POLITECNICO DIMILANO
DIPARTIMENTO DIELETTRONICA, INFORMAZIONE E BIOINGEGNERIA
DOCTORALPROGRAMIN INFORMATION TECHNOLOGY
A M
ETHODOLOGICAL
F
RAMEWORK TO
U
NDERSTAND AND
L
EVERAGE THE
I
MPACT OF
C
ONTENT ON
S
OCIAL
M
EDIA
I
NFLUENCE
Doctoral Dissertation of:
Leonardo Bruni
Advisor:
Prof. Chiara Francalanci
Tutor:
Prof. Barbara Pernici
The Chair of the Doctoral Program:
Prof. Carlo Fiorini
POLITECNICO DI MILANO
Dipartimento di Elettronica, Informazione e Bioingegneria Piazza Leonardo da Vinci, 32 I-20133 — Milano
It’s kind of fun to do the impossible. (Walt Disney)
Acknowledgements
First and foremost, I would like to thank my advisor. Her expertise, ex-cellent understanding and patient guidance had a major influence on this thesis, and this research work would not have been possible without her fundamental support. I am also grateful to all my colleagues.
Thanks to all the students who worked with me during these years, part of the work of this thesis has been developed thanks to their contribution.
My sincerely thanks go to the old friends I left in Tuscany and to the new ones I met in Milan. I enjoyed the atmosphere and their support.
I deeply thank my supportive, encouraging, and patient friend who shared with me the decision to move North. My time at Politecnico was made en-joyable in large part due to his invaluable friendship.
Finally, I would thank my family, for their continual support and for giving me the freedom to pursue my own interests. I cannot be grateful enough for their untiring support and unconditional belief in me.
And I want to thank all the others I probably forgot to mention in this list. . .
Leonardo
Milano, January 2014
Abstract
S
OCIALmedia have a strong impact on the way users interact and share information. The literature makes a distinction between influencers and influence. The former are social media users with a broad au-dience. For example, influencers can have a high number of followers on Twitter, or a multitude of friends on Facebook, or a broad array of connec-tions on LinkedIn. The term influence is instead used to refer to the social impact of the content shared by social media users.The majority of these studies has focused on the role of influencers. Our claim is that while the information shared by influencers has a broader reach, the content of messages plays a critical role and can be a determinant of the social influence of the message irrespective of the centrality of the message’s author. According to this perspective, influence is the actual im-pact of messages, which depends not only on the structure of the network, but also on the ability of message content to raise attention.
This thesis provides a conceptual framework and related software tools to assess influence. The assessment of influence is performed in two steps. First, an empirical analysis is conducted in order to verify the assumption that content can have an impact on influence. This analysis is performed on a per-post basis and by characterizing content in terms of sentiment, inclu-sion of multimedia and specificity. This focus at a post level is important to make a clear separation between influence and influencers and measure the impact of content without a bias from the content’s author. Then, we make an effort to translate our post-level findings into guidelines to be adopted by authors to maximize their influence. This is performed in two steps. First,
we describe an empirical analysis investigating the relationship between content and influence by approaching content measures at an author’s level and, thus, searching for the rules that tie author-level behavioural variables and authors’ influence. Second, we attempt the application of these rules in a practical case to create and promote a brand. To support both steps we have developed and continuously improved a software suite that supports assessment.
Riassunto
I
social media hanno un forte impatto sul modo in cui gli utenti interagi-scono online e condividono informazioni. In letteratura viene eviden-ziata una distinzione tra influencer e influence. I primi sono utenti che occupano una posizione di centralità nella rete. Ad esempio, gli influencer possono avere un alto numero di follower su Twitter o un elevato numero di amici su Facebook, oppure molte connessioni su LinkedIn. La parola influence è invece utilizzata per riferirsi all’impatto sociale del contenuto condiviso dagli utenti dei social media.La maggioranza di questi studi si è focalizzata sul ruolo degli influencer. È nostra opinione che, sebbene le informazioni condivise dagli influencer abbiamo indubbiamente una forte diffusione, il contenuto del messaggio assume comunque un ruolo critico e può essere determinante sulla influen-ce del messaggio indipendentemente dalla influen-centralità del suo autore. La influence rappresenta quindi l’impatto dei messaggi, la quale dipende non solo dalla struttura della rete ma anche dalla capacità del contenuto dei messaggi di generare interesse.
Questa Tesi fornisce un framework concettuale e i relativi strumenti soft-ware per valutare la social media influence. La valutazione iniziale si svol-ge in due fasi. Inizialmente, viene condotta un’analisi empirica preliminare volta a verificare che il contenuto può effettivamente avere un impatto sulla influence. Questa analisi è svolta a livello di singolo post e caratterizzando il contenuto in termini di sentiment, utilizzo di caratteristiche multimedia-li e specificità. Un’anamultimedia-lisi a questo multimedia-livello di granularità è importante per operare una netta separazione tra influence e influencer, permettendo così di
misurare l’impatto del contenuto senza l’influenza del suo autore. Succes-sivamente, i risultati di questa analisi sono stati tradotti in delle linee guida finalizzate a massimizzare la influence dei contenuti pubblicati sui social media. Anche questa operazione è svolta in due fasi. Viene prima descritta una analisi empirica finalizzata a comprendere la relazione tra contenuto e influence aggregando a livello di autore le variabili che caratterizzano il contenuto. Lo scopo è quello di individuare variabili che legano il compor-tamento dell’autore alla sua influence. Infine, i risultati delle analisi sono stati impiegati in un caso reale al fine di creare e promuovere un brand. A supporto di queste due fasi, si sono sviluppati gli strumenti software neces-sari ad abilitare le analisi.
Contents
1 Introduction 21
2 State of the Art 27
2.1 Influence and Influencers . . . 27
2.2 From Influencers to Web Influence . . . 28
2.2.1 Structural Variables . . . 29 2.2.2 Content-based Variables . . . 30 2.2.3 Semantic Variables . . . 31 2.3 User Matching . . . 36 2.4 Literature gap . . . 38 3 System Architecture 41 3.1 Basic System Modules . . . 43
3.2 Extended Module: Irony Identification . . . 46
3.2.1 Preliminary Analyses . . . 46
3.2.2 Empirical Testing . . . 48
3.3 Extended Module: User Matching . . . 49
3.3.1 System Architecture . . . 50
3.3.2 Empirical Testing . . . 60
3.4 Conclusions . . . 76
4 Empirical Analysis of the Dynamics of Retweeting 79 4.1 Research Hypotheses . . . 80
4.2 Methodology . . . 84
Contents
4.2.2 Tools for Data Analyses . . . 84
4.3 Empirical Results . . . 84
4.4 Discussion and Conclusions . . . 92
5 A Comprehensive Framework 95 5.1 A Model of Influence . . . 97
5.2 Variables and Data Sample . . . 99
5.2.1 Variable Definition and Operationalization . . . 99
5.2.2 Data Sample . . . 101
5.3 Empirical Results . . . 102
5.4 Discussion . . . 106
6 The Early Stages of a Brand Influence Experiment 111 6.1 Methodology . . . 112
6.1.1 Domain . . . 113
6.1.2 The Fanpage . . . 114
6.1.3 Posting Activity . . . 115
6.2 An App Supporting The Community . . . 116
6.3 Analysis of the Results . . . 118
6.3.1 Social pages . . . 118
6.3.2 Mobile app . . . 121
7 Conclusions 125
List of Figures
1.1 Overall conceptual framework of the thesis. . . 23
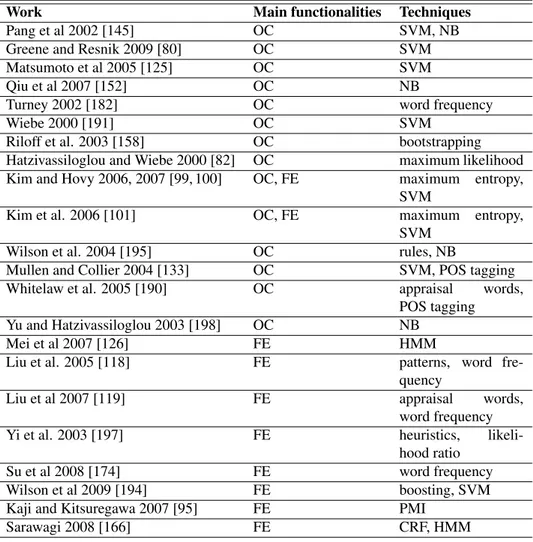
3.1 Architecture of SentiEngine. . . 44
3.2 Architecture of the user matching system. . . 51
3.3 Example of ngram similarity . . . 55
3.4 Example of weakness for the ngram similarity . . . 55
3.5 Examples of the longest common substring similarity . . . . 56
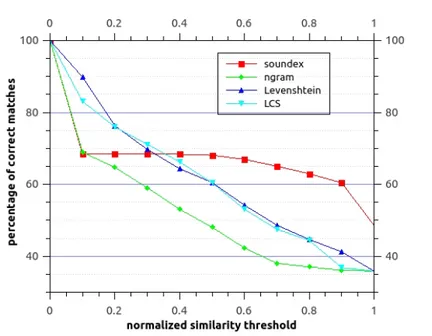
3.6 Variation of the percentage of correct matches with respect to different normalized similarity thresholds. . . 66
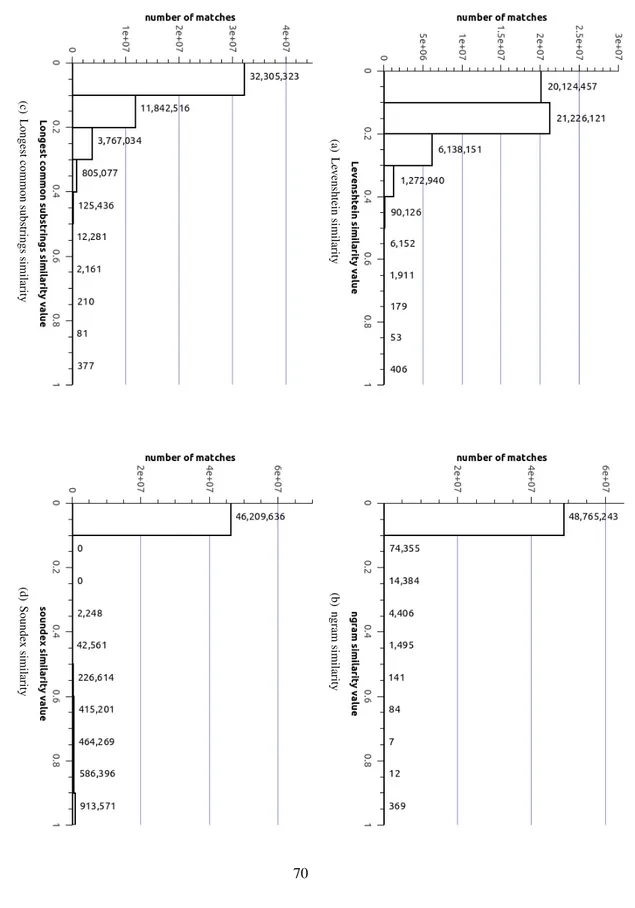
3.7 Histograms of the distribution for the different similarity measures. . . 67
3.8 Histograms of the distribution for the different similarity measures. . . 70
3.9 Performance behaviour with respect to the normalized simi-larity threshold. . . 72
3.10 Precision trend with respect to the normalized similarity thresh-old. . . 73
3.11 Recall trend with respect to the normalized similarity thresh-old. . . 74
3.12 F1-measure trend with respect to the normalized similarity threshold. . . 74
3.13 F1-measure trend with respect to the normalized similarity threshold. . . 77
List of Figures
4.1 Conceptual framework of this chapter, contextualized in the
overall framework. . . 80
4.2 Cumulative distribution function and density of number of retweets per each tweet with sentiment. . . 85
4.3 Time distribution of the number of retweets with sentiment and different retweeting time over sentiment. . . 86
4.4 Density of peaks of retweets in the first 4 hours with linear scale and log-log scale. . . 87
5.1 Conceptual framework of this chapter, contextualized in the overall framework. . . 96
5.2 Retweeting Process Model In-the-large. . . 100
5.3 Retweeting Process Model In-the-small. . . 101
5.4 Research model. . . 105
6.1 Conceptual work-steps of this chapter. . . 112
6.2 Logo of the Rock Live Italia community. . . 115
6.3 Mockups of the Rock Live Italia app localized into the Italian language. . . 119
6.4 Rock Live Italia community Klout score history. . . 120
6.5 Klout score distribution. . . 120
6.6 Rock Live Italia community Klout score network breakdown. 121 6.7 Growth of the number of downloads. . . 122
6.8 Number of downloads per day. . . 123
List of Tables
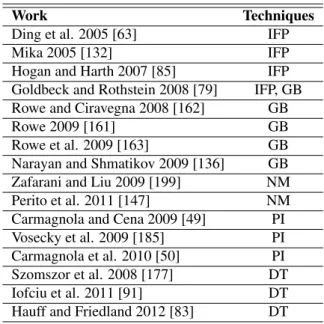
2.1 Content-based variables and related research contributions. . 31
2.2 Summary of reviewed work on sentiment analysis. . . 34
2.3 Summary of reviewed work on user matching. . . 39
3.1 Resources used by each software module. . . 43
3.2 Rule aiming at reducing the error due to irony. . . 48
3.3 Results of the test of the irony detection module. . . 49
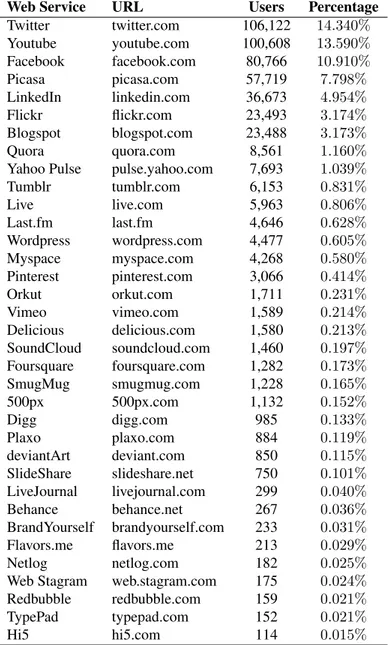
3.4 Other users’ profiles present in linkage information of Google Plus. . . 61
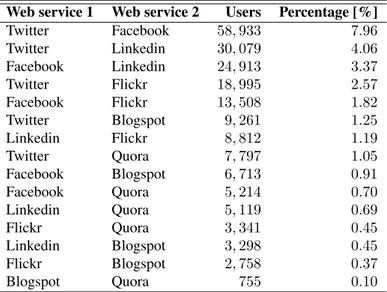
3.5 Frequency of couples of web services in the Google Plus dataset. . . 62
3.6 Confusion matrix for a problem with two classes. . . 64
4.1 Summary of datasets. . . 85
4.2 Cumulated percentage of number of peaks of retweets over time. . . 87
4.3 Spearman correlation coefficients and related significance values between the indegree centrality of each author and the minimum, average, and maximum time of retweet. . . . 88
4.4 Descriptive statistics of the sample (H 4.5). . . 88
4.5 T-test for equality of mean values (H 4.5). . . 89
4.6 Descriptive statistics of the sample (H 4.6). . . 89
4.7 T-test on retweeting of posts linking photos vs. videos (H 4.6). 89 4.8 Descriptive statistics of the sample (H 4.7). . . 90
List of Tables
4.9 T-test on sentiment of posts linking photos vs. videos (H 4.7). 90 4.10 Descriptive statistics of the sample (H 4.8). . . 91 4.11 T-test on speed of retweeting of post linking multimedia vs.
no link (H 4.8). . . 91 4.12 Descriptive statistics of the sample (H 4.9). . . 91 4.13 T-test on speed of retweeting of post linking photos vs. videos
(H 4.9). . . 92 4.14 Descriptive statistics of the sample (H 4.10). . . 92 4.15 T-test on speed of retweeting of post with sentiment linking
photos vs. videos (H 4.10). . . 92 5.1 Descriptive statistics of data sets DS1 (December 2012) and
DS2 (January 2013). . . 103 5.2 Correlation Matrix of Persistence Variable (Pearson index). . 104 5.3 Principal Component Analysis of Persistence Variable. . . . 105 5.4 Estimates of regression weights for the research model. . . . 107 5.5 Goodness-of-fit indices for the research model. . . 108 7.1 Summary of results. . . 126
CHAPTER
1
Introduction
s
OCIAL media have a strong impact on the way users interact and share information. The process through which users create and share opin-ions on brands, products, and services, i.e., the electronic word-of-mouth (eWOM) is gaining increasing attention. In the online context, the eWOM has been transformed from a communication act that takes place in a private one-to-one context to a one-to-many complex interaction. The reach of information sharing through eWOM can be both broad and fast. Companies know that controlling the dynamics of information sharing is very difficult. This need for improving control is one of the reasons why there is a growing interest in understanding how social networks can af-fect the dynamics of user interaction and information sharing. Indeed, by identifying and convincing a small number of influential individuals, a viral campaign can reach a wide audience at a small cost [130].Several previous studies have focused on the role of influencers, i.e., nodes with a central position in the network. In particular, microblogging platforms such as Twitter are the focus of a wide range of studies that aim at understanding how messages spread inside the social network and how the role of the message author impacts on message reach. Microblogging net-works are more and more used by companies as a communication medium
Chapter 1. Introduction
for the promotion and engagement of customers. While on traditional me-dia attention can focus not only on content, but also on the way a message is conveyed, on social media content plays a more central role [7]. Con-tent is even more central with microblogging, as the shortness of messages compels users to focus on the core of the information that they want to share. On Twitter, the standard size of a message limited to 140 characters is roughly the typical size of headlines and encourages users to produce content that are easy to consume.
As a matter of fact, some of the influencers on social media are a “net-work phenomenon” and, clearly, is what they have said that has had an impact in the past and represents the reason for their current breadth of audience, not the other way round [11]. Our claim is that despite the fact that the information shared by influencers has a broader reach, the content of messages plays a critical role and can be a determinant of the social in-fluence of a message irrespective of the centrality of the message’s author. This thesis takes a first step towards understanding the relationship between content and influence by addressing the following research questions: i) is content a driver of social media influence?; ii) what are the characteristics of content that help increase social media influence? These questions are rather unexplored by the current literature.
Even though the breadth of the audience was considered the first and foremost indicator of influence [54, 69, 89, 171], the more recent literature has associated the complexity of the concept of influence with the diversity of content [19, 134, 175]. Considering the successful case of Twitter, it has been observed that influencers are prominent social media users, but we cannot expect that the content that they share is bound to have high influence [24]. These literature results provide the theoretical foundations to support the hypothesis that the content of messages plays a critical role and can be a determinant of the social influence of the message irrespective of the centrality of the message’s author.
Figure 1.1 depicts the global conceptual framework that provides the theoretical foundations of this work. The goal of the research presented in this thesis is to analyze the set of relationships existing between content of posts and influence on social media. Content is evaluated from both a per-post and per-author perspective as represented by the boxes with rounded corners in the upper part of Figure 1.1.
Measuring influence is a complex task because there is no precise con-sensus as to what influence is and how to measure it. In the context of Twit-ter, some studies indicate that a person’s influence is related to the propa-gation and repercussion of tweets [52]. Previous literature also recognizes
Figure 1.1: Overall conceptual framework of the thesis.
that fundamental goal of any social media user is to post content that is not only shared by many users but also shared frequently [11, 15]. Based on these considerations, the influence variable is defined in this thesis by con-sidering the two most suggested attributes in literature. Figure 1.1 depicts such assumptions by grouping together the two variables in a dashed box, accordingly labeled Influence.
The relationship among the content and the influence on social media is analyzed by considering two different yet complementary perspectives, such as those of per-post and per-author. One of the most commonly weak-nesses in the literature is that analysis often relies on assumptions based on the literature on traditional media, such as television or radio. However, traditional media are based on broadcasting rather than communication, while social media are truly interactive. It is very common that influencers say something totally uninteresting and, as a consequence, they obtain lit-tle or no attention. On the contrary, if social media users are interested in something, they typically show it by participating in the conversation with a variety of mechanisms and, most commonly, by sharing the content that they have liked. A content that has had an impact on a user’s mind is shared [200]. Thus, the analysis is performed on a per-post basis and by characterizing content in terms of sentiment, inclusion of multimedia and specificity. This focus at a post level is important to make a clear separation between influence and influencers and measure the impact of content with-out a bias from the content’s author. Then, we make an effort to translate
Chapter 1. Introduction
our post-level findings into guidelines to be adopted by authors to maximize their influence. This is performed in two steps. First, we describe an empir-ical analysis investigating the relationship between content and influence by approaching content measures at an author’s level and, thus, searching for the rules that tie author-level behavioural variables and authors’ influ-ence. Second, we attempt the application of these rules in a practical case to create and promote a brand.
The organization of the thesis follows a stream of research that has been planned in order to provide subsequent steps of analysis to the overall re-search problem of this work. The following paragraphs describe the global structure of the thesis. Tourism domain has been used as a running example as it is one of the most engaged industry in the field of social networks [47]. Chapter 2 presents a critical review of the state of the art. Accordingly to the goal of this work, the chapter reviews the state of the art related to the main topics. Previous research works addressing the relationship among the variables object of this study are discussed, in particular those regarding the controversial relationship between influencers and influence. Coherently with the overall conceptual framework presented in the previ-ous paragraphs, the existing literature on the association of the concept of influence with the diversity of content is also discussed.
From the literature discussed in the chapter, a gap clearly emerges on the interconnection and the impact that content can have on the diffusion of the information on social media. The research presented in this thesis focuses on this gap.
Chapter 3 describes and analyzes in detail the developed software tools. All the modules and algorithms needed for assessing influence are dis-cussed and tested individually. Twitter, probably the most tough example that current tools are dealing with, has been used as testbed. Because we are interested in dealing with content of posts, an important source of error with which we have to deal can be identified in the irony, a significant aspect of many online texts [154]. The software component aiming at reducing the error due to irony is developed as part of this thesis and discussed in details in that chapter. As noted by Hölzer et al. [86], social media users are ac-tive in more than one social network. Based on this consideration, further software modules have been developed and tested aiming at enabling the possibility to extend the findings of this research to profiles of a same user
on different social networks.
Chapter 4 address the complex relationship existing among content of messages and influence on social media. The analysis is conducted irre-spective of the message’s author. Based on the literature on traditional media, the first set of hypotheses in the chapter states that the sentiment of the message is associated with the influence of the message itself. The second set of hypotheses suggests that the use of multimedia content may positively condition the influence of the message in terms of both temporal dynamics and volumes of sharing.
Chapter 5 provides a more comprehensive perspective of analysis to the variables addressed in this study. In particular, the chapter analyzes the problem of assessing the relationship between influence on social media and content characterized by volumes and specificity of the message, with a particular focus on the behaviour of the author. Based on the literature on public speech, the research hypotheses in the chapter posit that both volumes of content, i.e., frequency of posting activity, and specificity are positively associated with the influence. In particular, each hypothesis is further investigated in terms of more specific variables such as frequency, amplitude and persistence of sharing in order to fully understand both the quantitative and temporal aspects of influence.
Findings from the empirical assessment of influence discussed in this thesis are exploited in Chapter 6 to define a prescriptive methodology that supports effective communication providing a set of guidelines that help maximize the influence of communication messages. More specifically, our goal is that of creating and promoting a brand by means the creation of a fan page on the main social networks and exploiting the findings about influence to grow a web community. The work presented in this chapter is still ongoing and the community may be used as a testbed for our method-ology.
Finally, Chapter 7 presents a concluding discussion and analysis of the results exposed throughout the previous chapters. Some of these results are still controversial, and leave the research field open for future work, as discussed contextually.
CHAPTER
2
State of the Art
T
HIS thesis focuses on the analysis of the complex relationshipbe-tween the content of messages and their social influence irrespective of the centrality of the message’s author. This chapter introduces these aspects and reviews the related state of the art.
The chapter is organized as follow: Section 2.1 introduces the concepts of influencer and web influence. Section 2.2 presents a review of the ex-isting literature on this topic discussing the main variables used to describe social influence. More specifically, in Section 2.2.3 the state of the art re-lated to the irony detection problem is reviewed. Section 2.3 presents an introduction of the user matching task. Finally, Section 2.4 summarizes the literature gap that is the focus of this thesis.
2.1
Influence and InfluencersThe Internet has enabled a high degree of interaction among people and organizations in a bidirectional way: not only organizations can reach a large number of potential customers through spreading their content, but also people have the possibility to freely express their opinions and thoughts
Chapter 2. State of the Art
that will be easily accessible to all the Internet community, both people and organizations [62]. Moreover, the spread of Web 2.0 technologies has enabled an active role of users who are able to share content more easily than in the past. These technologies have led to the creation of services such as social networks, forums, and blogs where people write about their experiences.
In this context, the process through which users create and share opin-ions, i.e. the electronic word of mouth (eWOM), is gaining increasing at-tention. In the online context, the eWOM has been transformed from a communication act that takes place in a private to-one context to a one-to-manycomplex interaction. Just think of Twitter and its easy mechanism of retweet that enables the spread of a message in a few seconds [156].
The literature on social media makes a distinction between influencers and influence. The former are social media users with a broad audience. For example, influencers can have a high number of followers on Twitter, or a multitude of friends on Facebook, or a broad array of connections on LinkedIn. The term influence is instead used to refer to the social impact of the content shared by social media users.
The breadth of the audience was considered the first and foremost indi-cator of influence for traditional media, such as television or radio. How-ever, traditional media are based on broadcasting rather than communica-tion, while social media are truly interactive. It is very common that in-fluencers say something totally uninteresting and, as a consequence, they obtain little or no attention. On the contrary, if social media users are in-terested in something, they typically show it by participating in the conver-sation with a variety of mechanisms and, most commonly, by sharing the content that they have liked. Influencers are prominent social media users, but we cannot expect that the content that they share is bound to have high influence [24].
2.2
From Influencers to Web InfluenceThis work presents a classification of the literature about influencers and web influence based on the following types of variables:
• structural variables, i.e. based on the evaluation of the structural properties of the social network of the users. This kind of variable is mainly used to identify influencers.
• content-based variables, i.e. based on a syntactic analysis of the post.
2.2. From Influencers to Web Influence
• semantic variables, i.e. based on a semantic analysis of the post. A further goal of this kind of analysis is that to reduce the error due to the interpretation of natural language such as irony or word sense disambiguation.
2.2.1 Structural Variables
In previous literature, the characterization of a social media user as an influ-encer has been primarily based on the evaluation of the structural properties of the social network of that user. Centrality metrics are the most widely used parameters for the structural evaluation of a user’s social network. The concept of centrality has been defined as the importance of an individ-ual within a network [69]. Centrality has attracted a considerable attention as it clearly recalls notions like social power, influence, and prestige. In 1979, Freeman has introduced the first metric of centrality, called degree centrality [69]. This metric is defined as the number of links of a node normalized to the total number of links in the network. Degree centrality represents the simplest and most widely used indicator of centrality, as it is intuitive and easy to calculate [54]. A node that is directly connected to a high number of other nodes is obviously central to the network and likely to play an important role [171]. A node with a high degree centrality has been found to be more actively involved in the network’s activities [89].
The relation between nodes in a network may not be mutual and sym-metrical. Accordingly, a distinction is made between indegree and out-degree centrality, measuring the number of incoming and outgoing links, respectively [188]. This distinction is particularly useful in social networks that are built upon asymmetrical relations. For example, Twitter makes a distinction between followers and followees, to allow users to read other users’ public content without a need for mutual acquaintance or introduc-tion. On Twitter, influencers are typically measured based on their indegree centrality, i.e. their number of followers.
Due to its fame and its theoretical similarity to the concept of degree cen-trality, the PageRank score [36] has been frequently adopted to evaluate in-fluencers. Interestingly, a tweet has been found to have a larger propagation if its author has a higher PageRank score [14, 108]. The authors’ ranking provided by the PageRank algorithm has been proved to be similar to that obtained with the number of followers. However, it has been found to be different from the ranking provided by the volumes of retweets [108, 115].
These last studies have originated a stream of literature aimed at iden-tifying influencers by taking into consideration other structural metrics in
Chapter 2. State of the Art
addition to degree centrality. The alpha-centrality metric has been found to be the best performer in predicting the number of Digg votes within a set of 12 structural metrics [75, 155]. A previous study has focused on an in-depth analysis of 12 selected Twitter users in the context of the Ecology Web Project [114]. Users were identified as influencers based on their ab-solute volumes of retweets and then divided into three clusters (celebrities, social media analysts, and news providers). Results highlighted how the volumes of retweets are positively correlated with the level of users’ activ-ity (number of tweets) and their indegree centralactiv-ity (number of followers). The size of this study sample limited to 12 authors does not support gen-eralization, but has encouraged a shift of attention towards non-structural metrics.
In 2010, a first large-scale empirical study has been conducted to test the generalizability of the positive relationship between breadth of audience and influence on Twitter [24]. Empirical evidence on six million Twitter users has shown no significant statistical correlation between the number of followers and the number of retweets and mentions [24]. The authors’ interpretation of this finding is that the identification of influencers should not be based on a single metric. This interpretation is grounded on the inherent complexity of the concept of influence.
2.2.2 Content-based Variables
The more recent literature has associated the complexity of the concept of influence with the diversity of content. Several research works have ad-dressed the need for considering content-based metrics of influence [19, 134, 175]. Clearly, this view involves a significant change in perspective, as assessing influence does not provide a static and general ranking of in-fluencers as a result.
Content features such as the inclusion of mentions, URLs, or trending words have been proved to increase the ability of predicting retweeting probability [149]. The inclusion of URLs or hashtags in tweets has been extensively used in studies on information propagation to define models for predicting mentions [71], retweeting probability [19, 175], and topic adop-tion [116, 180]. Hashtags have also been considered in studies on users’ characterization [6], content categorization [112], and content-based filtra-tion [64]. A few studies have considered the categorizafiltra-tion of content, i.e. the topic of posts, to investigate the dynamics of the retweeting pro-cess [135]. Table 2.1 summarizes the content-based variables that have been previously put forward pointing to the corresponding research
contri-2.2. From Influencers to Web Influence
Table 2.1: Content-based variables and related research contributions.
Observed variables Reference
Hashtags Laniado and Mika 2010 [112]
URLs Galuba et al. 2010 [71]
Categorization of the content: self-promoting vs. sharing information
Naaman et al. 2010 [134] URLs; Hashtags Suh et al. 2010 [175] Topics; Entities (i.e., people, events, . . . ) Abel et al. 2011 [6]
URLs Bakshy et al. 2011 [19]
Social features (i.e, number of followers, friends, . . . ); Tweet features (i.e., number of hashtags,
mentions, URLs, . . . )
Petrovic et al. 2011 [149]
Hashtags; Graph topology features Tsur and Rappoport 2012 [180]
Topics Li et al. 2013 [116]
butions.
2.2.3 Semantic Variables
Opinion classification
Exploiting semantic information, as the polarity of the opinions expressed in users’ comments, can further improve the understanding of the dynamics of influence. The literature on sentiment analysis is rich. More specifically, opinion classification has always been one of the main topics in the aca-demic field of sentiment analysis [16, 31, 35, 60, 72, 78, 98, 137, 179, 192]. These works usually conduct the analysis as a text classification problem, which is done at two levels: the first one focuses at the document level, to extract a document general evaluation, while the second goes deep to the sentence level to classify each phrase into subjective and objective and the former into positive, negative and neutral.
Document-level classification is aimed at understanding the sentiment of a whole document, saying whether the overall feeling is either positive or negative. Many techniques to classify documents are based on super-vised learning methods, while there are also some approaches based on unsupervised learning. In the former case the system needs two document sets in order to compute the final value of sentiment: a training set and a test set. The literature usually uses review databases where users give a score (e.g. number of stars, likert scale evaluation) and a comment to obtain such sets [98, 145]. The work presented in [145] has classified movie reviews using Naive Bayes (NB) and Support Vector Machines (SVM), showing
Chapter 2. State of the Art
how SVM generally outperforms NB. The former is more used for movie reviews [80, 125], since training is faster, while the latter is more common in the case of Web discourse [152]. On the other hand, non-supervised algorithms use the two concepts of opinion phrase and opinion word, i.e. phrases and words which have a strong sentiment value. The work in [182] extracts contiguous couples of adjectives and adverbs, showing that these two parts of speech usually determine most of the sentiment. The choice to use words couples is done in order to find syntax patterns and to use some context to understand sentiment properly. The main features used by machine learning approaches, both supervised and non-supervised, are the following: word-frequency [81], POS-tagging [81, 133, 190], opinion word and opinion phrases [158], and the use of syntactic relations among words [61, 73, 125, 139]. The debate on effectiveness of different classifiers has been discussed also in [151].
The problem of analyzing sentences can be considered harder than that of classifying documents [198]. Similar to document classification, the lit-erature on sentence classification has focused on NB [195] and SVM [191] methods, but it has also used approaches based on classifiers, as bootstrap-ping [158], and statistics, such as logistic transformation and maximum likelihood [82], and similarity [198]. Bootstrapping [157, 158] is mainly used to automatically tag and label data, which will eventually compose the training set. Three methods to find subjective sentences, i.e. those sen-tences which contain sentiment, are described in [198]: sentence similarity, single and multiple NB classifiers. The latter techniques obtain better re-sults than the former in the case of opinion sentences while are overcome when analyzing objective phrases. In this work the problem of identify-ing sidentify-ingle word polarity is faced. In order to determine semantically ori-ented words, a log-likelihood ratio is used, to measure the co-occurrence of words with a known seed set of semantically oriented words. The final sentiment of each phrase is determined by the difference between the num-ber of found positive words and negative ones, in the same way of [100]. In this case, authors extend the work in [182], which used only singletons as seed words, varying their number, and obtaining slightly better results. In the work by Hatzivassiloglou and Wiebe [82] authors investigate on a similar problem but focusing on gradable adjectives, i.e. able to describe measurable properties such as age, height, weight, etc. Another problem, discussed in [99–101] regards the identification of reasons and helpfulness in online product reviews using maximum entropy and SVM.
The aforementioned literature has dealt with document and sentence sentiment analysis. In those cases, the main objective of the analysis is
2.2. From Influencers to Web Influence
an aggregate evaluation of sentiment at different levels. In some circum-stances, such a level of aggregation can be not detailed enough for the final objective of the analysis. For instance, a product evaluation could be nega-tive for some of its characteristics and posinega-tive for others, thus resulting in a negative overall sentiment which hides the positive opinion on some prod-uct features. Indeed, people tend to have different opinions about different features of a product [118]. Feature based sentiment analysis is aimed at (i) identifying the characteristics of the opinioned subject and (ii) evaluating the opinion for each specific characteristic. The most used techniques to extract features are Conditional Random Fields (CRF) [166], and Hidden Markov Models (HMM) [126, 166]. Yi et al. [197] used relations among words and the given topic to find a preliminary set of features, while the candidate feature selection is based on heuristics, finally the feature selec-tion is based on a mixture language model, with precision between 32% and 68%, and likelihood ratio, with precision between 68% and 100%. Liu et al. [119] used appraisal words selecting the most frequent and exclud-ing stopwords. In this way, authors show that feature selection is able to outperform a bag-of-words-based selection. The work by Su et al. [174] leverages the co-occurrence of feature words and opinion words using clus-ter analysis to assign sentiment to specific features. In particular, features are extracted among nouns and the refinement is conducted using mutual reinforcement with opinion words, taken among adjectives. More recently, Wilson et al. [194] have contributed to the field with subjectivity and con-textual polarity, indeed positive and negative words from a lexicon are used in neutral contexts. In both cases, a machine learning approach based on boosting outperformed memory-based learning and SVM, obtaining a pre-cision of 72.4% for distinguishing between neutral and polar sentences, while the precision was 74.3% for the sentiment analysis. The work by Kaji and Kitsuregawa [95] exploits the strength of massive data to obtain higher precision even in front of a lower recall to extract polar sentences start-ing from hand-made and carefully chosen language and layout structures for Japanese language, then polarity is chosen through Point-wise Mutual Information (PMI). The precision obtained is around 92%.
To our knowledge, there is a lack of works able to cover the require-ments discussed above exhaustively. Table 2.2 summarizes the reviewed literature work on sentiment analysis, classifying the work according to the main feature, i.e. opinion classification (OC), and feature extraction (FE). Moreover, algorithmic techniques are indicated.
Chapter 2. State of the Art
Table 2.2: Summary of reviewed work on sentiment analysis.
Work Main functionalities Techniques
Pang et al 2002 [145] OC SVM, NB
Greene and Resnik 2009 [80] OC SVM
Matsumoto et al 2005 [125] OC SVM
Qiu et al 2007 [152] OC NB
Turney 2002 [182] OC word frequency
Wiebe 2000 [191] OC SVM
Riloff et al. 2003 [158] OC bootstrapping
Hatzivassiloglou and Wiebe 2000 [82] OC maximum likelihood Kim and Hovy 2006, 2007 [99, 100] OC, FE maximum entropy,
SVM
Kim et al. 2006 [101] OC, FE maximum entropy,
SVM
Wilson et al. 2004 [195] OC rules, NB
Mullen and Collier 2004 [133] OC SVM, POS tagging
Whitelaw et al. 2005 [190] OC appraisal words,
POS tagging Yu and Hatzivassiloglou 2003 [198] OC NB
Mei et al 2007 [126] FE HMM
Liu et al. 2005 [118] FE patterns, word
fre-quency
Liu et al 2007 [119] FE appraisal words,
word frequency
Yi et al. 2003 [197] FE heuristics,
likeli-hood ratio
Su et al 2008 [174] FE word frequency
Wilson et al 2009 [194] FE boosting, SVM
Kaji and Kitsuregawa 2007 [95] FE PMI
Sarawagi 2008 [166] FE CRF, HMM
Irony
Data quality is a common problem in the field of ensuring quality for data to be analyzed in the context of automatic analysis, since these analyses are subject to errors due to the non-structured and semi-structured nature of Web data. In particular, extracting an opinion from a text and assessing the degree to which the opinion is positive or negative is technically error prone. An important source of error can be identified in the irony, a perva-sive aspect of many online texts [154]. According to Gibbs [76], “people comfortably use various forms of irony (i.e., jocularity, sarcasm, hyper-bole, rhetorical questions, and understatement) to convey a wide range of both blatant and subtle interpersonal meanings”. Moreover, “the speaker’s
2.2. From Influencers to Web Influence
intonation is often seen as an important clue to ironic meaning” [76] and “there appears not to be a single pattern of prosodic cues when people speak ironically” [76]. Thus, its correct identification in user generated content is made difficult by the absence of face-to-face contact and vocal intonation. As the media increasingly become more social, the problem of irony detec-tion will become even more difficult. Very little work has focused on the problem of irony identification in free text.
Kreuz and Caucci [106] studied the importance of several lexical factors in the identification of ironic/sarcastic statements. They asked some partic-ipants to read excerpts from longer narratives randomly collected through Google Books Search, and then to rate how likely it was that the writer was being sarcastic. The collected dataset contains more that 100,000 published works of a wide variety of genres including historical novels, romance nov-els, and science fiction. Google Book Search was used to find only text containing the phrase said sarcastically. The word sarcastically was re-moved, leaving just the phrase [speaker] said, before asking participants How likely is it that the speaker was being sarcastic?. A regression anal-ysis was done in order to determine whether specific lexical factors (e.g., the use of certain parts of speech, or punctuation) reliably predict readers’ perceptions of sarcasm. Results highlights how only the presence of inter-jections can be considered a good predictor.
Carvalho et al. [51] investigated the accuracy of a set of surface patterns in identifying ironic sentences in comments submitted by users to an on-line Portuguese newspaper. They collected 8,211 news and corresponding comments posted by on-line readers. For each comment, a Named-entity recognition was performed by dictionary look-up, using a NE lexicon with 1,226 names of frequently mentioned politicians. Moreover, they computed polarity of words, specifically adjectives and nouns, through an ad-hoc sen-timent lexicon with manually annotated polarities. Finally, they scanned the collection for matching each sentence containing at least one person name against a set of eight linguistic patterns (diminutive forms, demon-strative determiners, interjections, verb morphology, cross-constructions, heavy punctuation, quotation marks, and laughter expressions). Results show that it is possible to find ironic sentences with a precision ranging from 45% to 85% by exploring certain clues in user comments. More specifically, the most useful patterns are emoticons and onomatopoeic ex-pressions for laughter, heavy punctuation marks, quotation marks and pos-itive interjections.
Other works have addressed closely related problems, such as the de-tection of humorous text, hostile messages or, more generally, non-literal
Chapter 2. State of the Art
use of language [29, 178]. Birke and Sarkar [30] present an active learn-ing approach used to create an annotated corpus of literal and non-literal usages of verbs exploiting nearly unsupervised word-sense disambiguation and clustering techniques. Mihalcea and Strapparava [131] showed that automatic classification techniques can be successfully applied to the task of humor recognition. They made several classification experiments on a dataset composed of short sentences. More specifically, experiments con-sidered humor specific stylistic features (i.e., alliteration, adult slang, etc.) and content-based features (i.e., unigrams).
The works discussed above highlight and discuss interesting lexical fac-tors that can be successfully exploited in the identification of ironic state-ments. However, these works are evaluated on corpus made of formal or middle-formal texts, i.e. texts in which the structure usually follows regular structure and the vocabulary is coherent with the context/theme of the dis-cussion. This thesis generalizes these findings to texts coming from social networks that are full of slang, lack correct punctuation and is not possible to find a unique discourse tone [159, 167].
2.3
User MatchingOver the last decade, the popularity of Online Social Networks (OSNs) has grown at phenomenal rates. Prior studies have shown that users tend to have multiple aliases in multiple OSNs [86]. Being able to link users’ multi-ple online profiles facilitates analysis across different social networks [86]. This would enable the possibility to apply the per-author model of influ-ence to any social media in which a user is active, thus studying if there are differences in the dynamics of the influence.
In the past years, many studies have addressed the problem of user matching but most of the proposed methods are too restrictive and are not able to deal with the dynamics of OSNs. More specifically, these methods assume that two profiles belong to the same user only if the values of their Inverse Functional Property (e.g. the email address, homepage, etc.) are the same [63, 79, 85, 132]. Mika [132] performed matching computing the similarity between two first names. However, results show how considering only the name is not enough. Bortoli et al. [32] discuss the problem related to the weakness of the use of the email address as identifier. An email ad-dress is not a good identifier for the following reasons: (i) people change email address (change work/study institution, choose better provider, etc.); (ii) people use more than one email address depending on the context of use (work, on-line gaming and shopping, family and friends relationship,
2.3. User Matching
etc.); (iii) email addresses can act as proxies for more than one person. Other studies exploit the concept of similarity. The approach of calculat-ing a similarity score between a pair of entities has been successfully used in many areas in the past, such as string distance [28, 55] and information filtering [109]. These approaches have been extended into further applica-tions, including genetics, natural language processing and image process-ing [10, 117, 196]. Zafarani and Liu [199] provide evidence on the exis-tence of a mapping among identities across multiple communities. Based on their evaluations, it turns out that usernames can be used quite success-fully to identify corresponding users in different OSNs. The accuracy level highlights how such a simple approach can be successful for users that use similar identifiers across communities. A similar conclusion is stated by Perito et al. [147]. They investigate the feasibility of using usernames to trace or link multiple profiles across services that belong to the same indi-vidual. Experiments show that a significant portion of the users’ profiles can be linked using their usernames.
Various graph based techniques have been proposed for matching ac-counts belonging to the same real person across different social networks [79, 161–163]. Narayan and Shmatikov [136] present a framework for analyz-ing privacy and anonymity in social networks and develop an identification algorithm based purely on the network topology. They show that a third of the users who are verifiable members of both Flickr and Twitter can be recognized in the completely anonymous Twitter graph with only 12% er-ror rate. Analysing blogging websites, Golbeck et al. [79] generated Friend Of A Friend (FOAF) ontology based graphs and linked multiple user ac-counts based on several identifiers. Their framework allows users to give more importance to some attributes. Rowe and Ciravegna [162] propose a method to match users by mainly using the social circles of the users gener-ated from the FOAF files. Social circles represent a group of people linked to a central individual by some identifiable common relation. However, the proposed approach is not fully automatic since it involves the user in both selecting their key identity features and validating the retrieved informa-tion. It is worth to notice that FOAF based data might not be available for all social networks.
User profile attributes were used by the majority of the studies to iden-tify accounts belonging to the same real person. Carmagnola and Cena [49] propose to exploit a set of identification properties that are combined using an identification algorithm which computes a weighted score, and if the score is above a threshold, two profiles are marked to be matched. A simi-lar approach is proposed by Vosecky et al. [185]. They proposed a threshold
Chapter 2. State of the Art
based approach for comparing profile attributes using various string match-ing techniques to compare attributes of user profiles from Facebook and StudiVZ. The precision achieved is 83%, however the recall is omitted. A similar approach but with slightly different objective is proposed by Car-magnola et al. [50]. The algorithm receives in input the small set of known data about a specific user and returns a set of profiles associated to an iden-tification probability that represents the chance they belong to the searched user. Moreover, it returns a set of probable attributes, like user’s age, city, interests, profession, etc., obtained from the user’s data included in the re-trieved profiles.
Hauff and Friedland [83] point out how users who are active on the social networks produce digital traces continuously by posting messages, sharing videos and commenting on news items. This observation is also supported by a precedent research of Iofciu et al. [91]. Their work aims at performing likely user matches even when profile information is not enough. For a period of three months Hauff and Friedland [83] followed ap-proximately 50,000 Twitter users. Then, they tried to identify a matching Flickr account by searching tweets with URLs containing flickr.com and thus by searching Twitter user names for with the same name on Flickr. In total, only 233 verified Twitter-Flickr account matches were found. Com-pared to user name based matching, they found content based matching to be much more difficult [91]. Szomszor et al. [177] perform a cross-folksonomies profiling based on collecting all the tags used by a user on different Social Systems and using Google Social Graph API to automati-cally identify users on different services.
Some of the major limitations of the techniques discussed above are: (i) computationally expensive; (ii) manual assignment of weights and thresh-olds; (iii) experiments performed on small dataset while the real number of social networks are huge. Section 3.3 addresses these concerns.
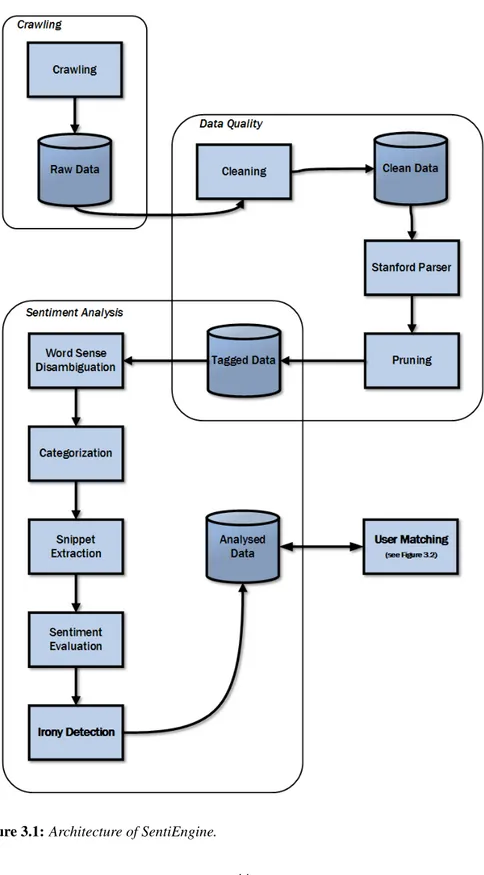
Table 2.3 summarizes the reviewed literature work on user matching, classifying the work according to the used techniques, i.e. Inverse Func-tional Property (IFP), nickname matching (NM), graph based (GB), profile information (PI) and digital traces (DT).
2.4
Literature gapThis chapter has reviewed the literature in different fields related to the do-main of application of this thesis. The literature on social media makes a distinction between influencers and influence. As discussed in the previous sections, the literature mainly focuses on the concept of influencers, while
2.4. Literature gap
Table 2.3: Summary of reviewed work on user matching.
Work Techniques
Ding et al. 2005 [63] IFP
Mika 2005 [132] IFP
Hogan and Harth 2007 [85] IFP Goldbeck and Rothstein 2008 [79] IFP, GB Rowe and Ciravegna 2008 [162] GB
Rowe 2009 [161] GB
Rowe et al. 2009 [163] GB Narayan and Shmatikov 2009 [136] GB Zafarani and Liu 2009 [199] NM Perito et al. 2011 [147] NM Carmagnola and Cena 2009 [49] PI Vosecky et al. 2009 [185] PI Carmagnola et al. 2010 [50] PI Szomszor et al. 2008 [177] DT Iofciu et al. 2011 [91] DT Hauff and Friedland 2012 [83] DT
the relationship between content and influence is rather unexplored. This thesis takes a behavioural perspective by investigating characteristics of content that are an outcome of behavioural decision made by social media users. This work proposes a model that helps users make their behavioural choices to increase their influence. This need is widely recognized among companies, which should be able to rely on dependable guidelines to im-prove their social media presence and create tangible business value [113]. The assessment of influence is performed both from a post and per-author perspective.
A further goal of this work is to increase the performance of sentiment analyses from a data quality perspective. This thesis has built a set of mod-ules that increase the quality of the analysis of non-structured data, coming from social network discourse, which is hard to be computed by literature and industrial tools. In this work the sentiment analysis process is modified with the introduction of a module aiming at reducing the error due to irony. Finally, the literature has highlighted that users tend to have multiple aliases in multiple OSNs [86]. A set of both well-known and brand new metrics have been defined in order to match users on different social net-work. This would enable the possibility to apply the per-author model of influence to any social media in which a user is active, thus studying if there are differences in the dynamics of the influence.
CHAPTER
3
System Architecture
T
HIS thesis aims to provide evidence about the role of the content ofmessages in their social influence. Most companies concur that the analysis of the Web could provide invaluable insights for their busi-ness, as a very large, rich, and constantly updated knowledge base. Unfor-tunately, managers also believe that existing tools are immature and, since critical decisions would be taken on the basis of Web information, they are admittedly cautious [144]. The tools supporting the automated analysis of Web data are very complex and building such tool represents an open re-search challenge. The objective of the work described in this chapter is to face this research challenge.
Existing tools for web analyses can be divided into two categories: se-mantic and non sese-mantic. The first (Nielsen BuzzMetrics, Conversition Evolisten, SAS Teragram, and Insight) base their evaluation of the con-tent of Web information on the semantic interpretation of natural language. The second (Radian6, BuzzLogic) base their competitiveness on the vastity of the Web information that they consider (high number of sources), but provide a gross evaluation of the content that is obtained without an under-standing of the semantic of the content itself. This research takes the first
Chapter 3. System Architecture
approach and proposes targeted improvements of the semantic processing of social information.
The automated interpretation of natural language is still subject to error, but has reached enough quality to find broad application in document man-agement and knowledge manman-agement applications. In this respect, Web information raises new challenges related to the low quality of text of Web conversations. If text comes from official information, such as online news-papers, it can be assumed to be reliable, mostly well-written and easy to interpret. If it comes from Web 2.0 sites, such as microblogging, it must be cleaned before interpretation. This data cleaning component represents the first critical component that is missing in most existing tools and is imple-mented and tested as part of this research work [40].
Furthermore, as well pointed out in a special report published by the Economist on February 27th 2010 [59], one of the biggest challenges for future ICTs is overcoming the massive information overload due to the in-creasing availability of data acquisition and exchange. As a consequence, the definition of feasible methods able to both assess the quality of the in-formation and to evaluate its relevance to specific tasks is crucial. In the relevance evaluation, semantic tools are assumed to provide more depend-able evaluation compared to non semantic tools. The software necessary to activate the semantic interpretation of natural language represents the second component that is implemented and tested as part of this research work [21].
It is necessary to observe that data quality is a key variable for these tools, since these analyses are subject to errors due to the non-structured or semi-structured nature of Web data. In particular, extracting an opinion from a text and assessing the degree to which the opinion is positive or negative is technically error prone. An important source of error can be identified in the irony, a significant aspect of many online texts [154]. Its correct identification is made difficult by the absence of face-to-face contact and vocal intonation. As the media increasingly become more social, the problem of irony detection will become even more difficult. A software component aiming at reducing the error due to irony is developed as part of this work (see Section 3.2).
Today, it is common that people are users of more than one social net-work. Linking users’ multiple online profiles facilitates analysis across dif-ferent social networks [86]. Companies find this kind of matching inter-esting since it would allow them to better profile their customers. On the other hand, it helps in detecting and protecting users from various privacy and security threats arising due to vast amount of publicly available user
3.1. Basic System Modules
Table 3.1: Resources used by each software module.
Module Resources
Crawling Twitter, Facebook
Cleaning NoSlang [3], Freebase [1], WordNet [67] Pruning Google Dictionary [2], WordNet [67] Word Sense Disambiguation Domain Data, WordNet [67]
Categorization Domain Data Sentiment Evaluation SentiWordNet [66]
information [123]. Prior studies have shown that individuals tend to have multiple aliases [86]. In this work, we discuss the analysis and results from applying automated classifiers for matching users’ profiles across differ-ent social networks, in an attempt to rationalize semantic analysis and help reduce the information overload problem pointed out in [59].
The software components that will be discussed in detail in the remain-ing of this chapter can provide insights from both a practical and a scientific standpoint.
3.1
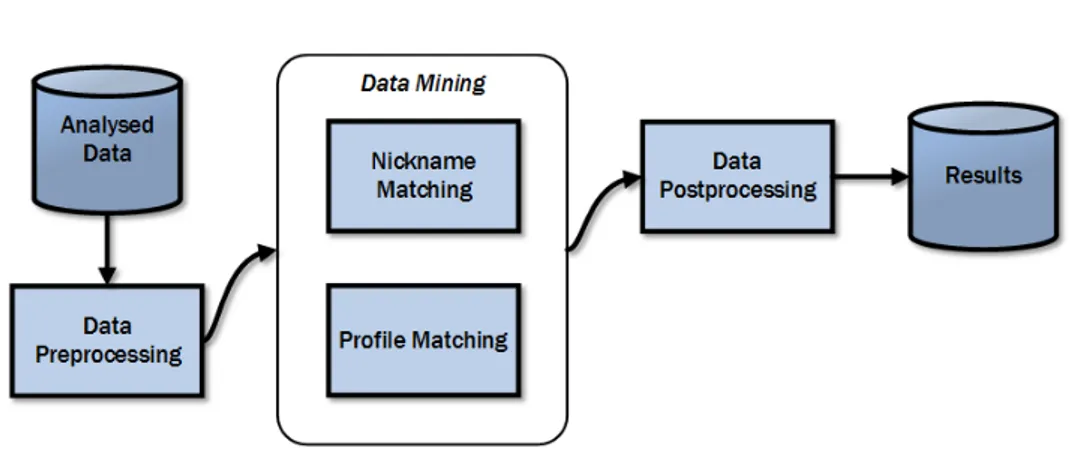
Basic System ModulesThe architecture of the developed tool1, called SentiEngine, is designed to
leverage data quality techniques to select information sources and to obtain clean data. The overall architecture of SentiEngine is shown in Figure 3.1, while Table 3.1 reports the external resources used by each software mod-ule.
Crawling module
The crawling module can be considered a standard part of many applica-tions. It is needed to populate the database of raw data that will be pro-cessed in the data quality phase. Table 3.1 shows the example in the tourism domain with two main information sources.
Data quality module
In the case of SentiEngine, the architecture of the data quality module is centered on the correctness of data. SentiEngine contains a set of modules that act directly on data to ensure a better quality. The aim of such modules
1The contents of this section is the result of a joint research work conducted with Donato Barbagallo at
the Department of Electronics, Information and Bioengineering of Politecnico di Milano. As a consequence, the results presented in that section overlap those presented by Barbagallo [20] and Bruni [40] and should be considered as a starting point for the results in the remaining of this thesis.
Chapter 3. System Architecture
3.1. Basic System Modules
is to help the Stanford parser [102], i.e. the syntactic parser used in the ap-plication, to perform a correct syntactic analysis. In order to raise the over-all data quality, the system performs two steps: (i) the cleaning phase [40], through which it tries to recover sentences containing spelling errors or data which would make the parser fail, such as emoticons or URLs; this phase is needed not to have levels of recall that could be too low because of the following pruning phase; (ii) subsequently, the pruning module [20] tries to discard those sentences whose syntactic analysis is probably wrong, e.g. adverbs tagged as nouns. This operation is based on a set of rules that are used to prune data. The rules are semantic, e.g., based on disambiguation. All the data that will be considered compliant to the rules will be entered into the tagged data database, i.e. data are decorated with POS tagging in-formation. In this phase the support of a rich and updated vocabulary is fundamental, because, even if some sources’ language can be consistent with the context, such as TripAvisor and LonelyPlanet in the tourism do-main, other sources, such as Twitter, are general and are not restricted to a small set of words. For this reason even words belonging to many do-mains must be recognized, thus SentiEngine uses a semantic network as WordNet [67], and vocabularies as NoSlang [3], GoogleDictionary [2], and FreeBase [1] in order to resolve slang expressions, find words which are not included in WordNet, e.g., pronouns like anyone, and have a good database for proper nouns, respectively.
Sentiment analysis module
Tagged data are passed to the sentiment analysis module. Sentiment anal-ysis is supported by a domain knowledge database that is used by a cat-egorization module that will assign the sentence to the correct classifica-tion. Then, the snippet extraction module is in charge of extracting the words that carry some sentiment. SentiEngine’s sentiment analysis mod-ule is complex, since it is in charge to perform disambiguation [21] and irony detection (see Section 3.2). This task is carried out using domain data that integrate WordNet and help in the classification of sentences and re-lated portions of text. Sentiment is assigned through a global evaluation of the sentence using SentiWordNet [66], a database of sentiment annotated words, where all the lemmas, including adjective, verbs, nouns, and adverbs are tagged with a sentiment value. In this way, SentiEngine is able to give a sentiment value even when the sentiment is not carried only by adjectives. Finally, the sentiment is weighed according to the metrics calculated by the source weightingmodule and influencers are found (see Section 3.3).
Chapter 3. System Architecture
3.2
Extended Module: Irony IdentificationWe investigate the accuracy of a set of patterns in identifying ironic sen-tences in Twitter and using these patterns to improve the quality of our sentiment analysis module. We adopt the term irony for referring to the specific case where a word or expression with prior positive polarity is used for expressing a negative opinion or viceversa. The focus is on identifying irony in sentences containing sentiment since these sentences are more ex-posed to irony, thus representing an important source of error for tools like SentiEngine. We show that it is possible to identify ironic sentences with relatively high precision by exploring certain clues in user tweets, such as emoticons, onomatopoeic expressions, heavy punctuation marks and quo-tation marks.
3.2.1 Preliminary Analyses
A preliminary manual analysis of a dataset of tweets is conducted in order to identify which clues can be better used to identify ironic sentences in Twitter. The framework for the irony detection task is built upon the result of this preliminary analysis.
The initial dataset is composed of the tweets published in the last quarter of 2011 and belong to a tourism context. More specifically, the analysed tweets are those identified by SentiEngine according to the following con-ditions: (i) the tweet is related to the city of Milan; (ii) the tweet contains at least one opinion with sentiment. It is worth to notice that in a single tweet it could be possible to find more than one opinion and even of different polarity. Then, we build three subsets of about 500 tweets. Each subset is composed of tweets that contain a specific irony clue and it is filled start-ing from the oldest posted tweet to the most recent one till the size of 500 tweets is reached. The considered clues are: emoticons, onomatopoeic ex-pressions and heavy punctuation.
The dataset related to the emoticons is characterized by the following statistics:
• 424 tweets (84.63%) express at least a positive opinion; • 80 tweets (15.97%) express at least a negative opinion; • 498 tweets (99.40%) contain at least a positive emoticon; • 7 tweets (1.40%) contain at least a negative emoticon.
3.2. Extended Module: Irony Identification
The statistics are consistent with the literature. Indeed, the literature pro-vides evidence that social media users tend to be self-promoting by gener-ating a higher number of messages with a positive sentiment [27,92]. More specifically:
• 422 positive tweets (84.23%) contain a positive emotion; • 5 positive tweets (1.00%) contain a negative emotion; • 79 negative tweets (15.77%) contain a positive emotion; • 2 negative tweets (0.40%) contain a negative emoticon.
A more in-depth analysis highlights that the presence of an emoticon inverts the polarity of 9 positive tweets and 70 negative ones.
Onomatopoeic expressions are the transposition of sound in a written form. Contrary to the case of emoticons, onomatopoeic expressions cannot be classified as positive or negative by themselves. Indeed, their polarity is given by the context in which they are used. The dataset related to the Onomatopoeic expressions is characterized by the following statistics:
• 328 tweets (65.21%) express at least a positive opinion; • 175 tweets (34.79%) express at least a negative opinion. A more in-depth analysis highlights the following:
• the polarity of 322 positive tweets does not need to be inverted; • the polarity of 2 negative tweets does not need to be inverted; • the polarity of 6 positive tweets needs to be inverted;
• the polarity of 173 negative tweets needs to be inverted.
Finally, the preliminary analysis about heavy punctuation does not high-light any useful hint to address the problem of irony identification. Indeed, only the presence of heavy punctuation in a tweet seems not to be enough to identify an ironic sentence.
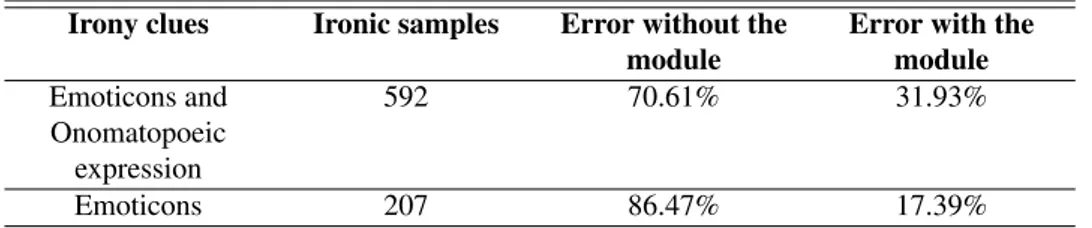
Analyses highlight how irony affects negative sentences more than pos-itive ones. Indeed, taking as example the case of emoticons, 70 negative tweets out of 80 need an inversion of the polarity (87.50%). On the con-trary, only 9 positive tweets out of 424 need an inversion of the polarity (0.02%). This observation leads us to define the rule shown in Table 3.2. The following section will provide an empirical evaluation of this rule.
Chapter 3. System Architecture
Tweet polarity Positive (+) Negative (-) Emoticon Positive (+) Do not invert Invert
Negative (-) Do not invert Do not invert Table 3.2: Rule aiming at reducing the error due to irony.
3.2.2 Empirical Testing
The irony detection and correction module takes as input the result of the main module of SentiEngine (see Figure 3.1). Thus, each instance of the input of this module is a single tweet enriched with information about cate-gorization and polarity. As discussed in the previous sections, both catego-rization and polarity are operations that are performed on a per-word basis. Thus, for instance a single tweet is not positive itself, but it may contain a positive opinion about a particular concept expressed in the text of the message. The same tweet may contain also a negative opinion or other pos-itive opinions. Consistent with the overall tool, the irony detection module works on a per-word basis.
This test is based on a sample of tweets collected in the last quarter of 2011. The collection of tweets has been performed by querying the public Twitter APIs by means of an automated collection tool developed ad-hoc. Twitter APIs have been queried with the crawling keyword “Milan”. The English language is considered. Collected tweets have been first analyzed with the semantic engine in order to categorize the content of each tweet. Only tweets containing the keyword “Milan” with the meaning of touris-tic destination are taken into account. The final dataset counts 1,476,411 tweets. Among them, 70,409 tweets contain at least a positive opinion and 16,412 tweets contains at least a negative opinion. Once again these statis-tics are consistent with the literature, showing that social media users tend to be self-promoting by generating a higher number of messages with a positive sentiment [27, 92].
The module works according to the Algorithm 1 where DS is the whole dataset, containsOpinion(tweet) is a function that states if the tweet con-tains at least an opinion, and applyIronyRule(opinion, emoticon) applies the rule defined in Table 3.2. The algorithm used for the onomatopoeic ex-pression follows the same schema.
Table 3.3 reports the results of the test. It is possible to note how the error undergoes an algebraic reduction of about 38% in the case that both emoticons and onomatopoeic expressions are used as clues for the detection of irony. The reduction is further increased up to 69% if we consider only