CAMPUS DI CESENA
SCUOLA DI INGEGNERIA E ARCHITETTURA
Corso di Laurea Magistrale in Ingegneria Informatica
PROGETTO DI UN’APPLICAZIONE WEB
PER SERVIZI DI MOBILIT `
A URBANA
TRAMITE L’USO DI OPENDATA
Tesi in
Laboratorio di Reti di Telecomunicazioni LM
Relatore
Prof. Walter Cerroni
Correlatore
Prof. Franco Callegati
Presentata da
Andrea Giulia Cialotti
1
Introduzione agli OpenData
1
1.1
Cosa sono gli OpenData . . . .
2
1.2
Come far diventare i dati OpenData . . . .
10
1.3
Linked Open Data e Web Semantico
. . . .
16
1.3.1
Resource Description Framework
. . . .
19
2
Analisi ed elaborazione degli OpenData di Tper
23
2.1
Requisiti dell’applicazione . . . .
23
2.2
Database di Tper . . . .
24
3
Progetto dell’Applicazione
45
3.1
Geocoding . . . .
45
3.2
Selezione fermate . . . .
48
3.3
Interazione con il Web Service HelloBus
. . . .
63
4
Casi d’uso dell’Applicazione
69
5
Conclusioni e Sviluppi Futuri
81
Apertura, partecipazione, collaborazione e possibilit`
a di creare una
compe-tenza collettiva sono i motivi che portano alla nascita e alla diffusione degli
OpenData, i quali favoriscono l’interoperabilit`
a e la trasparenza dei governi
nei confronti dei cittadini, inoltre migliorano l’efficienza delle
amministrazio-ni pubbliche, e mettono in grado le persone di affrontare meglio le decisioamministrazio-ni
che riguardano la loro vita potendo utilizzare informazioni che prima non
erano disponibili.
Il lavoro svolto nell’elaborato si colloca nel settore della mobilit`
a urbana e
nasce dalla decisione dell’azienda Tper di mettere a disposizione i propri dati
in formato OpenData sul sito web http://www.tper.it/tper-open-data.
L’o-biettivo principale `
e la realizzazione di un’applicazione in grado di fornire
informazioni in tempo reale sulle linee di autobus, e relative fermate, in una
determinata area di interesse.
Il primo capitolo definisce gli OpenData, cio`
e dati accessibili a chiunque
sen-za vincoli di natura giuridica e tecnologica, sottolineandone l’importansen-za e la
notevole diffusione che hanno avuto negli ultimi anni, infine presenta alcuni
progetti attualmente attivi come OpenStreetMap e wheredoesmymoneygo.
Il secondo capitolo introduce i requisiti dell’applicazione in particolare
il-lustrando le modalit`
a con le quali l’utente pu`
o interagire con essa, ovvero
inserendo nella richiesta la propria posizione nei formati di indirizzo postale
o di coordinate geografiche, ed il tempo di percorrenza massimo che `
e
dispo-sto ad impiegare per raggiungere le fermate. Inoltre presenta gli OpenData
di Tper e l’elaborazione necessaria per poterli utilizzare nell’applicazione.
Il terzo capitolo espone il processo di produzione dell’applicazione
descriven-do nel dettaglio come vengono effettuate la traduzione da indirizzo postale
a coordinate geografiche, la selezione delle fermate che rispettano i requisiti
specificati dall’utente, e l’interazione con il Web Service HelloBus.
al-Introduzione agli OpenData
L’idea che la conoscenza deve essere un bene comune era gi`
a nota ancor
pri-ma della nascita del World Wide Web. Nel 1942 il sociologo Robert King
Merton discusse l’importanza di mettere i risultati della ricerca a
disposizio-ne di chiunque.
E’ fondamentale che ogni ricercatore contribuisca alla conoscenza comune,
rinunciando ai propri diritti di propriet`
a intellettuale sulla sua ricerca per
permettere alla conoscenza di andare avanti. Il World Wide Web viene
in-ventato proprio per questi motivi, e per favorire la comunicazione e la
coo-perazione tra i ricercatori del CERN da Tim Berners-Lee nel 1989.
Il primo ambito in cui `
e stata sperimentata questa cultura `
e l’Open Source
che si fonda sui concetti di apertura, partecipazione e collaborazione. Si pu`
o
imparare dal lavoro di altri ma in cambio si deve poi pubblicare il proprio:
in questo modo si crea una competenza collettiva. Nel 2009 come si evince
dall’Open Government Directive [1] emanata dal presidente Obama, la quale
indica delle linee guida per favorire la trasparenza del governo, e
dall’inter-vento di Tim Berners-Lee al TED (Technology, Entertainment, Design) [2],
tali principi trovano utile applicazione anche nella raccolta e gestione dei
da-ti.
I dati prodotti dalla pubblica amministrazione, in quanto finanziati da
de-naro pubblico, devono ritornare ai contribuenti, e alla comunit`
a in generale,
sotto forma di dati aperti e universalmente disponibili.
Questi sono i motivi che hanno portato alla nascita degli OpenData, i quali
favoriscono l’interoperabilit`
a, cio`
e la possibilit`
a di elaborare dati provenienti
da fonti diverse e utilizzarli per migliorare prodotti e servizi esistenti o per
svilupparne di nuovi. Inoltre favoriscono la trasparenza dei governi nei
con-fronti dei cittadini, migliorano l’efficienza delle amministrazioni pubbliche,
promuovono la collaborazione, mettono in grado le persone di affrontare
me-glio le decisioni che riguardano la loro vita, potendo utilizzare informazioni
che prima non erano disponibili.
La diffusione degli OpenData non porta solo un aumento dei dati, ma un
aumento della qualit`
a dei dati in termini di valore economico, sociale e
cul-turale che scaturisce dagli infiniti usi che possono esserne fatti.
Gli OpenData non focalizzano la loro utilit`
a esclusivamente nel settore
del-le Pubbliche Amministrazioni, bens`ı trovano utidel-le applicazione anche altri
settori tra i quali: scientifico, finanziario, statistico, ambientale, culturale,
geografico, meteorologico e trasportuale.
Esempi di applicazioni che utilizzano OpenData sono
00wheredoesmymoneygo
00un progetto inglese che permette di vedere come viene speso il denaro
incas-sato dal governo mediante le tasse,
00openstreetmap
00il quale permette di
visualizzare e modificare cartine geografiche dell’interno pianeta con un
livel-lo di dettaglio molto elevato,
00OpenP arlamento
00che consente di monitorare
le attivit`
a svolte nel parlamento e il processo di attuazione delle leggi.
1.1
Cosa sono gli OpenData
Secondo la OpenDefinition [3] gli OpenData sono:
00
dati che possono essere utilizzati gratuitamente, riutilizzati e ridistribuiti da
tutti. L’unico vincolo che possono avere nell’utilizzo, `
e al pi`
u quello di
indi-care la fonte e condividerli utilizzando la stessa licenza da questa adottata
00Tale definizione implica che gli OpenData sono dati accessibili a chiunque,
senza vincoli di natura giuridica, ad esempio licenze che ne vincolino la
ven-dita o la distribuzione a terzi, e di natura tecnologica, ad esempio dati in
formati proprietari, o non provvisti di documentazione adeguata che ne
con-senta la comprensione. La licenza pu`
o tuttavia imporre l’attribuizione, cio`
e
l’obbligo di citare la fonte dalla quale proviene il contenuto, e l’integrit`
a, cio`
e
nel caso in cui un database venga distribuito in forma modificata deve avere
un nome o un numero di versione che lo distingua dall’opera originaria.
Gli standard internazionali per la trasparenza [4], hanno stabilito che gli
OpenData sono:
1. Completi
Tutti gli elementi appartenenti ad un database pubblico devono
es-sere pubblicati, inclusi i contenuti archiviati in formato non digitale
(eventualmente digitalizzandoli), ed i dati e le spiegazioni dei metodi
utilizzati per generare i dati aggregati e derivati.
2. Elementari
I dati devono essere raccolti alla fonte, e devono essere pubblicati con il
livello di dettaglio con cui sono stati raccolti. I dati non sempre sono in
un formato utilizzabile quando vengono raccolti, quindi in questi casi
si pu`
o eseguire un’elaborazione post-raccolta, a condizione che i dati
risultanti siano in formato che rifletta la capacit`
a e la granularit`
a del
meccanismo di raccolta originale. I dati non devono MAI essere persi.
3. Tempestivi
I dati devono essere resi disponibili il pi`
u rapidamente possibile al fine
di massimizzare il valore per il pubblico. Gli aggiornamenti devono
essere facilmente individuabili anche all’interno di database di grandi
dimensioni, attraverso meccanismi come feed RSS, funzioni di ricerca
in grado di filtrare in base alla data, e archivi che contengono snapshot
del database prese a intervalli regolari.
4. Accessibili
I dati devono essere a disposizione di chiunque, per la pi`
u vasta gamma
di scopi possibili. Quindi devono essere condivisibili in modo
sempli-ce, ogni pagina o documento pubblicato deve essere identificato con un
URI, che pu`
o essere diffuso via email, siti web, o social network.
L’u-tente deve poter accedere al database completo senza dover effettuare
nessuna registrazione o pagamento. Inoltre dovrebbe essere possibile il
download dell’intero database attraverso protocolli come l’FTP, o
l’r-sync (per sistemi Unix), e i dati dovrebbero essere forniti di API ben
documentate, al fine di consentire anche elaborazioni automatizzate,
ad esempio attraverso agenti software. L’accessibilit`
a dovrebbe essere
garantita anche per persone con disabilit`
a, ad esempio per i non vedenti
attraverso software screen reader che interpreta il dato e lo invia ad un
monitor Braille, o ne effettua una riproduzione audio. Infine dovrebbe
essere presente un software che consenta di tradurre il documento nella
lingua desiderata, per permettere di usufruire del dato anche a persone
che non conoscono la lingua.
5. Utilizzabili da una macchina
I dati devono essere disponibili sia un formato leggibile dagli utenti,
sia in uno strutturato in modo da permettere l’elaborazione
automa-tizzata. Per esempio la pubblicazione di intervento ad una conferenza
in formato video o audio, dovrebbe essere accompagnata dalla sua
tra-scrizione. In particolare i database devono essere forniti in un formato
semplice da processare, come ad esempio CSV, JSON o XML e devono
sempre essere accompagnati da una documentazione chiara che spieghi
dettagliatamente il significato di ogni campo.
6. Non proprietari
I dati devono essere disponibili in un formato aperto cio`
e un formato:
sul quale nessun ente ha il controllo esclusivo; non soggetto a controlli
di propriet`
a intellettuale in nessun paese; per il quale i documenti che
ne definiscono la struttura sono liberamente accessibili. HTML e XML
sono esempi di formati aperti.
7. Utilizzabili liberamente
I possibili utilizzatori o usi(ad esempio l’uso commerciale) dei dati non
devono essere limitati da protezioni della propriet`
a intellettuale, come
ad esempio copyright, marchi, brevetti. Questo deve essere specificato
esplicitamente nella licenza (ulteriori dettagli nella sezione 1.2).
8. Sindacabili
Ogni ente pubblico o privato, quando pubblica dei dati deve fornire i
contatti di una persona, che `
e stata incaricata di rispondere a domande
e reclami sui contenuti pubblicati.
9. Individuabili
I dati devono essere trovati facilmente da chi li sta cercando. A tal fine
devono essere inclusi in liste appropriate, le quali devono essere
acces-sibile ai motori di ricerca, e mantenute aggiornate. Inoltre `
e opportuno
fornire i siti web contenenti i dati di sitemap complete e includerle nei
maggiori motori di ricerca.
10. Permanenti
Con il passare del tempo i dati devono essere archiviati in un modo che
soddisfi i criteri precedenti.
Gli OpenData favoriscono l’interoperabilit`
a, cio`
e la possibilit`
a di elaborare
dati provenienti da fonti diverse e utilizzarli per migliorare prodotti e servizi
esistenti o per svilupparne di nuovi. Inoltre favoriscono la trasparenza dei
governi nei confronti dei cittadini, migliorano l’efficienza delle
amministrazio-ni pubbliche, promuovono la collaborazione, mettono in grado le persone di
affrontare meglio le decisioni che riguardano la loro vita, potendo utilizzare
informazioni che prima non erano disponibili. La diffusione degli OpenData
non porta solo un aumento dei dati, ma un aumento della qualit`
a dei dati in
termini di valore economico, sociale e culturale che scaturisce dagli infiniti
usi che possono esserne fatti.
Esempi di progetti che utilizzano gli Open Data sono:
- husetsweb.dk [5] che permette alle famiglie di vedere come massimizzare
l’efficienza dell’energia nella loro casa, includendo una pianificazione
finanziaria e trovando costruttori che svolgano i lavori necessari. Esso
utilizza le informazioni catastali e quelle relative ai sussidi governativi;
- wheredoesmymoneygo [6] un progetto inglese che permette di vedere
- BikeDistrict il quale calcola gli itinerari pi`
u adatti alle esigenze di chi
utilizza la bici a Milano, permettendo di scegliere il percorso in base al
tipo di terreno (asfaltato, sterrato), alla presenza di piste ciclabili, di
semafori, e di rotaie.
- OpenStreetMap [7] equivalente di GoogleMaps con dati e codice in un
formato aperto. E’ molto pi`
u accurato di GoogleMaps in quanto `
e stato
realizzato collettivamente da volontari, e chiunque pu`
o modificare le
mappe e aggiungere dettagli.
(a) Piazza Maggiore, Bologna con GoogleMaps
(b) Piazza Maggiore, Bologna con OpenStreetMap
- Google Translate il servizio di traduzione di Google, il quale utilizzando
i numerosi documenti dell’unione europea disponibili in tutte le lingue
per addestrare gli algoritmi di traduzione `
e migliorato notevolmente.
- energy.publicdata.eu/ee/vis.html [8] che permette di visualizzare delle
statistiche sull’energia in europa in diversi anni, ad esempio percentuale
di energia rinnovabile, dipendenza energetica dei paesi, emissione di
anidride carbonica.
- OpenParlamento dove si possono monitorare le attivit`
a svolte nel
par-lamento e il processo di attuazione delle leggi, permettendo ai cittadini
di sapere esattamente cosa sta succedendo e quali parlamentari sono
responsabili delle decisioni prese.
In Italia si inizi`
o a parlare di OpenData nel 2007 con il progetto
Open-StreetMap, quando alcune amministrazioni locali grazie all’iniziativa di
al-cuni volontari hanno pubblicato con licenza aperta i dati riguardanti i propri
stradari. Dalla fine del 2011 `
e online dati.gov.it.
Poi in seguito sono stati pubblicati dati.emilia-romagna.it,
dati.comune.bologna.it, it.ckan.net (sito per la catalogazione di dataset,
ba-sato sul software CKAN), e datiopen.it che offre gratuitamente tutti i servizi
di caricamento, visualizzazione e segnalazione, e numerosi altri.
A marzo 2013, come riporta dati.gov.it in Italia si contano 5634 dataset
resi disponibili.
Come si pu`
o vedere anche dalla cartina seguente, che mostra la distribuzione
delle amministrazioni che rilasciano OpenData in Italia, la maggior parte dei
dataset resi disponibili `
e localizzata nelle regioni settentrionali. Si noti che
l’area della bolla `
e direttamente proporzionale al numero dei dataset
rilascia-ti dalla specifica amministrazione.
Nonostante il movimento Open Data in Italia sia relativamente giovane,
rap-presenta una realt`
a vitale e attiva anche nei confronti delle altre realt`
a
eu-ropee, trascinato soprattutto dall’obbiettivo della trasparenza
amministra-tiva. Infatti l’Agenzia per l’Italia Digitale ha stabilito dal 19 marzo 2013
l’OpenData by default cio`
e tutti i dati e documenti che le pubbliche
ammini-strazioni pubblicano con qualsiasi modalit`
a, senza l’espressa adozione di una
licenza d’uso, si intendono rilasciati come dati aperti.
Figura 1.1: Classifica elaborata dalla EPSI (European Public Sector
Infor-mation [9]) ottenuta dalla media di diversi fattori: l’implementazione della
direttiva PSI, la pratica di riuso, i formati, il prezzo, accordi esclusivi, PSI
locale, eventi e attivit`
a. L’Italia si trova al 5
◦posto, e per gli eventi e attivit`
a
al 1
◦posto con la Gran Bretagna.
1.2
Come far diventare i dati OpenData
Quando un titolare di un database decide di farlo diventare aperto deve
pri-vilegiare la tempestivit`
a, ovvero preferire di pubblicare parti pi`
u piccole del
database ma pi`
u velocemente. Non `
e vi `
e nessuna richiesta o obbligo di
rendere tutti i dati aperti, anche perch`
e non `
e sempre detto che tutti i dati
che vengono pubblicati suscitino reale interesse alle persone. Infatti `
e
fon-damentale essere sempre in contatto con i potenziali utilizzatori (cittadini,
imprenditori, sviluppatori) del dataset che `
e stato pubblicato, al fine di
capi-re come aumentacapi-re il valocapi-re e la qualit`
a dei dati pubblicati. Inoltre si devono
tenere in considerazione tutte le conseguenze che comporta la pubblicazione
dei dati, come ad esempio la possibilit`
a di ricavare dati derivati mediante
elaborazioni, oppure la possibilit`
a di cambiare il modo di presentarli, oppure
ancora che vengano utilizzati all’interno di sistemi pi`
u complessi insieme a
dati provenienti da sorgenti diverse.
L’Open Knowledge Foundation ha identificato quattro grandi fasi per
rende-re i dati aperti, molti delle quali possono esserende-re fatte contemporaneamente:
scegliere il dataset, stabilire il tipo di licenza, rendere i dati disponibili,
ren-dere i dati rintracciabili.
Fase 1 : Scegliere il dataset
Durante questa fase si deve capire quale dataset pu`
o essere reso pubblico,
su-scita interesse alla community, pu`
o essere pubblicato interamente cos`ı com’`
e,
oppure `
e pubblicabile solo una sua parte, oppure `
e pubblicabile ma solo dopo
alcune modifiche. In base a queste considerazioni si deve stilare una lista dei
database candidati a diventare aperti e successivamente chiedere dei
riscon-tri via web, tramite i social network, mailing list, forum, blog, evitando di
richiedere registrazioni le quali ridurrebbero il numero delle risposte.
Inoltre una buona pratica `
e far riferimento ad eventuali OpenData gi`
a
presen-ti, specialmente quelli nel settore a cui appartiene il dataset che si vuole
pub-blicare e divulgare la notizia della pubblicazione del dataset il pi`
u possibile,
soprattutto alle autorit`
a competenti e agli esperti del settore del dataset.
Fase 2 : Stabilire il tipo di licenza
Nella maggior parte delle giurisdizioni ci sono delle leggi sulla propriet`
a
in-tellettuale dei dati che impediscono a terzi di utilizzare e distribuire i dati
senza un permesso esplicito del titolare. Quando si decide si rendere i propri
dati aperti `
e fondamentale assegnargli una licenza. Il progetto Open Data
Commons [10] della Open Knowledge Foundation [11], ha specificato alcune
linee guida da seguire per definire le Licenze riguardanti gli OpenData. In
particolare ha definito alcune tipi di licenza, specificando che questi
docu-menti non hanno alcun valore giuridico, ed `
e opportuno che siano analizzati
da un legale e confrontati con la legislatura del paese di interesse, prima di
essere utilizzati:
ODC Public Domain Dedication and License
Consente di :
• copiare, distribuire, utilizzare il database per qualsiasi fine;
• elaborare il database per produrre una nuova opera;
• modificare, trasformare il database.
Non impone nessun vincolo.
Per attribuire ad un database tale licenza si deve copiare il testo
in-tegrale in un file LICENSE.txt, che dovr`
a essere messo all’interno del
database, oppure riportare la seguente dichiarazione in tutti i siti o le
locazioni in cui si trova il database:
T h i s { D A T A ( B A S E ) - N A M E } is m a d e a v a i l a b l e u n d e r the P u b l i c D o m a i n D e d i c a t i o n and L i c e n s e
v e r s i o n v1 .0 w h o s e f u l l t e x t can be f o u n d at h t t p :// o p e n d a t a c o m m o n s . org / l i c e n s e s / p d d l /
ODC Open Database License
Si riferisce sia ai dati contenuti nel database, sia alla loro struttura, e
alle modalit`
a con le quali si pu`
o accedere ad essi.
Consente di :
• copiare, distribuire, utilizzare il database per qualsiasi fine;
• elaborare il database per produrre una nuova opera;
• modificare, trasformare il database.
Impone i seguenti vincoli:
• Attribuzione: si deve citare la fonte originale in ogni utilizzo
pub-blico del database, o opera prodotta con il database nel modo
descritto nella licenza. Inoltre deve essere precisato che ogni
in-formazione relativa al database originale deve rimanere intatta,
ci`
o significa che se viene creata un’estensione del database con dei
dati derivati, questa dovr`
a avere un nome e una versione che la
distinguano dal database originale.
• Condivisione allo stesso modo (Share-alike): se si vuole pubblicare
una versione modificata del database, o un’opera prodotta da una
versione modificata del database, lo si deve fare con lo stesso tipo
di licenza del database originale.
• Mantenerlo aperto: se si distribuisce il database, o una sua
versio-ne modificata si possono usare delle misure tecnologiche per
limi-tarne la diffusione (tipo Digital Rights Management ad esempio
il codice seriale), a condizione di distribuirne anche una versione
senza nessuna misura limitativa.
Per attribuire ad un database tale licenza si deve copiare il testo
in-tegrale in un file LICENSE.txt, che dovr`
a essere messo all’interno del
database, oppure riportare la seguente dichiarazione in tutti i siti o le
locazioni in cui si trova il database:
T h i s { D A T A ( B A S E ) - N A M E } is m a d e a v a i l a b l e u n d e r O p e n D a t a b a s e L i c e n s e w h o s e f u l l t e x t can be f o u n d at h t t p :// o p e n d a t a c o m m o n s . org / l i c e n s e s / o d b l /. Any r i g h t s in i n d i v i d u a l c o n t e n t s of the d a t a b a s e are l i c e n s e d u n d e r the D a t a b a s e C o n t e n t s L i c e n s e w h o s e t e x t can be f o u n d at h t t p :// o p e n d a t a c o m m o n s . org / l i c e n s e s / d b c l /
Open Data Commons Attribution License
Consente di:
• copiare, distribuire, utilizzare il database per qualsiasi fine;
• elaborare il database per produrre una nuova opera;
• modificare, trasformare il database.
Impone i seguenti vincoli:
• Attribuzione: si deve citare la fonte originale in ogni utilizzo
pub-blico del database, o opera prodotta con il database nel modo
descritto nella licenza. Inoltre deve essere precisato che ogni
in-formazione relativa al database originale deve rimanere intatta,
ci`
o significa che se viene creata un’estensione del database con dei
dati derivati, questa dovr`
a avere un nome e una versione che la
distinguano dal database originale.
Per attribuire ad un database tale licenza si deve copiare il testo
in-tegrale in un file LICENSE.txt, che dovr`
a essere messo all’interno del
database, oppure riportare la seguente dichiarazione in tutti i siti o le
locazioni in cui si trova il database:
C o n t a i n s i n f o r m a t i o n f r o m D A T A B A S E N A M E w h i c h is m a d e a v a i l a b l e u n d e r the A t t r i b u t i o n L i c e n s e
w h o s e t e x t can be f o u n d at
h t t p :// o p e n d a t a c o m m o n s . org / l i c e n s e s / by / 1 . 0 /
Creative Commons Zero License (CC0)
(a) Marchio licenze CC (b) Licenza
CC0
Fa parte delle licenze Creative Commons [12], le quali forniscono la
licenza con un design a tre livelli:
1. documento legale: con strutturazione e termini linguistici legali;
2. documento interpretabile da persone normali : non ha valenza
le-gale, serve per far comprendere a persone non competenti quali
diritti da la licenza;
3. documento machine-readable: agevola la diffusione e la
rintraccia-bilit`
a della licenza, utilizzando il linguaggio Creative Commons
Rights Expression Language (CC REL) il quale specifica come la
licenza pu`
o essere descritta in RDF (ulteriori dettagli in 1.3.1).
La licenza CC0 [13] indica che l’autore ha reso la sua opera di dominio
pubblico, rinunciando a tutti i suoi diritti e diritti connessi o simili che
detiene su di essa, quali i suoi diritti morali (per quanto rinunciabili),
i suoi diritti all’immagine o alla riservatezza, diritti che lo proteggono
contro la concorrenza sleale, e diritti sulle banche di dati che limitino
l’estrazione, la disseminazione ed il riuso dei dati. Inoltre egli non
fornisce nessuna garanzia sull’opera, e declina ogni responsabilit`
a per
tutti gli usi che possono essere fatti dell’opera nella misura consentita
dalla legge.
Per quanto riguarda l’Italia, `
e stata sviluppata l’Italian Open Data
License (IODL):
Esistono due versioni di questa licenza, ovvero IODL v1.0 [14] pubblicata nel
2010 e IODL v2.0 [15] pubblicata nel 2012, le quali consentono di:
• copiare, distribuire, utilizzare il database per qualsiasi fine;
• elaborare il database per produrre una nuova opera;
• modificare, trasformare il database.
L’Italian Open Data License v1.0 si distingue dalla v2.0 perch`
e la prima
impone i vincoli di attribuizione e di condivisione allo stesso modo
(compa-tibile con la licenza Open Database), mentre la seconda solo il vincolo di
attribuizione (compatibile con la Open Data Commons Attribution).
Fase 3 : Rendere i dati disponibili
I database devono essere disposizione di chiunque, preferibilmente attraverso
un download gratuito su un sito web, in un formato comprensibile dalle
per-sone, ed anche in un formato che ne permetta l’utilizzo attraverso un processo
automatico. Inoltre deve essere possibile accedervi da qualsiasi piattaforma.
Il modo pi`
u semplice `
e permettere il download del database sul proprio sito
web, ma in questo modo si limita l’utilizzo del database alle sole persone che
sono a conoscenza del sito. Per questa ragione sono presenti diversi siti web
che si occupano di raccogliere database relativi ad un particolare settore, ad
esempio cosm.com `
e pensato per connettere dispositivi e apps, scambiarsi
dati e idee tra sviluppatori. Altri modi per condividere il database sono
at-traverso un server FTP, o con BitTorrent.
I dati possono essere pubblicati anche con API (Application Programming
Interface) le quali permettono di eseguire diverse elaborazioni sui di essi, ad
esempio selezionare un sottoinsieme di dati dal database, con il vantaggio
che poich`
e si connettono al database in tempo reale restituiranno sempre
i dati pi`
u aggiornati. Un esempio di approccio via API `
e l’accesso ai dati
mediante Web Services, con query la cui sintassi `
e descritta in formato XML
all’interno della Web Service Description. I dati pubblicati con le API sono
strettamente dipendenti dal fornitore del database, perci`
o se questo effettua
delle modifiche strutturali del database potrebbero non essere disponibili per
un certo intervallo di tempo.
Diversamente quelli diffusi all’interno di file potrebbero non essere
aggiorna-ti, per`
o rimangono sempre disponibili anche quando il fornitore effettua delle
modifiche.
Fase 4 : Rendere i dati rintracciabili
Gli OpenData non hanno alcun valore se non vengono utilizzati da nessuno.
E’ fondamentale utilizzare tutti i mezzi possibili per divulgare il fatto che il
database `
e diventato aperto ad esempio social network, mailing list, forum,
conferenze, barcamps (conferenze online), e hackadays (hackathlon). Inoltre
un approccio tipico `
e usare i tool esistenti che si occupano di raccogliere e
indicizzare i database, come ad esempio datahub.io che contiene database
provenienti da tutto il mondo. Oltre a questi sono disponibili online anche
dei tool per realizzare queste raccolte di OpenData da zero, uno di questi `
e
ckan.org.
1.3
Linked Open Data e Web Semantico
I Linked Open Data sono degli Open Data connessi tra loro tramite delle
relazioni di semantica, le quali sono esprimibili nei dati stessi in un formato
comprensibile dalle persone e dalle macchine che si chiama RDF (Resource
Description Framework). In particolare viene utilizzato il modello RDF per
descrivere il significato dei dati, e i link RDF per collegare i dati sulla base
del loro significato. Infatti i Linked Open Data stanno alla base della teoria
sul Web Semantico, un web nel quale si potr`
a navigare non solo sulla base
della sintassi dei dati, ma anche sulla base del loro significato sfruttando i
collegamenti RDF.
Ad esempio, quando un utente sta cercando dei dati relativi ad una persona
da una sorgente, potrebbe essere interessato alle informazioni relative alla
citt`
a dove abita quella persona. Queste informazioni possono essere ottenute
seguendo un collegamento RDF dal dataset contenente i dati della persona,
ad un altro dataset che le contiene. Quindi la ricerca di un documento non
viene pi`
u fatta mediante collegamenti ipertestuali ma tramite collegamenti
RDF. I collegamenti RDF possono essere interpretati da motori di ricerca
semantici, che permetteranno ricerche sofisticate con query che non
restitui-ranno pi`
u dei semplici link a pagine HTML, ma dati strutturati che potranno
essere utilizzati immediatamente all’interno di altre applicazioni.
Il Linking Open Data `
e un progetto del W3C che si occupa di pubblicare
da-taset in formato RDF e creare collegamenti RDF tra gli elementi provenienti
da dataset diversi.
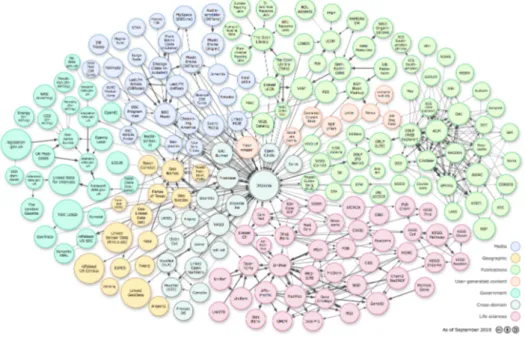
La figura 1.2 mostra i dataset resi aperti e collegati nel 2011, i quali sono
circa 295, composti da oltre 31 miliardi di triple RDF, collegate da circa 504
milioni di link RDF.
Figura 1.2: Linking Open Data cloud (2011): dataset pubblicati e le loro
relazioni.
Tim Berners-Lee, l’inventore del World Wide Web, nel 2006 ha indicato un
insieme di regole da seguire per pubblicare i dati sul web, in modo che essi
diventino parte di uno spazio di dati globale:
1. indentificare le risorse con Uniform Resource Identifier (URI);
2. usare HTTP URI in modo che si possano fare riferimenti facilmente e
possano essere cercati sia da persone che da user agent;
3. quando qualcuno cerca una risorsa, fornirgli informazioni utili e
colle-gate all’URI della risorsa, utilizzando i formati standard (RDF,
SPAR-QL);
4. includere collegamenti ad altre URI collegate al contenuto mostrato,
per migliorare la ricerca di altre informazioni utili nel Web.
Inoltre ha anche classificato il grado di apertura dei dati, in cinque livelli
progressivi, associati al numero di stelle:
1 stella: il dato `
e disponibile sul web (in qualsiasi formato) ma con
una licenza aperta;
2 stelle: il dato `
e disponibile in un formato strutturato che pu`
o essere
interpretato da un software (per esempio un foglio di calcolo Microsoft
Excel);
3 stelle: il dato `
e in un formato strutturato non proprietario (CSV);
4 stelle: oltre a rispettare tutti i criteri precedenti, il dato
utiliz-za standard web interpretabili dalle applicazioni che ne descrivono il
significato (RDF);
5 stelle: il dato rispetta tutti gli altri criteri e inoltre contiene
colle-gamenti ad altri dati (linked data) al fine di fornire un contesto alle
proprie informazioni.
1.3.1
Resource Description Framework
RDF `
e un framework per descrivere le risorse web e le loro relazioni
seman-tiche attraverso grafici, in un modo interpretabile sia dalle persone che dalle
macchine (con la sintassi XML). Il modello RDF codifica i dati nella forma
di triple < soggetto, predicato, oggetto >.
Il soggetto di una tripla `
e l’URI che identifica la risorsa descritta. L’oggetto
pu`
o essere sia un semplice valore letterale, tipo una stringa, un numero, o una
data; o l’URI di un’altra risorsa che ha una certa relazione con il soggetto.
Il predicato indica che tipo di relazione intercorre tra il soggetto e l’oggetto,
ad esempio
00data di nascita
00,
00datore di lavoro
00. Il predicato `
e anch’esso un
URI. Gli URI dei predicati si trovano nei vocabolari, i quali sono raccolte di
URI che possono essere usate per rappresentare informazioni riguardanti un
certo dominio. Tra i vocabolari well-known sviluppati dalla Semantic Web
community si possono trovare:
- Friend-of-a-Friend (FOAF), per descrivere i legami tra le persone;
- Dublin Core (DC), per descrivere qualsiasi materiale digitale;
- Semantically-Interlinked Online Communities (SIOC), rappresenta
le principali community online;
- Description of a Project (DOAP), per descrivere progetti;
- Simple Knowledge Organization System (SKOS) per rappresentare
glossari, classificazioni, tassonomie e qualsiasi tipo di vocabolario
strut-turato;
- Geonames `
e un vocabolario geografico open con oltre 10 milioni di nomi
di luoghi;
- Music Ontology, contiene termini per descrivere artisti, album e pezzi;
- Review Vocabulary, per descrivere le recensioni;
- Creative Commons (CC), contiene i vocaboli delle licenze.
Si possono anche definire dei vocaboli nuovi, che non sono presenti nelle
ontologie gi`
a definiti attraverso RDF Vocabulary Description Language 1.0:
RDF Schema. I link RDF sono fondamentali per il Web dei dati (o web
semantico) perch`
e permettono di collegare isole di dati in uno spazio globale
di dati interconnessi, e di scoprire sorgenti di dati aggiuntive.
I collegamenti RDF si dividono in collegamenti interni e collegamenti
ester-ni : i primi sono triple RDF nelle quali il soggetto e l’oggetto sono riferimenti
URI che puntano alla stessa sorgente di dati, mentre i secondi sono triple
RDF nelle quali il soggetto `
e un riferimento URI nello spazio dei nomi di un
dataset, mentre il predicato e/o l’oggetto sono riferimenti URI che puntano
a spazi di nomi di altri dataset. Dereferenziando queste URI si ottiene la
descrizione delle risorse collegate fornita dal server remoto. Si noti che per
dereferenziare si intende l’atto di recuperare una rappresentazione di una
ri-sorsa o la descrizione semantica di una riri-sorsa creata dal possessore dell’URI.
Se la rappresentazione della risorsa recuperata `
e un RDF contenente ulteriori
URI, questa operazione pu`
o essere fatta ricorsivamente. Questo `
e il
mecca-nismo con il quale si naviga nel web semantico.
Ci sono 3 tipi di collegamenti RDF:
- relazionali: puntano alle cose connesse in altre sorgenti di dati, per
esempio, altre persone, luoghi o generi. Ad esempio i collegamenti di
relazioni permettono alle persone di ottenere informazioni riguardanti
il luogo dove vivono, o dati bibliografici riguardanti le pubblicazioni
che hanno fatto.
- di identit`
a: puntano agli alias URI usati da altre sorgenti di dati per
identificare lo stesso oggetto reale o concetto astratto. I collegamenti di
identit`
a permettono ai client di recuperare ulteriori descrizioni
riguar-danti un’entit`
a da altre sorgenti di dati. Inoltre hanno un’importante
funzione sociale perch`
e permettono di esprimere diversi punti di vista
riguardo alle entit`
a e ai concetti.
- di vocabolario: puntano dai dati alle definizioni nei vocabolari dei
termini che sono usati per rappresentare i dati, cos`ı come da queste
definizioni alle definizioni dei relativi termini negli altri vocabolari. I
collegamenti di vocabolario rendono i dati autodescrittivi e permettono
alle applicazioni di comprendere e integrare i dati attraverso l’uso dei
vocabolari.
Non si devono confondere gli identificatori di documenti Web, con gli
identi-ficatori di altre risorse. Un determinato URI pu`
o identificare un documento
Web oppure una risorsa (anche esterna al Web).
La domanda sorge spontanea:
Come si recuperano le rappresentazioni delle
risorse mediante i loro URI?
00.
La figura seguente riporta la relazione tra una risorsa e i documenti che la
rappresentano.
Il protocollo HTTP quando l’accesso ad una pagina Web va a buon fine
resti-tuisce il codice di stato 200, per`
o quando si pubblicano URI che identificano
entit`
a che non sono necessariamente documenti Web `
e necessario un
approc-cio specifico. Il W3C ha proposto due soluzioni: utilizzare hash URI, oppure
il codice di stato 303.
Hash URI
Questa soluzione consiste nell’utilizzare URI che contengono una parte
speciale che `
e separata dal resto dell’URI da un simbolo hash (
00#
00).
Quando un client vuole recuperate un URI hash, la parte dell’URI
che si trova dopo il simbolo hash viene tagliata prima di effettuare la
richiesta HTTP al server. Questo significa che un hash URI non pu`
o
essere recuperata direttamente, di conseguenza si intuisce che pu`
o non
identificare necessariamente un documento Web. Infatti le URI hash
possono essere usate per identificare documenti Web e risorse senza
creare ambiguit`
a. Se l’URI richiesta corrisponde ad un documento web,
e ad un documento RDF il server decider`
a quale restituire. Tipicamente
questa decisione viene presa tenendo conto delle preferenze del client,
e della configurazione del server. Successivamente utilizzer`
a l’header
Content-Location per indicare l’esito della scelta.
Codice di stato 303
Questa soluzione consiste nell’utilizzare il codice di stato speciale 303
See Other, per indicare che la risorsa richiesta non `
e un normale
do-cumento Web, quindi il server restituir`
a la locazione di un documento
contenente informazioni sulla risorsa richiesta. In questo modo si evita
ambiguit`
a tra oggetti del mondo reale e risorse che li rappresentano.
In altre parole, se il server risponde con un normale codice di stato nel
range 2XX, tipo 200 OK, allora il client sa che l’URI identifica un
do-cumento Web, altrimenti se risponde con un codice 303 allora significa
che l’URI identifica una risorsa reale e il client verr`
a reindirizzato ad
un documento che rappresenta la risorsa. Nel caso in cui il documento
RDF e la sua rappresentazione HTML coincidono, allora il client viene
reindirizzato su un documento generico dove potr`
a recuperare il
docu-mento RDF, o la sua rappresentazione HTML.
Avere dei documenti generici che contengono URI di rappresentazioni
della risorsa pi`
u specifiche, permettono un maggior numero di utilizzi ed
elaborazioni della risorsa. Ad esempio un documento generico
riguar-dante un libro, pu`
o contenere URI di documenti contenti il libro nelle
varie traduzioni. Se invece l’URI del documento RDF della risorsa
dif-ferisce da quello della sua rappresentazione HTML, il server restituisce
immediatamente il documento RDF o la sua rappresentazione HTML.
Analisi ed elaborazione degli
OpenData di Tper
2.1
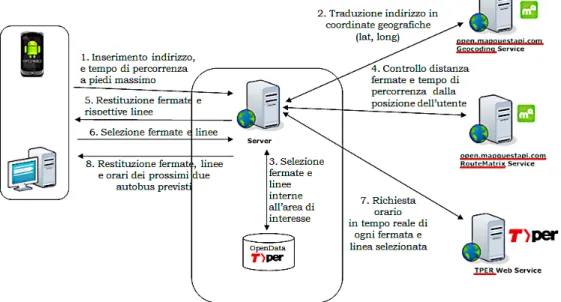
Requisiti dell’applicazione
L’applicazione ha lo scopo principale di fornire informazioni in tempo reale
sui servizi di mobilit`
a urbana, riguardanti linee di autobus e relative fermate
in una determinata zona di interesse all’interno dell’area di Bologna.
L’utente interagisce con l’applicazione inserendo inizialmente la posizione in
cui si trova utilizzando, come possibili formati, l’indirizzo postale o le
coor-dinate geografiche, ed inserendo poi il massimo tempo di percorrenza a piedi
che `
e disposto a impiegare per raggiungere la fermata. Il server seleziona tra i
dati forniti da Tper tutte le fermate che soddisfano i requisiti della richiesta,
e le linee che transitano su di esse. Le fermate scelte, con le rispettive linee,
verranno restituite all’utente, che dovr`
a specificare il suo interesse verso
tut-te le possibilit`
a o parte di esse. Infine l’applicazione restituir`
a gli orari reali
dei prossimi due autobus in arrivo per ciascuna linea indicata, i quali sono
ottenuti dal Web Service Hello Bus di Tper.
Il servizio dovr`
a presentare le informazioni con un livello di dettaglio tale
da consentire la comprensione a chiunque, sia pendolari che usufruiscono
abitualmente dei servizi di mobilit`
a urbana di Bologna, sia utenti con poca
confidenza con la rete di trasporti di Tper o con la citt`
a in generale.
Inoltre dovr`
a gestire un numero elevato di utenti che effettuano richieste
eterogenee, tra le quali per`
o potranno emergere categorie di utenti con una
richiesta uguale o con caratteristiche simili, come ad esempio l’insieme
de-gli studenti di una scuola, ognuno dei quali richiede informazioni inerenti le
fermate nei pressi della scuola. In quest’ottica si `
e poi ipotizzata la
possibi-lit`
a di inserire un tablet all’interno dell’atrio scolastico in modo da fornire le
informazioni agli studenti in maniera automatica.
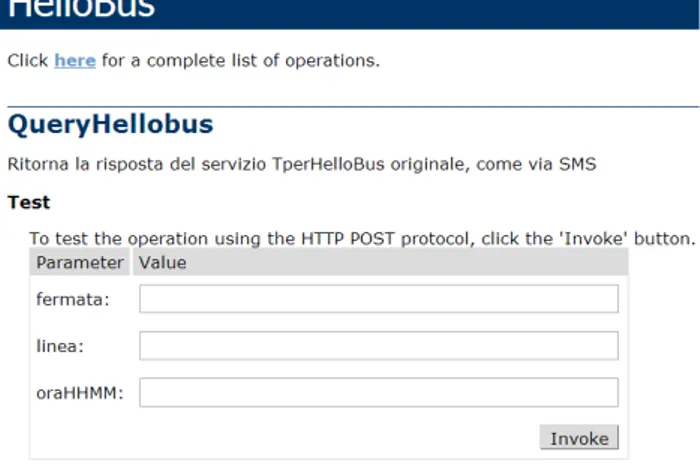
Figura 2.1: Form dell’Hello Bus Web Server di Tper
2.2
Database di Tper
L’azienda Tper fornisce due tipologie di OpenData: una riguarda le
infor-mazioni statiche (ad esempio dove sono collocate le fermate, quali tragitti
effettuano le linee), le quali sono ottenibili scaricando i file in formato xml
o csv dal loro sito; e l’altra riguarda le informazioni in tempo reale (ritardi
degli autobus), le quali vengono restituite mediante query al Web Service
Hello Bus.
Poich`
e il sito di Tper non presenta nessuna documentazione in merito agli
OpenData pubblicati, `
e stato necessario uno studio per comprendere il
signi-ficato dei dati mediante la tecnica del reverse engineering.
Dallo studio `
e emerso che all’interno del database vi sono quattro entit`
a
fondamentali: Fermata, Linea, Percorso e Arco.
Fermata
Pensilina caratterizzata da un codice che la identifica univocamente
e informazioni relative alla sua collocazione geografica. Due pensiline
Figura 2.2: Pagina web degli OpenData di Tper. Vengono posti in evidenza
quelli utilizzati nell’applicazione.
poste sui lati opposti di una strada sono rappresentate da due Fermate
diverse con codici di identificazione diversi.
Linea
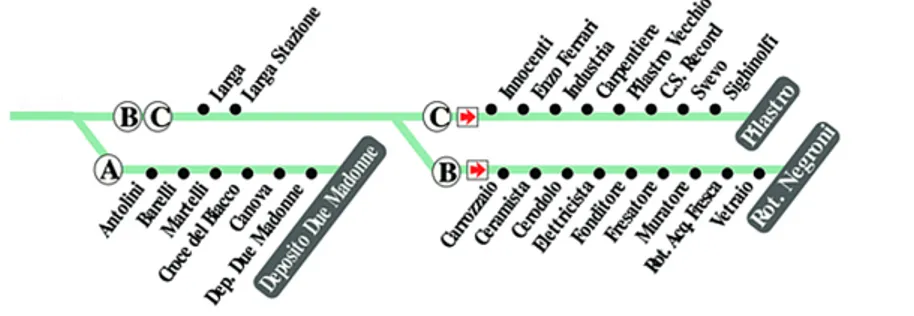
Tratta principale ed eventuali sottotratte secondarie. Ad esempio con
linea 14 si intende la linea 14 che effettua la tratta principale e le linee
14A, 14B, 14C che seguono parte della tratta principale e poi si
scosta-no da questa fiscosta-no a terminare in capolinea diversi. Oppure al contrario
partono da capolinea diversi e poi si immettono nella tratta principale.
Essa nei giorni feriali effettua la tratta da Piazza Giovanni XXIII e
arrivato alla fermata Tangenziale di San Vitale si suddivide nella linea
14A che prosegue per la fermata Antolini fino al capolinea Deposito
Due Madonne, e nelle linee 14B e 14C che proseguono insieme nelle
fermate Larga e Larga Stazione.
Successivamente il 14B passa per la fermata Carrozzaio con
destina-zione Rot. Negroni, mentre il 14C transita per la fermata Innocenti
Figura 2.3: Linea 14 Barca - Ospedale S. Orsola - Due Madonne/Pilastro
Figura 2.4:
Linee 14A, 14B, 14C Barca - Ospedale S. Orsola - Due
Madonne/Pilastro
Percorso
Tratta o sottotratta, intesa come insieme di fermate, effettuata da una
determinata linea in un giorno feriale o festivo. Un percorso viene
identificato univocamente dalla linea, un numero (unico all’interno della
linea), ed un verso. Ogni linea ha almeno quattro percorsi:
- la sequenza delle fermate sulla tratta principale in una direzione
effettuata nei giorni feriali;
- la sequenza delle fermate sulla tratta principale nella stessa
dire-zione effettuata nei giorni festivi;
- la sequenza delle fermate sulla tratta principale nella direzione
opposta effettuata nei giorni feriali;
- la sequenza delle fermate sulla tratta principale nella stessa
dire-zione effettuata nei giorni festivi.
Ad esempio la linea 14 ha in totale 12 percorsi.
Arco
Sequenza ordinata di punti in una certa direzione situati in
corrispon-denza di una fermata oppure fra due fermate consecutive. Ogni
percor-so `
e espresso come sequenza di archi che sono a loro volta una sequenza
di fermate e punti tra di esse. Inoltre lo stesso arco pu`
o appartenere
a pi`
u percorsi, nel caso in cui abbiano parte di una tratta in comune.
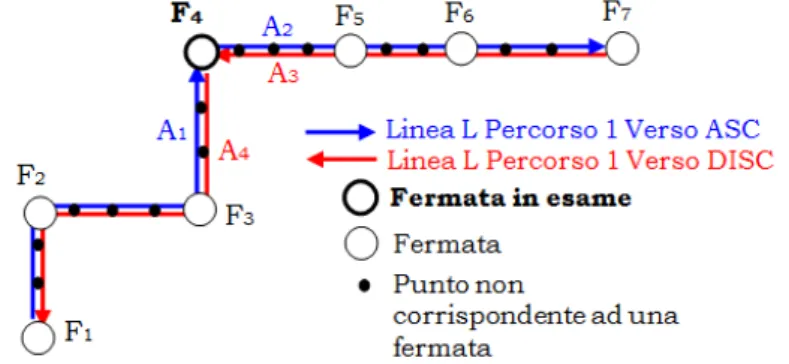
Ad esempio, come si vede in fig. 2.5, presa una linea L e una specifica
fermata F
4di un percorso essa presenta quattro archi incidenti: un
arco entrante che ha come ultima fermata F
4, e un arco uscente, che
ha come prima fermata F
4per ambedue le direzioni.
Le informazioni sono contenute all’interno delle seguenti tabelle:
- Elenco delle fermate bus, contiene informazioni sulle fermate e
sul-la loro collocazione geografica nei formati di indirizzo postale e
coordi-nate geografiche (latitudine e longitudine).
Figura 2.5: Esempio di fermata con 4 archi incidenti su di essa.
- Elenco delle linee bus, contiene una lista delle linee bus.
- Linee bus come sequenza di fermate, contiene informazioni su
tut-te le fermatut-te effettuatut-te da ciascuna linea, senza per`
o indicarne l’ordine.
- Linee bus come sequenza di archi, contiene tutti i percorsi
effet-tuati da ciascuna linea, descritti come sequenza ordinata di archi in
una direzione. L’ordine degli archi viene indicato mediante il campo
posizione.
- Elenco degli archi delle linee bus, contiene una lista di archi
descritti come sequenza ordinata di punti collocati o meno in
corrispon-denza di una fermata. L’ordine `
e indicato dall’ offset posizione, che
vale 0 per il punto iniziale dell’arco e cresce per i punti successivi,
men-tre il codice fermata vale 0 se il punto non `
e collocato su una fermata,
altrimenti assume il codice della fermata.
- Elenco delle zone, contiene i dati relativi alle zone.
L’applicazione si propone di fornire all’utente informazioni sulle fermate
po-sizionate all’interno dell’area di interesse e relative linee che transitano su di
esse. In particolare, per quanto concerne le linee, `
e opportuno indicarne il
nu-mero e la destinazione, ovvero il capolinea, in modo che l’utente comprenda
su quale lato della strada transiter`
a l’autobus diretto alla sua destinazione.
Come si pu`
o notare dalla descrizione precedente, tale informazione non `
e
presente esplicitamente all’interno del database, ma pu`
o essere ricavata
ese-guendo alcune queries.
Data una fermata F ed una linea L che transita su di essa, il capolinea si
ricava come ultima fermata dell’ultimo arco del percorso di L di cui fa parte
F. Segue una descrizione dettagliata della query, implementata in mysql, che
restituisce la destinazione delle linee di ogni fermata, e delle sottoqueries che
la compongono, partendo dalla sottoquery pi`
u innestata a quella generale.
1) Query Archi Fermata
Seleziona per ogni fermata tutti gli archi incidenti su di essa.
C R E A T E V I E W Q u e r y _ A r c h i _ F e r m a t a AS S E L E C T E l e n c o _ A r c h i . c o d i c e _ f e r m a t a , E l e n c o _ F e r m a t e . D e n o m i n a z i o n e , E l e n c o _ F e r m a t e . U b i c a z i o n e , E l e n c o _ F e r m a t e . Comune , E l e n c o _ F e r m a t e . L a t i t u d i n e , E l e n c o _ F e r m a t e . L o n g i t u d i n e , E l e n c o _ F e r m a t e . Zona , E l e n c o _ A r c h i . c o d i c e AS c o d i c e _ a r c o F R O M E l e n c o _ F e r m a t e I N N E R J O I N E l e n c o _ A r c h i ON E l e n c o _ F e r m a t e . c o d i c e = E l e n c o _ A r c h i . c o d i c e _ f e r m a t a ;
2) Query Archi Fermata Linea
Seleziona per ogni linea tutti gli archi incidenti su ciascuna delle sue fermate.
C R E A T E V I E W Q u e r y _ A r c h i _ F e r m a t a _ L i n e a AS S E L E C T Q u e r y _ A r c h i _ F e r m a t a . c o d i c e _ f e r m a t a , Q u e r y _ A r c h i _ F e r m a t a . D e n o m i n a z i o n e , Q u e r y _ A r c h i _ F e r m a t a . U b i c a z i o n e , Q u e r y _ A r c h i _ F e r m a t a . Comune , Q u e r y _ A r c h i _ F e r m a t a . L a t i t u d i n e , Q u e r y _ A r c h i _ F e r m a t a . L o n g i t u d i n e , Q u e r y _ A r c h i _ F e r m a t a . Zona , L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ l i n e a , L i n e e _ S e q u e n z a _ A r c h i . verso , L i n e e _ S e q u e n z a _ A r c h i . p e r c o r s o , L i n e e _ S e q u e n z a _ A r c h i . p o s i z i o n e , L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ a r c o F R O M L i n e e _ S e q u e n z a _ A r c h i I N N E R J O I N Q u e r y _ A r c h i _ F e r m a t a ON L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ a r c o = Q u e r y _ A r c h i _ F e r m a t a . c o d i c e _ a r c o ;
3) Query Linea Percorso UltimaPosizione
Seleziona l’ultima posizione di ogni percorso effettuato da ciascuna linea.
C R E A T E V I E W Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e AS S E L E C T c o d i c e _ l i n e a , verso , p e r c o r s o ,
MAX ( p o s i z i o n e ) AS u l t i m a _ p o s i z i o n e F R O M L i n e e _ S e q u e n z a _ A r c h i
4) Query Linea Percorso UltimoArco
Seleziona l’ultimo arco di ogni percorso effettuato da ciascuna linea.
C R E A T E V I E W Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o AS S E L E C T L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ l i n e a , L i n e e _ S e q u e n z a _ A r c h i . verso , L i n e e _ S e q u e n z a _ A r c h i . p e r c o r s o , Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e . u l t i m a _ p o s i z i o n e , L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ a r c o AS u l t i m o _ a r c o F R O M L i n e e _ S e q u e n z a _ A r c h i I N N E R J O I N Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e ON ( L i n e e _ S e q u e n z a _ A r c h i . p o s i z i o n e = Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e . u l t i m a _ p o s i z i o n e ) AND ( L i n e e _ S e q u e n z a _ A r c h i . v e r s o = Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e . v e r s o ) AND ( L i n e e _ S e q u e n z a _ A r c h i . p e r c o r s o = Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e . p e r c o r s o ) AND ( L i n e e _ S e q u e n z a _ A r c h i . c o d i c e _ l i n e a = Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m a P o s i z i o n e . c o d i c e _ l i n e a );
5) Query Fermata Linea Percorso Verso UltimoArco
Seleziona, per ogni fermata, ogni possibile arco finale dei percorsi seguiti da
ciascuna linea che transita su di essa.
C R E A T E V I E W Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o AS S E L E C T D I S T I N C T Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . c o d i c e _ f e r m a t a , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . D e n o m i n a z i o n e , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . U b i c a z i o n e , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . Comune , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . L a t i t u d i n e , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . L o n g i t u d i n e , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . Zona , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . c o d i c e _ l i n e a , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . verso , Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . p e r c o r s o , Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o . u l t i m o _ a r c o
F R O M Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o I N N E R J O I N Q u e r y _ A r c h i _ F e r m a t a _ L i n e a ON ( Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o . p e r c o r s o = Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . p e r c o r s o ) AND ( Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o . v e r s o = Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . v e r s o ) AND ( Q u e r y _ L i n e a _ P e r c o r s o _ U l t i m o A r c o . c o d i c e _ l i n e a = Q u e r y _ A r c h i _ F e r m a t a _ L i n e a . c o d i c e _ l i n e a );
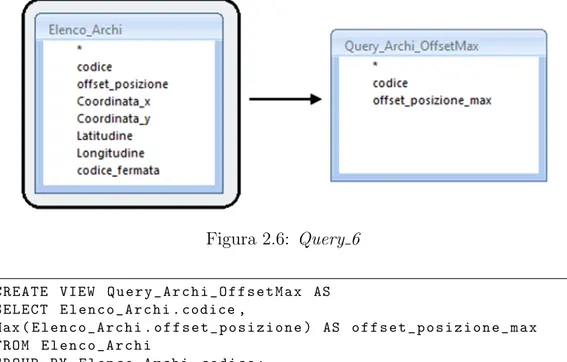
6) Query Archi OffsetMax
Seleziona l’offset posizione massimo per ogni arco.
Figura 2.6: Query 6
C R E A T E V I E W Q u e r y _ A r c h i _ O f f s e t M a x AS S E L E C T E l e n c o _ A r c h i . codice , Max ( E l e n c o _ A r c h i . o f f s e t _ p o s i z i o n e ) AS o f f s e t _ p o s i z i o n e _ m a x F R O M E l e n c o _ A r c h i G R O U P BY E l e n c o _ A r c h i . c o d i c e ;7) Query Archi Offset UltimaFermata
Seleziona l’ultima fermata di ogni arco, ovvero quella con l’offset posizione
massimo.
C R E A T E V I E W Q u e r y _ A r c h i _ O f f s e t _ U l t i m a F e r m a t a AS S E L E C T E l e n c o _ A r c h i . c o d i c e AS c o d i c e _ a r c o , E l e n c o _ A r c h i . o f f s e t _ p o s i z i o n e , E l e n c o _ A r c h i . c o d i c e _ f e r m a t a AS u l t i m a _ f e r m a t a F R O M E l e n c o _ A r c h i I N N E R J O I N Q u e r y _ A r c h i _ O f f s e t M a x ON ( E l e n c o _ A r c h i . c o d i c e = Q u e r y _ A r c h i _ O f f s e t M a x . c o d i c e ) AND ( E l e n c o _ A r c h i . o f f s e t _ p o s i z i o n e = Q u e r y _ A r c h i _ O f f s e t M a x . o f f s e t _ p o s i z i o n e _ m a x );8) Query Fermata Linea Percorso Verso
UltimoArcoUltimaFermata
Presa una determinata fermata, per ogni percorso delle linee che la
preve-dono, viene selezionato il codice della fermata capolinea. Si noti che pi`
u
percorsi di una linea possono avere lo stesso capolinea.
C R E A T E V I E W
Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o U l t i m a F e r m a t a AS
S E L E C T Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . c o d i c e _ f e r m a t a , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . D e n o m i n a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . U b i c a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . Comune , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . L a t i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . L o n g i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . Zona , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . c o d i c e _ l i n e a , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . verso , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . p e r c o r s o , Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . u l t i m o _ a r c o , Q u e r y _ A r c h i _ O f f s e t _ U l t i m a F e r m a t a . o f f s e t _ p o s i z i o n e , Q u e r y _ A r c h i _ O f f s e t _ U l t i m a F e r m a t a . u l t i m a _ f e r m a t a AS c o d i c e _ c a p o l i n e a F R O M Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o I N N E R J O I N Q u e r y _ A r c h i _ O f f s e t _ U l t i m a F e r m a t a ON Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o . u l t i m o _ a r c o = Q u e r y _ A r c h i _ O f f s e t _ U l t i m a F e r m a t a . c o d i c e _ a r c o ;
9) Query Fermata Linea Capolinea
Partendo dalla vista precedente, ignorando il concetto di percorso, seleziona
solo i capolinea distinti delle linee.
C R E A T E V I E W Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a AS S E L E C T c o d i c e _ f e r m a t a , D e n o m i n a z i o n e , U b i c a z i o n e , Comune , L a t i t u d i n e , L o n g i t u d i n e , Zona , c o d i c e _ l i n e a , verso , u l t i m o _ a r c o , c o d i c e _ c a p o l i n e a F R O M Q u e r y _ F e r m a t a _ L i n e a _ P e r c o r s o _ V e r s o _ U l t i m o A r c o U l t i m a F e r m a t a G R O U P BY c o d i c e _ f e r m a t a , D e n o m i n a z i o n e , U b i c a z i o n e , Comune , L a t i t u d i n e , L o n g i t u d i n e , Zona , c o d i c e _ l i n e a , verso , u l t i m o _ a r c o , c o d i c e _ c a p o l i n e a ;
10) Query Fermata Linea Capolinea CodiceZona
Associa ad ogni codice capolinea la sua Denominazione e il codice della
zona.
C R E A T E V I E W Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a AS S E L E C T Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . c o d i c e _ f e r m a t a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . D e n o m i n a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . U b i c a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . Comune , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . L a t i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . L o n g i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . Zona , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . c o d i c e _ l i n e a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . verso , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . c o d i c e _ c a p o l i n e a , E l e n c o _ F e r m a t e . D e n o m i n a z i o n e AS d e n o m i n a z i o n e _ c a p o l i n e a , E l e n c o _ F e r m a t e . Z o n a AS z o n a _ c a p o l i n e a F R O M Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a I N N E R J O I N E l e n c o _ F e r m a t e ON Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a . c o d i c e _ c a p o l i n e a = E l e n c o _ F e r m a t e . c o d i c e ;
11) Query Fermata Linea ZonaCapolinea
Osservando la vista precedente si pu`
o notare che prendendo come fermata
un capolinea, questo ha come capolinea in una certa direzione se stesso.
Poich`
e lo scopo della query `
e indicare la destinazione delle linee, tutti i record
che presentano fermata e capolinea uguali devono essere eliminati.
Pertanto la vista presente associa ad ogni capolinea il nome della zona ed
elimina tutti i record nei quali la fermata e il capolinea coincidono.
C R E A T E V I E W Q u e r y _ F e r m a t a _ L i n e a _ Z o n a C a p o l i n e a AS S E L E C T Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . c o d i c e _ f e r m a t a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . D e n o m i n a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . U b i c a z i o n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . Comune , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . L a t i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . L o n g i t u d i n e , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . Zona , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . c o d i c e _ l i n e a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . verso ,
Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . c o d i c e _ c a p o l i n e a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . d e n o m i n a z i o n e _ c a p o l i n e a , Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . z o n a _ c a p o l i n e a , E l e n c o _ Z o n e . d e s c r i z i o n e F R O M Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a I N N E R J O I N E l e n c o _ Z o n e ON Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . z o n a _ c a p o l i n e a = E l e n c o _ Z o n e . c o d i c e W H E R E ( Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . c o d i c e _ f e r m a t a < > Q u e r y _ F e r m a t a _ L i n e a _ C a p o l i n e a _ C o d i c e Z o n a . c o d i c e _ c a p o l i n e a );
12)Query Fermate Linee Capolinea
Concretizza la vista precedente in una tabella fisica sul database. Tale tabella
verr`
a utilizzata per la ricerca delle fermate interne all’area di interesse.
C R E A T E T A B L E F e r m a t e _ L i n e e _ C a p o l i n e a (
id INT NOT N U L L A U T O _ I N C R E M E N T P R I M A R Y KEY , c o d i c e _ f e r m a t a V A R C H A R (10) , D e n o m i n a z i o n e V A R C H A R (30) , U b i c a z i o n e V A R C H A R (30) , C o m u n e V A R C H A R (30) , L a t i t u d i n e D O U B L E (8 ,6) , L o n g i t u d i n e D O U B L E (8 ,6) , Z o n a V A R C H A R (10) , c o d i c e _ l i n e a V A R C H A R (10) , v e r s o V A R C H A R (4) , c o d i c e _ c a p o l i n e a V A R C H A R (10) , d e n o m i n a z i o n e _ c a p o l i n e a V A R C H A R (30) , z o n a _ c a p o l i n e a V A R C H A R (10) , I N D E X l a t i t u d i n e I D X ( L a t i t u d i n e ) ) S E L E C T c o d i c e _ f e r m a t a , D e n o m i n a z i o n e , U b i c a z i o n e , Comune , L a t i t u d i n e , L o n g i t u d i n e , Zona , c o d i c e _ l i n e a , c o d i c e _ c a p o l i n e a , d e n o m i n a z i o n e _ c a p o l i n e a , z o n a _ c a p o l i n e a F R O M Q u e r y _ F e r m a t a _ L i n e a _ Z o n a C a p o l i n e a ;
Mediante la query
S E L E C T c o d i c e _ f e r m a t a , D e n o m i n a z i o n e , U b i c a z i o n e , c o d i c e _ l i n e a , verso , c o d i c e _ c a p o l i n e a , d e n o m i n a z i o n e _ c a p o l i n e a F R O M F e r m a t e _ L i n e e _ C a p o l i n e a W H E R E ( c o d i c e _ l i n e a = 14) AND ( D e n o m i n a z i o n e = C e r t o s a );si ottiene la vista seguente, che riporta i capolinea corretti come si pu`
o
veri-ficare con le fig. 2.3 e 2.4.
Al fine di migliorare le prestazioni delle queries sono stati aggiunti alcuni
indi-ci sui campi interessati dai join, in particolare alla tabella Linee Sequenza Archi
sono stati aggiunti l’indice multiplo percorsoLineaIDX sui campi codice linea,
verso, percorso, posizione e l’indice codiceArcoIDX sul campo codice arco.
C R E A T E I N D E X p e r c o r s o L i n e a I D X ON L i n e e _ S e q u e n z a _ A r c h i ( c o d i c e _ l i n e a , verso , p e r c o r s o , p o s i z i o n e );
C R E A T E I N D E X c o d i c e A r c o I D X ON L i n e e _ S e q u e n z a _ A r c h i ( c o d i c e _ a r c o );
Mentre nella tabella Elenco Archi `
e stato creato l’indice codiceFermataIDX.
C R E A T E I N D E X c o d i c e F e r m a t a I D X ON E l e n c o _ A r c h i ( c o d i c e _ f e r m a t a );
Infine allo scopo di migliorare la ricerca delle fermate all’interno dell’area di
interesse, che viene fatta sulla base delle coordinate geografiche sono stati
inseriti gli indici latitudineIDX e longitudineIDX.
C R E A T E I N D E X l o n g i t u d i n e I D X
ON F e r m a t e _ L i n e e _ C a p o l i n e a ( L o n g i t u d i n e ); C R E A T E I N D E X l a t i t u d i n e I D X
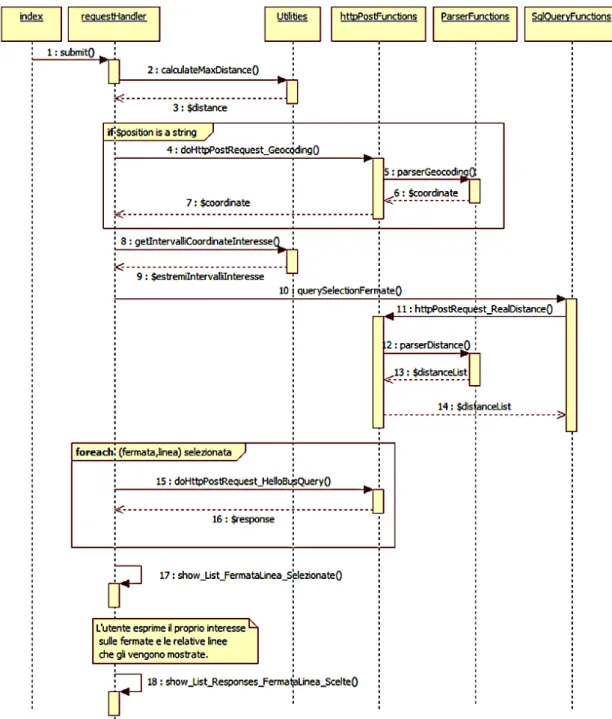
Progetto dell’Applicazione
3.1
Geocoding
L’utente interagisce con l’applicazione, come descritto nella sezione 2.1
inse-rendo inizialmente la sua posizione e il massimo tempo di percorrenza che
vuole impiegare per raggiungere una fermata. La posizione pu`
o essere
espres-sa in formato di indirizzo postale oppure di coordinate geografiche (latitudine
e longitudine). Nel primo caso `
e necessaria una traduzione, in letteratura
no-ta con il nome di Geocoding, da indirizzo posno-tale a coordinate geografiche,
ovvero latitudine e longitudine. A tale scopo viene utilizzato il servizio di
Geocoding di open.mapquestapi.com[21], il quale utilizza gli OpenData di
OpenStreetMap[7].
Si pu`
o interagire con esso attraverso il protocollo HTTP inviando messaggi nei
quali si specifica l’indirizzo, e il formato dell’output. Di seguito viene
ripor-tato l’header del messaggio HTTP per richiedere la traduzione dell’indirizzo di
Piazza Maggiore di Bologna in coordinate geografiche con output in formato
xml. Si noti che per poter usufruire del servizio `
e necessario specificare una
chiave, che viene fornita previa registrazione sul sito.
h t t p : // o p e n . m a p q u e s t a p i . com / g e o c o d i n g / v1 / a d d r e s s ? key = Y O U R \ _ K E Y \ _ H E R E & c a l l b a c k = r e n d e r G e o c o d e &
o u t F o r m a t = xml & l o c a t i o n = p i a z z a m a g g i o r e b o l o g n a
![Figura 1.1: Classifica elaborata dalla EPSI (European Public Sector Infor- Infor-mation [9]) ottenuta dalla media di diversi fattori: l’implementazione della direttiva PSI, la pratica di riuso, i formati, il prezzo, accordi esclusivi, PSI locale, eventi e](https://thumb-eu.123doks.com/thumbv2/123dokorg/7467098.102106/18.892.236.595.323.633/figura-classifica-elaborata-european-ottenuta-implementazione-direttiva-esclusivi.webp)