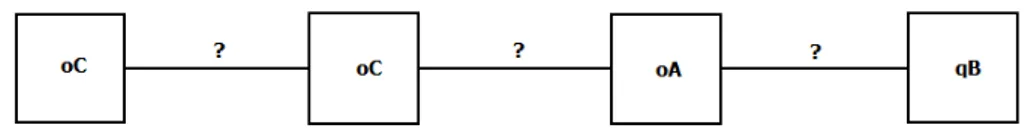Politecnico di Milano
Scuola di Ingegneria Industriale e dell’Informazione
Dipartimento di Elettronica, Informazione e Bioingegneria
AIDA: Automatic Index with DAta mining
Tesi di Laurea Magistrale in Ingegneria InformaticaRelatore: Prof. Letizia TANCA Correlatore: Ing. Mirjana MAZURAN
Matteo SIMONI Matr. n. 796384
Sommario
Il lavoro di tesi propone una metodologia ed un tool a supporto della gestio-ne automatica degli indici in una base di dati relazionale.
L’obiettivo fondamentale della metodologia `e quello di liberare l’ammini-stratore della base di dati dal gravoso e complesso compito di scelta degli indici affindandosi ad un supporto automatico.
Il lavoro si basa su un idea gi`a esistente in letteratura che viene modificata introducendo l’utilizzo di tecniche di Data Mining in modo che il prodotto finale possa, basandosi sulla storia passata, imparare ad anticipare gli eventi che accadranno; la proposta `e supportata da una tool che la integra e ne dimostra il funzionamento.
Ringraziamenti
Desidero ringraziare la Professoressa Letizia Tanca e l’Ing. Mirjana Mazu-ran che mi hanno guidato nella realizzazione di questa tesi.
Grazie all’Ing. Francesco Merlo per aver proposto il problema iniziale da affrontare.
Grazie a Riccardo, compagno in questi anni di universit`a, con il quale ho condiviso le fatiche, ma anche le gioie dello studio e del lavoro.
Grazie a Marta, la mia fidanzata, sempre pronta a sorreggermi quando tut-to sembrava nero, a spronarmi a continuare senza mai mollare, a gioire e festeggiare insieme a me.
Grazie ad Andrea, Amico fidato e compagno di mille avventure, di chiac-cherate, racconti ed emozioni condivise.
Grazie a mio fratello Stefano, vero esempio e punto di riferimento.
Grazie a tutti i miei amici, a tutti coloro che hanno voluto e continuano a condividere la loro strada con la mia: grazie perch`e da tutti ho potuto imparare qualcosa di nuovo e di bello.
Grazie a mamma e a pap`a perch`e mi hanno dato la grande opportunit`a di studiare e perch`e sono sempre pronti a sacrificarsi per me, a spingermi a dare il meglio e ad indicarmi la giusta via. Grazie perch`e senza di voi non avrei mai potuto raggiungere questo grande traguardo, questa tappa importante della mia vita.
Indice
Sommario III
Ringraziamenti V
Indice VII
Elenco delle figure IX
Elenco delle tabelle XI
Elenco degli algoritmi XII
1 Introduzione 1
2 Stato dell’arte sui sistemi 6
2.1 Rassegna dei sistemi esistenti . . . 7
2.2 Analisi dettagliata del sistema PIM . . . 17
3 Stato dell’arte sul SPM 21 3.1 Notazione . . . 22
3.2 Categorie di algoritmi per SPM . . . 24
3.2.1 Algoritmi Apriori-like . . . 24
3.2.2 Algoritmi BFS (Breadth First Search)-based . . . 25
3.2.3 Algoritmi DFS (Depth First Search)-based . . . 25
3.2.4 Algoritmi closed sequential pattern based . . . 25 VII
3.2.5 Algoritmi incremental based . . . 26
3.3 Analisi dettagliata di PrefixSpan . . . 31
3.3.1 Notazioni preliminari . . . 31
3.3.2 L’algoritmo . . . 33
3.3.3 Un esempio illustrativo . . . 34
4 L’approccio AIDA 38 4.1 Notazioni preliminari . . . 38
4.2 Alcuni esempi illustrativi . . . 44
4.2.1 Timestamp semplificati . . . 44 4.2.2 Timestamp reali . . . 49 4.3 L’algoritmo . . . 65 4.4 Scenari applicativi . . . 68 5 Il software AIDA 70 5.1 L’architettura . . . 71 5.2 Il Manuale Utente . . . 75 6 Sperimentazione 83
7 Conclusioni e sviluppi futuri 96
Elenco delle figure
2.1 PIM - Architettura . . . 17
4.1 Pattern Sequenziale nel nostro dominio applicativo . . . 39
4.2 Pattern Sequenziale nel nostro dominio applicativo apliato con il concetto di durata . . . 39
4.3 Pattern Sequenziale completo . . . 40
4.4 Pattern Sequenziale di lunghezza 2 in forma grafica . . . 50
4.5 Pattern Sequenziale di lunghezza 2 in forma grafica con tempi 52 4.6 Pattern Sequenziale di lunghezza 3 in forma grafica . . . 52
4.7 Pattern Sequenziale di lunghezza 3 in forma grafica con tempi 54 4.8 Pattern Sequenziale di lunghezza 4 in forma grafica . . . 55
4.9 Pattern Sequenziale di lunghezza 4 in forma grafica con tempi 57 5.1 Struttura di una riga del log delle operazioni di PostgreSql . . 71
5.2 Struttura di una riga del log delle operazioni di MySQL . . . 71
5.3 Paradigma Model-View-Controller . . . 72
5.4 Architettura del tool Aida . . . 73
5.5 Fase di apprendimento− situazione iniziale . . . 76
5.6 Fase di apprendimento− finestra di navigazione . . . 77
5.7 Fase di apprendimento− selezione delle teQuery . . . 77
5.8 Fase di apprendimento− teQuery selezionate . . . 78 5.9 Fase di apprendimento− output della fase di apprendimento 79
5.10 Fase di apprendimento − pattern sequenziale completo in
forma testuale . . . 80
5.11 Fase di previsione − schermata iniziale . . . 80
5.12 Fase di previsione − output . . . 82
6.1 Struttura della tabella “individuals syntonizations live” . . . 86
6.2 Prima ipotesi di calcolo di Precisione e Recupero . . . 87
6.3 Valori della Precisione con la prima ipotesi di calcolo . . . 88
6.4 Valori del Recupero con la prima ipotesi di calcolo . . . 88
6.5 Pattern sequenziale su due finestre di query diverse . . . 89
6.6 Seconda ipotesi di calcolo di Precisione e Recupero . . . 90
6.7 Esempio di Ovefitting. Errore sui dati di training (blu) ed errore sui dati di test (rosso) . . . 91
6.8 Valori della Precisione con la seconda ipotesi di calcolo . . . . 91
6.9 Valori del Recupero con la seconda ipotesi di calcolo . . . 93
6.10 Sequential Pattern trovati con supporto minimo 0,3 . . . 94
6.11 Sequential Pattern trovati con supporto minimo 0,35 . . . 94
6.12 Sequential Pattern trovati con supporto minimo 0,4 . . . 94
6.13 Sequential Pattern trovati con supporto minimo 0,45 . . . 94
6.14 Valori della F-measure con la seconda ipotesi di calcolo al variare del supporto minimo . . . 95
Elenco delle tabelle
2.1 Categorizzazione dei tool per la ricerca automatica di indici
(Parte 1) . . . 14
2.2 Categorizzazione dei tool per la ricerca automatica di indici (Parte 2) . . . 15
2.3 Categorizzazione dei tool per la ricerca automatica di indici (Parte 3) . . . 16
3.1 Sequenze di ingresso . . . 22
3.2 Confronto tra gli algortimi per la ricerca di pattern sequenziali (tratta da [24]) . . . 29
3.3 Database di esempio . . . 32
3.4 I pattern di lunghezza 1 identificati . . . 34
3.5 I pDB rispetto ai pattern frequenti di lunghezza 1 . . . 35
3.6 Estratto della Tabella 3.5 . . . 36
3.7 Occorrenze dei pattern di lunghezza 1 . . . 36
3.8 S|<db> e S|<dc> . . . 36
3.9 I pattern sequenziali di lunghezza uno (e le loro occorrenze) derivati da S|<dc>. . . 37
3.10 I pattern sequenziali di lunghezza 3 . . . 37
6.1 Valori della Precisione con la seconda ipotesi di calcolo . . . . 92
6.2 Valori della Recupero con la seconda ipotesi di calcolo . . . . 92 XI
1 PrefixSpan Main . . . 33 2 PrefixSpan . . . 34 3 Aida . . . 65 4 AidaTraining . . . 66 5 AidaForecasting . . . 68 XII
Capitolo 1
Introduzione
“Who controls the past controls the future. Who controls the present controls the past.”
George Orwell Il lavoro di tesi propone una metodologia ed un tool a supporto della gestione automatica degli indici in una base di dati relazionale.
Un indice `e una struttura dati realizzata per migliorare i tempi di ricer-ca di determinati valori all’interno di una base di dati. Una tabella senza indici obbliga il sistema a leggere tutti i dati presenti in essa per ogni ri-cerca. L’indice, invece, consente di ridurre l’insieme dei dati da leggere per completare la ricerca in esecuzione in modo da richiedere tempi pi`u brevi. Ad esempio, se si ha un insieme di dati disordinato, `e possibile crearne un “indice” in ordine alfabetico e sfruttare le propriet`a dell’ordine alfabe-tico per arrivare prima al dato o ai dati cercati. Si potrebbe pensare, ad esempio, di applicare una ricerca dicotomica sull’insieme ordinato per repe-rire in tempi pi`u brevi le informazioni richieste. Nell’esempio si pu`o pensare di considerare per primo un dato a met`a dell’insieme: se la lettera iniziale
del dato cercato viene alfabeticamente prima della lettera iniziale del dato considerato, la seconda met`a dei dati non viene considerata; in caso contra-rio `e la prima met`a dei dati a non essere considerata.
Gli indici possono anche avere, per`o, degli effetti negativi in quanto rendono pi`u lente le operazioni di inserimenti e modifica (update) ed aumentano lo spazio occupato nella memoria di massa: poich`e il numero di indici candi-dati per un determinato schema pu`o essere enorme e a causa delle risorse limitate a disposizione, prima di definire su quali campi creare gli indici oc-corre valutare quali siano le operazioni di selezione pi`u frequenti. La giusta scelta degli indici in uno schema, per`o, pu`o migliorare notevolmente le pre-stazioni dell’operazione di lettura, ma una scelta errata pu`o portare a un crollo prestazionale.
Al giorno d’oggi, l’utilizzo di una base di dati pu`o essere molto comples-so, con un enorme volume di dati da gestire e la richiesta sempre crescente di affidabilit`a e troughput alti e basso tempo di risposta. Per questo motivo gli indici e la loro corretta scelta giocano un ruolo sempre pi`u fondamen-tale. Anche nell’ambito del datawarehousing, sebbene non sia considerato in questo lavoro, a causa dei tempi di esecuzione delle operazioni molto pi`u dilatati rispetto a quelli nell’ambito dei database, gli indici assumono una fondamentale importanza per ottenere ragionevoli prestazioni.
Naturalmente un indice non `e “giusto” in assoluto, ma la scelta viene fatta in base all’interrogazione o alle interrogazioni di cui si vuole migliorare il tempo di esecuzione. Questa scelta pu`o essere fatta manualmente, ma risul-terebbe molto costosa in termini di tempo e di risorse. In particolare, poi, al crescere del numero di tabelle e del numero di attributi per ogni tabel-la, questo diventerebbe un compito ingestibile poich`e l’amministratore della base di dati dovrebbe avere una profonda conoscenza di numerosi aspetti implementativi del DBMS, dell’hardware, delle strategie di progettazione
3 dei database fisici e delle caratteristiche dei dati salvati e di quelli che anco-ra devono essere gestiti [46]. Per questi motivi, fin dagli anni ’70, numerosi studi sono stati svolti in questo campo e diverse tecniche e strumenti per supportare automaticamente (o semi-automaticamente) il lavoro dei DBA sono stati prodotti.
L’orientamento verso sistemi che potessero svolgere questo compito in modo completamente automatico `e stato pi`u che naturale, ma diversi sono stati i metodi per farlo.
L’obiettivo fondamentale del presente lavoro `e quello di fornire una me-todologia ed un tool a supporto degli amministratori di basi di dati (DBA) per la manutenzione automatica degli indici in una base di dati relazionale in modo da ridurre il tempo di esecuzione e quindi migliorare le performance del sistema quando deve gestire delle operazioni particolarmente impegnati-ve in termini di utilizzo di risorse e tempo di risposta. Molte tecniche sono, come detto, gi`a state proposte ed il campo notevolemente esplorato, ma il lavoro si vuole inserire in questo contesto proponendo un nuovo approccio con una metodologia mai prima d’ora utilizzata. La maggior parte di questi metodi, infatti, sono reattivi, cio`e agiscono dopo l’esecuzione di una query e quindi dopo che il problema di performance `e stato rilevato. Soltanto re-centemente, `e stato presentato [18], che cerca di agire prima dell’esecuzione di una query con lunghi tempi di esecuzione prevedendo il momento in cui essa sar`a eseguita. Il modello proposto, infatti, riprende alcuni aspetti gi`a utilizzati da quest’ultimo in letteratura, ma utilizza un approccio innovati-vo attraverso tecniche di apprendimento dai dati, in particolare la ricerca di sequenze frequenti nell’ambito del data mining. Esse, opportunamente modificate per i nostri scopi, potranno essere utili per imparare dalla storia passata delle interrogazioni eseguite e modificare il comportamento del siste-ma durante il suo funzionamento ottenendo migliori prestazioni grazie alla
capacit`a di prevedere e, quindi, di gestire al meglio attraverso una preventiva manutenzione degli indici, l’esecuzione di una determinata query. In parti-colare esse non si focalizzano pi`u, come succedeva fino ad ora, sulla storia delle occorrenze di una determinata query di cui si vuole migliorare il costo di esecuzione, ma anche sul “contesto” in cui quest’ultima `e inserita. Con il termine contesto intendiamo l’insieme di operazioni che precedono quella in considerazione: in ambiti in cui queste sono ricorrenti e concatenate, infatti, `e probabile che una di esse ne segua altre ben precise e definite. Conoscendo, quindi, le relazioni di ordinamento che intercorrono tra le diverse operazioni, `e possibile una migliore e pi`u accurata previsione delle prossima esecuzione della query considerata.
Per fare tutto ci`o, AIDA, la metodologia presentata in questo lavoro, imple-menta le seguenti funzionalit`a:
• Identificazione delle “time-expensive queries” (da qui in poi teQuery,
definizione precisa come in [18]), cio`e delle query che necessitano di un miglioramento nei tempi di esecuzione;
• Estrazione dai dati delle esecuzioni gi`a avvenute della conoscenza
ne-cessaria a predire la prossima esecuzione di una teQuery;
• Programmazione della manutenzione degli indici prima dell’esecuzione
della teQuery;
• Manutenzione degli indici dopo l’esecuzione di una teQuery o dopo la
fine di validit`a di una predizione.
Naturalmente, applicando questo metodo, supponiamo noti gli indici che migliorano le prestazioni della teQuery in considerazione. Diverse possono essere le modalit`a per identificarli: sarebbe possibile cercarli manualmente oppure attraverso tecniche pi`u strutturate presenti in letteratura. Il sistema funziona in maniera continua e senza l’intervento del DBA. Per la parte di
5 estrazione della conoscenza dai dati viene utilizzata la tecnica del Sequential Pattern Mining. Questa permette di conoscere la correlazione cronologica di una determinata serie di queries ripetuta frequentemente e quindi utile a sapere quando la teQuery sta per essere eseguita.
Il lavoro di tesi `e strutturato come segue. Il capitolo 2 presenta una rassegna dello stato dell’arte relativo agli strumenti fino ad oggi realizzati e alle tecniche che essi implementano con un confronto con la metodologia proposta in questo lavoro.
Il capitolo 3 introduce la tecnica del Sequential Pattern Mining per l’e-strazione di sequenze ricorrenti da un insieme di elementi ordinati e fa una categorizzazione degli algoritmi che realizzano questa tecnica spiegando qua-le verr`a scelto per i nostri scopi e perch`e.
Il capitolo 4, invece, presenta AIDA, spiegandone l’idea di base con al-cuni esempi e presentando poi lo pseudocodice del suo funzionamento.
Il capitolo 5, presenta la demo del tool che implementa la nostra idea, la sua architettura e il manuale d’uso. Esso spiega gli input necessari e gli output ottenuti, oltre all’utilizzo, passo dopo passo, del software prodotto.
Il capitolo 6, presenta alcuni risultati della fase di sperimentazione della metodologia e dello strumento software.
Il capitolo 7, infine, presenta le conclusioni del lavoro e accenna a suoi possibili sviluppi futuri.
Stato dell’arte sui sistemi per
la costruzione automatica di
indici
“Historia magistra vitae.”
Cicerone Con il passare del tempo i database sono diventati sempre pi`u complessi e hanno dovuto gestire un sempre crescente volume di dati. Nonostante que-sto, un alto troughput e un tempo di risposta sempre inferiore sono tra le prime richieste avanzate dagli utenti. In questo scenario giocano un ruolo fondamentale gli indici che possono notevolmente migliorare le prestazioni di un Data Base Management System (DBMS). La scelta di questi indici e la loro implementazione `e un lavoro complesso, critico e altamente specia-lizzato. Per questo si `e iniziato a pensare a dei sistemi automatici fin dalla seconda met`a degli anni ’70 che sostituissero un lavoro altrimenti manuale. Da quegli anni fino ad oggi, molti tool sono stati proposti per soddisfare quest’esigenza, ognuno con le sue peculiarit`a.
2.1. RASSEGNA DEI SISTEMI ESISTENTI 7 Generalmente questi sistemi ricevono in ingresso il log delle operazioni ese-guite su una base di dati (detto “Workload”) e, a seconda della tipologia, producono in uscita diversi risultati: alcuni restituiscono solamente gli indici da costruire; altri, invece, eseguono anche l’operazione stessa di costruzione. Questa operazione, in particolare, pu`o essere fatta a seguito di una richiesta al DBA oppure in modo completamenta automatico.
A seguire, sar`a spiegato il significato di alcune caratteristiche utili a realiz-zare una precisa categorizzazione di tali tool:
• Offline (workload fisso in ingresso. Le operazioni eseguite vengono
salvate e periodicamente vengono passate tutte insieme al tool) o On-line (monitora continuamente workload del DB. Quando un’operazione viene eseguita sulla base di dati, viene anche passata come input al tool)
• Manuale (suggerisce indici, ma non li implementa), Semi-automatico
(suggerisce indici e chiede al DBA se possono essere implementati. In caso affermativo esegue l’operazione) o Automatico (implementa gli indici senza richiedere il permesso al DBA)
• Reattivo (implementa indici in seguito all’esecuzione di una o pi`u
que-ry) o Proattivo (implementa indici prima dell’esecuzione di una o pi`u query)
2.1
Rassegna dei sistemi esistenti
Tra i primi a lavorare in questo campo vi furono [1] e soprattutto [2] che applicavano un algoritmo euristico (esso usa in particolare cinque euristi-che per cinque problemi ben definiti) con un modello di costo semplice, ma abbastanza flessibile (tenendo in considerazione il costo di creazione degli indici e lo spazio che essi occupavano in memoria) che seleziona gli attributi per i quali `e pi`u utile la costruzione di un indice in modo da ottenere un
minor costo di esecuzione delle operazioni sulla base di dati. L’algoritmo raccoglie delle statistiche ad ogni esecuzione di un’interrogazione e, attra-verso la tecnica dell’“exponential smoothing” ([3], [4]), - una tecnica che utilizza i dati di serie temporali per fare stime dei valori futuri - le confronta con le precedenti per identificare l’insieme di attributi pi`u adatto alla co-struzione degli indici. Questa tecnica, a differenza della media mobile in cui le osservazioni hanno tutte lo stesso peso, attribuisce pesi esponenzialmente decrescenti alle osservazioni passate in modo che esse incidano meno rispetto ad osservazioni pi`u recenti e, facendo ci`o, la stima viene fatta sempre pi`u contestuale alle ultime osservazioni fatte. Successivamente hanno iniziato a diffondersi strumenti a livello industriale e la ricerca in questo campo ha preso sempre pi`u piede.
Numerose realizzazioni di strumenti con diverse caratteristiche che svolges-sero automaticamente la ricerca di indici appropriati per una base di dati sono state sviluppate: nel 2007 [5] e [6] presentarono un tool intrusivo e onli-ne (costantemente in esecuzioonli-ne) come compoonli-nente di Microsft SQL Server 2005. Esso funziona come segue: nel processo di ottimizzazione di una que-ry q, la chiamata all’ottimizzatore `e deviata ad un modulo detto “Index Analysis” (IA) che identifica usando un albero AND/OR per le richieste -un insieme di indici candidati che potrebbero ridurre il tempo di esecuzione di q. Gli alberi di ricerca AND-OR sono una rappresentazione delle se-quenze decisionali. Essi permettono di analizzare alcuni aspetti contingenti dell’ambiente esterno al fine di rendere quasi istantanea la decisione finale (decisione “meccanica“). Le condizioni OR sono le contingenze orizzontali (due condizioni alternative), mentre le condizioni AND sono le contingen-ze verticali (due condizioni che devono essere valide contemporaneamente). Successivamente la query q viene ottimizzata e processata come in un DBMS tradizionale, ma durante l’esecuzione, IA stima i potenziali benefici
appor-2.1. RASSEGNA DEI SISTEMI ESISTENTI 9 tati dagli indici candidati e i benefici degli indici fisici. Dopo l’esecuzione vengono analizzati questi benefici dal modulo “Cost/Benefit Adjustement” e, basandosi su queste analisi, vengono inviate le richieste di creazione o distruzione di indici allo scheduler, il componente atto a questo compito. A seguire, poi, numerosi altri strumenti ed altrettante metodologie sono stati pensati ed implementati. La maggioranza di essi, `e stata realizzata per uno specifico DBMS: in particolare, l’attenzione si `e focalizzata su IBM DB2 e PostgrSQL.
Riguardo al primo, [11] e [12] hanno proposto QUIET, un middleware (livel-lo intermedio tra chi fa la richiesta e chi fornisce la risposta) che suggerisce automaticamente la creazione di indici. La soluzione si basa su comandi proprietari di DB2 e non `e quindi compatibile con altri DBMS. Questo ap-proccio comprende un modello di costo che tiene in considerazione i costi per la creazione e per la manutenzione degli indici e una strategia di scelta degli indici pi`u adatti: essa, per ogni query, restituisce l’intero insieme di indici utili che viene usato per aggiornare la configurazione globale degli in-dici (che comprende sia quelli virtuali che quelli materializzati). Una volta fatto ci`o, il tool, tenendo in cosiderazione lo spazio disponibile, decide se mantenere gli indici gi`a materializzati o se materializzare alcuni degli indici virtuali basandosi sul modello di costo: se il profitto per la nuova configu-razione (quella con implementato il nuovo indice) `e maggiore del profitto di quella vecchia (senza indice), allora esso viene implementato.
In [14] viene, invece, presentato un nuovo framework che pu`o aiutare il DBA a comprendere le interazioni nell’insieme di indici raccomandati. Viene for-malizzata la definizione di interazione tra indici e presentato un algoritmo
per identificare queste ultime in un set di indici raccomandati. Inoltre ven-gono presentati due tool intrusiv semprei per IBM DB2 che utilizzano le informazioni sulle interazioni tra indici.
Per quanto riguarda PostgreSQL, invece, un tool online che `e stato imple-mentato in modo intrusivo `e COLT (Continuous On-Line Tuning) presentato da [7] e [8]. Esso rimpiazza l’ottimizzatore di PostgreSQL con un “Exten-ded Query Optimizer” (EQO) e aggiunge un “Self Tuning Module” (STM). Anche questo, come il precedente, `e un algoritmo reattivo: per ogni query q, STM seleziona un insieme di indici candidati (CI) che comprendono sia indici fisici che ipotetici. Per ogni indice i in CI, EQO genera un piano di esecuzione per q e ne calcola il guadagno. Alla fine di un’epoca (fase di osservazione che corrisponde al tempo di esecuzione di dieci query) l’insieme CI viene analizzato e vengono fatte le opportune modifiche agli indici. Il tempo fisso di un’epoca `e uno svantaggio perch`e il numero fisso di query potrebbe non essere adatto ai bisogni del database.
Ancora un approccio intrusivo e online `e [9]. Anch’esso `e reattivo in quanto `e costituito da una fase di osservazione e di identificazione degli indici candi-dati per ogni query q (usando le euristiche descritte in [10]) alla quale segue una doppia ottimizzazione (una volta considerando gli indici e una volta no) e di valutazione con la conseguente fase di implementazione degli indici pi`u adatti. Anche qui viene usato il concetto di epoca di [7] e [8], ma in modo pi`u dinamico.
Negli ultimi anni, poi, sono state presentate soluzioni pi`u interattive: PA-RINDA (PARtition and INDex Advisor), presentato da [15] e [16] `e un tool intrusivo che permette al DBA di suggerire manualmente un set di
indi-2.1. RASSEGNA DEI SISTEMI ESISTENTI 11 ci candidati per un dato workload e mostra i benefici portati da questo insieme. Esso propone anche uno “scheduler” per implementare gli indici suggeriti che monitora continuamente lo workload in ingresso per suggerire nuovi indici (attraverso la tecnica ILP - Integer Linear Programming, pro-grammazione lineare intera - che permette la scelta degli indici pi`u adatti mappando e risolvendo un problema di programmazione lineare proposta da [19]) e nuove partizioni (usando la tecnica “AutoPart” proposta da [20]) quando questi portano a un sufficiente guadagno.
Questo aumento di interattivit`a ha portato a una nuova tecnica di scelta degli indici, chiamata “semi-automatic index tuning”, presentata da [17]. L’idea `e quella di generare dei suggerimenti di indici non solo basati sulle effettive prestazioni di una loro implementazione, ma anche sulle preferenze del DBA che possono essere esplicite (il DBA vota positivamente l’indice oppure no) o implicite (il DBA sceglie di implementare o di rimuovere l’in-dice). La responsabilit`a della materializzazione di indici `e completamente lasciata al DBA. Essi partono da un’idea di [21] che si concetrava, per`o, su uno workload fisso (offline). Al contrario, essi, propongono una soluzione online.
Tutti gli algoritmi e i tool presentati fino a questo punto sono reattivi: essi, appunto, reagiscono dopo che sono stati rilevati problemi di prestazioni e cambiano la configurazione di indici dopo che lo workload `e stato eseguito. Recentemente, invece, si `e pensato ad un nuovo approccio proattivo che vie-ne ripreso anche vie-nella metodologia e vie-nel tool presentati in questo lavoro. Il problema dell’approccio reattivo `e che esso deve aspettare che qualcosa non funzioni bene per potersi adattare: ad esempio, si deve attendere
l’e-secuzione di una query con un lungo tempo di el’e-secuzione perch`e il sistema decida di implmentare gli indici adatti ad una sua pi`u rapida esecuzione. L’approccio proattivo si discosta da quest’idea poich`e fa delle previsioni sul futuro e si adatta in base ad esse prima che il fatto predetto avvenga: cos`ı facendo, nel caso in cui la previsione fosse giusta, il sistema sarebbe gi`a pronto per l’evento che sta per accadere. Nel nostro caso, si prevede quan-do una determinata query molto costosa in termini temporali sar`a eseguita e, prima che ci`o avvenga, si implementano gli indici adatti ad una sua pi`u rapida esecuzione. Il punto sconveniente dell’approccio proattivo `e che il sistema, per poter fare previsioni, deve conoscere la storia passata e quin-di, almeno inizialmente, si deve aspettare che essa avvenga senza poter fare molto; d’altra parte, per`o, questo avviene solo nella fase iniziale, al contrario dell’approccio reattivo in cui succede pressoch`e ogni volta.
In [18] viene presentato PIM (Proactive Index Maintenance), un tool indi-pendente dal DBMS che `e continuamente in esecuzione e che non necessita dell’intervento del DBA. Esso si interfaccia con i diversi DBMS attraverso appositi driver specifici (a causa delle strutture diverse di questi ultimi) tra cui: driver per l’accesso al workload, driver per l’accesso alle statistiche e driver per gli aggiornamenti del DBMS. Il componente“Workload Obtaine-ment” (WO), poi, ottiene i log di questi ultimi che inserisce nel suo metabase nella forma <espressione SQL, piano di esecuzione, costo stimato>. Avendo a disposizione il workload, identifica le teQuery (definizione completa nella Sezione 2.2).
Questo, dopo aver ottenuto il piano di esecuzione reale da parte del DBMS per la query in questione, lo analizza e cerca le operazioni che non fanno uso di indici per rimpiazzarle con altre equivalenti che, per`o, usano gli stessi. Una volta trovata le strutture di indici pi`u appropriate per queste ultime, anche la coppia <teQuery, struttura di indici> viene salvata nel “metaba-se”. Con un software esterno, poi, per ogni teQuery q, viene identificata la
2.1. RASSEGNA DEI SISTEMI ESISTENTI 13 distribuzione statistica (normale, binomiale, poisson, ecc) che meglio rap-presenta la storia delle sue esecuzioni e da questa PIM identifica il miglior modello di predizione (regressione lineare, MLP (Multi Layer Perceptron), RBF (Radial Basis Function), ecc). A questo punto PIM `e in grado di preve-dere, basandosi sul modello di predizione, quando una query q sar`a eseguita la prossima volta: per fare ci`o esso cattura dal Local Metabase le ultime n esecuzioni di q (n dipende dalla finestra temporale usata per il modello di predizione) e manda una richiesta nella forma <q, Iq, Nq-t> al DLL
Gene-rator (che poi la invier`a a uno Scheduler che programma la creazione degli indici per la notte prima di Nq-t), dove q `e la query in questione, Iq`e l’indice
adatto ad essa e Nq `e la data prevista per la prossima esecuzione di q e t
`e un intero che indica quanti giorni prima di Nq la creazione degli indici
deve avvenire. Aumentare t, quindi, aumenta la probabilit`a di avere una predizione corretta, ma anche gli overhead dovuti all’update della tabella su cui sono definiti gli indici. PIM, inoltre, analizza il workload del DBMS per essere a conoscenza dell’esecuzione di un query q di cui era stata predetta l’esecuzione e per cui erano stati creati proattivamente indici. In questo approccio gli indici sono rimossi dopo uno dei seguenti eventi:
1. la query q `e stata eseguita; 2. sono passati k giorni dopo Nq.
ONLINE/ OFFLINE MANUALE/ AUTOMATICO/ SEMIAUTOMATICO REATTIVO/ PROATTIVO [5] [6] Online Automatico Reattivo [7] [8] Online Automatico Reattivo [11] [12] Online Automatico Reattivo [14] Offline Manuale Reattivo [15] [16]
[19] [20] Offline Semi-automatico Reattivo [17] Online Semi-automatico Reattivo [21] Online Semi-automatico Reattivo [18] Online Automatico Proattivo
Tabella 2.1: Categorizzazione dei tool per la ricerca automatica di indici (Parte 1)
2.1. RASSEGNA DEI SISTEMI ESISTENTI 15 BENEFICIO/ COSTO [5] [6] cost(W, S) = ∑n i=1
(ciSi+ transition(si− 1, si))
dove transition(s0, s1) = ∑
I∈s1−s0
(B(S0))I
W:Workload S: Configuration
(B(S0))I: Costo creazione indice I per la configurazione S.
[7] [8]
gain(I, q) =|cM− cI|
cM: costo esecuzione con gli indici materializzati
cI: costo esecuzione con gli indici in I in aggiunta
a quelli materializzati (se non sancora presenti) o tolti da quelli materializzati (se gi`a presenti). [11] [12]
profit(Q, I)=cost(Q)-cos(Q,I)
cost(Q): costo di escuzione di Q con gli indici gi`a esistenti cost(Q,I): costo di esecuzione di Q con, in aggiunta, gli indici di I [14] benefitq(X, Y) = costq(Y) costq(X∪ Y)
tiene in considerazione il grado di interazione tra X e Y. [15] [16]
[19] [20]
bik = max(0, c(i, ) c(i,Ck))
c(i, ): costo di esecuzione di i senza indici
c(i,Ck): costo di esecuzione di i con la configurazione di indici Ck
[17] benefitq(X, Y) = costq(Y) costq(X∪ Y)
tiene in considerazione il grado di interazione tra X e Y. [21] Utilizza il costo calcolato dal DBMS
hline [18]
Bi,q = max0, cost(q)-cost(q,i)
cost(q): costo di escuzione di Q senza lindice i cost(q,i): costo di escuzione di Q con lindice i Tabella 2.2: Categorizzazione dei tool per la ricerca automatica di indici (Parte 2)
OBIETTIVO DBMS [5] [6] Diminuzione del tempo di
esecuzione di una query Micorsoft SQL Server 2005 [7] [8] Diminuzione del tempo di
esecuzione di una query PostgreSQL [11] [12] Diminuzione del tempo di
esecuzione di una query IBM DB2 Version 8.1 [14] Diminuzione del tempo di
esecuzione di una query IBM DB2 Express-C [15] [16]
[19] [20] Diminuzione del tempo di
esecuzione di una query PostgreSQL [15], SQL Server 2000 [20] [17] Diminuzione del tempo di
esecuzione di una query IBM DB2 Express-C [21] Diminuzione del tempo di
esecuzione di una query Micorsoft SQL Server (versione non specificata) [18] Diminuzione del tempo di
esecuzione di una query Indipendente dal DBMS Tabella 2.3: Categorizzazione dei tool per la ricerca automatica di indici (Parte 3)
2.2. ANALISI DETTAGLIATA DEL SISTEMA PIM 17
2.2
Analisi dettagliata del sistema PIM
In questa sezione vogliamo fare un’analisi approfondita di PIM [18], la me-todologia prima accennata che `e stata usata come base su cui proporre la nostra nuova tecnica. Essa, infatti, a nostro parere, propone idee buone e innovative, ma con alcuni punti miglirabili.
Di seguito, in figura 2.1, mostriamo l’architettura del sistema, utile a capirne il funzionamento spiegato successivamente.
Figura 2.1: PIM - Architettura
Esso accede al workload del DBMS ed estrae, per ogni query, i relativi dati nella forma <SQL expression, execution plan, costs, datetime> che saranno usati per la ricerca automatica degli indici. Fatt`o ci`o li inserisce nel “Local Metabase” (LM), un database interno al sistema e strutturato per i suoi scopi. Dopo aver decomposto il valore di datetime in giorno (1-31) e
mese (1-12) vengono selezionate le query time-expensive. Una query si dice time-expensive se:
1. RTq > t, dove RTq `e il tempo di risposta di q e t `e un parametro
costante (9000s);
2. Fq < k, dove Fq`e il numero di esecuzioni di q diviso per il periodo di
osservazione (in mesi) e k `e un parametro costante (5. q `e eseguita tra una e quattro volte al mese in media);
3. c’`e almeno una struttura di indici i tale per cui Bi,q> ECCi dove ECCi
`e il costo stimato per la creazione della struttura i e Bi,q`e il beneficio
dato dalla presenza della struttura di indici i durante l’esecuzione della query q rispetto all’esecuzione della stessa senza quella struttura. Per ogni teQuery viene trovato l’indice pi`u appropriato e salvato (as esempio, con la tecnica degli “Hypothetical Execution Plan”, dopo aver ottenuto il piano di esecuzione reale da parte del DBMS per la query in questione, lo analizza e cerca le operazioni che non fanno uso di indici per rimpiazzarle con altre equivalenti che, per`o, usano gli stessi.) Fatto ci`o, per ogni teQuery si accede alla storia delle esecuzioni per trovare la distribuzione statistica che meglio la rappresenta. A questo punto viene scelto il modello di predizione pi`u adatto tra regressione lineare, MLP (Multi Layer Perceptron) e RBF (Radial Basis Function). Per ogni modello di predizione vengono valutate diverse istanze caratterizzate da paramentri differenti. Per implementare, istruire e validare le due reti neurali (MLP e RBF) viene usato Weka, mentre per la regressione lineare viene usato un tool Java. Il risultato di questa operazione `e il miglior modello di predizione (con la configurazione associata) per ogni teQuery. Per scegliere la migliore istanza del modello di predizione per ogni query vengono usati il coefficiente di correlazione (compreso tra -1,
2.2. ANALISI DETTAGLIATA DEL SISTEMA PIM 19 negativamente correlati, e +1, positivamente correlati)
r = n
∑
xy− (∑x)(∑y)
√
[n∑x2− (∑x)2][n∑y2− (∑y)2]
e la radice dell’errore quadratico medio (RMSE, Root Mean Square Error) che `e la misura della differenza tra i valori predetti da un modello e i valori effettivamente osservati. Dopo aver trovato il moglior modello per ogni que-ry q, PIM lo usa per prevedere la prossima esecuzione di una determinata query ed inviare una richiesta di creazione degli indici in Iq al DDL
Gene-rator.
L’approccio che proponiamo in questo lavoro riprende gran parte dei concet-ti di PIM: anch’esso vuole essere un tool proatconcet-tivo che possa implementare gli indici prima che la teQuery venga eseguita, anch’esso calcola le strutture indici pi`u appropriate per le teQuery in questione e le salva per implemen-tarle quando si predice che una delle suddette query stia per essere eseguita. La parte in cui si differenzia sostanzialmente da PIM `e la predizione della prossima esecuzione della teQuery in questione: PIM, come gi`a detto, ana-lizza la distribuzione dei tempi di esecuzione di una determinata teQuery e, attraverso tool esterni, trova la distribuzione statistica che meglio la rap-presenta. A questo punto viene scelto il modello di predizione pi`u adatto tra regressione lineare, MLP (Multi Layer Perceptron) e RBF (Radial Basis Function) che sar`a poi usato per prevedere quando la query sar`a eseguita nuovamente. Facendo ci`o, per`o, si prevede il momento dell’esecuzione di una determinata query basandosi solo sulla storia delle esecuzioni passate della stessa: il nostro approccio, invece, propone di considerare il “contesto” in cui la query si trova, quindi anche l’esecuzione di altre operazioni prima di essa. L’obiettivo `e quello di poter sapere, osservando le operazioni esegui-te sulla base di dati, se e tra quanto una deesegui-terminata query sar`a eseguita,
in modo da potersi preparare implementando gli indici adatti per una sua migliore esecuzione. Per fare ci`o si `e pensato di applicare tecniche di Data Mining, in modo da poter istruire il tool osservando la storia passata dell’in-tero database e non solo delle occorrenze di una determinata query in modo da renderlo in grado di fare predizioni.
In un primo tempo, l’idea `e stata quella di applicare le regole di associa-zione per prevedere l’esecuassocia-zione di una teQuery basandosi sull’esecuassocia-zione di altre query. Le regole di associazione [26] sono una tecnica di Data Mining usata per scoprire relazioni di correlazione tra i dati in grandi insiemi di transazioni. Il problema che `e sorto `e che esse guardano ai dati all’interno di una transazione senza distinzione di ordine. Nel nostro dominio applica-tivo, per`o, poich´e deve essere predetta l’esecuzione di una query basandosi sull’esecuzione di altre, l’ordine in cui esse avvengono risulta essere fonda-mentale. Per questo motivo si `e deciso di utilizzare la tecnica del Sequential Pattern Mining (spiegata in modo preciso nel Capitolo 3) che consente di trovare, in un insieme di dati, sequenze ricorrenti che, in quanti tali, tengono in considerazione l’ordine degli elementi che le compongono.
Capitolo 3
Stato dell’arte sul Sequential
Pattern Mining
“Knowledge is what we get when an observer, preferably a scientifically trained observer, provides us with a copy of reality that we can all recognize.”
Christopher Lasch Il Sequential Pattern Mining (SPM) [22] `e una tecnica di Data Mining che permette di estrarre sequenze di elementi che si ripetono “spesso” nell’in-sieme di valori in ingresso. Esso tiene in considerazione l’ordine all’interno della transazione al contrario delle regole di associazione che non lo fanno, poich´e cercano semplicemente nell’insieme degli elementi disponibili. Esso `e utilizzato nella organizzazione d’impresa, nell’area della biologia e nel web mining per analizzare log distribuiti su pi`u server. Nel nostro caso, poich`e il log di operazioni di un database relazionale `e una sequenza temporale, per noi `e importante poter considerare l’ordine di queste ultime in modo da co-noscere cosa `e avvenuto prima dell’esecuzione della query in considerazione. Per questo motivo il SPM risulta essere la tecnica pi`u adatta.
Per chiarire il concetto di “spesso”, intoduciamo la definizione di supporto. Questa pu`o essere espressa in due modi:
• Supporto Relativo: indica il numero minimo di sequenze dei dati in
ingresso in cui deve essere presenta un pattern perch`e possa essere considerato frequente;
• Supporto Assoluto: indica la percentuale minima (compresa tra 0 e 1)
di sequenze dei dati in ingresso in cui deve essere presenta un pattern perch`e possa essere considerato frequente
Numerosi algoritmi sono stati presentati partendo dai pi`u datati che si basavano sulla propriet`a dell’algoritmo Apriori [23].
3.1
Notazione
Una sequenza `e una lista ordinata di eventi < e1e2. . . eI>. Date due
sequen-ze α =< x1x2. . . xn> e β =< y1y2. . . ym>, allora α `e detta sotto-sequenza
di β, ovvero α⊆ β, se esistono degli interi 1 ≤ j1 < j2 < . . . < jn ≤ m tali
che x1 ⊆ yj1, x2 ⊆ yj2, . . . , e xn ⊆ yjn. Se α e β contegono le seguenti
se-quenze α = < (xy), t > e β = < (xyz), (zt) >, allora β `e una super-sequenza di α. SID Sequenza 10 <l(lmn)(ln)o(nq)> 20 <(lo)n(mn)(lp)> 30 <(pq)(lm)(oq)nm> 40 <pr(lq)nmo>
Tabella 3.1: Sequenze di ingresso
Si considerino i dati in Tabella 3.1. Essi sono una piccola parte di un da-tabase di sequenze in cui ogni riga `e composta da un ID (SID `e l’acronimo
3.1. NOTAZIONE 23 di Sequence ID, cio`e ID della sequenza) che `e chiave primaria e da una se-quenza composta da un insieme di elementi. Ogni elemento pu`o contenere un item o un insieme di item (messi tra parentesi tonde). Gli item in un elemento non sono ordinati e sono elencati in ordine alfabetico. Per esem-pio, riferendoci ai dati della Tabella 3.1, <l(mn)on> `e una sottosequenza di <l(lmn)(ln)o(nq)>. Se la soglia di supporto minimo `e pari a 2, allora
<(lm)n> `e un sequential pattern valido. (Esempio da [24]).
In questo contesto possono essere individuate tre categorie di pattern:
• Pattern Periodici: questo modello `e usato per prevedere l’occorrenza
di alcuni eventi nel futuro. Esso, in una sequenza in ingresso come <x y z x y z x y z>, trova il pattern <x y z>. Essendo molto restrittivo viene introdotta la nozione di Pattern Periodico Parizale in cui i pat-tern trovati sono nella forma <x*y> dove * `e un insieme di item di dimensione qualunque.
• Pattern Statisticamente Significativi: vengono usati due indici,
sup-porto e confidenza, per valutare i pattern. Quelli pi`u rari rischiano di andare persi ed esiste il problema di identificare la posizione del-l’occorrenza di un pattern. Per informazioni pi`u dettagliate, numerosi lavori sono stati presentati in [25].
• Pattern Aprrossimati: i due approcci precedenti tengono in
conside-razione soltanto la corrispondenza perfetta dei pattern, mentre qui si considera un pattern approssimato che `e una sequenza di simboli le cui occorrenze in una sequenza appaiono con un valore maggiore di una determinata soglia.
Risulta utile, inoltre, definire una distinzione tra due tipologie di log su cui gli algoritmi possono essere applicati:
• Log Statici: l’algortimo usa come ingresso un insieme di dati e, alla
successiva esecuzione, usa dati completamente nuovi, dimenticandosi di quelli gi`a usati.
• Log Dinamici: l’algortimo usa come ingresso un insieme di dati e, alla
successiva esecuzione, usa lo stesso insieme della precedente esecuzione a cui aggiunge i nuovi dati.
Il problema di trovare pattern frequenti, quindi, corrisponde ad avere a di-sposizione uno stream di dati ed essere in grado di individuare delle sottose-quenze di lunghezza finita che ricorrono nello stream in maniera frequente, ovvero il cui supporto supera una soglia predefinita chiamata “supporto minimo”.
3.2
Categorie di algoritmi per SPM
In [24] sono state individuate le seguenti categorie per gli algoritmi di SPM: Apriori-like, BFS (Breadth First based, DFS (Depth First Search)-based, closed sequential pattern based e incremental based.
3.2.1 Algoritmi Apriori-like
Si basano sulle tecniche dell’algoritmo Apriori [23] e sulla sua propriet`a fondamentale: “una sequenza `e frequente solo se tutte le sue sotto-sequenze sono a loro volta frequenti”. Questo significa che le sequenze frequenti di lunghezza k possono essere ricavate nel seguente modo: dal database delle sequenze vengono estratte quelle frequenti di lunghezza 1; queste sono poi combinate per ricavare le sequenze frequenti candidate di lunghezza 2 e il processo viene ripetuto fino a ricavare quelle di lunghezza k.
3.2. CATEGORIE DI ALGORITMI PER SPM 25
3.2.2 Algoritmi BFS (Breadth First Search)-based
Riprendono tecniche di Apriori poich`e generano le sotto-sequenze “in am-piezza”: al primo passo generano tutte le sottosequenze di lunghezza uno, al secondo tutte quelle di lunghezza due e cos`ı via.
• GSP [27] • MFS [28]
3.2.3 Algoritmi DFS (Depth First Search)-based
Generano le sottosequenze “in profondit`a”: per ogni sottosequenza frequente di lunghezza uno trovata vengono subito generate tutte quelle di lunghezza superiore fino a quella massima e vengono rimosse quelle che non rispettano la soglia del supporto minimo.
• SPADE [29] • FreeSpan [30] • PrefixSpan [31] • SPAM [32]
3.2.4 Algoritmi closed sequential pattern based
Un pattern sequenziale frequente, come detto, `e un pattern che appare al-meno in un numero di sequenze definito dal supporto minimo. Un closed sequential pattern, invece, `e un pattern che non `e gi`a incluso in un altro pattern frequente che ha esattamente il suo stesso supporto. Questo contri-buisce a diminuire il numero di sottosequenze generate con un gudagno in termini di tempo e di spazio di memoria.
• CloSpan [33] • BIDE [34]
3.2.5 Algoritmi incremental based
Usati per log incrementali in cui vengono aggiunte righe e quindi l’algoritmo viene riapplicato su finestre sempre pi`u grandi. I sequential pattern, inoltre, vanno aggiornati e non ricalcolati da zero.
• SuffixTree [35] • FASTUP [36] • ISM [37] • ISE [38] • GSP+ e MFS+ [39] • IncSP [40] • IncSpan [41] • IncSpan+ [42] • MILE [43]
I campi di applicazione dei vari algoritmi, quindi, sono molto diversi e una corretta scelta del miglior algoritmo dipende certamente dall’utilizzo che se ne vuole fare, dai dati disponibili e dai risultati che si vogliono ottenere. La Tabella 3.2 mette a confronto gli algoritmi citati analizzandoli sulla base delle seguenti caratteristiche:
• Database Multi-Scan: viene analizzato il database originale per
sapere se le sequenze candidate prodotte sono frequenti oppure no.
• Candidate Sequence Pruning: gli algoritmi con questa
caratte-ristica possono usare una struttura dati per anticipare nel processo di estrazione, il pruning, cio`e l’eliminazione, di alcune delle sequenze candidate.
3.2. CATEGORIE DI ALGORITMI PER SPM 27
• Search Space Partitioning: `e una caratteristica degli algoritmi
Pattern-Growth. Permette il partizionamento dello spazio di ricer-ca delle sequenze ricer-candidate generate per una gestione della memoria pi`u efficiente.
• DFS based approach: ogni percorso deve essere analizzato fino alla
fine prima di passare al percorso successivo. E’ un’analisi fatta in profondit`a.
• BFS based approach: permette una ricerca livello per livello. (Tutti
i percorsi analizzati a un determinato livello, poi tutti analizzati al livello successivo, ..)
• Regular expression constraint: gli algoritmi con questa
caratteri-stica hanno la propriet`a “growth-based anti-monotonic” per i vincoli che dice: “una sequenza deve essere raggiungibile crescendo da ogni componente che coincide con una parte dell’espressione regolare”.
• Top-down search: il mining dei sequential pattern pu`o essere fatto
costruendo l’insieme dei “projected databases” (Concetto meglio spie-gato nel capitolo successivo) e facendo il mining ricorsivamente su di essi.
• Bottom-up search: approccio usato dagli algoritmi basati su Apriori
che trovano sequenze frequenti come composizione di sotto-sequenze a loro volta frequenti.
• Tree-projection: questa caratteristica utilizza la ricerca condizionale
sullo spazio di ricerca rappresentato come un albero. E’ usato come database “in-memoria” alternativo.
• Suffix growth vs Prefix growth: questa caratteristica permette
frequenti. Essa permette di ridurre la quantit`a di memoria richiesta per mantenere tutte le diverse sequenze candidate che condividono lo stesso suffisso/prefisso.
• Database vertical projection: gli algoritmi con questa
caratteristi-ca visitano il database solo una o due volte per ottenere uno schema verticale (bitmap/position indication table) di quest’ultimo piuttosto del classico schema orizzontale.
3.2. CATEGORIE DI ALGORITMI PER SPM 29 AprioriAll GPS SP ADE F reeSpan SP AM ISM IncSP ISE IncSP AN MILE Static Database V V V V V V Incremen tal Database V V V V V DataBase MultiScan V V V Candidate Sequence Pruning V V V V V V V Searc h Space P artitioning V V V DFS based Approac h V V V V BFS based Approac h V Regular Expression Constrain t V V T op-do wn Searc h V V Bottom-up Searc h V V V V T ree-pro jection V V Suffix Gro wth V Prefix Gro wth V V V Database V ertical Pro jection V V T ab ella 3.2: Confron to tra gli algortimi p er la ricerca di pattern sequenziali (tratta da [24 ])
Tra i vari algoritmi presentati si `e dovuto scegliere il migliore per l’approccio presentato in questo lavoro.
Nella tecnica che sar`a spiegata in dettaglio nei capitoli successivi (in parti-colare nel Capitolo 4), il log delle operazioni viene fornito periodicamente in ingresso ed `e un pezzo dello stream di dati che il sistema ha ricevuto. Poich`e, ad ogni esecuzione, il log in ingresso `e sempre diverso da quello del-l’esecuzione precedente, l’algoritmo per il SPM si trova a dover gestire ogni volta un input totalmente nuovo che pu`o quindi essere considerato come un log statico. Per questo motivo sono stati esclusi tutti gli algoritmi che funzionano bene per i log incrementali e ci si `e concentrati su quelli pen-sati per i log statici. Non espandere i pattern sequenziali, ma ricrearli da zero periodicamente, poi, nella nostra situazione ha perfettamente senso in quanto `e possibile e sensato che dopo un certo lasso temporale le operazioni eseguite frequentemente su una base di dati non siano pi`u le stesse. Tra gli algoritmi rimanenti, infine, si `e pensato di escludere quelli pi`u vecchi e con performance inferiori che richiedevano pi`u passate sul database delle sequenze da analizzare (AprioriAll e GPS). Anche SPADE richiede la ge-nerazione di candidate e l’utilizzo di molta memoria (avendo un approccio basato su Apriori), caratteristiche che limitano fortemente le sue presta-zioni, per questo `e stato escluso. Tra i due rimanenti algoritmi (FreeSpan e PrefixSpan) che hanno un approccio basato su Pattern-Growth `e stato scelto il secondo che `e un miglioramento del primo. Entrambi si basano sui projected-database che partecipano primariamente al costo totale del-l’algoritmo: se un pattern appare in tutte le sequenze di un database, con il primo algoritmo, il projected-database finisce per coincidere con l’intero database richiedendo un enorme impiego di risorse. Il secondo algoritmo, invece, proiettando soltanto sui prefissi frequenti, diminuisce l’impiego di risorse garantendo prestazioni migliori. Per questo motivo l’algoritmo scelto da implementare nel tool `e PrefixSpan.
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN 31
3.3
Analisi dettagliata di PrefixSpan
PrefixSpan (Prefix-projected Sequential Pattern mining) [31] `e un algoritmo “pattern-growth” presentato nel 2001. Gli algoritmi “pattern-growth” sono una delle metodologie per estrarre pattern frequenti. Il metodo “pattern-growth” analizza la collezione di dati con approccio “dividi e conquista”: per prima cosa trova l’insieme dei pattern frequenti di dimensione 1 e poi, per ogni pattern p, deriva il p-projected database ricorsivamente. Nei projecetd-database, poi, vengono ricercati i sequential pattern frequenti. Poich`e la col-lezione di dati `e decomposta progressivamente in insiemi pi`u piccoli, questo approccio diminuisce le dimensioni del spazio di ricerca permettendo una maggiore efficienza e scalabilit`a.
3.3.1 Notazioni preliminari
Poich`e gli item all’interno di un elemento di una sequenza possono assumere un ordine qualsiasi, senza perdita di generalit`a, si assume che siano in ordine alfabetico in modo da rendere unica la rappresentazione di una sequenza. Quindi <a(bac)d(ef)> sar`a considerata come <a(abc)d(ef)>.
Data una sequenza α =< e1e2. . . en>, una sequenza β =< e′1e′2. . . e′m>
con (m<n) `e detta prefisso di α se e solo se: 1. e′i=eiper (i<m-1);
2. e′m⊆ em;
3. tutti gli elementi in (em− e′m) sono alfabeticamente dopo in e′m.
Data una sequenza α e una sequenza β tale che β `e una sottosequenza di α, una sottosequenza α′ di α `e detta proiezione di α rispetto a β se e solo se:
1. α′ ha prefisso β
2. non esiste una supersequenza α′′di α′ tale che α′′`e una sottosequenza di α e ha prefisso β.
Sia α′= <e1e2. . . en> la proiezione di α rispetto al prefisso β = <e1e2. . . em−1e′m>
(m≤n). La sequenza γ = < e′′mem+1 . . . en> `e detta suffisso di α rispetto al
prefisso β dove e′′m= (em− e′m). Vediamo che α = β· γ.
Ad esempio, <a>, <aa>, <a(ab)> e <a(abc)> sono prefissi della se-quenza <a(abc)(ac)d(cf)>. <(abc)(ac)d(cf)> `e il suffisso della stessa se-quenza rispetto ad <a>, <( bc)(ac)d(cf)> rispetto ad <aa> e <( c)(ac)d(cf)> rispetto a <ab>, dove il simbolo “ ” sta ad indicare che uno o pi`u item del primo elemento del suffisso fanno parte del prefisso rispetto a cui esso si calcola. In <( bc)(ac)d(cf)>, infatti, l’item a del primo elemento fa parte del prefisso rispetto a cui il suffisso `e stato derivato.
Il projected-database (d’ora in poi “pDB”) `e la proiezione del database originale basandosi su un determinato criterio: in FreeSpan gli elementi presenti nelle sequenze vengono ordinati per supporto decrescente in un vettore f list e il p-projected database S|p `e l’insieme di sequenze aventi p come sottosequenza; in PrefixSpan il S|p `e la collezione di suffissi delle sequenze nel database originale che hanno come prefisso p. Ad esempio, dato l’insieme di sequenze:
ID Sequenza 10 <a(abc)(ac)d(cf)>
20 <(ad)c(bc)(ae))>
30 <(ef)(ab)(df)cb>
40 <eg(af)cbc>
Tabella 3.3: Database di esempio
il S|a `e composto dai suffissi di ogni sequenza che hanno come prefisso l’elemento a, quindi: <(abc)(ac)d(cf)> come suffiso di a nella sequenza con id uguale a 10, <( d)c(bc)(ae)> come suffiso di a nella sequenza con id uguale a 20, <( b)(df)cb> come suffiso di a nella sequenza con id uguale a 30 e <( f)cbc> come suffiso di a nella sequenza con id uguale a 40.
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN 33
3.3.2 L’algoritmo
L’algoritmo `e composto dalla routine principale (Algoritmo 1) che viene chiamata soltanto la prima volta e da una subroutine (Algoritmo 2) che si richiama ricorsivamente.
L’ Algoritmo 1, come si vede nel campo Data, riceve in ingresso il database delle sequenze e l’insieme vuoto di pattern sequenziali. Esso semplicemente richiama la subroutine (riga 1) e finisce.
L’ Algoritmo 2 riceve in ingresso tre parametri, visibili nel campo Data: α: un pattern sequenziale; l: la lunghezza di α; S|α: l’α-projected database, se
α̸=<>; altrimenti la base di dati sequenziale S.
Per prima cosa scansisce S|α una volta, trova l’insieme degli item b
frequen-ti (riga 1). Fatto ci`o, tra quelli trovati, vengono mantenuti solo quelli tali che: b pu`o essere aggiunto all’ultimo elemento di α per formare un pattern sequenziale o <b> pu`o essere aggiunto ad α per formare un pattern sequen-ziale (righe 3-5).
Ogni item frequente b viene aggiunto ad α per formare un pattern sequen-ziale α′ (righe 7-13), e viene usato α′ come output (campo Result). Infine, per ogni α′, viene costruito l’α′-projected database S|α′ (riga 14) e viene
richiamato PrefixSpan(α′, l+1, S|α′) (riga 15).
Data: <>, S
1 Call PrefixSpan(<>, 0, S);
Data: α, l, S|α
Result: α′
1 frequent set = findFrequentItem(S|α);
2 forall the items pi ∈ frequent set do
3 if add(pi, getLastElement(α)) == New Sequential Pattern ||
add(pi, α) == New Sequential Pattern then
4 pi∪ completing set;
5 end
6 end
7 forall the items bi ∈ completing set do
8 if add(pi, getLastElement(α)) == New Sequential Pattern
then
9 α′ = add(pi, getLastElement(α));
10 end
11 else if add(pi, α) == New Sequential Pattern then 12 α′ = add(pi, α); 13 end 14 S|α′ = get pDB(S|α, α′); 15 Call PrefixSpan(α′, l+1, S|α′); 16 end Algoritmo 2: PrefixSpan 3.3.3 Un esempio illustrativo
Sia dato il database S della Tabella 3.3 nel quale si vogliono ricercare pattern sequenziali con supporto minimo pari a 2.
Esso viene esaminato per trovare tutti gli elementi frequenti nelle sequenze. Ogni item `e un pattern sequenziale di lunghezza 1. Contando le occor-renze di questi pattern sequenziali, possiamo derivare la Tabella 3.4 che le riassume.
<a> <b> <c> <d> <e> <f> <g>
4 4 4 3 3 3 1 Tabella 3.4: I pattern di lunghezza 1 identificati
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN 35 sequenze che compongono S e lo stesso vale per <b> e <c>, mentre <d> compare solo nelle sequenze con id uguale a 10, 20 e 30. Ragionamenti simili sono fatti anche per gli altri pattern sequenziali trovati. Il pattern sequen-ziale <g> non viene considerato poich`e ha supporto inferiore al supporto minimo scelto per l’escuzione dell’algoritmo, infatti esso compare solo nella sequenza con id uguale a 40. Una volta eliminati i pattern sequenziali che non hanno supporto sufficiente, l’algoritmo divide lo spazio di ricerca in sei sottoinsiemi: ognuno `e il pDB del database iniziale S costruito rispetto ad uno dei pattern sequenziali elencati nella Tabella 3.4.
S|<a> S|<b> S|<c>
<(abc)(ac)d(cf)> <( c)(ac)d(cf)> <(ac)d(cf)> <( d)c(bc)(ae)> <( c)(ae)> <(bc)(ae)> <( b)(df)cb> <(df)cb> <b> <( f)cbc> <c> <bc> S|<d> S|<e> S|<f> <(cf)> <( f)(ab)(df)cb> <(ab)(df)cb> <c(bc)(ae)> <(af)cbc> <cbc> <( f)cb>
Tabella 3.5: I pDB rispetto ai pattern frequenti di lunghezza 1 S|<a>, ad esempio, `e composto dai suffissi di <a> nelle sequenze di S in
cui esso compariva: essi, come gi`a detto, si ottengono considerando la parte di sequenza che segue l’elemento rispetto a cui si sta calcolando il pDB. Per la sequenza <a(abc)(ac)d(cf)>, infatti, considerando l’elemento <a>, il suf-fisso `e <(abc)(ac)d(cf)> ottenuto considerando ci`o che segue la prima occor-renza di <a>; per la sequenza <(ad)c(bc)(ae)> il suffisso `e <( d)c(bc)(ae)>; per la sequenza <(ef)(ab)(df)cb> il suffisso `e <( b)(df)cb> e per la sequenza
<eg(af)cbc> il suffisso `e <( f)cbc>. L’insieme di questi suffissi costituisce S|<a>. Lo stesso procedimento viene applicato agli altri pattern sequenziali
di lunghezza 1 trovati. Da notare che alcuni pDB hanno meno elemeni di altri: questo avviene perch`e si considerano solo le sequenze di S in cui l’e-lemento che si usa per calcolare i suffissi `e effettivamente presente. S|<d>,
ad esempio, `e composto da tre elementi perch`e <d> era presente solo nel-le sequenze con id uguanel-le a 10, 20 e 30. Per comodit`a di esempio e per semplicit`a, scegliamo di concentrarci su uno dei pDB poich`e il medesimo procedimento viene ripetuto per gli altri. Scegliamo S|<d> come in Tabella
3.6.
S|<d>
<(cf)> <c(bc)(ae)> <( f)cb>
Tabella 3.6: Estratto della Tabella 3.5
Da questo vengono ricavati i pattern sequenziali di lunghezza 1 e viene contata la loro occorrenza. Dal conteggio delle occorrenze si ricava la Tabella 3.7.
<a> <b> <c> <d> <e> < e> <f> < f>
1 2 3 0 1 0 1 1 Tabella 3.7: Occorrenze dei pattern di lunghezza 1
Tenenedo in considerazione il supporto minimo, consideriamo soltanto quelli che hanno un numero di occorrenze maggiore di 1. Ognuno di essi viene usato insieme a <d> per trovare i pattern sequenziali di lunghezza 2 sul database iniziale S. I risultanti sono <db> e <dc>. Essi sono usati per costruire S|<db> e S|<dc> che possiamo vedere nella Tabella 3.8.
<db> <dc> <( c)> <(bc)>
<b>
Tabella 3.8: S|<db> e S|<dc>
In S|<db> non vengono contate le occorrenze dei pattern sequenziali di
lunghezza 1 poich`e c’`e solo una sequenza, quindi uno qualsiasi di essi non avr`a supporto minimo sufficiente per essere scelto. In S|<dc>, invece,
possia-3.3. ANALISI DETTAGLIATA DI PREFIXSPAN 37 mo trovare i pattern sequenziali elencati in Tabella 3.9 con il relativo numero di occorrenze in S|<dc>.
<b> <c>
2 1
Tabella 3.9: I pattern sequenziali di lunghezza uno (e le loro occorrenze) derivati da S|<dc>.
Poich`e il numero di occorrenze di <c> non `e sufficiente a soddisfare il supporto minimo, l’unico elemento che consideriamo `e <b> che ci permette di trovare un pattern sequenziale di lunghezza 3 valido: <dcb>. Calcolando S|<dcb>otteniamo i risultati in Tabella 3.10. Come si pu`o vedere esso `e un
insieme vuoto , quindi l’algoritmo si ferma.
<dcb> < >
Tabella 3.10: I pattern sequenziali di lunghezza 3
Come gi`a specificato in precedenza, in questo esempio abbiamo segui-to solo un ramo dell’albero delle soluzioni generasegui-to dall’algoritmo e quindi quello mostrato `e solo un sottoinsieme di queste ultime.
L’approccio AIDA
“Creating a new theory is not like destroying an old barn and erecting a skyscraper in its place. It is rather like climbing a mountain, gaining new and wider views, discovering unexpected connections between our starting points and its rich environment. But the point from which we started out still exists and can be seen, although it appears smaller and forms a tiny part of our broad view gained by the mastery of the obstacles on our adventurous way up.”
Albert Einstein L’idea di base del nostro algoritmo chiamato “AIDA” (Automatic Index with DAta mining) `e simile a quella di “Proactive Index Maintenance” di Me-deriros del 2012, ma, con due differenze: la prima `e il metodo di predizione dell’esecuzione di una teQuery, mentre la seconda `e che, una volta prevista l’esecuzione di una di esse, viene programmata la manutenzione e non la creazione degli indici pi`u adatti a migliorare le prestazioni dell’operazione.
4.1
Notazioni preliminari
Innanzitutto `e necessario definire alcuni concetti: un pattern sequenziale `e, come gi`a visto, una successione ordinata di elementi ricorrenti. Inizialmente,
4.1. NOTAZIONI PRELIMINARI 39 nel nostro dominio applicativo, si era pensato di associare ad ogni elemento una query, ma si `e poi ritenuto sensato ampliare il concetto, associando ad ognuno di essi un’operazione eseguita sulla base di dati (query, inserimento, update e cancellazione) e soltanto all’ultimo necessariamente una query (in particolare una teQuery), come possiamo vedere in Figura 4.1. Gli elementi in questione, d’ora in poi, saranno chiamati nodi nella nostra trattazione. Come si pu`o capire, nel nostro lavoro, usando le definizioni della Sezione 3.1, un nodo non `e mai un elemento composto da pi`u item, ma solo da un singolo item.
Figura 4.1: Pattern Sequenziale nel nostro dominio applicativo Ogni elemento che sta tra un nodo e il suo successivo all’interno del pat-tern sequenziale, invece, sar`a definito arco.
Sono proprio gli archi che ci permettono di estendere il concetto di pattern sequenziale: per applicare il nostro metodo, infatti, `e necessario sapere quan-to tempo trascorre tra l’occorrenza di un nodo e quella del suo successivo; questo dato, che definiamo come durata di un arco, sar`a associato all’arco stesso, come da Figura 4.2.
Figura 4.2: Pattern Sequenziale nel nostro dominio applicativo apliato con il concetto di durata
Questo significa che, nell’esempio, l’“operazione2” `e avvenuta “durata1” istanti di tempo dopo l’“operazione1” e che la “Time-expensive Query” `e avvenuta “durata2” istanti di tempo dopo l’“operazione2”.
Nella prima fase del nostro metodo, detta “fase di apprendimento”, oltre ad essere estratti tutti i pattern sequenziali dal log statico in ingresso, vengono
anche arricchiti con le loro durate. Una volta fatto ci`o, per ogni pattern, avremo pi`u di un’istanza con durate diverse associate agli archi: il nostro obiettivo sar`a quello di ottenere una sola istanza per ogni pattern che rias-suma tutte queste informazioni. Per fare ci`o, ad ogni arco, quindi, verr`a associato un valore del tipo (m±k), dove m `e definita come la media e k come la tolleranza. La prima non `e altro che la media aritmetica di tutte le istanze di durata associate a quell’arco, mentre la seconda `e la met`a della differenza tra il valore massimo e il valore minimo tra le istanze di durata associate a quello stesso arco, aumentata di 1.
Una volta fatto ci`o, quello che si ottiene `e un pattern sequenziale completo come in Figura 4.3.
Figura 4.3: Pattern Sequenziale completo
Con m e k otteniamo un intervallo temporale che ben ricalca la situa-zione trascorsa e che sar`a utile per conoscere quella futura. Quella descritta fino ad ora, infatti, `e la prima fase dell’algoritmo in cui il sistema analizza la situazione passata per estrarne dati utili alla fase successiva; a questo punto inizia la seconda detta “fase di previsione”. I valori trovati nella fase prece-dente saranno usati in due situazioni: la prima per vedere se le occorrenze delle operazioni che compongono il pattern sequenziale avvengono nei tempi minimi e massimi stabiliti, cio`e per controllare che il pattern non si estenda troppo nel tempo divenendo poco significativo, mentre la seconda per sa-pere quando programmare la manutenzione degli indici in modo da essere pronti per l’esecuzione della teQuery. Inizialmente, come valore da utilizzare per la tolleranza, si era pensato alla varianza dei valori delle durate delle istanze associate agli archi, ma la scelta si `e rivelata infruttuosa in quanto il valore risultante era sempre molto alto. Ci`o rendeva non significativi i