49
II. Progettazione della libreria C++ per il supporto del
linguaggio UML
2.1 Uno sguardo a ciò che offre la comunità Open Source
Note le specifiche del linguaggio UML non resta che passare al progetto di una libreria in C++ che implementi il metamodello UML descritto nella specifica ufficiale di OMG [UMLS]; si potrebbe dire quasi che la progettazione consiste in una traduzione dalle metaclassi del metamodello a classi del linguaggio C++ che ripropongano gli stessi elementi del metamodello. La cosa non è certamente così diretta, infatti il metamodello dello UML è di tipo logico e non fisico (cioè implementativo), quindi le implementazioni di tale metamodello devono essere conformi alla sua semantica, ma in questo modo non si ha alcuna informazione sul dettaglio implementativo del progetto. Questo è stato fatto di proposito dai metodologi per non legare lo UML ad un particolare linguaggio di programmazione o ad un particolare processo di progettazione.
Quindi, per ottenere una buona progettazione dell’implementazione della libreria UML in C++, si dovranno tradurre nel modo più semplice e corretto le definizioni della semantica UML, usando i tipi e le strutture dati standard del linguaggio C++.
Per avere una base solida da dove partire si è dato uno sguardo alle librerie Open Source che offrano un servizio simile a quello della libreria oggetto di
50
questa tesi. E’ risultata la presenza della libreria di Novosoft, denominata NSUML (Novosoft UML), che supporta il metamodello UML implementandolo in Java.
Queste librerie sono state usate come fondamento di un noto tool Open Source per la modellazione di sistemi attraverso il linguaggio e la notazione UML: ArgoUML di Tigris.org [Tig].
Nel seguente capitolo si vede come a partire dalla libreria NSUML è stata progettata in dettaglio la libreria UML in C++, che in seguito indicheremo con CppUML.
2.2 Progetto della libreria UML in C++ (CppUML)
Nella guida per i programmatori che utilizzano la libreria NSUML [Nov99] si asserisce che questa è basata su Java, è moderna e di alta qualità e può supportare i modelli UML dell’utente. Inoltre si dichiara che il modello è memorizzato attraverso una struttura compatta, che provvede all’accesso delle caratteristiche (features) del metamodello, quali gli attributi o i ruoli delle estremità opposte delle associazioni fra metaclassi. Si garantisce poi che la libreria NSUML permette tutti i tipi di operazioni su un metamodello, quali la generazione di un modello utente, l’accesso agli elementi del modello, la loro modifica e la possibilità di aggiungere o togliere nuove caratteristiche agli elementi del modello. Inoltre NSUML supporta l’integrità e l’esattezza di un modello utente attraverso dei controlli e delle azioni che vengono eseguiti ad ogni
51
operazione su un’istanza di un elemento del metamodello. NSUML si basa sul modello fisico dello UML, specificato da OMG nel capitolo 6 del documento “OMG Unified Modeling Language Specification” versione 1.3, giugno 1999. Inoltre NSUML prevede altri metodi non previsti dalla specifica di OMG, come il supporto della politica dello undo/redo, cioè l’annullamento o la ripetizione dell’ultima modifica al modello utente.
A questo punto si può già anticipare che i metodi della libreria NSUML non previsti dalla specifica di OMG sono stati scartati dalla progettazione e dall’implementazione della libreria CppUML. I motivi di questa scelta sono essenzialmente due:
• nella specifica dei requisiti della libreria CppUML ci si è posti come obiettivo di essere più fedeli possibile alla specifica del metamodello UML, cercando di evitare di aggiungere metodi e strutture superflue;
• il supporto dello undo/redo, se si va a vedere come è implementato nella libreria NSUML, appesantisce molto i tempi di esecuzione e la struttura stessa di ogni classe che funge da metaelemento; infatti NSUML non fa altro che raddoppiare l’informazione che tiene traccia della struttura attuale e di quella precedente all’ultima operazione in ciascuna istanza di classe. Inoltre è più appropriato che il supporto dello undo/redo sia gestito dallo stesso tool che utilizzerà la libreria CppUML, senza che quest’ultima sia contaminata da concetti in realtà estranei alla sua specifica astratta.
52
Poi, per la progettazione della libreria CppUML, si è tenuto conto della specifica di OMG UML, versione 1.4, settembre 2001 e non della versione 1.3 come per quella di NSUML. Per quanto riguarda le dichiarazioni di Novosoft riguardo alla propria libreria, altrettanto e a maggior ragione si può dire della libreria CppUML, infatti è stata presa la struttura dell’implementazione della NSUML e sono state aggiunte e tolte caratteristiche opportunamente.
2.2.1 CppUML metamodello
Come già detto si è proceduto alla creazione di classi C++ che fossero ciascuna la traduzione della corrispondente metaclasse del metamodello UML.
I nomi delle classi sono stati ripresi dai nomi delle corrispondenti metaclassi della specifica dello UML senza variazioni. Quindi ad un metaelemento Classifier del metamodello UML corrisponde una classe C++ con nome Classifier. Il riproporre i nomi come da metamodello non genera ambiguità perché nel metamodello i nomi dei metaelementi iniziano con lettera maiuscola, mentre i simboli del linguaggio C++ iniziano con lettera minuscola: in questo modo non vi è ambiguità fra la classe Class e la parola chiave class del C++ che serve per dichiarare una classe.
Dettagli implementativi
Rispetto al metamodello dello UML sono stati aggiunti i nomi per le estremità delle associazioni che ne sono sprovviste, cioè che non possiedono il rolename, con la convenzione di assegnare loro i nomi delle metaclassi ad esse
53
connesse con la lettera iniziale minuscola; nel caso di duplicati si aggiunge un numero come suffisso.
Mentre NSUML definisce delle classi enumerazione con al loro interno degli attributi che definiscono i singoli valori che assume la corrispondente enumerazione del metamodello, in CppUML le enumerazioni del metamodello UML sono tradotte più semplicemente con un tipo enumerazione C++ avente etichetta uguale al corrispondente nome della enumerazione contenuta nel package Data Types. Come esempio segue un estratto del codice:
enum AggregationKind {none, aggregate, composite};
enum CallConcurrencyKind {sequential, guarded, concurrent};
Inoltre l’enumerazione Boolean non è stata aggiunta perché identica semanticamente al tipo di dati bool in C++.
Da notare che è stato aggiunto come prefisso il carattere ‘_’ ad enumerazioni che si confondono con le parole chiave del linguaggio C++, come riportato nella seguente riga di codice:
enum VisibilityKind{_public , _protected, _private, package};
Come nella libreria NSUML anche nella CppUML la classe associazione ElementOwnership del Core package – Backbone è stata assimilata nella classe ModelElement spostando gli attributi isSpecification e visibility dalla stessa classe ElementOwnership alla classe ModelElement.
MultiplicityRange e Multiplicity
54 class MultiplicityRange
{
public:
MultiplicityRange(string) ;
MultiplicityRange(int lower, int upper);
bool operator!=(const MultiplicityRange &s) const bool operator==(const MultiplicityRange &s) const
int getUpper() { return upper;} int getLower() { return lower; } string toString() ;
string b2s(int i) ; int s2b(const char* b) ; private:
int lower; int upper; } ;
Questa classe implementa il metaelemento del package DataTypes come lo si definisce nella specifica: i due interi lower e upper sono gli estremi dell’intervallo di numeri interi che una istanza della classe MultiplicityRange definisce. Si hanno due costruttori della classe: il primo ha come parametro una stringa22 che rappresenta l’intervallo, il secondo ha invece come parametri i due interi che lo delimitano. I metodi getUpper e getLower restituiscono rispettivamente l’estremo superiore e l’estremo inferiore dell’intervallo. Il metodo toString invece restituisce una stringa della libreria standard del C++ che indica l’intervallo di interi definito da una istanza della classe secondo le convenzioni definite dallo UML stesso: ad esempio l’intervallo di interi compresi tra 5 e 21 è rappresentato dalla stringa “5..21”, altrimenti l’intervallo del solo numero 9 è rappresentato da “9”.
22
Nel paragrafo 2.3.3 si illustrano le funzioni che gestiscono le stringhe che rappresentano un intervallo o un insieme di intervalli di interi.
55
Il metodo b2s trasforma un intero nei corrispondenti caratteri che lo rappresentano, nel caso di molteplicità illimitata restituisce “*”; tale convenzione può servire nel caso di intervalli illimitati.
Il metodo s2b è il reciproco di b2s.
Il metalemento Multiplicity è stato tradotto nella seguente classe: class Multiplicity
{
public:
static const int N=-1; Multiplicity(string ) ;
Multiplicity(int lower=1, int upper=1) ; // Default Multiplicity(Coda<MultiplicityRange>) ;
Coda<MultiplicityRange> getRanges() int getUpper()
int getLower()
string toString() const;
bool operator==(const Multiplicity &); void setMultiplicity(string); string getMultiplicity(); private: Coda<MultiplicityRange> parseRanges(string) ; Coda<MultiplicityRange> ranges; };
La classe Multiplicity serve, ad esempio, a descrivere la molteplicità di un ruolo di una associazione, per questo è definita nella specifica come un insieme di numeri interi non negativi. Per realizzare la classe Multiplicity è stata utilizzata una struttura di tipo Coda23 che mantiene una coda di istanze di MultiplicityRange che definiscono l’insieme di interi. Ad esempio l’insieme “5..10,15,35..70”, che è l’insieme degli interi che sono compresi tra 5 e 10, più il 15, più quelli tra 35 e 70,
23
56
è memorizzato in una istanza di Multiplicity che contiene una coda di 3 istanze di MultiplicityRange: la prima indica l’intervallo “5..10”, la seconda “15”, la terza “35..70”. Vi è inoltre una funzione parseRanges che legge una stringa che rappresenta l’insieme di interi e restituisce la coda di MultiplicityRange che li memorizza. Gli altri metodi hanno nomi intuitivi che sono costruiti con le convenzioni adottate per i metodi delle classi che rappresentano i metaelementi.
La classe Base
Come nella libreria di Novosoft è stata aggiunta nella gerarchia delle classi che rappresentano il metamodello UML una classe denominata Base, radice di tutte le classi della gerarchia di generalizzazione del metamodello UML. Questo ci è servito per aggiungere attraverso l’ereditarietà delle funzionalità estranee alla specifica del metamodello UML. Ad esempio nella classe Base è dichiarata la seguente funzione:
virtual string getUMLClassName();
Questa funzione, per ogni istanza di classe, restituisce il nome di tale classe. In questo modo, quando si esaminano (attraverso l’uso di un puntatore alla classe Base chiamato ad esempio ptrBase) delle istanze di classi della libreria CppUML collegate fra loro tramite dei link24, si può sapere in ogni momento di che tipo è l’oggetto riferito dal puntatore, usando un’istruzione come la seguente: NomeClasse=ptrBase->getUMLClassName();
24
57
Dopo l’esecuzione di questa istruzione la variabile NomeClasse tipo string contiene una stringa che specifica il nome della classe di appartenenza dell’oggetto puntato attualmente da ptrBase. Tutto questo grazie anche al fatto che la funzione getUMLClassName() è stata dichiarata virtual e quindi per ogni istanza di una classe facente parte della gerarchia delle classi della libreria CppUML, di cui Base è capostipite, viene chiamata l’implementazione riferita all’oggetto attualmente puntato da ptrBase (polimorfismo). In questo modo si può fare un cast del puntatore ptrBase alla classe Base per ottenere un puntatore alla classe attualmente puntata e così poter accedere a tutti i metodi esclusivi della classe.
La classe Base ha un’altra importante funzionalità che non è prevista dalla libreria NSUML e che invece è stata introdotta in quella CppUML. Si è pensato infatti di predisporre questa libreria ad essere visualizzata attraverso altre classi che si occupano di presentare all’utente il modello che sta costruendo, attraverso un eventuale tool che adopera la libreria CppUML. Per questo si è pensato a un pattern già ben conosciuto quale MVC (Model-View-Controller) [Gam00] che divide ogni applicazione in tre parti indipendenti:
• Model, memorizza i dati della applicazione attraverso una struttura e una logica propria;
• View, rappresenta all’utente ciò che è memorizzato da Model e visualizza i controlli per l’utente (bottoni, menù pull-down…);
58
Questo pattern verrà approfondito nel paragrafo 2.4 e sarà presentata la specializzazione che si è scelta per questa libreria: il pattern Observer. L’interfaccia della classe Base contiene le operazioni richieste per il pattern Observer.
2.2.2 Accesso agli attributi e alle associazioni
Le classi della libreria CppUML possono contenere degli attributi secondo la specifica di UML e i tipi di questi attributi saranno quelli nativi del linguaggio C++ (integer, string, bool, ...) e quelli definiti nel package DataTypes.
Due metaclassi possono essere connesse attraverso un’associazione. Ogni attributo di una metaclasse ed ogni ruolo (estremo) di un’associazione, che è legato alla stessa metaclasse, è mappato in un insieme di metodi e attributi della classe della libreria CppUML che rappresenta la stessa metaclasse. Questi metodi permettono l’accesso all’attributo o al ruolo e la possibilità di modificare il loro valore. C’è una semplice corrispondenza tra i nomi degli attributi o dei ruoli in UML e i nomi dei metodi e degli attributi della libreria CppUML. Questa sezione contiene una classificazione dei metodi per un utente della libreria che volesse accedere agli attributi e alle associazioni, una descrizione delle regole per dare il nome ai metodi e la loro semantica.
• Gli attributi sono divisi in due categorie: booleani e non-booleani. L’insieme dei metodi per accedere a queste due categorie di attributi è lo stesso, ma c’è una piccola differenza nelle convenzioni per i nomi.
59
• I ruoli nelle associazioni sono divisi in tre categorie: riferimento, insieme e lista ordinata. Se un ruolo ha molteplicità 1 o 0..1 significa quindi che per ogni istanza di associazione ci può essere al più una sola istanza di metaclasse collegata a quel ruolo, allora tale ruolo apparterrà alla categoria riferimento. I ruoli che invece hanno diversa molteplicità apparterranno alla categoria insieme, se le istanze collegate a tale estremo di associazione non sono ordinate, o alla categoria lista ordinata, se invece le istanze sono ordinate.
Alcuni metodi della libreria CppUML sono pubblici, ma sono esclusivamente destinati ad uso interno alla libreria stessa. I nomi di tali metodi hanno come prefisso: “internal”.
Accesso agli attributi
Le classi della libreria CppUML immagazzinano gli attributi come oggetti privati. L’accesso agli attributi di una istanza di metaclasse, che in seguito possiamo anche indicare con il termine generico “oggetto”, è organizzato con l’aiuto di due metodi classificati come metodi Getter e Setter. La semantica di questi metodi è la seguente: Getter è un metodo che restituisce il valore dell’attributo, invece Setter è un metodo che pone il valore dell’attributo uguale a un parametro passato dall’utente. Per esempio, la metaclasse Abstraction ha l’attributo mapping, che appartiene alla metaclasse MappingExpression.
60
Figura 2.1 – Metaclasse Abstraction25.
La corrispondente classe della libreria CppUML ha la seguente forma: class Abstraction: public Dependency
{ …
// attributes
// attribute: mapping
MappingExpression getMapping();
void setMapping(MappingExpression arg); ... // associations ... private: MappingExpression mapping; }
Il metodo getMapping() è un metodo di tipo Getter, invece il metodo setMapping() è un metodo di tipo Setter. La regola per dare il nome a metodi che si riferiscono ad attributi non-booleani è la seguente: il nome del metodo Getter si ottiene prendendo il nome dell’attributo, di cui il metodo deve restituire il valore, con l’iniziale maiuscola, mentre per convenzione gli attributi iniziano per lettera minuscola, ed aggiungendovi il prefisso “get”. Similmente avviene per il metodo “Setter” tranne che per il prefisso che è “set”.
25
La metaclasse Abstraction è stata visualizzata con il tool UML, obiettivo secondario di questa tesi. Tutti i diagrammi di classe che seguiranno sono stati disegnati con il tool medesimo tranne quelli con una nota che specifica una diversa provenienza.
61
Nel caso di attributi booleani vi è una distinzione per facilitare l’utente a ricordare che l’attributo ha valore logico vero o falso (true, false).
Ad esempio si veda il seguente frammento di codice: class AssociationEnd: public ModelElement
{ public: AssociationEnd(); ~AssociationEnd(); string getUMLClassName(); // attributes … // attribute: isNavigable bool isNavigable(); void setNavigable(bool); // associations … private: … bool navigable; } ;
Qui il nome dell’attributo di tipo booleano è navigable, altra piccola differenza con la specifica ufficiale UML dove l’attributo è chiamato isNavigable. La regola per ottenere il nome del metodo Getter si modifica per il solo prefisso che in questo caso è “is”.
Accesso alle associazioni
Nella libreria CppUML ogni associazione del metamodello è costituita da una associazione tra due elementi (classi) della libreria. Un’associazione possiede due ruoli (estremità) ed ogni ruolo ha un nome ed una molteplicità che lo
62
caratterizzano. Il ruolo connesso ad un elemento, che è l’oggetto che attualmente si considera, è detto ruolo target; il ruolo connesso all’elemento opposto rispetto alla associazione è detto source.
La libreria CppUML non ha delle classi specifiche per realizzare le associazioni fra le metaclassi del metamodello UML. Più semplicemente mappa un’associazione negli attributi e nei metodi delle classi che rappresentano le metaclassi che sono legate dalla stessa associazione. In sostanza si può considerare che le classi della libreria contengono e trattano l’informazione che riguarda il solo ruolo source dell’associazione cui sono legate.
Esempio:
Figura 2.2 – Associazione fra due classi della libreria CppUML.
Nella figura 2.2 si possono vedere due classi: Feature e Classifier con un’associazione senza nome fra di esse:
1. il ruolo di nome owner è il ruolo source per la classe Feature e ha molteplicità 0..1;
2. il ruolo di nome feature è il ruolo source per la classe Classifier e ha una molteplicità illimitata, con elementi ordinati;
3. l’associazione va interpretata nel seguente modo: qualsiasi istanza di un Classifier può contenere un numero arbitrario di istanze di Feature che
63
vengono mantenute ordinate. Qualsiasi istanza di Feature può essere legata al più ad una sola istanza di Classifier.
Il ruolo owner è un ruolo di tipo riferimento, invece feature è di tipo lista ordinata. CppUML mappa questi ruoli nei seguenti attributi privati:
Classifier* owner;
Coda<Feature*> features;
A questo punto ogni istanza della classe Feature contiene, nell’attributo owner di tipo puntatore ad una istanza di Classifier, l’informazione che specifica qual’è l’istanza di Classifier che la possiede. Viceversa una istanza di Classifier mantiene l’informazione di quali istanze di Feature possiede all’interno di una struttura26 ordinata di puntatori ad istanze di Feature denominata features (vi è il suffisso “s” perché è una lista, quindi può contenere più elementi).
Essendo attributi privati non vi è un accesso diretto a questi campi, quindi si forniscono dei metodi Getter e Setter specializzati per ogni categoria di ruolo.
Ruolo tipo riferimento
Come già detto, il ruolo tipo riferimento ha molteplicità 1 o 0..1. Basandoci sul precedente esempio di ruolo owner di tipo riferimento, si mostrano ora quali sono i nuovi metodi che sono necessari per un ruolo riferimento e si illustra la loro
26
La struttura adoperata è di tipo Coda, che supporta tutte le funzionalità necessarie a memorizzare una lista ordinata, anche se è strutturata come una coda. Si veda il paragrafo 2.3.1.
64
semantica. Si consideri la sintassi dei metodi per il ruolo owner che sono contenuti nella classe Feature attraverso il seguente frammento di codice:
class Feature: public virtual ModelElement { public: Feature(); ~Feature(); string getUMLClassName(); // attributes …
// opposite role: owner this role: feature Classifier* getOwner(); void setOwner(Classifier* ); void internalRefByOwner(Classifier* ); void internalUnrefByOwner(Classifier* ); private: … Classifier* owner; }
Analizzando questa dichiarazione della classe Feature si può vedere che al ruolo riferimento sono associati gli stessi metodi Getter e Setter associati a qualsiasi altro attributo, più due altri metodi interni, che la libreria usa per mantenere la consistenza del modello utente.
La semantica del metodo Setter è diversa, infatti, nel caso di un accesso ad un attributo, un metodo Setter aggiorna semplicemente il corrispondente campo privato con il nuovo valore dell’attributo contenuto nel parametro. Invece per un metodo Setter di un ruolo si deve mantenere la correttezza del modello generato dall’utente e nel caso di una associazione va fatto un controllo bilaterale.
Infatti prendiamo in esame l’implementazione del metodo setOwner(...): void Feature::setOwner(Classifier* arg)
65 if (owner != arg) { if (owner != NULL) { owner->removeFeature(this); } if (arg != NULL) { arg->addFeature(this); } } owner=arg; Notify(Nowner); }
• Controlla che il valore del parametro arg differisca dal valore dell’attributo owner. Se sono identici non importa fare alcuna modifica e termina.
• Controlla che il puntatore arg non sia di valore nullo.
• Rimuove il riferimento all’istanza di Feature attuale dall’istanza di Classifier puntata dal vecchio valore di owner.
• Aggiunge il riferimento all’istanza di Feature attuale all’istanza di Classifier puntato dal parametro arg.
• Aggiorna il valore di owner con il nuovo valore di arg.
• Notifica il cambiamento ad eventuali osservatori dell’istanza della Feature (questo aspetto verrà discusso nel paragrafo 2.4).
Per quanto riguarda i metodi di tipo interno, cioè che l’utente non è autorizzato ad usare, si può dire che internalRefByOwner(Classifier* arg ) viene invocato da un oggetto tipo Classifier che aggiunge alla lista features, attraverso una qualsiasi operazione tipo Setter, l’oggetto tipo Feature, di cui invoca internalRefByOwner(this); in questo modo l’oggetto Classifier notifica all’oggetto Feature di essere il suo proprietario.
66
Invece internalUnrefByOwner(Classifier* arg) è invocato da un oggetto tipo Classifier che rimuove dalla lista features l’oggetto tipo Feature, di cui invoca internalUnrefByOwner (this): in questo modo l’oggetto Classifier notifica all’oggetto Feature che non è più il suo proprietario.
Ruolo tipo lista ordinata
Il ruolo tipo lista ordinata ha molteplicità illimitata, cioè a tale estremo può essere collegato un insieme illimitato di istanze della classe legata a tale estremo, ed è ordinato, cioè la lista dei puntatori alle istanze è mantenuta ordinata.
Consideriamo di nuovo l’esempio del ruolo feature tipo lista ordinata: questo ruolo è il ruolo source rispetto alla classe Classifier. Come esempio vediamo il seguente frammento di codice:
class Classifier: public Namespace, public GeneralizableElement { public: Classifier(); ~Classifier(); string getUMLClassName(); // attributes …
// opposite role: feature this role: owner Coda<Feature*> getFeatures();
void setFeatures(Coda<Feature*>); void addFeature(Feature*);
void removeFeature(Feature*); void addFeature(int , Feature*); void removeFeature(int);
void setFeature(int __pos, Feature*); Feature* getFeature(int );
private: …
67
Si possono vedere di nuovo i noti metodi Getter e Setter, ma con diverse semantiche, più altri sei nuovi metodi.
• Il metodo getFeatures() invece di un puntatore restituisce una copia della struttura tipo Coda, che in seguito chiameremo più sinteticamente “lista”, contenente i puntatori ordinati alle istanze di Feature che l’attuale istanza del Classifier possiede.
• Il metodo setFeatures(Coda<Feature*> arg) analizza le differenze tra il parametro arg e l’attributo features, che contiene la lista da aggiornare con la nuova lista contenuta in arg; aggiorna features con gli elementi che prima non c’erano, cancella quelli che non sono presenti nel parametro arg e mantiene consistente il modello utente notificando alla istanze di Feature, che sono controparti dell’associazione owner-feature prima e dopo l’operazione di aggiornamento, i cambiamenti avvenuti, invocando opportunamente i metodi internalRefByOwner(this) e internalUnrefByOwner(this).
La semantica dei restanti sei metodi è chiara a partire dalla loro sintassi.
• addFeature(Feature* arg) aggiunge il parametro arg, riferimento ad istanza di Feature, alla lista contenuta nell’attributo features e notifica all’oggetto puntato da arg che appartiene all’oggetto tipo Classifier di cui abbiamo invocato il metodo AddFeature(Feature* arg).
• removeFeature(Feature* arg) cerca il riferimento all’oggetto tipo Feature nella lista features, lo cancella e notifica allo stesso oggetto il cambiamento avvenuto.
68
• addFeature(int pos, Feature* arg) aggiunge un nuovo riferimento arg nella lista features nel punto indicato dall’intero pos che indica il numero d’ordine, la posizione dove inserire arg. Come nei casi precedenti si occupa della consistenza del modello utente.
• removeFeature(int pos) rimuove il riferimento che si trova nella lista nella posizione indicata dal parametro pos. Come nei casi precedenti si occupa della consistenza del modello utente.
• setFeature(int pos,Feature* arg) sostituisce il vecchio riferimento nella lista features nella posizione indicata dal parametro pos con il nuovo riferimento arg. Come nei casi precedenti si occupa della consistenza del modello utente.
• getFeature(int pos) restituisce il riferimento ad un oggetto Feature che risiede nella posizione indicata dal parametro pos nella lista features.
Tutti i metodi quindi supportano la semantica dell’associazione: un riferimento ad un oggetto Feature cancellato dalla lista features implica che lo stesso oggetto cambi il proprio attributo owner nel valore NULL; invece per un riferimento aggiunto alla lista features implica che l’oggetto riferito aggiorni il proprio attributo owner con il riferimento all’oggetto Classifier che lo ha aggiunto tra le Feature che possiede.
Ruolo tipo insieme
Un ruolo tipo insieme è un ruolo che possiede una molteplicità non ordinata differente da 1 o da 0..1.
69 Si consideri il seguente esempio:
Figura 2.3 –Associazioni fra due classi della libreria CppUML.
Si consideri l’associazione caratterizzata dai ruoli generalization e child fra le due metaclassi Generalization e GeneralizableElement. Si può notare che il ruolo generalization è di tipo insieme in quanto ha molteplicità non ordinata. Quindi la classe GeneralizableElement contiene una lista non ordinata di tutti i riferimenti ad oggetti tipo Generalization di nome generalizations. Per la lista si può adoperare la stessa struttura Coda che abbiamo adoperato in precedenza, al più ha metodi in eccesso per il mantenimento dell’ordine. Segue un frammento di codice che illustra quali metodi sono stati scelti per gestire questo tipo di ruolo:
class GeneralizableElement: public virtual ModelElement {
public:
GeneralizableElement(); ~GeneralizableElement(); string getUMLClassName();
// opposite role: generalization this role: child Coda<Generalization*> getGeneralizations(); void setGeneralizations(Coda<Generalization*>); void addGeneralization(Generalization*); void removeGeneralization(Generalization*); void internalRefByGeneralization(Generalization*); void internalUnrefByGeneralization(Generalization*);
70 private:
…
Coda<Generalization*> generalizations; }
Si possono vedere solo quattro metodi per l’utente invece degli otto di un ruolo tipo lista ordinata. La semantica è simile a quella descritta per gli omonimi metodi testé analizzati per i ruoli tipo lista ordinata. Ovviamente qui mancano quei metodi che supportano la gestione dell’ordinamento della lista generalizations, che infatti non è ordinata.
Principi per classificare un ruolo di un’associazione
Si riassumono ora come sono classificati i ruoli di un’associazione in base alla loro molteplicità nell’ambito della libreria CppUML. Si prenda in esame la seguente tabella:
Classificazione di un ruolo
Tipo di ruolo Molteplicità Molteplicità ammesse
Riferimento (0..1) (0..1), (1)
Insieme (0..*) (2..*), (1..*), (0..*), (*)
Lista Ordinata (0..*)ordinata Tutte le precedenti ordinate
Tabella 2.1 – Classificazione dei ruoli.
La terza colonna illustra quali sono i tipi di molteplicità che si possono esprimere con la libreria CppUML. E’ chiaro che con questa classificazione dei ruoli si possono rappresentare tutti i tipi di molteplicità. Infatti se un ruolo di un’associazione avesse come molteplicità (1, 4..6, 8..*) lo si classificherebbe come ruolo tipo insieme in base al fatto che è non ordinato e contiene più di un elemento.
71
In conclusione si ricordano i principali metodi per accedere ad una associazione:
• se una metaclasse ha come ruolo source di un’associazione un ruolo tipo riferimento allora la corrispondente classe della libreria CppUML contiene solo due metodi per l’utente (Getter e Setter), i cui nomi hanno come prefisso “get” e “set”;
• se una metaclasse ha come ruolo source di un’associazione un ruolo tipo insieme allora la corrispondente classe della libreria CppUML contiene quattro metodi per l’utente i cui nomi hanno come prefisso “get”, “set”, “add” e “remove”;
• se una metaclasse ha come ruolo source di un’associazione un ruolo tipo lista ordinata allora la corrispondente classe della libreria CppUML contiene otto metodi per l’utente due dei quali cominciano con il prefisso “get”, due con il prefisso “set”, due con il prefisso “add” e due con il prefisso “remove”.
2.3 Strutture e funzioni accessorie
In questo paragrafo vengono presentate le strutture e le funzioni che sono state realizzate per supportare le funzionalità della libreria CppUML.
2.3.1 La classe Coda
La classe Coda è stata realizzata per memorizzare una lista di elementi il cui tipo è istanziato di volta in volta, di facile e veloce accesso, e per avere metodi che
72
semplifichino le operazioni richieste dalla libreria CppUML rispetto a strutture predefinite. Per implementare tale lista è stata scelta una struttura dati tipo coda, ove gli elementi sono inseriti per default ad un capo della coda, il fondo, e sono rimossi dall’altro capo, la testa. Si dice quindi che la strategia di una coda è “primo dentro/primo fuori” (FIFO, first in/first out): in questo modo si ha un ordinamento per default degli elementi della coda basato sul tempo di inserimento. Per dare la possibilità ad una istanza di coda di contenere tipi di elementi diversi la classe Coda si avvale dell’utilizzo delle classi modello (template).
La classe Coda quindi è stata realizzata con due astrazioni di dati:
• la classe Coda stessa, che fornisce l’interfaccia pubblica e una coppia di elementi dati: davanti e indietro. La classe Coda è realizzata con una lista concatenata;
• una classe ItemCoda. Ogni elemento inserito in un oggetto della classe Coda è rappresentato da un oggetto della classe ItemCoda. Un oggetto di ItemCoda contiene un elemento di dati valore e un legame con il successivo oggetto di ItemCoda. Il tipo di dati effettivo di valore varia per ciascuna istanziazione di una classe Coda.
Segue la dichiarazione della classe Coda: template<class Tipo> class ItemCoda { public: ItemCoda(Tipo val) : Item(val),successivo(0) {} Tipo Item; ItemCoda *successivo;
73 } ; // Coda = Queue template<class Tipo> class Coda { public: Coda(){ davanti=indietro=0; }
Coda( const Coda<Tipo> &); // costruttore di copia ~Coda();
Tipo rimuovitesta();
void aggiungi( const Tipo&);
bool vuota() const { return davanti==0 ? true : false; }
/*
to look for an item of the queue there is a private attribute named cursor, it’s a pointer to ItemCoda’s objects.
Method resetcursor() set the cursor to the reference of the head of the queue.
Method cursorisnull() return true if cursor is equal to NULL.
Method shiftcursor() set cursor to the next ItemCoda object in the queue. */
void resetcursor() { cursor =davanti; }
bool cursorisnull() { if (cursor==0) return true ; else return false; } void shiftcursor() { cursor=cursor->successivo; } Tipo currentitem() const {
return cursor->Item; }
void setcurrentitem(Tipo newVal) { cursor->Item=newVal;}
/** Rimuove l'oggeto passato dalla coda e da' l'esito */ bool rimuovi(const Tipo &);
// operatore di assegnamento
Coda<Tipo> &operator=( const Coda<Tipo> &);
// to get the pointer to the first elem:
ItemCoda<Tipo> *getptrfirst() const { return davanti;} // to get last and fist item
Tipo getlast() const ;
Tipo getfirst() const ;
/** The same of Aggiungi */ void add(const Tipo &);
/** Remove passed object from coda(queue) and return true if there is success*/
bool remove(const Tipo &);
/** Remove the nth element if exist, if it doesn't exist throw error*/ Tipo remove(int );
/** To get the item at nth position of the queue*/ Tipo get(int);
74 void set(int,Tipo);
/** To add a new item at nth position*/ void add(int,Tipo);
/** To get the index of the Tipo parameter (return -1 if there isn't)*/ int getIndex(Tipo);
/** To get the number of items in the queue */ int size();
/** It erase all items*/ void eraseAllItems(); private:
/* Pointer to the head and the tail of the queue and the pointer cursor explained before*/
ItemCoda<Tipo> *davanti, *indietro, *cursor;
};
Come si può constatare i metodi offerti all’utente della classe Coda sono brevemente commentati ed offrono tutte le funzionalità utili, ad esempio, a gestire le liste di riferimenti ad oggetti legati ad un ruolo di un’associazione tipo lista ordinata.
2.3.2 La funzione bagdiff()
Si è visto come alcuni metodi, che gestiscono l’accesso alle associazioni del metamodello durante un’operazione di aggiornamento, necessitino di fare la differenza fra la vecchia lista di riferimenti ad oggetti contenuta nell’istanza della classe ed una nuova lista di riferimenti passati come parametro per aggiornare la vecchia lista. Per questo è fornita la seguente semplice funzione nominata bagdiff() che sottrae dalla lista passata come primo parametro la lista passata come secondo parametro e restituisce una lista differenza lasciando inalterati i parametri attuali:
template < class Tipo >
Coda<Tipo> bagdiff(Coda<Tipo> a,Coda<Tipo> b) {
75 a.remove(b.currentitem());
return a;} ;
2.3.3 Le funzioni per la gestione delle stringhe
Si è visto che per il metaelemento Multiplicity vi sono un costruttore e un metodo tipo Setter che hanno come parametro una stringa, che esprime una molteplicità con le convenzioni finora usate negli esempi. Una molteplicità infatti è composta da un insieme di intervalli, memorizzabili come istanze di MultiplicityRanges, che sono anche essi esprimibili con stringhe di un particolare formato: in questo caso un intervallo di interi è espresso con una prima serie di caratteri cifra adiacenti, che rappresentano l’estremo inferiore dell’intervallo in notazione decimale, seguiti da due caratteri “..” che separano la prima serie di caratteri dalla seconda serie di caratteri cifra che esprimono l’estremo superiore dell’intervallo, se l’intervallo contiene più di un numero intero. Quindi se volessimo esprimere gli interi che vanno da 5 a 26 gli esprimeremmo con la seguente stringa: “5..26”. Se invece volessimo esprimere l’intervallo il cui estremo superiore coincide con quello inferiore e quindi contiene il solo numero 5 lo esprimeremmo con la stringa: “5”.
Una molteplicità è allora esprimibile come una stringa costituita dalla giustapposizione delle stringhe, che esprimono gli intervalli di interi di cui è costituita, separate dal carattere “,”: quindi una molteplicità è, ad esempio, esprimibile con la stringa “5, 23..40, 62..120”.
76
Si pone quindi la necessità della presenza di alcune funzioni atte ad estrarre le singole sequenze di caratteri che rappresentano un numero intero estremo di un intervallo e di capire a quale intervallo appartengono e se rappresentano l’estremo inferiore o quello superiore.
Di seguito illustriamo le principali funzioni che si sono adoperate per questo scopo.
La funzione Tokenize(stringa, tokens, delimeters) ha come parametri:
• stringa, variabile tipo string non modificabile, e rappresenta la stringa che la funzione deve spezzare in funzione del parametro delimeters e il risultato è restituito nel vettore tokens;
• tokens, variabile tipo vector<string>, tipo appartenente alla libreria standard del C++, che all’uscita della funzione contiene le sottostringhe estratte dal parametro di ingresso stringa;
• delimeters, variabile tipo string, e contiene i caratteri che dividono le sottostringhe che si vogliono separare.
Quindi se si volessero ottenere gli intervalli di interi di cui è costituita una molteplicità si scriverebbe una linea di codice tipo: Tokenize(“5..10, 25, 50..90”, tokens, “, ”); dopo l’esecuzione di tale funzione il vettore tokens sarebbe costituito da tre elementi tipo stringa: “5..10”, “25”, “50..90”.
Similmente, se si volessero estrarre gli estremi inferiori e superiori di un intervallo si scriverebbe una linea tipo: Tokenize(“5..10”, tokens, “. ”); dopo
77
l’esecuzione di tale funzione il vettore tokens sarebbe costituito da due elementi tipo stringa: “5” e “10”.
Segue il codice della funzione: void Tokenize(const string& str,
vector<string>& tokens,
const string& delimiters = " ") {
// Skip delimiters at beginning.
string::size_type lastPos = str.find_first_not_of(delimiters, 0); // Find first "non-delimiter".
string::size_type pos = str.find_first_of(delimiters, lastPos);
while (string::npos != pos || string::npos != lastPos) {
// Found a token, add it to the vector.
tokens.push_back(str.substr(lastPos, pos - lastPos)); // Skip delimiters. Note the "not_of"
lastPos = str.find_first_not_of(delimiters, pos); // Find next "non-delimiter"
pos = str.find_first_of(delimiters, lastPos); }
}
Si pone a questo punto la necessità di una funzione che trasformi una stringa, che esprime un numero intero in base decimale, in un intero. Segue allora la funzione che si occupa di questo e che appartiene alla classe MultiplicityRanges; difatti è solo questa classe che deve adoperare una tale funzione e quindi si è pensato di renderla suo metodo esclusivo:
int MultiplicityRange:: s2b(const char* b) { int i; if((*b=='n') || (*b=='*')) return Multiplicity::N; else { i=atoi(b); if (i<0) {
cerr<< "illegal range bound"; exit(1);
78 return i;
} }
Le uniche precisazioni da fare sono che nel caso di stringa uguale ad ‘n’ o ad ‘*’, a causa delle convenzioni della notazione UML, si vuole esprimere una molteplicità illimitata, tale molteplicità è allora codificata con la costante N di valore uguale a –1. Per trasformare una stringa nel corrispondente intero si adopera la funzione atoi(char*) della libreria standard.
Segue ora il metodo della classe Multiplicity che legge una stringa str e ne ricava una lista che contiene le istanze di MultiplicityRange che rappresentano i singoli intervalli di cui è costituita la molteplicità espressa dalla stringa str, nel caso di stringa inconsistente solleva un errore:
Coda<MultiplicityRange> Multiplicity::parseRanges(string str) { Coda<MultiplicityRange> rc; vector<string> tokens; Tokenize(str, tokens," ,"); if (tokens.empty()) { cerr<<"Empty Multiplicity"; exit(-1); }
for (int i=0; i<tokens.size(); i++)
rc.add ( MultiplicityRange(tokens[i]) ) ; return rc;
}
Segue ora una funzione che converte un intero in una variabile tipo string della libreria standard C++. Si è dovuto implementarla ex novo perché le librerie standard hanno una funzione simile a questa che restituisce un puntatore a char e non una variabile tipo string, inoltre la documentazione assicura che tale funzione genera a volte qualche problema.
79
La funzione riprogettata si chiama myitoa(int value) e si appoggia su altre funzioni che la precedono nel seguente estratto di codice:
inline int mod(int a,int b) { return (a-(a/b)*b); }; //mod function
char single_itoa(int digit) {
string hash("0123456789"); return hash[digit];
}
string myitoa(int value) {
string cptr=""; int tempval, digit=0; if (value == 0) { //special case return cptr+="0"; } vector<string> buffer(10); tempval = value; while (tempval) { buffer[digit++]=single_itoa((mod(tempval,10))); //find the rightmost digit and put it on the buffer
tempval = tempval/10; //remove the rightmost digit }
for(digit--;digit>=0;digit--) cptr+=buffer[digit]; return cptr;
}
2.4 Estensione della libreria CppUML con il pattern Observer
Quando si è introdotto il metamodello della libreria CppUML nel paragrafo 2.2.3 si è visto che si è voluto predisporre la classe Base, capostipite di tutta la gerarchia delle classi di CppUML, ad essere visualizzata all’utente per mezzo di altre classi. Per questo è stato nominato il pattern MVC su cui segue una breve introduzione.
80 2.4.1 Pattern MVC
I pattern di progetto [Gam00] non sono altro che buone soluzioni di progetto a classi di problemi ricorrenti che possono essere riutilizzate ogni qualvolta le specifiche di un problema coincidono con quelle di un particolare pattern.
Il pattern MVC (Model-View-Controller) è un buon metodo per progettare un’applicazione controllata con una GUI (Graphic User Interface): questo pattern separa l’applicazione in tre classi principali che interagiscono in modo coordinato. 1. Model: contiene i dati e la logica dell’applicazione. Se l’utente attiva un
controllo, che chiama un metodo nell’oggetto tipo Model e comporta un cambiamento del suo stato, l’oggetto tipo Model notifica agli oggetti tipo View il cambiamento del proprio stato.
2. View: si occupa dell’aspetto della GUI e visualizza i dati dell’oggetto tipo Model. Quindi contiene tutta l’interfaccia visuale con cui un utente dell’applicazione interagisce. Quando giunge una notifica dall’oggetto tipo Model l’oggetto tipo View aggiorna la rappresentazione dei dati chiedendo come essi sono variati all’oggetto tipo Model. Una classe tipo View è tipicamente lunga e particolareggiata perché contiene moltissime specifiche riguardo l’aspetto della GUI.
3. Controller: colleziona tutti i controlli a disposizione della GUI. Quando un utente attiva un controllo questo chiama un metodo nell’oggetto tipo Model. Il pattern MVC aiuta a mantenere bassa la complessità di ogni classe (divide et impera). Quando si deve fare un debugging o si devono aggiungere nuove
81
caratteristiche, tipicamente si devono apportare modifiche ad una sola di queste classi o si fanno piccole aggiunte di codice correlate in tutte e tre le classi. Queste tre classi incapsulano tre diversi aspetti di una applicazione dotata di interfaccia grafica per l’utente (GUI).
Quindi MVC disaccoppia un oggetto tipo View (vista) dall’oggetto tipo Model (modello). Se volessimo però risolvere un problema di design più generale, cioè disaccoppiare gli oggetti in modo tale che il cambiamento su uno può interagire con un qualsiasi numero di altri oggetti, senza richiedere che l’oggetto cambiato conosca i dettagli degli altri, allora si dovrebbe adottare un pattern più generale: il pattern Observer.
2.4.2 Pattern Observer
Il pattern Observer [Gam00] astrae due classi di oggetti: il soggetto (subject) e l’osservatore (observer). La relazione tra soggetto e osservatore è uno-a-molti. Il soggetto e l’osservatore devono essere indipendenti, cioè possono essere usati indipendentemente l’uno dall’altro, quindi la relazione che li lega deve essere tale da disaccoppiare le due classi. Un effetto collaterale di questo pattern è che, dividendo un sistema in due classi di oggetti che cooperano, la consistenza tra gli oggetti è mantenuta automaticamente.
Ad esempio molte applicazioni, che adoperano un’interfaccia grafica per interagire con l’utente (GUI), separano diversi aspetti della stessa fonte di dati presentandoli con diversi tipi di viste. Le classi che definiscono i dati
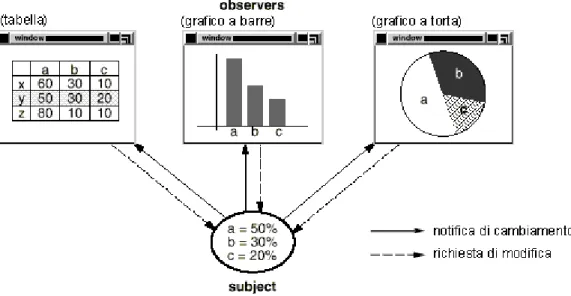
82
dell’applicazione e quelle che definiscono gli aspetti della presentazione delle precedenti devono poter essere riusabili indipendentemente per avere un maggior profitto della loro progettazione. Se, ad esempio, si deve rappresentare una certa informazione, contenuta in un data base che contiene delle percentuali, si possono usare contemporaneamente diversi tipi di presentazione dello stesso dato all’utente: tabella, grafico a barre, grafico a torta, ecc. (figura 2.4). Un oggetto tabella e un oggetto grafico a barre non conoscono l’esistenza l’uno dell’altro, ma tutto funziona correttamente. Quando l’utente cambia un dato nella tabella, il grafico a barre si aggiorna immediatamente e viceversa. Questo comportamento implica che la tabella e il grafico a barre siano dipendenti dall’oggetto che contiene il data base e quindi che quest’ultimo notifichi a questi ogni cambiamento del proprio stato. Non c’è alcun limite nel numero di oggetti che presentino il data base all’utente.
83
Figura 2.4 – Interazione fra un oggetto tipo subject e oggetti tipo observer27.
Il pattern Observer descrive come stabilire queste relazioni. Gli oggetti chiave in questo pattern sono il soggetto e l’osservatore. Un soggetto può avere un numero qualsiasi di osservatori che dipendono da questo. Ogniqualvolta il soggetto cambia stato, questo notifica a tutti i propri osservatori la variazione del suo stato. In risposta tutti gli osservatori richiedono al soggetto di sincronizzare il suo stato con il proprio.
Questo tipo di interazione è conosciuta anche come publish-subscribe. Il soggetto è l’editore delle notifiche, infatti questo invia le notifiche senza dover sapere chi sono i propri osservatori. Un qualsiasi numero di osservatori si può abbonare presso l’editore per ricevere le sue notifiche.
27
84 Applicabilità
Si usa il pattern Observer nei seguenti casi:
1. quando un’astrazione ha due aspetti, uno dipendente dall’altro. Incapsulando questi aspetti in oggetti separati si lascia la libertà di riusarli indipendentemente;
2. quando un cambiamento di un oggetto richiede il cambiamento degli altri e non si conosce il numero degli oggetti da cambiare;
3. quando un oggetto deve avere la possibilità di notificare ad altri oggetti il proprio cambiamento senza fare assunzioni su come questi oggetti siano fatti. In altre parole non si vuole che questi oggetti siano fortemente accoppiati.
Si può notare che il primo aspetto è proprio ciò che si richiede alla libreria CppUML, ovvero che l’aspetto della rappresentazione del modello (GUI) sia separato dal modello (rappresentato da oggetti della stessa libreria).
Il secondo aspetto è anch’esso importante, infatti, se un oggetto della libreria fosse rappresentato con più oggetti osservatore in diversi diagrammi di un tool di modellazione UML, si vuole che, se l’utente cambia lo stato di un osservatore, si generi immediatamente un cambiamento del soggetto e che questo notifichi il proprio cambiamento a tutti gli osservatori, di modo che si ristabilisca subito la consistenza della rappresentazione dello stesso soggetto in tutti i diagrammi.
85 Struttura
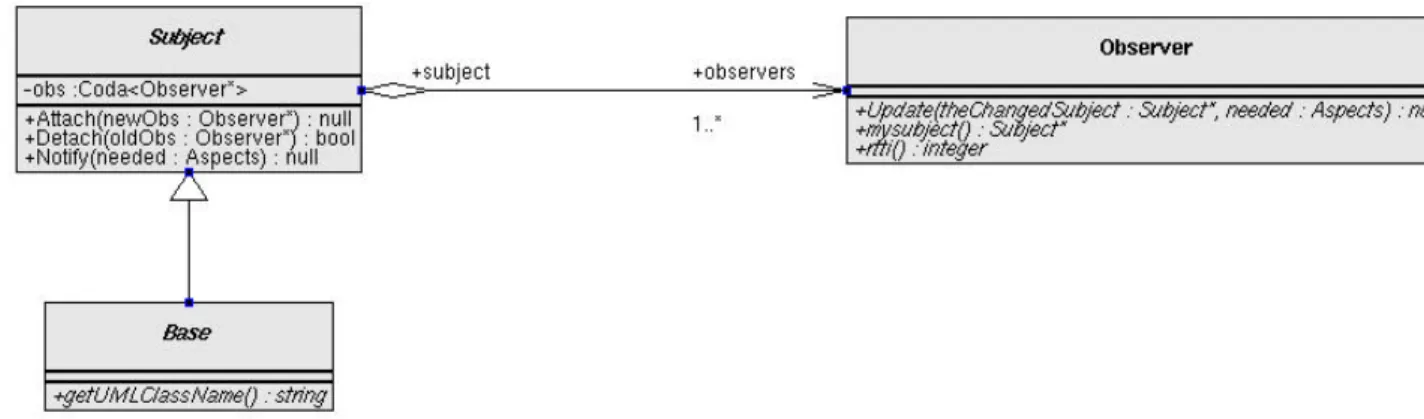
Figura 2.5 – Diagramma delle classi del pattern Observer28.
Partecipanti
• Soggetto (Subject): sa da chi è osservato, ma non sa come sono fatti gli osservatori. Qualsiasi numero di osservatori può osservare un soggetto. Il soggetto fornisce un’interfaccia per permettere ad un osservatore di iscriversi (Attach) alla lista degli osservatori o di farsi togliere (Detach) da tale lista.
• Osservatore (Observer): definisce un’interfaccia per gli oggetti di tipo osservatore cui un oggetto di tipo soggetto può volgere le notifiche di cambiamento del proprio stato.
• Soggetto concreto (ConcreteSubject): memorizza gli stati che interessano agli osservatori concreti e manda una notifica ai propri osservatori quando il proprio stato cambia.
28
86
• Osservatore concreto (ConcreteObserver): mantiene un riferimento ad un oggetto tipo soggetto concreto e mantiene il proprio stato consistente con l’oggetto riferito. Implementa l’interfaccia di aggiornamento dell’osservatore che serve a mantenere il proprio stato consistente con il soggetto osservato.
Collaborazioni
• Un soggetto concreto fa una notifica ai propri osservatori tutte le volte che avviene un cambiamento del proprio stato che può rendere inconsistente lo stato degli osservatori con il proprio.
• Dopo che un osservatore concreto è stato informato del cambiamento del soggetto concreto, l’osservatore concreto usa quest’informazione per sincronizzare il proprio stato con il soggetto.
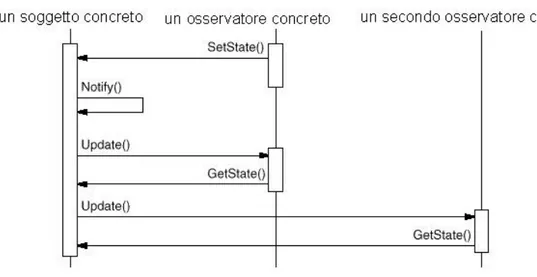
Il seguente diagramma di sequenza illustra l’interazione fra un soggetto e due osservatori:
87
Si noti che l’osservatore che inizia la richiesta di cambiamento di stato pospone il proprio aggiornamento finché non gli giunge la notifica dal soggetto. Notify() non sempre è chiamata dal soggetto stesso e vi sono diverse implementazioni sia di questo metodo che dei metodi di aggiornamento (Update()). Si discuteranno le scelte adottate per calare questo pattern nel progetto della libreria CppUML.
Conseguenze
Il pattern Observer permette di variare il soggetto indipendentemente dall’osservatore. Si può riutilizzare un soggetto senza riusare i suoi osservatori e viceversa. Si possono aggiungere nuovi tipi di osservatori senza modificare né il soggetto, né gli osservatori già esistenti.
Si discutono ora i benefici e i problemi di questo pattern.
1. Accoppiamento astratto fra soggetto e osservatori. Tutto ciò che un soggetto conosce è una lista di osservatori, ognuno dei quali ha una semplice interfaccia conforme a quella della classe astratta Observer. Il soggetto non sa come è fatta una classe concreta di osservatore. Quindi l’accoppiamento fra soggetto e osservatori è astratto e minimo.
2. Supporto della comunicazione broadcast: la notifica è un’operazione che automaticamente informa tutti gli osservatori (broadcast) che si sono sottoscritti al soggetto. Questo fatto lascia la libertà di aggiungere e rimuovere osservatori in qualsiasi momento dell’esecuzione. L’osservatore ha la responsabilità di gestire o ignorare una notifica da parte del proprio soggetto.
88
3. Aggiornamenti inaspettati. Dato che un osservatore non è a conoscenza se ci sono altri osservatori abbonati al proprio soggetto, si possono generare cascate di aggiornamenti: infatti se un osservatore cambia lo stato al proprio soggetto attraverso molte piccole operazioni sequenziali, accade che per ogni operazione vengono aggiornati tutti gli osservatori abbonati allo stesso soggetto. Questo fatto è aggravato dalla semplicità del protocollo di aggiornamento che non provvede i dettagli su ciò che è cambiato nel soggetto; in queste circostanze ciascun osservatore deve lavorare molto per aggiornare il proprio stato.
Implementazione
Si discutono alcuni problemi che riguardano l’implementazione.
1. Osservare più soggetti: potrebbe aver senso che un osservatore dipendesse da più di un soggetto. In questo caso sarebbe necessario estendere l’interfaccia di aggiornamento per permettere all’osservatore di discernere quale soggetto ha mandato la notifica. Una semplice soluzione è quella di inserire nel metodo dell’osservatore Update(…) un parametro tipo puntatore ad un soggetto. In questo modo il soggetto che fa una notifica di aggiornamento ad un osservatore passa, come parametro attuale, un riferimento a se stesso nella funzione Update(…), di modo che l’osservatore conosca qual è il soggetto che ha fatto la notifica e così lo possa esaminare.
89
2. Chi fa partire l’aggiornamento?: il meccanismo di notifica mantiene consistenti soggetto ed osservatori, ma qual è l’oggetto che chiama la funzione Notify() per iniziare l’aggiornamento degli osservatori? Seguono due opzioni:
a. inserire alla fine di ogni metodo del soggetto che cambi il suo stato una chiamata al metodo Notify(). Il vantaggio di questo approccio è che l’osservatore non deve ricordarsi di chiamare il metodo Notify() del soggetto dopo aver cambiato il suo stato. Lo svantaggio è che diverse operazioni consecutive, che modificano lo stato del soggetto, provocano diverse operazioni di aggiornamento, fatto che può risultare inefficiente;
b. rendere gli osservatori responsabili della chiamata del metodo Notify() dopo che hanno concluso di cambiare lo stato del soggetto. Il vantaggio è che non si avviano serie di aggiornamenti come nel caso precedente. Lo svantaggio è che questa responsabilità aumenta fortemente la possibilità di errore, perché è facile che un osservatore si dimentichi di chiamare Notify().
3. Puntatori a soggetti cancellati: cancellare un soggetto non deve generare riferimenti vacanti nei suoi osservatori. Un metodo per evitare questa eventualità è fare in modo che un soggetto notifichi la propria cancellazione ai propri osservatori appena prima della propria distruzione, così gli osservatori possono cancellare i propri riferimenti a questo soggetto.
90
4. Assicurarsi che lo stato del soggetto sia consistente prima della notifica: è importante assicurarsi che lo stato del soggetto sia consistente prima della notifica, altrimenti gli osservatori possono aggiornare il proprio stato con uno stato inconsistente del soggetto.
5. Specificare quali sono le modifiche di interesse durante le operazioni di aggiornamento: si può migliorare l’efficienza del metodo di aggiornamento Update() specificando qual è l’aspetto (Aspect) che è cambiato nello stato del soggetto, in tal modo gli osservatori richiederanno quel solo aspetto, alleggerendo molto lo scambio di informazioni. Quindi una tale funzione di aggiornamento sarebbe tipo:
Void Observer::Update(Subject* WhoChangedItsState, Aspect interest);
2.4.3 Applicazione del pattern Observer alla libreria CppUML
Nel precedente paragrafo si è esaminato il pattern Observer e nell’ambito dell’applicabilità si è visto che il punto 1. coincide con i requisiti richiesti alla libreria CppUML e che il punto 2. è anch’esso un aspetto importante.
Per estendere la libreria CppUML con questo pattern si dovrà far ereditare alla classe Base, capostipite di tutta la gerarchia di classi che compongono la libreria stessa, l’interfaccia della classe Subject: quindi si pone la classe Base figlia di una classe Subject attraverso una relazione di generalizzazione.
91
Figura 2.7 – Applicazione dell’interfaccia della classe Subject alla classe Base.
Sempre nel precedente paragrafo si sono discussi i problemi che possono insorgere nell’implementazione del pattern Observer: si è voluto quindi estendere l’interfaccia sia del soggetto che dell’osservatore, in modo tale da applicare i punti di discussione 1. e 5. del sottoparagrafo “Implementazione” del precedente paragrafo: infatti si può vedere dalla figura 2.7 come nel metodo Update(…) della classe Observer sia stato inserito il parametro theChangedSubject di tipo puntatore a Subject, di modo che un oggetto osservatore possa distinguere da quale soggetto provenga la notifica di cambiamento di stato. Con questa modifica si applica la soluzione presentata nel punto 1.. Inoltre, sempre nello stesso metodo Update(…), è stato inserito il parametro needed di tipo Aspects che specifica all’osservatore quale sia l’aspetto che è cambiato nel soggetto. Il tipo Aspects non è altro che una enumerazione dei possibili aspetti che possono cambiare in un soggetto, tra i quali è stato inserito il valore Nall (all needed) che significa che è stato modificato l’intero stato del soggetto. Lo stesso parametro è stato inserito nella funzione Notify(…) per specificare qual è la notifica da presentare agli osservatori. Con queste modifiche dell’interfaccia è stato applicato il punto 5..
92
Per quanto riguarda il punto 2. si è scelto che sia lo stesso soggetto a chiamare la funzione Notify(…) per ridurre al minimo eventuali errori. Gli svantaggi procurati da questa soluzione sono minimizzati grazie all’adozione della proposta offerta dal punto 5. che riduce comunque il traffico di messaggi durante l’aggiornamento.
Per quanto riguarda il punto 3. si può osservare che, in questo particolare caso, se si cancella un soggetto, i suoi osservatori non hanno più ragione di esistere; infatti il compito di un osservatore in questo ambito è di osservare un unico soggetto durante la propria vita; in questo modo, in tale situazione, conviene distruggere soggetto ed osservatore contemporaneamente (salvo verificare che non rimangano puntatori all’osservatore distrutto nelle strutture dati che gestiscono l’interfaccia grafica).
Per quanto riguarda il punto 4. si può semplicemente assicurare che è stato fatto un buon lavoro di debugging.
Nel seguente diagramma di classi vi è parte della gerarchia delle classi del package Core della libreria CppUML allo scopo di illustrare un soggetto concreto della libreria (Class) ed anticipare un suo osservatore concreto OClass, che fa parte del tool di modellazione che sarà introdotto nel seguente capitolo.
93
Figura 2.8 – Gerarchia di Classi che illustra un soggetto concreto Class ed un osservatore
concreto OClass.
Si può notare che nel diagramma di figura 2.8 è stata soppressa la visualizzazione dei metodi delle classi che fanno parte del metamodello della libreria CppUML, i cui nomi sono ricavabili dagli attributi attraverso le convenzioni che sono state descritte nel paragrafo 2.2.4.
Invece è stata soppressa la visualizzazione di tutti i metodi e di tutti gli attributi della classe OClass e dei suoi aggregati, perché in questo ambito interessa presentare esclusivamente l’applicazione del Pattern Observer alle classi
94
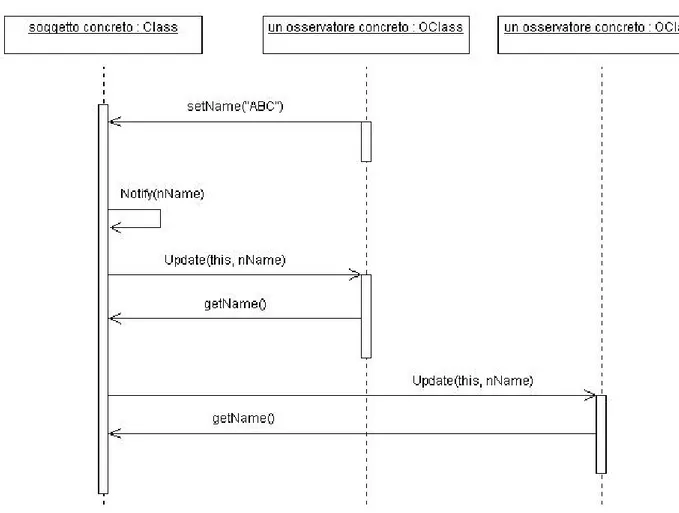
della libreria CppUML: la classe OClass è infatti un osservatore concreto, esterno alla libreria CppUML, della classe soggetto concreto Class; è stato lasciato in evidenza il solo attributo MySubject ove viene memorizzato il puntatore al soggetto attualmente osservato.
Nella figura 2.9 vi è un diagramma di sequenza che chiarisce come è modificato il protocollo di aggiornamento di un osservatore concreto da parte di un soggetto concreto attraverso l’interfaccia estesa delle classi Subject ed Observer testé presentata.
95
2.4.4 Codice sorgente dell’interfaccia fornita dal pattern Observer
Di seguito si fornisce il codice tratto dal file “subject.h” contenente le dichiarazioni delle classi Subject ed Observer:
/*************************************************************************** subject.h - description
--- begin : Thu Oct 3 2002
copyright : (C) 2002 by Gabriele Mezzetti email : [email protected]
***************************************************************************/
/*************************************************************************** * * * This program is free software; you can redistribute it and/or modify * * it under the terms of the GNU General Public License as published by * * the Free Software Foundation; either version 2 of the License, or * * (at your option) any later version. * * * ***************************************************************************/ #ifndef SUBJECT_H #define SUBJECT_H #include "coda.h" #include <string>
/* In this new type, Aspects, there are every characteristic of subjects that could be changend by an observer, so, when updating, the observer knows what aspect must ask. 'N' prefix means "needed characteristic", Nall means need all aspects! */
enum Aspects { Nname, NActiveObj, NRefresh, Nspecification, Nvisibility, Ncomments, NsupplierDependencies, Nnamespace, NclientDependencies, Nbody, NAnnotatedElements, NSuppliers, NClients, NOwnedElements,
Ndiscriminator, Npowertype, Nroot, Nleaf, Nabstract, Nspecializations, Ngeneralizations, NownerScope, Nowner, Nchild, Nparent, Nkind, NdefaultValue, NbehavioralFeature, Ntype, Nquery, Nparameters, NpowertypeRanges, Nassociations, NspecifiedEnds, NtypedParameters, NtypedFeatures, Nfeatures, NtargetScope, Nchangeability, Nmultiplicity, Nordering, Naggregation, Nnavigable, Nspecifications, Npartecipant, Nqualifiers, Nassociation,
NinitialValue, NassociationEnd, Nconnections, Nconcurrency, Nmethods, Nactive, Nall, NbaseClass, Nicon, NextendedElements, Nstereotype, Nmapping};
/**
*@author Gabriele Mezzetti */
96 class Subject; class Observer { public: virtual ~Observer(); //pure virtual
virtual void Update(Subject* thechangedSubject, Aspects needed=Nname)=0; //pure virtual
virtual Subject* mysubject()=0; virtual int rtti() const{ return 0;}; protected: Observer(); }; class Subject { public: virtual ~Subject();
virtual void Attach(Observer*); virtual bool Detach(Observer*);
virtual void Notify(Aspects needed=Nname);
Coda<Observer*> obs; protected:
Subject();
};
#endif
Si può notare che il metodo Update(…) della classe Observer è dichiarato virtuale puro, in modo tale che un osservatore concreto, ovvero istanziabile, sia costretto a ridefinire questo metodo: infatti un oggetto di questa classe deve avere una funzione di aggiornamento personalizzata in base alle sue caratteristiche e ai propri scopi di presentazione del modello all’utente.
La classe Subject invece definisce completamente la propria interfaccia ed ha al suo interno una struttura Coda per la memorizzazione dei puntatori ai propri
97
osservatori. In seguito segue un esempio della creazione di un oggetto concreto e del suo osservatore:
00: Class* subjA; 01: Oclass* obsA; 02: subjA= new Class();
03: obsA= new OClass(subjA, area_disegno); 04: subjA->Attach(obsA);
Nella linea 03 si crea un’istanza della classe OClass osservatrice di oggetti tipo Class: nel costruttore si passa come parametro il puntatore all’oggetto da osservare e un parametro che dice dove illustrare il soggetto (nel seguente capitolo si approfondirà questo aspetto).
Nella linea 04 si abbona l’osservatore al soggetto attraverso il metodo Attach(…) il cui parametro fornisce al soggetto il puntatore al nuovo osservatore.