API
Progettazione e realizzazione di un
software di gestione del corpus AVIP-API
1. INTRODUZIONE
1.1 OBIETTIVI DEL LAVORO
Il presente lavoro è stato svolto presso il centro di ricerche CIRASS nell’ambito di uno stage di formazione gestito dal Diploma Universitario di Ingegneria Informatica dell’ateneo “Federico II” di Napoli, ed è il frutto di una revisione e sinterizzazione della tesi di laurea del primo autore. Il lavoro é stato di prezioso supporto alle attività svolte nell’ambito del progetto di ricerca AVIP ed ha riguardato la progettazione e la realizzazione di un sistema software di gestione dei dati del corpus.
La condizione iniziale da cui è partito il lavoro, consisteva nell’esistenza di un insieme di files che costituivano una base di dati non convenientemente interrogabile. Gli interessati allo studio dei dialoghi, infatti, avrebbero potuto ricercare le informazioni, in assenza di un sistema di gestione, soltanto procedendo tramite ricerche manuali all’interno dei numerosi e complessi file che originariamente costituivano il corpus, ottenendo così risultati in tempi non ragionevoli.
Il lavoro svolto ha avuto come obiettivi la progettazione e la realizzazione dei seguenti componenti: • un Data Base (attraverso l’utilizzo di un DBMS) con il fine di strutturare e gestire tutte le
informazioni del Corpus linguistico AVIP.
• un Parser con il fine di analizzare, correggere ed immettere in modo diretto i dati contenuti nei files AVIP nel Data Base realizzato con l’utilizzo del DBMS.
• Un Generatore di Query capace di offrire specifiche funzionalità di interrogazione.
1.2 CICLI DI VITA DEL SOFTWARE ADOTTATI
La descrizione dell’attività svolta è suddivisa nei successivi capitoli come le fasi relative ai cicli di vita seguiti per la produzione dei singoli componenti richiesti e realizzati.
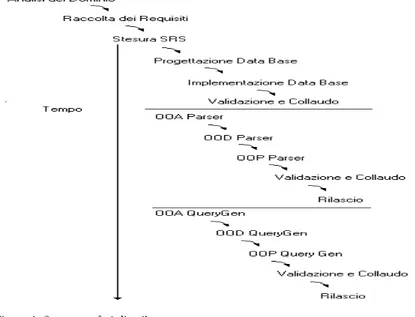
Figura 1: Sequenza fasi di sviluppo
Ogni singolo componente, come evidenziato in figura 1, è stato progettato e realizzato separatamente, rispettando il seguente ordine: Data Base, Parser, QueryGenerator.
Per la realizzazione del Data Base si è utilizzato il modello di cicli di vita dei sistemi informativi. Si è applicata una metodologia ampiamente consolidata e riconosciuta, quella cioè di scomporre la progettazione in Progettazione concettuale ed in Progettazione Logica.
Il modello di ciclo di vita del software adottato invece per lo sviluppo del Parser e del QueryGenerator è stato un modello a cascata con feedback (v. figura 2)
analisi requisiti e specifiche disegno codifica e testing integrazione e collaudo rilascio e manutenzione convalida convalida validazione validazione validazione Figura 2: Modello a Cascata con feedback
La metodologia di sviluppo utilizzata per la realizzazione del Parser e del QueryGenerator è stata quella Object-Oriented. Lo sviluppo è stato suddiviso nelle comuni fasi di OOA Object Oriented Analisys, OOD Object Oriented Design ed OOP Object Oriented Programming.
2. DESCRIZIONE DEL DOMINIO AVIP
2.1 INTRODUZIONE
Il progetto AVIP ha definito con adeguatezza, rispetto ad obiettivi primariamente stabiliti e circoscritti, criteri e norme di costruzione, d’organizzazione e di rappresentazione dei dati del corpus [1].
In questo capitolo sono descritti alcune norme e alcune entità costituenti il Corpus AVIP quali: i Dialoghi, i Turni, i Livelli di Etichettatura, i Parametri d’Analisi, ecc. con il fine di fornire supporto alla comprensione dei modelli d’analisi e di progettazione illustrati nei capitoli successivi.
2.2 I DIALOGHI
Ogni dialogo è svolto da due persone dette informatori. Il dialogo è basato sulla spiegazione di un ipotetico percorso indicato su una mappa. L’informatore che indica il percorso ha un ruolo detto di Information Giver mentre l’altro che richiede spiegazioni ha un ruolo detto di Information Follower. Di ogni Informatore sono stati annotati e memorizzati Nome, Età, Sesso, Luogo di Nascita.
Per quanto concerne le mappe, in AVIP esistono 4 coppie di mappe diverse indicate con le prime quattro lettere dell’alfabeto a,b,c,d più altre due coppie indicate con la lettera p o s relative alla porzione del corpus a dedicata al parlato infantile; per tale porzione sono state prese in esame le sole produzioni del bambino (sempre Follower) che può essere Normoudente o Ipoacusico.
Un dialogo è suddiviso logicamente in Turni dove per turno si intende la “presa di parola da parte di un informatore“.
Attributi relativi all’attività di registrazione sono inoltre la durata, la condizione di registrazione, la frequenza di campionamento (in AVIP sempre uguale a 22050Hz), la data di registrazione, ecc.
Ogni dialogo è sottoposto ai processi di etichettatura e di analisi descritti nei prossimi paragrafi.
2.3 LE TRASCRIZIONI AVIP: I LIVELLI DI ETICHETTATURA
Una classificazione delle trascrizioni d’interesse per il dominio applicativo descritto è la seguente:
Trascrizione fonetica: studia ed identifica con elevato grado di dettaglio ciascun suono (fono) articolato dall’informatore.
Trascrizione fonologica: evidenzia soltanto gli esiti dei fonemi (ciascun suono che assume funzione semanticamente distintiva in un linguaggio) e i mutamenti che per essi si sono verificati.
Siccome l’associazione di un codice dell’alfabeto di trascrizione ad un elemento fonico è detta etichettatura parleremo d’ora in avanti non di diversi tipi di trascrizione ma di diversi livelli di etichettatura. Il termine livelli è stato utilizzato per indicare l’esistenza di una gerarchia definita nel progetto tra le varie etichettature e descritta nei paragrafi successivi.
Per la codifica dei dati fonici nel corpus AVIP sono stati utilizzati i seguenti livelli di etichettatura. PHN: etichettatura fonetica stretta.
PHB: etichettatura fonetica larga o “fonologica della varietà” PHM: trascrizione fonemica parola per parola.
WRD: trascrizione ortografica parola per parola.
TON: etichettatura intonativa “foneticamente orientata” AUT: etichettatura intonativa “fonologicamente orientata”.
Il livello AUT è stato utilizzato soltanto dall’unità di ricerca di Bari e non rientra nel dominio informativo d’interesse per l’applicazione qui presentata..
2.4 I MARKERS
I Markers sono dei dati numerici utilizzati per delimitare l’istante d’inizio e quello di fine di un evento acustico etichettato in un dato livello. Essi rappresentano il numero d’ordine del campione di segnale acquisito corrispondente all’evento acustico etichettato.
2.5 RELAZIONI TRA I LIVELLI DI ETICHETTATURA PHN, PHB, PHM, WRD.
Tra i livelli PHN, PHB, PHM e WRD esistono le seguenti relazioni: 1. Inclusione temporale.
Partendo dall’elementare e comune concetto che le parole includono generalmente più suoni distinti (solitamente rappresentati da lettere nella forma scritta) è facile comprendere come un’etichetta di parola (livelli WRD o PHM) includa più etichette di fonemi (livelli PHB e PHN). L’inclusione è espressa dai valori dei marker.
2. Corrispondenza tra i valori dei marker.
Il Marker di inizio di un’etichetta di parola deve essere uguale al marker di inizio del fono o del fonema etichettato corrispondente alla lettera.Ovviamente non vale il contrario.
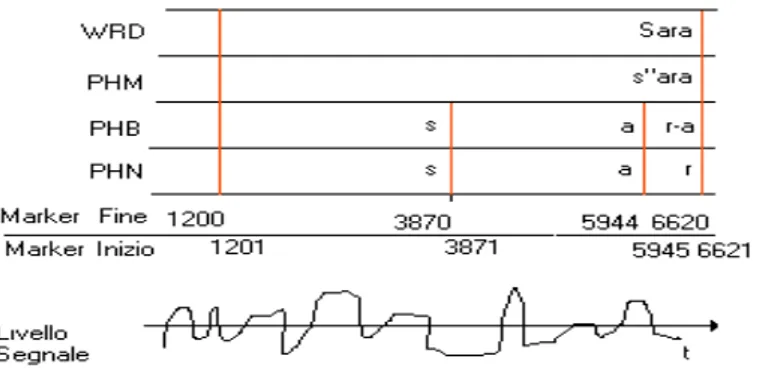
Figura 3: Relazioni tra i Markers dei livelli PHN,PHB,PHM,WRD
Le linee verticali rappresentano graficamente la segmentazione attuata dai marker di inizio e fine associati ad ogni entità trascritta in un dato livello. Ad esempio per il livelli PHN e PHB la ‘s’ ha come marker iniziale 1201 e come marker finale 3870.
Il livello PHN utilizza come unità fonica i singoli foni, il livello PHB utilizza come unità fonica i singoli fonemi mentre i livelli PHM e WRD utilizzano come unità le singole parole.
Dalle ‘dimensioni’ delle unità etichettate è possibile definire una relazione di inclusione temporale tra i livelli di etichettatura. Le norme che regolano il progetto AVIP garantiscono che i markers delimitatori di un’entità ad un dato livello, hanno sempre un corrispondente (stesso valore) nei livelli di gerarchia temporale paritetica o inferiore. Nell’esempio il marker destro dell’entità fonica a livello WRD (entità fonologica di tipo parola codificata con Sara) ha un marker corrispondente (stesso valore) sia nel livello gerarchicamente paritetico PHM (entità fonologica di tipo parola codificata con s”ara) sia nei livelli gerarchicamente inferiori (PHB e PHN) che analizzano entità fonologiche diverse (PHB entità fonologica di tipo fonema codificata con r-a, PHN entità fonetica di tipo fono codificata con r). Ragionando in verso opposto sulla gerarchia espressa in Figura 3 è evidente che l’esistenza di un corrispondente non è garantita per i livelli gerarchicamente superiori ad un dato livello.
Le relazioni d’inclusione e di corrispondenza tra i marker sono fondamentali per relazionare un’entità con se stessa codificata in diversi livelli.
Per la coppia di livelli (PHM, WRD) i marker sono in sostanza gli stessi poiché uguali sono le unità fonologiche analizzate (detti livelli Paritetici). Tali livelli sono gerarchicamente superiori ai livelli PHN e PHB.
Per coppia di livelli (PHN, PHB) invece la corrispondenza dei marker avviene per tutte le entità trascritte tranne per la trascrizione dei dittonghi, dei trittonghi o nei casi particolari di monottongazione e sinalefe. In questi casi il livello PHB non segmenta le entità è quindi è un livello gerarchicamente superiore al PHN. Tutti i turni dei dialoghi del progetto AVIP sono stati etichettati ai livelli PHN, PHB,
pisana in cui non è stato segnalato il marker d’inizio della prima parola assoluta del turno. L’informazione relativa al confine sinistro di parola è recuperabile ai livelli inferiori PHB e PHN.
2.6 IL LIVELLO DI ETICHETTATURA TON
Il livello TON è un livello utilizzato per l’analisi prosodica e quindi segmenta un testo parlato in unità prosodiche anche dette unità tonali. E’ un livello indipendente in termini temporali nel senso che non è prevista alcuna relazione di corrispondenza dei marker con quelli degli altri livelli.
Le etichette del livello TON trascrivono con uno specifico alfabeto le seguenti entità: • L’inizio o la fine di un’unità tonale
• Le variazioni della curva interpolante linearmente i campioni di frequenza fondamentale o Pitch. • Gli accenti.
• L’inizio e la fine di un unità tonale sono etichettate con i simboli [ e ].
• Le variazioni del Pitch sono etichettate con le lettere T, B, H, L, U, D, S mentre gli accenti sono etichettati con le cifre 0,1,2,3.
Accade spesso che in corrispondenza di una variazione del Pitch si verifica anche la presenza di un accento e quindi i due eventi sono etichettati insieme con stringhe tipo L1, H1, ecc. oppure che un determinato valore di Pitch avviene all’inizio o alla fine di un’unità tonale con stringhe del tipo ]T, B[, ecc.
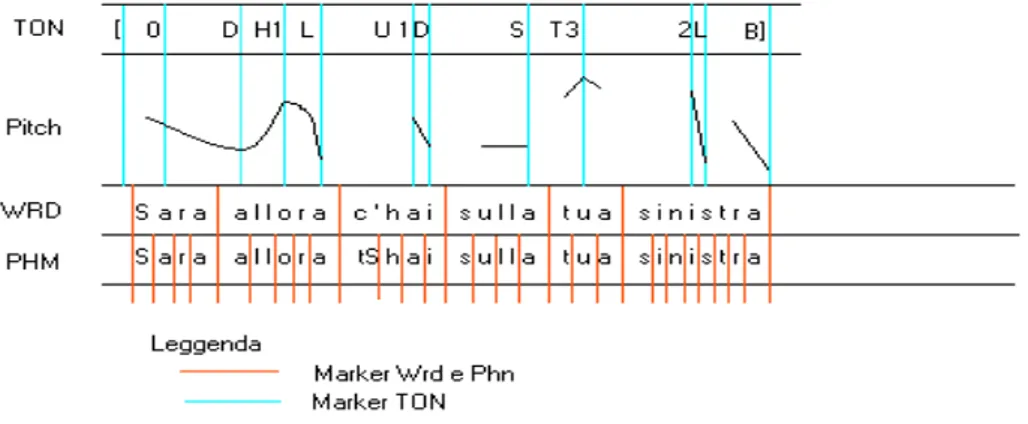
La figura 4 ha lo scopo di descrivere il livello d’etichettatura TON e di porlo in confronto con altri livelli d’etichettatura. Si è scelto di utilizzare nel confronto un livello d’etichettatura di parola WRD ed un livello d’etichettatura per singolo fono PHN.
Figura 4: Livello Ton in relazione con i livelli PHN e WRD
E’ evidente la totale mancanza di una corrispondenza dei marker del livello TON con quelli di un altro livello. Lo stesso inizio o fine dell’unità tonale può non corrispondere all’inizio o alla fine di una sequenza di trascrizioni degli altri livelli.
Allo stato attuale in AVIP il livello TON è stato utilizzato per etichettare soltanto alcuni turni di alcuni dialoghi.
2.7 I PARAMETRI D’ANALISI
I parametri fisici definiti ed utilizzati nel progetto AVIP verranno in seguito indicati come parametri d’analisi.
I parametri d’analisi sono: Pitch, Energia, Formanti, Durata. La durata di un frame in AVIP è costante e pari a 5ms.
2.8 RELAZIONI TRA I LIVELLI D’ETICHETTATURA PHN, PHB, WRD E PHM E I
PARAMETRI D’ANALISI
Ogni etichetta ha associati due markers che rappresentano il numero di campione d’inizio e fine dell’evento acustico registrato e rappresentato simbolicamente dall’etichetta stessa. Tali valori dei markers divisi per la frequenza di campionamento forniscono come dimensione degli istanti di tempo che sono appunto l’istante d’inizio e l’istante di fine dell’evento acustico. Le informazioni d’analisi sono valori discreti memorizzati in sequenza e riferiti a sezioni (frame) di segnale di 5ms.
Figura5- Relazione tra Etichette e i Parametri d'Analisi
Nei paragrafi precedenti sono state descritte le entità e le relazioni esistenti tra esse. Ora passiamo ad una breve descrizione della base di dati esistente prima dell’inizio del lavoro.
La base di dati AVIP era costituita da un insieme di files indipendenti ottenuti attraverso un certo insieme di operazioni. Molte operazioni esulano dagli scopi di questo documento e quindi non saranno descritte. Quelle di interesse per quest’ambito sono:
Etichettatura, cioè l’associazione di simboli (etichette) definiti nel progetto AVIP a ciascun determinato elemento del corpus. Come descritto nei precedenti paragrafi esistono più livelli d’etichettatura.
Segmentazione cioè la suddivisione in segmenti del segnale fonico. Per ogni segmento è definito l’inizio e la fine di un evento fonico
Analisi, cioè la determinazione di parametri di significato fisico relazionati agli eventi fonici (Frequenza fondamentale, Energia, Formanti)
Tutto il corpus AVIP è stato segmentato ed etichettato mediante un sistema software progettato e realizzato dall’unità di ricerca del Politecnico di Bari che si chiama SegWin. Allo stato attuale tutti i dialoghi sono stati etichettati con le etichettature dei livelli WRD, PHM, PHB e PHN mentre l’etichettatura TON è stata eseguita solo per alcuni turni . L’operazione di Analisi è stata eseguita con l’ausilio di routine software sviluppate presso il CIRASS.
I files sono sostanzialmente di tre tipi:
1. Files d’Analisi (contengono singolarmente per ogni frame informazioni circa lo Spettro, l’Energia, Pitch, ecc.) Il formato di ogni file è il seguente:
Pitch: per ogni frame, valore del Pitch in Hz (intero a 16 bit) e flag voiced/unvoiced (8 bit, 0 se unvoiced, 1 se voiced)
Energia: per ogni frame, energia in dB (intero a 16 bit) ed alla fine il valore massimo dell’energia, calcolato per tutto il file
Formanti: Per ogni frame, valore della 1°, della 2° e della 3° formante (int a 16 bit).
2. Files d’Etichettatura (contengono l’etichettatura dei livelli segmentali secondo quanto definito nel progetto AVIP)
Ciascun file d’etichettatura ha l'estensione corrispondente al livello d’etichettatura e contiene un record per ogni marker, in formato testo. Ogni record è così composto:
Tipo d’etichettatura Marker iniziale Marker finale Num. della parola Stringa
Il Tipo d'etichettatura è un campo di tre lettere coincidente con l'estensione del file relativo. Il Marker iniziale e il Marker finale sono allineati al file di segnale.
Il campo Stringa è l’etichetta di trascrizione dell’elemento.
3. File Header (contiene informazioni varie il cui significato dipende da tre lettere identificative della riga)
Ogni file d’intestazione è riferito ad un intero dialogo e quindi a più turni. Alcune righe presentano un codice identificativo di riga che ne indica il contenuto informativo e che può assumere uno dei seguenti valori:
ING: informazioni sull’Instruction Giver. Iniziali del nome, età, sesso, altre caratteristiche utili, ecc. INF: informazioni sull’Instruction Follower. Iniziali nome, età, sesso, altre caratteristiche utili, ecc. LET: informazioni sul lettore.
LOC: luogo e data di registrazione. CMP: frequenza di campionamento.
COD: numero e ordine dei byte utilizzati nel file di segnale. DUR:durata totale del dialogo o della lettura.
CON:condizioni generali della registrazione. CMT:commenti.
3. ANALISI E SPECIFICA DEI REQUISITI
3.1 INTRODUZIONE
E’ stato eseguito un attento studio dei documenti del progetto AVIP esistenti ed in particolare l’attenzione è stata rivolta al documento descrittivo del formato dei Files AVIP [2] ed al documento di specifica delle Norme e dei Codici che regolano l’attività di trascrizione nel progetto AVIP [1]. Allo stesso tempo sono state eseguite interviste ai soggetti interessati all’applicazione. I requisiti sono stati quindi specificati in maniera quanto più completa, consistente e non ambigua e trascritti in un documento di specifica dei requisiti SRS sviluppato secondo lo standard IEEE1994 che qui non riprodurremo ma che è disponibile a richiesta contattando gli autori del presente documento. In tale documento sono inclusi i requisiti relativi all’intero progetto.
Inoltre è stato sviluppato un documento di specifica dell’interfaccia utente in cui è stato è stata descritta l’iterazione attesa con l’utente.
La fase di analisi ha richiesto l’utilizzo e l’applicazione di modelli e di metodologie diversi per modellare i componenti Data Base, Parser e Generatore di Query.
Infatti, per il Data Base è stata utilizzata la metodologia di sviluppo dei sistemi informativi, mentre per il Parser ed il Generatore di Query è stata utilizzata una metodologia Object Oriented.
Ogni singolo componente è stato quindi analizzato separatamente, rispettando il seguente ordine: Data Base, Parser, QueryGenerator.
3.2 SPECIFICHE RIGUARDANTI L’INTERFACCIA UTENTE
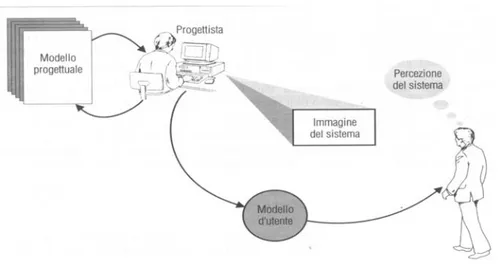
Nella progettazione di una interfaccia utente entrano in gioco tre modelli diversi, quello progettuale, quello implementativo e quello denominato modello dell’utente o percezione del sistema (v. figura 6). Ovviamente quest’ultimo risente della tipologia e del grado di esperienza che il committente/utente ha nell’utilizzo di software.
Figura 6- Percezione del sistema
In questo paragrafo è descritta la percezione dell’ interfaccia di interrogazione dei livelli di etichettatura del sistema da realizzare dal punto di vista del committente/utente.
In particolare si è descritto la successione di selezioni che il committente/ utente immagina di eseguire durante le interrogazioni.
La sequenza di selezioni previste è la seguente:
1. La selezione del sottoinsieme del corpus oggetto di interrogazione 2. Input di stringhe nei livelli di etichettatura
3. La selezione degli output desiderati
La selezione della parte del corpus oggetto di interrogazione è descritta in figura (v. fig.7) in cui le frecce indicano che la selezione di una opzione attiva una ulteriore richiesta di input.
L’input di stringhe nei livelli di etichettatura deve essere eseguito in apposite caselle di testo riferite ai singoli livelli etichettatura. Le richieste potranno avere come obiettivo la ricerca di elementi presenti con opportuna codifica (etichettatura) in diversi livelli. Tipiche interrogazioni saranno quelle che relazioneranno elementi tra due/tre livelli di etichettatura differenti. In figura 8 ad esempio è illustrata la modalità attesa dal committente per la ricerca di tutte le etichette che a livello PHN sono uguali a “!a” e che (AND) a livello WRD iniziano per “k” o (OR) iniziano per “p”.
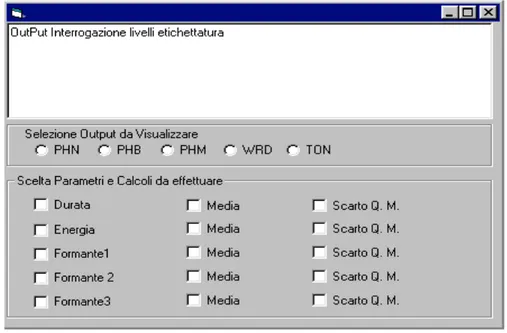
Figura 8- Interfaccia interrogazione livelli di etichettatura.
Nelle caselle l’utente potrà digitare tutti i simboli dell’alfabeto di etichettatura previsti per quel livello. Sarà cura dell’utente verificare la correttezza dei simboli forniti in input in quanto non è richiesto che il sistema riconosca gli alfabeti dei singoli livelli per segnalare eventuali errori di digitazione. Infine, una volta terminata la fase di input nei livelli di etichettatura il sistema dovrà fornire agli utenti la possibilità di selezionare il livello dove visualizzare l’Output .
L’utente potrà quindi selezionare una istanza di etichettatura trovata ed indicare i parametri di analisi d’interesse. Su tali parametri l’utente potrà inoltre indicare se calcolare media e/o scarto quadratico medio.
3.3 MODELLAZIONE CONCETTUALE DATA BASE
La modellazione concettuale ha come obiettivo la rappresentazione accurata e naturale dei dati d’interesse dal punto di vista del significato che hanno per l’applicazione da realizzare. Il modello sviluppato, detto Modello Entità – Relazione (E.R.) è un modello concettuale di dati atto a descrivere la realtà d’interesse a prescindere dai criteri di organizzazione degli elaboratori. E’ costituito da costrutti il cui significato logico è dettagliatamente descritto in [3]. Come documentazione di tale modello sono stati prodotti la tabella descrittiva delle entità e la tabella descrittiva delle relazioni.
Per lo sviluppo dello schema concettuale E.R. a partire dalle specifiche sono applicabili tutte le comuni tecniche ingegneristiche quali la strategia top-down, la strategia bottom-up , la strategia inside-out o le strategie miste . La strategia scelta per il modello concettuale del corpus AVIP è di tipo misto.
Sono stati inizialmente individuati i concetti principali (definendo il cosiddetto schema a “scheletro” ) e si è proceduto poi nello sviluppo separato dei concetti per raffinamenti successivi.
Tale scelta progettuale ha consentito di ottenere i seguenti vantaggi: 1. La scomposizione del problema in sottoproblemi.
2. L’inizio della progettazione prima che tutte le specifiche fossero complete. 3. L’integrazione immediata senza fasi di composizione.
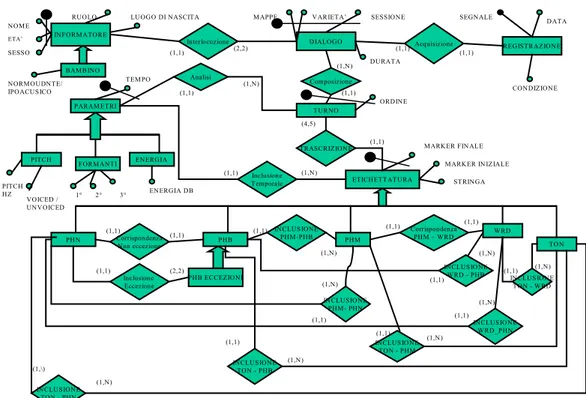
3.4 MODELLO E-R INFORMATORE DIALOGO TURNO WRD ETICHETTATURA PARAM ETRI PHN REGISTRAZIONE Interlocuzione Acquisizione Composizione Analisi TRASCRIZIONE Inclusione Eccezione INCLUSIONE WRD_PHN Corrispondenza PHM – WRD TON PHM PHB PITCH FORMANTI ENERGIA PHB ECCEZIONI INCLUSIONE PHM- PHN INCLUSIONE WRD - PHB Corrispondenza Non eccezione INCLUSIONE PHM -PHB Inclusione Temporale BAMBINO NOME ETA’ SESSO RUOLO NORMOUDNTE/ IPOACUSICO (1,1)
MAPPE VARIETA’ SESSIONE
DURATA
SEGNALE
DATA
CONDIZIONE ORDINE
MARKER FIN ALE MARKER IN IZIALE STRINGA VOICED / UNVOICED PITCH HZ 1° 2° 3° ENERGIA DB (2,2) (1,1) (1,1) (1,N) (1,N) (1,1) (1,1) (1,N) (1,1) (4,5) (1,1) (1,1) (1,1) (1,1) (2,2) (1,1) (1,N) (1,N) (1,1) (1,1) (1,1) (1,N) (1,N) (1,1) (1,1) TEM PO LUOGO DI NASCITA INCLUSIONE TON - WRD INCLUSIONE TON - PHM INCLUSIONE TON - PHB INCLUSIONE TON - PHN (1,N) (1,\) (1,N) (1,1) (1,N) (1,1) (1,N) (1,1)
Figura 10- Modello Entità Relazione
Documentazione del modello E- R: Dizionario dei Dati
Entità Descrizione Attributi Identificatore
Dialogo Conversazione tra due Informatori
Mappe,Varietà,Sessione,
Durata Mappe,Varietà,Sessione
Registrazione Dialogo memorizzato Data,Frequenza
Campionamento (CMP), Condizione, Nome File Audio
Nome File Audio
Informatore Persona che effettua il Dialogo
Nome, Età, Sesso, Luogo
di nascita, ruolo Nome, Età, Sesso Bambino Persona di Età Inferiore
ad anni 15 che effettua il Dialogo
Normoudente/ Ipoacusico Turno Parte del Dialogo. Inizia
ogni volta che l’informatore prende parola.
Ordine del turno Ordine del turno, Dialogo
Parametri Informazioni per l’analisi
"fisica" del segnale. Tempo Tempo, Turno. Pitch Frequenza fondamentale in
Hz riferita ad un frame del segnale.
PitchHz, Voiced/Unvoiced
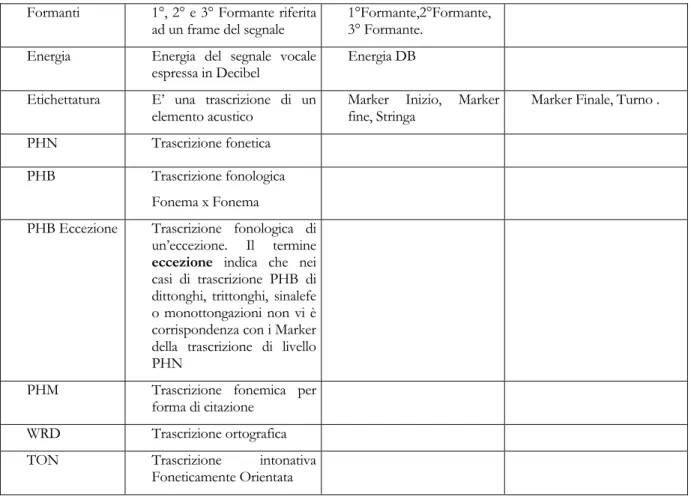
Formanti 1°, 2° e 3° Formante riferita
ad un frame del segnale 1°Formante,2°Formante,3° Formante. Energia Energia del segnale vocale
espressa in Decibel Energia DB Etichettatura E’ una trascrizione di un
elemento acustico Marker Inizio, Markerfine, Stringa Marker Finale, Turno . PHN Trascrizione fonetica
PHB Trascrizione fonologica Fonema x Fonema
PHB Eccezione Trascrizione fonologica di un’eccezione. Il termine
eccezione indica che nei
casi di trascrizione PHB di dittonghi, trittonghi, sinalefe o monottongazioni non vi è corrispondenza con i Marker della trascrizione di livello PHN
PHM Trascrizione fonemica per forma di citazione
WRD Trascrizione ortografica TON Trascrizione intonativa
Foneticamente Orientata
Tabella descrittiva delle Relazioni.
Relazione Descrizione Entità Coinvolte
Interlocuzione Associa un informatore al dialogo Informatore, Dialogo Composizione Associa un dialogo ai turni di cui è composto Dialogo, Turno Acquisizione Associa un dialogo alla sua registrazione Dialogo , Registrazione Inclusione temporale Associa ad un’etichetta i parametri ad essa
relativi Parametri, Etichettatura
Trascrizione Associa un turno alla sua etichettatura Turno, Etichettatura Corrispondenza
PHN-PHB Associa una trascrizione PHN con unatrascrizione PHB con gli stessi Marker PHN, PHB Inclusione PHB eccezione
– PHN Associa una trascrizione PHB che trascriveun’eccezione (dittongo, trittongo, ecc.) alle tra-scrizioni PHN che include
PHN, PHB eccezione
Inclusione PHM-PHN Associa una trascrizione PHM alle trascrizioni
PHN che include PHM, PHN
Inclusione WRD –PHB Associa una trascrizione WRD alle trascrizioni
PHB che include. WRD, PHN
Inclusione WRD- PHN Associa una trascrizione WRD alle trascrizioni
PHN che include. WRD, PHN
Inclusione PHB-PHM Associa una trascrizione PHM alle trascrizioni
Inclusione TON –WRD Associa una trascrizione TON alle trascrizioni
WRD che include. TON, WRD
Inclusione TON –PHM Associa una trascrizione TON alle trascrizioni
PHM che include. TON, PHM
Inclusione TON –PHB Associa una trascrizione TON alle trascrizioni
PHB che include. TON, PHB
Inclusione TON –PHN Associa una trascrizione TON alle trascrizioni
PHN che include. TON, PHN
3.5 OBJECT ORIENTED ANALISYS
La metodologia di sviluppo utilizzata per la realizzazione del Parser e del QueryGenerator è stata quella Object-Oriented.
Per le fasi di analisi e di progettazione (OOA ed OOD) si è utilizzato il linguaggio di modellazione UML, allo stato largamente diffuso, con cui si è potuto modellare il sistema.
Tra gli strumenti dello standard UML sono stati utilizzati i seguenti: • L’ Analisi dei casi d’uso
• I Diagramma delle classi
3.6 ANALISI DEI CASI D’USO
casi D’uso relativi al Corpus AVIP sono descritti di seguito in tre sezioni. Nella prima sezione sono descritti gli attori ed i casi d’uso .Nella seconda sezione sono descritte le relazioni tra i casi d’uso.Infine nella terza sezione sono descritti in modo testuale degli scenari relativi ai singoli casi d’uso.
Descrizione degli attori e dei casi d’uso.
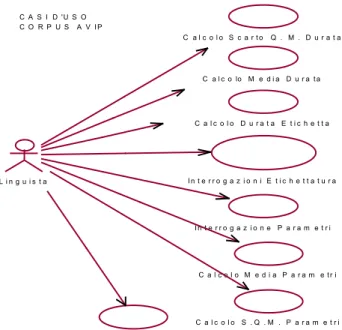
Dall’analisi dei requisiti del software di gestione del corpus è stato individuato un singolo attore del sistema.
Tale attore, denominato Linguista, rappresenta la classe degli utilizzatori del sistema che sono sostanzialmente persone che svolgono attività di studio della lingua parlata.
Il Caso d’uso Interrogazioni Etichettatura rappresenta il processo per ricercare le stringhe di etichettatura all’interno del Data Base AVIP.
Il Caso d’uso Calcolo Durata Etichettatura rappresenta il processo per calcolare la durata di una stringa di etichettatura all’interno del Data Base AVIP.
Il Caso d’uso Calcolo Media Durata rappresenta il processo per calcolare la media delle durate delle stringhe di etichettatura all’interno del Data Base AVIP.
Il Caso d’uso Calcolo Scarto Q.M. Durata rappresenta il processo per calcolare lo scarto quadratico medio delle durate delle stringhe di etichettatura all’interno del Data Base AVIP.
Il Caso d’uso Interrogazione Parametri rappresenta il processo per ricercare i valori di un parametro relativi ad una stringa di etichettatura.
Il Caso d’uso Calcolo Media Parametri rappresenta il processo per calcolare la media dei valori dei parametri relativi ad una stringa di etichettatura.
Il Caso d’uso Calcolo Scarto Q. M. Parametri rappresenta il processo per calcolare lo scarto quadratico medio dei parametri relativi ad una stringa di etichettatura.
Il Caso d’uso Parser Dialogo rappresenta il processo per analizzare, correggere ed immettere i dati AVIP nel Data Base AVIP.
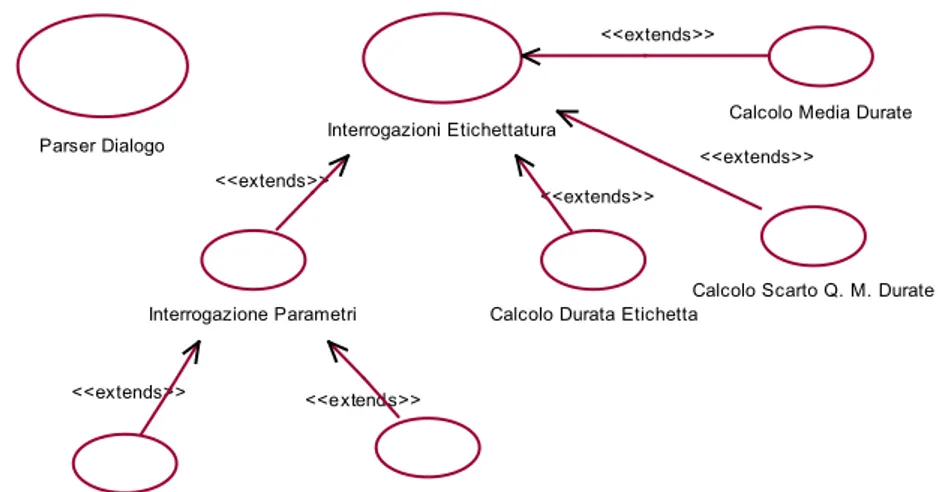
I Casi d’uso AVIP
C a l c o l o S . Q . M . P a r a m e t r i C a l c o l o S c a r t o Q . M . D u r a t a C a l c o lo M e d i a D u r a t a C a l c o l o D u r a t a E t i c h e t t a I n t e r r o g a z i o n i E t i c h e t t a t u r a I n t e r r o g a z i o n e P a r a m e t r i C a l c o l o M e d i a P a r a m e t r i P a r s e r D i a l o g o L i n g u i s t a C A S I D 'U S O C O R P U S A V I P
La Struttura dei Casi D’Uso. Interrogazioni Etichettatura Parser Dialogo RELAZIONI TRA I CASI D'USO <<extends>> <<extends>>
Calcol Media Parametri Calcolo Scart o . Q.M. Param etri
<<extends>> <<extends>>
<<extends>>
<<extends>>
Interrogazione Parametri Calcolo Durata Etichetta
Calcolo Scarto Q. M. Durate Calcolo Media Durate
Figura 12 - Struttura dei Casi D'uso
Descrizione degli scenari.
Gli scenari sono di seguito descritti secondo il seguente formato. • Numero Caso D’uso: Nome Caso D’ Uso
• Scenario: Numero scenario/Totale scenari del caso D’uso : Nome scenario • Numero Transizione. Descrizione
Inoltre ‘EX’ indica la relazione di estensione.
Esempio : EX 2.5 significa sostituire alla riga le righe del caso d’uso 2 che iniziano per 5.
1. CASO D’USO: Interrogazione Etichettatura.
Scenario 1/3: Interrogazione d’Etichettatura richiesta su Dialoghi non presenti nel Data Base. 1. Il linguista immette i dati dei Dialoghi su cui vuole ricercare le stringhe di etichettatura.
2. Il sistema ricerca nel Data Base le informazioni relative ai Dialoghi. Rileva l’assenza dei Dialoghi nel Data Base, quindi visualizza un messaggio d’errore e termina l’esecuzione.
Scenario 2/3: Interrogazione d’Etichettatura richiesta su Dialoghi presenti nel Data Base. Le stringhe ricercate non sono presenti nei dialoghi.
1. Il linguista immette i dati dei Dialoghi su cui vuole ricercare le stringhe di etichettatura.
2. Il sistema ricerca nel Data Base le informazioni relative ai Dialoghi. Rileva la presenza dei dialoghi nel Data Base e ne preleva i record visualizzando i dati dei Dialoghi a video.
3. Il linguista immette le stringhe da ricercare e i livelli di etichettatura dove cercarle.
4. Il sistema ricerca relativamente ai dialoghi richiesti le stringhe di etichettatura. Rileva l’assenza di stringhe nel Data Base. Visualizza un messaggio di errore e termina l’esecuzione.
Scenario 3/3: Interrogazione d’Etichettatura richiesta su Dialoghi presenti nel Data Base. Le stringhe ricercate sono presenti nel Data Base.
1. Il linguista immette i dati dei Dialoghi su cui vuole ricercare le stringhe di etichettatura.
2. Il sistema ricerca nel Data Base le informazioni relative ai Dialoghi. Rileva la presenza dei dialoghi nel Data Base, ne preleva i record e visualizza i dati dei Dialoghi a video.
3. Il linguista immette le stringhe da ricercare e i livelli di etichettatura dove cercarle.
4. Il sistema ricerca nel Data Base AVIP le stringhe di etichettatura cercate e rileva la presenza delle stringhe nel Data Base AVIP.
5. EX 2.5, EX 3.5: EX 4.5, EX 5.5, EX 6.5 Il sistema visualizza i dati delle stringhe trovate. 6. Il sistema attende nuove richieste di ricerca.
2. CASO D’USO: Calcolo Durata Etichetta.
Scenario 1/1: Richiesta del calcolo della durata di una stringa di etichettatura.
Sostituire EX 2.5 nel caso d’uso Interrogazioni di etichettatura scenario 3/3 riga 5 con: 5.1 Il sistema visualizza i dati delle stringhe trovate.
5.2 Il linguista chiede il calcolo della durata di una stringa di etichettatura. 5.3 I sistema determina la durata e visualizza il risultato.
3. CASO D’USO: Calcolo Media Durata.
Scenario 1/1: Richiesta della media della durata di più stringhe di etichettatura.
Sostituire EX 3.5 nel caso d’uso Interrogazioni di etichettatura scenario 3/3 riga 5 con: 5.1 Il sistema visualizza i dati delle stringhe trovate.
5.2 Il linguista chiede il calcolo della media delle durate delle stringhe di etichettatura. 5.3 I sistema determina la media delle durate e visualizza il risultato.
4. CASO D’USO: Calcolo Scarto Q. M. Durata.
Scenario 1/1: Richiesta del calcolo dello scarto quadratico medio delle durate di più stringhe di etichettatura.
Sostituire EX 4.5 nel caso d’uso Interrogazioni di etichettatura scenario 3/3 riga 5 con: 5.1 Il sistema visualizza i dati delle stringhe trovate.
5. CASO D’USO: Calcolo Durata Etichetta.
Scenario 1/1: Richiesta del calcolo della durata di una stringa di etichettatura.
Sostituire EX 5.5 nel caso d’uso Interrogazioni di etichettatura scenario 3/3 riga 5 con: 5.1 Il sistema visualizza i dati delle stringhe trovate.
5.2 Il linguista chiede il calcolo della durata di una stringa di etichettatura. 5.3 I sistema determina la durata e visualizza il risultato.
6. CASO D’USO: Interrogazione Parametri.
Scenario 1/1: Richiesta della ricerca dei parametri d’analisi relativi ad una stringa di etichettatura. Sostituire EX 6.5 nel caso d’uso Interrogazioni di etichettatura scenario 3/3 riga 5 con: 5.1 Il sistema visualizza i dati delle stringhe trovate.
5.2 Il linguista chiede la ricerca dei parametri d’analisi relativi ad una stringa di etichettatura.
5.3 I sistema ricerca nel Data Base AVIP i parametri d’analisi relativi alla stringa di etichettatura, preleva i record e visualizza a video le istanze trovate.
5.4 EXT 7.5.3: EXT 8.5.3: Il linguista legge i valori dei parametri d’analisi e ne prende nota. 7. CASO D’USO: Calcolo Media Parametri.
Scenario 1/1: Richiesta del calcolo della media dei valori dei parametri d’analisi relativi ad una stringa di etichettatura.
Sostituire EX 7.6.3 nel caso d’uso Interrogazioni Parametri riga 6.3 con:
5.3.1 Il linguista chiede il calcolo della media dei parametri relativi ad una stringa di etichettatura. 5.3.2 I sistema calcola la media e visualizza il valore a video.
8. CASO D’USO: Calcolo Scarto Quadratico Medio Parametri.
Scenario 1/1: Richiesta del calcolo dello scarto quadratico medio dei valori dei parametri d’analisi relativi ad una stringa di etichettatura.
Sostituire EX 8.6.3 nel caso d’uso Interrogazioni Parametri riga 6.3 con:
5.3.1 Il linguista chiede il calcolo dello scarto Quadratico medio dei parametri relativi ad una stringa di etichettatura.
5.3.2 I sistema calcola lo scarto quadratico medio e visualizza il valore a video. 9. CASO D’USO: Parser Dialogo.
Scenario 1/4: Nel Dialogo alcuni file non rispettano il formato AVIP previsto.
1. Il linguista avvia il programma ed indica il Nome e la Directory dove è memorizzato il Dialogo che vuole immettere nel Data Base ed il Nome e la Directory del Data Base.
2. Il sistema apre i files del dialogo in successione, li analizza e visualizza a video i dati relativi all’avanzamento dell’elaborazione.
3. Il sistema rileva che i dati nei files sono inesatti o incompleti, segnala a video un messaggio d’ errore e crea un file dove sono segnalati gli errori riscontrati durante l’elaborazione.
4. Il sistema termina l’esecuzione.
Scenario 2/4: Nel Dialogo mancano i files AVIP necessari.
1. Il linguista avvia il programma ed indica il Nome e la Directory dove è memorizzato il Dialogo che vuole immettere nel Data Base ed il Nome e la Directory del Data Base.
2. Il sistema apre i files del dialogo in successione, li analizza e visualizza a video i dati relativi all’avanzamento dell’elaborazione.
3. Il sistema rileva l’assenza di alcuni files, segnala a video un messaggio d’errore e crea un file dove sono segnalati gli errori riscontrati durante l’elaborazione.
4. Il linguista legge i messaggi di errore . 5. Il sistema termina l’esecuzione.
Scenario 3/4: Nel Dialogo alcuni files AVIP presentano errori di etichettatura.
1. Il linguista avvia il programma ed indica il Nome e la Directory dove è memorizzato il Dialogo che vuole immettere nel Data Base ed il Nome e la Directory del Data Base.
2. Il sistema apre i files del dialogo in successione, li analizza e visualizza a video i dati relativi all’avanzamento dell’elaborazione.
3. Il sistema rileva la presenza in alcuni files di errori di etichettatura. Per ogni errore segnala a video un messaggio d’errore ed analizza il file successivo.
4. Dopo aver analizzato ed immesso tutti i turni del Dialogo viene generato un files contenete gli errori rilevati.
5. Il sistema termina l’esecuzione.
Scenario 4/4: Dialogo senza errori di etichettatura.
1. Il linguista avvia il programma ed indica il Nome e la Directory dove è memorizzato il Dialogo che vuole immettere nel Data Base ed il Nome e la Directory del Data Base.
2. Il sistema apre i files del dialogo in successione, li analizza e li immette nel Data Base. Visualizza a video i dati relativi all’avanzamento dell’elaborazione.
3. Completata l’elaborazione di tutti i turni il sistema visualizza i nomi dei turni e dei files immessi.
4. Il sistema termina l’esecuzione.
3.7 I DIAGRAMMI DELLE CLASSI
Lo sviluppo dei modelli concettuali, come è il diagramma delle classi (con i dettagli del livello di analisi) relativi al Parser e al QueryGenerator si realizza innanzitutto attraverso l’individuazione delle classi di oggetti capaci di rappresentare il dominio di interesse. Per individuare le classi di oggetti si possono esaminare i requisiti del sistema da costruire. Dai requisiti è possibile individuare un insieme di classi candidate a far parte del modello concettuale.
Individuazione delle Classi del domino concettuale del Parser.
Partendo da quanto definito nel documento di specifica dei requisiti è evidente che il Parser ha un dominio concettuale d’interesse costituito essenzialmente dalle entità presenti nel Data Base (v. Modello E-R del Corpus AVIP.
A livello concettuale si individuano immediatamente tre parti principali del dominio da modellare e cioè i Dialoghi, i Files AVIP e il Data Base AVIP.
I Dialoghi sono le entità costituenti il Corpus e la cui modellazione è quella più strettamente legata al dominio AVIP.
Dalle specifiche si evince che per i Dialoghi andranno elaborati i dati relativi all’intero Dialogo, ad ogni Turno, agli Informatori, alle Etichettature (PHN, PHB,PHM,WRD,TON) , ai parametri d’analisi (F0 o Pitch, Formanti o FRM, Energia). Quindi come classi candidate a modellare i Dialoghi individuiamo le seguenti:
Etichetta
Dialogo Turni Inform atore Parametro
Per quanto riguarda i Files AVIP il Parser avrà accesso per la lettura dei dati AVIP ai file HDR (di intestazione), ai files di Etichettatura (Label) e ai file di Analisi. Quindi individuiamo una classe Files con la responsabilità di gestire la lettura dei file AVIP. Tale classe è specializzata nelle classi HDR, F0, FRM, ENC, Label ognuna con la responsabilità di fornire metodi di lettura dei corrispondenti files AVIP.
Label FRM ENC FilesA VIP Pi tch HDR
Infine per quanto riguarda il data base si individua una classe BdInterface che fornisce metodi per la connessione e l’esecuzione di operazioni sul Data Base, ed una classe, che chiameremo DbQuery che ha il compito di fornire le Query SQL necessarie per eseguire le operazioni sul Data Base.
DbQuery DbInterface
In aggiunta alle classi individuate, si possono individuare altre classi considerando i requisiti aggiuntivi rispetto alla lettura ed immissione dei dati AVIP all’interno del Data Base.
Infatti altri requisiti del Parser sono relativi agli i errori rilevati nei dati AVIP che compromettono il rispetto delle relazioni gerarchiche definite nel progetto tra le trascrizioni.
Questo errori comportavano:
• Il non allineamento dei dati nelle relazioni stesse.
• In taluni casi, il mancato rispetto dei vincoli di integrità referenziale nel Data Base. Tali errori sono dovuti in parte al cattivo funzionamento del Software di etichettatura e segmentazione SegWin utilizzato in AVIP ed in parte ad errori di data entry degli operatori. E’ stata necessaria la definizione di specifiche che richiedevano da parte del Parser anche la segnalazione e la correzione in automatico di alcune tipologie di errori.
Da queste specifiche è possibile individuare le seguenti classi con le seguenti responsabilità: 1. La classe Checker verifica gli allineamenti
Checker
2. La classe Corrector esegue le correzioni
Corrector
Infine, poiché nel Path dove è presente il Dialogo da sottoporre come ingresso al Parser devono essere presenti per ogni turno i files AVIP relativi alle trascrizioni, ai parametri, ecc. si è individuata una classe con la responsabilità di cercare i files necessari per ogni turno.
3. Searcher (cerca i files necessari).
S earcher
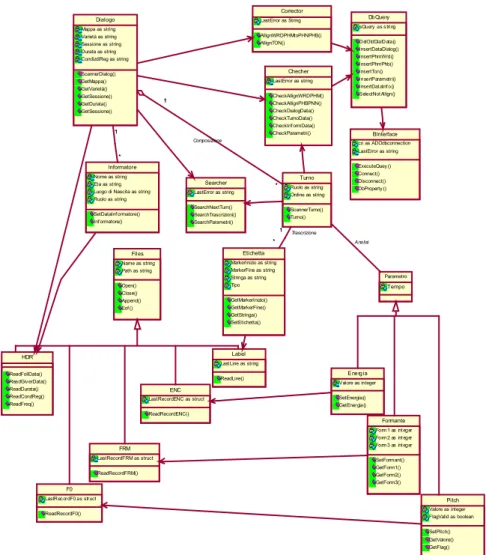
Diagramma delle Classi del Parser con dettaglio del livello di analisi.
Tra le classi precedentemente individuate vie è sostanzialmente un legame di tipo semantico e quindi una relazione di associazione.
Files Name as string Path as string Open() Close() Append() Eof () Label Last Line as string ReadLine() Parametro Tempo Etichetta MarkerInizio as string MarkerFine as string Stringa as string Tipo GetMarkerInizio() GetMarkerFine() GetStringa() SetEtichetta() BInterface cn as ADOdbconnection LastError as string ExecuteQuey () Connect() Disconnect() DbProperty () ENC LastRecordENC as struct ReadRecordENC() Energia Valore as integer SetEnergia() GetEnergia() FRM LastRecordFRM as struct ReadRecordFRM() Formante Form1 as int eger Form2 as int eger Form3 as int eger SetFormant() GetForm1() GetForm2() GetForm3() F0
LastRec ordF0 as struct ReadRecordF0() Pitch Valore as integer FlagValid as boolean SetPitch() GetValore() GetFlag() Informatore Nome as string Eta as string Luogo di Nascita as string Ruolo as string SetDataInf ormatore() Inf ormatore() HDR ReadFollData() ReadGiverData() ReadDurata() ReadCondReg() ReadFreq() Searcher LastError as string SearchNextTurn() SearchTrascrizioni() SearchParametri() Corrector LastError as String AllignWRDPHMtoPHNPHB() AllignTON() Dialogo Mappa as string Varietà as string Sessione as string Durata as string CondizdiReg as string ScannerDialog() GetMappa() GetVarietà() GetSessione() GetDurata() GetSessione() * 1 * 1 Turno Ruolo as string Ordine as string ScannerTurno() Turno() Analisi * 1 * 1 Trascrizione 1 * 1 * Composizione DbQuery sQuery as s tring DelOldDialData() InsertDataDialog() InsertPhmWrd() InsertPhmPhb() InsertTon() InsertParametri() InsertDat aInf o() SelectNot Allign() Checher LastError as string CheckAllignWRDPHM() CheckAllignPHBPNN() CheckDialogData() CheckTurnoData() CheckInf ormData() CheckParametri()
Figura 13-Diagramma delle Classi OOA
Individuazione delle Classi del domino concettuale del QueryGenerator.
Partendo da quanto definito nel documento di specifica dei requisiti è evidente che la parte del software di gestione del Corpus AVIP relativa alle funzionalità di interrogazione del Data Base deve prevedere una entità capace di convertire le richieste degli utenti in Query di selezione eseguibili sul data Base AVIP.
A livello concettuale per realizzare il componente di interrogazione richiesto è necessario modellare innanzitutto una classe che fornisca i servizi di “traduzione” delle richieste degli utenti in Query di selezione comprensibili al server di data base. Tale classe la chiameremo QueryGen.
Inoltre è necessario modellare un interfaccia verso il Data Base, che è la medesima precedentemente modellata per il Parser chiamata DBInterface.
D BInterfa ce
La realizzazione dei requisiti di interrogazione richiede la “composizione” di un comando in un linguaggio di interrogazione interpretabile da un DBMS. Tale “comando” dovrà contenere oltre ad istruzioni anche, in opportuno formato, le stringhe di etichettatura e gli operatori immessi dagli utenti. Quindi le richieste di interrogazione formulate dagli utenti andranno analizzate, scomposte ed infine inserite con opportuna logica all’interno del comando da fornire al DBMS.
Per l’esecuzione del compito sopra descritto si individua una classe che ha la responsabilità di analizzare, scomporre ed inserire le stringhe ricercate per ogni livello all’interno del comando di interrogazione. Questa classe la chiameremo LevelStringAnalizer.
LevelStringAnalizer
Diagramma delle Classi del QueryGenerator con dettagli del livello di analisi.
Tra le classi precedentemente individuate vie è sostanzialmente un legame di tipo semantico e quindi una relazione di associazione.
D B In t e rfa c e c n a s Ad o D b C o n n e c ti o m C o n n e c t() D i s c o n n e c t() E xe c u te Q u e ry() D b P ro p e rty() L e ve lS t rin g A n a liz e r L a s tL e ve l S tri n g a s s tri n g A n a li ze L e ve l S tr in g () L a b e l F i n d An d R e p l a c e () G e tL a s tL e v e lS tri n g () Q u e ry G e n L a s tQ u e ry a s s trin g In te rro g a te G ro u p D i a l o g s () In te rro g a te P a ra m i te r() In te rro g a te G ro u p D i a l o g () In te rro g a te L e ve ls () G e tL a s tQ u e ry()
4.PROGETTAZIONE
4.1 INTRODUZIONE
Anche in questo capitolo, come nel precedente, sono state separate le fasi relative allo sviluppo dei singoli componenti Data Base, Parser e QueryGenerator.
Per quanto riguarda il Data Base, la fase di progettazione, detta progettazione logica ha avuto come obiettivo la costruzione di uno schema logico in grado di descrivere in maniera corretta ed efficiente tutte le informazioni contenute nello schema Entità-Relazione. La costruzione di tale schema, detto modello Entità Relazione Ristrutturato è stata eseguita attraverso scelte progettuali basate su stime riguardanti i volumi dei dati a regime e dei “costi d’esecuzione” delle operazioni previste.
Dallo schema E.R ristrutturato è stato ricavato, con un processo di traduzione, il Modello Relazionale corrispondente .
Il DataBase è stato quindi implementato in ambiente Microsoft Access per la versione locale del Corpus.
Per quanto riguarda il Parser ed il QueryGenerator, la fase di progettazione, sviluppata con una metodologia ad oggetti e per questo detta Object Oriented Design (OOD), ha avuto come obiettivo l’identificazione e la modellazione di classi di oggetti facenti parte del “dominio della soluzione” e il raffinamento delle classi di oggetti già individuate durante le fase di OOA.
4.2 PROGETTAZIONE LOGICA DATA BASE
L’obiettivo della progettazione logica è quello di costruire uno schema logico in grado di descrivere in maniera corretta ed efficiente tutte le informazioni contenute nello schema Entità-Relazione prodotto nella fase di progettazione concettuale.
Non si tratta di una semplice traduzione da un modello ad un altro perché, prima di passare allo schema logico, lo schema Entità Relazione va ristrutturato per soddisfare due esigenze:
1. Quella di “semplificare” la traduzione. 2. Quella di ottimizzare il progetto.
La semplificazione dello schema si rende necessaria perché non tutti i costrutti del modello Entità Relazione hanno una traduzione naturale nei modelli logici.
L’esigenza d’ottimizzazione del progetto si rende necessaria poiché la progettazione logica costituisce la base per l’effettiva realizzazione dell’applicazione e deve tenere conto, per quanto possibile, delle sue prestazioni.
Pertanto di seguito saranno svolte due fasi di progettazione: • Ristrutturazione dello schema Entità Relazione.
Tale fase è indipendente dal modello logico scelto e si basa su criteri d’ottimizzazione dello schema e di semplificazione della fase successiva.
• Traduzione verso il modello logico.
Tale fase fa riferimento ad uno specifico modello logico, che nel nostro caso è il modello relazionale.
Analisi delle prestazioni del Modello Entità- Relazione
Si è affermato che uno schema E-R può essere modificato per ottimizzare gli indici di prestazione del progetto. Si parla d’indici perché le prestazioni di una base di dati non sono valutabili in maniera precisa in sede di progettazione logica in quanto dipendenti anche da parametri fisici, dal sistema DBMS utilizzato, e da altri fattori non prevedibili in questa fase.
E’ in ogni modo possibile effettuare studi di massima dei due parametri che generalmente regolano le prestazioni dei sistemi software:
1. Occupazione di memoria o Volume dei dati 2. Costo di un’operazione.
Per il Corpus AVIP sono state effettuate le seguenti stime dei volumi previsti a regime.
STIME
Numero Domande
N. Dialoghi 30
Turni per Dialogo (media) 320
Etichette WRD, PHM per turno (media) 9 Etichette PHB, PHN per turno (media) 28
Parametri per turno (media) 608
N. Dialoghi Bambini 5
Tali stime sono state utilizzate nei paragrafi seguenti per le valutazioni del volume dei dati e per la valutazione del costo delle operazioni.
Volume dei dati
Nella tabella o tavola dei volumi sono riportati tutti i concetti dello schema Entità Relazione con il volume previsto a regime per l’applicazione.
Informatore E 50
Bambini E 5
Dialogo E 30
Turno E 9600
Registrazione E 30
Numero Totale d’istanze d’Etichette E 710400
WRD per turno E 86400
PHM per turno E 86400
PHB per turno E 260736
PHB Eccezione x turno (3% PHB) E 8064
PHN per turno E 268800
TON per turno E
Numero Totale d’istanze di Parametri E 17510400
PITCH E 5836800 FORMANTI E 5836800 ENERGIA in byte E 5836800 Interlocuzione R 50 Acquisizione R 30 Composizione R 9600 Trascrizione R 48000 Analisi R 17510400 Inclusione Temporale R 17510400 Corrispondenza PHN - PHB R 260736 Inclusione Eccezione R 8064 Inclusione PHM – PHB R 268800 Inclusione PHM – PHN R 268800 Inclusione WRD – PHB R 268800 Inclusione WRD – PHN R 268800 Inclusione TON – WRD R 9 Inclusione TON – PHM R 9 Inclusione TON – PHB R 28 Inclusione TON – PHN R 28 Operazioni
Nella tabella o tavola delle operazioni sono riportate tutte le operazioni eseguibili e tutti i concetti che sono coinvolti nell’esecuzione dell’operazione.
Note. Tipo indica se I = Operazione Interattiva se B = Operazione Batch.
Gli utenti del Data Base AVIP hanno obiettivi di studio e d’analisi diversi. Ogni utente può essere quindi interessato alle informazioni contenute soltanto in alcuni dei livelli di trascrizione del corpus AVIP. Una stima della frequenza d’esecuzione d’ogni operazione essendo dipendente dall’utente non è effettuabile in modo ragionevole.
La tabella delle operazioni ha quindi il compito di elencare le operazioni considerate in fase di ristrutturazione e le entità del modello coinvolte.
4.3 RISTRUTTURAZIONE DELLO SCHEMA ENTITÀ RELAZIONE
I dati d’ingresso di questa fase sono il modello concettuale Entità–Relazione descritto precedentemente e il carico applicativo previsto in termini delle dimensioni dei dati e delle caratteristiche delle operazioni.
TABELLA DELLE OPERAZIONI
Tipo Entità Coinvolte Descrizione Operazione
Operazione 1 I Dialogo, Turno, Etichettatura, Pitch Interrogazione Pitch Operazione 2 I Dialogo, Turno, Etichettatura, Formanti Interrogazione Formanti Operazione 3 I Dialogo, Turno, Etichettatura, Energia Interrogazione Energia Operazione 4 I Dialogo, Turno, Etichettatura, WRD Interrogazione nel livello WRD Operazione 5 I Dialogo, Turno, Etichettatura, PHM Interrogazione nel livello PHM Operazione 6 I Dialogo, Turno, Etichettatura, PHB Interrogazione nel livello PHB Operazione 8 I Dialogo, Turno, Etichettatura, PHN Interrogazione nel livello PHN Operazione 9 I Dialogo, Turno, Etichettatura, TON Interrogazione nel livello TON Operazione 10 I Dialogo, Etichettatura Durata etichetta
Il risultato che si ottiene è uno schema Entità Relazione (v. fig. 15) ristrutturato che, in effetti, non è più un modello concettuale in quanto tiene conto degli aspetti realizzativi.
INFORMATORE DIALOGO REGISTRATO TURNO WRD - PHM PARAMETRI PHN - PHB Interlocuzione Composizione Analisi TRASCRIZIONE PHN- PHB TON INCLUSIONE WRD-PHM _PHN-PHB Inclusione Temporale PHM – WRD PARAMETRI NOME ETA’ SESSO RUOLO (1,1)
MAPPE VARIETA’ SESSIONE
DURATA NOMEFILEAUDIO FREQUENZACAMPIONAMENTO ORDINE RUOLO MARKER FINALE MARKER INIZIALE STRINGA WRD VOICED / UNVOICED PITCH HZ 1° 2° 3° ENERGIA DB (2,2) (1,N) (1,N) (1,1) (1,1) (1,1) (1,1) (1,1) (1,1) (1,N) TEMPO CONDIZIONE STRINGA PHM MARKER INIZIALE MARKER FINALE STRINGA PHN STRINGA PHB * TRASCRIZIONE WRD-PHM TRASCRIZIONETON Inclusione Temporale PHN-PHB PARAMETRI MARKER FINALE STRINGA TON (1,1) (1,1) (1,1) (1,1) (1,N) (1,N) (1,1) MARKER INIZIALE INCLUSIONE TON_PHNPHB INCLUSIONE TON_PHMWRD INCLUSIONE Temporale TON PARAMETRI LUOGO DI NASCITA (1,N) (1,1) (1,N) (1,1) (1,N) (1,1)
Figura 15- Modello Entità Relazione Ristrutturato
Di seguito sono elencate le modifiche e le ristrutturazioni effettuate allo schema concettuale E-R (v. fig. 10) che saranno presentate secondo lo schema seguente:
• Operazione eseguita: descrizione del tipo d’operazione eseguita. Motivazione: descrizione della scelta progettuale.
• Accorpo Entità Figlia Bambino nell’Entità padre Informatore.
Motivazione: l'Entità Bambino presenta un unico attributo Normoudente/Ipoacusico non presente nell’entità padre Informatore. Tale attributo fornisce un’informazione ridondante rispetto al valore assunto dall’attributo Varietà associato al dialogo che è uguale a "P" per i Bambini Normoudenti e ad "S" per i bambini Ipoacusici. Inoltre un bambino è distinto da un adulto attraverso il valore dell’attributo Età (Età < 15 anni se è un bambino). La specializzazione Bambino è eliminata.
• Accorpo Entità Dialogo – Registrazione
Motivazione: l'Entità Registrazione è legata da una relazione uno ad uno con l’entità Dialogo. L’entità risultante è identificata nel modello ristrutturato con Dialogo Registrato.
• Accorpo Entità padre Etichettatura nelle Entità Figlie PHN, PHB, PHM, WRD, TON. Motivazione: l'entità padre Etichettatura è eliminata e, per la proprietà dell’ereditarietà, i suoi attributi, il suo identificatore e le relazioni cui partecipa sono aggiunte alle entità figlie.
Le relazioni dell’entità padre sono sostituite dalle restrizioni delle relazioni sulle entità figlie. Nello schema ristrutturato le nuove relazioni che sostituiscono la relazione Trascrizione sono identificate con
Trascrizione PHN -PHB, Trascrizione WRD – PHM e Trascrizione TON.
Le nuove relazioni che sostituiscono la relazione Inclusione Temporale sono identificate con Inclusione
temporale PHN -PHB e Inclusione temporale WRD – PHM.
• Accorpo Entità PHM – WRD
Motivazione: le due entità presentano valori dei marker iniziali e finali uguali con corrispondenza uno ad uno. Definendole come unica entità si ottiene una notevole riduzione delle ridondanze e quindi di spazio occupato. Inoltre si riduce il tempo d’accesso per le operazioni d’interrogazioni riguardanti entrambi i livelli d’etichettatura effettuando un accesso ad unica entità.
La nuova entità è identificata sul modello ristrutturato con WRD – PHM. Le relazioni delle entità sono sostituite da nuove relazioni.
La relazione Corrispondenza PHM-WRD è eliminata.
Le relazione d’inclusione sono sostituite dalle nuove relazioni:
Inclusione TON_PHMWRD, Inclusione WRD-PHM_PHNPHB, Inclusione Temporale PHM-WRD_PARAMETRI.
• Accorpo Entità PHN – PHB
Motivazione: le due entità presentano valori dei marker iniziali e finali uguali con corrispondenza (1,1) tranne nei casi delle Eccezioni (Dittongo, Trittongo, ecc.)
Le relazioni delle entità sono sostituite da nuove relazioni.
Le relazioni Corrispondenza non eccezione ed Inclusione Eccezione sono eliminate.
Le relazione d’inclusione sono sostituite dalle nuove relazioni:
Inclusione TON_PHNPHB, Inclusione WRD-PHM_PHNPHB, Inclusione Temporale PHN-PHB_PARAMETRI.
• Accorpo entità figlia PHB Eccezioni nell’Entità padre PHB.
Motivazione: la specializzazione PHB Eccezioni è stata eseguita nel modello concettuale al fine di evidenziare le diverse relazioni PHN - PHB ECCEZIONI e PHN - PHB.
Questa scelta modifica la relazione esistente tra le entità PHN – PHB ed implica la modifica delle proprietà dell’attributo Stringa PHB che diviene un attributo con valori nulli ammessi.
• Accorpo Entità figlie Pitch, Formanti, Energia nell’Entità padre Parametri.
Motivazione: la specializzazioni Pitch, Formanti ed Energia è stata eseguita nel modello concettuale al fine di evidenziare le diverse tipologie dei parametri d’analisi.
Dato che tali Entità hanno lo stesso identificatore, accorpandole si ottiene una riduzione delle ridondanze dei dati e quindi dello spazio di memoria occupato. Inoltre tale scelta consente di ottenere un accesso ad un'unica Entità e quindi una riduzione dei tempi d’accesso per le interrogazioni che richiedono la ricerca di due o tre parametri contemporaneamente.
4.4 TRADUZIONE VERSO IL MODELLO RELAZIONALE Dallo schema E-R ristrutturato si costruisce uno schema logico Relazionale.
Figura 16 - Il modello relazionale
4.5 STIMA DEL VOLUME DEI DATI DEL CORPUS AVIP
In questa sezione è stimato il volume complessivo dei dati d’analisi e dei dati d’etichettatura che saranno immessi nel Data Base AVIP.
Tale stima è utile ad eseguire le seguenti valutazioni:
• Valutazione e la scelta dell’ambiente DBMS da utilizzare per la realizzazione del Data Base AVIP. • Valutazione e definizione dei requisiti di sistema su cui saranno memorizzati i dati AVIP.
Spazio in Byte occupato dai dati d’ogni parametro
Formante Pitch Energia Totale Byte
Parametri 6 3 2 11
Spazio in Byte occupato dai dati d’ogni etichettatura
Nome livello Marker In Marker Fin Stringa Totale Byte
WRD 4 4 30 38
PHM 4 4 30 38
PHB 4 4 9 17
PHN 4 4 9 17
Spazio TOTALE occupato dai dati
STIMA TOTALE 70,29419 Mb
Per la determinazione della Memoria Secondaria effettivamente occupata dal Data Base vanno aggiunti l’occupazione di memoria degli indici implementati dal DBMS ed il volume dei dati delle istanze delle altre tabelle (Dialoghi, Informatori, Turni) non incluse nel calcolo precedente.
4.6 OBJECT ORIENTED DESIGN
Utilizzando una metodologia OOAD (OOA + OOD), la rappresentazione della soluzione include buona parte del modello OOA. In questi casi la separazione tra modelli di analisi e modelli di progetto è “sfumata”. La differenza sostanziale e che gli oggetti dell’OOA hanno un significato concettuale del dominio del problema, mentre in OOD gli oggetti vengono raffinati o aggiunti pensando alla loro “realizzazione”.
La fase di progettazione ha come output modelli di progetto di alto e di basso livello. Si può pensare di dividere la progettazione in progettazione di alto livello (high-level design) e di basso livello (low-level design).
Nelle figure 17 e 18 sono illustrati i modelli delle classi con dettagli del livello alto (high-level design) sviluppati per il Parser e per il QueryGenerator.
D B Interfac e cn as Ad oD bC o nn e c ti o m C o n n e c t() D is co n n e c t() E xe c u te Q u e ry() D b P ro p e rty() Q uery G en L a s tQ ue ry a s s trin g L a s tE rro r a s s tr in g In te r ro g a te G ro u p D ia lo g s () In te r ro g a te P a r am it er() In te r ro g a te G ro u pD ia lo g () In t er ro g a t eL e v e ls () Ge tL a s t E rror () G e tL a s tQ u e ry()
LevelS tringA naliz er L a s tL e ve lS trin g a s s trin g L a s tE rro r a s s trin g An a lize L e ve lS trin g () L a b e lFin d An d R e p la ce () G e tL a s tL e ve lS trin g () G e tL a s tE rro r()
Figura 17-Diagramma delle classi OOD del QueryGenerator
Durante la fase di low-level design, sono state eseguite scelte di progetto riferite a criteri di ottimizzazione e/o legate al particolare ambiente di sviluppo utilizzato.
Files N am e as string Path as string Open() C lose() Append() Eof () Label LastLine as string R ea dL ine () Param etro T em po Etichetta MarkerInizio as string MarkerF ine as string Stringa as string Tipo G etMar ke rIn izio () GetMarkerF ine() GetStringa() SetEtic he tta () Inform atore N om e as string Eta as string Luogo di N asc ita as string R uolo as string SetD ataInf orm atore() Inf orm atore()
HDR R eadF ollD ata() R eadGiv erD ata() R eadD urata() R eadC ondR eg() R eadF req()
Se archer Las tE rro r a s s tri ng Se arc hN extTurn () SearchTrasc rizioni() Se arc hP aram etr i()
T urno R uolo as string Ord ine a s s tring ScannerTurno () Turno() Analisi * 1 * 1 Trascrizione DB In terface cn as AD Odoconnection Las tError as s tring Exec uteQuey () C onnect() D isconnec t() D bProperty () DbQ uery sQuery as string Las tError as string D elOldD ialD ata() InsertD ataD ialog() InsertPhm W rd() InsertPhm Phb() InsertTon() InsertParam etri() InsertD ataInf o() SelectN otAllign() ENC La stR ec ordEN C as s tru ct Re adRe cordE NC () E nergia Valore as integer SetEnergia() GetEnergia() FR M
Las tR ecordF R M as struc t R eadR ecordF R M()
Form ante F orm 1 as integer F orm 2 as integer F orm 3 as integer SetF orm ant() GetF orm 1() GetF orm 2() GetF orm 3() F0
Las tR ec ord F0 a s s tru ct R eadR ecor dF 0() Pitch Valore as integer F lagValid as boolean SetPitch() GetValore() GetF lag() Dialogo Mappa as string Varietà as string Sessione as string D urata as s tring C ondizdiR eg as string Sc annerD ialog() GetMappa() GetVarietà() GetSessione() GetD urata() GetSessione() * 1 * 1 1 * 1 * Composizione Corrector LastError as String AllignW R D PHM toPH N PH B() AllignTON () Che ch er L as tEr ror as s tring C heckAll ignW RD PH M () C he c kAll ignPH BP N N () C he ck Di alo gD ata () C heckTu rnoD ata () C he ck Di alo gD ata () C he ck Inf or mD at a() C heckParam etri()
M sgE rr orGestor ErrorD esc as string Ty peMs g as integer setError() ShowError() W riteLineErrorF ile()
Figura 18. Diagramma delle classi con dettagli OOD del Parser
In particolare, una scelta significativa adottata, è stata quella di utilizzare, per l’accesso al data base AVIP, la libreria di oggetti Microsoft ADO 2.1. Questa libreria di oggetti viene utilizzata sia dal Parser che dal QueryGenerator come mostrato in figura 19 .
Parser VB Activex Data Object 2.1
Libreria di oggetti riusabili per l'accesso ai dati di fonti OLEDB QueryGenerator
Figura 19- Component Diagram
4.7 PROGETTAZIONE DELL’INTERFACCIA UTENTE
Per il corpus linguistico AVIP le specifiche d’utente riguardanti l’interfaccia riguardano in sostanza il QueryGenerator mentre per il Parser non sono stati espressi requisiti particolari. Tralasciando una specifica dettagliata del processo di progettazione dell’interfaccia, in questo paragrafo è di interesse sottolineare le scelte progettuali che maggiormente hanno caratterizzato e differenziato il modello d’interfaccia implementato dal modello di interfaccia immaginato dal committente. Le scelte progettuali principali sono state le seguenti:
• Adozione dei menu e della barra dei comandi.
• Il requisito di “selezione della parte del corpus oggetto di interrogazione” è implementato in un unico form.
• Introduzione di altre due caselle di testo che nei fatti consentono di realizzare il requisito di poter esprimere interrogazioni di ricerca di trascrizioni WRD seguite da altre trascrizioni WRD (in sostituzione del operatore “seguito da”). Tale scelta progettuale è stata giustificata dall’utilizzo effettivo che l’utente richiedeva dell’operatore e cioè la ricerca di una sequenza Etich seguita da un altra Etich. Le sequenze di fonemi sono esprimibili con la sintassi e le condizioni dei livelli di etichettatura superiori e quindi necessario fornire la possibilità di esprimere condizioni di sequenza ai soli livelli gerarchici superiori e cioè ai quelli di trascrizione per “parola” WRD e PHM. La definizione di un operatore era sovrabbondante rispetto alle effettive esigenze.
• La visualizzazione dei risultati dei parametri avviene in un terzo form in cui è possibile selezionare il livello di etichettatura a cui l’output farà riferimento.
5.CODIFICA E TESTING
5.1 INTRODUZIONE
La fase di codifica è stata eseguita adottando la metodologia ad oggetti. Come ambiente di programmazione è stato utilizzato Microsoft Visual Basic 6. In tale ambiente è stata usata la libreria Microsoft ADO (ActiveX Data Objects) ver. 2.1 che consente al software Parser e QueryGenerator (clients) di accedere e gestire i dati presenti in un server di database di qualunque provider OLE DB desiderato. Inoltre per eseguire le interrogazioni è stato utilizzato il linguaggio SQL.
5.2 SCELTA DELL’AMBIENTE DI PROGRAMMAZIONE VISUAL BASIC
Microsoft Visual Basic è un linguaggio di programmazione che consente di sviluppare in modo estremamente semplice e veloce applicazioni per il sistema operativo Microsoft Windows®.
Visual Basic dispone di diverse librerie che forniscono, con tecnologie differenti, funzionalità di creazione e di accesso ai database. In particolare è stata utilizzata per questo progetto la libreria Microsoft ADO 2.1
Microsoft ADO (ActiveX Data Objects) è una libreria d’oggetti che consente di accedere e gestire i dati presenti in un server di database di qualunque provider OLE DB desiderato. OLE DB è un’interfaccia di basso livello che introduce un modello d’accesso ai dati "universale". OLE DB, infatti, consente di gestire qualsiasi tipo di dati indipendentemente dal formato o dal metodo di memorizzazione.
ADO è stata utilizzata nella classe DBInterface, utilizzata sia dal componente Parser che dal componente QueryGenerator. La classe DBInterface è descritta nei prossimi paragrafi.
Grazie all’utilizzo di ADO, sia il QueryGenerator che il Parser possono accedere indistintamente a diversi DBMS come Microsoft Access e come Microsoft SQL Server .
5.3 LINGUAGGIO SQL
Le funzionalità di interrogazione fornite dal QueryGenerator e di inserimento e modifica dati fornite dal Parser sono state implementate attraverso l’utilizzo del linguaggio SQL.
SQL. è un acronimo di Structured Query Language, un linguaggio d’interrogazione per le basi di dati relazionali. La sua ampissima diffusione è legata sostanzialmente all’intensa opera di standardizzazione che si è concentrata sul linguaggio, svolta da organismi internazionali quali ISO (International Standard Organization) e ANSI (American National Standard Istitute). SQL non è soltanto un linguaggio
di primitive per la definizione dello schema di una base di dati relazionale), sia funzionalità di un Data Manipulation Language (con un insieme di primitive per la modifica dell’istanza di una base di dati). SQL esprime le interrogazioni in modo dichiarativo, ovvero, si specifica l’obiettivo dell’interrogazione e non il modo in cui ottenerlo.
Un’ interrogazione SQL per essere eseguita deve essere “tradotta” in una equivalente espressione procedurale nel linguaggio interno al sistema di gestione di base di dati (DBMS). Tale linguaggio interno è nascosto all’utente del sistema DBMS. La traduzione viene eseguita da un interprete o compilatore interni al DBMS utilizzato. In altre parole un utente del DBMS o un programmatore che realizza applicazioni di accesso alla base di dati, possono trascurare gli aspetti di traduzione e di ottimizzazione delle interrogazioni nel linguaggio interno al DBMS.
5.4 TESTING
Il Testing è un processo d’esecuzione del software allo scopo di rilevarne i malfunzionamenti. Un malfunzionamento è l’incapacità del software di comportarsi secondo le attese e può essere rilevato soltanto mediante esecuzione. La tesi di Dijkstra afferma che il "Testing non può dimostrare l’assenza di difetti,
ma solo mostrarne la presenza".
Il processo di Testing è fondamentale per garantire la qualità del software e la sua applicazione richiede:
1. Valutazione dei risultati del test, ovvero la conoscenza precisa del comportamento atteso dal sistema, per poterlo confrontare con quello osservato.
2. Criterio di terminazione del testing, ovvero quando si può ritenere di aver testato il software a sufficienza.
3. Criteri di selezione dei casi di test, ovvero la specifica delle condizioni che vanno soddisfatte da un test.
Per il Testing del “Software di gestione del corpus linguistico AVIP” sono stati applicati i seguenti criteri: 1. Valutazione dei risultati: la valutazione dei risultati del Testing è stata eseguita sia in base all’esame
del comportamento atteso definito nelle specifiche e sia secondo giudizi logici.
2. Terminazione del Testing: la valutazione della terminazione del testing è stata effettuata applicando un criterio di copertura, legato ad un criterio di selezione dei casi di test.
Criterio di selezione dei Casi di Test: il criterio specifica le condizioni che devono essere soddisfatte da un test. Come classe di criterio è stata applicata una metodologia black box. Ciò significa che ci si è posto l’obiettivo di derivare insiemi di condizioni d’ingresso che esercitano completamente i requisiti funzionali
del software. Il dominio dei dati d’ingresso è stato suddiviso in classi di test in modo tale che, se il programma è risultato corretto per un caso di test lo si è potuto ragionevolmente considerare corretto per ogni test in quella classe. La definizione delle condizioni sulle variabili d’ingresso ha consentito la definizione delle cosiddette classi d’equivalenza. Una classe d’equivalenza rappresenta un insieme di stati validi o non validi per una condizione delle variabili d’ingresso. Ogni classe d’equivalenza poi è stata “coperta” da un caso di test. Il criterio di copertura applicato consiste nell’eseguire un caso di test per ogni classe non valida e casi di testo che comprendono il maggior numero di classi valide. Per il componenti Parser e QueryGenerator sono state individuate le classi d’equivalenza ed eseguiti i casi di test.
In particolare:
• Per il Parser sono state analizzate le condizioni sul formato dei files AVIP e le condizioni sulle relazioni dei Marker relativi alle Etichettature.
• Per il QueryGenerator sono state analizzate le condizioni riguardanti la sintassi di interrogazione.
Tutte le classi di equivalenza prodotte non faranno parte del presente documento ma saranno fornite agli eventuali richiedenti.