Efficient Distributed Load
Balancing for Parallel Algorithms
Biagio Cosenza
November 2010
Dottorato di Ricerca in Informatica
IX Ciclo Nuova Serie
Universit`
a degli Studi di Salerno
Supervisor
PhD Program Chair
Supervisor
Prof. Vittorio Scarano, Dip. di Informatica, Universit`a degli Studi di Salerno, Italy PhD Program Chair
Prof. Margherita Napoli, Dip. di Informatica, Universit`a degli Studi di Salerno, Italy PhD Committee
Prof. Domenico Talia, Universit`a della Calabria, Italy
Prof. Marco Faella, Universit`a degli Studi di Napoli Federico II, Italy Prof. Alfredo De Santis, Universit`a degli Studi di Salerno, Italy Dean
Prof. Alberto Negro, Dip. di Informatica, Universit`a degli Studi di Salerno, Italy
Thesis submitted on November 30th, 2010 Date of defense April 29th, 2011
Biagio Cosenza
ISISLab, Dip. di Informatica Universit`a degli Studi di Salerno
Via Ponte don Melillo, 84084 Fisciano (Salerno), Italy [email protected]
Abstract
With the advent of massive parallel processing technology, exploiting the power offered by hundreds, or even thousands of processors is all but a trivial task. Computing by using multi-processor, multi-core or many-core adds a number of additional challenges related to the cooperation and communication of multiple processing units.
The uneven distribution of data among the various processors, i.e. the load imbalance, represents one of the major problems in data parallel applications. Without good load distribution strategies, we cannot reach good speedup, thus good efficiency.
Load balancing strategies can be classified in several ways, according to the methods used to balance workload. For instance, dynamic load balancing algo-rithms make scheduling decisions during the execution and commonly results in better performance compared to static approaches, where task assignment is done before the execution.
Even more important is the difference between centralized and distributed load balancing approaches. In fact, despite that centralized algorithms have a wider vision of the computation, hence may exploit smarter balancing tech-niques, they expose global synchronization and communication bottlenecks in-volving the master node. This definitely does not assure scalability with the number of processors.
This dissertation studies the impact of different load balancing strategies. In particular, one of the key observations driving our work is that distributed algorithms work better than centralized ones in the context of load balancing for multi-processors (alike for multi-cores and many-cores as well).
We first show a centralized approach for load balancing, then we propose sev-eral distributed approaches for problems having different parallelization, work-load distribution and communication pattern. We try to efficiently combine sev-eral approaches to improve performance, in particular using predictive metrics to obtain a per task compute-time estimation, using adaptive subdivision, im-proving dynamic load balancing and addressing distributed balancing schemas. The main challenge tackled on this thesis has been to combine all these ap-proaches together in new and efficient load balancing schemas.
We assess the proposed balancing techniques, starting from centralized ap-proaches to distributed ones, in distinctive real case scenarios: Mesh-like com-putation, Parallel Ray Tracing, and Agent-based Simulations. Moreover, we test our algorithms with parallel hardware such has cluster of workstations, multi-core processors and exploiting SIMD vectorial instruction set.
Finally, we conclude the thesis with several remarks, about the impact of distributed techniques, the effect of the communication pattern and workload distribution, the use of cost estimation for adaptive partitioning, the trade-off fast versus accuracy in prediction-based approaches, the effectiveness of work stealing combined with sorting, and a non-trivial way to exploit hybrid CPU-GPU computations.
Keywords: parallel computing, load balancing, distributed algorithms, adaptive subdivision, dynamic load balancing, scheduling, scalability, task sort-ing, work stealsort-ing, agent-based simulations, Reynolds’s behavioral model, mesh-like computation, ray tracing algorithms, parallel ray tracing, image space tech-niques, path tracing, Whitted ray tracing, SIMD parallelism, message passing, multi threading, GPU techniques
Acknowledgments
This dissertation could not have come about without the help and support of many people.
First, I would like to thank my advisor, Prof. Vittorio Scarano.
He has taught me how to articulate my ideas and how to step back to see the bigger picture. Particularly, I appreciate the freedom he gave me to explore my ideas; while this freedom has taken me down some garden paths, it has taught me a lot about the research process and strengthened my skills as a researcher. Moreover, the most important contribution that he has made in my life is that he has taught me how important is to have fun in my job.
I would like to express my gratitude to all members of the ISIS Research Lab: Gennaro, Rosario, Delfina, Raffaele, Bernardo, Ugo, Ilaria and Pina – and Prof. Alberto Negro and Filomena De Santis. A special mention is to Gennaro Cordasco, for his useful feedback and suggestions on my thesis, and to Rosario De Chiara, with his hints and fancy graphs.
There are several friends who I should thank for making my stay in Salerno enjoyable. Is a long list, comprising Edoardo, Raffaele, Pina, Nazario, Terry, my PhD mates, and many others countless friends.
A Dankesch¨on is to Prof. Carsten Dachsbacher, for patiently teaching me most of the bells and whistles of computer graphics. I entered the field of graphics with few prior experience, and he took me on and was patient as I learned the ropes. Working with him has been a wonderful learning experience, and I appreciate the time and effort he has taken to improve my work.
I should greatly appreciate people at VISUS in Stuttgart, especially Prof. Thomas Ertl for hosting me in several projects and thereby introducing me into his group, Guido Reina for letting me feel at home, Gregor, Filip, Sven, Michael and Thomas for many helpful discussions, and all other people at VISUS that have certainly broadened my view and made my stay there a great experience. I would like to thank the PhD Committee members for kindly accepting to review this thesis.
I have to mention many other people (in random order): Alexander Schultz and Rainer Keller from HLRS Stuttgart, for always helping out once help was needed during the two HPC-Europa Projects; Manta team from University of Utah for sharing their code on ray tracing and for their feedbacks; Bj¨orn Knafla from Universit¨at Kassel, for its insightful thoughts on Agent-based Simulation; Ursula Habel from IZ Stuttgart, for being helpful during the DAAD Scholarship; Elena Orsini from Universit¨at Hohenheim, for her invaluable friendship; Gio-vanni Erbacci from CINECA Bologna for his helpful support with both ISCRA and HPC-Europa grants; Roberto Ciavarella from ENEA Portici for his quick solutions to my complex setup problems at ENEA Grid; the Italians group in Stuttgart for their nice Stammtisch.
My work has been funded by several grants: HPC-Europa++, HPC-Europa2, a DAAD (Deutscher Akademischer Austausch Dienst) Scholarship, and a IS-CRA Cineca. I want to thank people behind these organizations for offering similar opportunities.
Last but not least, I would like to thank my family: my father Fabio, my mother Caterina, and my little brother Giuseppe.
Beyond people, I have a final thanksgiving for a place. A place where I had inspiring thoughts and ideas, where friendly people always have something to tell and ask, and their smiles made my time there valuable. This place is my hometown, la Calabria.
Contents
1 Introduction 15
1.1 Introducing Parallel Computing . . . 16
1.1.1 The Need of Parallel Computing . . . 16
1.1.2 Why Now? . . . 17
1.1.3 Parallel Architectures . . . 17
1.1.4 Scalability and Efficiency . . . 20
1.1.5 Challenges on Parallel Programming . . . 22
1.2 Why do we care about Load Balancing? . . . 23
1.2.1 The Problem of Load Balancing . . . 23
1.2.2 Aspects of Load Balancing . . . 24
1.2.3 Intuition: Distributed Load Balancing is More Efficient . 25 1.3 Previous work . . . 25
1.4 Contributions of This Dissertation . . . 27
1.4.1 Assessing Load Balancing Algorithms in Real Applications 27 1.4.2 Parallel Ray Tracing . . . 28
1.4.3 Agent-based Simulation . . . 28
1.4.4 Organization of the Thesis . . . 29
2 Load Balancing on Mesh-like Computations 31 2.1 Introduction . . . 31
2.1.1 Mesh-like computations . . . 32
2.1.2 Our result . . . 33
2.1.3 Previous Works . . . 34
2.2 Our Strategy . . . 35
2.2.1 The Prediction Binary Tree . . . 36
2.3 Case study: Parallel Ray Tracing . . . 40
2.3.1 Exploiting PBT for Parallel Ray Tracing . . . 43
2.4 Experiments and Results . . . 43
2.4.1 Setting of the experiments . . . 44
2.4.2 Results . . . 45
2.5 Conclusion . . . 50
3 Load Balancing based on Cost Evaluation 53 3.1 Introduction . . . 54
3.2 Previous Work . . . 55
3.3 Overview . . . 56
3.4 The Cost Map . . . 57
3.4.1 Rendering Cost Evaluation . . . 58
3.4.2 A GPU-based Cost Map . . . 58
3.4.3 Cost Estimation Error Analysis . . . 61
3.5 Load Balancing . . . 63
3.6 Implementation . . . 65
CONTENTS
3.6.2 Work Stealing . . . 65
3.6.3 Multi-threading Parallelization for Multi-core CPUs . . . 66
3.6.4 Network and Latency Hiding . . . 68
3.6.5 Asynchronous Prediction . . . 68
3.7 Results . . . 68
3.8 Discussion . . . 70
3.9 Conclusion . . . 73
4 Distributed Load Balancing on Agent-Based Simulations 77 4.1 Introduction . . . 78
4.1.1 Related work . . . 79
4.1.2 Our Result . . . 81
4.2 Background . . . 81
4.2.1 Behavior Model . . . 81
4.2.2 Parallel Agent Simulation . . . 82
4.3 Agents partitioning . . . 82
4.3.1 Handling the boundary . . . 83
4.3.2 Special Cases . . . 84
4.4 Distributed load balancing schemes . . . 85
4.4.1 Static partitioning (static) . . . . 86
4.4.2 Region wide load balancing (dynamic1) . . . . 86
4.4.3 Mitigated region wide load balancing (dynamic2) . . . . . 86
4.4.4 Restricted assumption load balancing (dynamic3) . . . . . 87
4.4.5 Generalization to multiple workers . . . 88
4.5 Tests and performances . . . 88
4.5.1 Test setting . . . 88
4.5.2 Load balancing analysis . . . 89
4.6 Conclusion . . . 92
5 Conclusion: Lesson Learned 95 A Listing of test hardware platforms 99 A.1 HLRS, Universit¨at Stuttgart . . . 99
A.2 ENEA Supercomputing, Portici . . . 99
A.3 VISUS Stuttgart . . . 100
A.4 ISISLab, Universit`a degli Studi di Salerno . . . 100
A.5 CINECA Supercomputing, Bologna . . . 101
B List of Related Publications 103
List of Figures
2.1 Interaction between components of a parallel scheduler using a
Predictor . . . 33
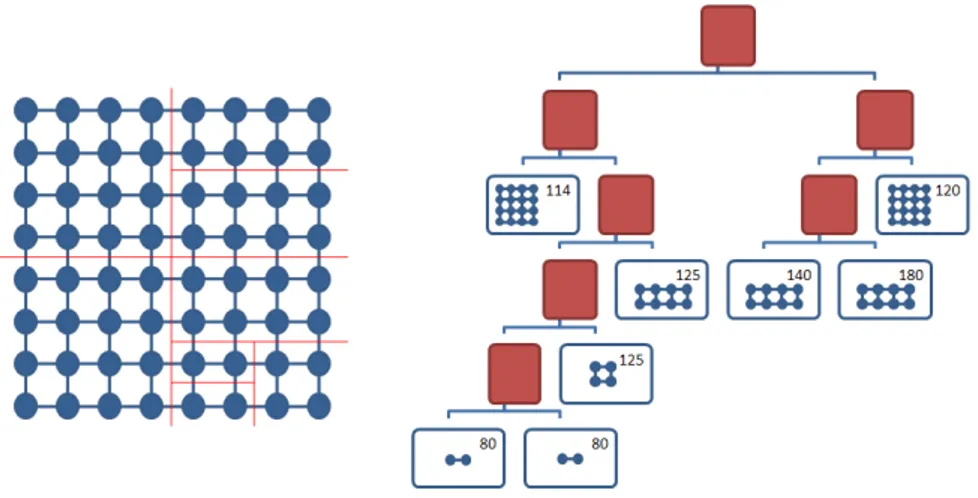
2.2 An example of a PBT tree . . . 37
2.3 A merge and split operation on the PBT tree . . . 39
2.4 A frame in the walk-trough for scene ERW6-4 . . . 44
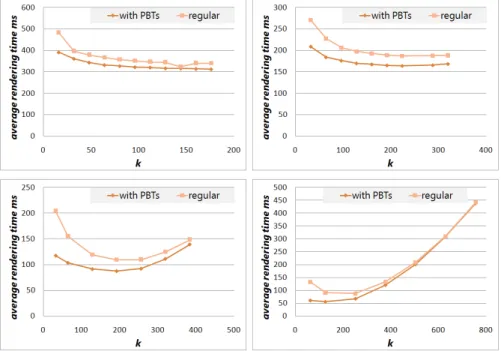
2.5 Average per frame rendering time on increasing k, comparing regular and PBT-based job assignments . . . 45
2.6 Optimal subdivision granularity with both regular and PBT sub-division . . . 46
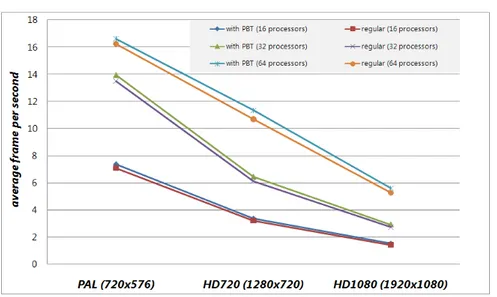
2.7 Scalability of the PBT-based approach . . . 48
2.8 Amphitheater test scene . . . 48
2.9 Average frame rate using different resolutions . . . 50
2.10 Contributions in rendering time with 32 and 64 processors . . . . 51
3.1 Example of rendering, cost map, tiling and GPU-based images used in this work . . . 54
3.2 A comparison of the real cost and our GPU-based cost estimate . 57 3.3 Estimating the rendering cost . . . 59
3.4 Sampling pattern . . . 61
3.5 Off-screen geometry problem . . . 62
3.6 Error distribution of the estimation . . . 63
3.7 Work stealing and tile assignment . . . 66
3.8 Multi-threading with tile buffering . . . 67
3.9 Summary of the parameters used for rendering and cost map computation . . . 70
3.10 Steal transfers analysis . . . 70
3.11 Scalability for up to 16 workers measured for the Cornell box . . 72
3.12 Images rendered with our parallel ray tracer . . . 74
3.13 Effectiveness of the cost map generation in different test scenes . 76 4.1 Agent-based Simulation snapshots . . . 80
4.2 The simulation carried out on 4 workers . . . 81
4.3 Load balancing with two workers . . . 83
4.4 Four cases for agent position when moving to a new simulation step. . . 84
4.5 Load balancing with multiple workers . . . 87
4.6 Distribution of agents per worker . . . 88
4.7 Number of agents per worker . . . 90
List of Tables
2.1 Results of the predictions in 85th, 90th and 95th percentile. . . . 47
2.2 Description of the test scenes used for spatial coherence tests . . 49 3.1 Cost map computation timings . . . 61 3.2 Performance comparison for our four test scenes . . . 75 3.3 Exploiting multi-threading scalability with a different number of
threads and setups . . . 75 3.4 Scalability for the Cornell box test scene using different balancing
techniques . . . 75 4.1 Load balancing/communication results . . . 94
List of Algorithms
1 PBT-Update . . . 38
2 Approximated cost map computation algorithm . . . 60
3 The SAT-tiling algorithm . . . 64
1
Introduction
In 1965 Gordon Moore made a prediction about the semiconductor industry that has become the stuff of legend. Moore’s Law predicted the incredibly growth that the semiconductor industry has experienced over the last 50 years [70]. Starting from nothing, it has now passed $200 billion in annual revenue and Moore’s Law has become the foundation of a trillion-dollar electronics industry. However, many parameters relating to the industry have changed almost expo-nentially with time, including chip complexity, chip performance, feature size, and the numbers of transistors produced each year. Several times in the past, it appeared that technological barriers such as power consumption would slow or even stop the growth trends.
Lately, the same Moore [71] admitted that a new, more fundamental barrier is emerging that the technology is approaching atomic dimensions, raising all sorts of new challenges. He said:
No exponential change of a physical quantity can, however, con-tinue forever. For one reason or another something limits concon-tinued growth. For our industry many of the exponential trends are ap-proaching limits that require new means for circumvention if we are to continue the historic rate of progress.
Nevertheless, Moore’s Law is not dead yet. The number of transistors on modern processors continues to double every 18 months, but those transistors are now just manifesting themselves as additional processing cores.
In single-core processor1, one way to increase performance is to increase
clock rates, but with heating and energy concerns, that only goes so far. The increased density of multi-core processors 2 allows each core to be clocked well
below its theoretical maximum, which assists with heat dissipation and power management.
Despite, in the past, the promise of parallelism has fascinated researchers, for at least three decades single-processor computing always prevailed. Such a
1
Here the term indicates a single processor with a single core
2
An architecture that supports multiple cores in a single processor package that replicates the cache coherent, shared address space architecture common to traditional multi-processor computers. Typically, multi-core processors put multiple cores in a given thermal envelope and emphasize the best-possible single-thread (or single-core) performance [59]
CHAPTER 1. INTRODUCTION
switch to parallel microprocessors is a milestone in the history of computing and the new belief now is that the number of cores on a chip doubles with each silicon generation.
In this new era, programmers who care about performance must get up off their recliners and start making their programs parallel. Today, increasing parallelism is the primary method of improving performance.
A major reason slowing deployment of parallel programs is that efficient parallel programs are difficult to write. Parallel programming adds a second di-mension to programming: not just when will a particular operation be executed, but where, i.e. what processor will perform it. A vast number of parallelizable applications do not have a regular structure for efficient parallelization. Such applications require load balancing to perform efficiently in parallel. The load in these applications may also change over time, requiring rebalancing. The programmer is left with the choice of either distributing computation naively, producing poorly-performing programs, or spending more development time in-cluding load balancing code in the application.
1.1 Introducing Parallel Computing
1.1.1
The need of Parallel Computing
Nowadays, there is a strong need for computational power.
CFD (Computational Fluid Dynamics) applications require millions of cal-culations to simulate the interaction of liquids and gases with surfaces defined by boundary conditions. Even with high-speed supercomputers, only approximate solutions can be achieved in many cases. Numerical weather prediction uses cur-rent weather conditions as input into mathematical models of the atmosphere to predict the weather. In order to handle such as huge datasets and to perform complex calculations on a resolution fine enough to make the results useful, some of the most powerful supercomputers in the world are required. In chemistry, MD (Molecular Dynamics) simulations, in which atoms and molecules are al-lowed to interact for a period of time by approximations of known physics, give a view of the motion of the particles. This kind of simulation may involve from few thousand to millions of atoms. The huge datasets used by bioinformatics and astrophysics need time-consuming algorithms for their analysis. Compu-tational finance utilizes various compuCompu-tationally intensive methods like Monte Carlo simulations, in order to understand financial risk of a specific financial instrument.
These represent just a fast outlook to a wide and growing area of applications for high performance computing, all having a strong need of computational power.
Simultaneously, the only way to assure higher compute availability is towards parallel computing. Hence, future high performance hardware will be inherently parallel, exposing together several forms of parallelism, such as (well known) multi-processors and (new) many-cores.
1.1. INTRODUCING PARALLEL COMPUTING
Luckily, real world applications are naturally parallel. But unluckily, parallel programming is hard.
Computing with multiple processors involves the same effort we had when computing single processor, but yet adds a number of new challenges related to the cooperation and communication of multiple processors. None of these new factors are trivial, giving a good reason of why scientist and programmers find parallel computing so challenging.
1.1.2
Why Now?
Researchers are discussing in deep this step toward parallel architectures and its impact in hardware and software [3]. In fact, today three walls are forcing microprocessor manufacturers to bet their futures on parallel microprocessors: the Power wall, the Memory wall [108] and the Instruction Level Parallelism (ILP) wall.
In the past, we stated that power is free but transistors are expensive. Now a Power wall let us deduce the opposite: power is expensive, but transistors are free. Hence, we can put more transistors on a chip than we have the power to turn on. This forces us to concede the battle for maximum performance of individual processing elements, in order to win the war for application efficiency through optimizing total system performance.
The Memory wall, i.e. the growing disparity of speed between CPU and memory outside the CPU chip [108], would become an overwhelming bottleneck in computer performance and it will change the way to optimize programs. Thus, multiply is no longer considered a harming slow operation, if compared to load and store.
Similarly, there are diminishing returns on finding more ILP [55].
Furthermore, performance improvements do not yield both lower latency and higher bandwidth, this because (across many technologies) bandwidth improves by at least the square of the improvement in latency [82].
It is clear that many-core 3 is the future of computing. Furthermore, it is unwise to presume that multi-core architectures and programming models suit-able for 2 to 32 processors (or cores) can incrementally evolve to serve systems equipped with more than 1,000 processors. The elaborate tuning of next gener-ation hardware let us suppose that auto-tuner tools should be more important than conventional compilers in translating parallel programs.
1.1.3
Parallel Architectures
In this thesis, we exploit several kinds of parallel architectures. In Appendix A, we show a list of hardware platforms used. We tried to exploit parallelism in
3
The term many-core indicates to an architecture that supports multiple cores in a single processor package where the supporting infrastructure (interconnect, memory hierarchy, etc) is designed to support high levels of scalability, going well beyond that encountered in multi-processor computer. Many-core multi-processors put more cores in a given thermal envelop than the corresponding multi-core processors, consciously compromising single-core performance in favor of parallel performance [58].
CHAPTER 1. INTRODUCTION
different ways, using different parallel programming paradigms (e.g. message passing, multi threading and vectorial instructions) and hardware architectures (e.g. cluster of workstations with distribute memory and multi-core with shared memory).
Processing element and processor We often use the word processor. How-ever, sometime is more indicated the generic term processing element. A process-ing element refers to a hardware element that executes a stream of instructions. The context defines what unit of hardware is considered a processing element (e.g. core, processor, or computer). Note that the context depends on both hardware and software platform configuration. For example, let us consider a cluster of SMP workstations. In some programming environments, each work-station is viewed as executing a single instruction stream; in this case, a pro-cessing element is a workstation. A different programming environment running on the same hardware, however, may view each processor or core of the indi-vidual workstation as executing an indiindi-vidual instruction stream; in this case, the processing element is the processor or core rather than the workstation. Data processing Following Flynn’s classification of parallel architectures, an architecture can be classified by whether it processes a single instruction at a time or multiple instructions simultaneously, and whether it operates on one or multiple data sets [47].
SISD (Single Instruction Single Data) machines are conventional serial com-puters that process only one stream of instructions and one stream of data. Instructions are executed sequentially but may be overlapped by pipelining. As long as everything can be regarded as a single processing element, the architec-ture remains SISD.
SIMD (Single Instruction Multiple Data) encompasses computers that have many identical interconnected processing elements under the supervision of a single control unit. The control unit transmits the same instruction, simulta-neously, to all processing elements. Processing elements simultaneously execute the same instruction and are said to be lock-stepped together. Each process-ing element works on data from its own memory and hence on distinct data streams. The execution of instructions is said to be synchronous, because every processing element must be allowed to complete its instruction before the next instruction is taken for execution. For example, array processors and GPU are SIMD machines (for GPU, is often preferred the acronym SIMT, Single Instruc-tion Multiple Threads). Another well-known example of SIMD is the Intel SSE vectorial instruction set (such instructions are explored in Chapter 3).
In MISD (Multiple Instruction Single Data), multiple instructions operate on a single data stream. It is an uncommon architecture, which is generally used for fault tolerance. There are few examples of such computer.
When using MIMD (Multiple Instruction Multiple Data), multiple autonomous processing elements simultaneously execute different instructions on different data. Computers have many interconnected processing elements, each of which
1.1. INTRODUCING PARALLEL COMPUTING
has their own control unit. The processing elements work on their own data with their own instructions. Tasks executed by different processing elements can start or finish at different times. They are not lock-stepped, as in SIMD computers, but run asynchronously. Distributed systems are usually MIMD architectures, exploiting either a single shared memory space or a distributed one. Examples of such platforms are cluster of workstations, multi-processors PCs, and IBM SP. In this dissertation, all our works exploit MIMD parallelism, in particular cluster of workstations (Chapters 2, 3 and 4) and multi-threading (Chapter 3).
Memory Flynn classification is limited to data processing. However, with next generation parallel hardware, memory will be more important than pro-cessing. By a memory-centric viewpoint, we roughly classify parallel platforms in three categories: distributed memory, shared memory and shared address space.
Distributed memory machines are considered those in which each processor has a local memory with its own address space. A processor’s memory cannot be accessed directly by another processor, requiring both processors to be in-volved when communicating values from one memory to another. An example of distributed memory machines is a cluster of workstations. All hardware ar-chitectures used in this dissertation and enlisted in Appendix A are clusters of workstations with distributed memory system.
Shared memory machines are those in which a single address space and global memory are shared between multiple processors. Each processor owns a local cache, and its values are kept coherent with the global memory by the operating system. Data exchange between processors happens simply by placing the values, or pointers to values, in a predefined location and synchronizing appropriately
In this dissertation, we developed some specific techniques for shared mem-ory machines (in particular in Chapter 3).
Shared address space architectures are those in which each processor has its own local memory, but a single shared address space is mapped across dis-tinct memories. Such architectures allow a processor to access other processors’ memory without their direct involvement, but they differ from shared mem-ory machines in that there is no implicit caching of values located on remote machines.
Many modern machines are also built using a combination of these technolo-gies in a hierarchical fashion. For instance, most clusters consist of a number of shared memory machines connected by a network, resulting in a hybrid of shared and distributed memory characteristics. IBM’s large-scale SP machines are an example of this design (Appendix A.5).
We may further distinguish UMA (Uniform Memory Access) from NUMA (Non-Uniform Memory Access) machines: In the first, access time to a memory location is independent of which processor makes the request or which memory chip contains the transferred data; in the latter, memory access time depends
CHAPTER 1. INTRODUCTION
on the memory location relative to a processor.
1.1.4
Scalability and Efficiency
As in the sequential world, many metrics from program execution provide hints to the overall efficiency and effectiveness of a running program. These metrics are crucial in order to understand and evaluate implementations running on such new parallel architectures. We introduce some measures of the effectiveness of a parallel program commonly used in parallel computing: speedup, scalability and efficiency. Thus, we discuss about two tools used to predict and estimate parallel speedup: The Amdahl and Gustafson’s Laws.
Speedup In parallel computing, speedup refers to how much a parallel al-gorithm is faster than a corresponding sequential one. It is defined as the single-processor execution time divided by the execution time on p processors:
speedupp=
T1
Tp
where p is the number of processors, T1is the execution time of the sequential
algorithm, Tp is the execution time of the parallel algorithm with p processors.
When running an algorithm with linear speedup, doubling the number of processors doubles the speed. As this is ideal, it is considered very good scala-bility.
There are two ways to indicate T1. If we consider the execution time of
the best sequential algorithm, then we have an absolute speedup. Instead, if we consider the execution time of the same parallel algorithm on one processor, we have a relative speedup. Of course, the best serial implementation is faster than the parallel one with one processor. Relative speedup is usually implied if the type of speedup is not specified, because it does not require implementation of the sequential algorithm.
It is a challenging task to achieve a good speedup. This because the parallel implementation of most interesting programs requires work beyond, which is not required for the sequential algorithm (e.g. synchronization and communication between processors).
In some rare cases, a super linear speedup may happen. The rationale behind a super linear speedup is that the parallelization of many algorithms requires, on each processor, allocating approximately 1/p of the sequential program’s memory. This causes the working set of each processor to decrease as p increases, allowing it to make better use of the memory hierarchy. If this effect overcomes the overhead of communication, we can reach a linear, or even a super linear speedup. An example of problem where super linear speedup can occur is a problem performing backtracking in parallel: One processor can prune a branch of the exhaustive search that another processor would have taken otherwise.
1.1. INTRODUCING PARALLEL COMPUTING
Scalability Generally speaking, scalability indicates the ability of a paral-lel system to handle a growing amount of processors. In the context of high performance computing there are two common notions of scalability: strong scalability and weak scalability. The first defines how the solution time varies with the number of processors, for a fixed total problem size. The latter de-fines how the solution time varies with the problem size, for a fixed number of processors. In this dissertation, if not specified, we indicate with scalability the strong scalability.
When we discuss about scalability, we often refer to the parallel speedup of a program. In fact, parallel performance scalability is typically reported using a graph showing speedup versus the number of processors.
Efficiency A further metric used to measure parallel performance is efficiency. Parallel efficiency is so defined:
ef f iciencyp=
speedupp
p =
T1
pTp
Efficiency is a value between zero and one (or a percentage value), indicating how much the processors are utilized in solving the problem. Algorithms with linear speedup show an efficiency of 1, while algorithms difficult to parallelize have efficiency that approaches zero as the number of processors increases (e.g. 1/logp).
Amdahl’s Law As Amdahl observed 40 years ago, the less parallel portion of a program can limit performance on a parallel computer [2]. Amdahl’s law states that, if p is the number of processors, α is the amount of time spent (by a serial processor) on serial parts of a program and (1 − α) is the amount of time spent (by a serial processor) on parts of the program that can be done in parallel, then speedup is given by
speedupp=
1 α +1−αp
This law is used to find the maximum expected improvement to an overall system when only part of the system is improved. For instance, it can be used to predict the theoretical maximum speedup using multiple processors
Gustafson’s Law Amdahl’s law has been criticized for several reasons, e.g. it does not scale the availability of computing power as the number of machines increases. In 1988, Gustafson introduced a new law [52]. He proposed that the programmer sets the size of problems in order to use the available equipment to solve problems within a practical fixed time. According to the Gustafson’s Law, the speedup is defined as:
CHAPTER 1. INTRODUCTION
Gustafson’s Law says that more processors are available, larger problems can be solved in the same time. Here, the target is to reformulate problems so that solving a larger problem in the same amount of time would be possible.
Both Amdahl and Gustafson’s Laws are yet useful tools to predict the speedup using multiple processors.
1.1.5
Challenges on Parallel Programming
The development of parallel system will focus on new aspects.
On the parallel hardware front, things seem to be clearer. Hardware archi-tects working on many-core systems seem to have a deep understanding about troubles and issues of designing future multi-core and multi-processor system. They know that there will be many-cores, and these cores in a single processor may be different. They know there will be a scalable on-die interconnect and caches will need to adapt to the workloads to maximize locality.
Conversely, on the software front, it’s chaos. Do we need new programming languages? Alternatively, is it enough to extend existing languages?
New programming models and languages, to be successful, should be indepen-dent of the number of processors. We cannot think that languages designed for 16-32 threads can even work well with thousands of threads.
An aspect like synchronization is critical. The latency of synchronization is high and so it is advantageous to synchronize as little as possible. By converse, most modern networks perform best with large data transfers, hence using a higher granularity of data movement.
Data can be accessed by computational tasks that are spread over differ-ent processing elemdiffer-ents. Thus, we need to optimize data placemdiffer-ent so that communication is minimized, and to minimize remote accesses.
Efficient parallel programs should support together several models of paral-lelism: task-level parallelism, word-level parallelism, and bit-level parallelism.
Finally, the mapping of computational tasks to processing elements must be performed in such a way that the elements are idle (waiting for data or syn-chronization) as little as possible. This well-known problem, the load balancing problem, is probably one of the harder challenge for parallel programming.
Reconsidering metrics The advent of these new parallel architectures intro-duces new way to consider performance. In particular, several old beliefs about parallel performance metric should be reconsidered.
An old belief was that less than linear scaling for a multi-processor applica-tion is failure. Nowadays, with the current trends in parallel computing, any speedup via parallelism is a success.
Another old belief was that scalability is almost free. To build scalable ap-plications requires to have care of load balance, locality, and resource contention for shared resources. Moreover, reaching scalability for architectures having a huge amount of processors is all but easy.
1.2. WHY DO WE CARE ABOUT LOAD BALANCING?
1.2 Why do we care about Load Balancing?
A way to introduce the load balancing problem is by using an analogy.
A construction company having hundreds of workers has to build a new district in a city. The district comprises several houses, each of which having several floors. Supposing that more are the worker, shorter is the time to build a house, the aim of the company manager is to build the whole amount of house as soon as possible. This seems a classical easy to parallelize problem: If we have w workers and h houses, the best way to assign job is to assign about w/h workers to each house. However, if we suppose houses are not equal, the problem increases of complexity: Some houses have more floors, or more rooms, or they need extra-time for furniture and details. This means that the time need by a house to be built is not the same for each house. This inequality in house workload affects the overall finishing time: if half the house requires the double of the time need by the remaining house, half the worker will be idle for half the working time. As a result, the total time need by using a na¨ıve worker strategy is +33% higher than time need by the optimal one. Depending by the problem, things may be even worse. The workload can be extremely various (e.g. house A need 10x the time required by house B), with task arranged in a more complex way (e.g. that house A should be built before house B), having thousands of workers, or the building time cannot be exactly estimated a priori. This analogy is helpful to understand how important is load balancing in parallel computing. To build houses in shorter time means to solve problem effectively. To have idle workers means to waste computational resources (i.e. processors). To have tasks not well balanced means to lose efficiency.
1.2.1
The Problem of Load Balancing
The execution time of a parallel algorithm on a given processor is determined by the time required to perform its portion of the computation plus the overhead of any time spent performing communication or waiting for remote data values to arrive. Instead, the execution time of the algorithm as a whole is determined by the longest execution time of any of the processors. For this reason, it is advisable to balance the computation and communication between processors in such a way that the maximum per-processor execution time is minimal.
This is referred to as load balancing, since the conventional wisdom is that dividing work between the processors as evenly as possible will minimize idle time on each processor, thereby reducing the total execution time.
For some applications with constant workloads, using static load balancing is sufficient. However, a wide range of applications has workload that are un-predictable and/or change during the computation; such applications require dynamic load balancers that adjust the decomposition as the computation pro-ceeds.
Load imbalance is one of the major problems in data parallel applications. In fact, a common source of load imbalance is the uneven distribution of data
CHAPTER 1. INTRODUCTION
among the various processors in the system. Without good load distribution strategies, we cannot aims to reach good speedup, thus good efficiency.
The combination of both irregular and dynamic parallel applications with large-scale multi-core clusters poses significant challenges to achieving scalable performance. New scalable dynamic load balancing strategies are need that is why today it is yet a challenging problem.
1.2.2
Aspects of Load Balancing
Load balancing and Mapping Dividing a computation (henceforth, de-composition) into smaller computations (tasks) and assigning them to different processors for parallel executions (named mapping), represent two key steps in the design of parallel algorithms [65]. The whole computation is usually repre-sented via a directed acyclic graph (DAG) G = {N , E} which consists of a set of nodes N representing the tasks and a set of edges E representing interactions and/or dependencies among tasks. The number and, consequently, the size of tasks into which a given computation is decomposed determines the granularity of the decomposition. It may appear that the time required to solve a problem can be easily reduced, by simply increasing the granularity of decomposition, in order to perform more and more tasks in parallel, but this is not always true. Typically, interactions between tasks, and/or other important factors, limit our choice to coarse-grained granularity. Indeed, when the tasks being computed are mutually independent, the granularity of the decomposition does not affect the performances. However, dependencies among tasks incur inevitable communi-cation overhead when tasks are assigned to different processors. Moreover, the finer is the adopted granularity by the system, the more is the generated inter-tasks communication. The interaction between inter-tasks is a direct consequence of the fact that exchanging information (e.g. input, output, or intermediate data) is usually needed.
Load balancing and mapping are two closely related problems. In fact, a good mapping strategy should strive to achieve two conflicting goals: (1) balance the overall load distribution, and (2) minimize tasks inter-processors dependency; by mapping tasks with a high degree of mutual dependency onto the same processor. As an example of dependency, many mapping strategies exploits tasks’ locality to reduce inter-processors communications [78] but it should be emphasized that dependency can also refer to other issues such as locality of access to memory (effective usage of caching).
Load balancing strategies can be classified in several ways, according to the method used to balance workload.
Static vs Dynamic Static load balancing makes the tasks distribution before execution according to the information of the system workload. Such a decision may not apply to a dynamical environment. Dynamic load balancing, on the other hand, makes more informative load balancing decisions during execution by the runtime state information. In general, dynamic approaches result in
1.3. PREVIOUS WORK
better performance. However, the drawbacks of the dynamic approaches include the runtime overhead for collecting the resource status and the need of precise information about performance prediction.
Centralized vs Distributed Load balancing mechanisms can also be clas-sified as centralized and decentralized. The centralized approach adopts one computing node as the scheduler which gathers the system informations and performs load balancing decisions. Instead, the decentralized approach allows the nodes in the system involving in the load balancing decisions. However, it is very costly to obtain and maintain the dynamic system information. Despite that centralized algorithm have a wider vision of the computation, hence may exploit smarter balancing techniques, they have two problems: the presence of a global synchronization, and the communication bottleneck that involves the master node.
Prediction Prediction-based approach offers a further change to improve load balancing: If we know in advance an estimation of the computational time need by a task, we may use this information to distribute workload between proces-sors in a better way. Such prediction could be exploited in several ways. For instance, we can perform an adaptive partitioning during decomposition, or in-stead improve load balancing decision at runtime (i.e. dynamic load balancing).
1.2.3
Intuition: Distributed Load Balancing is More
Effi-cient
The key observation for improving load balancing of multi-processor (rather multi-core or many-core) architectures is that, in this context, distributed al-gorithms work better than centralized ones. This is due to several emerging factors.
First, having a huge amount of processors, synchronizations should be han-dled carefully. Global centralized synchronizations are a bottleneck and kill performance, especially when the number of processor is high. We need to syn-chronize the fewer possible number of processors, hence to move from centralized synchronization schemas to distributed ones.
Second, in modern architecture using several level of memory hierarchies, only coherent memory accesses are fast. Data locality is even good when per-forming data transfers: processor sharing a level of memory (e.g. L2 or L3) have faster transfer rate. This is another point that advantage distributed load balancing schemas.
1.3 Previous work
Several effective distributed load balancing strategies have been developed in the last couple of years, for a number of various applications [68].
CHAPTER 1. INTRODUCTION
According to [3], we roughly identify seven categories of parallel problem, discussing related approaches to load balancing.
Dense Linear Algebra, where data sets are dense matrices or vectors, is implemented by library such as BLAS [9] and SCALAPACK [21]. Generally, such applications use unit-stride memory accesses to read data from rows, and strided accesses to read data from columns. A classical approach to balance workload in SCALAPACK is the cyclic block data distribution, in order to assure scalability [42].
In Sparse Linear Algebra, data sets include many zero values. Data is usually stored in compressed matrices to reduce the storage and bandwidth requirements to access all of the nonzero values. An example is block compressed sparse row (BCSR). Because of the compressed formats, data is generally accessed with indexed loads and stores. DLA methods often present a higher load unbalance than SLA ones. For instance, the LU factorization approached in [39] requires accurate implementations and strategies when ported to a distributed memory parallel architecture [67].
Fast Fourier Transform (FFT) is an example of Spectral methods. They use multiple butterfly stages, which combine multiply-add operations and a specific pattern of data permutation, with all-to-all communication for some stages and strictly local for others. This class of problems usually requires all-to-all commu-nication to implement a 3D transpose, which requires commucommu-nication between every link. If we consider the FFT, there have been many implementations for different architectures, ranging from hypercube [62] to CRAY-2 [14]. Recently, Chen et al. optimized FFT on a multi-core architecture introducing strategies to balance workload among threads [20].
N-Body methods compute the interactions between many discrete points. Variations include particle-particle methods, where every point depends on all others, leading to an O(N2) calculation, and hierarchical particle methods,
which combine forces or potentials from multiple points to reduce the com-putational complexity to O(N log N ) or O(N ). Load balancing is critical for this class of problems, and several solution have been proposed [5, 4], even for more recent multi-core GPU architectures [61].
In Structured Grids, points inside a regular grid are conceptually updated together. Similar techniques have a high spatial locality. Updates may be in place or between two versions of the grid. In areas of interest, grid may be subdivided into finer grids (e.g. Adaptive Mesh Refinement) and the transition between granularities may happen dynamically. An interesting problem belong-ing to this class is Lattice Boltzmann simulations. Recent work in this topic introduced an auto-tuning approach in order improve performance on multi-core architectures [107].
In Unstructured (or irregular) Grids, location and connectivity of neighbor-ing points must be explicit. Unlike structured grids, unstructured grids require a connectivity list, which specifies the way a given set of vertexes make up in-dividual elements. Grids of this type may be used in finite element analysis when the input to be analyzed has an irregular shape. The points on the grid are updated together. Updates typically involve multiple levels of memory
1.4. CONTRIBUTIONS OF THIS DISSERTATION
erence indirection, as an update to any point requires first determining a list of neighboring points, and then loading values from those neighboring points. Finite Element Method (FEM) is a known problem where adaptive refinement solutions introduce troubles in load balancing [40, 64, 109].
On Monte Carlo methods, calculations depend on statistical results of re-peated random trials. Usually, they are considered an embarrassingly parallel problem, whereas communication is typically not dominant. An example of such methods is the Quasi-Monte Carlo Ray tracing (we will consider Parallel Ray Tracing as a case study). This class of computational problem often presents high irregularity, therefore load unbalance. For example, in the context of Par-allel Ray Tracing, several previous works afford the problem of load balancing [35, 103].
There are many other problems not included in this classification, such as Graph Traversal applications, Finite State Machines, Combinational Logic, and many others Computer Graphics problems.
1.4 Contributions of This Dissertation
In this dissertation, we first show a centralized approach to load balancing (Chapter 2), then we propose some distributed approaches for two specific prob-lems having different parallelization and communication pattern (Chapter 3 and 4). We try to efficiently combine different approaches to improve performance, in particular using predictive metrics to obtain a per task compute-time es-timation, using adaptive subdivision, improving dynamic load balancing and addressing distributed balancing schemas. The main challenge tackled on this thesis has been to combine all these approaches together in new and efficient load balancing schemas.
1.4.1
Assessing Load Balancing Algorithms in Real
Ap-plications
Despite several theoretical works address load balancing with theoretical models and elegant solutions, we believe that nowadays architectures, which expose complex memories arrangement and different kind of parallelism together, are too complex and need real world case studies. The conventional way to guide and evaluate architecture innovation is to study a benchmark suite based on existing programs. Similarly, [3] introduces the Seven Dwarfs, which constitute class of parallel problems where membership in a class defines similarity in computation and data movement. The Dwarfs specifies a high-level abstraction, in order to allow reasoning about their behavior across a broad range of applications. Problems that are members of a particular class can be implemented differently and the underlying numerical methods may change over time, but the claim is that the underlying patterns have persisted through generations of changes and will remain important into the future.
CHAPTER 1. INTRODUCTION
In this dissertation, we contribute to each proposed technique with imple-mentations in real world scenario and well-known problems, discussing results and issues emerging from implementations on parallel hardware.
1.4.2
Parallel Ray Tracing
Many applications exhibit irregularity between units of parallel computation. Such as irregularities can be due to several factors.
Algorithm presenting recursion, where each branch of recursion reaches dif-ferent deep, are a typical class of problem presenting load imbalance. An ex-ample of this kind of problem comes from the Computer Graphics: Parallel Ray Tracing . Depending by the particular rendering technique we use, we may have a difference of computation between pixels that is high. The paradox of ray tracing algorithms is that they present both an embarrassingly parallel pattern and a high work unbalance. Hence, a little or no effort is required to separate the problem into a number of parallel tasks, and there is not dependency (or communication) between those parallel tasks; however, a na¨ıve subdivision and assignment policy do not guarantee best performance.
We study in deep this problem: First, we introduce Parallel Ray Tracing such as a case of mesh-based computations, proposing an interesting centralized balancing technique called Prediction Binary Tree (Chapter 2). Second, we develop a state of the art implementation that exploit parallelism in several ways (using SIMD, multi-threading, and MPI between node clusters), and we apply several techniques to improve load balancing in all parallelism levels (Chapter 3). In particular, we use a various and powerful set of tools like:
• randomized work stealing, a distributed dynamic load balancing scheme, popularized by the runtime system for the Cilk parallel programming lan-guage [10]
• GPU-based rendering techniques to compute a per-task prediction • adaptive subdivision techniques based on cost prediction
• pooling strategy to best combine multi-threading parallelism with dis-tributed multi-processors balancing techniques
The combined use of these tools is a winning strategy, in particular when we address complex parallel architecture having a high number of processors.
1.4.3
Agent-based Simulation
Irregularity often arises due to the sparsity present in the data. For example, in scientific simulations spatial sparsity of the system often translates into sparsity in the numerical model. An example of this kind of irregularity is a class of simulations dubbed Agent-based Simulations. These simulations represent a challenging problem for parallel load balancing for several reasons. First, data locality strongly leverages good parallel performance. Thus, we should carefully
1.4. CONTRIBUTIONS OF THIS DISSERTATION
handle expensive data movement between processors. In the context of agent-based simulation on distributed memory architecture, in particular, the use of algorithms like work stealing with very random steals is not suitable. By converse, such simulations seem to be a perfect candidate to experience different kind of distributed strategies. The second reason is that agent models often lend to clusterize agents, hence producing a high load unbalance. We afford in detail problems and issues of Agent-based Simulations in Chapter 4, proposing a new distributed dynamic load balancing schema.
1.4.4
Organization of the Thesis
In Chapter 2 we introduce the problem of load balancing in mesh-like compu-tations to be mapped on a cluster of processors. We show a centralized and effective algorithm called Prediction Binary Tree in order to subdivide work in equally computationally-balanced tasks. Thus, we asset the problem on a significant problem, Parallel Ray Tracing.
In Chapter 3 we show a state of the art parallel implementation of the ray tracing algorithm, tuned for an hybrid cluster of multi-core workstations and a GPU visualization node. The highly optimized packet-based ray tracing implementation allows the computation of millions of ray-triangle intersections per second, and fully exploit modern multi-core CPUs or GPUs. Load balancing is attacked by presenting a method that uses a cheap GPU rendering technique to compute a cost map: an estimation of the per-pixel cost when rendering the image using ray tracing. Using this information, we improve load balancing, task scheduling, and work stealing strategies.
In Chapter 4, we focus on Agent-based Simulation where a large number of agents move in the space, obeying to some simple rules. We present a novel distributed load balancing schema for a parallel implementation of such sim-ulations. The purpose of such schema is to achieve a high scalability. Our load balancing approach is designed to be lightweight and totally distributed: the calculations for the balancing take place at each computational step, and influences the successive step.
Finally, Chapter 5 outlines some important considerations emerged among all the work presented in such dissertation.
Appendix A enlists the hardware platforms used; Appendix B enlists the publications related to the dissertation.
2
Load Balancing on Mesh-like
Computations
In this Chapter we consider mesh-like computations, where a set of t indepen-dent tasks are represented as items in a bidimensional mesh. We are interested in decomposition/mapping strategy for step-wise mesh-like computations, i.e. data is computed in successive phases.
We aim at exploiting the temporal coherence among successive phases of a computation, in order to implement a load balancing technique to be mapped on a cluster of processors. A key concept, on which the load balancing schema is built on, is the use of a Predictor component that is in charge of providing an estimation of the unbalancing between successive phases. By using this in-formation, our method partitions the computation in balanced tasks through the Prediction Binary Tree (PBT). At each new phase, current PBT is updated by using previous phase computing time for each task as next-phases cost esti-mate. The PBT is designed so that it balances the load across the tasks as well as reduces dependency among processors for higher performances. Reducing de-pendency is obtained by using rectangular tiles of the mesh, of almost-square shape (i.e. one dimension is at most twice the other). By reducing dependency, one can reduce inter-processors communication or exploit local dependencies among tasks (such as data locality). Furthermore, we also provide two heuris-tics which take advantage of data-locality.
Our strategy has been assessed on a significant problem, Parallel Ray Trac-ing. Our implementation shows a good scalability, and improves performance in both cheaper commodity cluster and high performance clusters with low latency networks. We report different measurements showing that tasks granularity is a key point for the performances of our decomposition/mapping strategy.
2.1 Introduction
The number, and as a result, the size of tasks into which a given computation is decomposed determines the granularity of the decomposition. Increasing the granularity of decomposition, may help to have a better load balancing.
How-CHAPTER 2. LOAD BALANCING ON MESH-LIKE COMPUTATIONS
ever, several factors force our choice to coarse-grained granularity. For instance, dependencies among tasks incur inevitable communication overhead when tasks are assigned to different processors. Moreover, the finer is the adopted granu-larity by the system, the more is the generated inter-tasks communication. The interaction between tasks is a direct consequence of the fact that exchanging information (e.g. input, output, or intermediate data) is usually needed.
A good mapping strategy should strive to achieve two conflicting goals: (1) balance the overall load distribution, and (2) minimize tasks inter-processors dependency; by mapping tasks with a high degree of mutual dependency onto the same processor. As an example of dependency, many mapping strategies exploits tasks’ locality to reduce inter-processors communications [78] but it should be emphasized that dependency can also refer to other issues such as locality of access to memory (effective usage of caching).
The mapping problem becomes quite intricate if one has to consider that: 1. task sizes are not uniform, that is, the amount of time required by each
task may vary significantly; 2. task sizes are not known a priori;
3. different mapping strategies may provide different overheads (such as scheduling and data-movement overhead).
Indeed, even when task sizes are known, in general, the problem of obtaining an optimal mapping is an NP-complete problem for non-uniform tasks (to wit, it can be reduced to the 0-1 Knapsack problem [24]).
2.1.1
Mesh-like computations
Ore study focus on mesh-like computations, where a set of t independent tasks are represented as items in a bidimensional mesh. Edges among items in this mesh represent tasks dependencies. In particular, we are interested in tiled map-ping strategies where the whole mesh is partitioned into m tiles (i.e., contiguous 2-dimensional blocks of items). Tiles have almost-square shape, that is, one di-mension is at most twice the other: in this way, assuming the load in processors is balanced (in terms of nodes), the dependencies inter-processors are minimized because of isoperimetric inequality in the Manhattan grid.
Tiled mappings are particularly suitable to exploit the local dependencies among tasks, be it the locality of interaction, i.e., when computation of an item requires other nearby items in the mesh or when there is a spatial coherence, i.e., when computation of neighbors item access to some common data. Hence, tiled mapping, in the former case, reduces the interaction overhead, and, in the latter case, improves the reuse of recently data access (cache).
We are interested in decomposition/mapping strategy for step-wise mesh-like computations, i.e. data is computed in successive phases. We assume that each task size is roughly similar among consecutive phases, that is, the amount of time required by item p in phase f is comparable to the amount of time required by p in phase f + 1 (temporal coherence).
2.1. INTRODUCTION
Figure 2.1: Interaction between components of a parallel scheduler using a Pre-dictor. Arrows indicate how components influence each others: (left) Traditional approach; (right) Our system with the Predictor.
2.1.2
Our result
In this Chapter we present a decomposition/mapping strategy for parallel mesh-like computations that exploits the temporal coherence, among computation phases, to perform load balancing on tasks. Our goal is to use temporal coher-ence to estimate the computing time of a new computation phase using previous phase computing time.
We introduce an iterative novel approach to implement decomposition/mapping scheduling. Our solution (see Figure 2.1) introduces a new component in the system design, dubbed Predictor that is in charge of providing an estimation of the computation time needed by a given tile, at each “phase”.
The key idea is that, by using the Predictor, it is possible to obtain a balanced decomposition without using a fine-grained granularity that may increase the inter-tasks communication of the systems, due to the interaction between clients, and, therefore, may harm the performances of the whole computation.
Our strategy performs a semi-static load balancing (decisions are made be-fore each computing phase). Temporal coherence is exploited using a Prediction Binary Tree where each leaf represents a tile which will be assigned to a worker as a task. At the beginning of every new phase, the mapping strategy, taking into account the previous phase times as estimates, evaluates the chance of up-dating the binary tree. Due to the temporal coherence property it provides a roughly balanced mapping. We also provide two heuristics which exploit the PBT in order to leverage on data locality.
We validate our strategy by using interactive rendering with Parallel Ray Tracing [106] algorithm, as a significant example of such a kind of computations. In this example our technique is applied rather naturally. Indeed, interactive Ray Tracing can be seen as a step-wise computation, where each frame to be rendered represents a phase. Moreover, each frame can be described as a mesh of items (pixels) and successive computations are typically characterized by temporal coherence.
For Parallel Ray Tracing, our technique experimentally exhibits good per-formances improvements, with different granularity (size of tiles), with respect to the static assignment of tiles (tasks) to processors. Furthermore we also provided an extensive set of experiments in order to evaluate:
CHAPTER 2. LOAD BALANCING ON MESH-LIKE COMPUTATIONS
1. the optimal granularity with different number of processors; 2. the scalability of our proposed system;
3. the correctness of the predictions exploiting temporal coherence;
4. the effectiveness of the locality coherence heuristics exploiting spatial co-herence;
5. the impact of resolution;
6. the overhead induced by the PBT.
It should be said that, besides other graphical applications (e.g. image dithering), there are further examples of mesh-like computations where our techniques can be fruitfully used, covering simple cases, such as matrix mul-tiplication, but also more complex computations, such as Distributed Adaptive Grid Hierarchies [79].
2.1.3
Previous Works
Decomposition/Mapping scheduling algorithms can be divided into two main approaches: list scheduling and cluster-based scheduling. In list scheduling [80], each task is first assigned a priority by considering the position of the task within the computation DAG G. Then tasks are sorted on priority and scheduled following this order on a set of available processors. Although this algorithm has a low complexity, the quality of scheduling is generally worse than that of algorithms in other classes. In cluster-based scheduling, processors are treated as clusters and the completion time is minimized by moving tasks among clusters [13, 65, 111]. At the end of clustering, heavily communicating tasks are assigned to the same processor. While this reduces inter-processor communication, it may lead to load imbalances or idle time slots [65].
In [76], a greedy strategy is proposed for the dynamic remapping of step-wise data parallel applications, such as fluid dynamics problems, on a homogeneous architecture. In these types of problems, multiple processors work independently on different regions of the data domain during each step. Between iterations, remapping is used for balancing the workload across the processors and thus, reducing the execution time. Unfortunately, this approach does not take care of locality of interaction and/or spatial coherence.
Several online approaches have also been proposed. An example is the work stealing model [12]. In this model when a processor completes its task it at-tempts to steal tasks assigned to other processors. We notice that, although online strategies are shown to be effective [12] and stable [7], they introduce communication overhead anyway. Furthermore, it is worth noting that online strategies, like work stealing, can be integrated with our assignment policy. In that case, being our load balancing efficient, online strategies introduce smaller overheads.
2.2. OUR STRATEGY
Many researchers have explored the use of time-balancing models to predict execution time in heterogeneous and dynamic environments. In these environ-ments, performance processors are both irregular and time-varying because of uneven underlying load on the various resources. In [110] authors use a conser-vative load prediction in order to predict the resource capacity over the future time interval. They use expected mean and variance of future resource capabil-ities in order to define an appropriate data mappings for dynamic resources.
2.2 Our Strategy
Our strategy is based on a traditional data parallel model. In this model, tasks are mapped onto processors and each task performs similar operations on differ-ent pieces of data (Principal Data Items (PDIs)). Auxiliary global information (Additional Data Items (ADIs)) is replicated on all the workers. This paral-lelization approach is particularly suited to the Master-workers paradigm.
In this paradigm, the master divides the whole job (the whole mesh) into a set of tasks, usually represented by tiles. Then, each task is sent to a worker which elaborates the tile and sends back the output. If other tiles are not yet computed, the master sends another task to the worker. Finally, the master obtains the results of the whole computation reassembling partial outputs.
Crucial point in this paradigm is the granularity of the mesh decomposition: in fact, the relationship between m, number of tiles, and n, number of workers, strongly influences the performances.
There are two opposite driving forces that act upon this design choice. The first one is concerned about the load balancing and requires m to be larger than n. In fact, if a tile corresponds to a zone of the mesh which requires a large amount of computation, then, it requires much more time with respect to a simpler tile. Then, a simple strategy to obtain a fair load balancing is to increase the number of tiles, so that the complexity of a zone of the mesh is shared among different items.
On the opposite side, two following considerations suggest a smaller m. An algorithm that has large m requires larger communication costs than an algo-rithm with smaller m, considering both the latency (more messages are required; therefore, messages may be queued up) and the bandwidth (communication overhead for each message). Other considerations that would suggest to use small m are (a) the locality of interaction and (b) the spatial coherence that are motivated because (i) computation of a task relies usually on nearby tasks and (ii) two close tasks usually access some common data. Then, in order to make an effective usage of the local cache for each node, it is important that the tiles are large enough, so that each worker can exploit spatial coherence of tiles, having a good degree of (local) cache hits.
Our strategy takes into account all the considerations above, by addressing the uneven spread of the load by using a Predictor component (the PBT), with a negligible overhead. The goal we aim to is to keep the load balanced with-out resorting to increase the number of tiles. Thereby, our solution does not