DISPENSE DEL CORSO DI
PROGRAMMAZIONE I CON
LABORATORIO
Marco Baioletti
Indice generale
1 Introduzione...6
1.1 Concetti di base...6
1.2 Problemi ed istanze... 6
1.3 Metodi per la descrizione degli algoritmi... 8
1.3.1 Diagrammi di flusso...8
1.3.2 Pseudo-codifica... 9
1.4 Proprietà degli algoritmi... 10
1.4.1 Eseguibilità...10
1.4.2 Finitezza e terminazione...11
1.4.3 Correttezza... 11
1.4.4 Efficienza... 11
1.5 Introduzione al costo computazionale ... 12
1.6 Esercizi...14
2 Livelli di programmazione... 16
2.1 Struttura di un elaboratore... 16
2.2 Il linguaggio macchina...17
2.3 Caratteristiche negative del L.M...18
2.4 La programmazione ad alto livello ed i paradigmi di programmazione...19
2.4.1 Il paradigma imperativo... 20 2.4.2 Il paradigma funzionale... 20 2.4.3 Il paradigma logico... 20 2.4.4 Il paradigma ad oggetti... 21 2.5 La traduzione... 21 2.5.1 La compilazione... 21 2.5.2 L'interpretazione...22
2.6 Le fasi della compilazione... 22
2.7 Gli strumenti della programmazione... 24
3 La sintassi dei linguaggi di programmazione... 25
3.1 Definizioni generali: stringhe e linguaggi... 25
3.2 Grammatiche...26
3.3 Grammatiche libere dal contesto ed alberi di derivazione...27
3.4 Forma estesa di Backus e Naur (EBNF)... 28
3.5 Alcuni semplici linguaggi in EBNF...29
3.6 Esercizi...30
4 Tipi di dati, variabili ed espressioni...31
4.1 Concetto di tipo di dato...31
4.2 Classificazione dei tipi di dato...31
4.2.1 Tipi di dati numerici... 32
Tipi interi... 32
Tipi reali... 33
Conversione di tipo... 34
Altri tipi numerici... 34
4.2.2 Tipi di dati non numerici... 34
Tipo logico...34 Tipo carattere...35 Tipo stringa...36 Tipo puntatore... 36 4.3 Costanti... 37 4.4 Variabili...37 4.5 Espressioni... 38
4.6 Introduzione alla semantica operazionale: il concetto di stato... 40
4.7 Semantica operazionale delle espressioni...41
4.8 Valutazione pigra... 42
4.9 Esercizi...43
5 Introduzione al linguaggio C++...44
5.1 Programma di esempio e sintassi di base...44
5.1.1 Commenti...44
5.1.2 Maiuscole e minuscole... 44
5.1.3 Spazi e indentazione...45
5.1.4 Struttura di un programma... 45
5.2 Dichiarazione di variabili e costanti... 46
5.3 Semantica operazionale delle istruzioni... 46
5.4 Assegnamento... 47
5.5 Istruzioni di Input/Output... 48
5.5.1 Istruzione di input... 48
5.5.2 Istruzione di output... 49
5.6 Sequenza di istruzioni e blocchi... 49
5.7 Effetti collaterali... 50
5.8 Esercizi...51
6 Programmazione strutturata e strutture di controllo condizionali... 52
6.1 Programmazione strutturata e teorema di Jacopini-Bohm...52
6.2 Sequenza e istruzioni composte... 54
6.3 Istruzione if-else... 54
6.4 If annidati e costrutto if-else-if... 57
6.5 Istruzione switch... 61
6.6 Operatore condizionale... 63
6.7 Esercizi...64
7 Strutture di controllo iterative... 65
7.1 Generalità sull'iterazione... 65
7.2 Istruzione while...65
7.3 Istruzione do-while... 68
7.4 Istruzione for...69
7.5 Iterazione limitata con il ciclo for...70
7.6 Indici definiti all'interno del for... 72
7.7 Cicli for annidati... 72
7.8 Varianti del ciclo for standard... 73
7.8.1 Estremo escluso...73
7.8.2 Ciclo all'indietro... 74
7.8.3 Ciclo a passo non unitario... 74
7.8.4 Condizione aggiuntiva... 74
7.9 Istruzioni break e continue...75
7.10 Esercizi...76
8 Correttezza dei programmi... 78
8.1 Il problema della correttezza e l'approccio mediante test... 78
8.2 Introduzione alla semantica assiomatica...78
8.3 Invarianti di ciclo e correttezza parziale... 79
8.4 Terminazione...81
8.5 Considerazioni finali e problema della fermata... 81
8.6 Esercizi...82
9 Tipi di dato strutturati... 83
9.1 Generalità...83
9.3 Implementazione delle operazioni elementari sugli array... 85
9.3.1 Riempimento... 86
9.3.2 Copia... 86
9.3.3 Lettura da tastiera... 86
9.3.4 Scrittura su schermo...86
9.3.5 Sommatoria e calcolo del massimo...86
9.3.6 Conteggio ed esistenza... 87 9.3.7 Filtro...88 9.4 Array multidimensionali... 88 9.5 Le stringhe... 89 9.6 Le strutture (record)... 90 9.7 Array di strutture... 92 9.8 Le unioni... 93
9.9 Creazione di tipi di dati...94
9.9.1 Tipi di dati enumerativi... 94
9.9.2 Nuovi tipi per costruzione...95
9.10 Esercizi...96
10 Algoritmi elementari...98
10.1 Algoritmi di ricerca... 98
10.1.1 Algoritmo di ricerca lineare... 98
10.1.2 Algoritmo di ricerca binaria... 99
10.2 Algoritmi di ordinamento...100
10.2.1 Algoritmo di ordinamento a bolle (Bubblesort)... 100
10.2.2 Algoritmo di ordinamento per selezione... 102
10.2.3 Algoritmo di ordinamento per inserzione... 103
10.3 Esercizi...104
11 Programmazione modulare e funzioni...105
11.1 Generalità sui sottoprogrammi...105
11.2 Funzioni... 105
11.2.1 Definizione di una funzione... 105
11.2.2 Chiamata di funzione... 106
11.2.3 Istruzione return... 107
11.3 Semantica della chiamata e passaggio dei parametri per valore... 108
11.3.1 Caratteristiche del passaggio per valore...109
11.4 Regole di visibilità... 109
11.5 Funzioni void...111
11.6 Passaggio per riferimento...112
11.7 Parametri di tipo strutturato... 114
11.7.1 Parametri di tipo array... 114
11.7.2 Passaggio per riferimento costante...115
11.7.3 Parametri di tipo struct... 116
11.8 Intento e passaggio...117
11.9 Definizione e dichiarazione di funzioni... 118
11.10 Record di attivazione... 119
11.11 Considerazione finali sull'uso delle funzioni... 123
11.12 Esercizi...123
12 Ricorsione...125
12.1 Definizioni ricorsive... 125
12.2 Ricorsione nei linguaggi di programmazione... 126
12.3 L'esempio del fattoriale...126
12.4 Programmazione ricorsive ed altri esempi di funzioni ricorsive... 129
12.4.2 Elevamento a potenza – metodo veloce... 130
12.4.3 Scrittura di un numero in binario... 131
12.4.4 Calcolo della successione di Fibonacci...132
12.5 Ricorsione sugli array... 132
12.5.1 Ricorsione a prefisso... 132
12.5.2 Ricorsione a suffisso... 133
12.5.3 Ricorsione “binaria”...133
12.5.4 Altri esempi di ricorsione sugli array... 134
12.6 Confronti tra ricorsione ed iterazione... 135
12.7 Esercizi...136
13 Puntatori e variabili dinamiche...137
13.1 Il tipo di dato puntatore...137
13.1.1 Dominio e dichiarazione di puntatori...137
13.1.2 Operazioni supportate... 138
13.2 Aritmetica dei puntatori... 139
13.3 Passaggio per riferimento e puntatori... 140
13.4 Allocazione dinamica...142
13.5 Array dinamici... 143
13.6 Esercizi...143
14 Liste ed altre strutture dati elementari... 145
14.1 Array e liste... 145
14.2 Implementazione delle liste puntate unidirezionali... 146
14.2.1 Strutture dati...146
14.2.2 Inserimento all'inizio...146
14.2.3 Inserimento in fondo... 147
14.2.4 Eliminazione del primo elemento... 147
14.2.5 Lettura da tastiera... 148
14.2.6 Inserimento dopo un dato nodo...149
14.2.7 Inserimento prima di un dato nodo... 149
14.2.8 Eliminazione dopo un dato nodo... 150
14.3 Scansione ed altre operazioni di base... 150
14.3.1 Scansione di una lista... 150
14.3.2 Scrittura sullo schermo...151
14.3.3 Calcolo della lunghezza... 152
14.3.4 Somma degli elementi di una lista... 152
14.3.5 Ricerca di un nodo avente una data chiave... 152
14.3.6 Eliminazione di un nodo avente una data chiave... 152
14.3.7 Copia di una lista...153
14.3.8 Ultimo elemento ed ennesimo elemento... 154
14.4 Liste e ricorsione...154
14.4.1 Calcolo della lunghezza... 155
14.4.2 Scrittura sullo schermo...155
14.4.3 Eliminazione di un nodo avente una data chiave... 155
14.4.4 Copia di una lista...156
14.5 Cenni ad altre strutture dati dinamiche... 156
14.5.1 Pile... 156
14.5.2 Code... 157
1 Introduzione
1.1 Concetti di base
La programmazione è la scienza che ha come oggetto di studio le metodologie e gli strumenti usati per creare programmi adatti ad essere eseguiti da un computer. Tra i concetti principali della programmazione troviamo quelli di programma e di linguaggio di programmazione.
Per capire meglio tali concetti è utile introdurre un concetto più generale rispetto a quello di programma, cioè quello di algoritmo.
Un algoritmo è un procedimento finito mediante il quale un agente di calcolo è in grado di risolvere in maniera automatica un compito complesso.
Innanzitutto chiariamo cosa si intende per agente di calcolo (o esecutore). Un agente di calcolo C è un dispositivo ideale dotato di due capacità:
• svolgere delle operazioni elementari (dette istruzioni di base dell'agente), il cui insieme è indicato con E;
• eseguire in maniera autonoma (o automatica) dei procedimenti finiti scritti con un linguaggio L a lui comprensibile ed espressi in termini delle istruzioni di base appartenenti a E.
L'agente di calcolo è l'esecutore materiale dell'algoritmo. L'agente di calcolo per antonomasia è il computer, ma è possibile immaginare algoritmi pensati per gli esseri umani (si pensi ai metodi imparati a scuola per svolgere le varie operazioni, quali l'addizione, la moltiplicazione, ecc.) o per dispositivi meccanici (attuatori, robot, ecc.). Infine un agente di calcolo puramente teorico molto studiato nell'informatica è la macchina di Turing.
È importante notare che oltre che eseguire le singole istruzioni di base, l'agente di calcolo deve essere in grado di eseguire dei programmi: ad esempio una semplice calcolatrice non può essere considerata un agente di calcolo perché non è in grado di svolgere che singole operazioni su richiesta dell'utente. Solo le calcolatrici programmabili possono essere equiparate ai computer. Un compito complesso è un'operazione che deve essere compiuta dall'agente di calcolo C ma che non rientra in E. Un algoritmo è perciò un procedimento che permette ad C di svolgere tali operazioni non elementari e deve essere scritto in L in termini delle sole operazioni di E, altrimenti non sarebbe possibile la sua esecuzione da parte di C.
Possono esistere compiti complessi così difficili per C tali che non è possibile trovare un procedimento risolutivo. Tali compiti sono da considerare irrisolvibili per C. Un esempio di problema non risolubile mediante un computer sarà illustrato nel capitolo 8.
Poiché un computer è quasi esclusivamente utilizzato come strumento per l'elaborazione dati, tra i principali compiti complessi risolubili da un computer troviamo i problemi computazionali.
1.2 Problemi ed istanze
Un problema computazionale è definito mediante
• un insieme I di possibili combinazioni dei dati in ingresso,
• una funzione o:IO che associa ad ogni possibile input i∈I il corrispondente output o(i)∈O. Un problema computazionale è quindi un compito di elaborazione di dati, in cui C ottiene dei dati in ingresso, deve calcolare dei risultati e inviarli all'esterno. È importante capire che nella descrizione del problema non è descritto come ottenere i risultati dai dati, ma solo in che relazione stanno fra di loro.
Presentiamo ora alcuni esempi di problemi computazionali
1. Dati due numeri interi a e b, calcolare il loro massimo comun divisore (abbreviato in MCD(a,b)). 2. Dato un numero naturale n, determinare se n è un numero primo.
3. Dati i coefficienti a,b,c di un'equazione di II grado ax2+bx+c=0, determinare le soluzioni reali o
stabilire che non ammette soluzioni
4. Data una sequenza finita di stringhe (ad esempio nominativi di persone), disporre le stringhe in ordine alfabetico.
5. Dato un grafo pesato (ad esempio una rete ferroviaria con le rispettive lunghezze dei collegamenti tra stazioni) e due vertici u e v (ad esempio la stazione di partenza e quella di arrivo) calcolare il percorso più breve che collega u a v.
Nel problema 1 l'insieme I corrisponde all'insieme di tutte le coppie di numeri interi (Z2), l'insieme
O coincide con Z, mentre la funzione o(a,b) è il MCD di a e b.
Nel problema 2 l'insieme I corrisponde all'insieme dei numeri naturali N, l'insieme O è composto da due elementi { vero, falso }, mentre la funzione o(n) è definita dalle leggi
o(n)=vero se n è primo o(n)=falso se n non è primo
Un problema in cui O={ vero, falso } (o simili) si chiama problema decisionale.
Nel problema 3 l'insieme I è l'insieme di tutte le terne di numeri reali a,b,c in cui a ≠0, l'insieme O è l'unione dell'insieme delle possibili coppie non ordinate di numeri reali distinti (nel caso vi siano due soluzioni distinte), dell'insieme dei numeri reali R (nel caso in cui vi siano due soluzioni reali coincidenti) e dell'insieme {⊥}, in cui il simbolo ⊥ significa che non vi sono soluzioni reali. La funzione o(a,b,c) è definita da
o(a,b,c)={x1,x2} se x1 e x2 sono soluzioni dell'equazione ax2+bx+c=0
o(a,b,c)=x1 se x1 è l'unica soluzione dell'equazione ax2+bx+c=0
o(a,b,c)=⊥ se l'equazione ax2+bx+c=0 non ammette soluzioni reali
Nel problema 4, I è l'insieme formato da tutte le sequenze finite di stringhe, O è il sottoinsieme di I formato dalle sole sequenze ordinate e la funzione o(s), in cui s è la sequenza da ordinare, è la sequenza s' che ha gli stessi elementi di s disposti però in ordine alfabetico.
Nel problema 5, I è l'insieme di tutti i grafi pesati e di tutte le coppie di vertici, O è costituito da tutti i percorsi possibili nei grafi presenti in I e o(G,u,v) è il percorso più breve dal vertice u al vertice v nel grafo G.
I problemi di quest'ultimo tipo sono detti di ottimizzazione, perché richiedono di trovare un elemento (in questo caso un percorso) che minimizza o massimizza una determinata funzione (nell'esempio minimizzare la lunghezza del percorso).
Dato un problema P, un'istanza di P si ottiene specificando una combinazione dei dati di ingresso. Un'istanza è quindi un elemento di I, a cui corrisponde l'elemento o(i) di O.
1. a=3, b=6 2. a=10, b=45 3. a=19, b=20 4. a=55, b=55 5. ecc.
1.3 Metodi per la descrizione degli algoritmi
Gli algoritmi possono essere descritti a parole, ad esempio per risolvere il problema 1 (calcolare il MCD di due numeri interi) si puo' utilizzare il procedimento descritto da Euclide nel settimo libro “Elementi”:
Si sottragga ripetutamente il più piccolo dei due numeri al più grande, fino a che i due numeri non diventano uguali. Il numero trovato è il massimo comun divisore dei due numeri di partenza. Per avere una descrizione più precisa e e con una terminologia uniforme si preferiscono usare metodi più formalizzati. Tra questi i più diffusi sono i diagrammi di flusso e lo pseudo-codice.
1.3.1 Diagrammi di flusso
Il diagramma è costituito da un insieme finito di nodi e da un insieme di frecce che collegano i nodi. I nodi sono di quattro tipi
1. Ellisse: inizio e fine del diagramma 2. Rettangolo: istruzioni di calcolo
3. Rombo: biforcazioni del diagramma associate a condizioni (vero/falso) 4. Parallelogramma: istruzioni di ingresso o di uscita
Sono ammessi punti di raccordo a cui si può arrivare seguendo percorsi diversi.
Ogni nodo del diagramma, ad eccezione dei rombi e del nodo finale, ha un'unica freccia uscente che lo collega al nodo che lo segue nell'ordine di esecuzione.
Il nodo finale non ha frecce uscenti, mentre il nodo iniziale non ha frecce entranti. I nodi rombo hanno due frecce uscenti: una etichettata con SÌ e una con NO.
L'esecuzione di un diagramma di flusso parte con il nodo INIZIO e sono eseguite le istruzioni che si incontrano durante il percorso, passando da un nodo a quello successivo seguendo le frecce. Arrivando ad un nodo rombo, il percorso prosegue percorrendo l'arco etichettato con SÌ se la condizione è vera, quello con NO se la condizione è falsa.
I nodi di calcolo richiedono di effettuare dei calcoli e di assegnare il risultato alle variabili. Ciò corrisponde ad una o più operazioni dell'insieme E. La forma più utilizzata è:
X ← e in cui X è una variabile ed e è un'espressione.
Le istruzioni di ingresso (contrassegnate dalla parola Leggi) consentono all'esecutore di ricevere dei dati dall'esterno, mentre quelle di uscita (contrassegnate dalla parola Scrivi) indicano all'esecutore di produrre all'esterno dei risultati.
L'esecuzione termina quando si arriva al nodo FINE.
È perfettamente lecito che in un diagramma di flusso ci siano nodi contenenti operazioni non elementari, purché sia noto (ad esempio con un altro algoritmo) come effettuare tali operazioni.
1.3.2 Pseudo-codifica
La pseudo-codifica utilizza un linguaggio testuale non troppo dissimile (almeno come struttura) rispetto ad un linguaggio di programmazione. Le versioni inglesi della pseudo-codifica hanno molte istruzioni simili a quelle presenti nei veri linguaggi di programmazione, come Algol, Pascal o C. Noi però utilizzeremo una versione italiana, avente le seguenti istruzioni:
1. Inizio, che segna l'inizio dell'algorimo. 2. Fine, che segna la fine dell'algoritmo. 3. Leggi, che ottiene dati dall'esterno. 4. Scrivi, che invia dati all'esterno.
5. Assegnamento, in una forma simile a quella usata nei diagrammi di flusso.
6. Se condizione Allora istruzioni_1 Altrimenti istruzioni_2 Fine-se, che indica di eseguire le istruzioni tra Allora e Altrimenti (chiamate istruzioni_1) se la condizione è vera, le istruzioni tra Altrimenti e Fine-Se (istruzioni_2) se è falsa. In ogni caso l'esecuzione continuerà con l'istruzione successiva alla Fine-Se.
7. Mentre condizione Ripeti istruzioni Fine-Ripeti, che indica di eseguire ripetutamente le istruzioni tra Ripeti e Fine-Ripeti fintantoché la condizione resta vera, quando questa diventa falsa il ciclo termina e l'esecuzione continua con l'istruzione successiva alla Fine-Ripeti.
Come esempio di algoritmo in pseudo-codifica presentiamo ancora l'algoritmo di Euclide per il M.C.D.: Inizio Leggi a,b Mentre a ≠ b Ripeti Se a>b Allora a ← a-b Altrimenti b ← b-a Fine-se Fine-Ripeti Scrivi a Fine
Anche in uno pseudo-codice possono comparire operazioni non elementari, se è noto come sia possibile eseguirle.
1.4 Proprietà degli algoritmi
Non tutti i procedimenti risolutivi per un determinato compito complesso possono essere considerati soluzioni algoritmiche valide. Infatti un algoritmo sviluppato per risolvere un problema P mediante un agente di calcolo C deve avere tre proprietà fondamentali per essere ritenuto tale
1. eseguibilità 2. finitezza 3. correttezza
Se almeno una di queste proprietà non è verificata il procedimento non è un algoritmo accettabile. Una quarta proprietà auspicabile, ma non indispensabile, è l'efficienza.
1.4.1 Eseguibilità
Un procedimento A si dice eseguibile da un agente di calcolo C se è scritto in modo tale che C sia in grado di eseguirlo in perfetta autonomia. A deve essere scritto in un linguaggio comprensibile a C e deve far riferimento solo ad operazioni eseguibili da C.
In A non ci devono essere istruzioni che richiedono particolari nozioni o abilità da parte di C, al di là di quelle viste per un agente di calcolo, né deve essere richiesto a C di prendere decisioni (al di là dei punti di scelta, che però sono decisioni che non sono a carico di C, ma dipendono dai dati in suo possesso).
1.4.2 Finitezza e terminazione
Un procedimento A si dice finito se C, per eseguire A, utilizza una quantità finita di risorse di calcolo, qualunque siano i dati in input che riceve, ovvero qualunque sia l'istanza del problema P. Tra le risorse usate da C per eseguire un procedimento le più importanti sono il tempo di calcolo e lo spazio in memoria. Il tempo di calcolo è approssimativamente indicato dal numero di passi che l'agente esegue, mentre lo spazio in memoria tiene conto dello spazio occupato dai dati elaborati. Per garantire la proprietà di finitezza è sufficiente provare che il procedimento termina sempre dopo un numero finito (non necessariamente costante) di passi. Tale proprietà è detta di terminazione, ed è sufficiente perché si presuppone che ogni passo consumi una quantità finita di risorse.
La terminazione è fondamentale in quanto un procedimento termina solo quando ha prodotto tutti i risultati desiderati. Perciò se un procedimento non termina dopo un numero finito di passi, C non è in grado di restituire i risultati voluti e quindi non riesce a svolgere il compito per cui A era stato ideato.
Dimostrare la terminazione di un procedimento può essere complicato e vedremo una tecnica per provare la terminazione di un programma nel capitolo 8.
L'algoritmo di Euclide termina qualsiasi siano i numeri a,b>0 per il seguente motivo: ad ogni passo accade sempre che uno dei due numeri diminuisce, rimanendo comunque entrambi maggiori di zero. Dopo un numero finito di passaggi diventeranno uguali e il procedimento terminerà, nel caso peggiore ciò si verificherà quando saranno tutti e due uguali a 1.
1.4.3 Correttezza
Un procedimento A si dice corretto per un problema P se i risultati prodotti coincidono da A con quelli previsti dalla funzione o nella definizione di P. In termini formali, A è corretto se, per ogni i∈ I, il risultato prodotto da A coincide con o(i).
È palese che un procedimento non corretto non è in grado di risolvere il problema per cui è stato designato e quindi non è utilizzabile.
Nel capitolo 8 vedremo delle tecniche dimostrative anche per la proprietà di correttezza.
L'algoritmo di Euclide è corretto perché ad ogni passo i due numeri sono modificati ma il loro MCD rimane inalterato. Quindi alla fine, essendo i due numeri uguali, il loro MCD coincide con essi, ma allo stesso tempo è rimasto uguale al MCD dei due numeri di partenza.
1.4.4 Efficienza
Se per un dato problema esiste un algoritmo A, allora è facile vedere che ne esistono infiniti: basta aggiungere istruzioni inutili ad A. Comunque per molti problemi possono esistere due o più algoritmi sostanzialmente diversi. In tali situazioni un criterio di scelta tra varie soluzioni algoritmiche si basa sul costo di ciascun algoritmo, preferendo quindi algoritmi con minor costo. Un algoritmo A si dice efficiente (rispetto ad una risorsa di calcolo R) se l'agente di calcolo C usa la quantità minima possibile di R per eseguire A. In termini più precisi A è efficiente se non esiste un algoritmo A' che risolve P richiedendo una quantità minore di R per la sua esecuzione.
L'efficienza è una proprietà auspicabile ma non sempre realizzabile.
Innanzitutto è molto difficile trovare algoritmi efficienti (detti anche ottimi), per cui nella pratica si preferisce usare uno tra i migliori algoritmi esistenti, nel senso che l'algoritmo scelto è il più efficiente tra tutti quelli che sono stati ideati, potendo comunque succedere che in futuro siano scoperti algoritmi migliori.
Inoltre in alcune situazioni, possono esistere più algoritmi che sono sostanzialmente alla pari: in alcune istanze è meglio uno, in altre è meglio un altro, e così via. In questi casi si dovrebbe cercare di capire quali sono le istanze più frequentemente risolte e utilizzare un algoritmo che su tali istanze si comporta meglio.
Infine può succedere che ci si possa accontentare anche di algoritmi non completamente efficienti (subottimali), perché magari sono più semplici da scrivere. Tale scelta deve essere oculata, evitando comunque di usare algoritmi troppo inefficienti.
1.5 Introduzione al costo computazionale
Il calcolo del costo di un algoritmo A, ideato per un problema P, in termini di una risorsa R non è semplice ma spesso è sufficiente avere una stima del costo piuttosto che l'andamento esatto.
Più in particolare anziché tentare di calcolare una funzione di costo c(i) per tutte le possibili istanze i di P, ci si accontenta di avere una funzione di costo c(d) che dipende dalle possibili grandezze d delle istanze di P.
Così facendo si ottiene un oggetto più facilmente calcolabile e confrontabile. Il problema è trovare una sintesi tra le tante (e in alcuni casi infinite) istanze aventi la stessa grandezza d.
La scelta più diffusa per la valutazione degli algoritmi è il costo nel caso peggiore, in cui c(d) è il costo dell'algoritmo quando tenta di risolvere la peggiore istanza possibile avente grandezza d. Come esempio di applicazione di questa tecnica vediamo la valutazione di due algoritmi per risolvere il seguente problema:
Data una sequenza S di n numeri naturali, determinare l'elemento più grande di S.
Il primo dei due algoritmi, che chiameremo M1, è basato sulla definizione di elemento più grande: è quell'elemento che è maggiore o uguale a tutti gli altri elementi di S.
In tale diagramma si usa l'operazione di estrazione di un elemento per volta da una sequenza (senza ripetizioni). Inoltre si noti che per controllare se un elemento è maggiore di tutti gli altri sono necessarie n-1 operazioni elementari di confronto.
Il secondo algoritmo, che chiameremo M2, si basa sul concetto di “massimo parziale”, cioè dell'elemento più grande tra quelli già estratti. M2 è illustrato dal seguente diagramma di flusso:
In tale diagramma si usa un ulteriore operazione che controlla se esistono elementi non ancora estratti dalla sequenza.
L'algoritmo M1 ha un costo nel caso peggiore, in termini di confronti svolti, che cresce in maniera quadratica rispetto a n (il numero di elementi della sequenza). Infatti nel caso peggiore l'elemento più grande viene estratto all'ultimo tentativo e quindi occorrono complessivamente n(n-1) operazioni di confronto.
L'algoritmo M2 invece usa sempre solo n-1 confronti. Pertanto M2 è migliore di M1, in quanto usa una quantità nettamente inferiore di operazioni per risolvere lo stesso problema.
1.6 Esercizi
1.1. Preparare la colazione.
1.2. Calcolare i coefficienti dell'equazione della retta y=mx+q che passa per due punti di coordinate (x1,y1) e (x2,y2) ricevuti come input.
1.3. Risolvere un'equazione di primo grado ax=b ricevendo come input i coefficienti sotto forma di numeri reali.
1.4. Risolvere un'equazione di secondo grado ax2+bx+c=0 ricevendo come input i coefficienti
sotto forma di numeri reali.
1.5. Determinare il plurale di un sostantivo italiano a partire dalla sua forma singolare. 1.6. Calcolare xn mediante moltiplicazioni successive (esempio 54=5⋅5⋅5⋅5)
1.7. Addizionare due numeri intere visti come sequenze di cifre decimali (ipotizzare che abbiano la stessa lunghezza).
2 Livelli di programmazione
2.1 Struttura di un elaboratore
Un computer convenzionale è organizzato secondo l'architettura di Von Neumann ed è composto da un processore, una memoria centrale, una o più memorie secondarie, vari dispositivi di ingresso/uscita e un bus che collega tra di loro le varie componenti.
Il processore è la parte del computer che esegue i programmi e le sue componenti principali sono l'unità di controllo (CU), l'unità logica-aritmetica (ALU) e i registri.
La CU riceve, decodifica le istruzioni e predispone la loro esecuzione attivando le componenti necessarie. L'ALU esegue le operazioni aritmetiche (come ad esempio l'addizione) e le operazioni logiche (come ad esempio l'operazione AND). Infine i registri sono delle piccole memorie di transito in cui il processore memorizza i dati su cui sta lavorando. Tra i registri assume particolare importanza il registro PC (program counter) il quale contiene l'indirizzo dell'istruzione corrente, cioè quella che il processore sta eseguendo.
La principale tipologia di memoria centrale è la RAM, che è la parte del computer che serve a memorizzare i programmi in esecuzione ed i relativi dati. E' organizzata in celle di uguale grandezza in bit, ognuna delle quali è identificata da un indirizzo (di solito numeri naturali consecutivi) e può contenere un numero intero (o in maniera equivalente una sequenza di bit).
In una memoria di tipo RAM sono possibili due operazioni: la lettura e la scrittura. L'operazione di lettura ha come operando un indirizzo i e restituisce come risultato il contenuto della cella con tale indirizzo.
Ad esempio nella RAM seguente:
indirizzo 0 1 2 3 4 5 6 7 8 9 ...
contenuto 35 32 44 71 0 13 8 99 123 45 ...
la lettura della cella 3 produce come risultato il valore 71.
L'operazione di scrittura ha due operandi, un indirizzo i e un valore v, e come effetto modifica la cella di indirizzo i sostituendo il contenuto attuale con v. Tale sostituzione è irreversibile.
Ad esempio scrivendo il valore 88 nella cella 5 si ottiene la situazione:
indirizzo 0 1 2 3 4 5 6 7 8 9 ...
contenuto 35 32 44 71 0 88 8 99 123 45 ...
La RAM è la memoria più veloce (a parte la memoria cache ed i registri) a disposizione del processore, in quanto le operazioni di lettura e di scrittura avvengono in tempi abbastanza rapidi in confronto alle altre operazioni svolte dal processore. Lo svantaggio maggiore è quello di essere volatile: il contenuto delle celle è conservato fintantoché la memoria è alimentata dalla corrente. Tra le memorie secondarie segnaliamo i dischi magnetici (floppy disc, hard disc), i dischi ottici (CD, DVD, ecc.), le memorie di tipo flash (pen drive), ecc. Tali memorie sono utilizzate per
contenere grandi quantità di dati e in maniera persistente (cioè in grado di mantenere il contenuto anche senza la presenza di corrente e in alcuni casi al di fuori del computer stesso). I dati nelle memorie di massa sono solitamente organizzati in file.
I principali dispositivi di ingresso (cioè quelli con cui è possibile ricevere dati dall'esterno) sono la tastiera, il mouse e il microfono. I principali dispositivi in uscita (cioè quelli con cui è possibile inviare dati all'esterno) sono il monitor, gli altoparlanti e la stampante. Infine quelli di ingresso/uscita sono il modem e la scheda di rete.
2.2 Il linguaggio macchina
Il processore è in grado di eseguire solo programmi scritti in un linguaggio particolare, chiamato
linguaggio macchina. Ogni istruzione è codificata mediante un numero naturale univoco, stabilito
in sede di progettazione del processore.
Scrivere programmi mediante codici numerici risulta essere estremamente scomodo, per cui si utilizza normalmente una versione “leggibile” del linguaggio macchina, detta linguaggio
assemblativo (assembly), in cui ogni istruzione è rappresentata simbolicamente mediante codici
mnemonici (ad esempio parole inglesi per esteso o abbreviate). Ad esempio l'istruzione mov eax,
ebx che indica di copiare il contenuto del registro ebx nel registro eax, si usa al posto del
corrispondente codice numerico.
Per avere un'idea della struttura di un programma in linguaggio macchina (da ora in avanti abbreviato in L.M.) riportiamo un'implementazione dell'algoritmo di Euclide per il processore Pentium, supponendo che sia memorizzato in RAM a partire dalla cella numero 1000.
1000 mov eax, (2000) 1004 mov ebx, (2004) 1008 cmp eax, ebx 1012 jeq 1036 1016 jlt 1028 1020 sub eax, ebx 1024 jmp 1008 1028 sub ebx, eax 1032 jmp 1008
1036 mov (2008), eax 1040 ret
Ogni istruzione è preceduta dall'indirizzo in cui è memorizzata, ad esempio l'istruzione mov eax,
(2000) si trova nella locazione di memoria 1000. Si noti che ogni istruzione occupa 4 celle di
memoria.
Le prime due istruzioni caricano nei registri eax e ebx i due numeri di cui calcolare il MCD, supponendo che essi siano memorizzati nelle locazioni 2000 e 2004.
L'istruzione all'indirizzo 1008 confronta il contenuto di eax con il contenuto di ebx.
L'istruzione successiva si chiede se i due dati confrontati sono uguali e in tal caso salta (rimanda l'esecuzione del programma) all'istruzione di indirizzo 1036.
Se invece i contenuti dei due registri non sono uguali, l'esecuzione prosegue con l'istruzione 1016, la quale si chiede se il contenuto del registro eax è minore di quello del registro ebx.
In caso affermativo l'esecuzione del programma continua all'istruzione 1028, altrimenti con l'istruzione successiva (1020).
Le istruzioni 1020 e 1028 svolgono compiti simili: la 1020 sottrae dal registro eax il contenuto di ebx e mette il risultato della sottrazione in eax, la 1028 effettua la stessa operazione scambiando i ruoli di eax e di ebx.
Le istruzioni 1024 e 1032 saltano all'istruzione 1008.
Infine l'istruzione 1036 copia il contenuto del registro eax nella locazione 2008 che conterrà quindi il risultato (il MCD dei due numeri) e l'istruzione successiva “termina” l'esecuzione del programma. In un comune linguaggio macchina esistono vari tipi di istruzioni:
1. Istruzioni logico-aritmetiche, che sono eseguite dall'ALU. Esempi di tali istruzioni visti nel programma sono sub e cmp, tra le altre troviamo add, mul, and, or, ecc.
2. Istruzioni di caricamento da e verso la memoria centrale, che servono a copiare dati dai registri verso la RAM o viceversa. Tra queste istruzioni possono esservi anche quelle che gestiscono una parte della memoria con una struttura a pila (stack). Un esempio di tale istruzione è mov che può copiare dati da una locazione di memoria verso un registro, da un registro verso una locazione di memoria o da registro a registro.
3. Istruzioni di I/O, mediante le quali il processore comunica con le periferiche inviando dati verso un dispositivo o ricevendo dati da esso.
4. Istruzioni di controllo, che alterano l'esecuzione del programma. Normalmente l'esecuzione di un programma avviene in modo sequenziale. Tale andamento può essere modificato attraverso le istruzioni di salto, le quali semplicemente modificano il contenuto del registro PC. Esse si distinguono in salto incondizionato (istruzione jmp), in cui il salto avviene sicuramente, e salto condizionato (istruzioni jeq e jlt), in cui il salto avviene solo se una determinata condizione (specificata nell'istruzione stessa) si verifica. Un'altra istruzione di controllo è la chiamata a sottoprogramma, di cui parleremo brevemente nel capitolo 11.
2.3 Caratteristiche negative del L.M.
Dall'esempio precedente, ma soprattutto da un'analisi più approfondita dei L.M., che in questa sede non è possibile svolgere, si possono trovare alcuni aspetti negativi della programmazione in tali linguaggi.
Innanzitutto il L.M. è molto “rudimentale”, ovvero le istruzioni elementari sono relativamente poche e hanno come operandi solo oggetti fisici del computer (celle di memoria, porte di I/O, registri, ecc.). Infatti ogni istruzione praticamente corrisponde ad una parte di hardware o, al limite, di firmware, il che limita fortemente il numero e la complessità delle istruzioni e che rende pressoché impossibile estendere o modificare il L.M. di un processore esistente.
Un'immediata conseguenza è la mancanza di astrazione: un programma in L.M. deve utilizzare solo istruzioni e dati previsti dalla progettazione del processore per cui tutti gli algoritmi devono essere scritti in modo da rientrare in questi vincoli. Ad esempio in un processore a 16 bit, i numeri interi a 32 bit devono essere trattati usando due registri o due celle di memoria e non possono essere considerati come un'unica entità. Allo stesso modo le operazioni su numeri a 32 bit vanno scomposte in operazioni su più celle o più registri. Non vi è modo di vedere i dati e le operazioni in maniera astratta.
Una caratteristica negativa ulteriore è quella della scarsa componibilità: l'unica forma possibile di composizione di istruzioni è la sequenza. Ad esempio non è possibile tradurre un'espressione complessa come A+B*C direttamente in L.M. ma è necessario scomporla in un'operazione di moltiplicazione B*C e in una successiva operazione di addizione tra A e un opportuno operando
(registro o cella di memoria) in cui è stato salvato il risultato precedente. Non vi è modo per il programmatore di “concatenare” le istruzioni di calcolo senza necessariamente scegliere il collegamento da usare. Allo stesso modo non esiste alcun modo di comporre cicli o strutture condizionali se non utilizzando sequenze di istruzioni e salti.
Queste ed altre caratteristiche rendono particolarmente difficile il compito dei programmatori in L.M.. Vi è però un altro grave problema in tale linguaggio.
Infatti un programma scritto in L.M. presenta una portabilità scarsa o nulla, nel senso che difficilmente sarà eseguibile in una piattaforma diversa da quella per cui è stato scritto. Innanzitutto tra due processori diversi vi sono solitamente insuperabili problemi di incompatibilità per i rispettivi L.M. dovuti a differenze architetturali. Ma anche a parità di processore, usare un programma con un sistema operativo diverso da quello previsto potrebbe non essere possibile. Infine un'altra causa di incompatibilità potrebbe nascere in quei programma in L.M. che accedono direttamente a componenti hardware, per cui anche semplicemente cambiando la configurazione esterna del sistema (cambiando ad esempio la scheda grafica) il programma non funziona più correttamente. La mancanza di portabilità fa sì che ogni volta che si cambia la configurazione hardware o software in cui un programma deve essere eseguito c'è il rischio che il programma debba essere riscritto o modificato pesantemente. Non è possibile pensare a soluzioni in L.M. che siano in qualche modo indipendenti dalla piattaforma.
2.4 La programmazione ad alto livello ed i paradigmi di
programmazione
Per superare le difficoltà e le caratteristiche negative del L.M. fin dagli anni cinquanta sono stati definiti dei linguaggi di programmazione ad alto livello. Essi non hanno la struttura tipica dei L.M. di un computer reale, ma sono organizzati in modo da essere più vicini ai linguaggi usati dall'uomo, come ad esempio la notazione algebrica per le espressioni o l'utilizzo di forme tipiche dei linguaggi naturali.
L'idea alla base dell'utilizzo di un qualsiasi linguaggio di programmazione è quella di liberare il programmatore dai problemi relativi all'uso del L.M. in modo da migliorare, anche in maniera considerevole, la facilità di scrittura e di mantenimento del codice e la produttività.
Usare un linguaggio ad alto livello consente al programmatore di lavorare con una macchina
astratta, più generale e molto più semplice da programmare, in cui si riesce meglio a concentrarsi
sugli aspetti algoritmici piuttosto che sugli aspetti tecnici del L.M..
Per consentire l'esecuzione di un programma scritto con un linguaggio siffatto vi è però bisogno di una fase di traduzione, illustrata nella sezione 2.X, in quanto nessun computer sarebbe in grado di eseguire direttamente programmi del genere.
Sono stati ideati un numero impressionante di linguaggi di programmazione, con grandi differenze in successo, diffusione e reale utilizzo. Esistono comunque un discreto numero di linguaggi che hanno avuto una certa rilevanza nell'informatica. Tra questi si possono distinguere i linguaggi orientati ad alcuni tipi di applicazioni (ad esempio Fortran per le applicazioni numeriche o Cobol per quelle gestionali) da quelli general-purpose (come ad esempio C++ o Java), cioè sufficientemente generali da poter essere usati in tutti i tipi di applicazione.
Una classificazione molto importante è data dal paradigma a cui si attengono i linguaggi. Il paradigma corrisponde al modo di intendere i concetti di programma e di programmazione.
2.4.1 Il paradigma imperativo
Nel paradigma imperativo le istruzioni sono visti come comandi che la macchina deve eseguire. La macchina possiede uno stato interno (una sorta di memoria) e la maggior parte dei comandi hanno lo scopo di modificare lo stato della macchina. Lo stato è composto da variabili modificabili attraverso le istruzioni di assegnamento. La maggior parte dei linguaggi prevedono istruzioni strutturate di tipo condizionale e di tipo iterativo. I programmi sono solitamente composti da vari
sottoprogrammi. Un livello più alto di strutturazione dei programmi è ottenuto, in alcuni linguaggi,
medianti i moduli.
Molti linguaggi di programmazione famosi appartengono a questa categoria: Fortran, Cobol, Algol, Basic, PL/I, Pascal, C, Ada.
I linguaggi imperativi definiscono una macchina astratta avente una struttura interna non troppo distante dalla struttura di un reale calcolatore, per cui la traduzione di un programma scritto in un linguaggio imperativo è più semplice e più efficace. Infatti i programmi che necessitano di alte prestazioni sono normalmente implementate mediante linguaggi imperativi.
2.4.2 Il paradigma funzionale
Nel paradigma funzionale le istruzioni sono visti come espressioni che la macchina deve valutare. In un linguaggio funzionale puro non esiste il concetto di stato e di variabile modificabile. Come tale non ha nemmeno senso l'utilizzo di strutture iterative, che sono sostituite dalla ricorsione. I programmi sono composti dalla definizione di funzioni, le quali possono anche essere di ordine superiore, cioè restituire come risultato altre funzioni.
Tra i linguaggi più noti in questa categoria vi sono Lisp, APL, Haskell, Miranda, ML e CaML. La macchina astratta definita nei linguaggi funzionali ha una struttura sostanzialmente diversa da quella di una macchina convenzionale, rendendo così difficile una traduzione efficiente. I linguaggi funzionali hanno però alcuni vantaggi rispetto a quelli imperativi, ad esempio sono più adatti ad elaborazioni di tipo simbolico e in generale le soluzioni scritte in questi linguaggi sono più compatte ed eleganti rispetto alle loro versioni nei linguaggi imperativi.
2.4.3 Il paradigma logico
Nel paradigma logico le istruzioni sono visti come interrogazioni a cui la macchina deve
rispondere mediante un processo di deduzione. Un'interrogazione può prevedere una risposta sì/no
(ad esempio “Luca è il padre di Laura ?”) oppure una risposta più articolata (ad esempio “Chi sono i figli di Simona ?”). Un programma è diviso in fatti e regole. I fatti denotano verità già note, mentre le regole permettono di dedurre nuove verità.
Le idee di programma e di istruzione in un linguaggio di tipo logico sono molto lontane dai rispettivi concetti tradizionali, infatti un programma logico è essenzialmente dichiarativo, cioè lascia molta libertà all'esecutore su come deve essere eseguito. Questo aspetto è molto diverso da quello tipicamente procedurale dei linguaggi imperativi e funzionali. Lo stesso processo di traduzione di un programma logico non è semplice e solo in tempi relativamente recenti sono stati proposti dei metodi non troppo inefficienti di traduzione.
Il linguaggio di programmazione logica per antonomasia è Prolog. Comunque un approccio dichiarativo si riscontra anche in SETL, Snobol e infine anche in SQL, il linguaggio di gestione dei database.
2.4.4 Il paradigma ad oggetti
Un paradigma trasversale è quello ad oggetti. E' possibile definire linguaggi funzionali ad oggetti (ad esempio OcaML e Ruby) e linguaggi logici ad oggetti, ma è molto più frequente trovare linguaggi imperativi ad oggetti (ad esempio Java, C++, C#). In questo tipo di linguaggi è possibile creare e manipolare oggetti, che sono componenti aventi uno stato interno e delle operazioni definite su di essi. Molti linguaggi richiedono la definizione di classi come tipologie di oggetti. Alcuni degli aspetti peculiari sono l'incapsulamento (restringere le operazioni che si possono svolgere sugli oggetti), l'ereditarietà (definire classi a partire da classi esistenti) e il polimorfismo. L'approccio ad oggetti presenta molti risvolti positivi nella costruzione di programmi, anche di grandi dimensioni e da parte di più sviluppatori, per cui ormai la maggior dei linguaggi ideati recentemente sono ad oggetti, come lo sono anche le versioni più recenti di linguaggi esistenti (ad esempio Fortran 95).
2.5 La traduzione
Come è già stato detto nelle sezioni precedenti, per superare la “barriera linguistica” che si crea tra il programmatore, che scrive i programmi usando un linguaggio ad alto livello, ed il computer, che è in grado di eseguire solo programmi scritti nel proprio L.M., è indispensabile una fase in cui il programma ad alto livello è tradotto in L.M. per essere eseguito.
Esistono due modalità di base per effettuare tale traduzione: la compilazione e l'interpretazione. Normalmente ogni linguaggio può essere utilizzato con una qualsiasi delle tecniche di traduzione, ma è prassi che ogni linguaggio abbia una forma preferita di traduzione.
È comunque possibile creare meccanismi misti di traduzione, come avviene di norma per il linguaggio Java, in cui si usa una compilazione seguita poi da un'interpretazione.
2.5.1 La compilazione
Nella compilazione si usa un programma, detto appunto compilatore, che riceve in input il programma da tradurre S (detto sorgente, solitamente sotto forma di file) scritto nel linguaggio ad alto livello L e che produce come risultato un programma equivalente E (detto eseguibile) scritto completamente nel L.M. di un computer M.
Per “eseguire” S basterà far eseguire E da M.
Gli aspetti positivi della compilazione sono notevoli.
Innanzitutto la traduzione è quindi svolta una sola volta prima dell'esecuzione, in una fase separata. Una volta ottenuto il programma E, questo può essere eseguito da M tante volte quante occorrono, anche senza avere a disposizione il sorgente S. Però ogni volta che S viene modificato, è necessaria una nuova fase di traduzione per aggiornare E.
La traduzione di S può essere fatta in maniera da rendere E il più efficiente possibile, mediante una o più fasi di ottimizzazione del codice. Tali fasi, che rendono più lenta la traduzione, hanno il vantaggio che possono invece rendere molto più veloce l'esecuzione di E.
Le prestazioni dei programmi compilati sono così buone che molti linguaggi convenzionali (Fortran, Cobol, Pascal, C, C++) sono normalmente utilizzati con la compilazione.
Un compilatore dipende da due parametri: il linguaggio di “partenza” L e la macchina di “destinazione” M. Normalmente M coincide con la macchina in cui si esegue la compilazione, ma nel caso della cross-compilazione queste due possono essere diverse.
Si noti che lo schema della traduzione per compilazione si può anche usare per tradurre da un linguaggio L1 verso un altro linguaggio L2, entrambi ad alto livello. Ad esempio è possibile costruire un traduttore automatico da Pascal a C.
Nella sezione successiva vedremo in maggiore dettaglio le varie fasi della compilazione di un programma.
2.5.2 L'interpretazione
Nell'interpretazione si usa un programma, detto interprete, che riceve in input il programma S, scritto nel linguaggio L, e l'eventuale input x per S e che produce come risultato quello che produrrebbe S a partire da x.
Detto in altri termini un interprete è un esecutore di programmi scritti in L. Dato che L è un linguaggio ad alto livello, l'esecuzione diretta è impossibile e quindi è necessario tradurre S nel linguaggio macchina di M (la macchina che esegue l'interprete).
La modalità di traduzione è sostanzialmente diversa da quella usata nella compilazione: un interprete traduce ed esegue immediatamente un'istruzione alla volta senza memorizzarne la traduzione. Alla fine perciò non produce nessun file eseguibile.
Ogni istruzione è tradotta ogni volta che viene eseguita. Quindi da un lato, le istruzioni che non sono eseguite non sono tradotte, invece nella compilazione il programma è tradotto per intero, anche se viene eseguito solo in parte. D'altra parte se un'istruzione è eseguita più volte (ad esempio perché è all'interno di un ciclo) viene ritradotta ogni volta ex novo.
In conclusione, l'esecuzione tramite interpretazione è molto più inefficiente della compilazione: l'esecuzione è ritardata dalla traduzione e i cicli sono particolarmente colpiti da questo fenomeno. È comunque vero che usando un interprete non vi è nessun tempo di attesa: appena l'interprete entra in funzione, il programma inizia ad essere tradotto ed eseguito subito. Invece con un compilatore il programmatore deve aspettare che l'intero programma sia stato tradotto, prima di poterlo avere in esecuzione. Questa caratteristica degli interpreti è particolarmente utile in ambiente interattivi, quali le shell dei sistemi operativi o le interfacce utente dei programmi di calcolo interattivi matematici e statistici, in cui l'uso dell'interpretazione è molto diffuso.
Si noti inoltre che addirittura il sorgente potrebbe essere modificato in corso di esecuzione, tranne che l'istruzione in corso. Comunque tale possibilità è poco utile nella pratica.
2.6 Le fasi della compilazione
La compilazione di un programma si svolge in varie fasi: 1. analisi lessicale
2. analisi sintattica
3. traduzione in assembly 4. ottimizzazione del codice
5. traduzione in linguaggio macchina (creazione del file oggetto)
6. collegamento con librerie ed altri file oggetti (creazione del file eseguibile)
L'analisi lessicale del sorgente scompone il programma in una sequenza di token: parole chiave, identificatori, operatori e simboli (parentesi, punteggiatura, ecc.) e costanti.
Ad esempio l'istruzione
if(x>4) a=3;
parola chiave if parentesi ( identificatore x operatore > costante intera 4 parentesi ) identificatore a operatore = costante intera 3 punto e virgola
L'analisi sintattica effettua una scansione del sorgente in versione tokenizzata utilizzando le regole grammaticali del linguaggio ottenendo una scomposizione in base alle funzioni grammaticali degli elementi.
Nell'esempio precedente produrrebbe la struttura:
La generazione del codice assembly produce una prima traduzione letterale mediante regole di traduzione (del tipo l'istruzione di assegnamento si traduce con un'istruzione mov, ecc.). Sia prima che dopo tale traduzione possono essere effettuate delle fasi di ottimizzazione del codice. Tali fasi riscrivono il codice in maniera da aumentare la velocità di esecuzione, pur producendo lo stesso risultato. Non è difficile immaginare che una traduzione letterale possa produrre codice inefficiente, dato che ogni istruzione è tradotta senza tenere conto delle altre. L'ottimizzazione potrebbe ridurre o eliminare tali inefficienze riorganizzando in maniera opportuna il programma in assembly.
Il risultato finale potrebbe essere equiparabile o al limite superiore ad una versione di S scritta direttamente in L.M. da un programmatore esperto. Infatti in alcuni casi le tecniche di ottimizzazione si spingono oltre le normali capacità umane di sfruttamento delle peculiarità del processore.
La traduzione in L.M. produce un programma scritto in L.M., detto programma oggetto, ma non completo e quindi non eseguibile dalla macchina. Infatti il programma oggetto potrebbe mancare dei collegamenti esterni, verso le librerie, contenenti funzioni già tradotte e rese disponibili al programmatore, o verso altri programmi oggetto (traduzioni in L.M. di altri sorgenti facenti parte dello stesso programma complessivo). Il primo tipo di collegamenti esterni è quello più diffuso: è praticamente impossibile scrivere un programma che non faccia uso di funzioni presenti nelle librerie, ad esempio in C tutte le istruzioni di ingresso/uscita sono implementate nelle librerie. Il secondo tipo di collegamenti è necessario nel caso della compilazione separata, di cui si discuterà nel capitolo 11. I collegamenti esterni sono lasciati in sospeso durante la fase di produzione dei programmi oggetto.
E' quindi indispensabile una fase finale, detta di collegamento (linking) e svolta da un programma chiamato linker, che ha lo scopo di risolvere i collegamenti esterni, completando le istruzioni che ne fanno uso. Alla fine di tale fase si ottiene un unico file eseguibile mediante fusione dei programmi oggetti ed eventualmente delle librerie, pronto per essere eseguito dalla macchina.
istruzione if
condizione
istruzione
maggiore_di
assegnamento
2.7 Gli strumenti della programmazione
Tra gli strumenti software utilizzati nella programmazione, oltre ai compilatori e agli interpreti, i più importanti sono gli editor, gli ambienti di esecuzione e i debugger.
Gli editor sono programmi che consentono al programmatore di scrivere in maniera efficace i programmi sorgenti. Gli editor moderni effettuano alcuni controlli di sintassi delle istruzione durante la digitazione (ad esempio tramite il syntax highlighting), evitando così alla fonte alcuni errori di sintassi, e aiutano il programmatore mediante di meccanismi di completamento del codice.
Gli ambienti di esecuzione consentono di far eseguire i programmi compilati, anche in maniera controllata. I debugger permettono modalità di esecuzione diverse dal solito:
• esecuzione “un passo alla volta”, in cui è possibile eseguire una singola istruzione, vedere il contenuto delle variabili, eventualmente modificarle e ripartire con l'istruzione successiva
• esecuzione con “break-point”, in cui è possibile inserire dei punti di fermata (break-point) all'interno di un programma, eseguirlo normalmente, controllare cosa succede al break-point e poi ripartire
• tracciare il valore delle variabili
Gli ambienti integrati di sviluppo (IDE) sono infine degli insiemi di programmi che comprendono, tra l'altro, editor, compilatore, ambiente di esecuzione e debugger e che permettono di gestire un programma dalla digitazione del codice all'esecuzione tutto all'interno dello stesso sistema.
3 La sintassi dei linguaggi di programmazione
Forniremo in questo capitolo alcuni concetti di base sui linguaggi formali, per poi introdurre il formalismo di Backus-Naur nella versione estesa (EBNF) che sarà utilizzato in queste dispense per definire la sintassi del linguaggio di programmazione C++.
3.1 Definizioni generali: stringhe e linguaggi
Un alfabeto è un insieme finito di simboli.
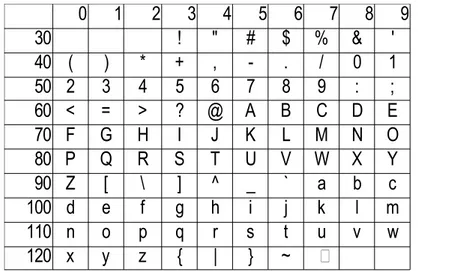
Esempi di alfabeti sono l'insieme delle cifre binarie {0,1}, quello delle cifre decimali {0,1,2,3,4,5,6,7,8,9}, quello delle lettere maiuscole {A,B,C,...,Z}. Un alfabeto molto utilizzato nell'informatica è il set dei caratteri ASCII.
Una stringa su un alfabeto A è una sequenza finita di simboli di A. La stringa vuota, cioè quella composta da zero simboli, si indica con ε.
L'insieme di tutte le stringhe su A si indica con A*.
Ad esempio se A={0,1} allora A*={ ε, 0, 1, 00, 01, 10, 11, 000, 001, ..., 110, 111, 0000, ...}
La lunghezza di una stringa w è il numero di simboli di cui w è composta (contando anche le ripetizioni) e si indica con |w|.
Ad esempio | abcbd | = 5. Chiaramente | ε |=0.
Date due stringhe u e v, la concatenazione di u con v è la stringa indicata con u ⋅ v che si ottiene
prendendo prima tutti i simboli che compongono u e poi di seguito quelli che compongono v. Chiaramente | u ⋅ v | = | u | + | v |. Ad esempio 011 ⋅ 10 = 01110, mentre 10 ⋅ 011 = 10011.
L'operazione di concatenazione è un'operazione associativa, ovvero u ⋅ (w ⋅ v) = (u ⋅ w) ⋅ v . Ad
esempio sia con (011 ⋅ 10) ⋅ 11= 01110 ⋅ 11=0111011 che con 011 ⋅ (10 ⋅ 11)= 011 ⋅ 1011=0111011
si ottiene lo stesso risultato. Invece non vale in generale la legge commutativa, come dimostra l'esempio 01 ⋅ 10 = 0110, mentre 10 ⋅ 01 = 1001. La stringa vuota agisce da elemento neutro della concatenazione in quanto u ⋅ε = ε ⋅ u=u per ogni stringa u.
Date due stringhe u e v, si dirà che u occorre in v se esiste una sottosequenza di simboli consecutivi di v che corrisponde elemento per elemento a u. Ad esempio la stringa 011 occorre in 1101101, la stringa 00 occorre in 01001101 e in 01001100. Si noti che 00 occorre due volte in 01001100.
Un linguaggio su A è un qualsiasi sottoinsieme di A* . Alcuni esempi di linguaggi sono
1.su A={a,b,c} il linguaggio delle stringhe con al massimo 5 simboli
2.su A={1,2,3,4} il linguaggio delle stringhe che viste come numeri naturali sono minori di 2000 (ad esempio1234 e 1442 lo sono, mentre 2112 non lo è).
3.su A={0,1} il linguaggio di tutte le stringhe che terminano per 0
4.su A={0,1} il linguaggio di tutte le stringhe palindrome (cioè che lette da sinistra a destra sono
Si noti che i linguaggi 1 e 2 sono finiti ed è possibile elencarne tutte le stringhe. Invece i linguaggi 3 e 4 sono infiniti, quindi per specificarli è necessario descriverli a parole o usare un meccanismo formale. Un meccanismo di definizione dei linguaggi che useremo è quello generativo mediante una grammatica formale.
Il concetto chiave di grammatica è quello di produzione.
Una produzione è una coppia di stringhe, indicata con u→v. Una produzione u→v è applicabile ad
una stringa w se u occorre in w. La produzione genera una o più stringhe che si ottengono da w sostituendo una sola volta la stringa u con la stringa v, in un qualsiasi punto in cui u occorre in w. Con w w' si indica il fatto che la stringa w' si ottiene da w mediante l'applicazione di una data produzione. Ad esempio data la produzione 10→ 01 si ha che 010001011 001001011 ed anche 010001011 010000111. Mentre a partire da 010001111 si ha solo 010001111 001001111. In generale a partire da una stringa w si possono generare più stringhe, se la parte sinistra u della produzione occorre più volte in w.
3.2 Grammatiche
Una grammatica è definita mediante quattro componenti:
● T, alfabeto di simboli terminali ● N, alfabeto di simboli non terminali ● S, un particolare simbolo di N
● P, un insieme finito di produzioni; in ogni produzione u→v, u e v sono stringhe su NT e u
deve contenere almeno un simbolo non terminale
Una grammatica (T,N,S,P) genera il linguaggio su T formato da tutte (e sole) le stringhe w di T che si ottengono da S mediante un numero finito di applicazioni delle produzioni.
Ad esempio la grammatica avente alfabeto terminale T={ a,b,c}, alfabeto non terminale N={S,A,B}, simbolo iniziale S e produzioni { S→ AB, S→ A, A→ a, A→ bB, B→ c} genera il linguaggio { a, bc, ac, bcc }. Infatti
1.la stringa a si ottiene da S A, A a
2.la stringa bc si ottiene da S A, A bB, bB bc 3.la stringa ac si ottiene da S AB, AB aB, aB ac
4.la stringa bcc si ottiene da S AB, AB bBB, bBB bcB, bcB bcc 5.non è possibile ottenere altre stringhe su T
La sequenza di stringhe intermedie che si ottengono per arrivare alla stringa voluta si chiama
derivazione. Ad esempio una derivazione di bcc è la sequenza S, AB, bBB, bcB, bcc.
Per generare linguaggi infiniti è necessario avere alcune produzioni ricorsive, ovvero quelle in cui la parte sinistra occorre nella parte destra. Ad esempio per generare il linguaggio delle stringhe su {0,1} che iniziano per 1 e che contengono poi solo il simbolo 0 {1, 10, 100, 1000, 10000, … } si può usare la grammatica
{ S→ 1, S→ 1A, A→ 0, A→ 0A }.
Ad esempio la stringa 1000 si ottiene mediante S 1A, 1A 10A, 10A 100A, 100A
1000.
Le costanti intere decimali senza segno esprimibili in C possono essere 0 o devono iniziare per una cifra diversa da 0. Una grammatica che genera tale linguaggio è data dalle produzioni
{ I→ C, I→ DJ, J→ C, J→ CJ, D→1, D→2, …, D→9, C→0, C→D}.
Ad esempio 15 si ottiene attraverso questa derivazione I, DJ, 1J, 1C, 1D, 15.
3.3 Grammatiche libere dal contesto ed alberi di derivazione
Una grammatica è libera dal contesto se in ogni produzione u→v si ha che |u|=1, ovvero che u è
formato da un solo simbolo non terminale e da nessun simbolo terminale.
Un linguaggio è libero dal contesto se è generato da una grammatica libera dal contesto. I linguaggi liberi dal contesto sono molto utilizzati nell'informatica, oltre che nella linguistica.
Data una grammatica libera dal contesto G si può definire (almeno) un albero di derivazione per ogni stringa w appartenente al linguaggio generato da G. In realtà l'albero, come dice il nome, è associato alla derivazione di w.
La radice dell'albero è il simbolo iniziale di G, mentre le foglie sono i simboli di w, disposti nell'albero da sinistra verso destra. Ogni nodo interno (cioè escluse le foglie) contiene un simbolo non terminale ed è collegato direttamente ai simboli presenti nel lato destro della produzione che è stata utilizzata per ottenere w.
Ad esempio per w=15 l'albero di derivazione è
I
D
J
D
J
C
1
5
Una grammatica si dice ambigua se esiste una stringa del linguaggio generato avente almeno due alberi di derivazione diversi.
Un esempio di grammatica ambigua è la grammatica che genera le espressioni (polinomiali) con le variabili x,y,z
{E→ (E), E→ V, E→ E+E, E→ E-E, E→ E*E, V→ x, V→ y, V→ z} La stringa x+y*z ammette due alberi di derivazione
i quali corrispondono a due diverse letture dell'espressione corrispondente. L'albero (a) corrisponde ad interpretare l'espressione (x+y)*z, mentre l'albero (b) corrisponde a x+(y*z). Ovviamente la lettura corretta è la seconda, perché in matematica (e nei normali linguaggi di programmazione) la moltiplicazione ha priorità maggiore dell'addizione.
Per rendere non ambigua tale grammatica è possibile riorganizzare le produzioni. Altrimenti è possibile indicare, medianti ulteriori specificazioni, quale degli alberi di derivazione, ovvero quale delle interpretazioni possibili, è quello corretto. Nel caso delle espressioni è sufficiente indicare la priorità degli operatori.
3.4 Forma estesa di Backus e Naur (EBNF)
Al posto delle grammatiche (libere dal contesto) si preferisce utilizzare una rappresentazione più compatta, ma perfettamente equivalente, ad una grammatica, chiamata forma estesa di Backus e
Naur (Extended Backus Naur Form, EBNF).
I simboli non terminali sono sostituiti da nomi (stringhe) composti da più caratteri, mentre le stringhe di simboli terminali (anche i singoli simboli terminali) devono essere delimitati da virgolette. Il simbolo → è sostituito da ::=.
Per cui al posto delle produzioni I→ C, I→ DJ, D→1, D→2,..., D→9 si scriverà
E
E
E
E
E
V
V
V
x
+
y
z
*
E
E
E
V
z
*
E
E
V
V
x
y
+
costante_int_dec_senza_segno ::= cifra
costante_int_dec_senza_segno ::= cifra_non_zero resto_costante_int_dec_senza_segno cifra_non_zero ::= “1”
cifra_non_zero ::= “2” …
cifra_non_zero ::= “9”
In maniera più compatta tante produzioni aventi a sinistra lo stesso simbolo non terminale u::=v1
u::=v2 … u::=vn
possono essere accorpate in un'unica produzione indicata con la notazione u ::= v1 | v2 | … | vn
Ad esempio
costante_int_dec_senza_segno ::= cifra | cifra_non_zero resto_numero cifra_non_zero ::= “1” | “2” | … | “9”
In generale il simbolo | separa due o più alternative tra cui scegliere.
Le parentesi quadre servono ad indicare delle parti facoltative, cioè che possono essere presenti oppure no.
Ad esempio nella produzione
istruzione_if ::= “if” condizione “then” istruzione [ “else” istruzione ]
si intende dire che la parte composta da else e una seconda istruzione è una parte facoltativa. Quindi un'istruzione if legale può essere di due tipi: uno con else ed uno senza else.
Le parentesi graffe servono invece ad indicare delle parti che possono essere ripetute un numero arbitrario di volte.
Ad esempio nella produzione
sequenza ::= “begin” { istruzione “;” } “end”
si intende dire che una sequenza inizia con begin, contiene un numero imprecisato di istruzioni e termina con end.
3.5 Alcuni semplici linguaggi in EBNF
Il linguaggio delle costanti intere decimali è generato dalla seguente grammatica costante_int_dec ::= [ “+” | “-” ] costante_int_dec_senza_segno
costante_int_dec_senza_segno ::= cifra | cifra_non_zero { cifra } cifra ::= “0” | “1” | “2” | ... | “9”
Il linguaggio degli identificatori è generato dalla seguente grammatica identificatore ::= lettera { ( cifra | lettera ) }
lettera ::= “_” | “A” | “B” | ... | “Z” | “a” | “b” | ... | “z” cifra ::= “0” | “1” | “2” | ... | “9”
3.6 Esercizi
3.1. Scrivere una grammatica per generare semplici frasi italiane del tipo soggetto verbo complemento oggetto, in cui il soggetto, il verbo e il complemento oggetto possono essere presi da un elenco piccolo
3.2. Scrivere una grammatica che descrive il linguaggio { a, b, c, xa, yb, zc, xxa, yyb, zzc, xxxa, yyyb, zzzc, ... }
3.3.Scrivere una grammatica che descrive il linguaggio delle stringhe palindrome sull'alfabeto { a,b} (cioè che sono uguali se lette in entrambe le direzioni, ad esempio abba o abababa).
3.4. Si renda non ambigua la grammatica delle espressioni polinomiali.
3.5. Scrivere in EBNF una grammatica per indicare la dichiarazione delle variabili in Pascal, che è fatta con la parola chiave VAR, una serie di identificatori separati da virgole, i due punti e il tipo.