SOMMARIO
INTRODUZIONE...4
DASP (DIGITAL AUDIO SIGNAL PROCESSING) ...4
1_ASPETTI PERCETTIVI DEL RIVERBERO ...7
1.1_BACKGROUND FISICO E PERCETTIVO DEL RIVERBERO...7
1.2_APPROCCIO AGLI ALGORITMI DI RIVERBERO...9
1.3_MISURAZIONE DEL RIVERBERO...12
Esempio...12
1.4_PERCEZIONE DELLA DENSITÀ D’ECO DELLA DENSITÀ DI MODO...16
1.5_METRICA PERCETTIVA PER IL RIVERBERO IDEALE...20
1.6_RIVERBERO VICINO...26
2_MODELLAZIONE ACUSTICA CON RITARDO DIGITALE ...31
2.1_LINEA DI RITARDO (DELAY LINE)...31
2.2_SIMULAZIONE DELLA PROPAGAZIONE DI UN’ONDA ACUSTICA...32
2.2.1_Onde viaggianti...32
2.2.2_Onda viaggiante con attenuazione...32
2.2.3_Conversione della Distanza di Propagazione in Durata del Delay...33
2.2.4_Onde sferiche prodotte da una sorgente puntiforme ...34
2.2.5_Fenomeno di Riflessione nel caso di onde Piane o Sferiche...35
2.2.6_Simulatore d’Eco ...36
2.3_PROPAGAZIONE ACUSTICA CON PERDITE...38
2.3.1_Assorbimento dell’aria...38
2.3.2_Onde viaggianti con Dispersione...41
2.3.4_Sommario ...41
2.4_DELAY LINE CON PRELIEVO (TAPPED DELAY LINE, TDL) ...42
2.4.1_Esempio TDL...42
2.4.2_Tapped Delay Line Trasposte ...43
2.4.3_TDL per Elaborazione Parallela ...43
2.4.4_Filtri FIR Causali...44
2.5_FILTRI A PETTINE (COMB FILTERS, CF) ...45
2.5.1_Filtri a Pettine ad alimentazione diretta (CF Feedforward) ...45
2.5.2_Filtri a Pettine con Reazione (CF in Feedback)...47
2.5.3_Equivalenze tra CF e TDL ...51
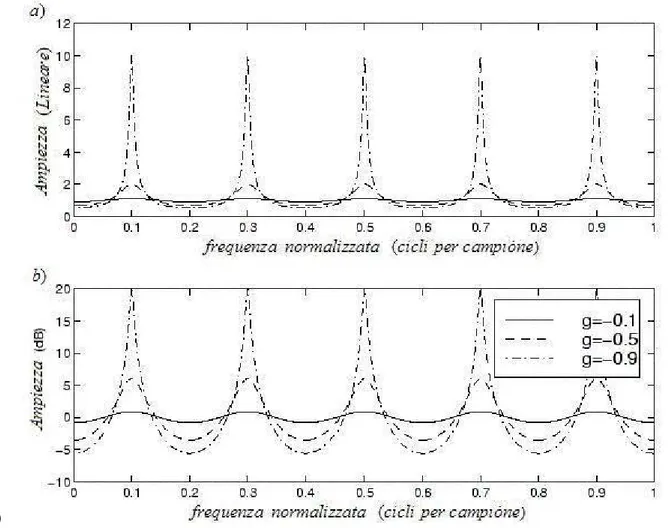
2.5.4_Filtri a Pettine Tempo Varianti...52
2.6_RETI DI RITARDO IN REAZIONE (FEEDBACK DELAY NETWORKS, FDN) ...53
2.6.1_FDN e descrizione dell’equazione di stato ...53
2.6.2_FDN Single-Input, Single-Output (SISO)...54
2.6.3_Stabilità delle FDN ...56
2.7_FILTRI PASSATUTTO...58
2.7.1_Filtro passatutto con coppia CF ...58
2.7.2_Filtri Passatutto Composti (Allpass Nested Filter, ANF)...59
2.7.3_Generalizzazione di filtri Passatutto...61
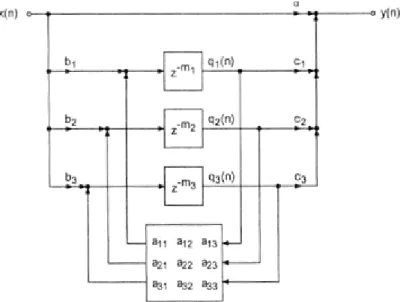
2.7.4_Filtro Passatutto MIMO di Gerzon...62
3_RIVERBERO ARTIFICIALE...66
3.1_IL PROBLEMA DELLA SIMULAZIONE DEL RIVERBERO...66
3.1.1_Modellazione del Riverbero esatto attraverso la funzione di trasferimento...67
3.1.3_Possibilità di un modello fisico di Riverbero...68
3.2_RIFLESSIONI VICINE...70
3.2.1_Esempi d’implementazione di algoritmi per il riverbero vicino...72
3.3_APPROSSIMAZIONI PER IL RIVERBERO LONTANO...79
3.3.1_Requisiti per il Riverbero Lontano...79
3.3.2_CF e Passatutto...80
3.3.3_Serie a Parallelo ...80
3.3.4_Densità modale e densità d’eco ...82
3.3.5_Filtri di Schroeder...84
3.3.6_Uscite incorrelate...86
3.3.7_Il Riverberatore di Schroeder JCRev...88
3.3.8_Riverberatore di Moorer...90
3.4_RIVERBERATORI PASSATUTTO...91
3.4.1_Riverberatore di Gardner ...92
3.4.2_Riverberatore di Dattorro...93
3.5_RIVERBERATORI FDN...95
3.5.1_Il riverberatore di Jot...96
3.5.2_Matrice di Feedback senza Perdite...97
3.5.2_Lunghezze di Delay ...102
3.5.3_Tempo di Riverbero...104
3.5.4_ Progetto di Filtri di Ritardo...104
3.5.5_Filtro a Correzione Tonale ...107
3.5.6_Considerazioni per il riverbero FDN...108
3.6_ RIVERBERATORI A GUIDA D’ONDA DIGITALE...110
3.6.1_Guide d’Onda Digitali (Delay Lines Bidirezionali) ...110
3.6.2_Dispersione del segnale (Scattering) ...111
3.6.3_Reti digitali di guide d’onda, DWN ...112
3.6.4_FDN e DWN...113
3.6.5_Scattering senza perdite...114
3.6.6_Scattering con perdite ...115
3.6.7_Griglia di guide d’onda digitali per il Riverbero ...119
3.6.8_Condizioni Generali per assenza di perdite...122
3.7_ IMPLEMENTAZIONE DEI FILTRI DI ASSORBIMENTO E CORREZIONE...126
3.8_ALGORITMI MULTI-RATE...127
3.9_ALGORITMI TEMPO-VARIANTI...127
CONCLUSIONI...129
Introduzione
DASP (Digital Audio Signal Processing)
Trascorriamo gran parte del nostro tempo in ambienti riverberanti: in ufficio, in teatro, nelle sale da concerto, nelle strade di città, nei boschi e in generale in qualunque tipo di ambiente i suoni che udiamo sono accompagnati da loro riflessioni ritardate provenienti da svariate direzioni. Quando il suono è ben distinto e non ce ne accorgiamo, vuol dire che l'ambiente è stato trattato in modo efficace; se le riflessioni avvengono immediatamente dopo il suono iniziale, il risultato non è percepito come un evento sonoro separato. In generale le riflessioni modificano la percezione del suono, cambiandone l'intensità, il timbro e, cosa più importante, le caratteristiche spaziali. Riflessioni tardive, comuni in ambienti molto riverberanti come le sale da concerto e le cattedrali, spesso plasmano un’atmosfera del tutto diversa dal suono in primo piano.
Detto questo, si capisce come, nella produzione audio professionale, il riverbero rivesta un ruolo molto importante nella valorizzazione della musica e dei suoni. La creazione di un ambiente con caratteristiche acustiche studiate correttamente aggiunge qualità e profondità naturale al suono registrato, influenzando la performance, tanto quanto le caratteristiche sonore complessive. Nelle situazioni in cui è necessario aggiungere l'ambiente di una determinata stanza, dare un senso di spazialità alla produzione o posizionare una sorgente sonora, si usano metodi artificiali di riverbero. L'uso del DSP nella elaborazione di segnali audio (Digital Audio Signal Processing, DASP), sta acquistando sempre più impiego, grazie al continuo aumentare delle prestazioni dei processori. La capacità di manipolazione numerica usata nei calcoli del DSP permette di ottenere importanti funzioni quali l'equalizzazione,il cambiamento di intonazione e di guadagno nonché una grande varietà di effetti, agendo sia non in tempo reale con sistemi di hard disk o workstation sia in tempo reale con blocchi processori real-time dedicati.
Il processo di DSP, è costituito da 3 funzioni basilari: l’addizione, la moltiplicazione e il ritardo (delay), che, opportunamente combinate, permettono di realizzare tutto questo.
Un delay semplice ci permette di creare un'ampia gamma di effetti:
• ripetendo il delay, cioè, facendo rientrare di nuovo una porzione del segnale ritardato nel segnale stesso, si ottengono echi ripetuti; aggiungendo stadi di moltiplicazione è possibile variare l'ammontare del guadagno che deve essere reinserito e quindi controllare sia il livello sia il numero degli echi; questo tipo di effetto è creato mediante ritardi di 35-40ms o più che l'ascoltatore percepisce, in effetti, come discreti.
• se il ritardo è ridotto è tra i 15-35ms, gli echi sono troppo ravvicinati perché l'ascoltatore possa percepirli come discreti: si ottiene un effetto raddoppio; l'effetto finale è un
accrescimento della densità del suono e può essere usato per i cori, i fiati, le sezioni di archi e altri insiemi musicali, per aumentarne appunto le dimensioni.
• sotto i 5ms si hanno delle cancellazioni, il risultato della somma tra il segnale originale e quello ritardato di un tempo così breve è una serie di picchi e cadute della risposta in frequenza del segnale stesso, una risposta "a pettine".Variando il tempo di uno o più di questi delay ravvicinati, si può ottenere un effetto di costante scivolamento di fase: da un minimo (PHASING) fino a portare a variazioni di tempo e intonazione (FLANGING). Se si combinano due segnali identici leggermente ritardati che abbiano un’intonazione lievemente diversa tra loro, si può ottenere l'effetto CHORUS usato per aggiungere profondità, ricchezza e contenuto armonico al suono. Riducendo ulteriormente i tempi di ritardo al di sotto del µs si influenza il livello di campionamento del segnale fino al punto di riuscire un'equalizzazione selettiva, ad esempio filtro SHELVING alle basse o alle alte frequenze; aggiungendo ulteriori stadi di delay e moltiplicazione si possono assemblare complessi stadi di equalizzazione.
Un ritardo (delay) digitale viene, in pratica, effettuato memorizzando il campione audio direttamente in una RAM e rileggendolo dopo un intervallo di tempo ben preciso oppure impiegando degli "shift register".
Il riverbero si può ottenere combinando opportunamente le tre circuiterie logiche "a blocchi", attraverso programmi software con algoritmi dedicati variando i valori dei campioni audio in maniera prevedibile. E' possibile creare un numero quasi infinito di caratteristiche di riverbero usando un numero determinato di linee di ritardo, e controllandone l'ampiezza e le relazioni temporali. In commercio, esistono unità di riverbero digitali dedicate che usano co-processori di segnale ad alta velocità all'interno della loro catena digitale e che sono in grado di attuare calcoli sempre più complessi di DSP in tempo reale; usano alcuni algoritmi digitali che si traducono appunto in riverbero e permettono di esercitare un notevole controllo sulle caratteristiche di riverbero: il livello, il tempo di attenuazione, ritardo pre-eco, equalizzazione basse e alte frequenze e i punti d’incrocio (crossover) degli equalizzatori variabili [2].
1_Aspetti percettivi del Riverbero
I metodi logici basati su una modellazione fisica o ingresso-uscita, sono molto costosi in termini di calcolo per molte applicazioni basate sul Signal Processing. Questo ci porta a chiederci quali sono gli aspetti fondamentali del riverbero, e come si possano riprodurre con strutture computazionali più efficienti.
1.1_Background fisico e percettivo del riverbero
Il processo di riverbero inizia con la produzione di un suono da parte di una sorgente sonora, posta in un punto all’interno di un ambiente. L’onda di pressione acustica che si crea, si espande radicalmente intorno, raggiunge le pareti e le altre superfici, dove la sua energia è riflessa e assorbita. Se la superficie incontrata è larga (rispetto alla lunghezza d’onda, λ), uniforme e rigida, produce una riflessione, simile al modo in cui uno specchio riflette una luce; se la superficie è piccola (rispetto a λ), non uniforme ed elastica, il fenomeno di riflessione è più complesso e porta, in generale, alla diffusione del suono in varie direzioni: il riverbero è costituito da tutta l’energia riflessa. La propagazione dell’onda continua indefinitamente ma, per motivi pratici, si considera che la propagazione termini quando l’intensità del fronte d’onda scende al di sotto dell’intensità del rumore ambientale.
L’ascoltatore percepirà prima il suono diretto proveniente dalla sorgente, seguito dalle riflessioni dalle superfici più vicine, dette echi vicini (early echoes). Dopo poche centinaia di ms, il numero delle onde riflesse diviene molto grande, quindi, il decadimento riverberante rimanente è caratterizzato una densa collezione di echi viaggianti in tutte le direzioni, la cui intensità è praticamente indipendente dal punto preso in considerazione all’interno dell’ambiente; questo fenomeno è chiamato riverbero lontano (o riverberazione), in quanto l’energia che si propaga in tutte le direzioni è la stessa. L’energia persa, dovuta all’assorbimento delle superfici, è proporzionale alla densità di energia dell’ambiente sonoro stesso; di conseguenza il riverbero diffuso decade esponenzialmente con il tempo.
Il processo di riverbero, quindi, si può rappresentare come una serie di ritardi molto ravvicinati nel tempo e si può dividere in tre sottocomponenti, come mostrato in figura 1.1:
Figura 1.1
1) segnale diretto: percepito quando il suono originario viaggia direttamente dalla sorgente all'ascoltatore.
2) riflessioni vicine: parte di segnale che per prima è riflessa verso l'ascoltatore da superfici ampie; di solito queste riflessioni comunicano all'ascoltatore informazioni subconscie per la percezione dello spazio e delle dimensioni dell'ambiente.
3) riverbero lontano o riverberazione: effetto acustico dato da riflessioni multiple casuali e ravvicinate ed è quello che determina le caratteristiche vere e proprie del fenomeno di riverbero. Questi segnali sono spezzettati nelle numerose riflessioni casuali che viaggiano da superficie a superficie dell'ambiente e sono talmente ravvicinate che il nostro orecchio le percepisce come un unico segnale che si affievolisce [2, pag].
Da un altro punto di vista:
Figura 1.2
1.2_Approccio agli algoritmi di riverbero
Dal punto di vista del Signal Processing, è conveniente pensare le sorgenti sonore e gli ascoltatori come sistemi con ingressi e uscite dove l'ampiezza del segnale di ingresso e di uscita corrispondono a variabili acustiche in determinati punti del luogo di ascolto. Facciamo l’ipotesi generale, che questi sistemi possano essere considerati Lineari Tempo Invarianti, anche se il movimento degli ascoltatori e delle sorgenti sonore non permetterebbero di fare l’ipotesi di tempo invarianza. In virtù di quanto detto, la trasformazione della pressione sonora dalla sorgente agli orecchi del singolo ascoltatore si può descrivere completamente con una funzione di trasferimento Stereo. Possiamo quindi simulare l’effetto dell’ambiente circostante convolvendo il segnale d’ingresso con la Risposta Impulsiva Binaurale (BIR):
( )
( )
( ) (
)
0 L Left L y t y t h τ x t τ τd +∞ = = =∫
−( )
( )
( ) (
)
0 R Right R y t y t h τ x t τ τd +∞ = = =∫
−dove hLeft (t) e hRight (t) sono le risposte impulsive per l’orecchio destro e sinistro, x(t) è il suono sorgente, yLeft e yRight sono i segnali risultanti per l‘orecchio sinistro e quello destro.
Un sistema Lineare Tempo-Discreto, che simula il comportamento ingresso- uscita di un ambiente immaginario o reale, è chiamato algoritmo di Riverbero o Riverberatore; il problema del progetto di un Riverberatore si può affrontare in due modi: fisico e percettivo.
1) L’Approccio Fisico cerca di simulare esattamente la propagazione del suono dalla sorgente all’ascoltatore per un dato ambiente, attraverso la misurazione della risposta impulsiva Binaurale nell’ambiente preso in considerazione e quindi, successivamente, il calcolo dell’integrale di convoluzione. Nel caso in cui l’ambiente non esista, deve predirne la risposta impulsiva, basandosi su pure considerazioni fisiche, perciò è necessaria la conoscenza dettagliata della geometria dell’ambiente stesso, delle proprietà di tutte e superfici, delle posizioni e delle direttività delle sorgenti e dei ricevitori; con queste informazioni, è possibile applicare le leggi fisiche di propagazione dell’onda acustica e quindi predire come il suono si propagherà nello spazio, creando un modello fisico dell’ambiente. Due modelli, entrambi utilizzati nella progettazione di sale da concerto e teatri, che derivano da quest’approccio sono:
a. Modello ray tracing: si prende un punto sorgente e attraverso le traiettorie dei raggi, i coefficienti di assorbimento dei muri, tetti e pavimenti, si determina la risposta impulsiva.
b. Modello virtual image: consiste nella creazione di ambienti virtuali con sorgenti immagine secondarie e così via: la somma di tutte le sorgenti immagine con i corrispondenti ritardi e attenuazioni forniscono la risposta impulsiva.
Questa tecnica, definita come Auralizzazione, si esegue per ogni coppia sorgente-ricevitore, mediante filtri a Risposta Impulsiva Finita (FIR) [7, Kleiner].
Il vantaggio di quest’approccio è che offre una relazione diretta tra le caratteristiche del luogo e il riverbero risultante. Di contro, è piuttosto poco flessibile e molto costoso a livello computazionale, confrontato con altri tipi di algoritmo; inoltre, a livello pratico, non c’è un modo facile per acquisire un controllo parametrico in tempo reale delle caratteristiche percettive del riverbero risultante, senza prima dover calcolare un alto numero di coefficienti dei filtri FIR.
2) L’Approccio Percettivo cerca di riprodurre solo le caratteristiche percettive salienti del riverbero. Supponiamo che ogni attributo del riverbero percettivamente indipendente di un ambiente corrisponda ad una dimensione di uno spazio N-dimensionale e che possa essere associato ad un modello fisico con una propria risposta impulsiva; allora, possiamo tentare di costruire un Riverberatore con un filtro digitale a N dimensioni che riproduca esattamente tutti gli N attributi percettivi. Si misura la risposta impulsiva dell’ambiente, dalla sua analisi stimiamo gli N parametri e li introduciamo nel filtro. Teoricamente, in questo modo, si dovrebbe produrre un riverbero percettivamente indistinguibile dall’originale, anche se i dettagli delle risposte impulsive potrebbero risultare considerevolmente differenti.
L’algoritmo di riverbero che risulta da questo tipo d’approccio, presenta molti vantaggi: _ può basarsi su efficienti filtri a Risposta Impulsiva Infinita (IIR).
_ può consentire il controllo in tempo reale di tutti i parametri percettivamente rilevanti e in correlati tra loro.
_ può simulare ambienti esistenti utilizzando l’approccio di analisi/sintesi appena visto.
D’altro canto, ha svantaggio di non fornire un metodo facile per cambiare le proprietà fisiche dell’ambiente.
Per questi motivi l’approccio percettivo è quello essenzialmente utilizzato per la realizzazione degli algoritmi di riverbero [3, pp.87-88].
1.3_Misurazione del riverbero
In virtù di quanto appena detto, il punto focale per la determinazione del fenomeno di riverbero in un dato ambiente è la determinazione della risposta impulsiva. Se l’ambiente è reale, la risposta impulsiva può essere misurata come risposta di un sistema con ingresso ed uscita rappresentati rispettivamente da una specifica sorgente impulsiva e da uno specifico ricevitore. Le sorgenti impulsive usate possono essere naturali come spari di pistola, scoppi di palloncini; un’altra possibilità è usare speaker omnidirezionali pilotati da un generatore elettronico di segnale. Tipici segnali di misurazione sono anche click, chirp, segnali di rumore pseudo-random, come ad esempio sequenze di codice a massima lunghezza (ML) [9]. Il click permette una misurazione diretta della risposta impulsiva, ma il risultato è povero in termini di rapporto segnale rumore, perché l’energia associata al picco di ampiezza è piccola; migliori sono i segnali di rumore pseudo-random perché hanno energia significativamente più grande per picco di ampiezza e permettono, quindi, un miglior rapporto SNR; inoltre, sono scelti in modo tale da permettere una deconvoluzione più facile.
Esempio
Vediamo ora un esempio di applicazione: misurazione della risposta impulsiva di un ambiente con sequenza pseudo-random generata con dei registri di shift in feedback; la sequenza ML è periodica, con periodo dove N è il numero di stati degli shift register e con un valore massimo a; la sua funzione di auto-correlazione, anch’essa periodica di periodo L è:
2N 1 L= −
Dopo essere passata attraverso un convertitore DA, la sequenza è diffusa nell’ambiente con uno speaker e allo stesso tempo il segnale è catturato da un microfono e registrato su un registratore DAT (Digital Audio Tape), come si vede in figura:
Nell’ipotesi che la lunghezza del periodo della sequenza sia maggiore di h(n) (altrimenti si verifica aliasing), la risposta impulsiva si ottiene calcolando la cross-correlazione circolare
( ) ( ) ( ) ( )
xy xx
r n =r n h n∗ ≈h n
La figura 1.4 mostra il procedimento di approssimazione della misura della risposta impulsiva di un ambiente:
Figura 1.4
Il segnale di misurazione, sequenza pseudo-random, posto in ingresso al sistema analogico (ambiente), è ottenuto attraverso la conversione DA della sequenza pseudo-random di eccitazione: x(n). Il segnale analogico di risposta viene riconvertito in una sequenza y(n) dopo la conversione AD. Le due sequenze x(n) e y(n) sono entrambe divise in sottobande attraverso un banco di filtri di analisi: x1,…, xp e y1,…, yp , rispettivamente. I sistemi sotto banda 1 1
1 ( ) ( ) ( ) A z H z B z = ,…, ( ) ( ) ( ) p p p A z H z B z =
danno in uscita y nˆ1( ),...,y nˆp( ) un approssimazione delle sequenze sottobanda y1,…, yp. Attraverso questa procedura si ottiene la risposta impulsiva in forma parametrica (set di parametri sottobanda) che può essere, quindi, simulata direttamente nel dominio digitale.
Le risposte impulsive di sottobanda, come già visto, si ottengono direttamente dalla funzione di cross-correlazione:
i i
i x y
h ≈r
e si approssimano attraverso filtri non ricorsivi e filtri a pettine (vedi in seguito) non ricorsivi che in totale realizzano la seguente funzione di trasferimento per la i-esima sottobanda:
0 0 ... ( ) ( ) 1 i i i i M n M i N i n i b b z H z h n z g z − ∞ i − − = + + = = −
∑
Se tronco la risposta impulsiva hi(n) di ogni sottobanda a K campioni, moltiplico entrambi i membri dell’equazione per 1 Nie confronto i coefficienti di z, per ogni sottobanda, ottengo:
i g z− − 0 0 1 0 1 1 2 1 1 1 1 2 0 0 0 0 0 1 0 0 0 M M M M N M M M M M N K K K K N h b h h b h h h h b h h h h g h h h h − − − + − − + − − − ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ − ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦
I coefficienti b0 b e g si determinano in due passi: M
1. calcolo del coefficiente g del filtro a pettine dall’inviluppo a decadimento esponenziale della risposta impulsiva misurata per la sottobanda
2. si determina il vettore
[
b0 b1 bM]
T dei coefficienti mediante il vettore[
1 0 g .]
TSi può dimostrare, e questo è valido per ogni sottobanda, che il polinomio al numeratore 0 ... Mi
M
b + +b z− è la diretta riproduzione dei primi M campioni della risposta impulsiva, mentre il polinomio al denominatore approssima il decadimento esponenziale della risposta impulsiva [Zöelzer], come mostrato in figura 1.5:
Confrontata con l’implementazione diretta della risposta impulsiva a larga banda, il vantaggio di questa tecnica è la riduzione della complessità di calcolo di un fattore 10; di contro, a causa del ritardo di gruppo, dovuto al banco di filtri, questo metodo non è adatto per le applicazioni in tempo reale [4, pp.183-184; 202-206].
La figura 1.6 mostra la risposta impulsiva di una tromba delle scale misurata usando sequenze ML:
Figura 1.6
all’estrema sinistra è visibile la risposta diretta, seguita da qualche eco vicino e poi dal riverbero lontano con attenuazione esponenziale.
Come si vede, gli echi vicini producono un’ampiezza più grande della risposta diretta, ciò si deve alla direttività sia degli speaker sia del microfono usato per la ripresa. L’ambiente può contenere un gran numero di sorgenti sonore in posizioni diverse, con propri diagrammi di direttività, e ciascuna produce un segnale indipendente. Il pattern degli echi vicini è dipendente dalla posizione e dalla direttività delle sorgenti e del ricevitore; quindi, il tipo di risposta impulsiva appena analizzata, non può caratterizzare un riverbero più complesso, come quella creata in una sala da concerto da un’orchestra sinfonica.
Le proprietà statistiche del riverbero lontano,invece, non cambiano significativamente con la posizione; di conseguenza, una risposta impulsiva punto-punto, non è in grado di caratterizzare il riverbero lontano dell’ambiente.
Tutto questo, in aggiunta a quanto detto prima, ci fa capire che il riverbero vicino e lontano hanno proprietà fisiche e percettive diverse e quindi ci permette di separare a livello logico la loro analisi [3, pp.88-90].
1.4_Percezione della Densità d’Eco della Densità di Modo
Il problema del riverbero può semplificarsi notevolmente senza rinunciare alla qualità percettiva. Densità temporale d’eco
Si può dimostrare intuitivamente che, per ambienti con geometrie regolari, la densità temporale d’eco aumenta come t2, dove t è il tempo. Una semplice dimostrazione si può fare per stanze rettangolari: consideriamo una singola onda sferica prodotta da un punto di sorgente nella stanza; immaginiamo di riempire tutto lo spazio 3D con cloni affiancati della stanza originale (senza sorgente), tutti con la stessa orientazione. Quando l'onda sferica si espande, interseca un numero di stanze approssimativamente proporzionale al suo raggio al quadrato.Poiché per un fronte d'onda in espansione il raggio è proporzionale al tempo (r = c∗t) il numero di stanze che contengono una sezione d'onda cresce come t2; nel caso di riflessioni d’onde di pressione da pareti senza perdita, il campo acustico nella stanza riverberante originale al tempo t si ottiene aggiungendo tutte le stanze insieme (cambiandole in alternanza lungo x e y). Ogni sezione d'onda attraversa ogni punto esattamente una volta in ogni immagine (clone) della stanza (le differenti immagini della stanza rappresentano le riflessioni); quindi, il numero di echi in ogni punto nella stanza, durante il tempo che è necessario ad un'onda piana per attraversare la stanza, è molto vicino al numero di sezioni d'onda nella stanza all'inizio di quell'intervallo di tempo.
Il modello delle sorgenti immagine per il riverbero per un ambiente a geometria regolare, porta ad un pattern regolare di sorgenti immagine. Il numero degli echi Nt che si producono prima del tempo “t” è uguale al numero di sorgenti immagine racchiuse da una sfera di diametro “ct” centrata sull’ascoltatore; poiché c’è una sorgente immagine per volume d’ambiente, il numero di sorgenti immagine racchiuse nella sfera si può stimare banalmente dividendo il volume della sfera per il volume dell’ambiente:
( )
3 2 4 3 t ct N V π≈ t ; e quindi, derivando rispetto al tempo t, otteniamo la densità temporale degli echi:
3 2 4 t dN c t dt V π =
Si può notare che, sebbene quest’equazione non sia accurata per periodi brevi, la densità degli echi cresce come il quadrato del tempo. Oltre un certo tempo,quindi, la densità diventa così grande che si può modellare statisticamente, senza perdita d’esattezza percettiva [5].
Densità di modo
Il comportamento riverberante di un ambiente in funzione della frequenza si può descrivere matematicamente in forma chiusa quando l’ambiente ha geometria regolare, ad esempio perfettamente rettangolare, con pareti rigide perfettamente riflettenti. Partendo dalla risoluzione dell’equazione d’onda acustica, con le condizioni al contorno imposte dalle pareti della stanza, si ottiene una soluzione basata sulle frequenze risonanti naturali dell’ambiente, i cosiddetti modi risonanti normali. Si può dimostrare che le frequenze risonanti di una stanza rettangolare sono date da: 2 2 2 2 y x z n x y z n n n c f L L L ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ = ⎜ ⎟ +⎜⎜ ⎟⎟ +⎜ ⎟ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠
dove f = n-esima frequenza armonica (Hz) ; n = numeri interi da 0 a +∞indipendenti l’uno dall’altro; = dimensioni della stanza (m).
, , x y z n n n , , x y z L L L x x
n L indica l’ -esima frequenza armonica (radianti/metro) dell’onda stazionaria fondamentale nella direzione x (L
x
n
x essendo la lunghezza della stanza lungo x); analogamente n L n L per le y y, z z
direzioni y e z. Così i modi di una stanza possono essere rappresentati su una griglia cartesiana 3D uniforme indicizzata da ( , , )n n nx y z . Gli intervalli lungo x, y e z sono dati da 1/Lx , 1 /Ly e 1/Lz. Dall’equazione si vede che la n-esima frequenza spaziale del modo è data dalla distanza dall’origine del punto della griglia di coordinate .
( , , )n n nx y z ( , , )n n nx y z
Il numero di modi della stanza aventi frequenza spaziale tra k e k + ∆ è uguale al numero dei punti della griglia posti nella corona sferica di raggio tra k e k + ∆; poiché la griglia è uniforme, questo numero cresce come k2. Il numero di modi risonanti in ogni data banda di frequenza, aumenta come
2
f , così che, sopra di una certa frequenza, i modi sono così densi che sono percettivamente equivalenti a una risposta in frequenza random generata statisticamente in modo appropriato. In particolare, non c’è bisogno di implementare risonanze così densamente ammassate che l’orecchio umano non può udire: per ottenere un’attenuazione uniforme del riverbero diffuso, un appropriato processo stocastico uniformemente campionato alla frequenza di campionamento audio, suonerà percettivamente in modo equivalente.
Il comportamento di un ambiente di forma irregolare, si può descrivere nei termini dei suoi modi normali, ma è impossibile ottenere una soluzione in forma chiusa; se Nf è il numero di modi normali al di sotto della frequenza f e V è il volume dell’ambiente, si può dimostrare che la densità modale:
2 3 4 f dN V f df c π ≈
vera, in generale, per qualunque tipo geometria.
Alle alte frequenze, la risposta in frequenza dell’ambiente è determinata da un gran numero di modi le cui curve di risonanza si sovrappongono; cioè, ad ogni frequenza, la risposta è la somma di risposte modali sovrapposte, che possono considerarsi indipendenti e distribuite casualmente; se, poi, il numero dei termini che danno contributo è sufficientemente grande, le parti reali e immaginarie della risposta si possono modellare come variabili casuali indipendenti e Gaussiane, la risposta in ampiezza della pressione risultante segue la distribuzione di probabilità di Raleigh. Questo modello porta ad una serie di proprietà statistiche del riverbero nei grandi ambienti tra cui:
• Separazione media dei massimi in Hz:
max 4 R f T ∆ ≈ ,
dove TR è il tempo di riverbero (par. 1.5). Si può dimostrare che questo modello statistico è confermato per frequenze più alte di 2000 R
g
T f
V
≈ Hz, dove V il volume dell’ambiente in m3. Ad esempio, una sala da concerto di 18.700 m3 e un TR di 1,8 secondi avrà un ∆fmax ≈ 2,2 Hz per frequenze più grandi di fg ≈ 20 Hz. [3, pp.95-98; 5].
Le figure seguenti mostrano il confronto, a varie frequenze, di due campi sonori che si creano all’interno di due stanze, una rettangolare e una non rettangolare, con stessa superficie interna [2]:
• a) modo 1,0,0 della stanza rettangolare (34,4 Hz) paragonato con quello della stanza non rettangolare (31,6 Hz).
• b) modo 3,1,0 della stanza rettangolare (81,1 Hz) paragonato con quello della stanza non rettangolare (85,5 Hz).
• c) modo 4,0,0 della stanza rettangolare (98 Hz) paragonato con quello della stanza non rettangolare (95,3 Hz).
1.5_Metrica Percettiva per il Riverbero Ideale
Un merito dell’architettura è quello di permettere l’ascolto delle performances acustiche ad un gran numero di persone, rinchiudendo le sorgenti sonore dentro le pareti e incrementando notevolmente l’energia sonora sugli ascoltatori rispetto al caso di campo libero, in particolare quelli lontano dalla sorgente. Questo fenomeno si può interpretare come un’equalizzazione applicata dall’insieme pareti, pavimento e soffitto, e si percepisce molto bene. Una misura del guadagno risultante si può ottenere dalla valutazione dell’EDR all’istante 0 (def. pag.23).
Vediamo alcuni parametri su cui è importante che un riverberatore ideale abbia il controllo [6, pp.1-13]
• G2(f): guadagno di potenza ad ogni frequenza
• Tempo di Riverbero T60(f): è un classico parametro oggettivo usato come misura del tempo di
riverbero percepito; gli studi di Sabine [10], hanno dimostrato che il tempo di decadimento riverberante è proporzionali al volume dell’ambiente V e inversamente proporzionali all’entità dell’assorbimento A: R V T A ∝
è il tempo necessario affinché il livello di riverbero decada di 60 dB al di sotto del livello sonoro iniziale, detto anche ; tradizionalmente, era misurato per l’intera risposta, ma dipende anche dalla frequenza, quindi, oggi si tende ad assegnare
diversi a seconda delle frequenze: uno per le basse frequenze,un’altro per le alte frequenze, e valori interpolati alle frequenza intermedie. Studi sulla percezione indicano che il tempo di riverbero dovrebbe calcolarsi indipendentemente in almeno tre bande di frequenza [3, pp.94-95; 7].
60( )
T f T60( )f
60( )
T f
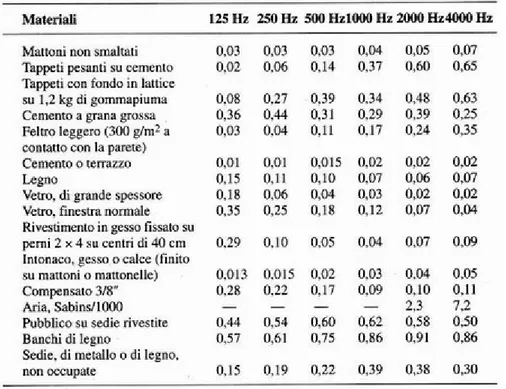
La maggior parte dei materiali porosi, come tappeti e tappezzeria, sono più assorbenti alle alte frequenze; di conseguenza, per la maggior parte degli ambienti, il si abbassa all’aumentare della frequenza. La tabella 1.1, [2], mostra alcuni coefficienti di assorbimento a varie frequenze per diversi materiali; un coefficiente di 0,27 significa che quel materiale assorbe il 27% dell’energia incidente, e ne riflette il 73%:
60( )
Tabella 1.1: coefficienti di assorbimento a varie frequenze
La figura 1.10 seguente mostra alcuni valori caratteristici di tempi di riverbero:
Figura 1.10: tempi di riverbero di ambienti diversi, per f = 512 Hz.
In assenza di altre informazioni il tempo di riverbero alle medie frequenze è forse la migliore misurazione da fare, rispetto ad ogni altra caratteristica riverberante dell’ambiente; ci
aspetteremmo che un ambiente con TR lungo suoni più riverberante rispetto ad uno con TR corto, ma non è proprio così: dipende dalla distanza tra la sorgente e l’ascoltatore, che influenza il livello del suono diretto rispetto a quello del riverbero; infatti, il livello sonoro del riverbero varia di poco attraverso tutta la stanza, mentre il suono diretto decade in modo inversamente proporzionale alla distanza; il rapporto tra il livello diretto e quello riverberante è un parametro di partenza importante per la nostra percezione della distanza della sorgente [11; 12, pp.895-904].
• Una misura acustica del rapporto diretto-riverberante è: Indice di Chiarezza, C:
( )
( )
80 2 0 10 2 80 10log ms ms p t dt C p t dt ∞ ⎧ ⎫ ⎪ ⎪ ⎪ ⎪ = ⎨ ⎬ ⎪ ⎪ ⎪ ⎪ ⎩ ⎭∫
∫
dBdove p(t) è la risposta impulsiva della stanza; è sostanzialmente un rapporto tra energie vicina e lontana, che indica il grado intelligibilità dei segnali musicali o parlati in un ambiente riverberante. In generale, infatti, l’energia vicina si interpreta come un tutt’uno con il suono diretto, perché incrementa l’intelligibilità fornendo energia utile allo scopo, mentre il riverbero lontano (o riverberazione) tende a fondere insieme sillabe e note [3, pp.98-99].
• Curva di Attenuazione dell’Energia: per misurare e definire il tempo di riverbero,
Schroeder [13] ha introdotto la Curva di Attenuazione dell’Energia (Energy Decay Curve, EDC) che è data dall’integrale del quadrato della risposta impulsiva h(t) dell’ambiente, calcolato dall’istante t all’infinito:
60( ) T f
( )
2( )
t EDC t h τ τd ∞∫
Come si può notare, EDC(t) è la quantità rimanente dell’energia del segnale nella risposta impulsiva del riverberatore dall’istante t in poi. L’EDC decade più uniformemente della risposta all’impulso stessa, e per questo motivo è più utile dei consueti inviluppi di ampiezza utilizzati per la stima del . h(t) può essere filtrata a banda stretta, per ottenere un EDC a particolari frequenze.
60( )
• Quando c’è una quantità sufficiente d’energia riverberante lontana, il riverbero forma un background di suono che si può percepire separatamente. L’udibilità del riverbero dipende molto dall’intensità del suono sorgente, così come dall’EDR, a causa del mascheramento del riverbero dal suono diretto; conseguentemente, la porzione vicina del decadimento riverberante, che è udibile durante i gap tra note e sillabe, contribuisce di più alla percezione del riverbero stesso di quanto faccia il decadimento lontano, che è udibile solo dopo il completo stop del suono; quindi, le misure esistenti per il riverbero si focalizzano nel decadimento dell’energia iniziale. Il tipo di misurazione più usata è il Tempo di Decadimento Vicino (EDT,Early Decay Time), calcolato come il tempo richiesto perché l’Integrale di Schroeder decada da 0 a –10dB (moltiplicato per 6, per facilitare il confronto con il TR) [14, pp.263-266]
• Cambio di Attenuazione dell’Energia: un modo utile per rappresentare il riverbero come una funzione tempo-frequenza, è quello di prendere la risposta impulsiva, suddividerla in bande di frequenza con dei filtri passabanda, calcolare gli integrali di Schroeder (vedi EDC) per ognuna di esse e mostrare il risultato in una superficie 3-D. Tutto ciò è stato formalizzato con il Cambio di Attenuazione dell’Energia (Energy Decay Relief,EDR); l’EDR è una distribuzione tempo-frequenza che generalizza il concetto di EDC in bande multiple di tempo-frequenza:
(
)
(
)
2 , M , n k m n EDR t f H m k =∑
dove H(m,k) indica l’ordine k della Short-Time Fourier Transform (STFT) nella finestra (frame) temporale m, e M indica il numero totale di intervalli temporali. La FFT dentro la STFT è usata tipicamente con una finestra di lunghezza di circa 30 o 40 ms, ad esempio.la “finestra di Hann”.
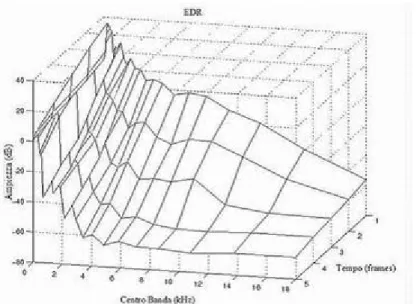
Così, EDR(tn, fk) rappresenta la quantità totale di energia del segnale rimanente nel riverberatore all’istante tn =nT nella banda di frequenza centrata in fk = k∗fs /N Hz, dove N indica la lunghezza della FFT. Da notare che EDR(0,ω ) fornisce il guadagno di potenza in funzione della frequenza. Nelle figure seguenti sono mostrate le EDR della risposta impulsiva della cassa di un violino e della Boston Symphony Hall, che può essere considerata come una stanza riverberante molto piccola. Per una migliore corrispondenza con l’andamento del sistema di percezione audio umano, l’asse delle frequenze è in scala Bark e l’energia è sommata entro ogni banda Bark (una banda critica dell’udito è uguale ad un Bark).
Figura 1.11: EDR della risposta impulsiva di una cassa di violino
Figura 1.12: EDR della “Boston Symphony Hall”
Come potevamo aspettarci, il riverbero decade più velocemente alle alte frequenze.
La porzione più lontana dell’EDR si può descrivere con l’inviluppo della risposta in frequenza, G(ω ) e il TR, entrambi funzioni della frequenza [5; 3, pp.94-96].
• Poiché il riverbero lontano è ampiamente diffuso, i segnali in arrivo all’orecchio destro e sinistro saranno in gran parte incorrelati; l’impressione che ne risulta è che l’ascoltatore sia immerso nel riverbero:
Funzione di Cross-correlazione InterAurale, (InterAural Cross-correlation Function):
da cui il Coefficiente di Cross-correlazione InterAurale (InterAural Cross-correlation Coefficient, IACC) [15, pp.998-1007]:
IACC │IACF(τ)│max, per -1< τ < +1 ms
( )
(
)
( )
2 1 2 2 1 1 2 2 2 ( ) ( ) t L R t t t L R t t p t p t d IACF p t dt p t d τ τ τ τ + ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠∫
∫
∫
dove pL e pR sono le pressioni all’ingresso dei canali uditivi sinistro e destro, rispettivamente; i limiti di integrazione t1 e t2 sono scelti 0 e 80 ms, rispettivamente, per la zona delle riflessioni vicine (Early); invece, tra 0.08 e 3 secondi per la zona delle riflessioni lontane (Late). Posso ottenere, quindi, una misurazione caratteristica con IACCR per il riverbero vicino e una IACCL per il riverbero lontano. In generale, per il riverbero lontano, ci aspettiamo di ottenere bassi valori per quasi tutti gli ambienti [3, pp.93-94].
1.6_Riverbero vicino
Assumendo che le dimensioni delle superfici riflettenti dell’ambiente, siano molto più grandi della lunghezza d’onda del suono prodotto dalla sorgente, il riverbero vicino si può studiare facilmente considerando un semplice modello geometrico della stanza, sfruttando il “metodo delle immagini”[3, pp.90-92]. Questo metodo, permette di pensare sorgenti-pareti riflettenti come un insieme di sorgenti multiple senza pareti che, frequentemente, sono “invisibili” dalla posizione dell’ascoltatore e quindi si devono calcolare caso per caso. Se l’ambiente ha una superficie regolare, il modello dell’immagine è semplice da calcolare. Quando, invece, la forma è irregolare (vedi figura 1.7 [2]), il problema è più complesso:
Figura 1.7
ma è stato risolto in dettaglio [16, pp.1827-1836]. Se le superfici riflettenti sono N, il numero delle sorgenti immagine di ordine k è Nk (da notare che il metodo delle immagini non è utilizzabile per studiare il riverbero lontano, in quanto il numero delle sorgenti aumenta esponenzialmente e il modello di riflessione appena visto non è più accurato).
Allo scopo di calcolare la risposta impulsiva nella posizione dell’ascoltatore, si sommano tutti i contributi da tutte le sorgenti immagine, ognuna delle quali contribuisce con un impulso ritardato (eco):
_ il tempo di ritardo (delay) si ottiene dividendo la distanza sorgente-ascoltatore per la velocità del suono nell’ambiente.
_ l’ampiezza dell’eco è inversamente proporzionale alla distanza percorsa e direttamente proporzionale al prodotto dei coefficienti di riflessione delle superfici incontrate.
Usando dei Filtri Lineari [17, pp.259-291], possiamo realizzare un modello più accurato, che tiene conto della dipendenza dell’assorbimento in funzione della frequenza:
Figura 1.8
così, lo spettro di ogni eco A(ω) che raggiunge l’ascoltatore, è determinato dal prodotto di tutte le funzioni di trasferimento Γj
( )
ω coinvolte nella storia dell’eco.Se:
S è il numero di pareti incontrate,
( )
j ω
Γ è la funzione di trasferimento dipendente dalla frequenza che modella la riflessione con la con la j-esima parete.
( )
G ω rappresenta le perdite per assorbimento e il tempo di ritardo dovuto alla propagazione in aria ⇒
( )
A ω = G( )
ω( )
1 S j j ω = Γ∏
dove 1 ≤ j ≤ SInformazioni importanti che vanno introdotte nella simulazione riguardano la direzione degli echi; la risposta vicina, infatti, è composta da riflessioni discrete che arrivano da direzioni specifiche. I riferimenti uditivi per la localizzazione del suono sono identificati dalla trasformazione della pressione sonora effettuata nel passaggio tronco, capo, orecchio esterno; questa trasformazione che
parte dalla posizione specifica della sorgente nell’ambiente e arriva fino all’apparato uditivo è descritta da una funzione definita come “HRTF” (Head-Related Transfer Function, cioè, altamente relazionata con la testa); l’HRTF è comunemente misurata usando soggetti umani o microfoni sulla testa di manichini e consiste di due risposte: una per l’orecchio sinistro e una per quello destro.Di conseguenza, quando effettuiamo il calcolo della funzione binaurale completa, bisogna anche convolvere ogni eco direzionale con il corrispondente HRTF, relativo appunto alla direzione dell’eco stesso [18, pp.858-867; 19].
I parametri direzionali binaurali catturati dalle HRTF, sono:
_ ITD, Differenza di Tempo Interaurale (Interaural Time Difference) _ IID, Differenza di Intensità Interaurale (Interaural Intensity Difference)
Gli echi che arrivano dalle direzioni più laterali, sono importanti perché modificano la caratteristica spaziale del riverbero percepita; in questi casi l’ITD si può simulare facilmente, tramite un ritardo corrispondente alla differenza tra le lunghezze delle traiettorie verso i due orecchi:
Figura 1.9
Allo stesso modo, l’IID può modellarsi come un filtro passabasso del segnale che arriva all’orecchio opposto.
1.8_Sommario e propositi di progetto
I modelli geometrici ci permettono la predizione della risposta riverberante vicina di un ambiente, che consiste di un set di impulsi ritardati e attenuati. Una modellazione dell’assorbimento e della diffusione tenderà a riempire tutti gli intervalli con energia. Si possono usare filtri lineari per modellare l’assorbimento e, in grado minore, la diffusione, permettendo la riproduzione delle proprietà direzionali della risposta vicina.
Il riverbero lontano è caratterizzato da una densa collezione di echi viaggianti in tutte le direzioni, in altre parole da un campo sonoro diffuso. Il tempo di decadimento del riverbero diffuso alle medie frequenze si può descrivere in larga misura in termini del TR; una descrizione più accurata, che considera l’EDF dell’ambiente, ci induce ad analizzare sia l’inviluppo della risposta in frequenza sia il tempo di decadimento dell’energia, entrambi funzioni della frequenza. L’approccio modale rivela che la riverberazione si può descrivere statisticamente per frequenze sufficientemente alte; quindi, certe proprietà statistiche della stanza, come la spaziatura media e le altezze delle frequenze massime, sono indipendenti dalla forma della stanza. Il riverbero vicino si fonde, percettivamente, con il suono diretto modificando la sua intensità, il timbro e l’impressione spaziale, da cui le riflessioni laterali sono necessarie per la modifica spaziale del suono diretto stesso. Il livello del suono diretto, relativamente al riverbero, cambia in funzione della distanza dalla sorgente e serve come riferimento importante per la percezione della distanza. In generale, l’incremento dell’energia vicina, rispetto a quella totale, contribuisce all’intelligibilità del segnale. Esistono diversi attributi soggettivi del riverbero, discussi in letteratura; molti di questi sono monoaurali, direttamente collegati con le misure acustiche che si possono ricavare dall’EDR. Di conseguenza, è conveniente pensare l’EDR come rappresentativa di tutte le misure monoaurali oggettive della risposta impulsiva di un ambiente. Si presume che dettagli superiori siano irrilevanti, in modo particolare nella risposta lontana; ma non sono stati ancora fatti studi sistematici per determinare la risoluzione richiesta per riprodurre percettivamente una risposta riverberante dalla sua EDR. Così, allo scopo di simulare il riverbero di un ambiente in modo percettivamente convincente, è necessario simulare sia i pattern degli echi vicini, con particolare attenzione agli echi laterali, sia l’EDR lontano. Il riverbero lontano può essere parametrizzato attraverso l’inviluppo della risposta in frequenza e il tempo di riverbero, entrambi funzioni della frequenza. Il proposito è progettare un riverberatore artificiale che ha densità d’eco sufficiente nel dominio del tempo, sufficiente densità di massimi nel dominio della frequenza ed un timbro naturale senza aggiunta di colore.
2. Modellazione acustica
con ritardo digitale
2_Modellazione Acustica con Ritardo Digitale
Vediamo ora la simulazione di onde viaggianti in mezzi Lineari Tempo Invarianti (LTI); anche se ci interesseremo principalmente alla propagazione in aria, le onde che si propagano su corde vibranti si comportano analogamente.
2.1_Linea di Ritardo (Delay Line)
La delay line è un’unità funzionale elementare che imita il ritardo di propagazione acustico.E’ un blocco fondamentale per la costruzione di un riverberatore artificiale digitale e per i processori di effetti di ritardo; la sua funzione è quella d’introdurre un tempo di ritardo tra il suo ingresso e la sua uscita, come mostrato in Fig. 2.1
Figura 2.1: linea di ritardo a M-campioni.
dove M è il ritardo tra l’ingresso e l’uscita della delay-line, x(n) è il segnale di ingresso, y (n) è il segnale di uscita specificato dalla relazione:
( ) ( )
y n =x n M− , per n = 0,1,2,…. dove x(n) 0 per n < 0.
Prima dell’era digitale, le linee di ritardo erano molto costose e imprecise nella loro forma “analogica”, basti pensare che i “riverberatori a molla” (usati negli amplificatori da chitarra) usano molle metalliche e linee di ritardo analogiche; sufficienti per lo scopo ma rumorosi; per creare ritardi lunghi necessitano di molle di lunghezza proibitiva e inoltre i valori numerici dei ritardi ottenuti possono essere solo interi. Nel dominio digitale, un ritardo di N campioni può essere implementato facilmente e si possono ottenere ritardi di qualunque valore usando tecniche di interpolazione [5]
2.2_Simulazione della Propagazione di un’Onda Acustica
2.2.1_Onde viaggianti
Per simulare la propagazione di un’onda acustica, in generale, si usano le linee di delay. In generale, un’onda viaggiante (traveling wave) è un tipo ideale di onda che si propaga in una direzione senza cambiamenti significativi sulla propria forma. Una classe importante di onde viaggianti è rappresentata dalle “onde piane” nello spazio, che possono creare “onde stazionarie “ in ambienti con pareti rettangolari parallele, a forma cioè di parallelepipedo o “scatola da scarpe”. In generale, il suono diretto proveniente da una sorgente sonora lontana (in termini di lunghezze d’onda λ ) può essere ben approssimato come un’onda piana e perciò come un’onda viaggiante ideale. Un altro caso in cui predominano le onde piane è il tubo cilindrico, come il tubo del clarinetto o le parti diritte di una tromba; anche l’“apparato vocale” è generalmente simulato usando le onde piane, anche se in questo caso c’è un alto errore di approssimazione. In questo modo si possono simulare, con un alto grado di accuratezza percettiva, anche onde “trasversali” e “longitudinali” in una corda vibrante (es. chitarra, archi), approssimandole come ideali, implementando perdite e dispersione una volta per periodo in un punto particolare.In un tubo conico, invece, ci troviamo di fronte a regioni di “onde sferiche”: sono onde anch’esse viaggianti (come le onde piane) e possiamo usare opportune delay line per simulare la loro propagazione; vedremo il caso di onde sferiche prodotte da una sorgente puntiforme.
2.2.2_Onda viaggiante con attenuazione
Figura 2.2: Simulatore di onda viaggiante con attenuazione. Aggiunta di un moltiplicatore per un coefficiente di attenuazione gM < 1 in cascata al ritardo di M campioni.
Per simulare una qualunque onda viaggiante che si propaga in una direzione con forma d’onda costante, si può usare una delay line, vista prima. Se l’onda viaggiante si attenua durante la propagazione con lo stesso fattore di attenuazione ad ogni frequenza, l’attenuazione può essere rappresentata con un semplice moltiplicatore per un semplice fattore di scala posto all’uscita (o all’ingresso) della delay line stessa; se l’attenuazione dopo il singolo istante temporale è g, dopo M passi temporali, basta semplicemente moltiplicare per il fattore cumulativo gM. In questo modo la
simulazione ingresso-uscita è esatta, ma i campioni intermedi di segnale sono affetti da piccoli errori di guadagno. E’ possibile però usare fattori moltiplicativi di correzione; ad esempio, si può prelevare il segnale di mezzo della delay line usando un coefficiente di gM2, così da farne una
seconda uscita esatta. In conclusione, l’efficienza di calcolo può essere migliorata con il costo di un semplice moltiplicatore il cui coefficiente si ottiene sommando le perdite fino alle uscite d’interesse e nei punti d’interazione con altri simulatori. Da notare che questo tipo di modello di ritardo con attenuazione con fattore di scala è fisicamente esatto solo quando tutte le componenti frequenziali decadono con lo stesso fattore di proporzione.
Un modello acustico più accurato si ottiene sostituendo il fattore di scala costante con un filtro digitale G(z) che riesce ad implementare anche l’attenuazione in funzione della frequenza, come mostrato in fig. (2.3). Supponiamo per ora che G(z) sia un filtro Lineare Tempo Invariante (LTI) che implementa un fattore di attenuazione indipendente ad ogni frequenza.
Figura 2.3: Simulatore di onda viaggiante con attenuazione. In teoria, il filtro digitale G(z) fornisce una attenuazione arbitraria ad ogni frequenza. G e
(
jωT)
≤ per tutte le 1 ω.2.2.3_Conversione della Distanza di Propagazione in Durata del Delay
Possiamo considerare la memoria della delay line stessa come un “mezzo” in cui si propagano campioni di suono ad una velocità fissata c (in aria c = 345 m/s a 22° Celsius e a 1 atmosfera). Il segnale di ingresso x(n) può essere associato ad una sorgente sonora, mentre il segnale di uscita y(n) al punto di ascolto. Se y(n) è situato a d metri di distanza dalla superficie, indicando con T il periodo di campionamento, allora la lunghezza M della delay line dovrà essere:
* d M
c T
= campioni
In pratica si arrotonda il valore M ottenuto al più vicino intero, a meno che questo non causi una differenza udibile (come nel caso, che vedremo più in seguito, dei “filtri a pettine”, in cui il tempo d’eco è così corto che il sistema non è realmente percepito come un’eco).
2.2.4_Onde sferiche prodotte da una sorgente puntiforme
La teoria della fisica acustica afferma che una sorgente puntiforme posta in un mezzo isotropo ideale produce un’onda sferica; secondo il “Principio di Huygens”, la propagazione di un’onda avviene come sovrapposizione di onde sferiche generate in ogni punto del fronte d’onda, il suono proveniente da una superficie radiante può essere calcolato come la somma dei singoli contributi delle onde sferiche proveniente da ogni punto della superficie, includendo tutte le riflessioni relative; quindi la propagazione di un’onda acustica può essere considerata linearmente come sovrapposizione di onde sferiche viaggianti. [20].
In prima approssimazione, l’energia di un’onda si conserva. In un’onda sferica di pressione di raggio r, l’energia del fronte d’onda si distribuisce lungo l’area della superficie sferica 4πr2.
Quindi, l’energia per unità di area di un’onda di pressione sferica in espansione decresce come
2
1 r : fenomeno di attenuazione per diffusione sferica.
La pressione sonora di un’onda viaggiante è proporzionale alla radice quadrata della sua energia per unità d’area. Per un’onda sferica viaggiante, quindi, l’ampiezza della pressione acustica è proporzionale a 1/r, dove r è il raggio della sfera. Fissato un sistema di coordinate cartesiane, l’ampiezza p(x2) nel punto x2=(x2, y2 ,z2) dovuta al punto di sorgente situato in x1 = (x1, y1, z1) è data da
P(x2) = 1 12
p r
dove p1 l’ampiezza per r12 = 0, e r12 è la distanza da x1 a x2:
12 2 1
r = x −x =
(
x2−x1) (
2+ y2−y1) (
2+ z2−z1)
2 Nella figura seguente è mostrato il caso 2D:Riassumendo, ogni punto di sorgente sonora produce onde viaggianti sferiche in tutte le direzioni con attenuazione 1/r, dove r è la distanza dalla sorgente, andamento che può essere considerato conseguenza della conservazione dell’energia delle onde di propagazione.
Possiamo immaginare tali onde come “raggi” provenienti dalla sorgente, simulandoli come una delay line in cascata con un moltiplicatore per un coefficiente di scaling (fattore di scala) di valore 1/r (vedi fig. 2.5):
Figura 2.5: Simulatore di onda sferica punto-punto: in cascata al ritardo di propagazione c’è il fattore di attenuazione g = 1/r.
Da notare il contrasto con le “onde piane” ideali, che si propagano senza nessuna attenuazione, per le quali ogni raggio può essere considerato senza attenuazione e la simulazione è fatta senza nessun fattore di scala.
2.2.5_Fenomeno di Riflessione nel caso di onde Piane o Sferiche
Quando un’onda sferica che si propaga raggiunge una parete o un altro tipo di ostacolo, viene riflessa e/o diffusa (fig. 1.7). Un fronte d’onda è riflesso quando sbatte su una superficie piana più grande per almeno qualche lunghezza d’onda in ogni direzione. In questo caso i fronti d’onda riflessi possono essere mappati semplicemente usando dei raggi di traccia, che si comportano secondo le “leggi di riflessione speculare” dell’ottica. Un’onda, invece, è diffusa quando incontra una superficie con rugosità e variazioni superficiali dell’ordine della grandezza d’onda. Oggetti più piccoli di una lunghezza d’onda producono una riflessione diffusa, che si avvicina tanto più ad un’onda sferica quanto più l’oggetto si avvicina a volume zero.In generale, ogni punto di un oggetto diffusore può essere considerato come emettitore di un nuovo fronte d’onda propagatesi sfericamente come reazione all’onda subentrante (principio di Huygens). Da notare che lo stesso processo accade nella riflessione ma ogni punto della superficie piatta si combina a formare un fronte d’onda più ordinato, che è lo stesso dell’onda incidente ma viaggia in un’altra direzione.In altri termini, la distinzione tra propagazione diffusa e riflessione è dipendente dalla frequenza dell’onda. Poiché il suono viaggia a circa 30cm per ms, un cubo di 30cm a lato “rifletterà specularmene” raggi diretti di energia sonora sopra 1kHz, mentre “diffonderà” l’energia sonora sotto 1kHz; ad esempio, una buona sala da concerti avrà una gran quantità di diffusione. Come
regola generale, il riverbero dovrebbe essere diffuso il più possibile, allo scopo di evitare cancellazioni dovute a onde stazionarie (modi energetici isolati). In altre parole, nel riverbero, il nostro scopo è propagare l’energia sonora uniformemente sia nello spazio sia nel tempo, senza pattern particolari sia spaziali sia temporali nel riverbero.
2.2.6_Simulatore d’Eco
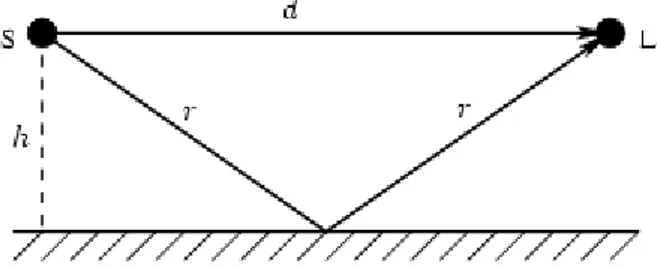
Un eco è uno dei problemi più semplici di modellazione acustica; si produce ogni volta che un suono che parte dalla sorgente (S) arriva all’ascoltatore (L) attraverso una propagazione “multipath” di un’onda acustica; si distingue bene quando arriva considerevolmente dopo il segnale diretto (o l’eco precedente), come nel caso di un battito di mani di fronte ad una parete, come si vede in figura 2.6:
Figura 2.6: Geometria di un eco acustico causata da una propagazione ``multipath'': segnale diretto + rimbalzo dal terreno.
In questo caso, per operare una simulazione realistica è opportuno scartare il “ritardo semplice” che tratta tutti i segnali allo stesso modo, perché non influisce sul timbro; il segnale diretto non ha alcuna implementazione né attenuazione dovuta alla propagazione, perché ciò che incide sul timbro è l’ampiezza relativa del segnale diretto e dei suoi echi
Figura 2.7: Simulazione acustica di una eco con una delay line, guadagno (g) e sommatore.
Il segnale diretto percorre una distanza d dalla sorgente all’ascoltatore, mentre per l’eco è r:
2 2 2 2 d r =h + ⎜ ⎟⎛ ⎞ ⎝ ⎠ quindi, la lunghezza M della delay line dovrebbe essere:
2r d M cT − = , mentre g invece : 1 2 1 2 r d g d r = = ,
dove c è la velocità del suono e T è l’intervallo di campionamento. Sostituendo il valore di r = h2+
(
d 2)
2 otteniamo il valore di g in funzione solamente di due variabili: l’altezza h e ladistanza d tra sorgente e ascoltatore:
(
)
2 1 1 2 g h d = +2.3_Propagazione Acustica con Perdite
L’attenuazione di un’onda acustica attraverso la propagazione sferica, non è la sola causa di attenuazione d’ampiezza di un’onda viaggiante. Nello spazio libero, c’è un’altra perdita addizionale significante causata dall’assorbimento dell’aria. L’assorbimento dell’aria varia con la frequenza: le alte frequenze sono più attenuate delle basse frequenze
2.3.1_Assorbimento dell’aria
Tenendo conto dell’assorbimento, l’intensità di un’onda acustica in funzione della distanza di propagazione x, è data da:
( )
0x
I x =I e− ξ
I0 = Intensità acustica alla sorgente
I(x) = Intensità acustica a x metri dalla sorgente
ξ = costante di attenuazione (1/metri) che dipende dalla frequenza, temperatura, umidità e pressione
Le tabelle seguenti indicano dei valori tipici dell’attenuazione dovuta all’assorbimento dell’aria a pressione atmosferica:
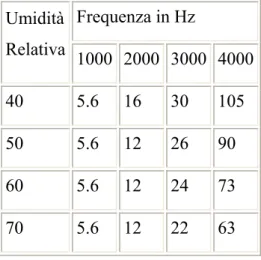
Tabella 2.1: costante di attenuazione [ ξ ] = [1/m] a 20°C e alla pressione atmosferica Frequenza in Hz Umidità Relativa 1000 2000 3000 4000 40 0.0013 0.0037 0.0069 0.0242 50 0.0013 0.0027 0.0060 0.0207 60 0.0013 0.0027 0.0055 0.0169 70 0.0013 0.0027 0.0050 0.0145
Tabella 2.2: Attenuazione in dB per km a 20°C e pressione atmosferica Frequenza in Hz Umidità Relativa 1000 2000 3000 4000 40 5.6 16 30 105 50 5.6 12 26 90 60 5.6 12 24 73 70 5.6 12 22 63
Onda piana ideale
Per un’onda piana ideale che si propaga non ci sono perdite per propagazione (cioè di attenuazione con andamento 1/r); poniamo che g(r, ω) sia il fattore di attenuazione associato alla propagazione sulla distanza r alla frequenza ω rad/sec; si può dimostrare che g dipende in modo esponenziale da r.
Onda piana con assorbimento indipendente dalla frequenza
Nell’ipotesi che, invece, oltre ad attenuazione per propagazione, si verifichi anche assorbimento indipendente dalla frequenza, la simulazione acustica si può facilmente modellare attraverso la sostituzione
1 1
z− ←gz−
nella funzione di trasferimento della delay line ideale; g indica l’attenuazione associata alla propagazione durante un periodo di campionamento (T sec). Così, per simulare l’assorbimento corrispondente ad un ritardo di M-campioni, si modifica opportunamente l’equazione alle differenze della delay line:
( ) M ( )
Figura 2.8: delay line con simulazione dell’assorbimento
Onda piana con assorbimento dipendente dalla frequenza
Più in generale, nel caso di assorbimento dell’aria dipendente dalla frequenza può essere modellato usando un filtraggio per campione G(z) invece del semplice coefficiente g:
( )
1 1
z− ←G z z−
Poiché l’assorbimento dell’aria non amplificherà mai un’onda a nessuna frequenza, abbiamo che
(
j T)
1G eω ≤ . Quindi una delay line con perdita per la simulazione di un’onda piana nel dominio della frequenza e del tempo rispettivamente è così descritta:
y(n) =
M volte
g g g∗ ∗ ∗ ∗ ∗ x(n – M) g
dove g(n) = g∗g∗g∗g…∗g indica la risposta impulsiva totale ottenuta dalla convoluzione effettuata M volte tra le risposte impulsive dei singoli filtri con perdita per campione G(z).
Onda sferica con assorbimento dipendente dalla frequenza
Per onde sferiche, esiste anche una dispersione dovuta alla propagazione sferica (vedi Onde sferiche da una sorgente puntiforme) che è proporzionale a 1/r:
( ) ( ) GM z z M ( ) Y z X z r − ∝ dove r è la distanza tra X e Y.
Da notare che il fattore dispersione per propagazione sferica ha una dipendenza Iperbolica (1/r) dalla distanza r, mentre la dispersione G per assorbimento dell’aria ha dipendenza Esponenziale da r.
2.3.2_Onde viaggianti con Dispersione
Insieme all’assorbimento dipendente dalla frequenza, utilizzando filtri Lineari Tempo Invarianti (LTI), che provvedono al delay dipendente dalla frequenza, possiamo simulare anche la propagazione dell’onda con dispersione. Nel caso di semplice dispersione senza attenuazione, il filtro diventa passatutto [21]. Un caso classico nell’acustica musicale, è la simulazione della corda del pianoforte.
2.3.4_Sommario
In conclusione, la propagazione punto-punto di un’onda piana viaggiante in un mezzo LTI si può simulare semplicemente usando:
_ delay line: simula la propagazione del ritardo temporale. _ filtro LTI: simula allo stesso tempo:
1) fattore di attenuazione indipendente ad ogni frequenza per mezzo della sua risposta in ampiezza (simulazione assorbimento dell’aria)
2) velocità di propagazione dipendente dalla frequenza usando la sua risposta in fase (simulazione dispersione).
_ fattore moltiplicativo, 1/r: simula una dispersione addizionale per propagazione sferica, essendo r la distanza dalla sorgente.
2.4_Delay Line con Prelievo (Tapped Delay Line, TDL)
Una tapped delay line (TDL) è una delay line con almeno un prelievo di segnale. Il “tap” (rubinetto) della delay line estrae un segnale di uscita da qualche parte dentro la Delay Line, lo pesa opportunamente attraverso la moltiplicazione per un coefficiente e poi in genere lo somma con altri prelievi per comporre un segnale di uscita. Un prelievo può avvenire con interpolazione o meno: se non opera un’interpolazione, estrae il segnale con un certo ritardo rispetto all’ingresso (di un valore intero fissato). Quindi, un tap implementa un ritardo più corto da un più lungo dell’intera delay line, come mostrato in figura 2.9:
Figura 2.9: Delay Line con singolo tap
Le TDL riescono a simulare in modo efficiente Echi Multipli utilizzando la stessa sorgente di segnale; per questo motivo sono molto usati per la creazione di riverbero in modo artificiale.
2.4.1_Esempio TDL
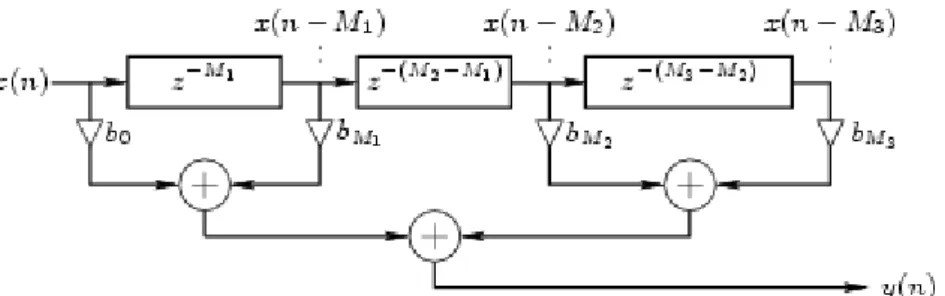
In figura possiamo vedere un esempio di TDL con due prelievi interni: la lunghezza totale della delay line è di M3 campioni, i prelievi interni sono individuati ad un ritardo di M1 e M2 campioni, rispettivamente. Il segnale di uscita è una combinazione lineare del segnale di ingresso x(n), della uscita della delay line x(n-M3) e dei due segnali estratti x(n-M1) e x(n-M2).
Figura 2.10: TDL con due prelievi
L’equazione alle differenze relativa alla TDL in figura è la seguente:
( )
1(
)
2(
)
3(
)
0 1 2
( ) M M M
corrispondente alla funzione di trasferimento: 3 1 2 1 2 3 0 ( ) M M M M M M H z = +b b z− +b z− +b z−
2.4.2_Tapped Delay Line Trasposte
Figura 2.11: Tapped Delay Line Trasposte (TTDL).
In molte applicazioni è necessario utilizzare configurazioni dei filtri digitali di tipo diverso. Per convertire un filtro digitale dalle forme dirette I e II alle configurazioni III e IV rispettivamente, si esegue un’opera di trasposizione. Una TDL trasposta si ottiene attraverso l’inversione del grafico di flusso diretto utilizzando il teorema di trasposizione [22].
2.4.3_TDL per Elaborazione Parallela
Quando si possono realizzare moltiplicazioni ed addizioni in parallelo, la complessità computazionale di una TDL è di O (1) moltiplicazioni e O (lg(K)) addizioni, dove K è il numero di prelievi (taps). La ridotta complessità computazionale è ottenuta grazie ad una disposizione ad albero binario. In figura è mostrato il caso K = 4
![Tabella 2.1: costante di attenuazione [ ξ ] = [1/m] a 20°C e alla pressione atmosferica Frequenza in Hz Umidità Relativa 1000 2000 3000 4000 40 0.0013 0.0037 0.0069 0.0242 50 0.0013 0.0027 0.0060 0.0207 60 0.0013 0.0027 0.0055 0.0169 70 0.0013 0.002](https://thumb-eu.123doks.com/thumbv2/123dokorg/7231963.78657/38.892.290.603.837.1097/tabella-costante-attenuazione-pressione-atmosferica-frequenza-umidità-relativa.webp)