ALMA MATER STUDIORUM – UNIVERSIT `
A DI BOLOGNA
CAMPUS DI CESENA
Scuola di Scienze
Corso di Laurea Magistrale in Ingegneria e Scienze Informatiche
IMPLEMENTAZIONE E ANALISI
COMPARATIVA DI TECNICHE DI FACE
MORPHING DETECTION
Elaborato in
VISIONE ARTIFICIALE
Relatore
Prof. ANNALISA FRANCO
Presentata da
ALBERTO GIUNTA
Terza Sessione di Laurea
Anno Accademico 2017 – 2018
PAROLE CHIAVE
Face Morphing Attack
Image Morphing
Biometrics
eMRTD
Automatic Border Control
Indice
1 Introduzione agli eMRTD 1
1.1 Documenti di identit`a elettronici . . . 2
1.1.1 eMRTD - Electronic Machine Readable Travel Documents 2 1.1.2 Caratteristiche di identificazione biometriche . . . 6
1.1.3 ABC - Automated Border Control . . . 10
1.2 Alterazioni dell’immagine del volto e conseguenti problematiche 11 2 Stato dell’arte 17 2.1 Approcci di single-image morph detection . . . 22
2.2 Approcci di double-image morph detection . . . 29
3 Algoritmo proposto 35 3.1 Pre-processing . . . 36
3.2 Estrazione di feature . . . 40
3.2.1 Local Binary Pattern Histograms (LBPH) . . . 41
3.2.2 CNN . . . 48 3.3 Classificazione . . . 56 3.3.1 SVM . . . 56 4 Risultati 63 4.1 Dataset . . . 63 4.2 Prove sperimentali . . . 68 4.2.1 Intra DB . . . 69 4.2.2 Extra DB . . . 69 4.3 Risultati . . . 71 vii
viii INDICE 4.3.1 Test Biometix . . . 71 4.3.2 Test su MorphDB D . . . 72 4.3.3 Test su MorphDB PS . . . 73 4.3.4 Considerazioni finali . . . 75 Conclusioni 85 Ringraziamenti 87 Bibliografia 89
Introduzione
I Machine Readable Travel Documents, pi`u noti come Passaporti Elettro-nici, contano oramai oltre il miliardo di unit`a in corso di validit`a e permettono ad oltre quattro miliardi di passeggeri di viaggiare ed attraversare confini ogni anno tramite via aerea.
Come tutti i pi`u importanti sistemi di sicurezza, anche i sistemi di verifica dell’identit`a presenti ai gate dei pi`u grandi aeroporti mondiali devono garan-tire il pi`u alto grado di sicurezza possibile evitando al contempo di essere di troppo intralcio per la loro utenza, o come in questo caso evitando di impedire o rallentare la normale circolazione dei passeggeri. Per fare ci`o un numero sempre maggiore di aeroporti si sta dotando di sistemi di verifica automatica dell’identit`a sulla base di informazioni biometriche dei viaggiatori, informazio-ni che legano indissolubilmente i documenti di viaggio al rispettivo titolare. Questi sistemi permettono un alto livello di efficienza e affidabilit`a, ma non so-no esenti da vulnerabilit`a. Risale infatti al 2014 la scoperta di una importante falla nei protocolli di sicurezza che permetterebbe ad un criminale di attraver-sare indisturbato i controlli aeroportuali tramite alcune semplici operazioni di fotoritocco.
Questa problematica ha preso il nome di Face Morphing Attack, e consi-ste nel presentare ai portali di ABC dei passaporti sostanzialmente validi e regolarmente emessi, ma con fotografie e quindi dati biometrici del volto che ne permettono l’uso da parte di pi`u di un solo soggetto, e quindi da parte di soggetti diversi rispetto al legittimo proprietario del documento.
Il campo di ricerca in ambito di Face Morphing Detection `e ancora molto giovane e attivo, nonch`e frammentato: ciascuno studio sull’argomento propone
x INTRODUZIONE tecniche in qualche modo differenti dalle precedenti e ne verifica l’efficacia su dataset proprietari e costruiti ad hoc da ciascun gruppo di ricercatori. Con il lavoro proposto in questa tesi si cerca di fare maggiore chiarezza sull’efficacia di diversi metodi di detection noti in letteratura, applicandoli a situazioni e dataset pi`u fedeli alla realt`a e facendone un’estensiva analisi comparativa.
Nel primo capitolo vengono introdotti gli Electronic Machine Readable Tra-vel Documents, le loro origini, la loro struttura e funzionamento generale. Si descrivono i principali tratti biometrici oggi in uso in questo campo, concen-trandosi principalmente sul viso. Si introducono brevemente anche i sistemi ABC e le loro vulnerabilit`a, soffermandosi con maggiore attenzione sul Face Morphing Attack, il suo funzionamento e le conseguenze che questo comporta. Nel secondo capitolo si procede ad analizzare lo stato dell’arte in ambito di Face Morphing Detection: vengono descritti i principali studi che presentano approcci basati su singola immagine e approcci differenziali, vengono analizzati i diversi metodi di estrazione di feature, di classificazione, ed i dataset utilizzati da ciascuno cos`ı come i principali risultati ottenuti.
Nel terzo capitolo si procede ad esporre l’algoritmo oggetto di questa tesi nelle sue principali fasi di pre-processing, estrazione di feature e classificazione. Per ciascuna di queste vengono descritti i diversi approcci che si `e scelto di esplorare e le motivazioni dietro tali scelte.
Nel quarto ed ultimo capitolo vengono descritti in maniera estensiva i diver-si dataset che sono stati utilizzati e la natura delle immagini di cui diver-si compon-gono. Vengono descritte le prove sperimentali effettuate su ciascun dataset e tra coppie di dataset distinti. Infine vengono riportati e commentati i risultati ottenuti.
Capitolo 1
Introduzione agli eMRTD
Secondo studi pubblicati dalla IATA1 (International Air Transport Asso-ciation) il numero annuale di passeggeri totali su voli commerciali segue, sin dai primi anni 2000, un trend in costante aumento, con un record misurato nel 2017 di almeno 4 miliardi di passeggeri [1], ed un numero di passaporti elettro-nici rilasciati a met`a 2017 che ha di poco superato il miliardo di unit`a [2]. Con numeri di questa portata risulta quindi evidente la necessit`a di analizzare ogni possibile minaccia alla sicurezza dei viaggiatori, cos`ı come possibili infrazioni alle norme internazionali vigenti in materia di libera circolazione di persone.
In questo capitolo si proceder`a ad introdurre dapprima le diverse caratte-ristiche dei documenti di identit`a elettronici, passando poi ad una descrizione delle caratteristiche biometriche pi`u in uso e alle vulnerabilit`a e attacchi a cui queste possono essere soggette.
1
https://www.iata.org/Pages/default.aspx
2 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
1.1
Documenti di identit`
a elettronici
I documenti di identit`a elettronici sono documenti in cui le informazioni rappresentative dell’identit`a di ciascuno sono non solo scritte a caratteri nor-malmente leggibili -sia da esseri umani che da lettori ottici (OCR)-, ma sono anche presenti all’interno di un chip RFID presente sul documento, insieme ad altre informazioni biometriche del soggetto, e sono codificate secondo le esigenze di sicurezza del Paese di emissione [3].
Per quanto sicuri, questi documenti non sono esenti da falle nei protocolli di sicurezza che li riguardano, e nel corso di questa tesi verranno analizzati alcuni attacchi di comprovato successo all’integrit`a di questi ultimi. Verranno inoltre esaminate e proposte possibili soluzioni e rimedi nel caso specifico dei passaporti elettronici e delle problematiche ad essi relative.
1.1.1
eMRTD - Electronic Machine Readable Travel
Do-cuments
Cenni storici
I primi lavori per la creazione di Machine Readable Travel Documents risal-gono al 1968, quando l’agenzia delle Nazioni Unite ICAO2 ha ufficializzato la necessit`a di accelerare la verifica dei passaporti e l’accettazione dei passeggeri negli aereoporti.
I primi frutti di questi sforzi si ebbero nel 1980, quando furono prodotte una serie di raccomandazioni per l’adozione di nuovi protocolli e tecnologie, inclusa l’adozione di un dispositivo OCR in quanto macchina predisposta alla lettura dei passaporti, tecnologia scelta a causa della sua comprovata efficacia, robustezza ed economicit`a. Queste raccomandazioni furono la base su cui si basarono Stati Uniti, Australia e Canada quando per primi iniziarono ad emettere passaporti elettronici.
2
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 3
Nel 1998 il NTWG3 facente parte di ICAO ha iniziato a lavorare per
sta-bilire quale fosse il pi`u adatto sistema di identificazione biometrico e con quali mezzi i tratti biometrici di ciascuno potessero essere conservati all’interno di documenti di identit`a. Dopo gli avvenimenti del 11 settembre 2001 gli USA modificarono i propri requisiti obbligando tutti i paesi che partecipavano al Visa Waiver Program a cominciare ad emettere passaporti elettronici entro il 26 ottobre 2006. Nel dicembre 2004 l’Unione Europea inizi`o a cercare una regolamentazione comune per ufficializzare ed abilitare la presenza di tratti biometrici nei documenti di viaggio. Nel febbraio 2005 venne approvata ed adottata dai paesi dell’Unione la prima versione delle specifiche tecniche per i passaporti elettronici, e tutti i Paesi dell’Unione rispettarono gli impegni previsti per ottobre 2006.
Nel 2006 a Budapest, il FIDIS, o ”Future of Identity in the Information Society”, un programma di ricerca sulla sicurezza finanziato dall’Unione Eu-ropea, ha pubblicato un report chiamato ”Budapest Declaration on Machine Readable Travel Documents” con l’obiettivo di sensibilizzare l’opinione pub-blica sulla pericolosit`a e sui fallaci protocolli di sicurezza intorno ai MRTD, che rendono i cittadini soggetti alla costante minaccia di furto di identit`a e violazione della privacy, e che secondo i ricercatori affliggono anche le odierne implementazioni di eMRTD emessi dall’Unione Europea [4].
Nel 2006 venne adottata dall’Unione Europea una seconda versione di speci-fiche tecniche per i passaporti elettronici che poteva essere adottata da ciascun Paese su base volontaria, e che prevedeva la memorizzazione delle impronte di-gitali, oltre che del volto del titolare, dietro un nuovo livello di sicurezza deno-minato Extended Access Control. L’obiettivo dietro questa misura di sicurezza aggiuntiva `e quello di considerare le informazioni biometriche dei cittadini co-me informazioni altaco-mente sensibili, che devono essere rese inaccessibili a terze parti non autorizzate dal Paese emittente del documento, come la polizia di frontiera o governi di Paesi ostili.[11]
4 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
Caratteristiche degli eMRTD
I MRTD (Machine Readable Transport Document) sono documenti di viag-gio ufficiali emessi da uno Stato o da un’organizzazione, usati dai loro titolari per spostamenti internazionali. Contengono varie informazioni relative all’i-dentit`a del titolare in un formato standardizzato, inclusa una sua fotografia, oltre ad altri elementi, alcuni obbligatori ed altri opzionali. Le informazioni obbligatorie (esclusa la foto) sono anche codificate nella cosiddetta Machine Readable Zone (MRZ) in due linee di testo scritte in font OCR e che possono comprendere solo numeri, lettere e i cosiddetti chevrons ”<<<” [5].
Figura 1.1: Esempio di pagina di passaporto contenente informazioni personali.
Gli eMRTD (electronic Machine Readable Travel Documents) sono inve-ce documenti ormai rilasciati da pi`u di 120 paesi nel mondo [2], e secondo le indicazioni suggerite da ICAO essi possono essere definiti come tali (ovvero ”elettronici”) grazie alla presenza di un circuito integrato ed alla chiara ed evi-dente apposizione del simbolo ”Chip Inside” sulla copertina o sul lato frontale del documento (se si tratta di un passaporto o di una smartcard).
Questo simbolo (Fig. ??) dovrebbe quindi apparire solo su un eMRTD che contenga un’antenna ed un circuito integrato contactless, con una capacit`a di memorizzazione di almeno 32 kB, codificato e criptato in accordo con gli standard definiti da ICAO stessa, ovvero tramite una infrastruttura a chiave
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 5
pubblica (PKI). Esso deve contenere almeno 1) le informazioni di identificazio-ne di base di un soggetto (nome e cognome, nazionalit`a, indirizzo di residenza, data di nascita) assieme ad 2) un’immagine del suo viso. A meno che quindi un eMRTD sia conforme a questi requisiti minimi non dovrebbe essere descritto come un eMRTD o mostrare il simbolo ”Chip Inside”.
Figura 1.2: A sinistra si pu`o vedere il simbolo ”Chip Inside” che contraddi-stingue i passaporti elettronici. A destra sono evidenziati in verde i paesi che emettono passaporti elettronici aggiornati al 2017.
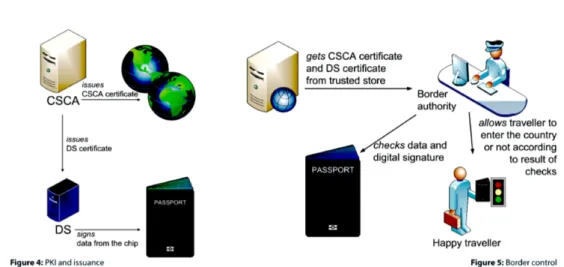
Come mostrato in Figura 1.3 dal momento che il chip contiene informa-zioni autenticate, un Paese che voglia emettere eMRTD deve mantenere una infrastruttura a chiave pubblica (PKI) adeguata e dedicata in strutture sicu-re. La ”radice” di questa PKI `e il cosiddetto Country Signing Certification Authority (CSCA). Il certificato dell’entit`a preposta a ”firmare” digitalmente il documento (Document Signer, DS), certificato a sua volta autenticato dalla CSCA, prova l’autenticit`a e integrit`a dei dati nel chip del documento e del collegamento con il Paese emittente.
6 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
Figura 1.3: Diagramma rappresentante il sistema PKI ed il ruolo di una CSCA.
Il compito principale dei passaporti elettronici [6], che coincide anche con l’intrinseco vantaggio che hanno sui passaporti ”analogici”, `e quello di:
• Rendere possibile il riconoscimento automatico dei viaggiatori nei varchi ABC.
• Fornire protezione contro il furto d’identit`a.
• Proteggere la privacy del viaggiatore e rendere pi`u complessa l’alterazione del documento per fini criminali.
Gli eMRTD (i passaporti nello specifico) sono il tipo di documento su cui ci si concentrer`a d’ora, assieme alle informazioni biometriche contenute all’interno del loro circuito integrato.
1.1.2
Caratteristiche di identificazione biometriche
”Identificazione Biometrica” `e un termine generico usato per descrivere me-todologie automatiche di riconoscimento di persone attraverso la misurazione di caratteristiche distintive fisiologiche o comportamentali di ciascuno.
Un ”Template Biometrico” `e invece una rappresentazione di un tratto bio-metrico distintivo, ad esempio l’immagine del volto, le impronte digitali o l’iri-de, codificata in maniera algoritmica. I template vengono utilizzati durante il
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 7
processo di autenticazione e necessitano di seguire standard condivisi a livello internazionale.
La visione di ICAO per rendere le tecnologie biometriche sempre pi`u inte-roperabili e internazionalmente riconosciute `e molto chiara, e tra le altre cose comprende:
• La specifica di una forma primaria (ed eventuali altre forme supplemen-tari) e interoperabile di tecnologia biometrica ad uso dei controlli di frontiera e degli enti incaricati dell’emissione di questo tipo di documenti. • L’eliminazione di ogni tipo di elemento proprietario ed esclusivo ricon-ducibile ad una singola entit`a, in maniera tale da liberare gli Stati che vogliano investire in tecnologie biometriche dal rischio di non poter cam-biare infrastruttura o fornitori di dispositivi di riconoscimento.
Nel campo dell’identificazione biometrica vengono utilizzati i seguenti ter-mini [7]:
• Verifica: confronto uno-a-uno tra i valori biometrici ottenuti in tempo reale dal titolare del eMRTD (attraverso l’utilizzo di dispositivi di scan-sione in loco) e un template biometrico memorizzato nel chip e creato quando il titolare ha fatto richiesta del documento presso l’ente del suo Paese di origine.
• Identificazione: ricerca uno-a-molti tra i valori biometrici del sogget-to ottenuti in tempo reale e una collezione dei template biometrici di tutti i soggetti gi`a registrati nel sistema. Questa operazione si verifica al momento della richiesta di ottenimento di un eMRTD per effettua-re un cosiddetto background check, e la qualit`a della sua performance incrementa notevolmente con la presenza di informazioni biometriche.
8 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
Il viso come tratto biometrico primario
Dopo un’indagine durata 5 anni sulle necessit`a operazionali di un tratto identificativo biometrico che fosse sia utilizzabile nella procedura di emissio-ne di eMRTD che in quella di controllo al confiemissio-ne e fosse consistente con le leggi sulla privacy di diversi stati, ICAO ha definito il riconoscimento facciale come tecnologia biometrica standard interoperabile e globalmente riconosciu-ta. Gli Stati possono comunque individualmente ed opzionalmente scegliere di utilizzare anche le impronte digitali e/o il riconoscimento dell’iride in aggiunta all’immagine del volto.[7]
Questa scelta da parte di ICAO `e supportata ed `e stata raggiunta grazie alle seguenti osservazioni:
• Le immagini del volto non divulgano informazioni che la persona non desidera volontariamente rivelare al pubblico.
• La fotografia del volto `e gi`a socialmente e culturalmente accettata inter-nazionalmente.
• L’immagine del volto `e gi`a richiesta e verificata come parte del protocollo di emissione di eMRTD.
• Il pubblico `e gi`a al corrente dell’uso dell’immagine del volto come metodo di verifica dell’identit`a.
• La cattura dell’immagine del volto non `e invasiva. L’utente finale non ha bisogno di interagire con nessuno strumento fisico affinch´e l’operazione vada a buon fine.
• Molti stati hanno uno storico di immagini del volto, che pu`o essere utilizzato a fini di confronto di identit`a con nuove immagini.
• In riferimento alle Watch List (liste di individui ricercati o tenuti sotto stretto controllo dalle autorit`a di polizia) l’immagine del volto `e spesso l’unico strumento di identificazione a disposizione.
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 9
• Il confronto di un volto con la sua rappresentazione in forma di fotogra-fia `e un’operazione relativamente semplice e a cui le autorit`a sono gi`a familiari.
• In caso il sistema notifichi un Falso Negativo, una comparazione visuale pu`o essere effettuata da parte degli ufficiali di confine, con un notevole vantaggio nella capacit`a e facilit`a di riconoscimento rispetto ad esempio a tratti come le impronte digitali.
Tutti i produttori di dispositivi per il riconoscimento facciale usano algorit-mi proprietari per generare i loro template biometrici. Queste codifiche sono secretate dai produttori in qualit`a di propriet`a intellettuale e sono immuni da reverse-engineering per riportare i dati codificati ad una immagine del volto riconoscibile. Le codifiche dei template biometrici del volto non sono quindi interoperabili tra i diversi produttori e l’unica via per raggiungere l’intero-perabilit`a `e quello di usare la fotografia catturata live e passarla in input al sistema di riconoscimento dello Stato ricevente. Quest’ultimo quindi dovrebbe usare il proprio algoritmo (che potrebbe essere o meno dello stesso produttore o versione dello Stato di emissione del documento) per comparare l’immagine del volto catturata in real time del titolare del documento con l’immagine letta dalla memoria del eMRTD in questione. [9]
Per definizione dello standard ICAO ed in rispetto allo standard ISO/IEC 19794-5 la fotografia del viso salvata all’interno di un eMRTD deve essere scan-sionata a colori a 300dpi, con circa 90 pixel tra le due pupille e una dimensione approssimativa di 640 kB a 24 bit per pixel, salvata in formato JPEG o JPEG 2000. L’immagine deve almeno rappresentare il volto nella sua interezza, dal limite inferiore del mento al limite superiore della fronte e in tutta la sua larghezza; al fine di rendere il meno complesso possibile il suo utilizzo per le autorit`a e per i programmi di riconoscimento automatico ICAO raccomanda di memorizzare l’immagine non ritagliata, cos`ı come `e stampata sul documento oppure di memorizzarla ritagliando seguendo i limiti appena espressi. Essa dovr`a anche essere adeguatamente ruotata affinch´e gli le pupille del soggetto risultino allineate parallelamente al bordo inferiore dell’immagine. Sar`a inoltre
10 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
a discrezione di ciascuno Stato decidere la linea guida da seguire per quanto riguarda la presenza di ornamenti facciali.
1.1.3
ABC - Automated Border Control
I sistemi ABC (Automated Border Control), anche chiamati eGate, sono barriere automatizzate dove i dati contenuti all’interno del chip degli eMRTD vengono letti, confrontati con i dati estratti in tempo reale, e viene stabilito se le due identit`a corrispondono o meno.
Figura 1.4: Flusso esemplificativo della procedura di verifica dell’identit`a di un soggetto nel caso di un eGate.
Gli eGate sono stati introdotti intorno alla met`a degli anni 2000 come metodo di lettura automatizzata dell’appena nato passaporto elettronico [8]. Gli eGate stanno venendo adottati da sempre pi`u aeroporti, e pi`u di 4800 unit`a erano operative Febbraio 2018. Gli eGate sono al momento in uso in oltre 180 aeroporti di 73 Paesi e si prevede un aumento nell’investimento in questo settore da parte degli aeroporti fino al 18% nel periodo 2018 - 2022 [9] [10].
Questo notevole investimento `e guidato anche dalla volont`a degli Stati, e dalla capacit`a di questi strumenti di ridurre notevolmente i costi operazionali
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 11
degli aeroporti, anche se perch´e ci`o avvenga dovr`a prima essere superata la pi`u grande sfida, ovvero quella di arrivare finalmente a risolvere i problemi di interoperabilit`a tra hardware e software dei maggiori produttori del settore (Gemalto, IDEMIA, NEC, SITA, Vision-Box).
1.2
Alterazioni dell’immagine del volto e
con-seguenti problematiche
Con la sempre pi`u diffusa adozione di sistemi di ABC, le vulnerabilit`a dei sistemi di riconoscimento facciale in quanto componenti fondamentali dei dispositivi di ABC hanno acquistato nel tempo sempre pi`u importanza e priorit`a.
Tipologie di attacco
Gli attacchi che coinvolgono queste componenti possono essere di due tipi: • Attacchi ai sistemi ABC: chiamati Presentation attack o Face spoo-fing attack sono tipicamente diretti verso i dispositivi di cattura delle immagini live (ad esempio le telecamere per la cattura dell’immagine del volto), presentando degli artefatti facciali. Questi attacchi richiedono una notevole mole di impegno nel generare l’artefatto e nel presentarlo al eGate in maniera consistente.
• Attacchi ai dati biometrici contenuti negli eMRTD: in questo ca-so l’attacco consiste nella manipolazione delle informazioni biometriche memorizzate all’interno del eMRTD. Una maniera poco efficace di fare ci`o `e la manipolazione di dati gi`a presenti, ad esempio nel caso di un passaporto perso o rubato. In questo caso per`o l’hash corrispondente ai dati memorizzati verrebbe modificato, rendendo di fatto immediata-mente riconoscibile l’attacco. Una modalit`a ben pi`u efficace `e quella di sfruttare una falla nel processo di richiesta ed emissione degli eMRTD, presente in gran parte dei protocolli attualmente in uso. Di seguito ci si
12 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
concentrer`a su quest’ultima tipologia d’attacco, che verr`a ora descritta pi`u nello specifico.
La falla abilitante della vulnerabilit`a descritta poc’anzi `e alla radice del processo di emissione dei passaporti: nella maggior parte dei Paesi `e infatti possibile per un cittadino portare personalmente una fotografia del proprio volto gi`a stampata su carta fotografica, in modo tale che alle autorit`a com-petenti non rimanga che scansionare la fotografia ed apporla al documento. Alcuni Paesi (come Nuova Zelanda, Estonia e Irlanda) permettono addirittura di avvalersi di portali web per la sottoscrizione delle pratiche di rinnovo, che comprendono anche il caricamento della propria fotografia in formato digitale. Questa prassi consente la presa in consegna da parte delle autorit`a di im-magini in cui le fattezze del richiedente potrebbero essere state alterate in maniera pi`u o meno volontaria e per fini pi`u o meno criminali.
Se l’alterazione non `e tale da essere rilevabile visivamente dall’ufficiale, la fotografia potr`a essere introdotta all’interno di un documento d’identit`a per-fettamente regolare. L’alterazione digitale pu`o riguardare modifiche di diversa natura quali ad esempio la modifica alla geometria del volto (stretching invo-lontario) o l’utilizzo di tecniche di beautification; l’alterazione oggetto di questo lavoro di tesi `e il morphing, descritto pi`u in dettaglio nella sezione seguente.
Face Morphing
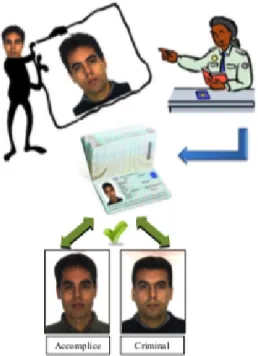
Il Face Morphing attack si mette in atto usando immagini morphed, ot-tenute dalla combinazione di volti appartenenti a differenti identit`a. Questo attacco prevede che al momento della verifica dell’identit`a all’eGate l’imma-gine salvata all’interno del eMRTD corrisponda a quella acquisita live di pi`u di un solo soggetto, facendo s`ı che non solo il titolare, ma anche altri possano identificarsi con lo stesso documento, come mostrato in Figura 1.5.
L’idea alla base dell’attacco `e quindi che un soggetto, che si presume essere un ricercato dalle autorit`a o a cui le autorit`a non diano la possibilit`a di uscire dal Paese di origine, trovi un soggetto con un volto a lui somigliante. A questo punto avendo a disposizione foto tessere di entrambi i volti, attraverso
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 13
Figura 1.5: Schematica di un possibile attacco realizzato tramite una imma-gine morphed. Questa immaimma-gine sar`a molto simile a quella del titolare del documento, e comprender`a delle feature facciali di un secondo soggetto (il criminale).
l’utilizzo di software di photo-editing liberamente disponibili online si effettua il morphing del volto del soggetto incensurato con il volto del criminale. Software come GIMP offriranno la possibilit`a all’utente di decidere in quale percentuale si vuole che il secondo volto sia rappresentato nel primo. Come dimostrato in [12] sar`a sufficiente una modifica minima praticamente impercettibile affinch´e l’attacco abbia successo, modifica che risulter`a invisibile anche agli occhi pi`u allenati, come quelli delle autorit`a aeroportuali abituate ad effettuare confronti di questo tipo su base giornaliera. Un esempio di questa procedura di modifica `e riportata in Figura 1.6.
Per rendere ancor meno visibile il morphing i trasgressori potranno inol-tre stampare e riacquisire, per poi stampare di nuovo la fotografia risultante, in modo tale da far s`ı che il ”rumore” introdotto dalle multiple stampe ed acquisizioni renda irrecuperabili le informazioni a livello di pixel della foto
14 CAPITOLO 1. INTRODUZIONE AGLI EMRTD
Figura 1.6: Le immagini pi`u esterne rappresentano immagini genuine del volto di due soggetti, mentre quella centrale rappresenta il risultato della procedura di face morphing.
alterata originariamente, informazioni che sarebbero altrimenti estremamente discriminanti in fase di analisi e verifica dell’identit`a.
A questo punto il soggetto incensurato, armato dell’immagine del suo volto modificata ad hoc e stampata, si presenter`a al rispettivo ufficio Statale e far`a richiesta di un passaporto a suo nome. Il passaporto che verr`a emesso succes-sivamente sar`a a tutti gli effetti perfettamente valido, regolarmente emesso e capace di superare tutti i classici controlli di integrit`a.
Il soggetto incensurato potr`a ora consegnare il proprio passaporto al ma-lintenzionato, che sar`a libero di andare in un aeroporto fornito di eGate. L’im-magine del suo volto catturata live corrisponder`a all’immagine memorizzata all’interno del eMRTD grazie al morphing effettuato sull’immagine apposta nel documento, dove sono quindi presenti alcuni suoi tratti facciali distintivi. Il software all’interno dell’eGate confronter`a le due identit`a e trover`a una corri-spondenza abbastanza alta da rientrare nelle soglie predefinite di accettazione. A questo punto il malintenzionato sar`a libero di lasciare il Paese indisturbato. L’analisi delle vulnerabilit`a eseguita ad una soglia di FAR (False Accep-tance Rate) di 0.1%, come raccomandato da FRONTEX per le operazioni di controllo alle frontiere, ha indicato la presenza di vulnerabilit`a nei confronti delle versioni sia digitali che fisiche delle immagini morphed [15].
CAPITOLO 1. INTRODUZIONE AGLI EMRTD 15
Diversi studi testimoniano anche la difficolt`a nell’identificazione di un’im-magine morphed da parte di umani. Uno studio in particolare ha evidenziato queste difficolt`a persino da parte di gruppi di persone che includevano anche esperti di riconoscimento, tra cui: 44 guardie di confine, 439 esperti di biome-trica e 104 persone comuni con limitate conoscenze di biomebiome-trica. Lo studio ha concluso che anche coloro dotati di occhio pi`u esperto ed allenato hanno fallito nell’identificare le immagini morphed [16].
`
E ormai dimostrato come le implicazioni della facilit`a di riproduzione di questo attacco, cos`ı come delle sue altissime probabilit`a di successo, costitui-scono una minaccia concreta alla sicurezza civile: dei criminali ricercati dalle autorit`a possono letteralmente usare passaporti autentici, conformi alle norme del Paese emittente, per eludere anche le norme di sicurezza pi`u stringenti ed entrare liberamente in un altro Paese utilizzando un’identit`a altrui.
Capitolo 2
Stato dell’arte
L’ambito della ricerca relativo al Face Morphing `e relativamente giovane ed `e nato nel 2014 contestualmente alla presentazione dello studio dal titolo ”The Magic Passport ” , da parte di Ferrara et al. [12] In questo paper per la prima volta `e stata messa in evidenza la pericolosit`a, cos`ı come l’estrema facilit`a di riproduzione di un Face Morphing Attack verso i sistemi di Automatic Border Control.
Gli autori hanno dimostrato come fosse possibile, data l’immagine del volto di due soggetti somiglianti tra loro, produrre una nuova immagine ex novo, che rappresentasse un volto estremamente simile a quello di uno dei due soggetti (il titolare del eMRTD) tanto da non suscitare allarme nel personale addetto al rilascio di eMRTD, ma che includesse anche tratti e caratteristiche facciali dell’altro soggetto, a tal punto che la somiglianza tra questa immagine e il volto di questo soggetto rientrassero nelle soglie di accettazione del software di riconoscimento facciale presenti nei gate degli aereoporti.
Per effettuare il morphing gli autori hanno seguito la seguente procedura: 1. Sono stati allineati i due volti utilizzando gli occhi come punto di
riferi-mento.
2. Tramite l’uso dello strumento di morphing GAP1, sono stati manual-mente selezionati alcuni tratti facciali determinanti come occhi, naso,
1
https://www.gimp.org/tutorials/Using_GAP/
18 CAPITOLO 2. STATO DELL’ARTE
sopracciglia.
3. Viene generata una sequenza di frame morphed, ovvero immagini che combinano in diverse percentuali i due volti. Sqi seleziona il frame che riporta i risultati migliori di matching con entrambe le identit`a.
4. Il frame selezionato viene manualmente ritoccato per renderlo anche conforme ai requisiti ICAO, eliminando artefatti, difetti e ombre.
Gli autori hanno effettuato diversi esperimenti, utilizzando software gratuiti e liberamente disponibili ed adoperabili come GIMP2 e GAP3 per il morphing
delle immagini, e SDK commerciali come VeryLookSDK 5.44 e LuxandSDK
4.05per l’operazione di riconoscimento facciale. A seguito dei test e conseguenti risultati riportati dagli autori, entrambi gli SDK di riconoscimento si sono rivelati totalmente vulnerabili a questa tipologia di attacco, portando gli autori alla logica conclusione che dare la possibilit`a ai cittadini di fornire alle autorit`a competenti una propria fotografia da apporre a documenti ufficiali comporta serie falle nei protocolli di sicurezza.
La soluzione pi`u semplice ed efficace nel lungo termine sarebbe sicuramente quella di acquisire le fotografie dei soggetti live, al momento della richiesta dei documenti, cos`ı come si fa per l’acquisizione delle impronte digitali. Questa soluzione richiede per`o ingenti investimenti economici e tecnologici da parte di ciascun Paese per dotare i propri uffici della tecnologia adatta, e tipicamente questo genere di cambiamenti richiede non poco tempo. Nel frattempo quindi `e necessario correre ai ripari in maniera alternativa e qui di seguito verranno elencati e brevemente descritti i principali approcci che sono stati sperimentati con pi`u o meno successo negli ultimi anni per quanto riguarda l’identificazione di Face Morphing Attacks.
2 https://www.gimp.org/ 3https://www.gimp.org/tutorials/Using_GAP/ 4http://www.neurotechnology.com/ 5 http://www.luxand.com/
CAPITOLO 2. STATO DELL’ARTE 19
Questi tentativi si possono dividere in due macro-tipologie:
• Single-image morph detection: il sistema di rilevamento processa in input una singola immagine che in questo caso corrisponde all’immagine salvata all’interno del documento, come ad esempio nello scenario di un controllo in fase di emissione di un eMRTD, e a partire da solamente questa immagine cerca di determinarne l’autenticit`a. Questo scenario `e anche definito no-reference morph detection.
• Double-image morph detection: oltre all’immagine memorizzata al-l’interno del eMRTD, viene usata un’immagine acquisita live ed in ma-niera controllata come fonte aggiuntiva di informazioni per il sistema di detection durante la fase di autenticazione ad un gate ABC. Il si-stema utilizzer`a le due immagini in maniera congiunta per confermare o meno la corrispondenza delle due identit`a. Questo scenario `e anche definito differential morph detection. Si noti anche che tutte le infor-mazioni utilizzate nello scenario no-reference possono essere allo stesso modo utilizzate anche in questo caso.
Come estensivamente descritto in [17] andrebbero fatte ulteriori distinzioni nei vari approcci sulla base dell’utilizzo per i test di:
• immagini digitali: la versione digitale dell’immagine viene presentata al sistema e di conseguenza il morphing attack viene rilevato attraverso l’uso di informazioni a livello di pixel. Questa situazione si pu`o ritrovare in Paesi come la Nuova Zelanda, Estonia e Irlanda, che usano immagini digitali per il rinnovo del passaporto.
• immagini stampate e successivamente riacquisite: questo `e il caso pi`u probabile e diffuso attraverso cui pu`o essere perpetrato un morphing attack. La procedura di stampa e successiva acquisizione portano ad una perdita degli artefatti e delle informazioni a livello di pixel create dalla procedura di morphing. Inoltre, vi `e anche l’aggiunta di nuove informazioni, come rumore e scan line, che contribuiscono a rendere il rilevamento del morphing attack ancora pi`u complesso.
20 CAPITOLO 2. STATO DELL’ARTE
I risultati riportati da ciascuno studio effettuato sull’argomento sono anche difficilmente raffrontabili tra loro a causa del fatto che raramente sono stati utilizzati gli stessi dataset: tipicamente i ricercatori hanno infatti creato, per ogni nuovo studio, un database ex novo a partire da diverse sorgenti e secondo diverse tecniche decise di volta in volta. Come `e stato espresso in [24], queste tecniche di generazione di database morphed non sono sempre state esenti da errori o inconsistenze che potrebbero aver portato a risultati ingannevoli. Questo `e accaduto ad esempio ogniqualvolta gli studiosi, nell’atto di creare immagini morphed, hanno seguito procedimenti diversi o pi`u approssimativi rispetto a quelli che potrebbero essere utilizzati da reali attaccanti, rendendo di fatto inutile le loro stesse analisi.
`
E invece piuttosto standard e condivisa la metrica di valutazione utilizza-ta per sutilizza-tabilire la bont`a di ciascun approccio. In questo, si ha la fortuna di poter far riferimento ad istituzioni super partes che operano a livello europeo (FRONTEX6), e mondiale (ICAO). FRONTEX `e l’agenzia europea della guar-dia di frontiera e costiera e il suo compito `e quello di aiutare i paesi dell’UE e pi`u in generale nella zona Schengen a gestire e controllare le loro frontie-re esterne. Essa agevola inoltfrontie-re la collaborazione tra le autorit`a di frontiera dei singoli paesi dell’UE fornendo assistenza tecnica e know how. Nel fare questo, ha anche provveduto a definire le soglie di riferimento per l’errore di classificazione ammesso per i sistemi di ABC.
Prima di approfondire ulteriormente i lavori correlati al morphing detec-tion, `e bene definire le metriche utilizzate dai ricercatori e da FRONTEX, al fine di agevolare la comprensione dei risultati che verranno riportati:
• False Accept Rate (FAR): la probabilit`a che un sistema biometrico identifichi incorrettamente un individuo o fallisca nel respingere un im-postore. Il FAR pu`o essere calcolato come F AR = N F A/N IIA, oppure F AR = N F A/N IV A, dove NFA `e il numero di false accettazioni, NIIA `
e il numero di tentate identificazioni da parte di impostori, NIVA `e il numero di tentate verifiche da parte di impostori[22].
6
CAPITOLO 2. STATO DELL’ARTE 21
• False Reject Rate (FRR): la probabilit`a che un sistema biometrico fallisca nell’identificare o nel verificare la legittima identit`a di un sog-getto. Il FRR pu`o essere calcolato come F RR = N F R/N EIA, oppure come F RR = N F R/N EV A, dove NFR `e il numero di False Rejections, NEIA `e il numero di tentativi di identificazione, NEVA `e il numero di tentativi di verifica. Questa stima assume che i tentativi siano rappresen-tativi per tutta la popolazione di soggetti. Il FRR normalmente esclude l’errore di fallimento nell’acquisizione. [22]
• Attack Presentation Classification Error Rate (APCER): termi-ne coniato in ambito di face morphing detection per la probabilit`a che una identit`a morphed venga riconosciuta come genuina 7.
• Bona Fide Presentation Classification Error Rate (BPCER)8:
con Bona Fide si intende, come da definizione ISO/IEC 20107-3, una ”interazione dell’individuo soggetto all’acquisizione biometrica con il si-stema di cattura dei dati biometrici nelle modalit`a previste dalla policy del sistema biometrico”. Questa metrica, coniata anch’essa in ambito di face morphing detection indica la probabilit`a che una identit`a genuina venga erroneamente classificata come tentativo di attacco, e quindi come identit`a morphed.
Per quanto riguarda il processo di verifica, FRONTEX raccomanda che la configurazione degli algoritmi di verifica facciale assicurino un livello di sicu-rezza in termini di False Accept Rate (FAR) pari allo 0.001 (0.1%) o inferiori. A questa configurazione, il False Reject Rate (FRR) non dovrebbe essere su-periore a 0.05 (5%). Questi livelli di performance dovrebbero inoltre essere convalidati da laboratori di test indipendenti o agenzie ufficiali, e non solo dai fornitori e/o produttori di algoritmi e dispositivi.
7
https://sites.google.com/site/faceantispoofing/evaluation
8
22 CAPITOLO 2. STATO DELL’ARTE
2.1
Approcci di single-image morph detection
L’approccio single-image `e quello che `e stato maggiormente studiato ed esplorato nei primi periodi di ricerca sul Face Morphing Detection. Esso com-porta essenzialmente l’estrazione di informazioni discriminanti per la classifi-cazione dalla sola immagine memorizzata all’interno del eMRTD, per verificare che non sia stata alterata ad hoc.
Raghavendra et al.[14] hanno inizialmente realizzato un database composto di 450 immagini morphed, a partire da 110 soggetti di diverse et`a, etnie e genere. Come in molti altri casi, gli studiosi hanno provveduto loro stessi al morphing delle immagini utilizzando GIMP e GAP e selezionando manual-mente il frame pi`u adatto ai test, dopo aver combinato i vari soggetti a gruppi di due o di tre.
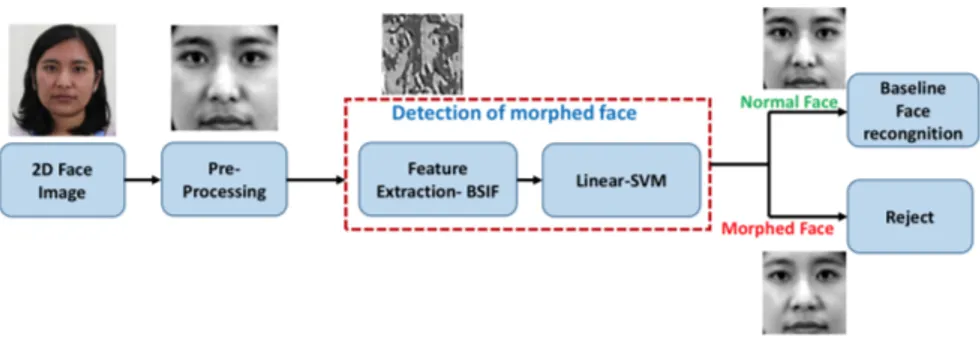
Gli autori hanno poi proposto una metodologia di detection basata su micro-texture facciali estratte utilizzando filtri appositi. Pi`u nello specifico, le immagini attraversano una classica fase di pre-processing dove il volto viene dapprima rilevato (tramite l’algoritmo Viola-Jones9), normalizzato e
ritaglia-to. Successivamente si passa alla fase di estrazione, dove delle micro-texture feature vengono estratte utilizzando filtri BSIF10 (Binarized Statistical Image
Features)??. Questi sono filtri che sono gi`a stati usati con successo in cam-po biometrico, e si tratta filtri statisticamente indipendenti ottenuti (tramite insegnamento non supervisionato) a partire da 50000 patch di immagini raffi-guranti 13 differenti scenari naturali. Ogni pixel dell’immagine del volto viene quindi dato in input ai filtri BSIF, e l’output viene salvato in codice binario. Queste informazioni verranno poi utilizzate per addestrare un classificatore SVM con kernel lineare.
Per i test `e stato utilizzato il SDK Verilook con una soglia di FAR pari allo 0.1%, come raccomandato da FRONTEX, e l’approccio proposto basato sui filtri BSIF `e stato comparato ad altri quattro approcci gi`a testati nell’ambito
9Robust Real-time Object Detection, Paul Viola, Michael Jones, 2001 10
CAPITOLO 2. STATO DELL’ARTE 23
Figura 2.1: Diagramma a blocchi dell’approccio proposto per il Face Morphing Detection.
del morphing detection, e basati su altre modalit`a di estrazione delle featu-re come IQA (Image Quality Analysis), LBP (Local Binary Patterns), LPQ (Local Phase Quantisation) e 2DFFT (2D Fast Fourier Transform). Il metodo proposto, basato su filtri BSIF, ha ottenuto i risultati migliori con un APCER pari a 3.46% che lo rende di fatto una tecnica teoricamente applicabile a sce-nari di applicazione reali.
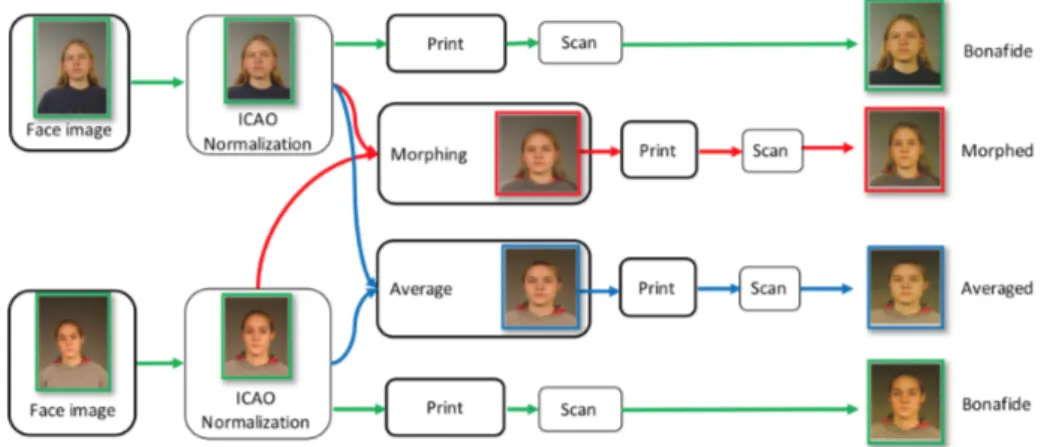
Raghavendra et al.[17] si sono spinti a trovare una soluzione che pi`u di tut-te rifletta il problema dei morphing attack in scenari reali, quindi basandosi su immagini a colori stampate e successivamente scansionate, e che rispet-tino tutti i requisiti ICAO. Gli autori hanno quindi inizialmente provveduto a costruire un database chiamato MAFI (Morph and Averaged Face Image database) composto di immagini morphed e averaged create a partire da 163 diverse identit`a ed utilizzando immagini a colori e che abbiano in precedenza attraversato il processo di stampa e scansione.
Per quanto riguarda il processo di detection, gli autori sostengono sia ne-cessario l’utilizzo di diversi spazi colore come HSV e YCbCr per separare le componenti dell’immagine che possono rivelare gli artefatti derivanti dal mor-phing, che il processo di stampa e successiva acquisizione avevano eliminato o compresso. Sono stati poi utilizzati i LBP (Local Binary Pattern) per estrar-re le informazioni pi`u caratterizzanti di ciascuna immagine, necessarie per la
24 CAPITOLO 2. STATO DELL’ARTE
Figura 2.2: Illustrazione dettagliata del processo di creazione del database.
classificazione tramite Pro-CRC (Probabilistic Collaborative Representation Classifier)??.
Figura 2.3: Schematica del metodo di detection proposto.
Nei test effettuati il metodo proposto `e stato comparato con altri approc-ci di estrazione di feature (LBP, BSIF...) e classificazione, sia per immagini morphed che averaged, e ad un valore prefissato di APCER pari al 5% e 10%, l’approccio proposto dallo studio `e stato di gran lunga il pi`u efficace. Le presta-zioni nel caso di immagini averaged sono risultate inoltre di almeno un ordine di grandezza migliori rispetto al caso di immagini morphed con lo stesso ap-proccio.
In Raghavendra et al.[16] si affronta il problema del morphing sia nel caso di immagini digitali che in quello di immagini stampate e successivamente
CAPITOLO 2. STATO DELL’ARTE 25
riacquisite con diversi scanner. Gli autori hanno utilizzato ed espanso il data-base di immagini sia genuine che morphed, e sia digitali che scansionate, messo a disposizione in [19].
Gli autori hanno inoltre proposto un nuovo framework di detection basato sull’uso di reti neurali per l’estrazione di feature dalle immagini e di un classi-ficatore Pro-CRC per lo step di classificazione finale.
Pi`u nello specifico le immagini hanno attraversato dapprima una classica fa-se di preprocessing, dove l’immagine del volto `e stata innanzitutto rilevata tramite utilizzo dell’algoritmo Viola-Jones, normalizzata ed infine ritagliata e ridimensionata per poter essere comodamente fornita in input alle reti neurali che verranno utilizzate di seguito.
Il passo successivo riguarda la fusione in un unico vettore delle feature estrat-te tramiestrat-te reti come AlexNet11 e VGG1912. Queste sono delle D-CNN (Deep
Convolutional Neural Networks) ognuna con una sua particolare architettura, pre-allenate su uno stesso dataset (ImageNet13) e successivamente calibrate sul caso di immagini morphed. Per estrarre le feature viene impiegato il livello FC-6, ovvero il primo livello fortemente connesso di entrambe le reti, tramite la tecnica nota come Transfer Learning. I vettori di feature risultanti da questa operazione sono stati poi classificati tramite un classificatore Pro-CRC.
I risultati di questo studio dimostrano innanzitutto, come si `e gi`a visto anche in altri studi simili, la diversit`a intrinseca non solo tra immagini digitali e immagini stampate e acquisite, ma anche tra immagini acquisite con diversi modelli di scanner. In secondo luogo, i risultati riportati dimostrano anche la bont`a dell’approccio proposto, che si conferma essere il pi`u prestante tra i principali metodi di riferimento (estrazione tramite LBP, BSIF e classificazione tramite SVM) che sono stati messi a confronto. Va detto che a riconferma di precedenti analisi, anche in questo le immagini digitali forniscono prestazioni notevolmente migliori rispetto alle loro versioni stampate ed acquisite.
11https://en.wikipedia.org/wiki/AlexNet 12
https://arxiv.org/abs/1409.1556
13
26 CAPITOLO 2. STATO DELL’ARTE
Figura 2.4: Schematica del metodo di detection proposto.
Samek et al.[20] analizzano e comparano l’efficacia di diverse architetture di D-CNN per la detection di immagini morphed. Le reti che vengono testate sono:
• AlexNet: 5 livelli convoluzionali e 3 livelli fortemente connessi finali. • VGG19: 16 livelli convoluzionali di piccolissima dimensione (3x3) • GoogLeNet: architettura complessa, 22 livelli di cui alcuni di inception. Data la necessit`a di una grande mole di dati necessari per la fase di training delle reti neurali, gli autori hanno provveduto a creare una pipeline di mor-phing completamente automatizzata col fine di costruire un dataset di grandi dimensioni di immagini morphed a partire da 1250 immagini genuine di diverse identit`a.
La volont`a da parte degli autori di questo studio `e principalmente quella di far s`ı che la classificazione delle immagini avvenga non sulla base di in-formazioni e artefatti presenti a livello di pixel generati in fase di morphing, bens`ı sulla base di dettagli semantici come la forma, dimensione e posizione di tratti facciali distintivi. Per facilitare quindi l’apprendimento sotto questo punto di vista le immagini sono state volontariamente degradate con aggiunta di rumore e blur.
CAPITOLO 2. STATO DELL’ARTE 27
Per ogni architettura gli autori hanno analizzato l’accuratezza nella detec-tion sia nel caso di reti allenate da zero che nel caso di reti pre-allenate in materia di object classification sul dataset ILSVRC14.
I risultati migliori sono stati raggiunti dalla rete pre-allenata VGG19 con un FRR di 3.5% e un FAR di 0.8%. Le reti pre-allenate hanno in tutti i casi avuto prestazioni nettamente migliori rispetto a quelle allenate da zero. Questo suggerisce che le feature imparate per il task di object classification si possono rivelare utili anche nel morphing detection.
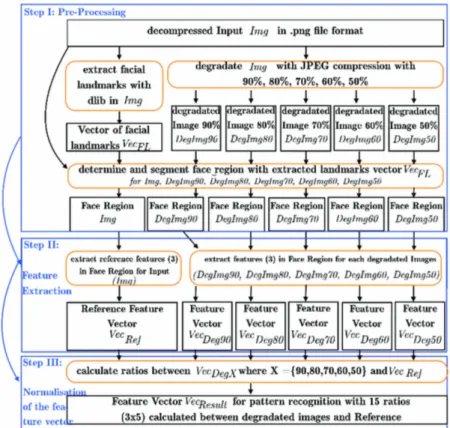
Neubert[21] introduce un approccio alla detection basato sull’analisi della de-gradazione delle immagini, come descritto anche in Figura 2.5. Questo punta a rilevare le anomalie risultanti dall’applicazione del processo di morphing. L’idea alla base `e che vi sono alcune feature facciali che reagiscono differente-mente alla degradazione a seconda che siano estratte da immagini genuine o immagini morphed, e la degradazione non dovrebbe avere tanto effetto sulle immagini morphed quanto ne ha sulle immagini genuine. Gli autori utilizzano tre corner feature detector sull’immagine del volto, e secondo la loro teoria, a causa della degradazione i corner rilevati nell’immagine degradata genuina dovrebbe essere presenti in numero estremamente inferiore, al contrario del-l’immagine degradata morphed che invece manterrebbe il numero di corner pressoch´e invariato (a causa delle operazioni di blending effettuate durante il morphing).
Per degradare manualmente le immagini gli autori hanno scelto di effettuare una compressione JPEG su un file non compresso di input, a diversi livelli di compressione. Per analizzare il processo di degradazione viene invece usato un feature set derivante dai metodi di edge detection di OpenCV15. I valori
estratti dalle immagini degradate vengono poi comparati con l’immagine di riferimento per descrivere la degradazione.
In scenari dove si `e provato ad imitare condizioni operative reali questo metodo si `e rivelato piuttosto efficace per quando riguarda la detection di
mor-14
http://image-net.org/challenges/LSVRC/
15
28 CAPITOLO 2. STATO DELL’ARTE
Figura 2.5: Schematica del metodo di detection proposto, basato su image degradation.
phing, con un’accuratezza del 86%, sebbene fatichi a classificare correttamente immagini genuine, con un’accuratezza del solo 68.4%. Il FRR `e quindi ritenuto troppo alto e non adatto ad applicazioni nel mondo reale, anche se gli autori sostengono la bont`a dell’approccio e la necessit`a di ulteriori approfondimenti.
CAPITOLO 2. STATO DELL’ARTE 29
2.2
Approcci di double-image morph
detec-tion
L’approccio double-image consiste tipicamente nell’estrazione di feature da due diverse immagini di un volto. A partire da queste feature si cerca di ottene-re un unico vettoottene-re di featuottene-re (ad esempio attraverso una diffeottene-renza di vettori) che verr`a poi utilizzato per la successiva classificazione in immagine morphed o genuina. Le due immagini utilizzate corrispondono a quella memorizzata all’interno del eMRTD e quella acquisita live all’eGate. Questo approccio `e rimasto per ora poco esplorato, e di seguito verranno descritti i principali ap-procci che sono stati tentati finora.
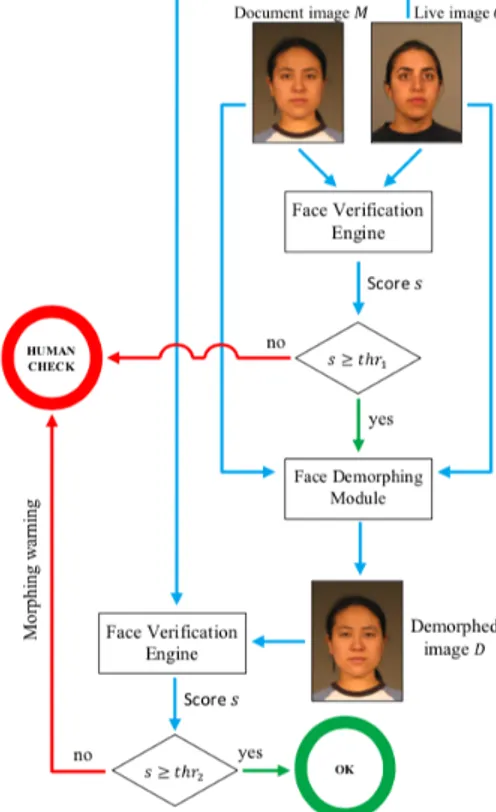
Ferrara et al.[13] esprimono l’idea di demorphing, che consiste nell’invertire il processo di morphing per verificare se ci siano state modificazioni all’immagine originale.
Per fare questo l’immagine (presunta) morphed salvata all’interno di un passaporto viene considerata come combinazione lineare M = A + C , dove A corrisponde all’immagine del volto dell’aiutante o accomplice, e C a quella del volto del criminale. Nel caso invece l’immagine memorizzata all’interno del documento sia autentica, M si pu`o considerare come una combinazione lineare di due immagini identiche e quindi M = C + C, dove C corrisponde all’immagine del volto del legittimo proprietario del documento.
Data la carenza di database pubblici e che contenessero immagini che fosse-ro conformi agli standard ICAO, gli autori hanno innanzitutto pfosse-rovveduto alla creazione di due nuovi database di immagini morphed, rispettivamente PMDB (Progressive Morphing Database) e MorphDB, a partire da altri database gi`a noti come AR, Color Feret e FRGC.
Successivamente `e stato descritto l’approccio tale per cui al momento del-la verifica deldel-la validit`a della foto viene eseguita l’operazione di demorphing D = M − ˇC, ovvero all’immagine M contenuta all’interno del passaporto si va a sottrarre l’immagine ˇC del volto del criminale acquisita in tempo reale
30 CAPITOLO 2. STATO DELL’ARTE
al eGate, ed il risultato di questa operazione viene comparato con l’immagi-ne acquisita live: se c’`e un riscontro positivo significa che le due immagini sono abbastanza simili da essere considerate provenienti dalla stessa persona, altrimenti si presume si stia avendo a che fare con un Face Morphing Attack.
Figura 2.6: Schematica del metodo di detection proposto, basato sull’operazione di demorphing.
I test effettuati su entrambi i database hanno riportato risultati piuttosto soddisfacenti: il metodo di detection proposto si `e infatti rivelato in grado di ridurre drasticamente (di almeno un ordine di grandezza, intorno al 6%) il FAR, mantenendo un FRR piuttosto limitato con un valore pari a 1%. Seppur questo approccio sia funzionante nella teoria necessita secondo gli autori di un test operativo per capire l’impatto che posa, illuminazione o aging in situazio-ni reali possono avere sull’accuratezza della tecsituazio-nica proposta. Una possibile soluzione per aumentare la robustezza del processo di demorphing potrebbe risiedere secondo gli autori nell’acquisizione di diversi frame live al gate, e non
CAPITOLO 2. STATO DELL’ARTE 31
soltanto una singola immagine, anche se questo richiederebbe ulteriori investi-gazioni e verifiche.
Scherhag et al.[15] propongono soluzioni specifiche sia al caso single-image (no-reference) che double-image (differential ).
Gli autori hanno proceduto a creare una fase di preprocessing, dove le immagini dei volti vengono de-saturate, ritagliate e normalizzate utilizzando la libreria Dlib16. Da queste immagini vengono poi estratte informazioni secondo
diverse tecniche ed algoritmi, tra i quali:
• Texture descriptors: LBP (Local Binary Patterns) e BSIF (Binarized statistical Image Features)
• Keypoint extractors: SIFT (Scale Invariant Feature Transform), SURF (Speeded Up Robust Features)
• Gradient estimators: HOG (Histogram of Gradients) e sharpness features.
• Deep learning: vettore di 128 elementi estratto tramite una DNN implementata nella libreria OpenFace17
Successivamente, nel caso si voglia classificare l’immagine in modalit`a no-reference, non sono necessare altre operazioni prima della classificazione vera e propria. Diversamente, nel caso differential, sar`a necessario eseguire la stessa procedura di estrazione che `e stata attuata per l’immagine di riferimento, anche per un’immagine live che si presume essere acquisita in real time al eGate. Dopodich´e dovr`a essere calcolato il vettore differenza a partire dai vettori di feature di queste due immagini. A questo punto `e possibile passare alla fase di classificazione, per la quale gli autori hanno allenato ed utilizzato una SVM con kernel RBF.
Nei test effettuati dagli autori per ogni metodo di estrazione di feature, e per il caso no-reference e differential, i risultati migliori sono portati generalmente
16
http://www.dlib.net
17
32 CAPITOLO 2. STATO DELL’ARTE
dall’approccio di estrazione tramite LBP e filtri BSIF nel caso differential, con invece scarsi risultati da parte dell’approccio tramite Deep Learning, che gli autori sostengono necessiti di un training pi`u accurato e mirato, col rischio sempre presente di un potenziale overfitting.
In Detecting Morphed Face Images Using Facial Landmarks i ricercatori hanno voluto concentrarsi sull’estrazione e classificazione dei landmark facciali pi`u ca-ratteristici e discriminanti, in quanto robusti all’invecchiamento del volto, che come anche gi`a detto `e un noto problema degli eMRTD. Essendo questo un approccio di tipo differential, i landmark vengono estratti sia dall’immagine bona fide che dalla immagine reference, ovvero quella memorizzata all’interno del documento. Tramite la libreria Dlib vengono quindi estratti 68 landmark, le cui differenze nelle due immagini sono state calcolate secondo due diverse modalit`a:
• Distance based: vengono calcolate le distanze euclidee tra le posizioni assolute e normalizzate dei landmark nelle due immagini, portando a un vettore di ”distance features” di 2278 elementi.
• Angle based: vengono comparati gli angoli di ciascun landmark rispet-to ad un loro landmark ”neighbor ” predefinirispet-to. Quesrispet-to evita problemi derivanti da cambiamenti di posa ed espressione che sarebbero invece presenti nel metodo distance-based, e porta quindi alla definizione di classificatori pi`u robusti.
Inoltre gli autori hanno sperimentato l’utilizzo di 3 diversi classificatori: • Random Forest con 500 stimatori.
• SVM senza kernel.
• SVM con kernel RBF (che `e il classificatore che ha ottenuto risultati migliori).
I risultati ottenuti da questo approccio non sono stati ottimi e non si sono rivelati accettabili per l’applicazione di quest’ultimo in scenari reali. Il miglior
CAPITOLO 2. STATO DELL’ARTE 33
valore di BPCER ottenuto ad un APCER fissato al 10% `e stato pari al 61.7%. Gli autori credono comunque che questo approccio possa rappresentare un buono spunto per le tecniche di utilizzo di landmark facciali per il morphing detection, e ritengono necessarie ulteriori indagini per fare pi`u chiarezza sulla questione.
Capitolo 3
Algoritmo proposto
L’algoritmo di detection che `e stato implementato, in tutte le sue varian-ti, `e stato ispirato dal recente studio del 2018 di Busch et al. denominato Towards detection of morphed face images in electronic travel documents[15]. Qui gli autori hanno implementato diversi metodi di estrazione di feature (tra cui LBP[40], BSIF[36], SIFT[38], SURF[39], HOG[41], D-CNN), e di classifi-cazione (No-reference e Differential). Nello sviluppo dell’algoritmo per questo lavoro di tesi ci si `e concentrati su alcune di queste tecniche, valutandone in modo approfondito alcune varianti e misurandone l’efficacia in rapporto ad alcuni fattori critici che caratterizzano questa problematica.
Lo stack tecnologico che si `e deciso di adoperare per usufruire delle funzio-nalit`a di image processing, face detection, feature extraction e classificazione richiesti da questo algoritmo `e composto dalle seguenti librerie:
• dlib1: libreria open source scritta in C++ che implementa numerose
tecniche di image processing e machine learning. Pi`u nello specifico essa `
e stata utilizzata per le sue capacit`a in ambito di face detection, face alignment e feature extraction.
• OpenFace2: libreria che si basa sul framework Torch3 e sulla libreria
1http://dlib.net/ 2 https://cmusatyalab.github.io/openface/ 3 http://torch.ch/ 35
36 CAPITOLO 3. ALGORITMO PROPOSTO
OpenCV4. Essa `e totalmente dedicata a fornire soluzioni per la face
re-cognition tramite uso di Deep Neural Networks (DNN). Tra le sue princi-pali funzionalit`a troviamo diverse modalit`a di face alignment e di feature extraction.
• scikit-learn5: libreria che implementa tecniche di machine learning
utiliz-zabile in Python. Fornisce API per i pi`u svariati algoritmi di classifica-zione, regressione e clustering, incluse Support Vector Machine (SVM), Random Forest, Gradient Boosting, e k-Means.
In questo capitolo verranno descritte nel dettaglio le tre fasi in cui si pu`o suddividere il funzionamento dell’algoritmo: pre-processing, estrazione di feature e classificazione.
3.1
Pre-processing
La prima macro fase dell’algoritmo prevede il pre-processing delle imma-gini dei volti, con l’obiettivo di ottenere immaimma-gini normalizzate in termini di dimensione, allineamento e spazio colore. Due importanti sotto-fasi del pre-processing sono face detection e face alignement, attuabili tramite tecniche presenti in entrambe le librerie dlib e OpenFace.
dlib
Per quanto riguarda la face detection, dlib fornisce la possibilit`a di otte-nere una bounding box e uno score di confidenza per ogni volto frontalmente orientato presente all’interno di un’immagine.
Internamente, questo `e possibile grazie ad un frontal face detector6,
im-plementato tramite classici descrittori HOG (Histogram of Oriented Features) combinati con un classificatore SVM lineare7.
4 https://opencv.org/ 5https://scikit-learn.org/stable/ 6 http://dlib.net/python/index.html#dlib.get_frontal_face_detector 7 http://dlib.net/face_landmark_detection.py.html
CAPITOLO 3. ALGORITMO PROPOSTO 37
La bounding box restituita da dlib rappresenta una precisa delimitazione della regione del volto che `e stato rilevato, e pu`o essere utilizzata per un crop delle immagini al fine di continuare ad analizzare solamente la porzione di foto di reale interesse, che in questo caso si `e deciso essere di una dimensione pari a 256x256 pixel.
Per la fase di face alignement `e possibile invece utilizzare il concetto di face chip8 presente in dlib, che data una rappresentazione di un volto in ter-mini dei landmark che sono stati rilevati procede a ruotarla affich´e la linea che unisce le pupille sia perfettamente orizzontale e a ridimensionarla alle dimen-sioni specificate, restituendone una versione matriciale.
Le immagini allineate, ritagliate e ridimensionate attraverso questo procedi-mento, come rappresentato in Figura 3.1 verranno identificate con la sigla 256-dlib.
Figura 3.1: Rilevamento, allineamento e ritaglio del volto presente all’interno di un’immagine tramite dlib.
OpenFace
Il procedimento di face detection di OpenFace fa internamente uso di dlib e del procedimento appena descritto, ed anche i modelli di landmark facciali utilizzati sono gli stessi; ci`o che cambia `e invece l’implementazione del
pro-8
38 CAPITOLO 3. ALGORITMO PROPOSTO
cesso di face alignement9. In questo caso `e possibile scegliere tra due
di-verse modalit`a di allineamento, rispettivamente INNER EYES AND BOTTOM LIP e OUTER EYES AND NOSE. A ciascuna di queste due modalit`a corrispondono i diversi indici dei landmark che verranno utilizzati per l’allineamento del volto tramite una trasformazione affine implementata in OpenCV1011, come
rappresentato in Figura 3.2.
Figura 3.2: Detection, allineamento e ritaglio del volto all’interno di un’imma-gine grazie al rilevamento di landmark e trasformazione affine implementati in OpenFace.
L’immagine ritagliata e allineata viene infine ridimensionata, e nel caso di OpenFace si `e scelto di optare per due diverse dimensioni: 96x96 `e la dimen-sione prescelta per poter dare le immagini pre-processate con OpenFace alla
9 https://openface-api.readthedocs.io/en/latest/openface.html# openface-aligndlib-class 10 https://openface-api.readthedocs.io/en/latest/_modules/openface/align_ dlib.html#AlignDlib 11 http://bamos.github.io/2016/01/19/openface-0.2.0/
CAPITOLO 3. ALGORITMO PROPOSTO 39
rete neurale che si dovr`a occupare di estrarre i vettori di feature da ciascuna di esse, dal momento che questa ha un layer di input di 96 neuroni. In aggiunta, `e stata selezionata anche la dimensione 256x256 per poter comparare l’efficacia di questo procedimento di preprocessing con quello ottenuto tramite dlib.
Le immagini allineate, ritagliate e ridimensionate attraverso questo proce-dimento verranno identificate con le sigla 96-eyesnose, 96-eyeslip, 256-eyesnose e 256-eyeslip, a seconda della loro dimensione e del metodo di allineamento a cui sono state soggette.
Le tecniche di rilevamento di face morphing sono estremamente sensibili all’allineamento del volto e di conseguenza acquisiscono enorme importanza i landmark facciali che vengono utilizzati dagli algoritmi di allineamento. I fa-cial landmark detector [42] presenti in dlib sono un’implementazione del lavoro proposto in One millisecond face alignment with an ensemble of regression trees da Kazemi et al.[25]. Vengono messi a disposizione due diversi detector che si differenziano innanzitutto nel numero di landmark con cui riescono a lavorare, rispettivamente 5 e 68 (Figura 3.3); da questa prima grande differenza dipende anche la diversa precisione, velocit`a di esecuzione e spazio occupato su disco da ciascuno (10Mb per il primo, 100Mb per il secondo). Il 68-point landmark detector, il pi`u preciso ed affidabile dei due, `e pre-addestrato sul dataset iBUG 300-W12, ma esiste anche un detector non ufficiale capace di rilevare 194
land-mark, pre-addestrato sul dataset HELEN13, che per`o non `e stato utilizzato all’interno di questo lavoro di tesi.
12
https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
13
40 CAPITOLO 3. ALGORITMO PROPOSTO
Figura 3.3: Nell’immagine a sinistra si pu`o notare la sovrimpressione dei land-mark ai volti presenti in ciascuna immagine. A destra invece si pu`o osservare una rappresentazione pi`u dettagliata del 68-point face landmark detector, dove a ciascun landmark corrisponde un indice univoco.
3.2
Estrazione di feature
Nella fase di pre-processing le immagini sono state normalizzate e unifor-mate tra loro, al fine di rendere il pi`u efficace possibile questa seconda fase di estrazione dei vettori di feature da ciascuna immagine. Anche qui, come nel pre-processing, sono stati implementati diversi metodi, al fine di avere una panoramica quanto pi`u ampia possibile su quale metodo sia pi`u efficace ed in quale caso. Si `e fatta la scelta di estrarre feature seguendo metodi molto diffe-renti: in un caso si `e optato per l’uso di Local Binary Pattern (LBP), mentre nell’altro sono state utilizzate delle Deep Convolutional Neural Networks (D-CNN) pre-addestrate. I due casi verranno ora approfonditi nel dettaglio, cos`ı come le diverse modalit`a con cui essi sono stati applicati.
CAPITOLO 3. ALGORITMO PROPOSTO 41
3.2.1
Local Binary Pattern Histograms (LBPH)
La tecnica di rappresentazione delle immagini nota come Local Binary Pat-tern (LBP) `e stata resa nota dal lavoro pubblicato nel 2002 da Ojala et al. inti-tolato Multiresolution Grayscale and Rotation Invariant Texture Classification with Local Binary Patterns[26]. Grazie anche alla semplicit`a di implementazio-ne e di computazioimplementazio-ne (che implementazio-ne permette applicazioni real-time) ed al loro potere discriminante, i LBP rappresentano un descrittore di feature largamente uti-lizzato in ambito di classificazione di texture di diversa natura; relativamente al campo della biometrica questa tecnica ha trovato grande riscontro nel rico-noscimento e classificazione di tratti biometrici come volto, iride e impronte digitali.
L’idea alla base dei LBP `e quella di elaborare e rappresentare un’immagine esaltandone gli edge e i cambiamenti di texture. Pi`u nello specifico, i LBP sono una rappresentazione locale delle texture e sono ottenuti comparando ciascun pixel con i pixel ad esso confinanti; in questo senso quindi i LBP sono un descrittore locale, e non globale come ad esempio i descrittori di Haralick, che al contrario corrispondono ad una rappresentazione di texture a livello globale, di tutta l’immagine.
La caratteristica della localit`a `e allo stesso tempo un vantaggio, poich´e per-mette di catturare minuzie e dettagli estremamente sottili, ed uno svantaggio, poich´e non rende possibile prendere in considerazione dettagli di pi`u ampio respiro, che eccedono la finestra di pixel fissa che viene presa in considerazione di volta in volta da questo algoritmo.
Il funzionamento di base dell’algoritmo utilizzato per ottenere una imma-gine LBP, esemplificato anche in Figura 3.4, `e il seguente:
1. Si definiscono i parametri di funzionamento dell’algoritmo, tra cui: • neighbors o points: numero di pixel che si vuole considerare nella
costruzione del LBP. Ne vengono solitamente considerati 8, che cor-rispondono all’intorno di pixel direttamente confinante con il pixel in esame.
42 CAPITOLO 3. ALGORITMO PROPOSTO
• radius: la distanza dal pixel in esame che corrisponde al punto centrale della finestra dei pixel che costituiranno poi il LBP. Questo parametro permette fondamentalmente di decidere l’ampiezza dello sguardo con cui si vogliono osservare le texture, ed `e solitamente impostato a 1.
• grid X e grid Y: il numero di celle, solitamente 8, in cui si vuole suddividere l’immagine in input su ciascun lato, al fine di poter mantenere anche informazioni di localit`a nei feature vector estratti e composti dagli istogrammi ottenuti da ciascuna cella in cui `e divisa l’immagine.
2. Si converte l’immagine in input in scala di grigi, al fine di poterla poi meglio trattare in quanto array bidimensionale.
3. Si procede a prendere in esame ciascun pixel dell’immagine con un ap-proccio noto come sliding window, e ad usarlo per un’operazione di thre-sholding. Vale a dire che per ciascun pixel dell’immagine si va ad osser-vare se nel suo intorno (intorno definito in base ai parametri neighbors e radius) sono presenti pixel con valori di intensit`a maggiori o minori ad esso.
4. A partire da questi pixel e dal loro valore di intensit`a si crea un LBP, ovvero una sequenza di numeri binari dove ciascun elemento della se-quenza corrisponde ad un pixel dell’intorno, ed `e impostato a 1 nel caso quest’ultimo abbia valore di intensit`a maggiore o uguale rispetto al pixel al centro della finestra, e a 0 altrimenti.
5. Si converte la sequenza binaria appena ottenuta in un numero decimale con il quale verr`a sovrascritto il pixel centrale che era stato preso in esame. Nel caso si voglia considerare un intorno di 8 pixel, ciascun ipotetico LBP sar`a composto da 8 bit ed il suo corrispondente decimale potr`a quindi assumere 28 = 256 diversi valori.
CAPITOLO 3. ALGORITMO PROPOSTO 43
Figura 3.4: Procedimento di estrazione di LBP: si determina un pixel centrale di riferimento ed una finestra di pixel nel suo intorno in base ai parametri nei-ghbor e radius, si effettua l’operazione di thresholding ed infine la conversione e sovrascrizione del numero decimale corrispondente al LBP estratto.
Come si pu`o notare in Figura 3.5, l’immagine ottenuta dopo averne ela-borato i LBP vede evidenziati edge e le texture presenti al suo interno. Ora che si ha a disposizione questa immagine `e finalmente possibile elaborarne il descrittore, ovvero si vanno a calcolare gli istogrammi di ogni cella della griglia in cui `e suddivisa l’immagine. In questa versione di LBP ciascun istogramma conterr`a 256 elementi (o bin), corrispondenti ognuno ad una diversa intensit`a di grigio, ed il valore di ogni bin corrisponder`a alla quantit`a di pixel aventi un determinato valore di intensit`a nell’immagine LBP. La concatenazione di tutti gli istogrammi ottenuti sar`a il feature vector che potr`a essere utilizzato in fase di classificazione per essere dato in input a SVM o reti neurali.
Figura 3.5: Procedimento di elaborazione degli istogrammi data un’immagine LBP: l’immagine viene suddivisa in una griglia; gli istogrammi di ciascuna cella vengono poi concatenati assieme per andare a formare il vettore di feature definitivo.