TURBO CODICI
2.1 INTRODUZIONE
Per migliorarne le prestazioni, nelle trasmissioni numeriche viene impiegata una codifica di canale. Tra i metodi usati, la maggiore efficienza dal punto di vista della protezione degli errori è data dai codici cosiddetti “Turbo”. Le loro prestazioni sono molto vicine alla curva di capacità di canale fissata da Shannon. In passato, i vari tentativi per raggiungere tale curva attraverso l’uso di codici casuali con parole lunghe, si sono scontrati con insormontabili difficoltà di decodifica. I decodificatori risultavano infatti di complessità proibitiva (crescente esponenzialmente con la lunghezza delle parole). Grazie all’invenzione di un algoritmo di decodifica iterativa (“turbo”), è stato possibile la decodifica di particolari codici casuali con complessità ragionevole.
2.2 CODIFICATORE E DECODIFICATORE TURBO
Il codificatore Turbo (Turbo Encoder) è un codificatore a blocco con una struttura apparentemente molto semplice. E’ costituito da due codificatori convoluzionali di tipo ricorsivo sistematico (RSC : Recursive Systematic Convolutional), chiamati codificatori costituenti, concatenati in parallelo. In base al tasso di codifica, ogni codificatore costituente, per ciascun bit d’ingresso produce in uscita, oltre ad una replica dello stesso bit (codificatore sistematico), un numero opportuno di bit aggiuntivi detti di parità. Se ad esempio il tasso di codifica fosse 1
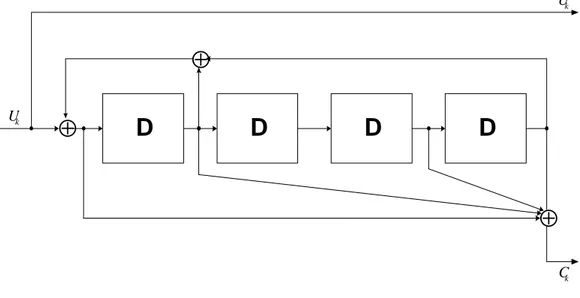
2, per ogni bit di sorgente otterrei in uscita il bit stesso più un bit di parità. A differenza dei codificatori convoluzionali standard, che sono di tipo in avanti (feedforward) senza reazione, i codificatori usati sono ricorsivi cioè con reazione. In figura 2.1 è riportato lo schema del codificatore RSC “Ryan” che è stato utilizzato nelle simulazioni.
D
D
D
D
⊕
⊕
⊕
k U k U k CFig. 2.1 Codificatore Convoluzionale Ricorsivo Sistematico Ryan
Analizziamo ora la particolare strutture dell’encoder in cui, come precedentemente riportato, i due codificatori costituenti sono concatenati in parallelo.
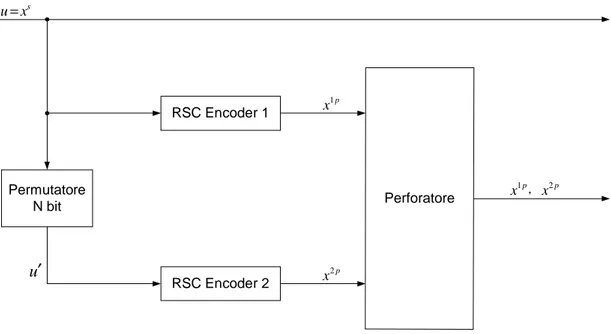
Permutatore N bit RSC Encoder 1 RSC Encoder 2 Perforatore s u x= u′ 2 p x 1 p x 1 p x , x2 p
Fig 2.2 Turbo Encoder
Un interleaver di lunghezza N è inserito tra i codificatori per dare casualità alle sequenze in ingresso ad essi e migliorare la capacità di correzione degli errori. Per costruire un blocco di simboli codificati, l’ RSC 1 riceve la sequenza di N simboli di sorgente u=xs e produce i bit di parità x . Viceversa l’ RSC 2 riceve una versione1 p permutata della sequenza dei bit di sorgente (u′) e produce i bit di parità x2 p. Lo sparpagliamento dei bit operato dall’interleaver è pseudo-casuale e serve per implementare la strategia di codifica casuale di Shannon. Lunghezze di blocco usuali per turbo codici vanno da un migliaio a qualche decina di migliaia di bit.
L’interleaver usato nelle simulazioni è quello detto Pseudo-Random Interleaver, che sfrutta un vettore di permutazione fissato. Per generare questo vettore, scelto N, si genera un numero reale casuale compreso tra 0 e 1 usando la funzione di libreria rand() del linguaggio C++. Quindi tale numero viene moltiplicato per N e si preleva la parte intera del risultato. Se il numero così ottenuto non compare ancora nel vettore di permutazione viene memorizzato, altrimenti viene scartato. Si ripete la suddetta procedura finché tutti i numeri interi compresi tra 1 e N non compaiono nel vettore di permutazione.
Per facilitare la decodifica si fa in modo che i codificatori costituenti inizino e terminino la loro evoluzione nello stato “nullo”. Per questo ad ogni blocco di N bit di sorgente vengono aggiunti opportuni bit detti bit di terminazione o di coda (Tail Termination).
Poiché tutti i codificatori costituenti sono sistematici, basta prelevare soltanto una delle loro uscite sistematiche visto che le altre sono soltanto una versione permutata di quella scelta. Nel caso di figura 2.2, senza perdere di generalità, si possono considerare entrambi i convoluzionali identici e con rate 1
2. Sembrerebbe quindi che ad ogni bit di sorgente l’intero codificatore produca oltre al bit sistematico, altri 2 bit di parità. Una sequenza di N bit informativi verrebbe dunque mappata in un'altra lunga 3N bit con rate complessivo pari ad 1
3. Nelle trasmissioni digitali però, per questioni di efficienza spettrale, è preferibile un rate pari ad 1
2 o maggiore. Per migliorare le prestazioni, ovvero aumentare il rate complessivo, viene adoperato il meccanismo di perforazione (Puncturing). Il puncturer ha il compito di ridurre la ridondanza introdotta dal codificatore turbo eliminando periodicamente i bit parity. Per ottenere rate 1
2 si possono eliminare, ad esempio, tutti i bit parity di posto pari all’uscita dell’RSC 1 e tutti quelli di posto dispari all’uscita dell’RSC 2 o viceversa. Sebbene la concatenazione in parallelo dei due RSC tramite l’interleaver crei un dizionario di codice altamente casuale, il codificatore turbo può essere rappresentato come una macchina sequenziale (lineare) a stati finiti. In teoria, perciò, il codice sarebbe decodificabile con algoritmi noti come quello di Viterbi. Il numero di stati nella descrizione della macchina sequenziale è però elevatissimo; infatti la memoria del codificatore, a causa dell’interleaver, è molto profonda e pari in generale alla lunghezza del blocco su cui si effettua la permutazione. Ogni tentativo di decodifica “tradizionale” basata su algoritmo di Viterbi o simili a complessità ridotta risulta, per l’elevato numero di stati, proibitivo.
La peculiarità dei codici turbo è allora tutta nel decodificatore il cui schema è riportato in figura 2.3.
La concatenazione dei due decoder è seriale a differenza di quella dei codificatori che è invece parallela e la decodifica è effettuata in modo iterativo.
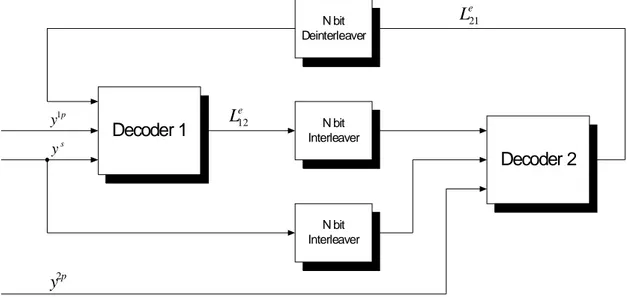
Decoder 1 Decoder 2 N bit Deinterleaver N bit Interleaver N bit Interleaver 1p y s y 2p y 12 e L 21 e L
Fig. 2.3 Turbo Decoder
Il decodificatore effettua più volte la stessa elaborazione sul segnale in uscita dal canale riportando indietro ogni volta un’informazione relativa all’affidabilità del bit di sorgente da decidere. L’affidabilità, anche chiamata informazione estrinseca, viene opportunamente riportata dall’uscita del secondo stadio verso l’ingresso del primo e, viceversa, dal primo al secondo. Questo continuo “scambio” di affidabilità somiglia al moto di rotazione vorticosa di un turbocompressore di un motore a scoppio. Tale somiglianza è stata l’elemento che ha dato il nome a questi codici. Per meglio capire l’intero processo di decodifica, bisogna puntualizzare la natura e il significato di questa informazione estrinseca. Analizziamo come sono costituiti i due stadi di decodifica. Essi si basano sull’algoritmo di decodifica a massima probabilità a-posteriori (MAP) di Bahl-Cocke-Jelinek-Raviv (BCJR) sviluppato negli anni ’70 e mai utilizzato fino all’avvento dei Turbo Codici. Si tratta di un algoritmo che opera a blocco. Nella versione originale, le uscite rumorose del canale (valori soft) venivano prese in blocco e producevano blocchi di N valori continui sui quali era possibile prendere una decisione a soglia. In questa maniera viene massimizzata la probabilità di una corretta decisione sul singolo bit condizionata all’aver osservato tutto il blocco di valori soft all’ingresso dell’algoritmo, ossia viene eseguito il criterio MAP. A differenza degli algoritmi di decodifica tradizionale, quello BCJR opera in maniera ricorsiva incrociata ossia fa un analisi partendo dal primo valore soft del blocco verso
l’ultimo e, diversamente dai tradizionali algoritmi di decodifica, anche a ritroso, cioè dall’ultimo valore soft del blocco verso il primo. Proprio per consentire la decodifica si usa inserire nel blocco i tail termination. In questo modo sia lo stato di partenza della decodifica tradizionale che quello della decodifica a ritroso sono noti ed è quindi possibile far partire correttamente i decodificatori. Si deve evidenziare il fatto che, a causa della decodifica a ritroso, è necessario attendere l’arrivo di tutto il blocco e quindi si ha un ritardo di decodifica.
Osserviamo ora i singoli decoder. Ciascuno di essi ha tre ingressi e una sola uscita
Soft-in/Soft-out
Decoder
( )
e i k L u s k y p k y( )
k L uFig. 2.4 Singolo decoder costituente il turbo decoder
Come si evince dalla figura 2.4, un ingresso è s k
y ossia il bit sistematico disturbato dal rumore, un altro è ykp ossia il bit di parità disturbato dal rumore ed infine l’ultimo ingresso è L uei( k) cioè l’informazione estrinseca o informazione a priori per u .k L’unica uscita L u( k), è il rapporto di verosimiglianza calcolato per u . Su di essa èk possibile prendere la decisione finale a soglia o può essere passata al decoder successivo se le iterazioni non sono ancora terminate. Questi valori continui vengono chiamati rapporti di log-probabilità a posteriori (LAPP), cioè il logaritmo del rapporto tra la probabilità che ogni bit assuma, rispettivamente, il valore +1 o –1 condizionatamente all’aver osservato tutto il blocco di segnale dato. Si indica con y il vettore di campioni soft di segnale rumoroso all’uscita del canale prodotti da un blocco di N dati.
Il rapporto di log-probabilità a posteriori è:
(
)
(
)
1| ( ) log 1| k k k P u L u P u = + = = − y y (2.2.1)Si vede chiaramente che questo rapporto, che è l’informazione di affidabilità prodotta dall’algoritmo BCJR, ha una natura soft. In particolare è non negativa se il valore più probabile a posteriori è +1, e negativa se il valore più probabile è –1. E’ quindi chiaro che la strategia di decisione consiste in un decisore a soglia. Quanto maggiore è il modulo di questo rapporto, tanto maggiore è la probabilità del simbolo deciso rispetto all’altra ovvero tanto maggiore è l’affidabilità della decisione.
Sfruttando la regola di Bayes, il LAPP può essere riscritto:
(
)
(
)
(
(
)
)
(
(
)
)
1| 1 1
( ) log log log
1| 1 1 k k k k k k k P u P u P u L u P u P u P u = + = + = + = = + = = − = − = − y y | y y |
(
)
(
)
1 log ( ) 1 k e k k P u L u P u = + = + = − y | y | (2.2.2)Normalmente, dato che i bit di sorgente sono equiprobabili, il secondo termine, la cosiddetta informazione a priori, è nullo. Se però in qualche modo si riuscisse, tramite ad esempio una decodifica di tentativo, ad avere un’informazione più precisa su queste due probabilità, il termine relativo all’informazione a priori diverrebbe non nullo. Lo si potrebbe allora utilizzare per calcolare nuovamente l’affidabilità L u
( )
kottenendo quindi un’informazione più precisa. Iterando più volte questo procedimento si riesce, salvo rari casi, ad ottenere l’affidabilità del messaggio ricostruito molto elevata e a diminuire così la probabilità di errore sul singolo bit. L’implementazione e meccanizzazione dell’algoritmo BCJR risulta essere complessa e verranno ora fornite brevemente alcune informazioni necessarie per capire l’implementazione dell’algoritmo e altre informazioni utili per discutere in seguito i risultati ottenuti.
Data la ricorsività dei codici, l’algoritmo utilizzato non è quello originale ma il Modified BCJR Algorithm for RSC codes. Si considera come formato di modulazione la BPSK ed il canale AWGN.
Verranno ora elencate alcune definizioni utili: - E1 sta per Encoder 1
- E2 sta per Encoder 2 - D1 sta per decoder 1 - D2 sta per decoder 2 - m è la memoria di un RSC
- S è il set di tutti i 2m stati di un RSC
- xs =
(
x x1s, 2s,K,xNs)
=(
u u1, 2,K,uN)
è la sequenza in ingresso all’encoder - xp =(
x1p,x2p,K,xNp)
è la sequenza parità generata da un RSC- yk =
(
y yks, kp)
è la versione rumorosa (AWGN) di(
x xks, kp)
-
(
, 1, ,)
b
a = y ya a+ yb
y K
- y=y1N =
(
y y1, 2,K,yN)
è la sequenza codificata disturbata da rumore ricevuta Il decodificatore MAP decide simbolo per simbolo: sceglie uk = +1 se(
k 1|)
(
k 1|)
P u = + y ≥P u = − y e decide uk = −1 altrimenti. In pratica, la regola di decisione su ogni simbolo è:
( )
k k
u =segno L u
dove L u
( )
k è il logaritmo del rapporto di probabilità a posteriori, il LAPP ratio, definito come:( )
(
(
1) ( )
) ( )
1 , , / log , , / k k s k k k s p s s s s p L u p s s s s p + − − − = ′ = = ′ = = ∑
∑
y y y y . (2.2.3)Tale rapporto, tenendo conto del traliccio del codificatore, può essere riscritto come:
(
)
(
)
1| ( ) log 1| k k k P u L u P u = + = = − y y (2.2.4)dove: sk∈S è lo stato del codificatore al tempo k; S+ è l’insieme di coppie ordinate
un bit d’ingresso uk = +1; S− è ancora tale insieme di coppie ordinate definite stavolta però per un bit d’ingresso uk = −1.
Osservando che nella (2.4) si può cancellare p y
( )
, l’algoritmo che si cerca deve calcolare soltanto p s s(
′, ,y)
= p s(
k−1=s s′, k =s,y)
. L’algoritmo BCJR per fare questo è:(
, ,)
k 1( ) ( ) ( )
k , kp s s′ y =α − s′ γ s s′ β s (2.2.5)
Si definisce ora la probabilità αk
( )
s ,γk( )
s s′, e βk( )
s . La αk( )
s = p s(
k =s,y1k)
si calcola ricorsivamente come:( )
1( ) ( )
, k k k s S s s s s α α − γ ′∈ ′ ′ =∑
(2.2.6)con la condizione iniziale
( )
0 0 1
α = eα0
(
s′ ≠ =0)
0 (2.2.7)(con questa condizione si mette in evidenza che inizialmente ci si aspetta che il codificatore si trovi nello stato 0 ).
La probabilità γk
( )
s s′, è definita come:( )
,(
, | 1)
k s s p sk s yk sk s
γ ′ = = − = ′ (2.2.8)
Infine, la probabilità βk
( )
s = p(
yNk+1|sk =s)
viene calcolata con una ricorsione all’indietro nel modo seguente:( )
( ) ( )
1 . k k k s S s s s s β − β γ ∈ ′ =∑
′ (2.2.9) con la condizione:( )
0 1N
β = e βN
(
s≠0)
=0 (2.2.10)(con questa condizione ci si aspetta che l’encoder finisca nello stato 0 dopo N bit d’ingresso, ovvero che sia presente il tail termination, composto da m bit, alla fine della sequenza informativa).
Dopo varie considerazioni e passaggi matematici, riportati per completezza in appendice, il risultato ottenuto, riguardo all’affidabilità del decodificatore D1, ad una certa iterazione è:
( )
( )
( )
1 21 12 s e e k c k k k L u =L y +L u +L u (2.2.11)Il primo termine a secondo membro,
0 4 b c rE L N
= in cui si è indicato con r il rate del
turbo encoder, è chiamato channel value, il secondo, Le21
( )
uk , è l’informazione estrinseca passata da D2 a D1 e il terzo, 12e( )
k
L u , sarà utilizzato come informazione estrinseca da D2.
A questo punto, le informazioni necessarie al funzionamento del turbo decoder sono evidenti. Innanzitutto, il turbo decoder deve conoscere in modo completo i tralicci dei codificatori RSC che costituiscono il turbo encoder (quindi il decoder dovrà possedere una tabella contenente i bit di ingresso e i parity bit per ogni possibile transizione di stato s′ →s). Bisognerà poi che possegga i vettori di permutazione e de-permutazione. Infatti D1 e D2 si scambiano l’informazione estrinseca o di “affidabilità” (reliability information) per ogni u ma, per esempio, l’informazionek che arriva a D2 è una versione permutata di quella che esce da D1. Nell’implementazione illustrata in seguito, si denoteranno questi vettori con P[] e Pinv[]: se u′ è la versione permutata della sequenza originale u , allora si scriverà:
for k=1:N uk′ =uP k[ ].
Inoltre, come già sostenuto, a causa della presenza L inc L u
( )
k , il MAP decoder dovrà conoscere la varianza del rumore.Infine, si nota che, un semplice modo per simulare il puncturing è, nel calcolo di
( )
,k s s
γ ′ , mettere a zero i simboli parity ricevuti y1pk o yk2 p, corrispondenti ai bit parità perforati, x1 pk o x1 pk . In questa maniera il codificatore non si deve occupare del puncturing.
Si descrive ora l’implementazione software utilizzata per ricavare i risultati delle simulazioni. Va notato il fatto che la presenza dell’interleaver fa in modo che quasi sicuramente il secondo encoder non finisce nello stato 0, e quindi la condizione su
( )2
( )
N s
β% cambia rispetto a quella descritta in precedenza.
Si puntualizza che la decisione sul bit è stata presa, dopo l’iterazione n-esima, all’uscita del decoder D1 paragonando quindi L u1
( )
k alla soglia posta in zero (in letteratura si trova sia questa opzione che quella di decidere all’uscita di D2).Inizializzazione D1: - 0( )1
( )
1se 0 0se 0 s s s α = = ≠ % - ( )1( )
1se 0 0 se 0 N s s s β = = ≠ % - 21e( )
0 k L u = per k = 1, 2, …, N D2: - 0( )2( )
1 se 0 0se 0 s s s α = = ≠ % - N( )2( )
s 1 Mβ% = per tutti gli s, con M pari al numero totale di stati del codificatore RSC
- L12e
( )
uk non deve essere inizializzato perché sarà trovato da D1 dopo la prima mezza iterazioneIterazione n-esima D1:
for k = 1 : N
- ricevi yk =
(
y yks, k1p)
dove y1pk è la versione rumorosa del bit parity uscito da E1 - calcola γk( )
s s′, dalla A.8 per tutte le possibili transizioni di stato(
s′ →s)
(intale formula u assume il valore dell’ingresso del codificatore che ha causatok quella precisa transizione s′ →s; L ue
( )
k è in questo caso L21e(
uPinv k[ ])
, ovvero l’informazione estrinseca de-permutata scaturita nell’iterazione precedente da D2- calcolaα%k( )1
( )
s per tutti gli s utilizzando la A.3. endfor k = N : 2
- calcola β%k( )1−1
( )
s per tutti gli s utilizzando la A.4. end for k = 1 : N - calcola 12( )
e k L u utilizzando:( )
( )( ) ( )
( )( )
( )( ) ( )
( )( )
1 1 1 12 1 1 1 , log , e k k k e s k e k k k s s s s s L u s s s s α γ β α γ β + − − − ′ ′ = ′ ′ ∑
∑
% % % % end D2: for k = 1 : N - ricevi yk =(
yP ks[ ],yk2p)
- calcola γk
( )
s s′, dalla A.8 per tutte le possibili transizioni di stato(
s′ →s)
(in tale formula u assume il valore dell’ingresso del codificatore che ha causatok quella precisa transizione s′ →s; L ue( )
k è in questo caso L12e( )
uP k[ ] , ovverol’informazione estrinseca permutata proveniente da D1: yks corrisponde a [ ] s P k
y , il bit sistematico permutato
- calcolaα%k( )2
( )
s per tutti gli s utilizzando la A.3 endfor k = N : 2
- calcola β%k( )2−1
( )
s per tutti gli s utilizzando la A.4. end for k = 1 : N - calcola Le21( )
uk utilizzando:( )
( )( ) ( )
( )( )
( )( ) ( )
( )( )
2 2 1 21 2 2 1 , log , e k k k e s k e k k k s s s s s L u s s s s α γ β α γ β + − − − ′ ′ = ′ ′ ∑
∑
% % % % endDopo l’ultima Iterazione
for k = 1 : N
- calcola L u1
( )
k =L yc ks+Le21(
uPinv k[ ])
+Le12( )
uk - se L u1( )
k ≥0 decidi uk = +1, altrimenti uk = −1. endCome detto in precedenza, la conoscenza dello stato iniziale e finale dei codificatori costituenti RSC, permette l’inizializzazione di α%0
( )
s ∀s e di β%N( )
s ∀s.Si descriveranno ora alcuni importanti casi di terminazione dei codificatori.
In tutti i casi presi in considerazione si è assunto come stato iniziale sia di E1 che di E2 lo stato 0. In pratica si è inizializzato entrambi i decodificatori nel seguente modo:
( )
0 1 se 0 0 se 0 s s s α = = ≠ %Nell’implementazione software descritta in precedenza si è considerato di conoscere lo stato finale di E1, ovvero di forzarlo a 0 tramite un tail. Si è potuto quindi inizializzare:
( )1
( )
1se 0 0 se 0 N s s s β = = ≠ %mentre non è stato possibile per i β%N( )2
( )
s . Per questi si è assunto:( )2
( )
1N s s
M
β% = ∀
dove M è il numero totale di stati del codificatore RSC. Questa scelta si basa sul fatto che, non sapendo in quale degli M stati si trovi il codificatore alla fine, si dà ad ogni stato la stessa probabilità, 1
M appunto.
Un’altra inizializzazione altrettanto valida è:
( )2
( )
( )2( )
N s N s s
β% =α% ∀
ma è possibile anche utilizzare quella mostrata in [6]:
( )2
( )
1N s s
N
β% = ∀
2.2 ASSOCIAZIONE DI UN TURBO CODICE AD UNA
MODULAZIONE AD ALTA EFFICIENZA SPETTRALE
In questo paragrafo verrà presentato un sistema di trasmissione che unisce i Turbo Codici, con la loro elevata capacità di correzione degli errori, con modulazioni efficienti in banda. In particolare si considererà la modulazione 4-QAM.
Si vuole associare una modulazione M-QAM (M =2m con m=2p) ad un codificatore turbo con rate r=
(
m m m− %)
come illustrato in figura 2.5.Con c e1 c si è denotato rispettivamente l’uscita parity del primo e del secondo2 codificatore che costituiscono il turbo encoder.
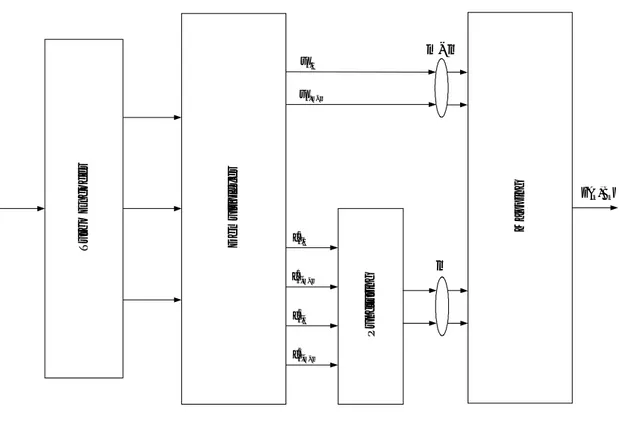
T u rb o E n c o d e r D e m u lt ip le x e r P u n c tu ri n g M a p p in g { } , k k A B m% m m− % ,1 k u , k m m u −% 1 ,1 k c 1 , k m m c −% 2 ,1 k c 2 , k m m c −%
Fig. 2.5 Turbo trasmettitore per modulazioni ad alta efficienza spettrale
Ogni punto della costellazione M-QAM al tempo k è rappresentato da una coppia di simboli reali
{
A Bk, k}
. Essi sono codificati tramite due set di p simboli,{ }
( ),A k i d , ( )
{ }
, B k id con i = 1, …, p, rispettivamente. Il mapping scelto è quello di Gray. Nel caso di una modulazione 16-QAM ad esempio, m vale 4 e p = 2 mentre A ek Bk appartengono all’alfabeto
{
± ±1, 3}
come illustrato in figura 2.6.Si può notare che alcuni bit dei set
{ }
dk i( ),A ,{ }
dk i( ),B sono maggiormente protetti dal rumore rispetto ad altri. Ad esempio, considerando l’asse orizzontale, dk( ),1A è meglioprotetto di dk( ),2A (dk( ),1A indica il primo quadrante, dk( ),2A può valere 0 o 1 sia nel primo che nel secondo quadrante), mentre sull’asse verticale l’avvantaggiato è dk( )B,1 .
0111 0011 1011 1111 0110 0010 1010 1110 0100 0000 1000 1100 0101 0001 1001 1101 ( ) ( ) ,1 1, ,2 0 A A k k d = d = ( ) ( ) ,1 0, ,2 1 B B k k d = d =
Fig 2.6 Mapping 16-QAM turbo
Comunque, sempre riferendosi al caso 16-QAM, per ottenere i due simboli A ek Bk
sono necessari quattro bit d . Se il rate totale del codificatore fossek 1
2, due di questi sarebbero informativi u mentre gli altri due sarebbero parity bitk c . Se invece il ratek totale del codificatore fosse 3
4, chiaramente tre dei quattro d sarebberok
d’informazione ed il rimanente bit sarebbe di parità.
Ad ogni simbolo della costellazione sono quindi associati due bit d’informazione se il rate vale 1
Non esistono pareri concordi su quali bit uscenti dal demultiplexer associare ai bit dk maggiormente protetti. Nelle simulazioni effettuate si è associato ad essi i bit sistematici u .k
Viene ora descritta la struttura del decodificatore. All’uscita del demodulatore si hanno, sul ramo in fase e su quello in quadratura, rispettivamente i due valori:
k k k
X = A +I
k k k
Y =B +Q
dove I ek Q sono due campioni di rumore gaussiano ed incorrelati e quindik indipendenti, a media nulla e con la stessa varianza σ2.
Si assume di utilizzare lo stesso Turbo Decoder descritto nel paragrafo 2.1, qualunque sia la modulazione M-QAM considerata. Con questo approccio, chiamato pragmatic approach, gli ingressi del Turbo Decoder sono decisioni soft associate con ogni bit dk i( ),A , dk i( )B, con i = 1, 2, …, p.
Quindi, date le osservazioni
{
X Yk, k}
, si dovrà calcolare il logaritmo del rapporto delle probabilità a posteriori (LAPP) associato ad ogni bit dk i( ),A , dk i( )B, con i = 1,2,…,p. Esso può essere calcolato, all’uscita del demodulatore, come:( )
( )
{
{
( )( )}
}
, , , Pr 1| , log Pr 0 | , j k i k k j k i j k i k k d X Y L d K d X Y = = = (2.3.1) con i = 1, …, p; j = A, B; K costanteed utilizzarlo come ingresso soft del turbo decoder come descritto in figura 2.7. Ricordando che gli osservati
{
X Yk, k}
sono disturbati da due campioni di rumore gaussiano indipendenti con la stessa varianza σ2 ed usando la regola di Bayes, il termine L d( )
k i( ),A , associato con i bit dk i( ),A (i = 1, …, p), dipenderà soltanto dall’osservato X e lo si può scrivere come:k( )
( )
(
)
(
)
1 1 2 2 1, 2 1 , 2 2 0, 2 1 1 exp 2 log 1 exp 2 p p k i A i k i k i i X a L d K X a σ σ − − = = − − = − − ∑
∑
i = 1, …, p (2.3.2)dove a1,i e a0,i rappresentano, rispettivamente, le realizzazioni dei simboli Ak condizionatamente a che valga dk i( ),A =1 oppure dk i( ),A =0.
D e m o d u la to re C a lc o lo d e l m o d u lo d e l L A P P D e m u lt ip le x e r T u rb o D e c o d e r k X k Y ( )
( )
,1 A k L d ( )( )
, A k p L d ( )( )
,1 B k L d ( )( )
, B k p L d( )
j L u( )
1 j L c( )
2 j L c j uFig 2.7 Turbo ricevitore per trasmissioni ad alta efficienza spettrale
In seguito verrà descritta la funzione del demultiplexer e come le L d
( )
k i( ),j , j = A, B vengono associate ai veri ingressi del turbo decoder L u( )
j , L c( )
1j , L c( )
2j .Allo stesso modo L d
( )
k i( ),B , associato con i bit dk i( ),B (i = 1, …, p), dipenderà soltanto dall’osservato Y ed avrà la stessa espressione dik( )
( )
, A k i L d con X sostituito dak Y edk 1,ia e a0,i sostituite da b1,i e b0,i rispettivamente.
Fatta eccezione per il caso M = 4, il calcolo di L d
( )
k i( ),j (j = A, B) conduce ad espressioni abbastanza complesse dipendenti dal rapporto segnale/rumore.Esistono però altre espressioni che bene approssimano le L d