri che ha nei confronti del truster. Il valore di fiducia (trust) del primo agente nei confronti del secondo è la stima del valore di B.
A questo parametro è direttamente collegato il concetto di confidenza, la quale è definita come l’accuratezza del valore di fiducia calcolato dato il numero di interazioni avute tra i due agenti.
Se tale valore scende sotto una certa soglia, il truster andrà a chiedere ad altri agenti l’opinione, cioè il valore di fiducia che essi hanno nei confronti del trustee.
La struttura di questi valori di fiducia è uguale a quella spiegata in prece-denza, e l’insieme dei valori delle due tuple andranno a creare i parametri α e β della distribuzione beta che rappresenta il valore di fiducia complessivo. Infine, l’agente truster è in grado di scartare i valori di fiducia passategli da altri agenti con intenti malevoli, cioè allo scopo di modificare l’opinione che il truster ha nei confronti del trustee calcolando un valore di accura-tezza, basato sulle passate interazioni con l’agente "malevolo"; se tale valore risulta essere sotto una certa soglia, tale valore verrà scartato.
EigenTrust [11] porta il concetto di reputation nelle reti peer-to-peer, usandola come metro di giudizio per la scelta dello user da cui scaricare un file. Ogni peer dopo un download assegna una valutazione alla fonte da cui l’ha scaricato: se il giudizio è positivo avrà valore +1 mentre in caso contrario assumerà valore -1.
La somma di tutti queste valutazioni va a formare il local trust value degli user. Il funzionamento del sistema si basa sul principio di transitive trust: un utente avrà un’alta reputazione degli utenti che gli forniscono file autentici.
Inoltre, lo user tenderà a fidarsi dell’opinione che questi peer hanno nei confronti di altri peer.
Nel campo della logica proposizionale, Ries et al. [12] hanno esposto Cer-tainLogic, un modello atto a valutare i termini logici soggetti ad incertezza, nello specifico utilizzando gli operatori logici AND, OR e NOT. Questo mo-dello è stato progettato come una rappresentazione della fiducia basata sulle prove (evidence-based), ma può essere utilizzata anche per rappresentare l’incertezza.
Il fulcro del modello è la definizione dell’opinione a riguardo della verità di un proposizione: tale valore è composto da una tupla (t,c,f ), con ogni elemento della tupla compreso tra 0 e 1, di cui t rappresenta la valutazione media. Questo numero è la misura del grado in cui osservazioni preceden-ti supportano la verità della proposizione, ed è associato alla numero di osservazioni che corroborano la veridicità di quest’ultima.
Il valore 0 è associato alla presenza di sole prove che contraddicono la proposizione, e il contrario per il valore 1.
Il secondo coefficiente, c, indica il grado per cui questa valutazione possa essere rappresentativa nel futuro; ad essa è associata il numero di osservazioni precedenti.
Lo stesso ragionamento applicato al parametro t può essere usato anche in questo caso.
Infine, l’aspettativa iniziale f esprime l’ipotesi espressa a riguardo della veridicità della proposizione in mancanza di prove.
Come per la beta reputation, anche CertainTrust valuta i parametri componenti l’opinione da diverse fonti:
iniziale di f sulla base della sua conoscenza dell’argomento preso in esame
• Da esperienze dirette o valutazione da parte di un sistema di reputa-zione o fiducia, il quale prende in considerareputa-zione le passate esperienze e raccomandazioni di terze parti.
• Può derivare da un opinione data nella logica soggettiva, la quale combina elementi della "belief theory" con elementi della probabilità Bayesiana
• Dalla distribuzione beta, come dimostrato da Joesang [6] e esposto in precedenza
Sabater e Sierra [13] propongono Regret, modello di reputazione completa-mente decentralizzato per sistemi multi-agente. Allo stesso modo di Eigen-Trust, ogni agente valuta l’interazione con un altro agente e salva i suoi voti in un database locale.
La media pesata di questi valori forma il valore di fiducia (trust value), con le valutazioni più recenti che hanno un peso maggiore.
Inoltre, si suppone che gli agenti si scambino le valutazioni tra di loro, secondo la loro rete sociale; si definisce rete sociale un grafo nel quale i nodi rappresentano gli agenti della "società" e gli archi le interazioni tra due agenti.
Le valutazioni di tutti gli agenti presenti nella social network contribui-scono a formare la witness reputation, nell’eventualità che l’agente giudicante non conosca l’agente con cui deve comunicare.
Infine, Regret introduce i concetti di reputazione del vicinato e di repu-tazione del sistema:
• La prima viene computata dalla reputation dei vicini dell’agente con cui si deve comunicare tramite regole di tipo fuzzy
• La reputazione del sistema è un meccanismo per assegnare valori di fiducia standard all’agente con cui si sta comunicando basati sul suo ruolo nell’interazione (venditore/compratore).
AllExperts, un sito internet che offre il giudizio di utenti esperti, ha creato un sistema di reputazione basato su quattro aspetti [14]:
• Conoscenza
• Chiarezza della risposta • Tempestività della risposta • Cortesia
Ognuna di queste sezioni ha una valutazione tra 1 e 10, con tale numero frutto della media aritmetica dei giudizi ricevuti. In aggiunta, è visualizzata la quantità delle domande ricevute da ogni esperto, oltre ad un punteggio, chiamato General Prestige, calcolato semplicemente come la somma di tutti le valutazioni medie che esso ha ricevuto.
Alla maggior parte degli esperti viene assegnato valutazione molto vici-ne al massimo, 10, cosicché il valore del Gevici-neral Prestige è molto vicino al numero di domande ricevute moltiplicato per dieci.
Huynh, Jenning e Shadbolt [15] hanno introdotto FIRE, un modello di trust e reputation che integra un ampio numero di fonti di informazioni allo scopo di giudicare in maniera completa le performance di un agente in un sistema aperto.
Il fulcro di FIRE sono una serie di moduli che valutano quattro tipi diversi di fiducia e reputazione:
• Interaction Trust, l’agente valuta le sue precedenti esperienze con l’a-gente target, determinando la sua attendibilità
• Witness Reputation, l’agente raccoglie informazioni sull’agente target grazie alle scambio di informazioni con altri agenti che hanno interagito con il target. Questo è possibile poiché i vari agenti possono scambiarsi le informazioni.
• Role-Based Trust, questo modulo considera il tipo di relazione che può esserci tra due agenti o le conoscenze che un agente potrebbe avere in un dato campo. Ad esempio, un agente potrebbe fidarsi di un altro agente se quest’ultimo fa parte di un certo gruppo, o dello stesso gruppo del primo.
• Certified Reputation, l’agente target cerca di guadagnarsi la fiducia presentando argomenti a suo favore, come delle testimonianze del suo comportamento da parte di altri agenti che hanno interagito con lui. Un ulteriore modello è stato proposto da Yun et al.[16] e mira a dare maggiore importanza alle valutazioni più recenti di un prodotto o servizio rispetto alla media aritmetica.
In particolare, si attribuisce un peso p al nuovo rating attribuito da uno user, con p un valore tra 0 e 1; un valore di p basso rende il valore della media meno sensibile alle valutazioni più recenti, ma accentua il ritardo con cui il valore della reputation si aggiorna.
Al contrario, un valore di p vicino ad 1 rende il valore complessivo del-la reputation maggiormente sensibile a cambiamenti (e in questo modo ad eventuali attacchi). In generale, p dovrebbe avere un valore basso se le va-lutazioni arrivano con altra frequenza, e valore elevato nel caso contrario. Oltre a diversi ricercatori anche le maggiori aziende al mondo hanno creato i loro sistemi per il calcolo della reputation degli utenti. eBay, la più grande casa d’aste del mondo, ha sviluppato il suo sistema di feedback per dare l’opportunità a compratori e venditori di dare una valutazione gli uni agli altri al termine di una transazione [14].
Tale valutazione può essere positiva (+1), neutrale (0) o negativa (-1), e la reputation complessiva di un utente risulta la somma di tutte le valutazioni positive a cui sono sottratte tutte le valutazioni negative.
Data la natura di tale valutazione è molto difficile riuscire a contraffare il punteggio di un utente in quanto la creazione di una transazione "falsa" comporta dei costi monetari.
Il difetto di questo sistema può risultare ingannevole: eBay attribuisce lo stesso punteggio a chi ha 50 valutazioni positive e a chi ha 60 valutazioni positive e 10 negative.
Nell’ambito dei forum, tra i vari sistemi di reputazione spicca quello introdotto da Slashdot [14], come possibile soluzione ai problemi di spam e di messaggi di bassa qualità. Allo scopo di creare un sistema più democratico e salutare, Slashdot ha introdotto un meccanismo di selezione automatica dei moderatori.
Nello specifico, esistono due diverse tipologie di moderatori, chiamati M 1 e M 2: i primi controllano i messaggi postati dagli utenti, i secondi sorvegliano l’operato dei primi. I moderatori di tipo M 1 vengono selezionati automatica-mente dal sistema tra gli utenti che frequentano maggiorautomatica-mente il forum. Ad ogni moderatore vengono assegnati un certo numero di punti moderazione e un certo lasso di tempo (solitamente tre giorni) in cui consumarli.
Un punto moderazione viene utilizzato nel momento in cui il moderatore valuta un messaggio, attribuendogli un giudizio negativo o positivo.
Ad ogni messaggio è associato un punteggio, con tale valore compreso tra -1 e 5, con il punteggio iniziale solitamente associato ad 1, ma che può variare a causa del voto del moderatore. In caso di giudizio positivo, tale voto verrà aumentato di un punto, e diminuito sempre della stessa quantità nel caso opposto.
Ogni utente che ha effettuato l’accesso ha un punteggio discreto (karma) legato a se, che possiede un valore compreso tra "Terrible" e "Excellent". All’atto della registrazione, ogni utente riceve una valutazione "Neutral", posizionata come valore medio tra i due estremi.
La valutazione di quest’ultimi può essere modificata a causa dell’attività dei moderatori, che contribuiscono ad alzare il punteggio degli utenti se at-tribuiscono score positivi ai loro messaggi o, al contrario, ad abbassarla nel caso contrario.
Il karma influisce sulla valutazione iniziale di ogni post da loro pubblicato: se positivo, ogni messaggio inizialmente avrà punteggio pari a 2, se negativo tale valore sarà 0 o -1. Inoltre, tale parametro condiziona anche il numero di giudizi che avranno da esprimere nel momento in cui verranno scelti come moderatori.
Per concludere, Slashdot ha introdotto una seconda tipologia di mode-ratori, o metamodemode-ratori, i quali hanno il compito di giudicare i moderatori M 1.
Ogni utente, loggato sul sito, che lo desidera, può diventare moderatore M 2: gli verranno assegnati 10 commenti da giudicare, e dovrà decidere se la moderazione è stata corretta, neutrale o errata. Codesta valutazione influirà sul valore Karma dei moderatori.
Amazon, la più grande azienda di e-commerce al mondo, ha introdotto un sistema di rating sia per i prodotti sia per gli utenti registrati al sito.
Nel primo caso, ogni utente registrato può dare una valutazione da una a 5 stelle in diverse categorie a qualsiasi oggetto acquistabile su sito, indi-pendentemente dal fatto che l’abbia comprato o meno.
Questo espone l’intera piattaforma ad eventuali attacchi atti a favorire (o a screditare) alcuni prodotti.
Per quanto riguarda gli utenti, le recensioni scritte da essi possono es-sere votate positivamente o negativamente da altri utenti; il numero di voti positivi e/o negativi, insieme ad altri parametri segreti, portano l’utente ad avere una posizione in classifica che, se sufficientemente elevata, attribuisce all’utente lo status di "top reviewer".
Anche in questo caso tale sistema ha diverse controindicazioni:
• Eventuali utenti "gelosi" posso valutare negativamente le recensioni di un utente con il solo scopo di fargli perdere lo status di recensore migliore
• Eventuali produttori possono offrire i loro prodotti ai recensori più fa-mosi in cambio di recensioni favorevoli, le quali portano tale prodotto ad una maggiore esposizione sul sito.
Come ultimo esempio viene introdotto PageRank, l’algoritmo usato da Goo-gle per posizionare i vari risultati del suo motore di ricerca. PageRank clas-sifica le pagine in base al numero di pagine che puntano a tale pagina.[17]. Questo è considerabile un sistema di reputazione poiché l’insieme degli hyper-links che rimandano ad una certa pagina viene visto come uno degli elementi usati per ottenere la reputazione complessiva.
Un hyperlink verso una specifica pagina può essere considerato come un giudizio positivo di quella specifica pagina. Questo algoritmo è una delle cause del sorpasso compiuto dal motore di ricerca di Google nei confronti di Altavista, leader del settore a fine anni 90’.
Nel modello descritto nel capitolo 3, la reputazione è associata al rispetto di alcuni vincoli sulle dimensioni di data quality imposti dall’utente in fase di scelta del data set.
In aggiunta a ciò, sono stati aggiunti nell’elenco dei possibili vincoli anche quelli su alcuni parametri di quality of service, come ad esempio il tempo di risposta (response time).
Per questo motivo nelle prossime due sezioni verranno trattate la qualità dei dati e la qualità del servizio, soffermandosi per ciascuna categoria sulle principali dimensioni che le compongono.
2.2
Data Quality
Negli ultimi anni il concetto di Data Quality è diventato di fondamentale importanza e considerato un aspetto critico dei vari processi interni ad una azienda. Dati di bassa qualità possono compromettere i vari processi deci-sionali, con possibili gravi conseguenze, come la perdita di svariati miliardi di dollari [18].
Come visto in [19] non c’è un’unica definizione di Data Quality, ma ne sono state proposte diverse, come "avere dei dati adatti all’uso" oppure "la valutazione dell’idoneità dei dati ad essere usati in un certo contesto". Più che essere considerata nel suo complesso, la qualità dei dati viene analiz-zata guardando diverse prospettive, dette dimensioni. Wang and Strong [20], Wand and Wang [21], Pipino, Lee and Wang [4] tra gli altri hanno già analizzato le diverse dimensioni, dando risultati diversi tra loro.
É possibile però ottenere un elenco di dimensioni trasversale alle diver-se interpretazioni; nello specifico accuratezza, consistenza, tempestività e completezza.
2.2.1 Accuracy
Come nel caso della Data Quality, anche l’accuracy (o accuratezza) ha diverse definizioni, ad esempio Wang and Strong [20] la definiscono come la misura in cui i dati sono corretti, certificati e affidabili. Redman [22] la descrive come la vicinanza che un valore v ha nei confronti di un valore v’, considerato corretto. Infine Ballou and Pazer [23] affermano che i dati sono accurati quando i valori presenti nel database corrispondo ai valori reali.
2.2.2 Consistency
Il termine consistency (consistenza) è legato al concetto di violazione delle regole semantiche definite per un elemento (o per un set di elementi)[24]; è
responsabile del controllo della correttezza delle relazioni logiche tra campi correlati.
Nella teoria relazionale si possono distinguere due categorie di controlli di integrità:
• Vincoli intra-relazionali • Vincoli inter-relazionali
I primi definiscono l’intervallo di valori validi per un attributo; un esempio può essere il vincolo legato al mese di nascita di una persona, che deve essere compreso tra "1" e "12". I vincoli inter-relazionali si riferiscono alle relazioni che intercorrono tra attributi diversi.
Il metodo più usato per calcolare il valore della consistenza è il seguente: Consistenza = 1 − N umeroV iolazioni
N umeroT otaleRelazioniConsistenza (2.1) 2.2.3 Completeness
La completeness (completezza) viene definita come "abilità di un sistema informativo di rappresentare ogni stato significativo di un sistema reale"[21]. Anche in questo caso, altri ricercatori hanno fornito diverse definizioni a riguardo:
• Misura in cui i dati sono sufficientemente ampi, profondi e adeguati per l’operazione in oggetto [21]
• Tutti i valori che dovrebbero essere raccolti [25]
• Rapporto tra i valori non nulli in una fonte di dati e la dimensione totale del data set [26]
Nel campo dei database relazionali, il concetto di completezza è legato molto spesso al significato che si attribuisce al valore NULL.
Questo valore generalmente ha il significato di valore mancante, cioè un valore che esiste nella realtà ma che non è disponibile nel database. Un valore può essere mancante perché esiste ma non si sa il valore, non esiste oppure il suo stato è sconosciuto [27].
2.2.4 Timeliness
Questa dimensione della Data Quality si riferisce all’ambito temporale dei database, se i dati all’interno di esso sono aggiornati rispetto ad eventuali cambiamenti esterni. Il concetto di tempestività è strettamente legato ai concetti di attualità (currency) e di volatilità (volatility), come dimostrato dalle definizioni date ai tre termini in ambito accademico:
• La tempestività si riferisce solamente al ritardo con cui un cambia-mento nel stato del mondo reale si riflette sullo stato del sistema informativo [21]
• La tempestività è la misura in cui l’età dei dati è adeguata per l’ope-razione in corso [21]
• La tempestività è l’età media di un dato in una sorgente di dati [26] • La tempestività è la misura in cui l’età dei dati è sufficientemente
aggiornata per l’operazione in corso [25]
• L’attualità è il grado di aggiornamento di un dato. Un dato è aggiorna-to se è corretaggiorna-to a fronte di possibili differenze rispetaggiorna-to al valore corretaggiorna-to dovuti a cambiamenti temporali [22].
• L’attualità descrive quando l’informazione viene immessa nel data-base o nella datawarehouse. La volatilità è il lasso di tempo in cui l’informazione è valida nel mondo reale [28]
• La tempestività ha due componenti: attualità e volatilità. La prima misura quanto è vecchia l’informazione, mentre la seconda rappresenta ogni quanto varia il valore di un attributo [29]
Ricollegandosi all’ultima definizione, la tempestività si può calcolare come:
T empestivita = max(0, 1 − N umeroV iolazioni
N umeroT otaleRelazioniConsistenza) (2.2) In aggiunta alle principali dimensioni della qualità dei dati, si possono con-siderare altre dimensioni minori:
• Precisione, o precision, usata normalmente solo per coefficienti nume-rici. É definita come la misura con cui esperimenti ripetuti mostrano risultati similari, cioè è la valutazione di quanto lo scostamento tra i vari risultati sia ampio. [30]
• Confidenza, la valutazione dell’affidabilità dell’analisi di qualità consi-derando il contesto in cui tali dati si trovano [4]
• Volume, definito come la quantità di dati necessaria affinché una ap-plicazione venga eseguita correttamente [19]. Non sempre è possibile calcolare tale dimensione in quanto potrebbe mancare una definizione della minima entità di dati necessaria.
• Distinzione, la dimensione della qualità dei dati che valuta quanto i dati all’interno della sorgente di dati non siano duplicati.
Come nel caso precedente, può essere calcolato solo in presenza di valore atteso.
2.3
Service Quality
La qualità del servizio è un elemento fondamentale per ottenere tutti gli obiettivi di un provider di servizi, affinché l’utente accetti il servizio propo-sto o per garantire le caratteristiche tecniche di uno o più servizi. Un servizio è definito come un azione effettuata da un’entità, il provider, per conto di un’altra entità, il richiedente [31].
La service quality si descrive come un set di attributi non funzionali di tutte quelle entità contestuali che sono considerate rilevanti rispetto all’interazione tra servizio e utente, includendo il servizio e il cliente stesso, il quale si affida alla qualità del servizio per soddisfare bisogni esplicitati o impliciti [32].
La service quality viene suddivisa in due categorie:
• Quality of Service (QoS), la quale include tutti quelle caratteristiche che possono essere misurate in maniera oggettiva, come ad esempio il tempo di esecuzione
• Quality of Experience (QoE), la quale include tutti quegli attributi che sono misurati in maniera soggettiva, come ad esempio l’usabilità, e che riflettono la percezione di utenti, o gruppi di utenti,a riguardo del servizio.
Nei prossimi paragrafi verranno spiegate le principali componenti della ser-vice quality [33], suddivise in 5 gruppi: performance, affidabilità, sicurezza, data-related e usabilità
2.3.1 Performance
Questa categoria contiene al suo interno tutti quegli attributi di qualità che descrivono quando funziona bene un servizio. In questo ambito, due componenti sono comuni a tutti i diversi approcci di ricerca, throughput e il tempo di risposta
• Throughput si definisce come il numero di richieste di servizi comple-tate in un certo periodo di tempo [34]
• Il tempo di risposta è il lasso di tempo che passa tra una richiesta e il completamento di tale richiesta [35]
2.3.2 Dependability
L’affidabilità di un sistema è l’abilità di completare servizi di cui "ci si possa fidare" [36]. Affinché un sistema sia affidabile, devono essere verificate le seguenti componenti:
• Disponibilità, descrive se il servizio è immediatamente disponibile per l’uso [37]
• Affidabilità, la probabilità che ad una richiesta segua una risposta in lasso di tempo accettabile [38]
2.3.3 Security
L’abilità di assicurare il non-ripudio dei messaggi, la confidenzialità e l’au-tenticazione dei parti coinvolte nello scambio [37]. Per non-ripudio si in-tende l’impossibilità da parte del mittente di poter negare la paternità del messaggio o della richiesta inviata.
La confidenzialità è la protezione dello scambio di dati o di messaggi nei confronti di terze parti.
Infine, l’autenticazione viene definita come il processo tramite il quale un sistema informatico, software o un utente verifica la presunta identità di un altro sistema/software/utente. L’insieme di questi attributi è chiamato Information Quality (IQ) [33].
2.3.4 Usability
Questo caratteristica raccoglie tutti gli attributi che possono essere misurati soggettivamente, basandosi sul feedback degli utenti. Si riferisce alla facilità con cui un utente può imparare, preparare ed interpretare un servizio e/o i suoi input od output [33].
2.4
Conclusioni
I modelli di reputation presentati hanno come punto focale l’interazione tra due entità. Per quanto validi non sono utilizzabili nel contesto di questo lavoro; in particolare, la maggior parte dei modelli considerati hanno come fulcro la reputazione che un elemento, che esso sia un nodo, un agente o un essere umano, ha nei confronti di un’altra entità simile.
Nel contesto preso in esame, la reputazione è un valore che descrive la fiducia che un utente ha nei confronti di una sorgente di dati, ed è quindi necessario la creazione di un modello che regoli tale interazione.
Come si vedrà nel prossimo capitolo, la reputazione è associata ad alcuni vincoli sulle dimensioni di data quality e quality of service imposti dall’utente in fase di scelta del data set.
Una volta assegnati tali vincoli, l’utente non ha più alcun tipo di intera-zione con il data set e la reputation viene utilizzata come parametro per la scelta del data set a cui è legata da eventuali utenti successivi.
Nei modelli di reputation presi in esame è assente una qualsiasi valuta-zione del contesto in cui avviene l’interavaluta-zione tra agenti o tra elementi, cioè non viene spiegato in quale ambiente la reputation entri in gioco.
Nel caso esaminato in questo lavoro di tesi, l’ambito in cui avviene l’in-terazione tra utente e sorgente di dati, il fog computing e in particolare la piattaforma DITAS, richiede che non solo i dati di tale fonte abbiano le richieste specificate dall’utente, ma che la comunicazione tra utente, DI-TAS e la sorgente di dati da usare nell’applicazione dell’utente abbia certe caratteristiche di qualità.
Il modello di reputation proposto nel prossimo capitolo oltre ad assegna-re un giudizio sulla base delle diverse dimensioni di data quality passegna-renderà in considerazione la qualità del servizio, assegnando un giudizio anche alle componenti di quest’ultima.
Capitolo 3
Contesto e Metodologia
Negli ultimi anni la quantità di dati generata dai dispositivi è in continuo aumento, nel 2014 si sono raggiunti i 650 Exabyte (1 Miliardo di Gigabyte) da dati scambiati all’interno della rete e tale numero è destinato ad aumentare considerevolmente nel futuro.
Uno dei problemi che suddetto fenomeno comporta è la difficoltà da parte degli utilizzatori dei dati di capire se essi abbiano qualità sufficiente ai loro scopi o se possano risultare utili.
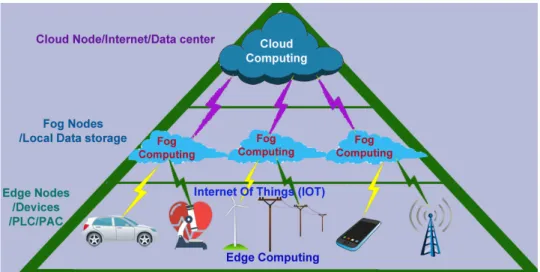
Il lavoro di tesi è collocato nel contesto della valutazione di sorgenti di dati, usando come metrica la reputation, uno dei tre componenti della Data Utility. Il suo scopo è la creazione di un valore, la reputation stessa, che aiuti gli sviluppatori di applicazioni data-intensive a scegliere la sorgente di dati adatta alle loro esigenze, non considerando solo i requisiti di qualità dei dati ma anche tutti quei vincoli legati normalmente alla qualità del servizio. Data l’importanza del contesto in cui si inserirà il concetto di data utility, e in particolare della reputation, si rende necessario introdurre il concetto di fog computing, l’architettura di rete orizzontale che connette le risorse di tipo cloud ai dispositivi.
Inoltre, un paragrafo verrà dedicato alla Data Utility, dandone una defi-nizione e spiegando il suo significato all’interno di DITAS.
Infine, verrà descritto il progetto DITAS, che si inserisce all’interno di questo contesto e all’interno del quale verrà creato e testato il modulo per il calcolo della reputazione.
3.2 introdurrà il contesto alla base della piattaforma usata, il Fog Compu-ting. Nella sezione successiva si tratterà di DITAS, la piattaforma fulcro del lavoro di tesi. Infine, alla Sezione 3.4 verrà introdotto il metodo alla base del calcolo della reputation.
3.1
Data Utility
In letteratura si trovano diverse definizioni riguardanti la data utility. Nel-l’ambito affaristico è definita come "business value conferito ai dati in un contesto specifico" [39] mentre in contesto IT viene descritta come "rilevan-za di una parte di informazione nel contesto in cui è inserita e di quanto differisce dalle altre porzioni" [40].
Come si può notare, entrambe le definizioni mettono in risalto la dipen-denza dell’utilità dei dati dal contesto in cui essi sono utilizzati.
Come stabilire il valore della Data Utility risulta essere molto complesso, a causa del contesto in cui i dati sono inseriti, molto spesso mutevole nel tempo.
La data utility è definita come un carattere dell’associazione tra un task e una sorgente di dati collegata ad un input di un task. É la rilevanza dei dati considerando il contesto in cui essi devono essere usati, in termini dello scopo dell’utente che li vuole utilizzare e dell’insieme delle caratteristiche del sistema [41].
La Data utility considera i seguenti elementi, espressi anche in Figura 3.1:
• I requisiti funzionali, il valore che esplica il grado con cui la sorgente ha il tipo di dati chiesti dall’utente
• I requisiti non funzionali, contenenti vincoli relativi ad dimensioni di Data Quality e di Service Quality
• La reputation, valore che rispecchia quanto l’utente si possa fidare di quel determinato data set.
Ogni sorgente di dati è associata ad un insieme di metadata che compongono la Potential Data Utility (PDU), la quale riassume le potenzialità di quel data
set; tale valore può essere aggiornato periodicamente in maniera indipendente dal contesto. La PDU è calcolata prendendo in considerazione i dati e le caratteristiche della sorgente di dati, e deriva dalla valutazione della qualità dei dati e dalla reputation.
La PDU è un modo oggettivo per classificare sorgenti di dati simili tra loro ed utilizzabile come un primo filtro per eliminare possibili data set candidati ad essere usati.
Figura 3.1: Modello delle componenti della Data Utility
In [42] è stato creato un modulo integrato in DITAS in grado di calcolare la data utility considerando solo le dimensioni di qualità dei dati. Nello specifico, dati in ingresso i requisiti funzionali, i requisiti non funzionali, il tipo di sorgente dati richiesta dall’utente e la classe di applicazioni in cui verranno usati i dati, esso riceverà come risultato una classifica di data set adeguati ai suoi scopi, ordinati in base alla loro data utility.
Il contesto dell’applicazione è di fondamentale importanza per compren-dere l’influenza sulla data quality di ogni singola dimensione, e ad ogni ap-plicazione è associata una lista di pesi legati ad ogni dimensione della qualità dei dati considerata.
L’insieme dei pesi verrà poi utilizzato alla sezione 3.4.3 nel calcolo del-l’entità delle violazioni ai vincoli imposti dall’utente.
L’intento di questo lavoro di tesi è quello di sviluppare il concetto di reputation già presente nel precedente modello, allargando la definizione da semplice valore che consideri solo la frequenza con cui tale sorgente di dati sia stata utilizzata e il suo tasso di utilizzo senza violazioni ad un valore completo, che consideri il data set a tutto tondo, considerando anche elementi esterni alla sorgente stessa.
Nei prossimi due paragrafi sarà esposto il contesto in cui si sviluppa questo lavoro di tesi, dando prima una definizione del fog computing e, successivamente, presentando una progetto all’interno di tale contesto.
3.2
Fog Computing
Il Fog computing è una piattaforma altamente virtualizzata che offre capacità di calcolo, immagazzinamento dati e servizi di rete tra i dispositivi terminali e i datacenter del Cloud computing [43], come visto in Figura 3.2.
Tutto ciò, in genere, ma non esclusivamente è offerto al confine (Ed-ge) della rete [44]. L’edge, o confine, è quella porzione della rete vicina ai dispositivi che generano i dati che normalmente vengono poi usati altrove.
Un’altra definizione è stata data da Vaquero [45], il quale lo definisce come un insieme di dispositivi decentralizzati che comunicano e, potenzial-mente, cooperano tra loro e con la rete al fine di eseguire immagazzinamento dati o calcoli per supportare funzioni di base della rete o nuovi servizi e applicazioni.
Il concetto cardine del fog computing è la mobilità dei dati e dei vari processi di elaborazione di quest’ultimi.
Figura 3.2: Schema Fog Computing, tratto da vanrish.com/blog/2017/12/03/fog-computing-and-edge-computing
In questo paradigma, le applicazioni considerano il cloud e l’edge come uno spazio continuo dove sia i dati sia i task ad essi assegnati possono essere spostati continuamente dall’edge al cloud o viceversa [41].
Al momento dell’esecuzione di un’applicazione si decide come e dove as-segnare le risorse computazionali e i dati da utilizzare allo scopo di massi-mizzare l’efficienza e le performance dell’applicazione.
DITAS si inserisce in questo contesto, creando una piattaforma che aiuti gli sviluppatori di applicazioni data-intensive ad automatizzare il processo di spostamento di dati e risorse basandosi sulle informazioni riguardanti la tipologia di dati, le caratteristiche dell’applicazione e sulle risorse disponibili nel cloud e nell’edge.
Questo progetto verrà presentato nel prossimo paragrafo, descrivendo le sue funzionalità e i suoi scopi.
3.3
DITAS
DITAS (Data-intensive application Improvement by moving daTA and com-putation in mixed cloud/fog environmentS) [1] è un progetto che ha l’o-biettivo di creare una piattaforma allo scopo di supportare la definizione e l’esecuzione di applicazioni data-intensive, con associato un SDK (Software Development Kit) e un ambiente di esecuzione capaci di gestire in manie-ra efficace gmanie-randi volumi di dati, i quali possono essere manie-raccolti, salvati e analizzati in Cloud o nell’Edge.
L’aspetto chiave di questo strumento è quello di consentire agli svilup-patori di progettare le applicazioni specificando quali vincoli o preferenze hanno a riguardo delle risorse che devono essere utilizzate. La struttura della piattaforma è mostrata in Figura 3.3.
Uno degli scopi di DITAS è quello di supportare gli utenti per ottenere e gestire i data set con i requisiti scelti da quest’ultimi.
Inoltre, permette agli sviluppatori di potersi concentrare solo sulla logica di business, lasciando alla piattaforma stessa il compito di scegliere le sorgenti di dati, dove salvare i dati e la gestione di tutte le tematiche di basso livello negli ambienti delle architetture eterogenee, come implica il contesto.
Figura 3.3: DITAS cloud platform architecture, tratta da [1]
La piattaforma migliora il deployment delle applicazioni data-intensive im-plementando la logica informativa nell’ambiente fog, dove le risorse apparte-nenti al cloud e all’edge sono combinate.
Inoltre, analizzando lo spostamento di dati e risorse computazionali al-l’interno dell’ambiente decide dove, quando e come mantenere i dati, se nel cloud o nell’edge e allo stesso modo sceglie come eseguire ogni parte dei task assegnati in modo da ottenere un equilibrio tra affidabilità, sicurezza, sostenibilità e costi.
DITAS inserisce un layer intermedio, chiamato Virtual Data Container, il quale incorpora la logica necessaria per permettere il corretto collegamento tra le applicazioni che devono essere eseguite e le sorgenti di dati disponibili [42].
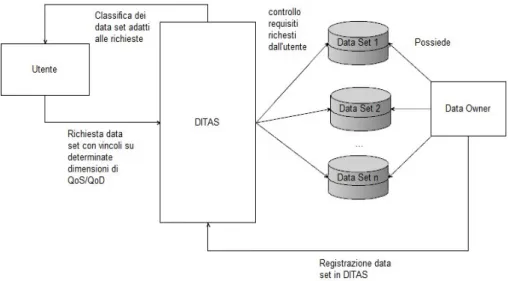
Prima di descrivere nel dettaglio il modello, è bene introdurre gli attori che operano nell’ambito di DITAS, come descritto in Figura 3.4:
• Il Data Owner, o Data Admin
Figura 3.4: Interazione tra utente, DITAS e data owner
Il primo è il proprietario del data set ed è colui che si occupa di rendere dispo-nibile tale set attraverso DITAS. All’atto della registrazione la piattaforma assegna un valore di reputation dipendente dalla qualità dei dati contenuti nella sorgente e la reputation del data owner.
L’utente è colui che utilizza la piattaforma per avere accesso alle sorgenti dati. Esso accede alla piattaforma facendo una richiesta di utilizzo di un data set, specificando un set di requisiti (vincoli) che tale sorgente di dati deve possedere e il peso che ha ogni dimensione di data quality o service quality. DITAS, ricevuta la richiesta controlla tutti i data set registrati e restituisce all’utente una classifica basata sulla data utility potenziale di ogni data set avente i requisiti richiesti.
Successivamente all’utilizzo di una sorgente di dati, il sistema aggiornerà automaticamente il valore della reputation del data set utilizzato sulla base di diversi parametri, di cui quello principale è il soddisfacimento dei vincoli descritti in precedenza.
Il dato aggregato della reputation dei vari data set forma il valore della reputation legata ad un data owner; tale coefficiente numerico può essere visto come simbolo di qualità e affidabilità delle sorgenti di dati fornite alla piattaforma.
In definitiva si può considerare DITAS come un service provider, che mette a disposizione dell’utente i dati provenienti da diversi data owner (e da diversi locazioni) come se fossero presenti in locale.
Il modello di reputation proposto si inserisce in questo contesto, asso-ciando ad ogni sorgente di dati presente sulla piattaforma un valore, il quale misuri sia la qualità dei dati presenti sia la qualità del servizio, cioè tutti quei parametri non direttamente legati al data set ma che possono inficiare l’esperienza di utilizzo dell’utente.
Questo si rende necessario considerando il contesto in cui è inserito DI-TAS; le comunicazioni tra data set e piattaforma e tra quest’ultima ed utente rivestono un ruolo fondamentale e il valore della reputation ne deve tenere conto.
Concludendo con un esempio, se un data set ha dei dati di alta qualità ma questi non sono sempre accessibili a causa di problemi di rete, o se il tempo di risposta è estremamente elevato, il valore della reputation di tale sorgente di dati risentirà, in negativo, di tali problematiche.
Nella prossima sezione si tratterà del modulo che calcolerà il valore della reputation di un data set, punto focale del lavoro di tesi.
3.4
Reputation model
La reputation è associata ad ogni data set presente sulla piattaforma DITAS e, come per gli altri vincoli sulle varie dimensioni di qualità dei dati, è una determinante nella scelta dell’utilizzo di tale data set da parte di un utente. Differentemente dalla struttura dei dati e dall’accessibilità di essi, la Data Utility può essere influenzata dal luogo in cui sono situati le sorgenti di dati. L’utente infatti effettua una scelta sulla base dei risultati forniti dalla piattaforma e, una volta selezionato il set di dati con cui lavorare, non può più esprimere un giudizio sulla bontà di tale set.
In questo ambito viene introdotta la reputazione come parametro nume-rico che descrive il grado in cui l’esecuzione di metodi associati ad un data set rispetti i requisiti richiesti dall’utente.
Per il calcolo della reputation di una sorgente si è deciso di considerare tre aspetti distinti, ognuno dei quali legato ad una diversa fase del ciclo di vita di un data set all’interno della piattaforma DITAS.
Il valore della reputation di un data set è definito in questo modo: R = Rini+ Rchoice+ Rex (3.1)
In particolare il valore massimo per la componente Rini legata alla
di tutte le sorgenti di dati possedute dal data owner, mentre il valore minimo è pari a 0.
Considerando il valore della reputation legata alla scelta del data set, il valore di Rchoice è compreso nell’intervallo [0,1].
Infine, il valore della reputation legato all’utilizzo del data set Rex ha valori nell’intervallo [0,3].
Uno schema delle varie componenti della reputation si può trovare alla Figura 3.5.
La prima componente si riferisce al processo di registrazione di una sor-gente di dati da parte di un data owner, con riferimenti alla valutazione di tale data owner.
Inoltre, ad esso si aggiunge un valore legato ad eventuali certificazioni assegnate da enti, possedute da tale data set.
Infine, largo peso sarà assegnato alla valutazione della qualità dei dati, calcolando il valore di data quality per ogni dimensione considerata.
Il secondo coefficiente valuta la scelta effettuata dall’utente sulla base delle sue richieste, cioè sui requisiti funzionali, i requisiti non funzionali, l’ambito della applicazione su cui dovranno essere usate le sorgenti di dati da scegliere e il tipo di data set desiderato.
La piattaforma, considerati i suoi requisiti, restituisce una classifica sulla base della Data Utility assegnata ad ogni data set avente i vincoli indicati.
A codesto ranking sono assegnati dei malus o dei bonus sulla base della scelta o della non scelta, considerata la posizione.
La terza ed ultima componente è legata all’impiego della sorgente di dati nell’applicazione descritta dall’utente. Sarà valutata la presenza o l’assenza di violazioni ai vincoli sulla qualità dei dati o sulla qualità del servizio, e in base a ciò decidere se assegnare un bonus o una penalizzazione al valore complessivo della reputation.
Le formule scelte per il calcolo di ciascuna componente della reputazione saranno descritte nel dettaglio nei prossimi paragrafi.
In definitiva, il valore di reputation di un data set è diviso in 3 componenti principali:
• Rini è la componente della reputation relativa al momento della
• Rchoice è la componente della reputation relativa alla scelta da parte di un utente di uno dei data set proposti da DITAS
• Rex è la componente della reputation relativa all’utilizzo di un metodo
di tale data set
Figura 3.5: Componenti della reputation
3.4.1 Reputation registrazione sorgenti Rini
Al momento della registrazione di un data set da parte di un data owner, DITAS inizializza la nuova sorgente di dati con questa componente.
Per la scelta dei valori che compongono tale misura, si è deciso di include-re in essa un valoinclude-re che rispecchia la valutazione assegnata dalla piattaforma al proprietario della sorgente di data.
La considerazione alla base del ragionamento è che un data owner che ha fornito sorgenti di dati di scarsa qualità probabilmente potrebbe ripetere l’errore in futuro.
Inoltre, considerando alcuni elementi presi dalla letteratura, si è deciso di includere un coefficiente legato alla presenza di alcune certificazioni rila-sciate da enti di certificazione accreditati alla sorgente di dati. All’atto della
registrazione, se il data set è associato a qualche certificazione, il data owner ne dovrà fornire una prova.
Successivamente, verificata l’autenticità della stessa, DITAS accrediterà un bonus al valore di Rini.
Il terzo ed ultimo parametro della componente è il valore della qualità dei dati. Osservando il contesto in cui è inserita la reputation e considerando l’interazione tra utente e sorgente di dati si rende necessario inserire la qualità dei dati all’interno di questa componente per dare un metro di paragone ai futuri utilizzatori.
Infatti, se i valori delle dimensioni che compongono la Data Quality sono bassi sarà più improbabile che la sorgente di dati registrata venga usata dagli utenti.
La prima componente è composta dai seguenti valori:
• Ro, valore è legato alla reputation del data owner, calcolata come la
media delle reputation di tutti i data set di cui quel data owner è proprietario. Nel caso in cui il data owner non abbia registrato altri data set, assume valore pari a 0.
• Ri è la “reputation istituzionale”, che assume valore 0 se il data set
registrato in DITAS non ha delle certificazioni rilasciate da enti di certificazione. Nel caso opposto, la certificazione andrà ad attribuire un valore pari a 0.5.
• Rq, collegato alla qualità del data set. All’atto della registrazione, il data set viene analizzato e ad ogni dimensione dndella qualità dei dati
(ad esempio accuratezza) o della qualità del servizio (response time) viene attribuito un valore.
Ogni valore dn può assumere valore compreso tra 0 e 1, con il valore 1 assegnato se il data set rispetta perfettamente la definizione della dimensione considerata.
Il valore 3 posto all’inizio della formula serve ad aumentare il contributo che tale voce porta ad Rini.
Unendo tutti questi elementi, si ottiene che la seguente formula: Rq = 3 ∗
(Pn
i=1dn)
Le dimensioni di data quality e data service considerate in questo caso sono accuratezza, completezza e tempo di risposta.
La prima è definita come la misura in cui i dati sono corretti, certificati e affidabili oppure come la vicinanza che un valore v ha nei confronti di un valore v’, considerato corretto.
La completezza è descritta come la misura in cui i dati sono sufficiente-mente ampi, profondi e adeguati per l’operazione in oggetto.
Infine, il tempo di risposta è il lasso di tempo che passa tra una richiesta e il completamento di tale richiesta.
3.4.2 Reputation legata alla scelta del data set Rchoice
Questa componente della reputation, Rchoice, è legata alla classifica dei data set consigliati da DITAS dopo aver ricevuto le richieste dell’utente.
Una volta volta che l’utente ha formalizzato le sue richieste in termini di requisiti funzionali, requisiti non funzionali, tipo di sorgente di dati richiesta e di tipo di applicazione da eseguire, DITAS formula una classifica, elencando i data set soddisfacenti i vincoli stabiliti.
In questo caso, si è deciso di penalizzare la reputation di un data set se questo non viene scelto nonostante sia primo (o nelle prime posizioni) della classifica.
Data la natura della componente, si è pensato a questa scelta perché nor-malmente l’utente sceglie il primo elemento consigliatogli dalla piattaforma DITAS, e di conseguenza il valore legato ad Rchoice è quindi un valore pari
ad 1, od un numero ad esso vicino.
L’unica circostanza in cui un utente potrebbe non scegliere una sorgente di dati suggerita da DITAS si verifica quando l’utente ha avuto esperienze negative con la fonti di dati o con il data owner stesso.
Infatti, essendo il valore complessivo della reputation incluso nella Data Utility del data set, se tale valore è basso anche il valore complessivo di utilità dei dati si abbasserà.
Rchoice è definito come:
Rchoice= min(1, Rchoice+ RC) (3.3)
In pratica, data la posizione x nella classifica del data set dopo una certa richiesta, se tale data set non viene effettivamente selezionato dall’utente subirà un malus in termini di reputation, proporzionale alla sua posizione in classifica.
• Se il data set x è in prima posizione e non viene scelto, tale data set avrà un malus y alla sua reputation;
• Se il data set x è in seconda posizione e non viene scelto, tale data set avrà un malus z alla sua reputation, con z<y; e a seguire per le altre posizioni della classifica.
Il malus, o il bonus, associato alla scelta o alla mancata scelta è definito come RC. Tale valore assumerà valore positivo o negativo in base alla scelta
dell’utente. Alla prima posizione è associato un malus di 0.1, alla seconda 0.05, alla terza 0.025, alla quarta 0.0125 e al quinto posto un malus sul valore di R2 pari a 0.005.
Si è deciso di scegliere dei valori di bonus/malus molto bassi, in modo da non inficiare il valore complessivo della componente nel caso essa non venga scelta.
Considerata la struttura della componente e la classifica che DITAS for-nisce all’utente, si nota come un solo elemento di quest’ultima vedrà aumen-tare il proprio valore di Rchoice, mentre il resto degli elementi avrà questa
componente diminuita di valore.
In caso di selezione, il valore di RC sarà positivo ed invertito rispetto a questo grafico: a posizione più bassa in classifica corrisponde un bonus maggiore al valore di RC.
Il valore iniziale di Rchoice è fissato ad 1, il massimo.
3.4.3 Reputation legata all’utilizzo del data set Rex
Nell’ultima componente verrà esposto come il modulo presentato aggiornerà il valore della reputation dopo un utilizzo della sorgente di dati considerata. Le formule considerate a tale riguardo sono due, una da applicare nell’e-ventualità in cui l’impiego del data set all’interno della applicazione non abbia violazioni riguardanti le dimensioni di qualità dei dati o di qualità del servizio, l’altra nel caso in cui almeno un vincolo venga violato.
Nel primo caso il valore di questa componente subirà un incremento, con il valore di quest’ultimo declinato da una formula in cui codesto valore è in funzione del precedente valore della reputation.
In caso contrario, una seconda equazione determinerà la penalità inflitta alla reputation della sorgente di dati.
I 3 coefficienti che compongono questa seconda equazione sono rispettiva-mente la classe di utilizzo, un coefficiente legato all’affidabilità passata della sorgente di dati e un terzo valore che rappresenta la gravità complessiva di una o più violazioni avvenute.
Il primo valore corrisponde al livello di servizio che l’utente richiede e al quale sono associati diversi coefficienti. Aumentando la classe di servizio au-menterà la soglia di prestazioni da esso richieste, il prezzo pagato dall’utente e la penalità in caso di mancato rispetto dei vincoli assegnati.
Il secondo termine è legato alle performance passate della sorgente di dati considerata, nello specifico al rapporto tra gli utilizzi a cui sono associati una o più violazioni e il numero totale di utilizzi di tale sorgente di dati.
Infine, l’ultimo elemento è il valore delle violazioni, cioè la sommatoria che racchiude tutte le differenze tra il valore atteso per una determinata dimen-sione di Data Quality/Service Quality ed il valore effettivamente ottenuto dall’utente.
Nel caso in cui almeno uno delle differenze all’interno della sommatoria sia diversa da zero, si avrà una violazione, la cui gravità è determinata dal valore totale delle diverse sottrazioni.
Per ogni dimensione di data quality o di service quality considerata, si possono avere diversi tipi di violazioni; nello specifico, per l’accuratezza si possono considerare due possibili casi:
• usando l’accuratezza di tipo booleana è considerata una violazione un valore di un attributo che non corrisponde al valore reale. Come esem-pio, si può considerare il numero di cfu di un esame del Politecnico, se il valore reale è 10 cfu e il valore restituito come risultato è un qualsiasi numero diverso da 10, si avrà una violazione.
• un valore è considerato errato, e quindi comporta una violazione, se non rientra in un intervallo di valori considerato accettabile per un determinato attributo del risultato.
![Figura 3.3: DITAS cloud platform architecture, tratta da [1]](https://thumb-eu.123doks.com/thumbv2/123dokorg/7504992.104785/39.892.177.713.191.572/figura-ditas-cloud-platform-architecture-tratta.webp)